Realizing an Integrated Multistage Support Vector Machine Model for Augmented Recognition of Unipolar Depression
 ,
, 
 ,
,  and
and 
Abstract
:1. Introduction
- The multiple imputation by chained equations (MICE) method is deployed for preprocessing and cleaning the gathered dataset
- The feature selection process is accomplished by employing the support vector machine-based recursive feature elimination (SVM RFE).
- The UD classification is performed using the proposed integrated multistage support vector machine classifier, which is built by employing the bagging random sampling approach.
2. Materials and Methods
2.1. Utilized Dataset
2.2. Data Cleaning and Preprocessing
2.3. Selection of Features
2.4. Machine Learning Approaches Considered
2.4.1. Logistic Regression Approach
2.4.2. Multilayer Perceptron Approach
- —preactivation function or Net input;
- —the weight associated with the connection link;
- —inputs (I1, I2, …, In);
- B—bias.
- —change in weights of the neurons;
- —learning rate;
- —predicted or desired output.
2.4.3. Random Forest Approach
2.4.4. SVM Classifier
2.5. Integrated MultiStage Support Vector Machine Classification Model
2.5.1. Design of Integrated Multistage Support Vector Machine Classifier
2.5.2. Ranking and Selection of Features
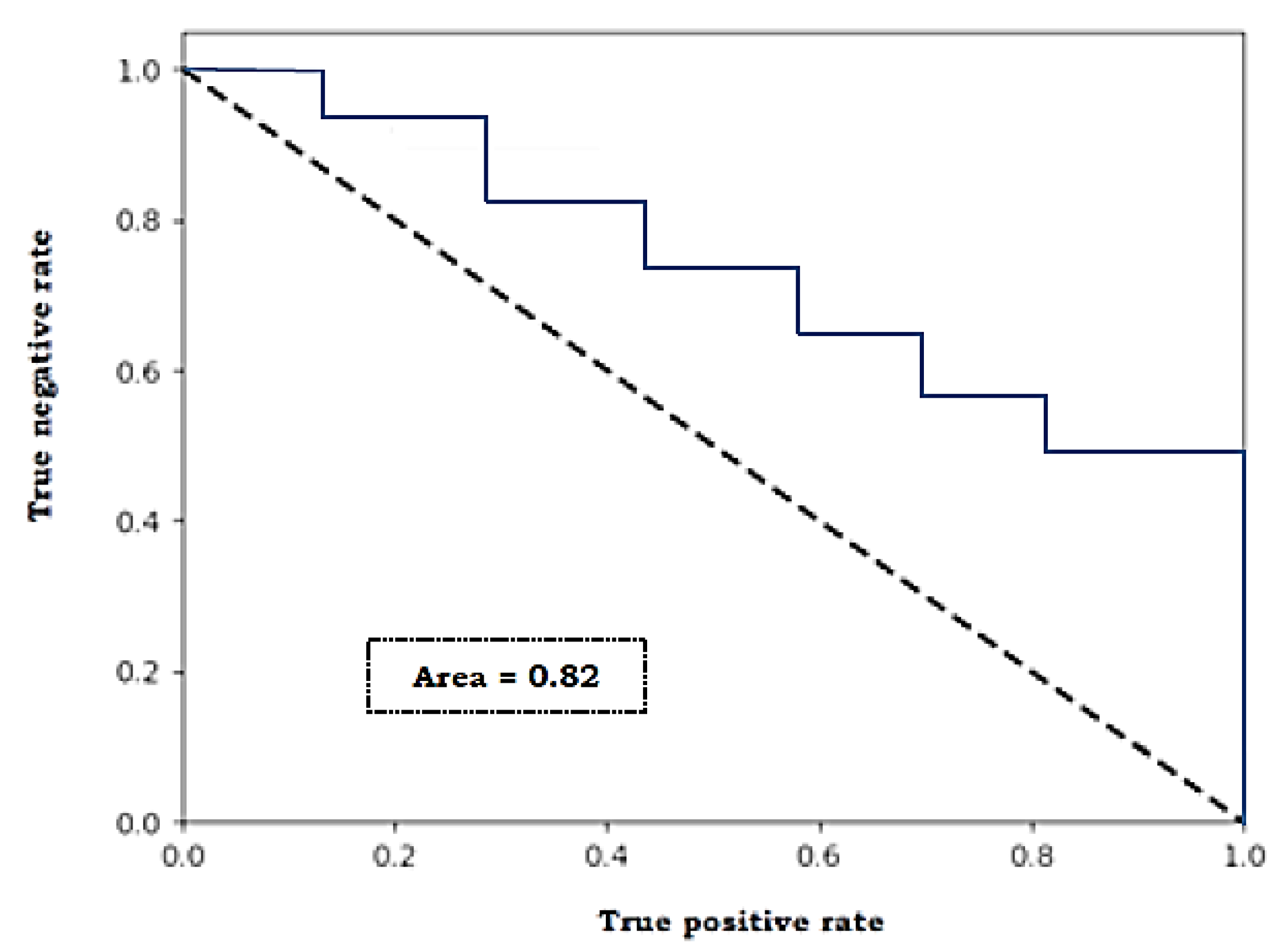
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Patalay, P.; Gage, S.H. Changes in millennial adolescent mental health and health-related behaviours over 10 years: A population cohort comparison study. Int. J. Epidemiol. 2019, 48, 1650–1664. [Google Scholar] [CrossRef] [PubMed]
- McElroy, E.; Fearon, P.; Belsky, J.; Fonagy, P.; Patalay, P. Networks of Depression and Anxiety Symptoms Across Development. J. Am. Acad. Child Adolesc. Psychiatry 2018, 57, 964–973. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fried, E.I.; Nesse, R.M.; Zivin, K.; Guille, C.; Sen, S. Depression is more than the sum score of its parts: Individual DSM symptoms have different risk factors. Psychol. Med. 2013, 44, 2067–2076. [Google Scholar] [CrossRef] [Green Version]
- Fried, E.I.; Nesse, R.M. Depression is not a consistent syndrome: An investigation of unique symptom patterns in the STAR*D study. J. Affect. Disord. 2014, 172, 96–102. [Google Scholar] [CrossRef] [Green Version]
- Klakk, H.; Kristensen, P.L.; Andersen, L.B.; Froberg, K.; Møller, N.C.; Grøntved, A. Symptoms of depression in young adulthood is associated with unfavorable clinical- and behavioral cardiovascular disease risk factors. Prev. Med. Rep. 2018, 11, 209–215. [Google Scholar] [CrossRef] [PubMed]
- Papakostas, G.I.; Petersen, T.; Mahal, Y.; Mischoulon, D.; Nierenberg, A.A.; Fava, M. Quality of life assessments in major depressive disorder: A review of the literature. Gen. Hosp. Psychiatry 2004, 26, 13–17. [Google Scholar] [CrossRef] [PubMed]
- Hamilton, M. A Rating Scale For Depression. J. Neurol. Neurosurg. Psychiatry 1960, 23, 56–62. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Azur, M.; Stuart, E.; Frangakis, C.; Leaf, P.J. Multiple imputation by chained equations: What is it and how does it work? Int. J. Methods Psychiatr. Res. 2011, 20, 40–49. [Google Scholar] [CrossRef]
- Raghunathan, T.W.; Lepkowksi, J.M.; Van Hoewyk, J.; Solenbeger, P. A multivariate technique for multiply imputing missing values using a sequence of regression models. Surv. Methodol. 2001, 27, 85–95. [Google Scholar]
- Van Buuren, S. Multiple imputation of discrete and continuous data by fully conditional specification. Stat. Methods Med. Res. 2007, 16, 219–242. [Google Scholar] [CrossRef]
- Schafer, J.L.; Graham, J.W. Missing data: Our view of the state of the art. Psychol. Methods 2002, 7, 147–177. [Google Scholar] [CrossRef] [PubMed]
- Peduzzi, P.; Concato, J.; Kemper, E.; Holford, T.R.; Feinstein, A.R. A simulation study of the number of events per variable in logistic regression analysis. J. Clin. Epidemiol. 1996, 49, 1373–1379. [Google Scholar] [CrossRef]
- Press, S.J.; Wilson, S. Choosing between logistic regression and discriminant analysis. J. Am. Stat. Assoc. 1978, 73, 699–705. [Google Scholar] [CrossRef]
- Gardner, M.; Dorling, S. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2011, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Kandaswamy, K.K.; Chou, K.-C.; Martinetz, T.; Möller, S.; Suganthan, P.N.; Sridharan, S.; Pugalenthi, G. AFP-Pred: A random forest approach for predicting antifreeze proteins from sequence-derived properties. J. Theor. Boil. 2011, 270, 56–62. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhou, H.; Zhou, Q.; Yang, F.; Luo, L. Structure damage detection based on random forest recursive feature elimination. Mech. Syst. Signal Process. 2014, 46, 82–90. [Google Scholar] [CrossRef]
- Hamed, T.; Dara, R.; Kremer, S.C. An Accurate, Fast Embedded Feature Selection for SVMs. In Proceedings of the 2014 13th International Conference on Machine Learning and Applications, Detroit, MI, USA, 3–5 December 2014; pp. 135–140. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.A.; LeCun, Y. What is the best multi-stage architecture for object recognition? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, September 27–October 4 2009; pp. 2146–2153. [Google Scholar]
- Chang, C.-Y.; Srinivasan, K.; Chen, M.-C.; Chen, S.-J. SVM-Enabled Intelligent Genetic Algorithmic Model for Realizing Efficient Universal Feature Selection in Breast Cyst Image Acquired via Ultrasound Sensing Systems. Sensors 2020, 20, 432. [Google Scholar] [CrossRef] [Green Version]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Tuia, D.; Pacifici, F.; Kanevski, M.; Emery, W.J. Classification of Very High Spatial Resolution Imagery Using Mathematical Morphology and Support Vector Machines. IEEE Trans. Geosci. Remote. Sens. 2009, 47, 3866–3879. [Google Scholar] [CrossRef]
- Ataş, M.; Yardimci, Y.; Temizel, A. A new approach to aflatoxin detection in chili pepper by machine vision. Comput. Electron. Agric. 2012, 87, 129–141. [Google Scholar] [CrossRef]
- Wang, R.; Li, R.; Lei, Y.; Zhu, Q. Tuning to optimize SVM approach for assisting ovarian cancer diagnosis with photoacoustic imaging. Bio-Med. Mater. Eng. 2015, 26, S975–S981. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Description |
|---|---|
| Age | Average Age 30. |
| Gender | Male/Female. |
| Sleep Quotient | Time taken to fall asleep. |
| Early Wake-Up | The irregular waking uptime. |
| Sleeping excessively | Irregular sleep hours. |
| Gloomy | Prolonged feelings of sadness, sometimes in the day or all the time. |
| Exasperation | Prolonged feelings of irritation, sometimes in the day or all the time. |
| Apprehensive or Nervous | Prolonged feelings of anxiousness or tension, sometimes in the day or all the time. |
| Response of the Individual to Preferred Happenings | Reactions, mood-wise to the events happening in life. |
| Relation between an Individual’s Mood and Time | Moods at different time of the day. |
| Mood Quality | If the individual is sad, is it because of something happened or sad for no reason. |
| Reduced Desire for food | Not eating enough food. |
| Augmented Desire for food | Eating more than enough food. |
| Weight Reduction | Losing more weight in two weeks without any reason. |
| Weight Increase | Gaining weight at a specific time. |
| Ability to make Decisions/Attentiveness | Failure in making decisions and losing focus. |
| Future Perspective | Positive and Negative thoughts about the future. |
| Suicidal Contemplations | Attempting to harm oneself. |
| Happiness Quotient | Feeling good or extremely annoyed with pleasure and enjoyment in life. |
| Fidgety | Constant pacing and difficulty in concentrating. |
| Physical Indications | Sweating, increased heartbeat, blurred vision, shivering, chest pain or none at all. |
| Paranoid Signs | Constant panic attacks or none at all. |
| Result | Depressed or Not Depressed. |
| Selected Features | Index |
|---|---|
| Gloomy | 1 |
| Exasperation | 2 |
| Apprehensive or Nervous | 3 |
| Response of the Individual to Preferred Happenings | 4 |
| Relation between an Individual’s Mood and Time | 5 |
| Suicidal Contemplations | 6 |
| Happiness Quotient | 7 |
| Physical Indications | 8 |
| Paranoid Signs | 9 |
| Parameters | Settings |
|---|---|
| fdev | 0.00001 |
| devmax | 0.999 |
| eps | 0.000001 |
| big | 9.9 × 1035 |
| mnlam | 5 |
| pmin | 0.00001 |
| exmx | 250 |
| prec | 0.0000000001 |
| mxit | 100 |
| factory | FALSE |
| Parameters | Settings |
|---|---|
| Max. output unit error | 0.2 |
| Learning function | Rprop Backprop |
| Modification | None |
| Print covariance and error | No |
| Cache the unit activations | No |
| Prune new hidden unit | No |
| Min. covariance change | 0.040 |
| Candidate patience | 25 |
| Max. no. of covariance updates | 200 |
| Activation function | LogSym |
| Error change | 0.010 |
| Output patience | 50 |
| Max. no. of epochs | 200 |
| Hyperparameter | Settings |
|---|---|
| mtry | 3 |
| sample size | 3040 |
| replacement | TRUE |
| node size | 1 |
| number of trees | 1000 |
| splitting rule | random |
| Hyperparameter | Settings |
|---|---|
| Kernel | RBF |
| Problem type | Classification |
| log2 C | −5, 15, 2 |
| log2 γ | 3, −15, −2 |
| Confusion Matrix | Formula |
|---|---|
| Specificity | TN/TN + FP |
| Recall | TP/TP + FN |
| Accuracy | TN + TP/TP + FP + TN + FN |
| Precision | TP/TP + FP |
| FScore | 2 × (Precision × Recall)/(Recall + Precision) |
| Evaluation Metric | LR (%) | MLP (%) | RF (%) | Bagging SVM (Majority Voting) | Proposed Model (%) |
|---|---|---|---|---|---|
| Specificity | 94.12 | 95.20 | 96.23 | 97.13 | 98.64 |
| Recall | 62.5 | 68.47 | 77.08 | 82.29 | 93.75 |
| Accuracy | 90.13 | 91.97 | 93.81 | 95.26 | 98.02 |
| Precision | 60.6 | 66.31 | 74.74 | 80.61 | 90.91 |
| FScore | 61.53 | 67.37 | 75.89 | 81.44 | 92.31 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Srinivasan, K.; Mahendran, N.; Vincent, D.R.; Chang, C.-Y.; Syed-Abdul, S. Realizing an Integrated Multistage Support Vector Machine Model for Augmented Recognition of Unipolar Depression. Electronics 2020, 9, 647. https://doi.org/10.3390/electronics9040647
Srinivasan K, Mahendran N, Vincent DR, Chang C-Y, Syed-Abdul S. Realizing an Integrated Multistage Support Vector Machine Model for Augmented Recognition of Unipolar Depression. Electronics. 2020; 9(4):647. https://doi.org/10.3390/electronics9040647
Chicago/Turabian StyleSrinivasan, Kathiravan, Nivedhitha Mahendran, Durai Raj Vincent, Chuan-Yu Chang, and Shabbir Syed-Abdul. 2020. "Realizing an Integrated Multistage Support Vector Machine Model for Augmented Recognition of Unipolar Depression" Electronics 9, no. 4: 647. https://doi.org/10.3390/electronics9040647
APA StyleSrinivasan, K., Mahendran, N., Vincent, D. R., Chang, C.-Y., & Syed-Abdul, S. (2020). Realizing an Integrated Multistage Support Vector Machine Model for Augmented Recognition of Unipolar Depression. Electronics, 9(4), 647. https://doi.org/10.3390/electronics9040647