Performance Analysis of a Clustering Model for QoS-Aware Service Recommendation


Abstract
:1. Introduction
- We build a new services features extraction system and extract the characteristics of services based on WSDL files and perform users clustering based on the QoS of the user who invokes the service.
- We exploit similar user clusters and services clusters by a collaborative filtering matrix factorization and obtain potential user QoS preferences to generate recommendations.
- We develop a novel recommendation method by jointly considering the QoS of users and service clustering, whereby improving the accuracy of the recommendation. We perform the experiment based on real data sets—called WSDream—and compare with other methods on the basis of MAE and RMSE. It turns out that our approach achieves a better performance compared to other mainstream approaches.
2. Related Works
3. RMUSC Architecture
3.1. Web Service Clustering Algorithm
3.1.1. WSDL Service Description Files
3.1.2. Web Service Feature Word Extraction
3.1.3. Web Service Clustering Decision
| Algorithm 1 K-means++ clustering based on service function feature word set matrix. |
|
3.2. User Clustering Algorithm
| Algorithm 2 Top-N user clustering algorithm |
|
3.3. User QoS Prediction Algorithm
| Algorithm 3 Gradient descent iteration to find the optimal solution |
|
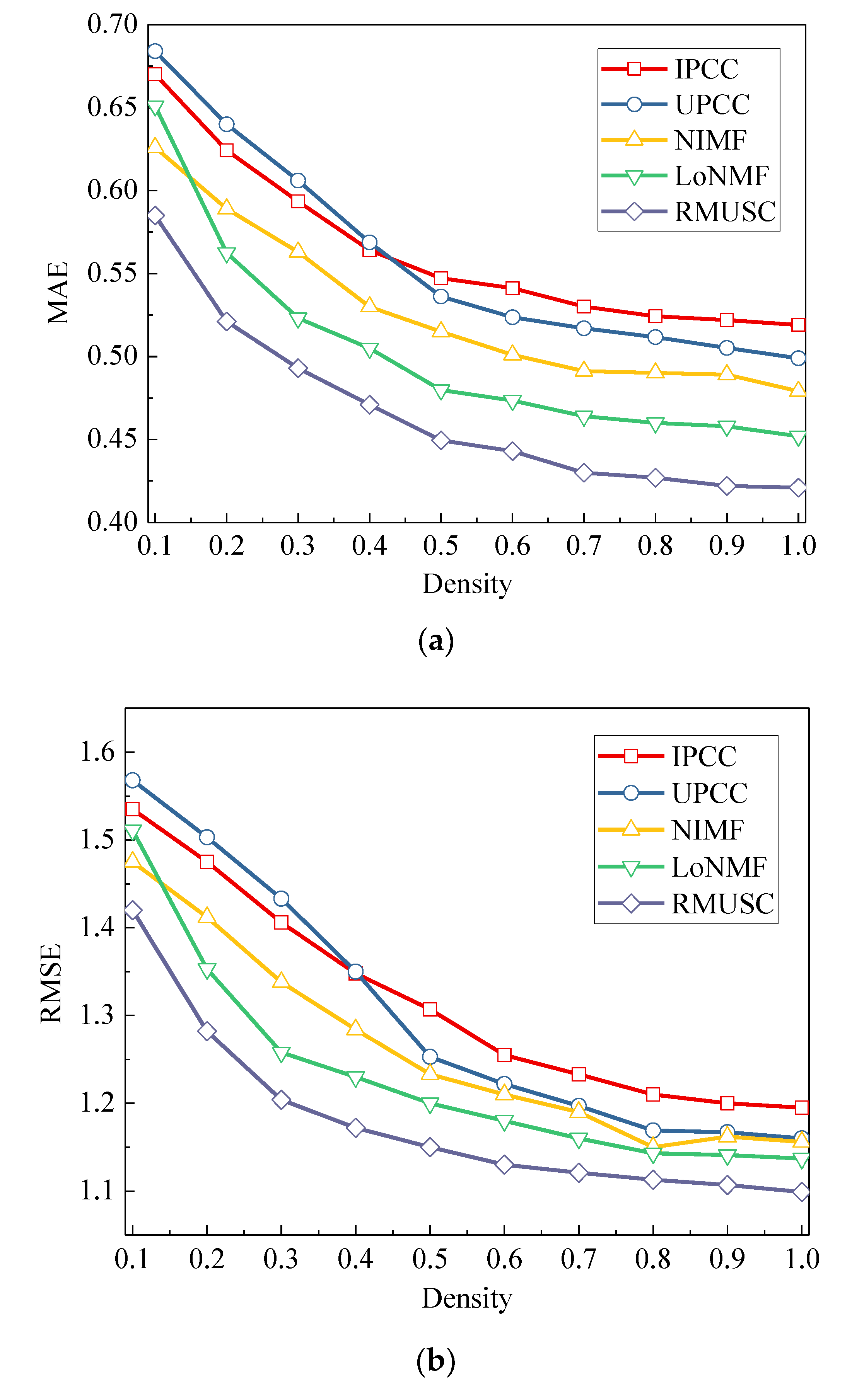
4. Simulation Results and Analysis
4.1. User Services Clustering Analysis
4.2. Effects of α, and Density on Service Recommendation
4.3. Service Recommendation Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, B.; Kong, W.; Guan, H.; Xiong, N. Air Quality Forcasting based on Gated Recurrent Long Short Term Memory Model in Internet of Things. IEEE Access 2019, 7, 69524–69534. [Google Scholar] [CrossRef]
- Niu, B.; Huang, Y. An Improved Method for Web Text Affective Cognition Computing Based on Knowledge Graph, Computers. Mater. Contin. 2019, 59, 1–14. [Google Scholar]
- Karande, A.M.; Kalbande, D.R. Web service selection based on QoS using tModel working on feed forward network. In Proceedings of the 2014 International Conference on Issues and Challenges in Intelligent Computing Techniques (ICICT), Ghaziabad, India, 7–8 February 2014; pp. 29–33. [Google Scholar]
- Wen, T.; Bao, J.; Ding, F. QoS-Aware Web Service Recommendation Model Based on Users and Services Clustering. In Proceedings of the International Conference on Information Technology and Electrical Engineering 2018, Xiamen, China, 7–8 December 2018; pp. 1–6. [Google Scholar]
- Jiang, W.; Chen, J.; Jiang, Y.; Xu, Y.; Wang, Y.; Tan, L.; Liang, G. A New Time-Aware Collaborative Filtering Intelligent Recommendation System. Comput. Mater. Contin. 2019, 61, 849–859. [Google Scholar] [CrossRef]
- Mao, C.; Chen, J. QoS prediction for Web services based on similarity-aware slope one collaborative filtering. Informatics 2013, 37, 139–148. [Google Scholar]
- Chellappa, R.K.; Sin, R.G. Personalization versus Privacy: An Empirical Examination of the Online Consumer’s Dilemma. Inf. Technol. Manag. 2005, 6, 181–202. [Google Scholar] [CrossRef]
- Chen, Z.; Limin, S.; Feng, L. Exploiting Web service geographical neighborhood for collaborative QoS prediction. Future Gener. Comput. Syst. 2017, 68, 248–259. [Google Scholar] [CrossRef]
- Zheng, Z.; Ma, H.; Lyu, M.R.; King, I. Collaborative Web service QoS prediction via neighborhood integrated matrix factorization. IEEE Trans. Serv. Comput. 2013, 6, 289–299. [Google Scholar] [CrossRef]
- Lo, W.; Yin, J.; Li, Y.; Wu, Z. Efficient Web service QoS prediction using local neighborhood matrix factorization. Eng. Appl. Artif. Intell. 2015, 38, 14–23. [Google Scholar] [CrossRef]
- Melville, P.; Mooney, R.J.; Nagarajan, R. Content-boosted collaborative filtering for improved recommendations. In Proceedings of the Eighteenth National Conference on Artificial Intelligence, Edmonton, AB, Canada, 28 July–1 August 2002; pp. 187–192. [Google Scholar]
- Yao, L.; Sheng, Q.Z.; Ngu, A.H.H.; Yu, J.; Segev, A. Unified Collaborative and Content-Based Web Service Recommendation. IEEE Trans. Serv. Comput. 2015, 8, 453–466. [Google Scholar] [CrossRef]
- Kang, G.; Liu, J.; Tang, M.; Liu, X.F.; Fletcher, K. Web service selection for resolving conflicting service requests. In Proceedings of the 9th IEEE International Conference on Web Services (ICWS’11), Washington, DC, USA, 5 July 2011; pp. 387–394. [Google Scholar]
- Wu, H.C.; Luk RW, P.; Wong, K.F. Interpreting TF-IDF term weights as making relevance decisions. ACM Trans. Inf. Syst. 2008, 26, 55–59. [Google Scholar] [CrossRef]
- Hwang, S.Y.; Hsu, C.; Lee, C.H. Service Selection for Web Services with Probabilistic QoS. IEEE Trans. Serv. Comput. 2017, 8, 467–480. [Google Scholar] [CrossRef]
- Zheng, Z.; Ma, H.; Lyu, M.R.; King, I. QoS-aware Web service recommendation by collaborative filtering. IEEE Trans. Serv. Comput. 2011, 4, 140–152. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhang, Y.; Lyu, M.R. Investigating QoS of Real-World Web Services. IEEE Trans. Serv. Comput. 2014, 7, 32–39. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th international conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Jung, K.Y.; Lee, J.H. Prediction of user preference in recommendation system using associative user clustering and Bayesian estimated value. In Proceedings of the Australian Joint Conference on Artificial Intelligence, Canberra, Australia, 2–6 December 2002; pp. 284–296. [Google Scholar]
- Zhang, R.; Li, C.; Sun, H.; Wang, Y.; Huai, J. Quality of Web service prediction by collective matrix factorization. In Proceedings of the 2014 IEEE International Conference on Services Computing (SCC), Anchorage, AK, USA, 27 June–2 July 2014; pp. 432–439. [Google Scholar]
- Cao, B.; Liu, J.; Wen, Y.; Li, H.; Xiao, Q.; Chen, J. QoS-aware service recommendation based on relational topic model and factorization machines for IoT Mashup applications. J. Parallel Distrib. Comput. 2019, 132, 177–189. [Google Scholar] [CrossRef]
- Tapang, C.C. Web Services Description Language (WSDL) Explained, Microsoft Developer Netw. Available online: http://www.fdi.ucm.es/profesor/jjruz/WebSI/Bibliografia/WSDL1.pdf (accessed on 15 April 2017).
- Wang, Z.; Cheng, B.; Zhang, W.; Chen, J. Q-Graphplan: QoS-Aware Automatic Service Composition with the Extended Planning Graph. IEEE Access 2020, 8, 8314–8323. [Google Scholar] [CrossRef]
- Messina, F.; Pappalardo, G.; Comi, A.; Rosaci, D.; Sarné, G.M.L. Combining reputation and QoS measures to improve cloud service composition. Int. J. Grid Util. Comput. 2017, 8, 142–151. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, Y.; Wang, F.; Sun, Z.; He, Q. Service Recommendation based on Quotient Space Granularity Analysis and Covering Algorithm on Spark. Knowl.-Based Syst. 2018, 147, S0950705118300662. [Google Scholar] [CrossRef]
- Yan, C.; Cui, X.; Qi, L.; Xu, X.; Zhang, X. Privacy-aware data publishing and integration for collaborative service recommendation. IEEE Access 2018, 6, 43021–43028. [Google Scholar] [CrossRef]
- Kumar, S.S.; Anouncia, S.M. QoS-Based Concurrent User-Service Grouping for Web Service Recommendation. Autom. Control Comput. Sci. 2018, 52, 220–230. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhang, Y.; Lyu, M.R. Distributed QoS evaluation for real-world Web services. In Proceedings of the 2010 IEEE International Conference on Web Services (ICWS), Miami, FL, USA, 5–10 July 2010; pp. 83–90. [Google Scholar]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Park, H.S.; Park, M.H.; Cho, S.B. Mobile information recommendation using multi-criteria decision making with Bayesian network. Int. J. Inf. Technol. Decis. Mak. 2015, 14, 317–338. [Google Scholar] [CrossRef]
- Gu, Q.; Zhou, J.; Ding, C. Collaborative filtering: Weighted nonnegative matrix factorization incorporating user and item graphs. In Proceedings of the 2010 SIAM International Conference on Data Mining (SDM), Columbus, OH, USA, 29 April–1 May 2010; pp. 199–210. [Google Scholar]
- Zhang, C.-X.; Zhang, Z.-K.; Yu, L.; Liu, C.; Liu, H.; Yan, X.-Y. Information filtering via collaborative user clustering modeling. Phys. A Stat. Mech. Appl. 2014, 396, 195–203. [Google Scholar] [CrossRef] [Green Version]
- Lo, W.; Yin, J.; Deng, S.; Li, Y.; Wu, Z. Collaborative Web service QoS prediction with location-based regularization. In Proceedings of the 2012 IEEE 19th International Conference on Web Services (ICWS), Honolulu, HI, USA, 24–29 June 2012; pp. 464–471. [Google Scholar]
- Chen, X.; Zheng, Z.; Liu, X.; Huang, Z.; Sun, H. Personalized QoS-aware Web service recommendation and visualization. IEEE Trans. Serv. Comput. 2013, 6, 35–47. [Google Scholar] [CrossRef]
- Lu, G.; Ji, X.; Li, J.; Yuan, D. Difference factor’ KNN collaborative filtering recommendation algorithm. In Advanced Data Mining and Applications; Springer: Cham, Switzerland, 2014; pp. 175–184. [Google Scholar]
- Deng, S.G.; Huang, L.T.; Wu, J.; Wu, Z.H. Trust-based personalized service recommendation: A network perspective. J. Comput. Sci. Technol. 2014, 29, 69–80. [Google Scholar] [CrossRef]
- Yin, J.; Lo, W.; Deng, S.; Li, Y.; Wu, Z.; Xiong, N. Colbar: A collaborative location-based regularization framework for QoS prediction. Inf. Sci. 2014, 265, 68–84. [Google Scholar] [CrossRef]
- Yu, D.; Liu, Y.; Xu, Y.; Yin, Y. Personalized QoS prediction for web services using latent factor models. In Proceedings of the 2014 IEEE International Conference on Services Computing (SCC), Anchorage, AK, USA, 27 June–2 July 2014; pp. 107–114. [Google Scholar]
- Zhang, L.; Zhang, B.; Liu, Y.; Gao, Y.; Zhu, Z. A web service QoS prediction approach based on collaborative filtering. In Proceedings of the 2010 IEEE Asia-Pacific Services Computing Conference, Hangzhou, China, 6–10 December 2010; pp. 725–731. [Google Scholar]
- Yu, T.; Zhang, Y.; Lin, K.J. Efficient algorithms for web services selection with end-to-end QoS constraints. ACM Trans. Web 2007, 1, 1–26. [Google Scholar] [CrossRef]
- Yu, Q.; Zheng, Z.; Wang, H. Trace norm regularized matrix factorization for service recommendation. In Proceedings of the 2013 IEEE 20th International Conference on Web Services (ICWS), Santa Clara, CA, USA, 28 June–3 July 2013; pp. 34–41. [Google Scholar]
- Tang, M.; Jiang, Y.; Liu, J.; Liu, X.F. Location-aware collaborative filtering for QoS-based service recommendation. In Proceedings of the 2012 IEEE 19th International Conference on Web Services, Honolulu, HI, USA, 24–29 June 2012; pp. 202–209. [Google Scholar]
- Yu, C.; Huang, L. Time-aware collaborative filtering for QoS-based service recommendation. In Proceedings of the 2014 IEEE International Conference on Web Services, Anchorage, AK, USA, 27 June–2 July 2014; pp. 265–272. [Google Scholar]
- Zhu, J.; He, P.; Zheng, Z.; Lyu, M. Towards online, accurate, and scalable QoS prediction for runtime service adaptation. In Proceedings of the IEEE 34th International Conference on Distributed Computing Systems, Madrid, Spain, 30 June–3 July 2014; pp. 237–318. [Google Scholar]
- Liu, G.; Meng, K.; Ding, J.; Nees, J.P.; Guo, H.; Zhang, X. An Entity-Association-Based Matrix Factorization Recommendation Algorithm. Comput. Mater. Contin. 2019, 58, 101–120. [Google Scholar]
- Kuang, L.; Xia, Y.; Mao, Y. Personalized services recommendation based on context-aware QoS prediction. In Proceedings of the 2012 IEEE Conference on Web Services, Honolulu, HI, USA, 24–29 June 2012; pp. 400–406. [Google Scholar]
- Iqbal, R.; Grzywaczewski, A.; Halloran, J.; Doctor, F.; Iqbal, K. Design implications for task-specific search utilities for retrieval and re-engineering of code. Enterp. Inf. Syst. 2015, 1751–7575. [Google Scholar] [CrossRef] [Green Version]
- He, P.; Zhu, J.; Zheng, Z.; Xu, J.; Lyu, M. Location-based hierarchical matrix factorization for Web service recommendation. In Proceedings of the 2014 IEEE Conference on Web Services, Anchorage, AK, USA, 27 June–2 July 2014; pp. 297–304. [Google Scholar]
- Gao, M.; Ling, B.; Yang, L.; Wen, J.; Xiong, Q.; Li, S. From similarity perspective: A robust collaborative filtering approach for service recommendations. Front. Comput. Sci. 2019, 13, 231–246. [Google Scholar] [CrossRef] [Green Version]
- Mahmud, S.; Iqbal, R.; Doctor, F. Cloud enabled data analytics and visualization framework for health-shocks prediction. Future Gener. Comput. Syst. 2015. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Yao, Z.; Gao, K. User recommendation method based on joint probability matrix decomposition in CPS networks. Comput. Commun. 2020, 157, 221–231. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label Type | Description |
|---|---|
| types | Type of data |
| message | Messages used by web services |
| … | … |
| portType | Web service execution |
| binding | Communication protocols |
| service | Service name |
| Method | User Side Factor | Service Side Factor |
|---|---|---|
| IPCC | √ | None |
| UPCC | √ | None |
| NIMF | √ | None |
| LoMMF | √ | None |
| RMUSC | √ | √ |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, F.; Wen, T.; Ren, S.; Bao, J. Performance Analysis of a Clustering Model for QoS-Aware Service Recommendation. Electronics 2020, 9, 740. https://doi.org/10.3390/electronics9050740
Ding F, Wen T, Ren S, Bao J. Performance Analysis of a Clustering Model for QoS-Aware Service Recommendation. Electronics. 2020; 9(5):740. https://doi.org/10.3390/electronics9050740
Chicago/Turabian StyleDing, Fei, Tao Wen, Suju Ren, and Jianmin Bao. 2020. "Performance Analysis of a Clustering Model for QoS-Aware Service Recommendation" Electronics 9, no. 5: 740. https://doi.org/10.3390/electronics9050740