2.1. PCE Imaging
In this paper, we employ a sensing scheme based on PCE or also known as Coded Aperture (CA) video frames as described in [
11].
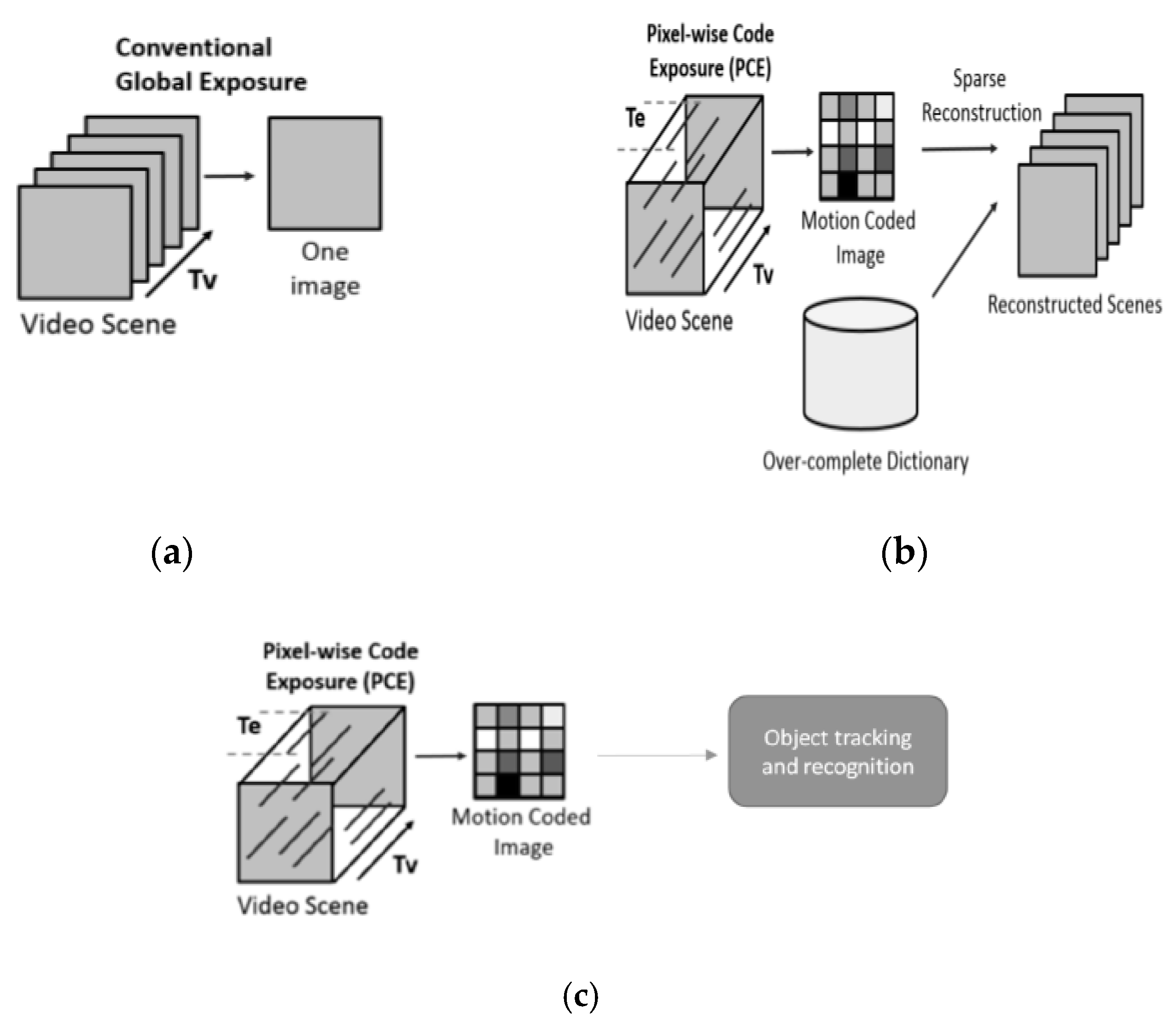
Figure 1 illustrates the differences between a conventional video sensing scheme and PCE, where random spatial pixel activation is combined with fixed temporal exposure duration. First, conventional cameras capture frames at certain frame rates such as 30 frames per second. In contrast, PCE camera captures a compressed frame called motion coded image over a fixed period of time (T
v). For example, a user can compress 30 conventional frames into a single motion coded frame. This will yield significant data compression ratio. Second, the PCE camera allows a user to use different exposure times for different pixel locations. For low lighting regions, more exposure times can be used and for strong light areas, short exposure can be exerted. This will allow high dynamic range. Moreover, power can also be saved via low sampling rate in the data acquisition process. As shown in
Figure 1, one conventional approach to using the motion coded images is to apply sparse reconstruction to reconstruct the original frames and this process may be very time consuming.
The coded aperture image
is obtained by
where
contains a video scene with an image size of
M N and the number of frames of
T;
contains the sensing data cube, which contains the exposure times for pixel located at (
m,n,t). The value of S (
m,n,t) is 1 for frames
t ∈ [
tstart,
tend] and 0 otherwise. [
tstart,
tend] denotes the start and end frame numbers for a particular pixel. It should be noted that coded exposure is in time domain and coded aperture is in spatial domain. Our proposed PCE imaging actually contains both coded exposure and coded aperture information. This can be seen from Equation (1) above. The elements of the full or a small portion of the sensing data cube in 3-dimensional spatio-temporal space can be activated based on system requirements. Hence, the S matrix contains both coded exposure and coded aperture information. We illustrate the PCE 50% Model in
Figure 2 below. In this example, colored dots denote non-zero entries (50% activated pixels being exposed) whereas white part of the spatio-temporal cube are all zero (these pixels are staying dormant). The vertical axis is the time domain, the horizontal axes are the image coordinates, and the reader is reminded that each exposed pixel stays active for an equivalent duration of 4 continuous frames. The “4” is design parameter for controlling exposure times. The larger the exposure times, the more smear the coded image will be in videos with motion.
The video scene
can be reconstructed via sparsity methods (
L1 or
L0). Details can be found in [
11]. However, the reconstruction process is time consuming and hence not suitable for real-time applications.
Instead of performing sparse reconstruction on PCE images, our scheme directly works on the PCE images. Utilizing raw PCE measurements has several challenges. First, moving targets may be smeared if the exposure times are long. Second, there are also missing pixels in the raw measurements because not all pixels are activated during the data collection process. Third, there are much fewer frames in the raw video because a number of original frames are compressed into a single coded frame. This means that the training data will be limited.
In this paper, we have focused on simulating PCE measurements. We then proceed to demonstrate that detection and classifying moving vehicles is feasible. We carried out multiple experiments with two diverse sensing models: PCE/CA Full and PCE/CA 50%. Full means that there are no missing pixels. We also denote this case as 0% missing case. The 50% case means 50% of the pixels in each frame are also missing in the PCE measurements.
The PCE Full Model (PCE Full or CA Full) is quite similar to a conventional video sensor: every pixel in the spatial scene is exposed for exactly the same duration of one second. This simple model still produces a compression ratio of 30:1. The number “30” is a design parameter, which means that 30 frames are averaged to generate a single coded frame. Based on our sponsor’s requirements, in our experiments, we have used 5 frames, which achieved 5 to 1 compression already. More details can also be found in [
25,
26,
27,
28,
29].
2.2. YOLO
YOLO tracker [
30] is fast and has similar performance as Faster R-CNN [
31]. We picked YOLO because it is easy to install and is also compatible with our hardware, which seems to have a hard time to install and run Faster R-CNN. The training of YOLO is quite simple. Images with ground truth target locations are needed. YOLO also comes with a classification module.
The input image is resized to 448 × 448.
Figure 3 shows the architecture of YOLO version 1. There are 24 convolutional layers and 2 fully connected layers. The output is 7 × 7 × 30.
In contrast to typical detectors that look at multiple locations in an image and return the highest scoring regions as detections, YOLO, as its namesake explains, looks at the entire image to make determinations on detections, giving each scoring global context. This method makes the prediction extremely fast, up to one thousand times faster than an R-CNN. It also works well with our current hardware. It is easy to install, requiring only two steps and few prerequisites. This differs greatly from many other detectors that require a very specific set of prerequisites to run a Caffe based system. YOLO works without the need for a GPU but, if initialized in the configuration file, easily compiles with the Compute Unified Device Architecture (CUDA), which is the NVIDIA toolkit, when constructing the build. YOLO also has a built-in classification module. However, the classification accuracy using YOLO is poor according to our past studies [
25,
26,
27,
28,
29]. While the poor accuracy may be due to a lack of training data, the created pipeline that feeds input data into YOLO and is therefore more effective at providing results.
One key advantage of YOLO is its speed as it can predict multiple bounding boxes per grid cell of size 7 × 7. For the optimization process during training, YOLO uses sum-squared error between the predictions and the ground truth to calculate loss. The loss function comprises the classification loss, the localization loss (errors between the predicted boundary box and the ground truth), and the confidence loss. More details can be found in [
30].
YOLO has its own starter model, Darknet-53, that can be used as a base to further train a given dataset. It contains, as the name would suggest, 53 convolutional layers. It is constructed in a way to optimize speed while also competing with larger convolutional networks.
In the training of YOLO, we trained the models based on missing rates. There may be other deep learning based detectors such as the Single Shot Detector (SSD) [
32] in the literature. We tried to use SSD. After some investigations, we observed that it is very difficult to custom trained it. In any event, our key objective is to demonstrate vehicle detection and confirmation using PCE measurements. Any relevant detectors can be used.
2.3. Real-Time System
As shown in
Figure 4, the key idea of the proposed system is to use a compressive sensing camera to capture certain scenes. The compressive measurements are wirelessly transmitted to a remote PC for processing. The PC has fast processors such as GPU to carry out the object detection and classification. The processed frames are then wirelessly transmitted to another laptop for display. This scenario is realistic in a sense that there are some applications that can be formalized in the same manner. One application scenario is for border monitoring. A border patrol agent can launch a drone with an onboard camera. Due to limited processing power on the drone, the object detection and classification cannot be done onboard. Instead, the videos are transmitted back to the agent who has a powerful PC, which then processes the videos. The results can be sent back to the control center or the agent for display. Another application is for situation assessment. A soldier at the frontline can sent a small drone with an onboard camera to monitor enemy’s activities. The compressive measurements are sent back to the control center from processing. The processed frames are then sent back to the soldier for display. A third application scenario was also mentioned in
Section 1 for search and rescue operations.
2.3.1. Tools Needed
The following tools are needed for real-time processing:
Ubuntu 16.04 LTS
Python 2.x
OpenCV 3.x
Hamachi
Haguichi
TeamViewer
For the operating system, each machine will need to be running on Ubuntu 16.04 LTS and have the following packages installed: Python 2.x, OpenCV 3.x, Hamachi, and Haguichi. This Linux distribution was chosen because it is compatible with the YOLO object detector/classifier. To be consistent, we decided to install the same distribution to each machine.
To run the scripts necessary for the demo, Python and OpenCV are required. The scripts are written in Python and utilizes OpenCV to manipulate the images. Finally, to enable communication between the machines, Hamachi and Haguichi need to be installed on each machine. Hamachi is a free software that allows computers to view other computers connected to the same server, as if they were on the same network. Haguichi is simply a GUI for Hamachi, built for Linux operating systems.
It is highly recommended that TeamViewer is installed on each machine to allow one person to execute the scripts needed. Having one person control each machine eliminates confusion and the need for coordination.
2.3.2. Setup for Each Machine
a. For All Machines
All machines must have an internet connection and be running Haguichi and TeamViewer. In the Haguichi menu, the user should be able to see the status of the other machines connected to the server and they should all be connected.
b. Data Acquisition Machine
This machine needs to be connected to the sensor used for data acquisition via USB. In this case, the sensor used is a Logitech camera.
c. Processing Machine
In the script used for processing, the outgoing IP address need to be changed depending on which machine is the desired receiving machine. In most cases, the IP address will typically stay the same if the same machines are used. Assuming that this machine has YOLO installed and they are fully functional, no further setup is required.
d. Display Machine
This machine does not require any further setup.
2.3.3. General Process of System
The system starts at the data acquisition machine. This machine captures data, via webcam, and condenses N frames into one. As of now, five frames are condensed into one. After the frame has been condensed, sub-sampling is applied to remove x% of pixels. The user is able to specify the percentage before executing the program. Typically, this percentage is 0 or 50%. After the processing is complete, the condensed and subsampled frame is sent to the processing machine via network socket. For test cases where there is more than 0% pixels missing, the image will be resized to half its original size to reduce transmission time.
The processing machine receives this data and decodes it for processing. After extensive investigations, it was determined that using only YOLO, for both detection and classification, is sufficient. This method gives us the fastest real-time results. After all processing, the processed frame is sent to the display machine.
This machine receives the processed data in the same way that the processing machine receives data from the processing machine. The only difference is that the data has not been resized from its original size. Once the data is received, the output is displayed on screen for the user to view the detection and classification results.
It is important to mention that when we send data via network sockets, this method encodes data into a bit stream to send to the receiving machine. The receiving machine will decode this bit stream to obtain the original data.
Below are diagrams to illustrate the flow of this system. The graphical flowchart shown in
Figure 5 is a high-level overview of the path the data takes. A camera captures the scene. The video frames are condensed using the PCE principle and wirelessly transmitted to a remote processor with fast GPUs. The processed results are sent to the display device wirelessly. The second flowchart shown in
Figure 6 is a more detailed look at the system.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}