The following sections describe the modules connected to the system for Intelligent Behaviors Selection (IBS), the technical interventions carried out to implement the proposed approach, and the components that are created to provide a bridge between the selection system and the robotic control software of the NAO platform.
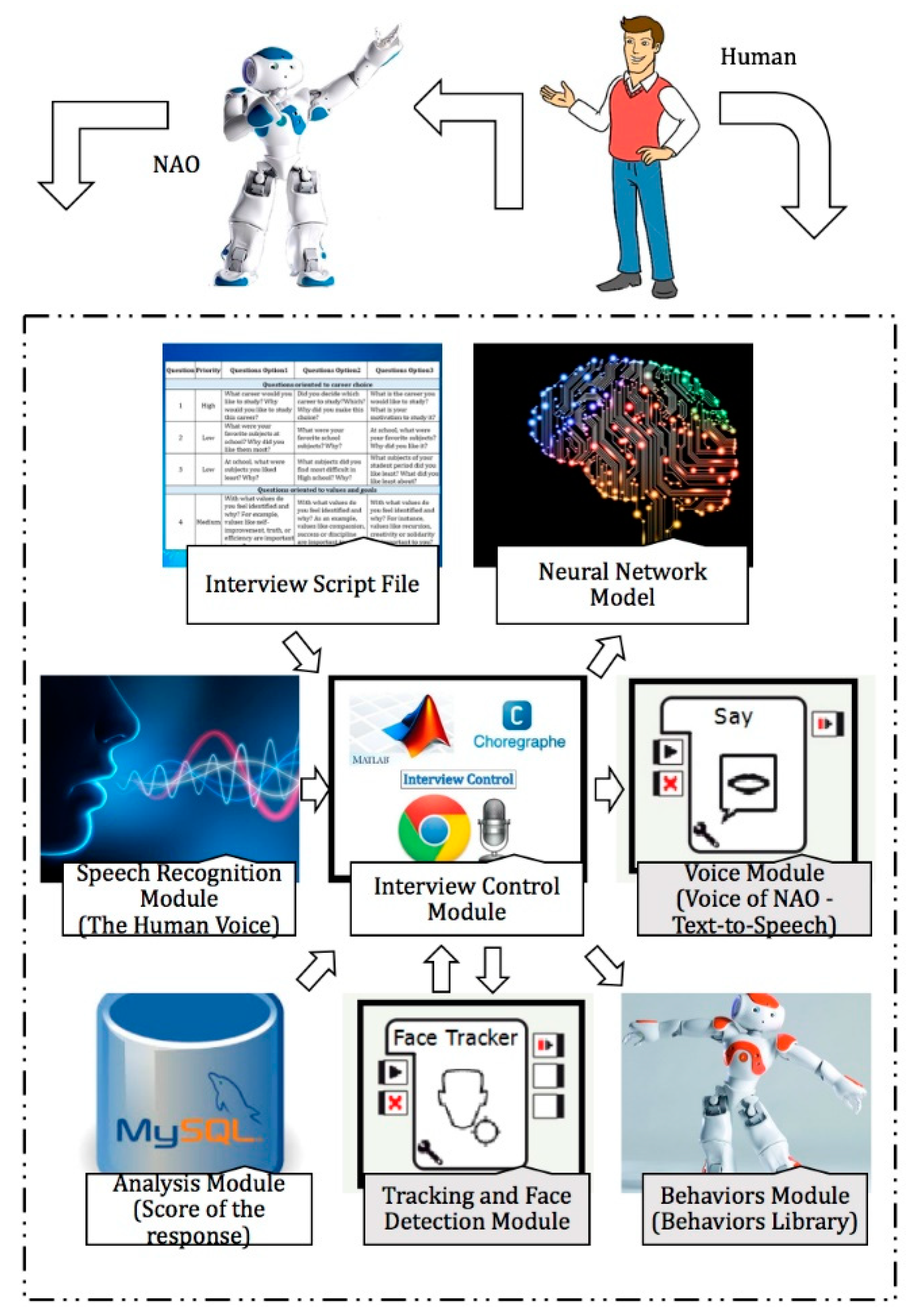
Figure 1 provides a schematic overview of the different modules and the communication paths between them. The gray boxes show modules running on the robot, and the white boxes show the components running on a connected computer. The chosen scenario (vocational guidance session) serves as suitable basic proof of the proposed approach. This scenario and its realization allow the intelligent selection of the behaviors.
4.2. Analysis Module
This module has two main functions:
(a) Calculate the Score of Answer, which is a numeric value that indicates whether the question is well answered. The score of the response will range from 0% to 100%.
(b) To provide a recommendation about a person’s vocational profile.
A matches search is performed between the words that make up the text string block from the speech recognition module and a set of words stored in a MySQL database. This database is made up of eight different tables: one for each question posed by NAO during the interview. Each table contains a set of words related to the question to which it belongs (Descriptor). For example, Table No. 1 in the database (corresponding to Question 1) consists of a list of occupations and careers related to each of the vocational profiles. Therefore, a Descriptor is defined as all those words that are contained in the response given by the user, which makes direct reference to what the robot is asking and allows the system to evaluate the vocational profile of the person. In addition, all tables store a common set of words that are used to evaluate the Interest and Cohesion of the answer given to the question.
Cohesion establishes the number of connectors that appear in the text. Connectors are words or expressions used to establish different types of relationships between words or sentences. By establishing the number of connectors in the text, we obtain an idea of the number of ideas that the person wants to convey in the answer provided. Interest is evaluated according to the number of matches found with words that indicate that the person has an inclination or predisposition towards a particular situation (e.g., liked, interest, interesting, or predilection). The analysis module performs the matches search for these three aspects. Therefore, the Score of the response is directly related to the number of Descriptors, Interest, and Cohesion in the text block.
Score of Answer: According to the number of matches in the Descriptor, Interest, and Cohesion, the score of the answer is calculated as shown in
Table 3 and in Equations (1)–(3).
Vocational Profile Evaluation: It is highly unlikely that a person has only one vocational interest; in general, we all have a vocational profile or a combination of interests [
14]. If the person says “My favorite subject in school was Math” in response to Question 2, they can be classified within an investigative vocation, but also within a conventional vocation, because in both cases, this subject is really interesting for both vocational groups.
The six vocational groups are organized according to the degree of interest they have shown in a specific behavioral characteristic. A behavioral characteristic refers to the information requested when the robot asks a question during the vocational guidance session. Continuing with the mentioned example, the interest in mathematics for every vocational group can be organized as follows: Investigative (6), Conventional (5), Enterprising (4), Artistic (3), Social (2), and Realistic (1). The number in parentheses indicates the order in which a characteristic appears within all vocational groups, with 1 being the least value (i.e., the vocation with the inferior characteristic) and 6 being the maximum (i.e., the vocation with the dominant characteristic).
The order in which a characteristic appears within all vocational groups is determined according to the work developed by [
10,
11]. When a table in the MySQL database is created on this basis, a percentage of the total rating of the question is assigned to each vocational group. These percentages have been assigned taking into account the order in which a characteristic appears within all vocational groups (see
Table 4).
The answer to a question may include several Descriptors. Therefore, the rating associated with each vocational group can be determined from Equation (4), where
n is the number of Descriptors in the answer,
W(vc)i is a percentage of the total rating of the question for each vocational group (
vc is the vocational group), Q
question is the rating of the question in the general interview, and
i represents each of the Descriptors. The summation of the results of each vocation corresponds to the rating of the question in the general interview.
4.5. Behavior Module
The different behaviors associated with the vocational guidance session are divided and prioritized as follows:
Level 1: Behaviors involving individual movements of the joints of the robot, head movements, changes in eye color, sounds, and the opening and closing of hands. Level 1 is divided into five categories, which group behaviors according to the body part of NAO used to execute the behavior. These are: (a) Facial Expressions, (b) Head Position, (c) Arms Position, (d) Hands Position, and (e) Sounds.
Level 2: The union of several behaviors in Level 1 generates personality traits in Level 2. NAO executes the different behaviors developed at Level 2 during the development of the vocational guidance session. These are divided into Question Behaviors (i.e., behaviors executed when the robot asks a question, greets someone, or says goodbye to the person) and Answer Behaviors (i.e., behaviors that are triggered depending on the answers to the questions posed).
4.5.1. Question Behaviors
Behaviors involving movements with the robot’s arms, randomly executed, are used to accompany the voice of the robot during a question, greeting, or farewell of the vocational guidance session and thus emphasize what it is saying.
4.5.2. Answer Behaviors
The set of 20 personality-descriptive adjectives (personality traits), selected in
Table 1, are grouped according to five different emotions: anger, boredom, interest, surprise, and joy. Each emotion has four associated adjectives, shown in
Table 8. The movement of each personality trait is pre-programmed, using Choregraphe in combination with the different Level 1 behaviors.
Figure 2 shows some examples of the construction of this type of behavior in Choregraphe.
Level 3: On Level 3, each of the behaviors associated with Level 2 has a variable that determines the frequency with which it appears during the interview. This variable is called
Frequency Weight (FW). By grouping emotions in some percentage, Level 3 will be obtained, and therefore a personality is defined. Frequency weight values are determined, taking into account the
Factor Loadings (FL) and correlation shown in
Table 1. In addition, frequency weight values are established in a range of 0–100 for every Level 2 behavior.
Figure 3 shows the proposed curve for determining the frequency weights.
A correlation of −1 (perfect negative correlation) is represented by frequency weight value 0. Non-correlation is determined at a value of 12.5, to reserve the interval of 0–12.5 to represent negative correlations. When the factor loadings value is close to zero, between −0.1 and +0.1, the relationship between the adjective and the factor is very weak. Therefore, there will be fewer negative than positive correlations in this interval, since negative correlations approach a correlation equal to zero, and positive correlations move away from this value. The frequency weight values will increase linearly for positive correlations. Finally, a frequency weight value of 100 represents a correlation of +1 (perfect positive correlation).
Figure 4 shows the curve obtained for Factor I (Extroversion) according to the graph shown in
Figure 3.
The percentages in red represent the total frequencies by emotion. Each factor is assigned a name according to its characteristic traits. For example, the frequency weights obtained for Factor II make it possible to describe the following personality:
Optimistic Personality: “Someone who is sympathetic, agreeable, enthusiastic; never loses his composure; and seldom gets angry.”
4.6. Neural Network Model
The use of artificial neural networks (ANNs) for recognizing patterns makes it possible to classify the selected behaviors. In this way, the system is capable of choosing the most appropriate behavior to be executed by the robot during a vocational guidance session. In pattern recognition, a neural network is required to classify inputs into a set of target categories. The inputs of the neural network are listed as follows:
Answer rating (score): rating of the response issued by the answer to the question asked (input1: score).
Question rating: the rating of the question asked by the robot according to the interview script shown in
Table 6 (input2: low priority question, medium priority question, or high priority question).
Emotion percentage: the percentage by emotion for each of the robot’s personalities (input3: %anger, input4: %boredom, input5: %interest, input6: %surprise, input7: %joy).
The outputs of the neural network are the set of behaviors of Level 2.
Figure 10 represents the neural network model for recognizing the twenty (20) behaviors. The ANN selects the right behavior, according to the personality parameters set, when an answer is given by the interviewee. This answer has to be qualified with a score before it enters into the neural network.
Training Data:
Table 9 shows how the five (5) emotions are organized according to the priority of the question and the score of the answer.
To calculate the upper limits for each score by priority, as shown in
Table 9, first, the proportion of each emotion within the complete set of emotions has to be determined, using Equation (5).
where
pi is equal to the percentage by emotion for each personality;
mi is the number of times the emotion is repeated, as shown in
Table 9; and
i represents each of the five emotions. Secondly, each priority has a number of emotions associated with it, so the total of existing
Xi in that priority has to be calculated. For example, in the case of high priority, this value is determined as shown in Equation (6).
To find the ranges of each qualifier for the answer (score), continuing with the example for high priority, it can be calculated as shown in Equations (7) to (11).
where AR represents the Answer Rating for each answer qualifier, E is an excellent qualifier, G is a good qualifier, A is an acceptable qualifier, I is an insufficient qualifier, and D is a deficient qualifier for response. As an example,
Table 10 shows the AR calculations for a reserved personality.
The selection of the appropriate behavior that the robot must display is carried out based on the results obtained with Equations (5) to (11) for calculating the upper limits for each score by priority (AR). For example, for a low priority of the question and a Reserved Personality (Type I), the upper limits of the score are as shown in
Figure 11.
Any response score between 0 and 21 should trigger a behavior corresponding to the boredom emotion. Therefore, values closer to zero correspond to questions answered less satisfactorily than questions with a score further away from this value. The higher the score value, the lower the robot’s tendency to become bored, which is the case with values close to zero, for example. This behavior is presented in an inverse way for surprise and interest emotions. In this way, the five emotions can be divided into negative emotions (anger and boredom) and positive emotions (interest, surprise, and joy).
The frequency weight values of each behavior allow us to calculate the limits at which it can be selected, considering the score of the response. In the case of positive emotions, these weights are organized in ascending order, and for negative emotions, in descending order. The limits for the four behaviors that make up each emotion are calculated with Equations (12) to (15).
where %BEH is equal to the percentage of frequency weights for each behavior within an emotion and AREmotion is the sum of the upper limits for each score by priority within the same emotion.
Figure 11 shows the results for these calculations. The percentages in red represent the total frequencies by emotion, and the values in green represent the percentage of frequency weights for each behavior.
The training data contain, in matrix form, all the different values that can be given to the vectors Inputs and Targets, to represent various models of the elements to be recognized. To train the network, covering all possibilities, 303 different data are needed for each personality. Two vectors are generated in this case, with 1515 types of samples, each one with one behavior for seven inputs. Due to the number of data required, the dataset is generated to cover all the set of 20 personality-descriptive behaviors (personality traits) based on the range of possibilities that each input can take. In this sense, for the nine questions, the answer scores (input 1) are assigned using a uniformly distributed pseudo-random function in the range of 0% to 100%, taking into account all different question priorities (Input 2) and all emotion percentage sets for each personality (Inputs 3 to 7). A supervised learning strategy is run for training different neural networks with different numbers of neurons in the hidden layer, looking for the topology with the best performance. Here, a feed-forward back-propagation neural network with twenty neurons (20) in the hidden layer is selected. The metrics used are Cross-Entropy (to measure performance) and Percent Error (to evaluate the percentage of misclassification). The data for training stood at 70% (1061 samples); for validation, 15% (227 samples); and for testing, 15% (227 samples). The confusion matrix shows the percentages of correct and incorrect classifications. In this way, it can determine how well the classification of the data is performed. The percentage of overall classification is 91.2% (See
Figure 12).






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}