1. Introduction
Cryptographic algorithms are grouped into two categories named symmetric algorithms and public key (or asymmetric) algorithms. The former uses a single key between two parties to enable a secure communication, where the key is kept private from all other parties. Symmetric algorithms are widely used because of its simplicity. However, a symmetric key algorithm requires an agreement between sender and receiver on the secret key. Asymmetric, or public key cryptosystems use two different keys called private keys and public keys. Whereas the private key is kept secret for the decryption process, the public key is used for encryption and can be revealed to all other parties. The encryption operation is conducted using a public key, and the encrypted message can only be decrypted using the corresponding private key. The security of Rivest, Shamir, and Adleman (RSA) cryptosystems [
1] and elliptic curve cryptosystems (ECC) [
2,
3] are based on the difficulty of solving some number theoretic problems and the difficulty of solving the elliptic curve discrete logarithm problems, respectively. However, these problems can be solved by the algorithm proposed by Shor [
4] in polynomial time with quantum computers. Therefore, stronger security systems or post-quantum cryptosystems have been proposed, and the National Institute of Standards and Technology (NIST) is standardizing them. Among lattice-based cryptosystems for the post-quantum era, ring learning with errors (LWE) is a promising candidate because its security proofs are based on the worst-case hardness of lattice problems that there is no known quantum algorithm can efficiently solve [
5]. A typical block diagram of a typical ring-LWE cryptoprocessor is shown in
Figure 1. Input message
m is encrypted into ciphertext (
,
) using arithmetic computation on public key (
a,
p) and error polynomials
,
, and
. Original message
m can be recovered from ciphertext (
,
) and private key
using the decryption operation.
The ring-LWE problem has been discussed in recent studies, both in software and hardware [
5,
7,
8,
9]. In Reference [
5], high-throughput ring-LWE cryptoprocessors are designed to perform ring-LWE encryption and decryption operations. In Reference [
7], an approach of integrating ring-LWE cryptography into existing fingerprint authentication systems to fully protect the fingerprint data are introduced. Authors in [
9] present the implementation of ring-LWE encryption on IoT processors.
In the ring-LWE cryptosystem, lattices with an algebraic structure like polynomial multiplication and addition are performed over a polynomial ring, typically
. Among these operations, polynomial multiplication is the most complex one that can be efficiently performed using number theoretic transform (NTT)-based polynomial multiplication [
5]. NTT multiplier is a modified version of fast Fourier transform (FFT) to work in a finite field without inaccurate floating point or complex arithmetic to compute polynomial multiplication efficiently [
10]. There are several NTT multiplier architectures that deploy single-path delay feedback (SDF) or multiple path delay commutator (MDC) structures in literature. For example, a high throughput multiplier using NTT cores with radix-2 SDF architecture is presented in [
11]. In Reference [
5], authors introduce radix-2 and radix-8 MDC architecture-based NTT cores for ring-LWE cryptoprocessors to obtain the encryption throughput of gigabits per seconds and decryption throughput of megabits per second. However, these architectures require large hardware resources and high computation time since the NTT polynomial multipliers work separately and NTT operations are not fully optimized.
In this paper, a novel approach to efficiently use arithmetic components in ring-LWE cryptoprocessors to achieve a high efficiency is presented. Specifically, the polynomial multiplier and polynomial adder that participate in the ring-LWE encryption operation are reused in decryption phase to reduce hardware complexity. Additionally, the NTT polynomial multiplier is designed using MDF architecture and deploying pipeline technique among all stages of NTT and INTT transforms to mitigate hardware complexity and speed up multiplication operations. Our contributions of this article are summarized as follows:
We propose a ring-LWE cryptoprocessor architecture in which the same arithmetic components, including one polynomial multiplier and one polynomial adder, are used in both encryption and decryption operations to reduce hardware complexity. As a result, the proposed ring-LWE cryptoprocessor requires less hardware resource than existing architectures to perform encryption and decryption operation.
We deploy the polynomial multiplier using NTT multiplier with parallel based MDF architecture to enhance the polynomial multiplication. Furthermore, the pipeline technique is applied in the proposed design to reduce the system latency.
We implement the proposed ring-LWE cryptoprocessor architecture on Xilinx Virtex-7 FPGA board and compare the obtained results with its predecessors. Performance evaluation results show that the proposed architecture offers a higher throughput and a better efficiency than others.
The remaining of this paper is structured as follows. In
Section 2, brief discussions on the ring-LWE cryptosystems are carried out.
Section 3 presents the proposed algorithm and architecture for ring-LWE cryptoprocessor.
Section 4 provides the results of implementation and comparison, and
Section 5 includes conclusions.
3. Proposed Ring-LWE Cryptoprocessor Architecture Using Shared Arithmetic Components
3.1. Proposed Algorithm for the Ring-LWE Cryptoprocessor
The proposed shared arithmetic components based ring-LWE cryptography algorithm is described in Algorithm 1. Two additional parameters
and
are used to control the encryption and decryption operations. Encryption operation is enabled when
, and the multiplier Mult2 and adder Add3 participate in encryption phase. Input message
m is encoded to get polynomial
. This encoded message is then added with error polynomial
and stored in
. Polynomials’ multiplications
and
are calculated by Mult1 and Mult2, respectively. Ciphertext
is computed by adding two polynomials
and
using polynomial addition function Add2, while
is conducted by addition function Add3. Ciphertext
is then successfully carried out.
| Algorithm 1: Proposed ring-LWE cryptography algorithm using shared arithmetic components |
Input:
Output: Ciphertext , or original messsage m
while do
for to do
if then
else
end if;
end for
end while
Return
while do
for to do
if ( then
else
end if;
end for;
end while;
Return
|
The decryption operation is enabled by the signal
. In this phase, multiplier Mult2 and adder Add3 that participate in the encryption phase are reconfigured to perform operations over the ring. Specifically, multiplier Mult2 calculates the multiplication between the cipher-text
and the polynomial
. The result of this multiplication is then transferred to adder Add3, where it is added to the cipher-text polynomial
to return the pre-decoded polynomial
. Finally, the original message
m is recovered from the pre-decoded message
using a decoder. The original message
m is recovered from the pre-decoded polynomial
using a decoder. If the
i-th coefficient of
satisfies the condition
, the corresponding
i-coefficient of message
m (
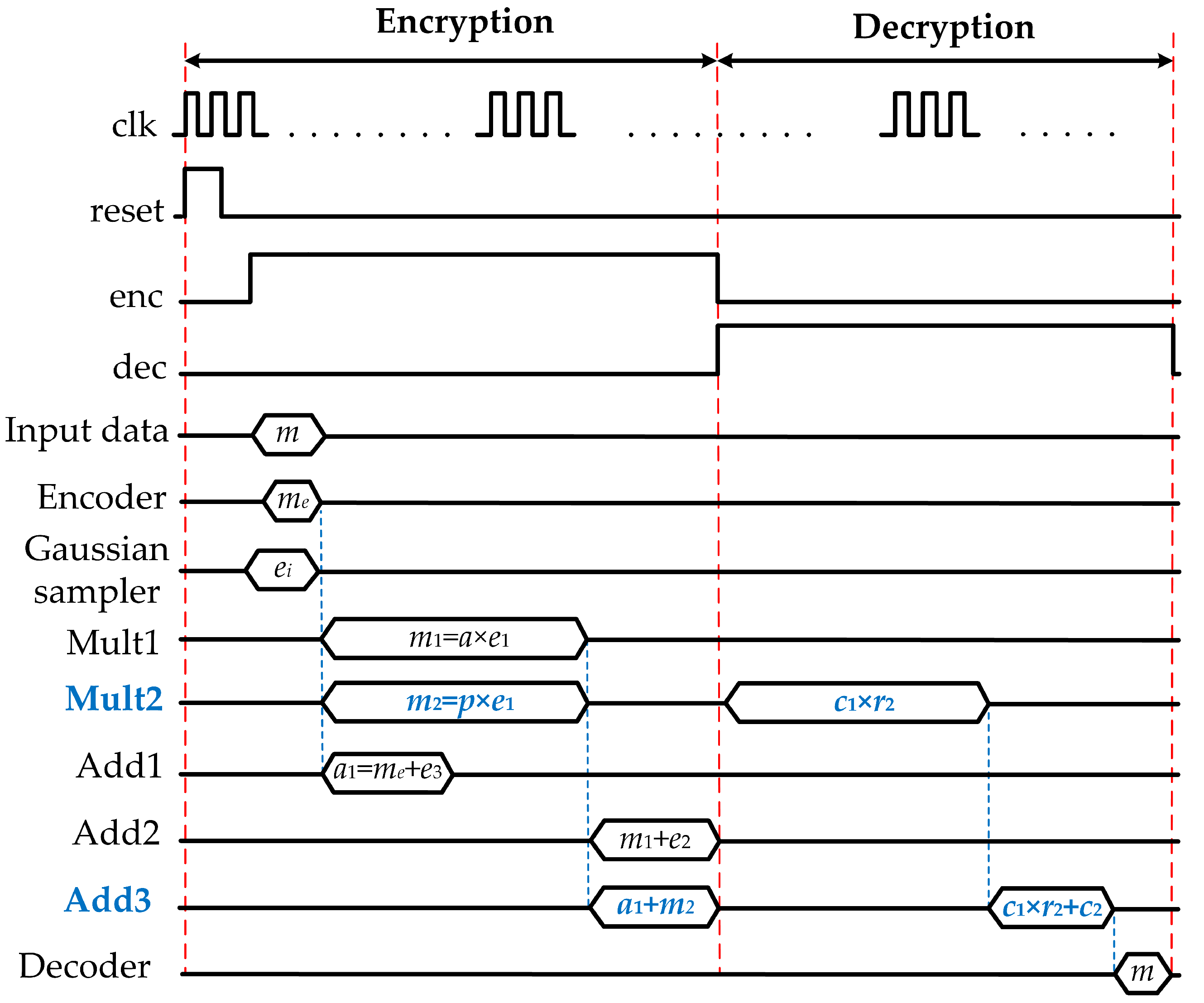
) is decoded to 1; otherwise, it is converted to 0. The detailed timing diagram of the proposed ring-LWE crytoprocessors is shown in
Figure 2.
When , polynomial multiplication is computed using the same multiplication resource Mult2 in encryption phase. Similarly, polynominal addition Add3 is reused to compute polynomial addition between polynomial and ciphertex . Finally, the original message m is retrieved by decoding message .
3.2. Ring-LWE Cryptoprocessor Architecture Using Shared Arithmetic Components
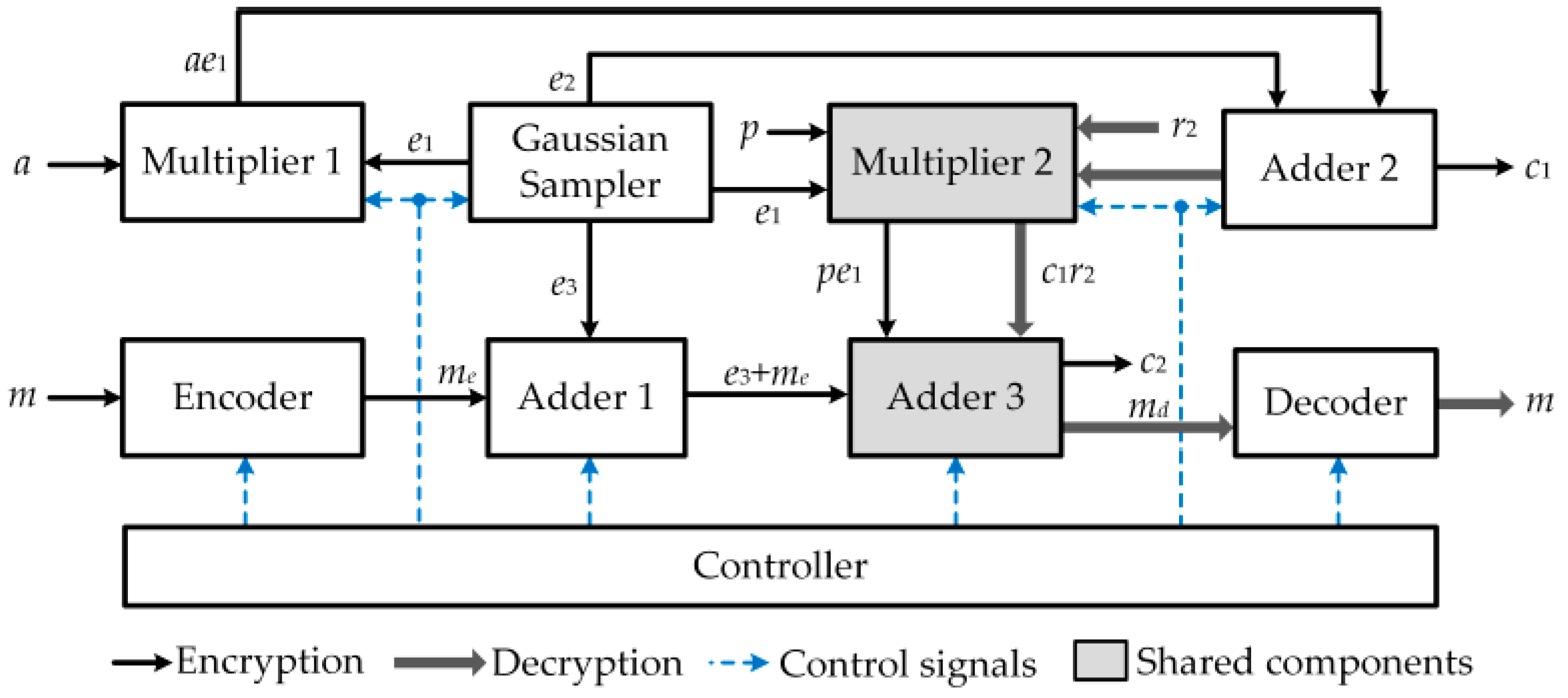
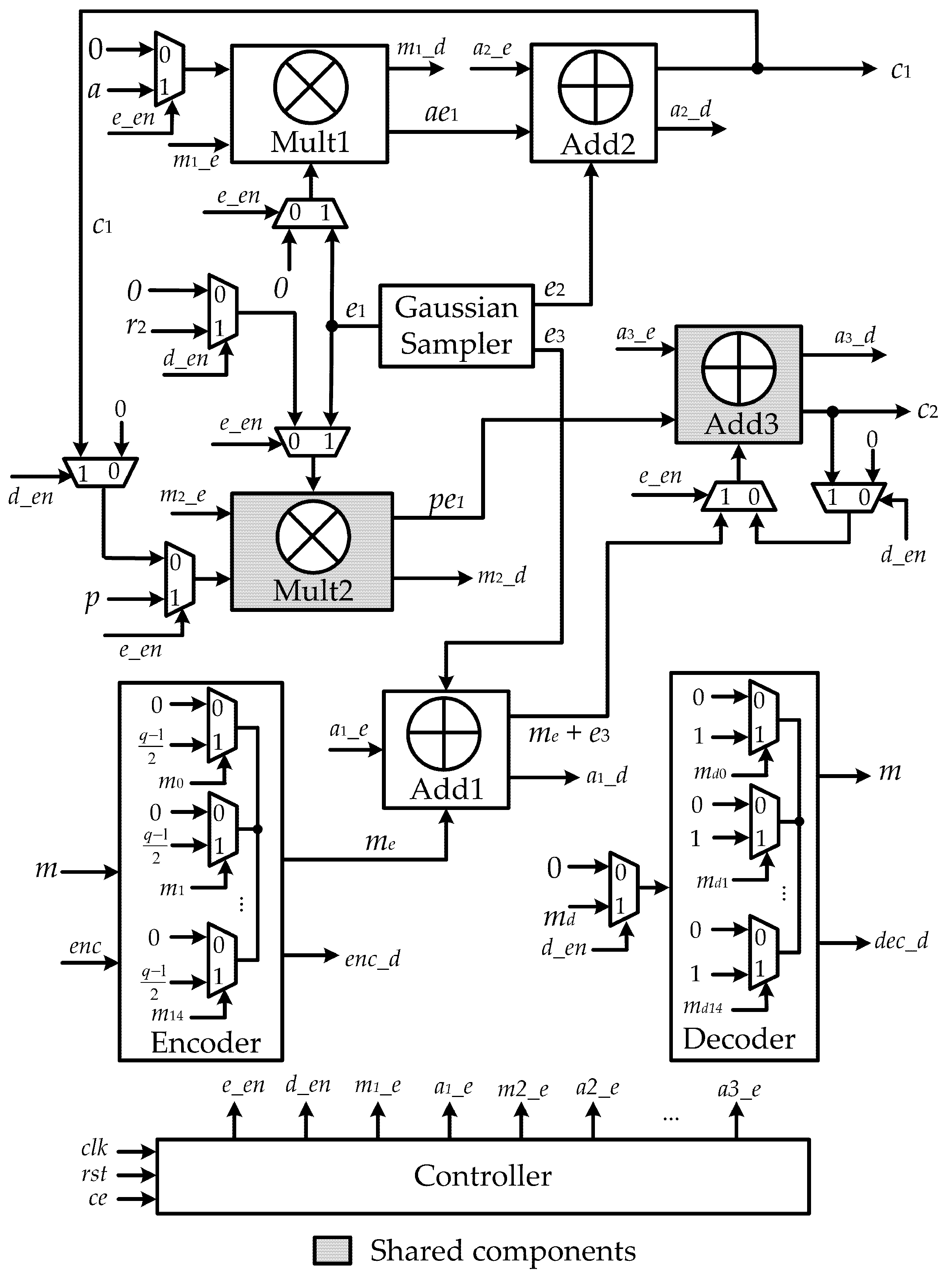
The proposed ring-LWE cryptoprocessor architecture using shared NTT polynomial multiplier and polynomial adder is illustrated in
Figure 3, which consists of an encoder, a Gaussian sampler, polynomial adders, polynomial multipliers, a decoder, and a controller. As can be seen, Multiplier 2 and Adder 3 are deployed to participate in both encryption and decryption operations. The detailed architecture is described in
Figure 4.
The encryption operation computes the cipher-text . This operation is enabled by the control signal . Initially, the input information m is encoded using an encoder. Each bit of the message m works as the control signal of the corresponding MUX, where its inputs are 0 or . The encoded message is constructed by the outputs of these MUXs. The encoded message is then added with the error polynomial using the adder Add1, controlled by signals and , to get the value . Multiplier Mult1 computes the product of the polynomial a and the error vector , while multiplier Mult2 calculates the multiplication of the public key p and . These multipliers are triggered by the control signals and , respectively. In the proposed architecture, we use different architectures of NTT multiplier, which are discussed in the following part. Two control signals and are assigned to 1 indicating that the multiplications at multipliers Mult1 and Mult2 are completely executed. The output of multiplier Mult1 becomes the input of adder Add 2, where it is added to the error vector to form the ciphertext . Concurrently, the output of multiplier Mult2 is added with the polynomial to generate ciphertext , performed by adder Add3. Upon control signals, and are equal to 1, and the encryption operation is fully accomplished. The ciphertext is carried out.
3.3. Proposed NTT Polynomial Multiplier Using MDF Architecture
To speed up the computation time and reduce the complexity of ring-LWE cryptoprocessors, a novel NTT polynomial multiplier using MDF architecture is proposed. The MDF architecture can provide a higher throughput rate with minimal hardware cost by combining the features of MDC and SDF. In MDF architecture, the SDF architecture is extended by using a multi-path approach. In order to achieve higher throughput rate, the number of data-paths can be increased to eight or even sixteen.
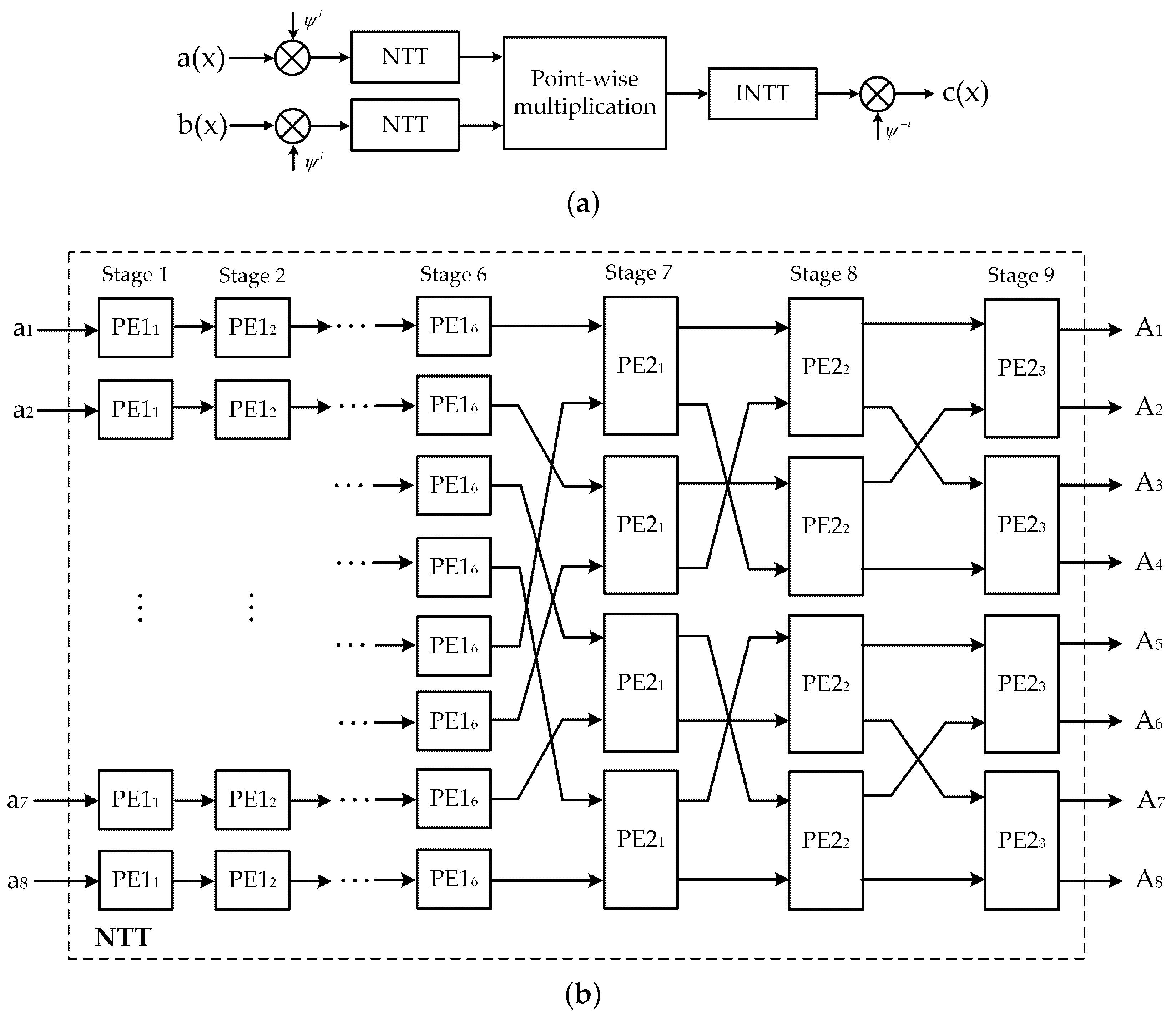
Theoretically, a NTT-based polynomial multiplier consists of three bit-reverse processes, two NTT processes, one point-wise multiplication, and one INTT process. By using the reverse Cooley–Tukey algorithm [
17] in the NTT-based polynomial multiplication operation, three bit-reverse operations are eliminated, as described in
Figure 5a. Therefore, the computation time and hardware complexity are greatly reduced. In addition, two NTT calculations for input polynomials are executed concomitantly to mitigate the multiplication latency. The pipeline technique is also applied between all stages of NTT multipliers to decrease critical path delay. In this work, the 8-parallel MDF architecture-based NTT multiplier is deployed. This multiplier is employed in the ring-LWE cryptoprocessors to conduct the encryption and decryption operations. The detail architecture of NTT core using 8-parallel MDF architecture is illustrated in
Figure 5b. In
Figure 5b, 512-coefficients of input polynomial are divided into eight parallel paths, each path consists of 64 coefficients. For example, path
of polynomial
in
Figure 5b consists of coefficients
,
,
, and so on. Two input polynomials
and
are processed using NTT transform architecture. After obtaining the NTT transform of two polynomials
and
, the point-wise multiplication operation is calculated, followed by the INTT transform to return the value of the multiplication operation. The architecture of INTT core is similar with NTT core architecture, which consists of processing elements PE1 and PE2, as presented in
Figure 5b. The proposed PE1 and PE2 architectures for the NTT core are detailed in
Figure 6.
4. Implementation Results and Comparison
The proposed architecture for ring-LWE cryptoprocessor is modeled in Verilog HDL, synthesized, and implemented using Xilinx VIVADO 2017.4 on a Virtex-7 FPGA platform. The implementation results of ring-LWE cryptoprocessor are summarized in
Table 1.
As can be seen from
Table 1, the proposed architecture requires less hardware resources, calculated in number of slices and LUTs, to conduct a completed ring-LWE encryption–decryption operation compared with similar parallel multiplier-based ring-LWE architectures presented in [
5,
6]. Specifically, to perform ring-LWE encryption and decryption operations, the proposed architecture uses only 23,707 slices and 61,258 LUTs, which is about 42% and 67.83% of that in [
5], respectively. Additionally, the encryption and decryption throughput of the proposed architecture are higher than that of architecture in [
6] and R8M architecture in [
5]. The architectures in [
18,
19] require a small number of slices and LUTs to perform encryption and decryption; however, these architectures require high latency to complete ring-LWE encryption and decryption operations. Therefore, the values of throughput offered by these architectures are smaller than 150 Mbps, as described in
Table 1.
Efficiency presented in [
20] can be used as a parameter to evaluate the performance of different designs on various FPGA platforms. In detail, the efficiency parameter represents the throughput value that one hardware unit (LUT) of an architecture can offer. As can be seen from
Table 1, the proposed ring-LWE cryptoprocessor architecture can offer a better value of efficiency compared with that of other architectures. Specifically, the obtained efficiency value of the proposed architecture is about two and seven times larger than that of architectures in [
5,
18], respectively. Comparison in encryption time, decryption time, and efficiency is described in
Figure 7.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}