FCC-Net: A Full-Coverage Collaborative Network for Weakly Supervised Remote Sensing Object Detection

Abstract
:1. Introduction
- (1)
- We propose a novel end-to-end remote sensing object detection network (FCC-Net) combining a weakly supervised detector and a strongly supervised detector for addressing the challenge of insufficient labeled remote sensing data, which improves the performance of only using image-level labels training significant;
- (2)
- We design a scale robust module on the top of the backbone using hybrid dilated convolutions and introduce a cascade multi-level pooling module for multiple feature fusion on the backend of the backbone, which promisingly suppresses the sensitivity of the network on scale changes to further enhance the ability of feature learning;
- (3)
- We define a focal-based classification and distance-based regression multitask collaborative loss function that can jointly optimize the region classification and regression in the RPN phase;
- (4)
- Our proposed method yields significant improvements compared with state-of-the-art methods on TGRS-HRRSD and DIOR datasets.
2. Related Work
2.1. Small Objects in Remote Sensing Images
2.2. Insufficient Training Examples of Remote Sensing Images
2.3. Foreground-Background Class Imbalance
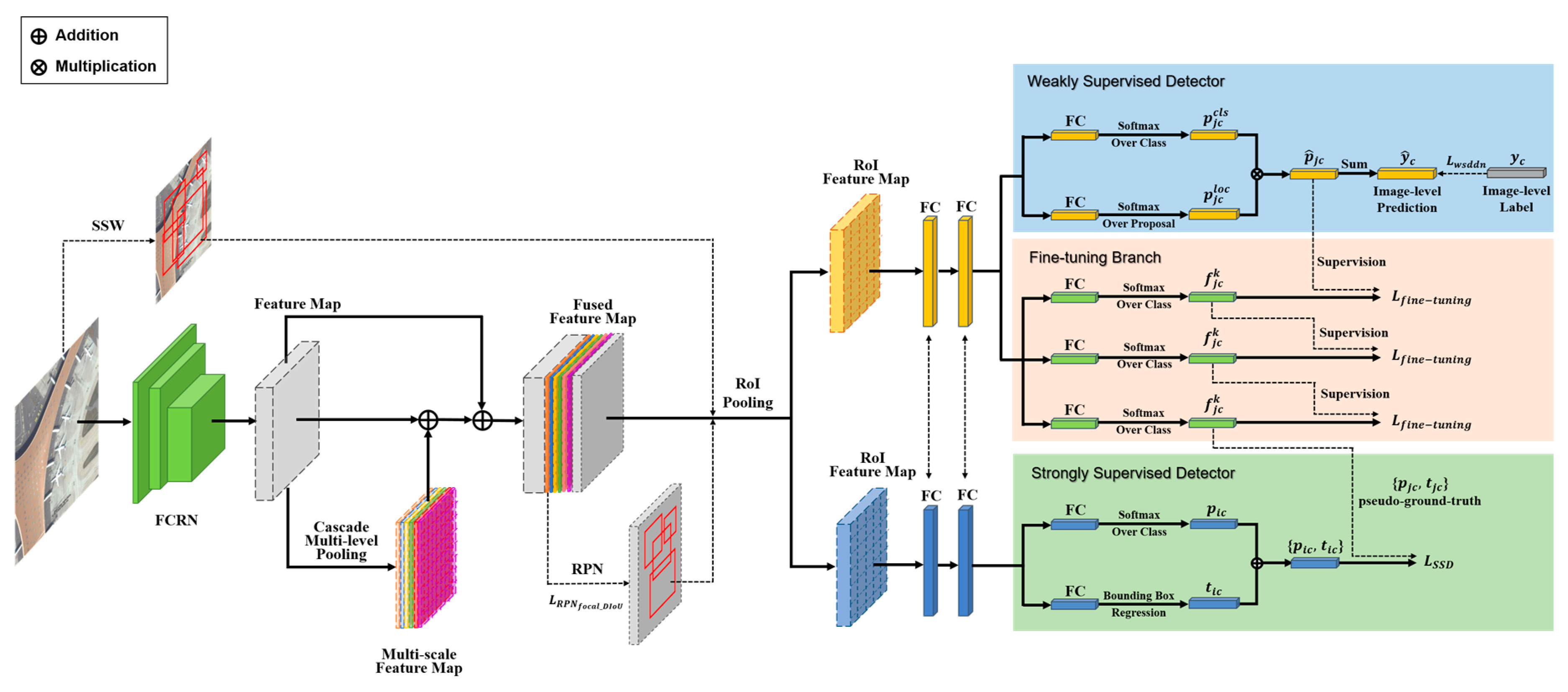
3. Proposed Method
- (1)
- Fine-tuning FCRN to extract more image edges and details information and utilizing CMPM to fuse multiscale features for better correlation between local–global information;
- (2)
- Training a weakly supervised detector (WSD) using image-level labels and adopting the fine-tuning branch to refine the proposal results of the WSD for obtaining the final pseudo-ground-truths;
- (3)
- Training a strongly supervised detector (SSD) with the pseudo-ground-truths generated by previous steps and minimizing the overall loss function in a stage-wise fashion to optimize the training process.
3.1. Scale Robust Backbone for High-Resolution Remote Sensing Images
3.1.1. Full-Coverage Residual Network
3.1.2. Cascade Multi-Level Pooling Module
3.2. Collaborative Detection SubNetwork for Weakly Supervised RSOD
3.2.1. Weakly Supervised Detector (WSD)
3.2.2. Strongly Supervised Detector (SSD)
3.3. Overall, Loss Function
| Algorithm 1 FCC-Net Algorithm |
Inputs: remote-sensing image I and image-level labels Output: Detection results
|
4. Experimental Settings
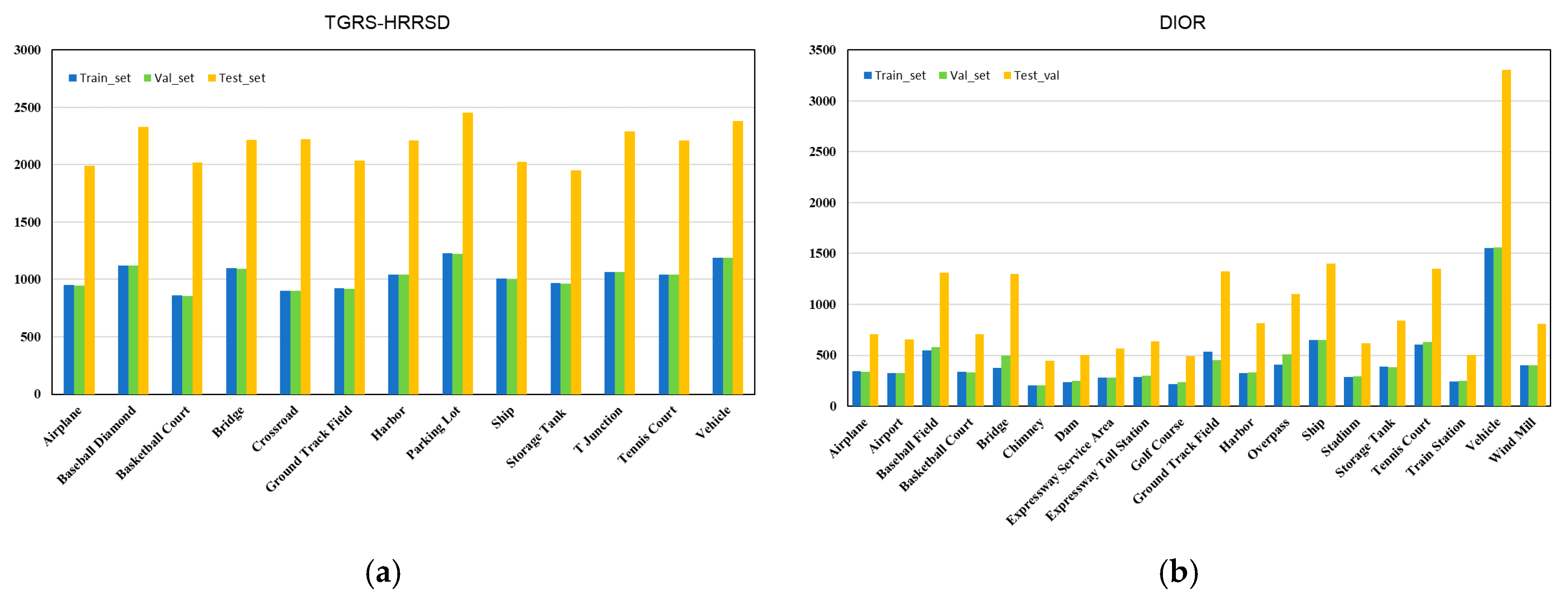
4.1. Datasets
4.2. Evaluation Metrics
4.2.1. Precision–Recall Curve
4.2.2. Average Precision and Mean Average Precision
4.2.3. Correct Location
4.3. Implementation Details
5. Experimental Results and Discussion
5.1. Evaluation on TGRS-HRRSD Dataset
5.2. Evaluation on DIOR Dataset
5.3. Ablation Experiments
5.4. Qualitative Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Campbell, J.B.; Wynne, R.H. Introduction to Remote Sensing, 5th ed.; Guilford Press: New York, NY, USA, 2011; ISBN 978-1-60918-176-5. [Google Scholar]
- Iliffe, J.; Lott, R. Datums and Map Projections for Remote Sensing, GIS and Surveying, 2nd ed.; Whittles Publishing: Scotland, UK, 2008. [Google Scholar]
- Gherboudj, I.; Ghedira, H. Assessment of solar energy potential over the United Arab Emirates using remote sensing and weather forecast data. Renew. Sustain. Energy Rev. 2016, 55, 1210–1224. [Google Scholar] [CrossRef]
- Lindgren, D. Land Use Planning and Remote Sensing; Taylor & Francis: Milton Park, UK, 1984; Volume 2. [Google Scholar]
- Liu, Y.; Wu, L. Geological Disaster Recognition on Optical Remote Sensing Images Using Deep Learning. Procedia Comput. Sci. 2016, 91, 566–575. [Google Scholar] [CrossRef] [Green Version]
- Chintalacheruvu, N. Video Based Vehicle Detection and its Application in Intelligent Transportation Systems. J. Transp. Technol. 2012, 2, 305–314. [Google Scholar] [CrossRef] [Green Version]
- Massad-Ivanir, N.; Shtenberg, G.; Raz, N.; Gazenbeek, C.; Budding, D.; Bos, M.P.; Segal, E. Porous Silicon-Based Biosensors: Towards Real-Time Optical Detection of Target Bacteria in the Food Industry. Sci. Rep. 2016, 6, 38099. [Google Scholar] [CrossRef] [PubMed]
- Jalilian, E.; Xu, Q.; Horton, L.; Fotouhi, A.; Reddy, S.; Manwar, R.; Daveluy, S.; Mehregan, D.; Gelovani, J.; Avanaki, K. Contrast-enhanced optical coherence tomography for melanoma detection: An in vitro study. J. Biophotonics 2020, 13, e201960097. [Google Scholar] [CrossRef]
- Turani, Z.; Fatemizadeh, E.; Blumetti, T.; Daveluy, S.; Moraes, A.F.; Chen, W.; Mehregan, D.; Andersen, P.E.; Nasiriavanaki, M. Optical radiomic signatures derived from optical coherence tomography images improve identification of melanoma. Cancer Res. 2019, 79, 2021–2030. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Mizuno, K.; Terachi, Y.; Takagi, K.; Izumi, S.; Kawaguchi, H.; Yoshimoto, M. Architectural study of HOG feature extraction processor for real-time object detection. In Proceedings of the 2012 IEEE Workshop on Signal Processing Systems (SiPS), Quebec City, QC, Canada, 17–19 October 2012; pp. 197–202. [Google Scholar]
- Xu, S.; Fang, T.; Li, D.; Wang, S. Object classification of aerial images with bag-of-visual words. IEEE Geosci. Remote Sens. Lett. 2009, 7, 366–370. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Zheng, X.; Yuan, Y. Remote sensing scene classification by unsupervised representation learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5148–5157. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and robust convolutional neural network for very high-resolution remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 765–781. [Google Scholar]
- Zhang, W.; Wang, S.; Thachan, S.; Chen, J.; Qian, Y. Deconv R-CNN for small object detection on remote sensing images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; pp. 2483–2486. [Google Scholar]
- Deng, Z.; Sun, H.; Lei, L.; Zou, S.; Zou, H. Object Detection in Remote Sensing Imagery with Multi-scale Deformable Convolutional Networks. Acta Geod. Et Cartogr. Sin. 2018, 47, 1216–1227. [Google Scholar]
- Liu, W.; Ma, L.; Wang, J.; Chen, H. Detection of multiclass objects in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 791–795. [Google Scholar] [CrossRef]
- Ding, P.; Zhang, Y.; Deng, W.; Jia, P.; Kuijper, A. A light and faster regional convolutional neural network for object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 141, 208–218. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [Green Version]
- Ji, H.; Gao, Z.; Mei, T.; Li, Y. Improved faster R-CNN with multiscale feature fusion and homography augmentation for vehicle detection in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1761–1765. [Google Scholar] [CrossRef]
- Cheng, G.; Si, Y.; Hong, H.; Yao, X.; Guo, L. Cross-Scale Feature Fusion for Object Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Ying, X.; Wang, Q.; Li, X.; Yu, M.; Jiang, H.; Gao, J.; Liu, Z.; Yu, R. Multi-attention object detection model in remote sensing images based on multi-scale. IEEE Access 2019, 7, 94508–94519. [Google Scholar] [CrossRef]
- Chen, J.; Wan, L.; Zhu, J.; Xu, G.; Deng, M. Multi-scale spatial and channel-wise attention for improving object detection in remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2019, 17, 681–685. [Google Scholar] [CrossRef]
- Yan, J.; Wang, H.; Yan, M.; Diao, W.; Sun, X.; Li, H. IoU-adaptive deformable R-CNN: Make full use of IoU for multi-class object detection in remote sensing imagery. Remote Sens. 2019, 11, 286. [Google Scholar] [CrossRef] [Green Version]
- Qian, X.; Lin, S.; Cheng, G.; Yao, X.; Ren, H.; Wang, W. Object Detection in Remote Sensing Images Based on Improved Bounding Box Regression and Multi-Level Features Fusion. Remote Sens. 2020, 12, 143. [Google Scholar] [CrossRef] [Green Version]
- Qiu, S.; Wen, G.; Deng, Z.; Liu, J.; Fan, Y. Accurate non-maximum suppression for object detection in high-resolution remote sensing images. Remote Sens. Lett. 2018, 9, 237–246. [Google Scholar] [CrossRef]
- Zhu, M.; Xu, Y.; Ma, S.; Li, S.; Ma, H.; Han, Y. Effective Airplane Detection in Remote Sensing Images Based on Multilayer Feature Fusion and Improved Nonmaximal Suppression Algorithm. Remote Sens. 2019, 11, 1062. [Google Scholar] [CrossRef] [Green Version]
- Bilen, H.; Vedaldi, A. Weakly supervised deep detection networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2846–2854. [Google Scholar]
- Tang, P.; Wang, X.; Bai, X.; Liu, W. Multiple instance detection network with online instance classifier refinement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2843–2851. [Google Scholar]
- Tang, P.; Wang, X.; Bai, S.; Liu, W.; Yuille, A. PCL: Proposal Cluster Learning for Weakly Supervised Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 176–191. [Google Scholar] [CrossRef] [Green Version]
- Wan, F.; Wei, P.; Han, Z.; Jiao, J.; Ye, Q. Min-Entropy Latent Model for Weakly Supervised Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2395–2409. [Google Scholar] [CrossRef] [Green Version]
- Inoue, N.; Furuta, R.; Yamasaki, T.; Aizawa, K. Cross-domain weakly-supervised object detection through progressive domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5001–5009. [Google Scholar]
- Wan, F.; Liu, C.; Ke, W.; Ji, X.; Jiao, J.; Ye, Q. C-MIL: Continuation multiple instance learning for weakly supervised object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2199–2208. [Google Scholar]
- Zhang, Y.; Bai, Y.; Ding, M.; Li, Y.; Ghanem, B. W2f: A weakly-supervised to fully-supervised framework for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 928–936. [Google Scholar]
- Wang, J.; Yao, J.; Zhang, Y.; Zhang, R. Collaborative learning for weakly supervised object detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 971–977. [Google Scholar]
- Wang, X.; Wang, J.; Tang, P.; Liu, W. Weakly-and Semi-Supervised Fast Region-Based CNN for Object Detection. J. Comput. Sci. Technol. 2019, 34, 1269–1278. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object detection in optical remote sensing images based on weakly supervised learning and high-level feature learning. IEEE Trans. Geosci. Remote Sens. 2014, 53, 3325–3337. [Google Scholar] [CrossRef] [Green Version]
- Zhou, P.; Cheng, G.; Liu, Z.; Bu, S.; Hu, X. Weakly supervised target detection in remote sensing images based on transferred deep features and negative bootstrapping. Multidim. Syst. Sign. Process. 2015, 27, 925–944. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly supervised learning based on coupled convolutional neural networks for aircraft detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Ji, J.; Zhang, T.; Yang, Z.; Jiang, L.; Zhong, W.; Xiong, H. Aircraft Detection from Remote Sensing Image Based on A Weakly Supervised Attention Model. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 322–325. [Google Scholar]
- Xu, J.; Wan, S.; Jin, P.; Tian, Q. An active region corrected method for weakly supervised aircraft detection in remote sensing images. In Proceedings of the Eleventh International Conference on Digital Image Processing, Guangzhou, China, 11–13 May 2019; Volume 11179, p. 111792H. [Google Scholar]
- Wu, X.; Hong, D.; Tian, J.; Kieft, R.; Tao, R. A weakly-supervised deep network for DSM-aided vehicle detection. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1318–1321. [Google Scholar]
- Cai, B.; Jiang, Z.; Zhang, H.; Zhao, D.; Yao, Y. Airport Detection Using End-to-End Convolutional Neural Network with Hard Example Mining. Remote Sens. 2017, 9, 1198. [Google Scholar] [CrossRef] [Green Version]
- Koga, Y.; Miyazaki, H.; Shibasaki, R. A CNN-based method of vehicle detection from aerial images using hard example mining. Remote Sens. 2018, 10, 124. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Sang, J.; Zhang, Q.; Xiang, H.; Cai, B.; Xia, X. Multi-Scale Vehicle Detection for Foreground-Background Class Imbalance with Improved YOLOv2. Sensors 2019, 19, 3336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sergievskiy, N.; Ponamarev, A. Reduced focal loss: 1st place solution to xview object detection in satellite imagery. arXiv 2019, arXiv:1903.01347. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Kosugi, S.; Yamasaki, T.; Aizawa, K. Object-aware instance labeling for weakly supervised object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6064–6072. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar] [CrossRef]
- Sun, H.; Sun, X.; Wang, H.; Li, Y.; Li, X. Automatic target detection in high-resolution remote sensing images using spatial sparse coding bag-of-words model. IEEE Trans. Geosci. Remote Sens. 2012, 9, 109–113. [Google Scholar] [CrossRef]
- Han, J.; Zhou, P.; Zhang, D.; Cheng, G.; Guo, L.; Liu, Z.; Bu, S.; Wu, J. Efficient, simultaneous detection of multi-class geospatial targets based on visual saliency modeling and discriminative learning of sparse coding. ISPRS J. Photogramm. Remote Sens. 2014, 89, 37–48. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Peicheng, Z.; Cheng, G.; Junwei, H. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7416. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ResNet-50 | Modified | |||
|---|---|---|---|---|
| Stage | Layer | Output_Size | Layer | Output_Size |
| Stage 1 | 7 × 7, 64, stride 2 | 1/2 | 7 × 7, 64, stride 2 | 1/2 |
| Stage 2 | 3 × 3, max-pooling, stride 2 | 1/4 | 3 × 3, max-pooling, stride 2 | 1/4 |
| Stage 3 | 1/8 | 1/8 | ||
| Stage 4 | 1/16 | 1/8 | ||
| Stage 5 | 1/32 | 1/8 | ||
| Avg-Pooling, FC Layer, Softmax | Removed | |||
| Methods | The Class AP | mAP | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | ||
| BoW [12] | 36.8 | 7.0 | 4.4 | 7.2 | 12.2 | 42.1 | 24.1 | 5.3 | 39.3 | 51.5 | 0.7 | 12.5 | 11.4 | 18.9 |
| SSCBoW [64] | 59.3 | 35.0 | 7.9 | 9.3 | 11.6 | 7.6 | 53.5 | 6.8 | 37.6 | 26.3 | 0.8 | 12.2 | 30.5 | 23.0 |
| FDDL [65] | 30.5 | 20.4 | 2.5 | 10.1 | 18.2 | 15.0 | 19.3 | 7.4 | 33.2 | 72.7 | 1.9 | 16.0 | 4.0 | 19.3 |
| COPD [66] | 62.5 | 52.2 | 9.6 | 7.1 | 8.6 | 72.4 | 47.8 | 17.4 | 45.3 | 50.1 | 1.6 | 58.1 | 32.7 | 35.8 |
| Transformed CNN [13] | 77.5 | 57.6 | 18.0 | 20.0 | 25.9 | 76.3 | 54.1 | 16.6 | 49.7 | 79.1 | 2.4 | 70.8 | 41.3 | 45.3 |
| RICNN [67] | 78.1 | 59.6 | 23.0 | 27.4 | 26.6 | 78.0 | 47.8 | 20.5 | 56.5 | 81.0 | 9.3 | 66.4 | 52.0 | 48.2 |
| YOLOv2 [68] | 84.6 | 62.2 | 41.3 | 79.0 | 43.4 | 94.4 | 74.4 | 45.8 | 78.5 | 72.4 | 46.8 | 67.6 | 65.1 | 65.8 |
| Fast R-CNN [23] | 83.3 | 83.6 | 36.7 | 75.1 | 67.1 | 90.0 | 76.0 | 37.5 | 75.0 | 79.8 | 39.2 | 75.0 | 46.1 | 66.5 |
| Faster R-CNN [18] | 90.8 | 86.9 | 47.9 | 85.5 | 88.6 | 90.6 | 89.4 | 63.3 | 88.5 | 88.7 | 75.1 | 80.7 | 84.0 | 81.5 |
| WSDDN [40] | 47.9 | 51.4 | 13.6 | 3.0 | 18.0 | 89.6 | 22.6 | 13.4 | 31.8 | 51.5 | 5.1 | 32.8 | 13.7 | 31.1 |
| OICR [41] | 34.2 | 33.5 | 23.1 | 2.9 | 13.1 | 88.9 | 9.0 | 17.6 | 50.9 | 73.3 | 13.2 | 36.1 | 14.6 | 32.3 |
| FCC-Net (FCRN + CMPM + MCL) | 64.6 | 52.3 | 21.1 | 22.4 | 28.6 | 90.3 | 18.2 | 25.3 | 60.5 | 72.6 | 18.2 | 43.6 | 35.8 | 42.6 |
| Methods | mAP | CorLoc |
|---|---|---|
| WSDDN [40] | 31.1 | 31.6 |
| OICR [41] | 32.3 | 37.4 |
| FCC-Net (FCRN + CMPM + MCL) | 42.6 | 50.7 |
| Methods | Faster R-CNN [18] | RetinaNet [25] | FCC-Net | |||
|---|---|---|---|---|---|---|
| VGG16 | ResNet-50 | ResNet-101 | ResNet-50 | FRCN | FRCN + CMPM | |
| mAP | 54.1 | 65.7 | 66.1 | 17.2 | 17.7 | 18.1 |
| Methods | The Class AP | mAP | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 | C20 | ||
| Fast R-CNN [23] | 44.2 | 66.8 | 67.0 | 60.5 | 15.6 | 72.3 | 52.0 | 65.9 | 44.8 | 72.1 | 62.9 | 46.2 | 38.0 | 32.1 | 71.0 | 35.0 | 58.3 | 37.9 | 19.2 | 38.1 | 50.0 |
| Faster R-CNN [18] | 53.6 | 49.3 | 78.8 | 66.2 | 28.0 | 70.9 | 62.3 | 69.0 | 55.2 | 68.0 | 56.9 | 50.2 | 50.1 | 27.7 | 73.0 | 39.8 | 75.2 | 38.6 | 23.6 | 45.4 | 54.1 |
| WSDDN [40] | 9.1 | 39.7 | 37.8 | 20.2 | 0.3 | 12.2 | 0.6 | 0.7 | 11.9 | 4.9 | 42.4 | 4.7 | 1.1 | 0.7 | 63.0 | 4.0 | 6.1 | 0.5 | 4.6 | 1.1 | 13.3 |
| OICR [41] | 8.7 | 28.3 | 44.1 | 18.2 | 1.3 | 20.2 | 0.1 | 0.7 | 29.9 | 13.8 | 57.4 | 10.7 | 11.1 | 9.1 | 59.3 | 7.1 | 0.7 | 0.1 | 9.1 | 0.4 | 16.5 |
| FCC-Net (FRCN + CMPM + MCL) | 20.1 | 38.8 | 52.0 | 23.4 | 1.8 | 22.3 | 0.2 | 0.6 | 28.7 | 14.1 | 56.0 | 11.1 | 10.9 | 10.0 | 57.5 | 9.1 | 3.6 | 0.1 | 5.9 | 0.7 | 18.3 |
| Methods | mAP | CorLoc |
|---|---|---|
| WSDDN [40] | 13.3 | 32.4 |
| OICR [41] | 16.5 | 34.8 |
| FCC-Net (FCRN + CMPM + MCL) | 18.3 | 41.7 |
| Methods | The Class AP | mAP | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | ||
| FCC–VGG16 | 62.3 | 49.0 | 17.8 | 21.5 | 26.9 | 82.3 | 10.4 | 21.5 | 55.8 | 69.3 | 15.0 | 42.1 | 31.9 | 38.9 |
| FCC–Res50 | 62.5 | 49.1 | 18.0 | 20.9 | 27.6 | 84.7 | 10.1 | 23.9 | 56.0 | 69.4 | 14.9 | 42.7 | 32.4 | 39.4 |
| FCC–Res101 | 63.0 | 49.1 | 18.2 | 21.7 | 27.7 | 83.9 | 10.4 | 24.0 | 55.9 | 68.6 | 15.7 | 42.6 | 33.3 | 39.5 |
| FCC–FCRN | 63.5 | 49.7 | 19.2 | 22.6 | 29.9 | 83.3 | 11.3 | 25.1 | 57.8 | 72.6 | 18.2 | 43.9 | 32.1 | 40.7 |
| FCC–FCRN–CMPM | 64.7 | 51.6 | 20.6 | 24.2 | 28.1 | 88.3 | 19.2 | 26.2 | 59.2 | 72.4 | 18.1 | 44.5 | 35.0 | 42.5 |
| FCC–FCRN–CMPM–MCL | 64.6 | 52.3 | 21.1 | 22.4 | 28.6 | 90.3 | 18.2 | 25.3 | 60.5 | 72.6 | 18.2 | 43.6 | 35.8 | 42.6 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Shao, D.; Shu, X.; Zhang, C.; Wang, J. FCC-Net: A Full-Coverage Collaborative Network for Weakly Supervised Remote Sensing Object Detection. Electronics 2020, 9, 1356. https://doi.org/10.3390/electronics9091356
Chen S, Shao D, Shu X, Zhang C, Wang J. FCC-Net: A Full-Coverage Collaborative Network for Weakly Supervised Remote Sensing Object Detection. Electronics. 2020; 9(9):1356. https://doi.org/10.3390/electronics9091356
Chicago/Turabian StyleChen, Suting, Dongwei Shao, Xiao Shu, Chuang Zhang, and Jun Wang. 2020. "FCC-Net: A Full-Coverage Collaborative Network for Weakly Supervised Remote Sensing Object Detection" Electronics 9, no. 9: 1356. https://doi.org/10.3390/electronics9091356
APA StyleChen, S., Shao, D., Shu, X., Zhang, C., & Wang, J. (2020). FCC-Net: A Full-Coverage Collaborative Network for Weakly Supervised Remote Sensing Object Detection. Electronics, 9(9), 1356. https://doi.org/10.3390/electronics9091356