1. Introduction
A multi-robot system (MRS) is a set of autonomous agents, able to sense the environment, take decisions, communicate information, and cooperate in order to perform goals that are beyond the capabilities and the knowledge of each individual component [
1]. The strength of this architecture is indeed the possibility to accomplish complex global tasks through the realization of simple local rules by the interacting robotic agents. An MRS is thus mainly characterized by cooperative nature which is not altered by the addition and/or removal of a subset of elements. In this sense, it is robust and scalable [
2]: robustness refers to the ability of a system to tolerate the failure of one or more agents, while scalability originates from the system modularity.
Thanks to these features, in the last decade, the MRS architecture has emerged as an effective technology in military, civil, and industrial contexts, where it is employed in a wide range of application fields from the more traditional surveillance, monitoring, and tracking tasks with both fixed and mobile robotic agents [
3,
4,
5], to the modern physical interaction tasks involving loads cooperative grasping, transportation, and manipulation [
6,
7]. Nonetheless, the MRS scenario yields also new methodological challenges that need to be addressed and solved. Indeed, moving the focus from the single robotic agent to the robotic system implies the redefinition of the operation and control space, which involves not only the non-controllable surrounding environment but also the presence of neighboring robotic agents that may be collaborative or not. In this sense, architectural issues related to distributed or hierarchical strategies in controlling the MRS have to be considered [
8,
9,
10,
11], with an impact on both the information sharing and the control interplay among robots, in particular when the physical robot-to-robot interaction is required as in transportation/manipulation tasks. In this context, current MRS research effort is focused on the development of learning and optimal decision making algorithms to guarantee general improvements on efficiency, scalability, adaptivity, and robustness in presence of partial information availability and dynamic environments [
7,
12,
13].
Along this line, the attention in this work concerns a transportation task performed by cooperative mobile robots constituted by autonomous ground vehicles (AGVs) equipped with a generic manipulator whose end-effector (EE) consists of a (soft) gripper that allows to grasp the load of interest. Specifically, a model predictive control (MPC) architecture is adopted in conjunction with a leader–follower strategy to solve the cooperative tasks, namely trajectory planning towards the desired goal implementing obstacle avoidance for the leader and maintenance of the transportation formation along a feasible collision-free path for the follower [
14,
15].
1.1. Related Works
As explained in [
6,
16], when performing a cooperative transportation task, three main approaches can be distinguished in terms of load holding realization: pushing-only, grasping and caging. According to pushing-only strategies, the transport is achieved by pushing the load avoiding the physical attachment of the robots (see, e.g., [
17,
18,
19] and the references therein). Similarly, caging techniques envisage that robots arrange themselves around the load embracing and holding it tightly during the motion [
20]. On the other hand, grasping strategies rest on the presence of EEs that allow the robots to be physically (more or less elastically) attached to the load, and will represent the adopted solution for this paper case study.
As a first note in this respect, it is important to highlight that a fully decentralized approach may result difficult to realize in case of transported loads that cannot bear internal stresses induced by formation mismatch at the EE level. For this reason, centralized control schemes are typically proposed to face the problem of cooperative transportation. In [
21], for example, a centralized optimization approach is proposed, based on the calculation of a convex hull in space-time were no collisions can arise and deadlocks are prevented thanks to the global nature of the solution (differently from what can occur with a distributed local approach [
22]). Indeed this method allows for reconfiguration using the redundancy available for mobile manipulators and is more focused on collision avoidance. Additionally in [
23] a centralized method is proposed for an AGV transportation system with a particular attention on the force distribution and internal force analysis of the transported load, to yield an effective design of the control algorithm.
Interestingly, to address this issue by design, most of the existing solutions exploiting grasping strategies are based on a leader–follower paradigm wherein one robotic agent (the leader) is in charge to guide the rest of the MRS (the followers). Within the leader–follower framework the two approaches of centralized and decentralized can be found, where in the former case the followers follow the information given by a static leader, while in the latter the followers actively follow the leader motion. Several control techniques are utilized by leader–follower formation to ensure that the followers accurately follow the leader [
24], from the more classical linear techniques (e.g., proportional integral derivative (PID) control), to the non-linear based (e.g., sliding mode control), to name a few. With no aim of being exhaustive, some references exploring different control solution to address the single load cooperative transportation problem are reported in the following. In [
25] simulations and experiments are performed with two robots transporting a large and fragile load using a PID-based leader–follower control, proving the effectiveness of the approach in satisfying the load handling requirements.
In [
26] a dynamic control architecture of a team of two robots is presented where the control is design using the attractor dynamics approach. Simulations and real experiments in unknown and changing environments show stable behaviour of the two-robots system in accomplishing the joint transportation task.
The leader–follower control paradigm is adopted also in [
14,
27,
28] to design model predictive control (MPC) based distributed solutions for the cooperative transportation task. MPC schemes predict the future state of the plant over a finite horizon using a mathematical model and solve an optimal control problem to compute the control action by handling environment and plant constraints in the problem formulation (for a general overview on MPC we refer to [
29]). This last feature motivates the current extensive use of such a technique in solving path planning task, especially in the case of cluttered environments. Trajectory generation problem ensuring collision avoidance is, for instance, addressed in [
30,
31,
32] accounting for intelligent vehicles and also in [
33,
34,
35] for aerial platforms. In general, the use of MPC has become very popular due to the intrinsic flexibility in the formulation and possibility of easy adaptation to different objectives. The employment of the MPC approach for mobile manipulators can be found in [
36], where a decentralized nonlinear MPC (NMPC) is proposed with proofs of feasibility and convergence, and physical experiments are presented. A similar NMPC application is studied and simulated in [
37], which includes avoidance of collisions and of singular configurations for the manipulators. More recent studies like [
38] propose data-driven MPC solutions, where each robot employs sensor data to predict the future behavior of the others, instead of relying on mutual communication. Two observations are now in order. First, it is worthwhile to notice that it is also possible to generate trajectories for the single agent (e.g., the leader) in a much cheaper way than using the above MPC scheme, by exploiting popular algorithms as A-star or Rapidly-exploring Random Tree (RRT) [
39], followed by a trajectory smoothing procedure. It is nonetheless clear that these approaches only provide the geometric path, without consider constraints about the travel time or energy spent to move the robot from the initial point to the goal. Because of these requirements, MPC approaches remain preferable [
40]. Moreover, while in most of the MPC literature, collision avoidance is included in the problem formulation as hard constraints, some authors adopt the Potential Field Method [
41] for trajectory generation, which can be easily adapted for both the leader and the follower and can deal also with additional communication constraints [
42]. Local minima may appear with this latter approach, where the robots get stuck easily in presence of many obstacles, but recent advances propose ways to overcome this drawback [
43].
1.2. Contribution
Given these premises, the main contribution of this paper is the design and the implementation of an MPC-based leader–follower scheme that performs local trajectory planning for each robotic agent while also performing obstacle avoidance and maintaining grasping of the transported load. In particular, the proposed method improves the standard leader–follower approach, as in [
5], by accounting for the feasibility of the trajectory imposed by the leader to the follower. Specifically, the approach relies on a direct MPC formulation based on the convexification of the optimization space with linear constraints that are easily customizable depending on loads shapes. Formation errors and infeasibility in the trajectory calculation, caused by combination of the highly-reduced optimization space and leader–follower approaches, are mitigated via a novel recovery policy.
1.3. Paper Structure
The paper is organized as follows. After the formal statement of the problem in
Section 2, the main technical
Section 3,
Section 4 and
Section 5 discuss in detail the MPC approach for the leader–follower MRS, how obstacles are accounted for in the multi-robot optimization framework, and the feasibility-aware policy that is put in place to accommodate all constraints and requirements while ensuring the task accomplishment. Then, in
Section 6, a numerical validation is proposed to highlight the main features of the approach and assess its efficacy in performing the cooperative task in different complex scenarios. Finally,
Section 7 provides a summary of the study, together with some conclusive remarks.
1.4. Notation
In this work, vectors in and matrices in are indicated respectively with bold lowercase and bold uppercase letters. Calligraphic letters are reserved for sets. denotes the m-dimensional (column) vector having respectively all one entries, while and identify the null and the identity square matrices of dimension m. Finally, ⊗ indicates the standard Kronecker product.
2. Problem Formulation
Hereafter, we consider two autonomous ground robots made of a mobile base and a manipulator. These are required to transport a load in an environment populated by static and/or dynamic obstacles. The robots are supposed to grasp the load realizing a compliant contact. Within this context, the attention is focused on the development of a cooperative trajectory planning solution based on a leader–follower scheme for the two autonomous robots, which ensures the fulfillment of the transportation task in a decentralized way. According to [
15], since the grasping between the EE and the load is assumed to be compliant, the interaction wrench results to be proportional to the formation error. Hence, without loss of generality, the following assumptions are made for both the robotic agents (leader and follower):
all measurements, state and input quantities, as well as the environment obstacles, are referred to the position of the EE grasping the transported load; to allow control feasibility, the obstacle constraints on the EEs are compatible with those on the mobile base;
once a reference trajectory for the EE has been computed, a low-level controller is tasked to manage the position of the mobile base and the joints configuration of the manipulator such that the position of the EE is able to track the trajectory; such controller is assumed to have has full authority on the EE degrees of freedom, such that this latter can be modeled as a double integrator [
44] and the load is maintained at a constant height: the transportation problem can be therefore formulated in the two-dimensional plane;
the robot is equipped with sensing capabilities, so that it is aware of the environment and able to self-localize with respect to a common inertial frame; it is also able to communicate and exchange data with its transportation companion, through an ideal channel.
Given these assumptions, the combination of mobile base and manipulator is generic, and hereafter all quantities will be referred to the EE of the leader/follower. In the considered scenario we denote with and the position of the leader and the follower EE, respectively.
When accounting for the leader–follower paradigm, the cooperative trajectory planning problem consists in the definition of a desired trajectory
that drives the leader toward a final target position
, while the follower is required to maintain a certain distance
from the leader, so that the load is not stretched or the grasp is detached, i.e., its desired follower trajectory
is such that
An interesting remark is now in order. During the transportation phase that we consider, the design of safe trajectories (from initial to target position) for leader and follower, connected through the load grasping, implicitly regulates the load orientation. Indeed, this is motivated by the fact that the obstacle avoidance task for the two robots and the load is of primary importance with respect to the load orientation. Conversely, once the transportation phase is completed (and the target position is reached) there may be the additional need to re-orient the load for placing it at rest: this can be done through an explicit control action not induced by the obstacles and in any case referred to the grasping robots. This latter design is out of the scope of this study.
In the definition of the trajectories, it is also necessary to take into account the obstacles presence. We assume that the environment is populated by a set of
M static and/or dynamic obstacles, e.g., fixed structures and/or humans/other mobile robots whose dynamics is comparable with that of the transporting robots. For each
j-th obstacle,
, whose position is denoted by
, a radius
is defined as the minimum distance preventing a collision. In order to realistically face the obstacle avoidance task, we model both the leader and the follower as extended rigid bodies and we identify a set of
vertices accounting for the physical structure of the robots: these vertices denote points of interest of the robots we want to avoid the collision with to allow for its controlled motion. As a consequence, the obstacle avoidance is guaranteed when
where
denotes the absolute position of
i-th vertex (in the common inertial frame) being
the relative position of the
i-th vertex with respect to the leader/follower position. These vertices can be also defined on the load and, since the follower needs to keep a desired distance with the leader with no constraints on the mutual orientation, as in (
1), the relative position of the vertices on the load must be defined as a function
of the leader and follower position as
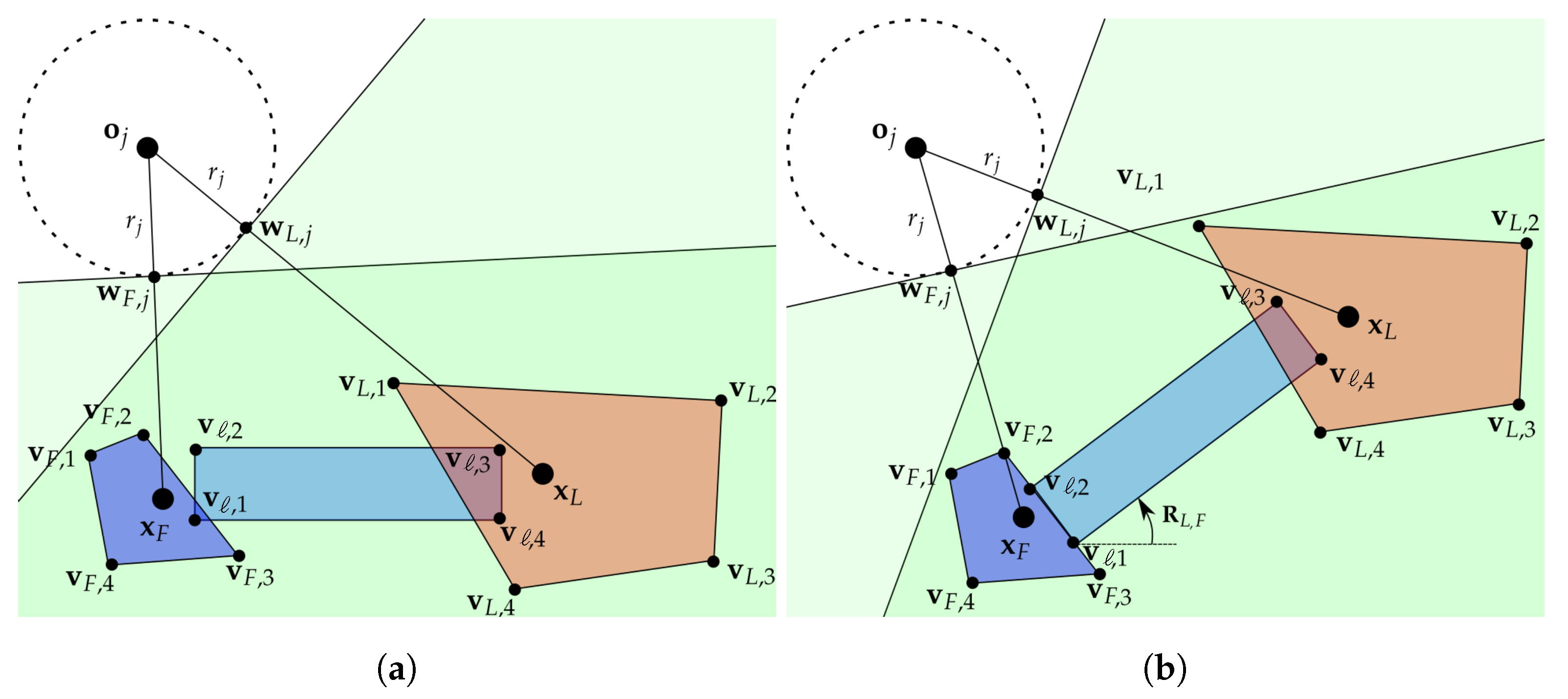
An example of such configuration and the vertices definition is graphically provided later on, in
Figure 1.
Given these premises, the final goal of the leader–follower approach is that the two agents will travel along trajectories
that are close to the desired reference
. Moreover, the goal of this work consists in the design of a trajectory generation method for the MRS composed of leader and follower, guaranteeing both the load grasping (i.e., the fulfillment of (
1)) and the obstacle avoidance (i.e., the fulfillment of (
2)). Formally, we aim to determine the desired trajectories
and
so that
In the remainder of the paper, the subscripts L and F are omitted for any quantity when the given observations are valid for both EEs. Moreover, without loss of generality, we assume in the rest of the work.
3. MPC-Based Strategy
To compute collision-free trajectories for leader and follower, namely
and
satisfying (4)–(6), we adopt an MPC-based formulation. Inspired also by the leader–follower framework proposed in [
45], the EE positions are assumed to be described by a double integrator model; hence, denoting with
and
the leader and the follower acceleration inputs, it holds that
Introducing also
and
as the leader and follower velocities, the full state of the EEs can be described by
which allows to write the dynamics of both the agents as the linear system
The system model (
9) can be discretized with sampling time
, thus obtaining
where, with a slight abuse of notation, it holds that
,
.
Given these premises, the cooperative trajectory planning problem is addressed by considering an MPC approach based on the iterative solution of the following optimization problem at each time instant
t
where
with
N being the total prediction horizon samples. In (
11)–(
15), the vectors
and
represent the state and input prediction respectively, while
and
denote the constraints sets. Given the predicted trajectory
, we generate online at time
t the desired trajectory for both leader and follower by considering the first sample of the MPC prediction, namely we have that
Notice that two different MPC problems need to be considered for the leader and the follower since both the objective and the constraints are different for the two EEs. Moreover, while recalling that completely decentralized approaches are particularly challenging in cooperative transportation tasks based on grasping [
6], the strategy outlined here rests on the following points and results in a decentralized scheme.
Exploiting the described MPC approach, the leader aims at iteratively solving the problem of reaching the target position , while performing obstacle avoidance (according to (6) given ) without accounting for the follower. The MPC scheme provides a prediction of the leader trajectory to communicate to the follower.
After this data exchange, the follower adopts the MPC strategy to compute its trajectory aiming at maintaining the distance with respect to the leader predicted trajectory and at performing obstacle avoidance for itself and the transported load.
Note that obstacle avoidance for the follower and the load are not considered by the leader to avoid a centralized procedure, which may lead the leader to compute a trajectory that results to be unfeasible from the follower side. However, such case can be detected and handled via the introduction of a proper recovery policy, as explained in
Section 5.
Hereafter, taking into account on the optimization problem (
11)–(
15), we provide a definition for the cost functions
,
and constraints set
,
,
,
for the leader–follower MPC problem. In particular, the state constraint are time-varying and such that
where
is the (same) constraint set on both leader and follower velocity and
is imposed by the collision avoidance requirement clarified in
Section 4.
3.1. Leader Objective Function
The principal goal of the leader is to determine a suitable trajectory such that the error with respect to the final target position
is minimized. For this reason, accounting for the MPC framework (
11)–(
15), we consider the quadratic cost function:
where the gain matrices
,
, and
allow to regulate the behavior of the leader in terms of convergence speed towards the target position and control effort.
The function (
18) can be rewritten in compact form as
by introducing the stacked versions of states, inputs, and corresponding weight matrices, namely
On the other hand, from the system dynamics (
10), for both the leader and the follower, it follows that
where
As a consequence, we can rewrite (
18) as
with
3.2. Follower Objective Function
The objective of the follower consists in minimizing the distance error with respect to the leader while tracking the shortest path. Since the problem is decentralized, the requirement (5) has to be treated as a desired condition instead of an hard constraint, thus implying the minimization of the squared formation error, defined as follows:
given
and
has been introduced in (
1). In detail, the follower aims at solving an MPC optimization problem wherein the cost function is given by a weighted sum of two terms:
a term accounting for the minimization of the error (
28) computed in correspondence to the predicted states
and
, namely
where
is a decaying weight factor;
a term accounting for the minimization of the travelled distance in the prediction horizon, namely
Therefore, the cost function associated to the follower results to be
where the parameter
allows to differently prioritize the two aforementioned minimization goal.
Similarly to the leader case, it is possible to rewrite the function (
31) as a function of the follower initial state
, of the follower predicted control input
and of the predicted leader trajectory
,
. In doing this, we introduce the vectors
and
, whose definition is analogous to that of
and
in (
20). Then, it holds:
where
and
are introduced in (
23). Moreover, we can further rewrite
as
where
and
Note that, differently from the leader case, the objective function is not quadratic.
3.3. Constraint Sets Definition
To conclude the section, we discuss the constraints that we want to consider regarding the state and control input of both the leader and the follower. From a practical point of view, these are imposed by the actuation limits that implies some bounds both on the velocity and on the acceleration of the EEs.
Formally, within the framework (
11)–(
15), we can defined the input constraint set as
where the inequality between vectors is considered component-wise. Equivalently, for each
k-th prediction sample,
, it holds that
and, considering the whole prediction horizon, we have that
A similar reasoning can be carried out for constraints affecting the velocity component of the state. Indeed, we consider the velocity constraint set from (
17) as:
that can be rewritten in terms of control input over the prediction horizon as follows
with
and
given
Both the input constraint set (
35) and the state constraints set (
38) are convex.
4. Obstacle Avoidance
In this work, we deal with an environment populated by static and/or dynamic obstacles, thus the cooperative trajectory planning problem has to be faced ensuring also the collision avoidance for the leader, the follower and the transported load. Specifically, as introduced in
Section 2, in this work we consider
M obstacles. Each
j-th obstacle,
, whose position is identified by
, is associated to a certain radius
. It is reasonable to include in the definition of the obstacle radius
also possible position measurement errors: formally, by defining the robot position errors as
,
, for each obstacle
characterized by virtual radius
, we can consider the effective radius
. Moreover, we recall that collision is avoided with respect to a set of
vertices
,
,
; with the aim to ease the discussion and without losing in generality, we will assume hereafter that (i) the cardinality
of the vertices set is the same for leader, follower, load, namely that they can be modeled with an equal number of boundary points, although different in shape and dimensions; (ii) this definition of vertices (and radius) is adequate to allow for obstacles detection in the considered scenario.
Inspired by the strategy proposed in [
46], for both the leader and the follower, we aim at figuring out the largest area that does not contain any obstacle and can be defined with linear constraints. With reference to
Figure 1a, in correspondence to any
j-th obstacle, we can first consider the point on the circle centered in
closest to the EE position
, given by:
Then, for the EE placed in
, it is possible to describe the largest half-plane that does not contain the
j-th obstacle: this is identified by the line orthogonal to the segment
and passing through
(green shaded areas in
Figure 1). In the light of this fact,
j-th obstacle avoidance is guaranteed when the following inequality is satisfied for each
i-th vertex,
:
where
and
Given these premises, the collision free area for any robot corresponds to the polyhedron resulting from the intersection of the
M half-planes defined as in (
42) by taking into account all the obstacles. In detail, we assume that collision avoidance is achieved if each of the
vertices belongs to the resulting convex set. Formally, this is ensured by the fulfillment of the following inequality for any
:
where
and
In order to account for the collision avoidance while solving the cooperative trajectory planning task, we include the constraint (
44) in the computation of both
and
. Note that any obstacle position can vary over time but, for the MPC formulation, it is assumed to be fixed during the prediction horizon.
4.1. On the Leader Side
Focusing on the leader, the obstacle avoidance requirement is guaranteed if the constraint (
44) is satisfied in correspondence to any element of the set
. Considering the EE initial state and dynamics, it is possible to verify that, for any
, the vector
is such that
where
. As a consequence, accounting for (
45), the obstacle avoidance from the leader side is ensured when the following condition is fulfilled for each
where
It follows that the leader constraint for obstacle avoidance (
17) at time
t is given by
which results to be a convex set since it is the intersection of (convex) half-planes representing the collision free area.
4.2. On the Follower Side
The reasoning carried out for the leader is valid also for the follower. Specifically, given
, the following obstacle avoidance condition can be derived
where
and
and
are defined as in (
48).
The follower is also charged to prevent the transported load from collisions. This requirement, depending on both the leader and follower position, yields to the non linear constraint derived in the following. Consider the unit vector
and the set
whose elements are the relative positions of the load vertices with respect to the follower position given an arbitrary fixed configuration, e.g., corresponding to the case
. Given the actual position of leader and follower, to ensure the obstacle avoidance by the transported load, we have to consider the position
of each
i-th vertex of the load,
. In the light of the given premises, it holds that
where
According to (
42), collision with the
j-th obstacle is then avoided if, for any
, we have that
and this constraint has to be included during the computation of
. As a consequence, observing that, for any
, it holds that
hence, the constraint set can be rewritten in a more compact fashion accounting for the whole prediction horizon and the complete set of obstacles as:
where
. Finally, the (convex) obstacle avoidance constraint set at the sample time
t for the follower is given by the following intersection:
5. Feasibility-Aware Recovery Policy
The decentralized strategy proposed in the previous sections entails that the trajectories of the leader and follower are generated separately, accounting for the diverse constraints characterizing the two robots, whose relative position with respect to the transported load is different. This approach may leads to undesired situations wherein the trajectory computed from the leader yields an infeasible optimum problem for the follower or the outlined follower trajectory produces a formation error that overcomes the inherent elasticity of the grasp structure, thus causing load stresses and eventually load break or grasp detachment. Nonetheless, according to the decentralized approach, it is possible to exploit the reciprocal communication between leader and follower to detect follower-infeasibility conditions and carry out a recovery policy.
Follower-infeasibility conditions generally occur in case of sharp bends or particularly cluttered environments. In the light of this fact, in this section, we propose a heuristic according to which the follower is able to assess if its trajectory in the next
samples would produce a formation error larger than a predefined threshold
and to communicate such information to the leader. Then, the leader will correct its behavior by generating a different (typically slower) trajectory compatible with the follower (and load) dynamics, according to the following conservative optimization functional
which temporarily replaces (
24) in the MPC computation. Algorithm 1, executed at each time instant
t, formalizes such introduced heuristic.
| Algorithm 1. Recovery policy. |
- 1:
MPC leader prediction considering in ( 18) - 2:
MPC follower prediction considering in ( 31) - 3:
if for any then - 4:
MPC leader prediction considering in ( 58) - 5:
MPC follower prediction considering in ( 31) computed for - 6:
- 7:
- 8:
else - 9:
- 10:
- 11:
end if
|
6. Numerical Results
This section is devoted to the validation of the proposed MPC solution for the trajectory planning problem within the context of cooperative transportation in a cluttered environment, as described in
Section 2. It has already been highlighted how such application involves the accomplishment of three distinct and simultaneous goals, which need to be consistently accommodated by the control action: the leader is required to reach the target position
, the follower is required to maintain the distance
from the leader, both the agents are required to avoid the obstacles and the follower also needs to prevent the transported load from collisions.
In the light of this fact, to assess the performance of the proposed solution, we account for the following three metrics:
the leader position with respect to the target position , given the assumption ;
the quadratic formation error
introduced in (
28);
the index
defined as follows
and corresponding to the distance between the closest pair of
i-th vertex and
j-th obstacle boundary. Note that this involves the obstacle radius so the collision is avoided for positive values of
.
Hereafter, we report the results for three different obstacles configurations:
- (i)
large static identical obstacles, forming a narrow passage;
- (ii)
static obstacles, of different size;
- (iii)
obstacles, where one obstacle can move, while the other are fixed but characterized by different radii. Some of these obstacles, in particular, are placed contiguously to each other so as to form a narrow corridor.
For all the configurations, the leader and follower parameters are reported in
Table 1.
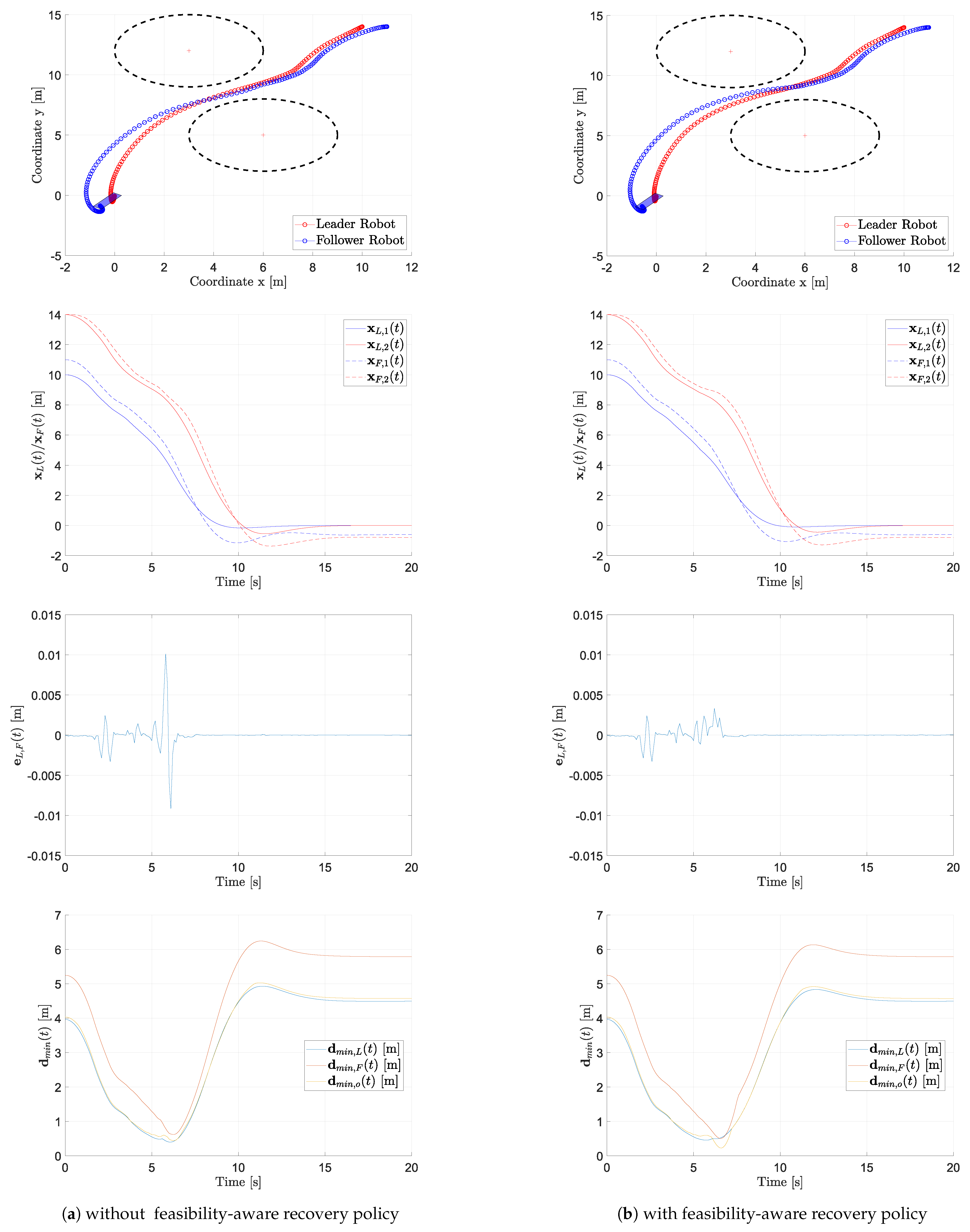
Configuration (i)
Figure 2 reports the outcome of one of the performed numerical simulation, providing both an overview of the scenario and of the task evolution and the behavior of the performance metrics. The two columns refer respectively to the case in which the recovery policy of
Section 5 is considered (right) or not (left). For both cases, we report the planar trajectory of the leader and follower (first panel, at the top) as well as the trend of their position components (second panel), the trend of the formation error
(third panel) and the trend of the index
for
(fourth panel).
The reported plots allow us to assess the performance of the proposed MPC-based trajectory generation strategy and, in particular, to appreciate the benefit deriving from the introduction of the feasibility-aware recovery policy. Indeed, it is possible to observe that, both with and without implementing the recovery policy, the leader converges towards the target position (second panel in
Figure 2). However, the employment of the recovery policy is motivated by the rapid increase of the leader–follower formation error at approximately
s, in correspondence to the narrow passage by the two obstacles: the modification of the MPC optimization function for the leader is effective in leading to a smaller formation error (third panel) at the cost of a slightly slower convergence speed. Finally, the plots in the bottom panel confirm that the agents and the load are able in both cases to keep the desired distance from the obstacles. As a further remark, we notice that the challenging region to overcome is the one closest to the obstacles, where the obstacle avoidance constraints are modified more quickly.
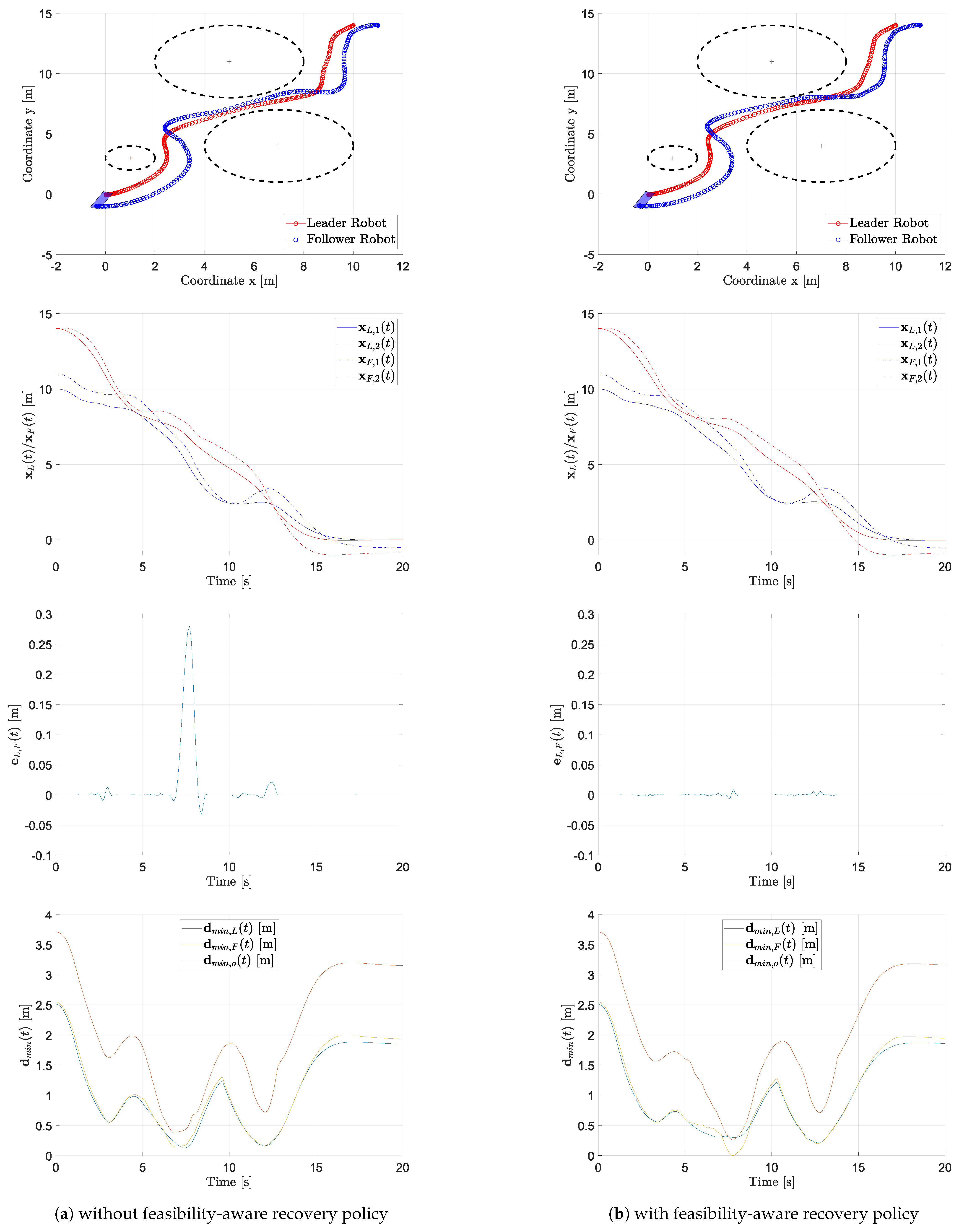
Configuration (ii)
This configuration differs from the previous because of the presence of an additional (static) obstacle, whose position is such to require an aggressive maneuver by the leader–follower system.
This scenario behavior is highlighted by the results reported in
Figure 3. As in the previous case, from the first and second panels, we observe that the leader can reach its target position, both implementing the recovery policy (
Figure 3b) and not implementing the recovery policy (
Figure 3a). As pointed out in the previous case, nearby the obstacles the linear constraints change very quickly and in this case it is more difficult for the follower to keep the formation error low: again, the constraints imposed by the two large obstacles with the additional presence of that along the predicted trajectory for the MRS, leads to a peak in the
metrics value, because the follower need to re-arrange its position accounting for both its own occupancy and that of the load. In this case, the feasibility-aware recovery policy turns out to be fundamental to limit the formation error: from the third panel we notice that the
is drastically reduced by slowing down the formation speed when needed. Finally, obstacle avoidance is granted in this case as well. Note that at around
s the load is very close to the constraint limit, which nonetheless does not raise a risk for physical collision if the radius accounts also for a certain safety margin.
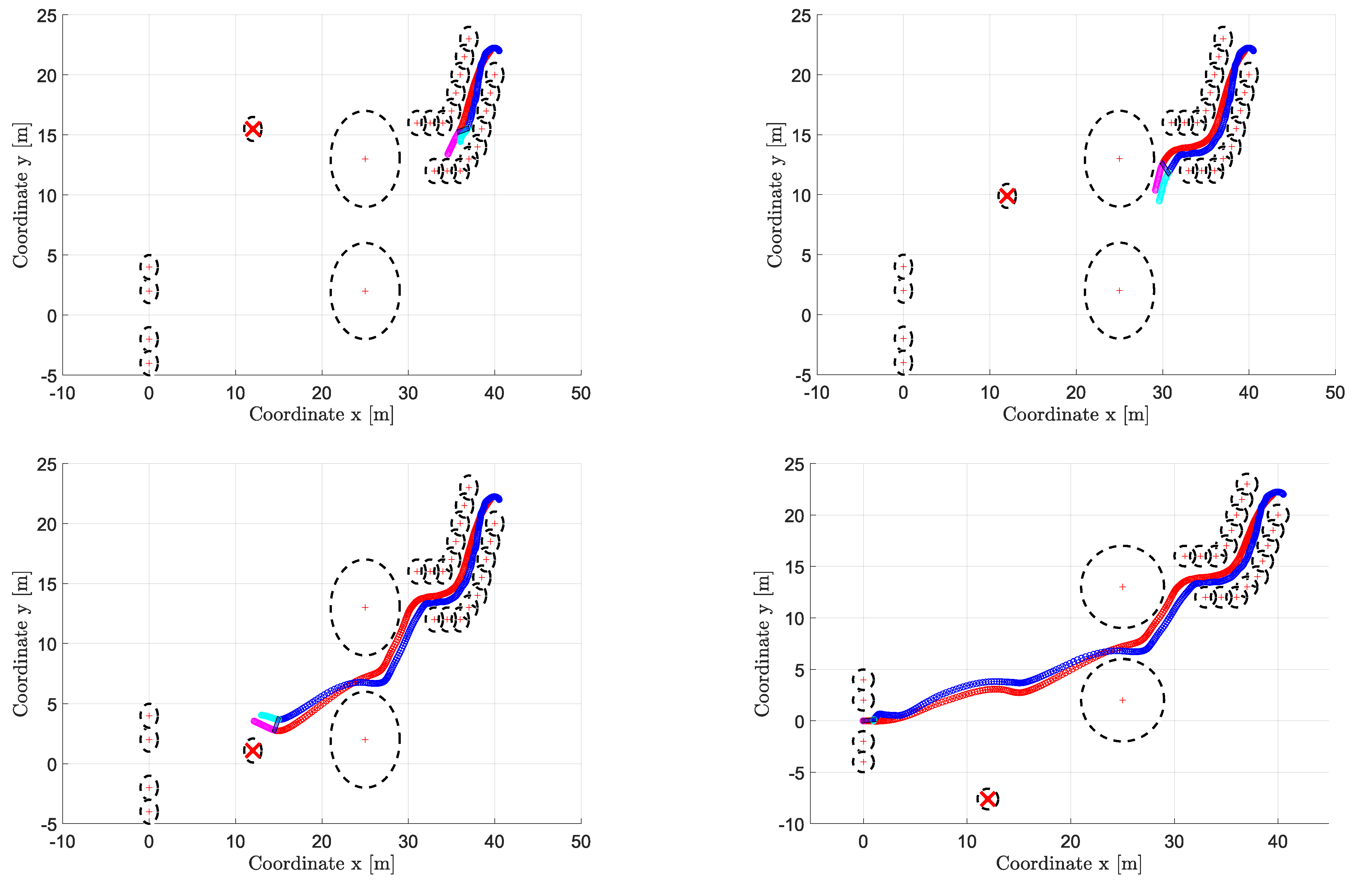
Configuration (iii)
The last configuration here presented includes 23 static obstacles (two bigger than the others) and a dynamic obstacle (in total
). In particular, the former are arranged so as to form a corridor and two narrow passages, one of which in correspondence to the target position; the moving obstacle, instead, travels along an unknown trajectory in the area in front of the target, as shown in
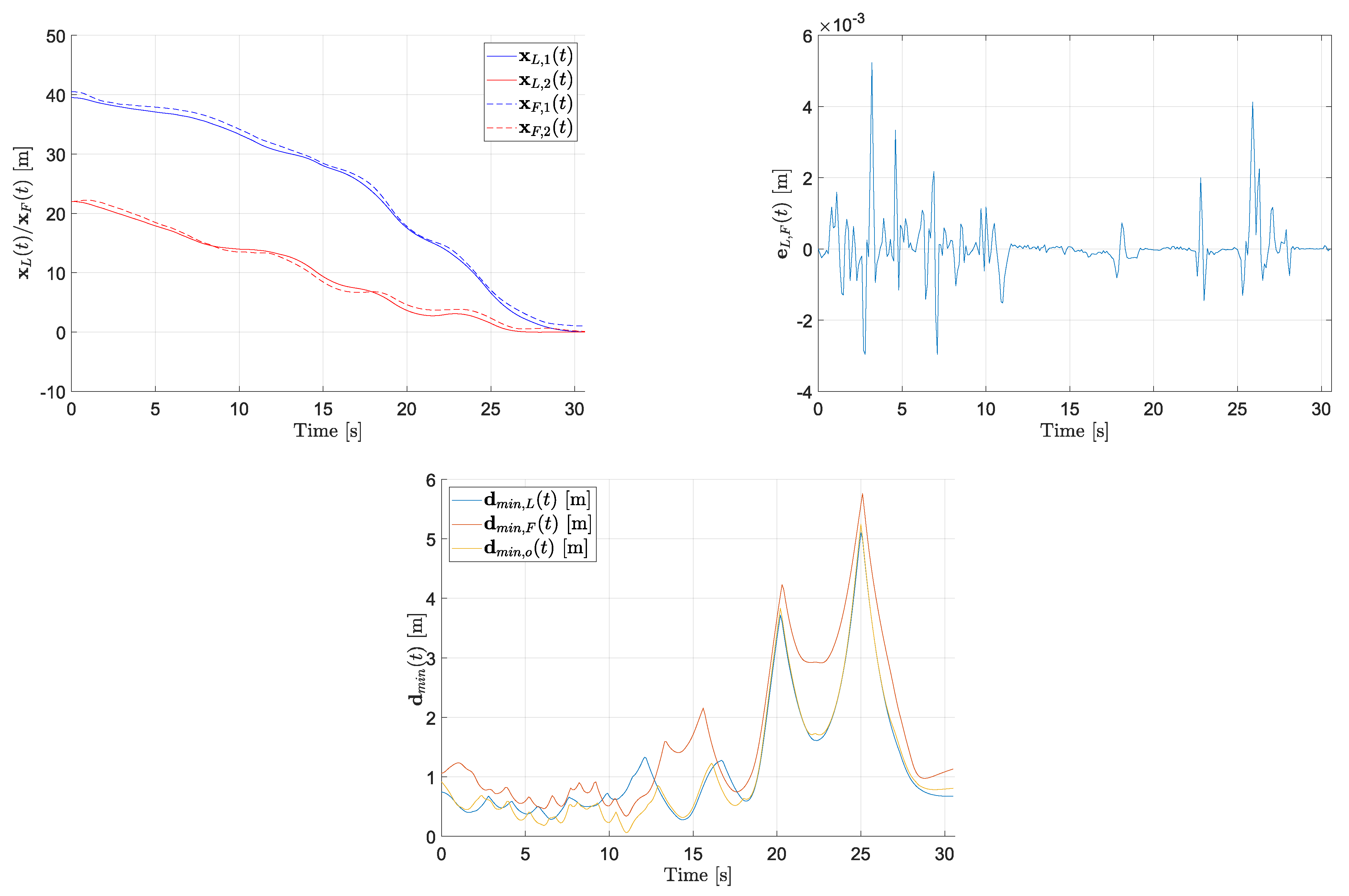
Figure 4.
In this case, only the control with the recovery policy is discussed: the plots in
Figure 4 show four snapshots of the MRS behavior, specifically at
s,
s,
s, and
s, and the performance index results reported in
Figure 5 confirm the effectiveness of the proposed trajectory planning solution. As a general comment, in such a complex scenario the implementation of the feasibility-aware recovery policy ensures both the minimization of the formation error (note the different scale w.r.t. to the plots in
Figure 2 and
Figure 3) and the collision avoidance while fulfilling the velocity constraints. In detail, we can well appreciate four dynamic phases on which to spend some comments:
t = 0–12 s: the MRS is travelling the corridor abiding several constraints, with an impact on the performance index (
59), which is low; moreover, the effects of the control of leader and follower on the load show in this phase a relatively higher formation error.
t = 12–20 s: the MRS is going through the narrow passage made of the two large obstacles, being very close to the upper obstacle at s and to the lower one at s.
t = 20–25 s: the motion is now in the open area where the main issue is represented by the presence of the mobile obstacle, which is intersecting the estimated MRS trajectory at s, thus causing the leader to react by planning a motion correction slightly upwards.
t = 25–30 s: the final phase is characterized by the maneuver of MRS and the action of the follower on the load, rotating it in order to enter the goal area horizontally (hence the noisy behavior of the formation error).
7. Conclusions
Motivated by the cutting-end research and application trends within MRS scenarios, we present a decentralized strategy to perform cooperative transportation by two mobile ground robots. The procedure is based on a leader–follower scheme and exploits an MPC approach running in parallel on both agents: the leader, basing on its own state, has the task of designing a potentially effective collision free trajectory for the whole MRS towards the goal. The follower, instead, has to accommodate the leader command with its proper and the load’s constraints to ensure the overall task transportation feasibility. In case the trajectory computed by the leader is not feasible for the follower/load movement, the leader is able to switch to a conservative recovery policy that ensures task completion. The proposed approach is discussed formally and the overall control procedure is validated in a simulation framework that includes different scenarios, highlighting the effectiveness of the technique and the role of the proposed recovery policy.
Interestingly, many different aspects that are worth to be studied stem from the methodology presented in this work, which mainly regard the control of the interaction between the transporting robots and the load, the regulation of the load orientation at the target position, the management of non-convex obstacles and of very dynamic environments.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}