
Nonlinear Model Predictive Horizon for Optimal Trajectory Generation


Abstract
:1. Introduction
- Formulating a novel motion planning approach (named NMPH), which employs a model of a closed-loop system under feedback linearization to efficiently solve for the optimal reference trajectory of the target closed-loop system;
- Designing a feedback linearization control law for a model augmented with integral states to achieve a more robust performance in the presence of modeling uncertainties.
- Implementing support for static and dynamic obstacles within the NMPH, enabling collision-free reference trajectory generation in unknown, dynamic environments;
- Validating the ability of the system to generate optimal trajectories for the quadrotor vehicle in real time using realistic flight environment simulation scenarios.
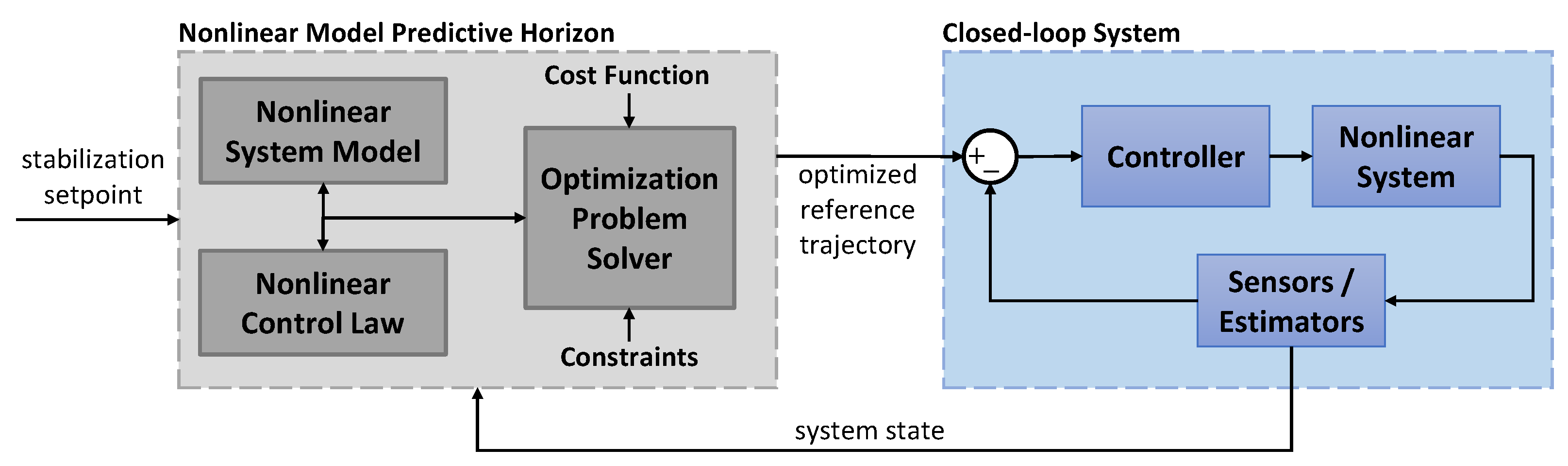
2. Nonlinear Model Predictive Horizon
- Predicts the trajectory of a nonlinear closed-loop system;
- Works in real-time using a specified time horizon;
- Uses a feedback linearization control law to reduce the nonconvexity of the optimization problem;
- Supports state and input constraints of the closed-loop system, and is able to account for environmental constraints such as dynamic obstacles;
- Assumes that a stable terminal point is specified, and the state vector of the closed-loop system is available (measured or estimated), and
- provides a combination of stabilization and tracking functionality:
- –
- Stabilization: provides a solution which guides the closed-loop system to a specified setpoint or terminal condition;
- –
- Tracking: generates a smooth reference trajectory for the closed-loop system to track or follow.
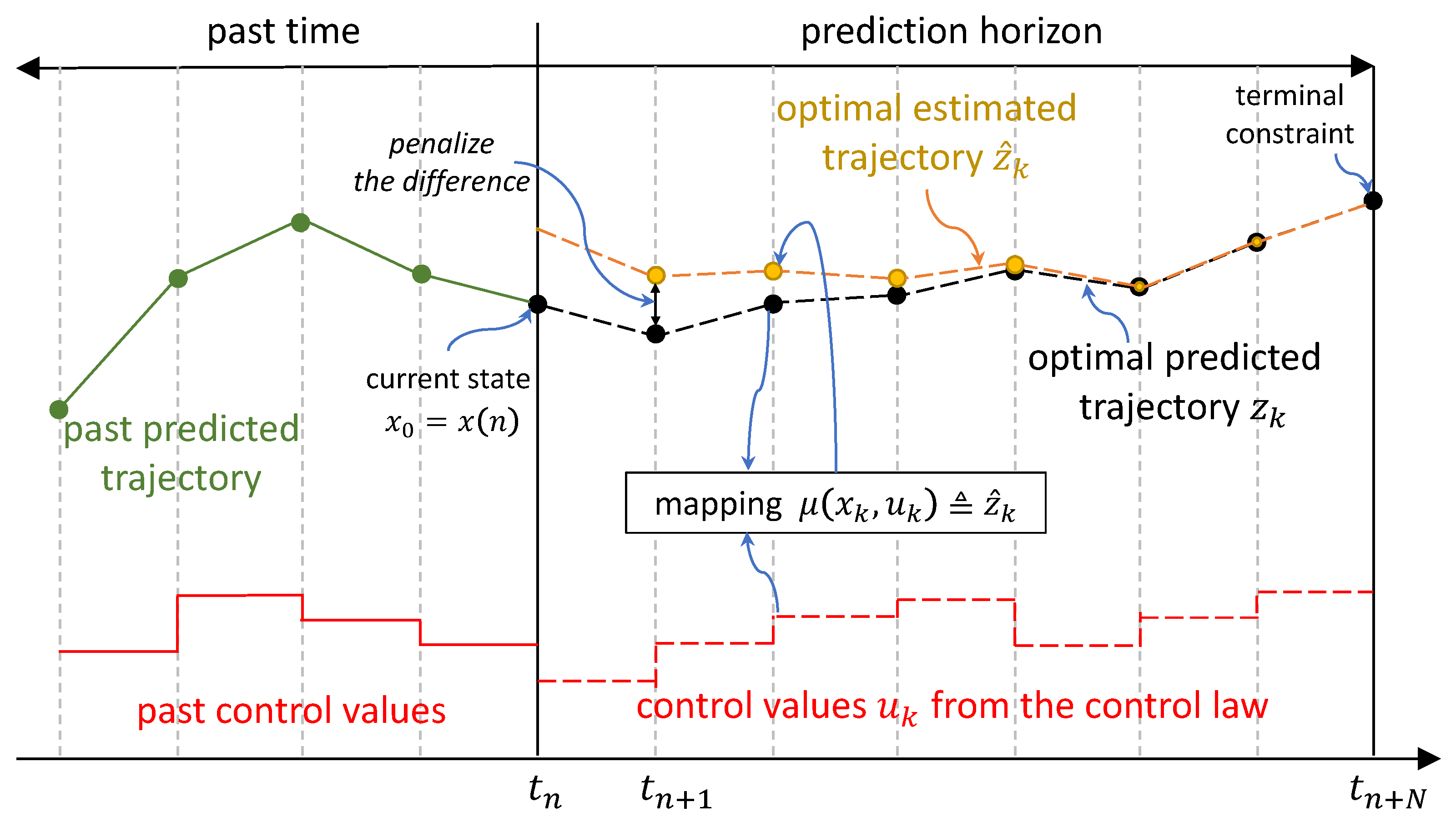
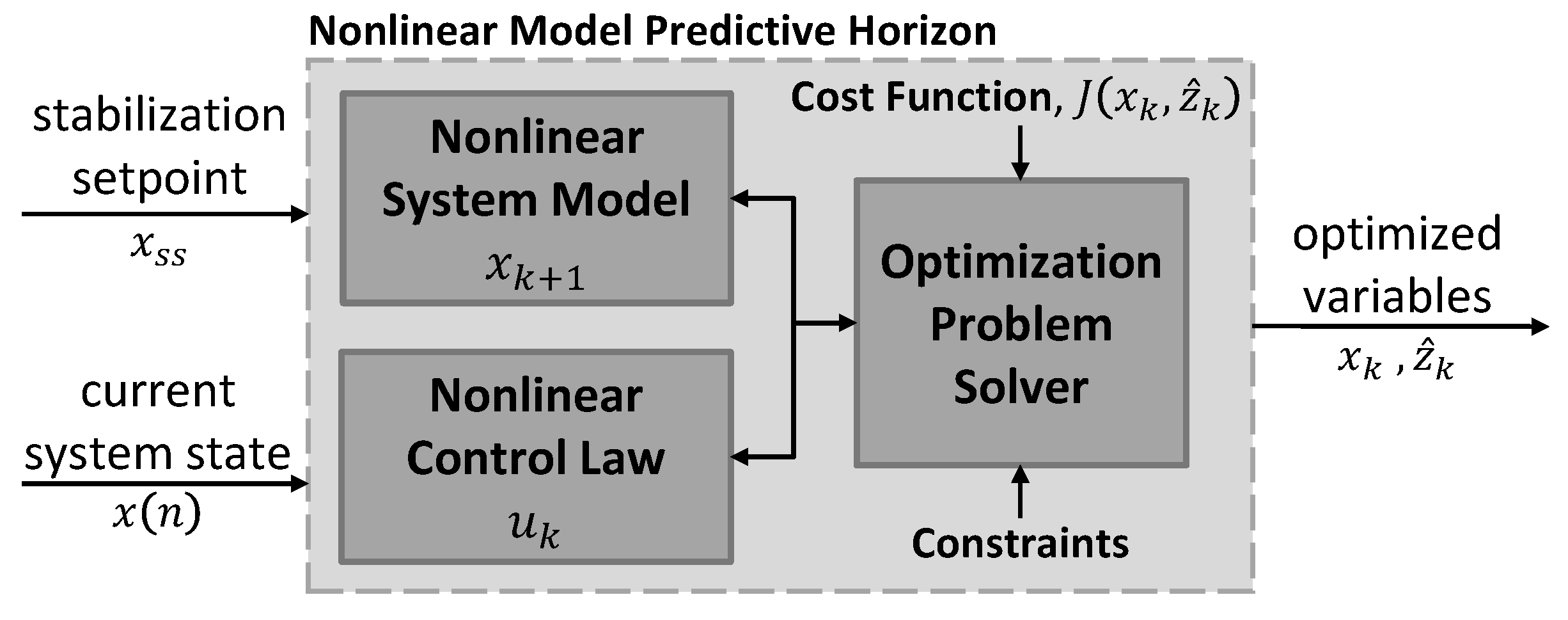
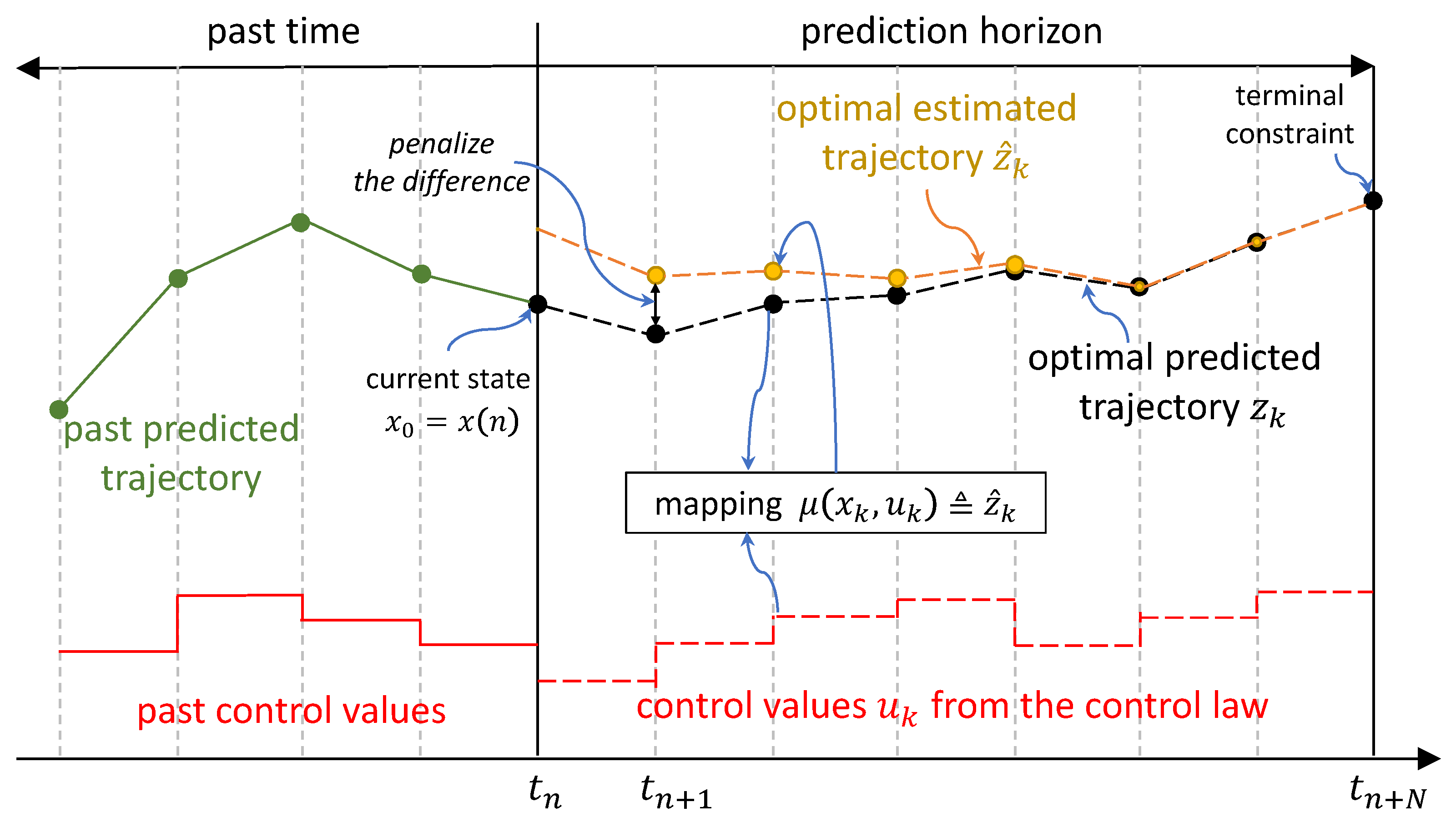
2.1. NMPH Algorithm
- is the predicted output trajectory sequence which represents a subset of the vector entries of the state sequence (in our case the quadrotor’s position and yaw angle). It is important to distinguish between , the current output of the actual closed-loop system, and , the predicted output sequence produced by the OTP solution.
- is the estimated reference trajectory sequence which is calculated by solving an optimization problem inside the NMPH. Using as the reference trajectory for the actual closed-loop system yields smoother flight paths plus the ability to deal with constraints such as obstacles in the environment. In this way, in (1c) acquires its value from the first predicted point of the sequence.
| Algorithm 1 NMPH algorithm with stabilizing terminal condition . |
| 1: Let ; measure the initial state |
| 2: whiledo |
| Solve the following Optimal Trajectory Problem,
|
| if then (estimated trajectory converging to terminal condition) |
| ; |
| else |
| break; |
| end |
| end |
- Measure or estimate the actual closed-loop system’s current state ;
- Obtain a prediction of the reference trajectory sequence for an admissible control input by minimizing the cost function over the prediction horizon subject to the dynamics of the closed-loop system plus state and input constraints;
- Send the predicted reference trajectory sequence to the closed-loop system for tracking;
- Repeat until the system reaches the desired terminal point or encounters an infeasible optimization solution.
- The stage cost is continuous and bounded from below, meaning that for all and .
- The terminal cost is a positive semi-definite function, which is continuously differentiable and satisfies
- The terminal constraint set is a subset of the state constraint set and it is compact.
- For every , there exists an estimate of the reference trajectory and predicted output trajectory sequences where both converge to the terminal setpoint and stay within the terminal region .
- The first j elements of the reference trajectory sequence are passed to the closed-loop system, which is different from the NMPC control problem where only the first element of the predicted control sequence is used. This provides some flexibility in choosing the rate at which the OTP is solved, which addresses the computation time issue of solving a Nonlinear Program (NLP).
- Thanks to recent advancements in computing, specifically graphics processing units (GPUs), the computations required for optimization problems can be performed very quickly, meaning solving the NLP problem for OTP or even OCP can be done in real-time. Irrespective of this, OTP has an advantage over OCP since the computational power requirement can be controlled by adjusting the rate of solving the optimization problem while allowing the vehicle to track the first j elements of the estimated reference trajectory.
- While the tailing elements of the reference trajectory sequence are discarded, the entire trajectory is still required to be calculated over the prediction horizon. The reason for this is that optimizing over the full horizon ensures a smooth trajectory from the initial state to the terminal setpoint.
- The optimization problem is solved iteratively using a reliable and accurate optimization approach based on the multiple shooting method and sequential quadratic programming.
2.2. NMPH Constraints
- The system states and the estimated reference trajectory are called admissible states and trajectories, respectively, and the control are called admissible control values for and . Hence, the admissible set can be defined as
- The control sequence and its associated estimated reference trajectory and state sequence from the time of the initial value up to time of the setpoint stabilization value are admissible if for and .
- The control law is called admissible if for all and .
- The estimated reference trajectory is called admissible if for all and .
2.3. NMPH Closed-Loop Form with Feedback Linearization Control Law
- (i)
- The controllability indices satisfy the condition ;
- (ii)
- The distributions are involutive and of constant rank for ;
- (iii)
- The rank of the distribution is .
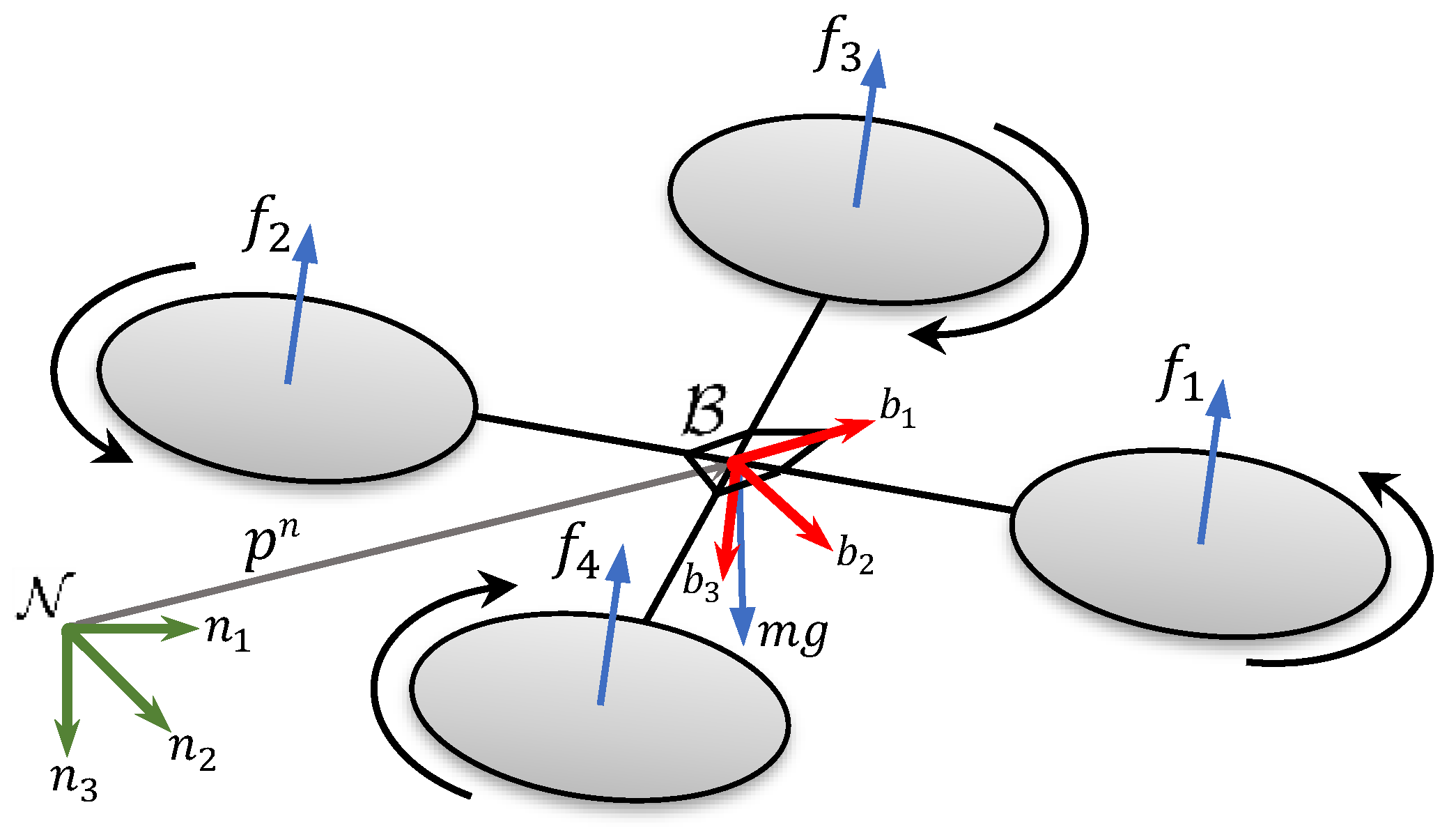
3. Application of NMPH to a Quadrotor Vehicle
3.1. System Model
3.2. Quadrotor Feedback Linearization Control
3.3. Trajectory Generation Using NMPH with Feedback Linearization
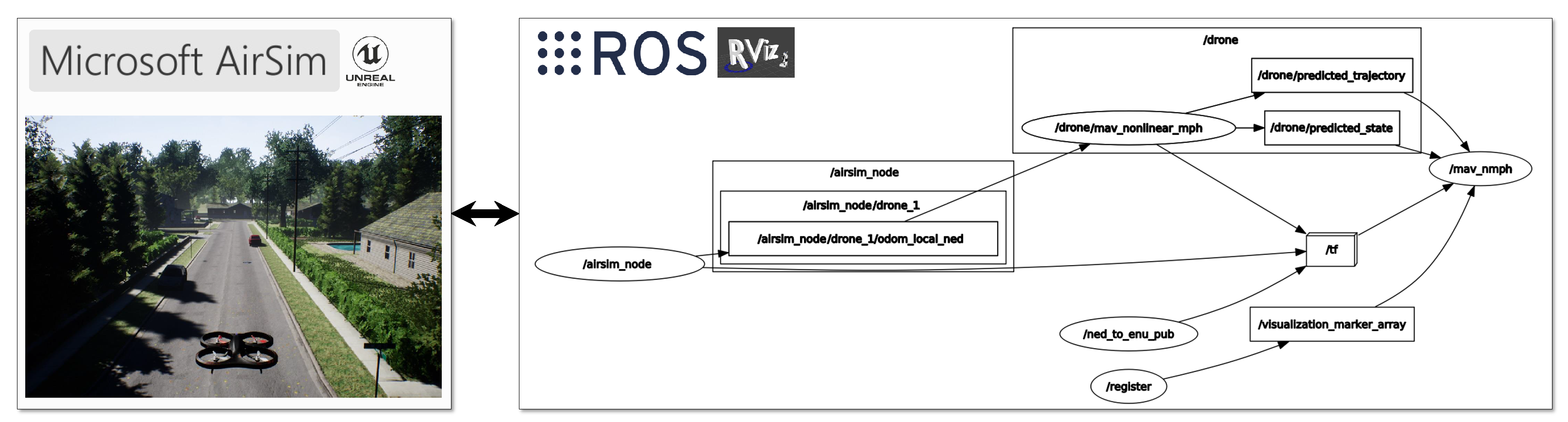
4. Simulation Results
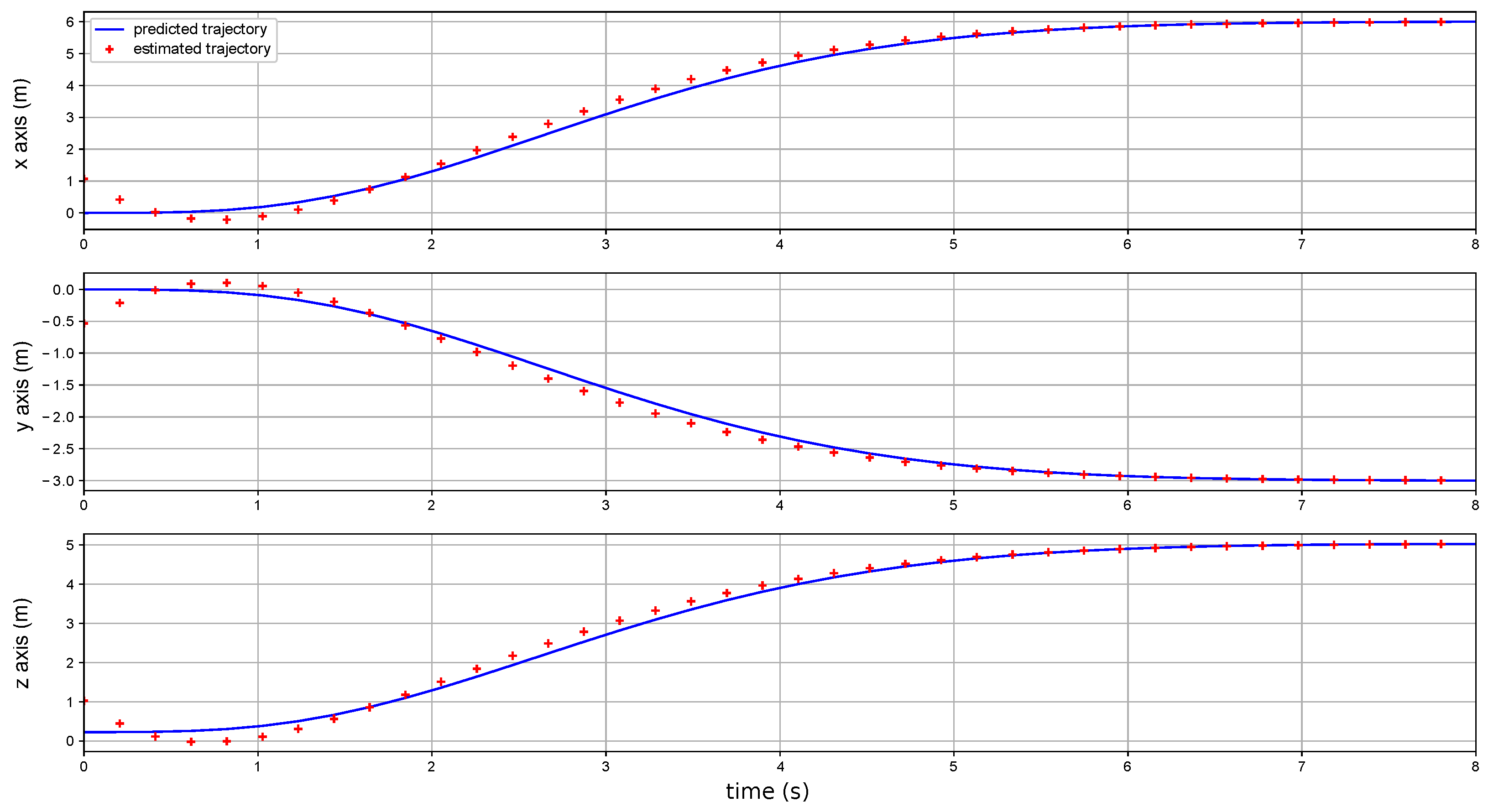
4.1. Predicted Output and Estimated Reference Trajectories
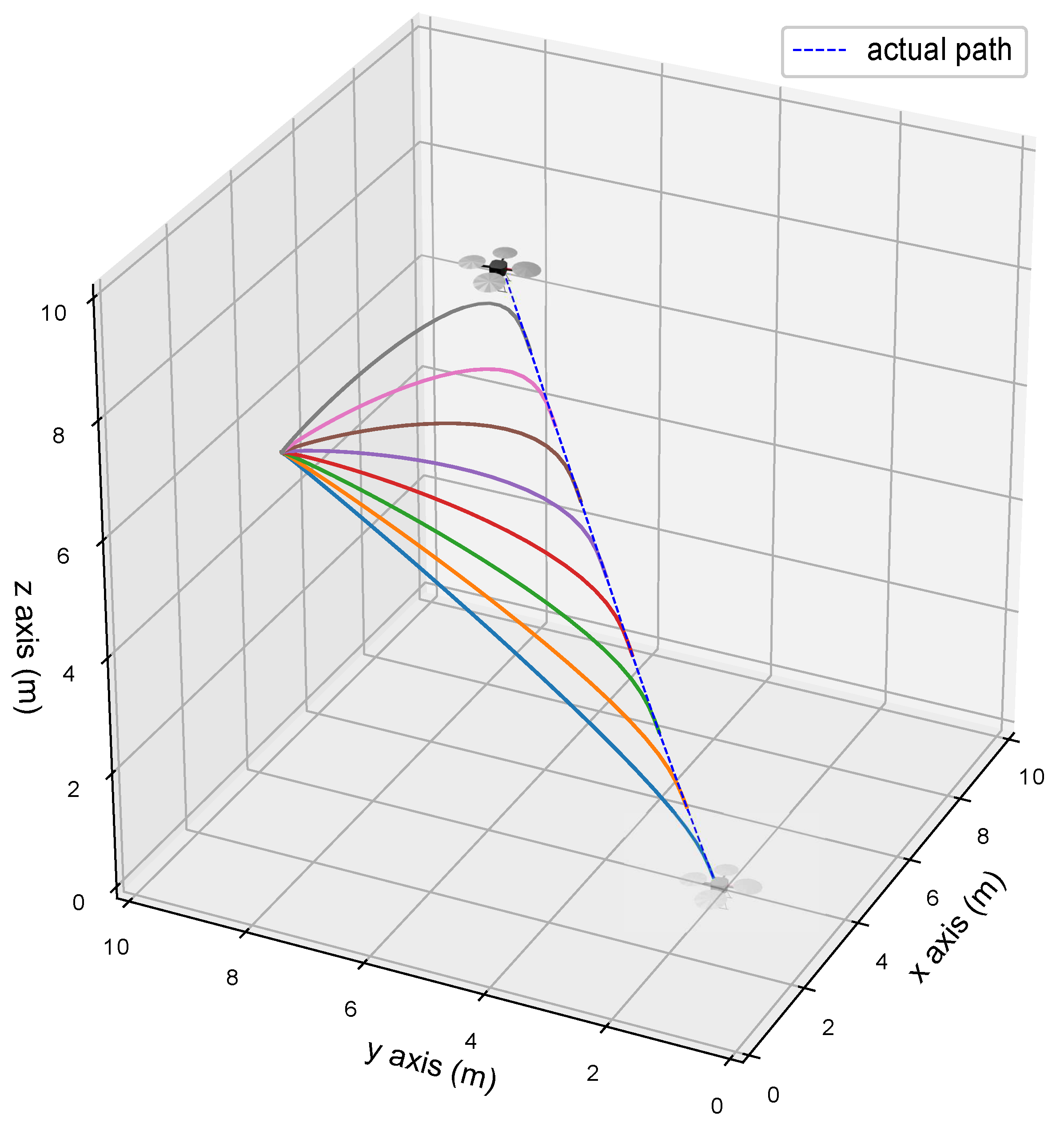
4.2. Trajectory Generation and Initial Conditions
4.3. Trajectory Tracking
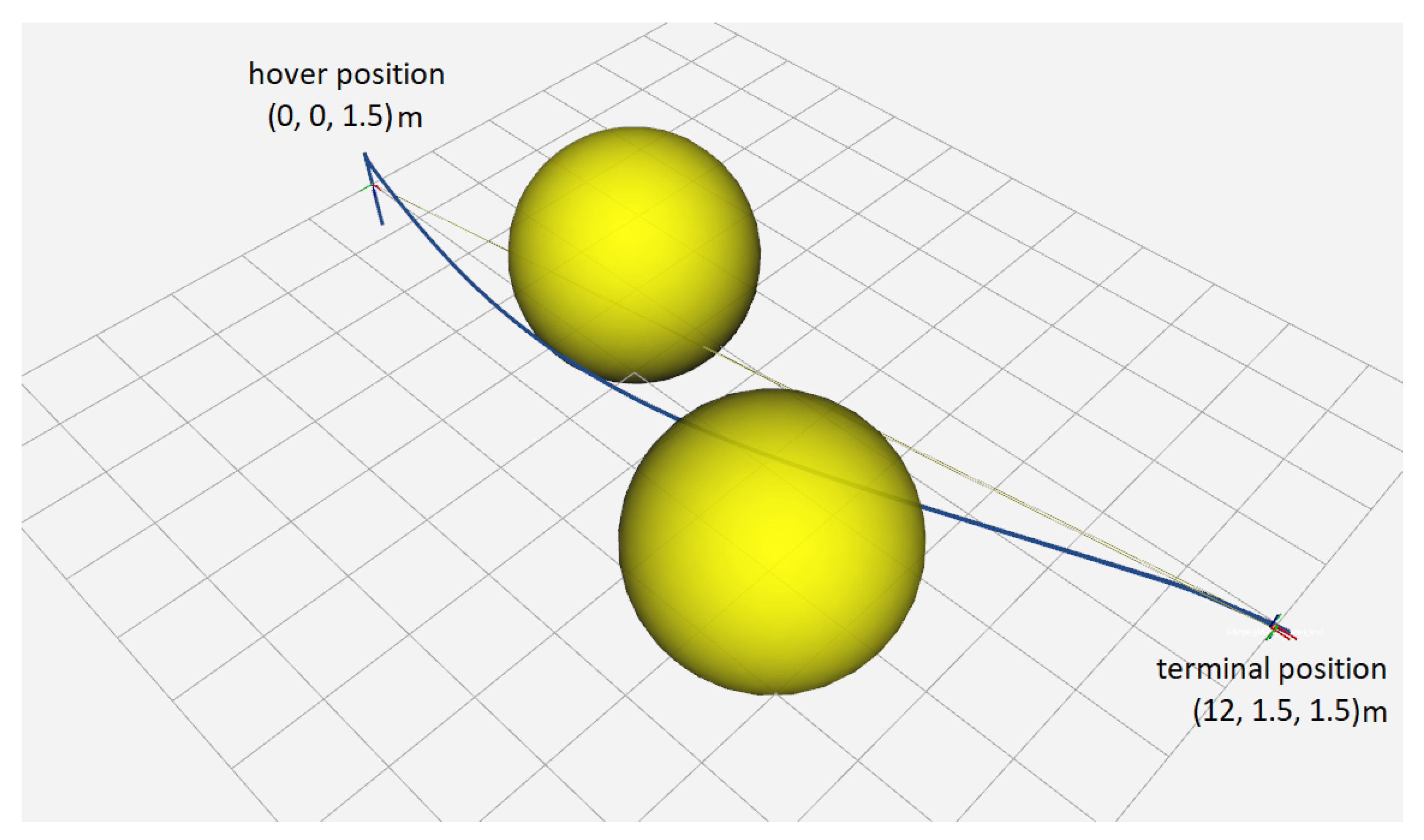
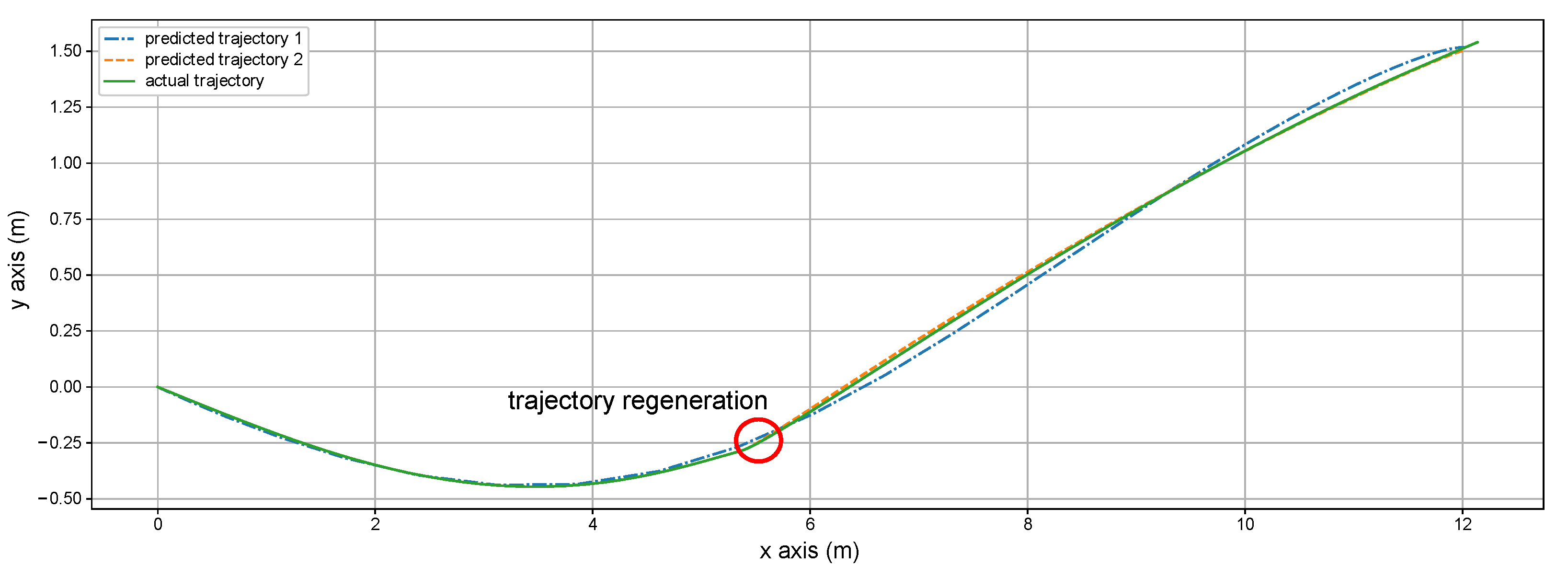
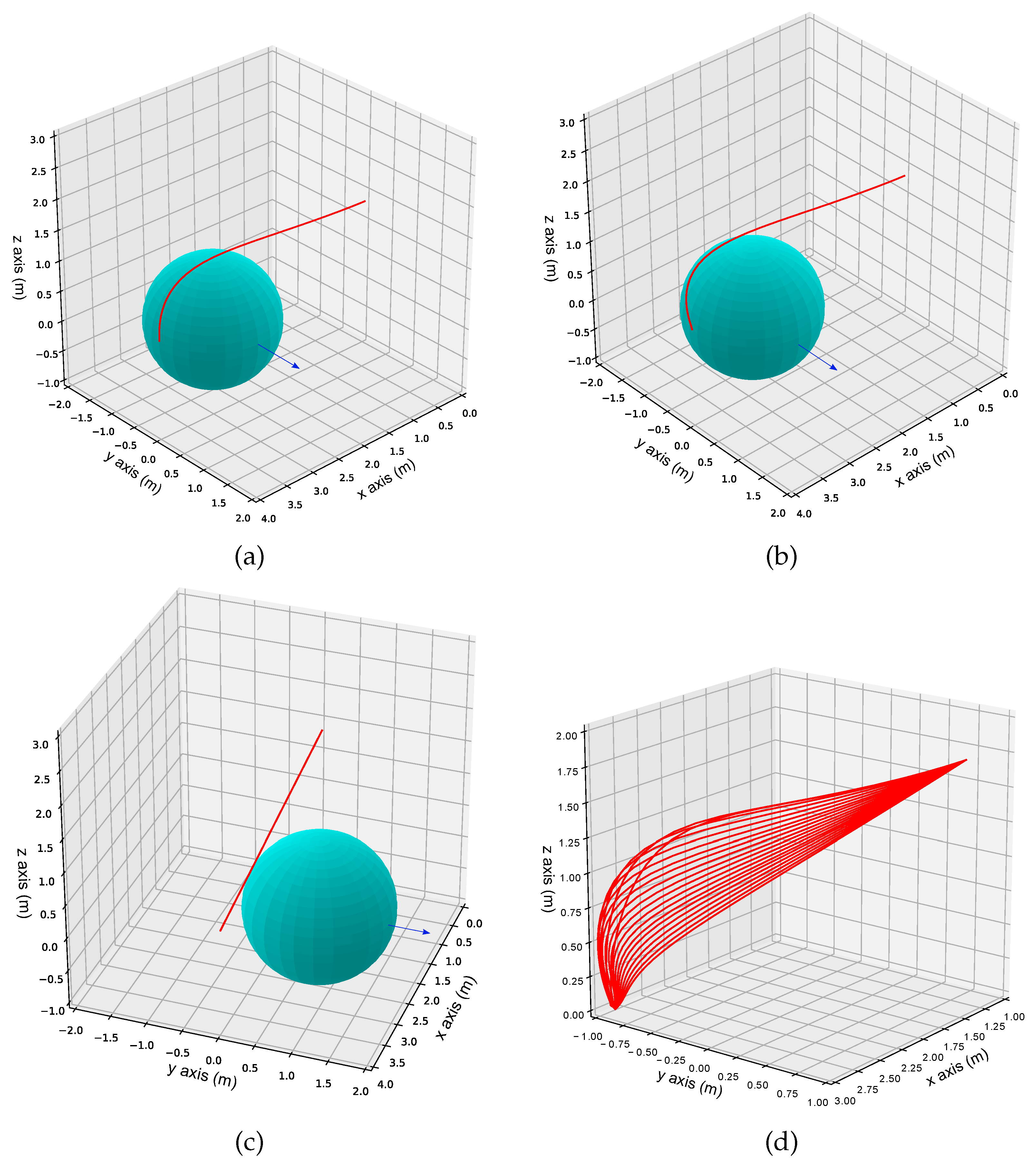
4.4. Dynamic Obstacle Avoidance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Richalet, J.; Rault, A.; Testud, J.; Papon, J. Model predictive heuristic control: Applications to industrial processes. Automatica 1978, 14, 413–428. [Google Scholar] [CrossRef]
- Garcia, C.E.; Prett, D.M.; Morari, M. Model predictive control: Theory and practice—A survey. Automatica 1989, 25, 335–348. [Google Scholar] [CrossRef]
- Grüne, L.; Pannek, J. Nonlinear Model Predictive Control: Theory and Algorithms; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- El Ghoumari, M.; Tantau, H.J.; Serrano, J. Non-linear constrained MPC: Real-time implementation of greenhouse air temperature control. Comput. Electron. Agric. 2005, 49, 345–356. [Google Scholar] [CrossRef]
- Santos, L.O.; Afonso, P.A.; Castro, J.A.; Oliveira, N.M.; Biegler, L.T. On-line implementation of nonlinear MPC: An experimental case study. Control Eng. Pract. 2001, 9, 847–857. [Google Scholar] [CrossRef] [Green Version]
- Aguiar, A.P.; Hespanha, J.P. Trajectory-tracking and path-following of underactuated autonomous vehicles with parametric modeling uncertainty. IEEE Trans. Autom. Control 2007, 52, 1362–1379. [Google Scholar] [CrossRef] [Green Version]
- Hovorka, R.; Canonico, V.; Chassin, L.J.; Haueter, U.; Massi-Benedetti, M.; Federici, M.O.; Pieber, T.R.; Schaller, H.C.; Schaupp, L.; Vering, T.; et al. Nonlinear model predictive control of glucose concentration in subjects with type 1 diabetes. Physiol. Meas. 2004, 25, 905. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Faulwasser, T.; Weber, T.; Zometa, P.; Findeisen, R. Implementation of nonlinear model predictive path-following control for an industrial robot. IEEE Trans. Control Syst. Technol. 2016, 25, 1505–1511. [Google Scholar] [CrossRef] [Green Version]
- Matschek, J.; Bethge, J.; Zometa, P.; Findeisen, R. Force feedback and path following using predictive control: Concept and application to a lightweight robot. IFAC-PapersOnLine 2017, 50, 9827–9832. [Google Scholar] [CrossRef]
- Matschek, J.; Bäthge, T.; Faulwasser, T.; Findeisen, R. Nonlinear predictive control for trajectory tracking and path following: An introduction and perspective. In Handbook of Model Predictive Control; Springer: Berlin/Heidelberg, Germany, 2019; pp. 169–198. [Google Scholar]
- Teatro, T.A.; Eklund, J.M.; Milman, R. Nonlinear model predictive control for omnidirectional robot motion planning and tracking with avoidance of moving obstacles. Can. J. Electr. Comput. Eng. 2014, 37, 151–156. [Google Scholar] [CrossRef]
- Ardakani, M.M.G.; Olofsson, B.; Robertsson, A.; Johansson, R. Model predictive control for real-time point-to-point trajectory generation. IEEE Trans. Autom. Sci. Eng. 2018, 16, 972–983. [Google Scholar] [CrossRef]
- Neunert, M.; De Crousaz, C.; Furrer, F.; Kamel, M.; Farshidian, F.; Siegwart, R.; Buchli, J. Fast nonlinear model predictive control for unified trajectory optimization and tracking. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1398–1404. [Google Scholar]
- Lee, T.; Leok, M.; McClamroch, N.H. Geometric Tracking Control of a Quadrotor UAV on SE(3). In Proceedings of the 49th IEEE Conference on Decision and Control, Atlanta, GA, USA, 15–17 December 2010; pp. 5420–5425. [Google Scholar]
- Bristeau, P.J.; Callou, F.; Vissière, D.; Petit, N. The Navigation and Control technology inside the AR.Drone micro UAV. In Proceedings of the 18th International Federation of Automatic Control World Congress, Milan, Italy, 28 August–2 September 2011; pp. 1477–1484. [Google Scholar]
- Mehndiratta, M.; Kayacan, E.; Patel, S.; Kayacan, E.; Chowdhary, G. Learning-based fast nonlinear model predictive control for custom-made 3D printed ground and aerial robots. In Handbook of Model Predictive Control; Springer: Berlin/Heidelberg, Germany, 2019; pp. 581–605. [Google Scholar]
- Findeisen, R. Nonlinear Model Predictive Control: A Sampled Data Feedback Perspective. Ph.D. Thesis, University of Stuttgart, Stuttgart, Germany, 2005. [Google Scholar]
- Houska, B.; Ferreau, H.; Diehl, M. ACADO Toolkit—An Open Source Framework for Automatic Control and Dynamic Optimization. Optim. Control Appl. Methods 2011, 32, 298–312. [Google Scholar] [CrossRef]
- Yu, S.; Li, X.; Chen, H.; Allgöwer, F. Nonlinear model predictive control for path following problems. Int. J. Robust Nonlinear Control 2015, 25, 1168–1182. [Google Scholar] [CrossRef]
- Marino, R.; Tomei, P. Nonlinear Control Design: Geometric, Adaptive, and Robust; Prentice Hall: London, UK, 1995. [Google Scholar]
- Wu, F.; Desoer, C. Global inverse function theorem. IEEE Trans. Circuit Theory 1972, 19, 199–201. [Google Scholar] [CrossRef]
- Xie, H. Dynamic Visual Servoing of Rotary Wing Unmanned Aerial Vehicles. Ph.D. Thesis, University of Alberta, Edmonton, AB, Canada, 2016. [Google Scholar]
- Rösmann, C.; Makarow, A.; Bertram, T. Online Motion Planning based on Nonlinear Model Predictive Control with Non-Euclidean Rotation Groups. arXiv 2020, arXiv:2006.03534. [Google Scholar]
- Sabatino, F. Quadrotor Control: Modeling, Nonlinear Control Design, and Simulation. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2015. [Google Scholar]
- Spitzer, A.; Michael, N. Feedback Linearization for Quadrotors with a Learned Acceleration Error Model. arXiv 2021, arXiv:2105.13527. [Google Scholar]
- Mokheari, A.; Benallegue, A.; Daachi, B. Robust feedback linearization and GH-inf controller for a quadrotor unmanned aerial vehicle. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 1198–1203. [Google Scholar]
- Kamel, M.; Stastny, T.; Alexis, K.; Siegwart, R. Model predictive control for trajectory tracking of unmanned aerial vehicles using robot operating system. In Robot Operating System (ROS); Springer: Berlin/Heidelberg, Germany, 2017; pp. 3–39. [Google Scholar]
- Boggs, P.T.; Tolle, J.W. Sequential quadratic programming. Acta Numer. 1995, 4, 1–51. [Google Scholar] [CrossRef] [Green Version]
- Ferreau, H.; Kirches, C.; Potschka, A.; Bock, H.; Diehl, M. qpOASES: A parametric active-set algorithm for quadratic programming. Math. Program. Comput. 2014, 6, 327–363. [Google Scholar] [CrossRef]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Proceedings of the Field and Service Robotics: Results of the 11th International Conference, Zurich, Switzerland, 12–15 September 2017; Springer Proceedings in Advanced Robotics. Hutter, M., Siegwart, R., Eds.; Springer: Cham, Switzerland, 2018; Volume 5, pp. 621–635. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NMPC | NMHE | NMPH (Ours) | |
|---|---|---|---|
| Objective | Predicts future control inputs and states of the system | Estimates the system states from previous measurements over the estimation horizon | Plans an optimal reference trajectory for the system under an existing feedback control design |
| Optimization Problem (OP) | Dynamic OP is solved iteratively for the optimal control inputs over the prediction horizon | OP is solved for state estimates and model parameters | Dynamic OP is solved iteratively for the optimal trajectory over the given prediction horizon |
| Cost/Objective Function | In general, a quadratic function which penalizes deviations of the predicted system states and control inputs. Composed of a stage cost and a terminal cost | In general, a quadratic function which penalizes deviations of the estimated outputs from the measured outputs. Composed of an arrival cost and a stage cost | Quadratic function which penalizes the deviation of the predicted system states and reference trajectory. Composed of a stage cost and a terminal cost |
| Optimization Variables | System inputs (states might be considered in some implementations) | System states and parameters | System states and prediction of the reference trajectory |
| Optimization Problem Convexity | Nonconvex | Nonconvex | Reduced nonconvexity or convex |
| Optimization Problem Constraints | Initial state; Nonlinear system model; Limits on states and control inputs | Nonlinear system model; Limits on states and parameter values | Initial state; Nonlinear system model; Limits on trajectories, states, controls; Obstacles |
| Optimization Performance | Depends on the accuracy of the system model and initial state estimate | Sensitive to the accuracy of the system model. Process noise may affect the solution, leading to inaccurate or unstable results | Relies on the accuracy of the system model, stability of closed-loop system, and accuracy of the initial state estimate |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Younes, Y.; Barczyk, M. Nonlinear Model Predictive Horizon for Optimal Trajectory Generation. Robotics 2021, 10, 90. https://doi.org/10.3390/robotics10030090
Al Younes Y, Barczyk M. Nonlinear Model Predictive Horizon for Optimal Trajectory Generation. Robotics. 2021; 10(3):90. https://doi.org/10.3390/robotics10030090
Chicago/Turabian StyleAl Younes, Younes, and Martin Barczyk. 2021. "Nonlinear Model Predictive Horizon for Optimal Trajectory Generation" Robotics 10, no. 3: 90. https://doi.org/10.3390/robotics10030090
APA StyleAl Younes, Y., & Barczyk, M. (2021). Nonlinear Model Predictive Horizon for Optimal Trajectory Generation. Robotics, 10(3), 90. https://doi.org/10.3390/robotics10030090