
Skill Fusion in Hybrid Robotic Framework for Visual Object Goal Navigation


Abstract
1. Introduction
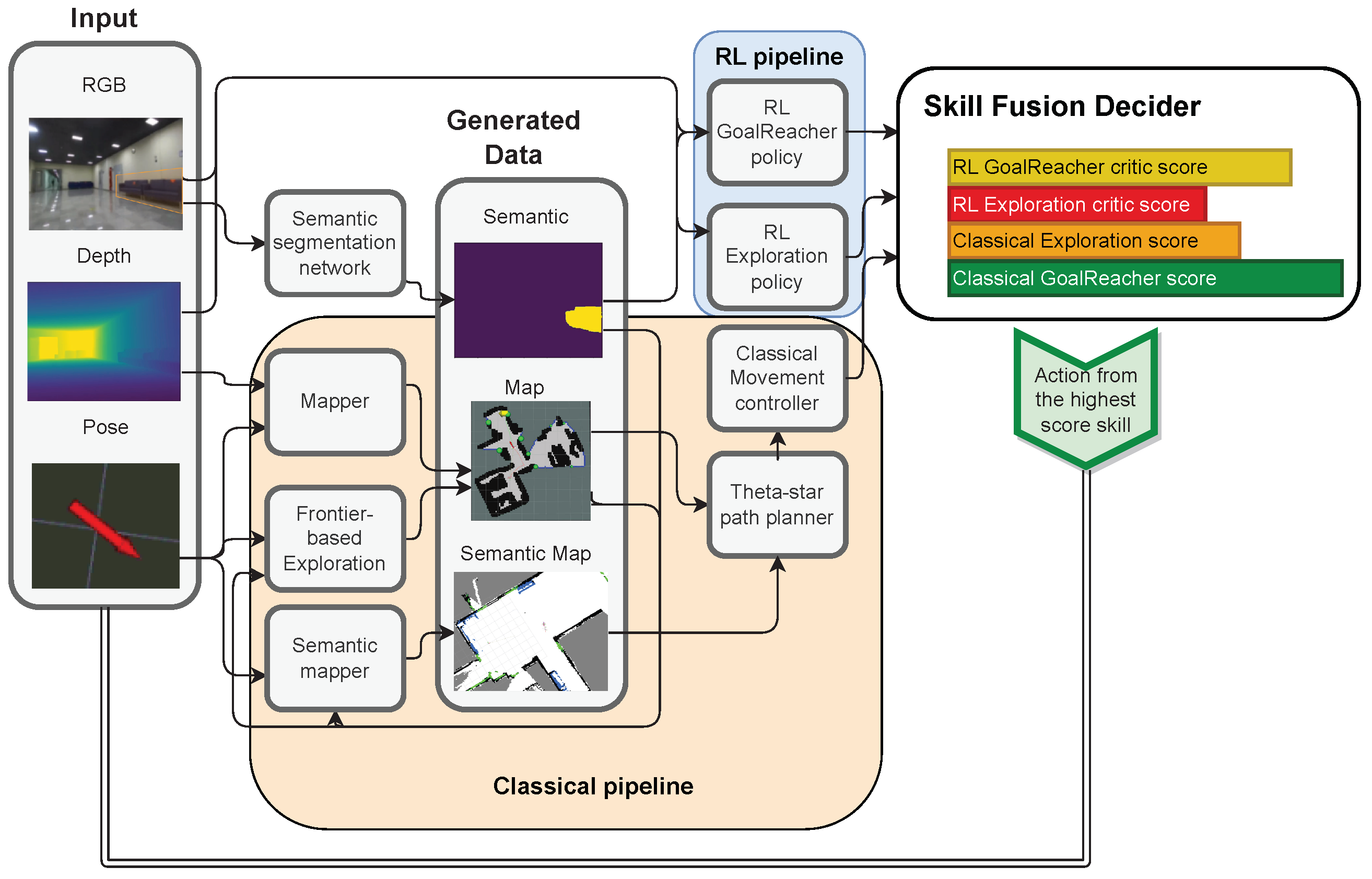
- We decomposed the ObjectNav problem into two distinct skills: Exploration, where the agent must search the area for the goal object, and GoalReacher, where the agent must navigate to the detected goal object and stop near it. We then built a modular architecture that incorporates both classical and learning-based implementations of each skill. During episodes, our agent manages all skills, depending on their internal reward estimation and external conditions.
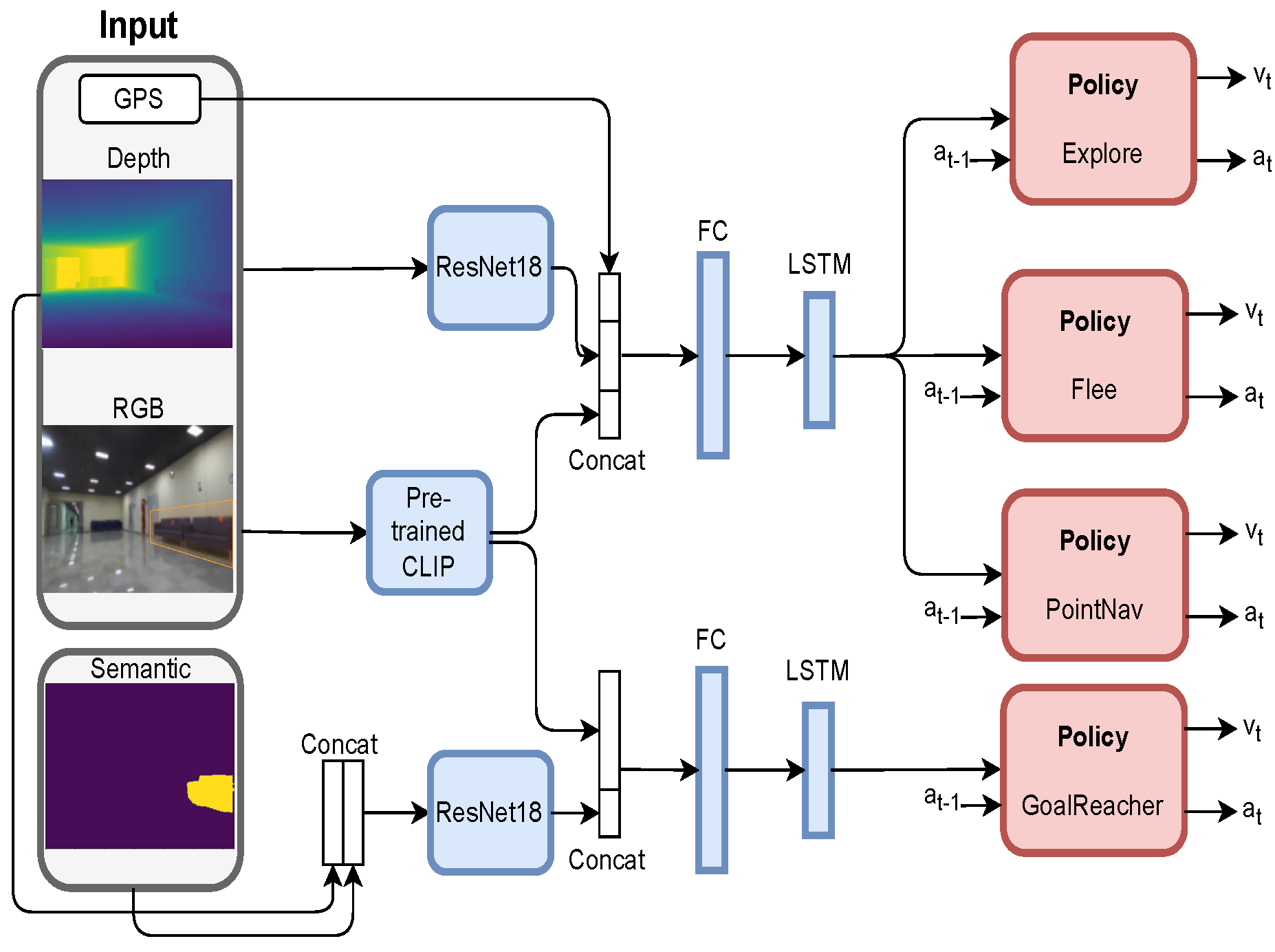
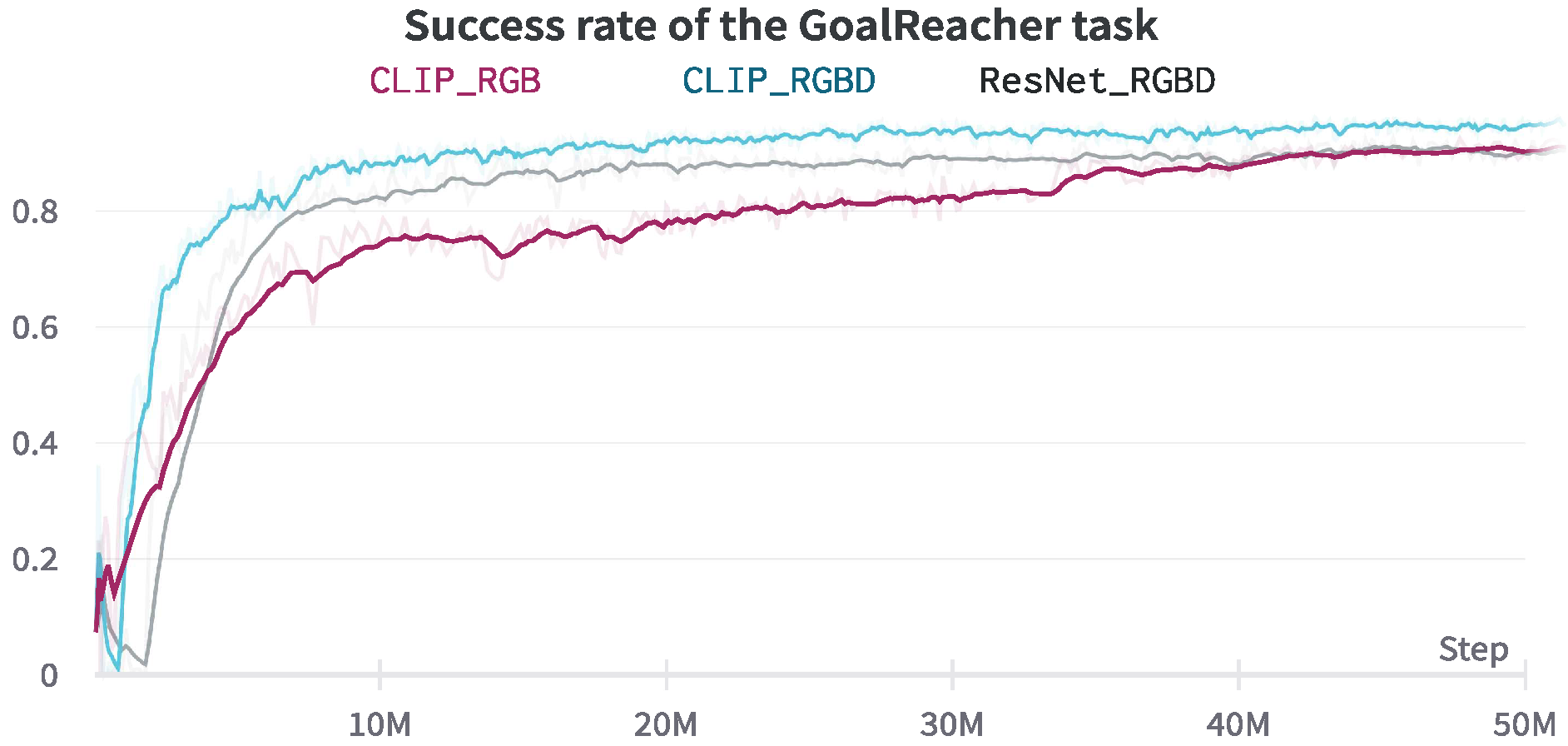
- To increase the robustness of our learning-based policy to external conditions, we used a pre-trained visual observation encoder and selected navigation tasks that require different behavior from the agent but have the same input. We trained these tasks together using an early fusion architecture [15] allowing our policy to use a single neural network with a shared recurrent embedding for all tasks and a separate head for each task.
- To address the problem of semantic noise (i.e., false detection of the goal objects, outliers, etc.), we incorporated a range of techniques for both non-learnable and learnable modules. For non-learnable modules, we utilized map-based erosion and fading. For learnable modules, we introduced a special “not sure” action that prevents a learnable policy from heading toward a falsely detected object by switching to exploration behavior.
2. Related Work
3. ObjectGoal Navigation Task
- Explore skill has the objective to observe as many areas as possible in a limited amount of time.
- GoalReacher skill has an objective to navigate the agent to the given object that was observed somehow and execute the callstop action within 1.0 m from it.
- PointNav skill has an objective to navigate the agent to a given point and execute callstop action within a 1.0 m distance from it.
- Flee skill has an objective to execute the callstop action at the furthest point from the starting one.
4. Classical Pipeline
4.1. Exploration Skill
4.2. GoalReacher Skill
5. Learning-Based Pipeline
5.1. Exploration Skill
- The Exploration skill reward is set as +1 when the agent visited a previously unexplored 1 m cell; otherwise, it was 0.
- The Flee skill reward is proportional to the distance from the starting point.
- The PointNav skill reward is proportional to the shortened distance to the goal, plus a reward if the agent executes a stop action within 1m of the goal point.
5.2. GoalReacher Skill
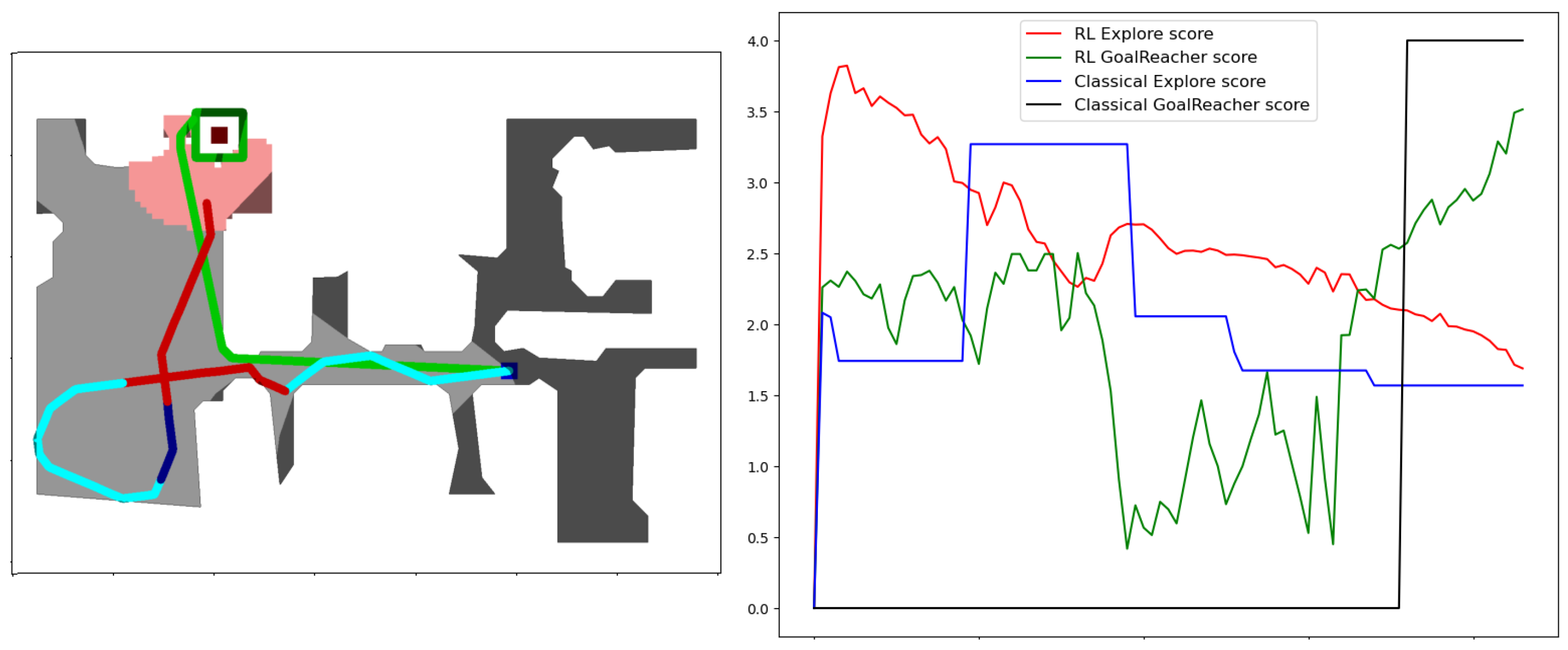
6. Skill Fusion Decider
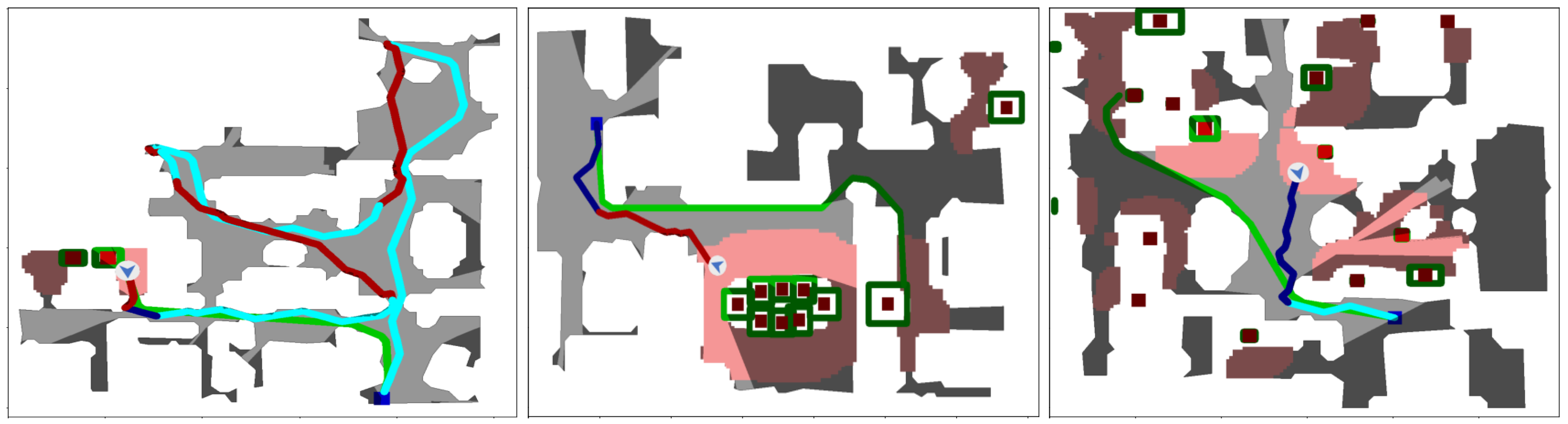
7. Experiments
7.1. Simulator Experiments
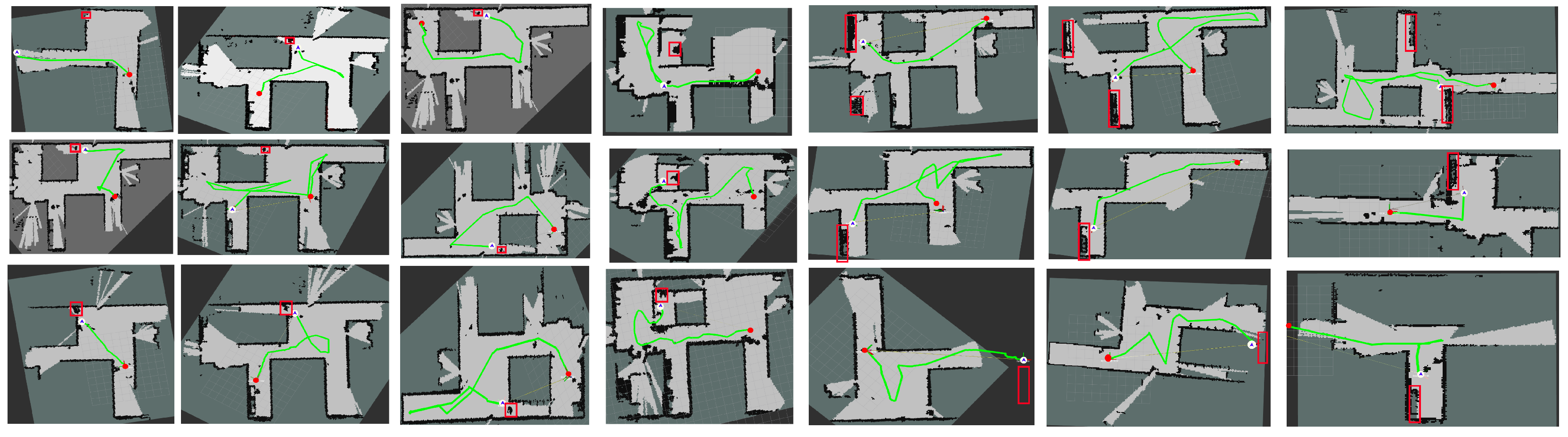
7.2. Robot Experiments
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wijmans, E.; Kadian, A.; Morcos, A.; Lee, S.; Essa, I.; Parikh, D.; Savva, M.; Batra, D. DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames. arXiv 2019. [Google Scholar] [CrossRef]
- Chaplot, D.S.; Gandhi, D.; Gupta, S.; Gupta, A.; Salakhutdinov, R. Learning to Explore using Active Neural SLAM. arXiv 2020. [Google Scholar] [CrossRef]
- Shacklett, B.; Wijmans, E.; Petrenko, A.; Savva, M.; Batra, D.; Koltun, V.; Fatahalian, K. Large Batch Simulation for Deep Reinforcement Learning. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, 3–7 May 2021. [Google Scholar]
- Batra, D.; Gokaslan, A.; Kembhavi, A.; Maksymets, O.; Mottaghi, R.; Savva, M.; Toshev, A.; Wijmans, E. ObjectNav Revisited: On Evaluation of Embodied Agents Navigating to Objects. arXiv 2020, arXiv:2006.13171. [Google Scholar]
- Bonin-Font, F.; Ortiz, A.; Oliver, G. Visual Navigation for Mobile Robots: A Survey. J. Intell. Robot. Syst. 2008, 53, 263–296. [Google Scholar] [CrossRef]
- Kadian, A.; Truong, J.; Gokaslan, A.; Clegg, A.; Wijmans, E.; Lee, S.; Savva, M.; Chernova, S.; Batra, D. Are we making real progress in simulated environments? measuring the sim2real gap in embodied visual navigation. arXiv 2019, arXiv:1912.06321. [Google Scholar]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Ye, J.; Batra, D.; Das, A.; Wijmans, E. Auxiliary tasks and exploration enable objectgoal navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 16117–16126. [Google Scholar]
- Xue, H.; Hein, B.; Bakr, M.; Schildbach, G.; Abel, B.; Rueckert, E. Using Deep Reinforcement Learning with Automatic Curriculum Learning for Mapless Navigation in Intralogistics. Appl. Sci. 2022, 12, 3153. [Google Scholar] [CrossRef]
- Fugal, J.; Bae, J.; Poonawala, H.A. On the Impact of Gravity Compensation on Reinforcement Learning in Goal-Reaching Tasks for Robotic Manipulators. Robotics 2021, 10, 46. [Google Scholar] [CrossRef]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef]
- Hafner, D.; Lillicrap, T.; Norouzi, M.; Ba, J. Mastering Atari with Discrete World Models. arXiv 2020. [Google Scholar] [CrossRef]
- Padmakumar, A.; Thomason, J.; Shrivastava, A.; Lange, P.; Narayan-Chen, A.; Gella, S.; Piramuthu, R.; Tur, G.; Hakkani-Tur, D. TEACh: Task-driven Embodied Agents that Chat. arXiv 2021. [Google Scholar] [CrossRef]
- Chaplot, D.S.; Gandhi, D.; Gupta, A.; Salakhutdinov, R. Object Goal Navigation using Goal-Oriented Semantic Exploration. arXiv 2020. [Google Scholar] [CrossRef]
- Gadzicki, K.; Khamsehashari, R.; Zetzsche, C. Early vs late fusion in multimodal convolutional neural networks. In Proceedings of the 2020 IEEE 23rd International Conference on Information Fusion (FUSION), Rustenburg, South Africa, 6–9 July 2020; pp. 1–6. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Gordon, D.; Kadian, A.; Parikh, D.; Hoffman, J.; Batra, D. SplitNet: Sim2Sim and Task2Task Transfer for Embodied Visual Navigation. arXiv 2019. [Google Scholar] [CrossRef]
- Reed, S.; Zolna, K.; Parisotto, E.; Colmenarejo, S.G.; Novikov, A.; Barth-Maron, G.; Gimenez, M.; Sulsky, Y.; Kay, J.; Springenberg, J.T.; et al. A Generalist Agent. arXiv 2022. [Google Scholar] [CrossRef]
- Yadav, K.; Ramrakhya, R.; Majumdar, A.; Berges, V.P.; Kuhar, S.; Batra, D.; Baevski, A.; Maksymets, O. Offline Visual Representation Learning for Embodied Navigation. arXiv 2022. [Google Scholar] [CrossRef]
- Baker, B.; Akkaya, I.; Zhokhov, P.; Huizinga, J.; Tang, J.; Ecoffet, A.; Houghton, B.; Sampedro, R.; Clune, J. Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos. arXiv 2022. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. arXiv 2021. [Google Scholar] [CrossRef]
- Khandelwal, A.; Weihs, L.; Mottaghi, R.; Kembhavi, A. Simple but Effective: CLIP Embeddings for Embodied AI. arXiv 2021. [Google Scholar] [CrossRef]
- Deitke, M.; VanderBilt, E.; Herrasti, A.; Weihs, L.; Salvador, J.; Ehsani, K.; Han, W.; Kolve, E.; Farhadi, A.; Kembhavi, A.; et al. ProcTHOR: Large-Scale Embodied AI Using Procedural Generation. arXiv 2022. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Sumikura, S.; Shibuya, M.; Sakurada, K. OpenVSLAM: A versatile visual SLAM framework. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2292–2295. [Google Scholar]
- Labbé, M.; Michaud, F. RTAB-Map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long-term online operation. J. Field Robot. 2019, 36, 416–446. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Nash, A.; Daniel, K.; Koenig, S.; Felner, A. Theta*: Any-angle path planning on grids. In Proceedings of the AAAI, Vancouver, BC, Canada, 22–26 July 2007; Volume 7, pp. 1177–1183. [Google Scholar]
- Faulwasser, T.; Weber, T.; Zometa, P.; Findeisen, R. Implementation of nonlinear model predictive path-following control for an industrial robot. IEEE Trans. Control Syst. Technol. 2016, 25, 1505–1511. [Google Scholar] [CrossRef]
- Soetanto, D.; Lapierre, L.; Pascoal, A. Adaptive, non-singular path-following control of dynamic wheeled robots. In Proceedings of the 42nd IEEE International Conference on Decision and Control (IEEE Cat. No. 03CH37475), Maui, HI, USA, 9–12 December 2003; Volume 2, pp. 1765–1770. [Google Scholar]
- Guo, H.; Cao, D.; Chen, H.; Sun, Z.; Hu, Y. Model predictive path following control for autonomous cars considering a measurable disturbance: Implementation, testing, and verification. Mech. Syst. Signal Process. 2019, 118, 41–60. [Google Scholar] [CrossRef]
- Santosh, D.; Achar, S.; Jawahar, C. Autonomous image-based exploration for mobile robot navigation. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; pp. 2717–2722. [Google Scholar]
- Gao, W.; Booker, M.; Adiwahono, A.; Yuan, M.; Wang, J.; Yun, Y.W. An improved frontier-based approach for autonomous exploration. In Proceedings of the 2018 15th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 18–21 November 2018; pp. 292–297. [Google Scholar]
- Muravyev, K.; Bokovoy, A.; Yakovlev, K. Enhancing exploration algorithms for navigation with visual SLAM. In Proceedings of the Russian Conference on Artificial Intelligence, Taganrog, Russia, 11–16 October 2021; pp. 197–212. [Google Scholar]
- Kojima, N.; Deng, J. To Learn or Not to Learn: Analyzing the Role of Learning for Navigation in Virtual Environments. arXiv 2019. [Google Scholar] [CrossRef]
- Mishkin, D.; Dosovitskiy, A.; Koltun, V. Benchmarking Classic and Learned Navigation in Complex 3D Environments. arXiv 2019. [Google Scholar] [CrossRef]
- Gupta, S.; Tolani, V.; Davidson, J.; Levine, S.; Sukthankar, R.; Malik, J. Cognitive Mapping and Planning for Visual Navigation. arXiv 2017. [Google Scholar] [CrossRef]
- Staroverov, A.; Yudin, D.A.; Belkin, I.; Adeshkin, V.; Solomentsev, Y.K.; Panov, A.I. Real-Time Object Navigation with Deep Neural Networks and Hierarchical Reinforcement Learning. IEEE Access 2020, 8, 195608–195621. [Google Scholar] [CrossRef]
- Staroverov, A.; Panov, A. Hierarchical Landmark Policy Optimization for Visual Indoor Navigation. IEEE Access 2022, 10, 70447–70455. [Google Scholar] [CrossRef]
- Rana, K.; Dasagi, V.; Haviland, J.; Talbot, B.; Milford, M.; Sünderhauf, N. Bayesian Controller Fusion: Leveraging Control Priors in Deep Reinforcement Learning for Robotics. arXiv 2023, arXiv:2107.09822. [Google Scholar] [CrossRef]
- Rozenberszki, D.; Majdik, A.L. LOL: Lidar-only odometry and localization in 3D point cloud maps. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 4379–4385. [Google Scholar]
- Ramakrishnan, S.K.; Gokaslan, A.; Wijmans, E.; Maksymets, O.; Clegg, A.; Turner, J.; Undersander, E.; Galuba, W.; Westbury, A.; Chang, A.X.; et al. Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI. arXiv 2021. [Google Scholar] [CrossRef]
- Savva, M.; Kadian, A.; Maksymets, O.; Zhao, Y.; Wijmans, E.; Jain, B.; Straub, J.; Liu, J.; Koltun, V.; Malik, J.; et al. Habitat: A Platform for Embodied AI Research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Success | SPL | SoftSPL |
|---|---|---|---|
| DDPPO [1] | 0.18 | 0.10 | 0.35 |
| SemExp [14] | 0.24 | 0.14 | 0.26 |
| Auxiliary RL [8] | 0.51 | 0.29 | 0.34 |
| SkillFusion | 0.64 | 0.36 | 0.38 |
| Skill | Metrics | |||
|---|---|---|---|---|
| Explore | GoalReacher | Success | SPL | SoftSPL |
| Classical | Classical | 0.410 | 0.182 | 0.263 |
| RL | RL | 0.403 | 0.224 | 0.321 |
| RL+Classical | Classical | 0.511 | 0.299 | 0.309 |
| RL+Classical | RL+Classical | 0.547 | 0.316 | 0.365 |
| Method | Success | SPL | SoftSPL |
|---|---|---|---|
| SkillFusion (with no semantic filtering) | 0.324 | 0.207 | 0.327 |
| SkillFusion (with semantic filtering) | 0.547 | 0.316 | 0.365 |
| SkillFusion (ground truth semantic) | 0.647 | 0.363 | 0.384 |
| Method | Scene | Success | SPL | SoftSPL | Path Length, m | Time, s |
|---|---|---|---|---|---|---|
| RL | Chair 1 | 0.67 | 0.53 | 0.42 | 22 | 170 |
| Chair 2 | 0 | 0 | 0.42 | 36 | 300 | |
| Sofa | 1 | 0.39 | 0.39 | 38 | 190 | |
| Average | 0.71 | 0.39 | 0.41 | 31 | 200 | |
| Classic | Chair 1 | 0.67 | 0.35 | 0.41 | 28 | 180 |
| Chair 2 | 1 | 0.40 | 0.40 | 33 | 220 | |
| Sofa | 1 | 0.75 | 0.75 | 24 | 110 | |
| Average | 0.86 | 0.53 | 0.56 | 27 | 170 | |
| SkillFusion | Chair 1 | 1 | 0.61 | 0.61 | 25 | 150 |
| Chair 2 | 1 | 0.61 | 0.61 | 22 | 140 | |
| Sofa | 1 | 0.77 | 0.77 | 22 | 110 | |
| Average | 1 | 0.65 | 0.65 | 23 | 130 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Staroverov, A.; Muravyev, K.; Yakovlev, K.; Panov, A.I. Skill Fusion in Hybrid Robotic Framework for Visual Object Goal Navigation. Robotics 2023, 12, 104. https://doi.org/10.3390/robotics12040104
Staroverov A, Muravyev K, Yakovlev K, Panov AI. Skill Fusion in Hybrid Robotic Framework for Visual Object Goal Navigation. Robotics. 2023; 12(4):104. https://doi.org/10.3390/robotics12040104
Chicago/Turabian StyleStaroverov, Aleksei, Kirill Muravyev, Konstantin Yakovlev, and Aleksandr I. Panov. 2023. "Skill Fusion in Hybrid Robotic Framework for Visual Object Goal Navigation" Robotics 12, no. 4: 104. https://doi.org/10.3390/robotics12040104
APA StyleStaroverov, A., Muravyev, K., Yakovlev, K., & Panov, A. I. (2023). Skill Fusion in Hybrid Robotic Framework for Visual Object Goal Navigation. Robotics, 12(4), 104. https://doi.org/10.3390/robotics12040104