1. Introduction
There is an abundance of different literature on vision-based robot control. In this technology, image information is used to measure the error between the current position and orientation (pose) of a robot and its desired reference pose [
1,
2]. A position-based visual servo (PBVS) system estimates the three-dimensional measurements of the target’s pose with respect to a camera Cartesian coordinate frame [
3], while an image-based visual servo (IBVS) system estimates two-dimensional measurements in image plane coordinates and directs the desired movement of the robot. A hybrid visual servo uses a combination of PBVS and IBVS, in which some errors are specified in the image pixel space and some in the Cartesian pose space.
A vision-guide robot control system may use visual information in two different ways: open-loop robot control and closed-loop visual feedback control. In the open-loop approach, the robot movement is based on the visual information extracted in the Cartesian frame; thus, the camera has to be calibrated with respect to the robot. However, camera calibration is known to be an error prone process. Perfect calibration of the robot/camera system is difficult, time-consuming, and sometimes even impossible to achieve.
There are two ways to implement vision-feedback robot control: the dynamic look-and-move system and the direct visual servo system [
4,
5]. The dynamic look-and-move system performs vision-feedback control of robot manipulation in a hierarchical manner. The higher-level vision system provides a desired pose reference input to a lower-level robot controller which then uses feedback from the joints to internally stabilize the robot. In direct visual servo control systems, a visual controller replaces the robot controller and directly computes input to the robot joints. The direct visual servo system usually requires high-speed vision feedback information, which places a high burden on both system hardware and software.
Image-based features such as points, lines, areas, regions, parallelism, and cross-ratios can be used to align a manipulator gripper with an object. Image features from projective geometry and invariance have been used for on-line calibration and for defining error functions and/or set-points for visual control [
6,
7]. Other issues related to visual measurement are camera configuration, the number of cameras, and the image processing techniques used. Commonly-used camera–robot system configurations are eye-in-hand, the standalone camera system, or a combination of both. The eye-in-hand system is preferred but requires either precision manipulation or active vision ability. In an active vision system, the camera has to be moved frequently for purposeful visual perception [
8].
Vision-guided control systems offer many advantages, such as flexibility, compensation for system uncertainty, and good tolerance to calibration errors. There are many applications of visually-guided robot manipulation systems, from pick-and-place, peg-in-hole, and bin-picking tasks to high precision autonomous assembly systems [
9,
10,
11,
12,
13]. Kragic and Christensen designed a tracking system for hand-eye coordination by integrating the two methods of voting and fuzzy logic. They showed the system’s robustness, in particular, for scenes with multiple moving objects and partial occlusion of the tracking object [
9]. A 2D vision-guided robotic assembly method with no manual calibration was proposed in [
10]. That system relies on a local calibration method to achieve a high accuracy alignment for the final assembly. A practical vision-based robotic bin-picking system has been reported in the literature, which performs detection and 3D pose estimation of objects in an unconstructed bin using a novel camera design, picks up parts from the bin, and conducts error detection and pose correction while the part is in the gripper [
11]. Two unique points in their work are a multi-flash camera that extracts robust depth edges and a fast. directional chamfer-matching algorithm that improves the accuracy of the chamfer match by including an edge orientation. Another study presented a fast peg-and-hole alignment system, in which a visual servoing approach with a single eye-in-hand high-speed camera is used to overcome the problem of position and attitude uncertainty [
12]. They adopted a high-speed 3-degrees of freedom (DOF) active peg to cooperate with the robot arm under high-speed visual feedback. A practical verification-based approach was also proposed to reduce the rate of wrong picking [
13]. The robot recognizes an object twice in a clutter working space and in hand after picking up an object.
The primary objective of this paper is the study of vision-guided robotic pick-and-place control systems with only one eye-in-hand camera based on a simple parallelogram model. Similar problems involving camera positioning on a parallel plane have been studied, and the approach has usually required the on-line computing of a Jacobian image matrix [
14,
15]. Affine visual servoing has been offered, whereby changes in the shape of image contours are used in order to control the positioning process [
14]. However, no experimental results were shown. Cretual and Chaumette studied the problem of positioning a robotic eye-in-hand camera in such a way that the image plane becomes parallel to a planar object [
15]. A dynamic visual servoing approach was also proposed to design a control loop upon the second order spatial derivatives of the optical flow. Our approach is easier to implement and does not require the computing of Jacobian matrices. In this paper, a simple and effective method for camera positioning and alignment control during robotic pick-and-place tasks is offered. The camera is mounted in a fixed position on the end-effector and provides images of the area below the gripper. A simple parallelogram model has been chosen to capture interesting features for use in vision servoing. The proposed positioning and alignment technique employs simple parallelism invariance to align the camera with a part based on a coarse and fine alignment strategy. Accurate absolute depth, from the camera to the part, can be obtained from its area in the image space. This means the pick-and-place task for 3D objects can be done without the need for a stereo vision system.
The rest of the paper is organized as follows.
Section 2 presents the visual measurement model based on planar parallelogram features.
Section 3 offers vision-based positioning and alignment control techniques in pick-and-place tasks.
Section 4 describes and discusses the experimental results obtained using a 6-axis industrial robot.
Section 5 concludes the paper.
2. Positioning and Alignment Based on Parallelogram Features
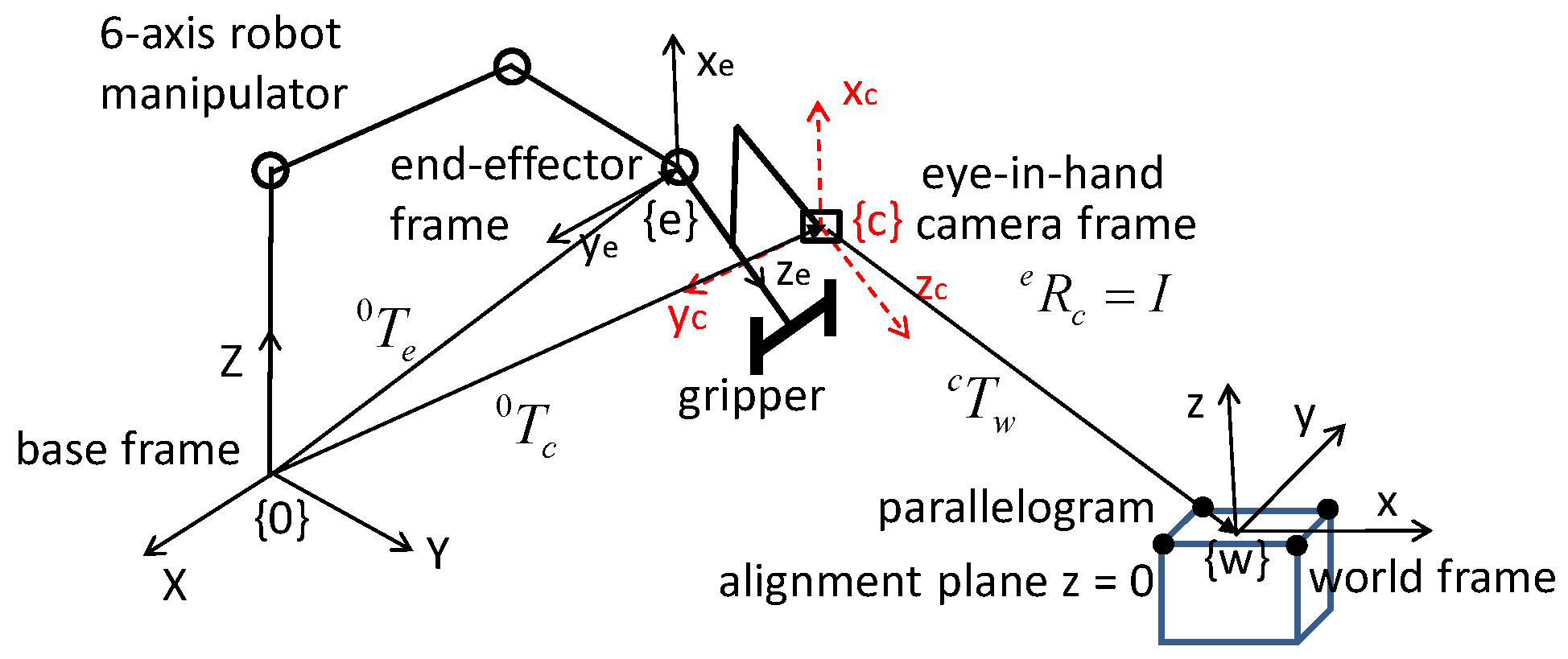
The coordinate frames of a 6-degrees of freedom (DOF) robot-gripper and single eye-in-camera system are defined as follows: the robot base coordinate frame {0}, end-effector coordinate frame {e}, eye-in-hand camera coordinate frame {c}, and world (or object/part) coordinate frame {w}. For simplicity, the eye-in-hand camera is installed so that the camera frame {c} and end-effector frame {e} are purely translational, and there is a rotational matrix .
Figure 1 shows coordinate systems of the robot-gripper-and-camera system. Position vectors
,
,
, and
are the translation vector of a target position relative to the base frame {0}, world frame {w}, camera frame {c}, and end-effector frame {e}, respectively. Image point
is a pixel coordinate in the image plane, such that the u-coordinate points to the
-axis and the v-coordinate points to the
-axis. Here,
,
, and
are defined as the basic rotational matrices of the rotational joints on the
x-,
y-, and
z-axes.
The eye-in-hand camera 6-DOF pose estimation method is based on the camera pinhole model and the rigid transformation of a parallelogram in the world coordinate frame’s
plane. The ideal pinhole camera model represents the relationship between the world space and the image space, while the relationship between the coordinate of the object point
and the image point
is given by
where the left-hand side (
) is a homogeneous coordinate representation of the image space and
H is a 3-by-3 homography matrix (or perspective projection matrix) up to a scale factor. A homograph is much easier to use for camera calibration with a flat world
z = 0, than a general 3D case. A point (
u,
v) in the image corresponds to a certain point in the world.
The homography matrix H is a matrix multiplication of two 3-by-3 matrices:
where
A is the camera intrinsic matrix, and
B the extrinsic coordinate transformation
B. The camera intrinsic matrix,
, represents the relationship between the camera coordinate system and its image space. Parameters
and
are the effective focal length in pixels of the camera along the xc and yc directions,
is the camera skew factor, and
is the coordinate of the principle point.
The extrinsic coordinate transformation matrix,
, represents the relationship between the camera coordinate system and the object coordinate system, the homogeneous matrix is
, where
, and the symbol
stands for
. Here, it is assumed that the camera intrinsic matrix
A is known in advance. There are several methods that can be applied to compute the camera intrinsic parameters, with Zhang’s plane target method [
16] being a popular one.
Let , , be the alignment feature points in the world coordinate plane in the counter-clockwise direction, satisfying the parallelogram property, i.e., and ; and , , are the corresponding image points in the image plane. From the above four feature points and , , one can compute the parallelogram-to-quadrilateral projection homography H up to a scale factor. Moreover, if and , then elements , and H is a parallelogram-to-parallelogram affine transformation; otherwise, H is a perspective projection transformation. Affine transformation means the addition of translation to linear transformation. The properties of affine transformation include lines map to lines, parallel lines remain parallel, and parallelograms map to parallelograms. As a result, the object is lying in a plane parallel to the image plane. The alignment control can then be easily performed by translating in the x-y plane and rotating about the z-axis.
When the homography matrix
H is an affine transformation, the absolute depth from camera to the object can be computed from
where
and
are the area of the parallelogram in the world space and in the image plane, respectively.
Once the projective matrix H has been computed, the extrinsic matrix B can be computed easily from
The above matrix inverse approach does not enforce the orthonormality of the first two columns of the rotation matrix
R,
. One easy and approximate solution is to adjust them to orthonormality, by letting
and then setting
and
to satisfy
and
. Usage of the third orthogonal unit vector
here is to guarantee that vectors
and
are orthogonal unit vectors. This simplified approach is easy to compute and acceptable, because we use the rotation matrix
R merely as an estimate during the initially coarse vision alignment stage. The homogeneous matrix from the object coordinate system to the camera coordinate system is then
4. Experimental Results and Discussions
The experimental robot used in this study was a Hiwin R605 6-axis industrial manipulator, which had an on–off gripper attached to its end-effector. A camera was installed on a fixed end-flange in front of and above the gripper. The eye-in-hand camera used was a low-cost Web color camera with a resolution of 720 × 1280 at 30 fps. The overall robot control system was based on a commercially provided robot controller running under a continuous look-and-move control strategy. The robot controller had built-in set-point control and point-to-point motion control utilities in both joint-space and Cartesian-space. We implement the robot vision and control software on a PC with Microsoft Visual C++ programming language and use OpenCV library functions, such as cvtColor, findContours, and approxPolyDP, for color segmentation and to search for an object’s vertices.
Figure 3 shows the experimental robot control system set-up, in which the geometric data of the 3D objects are known. Each packing part or target placing location is featured by a parallelogram.
Table 1 shows the camera’s intrinsic parameters. As the eye-in-hand camera is moving and close to the estimated object, the camera skew factor
.
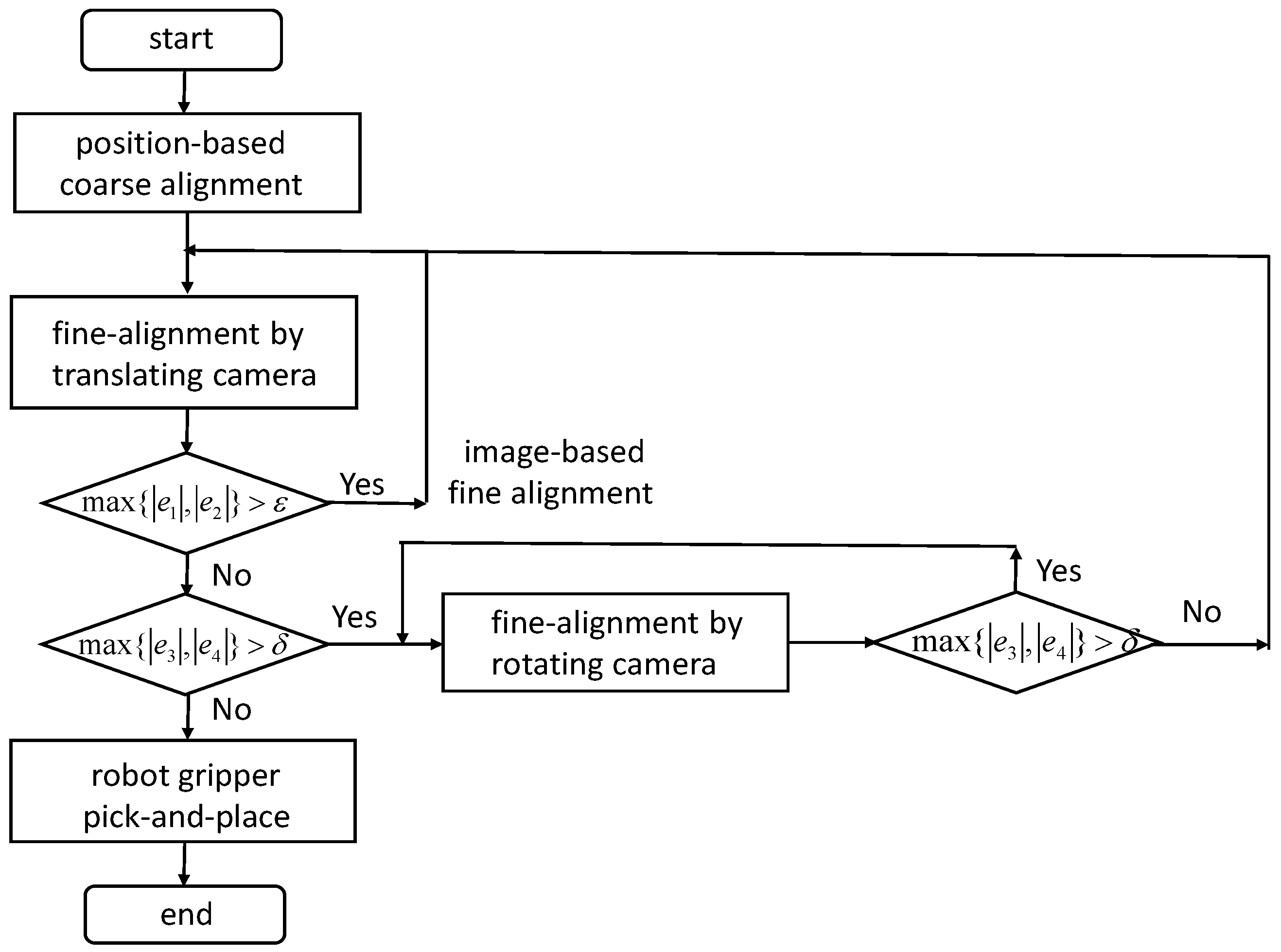
Figure 4 is a schematic of the control flow of the eye-in-hand camera alignment control and gripper pick-and-place control.
Table 2 shows the proportional incremental control gains in image-based fine-alignment control. Since the unit of
is angle error (in degrees) and that of
is depth error (in mm),
and
are used.
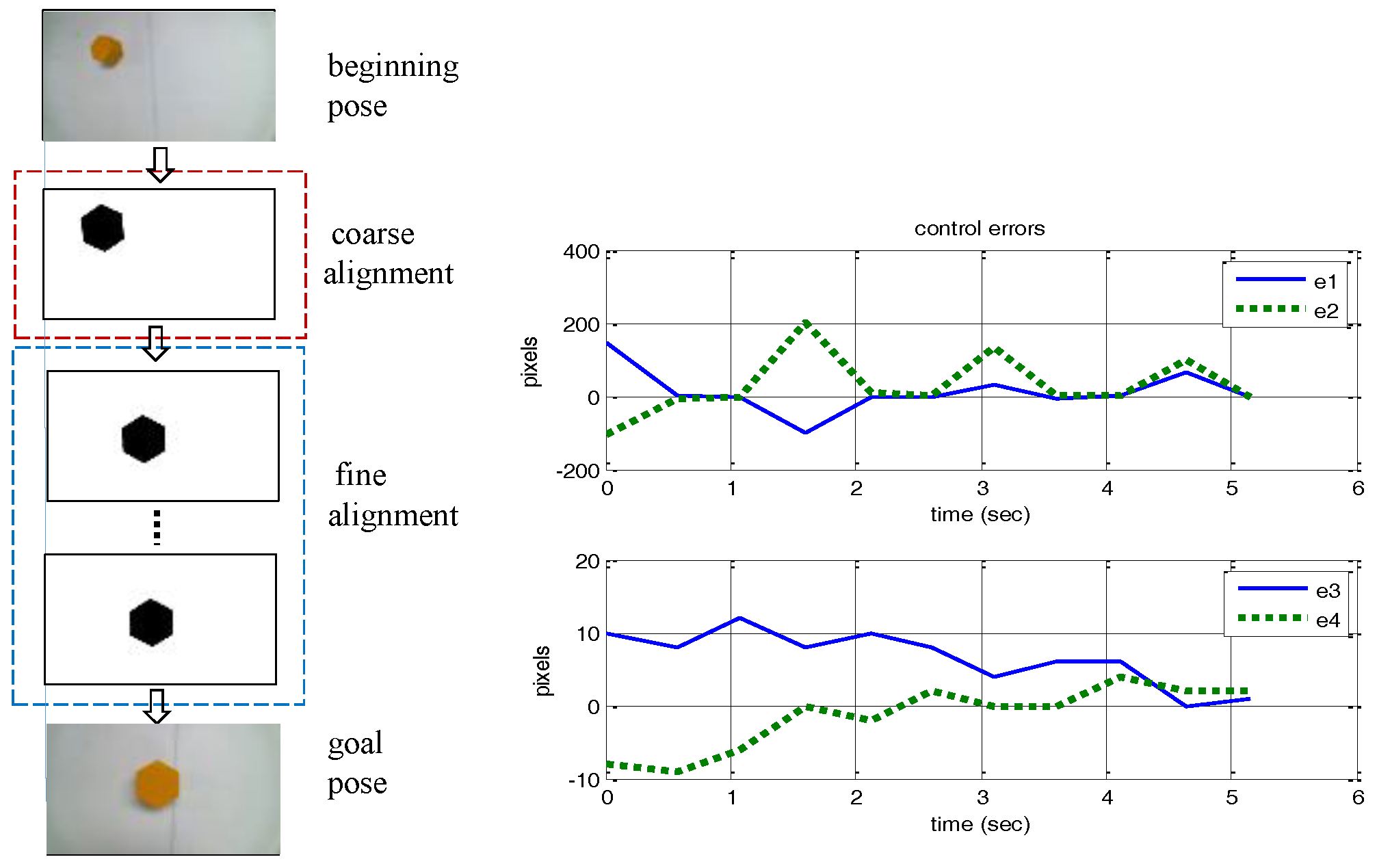
In the first alignment control experiment, the goal was to align the camera with a hexahedron part at the center and upright position in the image plane and then to cause the robot to pick up the part.
Figure 5 shows the camera alignment control result for picking up the part. The alignment goal pose is set to:
and the external parameters matrix at the beginning pose was computed as
The coarse alignment control motion was then set as .
The error bounds were then set to pixels and pixels for the following fine-alignment stage. After eight fine-alignment movements, the camera moved to the upright center position of the hexahedron at a depth of 200 mm. The positioning accuracy was within 1.0 mm and the orientation angle accuracy was within 1.0 degree. The robot vision control system follows a continuous look-and-move control scheme. The processing time of the object feature vision feedback is less than one second. In each vision control iteration, the robot’s movement follows a joint space point-to-point motion with set-points obtained from the vision control law and the robot’s inverse kinematics. Usually, a joint space point-to-point motion takes 0.5 to 1.0 s. The alignment control finishes within three iterations on average, and thus the vision-based alignment control task takes just a few seconds.
In the second alignment control experiment, the goal was to first align the camera with a square shape at the center and upright position in the image plane and then to cause the robot to place the object.
Figure 6 shows the camera alignment control result before placing the object. The goal alignment pose was set to
and the external parameters matrix at the beginning pose was computed as
The coarse alignment control motion was then set as .
In the fine-alignment stage, the error bounds were also set to pixels and pixels. After 7 fine-alignment movements, the camera is moved to the upright center position of the square shape at a depth of 300 mm. The positioning accuracy was within 1.0 mm and orientation angle accuracy was within 1.0 degree.
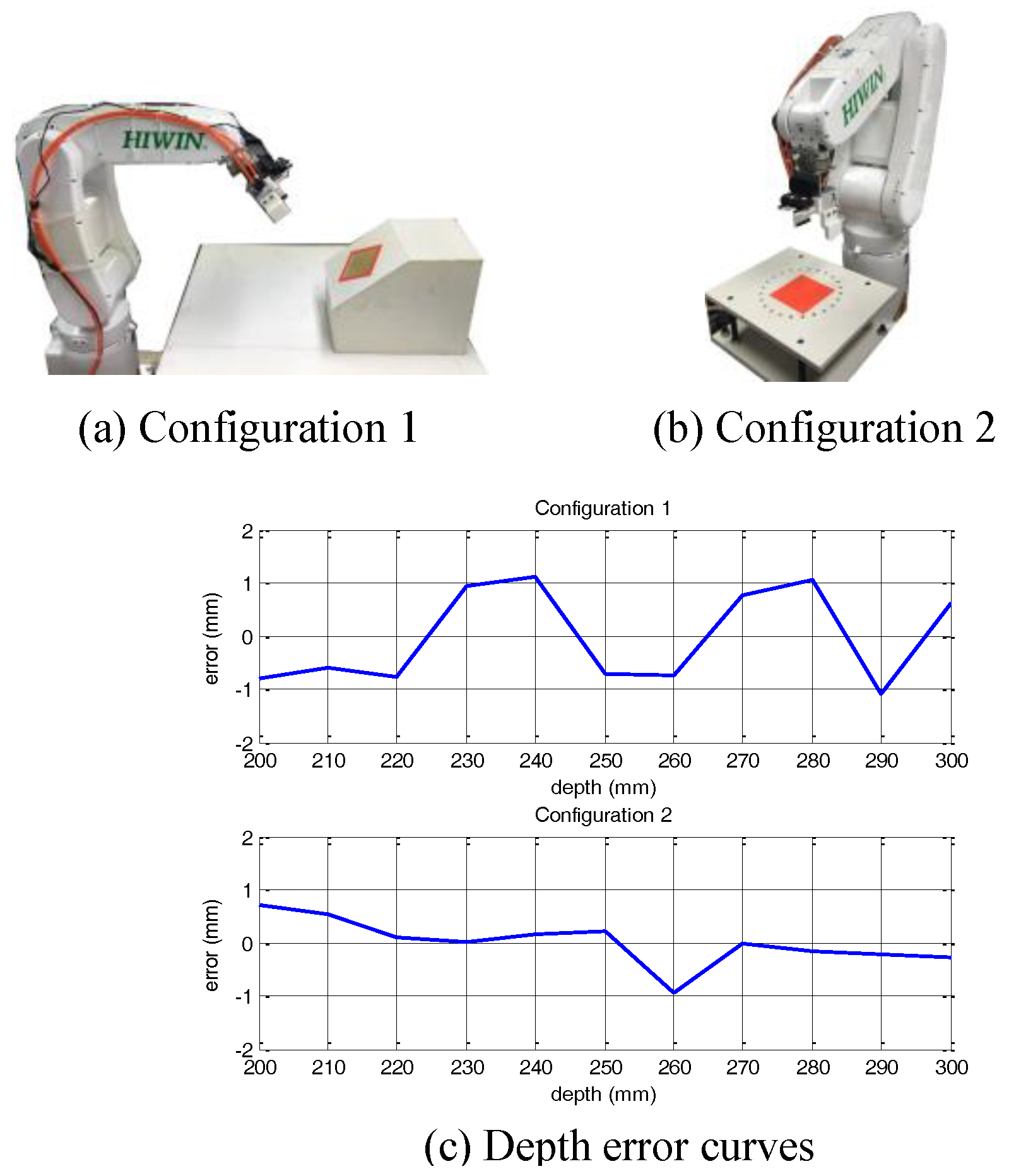
In the following depth error experiment, the approximate distance from the camera location to the object was between 200 mm and 300 mm during pose estimation.
Figure 7 shows the computed depth error, using Equation (3), for two different object poses after fine-alignment was done. The actual depth error was about 1.2 mm.
We next discuss the main advantages and disadvantages of similar eye-in-hand visual servo control systems, in which the target object is composed of four non-coplanar points, and perform experimental tests on a 6-DOF robot [
6,
17,
18]. We base the use of four characteristic points in total for six DOFs on a commonly used strategy. From the projection of these four points in the image frame, a set of six features can control all six DOFs of the robot manipulator: three for positioning control and three for orientation control.
The work by Hager uses projective geometry and projective invariance in robotic hand-eye coordination [
6]. This approach separates hand-eye coordination into application-independent hand-eye utilities and application-dependent geometric operations. The three basic position/alignment skills are planar positioning, parallel alignment, and positioning in the object coordinate. The experiments are based on tracking corners formed by the intersections of line segments. The accuracy of the placement is typically within 2.0 mm. Because all of the proposed control algorithm are nonlinear, this approach sometimes exhibits singularities within a viewable workspace.
Kosmopoulos experimented with a 6-DOF sunroof placement robot by monitoring four corners of a sunroof opening [
17]. That research identified the corners as the interaction points of the two line edges. The sunroof placement installation operation is thus done under a small workspace volume. The visual control system does not need to estimate the depth and there is no need for camera calibration. The control method is based on a local calculation of the image Jacobian matrix through training and is only suitable for relatively small deviations (10.0 mm and 1.0 degrees) from the end-effector nominal pose.
Recent work by Keshmiri and Xie combines optimized trajectory planning with an augmented image-based servo control [
18], using six visual features to facilitate the optimization procedure and depth-estimation. These features are the center of four feature points, the perimeter of the lines connecting each consecutive feature point, and three rotational angles from the deformation in the features by rotating the camera about its
x-axis,
y-axis and
z-axis. The planning procedure consists of three stages: moving the camera to estimate the depth of features, planning the best camera velocity to remove orientation errors, and planning the best camera velocity to remove position errors. A calibration error could deviate the robot from its ideal path, and the local minima problem may arise. Because this is global offline trajectory planning, it is therefore unable to work in a dynamically changing environment.
The main advantage of the proposed methodology is the simplicity of implementing the visual servo control without using the interaction matrix as a traditional method. Our method is based on the point error and area error of four feature points. We choose the parallelogram model so as to capture any interesting features for use in the 6-DOF imaged-based visual servo control. The positioning and alignment task employs only simple parallelism invariance and decoupled proportional control laws to position and align the camera with a target object. An accurate absolute depth, from the camera to the object, can be obtained from its area in the image space. Experimental results show excellent applicability of the proposed approach for pick-and-place tasks, and the overall errors are 1.2 mm for positioning and 1.0° for orientation angle.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}