Human-Robot Interfaces for Interactive Receptionist Systems and Wayfinding Applications



Abstract

1. Introduction
2. Related Work
2.1. Maps
2.2. Virtual Receptionist
2.3. Robotic Receptionist
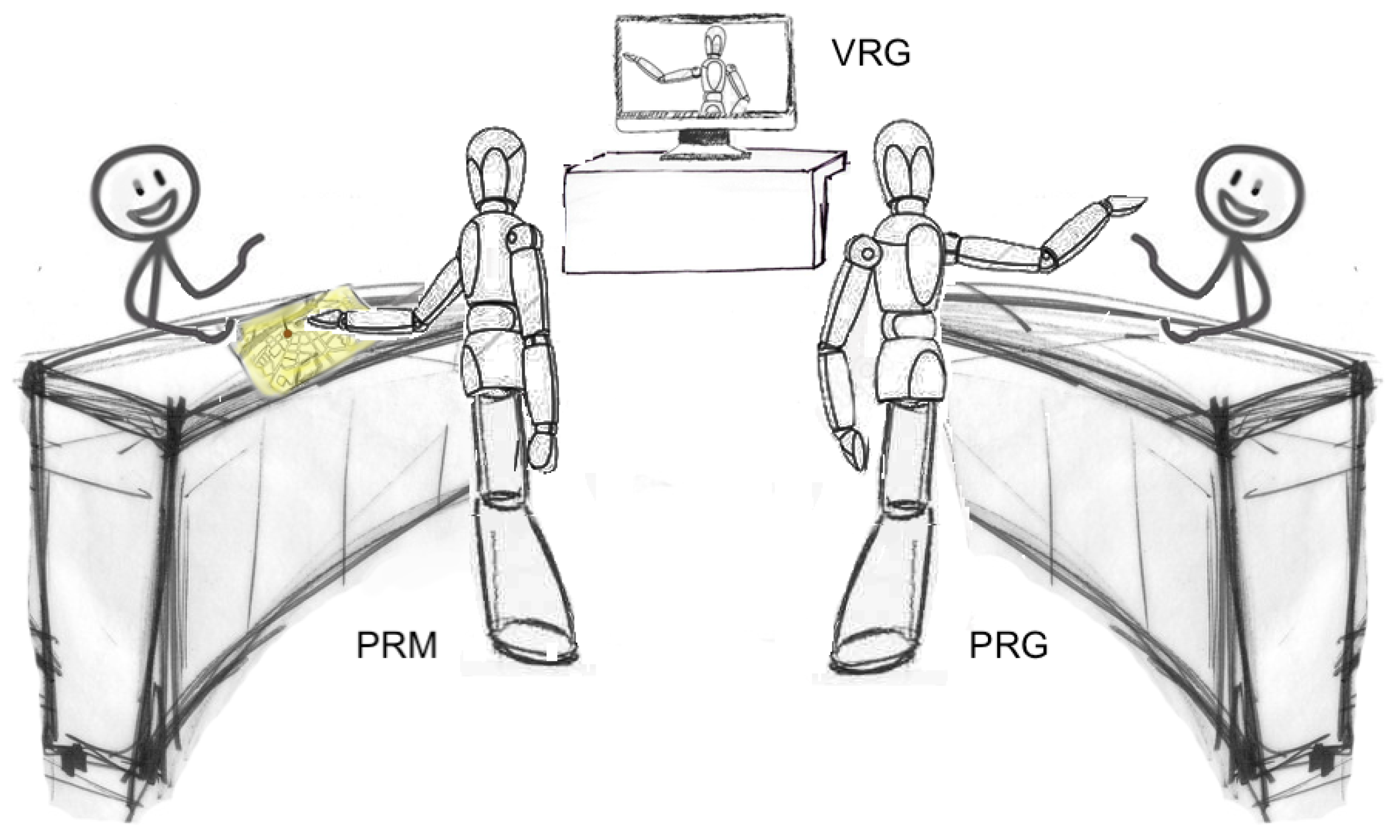
3. Research Goal
4. Receptionist Systems
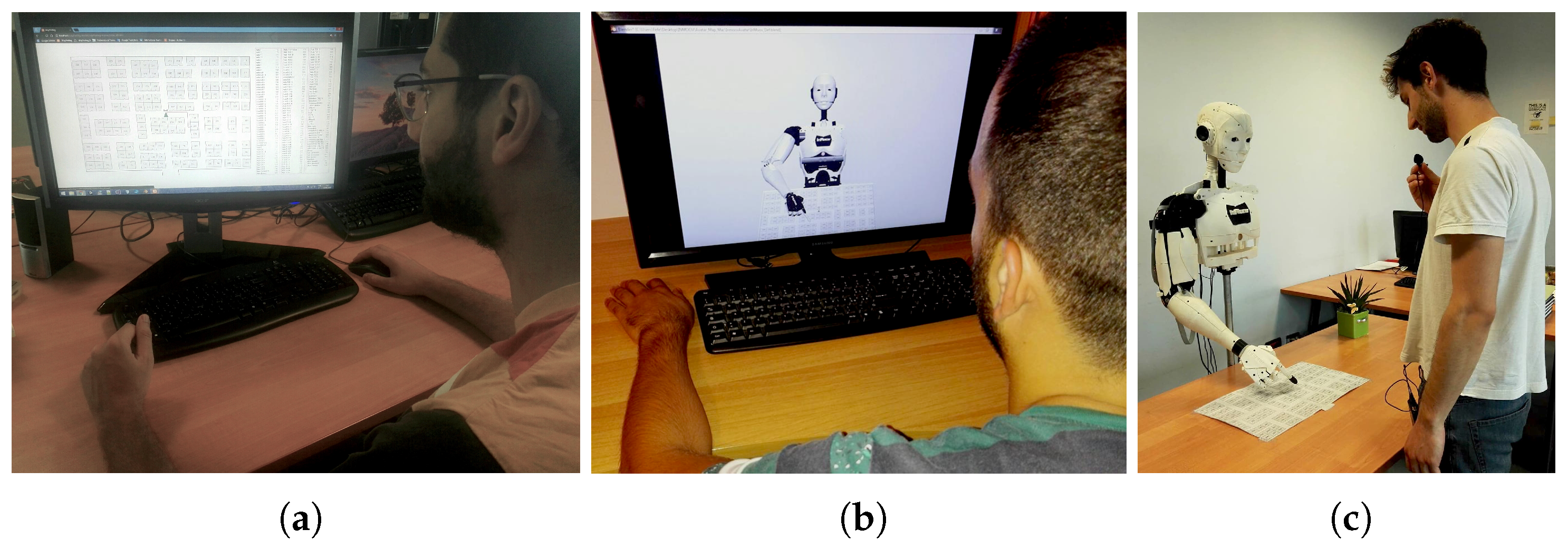
4.1. Physical Robot
4.1.1. Hardware Components
4.1.2. Software Components
- Face tracking: This module processes the video stream received from the cameras to detect the presence of human faces and their position in the robot’s field of view. It is based on MyRobotLab (http://www.myrobotlab.org) Tracking module, which can track human faces in real time through the OpenCV (https://opencv.org) library. When a face is tracked, the robot’s head is adjusted in order to keep the identified face in the center of its field of view. In a reception use case, in which the robot is expected to be placed in public and crowded areas, not all the detected people may want to start a conversation. Hence, in order to limit the number of unwanted activations, two events, i.e., foundFace and lostFace, were added to the original tracking module. The foundFace event is fired when a human face is detected in a given number of consecutive frames; similarly, the lostFace event is fired when no human face is detected in a pre-defined number of frames. Data produced by this module are sent the to Gaze module.
- Gaze: This module is responsible for managing robot’s head and eyes movements during the interaction with a human user. For instance, in the greetings and farewell phases, the robot’s gaze is oriented towards the user’s face. In the configuration studied in which the robot is giving directions by pointing destinations on a map, gaze is directed on the map.
- Chatbot: This module represents the brain of the system, and generates text responses based on received text stimuli. It relies on the A.L.I.C.E. bot (http://www.alicebot.org), an open source natural language processing chatterbot that uses a XML schema called AIML (Artificial Intelligence Markup Language) to allow the customization of a conversation. With AIML it is possible to define the keywords/phrases that the robot should capture and understand (related to greeting/farewell phases, as well as to destinations) and the answers it should provide (greeting/farewell expressions and directions). In addition, when a keyword/phrase concerning a destination is spotted, the AIML language can be used to activate robot’s arm gestures for giving directions, by sending required information to the Navigation module. The conversation logic adopted by the robot is illustrated in Figure 5: purple clouds represent examples of possible user inputs, whereas grey clouds are examples of possible robot’s answers.
- Voice recognition: This module receives voice commands from the microphone, converts them to text using the WebKit speech recognition APIs by Google, and sends the result to the Chatbot module.
- Voice synthesis: This module allows the robot to speak. It receives text messages from the Chatbot module, converts them into audio files through the MaryTTS (http://mary.dfki.de) speech synthesis engine, and sends them to the speakers. In addition, when a message is received, it triggers a moveMouth event, which makes the robot’s mouth move by synchronizing with words pronounced.
- Navigation: This is the main module that was developed in this work and integrated in MyRobotLab in order to provide users with directions for the requested destination. It is based on the IK module available in MyRobotLab, which was adapted to move the end-effector of robot’s arm and reproduce pointing gestures (in-the-air or on the map). The IK module does not guarantee that a runtime-computed solution always exhibits the same sequence of movements for the end-effector to reach the intended position. Moreover, should the solution fall in a kinematic singularity point, it would cause the robot’s arm to lose its ability to move, making it unusable. For these reasons, the module was modified to execute an IK pre-calculation phase, in which the end-effector is moved to the intended position by means of a controlled sequence of gestures made up of small displacements along the axes. When the desired position is reached, the gesture sequence is saved in the system and associated to the given destination. In order to make the robot move in a natural way, tracking data of a human arm executing the required gestures were recorded using a Microsoft Kinect depth camera and the OpenNI software (http://openni.ru/) and properly adapted to the considered scenario. When the destination is identified by the Chatbot module, the Navigation module loads the corresponding sequence and transmit gestures to the Gesture module, which actuates them.
- Gesture: This module was created within the present work. Its role is to make the robot execute the gesture sequence suitable for the particular direction-giving modality being considered (in-the-air or map pointing gestures) and the specific destination selected.
- Interaction logic: This module controls all the previous ones based on the flow of human-robot interaction and the direction-giving modality in use. As a matter of example, while the robot is speaking using the Voice synthesis module, the Voice recognition module needs to be stopped to avoid misbehavior.
4.2. Virtual Robot
4.3. Interactive Map
5. Experimental Results
5.1. First User Study: Route Tracing on a Map or Arm Pointing Gestures?
5.1.1. Experimental Setup and Procedure
5.1.2. Measures
5.1.3. Objective Observations
5.1.4. Subjective Observations
5.1.5. Discussion
5.2. Second User Study: The Role of Embodiment and Social Behavior
5.2.1. Experimental Setup and Procedure
5.2.2. Measures
5.2.3. Objective Observations
5.2.4. Subjective Observations
5.2.5. Discussion
6. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Thrun, S. Toward a framework for human-robot interaction. Hum.-Comput. Interact. 2004, 19, 9–24. [Google Scholar]
- Jones, J.L. Robots at the tipping point: The road to iRobot Roomba. IEEE Robot. Autom. Mag. 2006, 13, 76–78. [Google Scholar] [CrossRef]
- Ahn, H.S.; Sa, I.K.; Choi, J.Y. PDA-based mobile robot system with remote monitoring for home environment. IEEE Trans. Consum. Electron. 2009, 55, 1487–1495. [Google Scholar] [CrossRef]
- Yoshimi, T.; Matsuhira, N.; Suzuki, K.; Yamamoto, D.; Ozaki, F.; Hirokawa, J.; Ogawa, H. Development of a concept model of a robotic information home appliance, ApriAlpha. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Sendai, Japan, 28 September–2 October 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 1, pp. 205–211. [Google Scholar]
- Fujita, M. On activating human communications with pet-type robot AIBO. Proc. IEEE 2004, 92, 1804–1813. [Google Scholar] [CrossRef]
- Ahn, H.S.; Sa, I.K.; Lee, D.W.; Choi, D. A playmate robot system for playing the rock-paper-scissors game with humans. Artif. Life Robot. 2011, 16, 142. [Google Scholar] [CrossRef]
- Clabaugh, C.; Sha, F.; Ragusa, G.; Mataric, M. Towards a personalized model of number concepts learning in preschool children. In Proceedings of the ICRA Workshop on Machine Learning for Social Robotics, Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Tanaka, F.; Cicourel, A.; Movellan, J.R. Socialization between toddlers and robots at an early childhood education center. Proc. Natl. Acad. Sci. USA 2007, 104, 17954–17958. [Google Scholar] [CrossRef] [PubMed]
- Shibata, T.; Kawaguchi, Y.; Wada, K. Investigation on people living with Paro at home. In Proceedings of the IEEE International Conference on Robot and Human Interactive Communication, Viareggio, Italy, 13–15 September 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 470–475. [Google Scholar]
- Fasola, J.; Mataric, M. A socially assistive robot exercise coach for the elderly. J. Hum.-Robot Interact. 2013, 2, 3–32. [Google Scholar] [CrossRef]
- Dautenhahn, K. Socially intelligent robots: dimensions of human–robot interaction. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2007, 362, 679–704. [Google Scholar] [CrossRef] [PubMed]
- Minato, T.; Shimada, M.; Ishiguro, H.; Itakura, S. Development of an android robot for studying human-robot interaction. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Ottawa, ON, Canada, 17–20 May 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 424–434. [Google Scholar]
- Fong, T.; Nourbakhsh, I.; Dautenhahn, K. A survey of socially interactive robots. Robot. Auton. Syst. 2003, 42, 143–166. [Google Scholar] [CrossRef]
- Feil-Seifer, D.; Mataric, M.J. Defining socially assistive robotics. In Proceedings of the International Conference on Rehabilitation Robotics, Chicago, IL, USA, 28 June–1 July 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 465–468. [Google Scholar]
- Darken, R.P.; Peterson, B. Spatial Orientation, Wayfinding, and Representation. In Human Factors and Ergonomics. Handbook of Virtual Environments: Design, Implementation, and Applications; Lawrence Erlbaum Associates Publishers: Mahwah, NJ, USA, 2014. [Google Scholar]
- Montello, D.R.; Sas, C. Human Factors of Wayfinding in Navigation; CRC Press: Boca Raton, FL, USA, 2006. [Google Scholar]
- Levine, M. You-are-here maps: Psychological considerations. Environ. Behav. 1982, 14, 221–237. [Google Scholar] [CrossRef]
- Ishikawa, T.; Fujiwara, H.; Imai, O.; Okabe, A. Wayfinding with a GPS-based mobile navigation system: A comparison with maps and direct experience. J. Environ. Psychol. 2008, 28, 74–82. [Google Scholar] [CrossRef]
- Streeter, L.A.; Vitello, D.; Wonsiewicz, S.A. How to tell people where to go: Comparing navigational aids. Int. J. Man-Mach. Stud. 1985, 22, 549–562. [Google Scholar] [CrossRef]
- Coors, V.; Elting, C.; Kray, C.; Laakso, K. Presenting route instructions on mobile devices: From textual directions to 3D visualization. In Exploring Geovisualization; Elsevier: New York, NY, USA, 2005; pp. 529–550. [Google Scholar]
- Lorenz, A.; Thierbach, C.; Baur, N.; Kolbe, T.H. App-free zone: Paper maps as alternative to electronic indoor navigation aids and their empirical evaluation with large user bases. In Progress in Location-Based Services; Springer: Berlin/Heidelberg, Germany, 2013; pp. 319–338. [Google Scholar]
- Dillemuth, J. Map design evaluation for mobile display. Cartogr. Geogr. Inf. Sci. 2005, 32, 285–301. [Google Scholar] [CrossRef]
- Fewings, R. Wayfinding and airport terminal design. J. Navig. 2001, 54, 177–184. [Google Scholar] [CrossRef]
- Raisamo, R. A multimodal user interface for public information kiosks. In Proceedings of the Workshop on Perceptual User Interfaces, San Francisco, CA, USA, 5–6 November 1998; pp. 7–12. [Google Scholar]
- Bergweiler, S.; Deru, M.; Porta, D. Integrating a multitouch kiosk system with mobile devices and multimodal interaction. In Proceedings of the ACM International Conference on Interactive Tabletops and Surfaces, Saarbrücken, Germany, 7–10 November 2010; ACM: New York, NY, USA, 2010; pp. 245–246. [Google Scholar]
- Niculescu, A.I.; Yeo, K.H.; Banchs, R.E. Designing MUSE: A multimodal user experience for a shopping mall kiosk. In Proceedings of the International Conference on Human Agent Interaction, Singapore, 4–7 October 2016; ACM: New York, NY, USA, 2016; pp. 273–275. [Google Scholar]
- Tüzün, H.; Telli, E.; Alır, A. Usability testing of a 3D touch screen kiosk system for way-finding. Comput. Hum. Behav. 2016, 61, 73–79. [Google Scholar] [CrossRef]
- Wright, P.; Soroka, A.; Belt, S.; Pham, D.T.; Dimov, S.; De Roure, D.; Petrie, H. Using audio to support animated route information in a hospital touch-screen kiosk. Comput. Hum. Behav. 2010, 26, 753–759. [Google Scholar] [CrossRef]
- Toutziaris, V. Usability of an Adjusted IndoorTubes Map Design for Indoor Wayfinding on Mobile Devices. Master’s Thesis, Technical University of Munich, Munich, Germany, 19 May 2017. [Google Scholar]
- Google Maps. Available online: http://www.google.com/maps/ (accessed on 10 April 2018).
- HERE WeGo. Available online: http://wego.here.com (accessed on 10 April 2018).
- Mapwize. Available online: http://www.mapwize.io/en/ (accessed on 10 April 2018).
- Cartogram. Available online: http://www.cartogram.com (accessed on 10 April 2018).
- Wayfinding kiosk with 3D wayfinder. Available online: http://3dwayfinder.com (accessed on 10 April 2018).
- Kiosk wayfinder. Available online: http://www.kioskwebsite.com (accessed on 10 April 2018).
- Koda, T.; Maes, P. Agents with faces: The effect of personification. In Proceedings of the IEEE International Workshop on Robot and Human Communication, Tsukuba, Japan, 11–14 November 1996; IEEE: Piscataway, NJ, USA, 1996; pp. 189–194. [Google Scholar]
- Cassell, J.; Bickmore, T.; Campbell, L.; Vilhjalmsson, H.; Yan, H. More than just a pretty face: Conversational protocols and the affordances of embodiment. Knowl.-Based Syst. 2001, 14, 55–64. [Google Scholar] [CrossRef]
- Cassell, J. Embodied Conversational Agents; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Theune, M.; Hofs, D.; Kessel, M. The Virtual Guide: A direction giving embodied conversational agent. In Proceedings of the Annual Conference of the International Speech Communication Association, Antwerp, Belgium, 27–31 August 2007. [Google Scholar]
- Cassell, J.; Stocky, T.; Bickmore, T.; Gao, Y.; Nakano, Y.; Ryokai, K.; Tversky, D.; Vaucelle, C.; Vilhjálmsson, H. Mack: Media lab autonomous conversational kiosk. Proc. Imagina 2002, 2, 12–15. [Google Scholar]
- Stocky, T.A. Conveying Routes: Multimodal Generation and Spatial Intelligence in Embodied Conversational Agents. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2002. [Google Scholar]
- Nakano, Y.I.; Reinstein, G.; Stocky, T.; Cassell, J. Towards a model of face-to-face grounding. In Proceedings of the Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, Sapporo, Japan, 7–12 July 2003; pp. 553–561. [Google Scholar]
- Kopp, S.; Tepper, P.A.; Ferriman, K.; Striegnitz, K.; Cassell, J. Trading spaces: How humans and humanoids use speech and gesture to give directions. In Conversational Informatics: An Engineering Approach; Wiley: Hoboken, NJ, USA, 2007; pp. 133–160. [Google Scholar]
- Babu, S.; Schmugge, S.; Barnes, T.; Hodges, L.F. “What would you like to talk about?” An evaluation of social conversations with a virtual receptionist. In Proceedings of the International Workshop on Intelligent Virtual Agents, Marina del Rey, CA, USA, 21–23 August 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 169–180. [Google Scholar]
- Gockley, R.; Bruce, A.; Forlizzi, J.; Michalowski, M.; Mundell, A.; Rosenthal, S.; Sellner, B.; Simmons, R.; Snipes, K.; Schultz, A.C.; et al. Designing robots for long-term social interaction. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, USA, 2–6 August 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 1338–1343. [Google Scholar]
- Michalowski, M.P.; Sabanovic, S.; Simmons, R. A spatial model of engagement for a social robot. In Proceedings of the IEEE International Workshop on Advanced Motion Control, Istanbul, Turkey, 27–29 March 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 762–767. [Google Scholar]
- Lee, M.K.; Kiesler, S.; Forlizzi, J. Receptionist or information kiosk: how do people talk with a robot? In Proceedings of the ACM Conference on Computer Supported Cooperative Work, Savannah, GA, USA, 6–10 February 2010; ACM: New York, NY, USA, 2010; pp. 31–40. [Google Scholar]
- Cairco, L.; Wilson, D.M.; Fowler, V.; LeBlanc, M. AVARI: Animated virtual agent retrieving information. In Proceedings of the Annual Southeast Regional Conference, Clemson, SC, USA, 19–21 March 2009; ACM: New York, NY, USA, 2009; p. 16. [Google Scholar]
- Thomaz, A.L.; Chao, C. Turn-taking based on information flow for fluent human-robot interaction. AI Mag. 2011, 32, 53–63. [Google Scholar] [CrossRef]
- Salem, M.; Ziadee, M.; Sakr, M. Effects of politeness and interaction context on perception and experience of HRI. In Proceedings of the International Conference on Social Robotics, Bristol, UK, 27–29 October 2013; Springer: Cham, Switzerland, 2013; pp. 531–541. [Google Scholar]
- Rehmani, T.; Butt, S.; Baig, I.U.R.; Malik, M.Z.; Ali, M. Designing robot receptionist for overcoming poor infrastructure, low literacy and low rate of female interaction. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction, Chicago, IL, USA, 5–8 March 2018; ACM: New York, NY, USA, 2018; pp. 211–212. [Google Scholar]
- Nisimura, R.; Uchida, T.; Lee, A.; Saruwatari, H.; Shikano, K.; Matsumoto, Y. ASKA: Receptionist robot with speech dialogue system. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Lausanne, Switzerland, 30 September–4 October 2002; IEEE: Piscataway, NJ, USA, 2002; Volume 2, pp. 1314–1319. [Google Scholar]
- Holzapfel, H.; Waibel, A. Behavior models for learning and receptionist dialogs. In Proceedings of the Annual Conference of the International Speech Communication Association, Antwerp, Belgium, 27–31 August 2007. [Google Scholar]
- Cosgun, A.; Trevor, A.J.; Christensen, H.I. Did you mean this object?: Detecting ambiguity in pointing gesture targets. In Proceedings of the 10th ACM/IEEE international conference on Human-Robot Interaction (HRI) workshop on Towards a Framework for Joint Action, Portland, OR, USA, 2–5 March 2015. [Google Scholar]
- Hato, Y.; Satake, S.; Kanda, T.; Imai, M.; Hagita, N. Pointing to space: Modeling of deictic interaction referring to regions. In Proceedings of the 5th ACM/IEEE international conference on Human-robot interaction, Osaka, Japan, 2–5 March 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 301–308. [Google Scholar]
- Burghart, C.; Holzapfel, H.; Haeussling, R.; Breuer, S. Coding interaction patterns between human and receptionist robot. In Proceedings of the IEEE-RAS International Conference on Humanoid Robots, Pittsburgh, PA, USA, 29 November–1 December 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 454–460. [Google Scholar]
- Hashimoto, T.; Hiramatsu, S.; Tsuji, T.; Kobayashi, H. Realization and evaluation of realistic nod with receptionist robot SAYA. In Proceedings of the IEEE International Symposium on Robot and Human interactive Communication, Jeju, Korea, 26–29 August 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 326–331. [Google Scholar]
- Okuno, Y.; Kanda, T.; Imai, M.; Ishiguro, H.; Hagita, N. Providing route directions: Design of robot’s utterance, gesture, and timing. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction, La Jolla, CA, USA, 11–13 March 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 53–60. [Google Scholar]
- Bohus, D.; Saw, C.W.; Horvitz, E. Directions robot: In-the-wild experiences and lessons learned. In Proceedings of the International Conference on Autonomous Agents and Multi-agent Systems. International Foundation for Autonomous Agents and Multiagent Systems, Paris, France, 5–9 May 2014; pp. 637–644. [Google Scholar]
- Holthaus, P.; Wachsmuth, S. The receptionist robot. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction, Bielefeld, Germany, 3–6 March 2014; ACM: New York, NY, USA, 2014; p. 329. [Google Scholar]
- Trovato, G.; Ramos, J.G.; Azevedo, H.; Moroni, A.; Magossi, S.; Ishii, H.; Simmons, R.; Takanishi, A. “Olá, my name is Ana”: A study on Brazilians interacting with a receptionist robot. In Proceedings of the International Conference on Advanced Robotics, Istanbul, Turkey, 27–31 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 66–71. [Google Scholar]
- Trovato, G.; Ramos, J.; Azevedo, H.; Moroni, A.; Magossi, S.; Ishii, H.; Simmons, R.; Takanishi, A. Designing a receptionist robot: Effect of voice and appearance on anthropomorphism. In Proceedings of the IEEE International Symposium on Robot and Human Interactive Communication, Kobe, Japan, 31 August–3 September 2015; pp. 235–240. [Google Scholar]
- Hasegawa, D.; Cassell, J.; Araki, K. The role of embodiment and perspective in direction-giving systems. In Proceedings of the AAAI Fall Symposium: Dialog with Robots, Arlington, VA, USA, 11–13 November 2010. [Google Scholar]
- Bainbridge, W.A.; Hart, J.W.; Kim, E.S.; Scassellati, B. The benefits of interactions with physically present robots over video-displayed agents. Int. J. Soc. Robot. 2011, 3, 41–52. [Google Scholar] [CrossRef]
- Li, J. The benefit of being physically present: A survey of experimental works comparing copresent robots, telepresent robots and virtual agents. Int. J. Hum.-Comput. Stud. 2015, 77, 23–37. [Google Scholar] [CrossRef]
- Langevin, G. InMoov—Open Source 3D Printed Life-Size Robot. Available online: http://www.inmoov.fr (accessed on 10 April 2018).
- Lund, A.M. Measuring usability with the use questionnaire. Usability Interface 2001, 8, 3–6. [Google Scholar]
- Kalawsky, R.S. VRUSE—A computerised diagnostic tool for usability evaluation of virtual/synthetic environment systems. Appl. Ergon. 1999, 30, 11–25. [Google Scholar] [CrossRef]
- Fasola, J.; Mataric, M. Comparing Physical and Virtual Embodiment in a Socially Assistive Robot Exercise Coach for the Elderly; Technical Report; Center for Robotics and Embedded Systems: Los Angeles, CA, USA, 2011. [Google Scholar]
- Poresky, R.H.; Hendrix, C.; Mosier, J.E.; Samuelson, M.L. The companion animal bonding scale: Internal reliability and construct validity. Psychol. Rep. 1987, 60, 743–746. [Google Scholar] [CrossRef]
- McCroskey, J.C.; McCain, T.A. The Measurement of Interpersonal Attraction. Speech Monogr. 1974, 41, 261–266. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluated Aspect | Question/Statement |
|---|---|
| Satisfaction | |
| Q1 | The system is pleasant to use |
| Q2 | The system works the way I want it to work |
| Q3 | The system is fun to use |
| Q4 | I am satisfied with the system |
| User interaction | |
| Q5 | I was able to understand how to interact with the system |
| Q6 | I think that the way to interact with the system is simple and uncomplicated |
| Q7 | I was impressed with the way I could interact with the system |
| Q8 | I had the right level of control on the system |
| Q9 | I was always aware of what the system was doing |
| Q10 | I felt disorientated while using the system |
| Q11 | System behavior was self-explanatory |
| Q12 | I thought the user interface negatively influenced my performance |
| Q13 | The system response time did negatively affect my performance |
| Q14 | The system appeared to freeze or pause at intervals |
| Visual feedback | |
| Q15 | I think the aspect of the receptionist was visually pleasant |
| Q16 | I thought that the aspect of the receptionist negatively influenced my performance |
| Q17 | The aspect of the receptionist reduced my sense of being connected with it |
| Receptionist role | |
| Q18 | Good as a receptionist |
| Q19 | Give useful indications |
| Evaluated Aspect | VRG | PRG | PRM |
|---|---|---|---|
| Usability | |||
| Satisfaction +++ | 3.45 (1.05) | 4.18 (0.56) | 4.72 (0.45) |
| User interaction +++ | 3.96 (0.53) | 4.21 (0.52) | 4.59 (0.38) |
| Visual feedback +++ | 3.38 (0.95) | 4.04 (0.99) | 4.16 (1.03) |
| Receptionist role | |||
| Suitability +++ | 3.62 (0.52) | 3.72 (0.70) | 4.18 (0.70) |
| Evaluated Aspect | VRG vs. PRG | PRG vs. PRM | VRG vs. PRM | |||
|---|---|---|---|---|---|---|
| Usability | ||||||
| Satisfaction | 3.45 (1.05) | 4.18 (0.56) ++ | 4.18 (0.56) | 4.72 (0.45) +++ | 3.45 (1.05) | 4.72 (0.45) +++ |
| User interaction | 3.96 (0.53) | 4.21 (0.52) + | 4.21 (0.52) | 4.59 (0.38) +++ | 3.96 (0.53) | 4.59 (0.38) +++ |
| Visual feedback | 3.38 (0.95) | 4.04 (0.99) ++ | 4.04 (0.99) | 4.16 (1.03) | 3.38 (0.95) | 4.16 (1.03) ++ |
| Receptionist role | ||||||
| Receptionist | 3.62 (0.52) | 3.72 (0.70) | 3.72 (0.70) | 4.18 (0.70) +++ | 3.62 (0.52) | 4.18 (0.70) +++ |
| Evaluated Aspect | Question/Statement |
|---|---|
| Ease of use | |
| Q1 | The system is easy to use |
| Q2 | The system is simple to use |
| Q3 | The system is user friendly |
| Ease of learning | |
| Q4 | I learned how to use the system quickly |
| Q5 | I easily remember how to use the system |
| Q6 | It is easy to learn to use the system |
| Functionality | |
| Q7 | The level of control provided by the system was appropriate for the task |
| Q8 | The control provided by the system was ambiguous |
| Q9 | I found it easy to access all the functionalities of the system |
| Q10 | It was difficult to remember all the functions available |
| Consistency | |
| Q11 | The system behaved in a manner that I expected |
| Q12 | It was difficult to understand the operation of the system |
| Q13 | The information presented by the system was consistent |
| Q14 | I was confused by the operation of the system |
| Q15 | The sequence of inputs to perform a specific action matched my understanding of the task |
| Engagement | |
| Q16 | I felt successful to get involved in |
| Q17 | I felt bored |
| Q18 | I found it impressive |
| Q19 | I forgot everything around me |
| Q20 | I felt frustrated |
| Q21 | I felt completely absorbed |
| Q22 | I felt good |
| Q23 | System’s appearance reduced my sense of being involved |
| Receptionist role | |
| Q24 | How much did you enjoy receiving guidance from the system? |
| Q25 | How much would you like to receive guidance from the system in the future? |
| Q26 | Good as a receptionist |
| Q27 | Give useful indications |
| Social attraction | |
| Q28 | I think the robot could be a friend of mine |
| Q29 | I think I could spend a good time with the robot |
| Q30 | I could establish a personal relationship with the robot |
| Q31 | I would like to spend more time with the robot |
| Social presence | |
| Q32 | While you were interacting with the robot, how much did you feel as if it was a social being? |
| Q33 | While you were interacting with the robot, how much did you feel as if it was communicating with you? |
| Evaluated Aspect | IM | VRM | PRM |
|---|---|---|---|
| Usability | |||
| Ease of use +++ | 3.44 (1.15) | 4.39 (0.73) | 4.76 (0.47) |
| Ease of learning | 4.81 (0.31) | 4.83 (0.31) | 4.94 (0.17) |
| Satisfaction +++ | 3.28 (1.01) | 4.15 (0.88) | 4.65 (0.59) |
| Learnability + | 4.39 (0.78) | 4.44 (0.70) | 4.83 (0.38) |
| Efficiency +++ | 3.06 (1.21) | 4.22 (0.55) | 4.67 (0.59) |
| Memorability ++ | 4.50 (0.79) | 4.78 (0.43) | 4.94 (0.24) |
| Errors | 4.56 (0.70) | 4.61 (0.61) | 4.72 (0.46) |
| Functionality + | 3.78 (1.11) | 4.06 (0.94) | 4.61 (0.61) |
| User interaction +++ | 3.11 (1.60) | 4.22 (0.94) | 4.67 (0.49) |
| Visual feedback +++ | 1.94 (1.11) | 3.33 (0.97) | 4.22 (0.81) |
| Consistency + | 4.11 (0.76) | 4.61 (0.78) | 4.72 (0.57) |
| Engagement +++ | 2.11 (0.96) | 3.94 (0.80) | 4.72 (0.57) |
| Interaction | |||
| Enjoyable/Entertaining +++ | 2.29 (0.62) | 3.54 (0.64) | 4.25 (0.41) |
| Receptionist role | |||
| Suitability +++ | 2.96 (0.91) | 4.04 (0.90) | 4.60 (0.68) |
| Evaluated Aspect | IM vs. VRM | VRM vs. PRM | IM vs. PRM | |||
|---|---|---|---|---|---|---|
| Usability | ||||||
| Ease of use | 3.44 (1.15) | 4.39 (0.73) ++ | 4.39 (0.73) | 4.76 (0.47) | 3.44 (1.15) | 4.76 (0.47) +++ |
| Satisfaction | 3.28 (1.01) | 4.15 (0.88) ++ | 4.15 (0.88) | 4.65 (0.59) | 3.28 (1.01) | 4.65 (0.59) +++ |
| Learnability | 4.39 (0.78) | 4.44 (0.70) | 4.44 (0.70) | 4.83 (0.38) + | 4.39 (0.78) | 4.83 (0.38) + |
| Efficiency | 3.06 (1.21) | 4.22 (0.55) ++ | 4.22 (0.55) | 4.67 (0.59) + | 3.06 (1.21) | 4.67 (0.59) +++ |
| Memorability | 4.50 (0.79) | 4.78 (0.43) + | 4.78 (0.43) | 4.94 (0.24) | 4.50 (0.79) | 4.94 (0.24) + |
| Functionality | 3.78 (1.11) | 4.06 (0.94) | 4.06 (0.94) | 4.61 (0.61) + | 3.78 (1.11) | 4.61 (0.61) ++ |
| User interaction | 3.11 (1.60) | 4.22 (0.94) + | 4.22 (0.94) | 4.67 (0.49) + | 3.11 (1.60) | 4.67 (0.49) ++ |
| Visual feedback | 1.94 (1.11) | 3.33 (0.97) +++ | 3.33 (0.97) | 4.22 (0.81) ++ | 1.94 (1.11) | 4.22 (0.81) +++ |
| Consistency | 4.11 (0.76) | 4.61 (0.78) | 4.61 (0.78) | 4.72 (0.57) | 4.11 (0.76) | 4.72 (0.57) ++ |
| Engagement | 2.11 (0.96) | 3.94 (0.80) +++ | 3.94 (0.80) | 4.72 (0.57) +++ | 2.11 (0.96) | 4.72 (0.57) +++ |
| Interaction | ||||||
| Enjoyable/Entertaining | 2.29 (0.62) | 3.54 (0.64) +++ | 3.54 (0.64) | 4.25 (0.41) +++ | 2.29 (0.62) | 4.25 (0.41) +++ |
| Receptionist role | ||||||
| Suitability | 2.96 (0.91) | 4.04 (0.90) +++ | 4.04 (0.90) | 4.60 (0.68) + | 2.96 (0.91) | 4.60 (0.68) +++ |
| Evaluated Aspect | IM | VRM | PRM | IM = VRM | VRM = PRM | IM = PRM |
|---|---|---|---|---|---|---|
| Enjoy more | 0 (0%) | 2 (11%) | 16 (89%) | 0 (0%) | 0 (0%) | 0 (0%) |
| More intelligent | 0 (0%) | 2 (11%) | 13 (72%) | 0 (0%) | 3 (17%) | 0 (0%) |
| More useful | 5 (28%) | 4 (22%) | 7 (39%) | 0 (0%) | 1 (6%) | 1 (6%) |
| Prefer as receptionist | 1 (6%) | 2 (11%) | 14 (78%) | 0 (0%) | 1 (6%) | 0 (0%) |
| More frustrating | 14 (78%) | 3 (17%) | 1 (6%) | 0 (0%) | 0 (0%) | 0 (0%) |
| More boring | 17 (94%) | 1 (6%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) |
| More interesting | 0 (0%) | 1 (6%) | 17 (94%) | 0 (0%) | 0 (0%) | 0 (0%) |
| More entertaining | 0 (0%) | 2 (11%) | 15 (83%) | 0 (0%) | 1 (6%) | 0 (0%) |
| Chose from now on | 3 (17%) | 4 (22%) | 10 (56%) | 0 (0%) | 1 (6%) | 0 (0%) |
| Evaluated Aspect | VRM | PRM |
|---|---|---|
| Receptionist role | ||
| Companion ++ | 5.91 (1.83) | 7.82 (1.27) |
| Usefulness | 7.78 (2.12) | 8.65 (1.35) |
| Intelligence + | 7.75 (2.57) | 9.07 (0.98) |
| Social attraction +++ | 4.06 (2.11) | 6.97 (2.55) |
| Social presence +++ | 4.95 (1.81) | 7.31 (1.57) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bazzano, F.; Lamberti, F. Human-Robot Interfaces for Interactive Receptionist Systems and Wayfinding Applications. Robotics 2018, 7, 56. https://doi.org/10.3390/robotics7030056
Bazzano F, Lamberti F. Human-Robot Interfaces for Interactive Receptionist Systems and Wayfinding Applications. Robotics. 2018; 7(3):56. https://doi.org/10.3390/robotics7030056
Chicago/Turabian StyleBazzano, Federica, and Fabrizio Lamberti. 2018. "Human-Robot Interfaces for Interactive Receptionist Systems and Wayfinding Applications" Robotics 7, no. 3: 56. https://doi.org/10.3390/robotics7030056
APA StyleBazzano, F., & Lamberti, F. (2018). Human-Robot Interfaces for Interactive Receptionist Systems and Wayfinding Applications. Robotics, 7(3), 56. https://doi.org/10.3390/robotics7030056