1. Introduction
Numerous multi-camera shape recovery methods were previously developed for the three-dimensional (3D) modeling of physical objects (e.g., References [
1,
2,
3,
4,
5]). Passive methods, in contrast to active methods, do not depend on feedback from visible and infrared radiation [
6,
7,
8,
9,
10,
11,
12]. They are typically, grouped into static shape recovery, motion capture without deformation estimation, and motion capture with deformation estimation methods. Most such motion capture methods do not perform deformation estimation and solely rely on tracking through detection, due to factors such as constrained workspaces and off-line data processing. Some motion-capture methods, however, benefitted from deformation estimation for target windowing [
6], surveillance [
2,
3,
13,
14,
15,
16], and interception tasks [
17,
18,
19], although none offer a generalized approach for a priori unknown objects.
Static, passive shape-recovery methods focus on generating a single, fixed model of the target object. The structure-from-motion (SFM) technique [
20] generally estimates static geometry from uncalibrated cameras when provided with a large dataset of images [
21,
22,
23]. Stereo-triangulation depends on known camera calibration parameters for accurate triangulation. High-density stereo matching methods attempt to maximize the surface sampling density of target objects through patch-matching and resampling approaches [
4,
9,
24,
25]. The visual hull method carves a volumetric object through silhouette back-projection, and is capable of yielding accurate models given a large number of viewpoints [
26,
27,
28,
29]. Passive fusion methods further improve the accuracy of shape recovery by combining the visual hull approach with multi-view stereo [
30,
31,
32,
33]. All these static capture methods operate off-line and without an object model, as their objective is to generate a single instance of the model. In contrast, motion-capture methods recover shape over a set of demand instants where a known object model is used to improve capture accuracy.
Typical motion capture methods utilize an articulated object model (i.e., a skeleton model) that is fit to the recovered 3D data [
34,
35,
36,
37,
38]. The deformation of articulated objects is defined as the change in pose and orientation of the articulated links in the object. The accuracy of these methods is quantified by the angular joint error between the recovered model and ground truth. Markered motion capture methods yield higher-resolution shape recovery compared to articulated-object based methods, but depend on engineered surface features [
3,
39]. Several markerless motion-capture methods depend on off-line user-assisted processing for model generation [
40,
41,
42]. High-resolution motion-capture methods fit a known mesh model to the capture data to improve accuracy [
10,
43,
44]. Similarly, the known object model and material properties can be used to further improve the shape recovery [
45]. The visual hull technique can create a movie-strip motion capture sequence of objects [
8,
46,
47,
48] or estimate the 3D background by removing the dynamic objects in the scene [
49]. All these methods require some combination of off-line processing, a priori known models, and constrained workspaces to produce a collection of models at each demand instant resulting in a movie-strip representation. Deformation estimation, however, is absent.
Multi-camera deformation-estimation methods commonly implement either a Kalman filter (KF) [
50,
51,
52,
53], particle filter [
54], or particle swarm optimization (PSO) [
55] to track an object in a motion-capture sequence. Articulated-motion deformation prediction methods rely on a skeleton model of the target object. KFs were successfully implemented to estimate joint deformation for consecutive demand instants [
2,
13]. PSO-base methods were also shown to be successful in deformation estimation for articulated objects [
56,
57]. Mesh models combined with a KF tracking process produce greater surface accuracy for deformation estimation [
3,
14]. Patch-based methods track independent surface patches through an extended Kalman filter (EKF) [
58], and a particle filter [
59], producing deformation estimations of each patch. Many active-vision methods depend on deformation estimation, yet they develop ad-hoc solutions for a priori known objects, thus limiting the application to the selected target object [
2,
3,
13,
14]. It is, thus, evident that no formal method currently exists for multi-camera deformation estimation of a priori unknown objects.
Herein, a modular, multi-camera method is proposed for the surface-deformation estimation of a priori unknown, markerless objects. The method firstly selects all viable stereo-camera pairs and, then, for each demand instant, captures synchronized images, detects two-dimensional (2D) image features, matches features in stereo-camera pairs, and removes outliers. The selection of the 2D feature detector and outlier filtering is modular. The method triangulates the 2D matched features, removes 3D outliers, and processes the triangulated features through an adaptive particle filtering framework to produce a deformation estimation. The particle filtering and projection tasks are modular, allowing alternative tracking techniques with varying motion models. The novelty of the proposed method lies in is the ability to cope with a priori unknown, markerless objects to produce accurate deformation estimates, compared to previous methodologies that require the objects’ models. A distinction must be made between the proposed methodology, and existing monocular deformation estimation techniques in literature. Specifically, state-of-the-art methods were developed and are currently under development for the monocular tracking and deformation estimation of surfaces. These methods recover, on-line, the current surface deformation up to scale. Specifically, many of these methods do not have a goal of scaled deformation recovery, which would only be possible in multi-camera (not monocular) systems. In contrast, the proposed methodology relies on the use of a multi-camera system to extracted the scaled deformation of the target surface, and then integrates an adaptive particle filtering technique to predicted the expected deformation necessary for reactive systems.
The rest of the paper is organized as follows:
Section 2 outlines the problem addressed;
Section 3 introduces the proposed methodology;
Section 4 and
Section 5 present some of the simulations and experiments, respectively, used to validate the methodology; and
Section 6 concludes the paper.
2. Problem Formulation
The accurate surface deformation prediction of an a priori unknown object is the problem at hand. The object is defined as any combination of solids and or surfaces with uniformly distributed surface texture. The recovery of the object’s shape occurs at discrete points in time, t, designated as demand instants. The object is quantified by a collection of surface coordinate measurements for each demand instant, without regard for specific structures such as volumes or surfaces.
The deformation of the object is defined as the motion of its surface coordinates between two demand instants. The deformation results in non-rigid motion of the object. Thus, the objective is to develop a methodology to accurately predict the deformation of the object’s surface at the next demand instant, t + Δt, where Δt is the change in time, given C number of cameras, without an a priori model of the object.
The problem can be further broken down into several independent challenges.
Set-Up:
The work herein is constrained to passive range-data recovery. Active projection or laser scanners are not considered due to their dependence on a light-controlled environment. Successful detection of the object must produce accurate range data through triangulation of matched 2D features. The object must be located within the effective sensing range (ESR) of all cameras in the workspace.
Shape Recovery:
The system must extract object features from C images, correspond them for each camera pair, and determine which features pertain to the target object, and which do not. The challenge herein is the identification and segmentation of target features through extensive filtering techniques. Since the object model is not available for reference, an inherent error exists at every demand instant. Therefore, the shape-recovery method must account for such errors. Furthermore, without a distinct association between the object’s surface and extracted features, a robust tracking mechanism is necessary.
Shape Representation:
The shape representation of the target object must accurately represent the target object. The implementation of either a point cloud, mesh, or voxel-based object representation will determine the size and types of data that must be stored in the system, and how they may affect prediction. The shape representation of the object must be concise and robust for variable surface complexity.
Tracking:
The tracking process must account for the variable number of detected surface features. Each detected feature in 2D and 3D must be properly identified and recorded. Correct identification of features in 2D and 3D is essential for accurate triangulation and temporal tracking, and would result in the maximally dense shape prediction. The system must handle a large number of features in both 2D and 3D.
Prediction:
Shape-deformation prediction must be made from a functional representation of the deformation dynamics. The motion model chosen must be able to robustly track a range of motions that may occur in an object’s deformation, such as accelerations and cyclic motion. An error-compensation mechanism is necessary to ensure each prediction results in an overall reduction of prediction error relative to the motion dynamics. Furthermore, compensation may be required for handling motion outside the chosen model. The prediction method must handle a large varying number of features for which prediction is necessary.
3. Proposed Method
A novel, modular methodology is proposed herein for the surface deformation prediction of an a priori unknown object through a multi-camera system. The flow diagram of the proposed methodology is presented in
Figure 1. The first step of the method is the selection of camera pairs for stereo triangulation. Once the pairs are selected, the following tasks are carried out for each demand instant: (1) image capture from all cameras, (2) feature detection, (3) 2D matching and filtering, (4) triangulation and 3D filtering, and (5) tracking and prediction. The modular tasks, (2) to (5), enable robust implementation of the methodology for specific applications. The following sections describe, in detail, each task and the proposed architecture, the reasoning of each modular component for general application, and alternative architectures for modular components.
3.1. Camera-Pair Selection
The proposed methodology allows for a variable number of cameras in the workspace without a priori designation of stereo pairs. This task selects all viable stereo-camera configurations for C number of cameras based on their baseline separation, di, and angular separation θi.
Firstly, all possible camera pairs are stored into a camera-pair index list,
Kmax [2 ×
kmax], with the total number of pairs,
kmax, determined by
Then, each ith pair in Kmax is tested to ensure that (i) both cameras are oriented in a similar direction, (ii) the optical axis separation angle θi is within a user-defined limit θmax, and (iii) the baseline distance is within a user-defined limit dmax.
The orientation of the
ith camera pair is tested by checking whether the dot product of the optical axes is positive (directional orientation), and by calculating the angular separation of the optical axes. Thus, the angle of separation of the cameras of a pair can be directly calculated to solve for both conditions as
where
po(
cL) is the vector of the optical axis of the left camera, and
po(
cR) is the optical axis vector of the right camera of the
ith camera pair tested from
Kmax.
The user-defined limits for camera separation,
dmax, and
θmax must be set by the selection feature-detection algorithm. For example, dense photometric shape recovery methods [
4,
9,
24,
25,
60,
61] would require narrow baselines and low separation angles to maximize photometric consistency in a stereo pair. Unique key-based feature methods, such as scale-invariant feature transform (SIFT) [
62,
63], affine-SIFT (ASIFT) [
64], speeded-up robust features (SURF) [
65], or others [
66], allow for larger baseline widths and angular separations. In this paper, the limits were set to 350 mm and 45° based on findings by Lowe [
63] for unique key-based feature methods. The viable camera pairs were stored into an index list
K [2 ×
kv], where
kv is the total number of viable pairs. It is noted that, for the purpose of this work, SIFT features were chosen for simulations and experiments. Other approaches, such as photometric stereo, could also be implemented instead. However, it should be noted that photometric stereo methods require highly controlled lighting environments.
3.2. Image Capture and Feature Detection
The image-capture task ensures synchronized image acquisition from all cameras. Synchronization yields consistent photometric conditions for all cameras and ensures the shape recovered is non-deformed due to temporal blurring from unsynchronized images.
The main challenge in shape recovery is choosing a method that would best yield the maximally accurate shape of the object, given any limitations or assumptions of the system. Available methods include depth maps, structure-from-motion [
21,
22,
23], stereo-triangulation, and visual hulls. In the context of our problem, the chosen method must, thus, yield the most accurate
predicted deformation of the object.
Deformation prediction requires an estimate of the motion, i.e., the 3D points must be trackable. Therefore, depth maps and the visual hull technique cannot be utilized due to their lack of tracking abilities. The SFM technique requires the motion of either the cameras or the object in order to recover shape, which results in a delay in motion estimation. Furthermore, SFM is typically applied to cameras with unknown calibration parameters, and yields lower quality shape than would stereo-triangulation.
Dense stereo methods [
4,
9] rely on patch matching in narrow baseline-stereo configurations, and do not produce stable trackable features. Thus, the only viable method for deformation prediction that remains is feature-based stereo-triangulation. Stereo-triangulation with unique-key features allows for tracking and higher-accuracy shape recovery with known camera parameters, and does not depend on the complete visibility of the target object.
The feature detection task locates all 2D image features in each camera’s image at the current demand instant. SIFT features were chosen herein due to their robust tracking and implementation stability [
66,
67]. However, one can note that our modular methodology allows for any unique key-based method to be implemented in place of SIFT features. For example, ASIFT feature detection was shown to produce greater matching stability than would SIFT, although its implementation is currently limited in image size. Similarly, other methods were shown to operate faster than SIFT at the cost of matching stability. It is noted that SIFT features are stable up to 45° camera separation [
63]. Therefore, fast object motion and deformation between demand instants can result in lost features. This can be combated through the addition of newly identified features for every demand instant. Similarly, the hardware platform must be built per application such that the demand instant processing time is minimized, it is achievable by the camera hardware, and it correlates, to a degree, with the maximum motion per demand instant expected from the object. In the case of an unknown object, this becomes a hardware optimization problem. It is possible that the hardware may not match the deformation speed of the target object, at which point recovery would not be possible.
The features detected were then stored into a 2D database to offload random-access memory (RAM) requirements. Each feature was stored with its designated feature descriptor, pixel location, orientation, and the camera with which it was detected.
3.3. 2D Matching and Filtering
The 2D matching and filtering task consists of matching the detected features between pairs of cameras for each
ith pair in
K, and removing incorrect matches prior to triangulation. At first, all the previously detected features for the given cameras in the
ith pair were loaded from the database. The matching process is dictated by the chosen feature detector. Typically, matching consists of locating pairs of 2D features whose keys are most similar though a dot-product operation [
63]. The main difference for various feature-descriptors is the size of the key-identifier for the detected features; for example, SIFT features use a 128 8-bit integer key for each feature, while SURF uses a 64 8-bit key. Once the features for the
ith camera pair are matched, the incorrect matches must be removed through a filtering operation.
The filtering process allows for modularity in the 2D match filter implementation, i.e., the filter may be modified, replaced, or combined with another filter to remove outliers produced by the 2D matching process. The overall filter developed herein comprises two serial filters: the epipolar filter and the nearest-neighbor filter.
The epipolar filter consists of sorting the matched pair listings and checking for the following four conditions: (i) unique left to right match, (ii) multiple left features to single right feature matches, (iii) single left feature to multiple right feature matches, and (iv) repeated matches of the same left to right matches. These conditions arise when the feature detector locates more than one feature in the same pixel coordinates (usually at different orientations), or was unable to produce a single best match (cases ii and iii). All redundant matches in case iv are removed, as they are the same coordinate matches. Then, for each remaining matched pixel–coordinate pairs, the epipolar distance is calculated in pixels by measuring the perpendicular distance from the feature coordinate in the left image to the projected epipolar line of the corresponding feature from the right image. Herein, the maximum epipolar distance, dPmax, was set to 5% of the square root of the image area in pixels—this ensures the metric is scalable with larger or smaller images. All matches that do not fit the 5% criterion are removed.
The nearest-neighbor filter checks for the consistency of matched 2D features based on the location of the nearest neighbor matches. The filter loops over each remaining matched features in the left image, locates the
n-nearest neighbors of a feature, and creates a matrix of the vectors from the
jth 2D feature to the neighbors in the left, and corresponding right images,
VL [2 ×
n], and
VR [2 ×
n], respectively. The lengths of all vectors are calculated, and stored into vectors
dL,
dR, [
n × 1], which are then normalized by the sum of all vector lengths, and are stored in vectors
d*L, and
d*R. The vector angles are calculated as
which yields an angle from the
x-axis to each vector connecting the
jth feature to its
n-nearest neighbors. The angle vectors are then normalized by the sum of all angles and stored into vectors
and
. Thereafter, the means and standard deviations of the normalized length and angle vectors are calculated,
,
,
,
,
,
,
, and
. The final step of the filter is the calculation of errors for each left and right mean and standard deviation:
Above, any feature with a single error over 10% is removed, as it is most likely an incorrect match. The filters and their respective rejection criteria ensure the removal of most incorrect 2D matches that do not lie along the epipolar lines, and most incorrect matches that lie on the epipolar lines but are located in the incorrect image region.
The implemented serial filters are a robust approach to filtering and removing incorrect 2D matches from key-based features. The modularity of the methodology allows for alternative filter implementations, and configurations. For example, a random sampling consensus (RANSAC) filter may be implemented in place of the epipolar or nearest-neighbor filter, or added as a parallel filter, as it is commonly applied for stereo-matching operations in image stitching, and model fitting [
68,
69]. Alternatively, the optimized random sampling algorithm (ORSA) may be applied in place of both filters to estimate the fundamental matrix and remove matches through the estimated epipolar geometry [
64,
70,
71]. The main difference between the proposed method and methods such as RANCAS or the ORSA is that ours filters stereo matches using the known calibration data. RANSAC and ORSA, on the other hand, are robust estimators for determining the fundamental matrix for stereo-camera pairs. In contrast, the proposed method relies on triangulation of a known calibration, thus removing the need for estimation. The modularity of the method allows the user to choose task-specific implementations of the filtering, which were not considered in previous methods.
3.4. Triangulation and 3D Filtering
The 2D matched, filtered features for each ith camera-pair in K are triangulated through ray projection and intersection. This yields kv-sets of 3D coordinates corresponding to each stereo-camera pair. Triangulation may result in errors of the 3D coordinates, e.g., if the 2D filter was not able to remove all outliers, some may remain and appear following triangulation. Therefore, a modular 3D filtering process is proposed herein. The proposed methodology requires that all cameras in the system must be calibrated for complete triangulation. All cameras used in stereo pairs must be calibrated as such.
The 3D filter developed for the task is an ESR filter. The ESR filter removes all triangulated points outside of a stereo sensing range. The filter can operate in two modes—manual or automated. The former allows users to input the 3D range limits for each camera. Thus, any triangulated features outside this range for the ith camera pair would be removed. The latter mode calculates the depth of field of each camera of the ith pair, and takes the maximum and minimum limits from both cameras as the range plus a user-defined padding percentage, κ, which adds κ times the range of the ESR on both the near and far limits.
The ESR filter removes triangulated background artefacts and outliers too close to the cameras. The output of the triangulation and 3D filtering yields a matrix of sampled surface coordinates, X, and an indexed matching list for each camera pair in K that corresponds to all final, matched, and triangulated 2D features. The indexed 3D features are stored in a separate database to reduce the RAM load of the data used in the methodology. Off-RAM storage is a suggested improvement for functionality. Many features may be lost over time; thus, there is no need to retain them in the RAM. The ESR filter was found to be sufficient for 3D filtering following the extensive 2D match filtering.
Triangulation and 3D filtering produces
kT-sets of point clouds,
XTR(
k), for each
kth stereo-camera pair. Each point cloud is then used to create a triangular surface patch,
T(
k), of the target object through a Delaunay triangulation.
T(
k) is herein defined as the triangulation map, wherein
triangulation is the graphical subdivision of a planar object into triangles. The map is a size [
npolys × 3] index matrix whose rows index the three points from
XTR(
k) that make up a given surface patch polygon. The surface patch is obtained by firstly projecting the point cloud into each camera’s image plane as a set of 2D pixel coordinates. One set of 2D coordinates is then triangulated using Delaunay triangulation. The triangulation map is then applied to the second set of 2D coordinates and checked for inconsistencies, such as incorrect edges. Incorrect edges are a symptom of incorrectly triangulated 2D features. The incorrect edges are removed by removing the 3D points in
XTR(
k) that connect to the most incorrect edges. The result is a set of fully filtered point cloud matrices
XTR(
k) and their associated surface patches,
T(
k), as shown in
Figure 2.
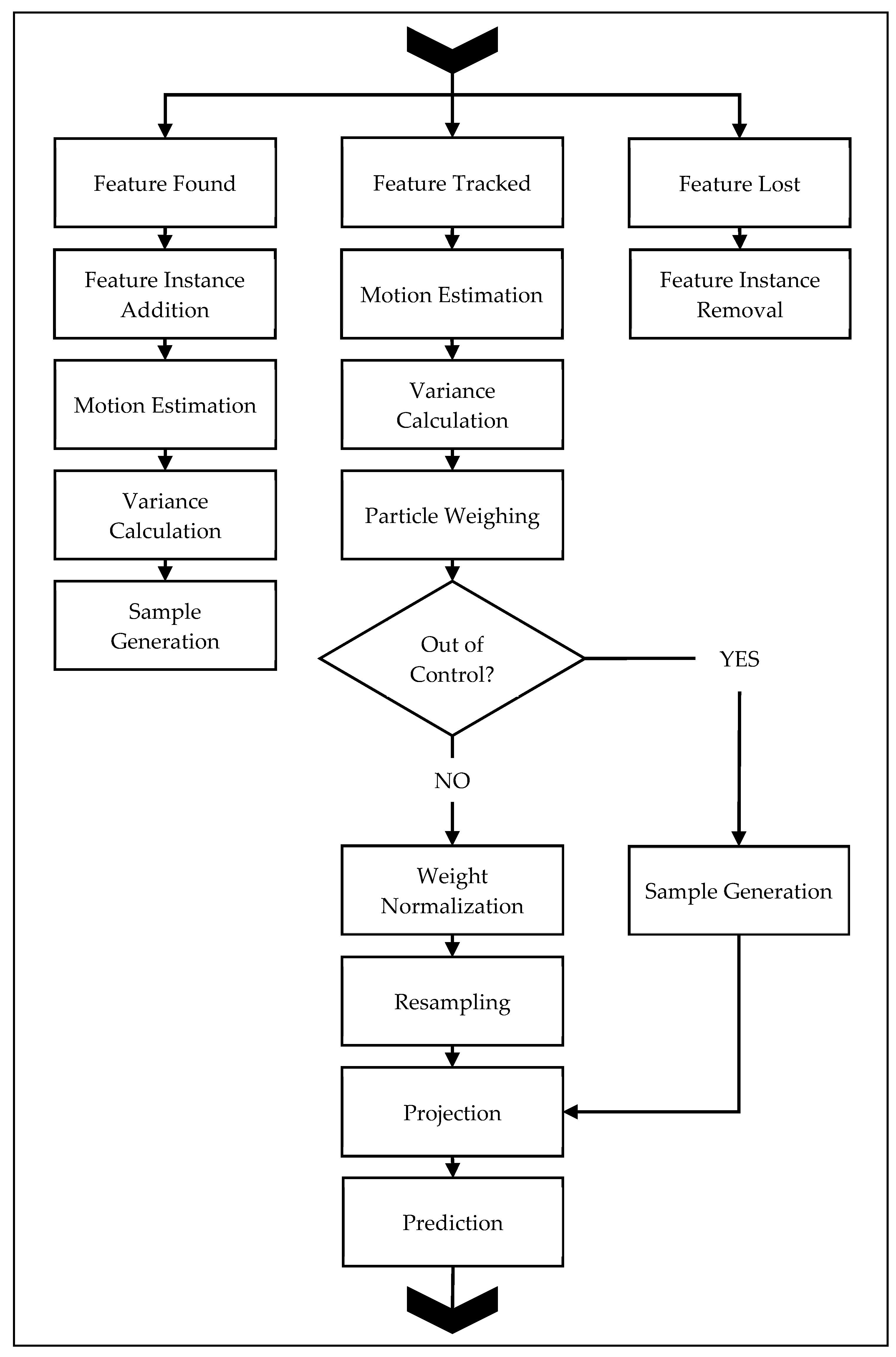
3.5. Tracking
The tracking process implements 3D tracking-through-detection with a user-defined motion model. An unknown object implies an unknown motion model, which may be simple or complex. In order to set a standard complexity for the motion model, a constant-acceleration model was chosen for the tracking and prediction process. The benefit of the constant-acceleration model is its applicability to a range of target motions with limited data requirement, i.e., only three data samples are necessary for prediction. Alternative motion models are discussed at the end of the section. The complete filtering algorithm is presented in
Figure 3, and consists of three major
streams:
feature found—the handling of new triangulated points,
feature tracked—the handling of points that were located across multiple consecutive demand instants, and
featurelLost—the handling of points that were previously located but were not located at the current demand instant.
The on-line adaptive particle filter loads the measurement data from the 3D database for the current and previous demand instants. Each 3D point from the previous demand instant is checked against the current set of 3D points based on the unique key-identifier assigned to them in triangulation to determine whether the point was tracked across demand instants. Three outcomes are possible: the point could have been tracked across demand instants, the point could have been lost, or the point is new.
Automatic initialization identifies all newly triangulated points, and allocates space for the necessary particles for tracking, and a state-space measurement history of the last five demand instants. This process works for tracking starting from Demand Instant 0, as all triangulated points will be labeled as
new in comparison with other methods that require an a priori demand-instant measurement [
3,
14].
The
feature found stream applies to all points detected in three or less consecutive demand instants. If the feature is only been detected in less than three consecutive instants, its state-space measurement is updated. Features triangulated in three consecutive demand instants have their motion estimated through a first- and second-order backward differencing operation.
where Δ
t is the change in time between demand instants,
X(
t) is the 3D positional measurement of the given point,
Ẋ is the estimated velocity, and
Ẍ is the estimated acceleration. The constant-acceleration model requires nine total states: three positions, three velocities, and three accelerations.
The total number of particles,
q, is user-defined. The number of particles used determines the accuracy of the prediction at the cost of computational power [
54]. The number of particles may be varied on-line based on the calculation of the total effective number of particles [
54,
72]. Herein, the number of particles was kept static throughout all demand instants to avoid dynamic memory reallocation tasks. Therefore, each particle filtering instance initialized is composed of a [9 ×
q] particle matrix. The particles are drawn from a normal distribution for each tracked point.
where
xj* is the nine-dimensional state-vector of the
jth tracked point, and
is its associated variance. The measurement variance,
, is set equal to the particle variance, to ensure the partiality weighing step also adapts on-line with varying deformation dynamics.
The particle variances are calculated as
which are updated with every measurement of a tracked point. The on-line updating of the variances ensures the particles remain within close proximity to the measurement. The initial set of particles is then generated given the motion model and the particle variance.
Points that are tracked for more than three consecutive demand instants are labeled as
tracked and are processed through the
feature tracked stream. As a new positional measurement becomes available at the current demand instant, the state-space measurement for a given point is calculated by Equations (8) and (9), and stored in the state-space measurement history. Thereafter, for each
jth point, the set of projected particles
Qj+ is loaded, and each nine-dimensional particle is weighed against the current state-space estimate
xj*.
where
Wj is the weight matrix of all particles for the
jth point. The weights are then normalized.
The normalized weight matrix
Wj* is of size [9 ×
q]. The summed term is checked for a zero-condition which occurs if the projection is too far off from the measured location. All states with a zero-sum condition bypass the resampling step, and new particles are generated from the most recent measurement. All remaining states with non-zero sums, i.e., states with accurate projections, are resampled through a sequential importance process [
54]. The regenerated states and resampled states are combined into an updated
Qj matrix.
3.6. Prediction
The prediction process relies on the user-defined motion model to correctly project the particles. The projection produces an estimate for all tracked particles’ poses for the consecutive demand instant. The prediction process occurs only in the
tracked stream and follows the projection step. The projection step requires the updated particle matrix
Qj, which is then projected to determine the expected state-space of the
jth point at the next demand instant.
where
Qj+ is the matrix of projected particles for the
jth point,
H is the [9 × 9] constant-acceleration state transition matrix, and
U is the [9 ×
q] uncertainty matrix based on the particle projection variance (Equation (11)). The particle matrices are then averaged to produce a single state-space estimate of the predicted point.
The projected state-space points are stored into a predicted pose matrix
X+. For each subset of tracked points from
X+ detected by the
ith camera pair, a surface mesh is applied. Thus, the resulting output of the methodology is a set of
n meshes that represent the predicted deformation of the object.
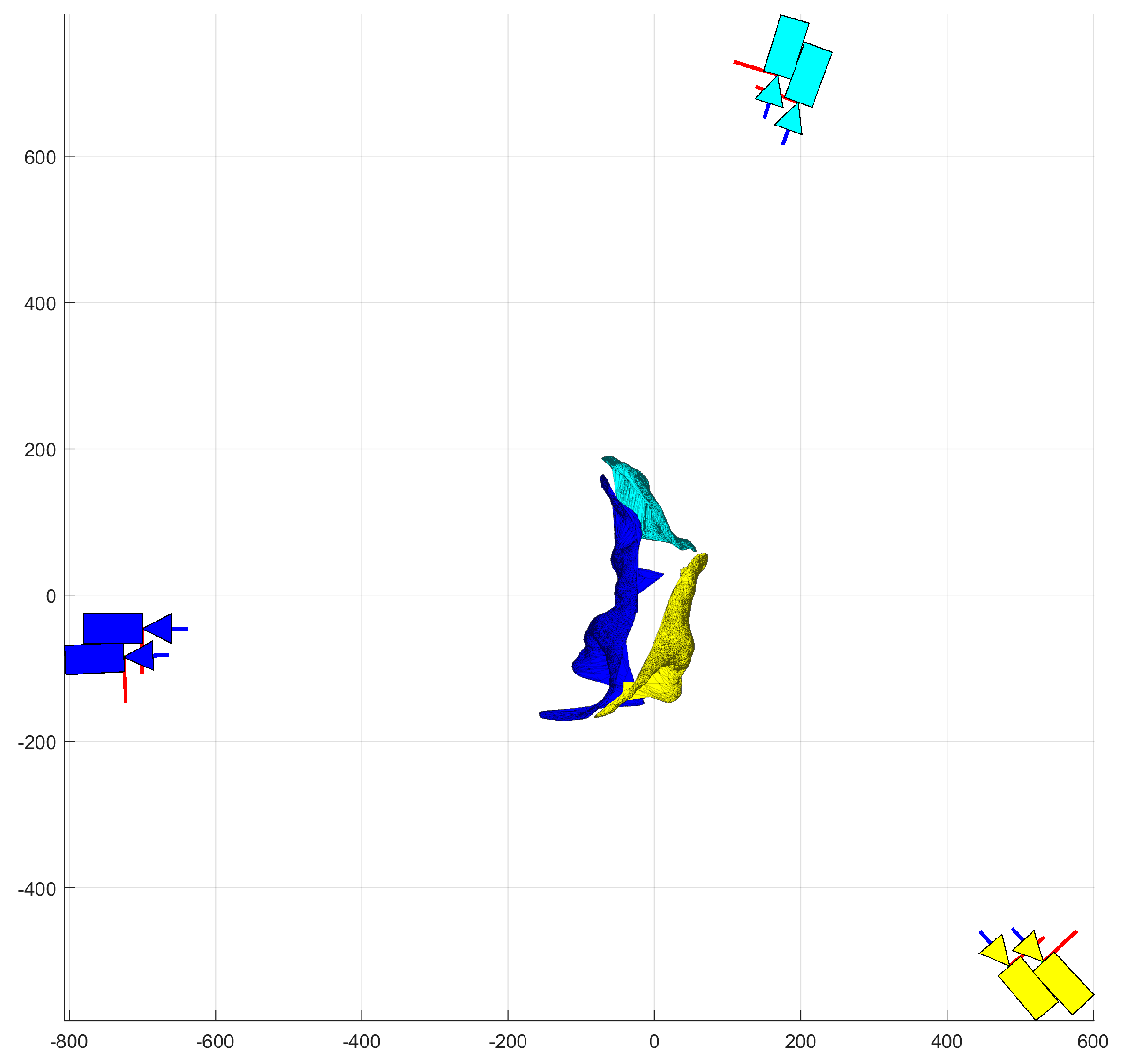
Figure 2 illustrates the predicted deformation of a dinosaur from three stereo-camera pairs where each colored surface patch correlates to a particular point-cloud prediction of the corresponding stereo pair.
Points that were previously detected and are lost at the current demand instant are labeled as lost, and are processed through the feature lost stream. The particle matrices and state-space measurement vectors associated with these points are removed from memory, but their unique key-identifiers remain, along with the associated 2D feature keys. Lost points that are detected anew in later demand instants are processed through the feature found stream.
The tracking and prediction task allows for modularity in the filtering methodology chosen, including particle filters, KFs [
50], EKFs [
73], unscented KFs [
74], and PSO [
55,
57]. The particle filter was chosen due to its robustness to non-Gaussian noise [
54,
75], and its common-place implementation in tracking methodologies [
76,
77]. A KF may not necessarily work well since camera noise is non-Gaussian [
78] and, thus, tracking may fail. EKFs and unscented KFs may be better suited than regular KFs for tracking as they do not explicitly depend on Gaussian process noise. PSO should function similarly to particle filtering methods, but would require an optimization step that filtering does not.
The motion model may be user-selected as well for specific tasks, if necessary. The constant-acceleration motion model may be replaced with another simpler or more complex model. A constant-velocity model would decrease the state-space size required and the number of initial tracking demand instants with lower accuracy prediction. A Fourier series model may be used for objects that would undergo cyclic motion [
58,
79]. One can note that the motion model selected would dictate the total number of demand instants required before an accurate prediction could be made. For example, a constant-velocity model only requires two demand instants, while a constant-acceleration model requires three. The constant-acceleration model was chosen herein as a
generalized approach for tracking due to its robustness to capturing human motion and certain non-linear motions.
4. Simulations
Extensive simulations were carried out using the Blender™ software [
80] for object animation and camera representation. The VLFeat™ [
81] library was used for image processing. MatLab™ was used to code the complete methodology. Six example simulations are presented herein to demonstrate the proposed methodology. Each simulation utilized a fixed stereo-camera pair.
All simulated camera models used a 32 × 18 mm Advanced Photo System type-C (APS-C) style sensor, with an image resolution of 1920 × 1080 pixels, and a focal length of 18 mm. Uniformly distributed color pixel noise was added to all images to simulate image noise. Furthermore, all triangulated data incorporated noise to simulate real-world errors in camera placement. The simulations used singular, textured object surfaces that deformed over a set of demand instants.
Three error metrics were used to analyze the performance of the methodology. The triangulation errors, et, were calculated as the Euclidean distance between a triangulated point and the nearest ground-truth surface. The prediction errors, ep, were calculated as the Euclidean distance between a predicted point and the nearest ground-truth surface. The relative prediction errors, ef, were calculated as the Euclidean distance between a predicted point locations and its actual triangulation location, for all tracked points. All three errors were normalized by the square root of the object’s surface area. The normalization ensures the error metrics are invariant to the size of the target object, and relative pose of the cameras.
Triangulation errors were calculated as follows:
where
zt(
j) is the shortest distance between the
jth triangulated point in
X to the surface of the true object model,
m is the total number of triangulated points at the given demand instant, and
S is the surface area of the true object model.
Prediction errors were calculated as follows:
where
zp is the shortest distance between the
jth predicted point in
X+ to the surface of the true object model, and
m is the total number of predicted points.
The relative prediction errors were calculated as follows:
4.1. Simulation 1
The first simulation consisted of an object surface undergoing a wave-like stretching deformation with a linear translation. A four-frame movie-strip of the object is presented in
Figure 4. This simulation tested the methodology’s ability to handle a more complex form of surface deformation with global motion. The errors remained under 1.3% for all three error metrics, and the total number of tracked and triangulated points remained fairly stable with a slight increase (
Figure 5). The slight increase in error from the third simulation is attributed to the compounded motion experienced by every tracked and triangulated point. Specifically, in the previous simulation, the tracked points only moved in the wave motion, while, in this example, they also moved perpendicularly to the wave motion, thus increasing the relative prediction errors.
4.2. Simulation 2
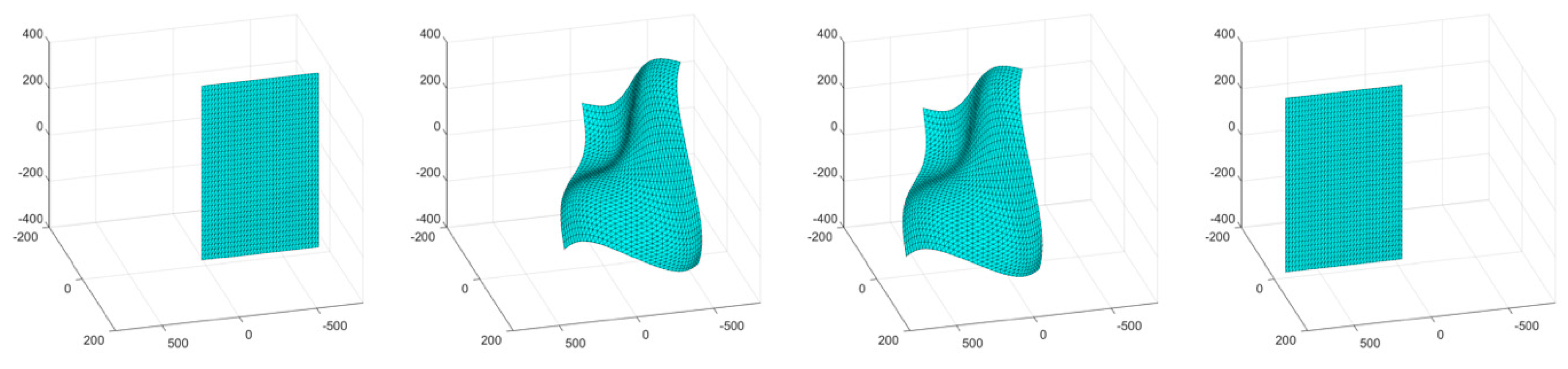
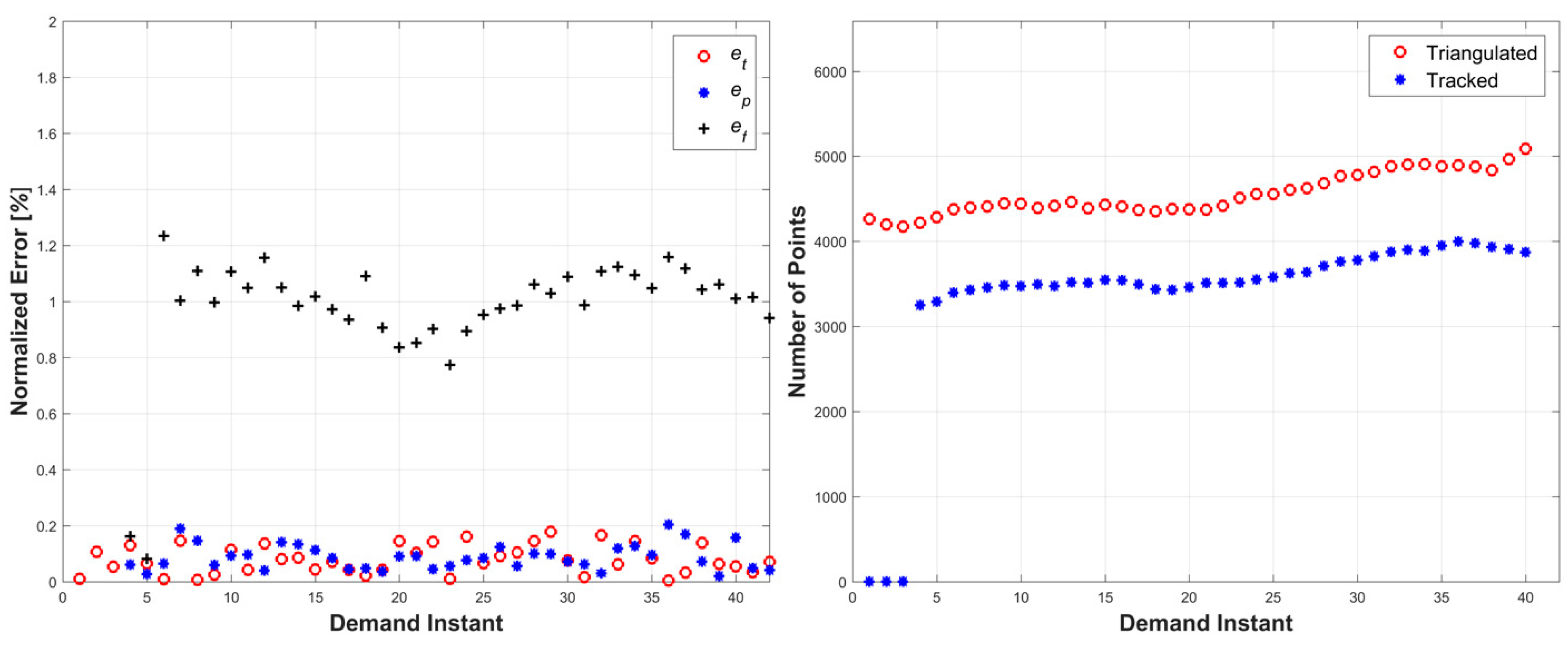
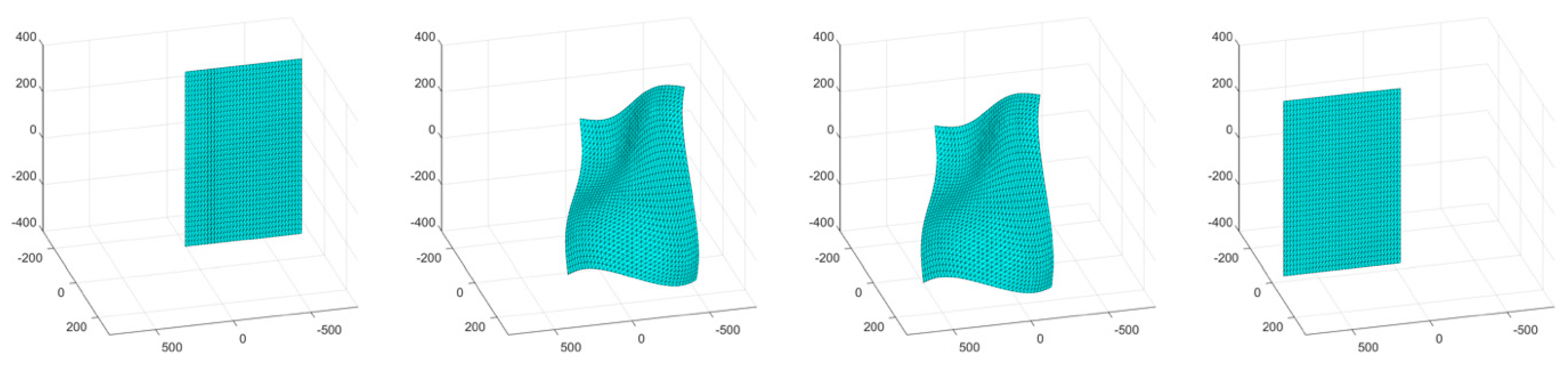
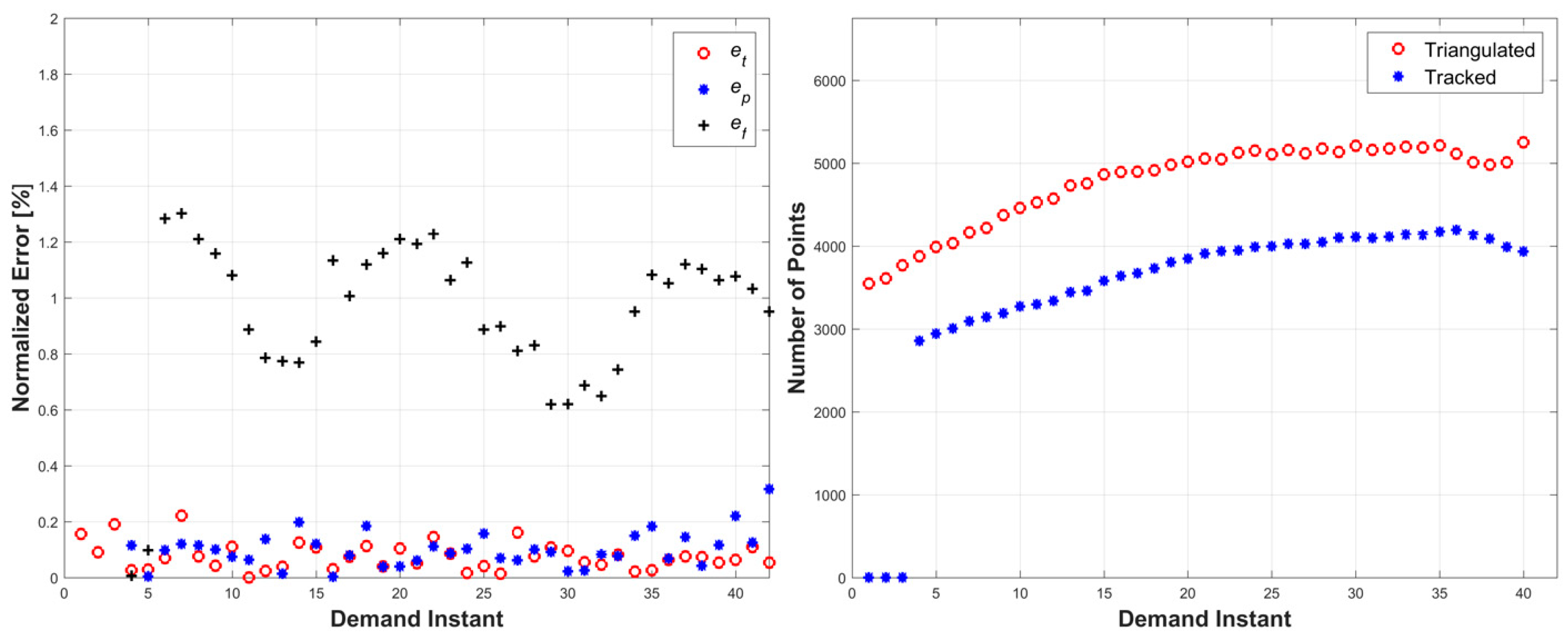
The second simulation consisted of an object surface undergoing a wave-like stretching with linear translations in two directions. A four-frame movie-strip of the object is presented in
Figure 6. This simulation tested the methodology’s ability to handle a more complex form of surface deformation with increased global motion. The errors remained under 1.4% for all three error metrics, and the total number of tracked and triangulated points gradually increased as the object moved closer to the cameras (
Figure 7). The cyclic error pattern for the relative prediction errors,
ef, is attributed to the acceleration profile of the motion where the lowest error values correspond to zero acceleration of the object.
4.3. Simulation 3
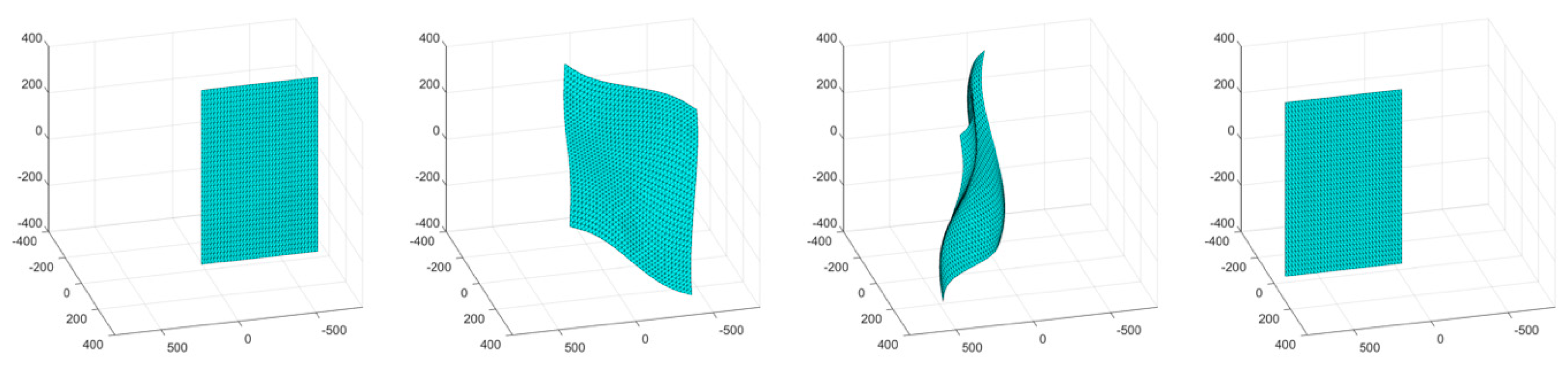
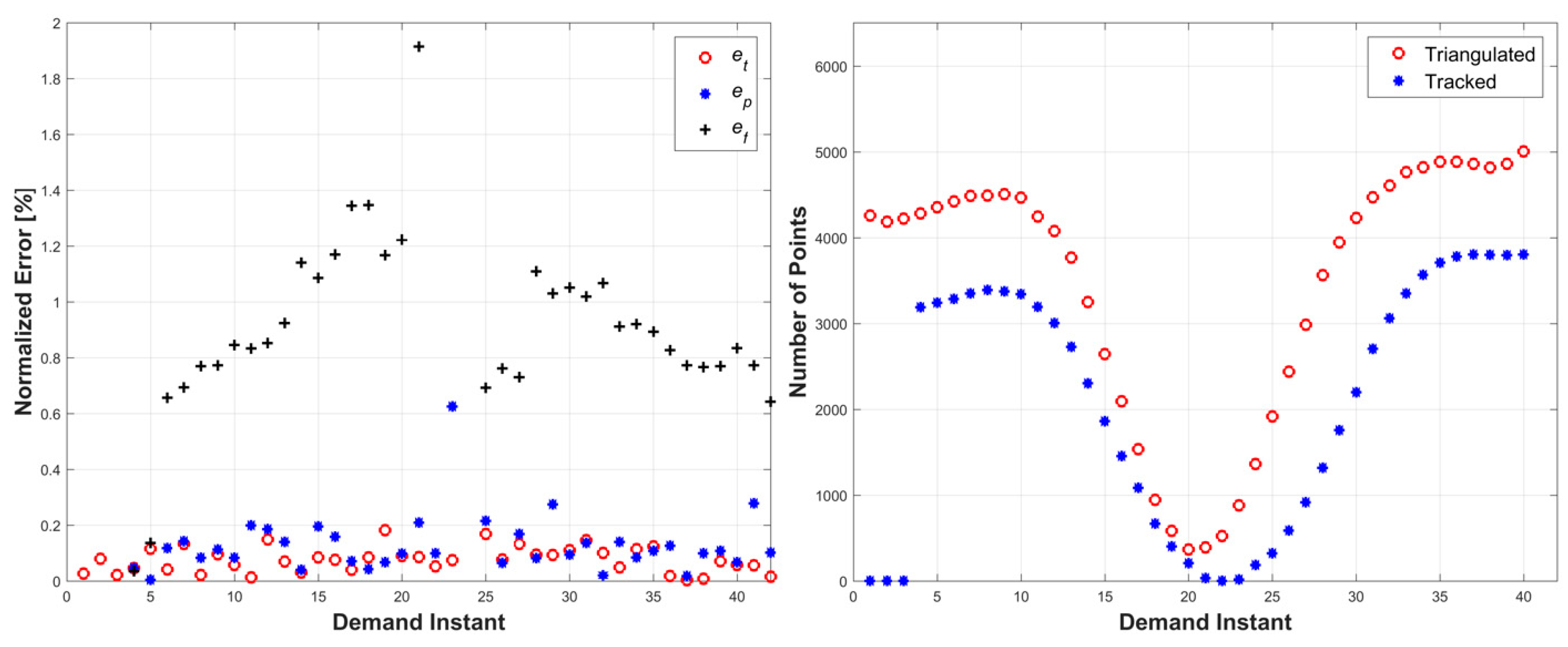
The third simulation consisted of a surface object undergoing a wave-like stretching with a linear translation and a rotation by 180°. A four-frame movie-strip of the object is presented in
Figure 8. This simulation tested the methodology’s ability to handle complex surface deformation with complete loss of visibility. The errors remained under 2% for all three error metrics, with an increasing trend as the object rotated to a parallel orientation with respect to the cameras, at which point none of the triangulated points could be tracked (due to loss of tracking data) (
Figure 9). The number of tracked and triangulated points reflected the error behavior. Specifically, as the object became parallel to the cameras, the number of triangulated points decreased to almost zero, while all of the tracked points were lost.
5. Experiments
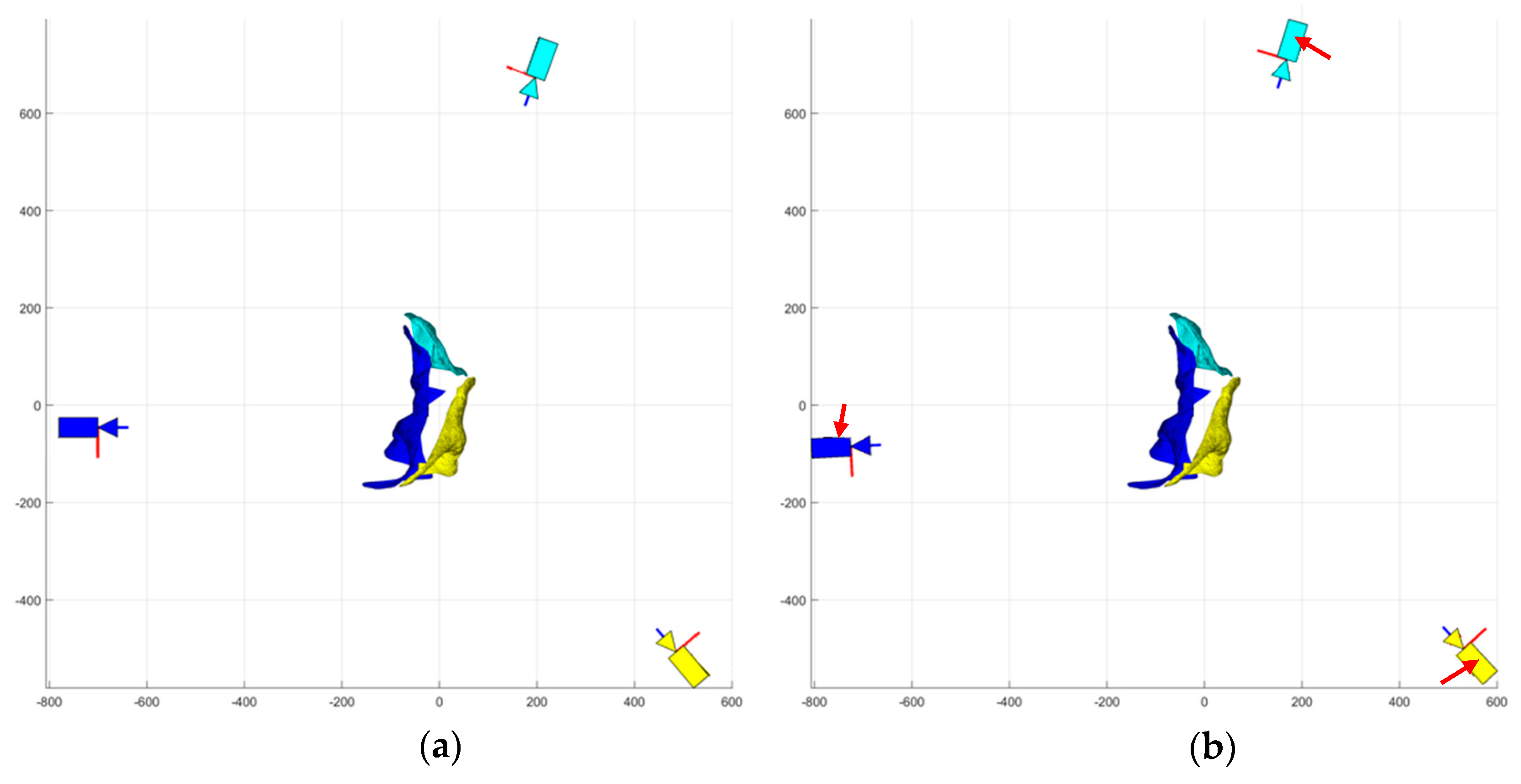
Experiments were conducted using a robotic deformable object, namely the PleoRB robot, as the target object. The experimental platform was composed of six calibrated Canon digital single-lens reflex (DSLR) Rebel T3i cameras, and one Intel i7 personal computer (PC) with 24 GB of RAM. The general layout of the experimental set-up is presented in
Figure 10 with the mobile cameras and the robot (deformable object) highlighted. As shown in the figure, all six cameras were placed on moving stages to attain any desired reconfiguration. Two cameras were placed on one-degree-of-freedom rotational stages, whereas the other four cameras were placed on two-degree-of-freedom stages—rotational and translational. During the experiments presented in this paper, only three two-degree-of-freedom cameras were utilized.
As noted above, the initial experimental configuration presented in
Figure 10 could not provide the desired static stereo-camera placement. Therefore, in order to achieve the desired configuration, as in
Figure 2, the experiments had to be conducted quasi-dynamically. Specifically, for a given demand instant, once the robot was moved and deformed into its desired surface, three two-degree of freedom cameras were moved into their first stereo-pair position (circular pattern, 120° separation) and captured their respective images (
Figure 11a). Next, the cameras were moved on an arc of 100 mm to their second stereo-camera positions and captured their respective second images (
Figure 11b). The robot was then deformed into its next pose of the sequence and the quasi-dynamic capture process was repeated. Thus, each object’s deformation required the reconfiguration of three of the four cameras to simulate stereo pairs.
The cameras were calibrated at fixed optical parameters, namely focal length, aperture, shutter speed, and image gain. The camera settings were chosen to maximize image sharpness and ensure correct depth of field. The average distance between the robot and each camera was 775 mm. The cameras were all electronically controlled through Universal Serial Bus (USB) using Canon’s camera control software development kit (SDK): EDSDK.
The target object, PleoRB robot, was chosen due to its surface texture and high degree-of-freedom (DOF) configuration (
Figure 12). The robot was composed of 15 servo motors actuating the mechanical armatures with a patterned texture rubber skin. The PleoRB robot was controlled through serial USB. A custom program was developed to individually set each servo motor’s position, ensuring repeatability. The volume and surface area of the robot were calculated manually by measuring each limb individually and approximating limbs with geometric objects such as cylinders, cones, and rectangles.
5.1. Background Segmentation
Background segmentation was outside of the scope of this work; however, it is a necessary aspect of the system for correct deformation estimation. The development of generic target segmentation algorithms is a field of computer vision in and of itself, with several notable examples available in References [
82,
83,
84,
85].
In order to overcome the problem of target segmentation, a run-time implementation of Grabcut was integrated into the process to segment the target object from the noisy background [
86]. The Grabcut method implements a graph-cut energy-minimization problem solved via maximum flow through a graph. The Grabcut process consists of the user providing a set of guide points on the input image that are near the target’s boundary. The algorithm then solves for the image boundary that optimizes the max-flow min-cut problem. The output of the algorithm is a binary image mask that labels the pixels as background or target (
Figure 13).
5.2. Results
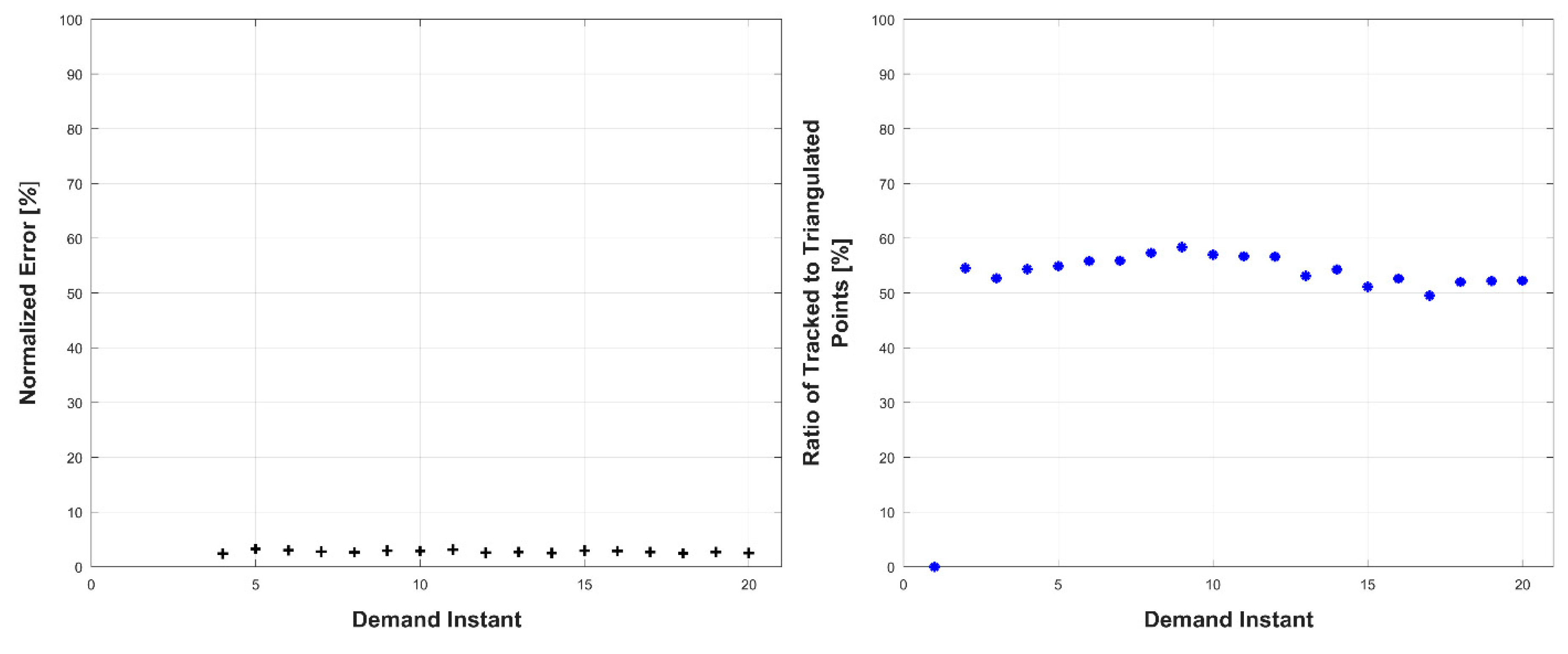
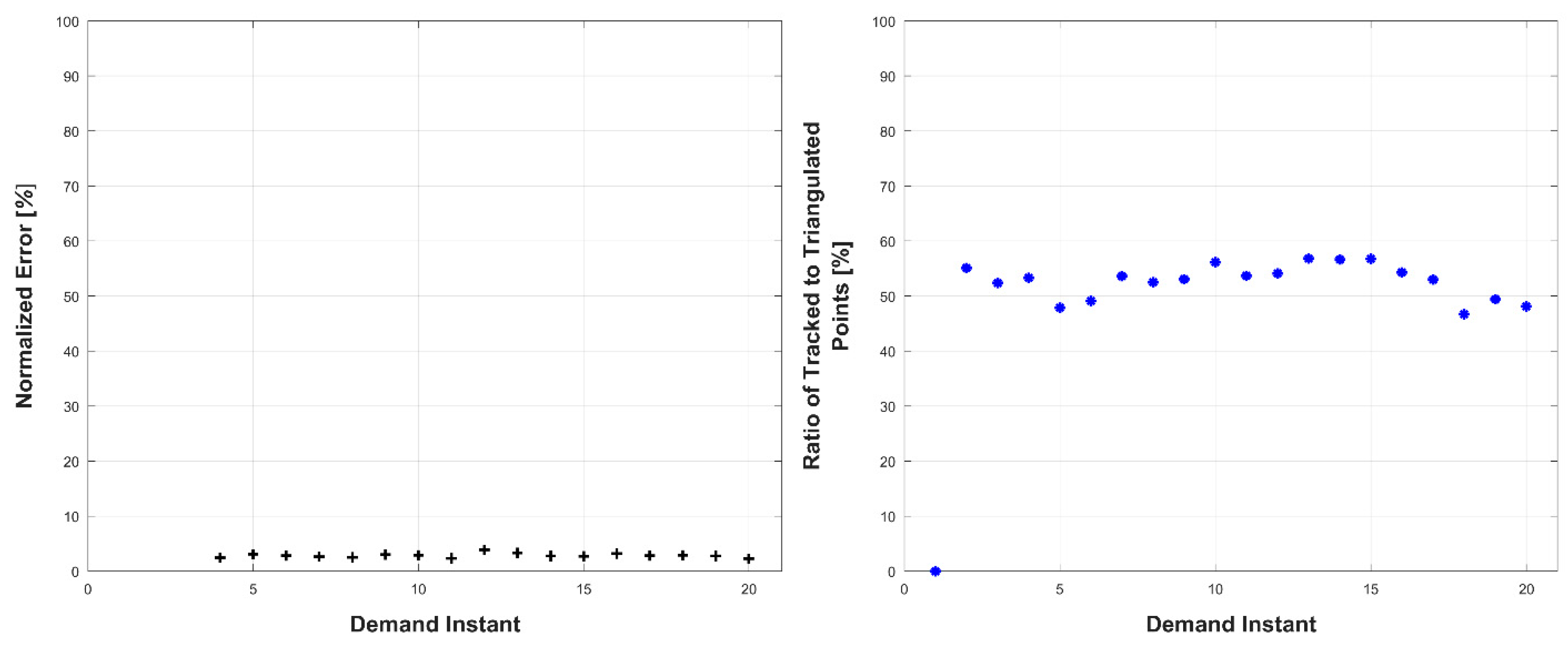
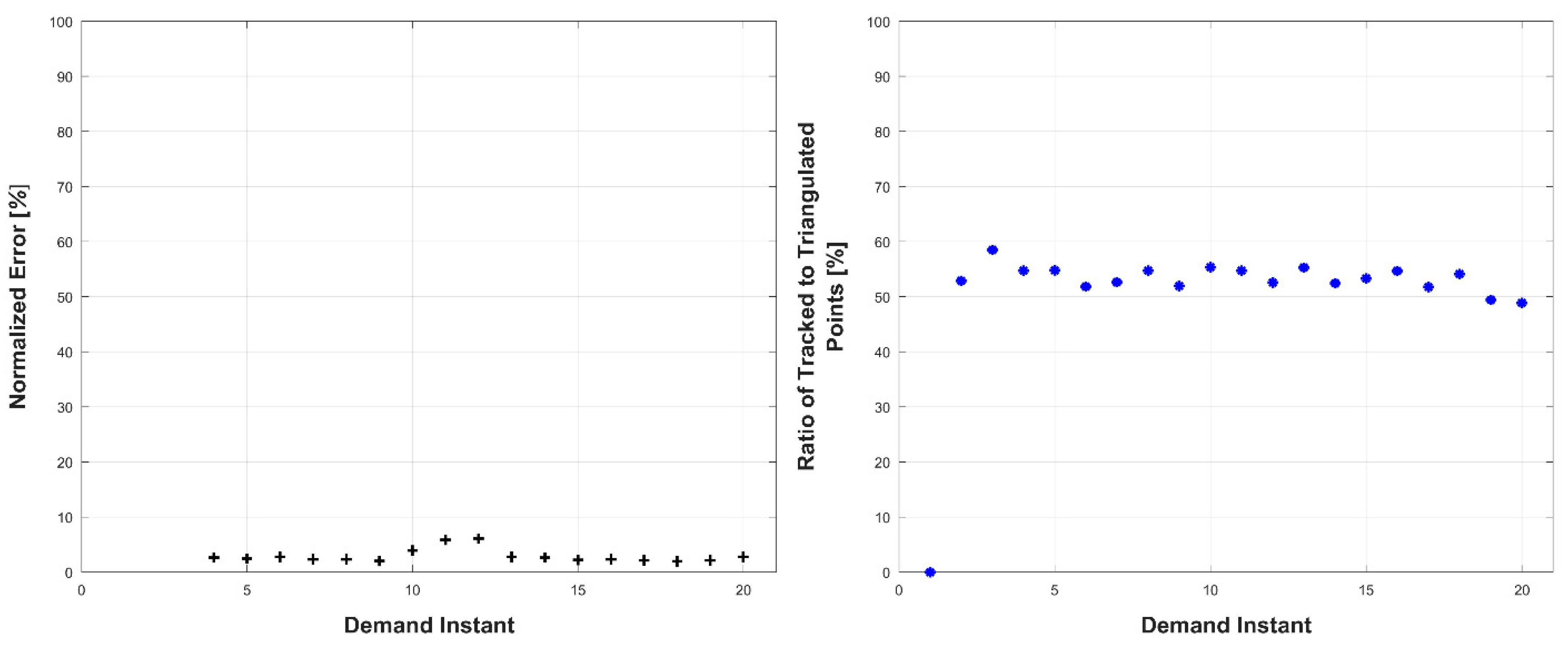
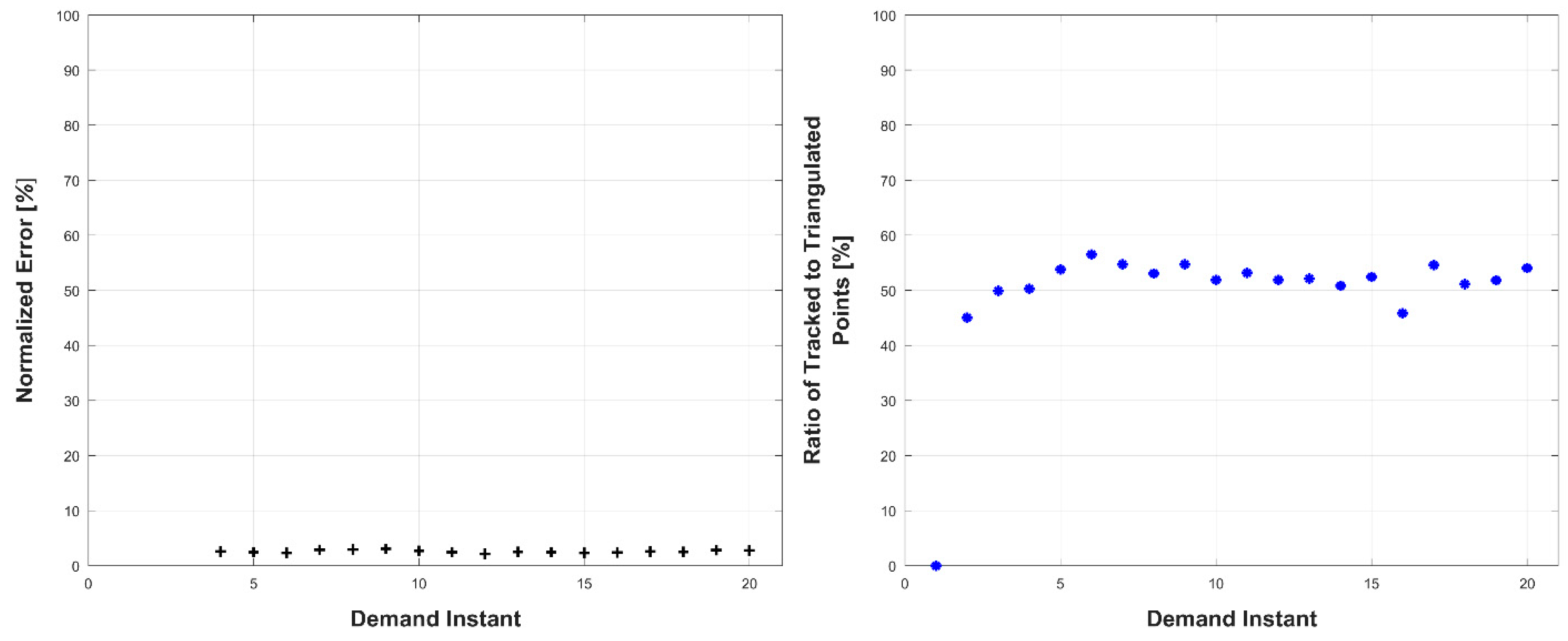
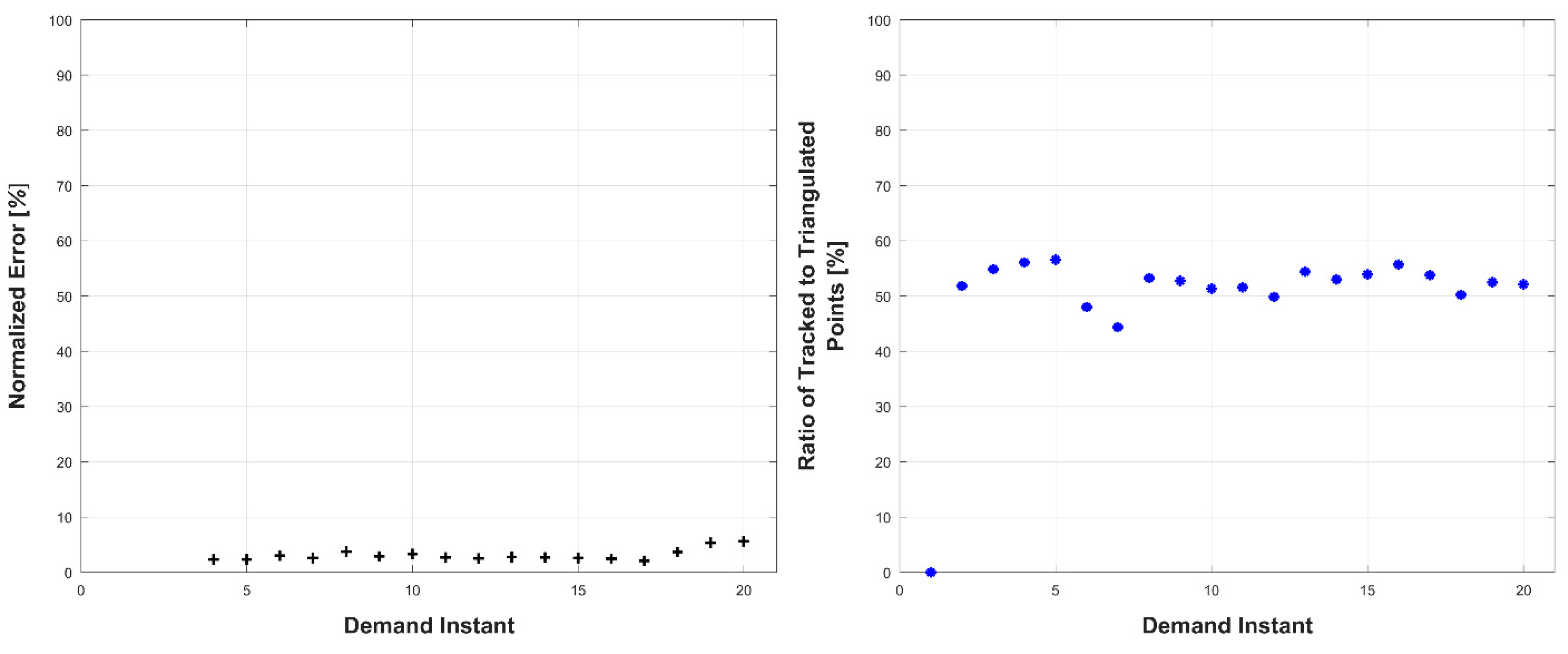
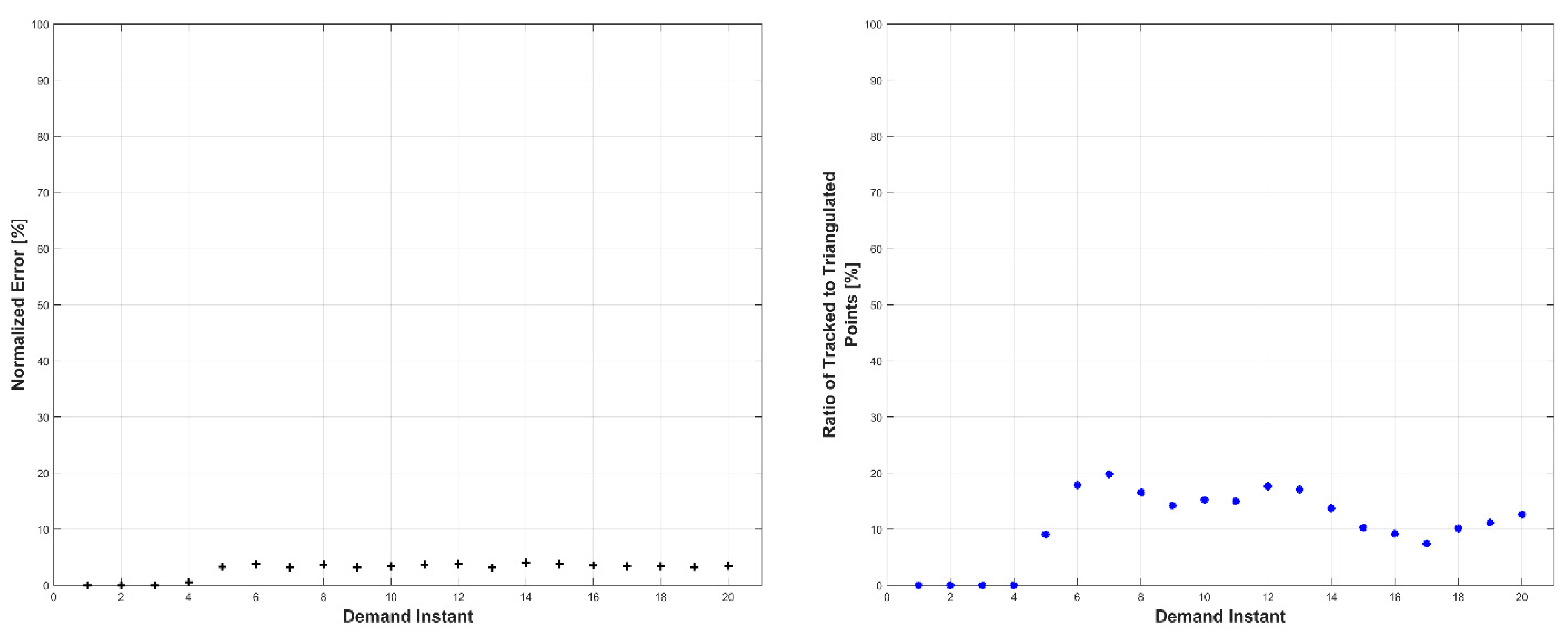
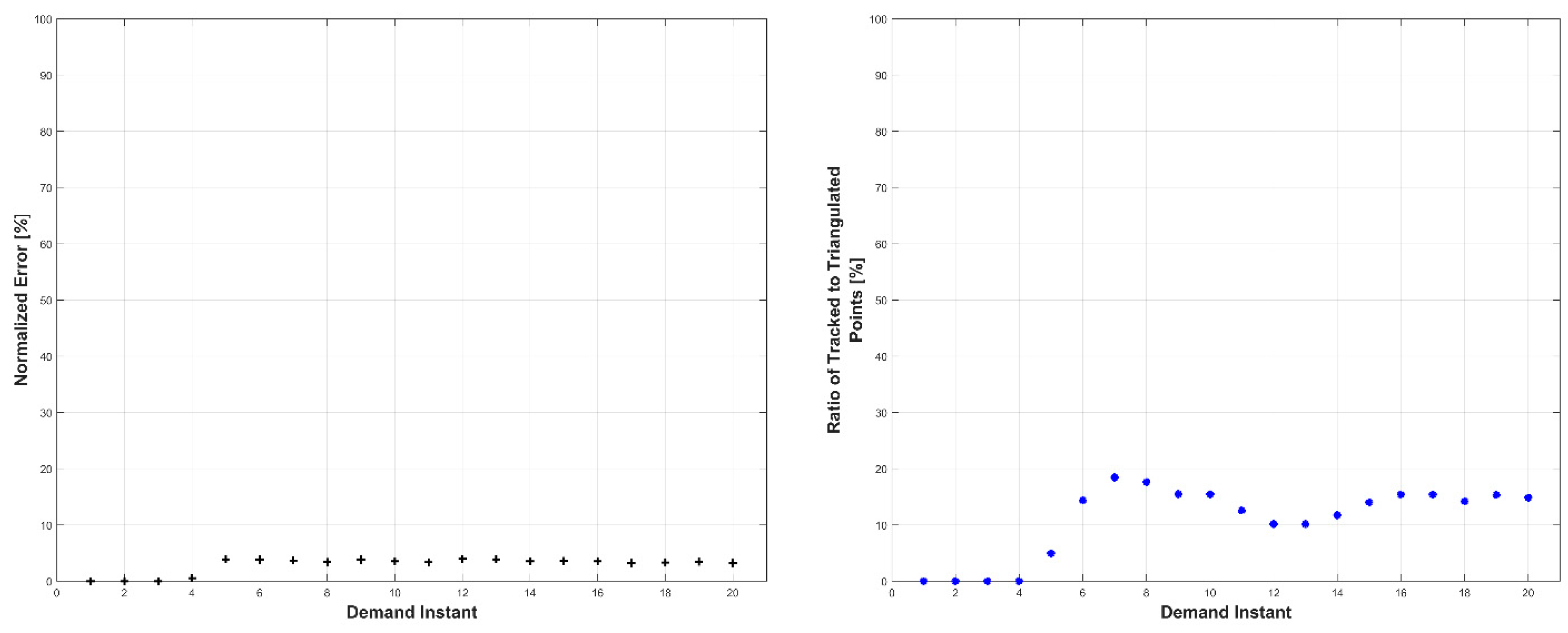
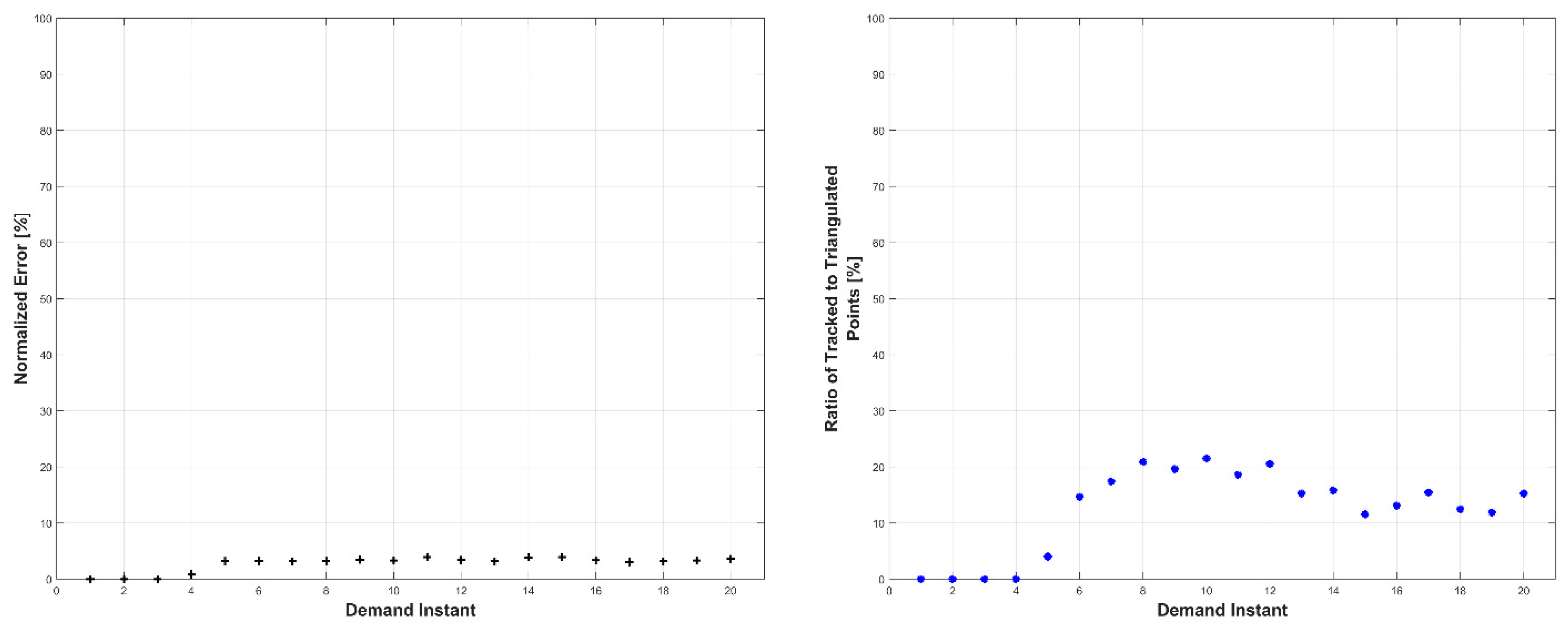
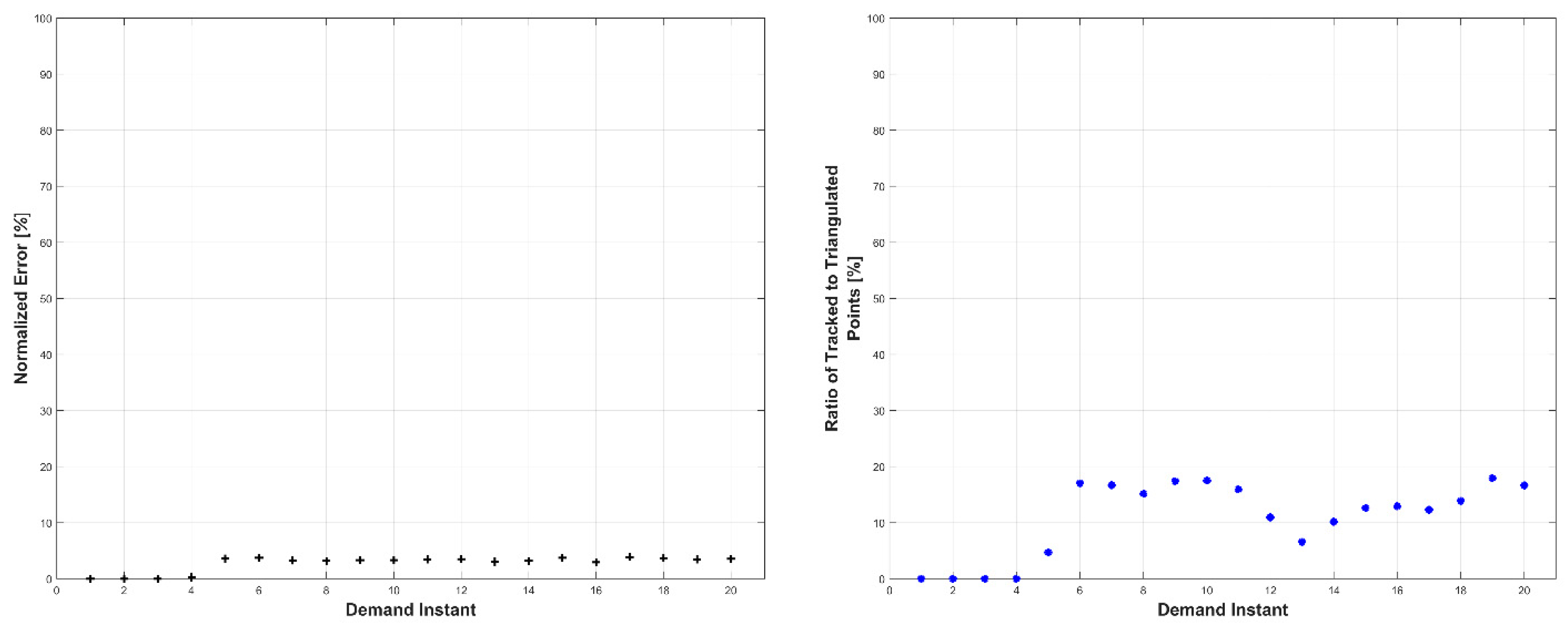
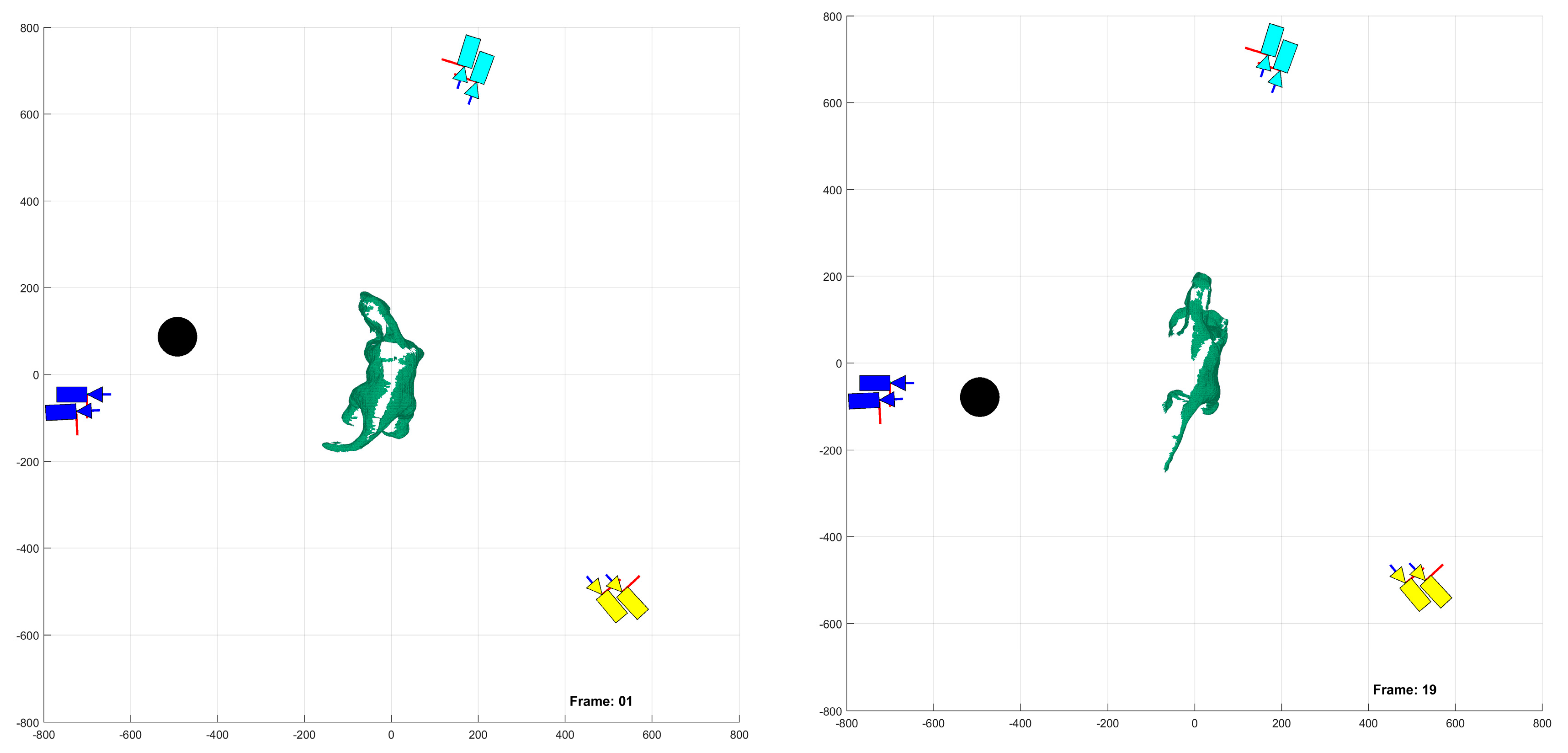
Experiments were conducted in two sets: occluded and unoccluded. The cameras were placed into three stereo pairs separated by 120° about the center of the robot. The robot deformed over a set of 20 demand instants. The unoccluded set of experiments consisted of five robot deformations without dynamic obstacles. The occluded set of experiments consisted of the same five deformations, but with a dynamic obstacle moving through the workspace partially occluding one pair of cameras.
The results, presented below in
Figure 14,
Figure 15,
Figure 16,
Figure 17,
Figure 18,
Figure 19,
Figure 20,
Figure 21,
Figure 22 and
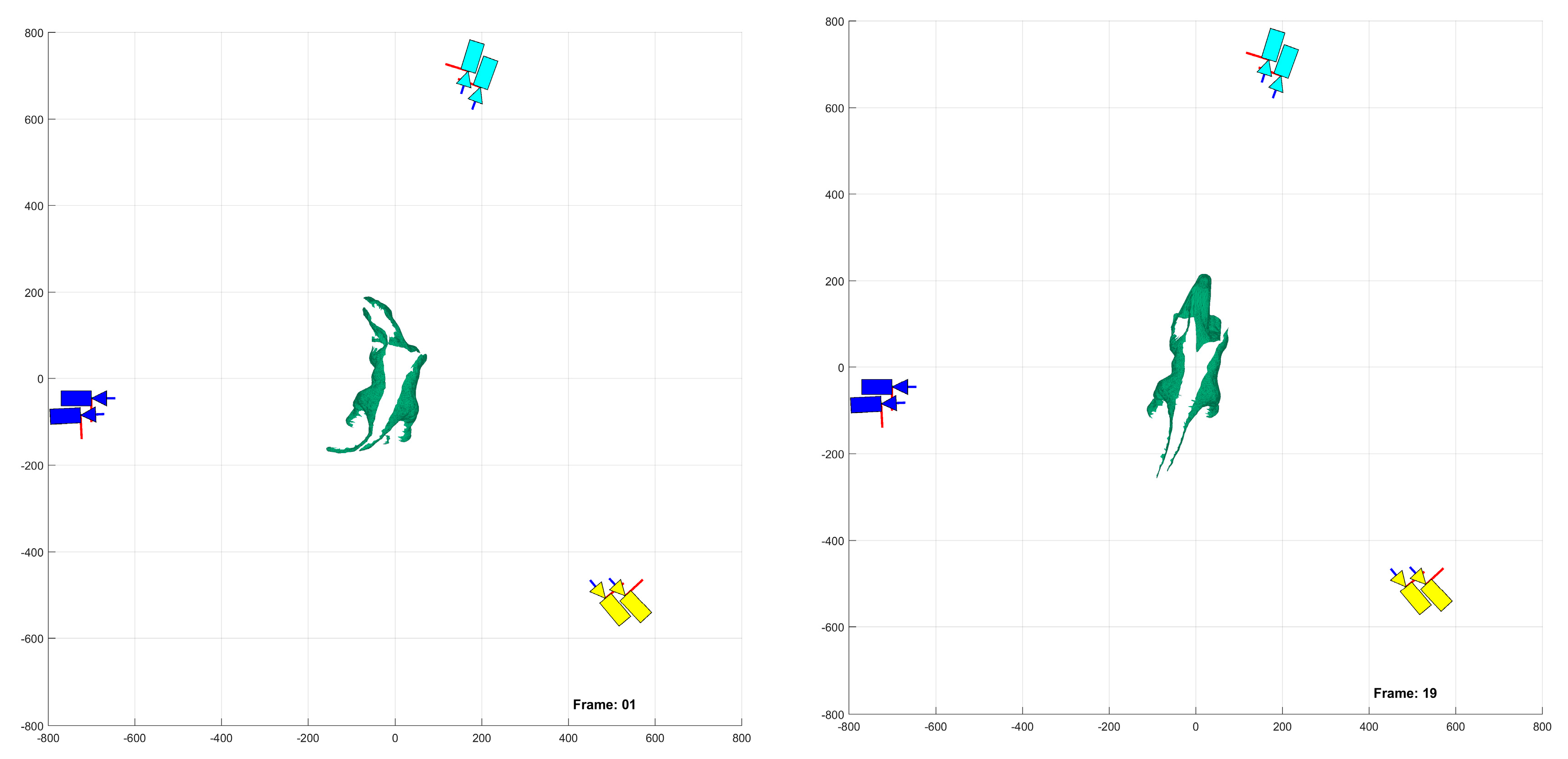
Figure 23, indicate the performance of the deformation estimation methodology when applied to a real-world scenario. In the case of both the occluded and unoccluded experiments, the methodology was capable of predicting the expected deformation of surface patches with less than 4% error. The major difference between the occluded and unoccluded results is the ratio of tracked to triangulated point at each demand instant. Specifically, in the unoccluded case, all three camera pairs triangulate and track a large portion of the target object resulting in an even ratio of tracked to triangulated points. Conversely, in the occluded case, the obstacle results in a large loss of triangulated and tracked points visible by one of the camera pairs; thus, the ratio of tracked to triangulated points is reduced. Movie-strip representations of the predicted surface deformations for one experiment from each occluded and unoccluded set are provided in
Appendix A for reference. Similarly, a movie-strip view of the predicted surface patch deformations alongside the camera views are provided for all unoccluded experiments in
Appendix B.
The average processing times per demand instant for each experiment are presented in
Table 1. It is noted that the image processing of each stereo pair was parallelized in software. All code was written in MatLab without specific optimization.
Unoccluded Experiments
Occluded Experiments
6. Conclusions
This paper presents a novel, modular, multi-camera method for deformation estimation of unknown, markerless 3D objects. We showed that the modular methodology is capable of accurate surface-deformation estimation of the target object under varying motions. The proposed method presents an approach for deformed shape estimation up to scale. Camera calibration could upgrade certain existing state-of-the-art methods with scale information; however, generally, there is no single method that could become comparable with a camera-calibration upgrade. Specifically, model-based methods would have an advantage of the model for optimized fitting, while monocular methods would require an update with a secondary camera, and the introduction of scaled triangulation, which would become the proposed method. Therefore, it is not possible to explicitly compare the proposed method with the existing state of the art without upgrading the latter to achieve the same objective as the proposed method.
The methodology uses an initial stereo-camera selection process. It is noted that, for the purposes of the simulations and experiments presented in this paper, the cameras were manually positioned, resulting in a trivial stereo-pair selection. Then, for each demand instant, images were captured for all cameras and a set of SIFT features were located in each image. The SIFT features were matched between each camera pair, and filtered to remove outliers. Stereo triangulation yielded a set of 3D points which were further filtered to remove outliers. The 3D points were tracked and projected through an adaptive particle filtering framework. Adaptive filtering allows for a varying number of tracked 3D points, and modifies tracking parameters on-line to ensure maximal accuracy in prediction. A constant-acceleration motion model ensures accurate tracking for large variations in tracked objects. The numerous simulations and experiments presented herein were used to validate the methodology. The results demonstrate the methodology’s robustness to varying types of motion, and its ability to estimate deformation even under large tracking losses in both completely controlled environments and real-world environments.






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}