
Deep Graph Convolutional Networks for Accurate Automatic Road Network Selection

Abstract
:1. Introduction
- To the best of our knowledge, this study is the first to adopt GCNs for road network selection. We used different types of graph-convolution models, specifically the standard GCN, GraphSAGE, and GAT, which are characterized by high computational efficiency and spatial locality.
- We introduce different deep strategies for GCNs and combine them with graph-convolution models to determine the most effective combination of selection models for road network selection tasks.
- In addition to the construction of the selection model, we focused on the importance of a rigorous evaluation system. In this work, the evaluation of road network selection results included two aspects. We evaluated the generalization of the selection model using the area under the receiver operating characteristic (ROC) curve (AUC) and also judged whether the spatial distribution of the roads was reasonable by considering expert selection results as a standard and performing a comparative analysis by calculating the selection accuracy and density, along with other indicators.
2. Related Work
2.1. Intelligent Road Network Selection Method
2.2. Development of Graph-Convolution Network (GCN)
3. Materials and Methods
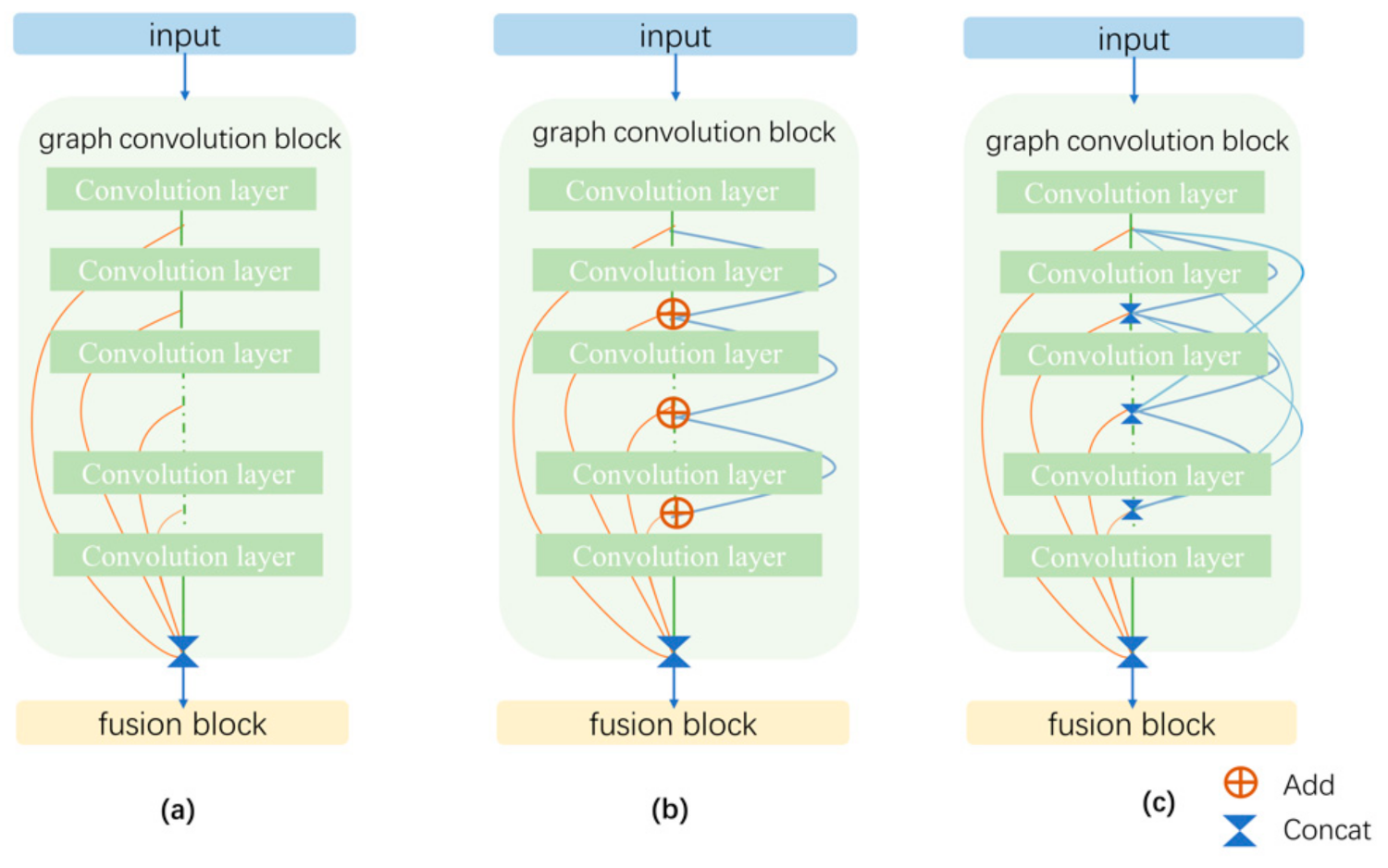
3.1. Graph Convolutional Network (GCN) Models and Their Deep Architectures
3.1.1. Graph Convolutional Network (GCN)
3.1.2. GraphSAGE
3.1.3. Graph Attention Network (GAT)
- Concat: This method performs a simple merge operation on all output features of hidden layers and obtains input of the prediction layer using a linear transformation. This method is suitable for small graphs or graphs having regular structures and low adaptability.
- Max-pooling: This method selects elements of the layer having the maximum information sequentially. Max-pooling is node-adaptive, and no additional learning parameters are introduced.
- LSTM-Attention: The key to LSTM-attention is the attention coefficient . For the first input to a bidirectional LSTM, each layer generates forward hidden features and backward hidden features . Next, these two features are merged to attain an attention score using linear mapping, which will be input into the SoftMax function and obtain the normalized attention coefficient . is the weighted average of the features of the hidden layers. The formula is as follows.
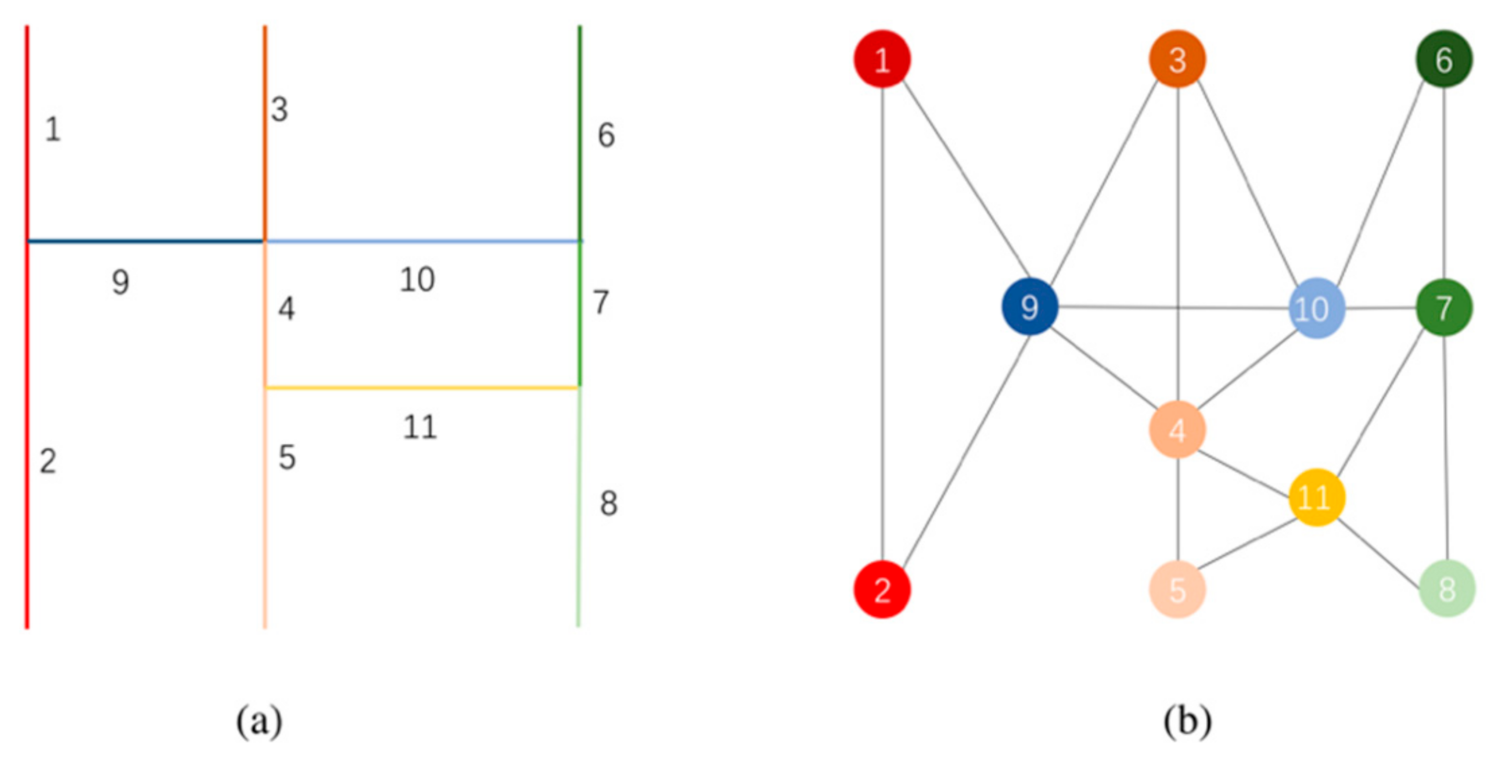
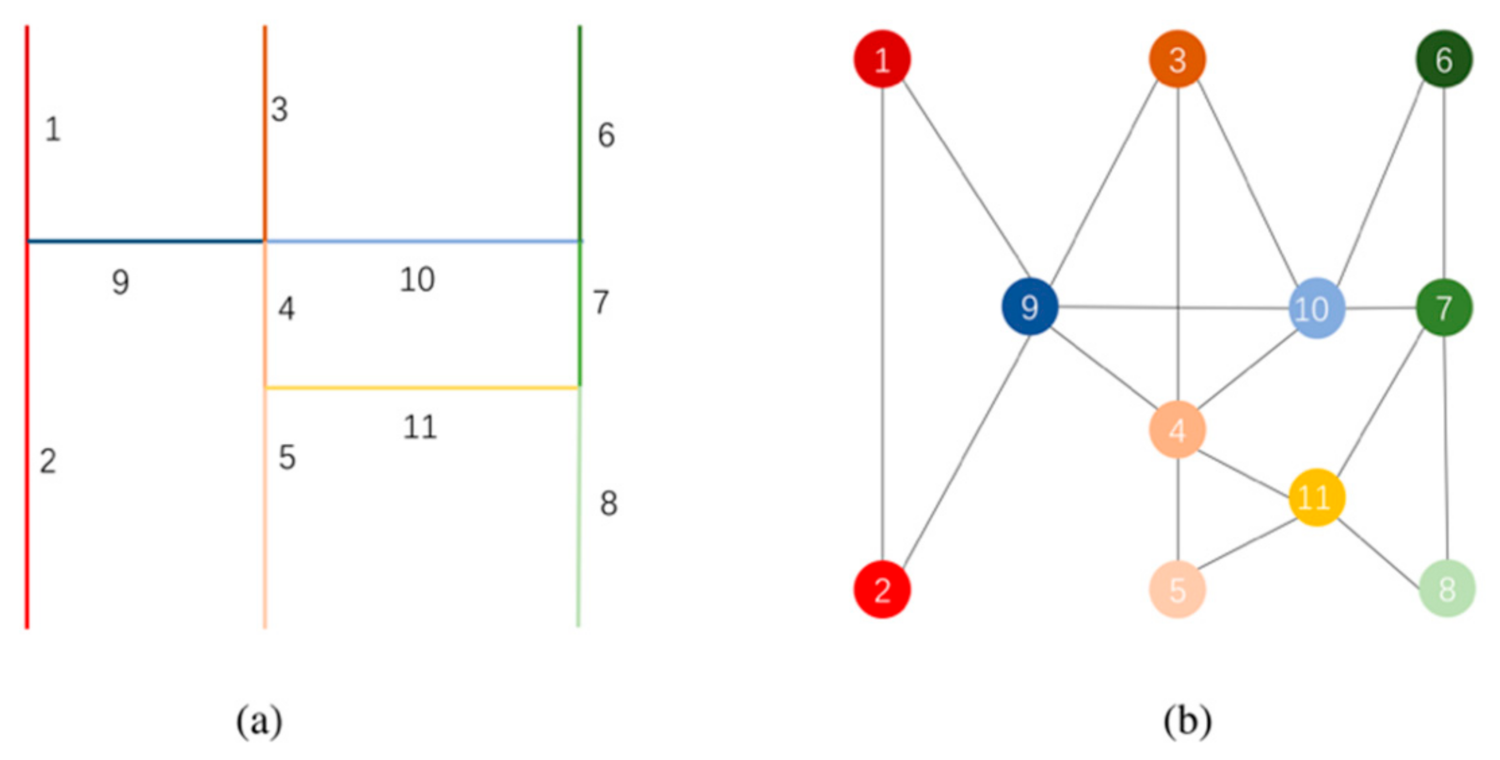
3.2. Dual Graph of Road Network and Its Selection Feature
- Direct representation: Because the road network is naturally a graph structure, it can directly take the road as the edge of the graph and the road intersection as the node.
- Dual representation: The road is abstracted as the node, with the intersection regarded as an edge [46].
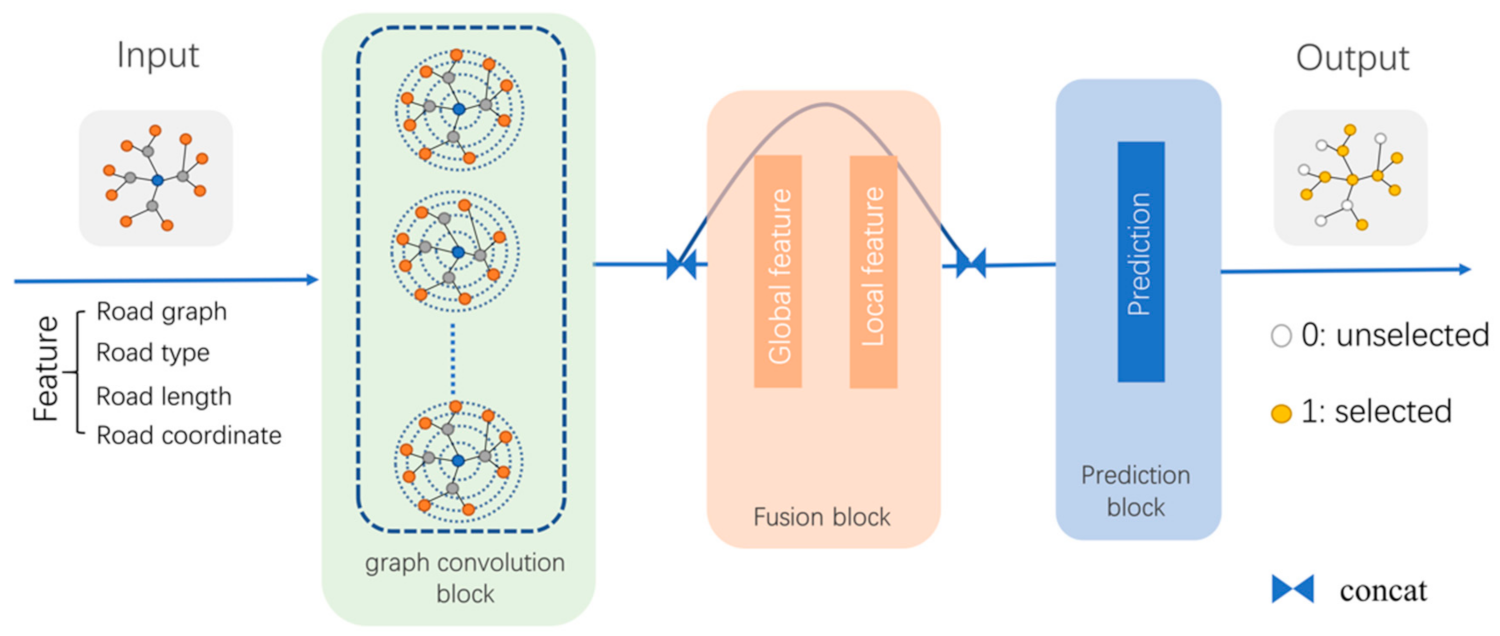
3.3. Design of the Selection Model Structure
3.4. Accuracy Evaluation Indexes
3.5. Implementation Process
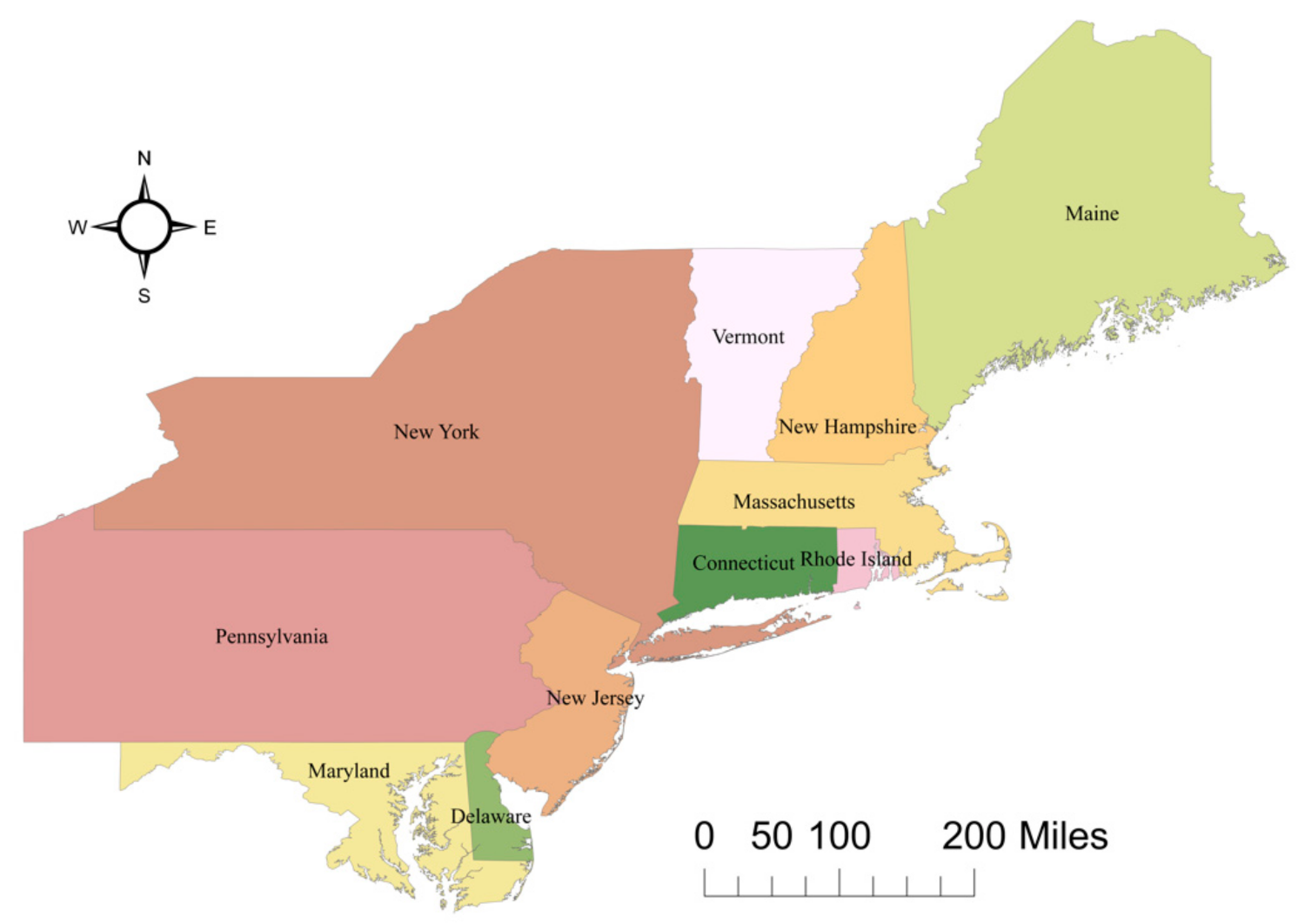
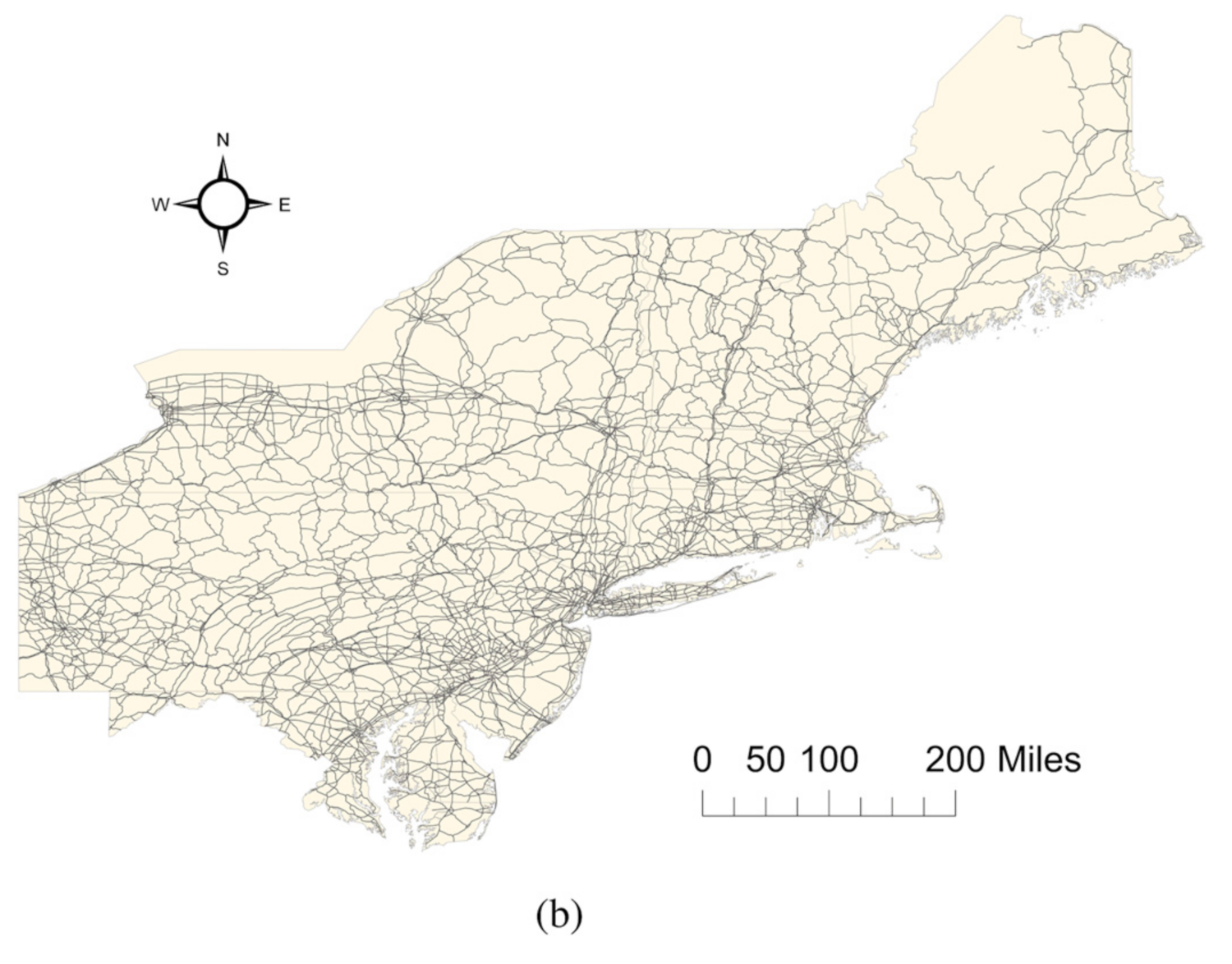
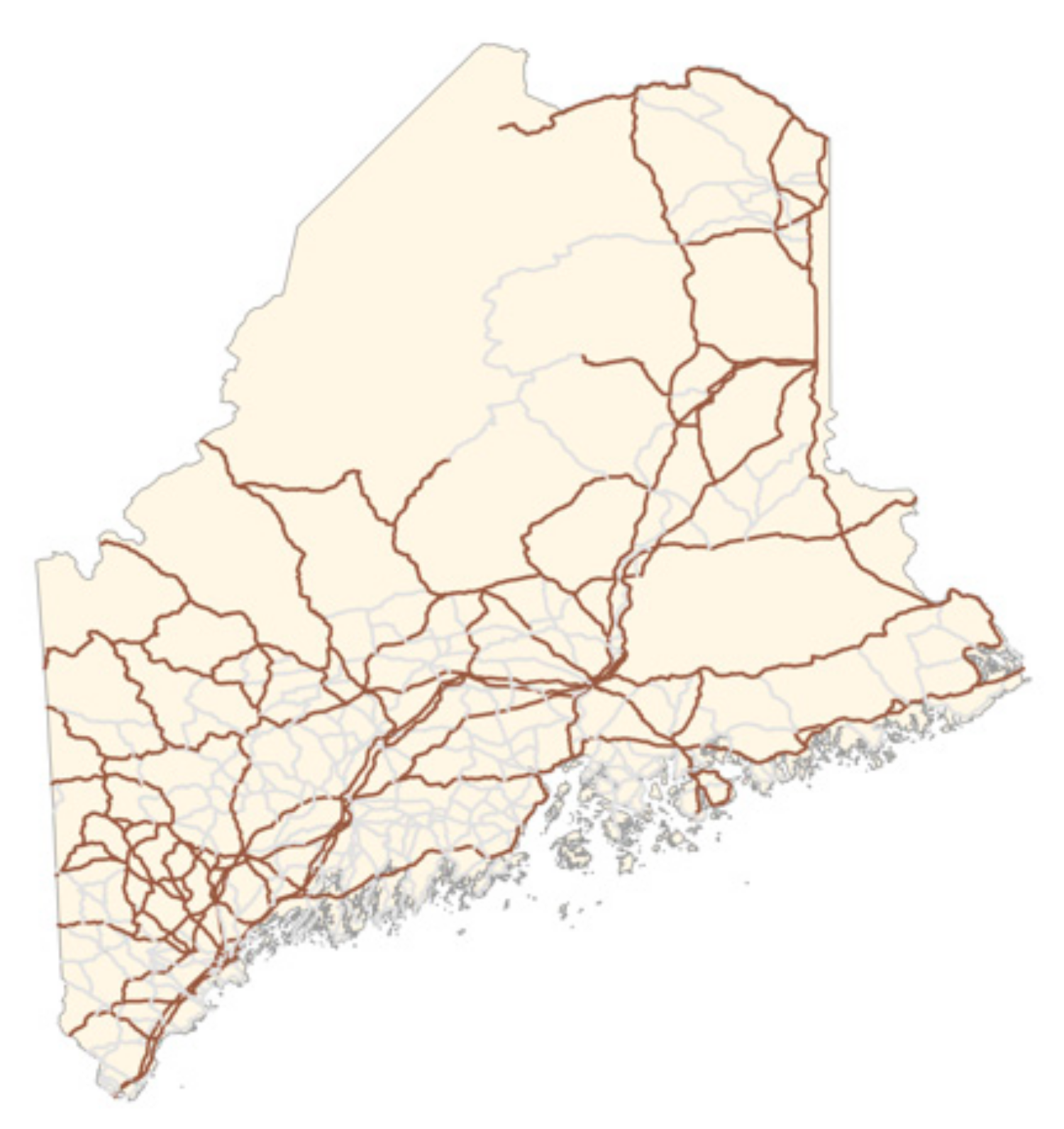
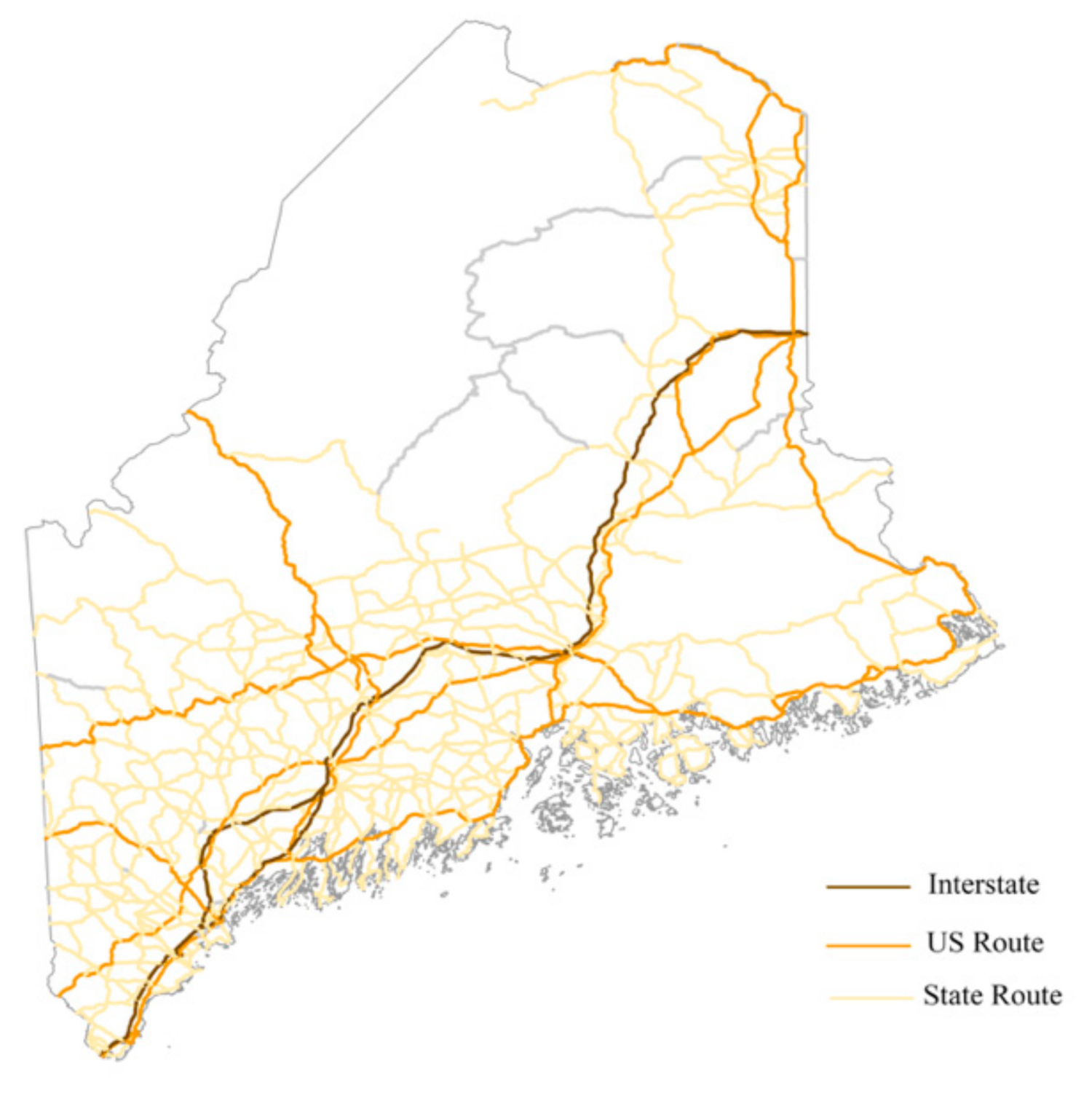
3.5.1. Study Area
3.5.2. Data Processing
3.5.3. Model Construction and Training
4. Results and Discussions
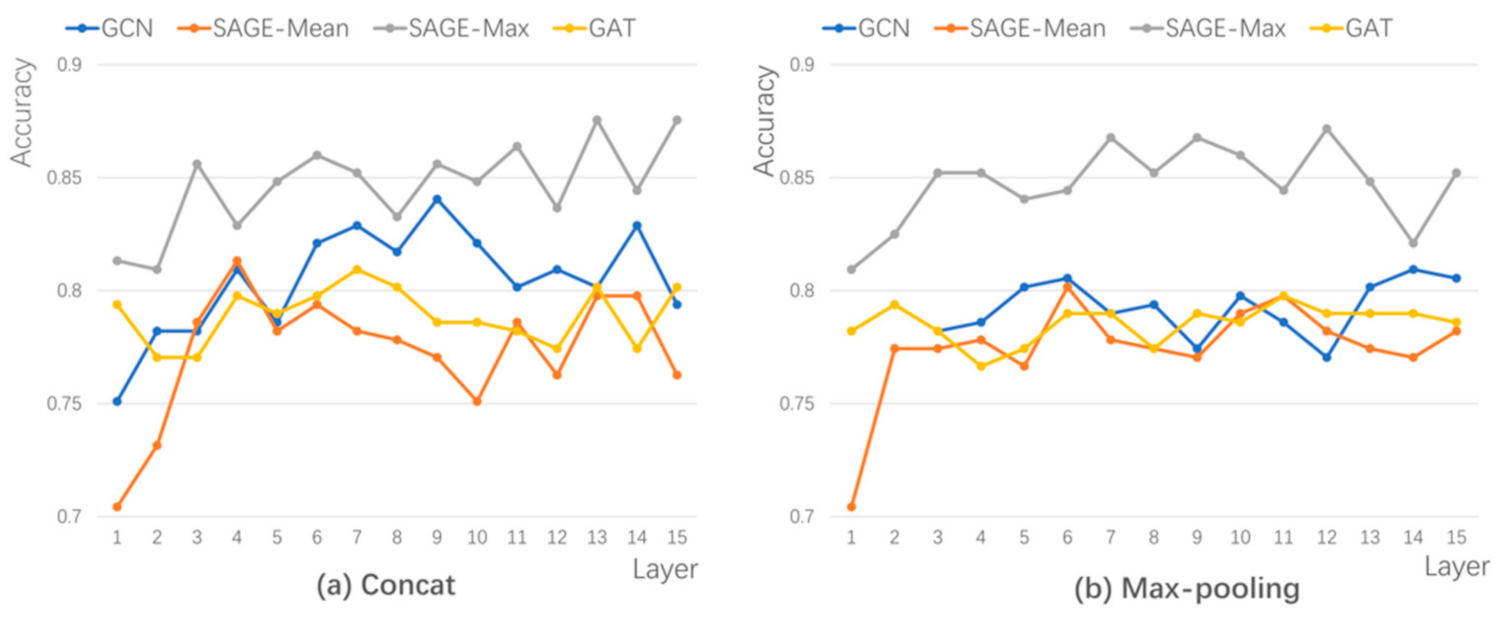
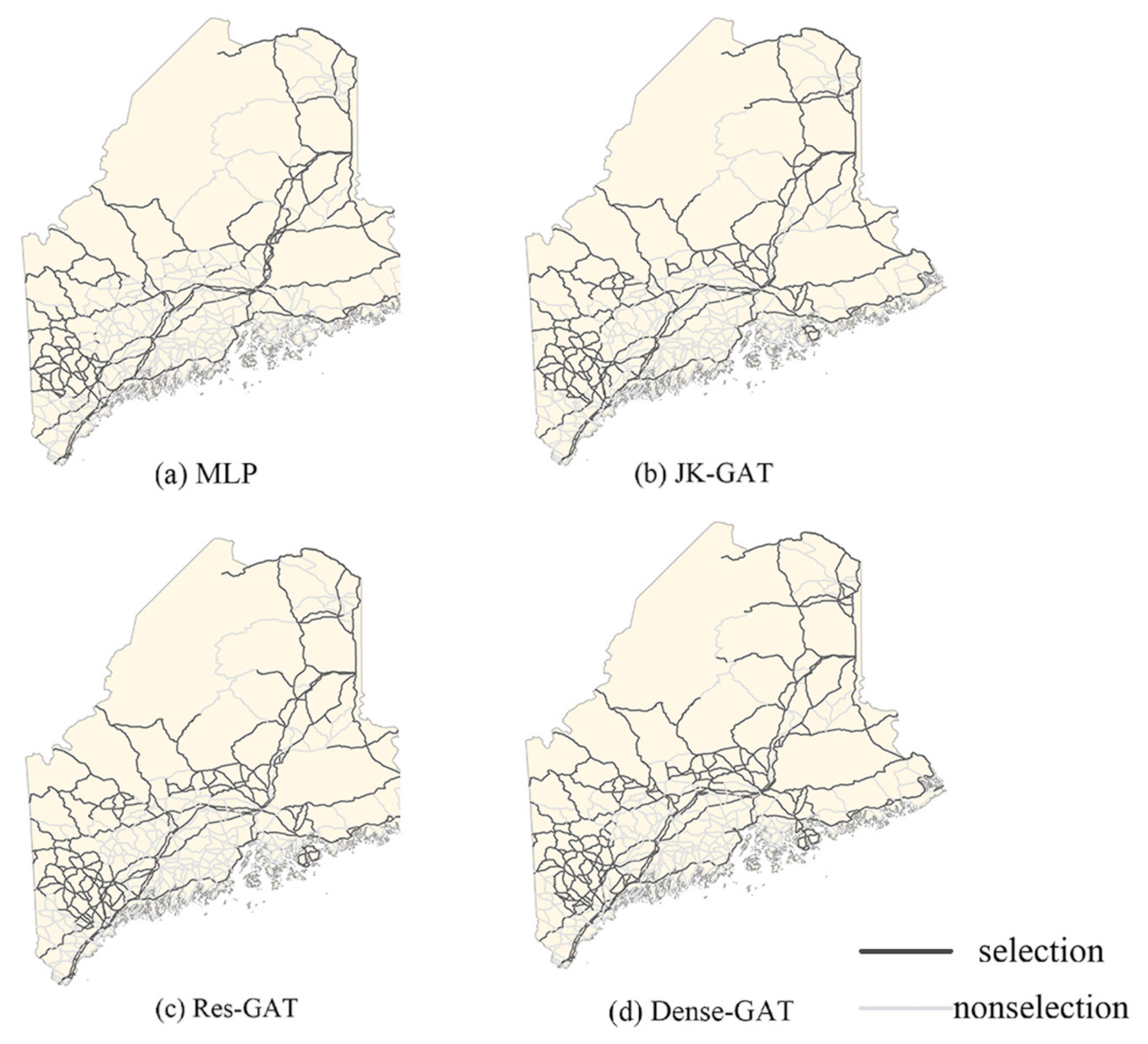
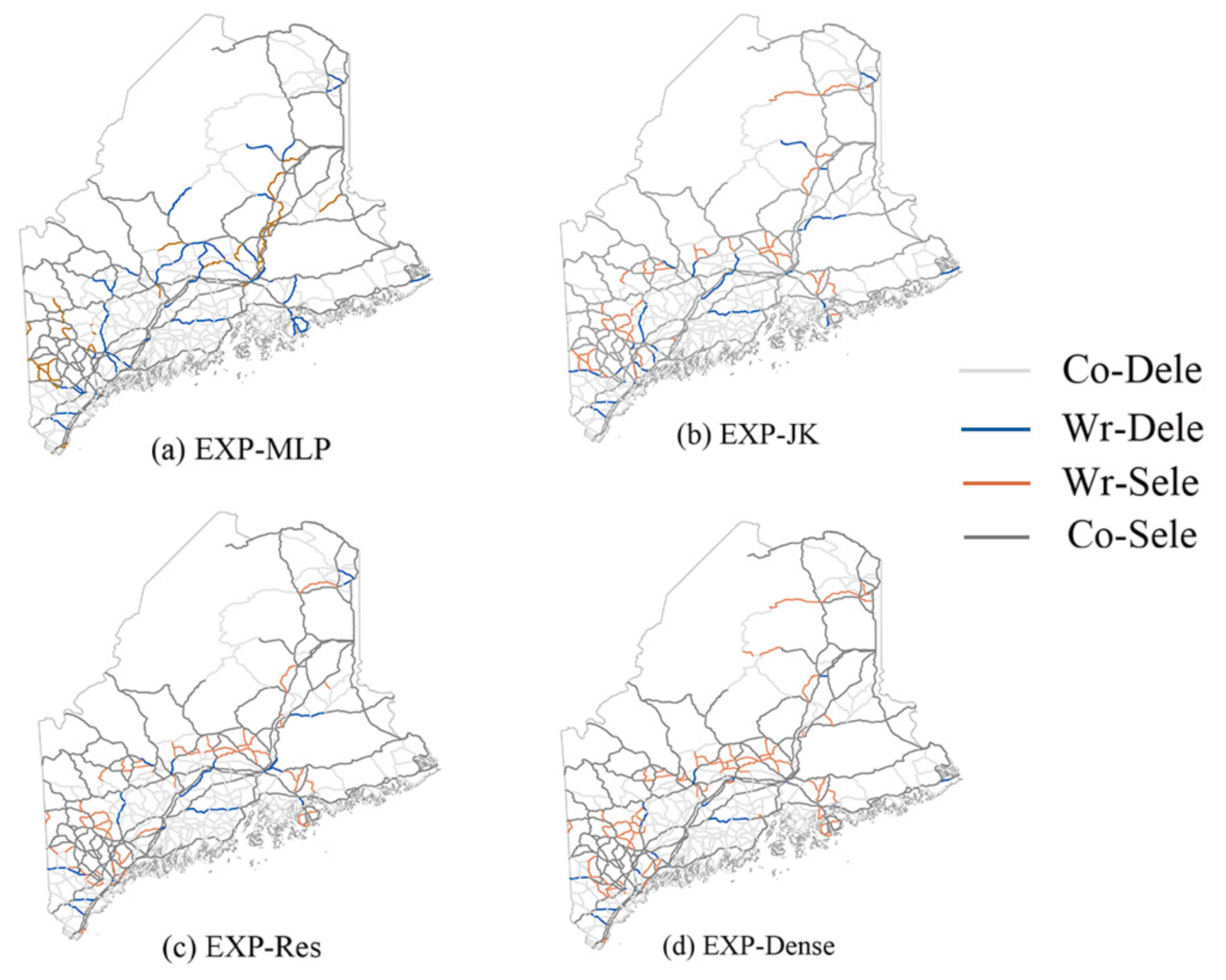
4.1. Predicted Results of Models
4.2. Analysis and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mackaness, W.A.; Beard, K.M. Use of Graph Theory to Support Map Generalization. Cartogr. Geogr. Inf. Syst. 1993, 20, 210–221. [Google Scholar] [CrossRef]
- Wang, J.Y.; Cui, T.J.; Wang, G.X. Application of Graph Theory in Automatic Selection of Road Network. J. Geomat. Sci. Technol. 1985, 1, 79–86. [Google Scholar]
- Thomson, R.C.; Richardson, D.E. The ‘Good Continuation’Principle of Perceptual Organization Applied to the Generalization of Road Networks. In Proceedings of the ICA 19th International Cartographic Conference, Ottawa, ON, Canada, 14–21 August 1999; pp. 1215–1223. [Google Scholar]
- Thomson, R.; Brooks, R. Generalisation of Geographical Networks. Gen. Geogr. Inf. 2007, 255–267. [Google Scholar] [CrossRef]
- Hu, Y.G.; Chen, J.; Li, Z.L. Selective Omission of Road Features Based on Mesh Density for Digital Map Generalization. Acta Geod. Cartogr. Sin. 2007, 351–357. [Google Scholar] [CrossRef]
- Aurenhammer, F. Voronoi Diagrams—a Survey of a Fundamental Geometric Data Structure. ACM Comput. Surv. 1991, 23, 345–405. [Google Scholar] [CrossRef]
- Yang, M.; Ai, T.H.; Zhou, Q. A Method of Road Network Generalization Considering Stroke Properties of Road Object. Acta Geod. Cartogr. Sin. 2013, 42, 581–587. [Google Scholar]
- Cai, Y.X.; Guo, Q.S. Method For Streets Progressive Selection Based On Neural Network Techniques. J. Geomat. 2008, 05, 24–26. [Google Scholar]
- Liu, K.; Li, J.; Shen, J.; Ma, J.S. Selection of Road Network Using BP Neural Network and Topological Parameters. J. Geomat. Sci. Technol. 2016, 33, 325–330. [Google Scholar]
- Liu, P.; Yuan, L.H.; Zhang, K.; Shen, J.; Ma, J.S. Intelligent Selection of OSM Road Network Based on RBF Neural Network. Geomat. World 2019, 26, 8–13. [Google Scholar]
- Jiang, B.; Harrie, L. Selection of Streets from a Network Using Self-Organizing Maps. Trans. GIS 2004, 8, 335–350. [Google Scholar] [CrossRef]
- Li, M.Z.; Xu, Z.; Li, Z.L.; Zhang, H.; Ti, P. A Hierarchical Random Graph Based Selection Method for Road Network Generalization. J. Geo-Inf. Sci. 2012, 14, 719–727. [Google Scholar] [CrossRef]
- Deng, H.Y.; Wu, F.; Zhai, R.J.; Liu, W.W. A Generalization Model of Road Networks Based on Genetic Algorithm. Geomat. Inf. Sci. Wuhan Univ. 2006, 164–167. [Google Scholar] [CrossRef]
- Wu, Z.H.; Pan, S.R.; Chen, F.W.; Long, G.D.; Zhang, C.Q.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Merriënboer, B.V.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ai, T.H. Some Thoughts on Deep Learning Enabling Cartography. Acta Geod. Cartogr. Sin. 2021, 50, 1–13. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Wilder, B.; Ewing, E.; Dilkina, B.; Tambe, M. End to End Learning and Optimization on Graphs. Adv. Neural Inf. Process. Syst. 2019, 32, 4672–4683. [Google Scholar]
- Li, Q.M.; Han, Z.C.; Wu, X.M. Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Xu, K.; Li, C.T.; Tian, Y.L.; Tomohiro, S.; Kawarabayashi, K.; Jegelka, S. Representation Learning on Graphs with Jumping Knowledge Networks. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5453–5462. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, G.H.; Muller, M.; Thabet, A.; Ghanem, B. DeepGCNs: Can GCNs Go As Deep As CNNs? In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–3 November 2019. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Grover, A.; Leskovec, J. Node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Guo, M.; Qian, H.Z.; Huang, Z.S.; Liu, H.L.; Ju, J.C. ID3 Decision Tree Oriented Knowledge Reasoning Model and Its Application in Road Network Selection. J. Geomat. Sci. Technol. 2012, 29, 308–312. [Google Scholar]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Liu, K.; Ma, J.S. Research on Intelligent Selection of Road Network Automatic Generalization Based on Kernel-Based Machine Learning; Nanjing University: Nanjing, China, 2017. [Google Scholar]
- Gori, M.; Monfardini, G.; Scarselli, F. A New Model for Learning in Graph Domains. In Proceedings of the IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 1 July–4 August 2005; Volume 2, pp. 729–734. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Micheli, A. Neural Network for Graphs: A Contextual Constructive Approach. IEEE Trans. Neural Netw. 2009, 20, 498–511. [Google Scholar] [CrossRef] [PubMed]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral Networks and Locally Connected Networks on Graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Belkin, M.; Niyogi, P. Laplacian Eigenmaps and Spectral Techniques for Embedding and Clustering. Proc. Nips 2001, 14, 585–591. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Zhang, Z.W.; Cui, P.; Wang, X.; Pei, J.; Yao, X.R.; Zhu, W.W. Arbitrary-Order Proximity Preserved Network Embedding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2778–2786. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Hamaguchi, T.; Oiwa, H.; Shimbo, M.; Matsumoto, Y. Knowledge Transfer for Out-of-Knowledge-Base Entities: A Graph Neural Network Approach. arXiv 2017, arXiv:1706.05674. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph Convolutional Neural Networks for Web-Scale Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar]
- Wang, H.W.; Zhang, F.Z.; Wang, J.L.; Zhao, M.; Li, W.J.; Xie, X.; Guo, M.Y. Exploring High-Order User Preference on the Knowledge Graph for Recommender Systems. ACM Trans. Inf. Syst. TOIS 2019, 37, 1–26. [Google Scholar] [CrossRef]
- Wang, M.Q.; Ai, T.H.; Yan, X.F.; Xiao, Y. Grid Pattern Recognition in Road Networks Based on Graph Convolution Network Model. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 1960–1969. [Google Scholar]
- Jepsen, T.S.; Jensen, C.S.; Nielsen, T.D. Relational Fusion Networks: Graph Convolutional Networks for Road Networks. IEEE Trans. Intell. Transp. Syst. 2020. [Google Scholar] [CrossRef]
- Yu, B.; Yin, H.T.; Zhu, Z.X. Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting. arXiv 2017, arXiv:1709.04875. [Google Scholar]
- Xu, Z.B.; Wang, Z.H.; Yan, H.W.; Wu, F.; Duan, X.Q.; Sun, L. A Method for Automatic Road Selection Combined with POI Data. J. Geo-Inf. Sci. 2018, 20, 159–166. [Google Scholar]
- Yuan, L.H.; Ma, J.S. Study on Ensemble Learning and Multi-Parameters System for OSM Road Network Selection; Nanjing University: Nanjing, China, 2018. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; Volume 30, pp. 1–6. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Unselect (0) | Select (1) | |
|---|---|---|---|
| Expert | |||
| Unselect (0) | Correct deletion (TN) | Wrong selection (FP) | |
| Select (1) | Wrong deletion (FN) | Correct selection (TP) | |
| Convolution | GCN | SAGE-Mean | SAGE-Max | GAT | |
|---|---|---|---|---|---|
| Connection | |||||
| JK | 88.38 | 87.76 | 87.04 | 91.68 | |
| Res | 89.41 | 88.89 | 86.67 | 91.25 | |
| Dense | 89.70 | 89.49 | 84.92 | 91.99 | |
| Incorrect Deletion | Incorrect Selection | Accuracy Rate (%) | Density (km/km2) | Prediction Time (s) | |
|---|---|---|---|---|---|
| Expert | - | - | - | 0.0431 | - |
| MLP | 109 | 71 | 85.83 | 0.0405 | 0.125 |
| JK-GAT | 82 | 69 | 88.12 | 0.0453 | 3.59 |
| Res-GAT | 65 | 89 | 87.88 | 0.0471 | 2.57 |
| Dense-GAT | 40 | 120 | 87.41 | 0.0509 | 5.84 |
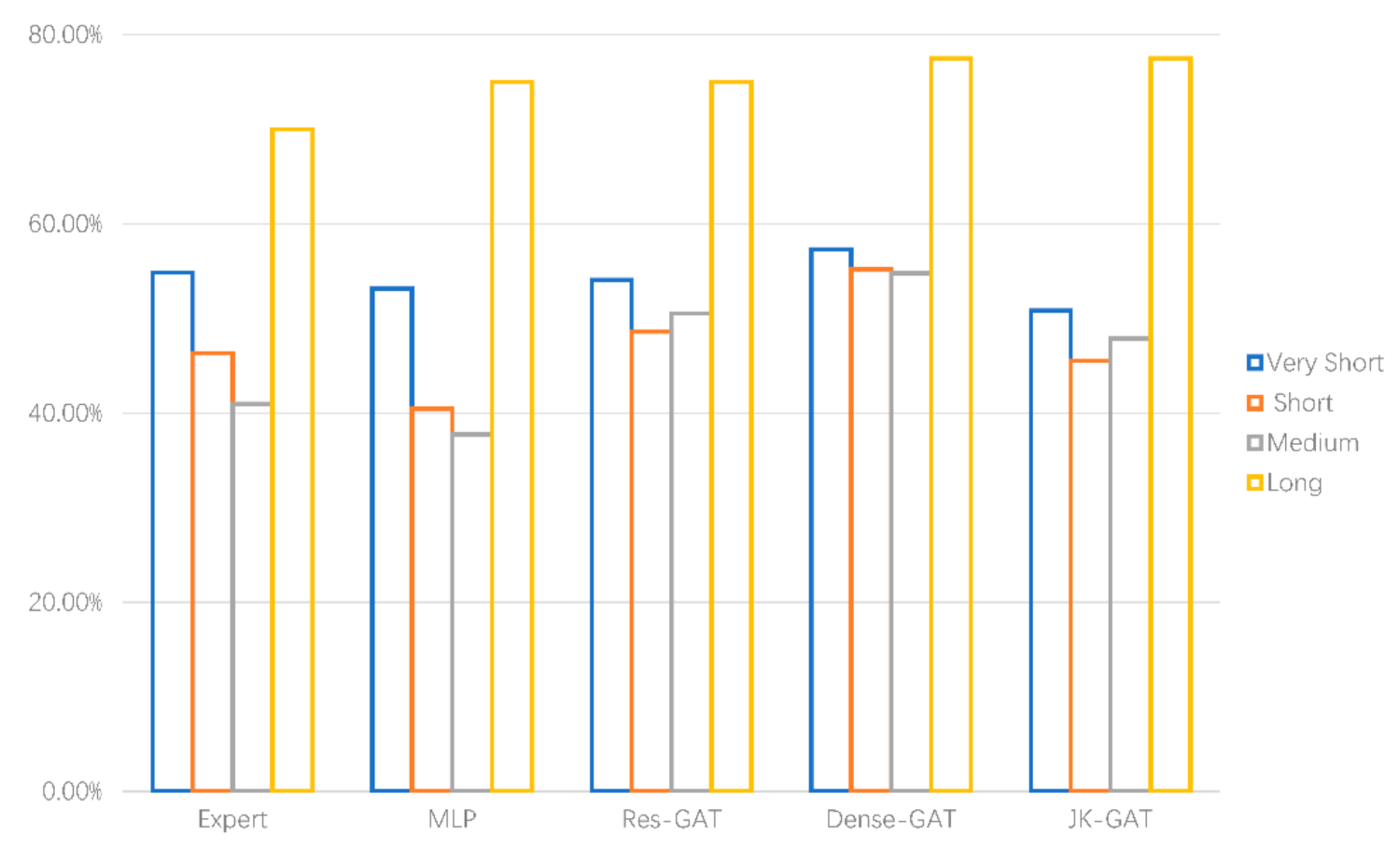
| SR | Very Short | Short | Medium | Long |
|---|---|---|---|---|
| Expert | 54.85% | 46.31% | 40.96% | 70% |
| MLP | 53.16% | 40.46% | 37.77% | 75% |
| JK-GAT | 50.85% | 45.55% | 47.87% | 77.5% |
| Res-GAT | 54.08% | 48.6% | 54.79% | 75% |
| Dense-GAT | 57.32% | 55.22% | 54.79% | 77.45% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, J.; Gao, Z.; Ma, J.; Shen, J.; Zhang, K. Deep Graph Convolutional Networks for Accurate Automatic Road Network Selection. ISPRS Int. J. Geo-Inf. 2021, 10, 768. https://doi.org/10.3390/ijgi10110768
Zheng J, Gao Z, Ma J, Shen J, Zhang K. Deep Graph Convolutional Networks for Accurate Automatic Road Network Selection. ISPRS International Journal of Geo-Information. 2021; 10(11):768. https://doi.org/10.3390/ijgi10110768
Chicago/Turabian StyleZheng, Jing, Ziren Gao, Jingsong Ma, Jie Shen, and Kang Zhang. 2021. "Deep Graph Convolutional Networks for Accurate Automatic Road Network Selection" ISPRS International Journal of Geo-Information 10, no. 11: 768. https://doi.org/10.3390/ijgi10110768
APA StyleZheng, J., Gao, Z., Ma, J., Shen, J., & Zhang, K. (2021). Deep Graph Convolutional Networks for Accurate Automatic Road Network Selection. ISPRS International Journal of Geo-Information, 10(11), 768. https://doi.org/10.3390/ijgi10110768