
A Century of French Railways: The Value of Remote Sensing and VGI in the Fusion of Historical Data


Abstract
:1. Introduction
2. Materials and Methods. Part 1: Public Data, Revision and Control
2.1. Shaping the Expected Target
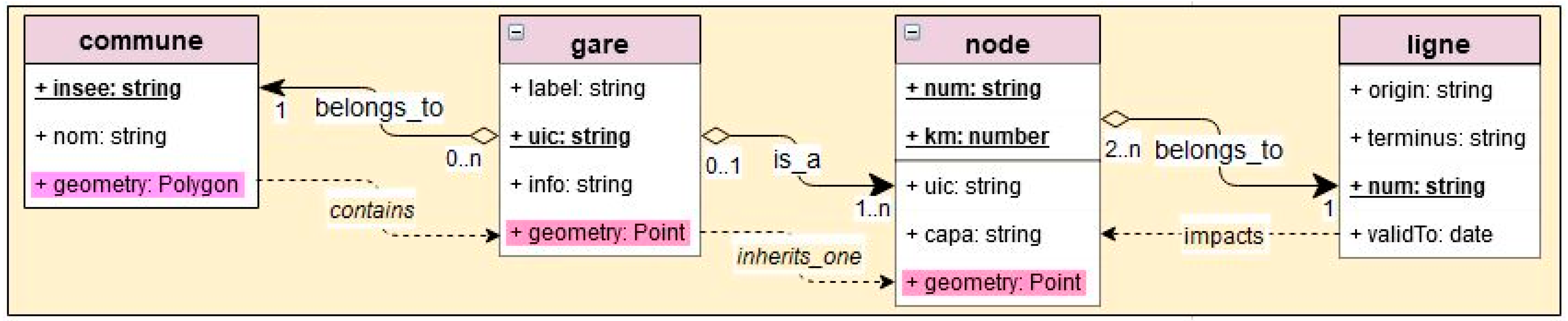
2.1.1. Target Goal, Constraints and Initial Schema
- -
- For each of the French communes, how far from its center is the closest gare?
- -
- Between closest garesof communes A and B, what is the closest path (kilometers)?
- -
- Comparing today and a century ago.
- The gare–commune relationship is straightforward, once all gares are geocoded;
- The gare–ligne relationship is the challenge: how to find old lignes and all their gares.
- -
- node → RailwayNode || RailwayStationNode;
- -
- gare → [RailwayNode(West), RailwayStationNode, RailwayNode(East)];
- -
- km (point kilométrique) → linear referencing,
- -
- uic (Union Internationale des Chemins de fer, the Worldwide Railway Organization (UIC) code) → RailwayStationCode, etc.
2.1.2. Target Attributes for Classes Commune, Gare, Ligne
- -
- insee = [primary key] official unique code for a commune, (may evolve with time);
- -
- num = [primary key] official number for a ligne, or any given unique code.;
- -
- uic = [primary key] official RailwayStationCodefor a gare, given by the UIC, the international railway organization, or any given unique code;
- -
- km = linear referencing, French:”point kilométrique”, German: “Streckenkilometer”;
- -
- the couple (num, km) is [primary key] for a gare (not two equal km for one num);
- -
- point = geocode of a node, and for the associated gare;
- -
- polygon = contour of a commune;
- -
- geometry in the sequel, is used to denote either point, or polygon.
- -
- validTo = year of end of service of a ligne (hence of all its gares). A ligne can be disused partly (% of full length) at different dates, definitively (French: déclassement) or reversibly. Most recent year is used (INSPIRE: validTo).
- -
- label = name given to a gare (should be in bijection with uic) or a node;
- -
- nom = toponym for a commune (when used for a gare, may differ from the label);
- -
- capa = use status, e.g., ‘cargo only’, ‘border point’, etc. used for display purposes.
- (1).
- (2).
- A couple (num, km) must be unique;
- (3).
- A couple (num, label), must be unique (see Section 2.3.1 and Appendix B);
- (4).
- The subset of all nodes of a same ligne (= num) must be strictly ordered by km;
- (5).
- Every gare belongs to one commune, whose polygon contains the garepoint. Sometimes, purposely, a gare has been built at the border of two communes (only one is recorded);
- (6).
- Every ligne has two ends: an origin node, and a terminus node. One ligne either is “active”, or has a “validTo” (alias “end”) date;
- (7).
- Every gare has one or more node(s), but a node may have no gare (e.g., a fork);
2.1.3. Target Notation and Generic Step-by-Step Approach for Collecting Values
2.2. Public Open Data Sources, and the Information Revision Problem
2.2.1. Description of the Available Public and Administrative Sources
2.2.2. Matching Attributes of the Public Sources with Target Attributes
- Target.num: matches SNCF*|Lignes:code_ligne, primary key for lignes. Mandatory;
- Target.label: matches SNCF1:nom, and SNCF2*:libelle;
- Target.km: matches SNCF2*:pk. Mandatory. Order must reflect the strict order of the nodes on the ligne;
- Target.uic: matches SNCF2*:code_uic. In SNCF1, uses Target.label instead;
- couples SNCF1:(code_ligne, nom) and SNCF2:(code_ligne, pk), are used as primary key for nodes what requires to check its uniqueness;
- Target.capa: derived from SNCF:nature, SNCF*:fret,voyageurs or Lignes:mnemo, whichever available;
- Target.geometry: matches SNCF1:(latitude,longitude), SNCF2*:geometry:point,
- Target.insee: present in Insee-geo or Insee-new datasets, is primary key for communes, and must be retrieved for a gare, by identifying which commune verifies Point_in_Polygon(geometry(gare), geometry(commune));
- Target.nom: matches SNCF2:commune, would rather be retrieved via Target.insee;
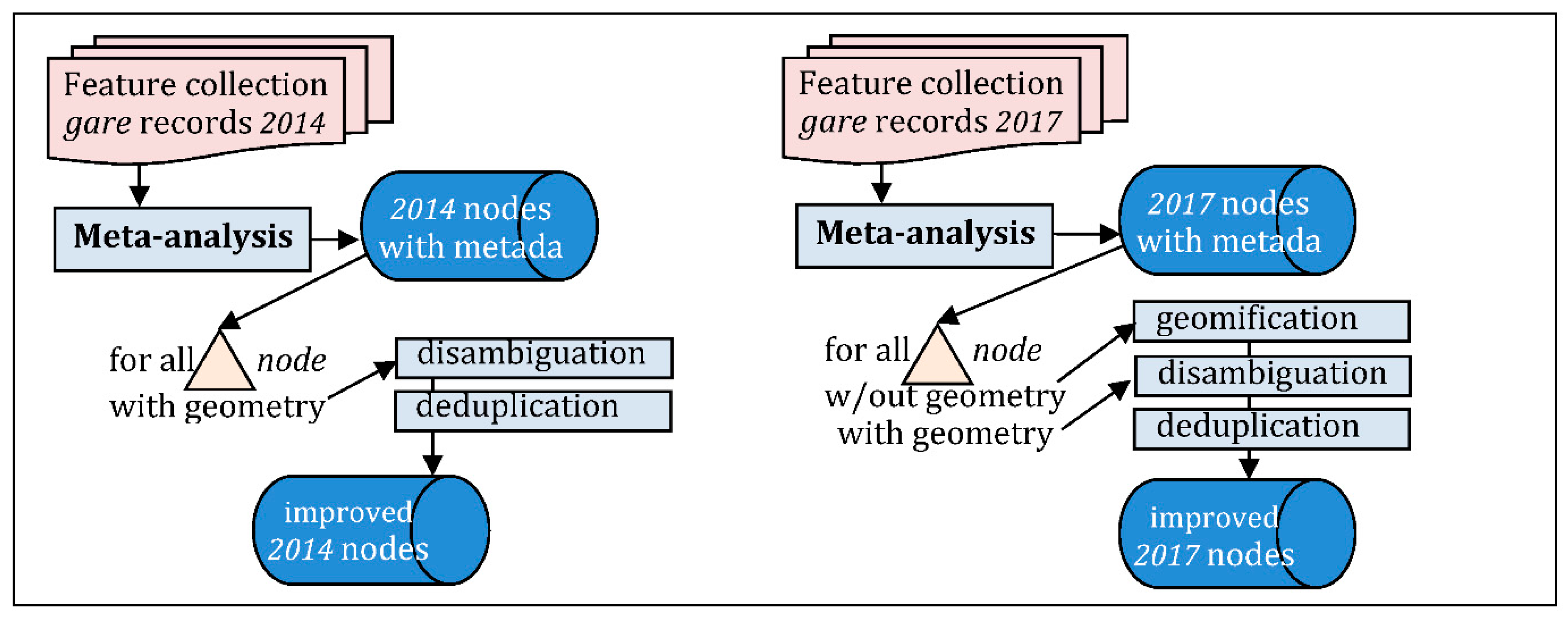
2.3. Meta-Analysis of Public Sources, Building a Similarity Measure, and Corrections
2.3.1. Meta-Analysis of Each Dataset, and Comparison
- Step 1: univariate meta-analysis with num and label values. Result: each node has a num and a label value, in both 2014 and 2017, what fulfills the target first requirement. All 6442 nodes have a geometry in 2014, but only 6812 nodes have a geometry in 2017.
- Step 2: multivariate meta-analysis with uic, label, and (uic-label) values: 2017 only.
- Step 3: multivariate meta-analysis with (label-num) and (uic-num) couples
- Step 4: inspect the geometry of Step3 couples: if a same label or uic occurs in several nodes, it denotes a junction-gare (=uic, ≠num). Associated geometryare expected to be equal: the computed deviation is broken down into five distance intervals (Table 4).
- Step 5: inspect the cardinal of Step3 couples, for every num value: thisgives the number of nodes per ligne (Table 5).
2.3.2. Conclusion of the Meta-Analysis
2.4. Combining the Available Sources: The Fusion/Revision Problem
2.4.1. Knowledge Representation and Measure of Similarity
- (a)
- and () quantify num, label, geometry for both x and y, into the [0, 1] interval;
- (b)
- is qualitative (true/false: 1/0). Checking equality on slug(label) rather than on label;
- (c)
- uses threshold values D1and D2, () uses D3 and D4, whichmeans that dissimilarity is not the complement of the similarity measure.
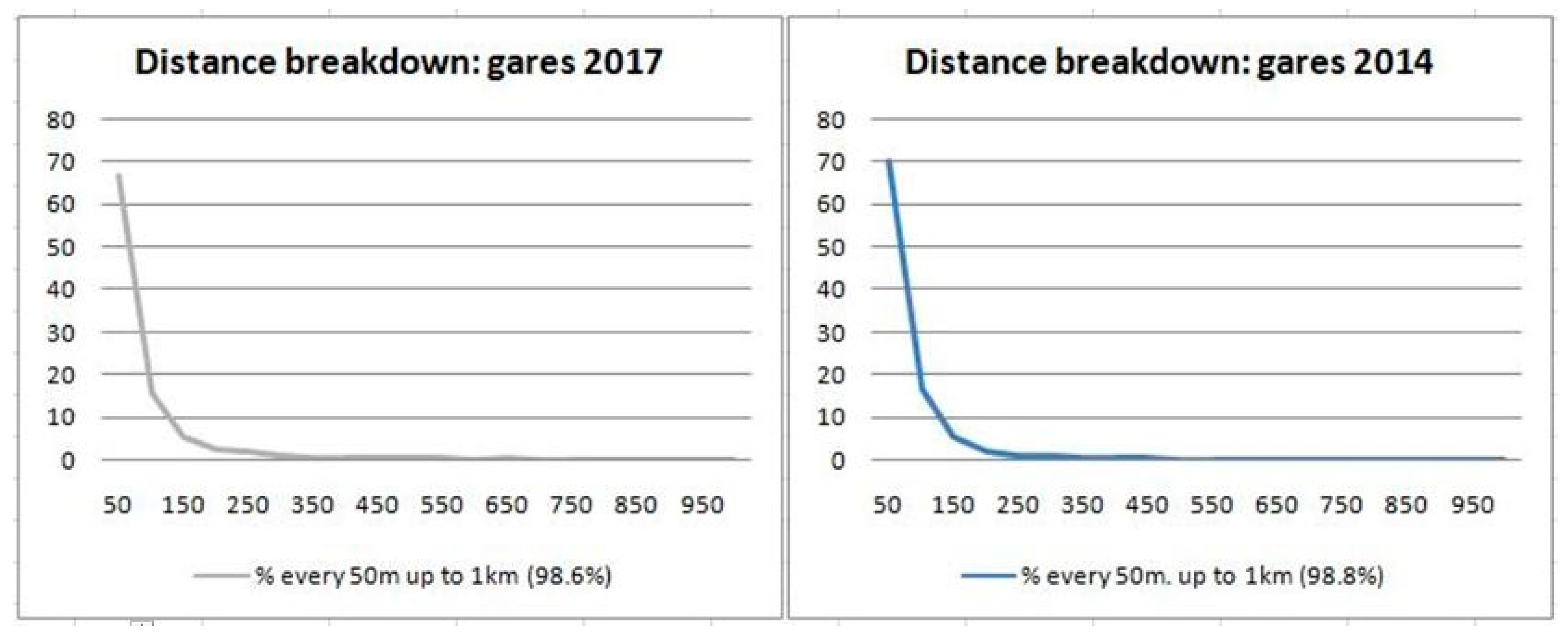
- the number of directpairs (left) decreases rapidly up to 150 m (88%), and slows down after 300 m (93%); and for reversepairs (right): 92% at 150 m, 96% at 300 m;
- both kinds of pair are less than 1.5% after 1 km; and only a few after 2 km.
2.4.2. Decision to Include a Node in the Similarity Neighborhood
- α means: at least % of the nodes of V(x) must be in Ci
- (a)
- rules are independent of the actual knowledge in the knowledge base;
- (b)
- rules are not restricted to the conceptual schema representation.
- 2017-node: f + {“tag”:tag(f), “dist”:dist(f,g′), “closest”:link_to-2014(g′)}
- 2014-node: g + {“tag”:tag(g), “dist”:dist(g,f′), “closest”:link_to-2017(f′)}
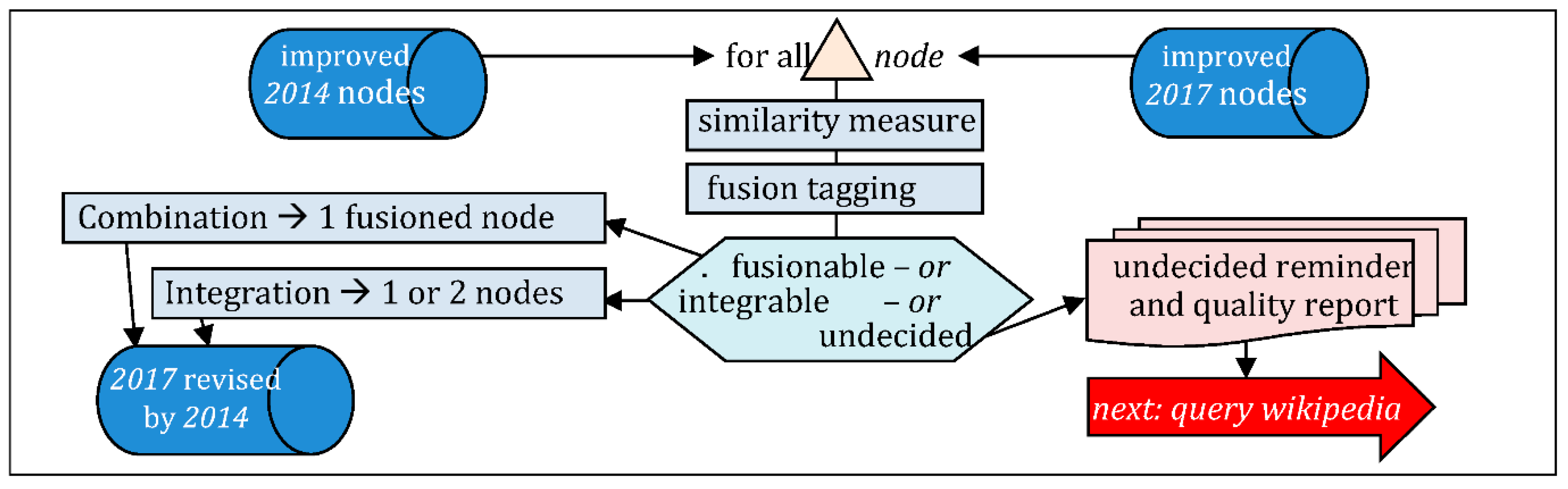
- fusionable: means that the node and its counterpart (closest is ok) are supposed to inform the same real gare and we can proceed with the fusion of their data;
- integrable: means that the node has no counterpart (closest is irrelevant) and can be kept as is (if in the right set), or adapted for integration (if from the other set).
- -
- direct revision:
- -
- reverse revision (for integration of “forgotten nodes”):

2.4.3. Fusion Combination, Integration, Revision and Conclusion
- -
- nature: which can be translated into a capa value (though losing some specificity).
- -
- geometry: the maximal distance being D2, use 2017 coordinates;
- -
- info: add approximation info about geometry (depending on dist).
- -
- geometry: straightforward, use 2014 coordinates;
- -
- nature: translate into a capa value (rather easy);
- -
- km: seek for the closest 2 nodeson the same ligne, then interpolate a value;
- -
- uic: build a unique code using numand km;
- -
- info: add uncertainty info about km and uic.
- -
- Software fusion is safe (6415 AP + PP tags = almost no false positives);
- -
- Software integration is safe (74 AN + PN tags = almost no false negatives).
- -
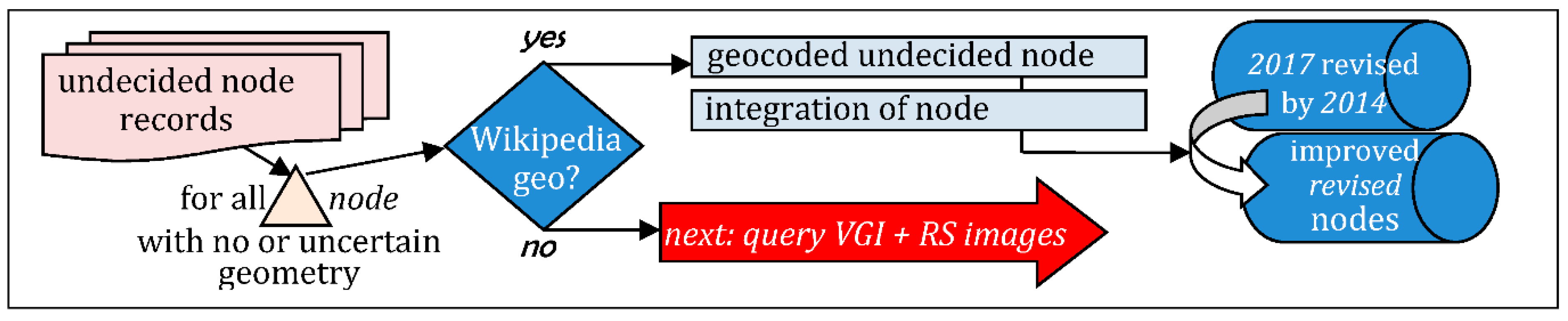
- The remaining 250 nodesfrom 2014 and 564 from 2017 for which the fusion decision is too uncertain, plus 718 with no geometry, from 2017are in total 1532.
- -
- 6489 nodes have been qualified;
- -
- 1532 nodes (label-num-km) -i.e.,: about 950 gares− can be confronted to VGI and remote sensing imagery for setting a controlled geometry.
3. Materials and Methods Part 2: Voluntary Geographic Information (VGI) Data Integration and Control
3.1. Gathering Information from Wikipedia Railway Specific Pages
3.1.1. Extracting Coordinates from Wikipedia
3.1.2. Extracting Semantic Information Using Wikipedia’s Infobox
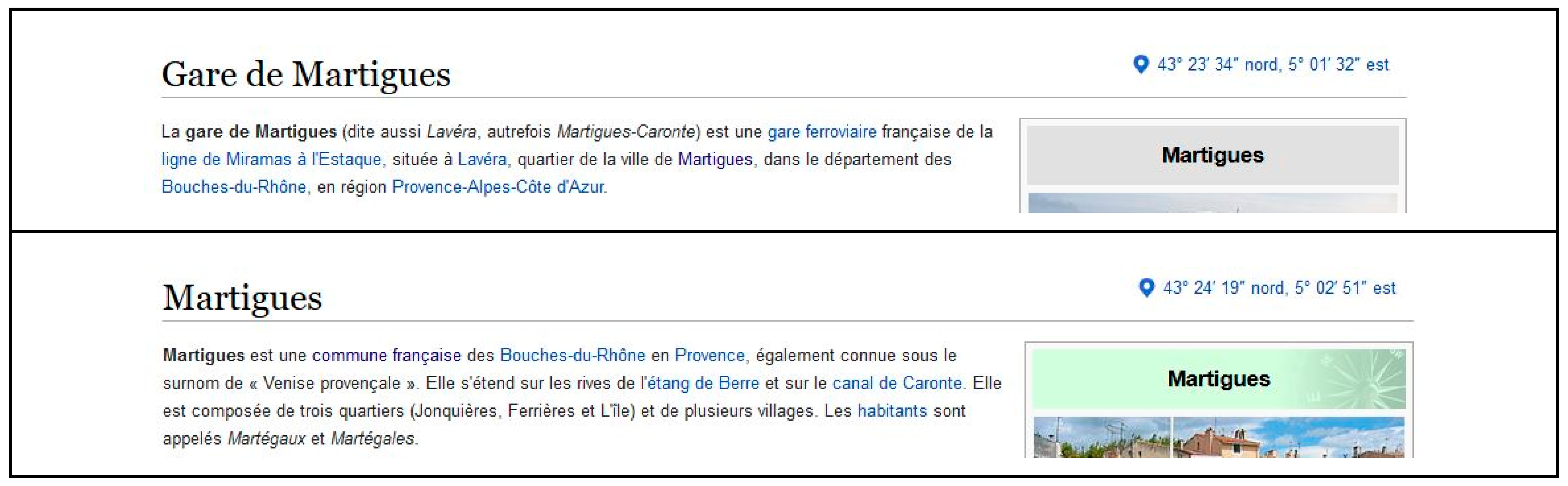
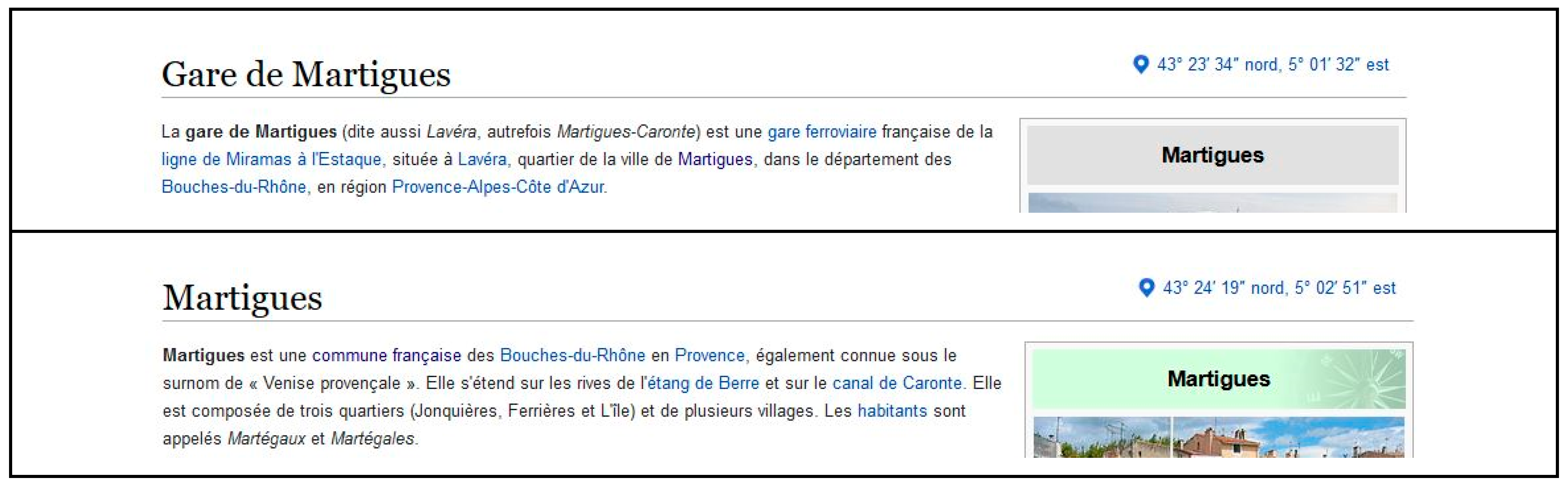
- commune:{{Infobox Commune de France}} contains coordinates, insee and more (Figure 7);
- gare: {{Infobox Gare …}}, contains coordinates, nom of the including commune, all or some of the lignes that connect to that gare (Figure 8).
- ligne:{{Infobox Ligne ferroviaire …}} see next Section 3.1.3.
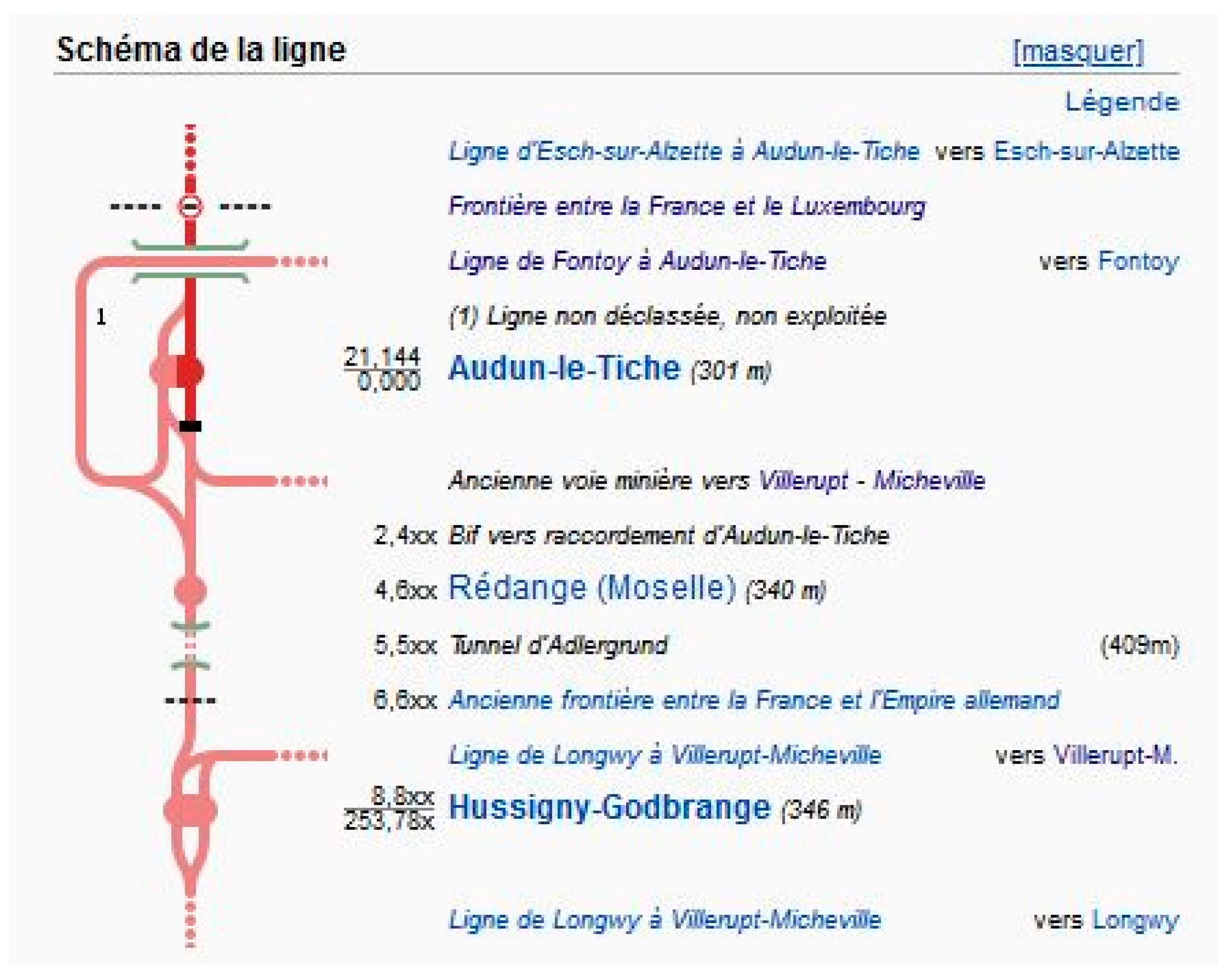
3.1.3. Extracting Data for all the Garesof a Same Ligne: The Routemap Semantics
- the Infobox BS-table complies with Modèles/BS, whose syntax is somewhat tricky, but was parsed successfully in most cases: only a few code failures, hard to overcome, have been met. Figure 10 illustrates a simple case of {{BS-table}}, code and result.
- The other difficulty is to deal with the cascade of asynchronous Internet requests for processing a single line.
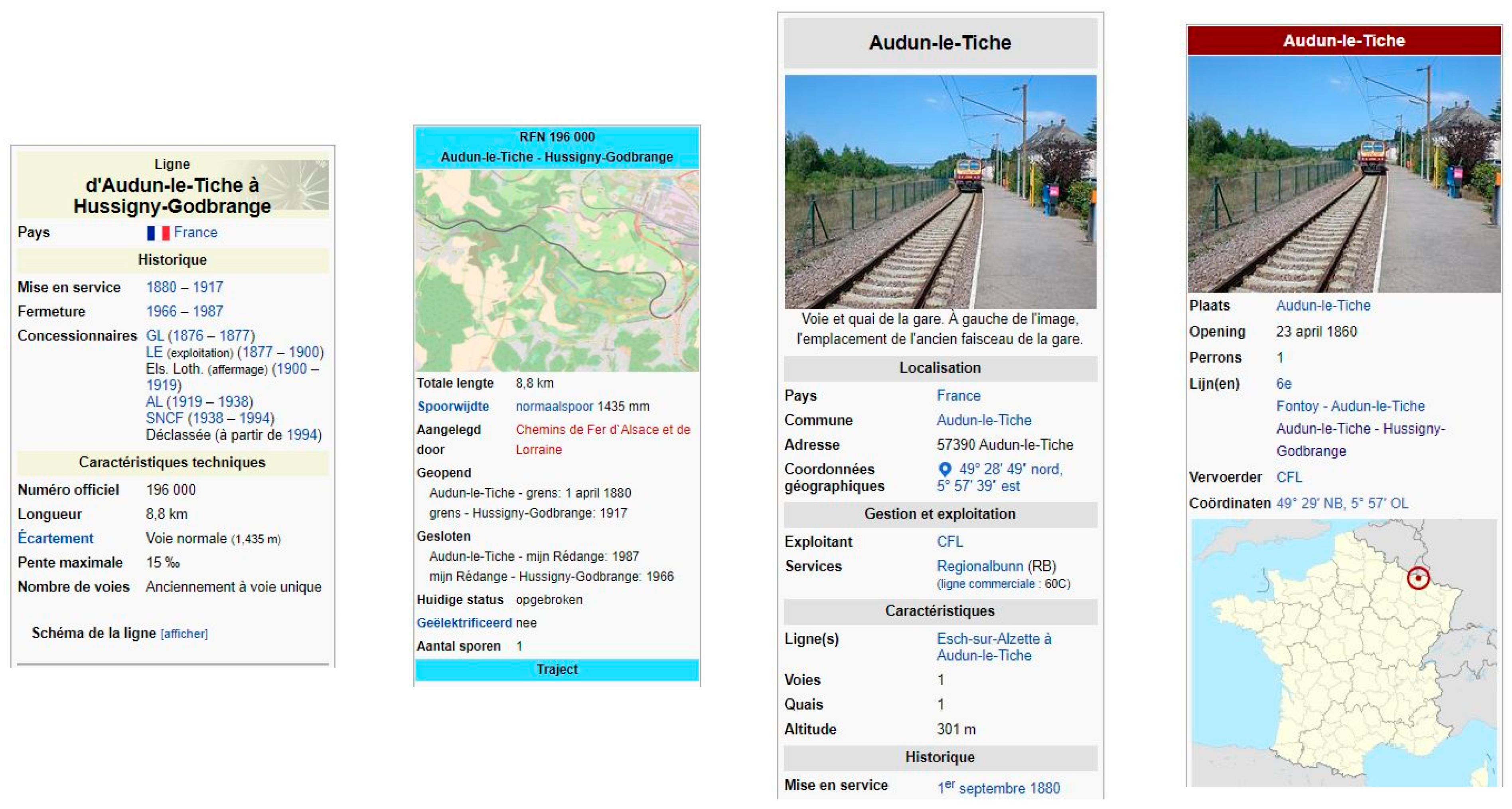
- num is in the Infobox main part (Infobox attribute numéro = 196,000);
- label, kmare in the BS-table, and km can be interpolated, if absent;
- nom is often given (if differing from label), insee must be determined later;
- geometry is null, but can be seekon ‘Gare d’Audun-le-Tiche’, ‘Gare de Rédange’, etc.
3.2. Gathering Information from VGI Pages
- -
- First step(a): identifying the existence of a gare onto a ligne;
- -
- Last step(d): obtaining coordinates data.
- “ligne A to B has such characteristics, and comprises: gare1, gare2 ... ”,
- The challenge is then to code a “parser” that delivers a list of nodes such as:
- {label:“A”, num:“AtoBcode”, km:“0”, info:“origin of A to B, characteristics“}
- {label:“gare1_name”, num:“AtoBcode”, km:“somerank information, or 1”}
- {label:“gare2_name”, num:“AtoBcode”, km:“somerank information, or 2”}
- …
- {label:“B”, num:“AtoBcode”, km:“max = length, or max rank”, info: “terminus”}
3.2.1. HTML-Style Tables
- is there a relevant key in that table? (e.g., num, insee, label?).
- visual: make a decision about relevance;
- manual: copy and paste the table text into a spreadsheet; convert into CSV format;
- software: fetch CSV file; join objects with routine mergeLigneInfo (Appendix A).
3.2.2. Coordinates Lists (Polyline for a Ligne) in Google KML or GPX Format
- manual: export the ligne data into KML format (from the Google page);
- software: convert into geojson, and if the gare is individualized: add it directly, or:
- manual: copy and paste the relevant geojson of the ligne;
3.2.3. Simple Lists of gares in Plain Text
- manual: copy-paste the text into a string constant;
- software: check if that ligne is already documented, or add a new ligne number num.
3.3. Remote-Sensing Information for the Assisted Visual Geocoding of Gares
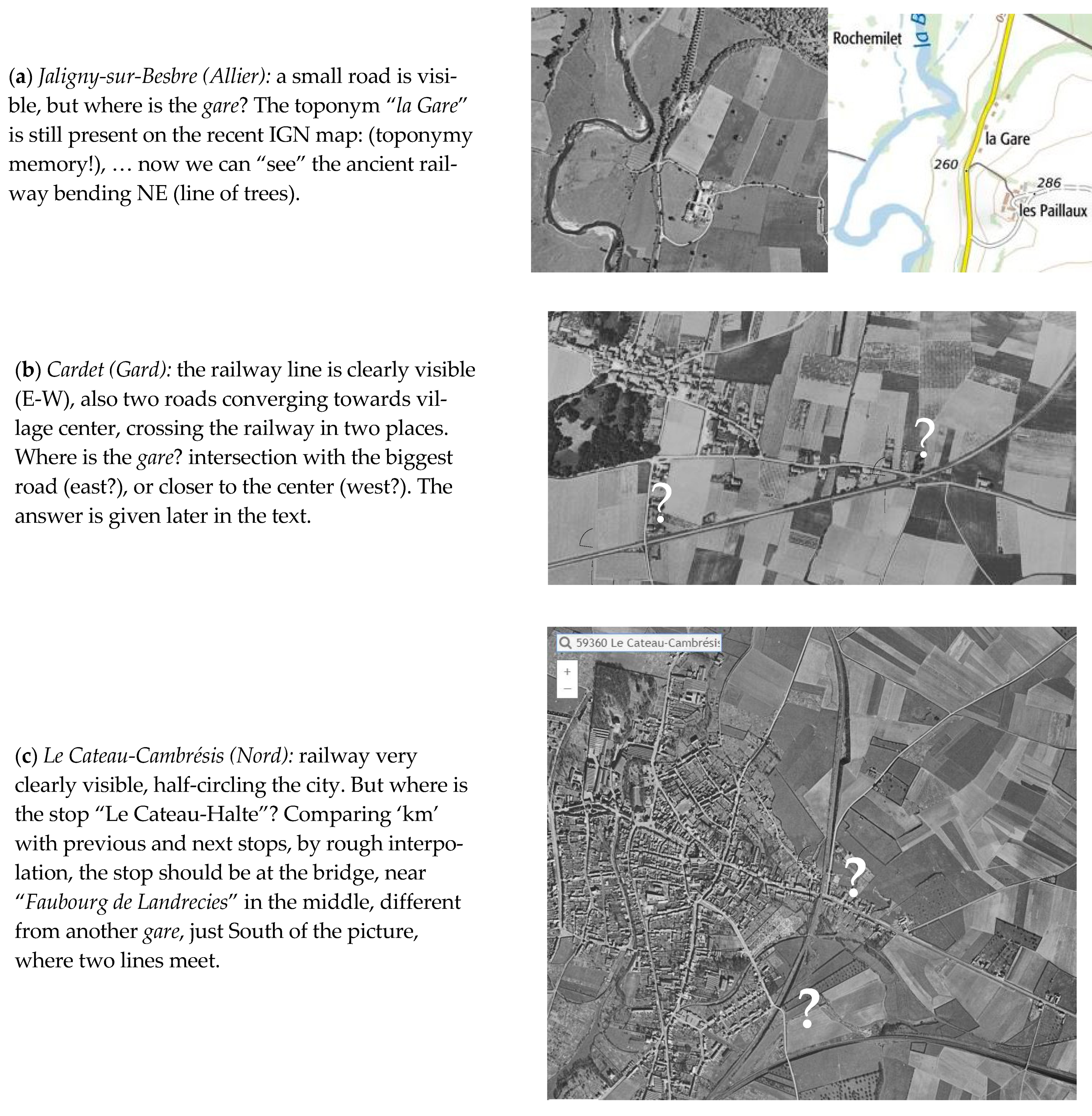
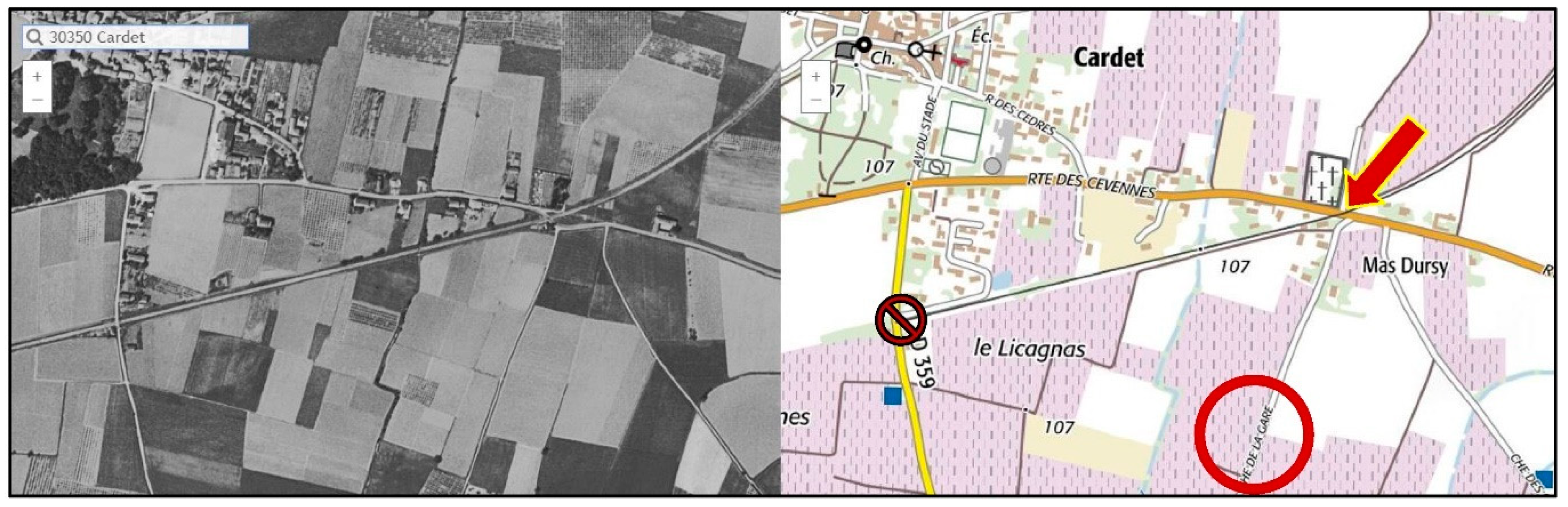
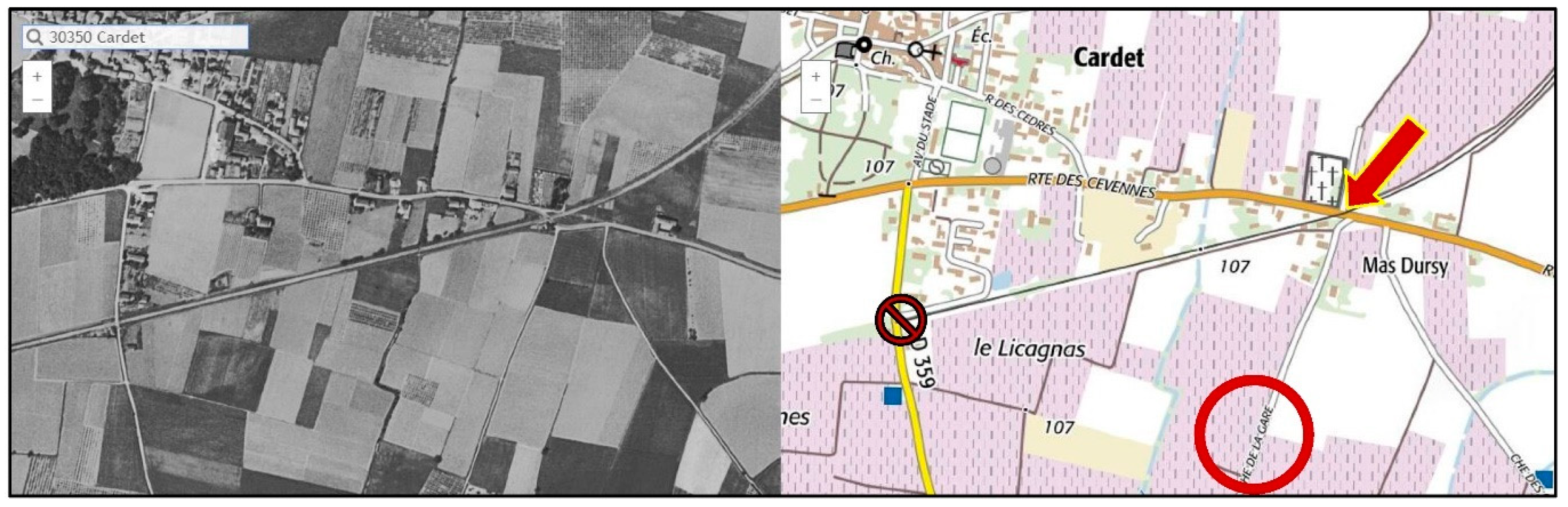
- (1) software: use a geocoder API (e.g., Google), querying coordinates for: French word “gare” + label. For instance, with Cardet (Gard), we can try a few query variants (Table 14). It is impossible to know which query will give the best answer (distance data have been added in Table 14, only after visual inspection);
- (2) manual/visual: use any approximation, or skip first step, and input the toponym into an online map facility providing, preferably ancient, maps and aerial photos.
- Today (2016–2018): Aerial image (≈1 m resolution), Vector cartography (≈1/10,000)
- Past (1947–1960): Aerial image (≈10 m resolution), Digitized map (≈1/25,000)
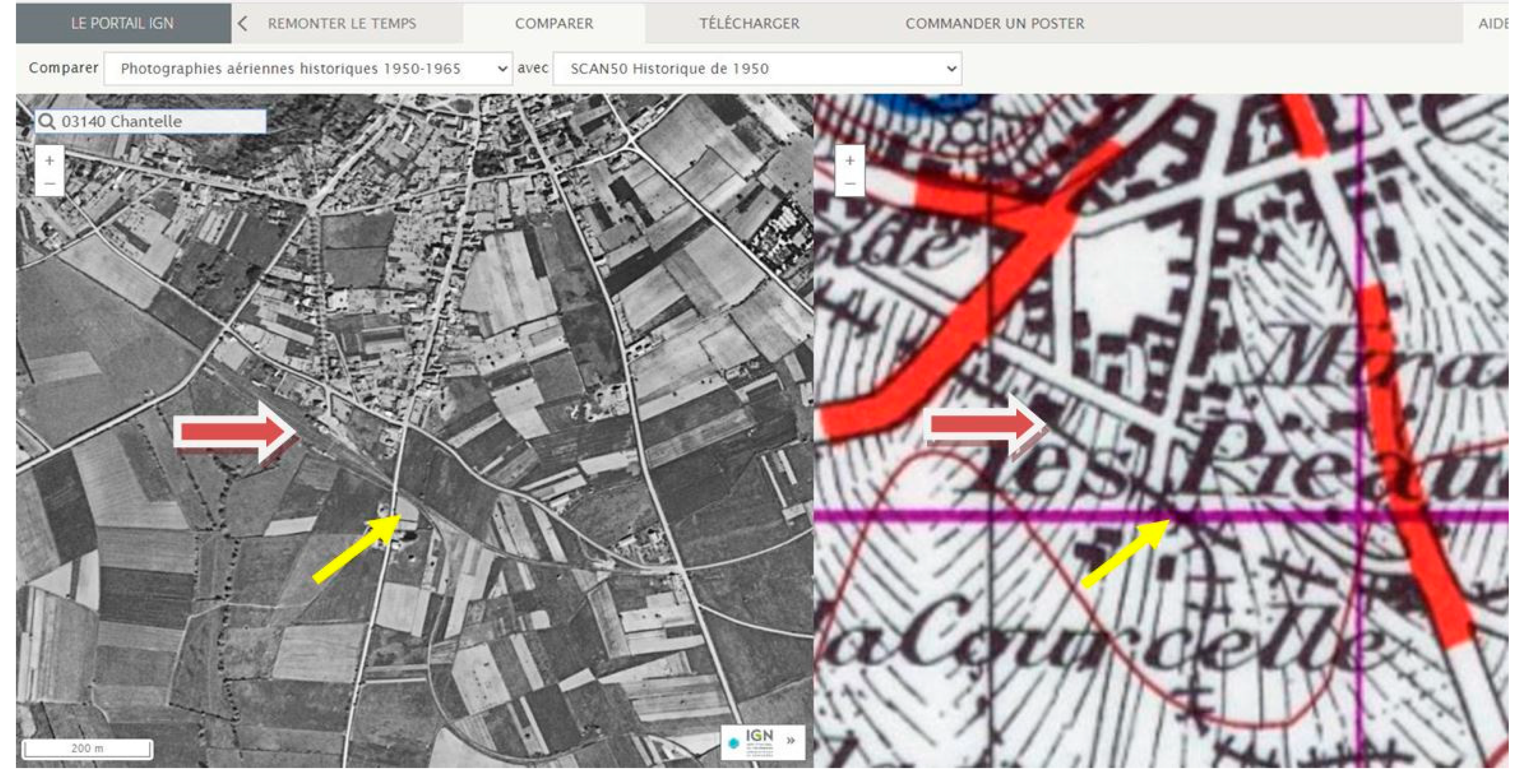
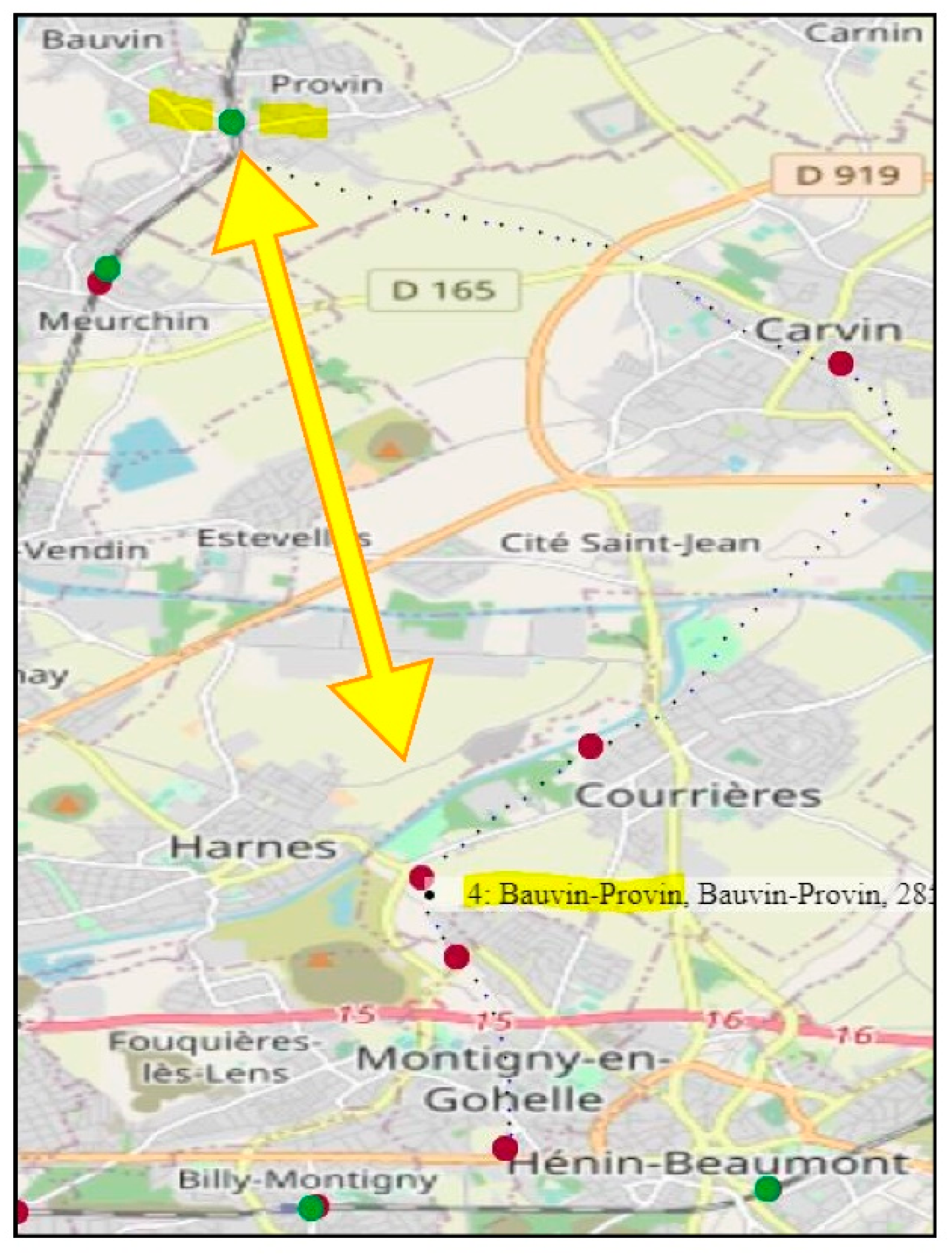
3.3.1. Dual Use of the Website RemonterLeTemps, (a) Direct Geocoding of Toponyms
- software: generate URI using routine checkToponymAt;
- visual: start with an intermediate zoom (e.g., z = 16) and focus on the section where the line is expected to reach the commune (e.g., SW corner);
- visual: inspect map-aerial photo combinations, focus on road-rail intersections;
- manual: input back coordinates into geometry of the gare.
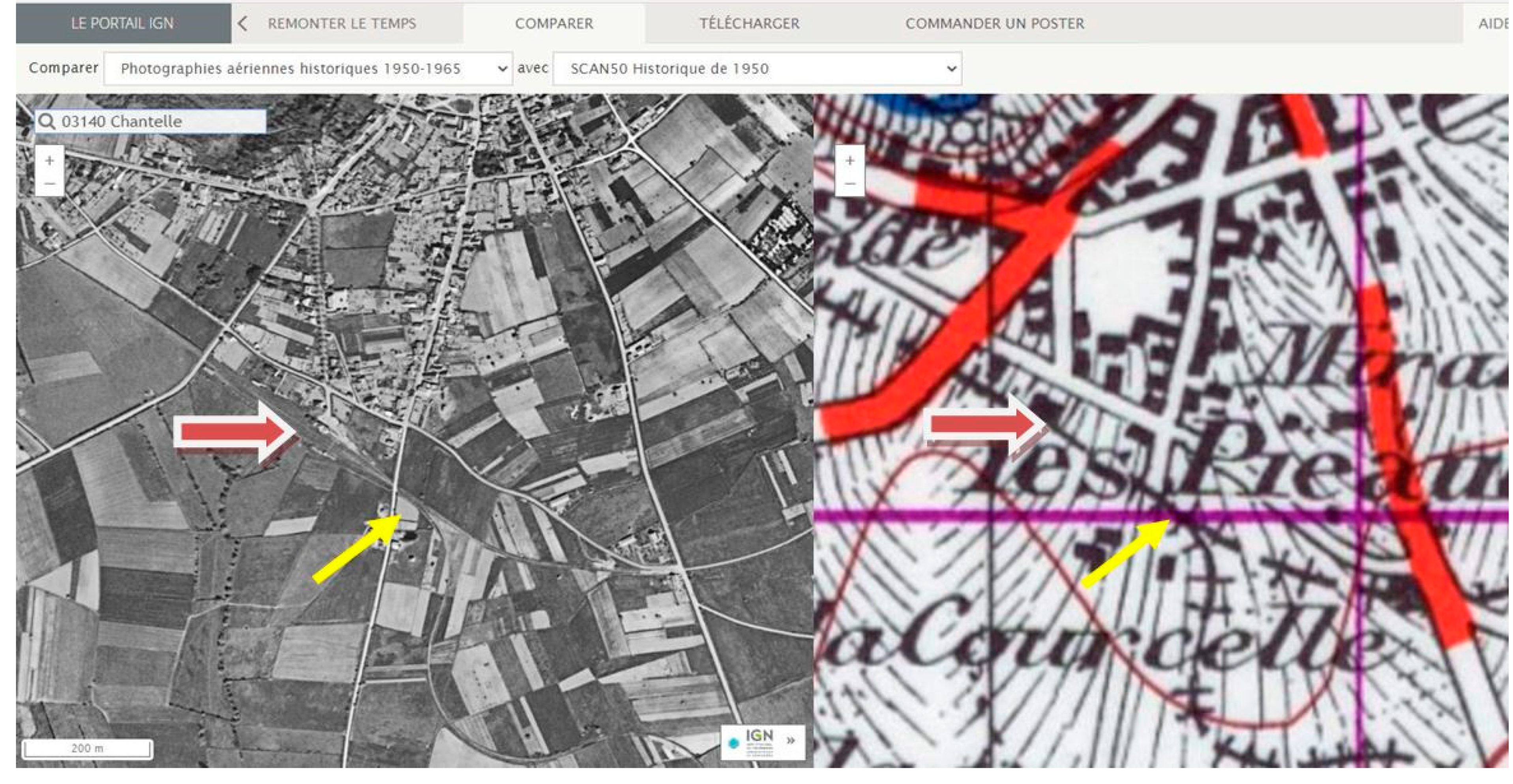
3.3.2. Dual Use of the Website RemonterLeTemps: (b) Visual Reverse-Geocoding
- software: generate URI using routine checkGeocodeAt (Annex), cross-check with a geocoder, to get commune name;
- visual: start with a high zoom (e.g., 19), and inspect map-aerial photo combinations, zoom-out to get neighbor toponyms (railway terminology may appear);
- manual: confirm, or infirm, the quality of the information for that node.
3.3.3. Hints for Alternatives
4. Results: The Overall Procedure, the Reconstructed Network, and Its Quality Control
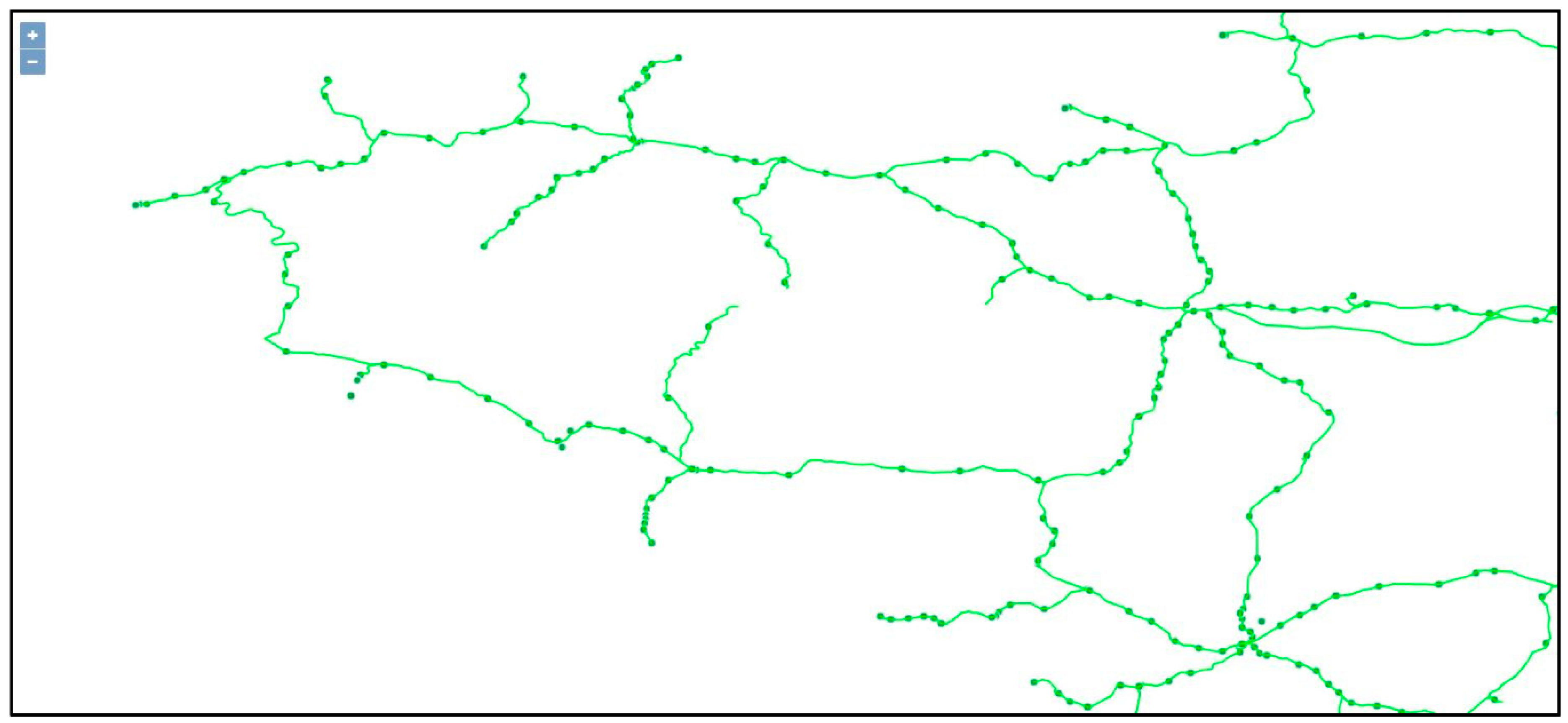
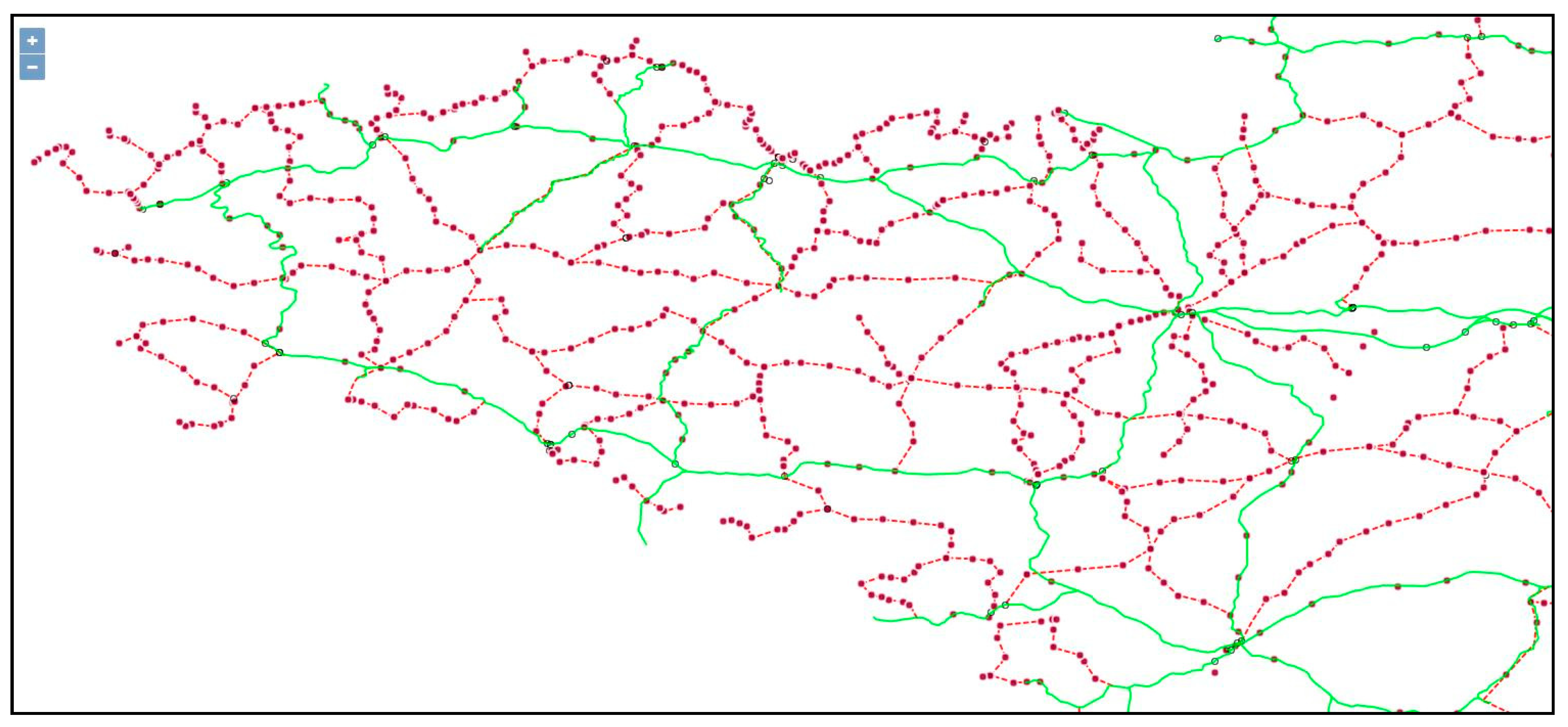
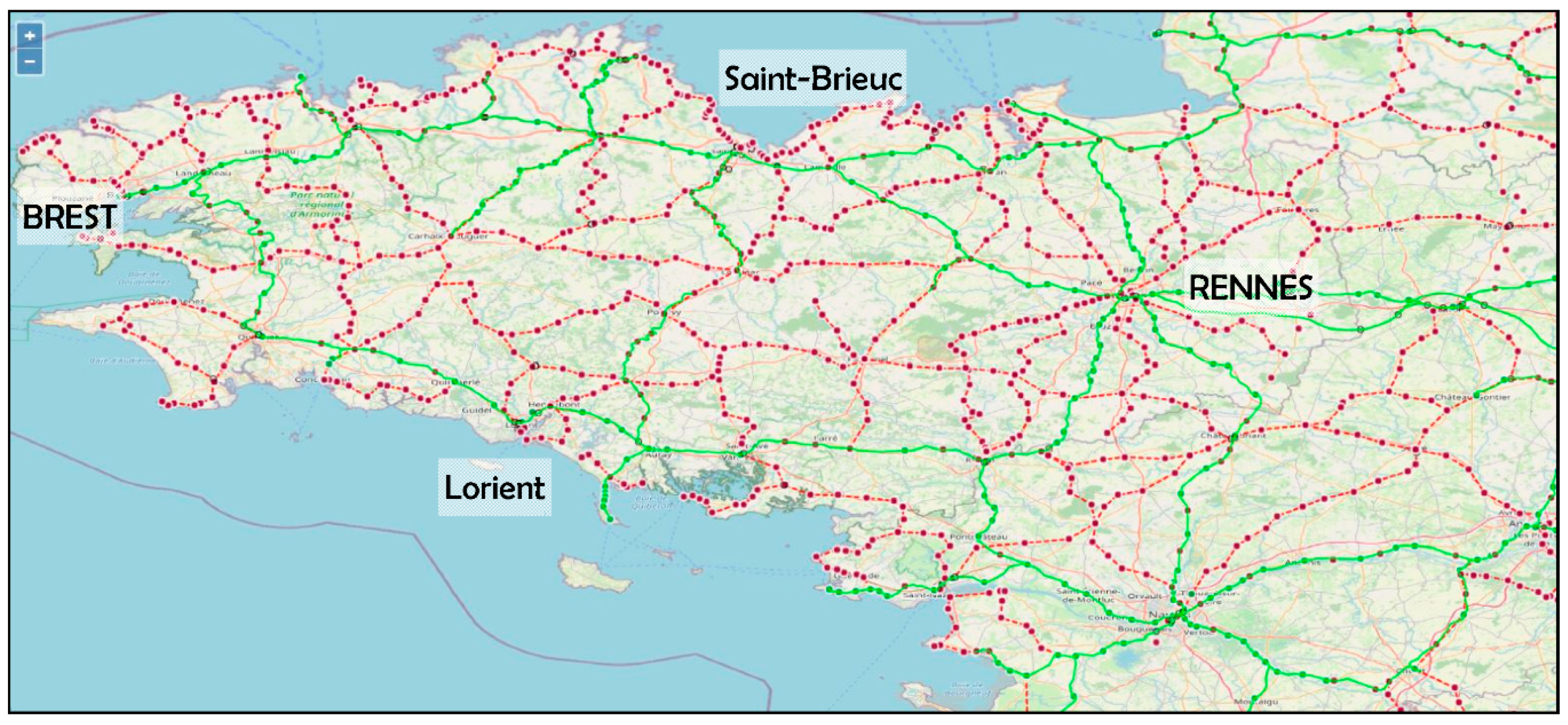
- the dataset “CARP” of French gares, over the 1920–2020 time span;
- the developed routines combined in a computer-assisted reconstruction procedure;
- quality controls increase confidence, or point out odd/missing data, to be fixed later.
4.1. The Reconstruted Network (CARP)
Displaying the CARP Dataset
- label disparity due to change between dates: the toponym-pattern (Appendix B.1);
- geometry deviation, due to network evolution and “fork-pattern” (Appendix B.2).
4.2. The Computer-Assisted Reconstruction Procedure for Past Railway Stations
4.2.1. The Generic Procedure for Reconstruction from Public Datasets: CARP-Main
- Meta-analysis (Figure 18): production of metadata, counting missing attributes, checking constraints (e.g., uniqueness), correction of ambiguities and duplicates, possibly completing some geometry, per-node addition of quality information;
- Three-steps fusion: similarity–measure, fusion–decision, attribute–combination (Figure 19), whichyields the revised dataset (=6489 nodes), plus dataset of remaining undecidednodes, i.e.,: no geometry (718), or too uncertain (250 in 2014, 564 in 2017);
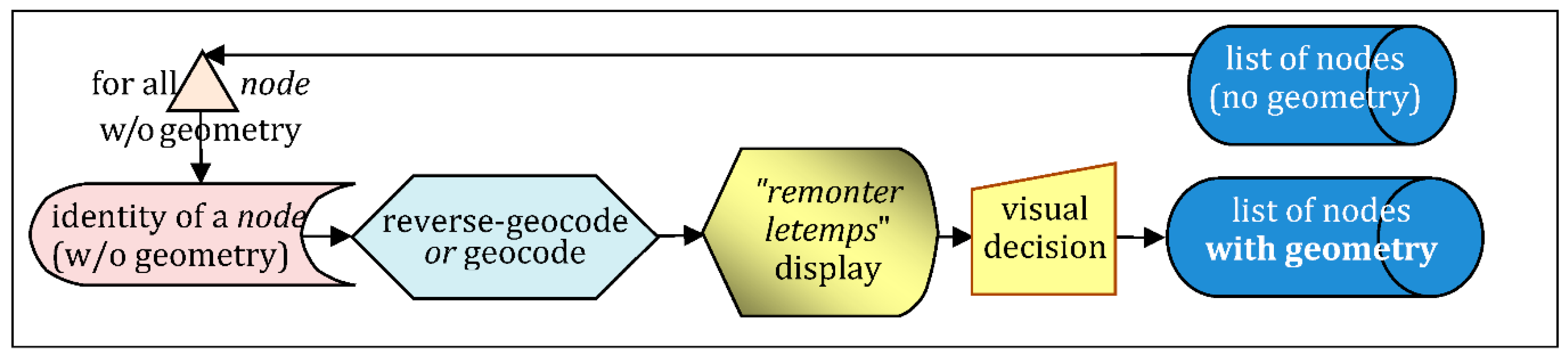
- Quest for geometry of undecided nodes (Figure 20), using Wikipedia or any direct geocoder, to get gare coordinates: it helped to integrate about 400 additional nodes;
- Visual inspection of Remote Sensing/old maps, for final improvements: it gave about 600 additional nodes originally in public datasets but without geometry (Figure 21).
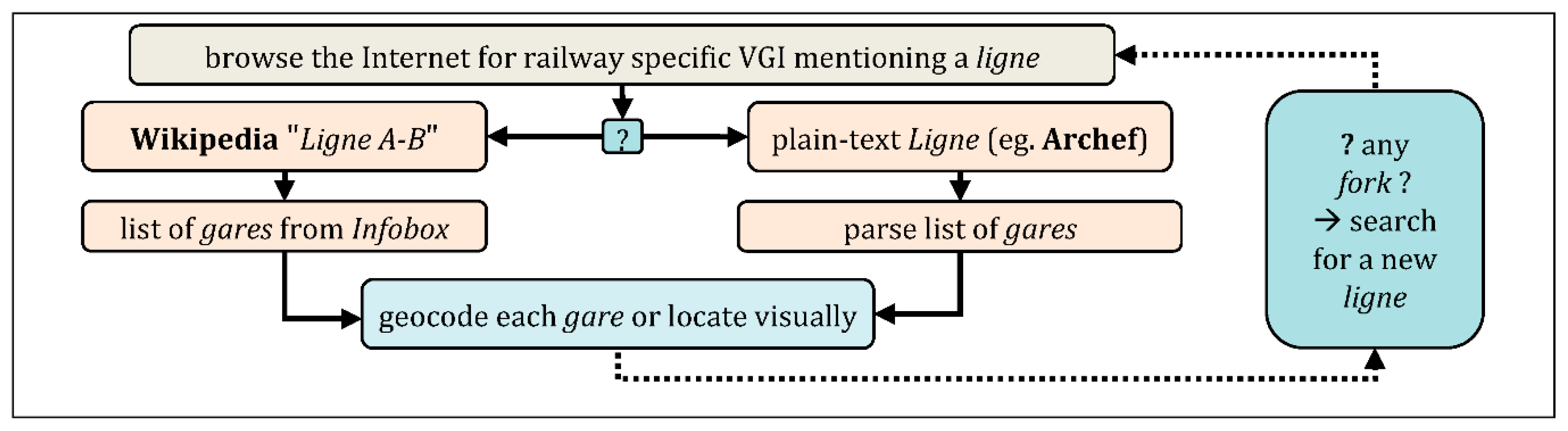
4.2.2. Addition of New Lignesand Gares, from VGI
- (a)
- from a ligne: list of nodes (routines executed on the server):f[i] = {“label”:”l”, “num”:”n”, “km”:”k”, “info”:”…”}, “geometry”:null;
- (b)
- f[i].geometry = {“type”:”Point”, “coordinates”:[lon,lat]};
- (c)
- for each node with geometry (Figure 23), check nom and insee, check km strict order, check label uniqueness in CARP dataset, check geometry deviation if a gare of the same label exists already. Report control result in info:{f[i].nom, f[i].insee} = getCommuneFromPoint(f[i].geometry?.coordinates);f[i].info += “ (commune_ok | commune_inconsistent) (km_checked) …”;The dataset built at this step is named “CARP-VGI”.
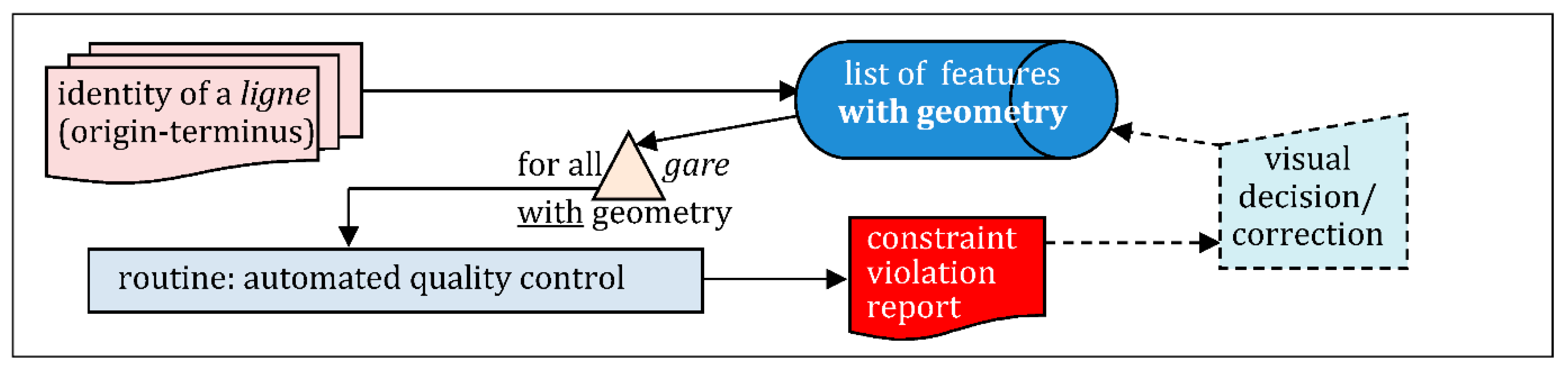
4.3. Posterior Quality Control, Revealing Additional Errors
4.3.1. Enacting Quality through Constraint Checking
- a gare has a label, a num, and a km, identifying it and the ligne to which it belongs;
- all gares sharing the same num, have their km in strict increasing order, from the gare tagged origin to the gare tagged terminus, what means at least two gares per ligne;
- a gare with an inseecommune code, has its geometry-point inside the geometry-polygon of that commune; every gare located in France can receive an inseecommune code;
- a garelabel is consistent with its communenom and insee. Quite often a label is the name of an existing commune (sometimes 2 communes names).
- {“label”:”Lézan”, “nom”:”Lézan”, …“coordinates”:[4.11488, 44.04241]},
4.3.2. A Posteriori Control of the Reconstructed Network
5. Discussion
5.1. Theoretical Issues in Building a Comprehensive Dataset from Internet Sources
5.1.1. Data Representation and Standards; Interoperability; Data Visualization; Issues in the Development of Tools
5.1.2. Data Quantity; Computation Intensivity
5.1.3. Data Quality; Version Control
- -
- Attribute accuracy: label (cf. both toponym-pattern and fork-pattern);
- -
- Logical consistency e.g., label, uic and (num,km) consistency (cf. ambiguities, duplicates);
- -
- Completeness: e.g., creating missing km by interpolation;
- -
- Positional accuracy: cf. fork pattern, computer-assisted visual geocoding;
- -
- Time period and contemporaneousness: e.g., comparing capa/gare with mnemo and validTo/ligne.
- -
- the evolution of the CARP dataset: a Git-type solution would improve it;
- -
- the lineage of data used in setting attribute values. Some retrospective information could be retrieved, partially, for that lineage mixes software and non-reproducible manual steps.
5.1.4. Data Availability; Data Access; Security
5.2. A Dataset for Further Social Sciences Studies
- nodes: +56%, lignes (≠num): +30%, communes (≠insee): +39%.
5.3. Similar Past Railway Network Reconstruction for European Countries
- and
5.4. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Code Description for Routines Mentioned in the Text

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| const metaAnalysis = (ff) => { /* maps nodes by same value of single attribute: (f.properties[key] = v) or couples of attributes: [k1,k2] with (v,w) */ }; metaAnalysis(gares); // analyzes quality based on keys and values |
| const disDuplicate /* marks “duplicate”= to be removed / to be kept */ gares.map(f =>disDuplicate(f)) |
| const slugify = (lib) => { /* light version, more rules may apply */ const dia = “éèêàâ...”, nodia = “eeeaa...”; /* diachritics */ lib.replace(“St-”,”Saint-”); /* also:“Ste-”,”Sainte-” */ lib = lib.toLowerCase(lib); dia.split().forEach((x,i) =>lib.replace(x,nodia[i]) /* removes */ return lib;} const similName = (fp, gp) => slugify(fp.label) == slugify(gp.label); |
| const disAmbiguous /* adds the correct department, marks “disambig” */ gares.map(f =>disAmbiguous(f)); |
| const sameuic = (uicf) => /* lists nodes whose uic = uicf, with geometry */ const bestgeo /* choose best geometry among list, or null */ const geom_ify /* if(bestgeo(list)) return (f.geometry = geo) or void */ gares.filter(hasGeometry).map(f =>geom_ify(f, sameuic(f.properties.uic)); |
| const uniques = (ff) => /* array of nodes whose num is unique */ const checkIsolated = (f,ff) => { const garesOnNum = (ff,num) =>ff.filter(f =>f.properties.num == num); const is_closest = (f,g,cum) => /* returns g, or cum, if closest to f */ const getClosest /* extracts: is_closest(f,g,cum) for each node */ f.properties.unic = getClosest(f, garesOnNum(ff, num)); return f;} uniques(ff).map(f =>checkIsolated (f,ff)); |
| const closestNode /* gets: closest node to f (f,old,new) */ const breaks = [ D1, D2, D3, D4, Infinity]; /* thresholds */ const pos = [“AP”,”PP”,”und”,”und”,”SN”], neg = [”SP”,”und”,”und”,“PN”,”AN”]; const dd = /* geographic “greatCircle distance” in meters */ const tt = /* starts with “und”, then update tag[i] depending on: similar label and rank in breaks[i-1] */ const fusionTags /* returns {fuse: tt; dist: dd; closest: closestNode } */ const garesA = fetch(“A_dataset”), garesB = fetch(“B_dataset”); garesB.filter(hasGeometry).map(f =>fusionTags (f,closestNode(f,garesA))); |
| /* Wikipedia English sites postfix any toponym N →N_railway_station, French sites have a variety, e.g.,: Gare_de_Martigues, Gare_d’Audun, Gare_des_Aubrais, Gare_du_Havre ... */ const prefix = [Gare_de_, Gare_d’, Gare_des_, Gare_du_]; const prefixWithGare = N => prefix[correctIndexOf(N)] + articleRemoved(N); |
| const Q1 =“.../api.php?action=query&prop=coordinates&format=json&titles=“; const ccOf /* get coordinates */ const ggOf = (cc,k) => cc? ({“coordinates”: cc, ”quality”:k}): null; const P1 = fetch(encodeURI(Q1 + prefixWithGare(topon)) .then(a =>a.json()).then(b => !b.contains(“missing”)? ggOf(ccOf(b.query.pages),”ok”): fetch(encodeURI(Q1 + topon)) // no prefix .then(a =>a.json().then(b =>ggOf(ccOf(b.query.pages),”approx”)); /* then use that promise P1 in combination with other promises */ |
| const Q2 = Q1.replace(“prop=coordinates”, “prop=revisions&rvslots=*&rvprop=content&formatversion=2”); const boxOf = json =>json.query.pages[0]?.revisions[0]?.slots?.main?.content; const addItem /* seek for item in boxOf */ const parseBox = (box, list) => box &&list&&list.length> 0 && list.reduce((acc,x) =>addItem(acc,x,box), {}) || ({“missing”:true}); const P2 = fetch(encodeURI(Q2 + topon)).then(a =>a.json) .then (b => parseBox(boxOf(b), [“latitude”, “longitude”, “insee”, “lignes” /* and as many as available */ ]); |
| const A = “URI_of_LignesSNCF”, B = “URI_of_CSV_file”; function CSV2Json(txt) /* returns JSON from CSV [{num, enddate},..] */ function mergeLigneInfo(a, b){ const match = (s,r) => r.enddate? (s.enddate= r.enddate&& s): s; return a.map(s => match(s, b.find(r =>r.num === s.num)[0])) } const P3 = Promise.all([fetch(A).then(a=>a.json()), fetch(B).then(a=>a.text()).then(CSV2Json)]) .then(([a,b])=> mergeLigneInfo(a,b)) |
| const SST = ‘semi_structured_text‘, Q2 = “cf A.10”, num = “unique_number”; function prefixLigne (A,B) { /* returns “Ligne_de_A_à_B” …*/ } function SSTtoJSON /* returns {origin, terminus, length, gares} from SST */ function stationsAlongLine (json, num) { const km = /* interpolates km according to length and rank */ const info = /* sets: “origin” or “terminus” or ... */ const properties = {“label”:json.gares[i], num, km, info}; return json.gares.map((s,i,t) => ({properties, “geometry”:null}); } const json = SSTtoJSON(SST); /* check if line exists, apply wikiBSTable, or stationsAlongLine */ fetch(Q2 + prefixLigne(json.origin, json.terminus))).then(a =>a.json()) .then(b => wikiBSTable(boxOf(b)), /* resolve with Routine */ b =>stationsAlongLine (json, num)); /* process the reject */ |
| /* GEO-LOCATION: open a window with RLT around toponym location – if found */ const RLT = “https://remonterletemps.ign.fr/comparer/basic?mode=doubleMap” + “&layer1=ORTHOIMAGERY.ORTHOPHOTOS.1950-1965” + “&layer2=GEOGRAPHICALGRIDSYSTEMS.MAPS.SCAN-EXPRESS.STANDARD”; /* then locate visualy */ |
| /* REVERSE GEO-LOCATION: open window at mkURI(lon,lat) */ const RLT = “as above”; const nom = reverseGeocode(lon,lat); // fromany online geocoder (or via API) const mkURI = (x,y) => RLT + “&x=“+x +”&y=“+y +”&z=20”; /* then locate visualy */ |
| /* const Q2, constboxOf(json) from A.10 */ function prefixLigne (A,B) /* returns “Ligne_de_A_à_B” or “Ligne_d’A …*/ function parseBStable(box){ /* get relevant items using parseBox(box, itemlist) */ const share = parseBox(box, [“num”, …, “schema”, “schema2”]); if(share.missing) return null; // page doesn’texist if(share.schema) return processBStable(share.schema); if(share.schema2) /* thereis an indirection to another page */ returnfetch(schema2).then(a =>a.json()).then(processBStable); //recursion! } constlineName = prefixWithLigne(“Audun-le-Tiche”, “Hussigny-Godbrange”); const P3 = fetch(encodeURI(Q2 + lineName)).then(a =>a.json()) .then(b =>parseBStable(boxOf(b)), b =>reject (b, “some comment”)); |
Appendix B. The Toponym-Pattern, the Fork-Pattern, and Graph Representation Issues
Appendix B.1. Revealing “Toponym-Patterns” from Suspect Fusion Examples
- accents: e.g., Benauge is sometimes recorded with an accent Bénauge;
- abbreviations: e.g., St-Paul instead of Saint-Paul;
- non-standard way of associating two names, e.g., the gare “Ermont-Eaubonne” is between two communes in Val d’Oise, sometimes written Ermont-Eaubonne (hyphen w/o space);
- non-uniqueness of a commune name: e.g., Cernay exists in five French départements. To distinguish them, add a department name: Cernay (Haut-Rhin);
- commune merging (2500+ merges in 2015–2019, versus 50 splits) in France, implies using a lexicon (Insee-geo) for converting to today’s nom and insee values;
- also: Paris-Nord can be Paris Gare du Nord and many similar cases of a base-name plus a specifier (no rule applies).
| Cause | Label2017 | Dist(m) | Label2014 |
|---|---|---|---|
| SP: label ≠ and dist ≤2 m. | Ambérieu-en-Bugey | 0 | Ambérieu |
| Arras | 0 | Achicourt | |
| Paris-Nord-Surface | 0 | Paris-Nord-Souterraine | |
| Bainville-sur-Madon | 0 | Bainville | |
| Paris-Austerlitz | 1 | Paris-Austerlitz (Banlieue) |
- Question is: Why different names at a same place?
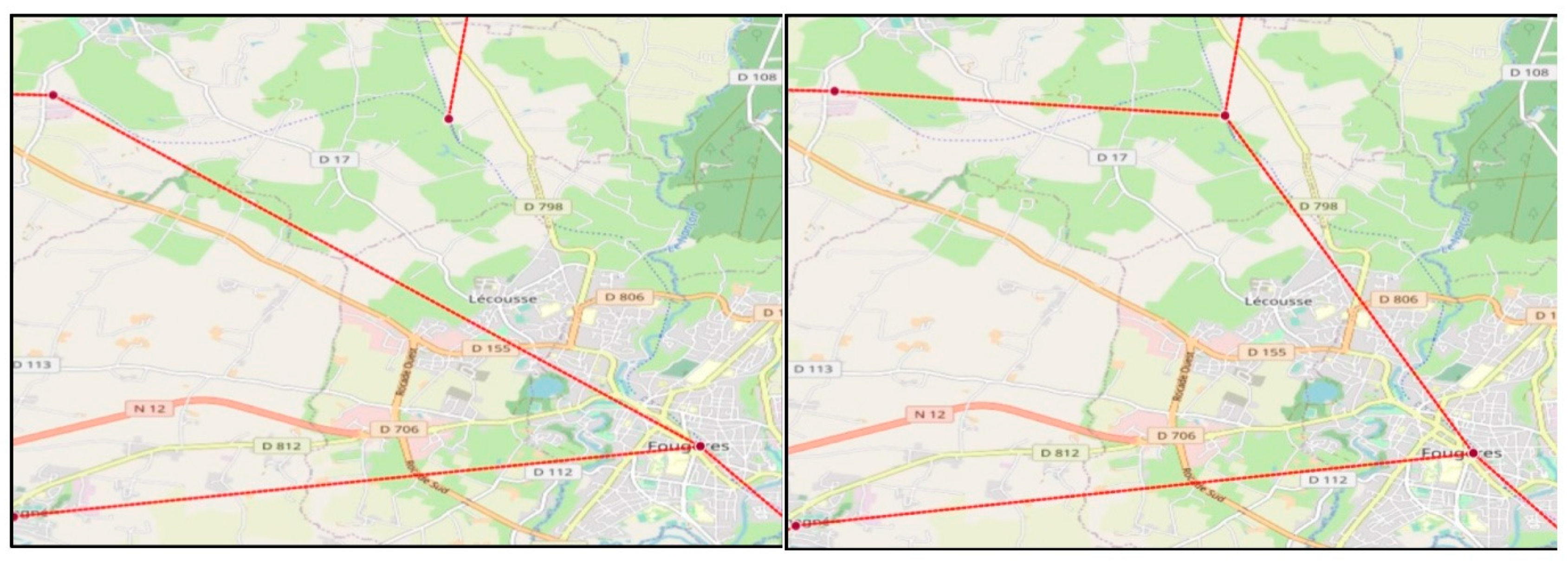
Appendix B.2. Revealing “Fork-Patterns” from Suspect Fusion Examples

| Cause | Label | Dist (m) |  |
SN: label = & dist > 2.2 km | Reims | 2273 | |
| Champdôtre-Pont | 2299 | ||
| Sillé-le-Guillaume | 2342 | ||
| Argentan | 2355 | ||
| Toucy-Ville | 3446 | ||
| Épinal | 3644 | ||
| Fougères | 4964 |
- Question is: Why the same gare names so far away?
Appendix B.3. The Target Schema and the Graph Representation of the Network


References
- De Block, G.; Polasky, J. Light railways and the rural–urban continuum: Technology, space and society in late nineteenth-century Belgium. J. Hist. Geogr. 2011, 37, 312–328. [Google Scholar] [CrossRef]
- Martí-Henneberg, J. European integration and national models for railway networks (1840–2010). J. Transp. Geogr. 2013, 26, 126–138. [Google Scholar] [CrossRef]
- Auphan, E. La contraction du réseau ferré français dans le temps et dans l’espace. In Colloque international Le secteur des transports ferroviaires dans la mondialisation; Univ. Versailles-Saint-Quentin-en-Yvelines: Versailles, France, 2013; Available online: https://f-origin.hypotheses.org/wp-content/blogs.dir/2536/files/2015/03/auphan-etienne-atelier-f.pdf (accessed on 14 September 2020).
- Report on implementation of the 2011 EU White Paper on Transport. Roadmap to a Single European Transport Area—Towards a Competitive and Resource-Efficient Transport System. Five Years Later: Achievements and Challenges. 2016. Available online: https://ec.europa.eu/transport/sites/transport/files/themes/strategies/doc/2011_white_paper/swd(2016)226.pdf (accessed on 14 September 2020).
- Siebert, L. Using GIS to Map Rail Network History. J. Transp. Hist. 2004, 25, 84–104. [Google Scholar] [CrossRef]
- Gregory, I.; Ell, P.S. Historical GIS: Technologies, Methodologies and Scholarship; (Cambridge Studies in Historical Geography); Cambridge University Press: Cambridge, UK, 2007; p. 227, (Cambridge Studies in Historical Geography). [Google Scholar]
- Morillas-Torné, M. Creation of a Geo-Spatial Database to Analyse Railways in Europe (1830–2010). A Historical GIS Approach. J. Geogr. Inf. Syst. 2012, 4, 176–187. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Liu, L.; Dai, Z.; Liu, X. Different Sourcing Point of Interest Matching Method Considering Multiple Constraints. ISPRS Int. J. GeoInf. 2020, 9, 214. [Google Scholar] [CrossRef] [Green Version]
- Normand, S.-L.T. Meta-analysis: Formulating, evaluating, combining, and reporting. Stat. Med. 1999, 15, 321–359. [Google Scholar] [CrossRef] [PubMed]
- Riley, R.D.; Price, M.J.; Jackson, D.; Wardle, M.; Gueyffier, F.; Wang, J.; Staessen, J.A.; White, I.R. Multivariate meta-analysis using individual participant data. Res. Syn. Meth. 2015, 6, 157–174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lan, T.; Longley, P. Geo-Referencing and Mapping 1901 Census Addresses for England and Wales. ISPRS Int. J. Geo-Inf. 2019, 8, 320. [Google Scholar] [CrossRef] [Green Version]
- Bloch, I. Information Fusion in Signal and Image Processing: Major Probabilistic and Non-Probabilistic Numerical Approaches; Wiley- Online Library: Hoboken, NJ, USA, 2008; ISBN 9781848210196. [Google Scholar]
- Benferhat, S.; Kacia, S.; LeBerre, D.; Williams, M.-A. Weakening conflicting information for iterated revision and knowledgeintegration. Artif. Intell. 2004, 153, 339–371. [Google Scholar] [CrossRef] [Green Version]
- Reichgelt, H. Knowledge Representation: An AI Perspective; AblexPublishing: New York, NY, USA, 1991; ISBN 10:0893915904. [Google Scholar]
- Johnson, B.A.; Iizuka, K. Integrating OpenStreetMap crowdsourced data and Landsattime-series imagery for rapid land use-land cover (LULC) mapping: Case study of the Laguna de Bay area of the Philippines. Appl. Geogr. 2016, 67, 140–149. [Google Scholar] [CrossRef]
- Younghoon, K.; Woohwan, J.; Kyuseok, S. Integration of graphs from different data sources using crowdsourcing. Inf. Sci. 2017, 385–386, 438–456. [Google Scholar] [CrossRef]
- Smith, M.J.; Wedge, R.; Veeramachaneni, K. FeatureHub: Towards collaborative datascience. In Proceedings of the IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 590–600. [Google Scholar]
- Juhász, L.; Rousell, A.; Jokar Arsanjani, J. Technical Guidelines to Extract and Analyze VGI from Different Platforms. Data 2016, 1, 15. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Chen, L.; Zhang, C. CrowdFusion: A Crowdsourced Approach on Data Fusion Refinement. In Proceedings of the IEEE 33rd International Conference on Data Engineering (ICDE), Tokyo, Japan, 19–21 October 2017; pp. 127–130. [Google Scholar]
- Gouvêa, C.; Loh, S.; FortesGarcia, L.F.; Brasil da Fonseca, E.; Wendt, I. Discovering Location Indicators of Toponyms from News to Improve Gazetteer-Based Geo-Referencing. In Proceedings of Brazilian Symposium on Geoinformatics; 2008; pp. 51–62. Available online: http://www.geoinfo.info/portuguese/geoinfo2008/artigos/p13.pdf (accessed on 8 March 2021).
- Hastings, J.T. Automated conflation of digital gazetteer data. Int. J. Geogr. Inf. Sci. 2008, 22, 1109–1127. [Google Scholar] [CrossRef]
- Wikipedia. Route-Diagram. Available online: https://simple.wikipedia.org/wiki/Template:Infobox_rail_line (accessed on 8 February 2021).
- Lange, D.; Böhm, C.; FelixNaumann, F. Extracting Structured Information from Wikipedia Articles to Populate Infoboxes. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, CA, USA, 26 October 2010; pp. 1661–1664. [Google Scholar] [CrossRef] [Green Version]
- Auer, S.; Lehmann, J. What Have Innsbruck and Leipzig in Common? Extracting Semantics from Wiki Content. In The Semantic Web: Research and Applications; Franconi, E., Kifer, M., May, W., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4519. [Google Scholar] [CrossRef] [Green Version]
- Vasseur, B.; Jeansoulin, R.; Devillers, R.; Frank, A. External quality evaluation of geographical applications: An ontological approach. Fundam. Spat. Data Qual. 2006, 255–270. [Google Scholar] [CrossRef]
- Daniel, F.; Kucherbaev, P.; Cappiello, C.; Benatallah, B.; Allahbakhsh, M. Quality Control in Crowdsourcing: A Survey of Quality Attributes, Assessment Techniques, and Assurance Actions. ACM Comput. Surv. 2018. [Google Scholar] [CrossRef] [Green Version]
- Senaratne, H.; Mobasheri, A.; Ali, L.; Capineri, C.; Haklay, M. Are view of volunteered geographic information quality assessment methods. Int. J. Geogr. Inf. Sci. 2017, 31, 139–167. [Google Scholar] [CrossRef]
- INSPIRE Thematic Working Group Transport Networks. Data Specification on Transport Networks—Technical Guidelines (D2.8.I.7). European Commission Joint Research Centre. April 2014. Available online: https://inspire.ec.europa.eu/id/document/tg/tn (accessed on 8 February 2021).
- Axelsson, P.; Wikström, L. OGC, InfraGML1.0: Part5 Railways—Encoding Standard. 2017. Available online: http://www.opengis.net/doc/standard/infragml/part5/1.0 (accessed on 8 February 2021).
- SNCF Réseaux. Available online: https://ressources.data.sncf.com/explore/dataset/liste-des-gares (accessed on 13 September 2020).
- Auphan, E. L’apogée des chemins de fer secondaires en France: Essai d’interprétation cartographique. Rev. D’histoire Des Chemins De Fer 2002, 24–25, 24–46. Available online: https://journals.openedition.org/rhcf/2028 (accessed on 8 February 2021). [CrossRef]
- SNCF. Available online: https://fr.m.wikipedia.org/wiki/SNCF_Gares_&_Connexions (accessed on 17 August 2020).
- Wikipedia. Available online: https://en.wikipedia.org/wiki/Wikipedia:Route_diagram_template (accessed on 17 August 2020).
- Wikipedia. Available online: https://de.wikipedia.org/wiki/Wikipedia:Formatvorlage_Bahnstrecke (accessed on 8 February 2021).
- Comber, A.; Wulder, M. Considering spatiotemporal processes in big data analysis: Insights from remote sensing of land cover and land use. Trans. GIS 2019, 23, 879–891. [Google Scholar] [CrossRef]
- Sreenivasaiah, P.K.; Kim, D.H. Current Trends and New Challenges of Databases and Web Applications for Systems Driven Biological Research. Front. Physiol. 2010, 1, 147. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- OSM. Available online: https://wiki.openstreetmap.org/wiki/Railway_stations (accessed on 8 February 2021).
- Gervais, M.; Bédard, Y.; Levesque, M.; Bernier, E.; Devillers, R. Data Quality issues and Geographic Knowledge Discovery. In Geographic Data Mining and Knowledge Discovery; Miller, H.J., Han, J., Eds.; 2009; Chapter 5; pp. 99–115. Available online: http://yvanbedard.scg.ulaval.ca/wp-content/documents/publications/518.pdf (accessed on 8 February 2021).
- Yang, S.; Wu, Y.; Sun, H.; Yan, X. Schemaless and Structureless Graph Querying. In Proceedings of the 40th International Conference on Very Large Databases (VLDB); 2014; Available online: https://yinghwu.github.io/mat/papers/Schemaless_and_Structureless_graph_querying-vldb14.pdf (accessed on 8 February 2021).
- Auphan, E.; Dupuy, G. Vingt ans de travaux scientifiques sur les réseaux et la mobilité ferroviaires. Rev. D’histoire Des Chemins De Fer 2009, 39, 95–101. [Google Scholar] [CrossRef]
- Eurostat. Modal Split of Inland Freight Transport. Statistics Explained Website. 2018. Available online: https://ec.europa.eu/eurostat/statistics-explained/index.php?title=File:Modal_split_of_inland_freight_transport,_2018_(%25_share_in_tonne-kilometres).png (accessed on 18 September 2020).
- European Environment Agency. Greenhouse Gas Emissions from Transport in Europe. 2020. Available online: https://www.eea.europa.eu/data-and-maps/indicators/transport-emissions-of-greenhouse-gases-7/assessment (accessed on 8 February 2021).






















|
| Sncf2020: “Réseau ferré de France”, last update: 2020, accessed: 8 March 2020 url: https://ressources.data.sncf.com/explore/dataset/liste-des-gares/ Schema (geojson) and counts (4148 features, with geometry): {code_ligne, libelle, fret, voyageurs, code_uic, pk, departemen, commune} +{geometry} |
| Sncf2017, orSNCF2: “Réseau ferré de France”, last update: 2017 url: (authors copy) not available anymore since end 2019, Schema (=Sncf2020) and counts (7702 features, only 6812 with geometry): |
| Sncf2014, orSNCF1: “Réseauferré de France”, last update: 2014, accessed: 8 March 2020 https://data.gouv.fr/fr/datasets/gares-ferroviaires-de-tous-types-exploitees-ou-non/ Schema (CSV) and counts (6442 features, all attributes: 6442): [code_ligne, nom, nature, latitude (WGS84), longitude (WGS84)] |
| Insee-new: official codes for commune (+2003–2021 administrative changes) url: https://www.insee.fr/fr/information/2028028 CSV, counts (35,589 features, 2577 changes in 2018, no geometry) |
| Insee-geo: commune contours (curated by G. David), accessed: 8 March 2020 url: https://france-geojson.gregoiredavid.fr/ geojson, counts (35,798 communes contours with geometry) |
| Lignes: “SNCF Réseau ferré de France”, created: (before 2017), accessed: 8 March 2020 https://ressources.data.sncf.com/explore/dataset/formes-des-lignes-du-rfn/ Schema (geojson) and counts (1779 features, with geometry): {libelle, code_ligne, mnemo}+{geometry} |
| Intervals (nb. Nodes) | [0, 150 m] | [150, 300] | [300, 1 km] | [1 km, 2 km] | [2 km, ∞] |
|---|---|---|---|---|---|
| “Close Enough” | “Rather Far” | ||||
| SNCF2014 (642 nodes/6442) | 550 | 48 | 32 | 6 | 6 |
| SNCF2017 (1360 nodes/7702) | 541 | 184 | 375 | 157 | 103 |
| Datasets and Link Attribute | Isolated Gare | 2-Gares Ligne | 3 to 7-Gares | 8 to 15-Gares | 16 to 30-Gares | 31 to Max Gares | (Total) |
| SNCF2017 num | 107 | 76 | 245 | 171 | 91 | 44 | 734 |
| SNCF2014 num | 94 | 62 | 191 | 130 | 76 | 40 | 593 |
| MetadataSncf2014: { “mime”:”csv”, “year”:”2014”, “nbfeatures”:6442, “schema#”: {“label”:6442, “num”:6442, “nature”:6442, “geometry”:6442}, (1) “unos#”: {“label”:6098, “num”:593},”duos#”{“num-label”:6436} (2) } |
| MetadataSncf2017: { “mime”:”geojson”, “year”:”2017”, “nbfeatures”:7702, “schema#”: {“label”:7702, “uic”:7702, “num”:7702, “km”:7702, “capa”:7702, “geometry”:6812}, “unos#”: {“label”:6813, “uic”:6817, “num”:734} } |
| |y∈V(x)| = |similarNumLabel(x,y)–normalizedShortDistance(x,y)| | (a) |
| similarNumLabel(x, y): (num(y) = num(x)) ∧ (slug(label(y)) = slug(label(x))) → 1 or 0 | (b) |
| normalizedShortDistance(x, y): let d = distanceGreatCircleInMeter(geometry(y), geometry(x)); if (d ≤ D1) → 1; elseif (D1 < d ≤ D2) → (D2 − d)/(D2-D1); elseif (d > D2) → 0 | (c) |
| |y∉V(x)|: |¬similarNumLabel(x,y)–normalizedGreatDistance(x,y)| | () |
| ¬similarNumLabel(x, y): (num(y) ≠ num(x)) ∨ (slug(label(y)) ≠ slug(label(x))) → 1 or 0 | () |
| normalizedGreatDistance(x, y): let d = distanceGreatCircleInMeter(geometry(y), geometry(x)); if (D4 ≤ d) → 1; elseif (D3 < d ≤ D4) → (D4 − d)/(D4 − D3); elseif (D3 > d) → 0 | () |
| Intervals | [0, 50 m] | [50, 100] | [100, 150] | [150, 200] | [200, 250] | [250, 300] | [300, 1 km] | [1 km, ∞] |
|---|---|---|---|---|---|---|---|---|
| direct positive | 4618 | 1082 | 375 | 161 | 113 | 72 | 321 | 58 |
| reverse positive | 4501 | 1072 | 348 | 135 | 70 | 48 | 129 | 18 |
| (a) | ||||||
| intervals | 0–D1 = 150 m. | D1–D2 = 250 m. | D2–D3 = 1000 m. | D3–D4 = 2000 m. | D4–∞. | |
| direct + | 6070 AP: 87.2% | 353 PP: 5.0% | total undecided | ← | 9 SN: 0.1% | |
| direct ¬ | 59 SP: 0.8% | → | 450 und: 6.4% | 18 PN: 0.2% | 25 AN: 0.4% | |
| (b) | ||||||
| intervals | 0–D1 = 150 m. | D1–D2 = 250 m. | D2–D3 = 1000 m. | D3–D4 = 2000 m. | D4–∞. | |
| reverse + | 5944 AP: 91.9% | 251 PP: 3.9% | total undecided | ← | 4 SNs: 0.3% | |
| reverse ¬ | 46 SP: 0.7% | → | 163 und: 2.5% | 4 PN: 0.2% | 30 AN: 0.8% | |
| MetadataSncf2014: { “mime”:”csv”, “year”:”2014”, “nbfeatures”:6442, “sch#”: {“label” … :6442, “closest”:6442, “fusable”:6189, “integrable”:33} } |
| MetadataSncf2017: { “url”:”g2017”, “mime”:”geojson”, “year”:”2017”, “nbfeatures”:7702, “sch#”: {“label” …:7702, “closest”:6984, “fusable”:6415, “integrable”:41, “coordinates”:6984} } |
| {{Infobox Ligne ferroviaire\n| nomligne = d’Audun-le-Tiche à Hussigny-Godbrange\n| mise en service = 1880\n| fermeture = 1966\n| fermeture2 = 1987\n| numéro = 196000\n| longueur = 8.8\n| écartement = normal\n| … … (more items) … schéma = \n{{BS-table}}\n … {{BSnn}} … series of items describing the nodes along that line (see next Table) … \n{{BS-table-fin}}\n }} |
| {{BS-table}} | |
| {{BSbis|…| … … |Ligne d’Esch-sur-Alzette à Audun-le-Tiche}} | |
| {{BS3bis|…| … … |Frontière entre la France et le Luxembourg} | border |
| {{BS5bis|…| … … |Ligne de Fontoy à Audun-le-Tiche}} | |
| {{BS5bis|…| … … |(1) Ligne non déclassée, non exploitée}} | |
| {{BS5bis|…| 21,144|Audun-le-Tiche |(301 m)}} | origin |
| {{BS5bis|…| … … |Ancienne voie vers Villerupt-Micheville}} | |
| {{BSbis|…| 2,4xx| |Bif vers raccordement d’Audun-le-Tiche|}} | branch |
| {{BSbis|…| 4,6xx|Rédange |(340 m)}} | label |
| {{BSbis|…| 5,5xx| |Tunnel d’Adlergrund|(409m)}} | tunnel |
| {{BSbis|…| 6,6xx| |Ancienne frontière France - Empire allemand}} | km |
| {{BS5bis|…| … … |Ligne de Longwy à Villerupt-Micheville}} | |
| {{BSbis|…| 8,8xx|Hussigny-Godbrange |(346 m)}} | branch |
| {{BSbis|..| … … |Ligne de Longwy à Villerupt-Micheville}} | terminus |
| {{BS-table-fin}} |
| Archef | http://archeoferroviaire.free.fr accessed on: 8 March 2021 records hundreds of secondary lines, including industrial, military lines, at a high-resolution |
| cdfFR | http://chemindeferenfrance.blogspot.com accessed on: 8 March 2021 gathers cartographic records about a hundred ancient lines |
| GeoCF | http://www.train.eryx.net/hscff/ accessed on: 8 March 2021 records hundreds of secondary lines (in revision) |
| Ligou | https://www.lignes-oubliees.com accessed on: 8 March 2021 “forgotten lines” records 1768 gares and 361 lignes |
| RDrail | http://rd-rail.fr/ by the author of “Les 400 profils des lignes voyageurs du réseau” (2 volumes) |
| Routes | https://routes.fandom.com/wiki/Portail:Transport_ferroviaire_français accessed on: 8 March 2021 several tables about ancient lines, about chronology |
| RuePT | https://rue_du_petit_train.pagesperso-orange.fr accessed on: 8 March 2021 records 6800 street signs mentioning the presence of a former gare (useful for disambiguating precise localization) |
| Traver | http://chemins.de.traverses.free.fr accessed on: 8 March 2021 gathers photographs and cartographic records about ancient lignes |
| Query | [lat,lon] | dist |
|---|---|---|
| ... true coordinates (see: Figure 14 and Section 3.3.3) = | [44.023710, 4.088814] | 0 |
| [lat,lon] = geocode(“gare, Cardet, France”) | [44.026042, 4.081059] | 672 m |
| [lat,lon] = geocode(“rue de la gare, Cardet, France”) | [44.010420, 4.084597] | 1515 m |
| [lat,lon] = geocode(“chemin de la gare, Cardet, France”) | [44.019122, 4.086764] | 536 m |
| Intervals (nb.Nodes) | [0, 150 m] | % | [150, 300] | [300, 1 km] | [1 km, 2 km] | [2 km, ∞] |
|---|---|---|---|---|---|---|
| 2014 (642 nodes/6442) | 550 | 85.7 | 48 | 32 | 6 | 6 |
| 2017 (1360 nodes/7702) | 541 | 40.0 | 184 | 375 | 157 | 103 |
| CARP (2116 nodes/10,747) | 1418 | 67.0 | 184 | 344 | 115 | 55 |
| Datasets | Isolated Gare | % | 2-Gares Ligne | 3 to 7-Gares | 8 to Max- | (Total) |
|---|---|---|---|---|---|---|
| 2014 num | 94 | 15.8 | 62 | 191 | 130 | 593 |
| 2017 num | 107 | 14.6 | 76 | 245 | 171 | 734 |
| CARP num | 50 | 5.2 | 163 | 259 | 486 | 958 |
| Sncf2014 (origin 2014) | 5266 | 14.7% | % of the 35,798 communes (updated year-2019) |
| Sncf2017 (origin 2014) | 5279 | 14.7% | |
| Sncf2020 (update 2020) | 3112 | 8.7% | |
| CARP (as of Jan.2021) | 7341 | 20.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeansoulin, R. A Century of French Railways: The Value of Remote Sensing and VGI in the Fusion of Historical Data. ISPRS Int. J. Geo-Inf. 2021, 10, 154. https://doi.org/10.3390/ijgi10030154
Jeansoulin R. A Century of French Railways: The Value of Remote Sensing and VGI in the Fusion of Historical Data. ISPRS International Journal of Geo-Information. 2021; 10(3):154. https://doi.org/10.3390/ijgi10030154
Chicago/Turabian StyleJeansoulin, Robert. 2021. "A Century of French Railways: The Value of Remote Sensing and VGI in the Fusion of Historical Data" ISPRS International Journal of Geo-Information 10, no. 3: 154. https://doi.org/10.3390/ijgi10030154
APA StyleJeansoulin, R. (2021). A Century of French Railways: The Value of Remote Sensing and VGI in the Fusion of Historical Data. ISPRS International Journal of Geo-Information, 10(3), 154. https://doi.org/10.3390/ijgi10030154