
Detecting Urban Events by Considering Long Temporal Dependency of Sentiment Strength in Geotagged Social Media Data


Abstract
:1. Introduction
2. Background
2.1. Urban Events Detection Method
2.2. Event Detection Studies Based on Social Media Data
2.3. Sina Weibo
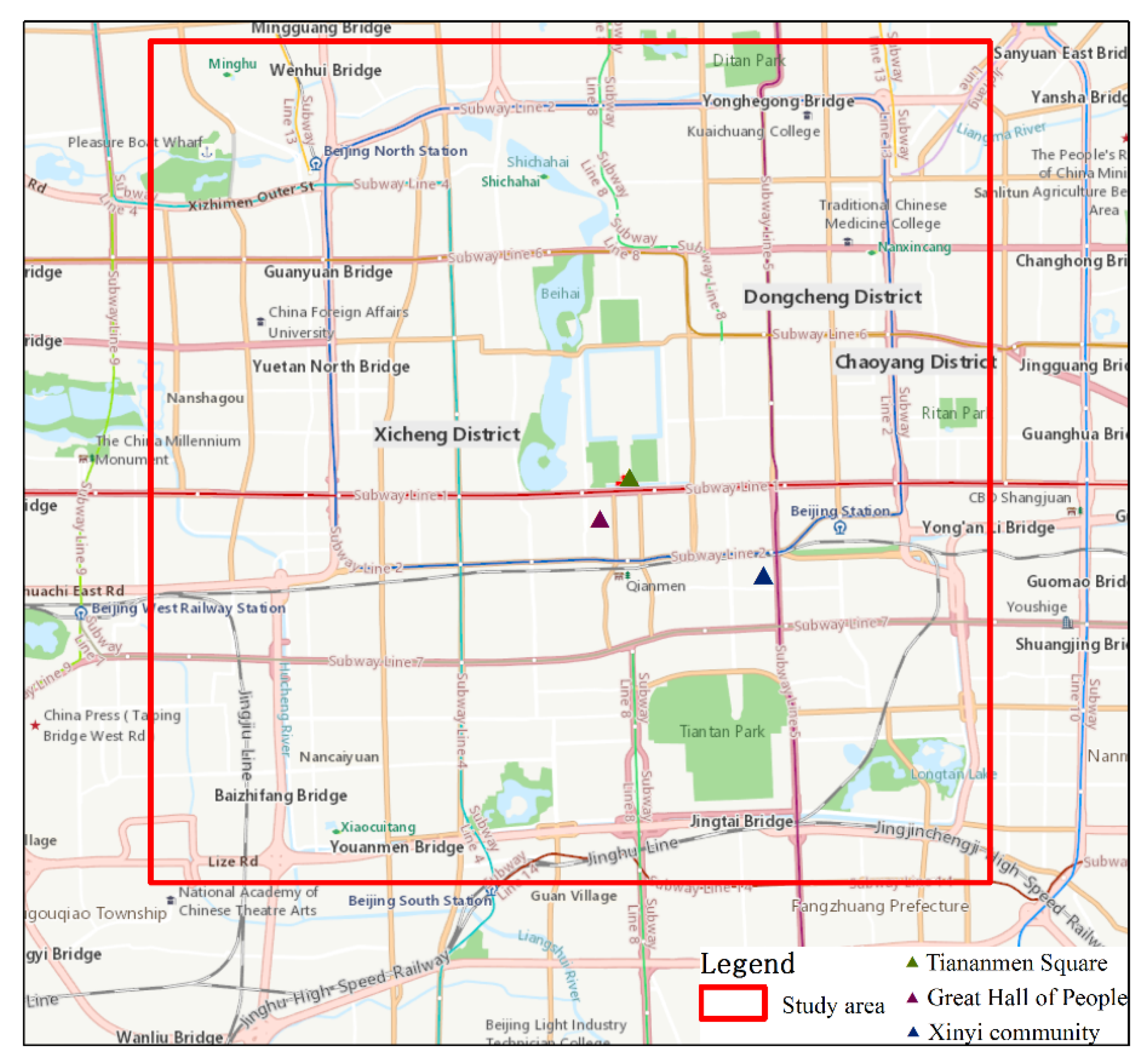
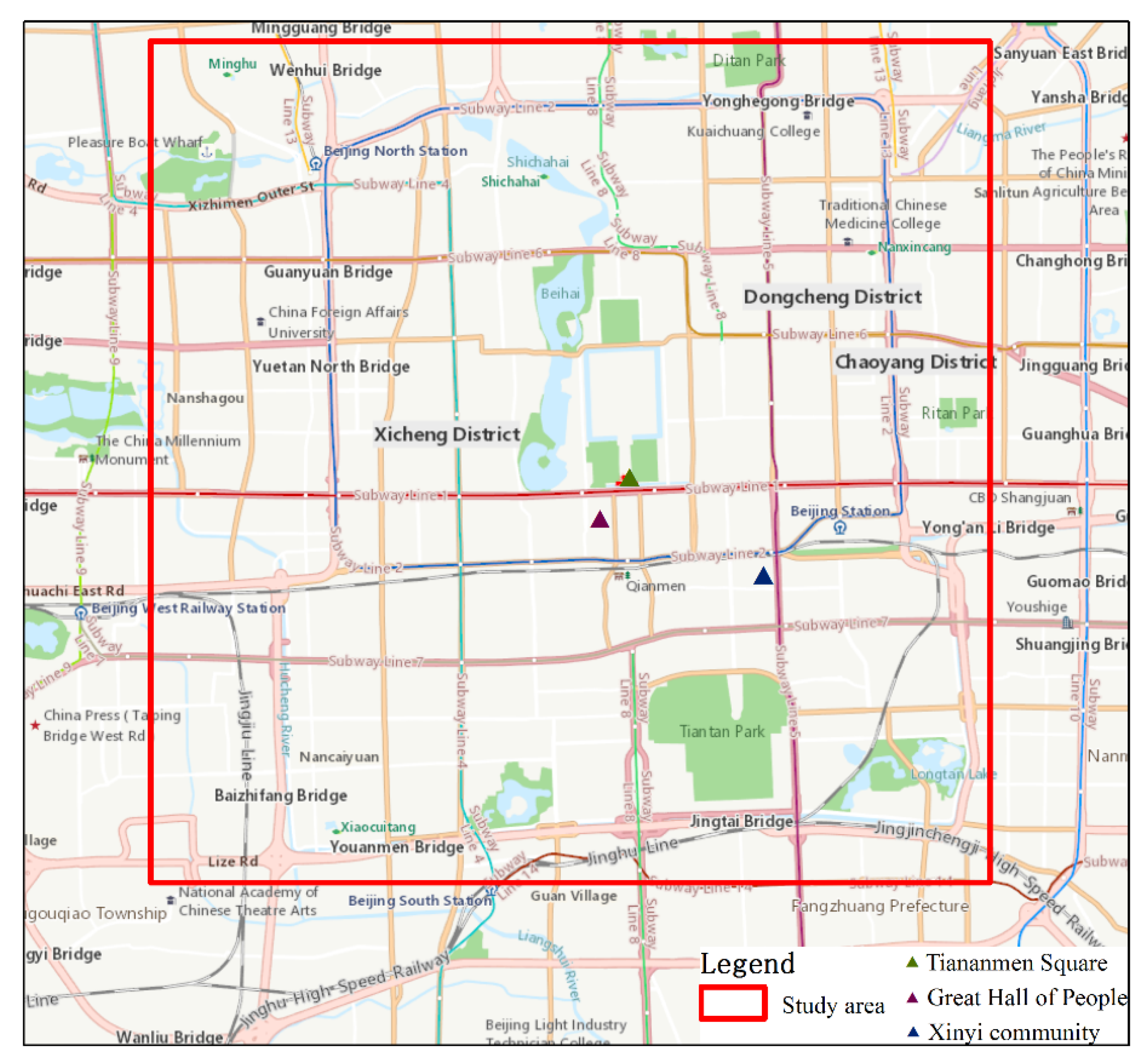
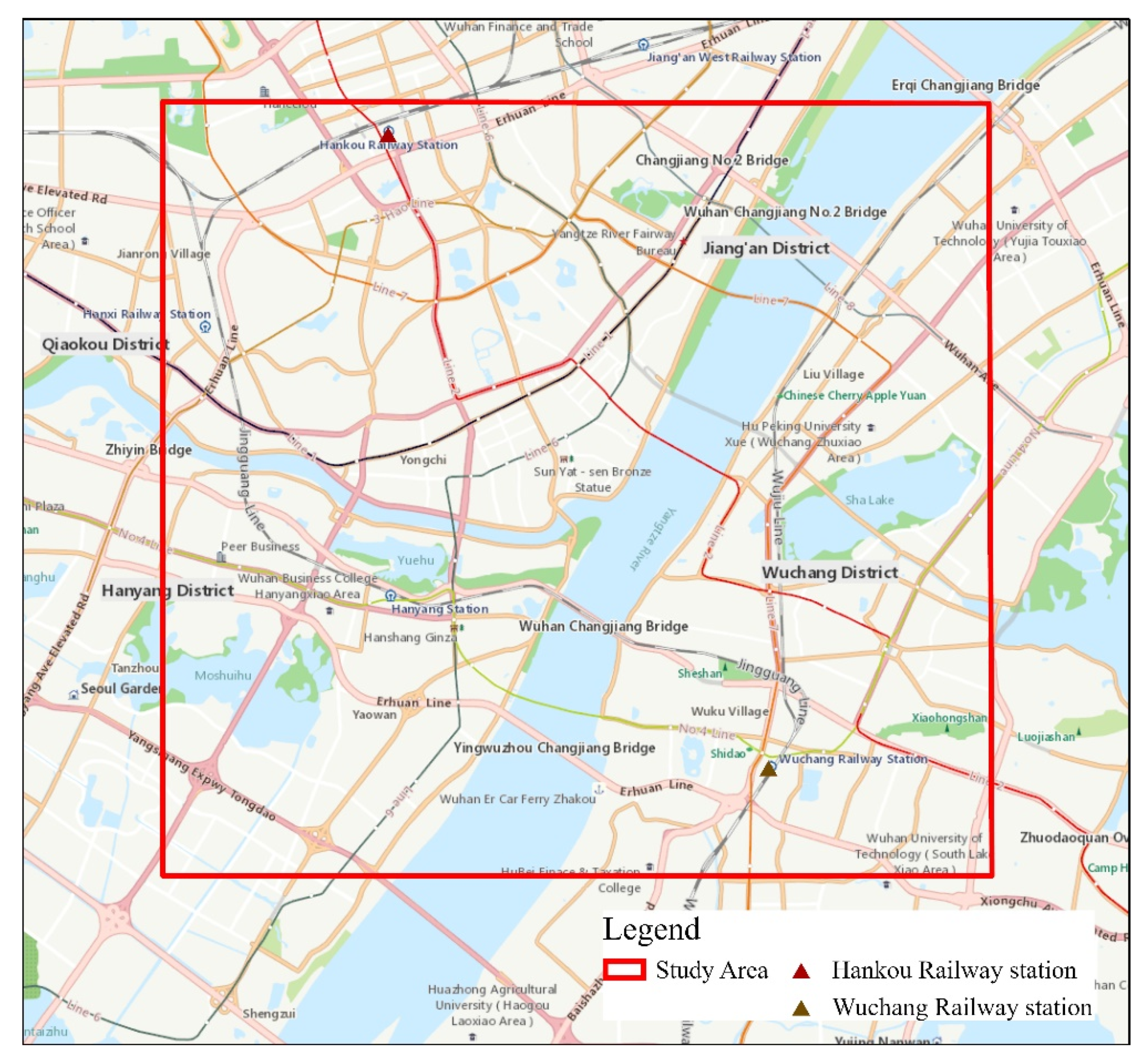
3. Study Area and Data
3.1. Study Area
3.2. Data Collection and Pre-Processing
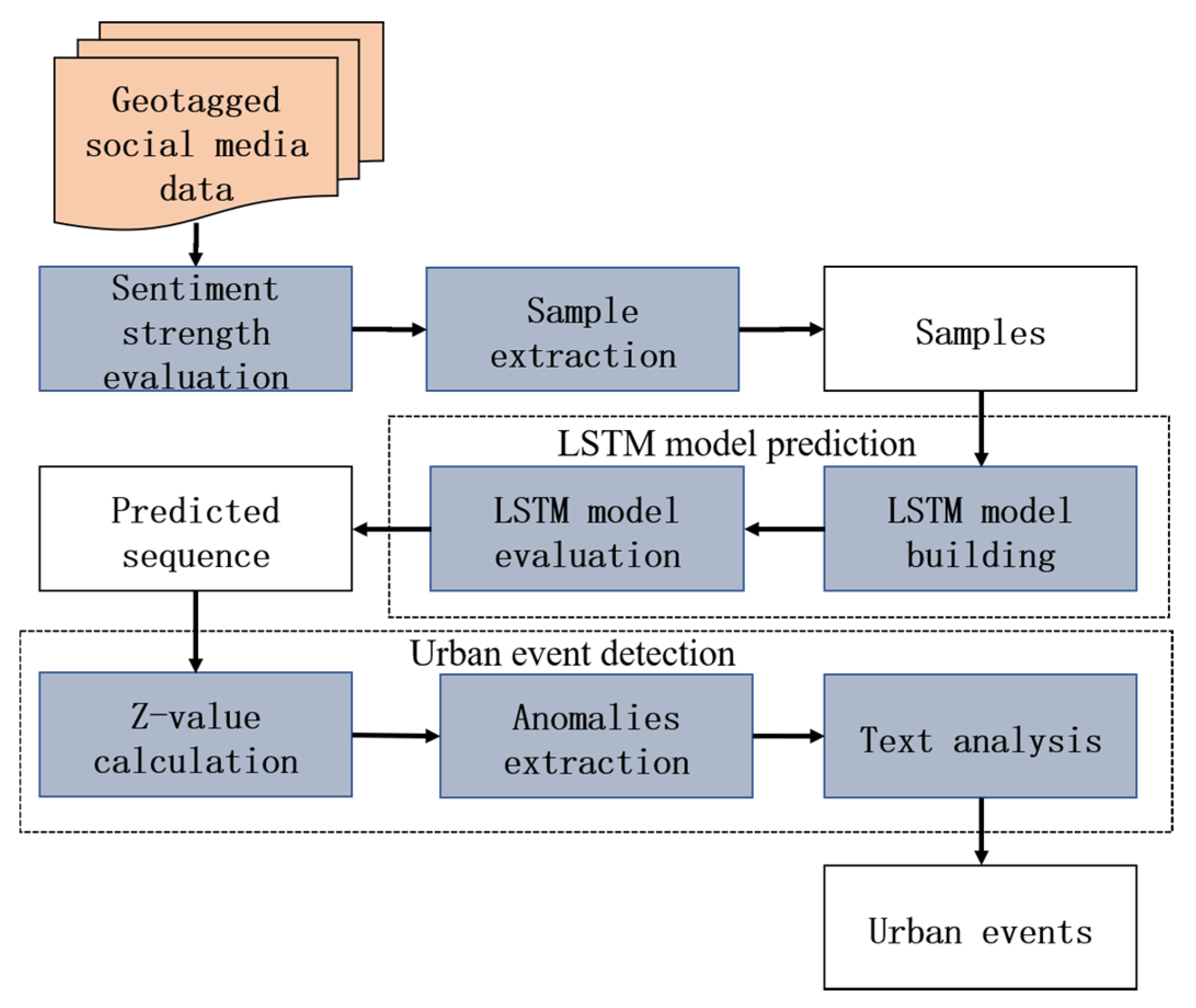
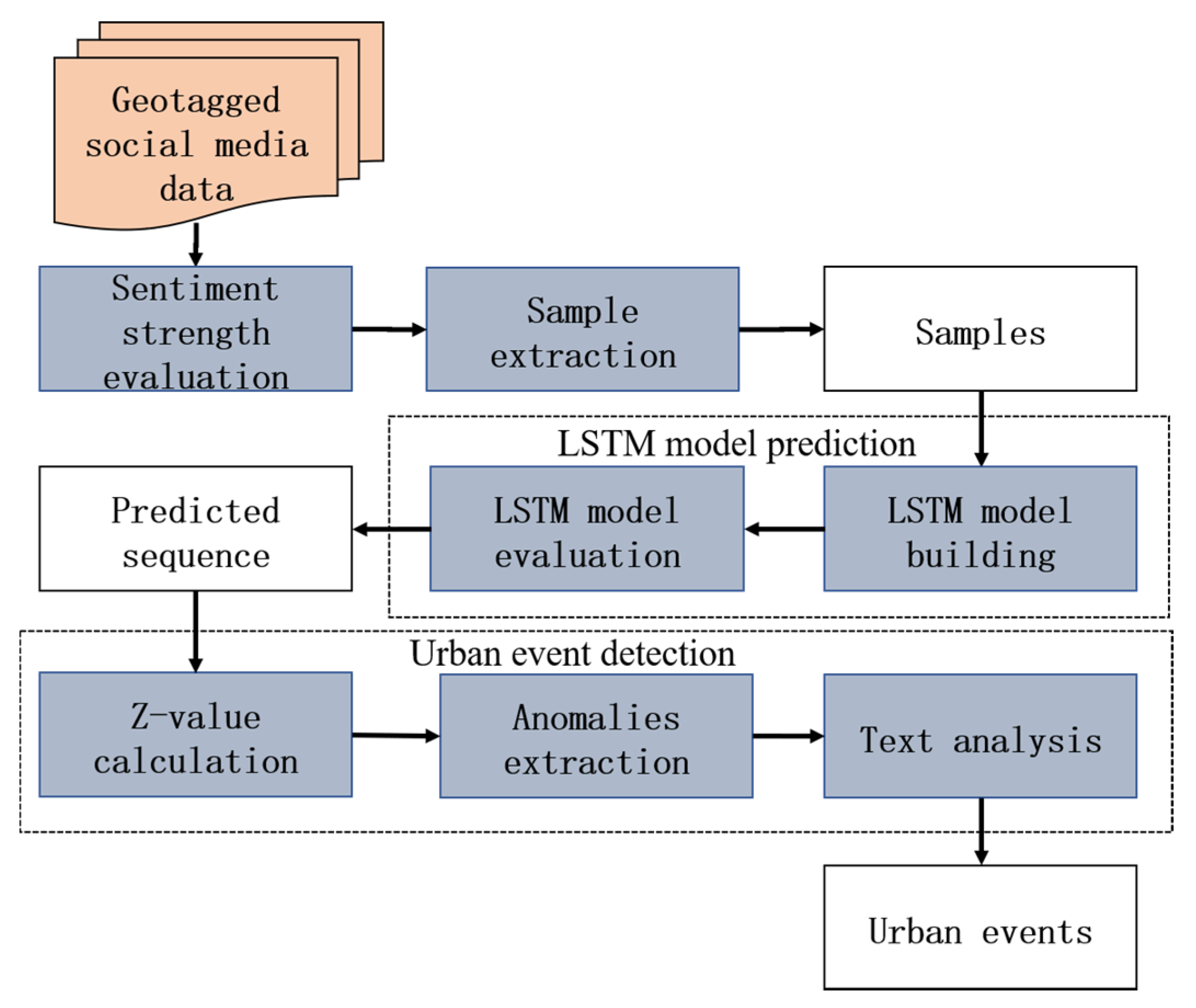
4. Method
4.1. Sentiment Strength Evaluation
4.2. Sample Extraction
4.3. Modeling Long Temporal Dependency
4.4. Model Evaluation
4.5. Event Detection
5. Results and Analysis
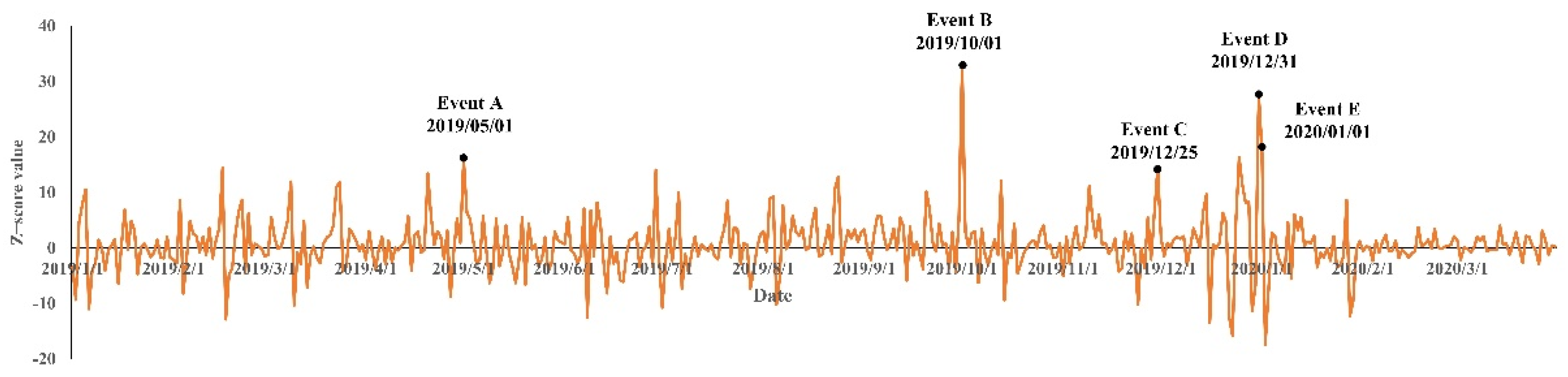
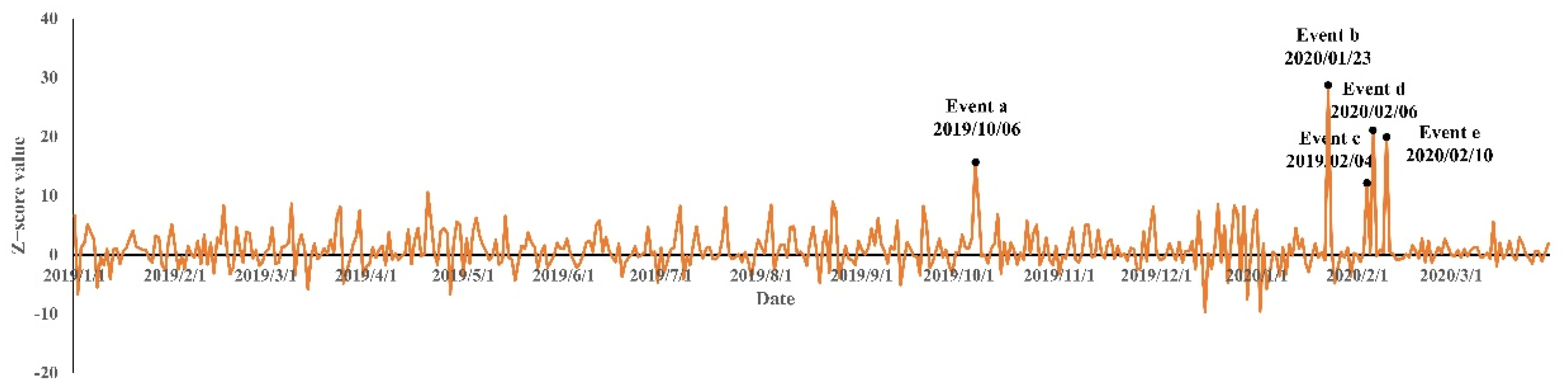
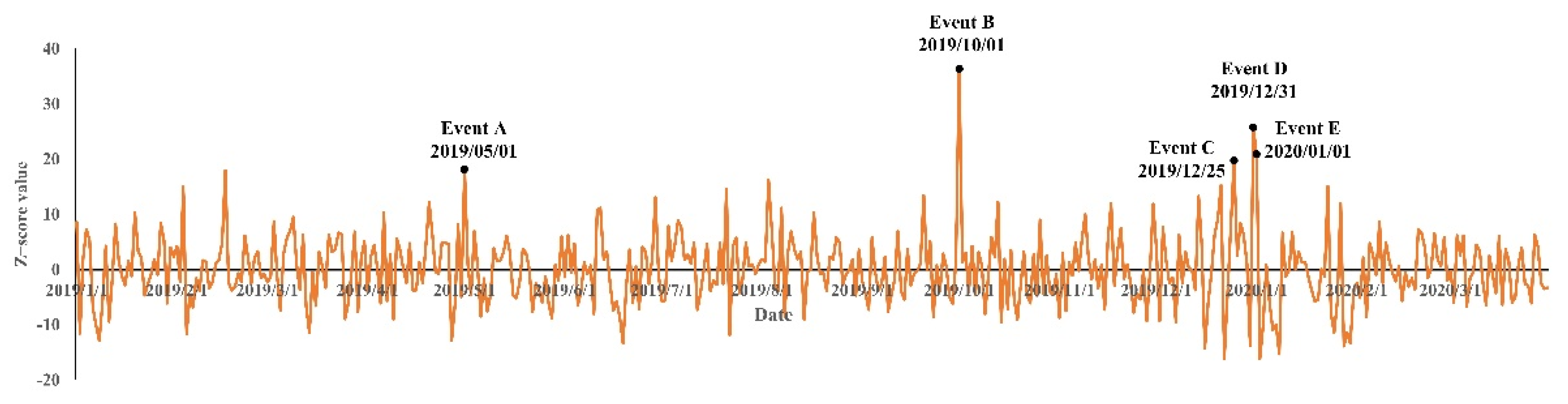
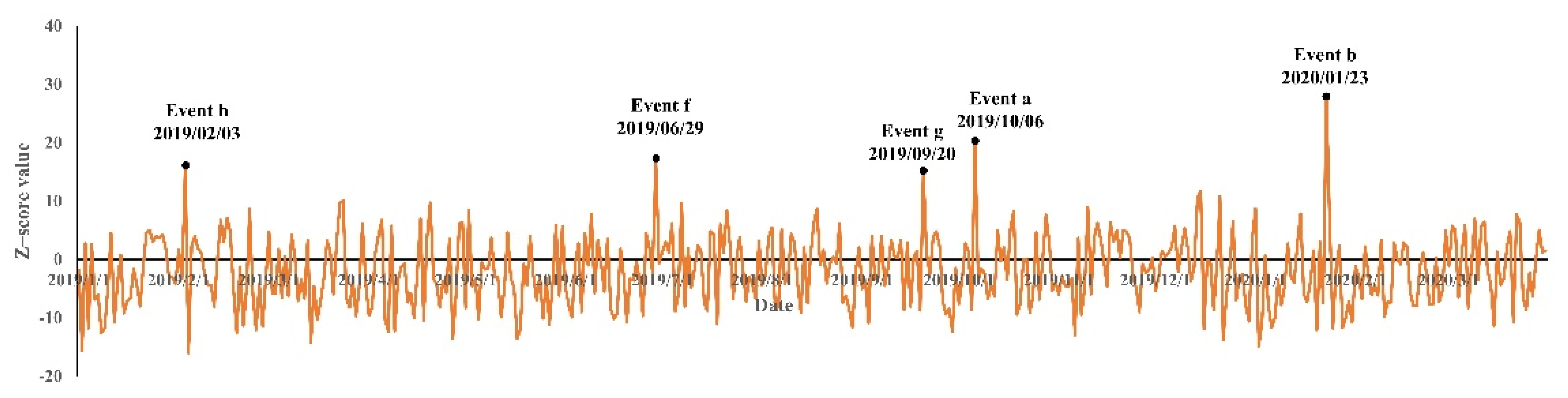
5.1. Analysis of Detection Results of LSTM
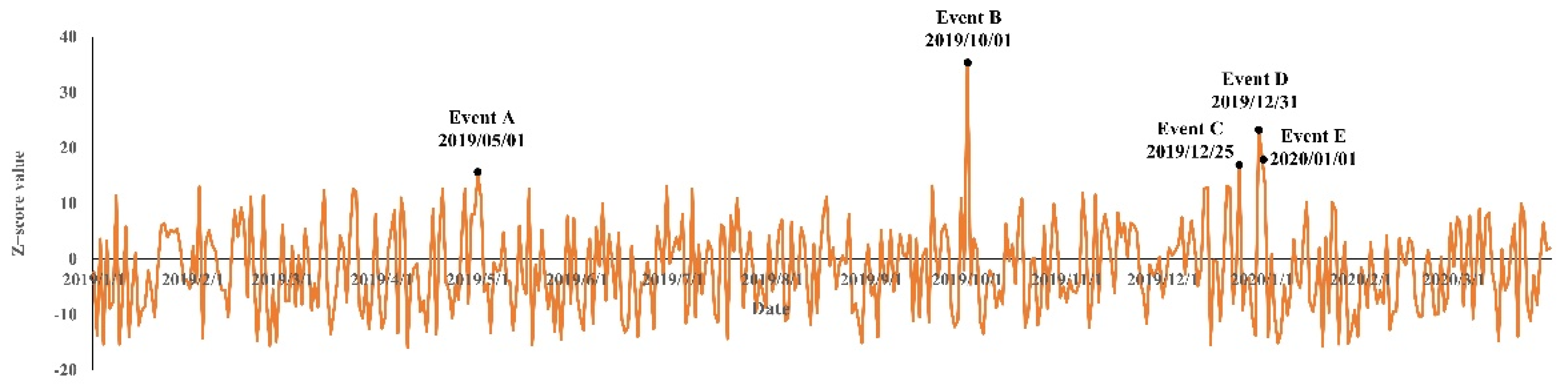
- Event A Labor Day.
- Event B Nation Day.
- Event C Christmas Day.
- Event D New Year’s Eve.
- Event E New Year’s Day.
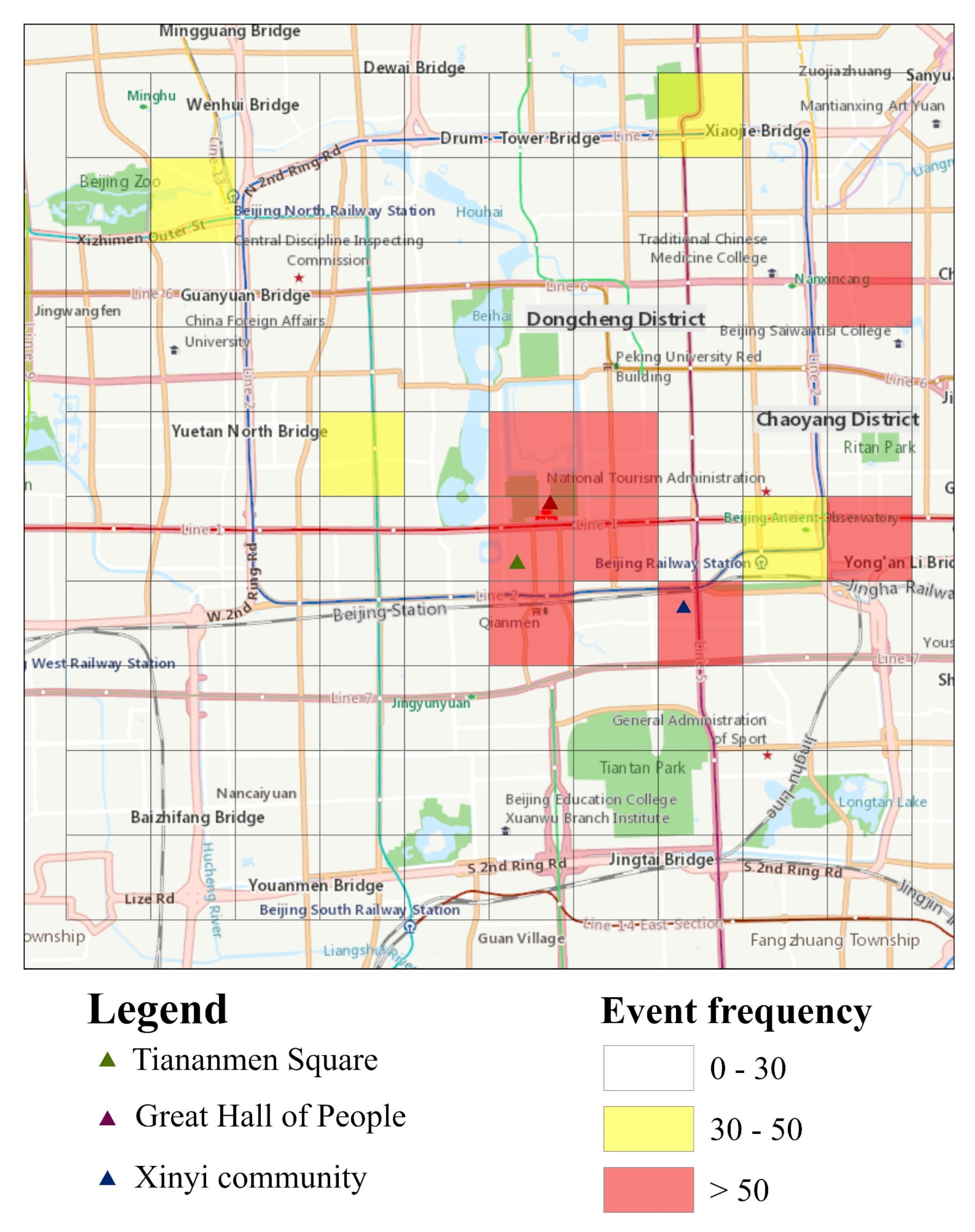
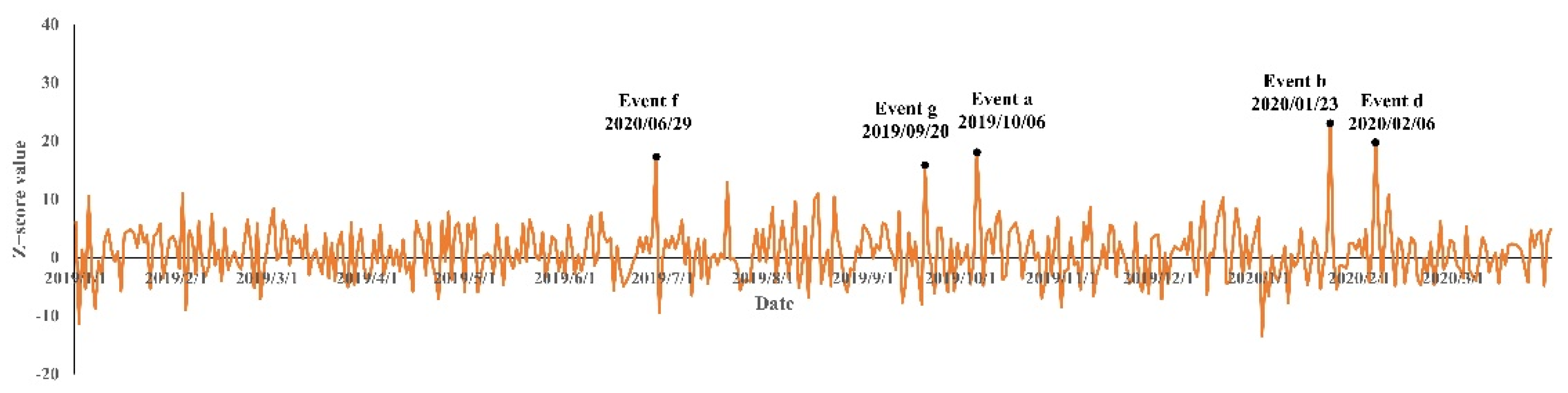
- Event a The traffic jam. As many people returned to Beijing on the last day of the Nation Day holiday, the traffic within Beijing significantly increased. The traffic jam in the road in Grid A prompted people to post negative sentiment on social media platforms.
- Event b Wuhan lockdown. Due to the Epidemic of COVID-19, Wuhan city was put into lockdown. The event of the Wuhan lockdown also shocked the residents in Beijing. Most residents express their best wishes to Wuhan. For example, they posted “Wuhan, come on!” on social media platforms.
- Event c Infected group. Some people who lived near Xinyi community were confirmed to be infected by COVID-19. This infected group caused panic within residents in Grid A.
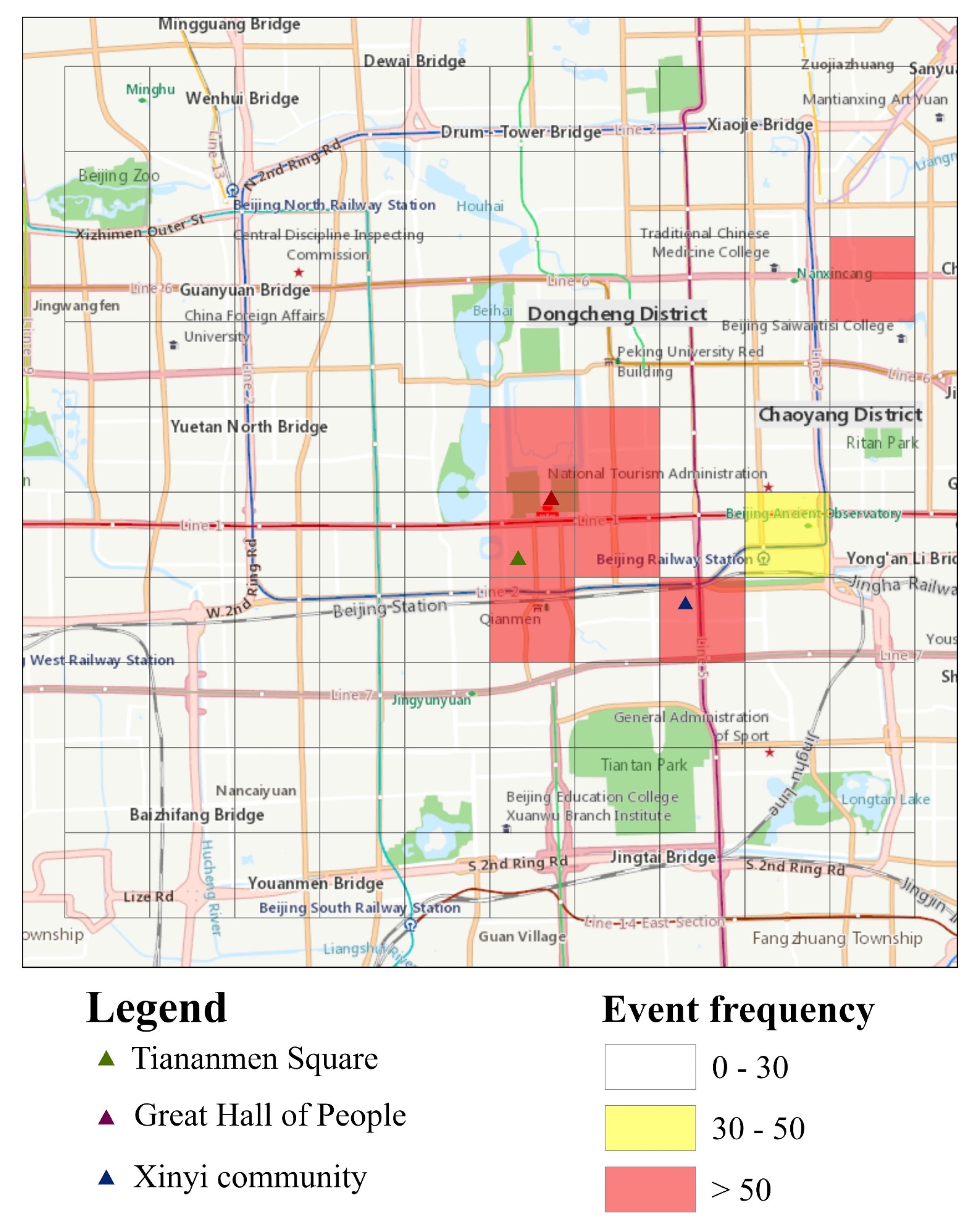
- Event d Confirmed cases of COVID-19 within the community. On 6 February 2020, a lady was confirmed to be infected by COVID-19. This lady returned to Beijing from Wuhan and is the first confirmed case within Xinyi community.
- Event e The closed management of the community. Owing to the COVID-19 epidemic, the manager of Xinyi community started to close the community on 23 January 2020. All outsiders, including employees of express, were not allowed to enter the community.
5.2. Comparative Analysis of Detection Results
6. Conclusions
- Data resource. Our method depends on the amount and quality of shared information through social media. The majority of social media users were young people. In addition, users are more prone to post positive sentiment on social media platforms. Therefore, social media data does have some disadvantages in urban event detection. In future, more reliable data resources, such as videos and questionnaires, will be introduced to correct the bias of social media data.
- Data set size. Although we combined the data in Beijing and Wuhan, the data set is not large enough for evaluating the scalability of our method. In the future, we will expand our data set by collecting more Chinese social media data and applying available and open-source data sets.
- Spatial units. In our case, 1 km × 1 km regular grids were applied as spatial units to divide the study area and the daily positive and negative sentiment strengths in each grid were counted. Different units can generate different detection results. Our research team will pay more attention to the effect of the spatial scales and shapes of units on urban event detection, and then obtain the best-fit spatial units.
- The types of events. Urban events can be divided into different types, such as festivals, traffic accidents and disease outbreaks. In this study, we mainly focused on the detection method based on geotagged social media data. The detected events were classified and named, manually. In future, we will develop an identification method for events.
- Sentiment strength evaluation. The sentiment strength in social media data is related to the geographic area and application domain. In this study, we applied a dictionary-based method proposed by a previous study. Without considering the impact of geographic area and application domain, the evaluation accuracy of sentiment strength is relatively low. In future, we will focus on studying the method of quantifying the sentiment strength with high accuracy.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xi, Z.; Guo, D. Urban event detection with big data of taxi OD trips: A time series decomposition approach. Trans. GIS 2017, 21, 560–574. [Google Scholar] [CrossRef]
- Shi, X.; Xue, B.; Tsou, M.-H.; Ye, X.; Spitzberg, B.; Gawron, J.M.; Corliss, H.; Lee, J.; Jin, R. Detecting events from the social media through exemplar-enhanced supervised learning. Int. J. Digit. Earth 2019, 12, 1083–1097. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, T.; Ye, X.; Zhu, J.; Lee, J. Using Social Media for Emergency Response and Urban Sustainability: A Case Study of the 2012 Beijing Rainstorm. Sustainability 2015, 8, 142–143. [Google Scholar] [CrossRef]
- Calabrese, F.; Colonna, M.; Lovisolo, P.; Parata, D.; Ratti, C. Real-Time Urban Monitoring Using Cell Phones: A Case Study in Rome. IEEE Trans. Intell. Transp. Syst. 2011, 12, 141–151. [Google Scholar] [CrossRef]
- Sasahara, K.; Hirata, Y.; Toyoda, M.; Kitsuregawa, M.; Aihara, K. Quantifying Collective Attention from Tweet Stream. PLoS ONE 2013, 8, e61823. [Google Scholar] [CrossRef]
- Hua, T.; Chen, F.; Zhao, L.; Lu, C.T.; Ramakrishnan, N. Automatic targeted-domain spatiotemporal event detection in twitter. Geoinformatica 2016, 20, 765–795. [Google Scholar] [CrossRef]
- Shi, Y.; Deng, M.; Yang, X.; Gong, J. Detecting anomalies in spatio-temporal flow data by constructing dynamic neighbourhoods. Comput. Environ. Urban Syst. 2018, 67, 80–96. [Google Scholar] [CrossRef]
- Xu, S.; Li, S.; Wen, R. Sensing and detecting traffic events using geosocial media data: A review. Comput. Environ. Urban Syst. 2018, 72, 146–160. [Google Scholar] [CrossRef]
- Tao, C.; Thomas, W. Event detection using Twitter: A spatio-temporal approach. PLoS ONE 2014, 9, e97807. [Google Scholar] [CrossRef]
- Wang, M.; Wu, H.; Zhang, T. Identifying critical outbreak time window of controversial events based on sentiment analysis. PLoS ONE 2020, 15, e0241355. [Google Scholar] [CrossRef]
- Yu, M.; Bambacus, M.; Cervone, G.; Clarke, K.; Duffy, D.; Huang, Q.; Li, J.; Li, W.; Li, Z.; Liu, Q.; et al. Spatiotemporal event detection: A review. Int. J. Digit. Earth 2020, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Nazir, F.; Ghazanfar, M.A.; Maqsood, M. Social media signal detection using tweets volume, hashtag, and sentiment analysis. Multimed. Tools Appl. 2019, 78, 3553–3586. [Google Scholar] [CrossRef]
- Hasan, M.; Orgun, M.A.; Schwitter, R. A survey on real-time event detection from the Twitter data stream. J. Inf. Sci. 2016, 44, 443–463. [Google Scholar] [CrossRef]
- Weiler, A.; Grossniklaus, M.; Scholl, M.H. Survey and Experimental Analysis of Event Detection Techniques for Twitter. Comput. J. 2017, 60, 329–346. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Sui, Z.; Kang, C.; Gao, Y. Uncovering Patterns of Inter-Urban Trip and Spatial Interaction from Social Media Check-In Data. PLoS ONE 2014, 9, e86026. [Google Scholar] [CrossRef] [PubMed]
- Kent, J.D.; Capello, H.T. Spatial patterns and demographic indicators of effective social media content during theHorsethief Canyon fire of 2012. Cartogr. Geogr. Inf. Sci. 2013, 40, 78–89. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutnik, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kong, X.; Xu, Z.; Shen, G.; Wang, J.; Yang, Q.; Zhang, B. Urban traffic congestion estimation and prediction based on floating car trajectory data. Future Gener. Comput. Syst. 2016, 61, 97–107. [Google Scholar] [CrossRef]
- Telang, A.; Deepak, P.; Joshi, S.; Deshpande, P.; Rajendran, R. Detecting localized homogeneous anomalies over spatio-temporal data. Data Min. Knowl. Discov. 2014, 28, 1480–1502. [Google Scholar] [CrossRef] [Green Version]
- Bianco, A.M.; Ben, M.G.; Martínez, E.J.; Yohai, V.J. Outlier Detection in Regression Models with ARIMA Errors using Robust Estimates. J. Forecast. 2001, 20, 565–579. [Google Scholar] [CrossRef]
- Cleveland, R.B.; Cleveland, W.S.; McRae, J.E.; Terpenning, I. STL: A seasonal trend decomposition procedure based on loess. J. Off. Stat. 1990, 6, 3–73. [Google Scholar]
- Chang, I.; Tiao, G.C.; Chen, C. Estimation of Time Series Parameters in the Presence of Outliers. Technometrics 1988, 30, 193–204. [Google Scholar] [CrossRef]
- Karlaftis, M.G.; Vlahogianni, E.I. Statistical methods versus neural networks in transportation research: Differences, similarities and some insights. Transp. Res. Part C Emerg. Technol. 2011, 19, 387–399. [Google Scholar] [CrossRef]
- Vlahogianni, E.I.; Golias, J.C.; Karlaftis, M.G. Short-term traffic forecasting: Overview of objectives and methods. Transp. Rev. 2004, 24, 533–557. [Google Scholar] [CrossRef]
- Lint, J.W.C.V.; Hoogendoorn, S.P.; Zuylen, H.J.V. Accurate freeway travel time prediction with state-space neural networks under missing data. Transp. Res. Part C Emerg. Technol. 2005, 13, 347–369. [Google Scholar] [CrossRef]
- Stathopoulos, A.; Karlaftis, M.G. A multivariate state space approach for urban traffic flow modeling and prediction. Transp. Res. Part C 2003, 11, 121–135. [Google Scholar] [CrossRef]
- Williams, G.; Baxter, R.; He, H.; Hawkins, S.; Gu, L. A Comparative Study of RNN for Outlier Detection in Data Mining. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi City, Japan, 9–12 December 2002; pp. 709–712. [Google Scholar] [CrossRef]
- Hawkins, S.; He, H.; Williams, G.; Baxter, R. Outlier Detection Using Replicator Neural Networks. In Proceedings of the 4th International Conference on Data Warehousing and Knowledge Discovery, Aix-en-Provence, France, 4–6 September 2002; pp. 170–180. [Google Scholar] [CrossRef]
- Ma, X.; Tao, Z.; Wang, Y.; Yu, H.; Wang, Y. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. Part C 2015, 54, 187–197. [Google Scholar] [CrossRef]
- Wu, H.; Chen, Z.; Sun, W.; Zheng, B. Modeling trajectories with recurrent neural networks. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3083–3090. [Google Scholar] [CrossRef] [Green Version]
- Kanwar, S.; Mangal, N.; Niyogi, R. Event Detection over Twitter Social Media. In Proceedings of the First International Conference on Intelligent Computing and Communication, Bhubaneswar, India, 16–17 September 2016; pp. 177–185. [Google Scholar] [CrossRef]
- Comito, C. NexT: A framework for next-place prediction on location based social networks. Knowl.-Based Syst. 2020, 204, 106205. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Tweet Analysis for Real-Time Event Detection and Earthquake Reporting System Development. IEEE Trans. Knowl. Data Eng. 2012, 25, 919–931. [Google Scholar] [CrossRef]
- Parikh, R.; Karlapalem, K. ET: Events from tweets. In Proceedings of the 22nd International Conference on World WideWeb, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 613–620. [Google Scholar] [CrossRef]
- Li, C.; Sun, A.; Datta, A. Twevent: Segment-based event detection from Tweets. In Proceedings of the ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 155–164. [Google Scholar] [CrossRef]
- Marcus, A.; Bernstein, M.S.; Badar, O. TwitInfo: Aggregating and visualizing microblogs for event exploration. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 227–236. [Google Scholar] [CrossRef] [Green Version]
- Xie, R.; Zhu, F.; Ma, H. CLEar: A real-time online observatory for bursty and viral events. Proc. VLDB Endow. 2014, 7, 1637–1640. [Google Scholar] [CrossRef]
- Ritter, A.; Mausam, E.O.; Clark, S. Open domain event extraction from Twitter. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 1104–1112. [Google Scholar] [CrossRef] [Green Version]
- You, Y.; Huang, G.; Cao, J. GEAM: A general and event-related aspects model for Twitter event detection. In Proceedings of the International Conference on Web Information Systems Engineering, Nanjing, China, 13–15 October 2013; pp. 319–332. [Google Scholar] [CrossRef]
- Mehrotra, R.; Sanner, S.; Buntine, W.; Xie, L. Improving LDA topic models for microblogs via tweet pooling and automatic labeling. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 889–892. [Google Scholar] [CrossRef] [Green Version]
- Tan, P.N.; Steinbach, M.; Kumar, V. Introduction to Data Mining; Addison-Wesley Longman Publishing: Boston, MA, USA, 2005. [Google Scholar]
- Hasan, M.; Orgun, M.A.; Schwitter, R. TwitterNews+: A framework for real time event detection from the Twitter data stream. In Proceedings of the 8th International Conference on Social Informatics, Bellevue, WA, USA, 11–14 November 2016; pp. 224–239. [Google Scholar] [CrossRef]
- Petrovic, S.; Osborne, M.; Lavrenko, V. Streaming first story detection with application to Twitter. In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Los Angeles, CA, USA, 1–6 June 2010; pp. 181–189. [Google Scholar]
- Ouyang, Y.; Guo, B.; Zhang, J. SentiStory: Multi-grained sentiment analysis and event summarization with crowdsourced social media data. Pers. Ubiquitous Comput. 2017, 21, 97–111. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, N.; Du, W. A New Geo-Propagation Model of Event Evolution Chain Based on Public Opinion and Epidemic Coupling. Int. J. Environ. Res. Public Health 2020, 17, 9235. [Google Scholar] [CrossRef]
- Jiang, D.; Luo, X.; Xuan, J. Sentiment Computing for the News Event Based on the Big Social Media Data. IEEE Access 2017, 99, 2373–2382. [Google Scholar] [CrossRef]
- Nuaimi, A.A.; Shamsi, A.A.; Shamsi, A.A. Social Media Analytics for Sentiment Analysis and Event Detection in Smart Cities. In Proceedings of the 4th International Conference on Natural Language Computing (NATL 2018), Dubai, United Arab Emirates, 28–29 April 2018. [Google Scholar]
- Salas, A.; Georgakis, P.; Ammari, A. Traffic Event Detection Framework Using Social Media. In Proceedings of the 2017 International Conference on Smart Grid and Smart Cities, Singapore, 23–26 July 2017. [Google Scholar]
- Zou, X.; Jing, Y.; Zhang, J. Sentiment-based and hashtag-based Chinese online bursty event detection. Multimed. Tools Appl. 2018, 77, 21725–21750. [Google Scholar]
- Yu, X.; Zhong, C.; Li, D. Sentiment analysis for news and social media in COVID-19. In Proceedings of the SIGSPATIAL ‘20: 28th International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2020. [Google Scholar]
- Jiang, W.; Wang, Y.; Dou, M.; Liu, S.; Shao, S.; Liu, H. Solving Competitive Location Problems with Social Media Data Based on Customers’ Local Sensitivities. ISPRS Int. J. Geo-Inf. 2019, 8, 202. [Google Scholar] [CrossRef] [Green Version]
- Hosseini, M.; Diraby, T.; Shalaby, A. Supporting sustainable system adoption: Socio-semantic analysis of transit rider debates on social media. Sustain. Cities Soc. 2018, 38, 123–136. [Google Scholar] [CrossRef]
- Rzeszewski, M.; Beluch, L. Spatial Characteristics of Twitter Users—Toward the Understanding of Geosocial Media Production. ISPRS Int. J. Geo-Inf. 2017, 6, 236. [Google Scholar] [CrossRef] [Green Version]
- Manoharan, S.; Ammayappan, S. Geospatial Social Media Analytics for Emotion Analysis of Theme Park Visitors using Text Mining and GIS. J. Inf. Technol. Digit. World 2020, 2, 100–107. [Google Scholar] [CrossRef]
- Chiu, C.; Chiu, N.H.; Sung, R.J. Opinion mining of hotel customer-generated contents in Chinese weblogs. Curr. Issues Tour. 2015, 18, 477–495. [Google Scholar] [CrossRef]
- Jiang, W.; Xiong, Z.; Su, Q.; Long, Y.; Song, X.; Sun, P. Using Geotagged Social Media Data to Explore Sentiment Changes in Tourist Flow: A Spatiotemporal Analytical Framework. ISPRS Int. J. Geo-Inf. 2021, 10, 135. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, X.; Ma, J. The influence of public spaces on neighborhood social interaction in transitional urban Beijing: Comparing local residents and migrants. Sci. Geogr. Sin. 2020, 40, 69–78. [Google Scholar]
- He, Y.; Chen, Y.; Li, Z. Analysis on spatial structural characteristics of land use of Beijing City. Trans. Chin. Soc. Agric. Eng. 2010, 26, 313–318. [Google Scholar]
- Dong, C.; Zhao, R.; Liu, J.-P.; Wang, G.-X.; Xu, X.-Z. Application of geographical parameter database to establishment of unit population database. Chin. Geogr. Sci. 2003, 1, 36–40. [Google Scholar] [CrossRef]
- Hung, C.C.; Peng, W.C. A regression-based approach for mining user movement patterns from random sample data. Data Knowl. Eng. 2011, 70, 1–20. [Google Scholar] [CrossRef]
- Wang, Y.; Teng, W.; Tsou, M.-H. Mapping Dynamic Urban Land Use Patterns with Crowdsourced Geo-Tagged Social Media (Sina-Weibo) and Commercial Points of Interest Collections in Beijing, China. Sustainability 2016, 8, 1202. [Google Scholar] [CrossRef] [Green Version]
- Schmidhuber, J.; Gers, F.; Eck, D. Learning nonregular languages: A comparison of simple recurrent networks and LSTM. Neural Comput. 2002, 14, 2039–2041. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Huang, C.; Hu, Q.; Jia, Z.; Yong, T. Personalized learning full-path recommendation model based on LSTM neural networks. Inf. Sci. 2018, 444, 135–152. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Crosby, T. How to Detect and Handle Outliers. Technometrics 1994, 36, 315–316. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | User_ID | User_ Gender | Created_at | Text | Geo | POI_ID | POI_Title | Source |
|---|---|---|---|---|---|---|---|---|
| XX | XX | Male | 11:06:53 28 August 2017 | 【助我赢取77.77元现金大奖。】骑ofo小黄车集齐5种七夕卡,赢77.77元现金大奖。(【Help me win a prize of RMB 77.77.】Collect 5 kinds of cards by riding shared bikes.) | 116.447613; 39.951815 | Null | Null | PP时光机 (PPP time machine) |
| XX | XX | Male | 22:23:14 22 September 2017 | 187音频[音乐]承接大小录音棚,MIDI教室,工作室等等。 ([Music] The company of 187 Music undertakes following businesses: recording studio, MIDI classroom, music studio and so on) | 116.320648; 39.912772 | Null | Null | 未通过审核的应用 (unapproved application) |
| XX | XX | Female | 19:23:19 24 December 2017 | 羽泉演唱会还有十分钟开始!!(There are 10 min before Quan Yu’s concert starts!!) | 116.441803; 39.932159 | XX | 北京工人体育馆 (Beijing Worker Gymnasium) | Samsung Galaxy S8 |
| XX | XX | Male | 10:50:49 1 January 2018 | 在这里祝福大家2018年身体健康,万事如意!开心每一天! (Wish everyone good health and good luck in 2018! Happy every day!) | 116.397659; 39.906021 | XX | 天安门广场(Tiananmen Square) | HUAWEI Mate 8 |
| XX | XX | Male | 12:10:20 19 April 2018 | 后海附近马路着火了,堵车了。[允悲]希望无人员受伤。(There is a traffic jam caused by the fire on the road near Houhai. [Sad]. Hope no one gets hurt.) | 116.385483; 39.942132 | XX | 后海公园 (Houhai Park) | iPhone 7 Plus |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, W.; Wang, Y.; Xiong, Z.; Song, X.; Long, Y.; Cao, W. Detecting Urban Events by Considering Long Temporal Dependency of Sentiment Strength in Geotagged Social Media Data. ISPRS Int. J. Geo-Inf. 2021, 10, 322. https://doi.org/10.3390/ijgi10050322
Jiang W, Wang Y, Xiong Z, Song X, Long Y, Cao W. Detecting Urban Events by Considering Long Temporal Dependency of Sentiment Strength in Geotagged Social Media Data. ISPRS International Journal of Geo-Information. 2021; 10(5):322. https://doi.org/10.3390/ijgi10050322
Chicago/Turabian StyleJiang, Wei, Yandong Wang, Zhengan Xiong, Xiaoqing Song, Yi Long, and Weidong Cao. 2021. "Detecting Urban Events by Considering Long Temporal Dependency of Sentiment Strength in Geotagged Social Media Data" ISPRS International Journal of Geo-Information 10, no. 5: 322. https://doi.org/10.3390/ijgi10050322
APA StyleJiang, W., Wang, Y., Xiong, Z., Song, X., Long, Y., & Cao, W. (2021). Detecting Urban Events by Considering Long Temporal Dependency of Sentiment Strength in Geotagged Social Media Data. ISPRS International Journal of Geo-Information, 10(5), 322. https://doi.org/10.3390/ijgi10050322