

Construction of a COVID-19 Pandemic Situation Knowledge Graph Considering Spatial Relationships: A Case Study of Guangzhou, China

Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data Collection
2.2.1. Pandemic Data Collection and Processing
2.2.2. Geographic Data Collection and Processing
2.3. Methodology
- (1)
- Data collection and processing as described in Section 2.2.
- (2)
- Ontology design of COVID-19 pandemic situation KG considering spatial relationships. In Section 2.3.2, we designed an ontology model, including designs of entity, attribute, and relationship.
- (3)
- Entity, non-spatial relationship, and non-spatial attribute extraction in the notifications. We used the pipeline method to extract entity relationships. We extracted the relationship between entity pairs and entity pairs using two independent methods. In the entity pairs extraction stage, we used the LTP to manually identify the head and tail entities. In the relationship recognition stage, we fine-tuned the BERT model to extract the relationships contained in the pandemic notifications. Some of the same entities in the notifications use different words; we manually aligned these entities. Then we organized them into structured triples in tables, such as <h_entity (h_attr1, h_attr2…), relationship (r_attr1, r_attr2…), t_entity (t_attr1,t_attr2…>, where the h_entity, t_entity and relationship refer to the head entity, tail entity and relationship between them; their respective attributes are in brackets.
- (4)
- Spatial relationship extraction. Based on the geographical entities involved in the notifications, we further obtained the spatial coordinates of the geographical entities and then calculated the distance and azimuth between the entities. They were also organized into structured triples, such as <hg_entity (hg_attr1, hg_attr2…), s_relationship (sr_attr1, sr_attr2…), tg_entity (tg_attr1,tg_attr2…>, where the hg_ entity, tg_ entity and s_relationship refer to the head entity, tail entity and relationship between them in a geographic triple; their respective attributes are in brackets.
- (5)
- Construction of pandemic situation KG considering spatial relationships. Based on the ontology design and structured triples, we coded the entities and assigned the same ID attributes to the same entities. Among these, the attribute of the spatial relationship stored the distance and direction information between the head entity and the tail entity. Finally, we used py2neo (a python library for neo4j) to store the structured triples and display them in neo4j.
2.3.1. Custom Dictionary
2.3.2. Ontology Design
2.3.3. Spatial Relationship Design of Geographic Entities
2.3.4. Non-Spatial Relationship Extraction Based on BERT Model
- (1)
- Model input representation
- (2)
- Relationship extraction
3. Experiments and Results
3.1. Experiments
3.1.1. Custom Dictionary Experiment
3.1.2. Non-Spatial Relationship Extraction Experiment
3.1.3. Graph Construction
3.2. Analysis of Experimental Results
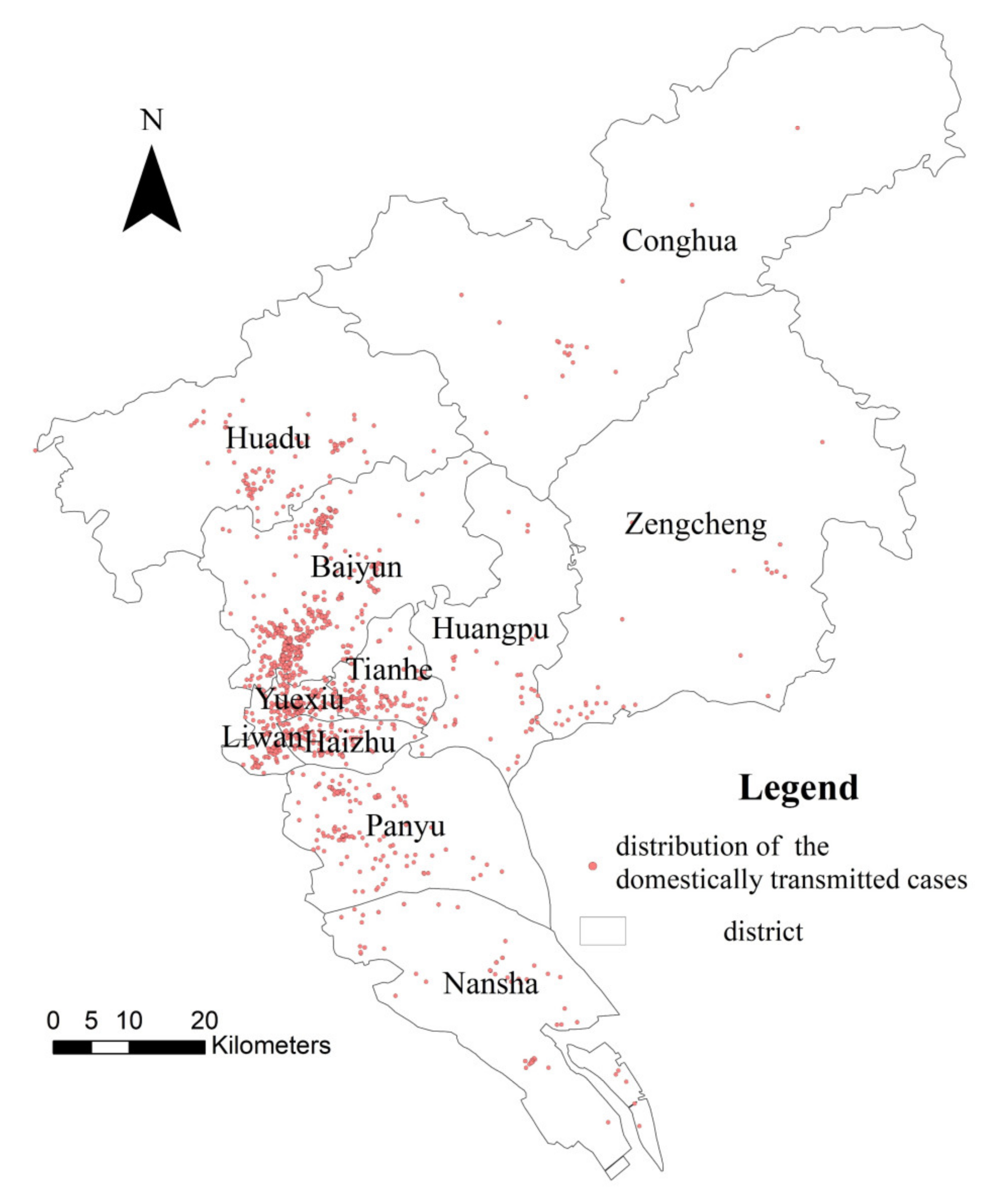
3.2.1. Spatial Analysis of Pandemic-Related Areas
3.2.2. Development of the Pandemic Situation
3.2.3. Sources of Imported Cases
3.2.4. Analysis of Case Relationships
4. Discussion
5. Conclusions
- (1)
- Most of the cases in Guangzhou revealed spatial clustering characteristics, and the cases are mainly distributed in Yuexiu, Tianhe, Baiyun, Liwan and Haizhu, which are located in or close to the downtown and have a high population density; most of the imported cases were students from developed countries such as the United States and Britain, as well as workers from developing countries such as Bangladesh and Saudi Arabia.
- (2)
- According to the disclosed notification data, the spread of COVID-19 in the Guangzhou population generally has not exceeded four generations. Most of the infected persons were close contacts or sub-close contacts of the “number one case”, indicating that rapid government response effectively prevented the further spread of the pandemic.
- (3)
- Compared with entity relationship extraction methods such as trigger word matching extraction and wrapper extraction, the entity relationship extraction of pandemic data achieved by the fine-tuned BERT model can be used to quantitatively evaluate RE accuracy, with relationship recognition accuracy for the Guangzhou pandemic reaching a level of 95.0%, thus indicating that the model has potential feasibility in the application of pandemic data entity-relationship extraction.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Tortajada, C.; Navarro, A.; Andreu-Ballester, J.C.; Mayor, A.; Anon, S.; Flores, J. Prevalence and Duration of Symptoms among Moderate and Severe COVID-19 Patients 12 Months after Discharge. Intern. Emerg. Med. 2022, 17, 929–934. [Google Scholar] [CrossRef]
- Rafique, N.; Tufaif, F.A.; Alhammali, W.; Alalwan, R.; Aljaroudi, A.; AlFaraj, F.; Latif, R.; Al-Asoom, L.I.; Alsunni, A.A.; Ghamdi, K.S.A.; et al. The Psychological Impact of COVID-19 on Residents of Saudi Arabia. PRBM 2022, 15, 1221–1234. [Google Scholar] [CrossRef] [PubMed]
- Dubin, J.M.; Bennett, N.E.; Halpern, J.A. The Adverse Impact of COVID-19 on Men’s Health. Curr. Opin. Urol. 2022, 32, 146–151. [Google Scholar] [CrossRef] [PubMed]
- Shen, H.; Fu, M.; Pan, H.; Yu, Z.; Chen, Y. The Impact of the COVID-19 Pandemic on Firm Performance. Emerg. Mark. Financ. Trade 2020, 56, 2213–2230. [Google Scholar] [CrossRef]
- Phan, D.H.B.; Narayan, P.K. Country Responses and the Reaction of the Stock Market to COVID-19—A Preliminary Exposition. Null 2020, 56, 2138–2150. [Google Scholar] [CrossRef]
- Yue, L.; Wang, X.; Tong, D. Structural Factors of Epidemic Transmission under Conditions of Inter-Provincial Openness: An Empirical Analysis of the COVID-19 Spread. Mobile Netw. Appl. 2022, 27, 808–821. [Google Scholar] [CrossRef]
- Kermack, W.O.; McKendrick, A.G.; Walker, G.T. A Contribution to the Mathematical Theory of Epidemics. Proc. R. Soc. London. Ser. A Contain. Pap. A Math. Phys. Character 1927, 115, 700–721. [Google Scholar] [CrossRef] [Green Version]
- Schwartz, I.B.; Smith, H.L. Infinite Subharmonic Bifurcation in an SEIR Epidemic Model. J. Math. Biology 1983, 18, 233–253. [Google Scholar] [CrossRef]
- Yadav, S.K.; Akhter, Y. Statistical Modeling for the Prediction of Infectious Disease Dissemination With Special Reference to COVID-19 Spread. Front. Public Health 2021, 9, 645405. [Google Scholar] [CrossRef]
- Huang, C.; Wang, Y.; Li, X.; Ren, L.; Zhao, J.; Hu, Y.; Zhang, L.; Fan, G.; Xu, J.; Gu, X.; et al. Clinical Features of Patients Infected with 2019 Novel Coronavirus in Wuhan, China. Lancet 2020, 395, 497–506. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Wang, L.; Li, M.; Zhou, X. Evaluating Transmission Heterogeneity and Super-Spreading Event of COVID-19 in a Metropolis of China. Int. J. Environ. Res. Public Health 2020, 17, 3705. [Google Scholar] [CrossRef]
- Ren, H.; Zhao, L.; Zhang, A.; Song, L.; Liao, Y.; Lu, W.; Cui, C. Early Forecasting of the Potential Risk Zones of COVID-19 in China’s Megacities. Sci. Total Environ. 2020, 729, 138995. [Google Scholar] [CrossRef]
- Desjardins, M.R.; Hohl, A.; Delmelle, E.M. Rapid Surveillance of COVID-19 in the United States Using a Prospective Space-Time Scan Statistic: Detecting and Evaluating Emerging Clusters. Appl. Geogr. 2020, 118, 102202. [Google Scholar] [CrossRef]
- Xiong, Y.; Wang, Y.; Chen, F.; Zhu, M. Spatial Statistics and Influencing Factors of the COVID-19 Epidemic at Both Prefecture and County Levels in Hubei Province, China. Int. J. Environ. Res. Public Health 2020, 17, 3903. [Google Scholar] [CrossRef]
- Kang, D.; Choi, H.; Kim, J.-H.; Choi, J. Spatial Epidemic Dynamics of the COVID-19 Outbreak in China. Int. J. Infect. Dis. 2020, 94, 96–102. [Google Scholar] [CrossRef]
- Studer, R.; Benjamins, V.R.; Fensel, D. Knowledge Engineering: Principles and Methods. Data Knowl. Eng. 1998, 25, 161–197. [Google Scholar] [CrossRef] [Green Version]
- Lin, Q.; Liu, J.; Pan, Y.; Zhang, L.; Hu, X.; Ma, J. Rule-Enhanced Iterative Complementation for Knowledge Graph Reasoning. Inf. Sci. 2021, 575, 66–79. [Google Scholar] [CrossRef]
- He, K.; Yao, L.; Zhang, J.; Li, Y.; Li, C. Construction of Genealogical Knowledge Graphs From Obituaries: Multitask Neural Network Extraction System. J. Med. Internet Res. 2021, 23, e25670. [Google Scholar] [CrossRef]
- Lin, J.; Zhao, Y.; Huang, W.; Liu, C.; Pu, H. Domain Knowledge Graph-Based Research Progress of Knowledge Representation. Neural Comput. Applic 2021, 33, 681–690. [Google Scholar] [CrossRef]
- Tuan, N.H.; Mohammadi, H.; Rezapour, S. A Mathematical Model for COVID-19 Transmission by Using the Caputo Fractional Derivative. Chaos Solitons Fractals 2020, 140, 110107. [Google Scholar] [CrossRef] [PubMed]
- Lipsitch, M.; Cohen, T.; Cooper, B.; Robins, J.M.; Ma, S.; James, L.; Gopalakrishna, G.; Chew, S.K.; Tan, C.C.; Samore, M.H.; et al. Transmission Dynamics and Control of Severe Acute Respiratory Syndrome. Science 2003, 300, 1966–1970. [Google Scholar] [CrossRef] [Green Version]
- Angelopoulou, A.; Mykoniatis, K. Hybrid Modelling and Simulation of the Effect of Vaccination on the COVID-19 Transmission. J. Simul. 2022, 12, 1–12. [Google Scholar] [CrossRef]
- Currie, C.S.M.; Fowler, J.W.; Kotiadis, K.; Monks, T.; Onggo, B.S.; Robertson, D.A.; Tako, A.A. How Simulation Modelling Can Help Reduce the Impact of COVID-19. J. Simul. 2020, 14, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Leslie, W.D.; Brunham, R.C. The Dynamics of HIV Spread: A Computer Simulation Model. Comput. Biomed. Res. 1990, 23, 380–401. [Google Scholar] [CrossRef]
- Jiang, B.; You, X.; Li, K.; Zhou, X.; Wen, H. Interactive Visual Analysis of COVID-19 Epidemic Situation Using Geographic Knowledge Graph. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 836–845. [Google Scholar] [CrossRef]
- Chen, X.; Liu, J.; Xu, L.; Li, J.; Zhang, W.; Liu, H. Construction of the COVID-19 Epidemic Cases Activity Knowledge Graph: A Case Study of Zhengzhou City. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 816–825. [Google Scholar] [CrossRef]
- Wu, J. Construct a Knowledge Graph for China Coronavirus (COVID-19) Patient Information Tracking. RMHP 2021, 14, 4321–4337. [Google Scholar] [CrossRef] [PubMed]
- Davahli, M.R.; Karwowski, W.; Fiok, K.; Murata, A.; Sapkota, N.; Farahani, F.V.; Al-Juaid, A.; Marek, T.; Taiar, R. The COVID-19 Infection Diffusion in the US and Japan: A Graph-Theoretical Approach. Biology 2022, 11, 125. [Google Scholar] [CrossRef] [PubMed]
- Flocco, D.; Palmer-Toy, B.; Wang, R.; Zhu, H.; Sonthalia, R.; Lin, J.; Bertozzi, A.L.; Jeffrey Brantingham, P. An Analysis of COVID-19 Knowledge Graph Construction and Applications. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15 December 2021; pp. 2631–2640. [Google Scholar]
- Li, Z.; Xu, Q.; Zhang, W.; Zhang, T. An Approach and Implementation for Knowledge Graph Construction and Q&A System. In Proceedings of the 2021 3rd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 3–5 December 2021; pp. 425–429. [Google Scholar]
- Li, X.; Cheng, R.; Najafi, M.; Chang, K.; Han, X.; Cao, H. M-Cypher: A GQL Framework Supporting Motifs. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, ACM, Virtual Event Ireland, 19 October 2020; pp. 3433–3436. [Google Scholar]
- Ding, K.; Han, H.; Li, L.; Yi, M. Research on Question Answering System for COVID-19 Based on Knowledge Graph. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 4659–4664. [Google Scholar]
- Tian, Y.; Li, X. Analysis on the Evolution Path of COVID-19 Network Public Opinion Based on the Event Evolutionary Graph. Inf. Stud. Theory Appl. 2021, 44, 76–83. [Google Scholar] [CrossRef]
- Kou, Z.; Shang, L.; Zhang, Y.; Wang, D. HC-COVID: A Hierarchical Crowdsource Knowledge Graph Approach to Explainable COVID-19 Misinformation Detection. Proc. ACM Hum. Comput. Interact. 2022, 6, 1–25. [Google Scholar] [CrossRef]
- Xu, X.; Li, Z.; Wang, R.; Zhao, L. Analysis of the Evolution of User Emotion and Opinion Leaders’ Information Dissemination Behavior in the Knowledge Q&A Community during COVID-19. Int. J. Environ. Res. Public Health 2021, 18, 12252. [Google Scholar] [CrossRef]
- Zhang, S.; Lin, X.; Zhang, X. Discovering DTI and DDI by Knowledge Graph with MHRW and Improved Neural Network. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Houston, TX, USA, 9 December 2021; pp. 588–593. [Google Scholar]
- Zeng, X.; Song, X.; Ma, T.; Pan, X.; Zhou, Y.; Hou, Y.; Zhang, Z.; Li, K.; Karypis, G.; Cheng, F. Repurpose Open Data to Discover Therapeutics for COVID-19 Using Deep Learning. J. Proteome Res. 2020, 19, 4624–4636. [Google Scholar] [CrossRef] [PubMed]
- Xie, Z.; Zhu, R.; Liu, J.; Zhou, G.; Huang, J.; Cui, X. GFCNet: Utilizing Graph Feature Collection Networks for Coronavirus Knowledge Graph Embeddings—ScienceDirect. Inf. Sci. 2022, 608, 1557–1571. [Google Scholar] [CrossRef]
- Han, Y.; Yang, L.; Jia, K.; Li, J.; Feng, S.; Chen, W.; Zhao, W.; Pereira, P. Spatial Distribution Characteristics of the COVID-19 Pandemic in Beijing and Its Relationship with Environmental Factors. Sci. Total Environ. 2021, 761, 144257. [Google Scholar] [CrossRef]
- Wang, J.; Wang, K.; Li, J.; Jiang, J.; Wang, Y.; Mei, J. Accelerating Epidemiological Investigation Analysis by Using NLP and Knowledge Reasoning: A Case Study on COVID-19. MIA Annu. Symp. Proc. 2020, 2020, 1258–1267. [Google Scholar]
- Liu, Z.; Ma, Y.; Cheng, Q.; Liu, Z. Finding Asymptomatic Spreaders in a COVID-19 Transmission Network by Graph Attention Networks. Viruses 2022, 14, 1659. [Google Scholar] [CrossRef]
- Tsao, S.-F.; Chen, H.; Tisseverasinghe, T.; Yang, Y.; Li, L.; Butt, Z.A. What Social Media Told Us in the Time of COVID-19: A Scoping Review. Lancet Digit. Health 2021, 3, 175–194. [Google Scholar] [CrossRef]
- Rau, L.F. Extracting Company Names from Text. In Proceedings of the Seventh IEEE Conference on Artificial Intelligence Application, Miami Beach, FL, USA, 24–28 August 1991; Volume i, pp. 29–32. [Google Scholar]
- Qiu, J.; Zhou, Y.; Wang, Q.; Ruan, T.; Gao, J. Chinese Clinical Named Entity Recognition Using Residual Dilated Convolutional Neural Network With Conditional Random Field. IEEE Trans. NanoBioscience 2019, 18, 306–315. [Google Scholar] [CrossRef] [PubMed]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Lafferty, J.D.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning, Williamstown, MA, USA, 1–28 June 2001; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; pp. 282–289. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Yan, H.; Deng, B.; Li, X.; Qiu, X. TENER: Adapting Transformer Encoder for Named Entity Recognition. arXiv 2019, arXiv:1911.04474. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Zelenko, D.; Aone, C.; Richardella, A. Kernel Methods for Relation Extraction. J. Mach. Learn. Res. 2003, 3, 1083–1106. [Google Scholar]
- Kambhatla, N. Combining Lexical, Syntactic, and Semantic Features with Maximum Entropy Models for Extracting Relations. In Proceedings of the ACL 2004 on Interactive Poster and Demonstration Sessions, New York, NY, USA, 21 July 2004; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; p. 22. [Google Scholar]
- Brin, S. Extracting Patterns and Relations from the World Wide Web. In Selected Papers from the International Workshop on The World Wide Web and Databases; Springer: Berlin/Heidelberg, Germany, 1998; pp. 172–183. [Google Scholar]
- Zhang, Z. Weakly-Supervised Relation Classification for Information Extraction. In Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management, Washington, DC, USA, 8–13 November 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 581–588. [Google Scholar]
- Kohonen, T. The Self-Organizing Map. Neurocomputing 1998, 21, 1–6. [Google Scholar] [CrossRef]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An Efficient K-Means Clustering Algorithm: Analysis and Implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by Passing Messages between Data Points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, K.; Feng, Y.; Huang, S.; Zhao, D. Semantic Relation Classification via Convolutional Neural Networks with Simple Negative Sampling. arXiv 2015, arXiv:1506.07650. [Google Scholar] [CrossRef]
- Zhang, S.; Zheng, D.; Hu, X.; Yang, M. Bidirectional Long Short-Term Memory Networks for Relation Classification. In Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation, Shanghai, China, 30 October–1 November 2015; pp. 73–78. [Google Scholar]
- Katiyar, A.; Cardie, C. Going out on a Limb: Joint Extraction of Entity Mentions and Relations without Dependency Trees. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 November 2017; pp. 917–928. [Google Scholar]
- Liang, L.-X.; Lin, L.; Lin, E.; Wen, W.-S.; Huang, G.-Y. A Joint Learning Model to Extract Entities and Relations for Chinese Literature Based on Self-Attention. Mathematics 2022, 10, 2216. [Google Scholar] [CrossRef]
- Yoo, S.; Jeong, O. Automating the Expansion of a Knowledge Graph. Expert Syst. Appl. 2020, 141, 112965. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, M.; Dong, W.; Zuo, M.; Wei, S.; Song, S.; Ai, D. An Entity Relationship Extraction Model Based on BERT-BLSTM-CRF for Food Safety Domain. Comput. Intell. Neurosci. 2022, 2022, 7773259. [Google Scholar] [CrossRef]
- Clementini, E.; Felice, P.D.; Hernández, D. Qualitative Representation of Positional Information. Artif. Intell. 1997, 95, 317–356. [Google Scholar] [CrossRef] [Green Version]
- Guo, J.; Du, S. Modeling Words for Qualitative Distance Based on Interval Type-2 Fuzzy Sets. ISPRS Int. J. Geo-Inf. 2018, 7, 291. [Google Scholar] [CrossRef] [Green Version]
- Goyal, R.K. Similarity Assessment for Cardinal Directions between Extended Spatial Objects. Ph.D. Thesis, The University of Maine, Orono, ME, USA, 2000. [Google Scholar]
- Frank, A.U. Qualitative Spatial Reasoning: Cardinal Directions as an Example. Int. J. Geogr. Inf. Syst. 1996, 10, 269–290. [Google Scholar] [CrossRef]
- Yan, H.; Guo, R. Theorization of Directional Relationship Description Based on Voronoi Diagram. Whdxxbxxkxb 2002, 27, 306–310. [Google Scholar]
- Egenhofer, M.J.; Franzosa, R.D. Point-Set Topological Spatial Relations. Int. J. Geogr. Inf. Syst. 1991, 5, 161–174. [Google Scholar] [CrossRef] [Green Version]
- Randell, D.; Cui, Z.; Cohn, A. A Spatial Logic Based on Regions and Connection. In Proceedings of the 1st International Conference on Principles of Knowledge Representation and Reasoning, Leeds, UK, 1 January 1992; pp. 165–176. [Google Scholar]
- Chang, S.-K.; Jungert, E.; Li, Y. The Design of Pictorial Databases Based upon the Theory of Symbolic Projections. In Design and Implementation of Large Spatial Databases; Buchmann, A.P., Günther, O., Smith, T.R., Wang, Y.-F., Eds.; Springer: Berlin/Heidelberg, Germany, 1990; pp. 301–323. [Google Scholar]
- Cobb, M.A.; Petry, F.E.; Shaw, K.B. Fuzzy Spatial Relationship Refinements Based on Minimum Bounding Rectangle Variations. Fuzzy Sets Syst. 2000, 113, 111–120. [Google Scholar] [CrossRef]
- Egenhofer, M.; Herring, J. Categorizing Binary Topological Relations between Regions, Lines and Points in Geographic Databases, the 9-Intersection: Formalism and Its Use for Naturallanguage Spatial Predicates. St. Barbar. CA Natl. Cent. Geogr. Inf. Anal. Tech. Rep. 1990, 94, 1–28. [Google Scholar]
- Chu, D.; Wan, B.; Li, H.; Dong, S.; Fu, J.; Liu, Y.; Huang, K.; Liu, H. A Machine Learning Approach to Extracting Spatial Information from Geological Texts in Chinese. Int. J. Geogr. Inf. Sci. 2005, 3406, 539–547. [Google Scholar] [CrossRef]
- Che, W.; Guo, J.; Cui, Y. Basic toolset and common data set. In Natural Language Processing: A Pre-trained Model Approach; Publishing House of Electronics: Beijing, China, 2021; pp. 45–68. [Google Scholar]
- OWL 2 Web Ontology Language Document Overview (Second Edition). Available online: https://www.w3.org/TR/owl2-overview/ (accessed on 23 July 2022).
- Lagoze, C.; Hunter, J. The ABC Ontology and Model. J. Digit. Inf. 2001, 2, 1–18. [Google Scholar]
- Peuquet, D.J.; Ci-Xiang, Z. An Algorithm to Determine the Directional Relationship between Arbitrarily-Shaped Polygons in the Plane. Pattern Recognit. 1987, 20, 65–74. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Description | Source | Content | Count |
|---|---|---|---|---|
| Pandemic | Guangzhou pandemic notification data | Guangzhou Municipal Health Commission | Text | 934 |
| Geographic | Names of Guangzhou POIs | Gaode map API | Names of POIs | 421,740 |
| POIs involved in pandemic data | Gaode pick coordinate system | Names and coordinates of POIs | 1391 | |
| Administrative division data | National Bureau of Statistics | Administrative division | 2800 |
| Head_ Entity | Relationship | Tail_ Entity | Meaning |
|---|---|---|---|
| place/POI | contain | place/POI | wide range of administrative divisions includes administrative divisions at lower levels; administrative divisions or larger areas of POIs contain smaller areas of premises |
| infected | samplingPoint | institution | the facility that takes nucleic acid samples from infected individuals |
| infected | permanentAddress | place/POI | common residence of infected persons |
| infected | travelDate | date | date the infected person traveled |
| place | arriveDate | date | date of arrival at a place |
| event | hasOccurPlace | place | the place where an event or action takes place |
| infected | patternOfFound | pattern | how infected person is found to be infected |
| date | controlledArea | place | the date when a place is designated “controlled-level” |
| infected | isolationMethod | isolation | how infected are isolated |
| infected | isolationPlace | place | place of isolation for infected persons |
| date | managedArea | place | the date when a place is designated “managed-level” |
| date | preventedArea | place | the date when a place is designated “prevented-level” |
| infected | hasNationality | nation | nationality of the infected person |
| infected | behavior | event | events experienced by the infected person |
| infected | nativePlace | place | the native place of the infected person |
| infected | meanOfTransport | transportation | mode of transportation of the infected person |
| isolation | isolateSdate | date | the date the infected person starts isolation |
| infected | comeFrom | country | country or region where the infected person comes from |
| infected | pointOfEntry | place | place of entry of the infected person |
| infected | entryTime | date | date of entry of the infected person |
| date | pandemic-RelatedArea | place | affected areas on a given day |
| transportation | nextTransportation | transportation | order in which the infected person traveled |
| country | nextCountry | country | order in which an infected person passed through a country or region |
| infected | diagnosisDate | date | when the infected person was diagnosed |
| infected | hasProfession | profession | infected person’s occupation |
| infected | PRelation | infected | relationship between cases |
| POI | spatial | POI | the spatial relationship between POIs |
| Parameter | Value |
|---|---|
| Epoch | 6 |
| Learning_rate | 0.002 |
| Batch_size | 4 |
| Dropout | 0.4 |
| Cluster | Radius | Population | Number of Cases | p-Value | Location of Centroid |
|---|---|---|---|---|---|
| cluster 1 | 19.82 km | 8649558 | 1065 | 1.00 × 10-17 | Baiyun |
| cluster 2 | 4.56 km | 875504 | 108 | 2.40× 10-2 | Baiyun |
| cluster 3 | 2.85 km | 484644 | 196 | 1.00× 10-17 | Liwan |
| cluster 4 | 2.01 km | 184581 | 109 | 1.00× 10-17 | Tianhe |
| cluster 5 | 1.56 km | 202505 | 42 | 1.70× 10-4 | Yuexiu |
| cluster 6 | 1.05 km | 210491 | 49 | 7.00× 10-7 | Haizhu |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Li, W.; Chen, Y.; Guo, Y. Construction of a COVID-19 Pandemic Situation Knowledge Graph Considering Spatial Relationships: A Case Study of Guangzhou, China. ISPRS Int. J. Geo-Inf. 2022, 11, 561. https://doi.org/10.3390/ijgi11110561
Yang X, Li W, Chen Y, Guo Y. Construction of a COVID-19 Pandemic Situation Knowledge Graph Considering Spatial Relationships: A Case Study of Guangzhou, China. ISPRS International Journal of Geo-Information. 2022; 11(11):561. https://doi.org/10.3390/ijgi11110561
Chicago/Turabian StyleYang, Xiaorui, Weihong Li, Yebin Chen, and Yunjian Guo. 2022. "Construction of a COVID-19 Pandemic Situation Knowledge Graph Considering Spatial Relationships: A Case Study of Guangzhou, China" ISPRS International Journal of Geo-Information 11, no. 11: 561. https://doi.org/10.3390/ijgi11110561