

DP-CSM: Efficient Differentially Private Synthesis for Human Mobility Trajectory with Coresets and Staircase Mechanism


Abstract
:1. Introduction
- We introduce coreset-based clustering into the location generalization stage to improve the efficiency and scalability of synthetic trajectory generation. Coresets, instead of the original dataset, are used for clustering, as they achieve similar utility and the same privacy level with the original dataset.
- We utilize the staircase mechanism, instead of the traditional Laplace mechanism, to perturb the counts of trajectories in the trajectory reconstruction stage to avoid adding excessive noise, thereby preserving high data utility under the same privacy budget and achieving better privacy and utility trade-off than existing methods.
- We provide theoretical proof that the proposed DP-CSM satisfies -differential privacy. Since trajectory reconstruction satisfies differential privacy, the DP-CSM also satisfies differential privacy (See Section 4.4 for detailed analysis).
- We conduct comprehensive experiments on three real-world trajectory datasets to evaluate the performance of the proposed method in terms of data utility and efficiency.
2. Related Work
2.1. Differentially Private Trajectory Data Publishing
2.1.1. Noisy Prefix Tree
2.1.2. Private Statistics
2.1.3. Cluster Centers
2.2. Differentially Private Sequential Data Publishing
3. Preliminaries
4. DP-CSM
4.1. The Framework
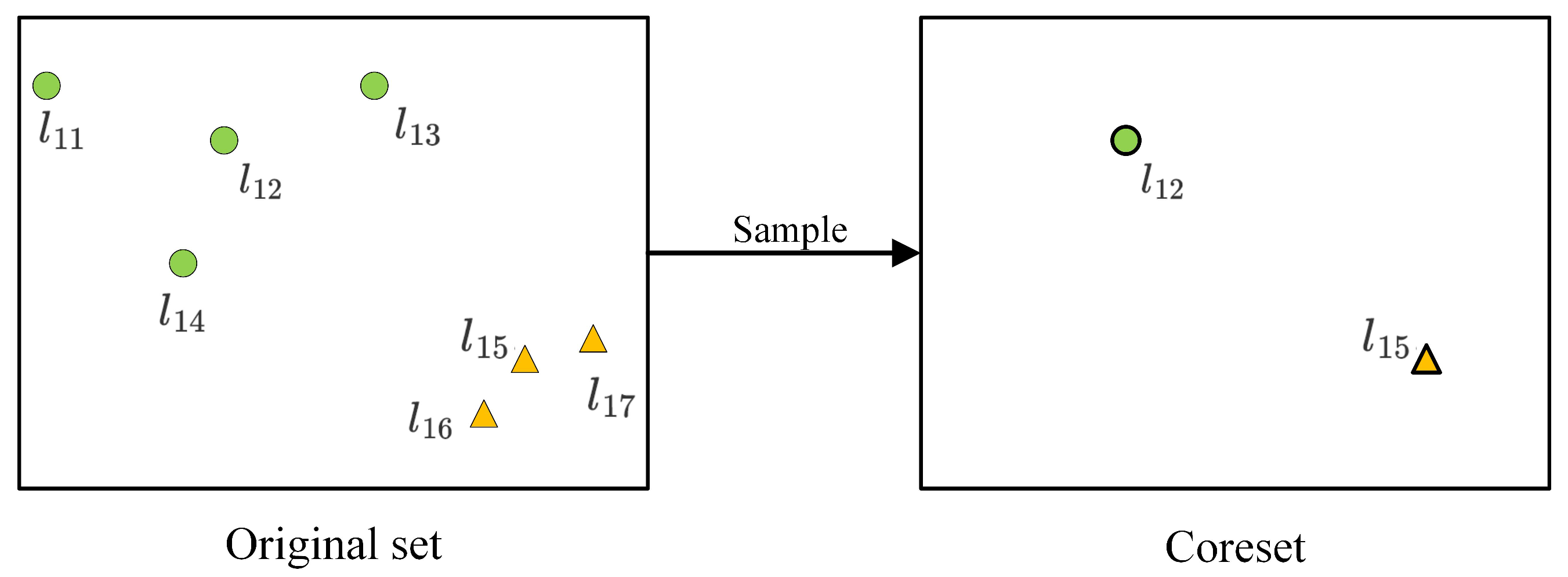
4.2. Coreset-Based Location Generalization
| Algorithm 1: coresets based location generalization algorithm |
Input: , k, m Output: |
| 1 forlocation dataset of each timestamp in do |
| 2 foreach location l in do |
| 3 compute ; // Compute sensitivity of l according to [28,29] |
| 4 end |
| 5 foreach do |
| 6 ; // Nomalization |
| 7 end |
| 8 Sample m weighted points from where each point x has weight and is sampled with probability ; |
| 9 Perform k-means on the coresets to obtain k cluster centers as generalized locations; |
| 10 end |
| 11 return; |
4.3. Trajectory Reconstruction
| Algorithm 2: Trajectory reconstruction algorithm |
Input: , , . Output: : reconstructed trajectories and their noisy counts. |
| 1 ; // Initialize an empty trajectory set |
| 2 ; //Construct all possible candidate trajectories |
| 3 foreach candidate reconstructed trajectory in do |
| 4 ; |
| 5 ifthen |
| 6 ; // add staircase noise to the counts |
| 7 ; // add reconstructed trajectories into |
| 8 end |
| 9 end |
| 10 ifthen |
| 11 //Supplement trajectories |
| 12 randomly sample trajectories from ; |
| 13 end |
| 14 return; // Output reconstructed trajectories and their noisy counts |
4.4. Privacy Analysis
- Case 1:
- For any generalized trajectory , we can derive that
- Case 2:
- For any generalized trajectory , the count of the generalized trajectory is obtained by adding noise that satisfies the staircase mechanism on the basis of the real count. According to staircase mechanism [27], we can derive that
- Case 3:
- For an arbitrary generalized trajectory , it can be divided into two sub-cases and .
- (a)
- Assuming , from the analysis of Section 4.3 and the probability density function of the staircase mechanism, we can derive that:That is:where represents the probability density function of the staircase mechanism.
- (b)
- We use to represent the minimum noisy count of the trajectory in the output trajectory dataset, then:That is:Thus we can derive that .
4.5. Complexity Analysis
5. Experiment
5.1. Experiment Setup
5.1.1. Datasets
5.1.2. Data Utility Metrics
5.2. Comparison of Data Utility
5.2.1. Spatial Distribution Similarity
5.2.2. Hausdorff Distance
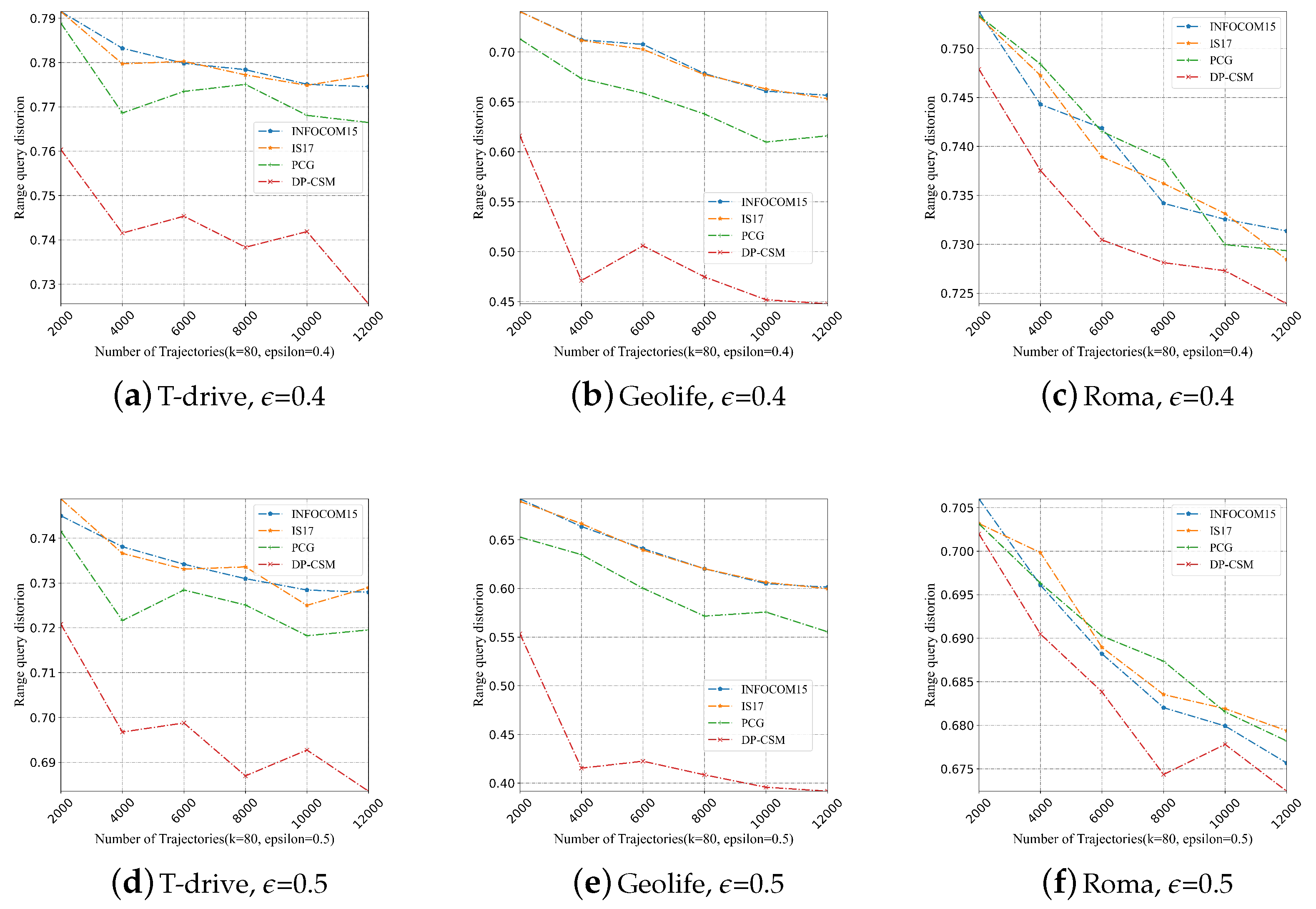
5.2.3. Range Query Distortion
5.2.4. Random Entropy
5.2.5. Temporal-Uncorrelated Entropy
5.2.6. Actual Entropy
5.2.7. Impacts of on Data Utility
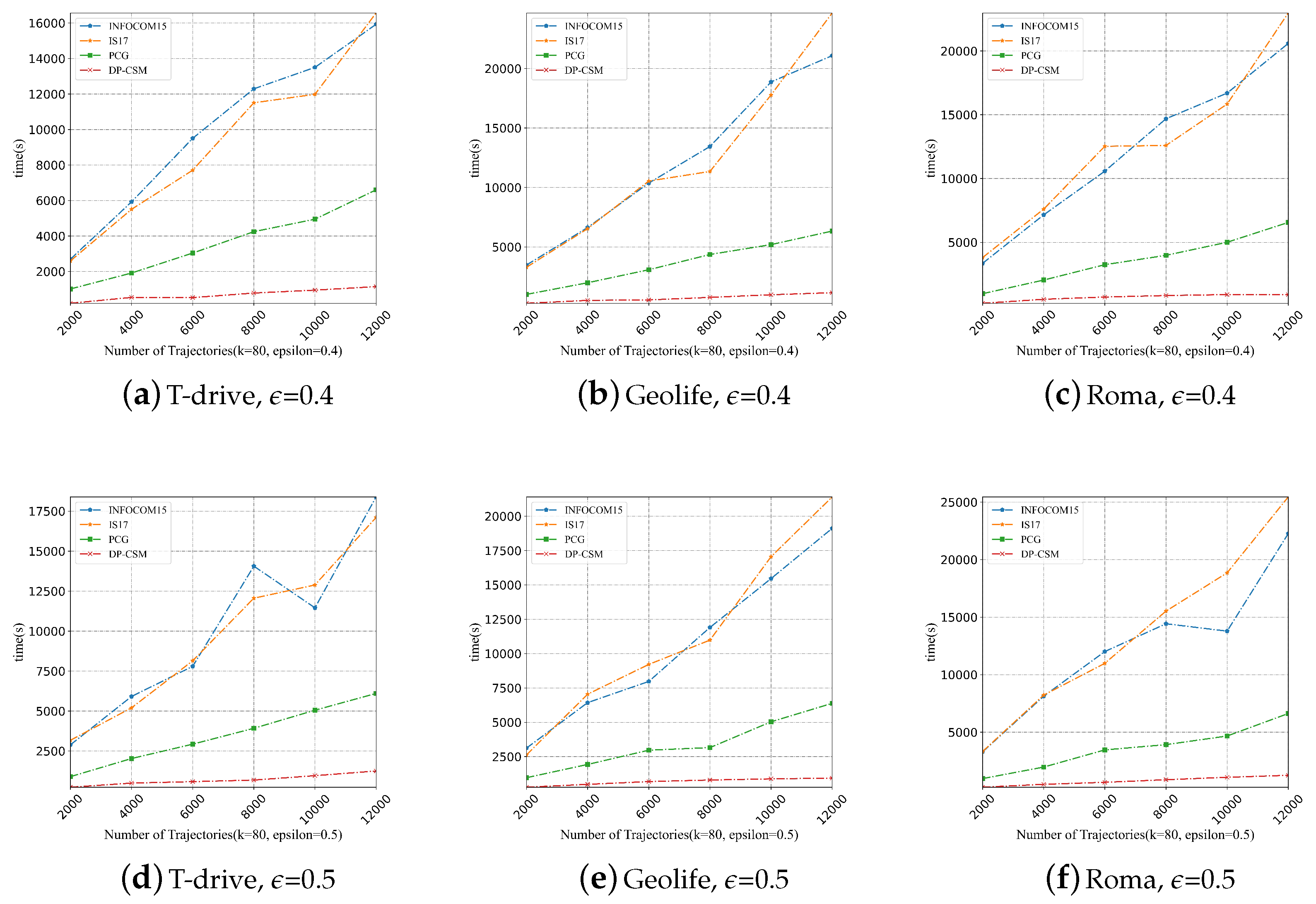
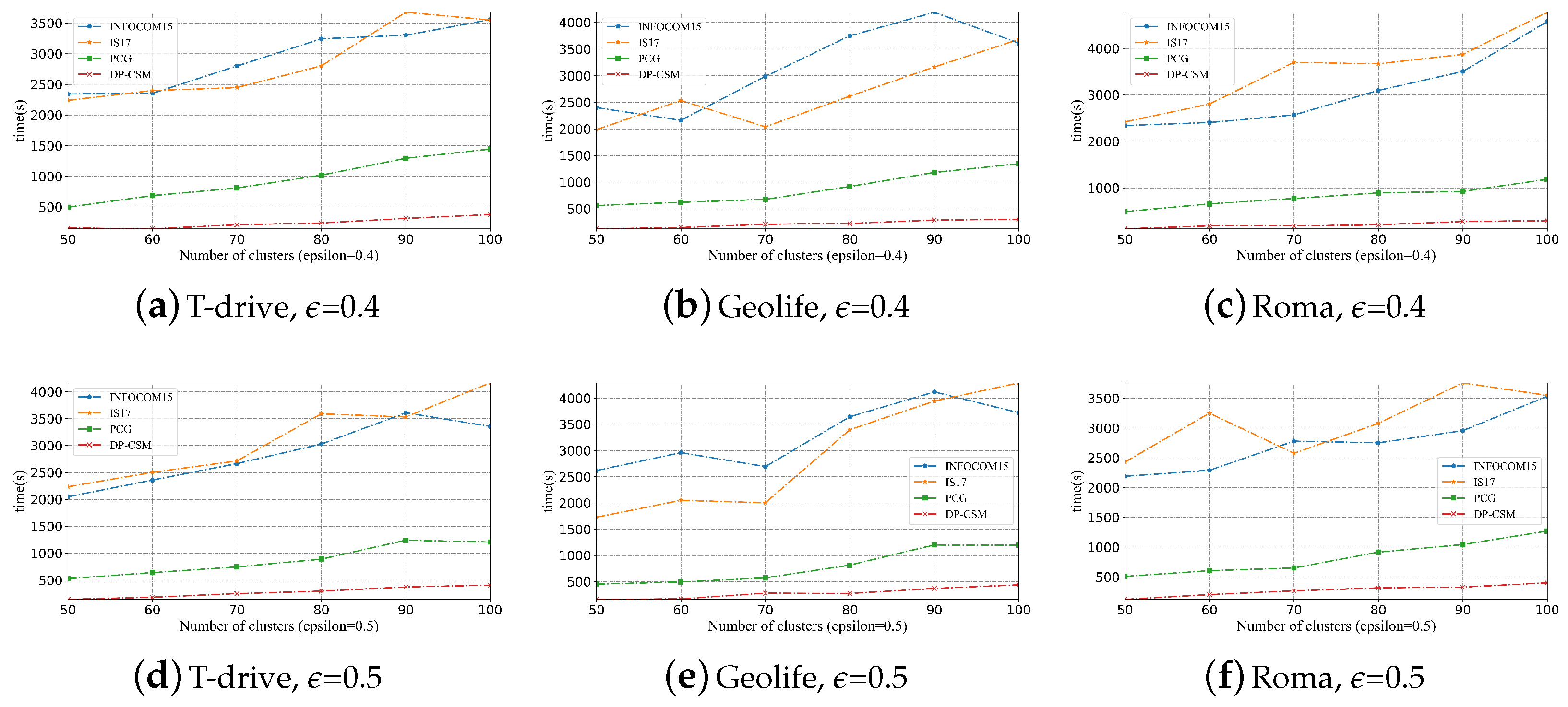
5.3. Comparison of Scalability
5.3.1. Impact of on Scalability
5.3.2. Impact of k on Scalability
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mahrez, Z.; Sabir, E.; Badidi, E.; Saad, W.; Sadik, M. Smart Urban Mobility: When Mobility Systems Meet Smart Data. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6222–6239. [Google Scholar] [CrossRef]
- Yuan, N.J.; Zheng, Y.; Xie, X.; Wang, Y.; Zheng, K.; Xiong, H. Discovering urban functional zones using latent activity trajectories. IEEE Trans. Knowl. Data Eng. 2014, 27, 712–725. [Google Scholar] [CrossRef]
- He, T.; Bao, J.; Li, R.; Ruan, S.; Li, Y.; Song, L.; He, H.; Zheng, Y. What is the Human Mobility in a New City: Transfer Mobility Knowledge Across Cities. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; ACM: Taipei, Taiwan, 2020; pp. 1355–1365. [Google Scholar] [CrossRef]
- Khazbak, Y.; Cao, G. Deanonymizing mobility traces with co-location information. In Proceedings of the 2017 IEEE Conference on Communications and Network Security (CNS), Las Vegas, NV, USA, 9–11 October 2017; IEEE: Las Vegas, NV, USA, 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Wang, H.; Gao, C.; Li, Y.; Wang, G.; Jin, D.; Sun, J. De-anonymization of Mobility Trajectories: Dissecting the Gaps between Theory and Practice. In Proceedings of the 2018 Network and Distributed System Security Symposium, San Diego, CA, USA, 18–21 February 2018; Internet Society: San Diego, CA, USA, 2018. [Google Scholar] [CrossRef]
- de Mattos, E.P.; Domingues, A.C.; Loureiro, A.A. Give Me Two Points and I’ll Tell You Who You Are. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; IEEE: Paris, France, 2019; pp. 1081–1087. [Google Scholar] [CrossRef]
- Abul, O.; Bonchi, F.; Nanni, M. Never Walk Alone: Uncertainty for Anonymity in Moving Objects Databases. In Proceedings of the IEEE International Conference on Data Engineering, Cancun, Mexico, 7–12 April 2008. [Google Scholar]
- Shao, D.; Jiang, K.; Kister, T.; Bressan, S.; Tan, K.L. Publishing Trajectory with Differential Privacy: A Priori vs. A Posteriori Sampling Mechanisms. In Database and Expert Systems Applications; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. L-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 3. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15 April 2007–20 April 2007. [Google Scholar]
- Ganta, S.R.; Kasiviswanathan, S.P.; Smith, A. Composition Attacks and Auxiliary Information in Data Privacy. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 265–273. [Google Scholar] [CrossRef] [Green Version]
- Kifer, D. Attacks on Privacy and DeFinetti’s Theorem. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, Providence, RI, USA, 29 June–2 July 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 127–138. [Google Scholar] [CrossRef]
- Mohammed, N.; Chen, R.; Fung, B.C.; Yu, P.S. Differentially private data release for data mining. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 493–501. [Google Scholar]
- Chen, R.; Fung, B.C.M.; Desai, B.C. Differentially Private Trajectory Data Publication. arXiv 2011, arXiv:1112.2020. [Google Scholar]
- Chen, R.; Acs, G.; Castelluccia, C. Differentially private sequential data publication via variable-length n-grams. In Proceedings of the 2012 ACM conference on Computer and Communications Security—CCS ’12, Raleigh, NC, USA, 16–18 October 2012; ACM Press: Raleigh, NC, USA, 2012; p. 638. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Cormode, G.; Machanavajjhala, A.; Procopiuc, C.M.; Srivastava, D. DPT: Differentially private trajectory synthesis using hierarchical reference systems. Proc. VLDB Endow. 2015, 8, 1154–1165. [Google Scholar] [CrossRef]
- Gursoy, E.M.; Liu, L.; Truex, S.; Yu, L.; Wei, W. Utility-Aware Synthesis of Differentially Private and Attack-Resilient Location Traces. In Proceedings of the ACM Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 196–211. [Google Scholar]
- Ghane, S.; Kulik, L.; Ramamohanarao, K. TGM: A Generative Mechanism for Publishing Trajectories with Differential Privacy. IEEE Internet Things J. 2020, 7, 2611–2621. [Google Scholar] [CrossRef]
- Liu, Q.; Yu, J.; Han, J.; Yao, X. Differentially private and utility-aware publication of trajectory data. Expert Syst. Appl. 2021, 180, 115120. [Google Scholar] [CrossRef]
- Al-Hussaeni, K.; Fung, B.C.; Iqbal, F.; Dagher, G.G.; Park, E.G. SafePath: Differentially-private publishing of passenger trajectories in transportation systems. Comput. Netw. 2018, 143, 126–139. [Google Scholar] [CrossRef]
- Cai, S.; Lyu, X.; Li, X.; Ban, D.; Zeng, T. A Trajectory Released Scheme for the Internet of Vehicles Based on Differential Privacy. IEEE Trans. Intell. Transp. Syst. 2021, 23, 16534–16547. [Google Scholar] [CrossRef]
- Gursoy, M.E.; Liu, L.; Truex, S.; Yu, L. Differentially Private and Utility Preserving Publication of Trajectory Data. IEEE Trans. Mob. Comput. 2019, 18, 2315–2329. [Google Scholar] [CrossRef]
- Hua, J.; Gao, Y.; Zhong, S. Differentially private publication of general time-serial trajectory data. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015; IEEE: Kowloon, Hong Kong, 2015; pp. 549–557. [Google Scholar] [CrossRef]
- Li, M.; Zhu, L.; Zhang, Z.; Xu, R. Achieving differential privacy of trajectory data publishing in participatory sensing. Inf. Sci. 2017, 400–401, 1–13. [Google Scholar] [CrossRef]
- Feldman, D.; Xiang, C.; Zhu, R.; Rus, D. Coresets for differentially private k-means clustering and applications to privacy in mobile sensor networks. In Proceedings of the 16th ACM/IEEE International Conference on Information Processing in Sensor Networks, Pittsburgh, PA, USA, 18–21 April 2017; pp. 3–15. [Google Scholar]
- Geng, Q.; Kairouz, P.; Oh, S.; Viswanath, P. The Staircase Mechanism in Differential Privacy. IEEE J. Sel. Top. Signal Process. 2015, 9, 1176–1184. [Google Scholar] [CrossRef]
- Bachem, O.; Lucic, M.; Krause, A. Practical Coreset Constructions for Machine Learning. arXiv 2017, arXiv:1703.06476v2. [Google Scholar]
- Bachem, O.; Lucic, M.; Krause, A. Scalable k-Means Clustering via Lightweight Coresets. arXiv 2017, arXiv:1702.08248. [Google Scholar]
- Chen, R.; Desai, B.C.; Fung, B.C.M.; Sossou, N.M. Differentially Private Transit Data Publication: A Case Study on the Montreal Transportation System. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 213–221. [Google Scholar]
- Zhang, J.; Xiao, X.; Xie, X. PrivTree: A Differentially Private Algorithm for Hierarchical Decompositions. In Proceedings of the 2016 International Conference on Management of Data-SIGMOD ’16, San Francisco, CA, USA, 26 June–1 July 2016; ACM Press: San Francisco, CA, USA, 2016; pp. 155–170. [Google Scholar] [CrossRef]
- Tang, P.; Chen, R.; Su, S.; Guo, S.; Ju, L.; Liu, G. Differentially Private Publication of Multi-Party Sequential Data. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 145–156. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Jing, Y.; Yu, Z.; Xing, X.; Sun, A.G. Driving with knowledge from the physical world. In Proceedings of the 17th SIGKDD Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 316–324. [Google Scholar]
- Yuan, J.; Zheng, Y.; Zhang, C.; Xie, W.; Xie, X.; Sun, G.; Huang, Y. T-drive: Driving directions based on taxi trajectories. In Proceedings of the 18th ACM SIGSPATIAL Conference on Advances in Geographical Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 99–108. [Google Scholar]
- Zheng, Y.; Zhang, L.; Xie, X.; Ma, W.Y. Mining interesting locations and travel sequences from GPS trajectories. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; pp. 791–800. [Google Scholar]
- Zheng, Y.; Li, Q.; Chen, Y.; Xie, X.; Ma, W.Y. Understanding mobility based on GPS data. In Proceedings of the 10th ACM conference on Ubiquitous Computing (Ubicomp 2008), Seoul, Republic of Korea, 21–24 September 2008; pp. 312–321. [Google Scholar]
- Zheng, Y.; Xie, X.; Ma, W.Y. GeoLife: A Collaborative Social Networking Service among User, Location and Trajectory. IEEE Data Eng. Bull. 2010, 32–39. [Google Scholar]
- Lorenzo, B.; Marco, B.; Pierpaolo, L.; Giuseppe, B.; Raul, A.; Antonello, R. CRAWDAD The Roma/Taxi Dataset (v. 2014-07-17). 2014. Available online: https://crawdad.org/roma/taxi/20140717 (accessed on 3 December 2022). [CrossRef]
- Brabazon, A.; O’Neill, M. Natural Computing in Computational Finance (Studies in Computational Intelligence). Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Hu, C.; Wolfson, O.E.; Trajcevski, G. Spatio-temporal data reduction with deterministic error bounds. VLDB J. 2006, 15, 211–228. [Google Scholar]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.L. Limits of predictability in human mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Locations in Coresets | Locations in Original Set | Weight before Sampling | Weight after Sampling |
|---|---|---|---|
| 1 | 4 | ||
| 1 | 3 |
| Generalized Trajectories | Raw Trajectories | Real Counts | Noisy Counts |
|---|---|---|---|
| 2 | 1 | ||
| 0 | 2 | ||
| 1 | 0 | ||
| 1 | 1 | ||
| 1 | 0 | ||
| 0 | 0 | ||
| 1 | 3 | ||
| 2 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, X.; Yu, J.; Han, J.; Lu, J.; Peng, H.; Wu, Y.; Cao, X. DP-CSM: Efficient Differentially Private Synthesis for Human Mobility Trajectory with Coresets and Staircase Mechanism. ISPRS Int. J. Geo-Inf. 2022, 11, 607. https://doi.org/10.3390/ijgi11120607
Yao X, Yu J, Han J, Lu J, Peng H, Wu Y, Cao X. DP-CSM: Efficient Differentially Private Synthesis for Human Mobility Trajectory with Coresets and Staircase Mechanism. ISPRS International Journal of Geo-Information. 2022; 11(12):607. https://doi.org/10.3390/ijgi11120607
Chicago/Turabian StyleYao, Xin, Juan Yu, Jianmin Han, Jianfeng Lu, Hao Peng, Yijia Wu, and Xiaoqian Cao. 2022. "DP-CSM: Efficient Differentially Private Synthesis for Human Mobility Trajectory with Coresets and Staircase Mechanism" ISPRS International Journal of Geo-Information 11, no. 12: 607. https://doi.org/10.3390/ijgi11120607
APA StyleYao, X., Yu, J., Han, J., Lu, J., Peng, H., Wu, Y., & Cao, X. (2022). DP-CSM: Efficient Differentially Private Synthesis for Human Mobility Trajectory with Coresets and Staircase Mechanism. ISPRS International Journal of Geo-Information, 11(12), 607. https://doi.org/10.3390/ijgi11120607