
Incorporating Spatial Autocorrelation in Machine Learning Models Using Spatial Lag and Eigenvector Spatial Filtering Features



Abstract
:1. Introduction
2. Related Work
3. Methods
3.1. Data Sources
3.1.1. Meuse River Dataset
3.1.2. California Housing Dataset
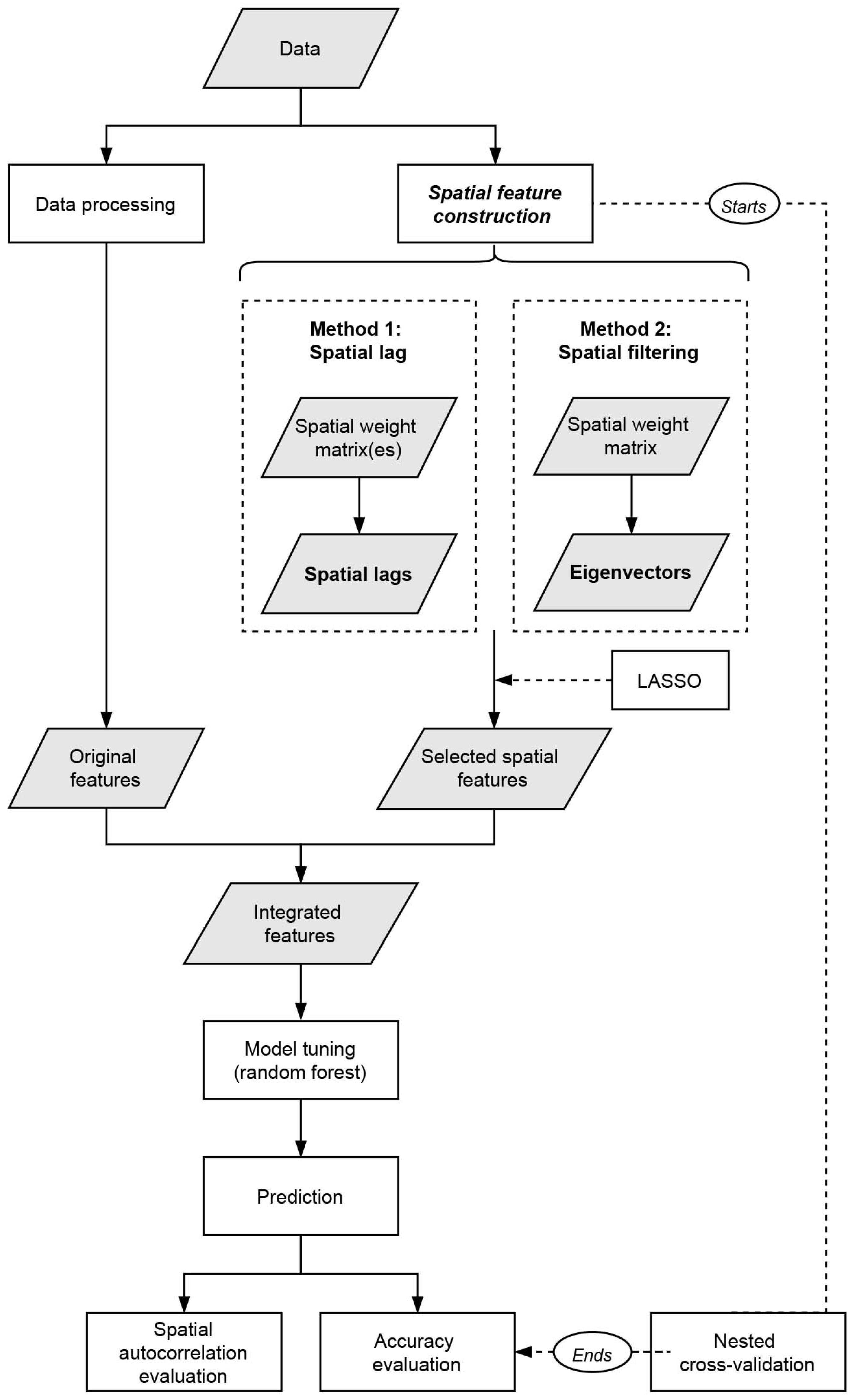
3.2. Construction and Processing of Spatial Features
3.2.1. Spatial Lag Features
3.2.2. Eigenvector Spatial Filtering
3.3. Machine Learning and Benchmarking Models
3.3.1. Random Forest
3.3.2. Geographically Weighted Regression
3.4. Performance Evaluation
- (a)
- Split the dataset into K outer folds.
- (b)
- For each outer fold k = 1, 2, …, K: outer loop for model evaluation:
- Take fold k as outer testing set outer-test; take the remaining folds as outer training set outer-train.
- Split the outer-train into L inner folds.
- For each inner fold l = 1, 2, …, L: inner loop for hyper-parameter tuning:
- i.
- Take fold l as inner testing set inner-test and the remaining as inner-train.
- ii.
- Calculate spatial features on the inner-train.
- iii.
- Perform cross-validated LASSO on inner-train with spatial features, and determine the lambda with “one-standard-error” rule; Select the spatial features with non-zero coefficients.
- iv.
- For each hyper-parameter candidate, fit a model on the inner-train with the combined feature set.
- v.
- Calculate the selected spatial features on the inner-test.
- vi.
- Evaluate the model on inner-test with the assessment metric.
- For each hyper-parameter candidate, average the assessment metric values across L folds and choose the best hyper-parameter. In our experiments, the hyperparameter that was tested was mtry.
- Calculate spatial features on the outer-train.
- Perform cross-validated LASSO on outer-train with spatial features, and determine the lambda with “one-standard-error” rule. Select the spatial features with non-zero coefficients.
- Train a model with the best hyper-parameter on the outer-train.
- Calculate the selected spatial features on the outer-test.
- Evaluate the model on outer-test with the assessment metric.
- (c)
- Average the metric values over K folds, and report the generalized performance.
3.5. Spatial Autocorrelation Evaluation
4. Results
4.1. Specifications of the Models
4.2. Importance of Explanatory Variables
4.3. Performance Evaluation—RMSE Error
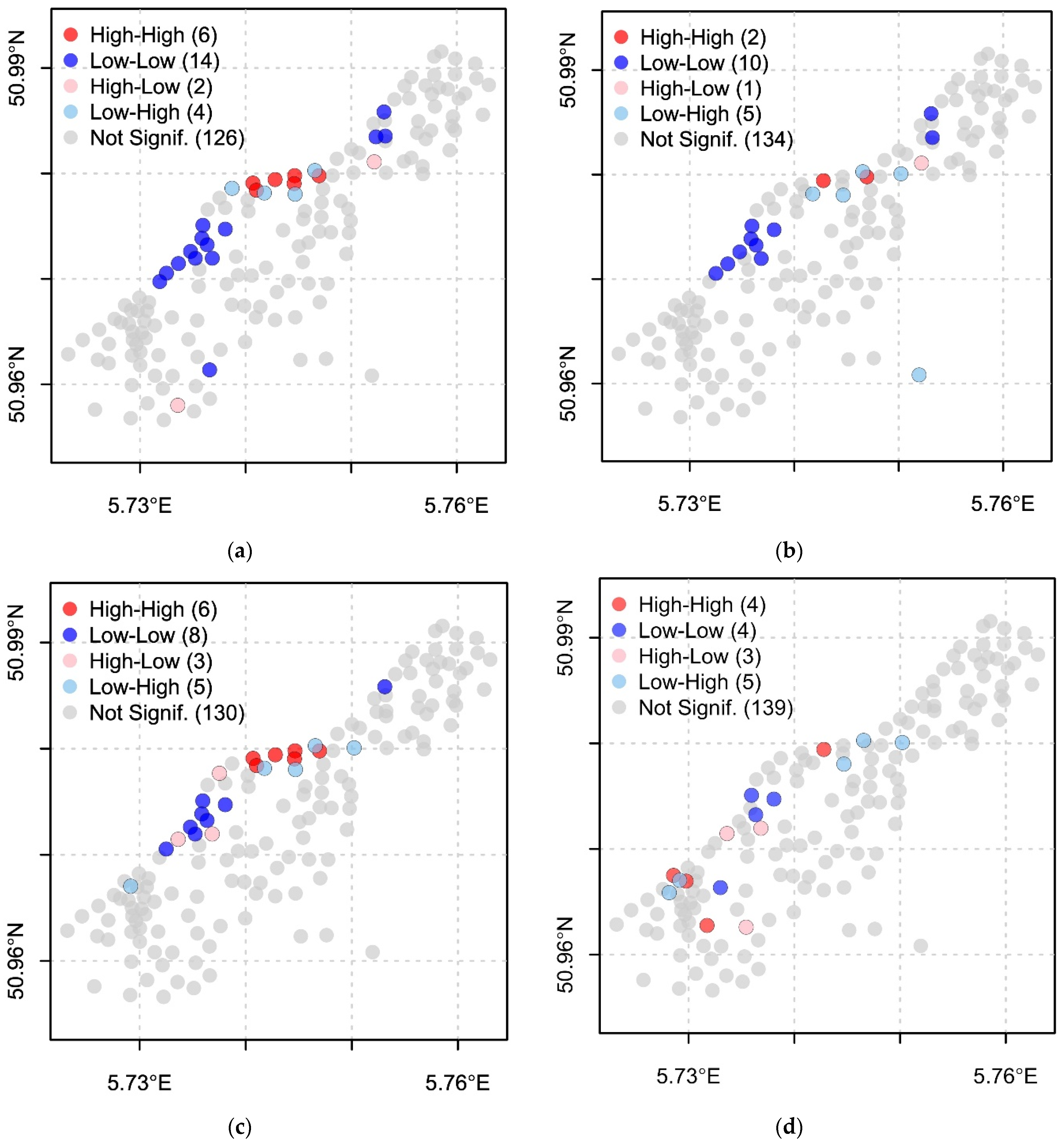
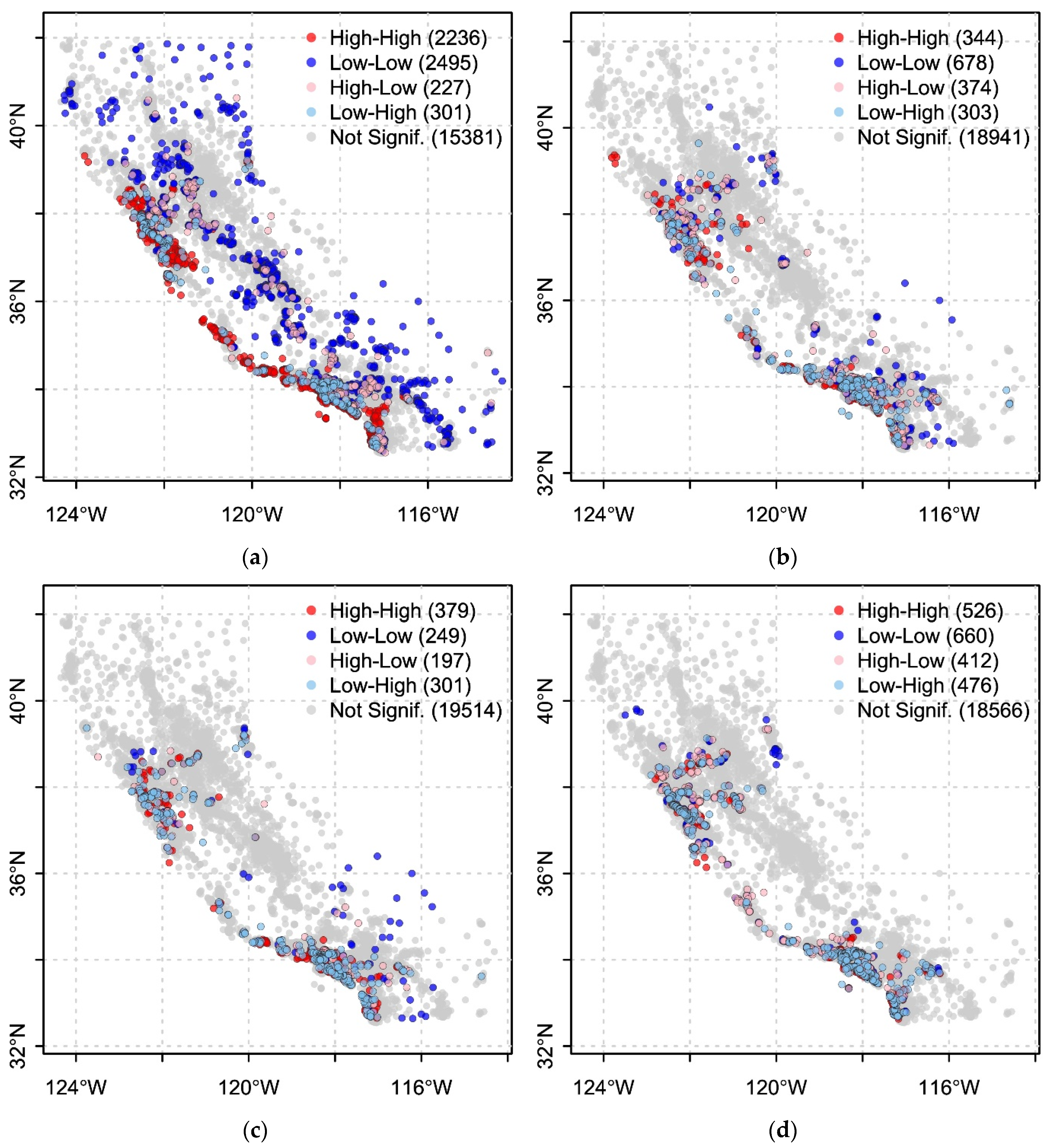
4.4. Spatial Autocorrelation Evaluation—Lobal and Local Moran’s I
5. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goodchild, M.F. The quality of big (geo) data. Dialogues Hum. Geogr. 2013, 3, 280–284. [Google Scholar] [CrossRef]
- Kitchin, R. Big data and human geography: Opportunities, challenges and risks. Dialogues Hum. Geogr. 2013, 3, 262–267. [Google Scholar] [CrossRef]
- Hoffmann, J.; Bar-Sinai, Y.; Lee, L.M.; Andrejevic, J.; Mishra, S.; Rubinstein, S.M.; Rycroft, C.H. Machine learning in a data-limited regime: Augmenting experiments with synthetic data uncovers order in crumpled sheets. Sci. Adv. 2019, 5, eaau6792. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aguilar, R.; Zurita-Milla, R.; Izquierdo-Verdiguier, E.; De By, R.A. A Cloud-Based Multi-Temporal Ensemble Classifier to Map Smallholder Farming Systems. Remote Sens. 2018, 10, 729. [Google Scholar] [CrossRef] [Green Version]
- Řezník, T.; Chytrý, J.; Trojanová, K. Machine Learning-Based Processing Proof-of-Concept Pipeline for Semi-Automatic Sentinel-2 Imagery Download, Cloudiness Filtering, Classifications and Updates of Open Land Use/Land Cover Datasets. ISPRS Int. J. Geo-Inf. 2021, 10, 102. [Google Scholar] [CrossRef]
- Pradhan, A.M.S.; Kim, Y.-T. Rainfall-Induced Shallow Landslide Susceptibility Mapping at Two Adjacent Catchments Using Advanced Machine Learning Algorithms. ISPRS Int. J. Geo-Inf. 2020, 9, 569. [Google Scholar] [CrossRef]
- Zurita-Milla, R.; Goncalves, R.; Izquierdo-Verdiguier, E.; Ostermann, F.O. Exploring Spring Onset at Continental Scales: Mapping Phenoregions and Correlating Temperature and Satellite-Based Phenometrics. IEEE Trans. Big Data 2019, 6, 583–593. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Kanevski, M.; Pozdnoukhov, A.; Timonin, V. Machine Learning Algorithms for GeoSpatial Data. Applications and Software Tools. In Proceedings of the 4th International Congress on Environmental Modelling and Software, Barcelona, Spain, 1 July 2008; p. 369. [Google Scholar]
- Shekhar, S.; Jiang, Z.; Ali, R.Y.; Eftelioglu, E.; Tang, X.; Gunturi, V.M.V.; Zhou, X. Spatiotemporal Data Mining: A Computational Perspective. ISPRS Int. J. Geo-Inf. 2015, 4, 2306–2338. [Google Scholar] [CrossRef]
- Michael, F.G. Geographical information science. Int. J. Geogr. Inf. Syst. 1992, 6, 31–45. [Google Scholar]
- Miller, H.J. Geographic representation in spatial analysis. J. Geogr. Syst. 2000, 2, 55–60. [Google Scholar] [CrossRef]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Anselin, L. Spatial Econometrics: Methods and Models; Springer: Dordrecht, The Netherlands, 1988. [Google Scholar] [CrossRef] [Green Version]
- Brunsdon, C.; Fotheringham, S.; Charlton, M. Geographically weighted regression. J. R. Stat. Soc. Ser. D 1996, 47, 431–443. [Google Scholar] [CrossRef]
- Löchl, M.; Axhausen, K.W. Modelling hedonic residential rents for land use and transport simulation while considering spatial effects. J. Transp. Land Use 2010, 3, 39–63. [Google Scholar] [CrossRef] [Green Version]
- Wheeler, D.C. Geographically Weighted Regression. In Handbook of Regional Science; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1435–1459. [Google Scholar]
- Fouedjio, F.; Klump, J. Exploring prediction uncertainty of spatial data in geostatistical and machine learning approaches. Environ. Earth Sci. 2019, 78, 38. [Google Scholar] [CrossRef]
- Kleijnen, J.P.C.; van Beers, W.C.M. Prediction for big data through Kriging: Small sequential and one-shot designs. Am. J. Math. Manag. Sci. 2020, 39, 199–213. [Google Scholar] [CrossRef]
- Murakami, D.; Griffith, D.A. Eigenvector Spatial Filtering for Large Data Sets: Fixed and Random Effects Approaches. Geogr. Anal. 2018, 51, 23–49. [Google Scholar] [CrossRef] [Green Version]
- Dormann, C.F.; McPherson, J.M.; Araújo, M.B.; Bivand, R.; Bolliger, J.; Carl, G.; Davies, R.G.; Hirzel, A.; Jetz, W.; Kissling, W.D.; et al. Methods to account for spatial autocorrelation in the analysis of species distributional data: A review. Ecography 2007, 30, 609–628. [Google Scholar] [CrossRef] [Green Version]
- Hengl, T.; Nussbaum, M.; Wright, M.N.; Heuvelink, G.B.M.; Gräler, B. Random forest as a generic framework for predictive modeling of spatial and spatio-temporal variables. PeerJ 2018, 6, e5518. [Google Scholar] [CrossRef] [Green Version]
- Meyer, H.; Reudenbach, C.; Wöllauer, S.; Nauss, T. Importance of spatial predictor variable selection in machine learning applications—Moving from data reproduction to spatial prediction. Ecol. Model. 2019, 411, 108815. [Google Scholar] [CrossRef] [Green Version]
- Pohjankukka, J.; Pahikkala, T.; Nevalainen, P.; Heikkonen, J. Estimating the prediction performance of spatial models via spatial k-fold cross validation. Int. J. Geogr. Inf. Sci. 2017, 31, 2001–2019. [Google Scholar] [CrossRef]
- Behrens, T.; Schmidt, K.; Rossel, R.A.V.; Gries, P.; Scholten, T.; Macmillan, R.A. Spatial modelling with Euclidean distance fields and machine learning. Eur. J. Soil Sci. 2018, 69, 757–770. [Google Scholar] [CrossRef]
- Li, T.; Shen, H.; Yuan, Q.; Zhang, X.; Zhang, L. Estimating Ground-Level PM2.5 by Fusing Satellite and Station Observations: A Geo-Intelligent Deep Learning Approach. Geophys. Res. Lett. 2017, 44, 11985–11993. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Ren, C.; Li, L.; Wang, Y.; Zhang, B.; Wang, Z.; Li, L. A Comparative Assessment of Geostatistical, Machine Learning, and Hybrid Approaches for Mapping Topsoil Organic Carbon Content. ISPRS Int. J. Geo-Inf. 2019, 8, 174. [Google Scholar] [CrossRef] [Green Version]
- Foresti, L.; Pozdnoukhov, A.; Tuia, D.; Kanevski, M. Extreme precipitation modelling using geostatistics and machine learning algorithms. In geoENV VII–Geostatistics for Environmental Applications; Springer: Dordrecht, The Netherlands, 2010; pp. 41–52. [Google Scholar]
- Hengl, T.; Heuvelink, G.B.M.; Kempen, B.; Leenaars, J.G.B.; Walsh, M.G.; Shepherd, K.D.; Sila, A.; Macmillan, R.A.; De Jesus, J.M.; Tamene, L.; et al. Mapping soil properties of Africa at 250 m resolution: Random forests significantly improve current predictions. PLoS ONE 2015, 10, e0125814. [Google Scholar] [CrossRef]
- Hengl, T.; Heuvelink, G.B.M.; Rossiter, D.G. About regression-kriging: From theory to interpretation of results. Comput. Geosci. 2007, 33, 1301–1315. [Google Scholar] [CrossRef]
- Mueller, E.; Sandoval, J.S.O.; Mudigonda, S.; Elliott, M. A Cluster-Based Machine Learning Ensemble Approach for Geospatial Data: Estimation of Health Insurance Status in Missouri. ISPRS Int. J. Geo-Inf. 2018, 8, 13. [Google Scholar] [CrossRef] [Green Version]
- Stojanova, D.; Ceci, M.; Appice, A.; Malerba, D.; Džeroski, S. Dealing with spatial autocorrelation when learning predictive clustering trees. Ecol. Inform. 2013, 13, 22–39. [Google Scholar] [CrossRef] [Green Version]
- Klemmer, K.; Koshiyama, A.; Flennerhag, S. Augmenting Correlation Structures in Spatial Data Using Deep Generative Models. Available online: https://arxiv.org/pdf/1905.09796.pdf (accessed on 23 December 2021).
- Kiely, T.J.; Bastian, N.D. The spatially conscious machine learning model. Stat. Anal. Data Min. ASA Data Sci. J. 2020, 13, 31–49. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, Q.; Xu, C.-Y.; Sun, P.; Hu, P. Reconstruction of high spatial resolution surface air temperature data across China: A new geo-intelligent multisource data-based machine learning technique. Sci. Total Environ. 2019, 665, 300–313. [Google Scholar] [CrossRef]
- Pebesma, E.J. Multivariable geostatistics in S: The gstat package. Comput. Geosci. 2004, 30, 683–691. [Google Scholar] [CrossRef]
- Bivand, R.S.; Pebesma, E.; Gómez-Rubio, V. Applied Spatial Data Analysis with R, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar] [CrossRef]
- D’Urso, P.; Vitale, V. A robust hierarchical clustering for georeferenced data. Spat. Stat. 2020, 35, 100407. [Google Scholar] [CrossRef]
- Ejigu, B.A.; Wencheko, E. Introducing covariate dependent weighting matrices in fitting autoregressive models and measuring spatio-environmental autocorrelation. Spat. Stat. 2020, 38, 100454. [Google Scholar] [CrossRef]
- Pace, R.K.; Barry, R. Sparse spatial autoregressions. Stat. Probab. Lett. 1997, 33, 291–297. [Google Scholar] [CrossRef]
- Bauman, D.; Drouet, T.; Dray, S.; Vleminckx, J. Disentangling good from bad practices in the selection of spatial or phylogenetic eigenvectors. Ecography 2018, 41, 1638–1649. [Google Scholar] [CrossRef] [Green Version]
- Debarsy, N.; LeSage, J. Flexible dependence modeling using convex combinations of different types of connectivity structures. Reg. Sci. Urban Econ. 2018, 69, 48–68. [Google Scholar] [CrossRef]
- Getis, A.; Griffith, D.A. Comparative Spatial Filtering in Regression Analysis. Geogr. Anal. 2002, 34, 130–140. [Google Scholar] [CrossRef]
- Griffith, D.; Chun, Y. Spatial Autocorrelation and Spatial Filtering. In Handbook of Regional Science; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1477–1507. [Google Scholar]
- Cupido, K.; Jevtić, P.; Paez, A. Spatial patterns of mortality in the United States: A spatial filtering approach. Insur. Math. Econ. 2020, 95, 28–38. [Google Scholar] [CrossRef]
- Paez, A. Using Spatial Filters and Exploratory Data Analysis to Enhance Regression Models of Spatial Data. Geogr. Anal. 2018, 51, 314–338. [Google Scholar] [CrossRef]
- Zhang, J.; Li, B.; Chen, Y.; Chen, M.; Fang, T.; Liu, Y. Eigenvector Spatial Filtering Regression Modeling of Ground PM2.5 Concentrations Using Remotely Sensed Data. Int. J. Environ. Res. Public Health 2018, 15, 1228. [Google Scholar] [CrossRef] [Green Version]
- Drineas, P.; Mahoney, M.W.; Cristianini, N. On the Nyström Method for Approximating a Gram Matrix for Improved Kernel-Based Learning. J. Mach. Learn. Res. 2005, 6, 2153–2175. [Google Scholar]
- Li, J.; Heap, A.D.; Potter, A.; Daniell, J.J. Application of machine learning methods to spatial interpolation of environmental variables. Environ. Model. Softw. 2011, 26, 1647–1659. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Friedman, J.H.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Caruana, R.; Karampatziakis, N.; Yessenalina, A. An empirical evaluation of supervised learning in high dimensions. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 96–103. [Google Scholar]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Vasan, K.K.; Surendiran, B. Dimensionality reduction using Principal Component Analysis for network intrusion detection. Perspect. Sci. 2016, 8, 510–512. [Google Scholar] [CrossRef] [Green Version]
- Abdulhammed, R.; Musafer, H.; Alessa, A.; Faezipour, M.; Abuzneid, A. Features Dimensionality Reduction Approaches for Machine Learning Based Network Intrusion Detection. Electronics 2019, 8, 322. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Delalleau, O.; Le Roux, N. The curse of dimensionality for local kernel machines. Technol. Rep. 2005, 1258, 12. [Google Scholar]
- Trunk, G.V. A problem of dimensionality: A simple example. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 306–307. [Google Scholar] [CrossRef]
- Verleysen, M.; François, D. The Curse of Dimensionality in Data Mining and Time Series Prediction. In International Work-Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2005; pp. 758–770. [Google Scholar] [CrossRef]
- Ma, L.; Fu, T.; Blaschke, T.; Li, M.; Tiede, D.; Zhou, Z.; Ma, X.; Chen, D. Evaluation of Feature Selection Methods for Object-Based Land Cover Mapping of Unmanned Aerial Vehicle Imagery Using Random Forest and Support Vector Machine Classifiers. ISPRS Int. J. Geo-Inf. 2017, 6, 51. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; VanHuysse, S.; Lennert, M.; Shimoni, M.; Kalogirou, S.; Wolff, E. Less is more: Optimizing classification performance through feature selection in a very-high-resolution remote sensing object-based urban application. GIScience Remote Sens. 2017, 55, 221–242. [Google Scholar] [CrossRef]
- Cellmer, R.; Cichulska, A.; Bełej, M. Spatial Analysis of Housing Prices and Market Activity with the Geographically Weighted Regression. ISPRS Int. J. Geo-Inf. 2020, 9, 380. [Google Scholar] [CrossRef]
- Chen, D.-R.; Truong, K. Using multilevel modeling and geographically weighted regression to identify spatial variations in the relationship between place-level disadvantages and obesity in Taiwan. Appl. Geogr. 2012, 32, 737–745. [Google Scholar] [CrossRef]
- Soler, I.P.; Gemar, G. Hedonic price models with geographically weighted regression: An application to hospitality. J. Destin. Mark. Manag. 2018, 9, 126–137. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, R.J.C.; Han, L.D.; Yang, L. Key Factors Affecting the Price of Airbnb Listings: A Geographically Weighted Approach. Sustainability 2017, 9, 1635. [Google Scholar] [CrossRef] [Green Version]
- Ali, K.; Partridge, M.D.; Olfert, M.R. Can geographically weighted regressions improve regional analysis and policy making? Int. Reg. Sci. Rev. 2007, 30, 300–329. [Google Scholar] [CrossRef]
- Cahill, M.; Mulligan, G. Using Geographically Weighted Regression to Explore Local Crime Patterns. Soc. Sci. Comput. Rev. 2007, 25, 174–193. [Google Scholar] [CrossRef]
- Charlton, M.; Fotheringham, A.S. Geographically Weighted Regression: A Tutorial on Using GWR in ArcGIS 9.3. 2009. Available online: https://www.geos.ed.ac.uk/~gisteac/fcl/gwr/gwr_arcgis/GWR_Tutorial.pdf (accessed on 1 January 2022).
- Oshan, T.M.; Li, Z.; Kang, W.; Wolf, L.J.; Fotheringham, A.S. mgwr: A Python Implementation of Multiscale Geographically Weighted Regression for Investigating Process Spatial Heterogeneity and Scale. ISPRS Int. J. Geo-Inf. 2019, 8, 269. [Google Scholar] [CrossRef] [Green Version]
- Schratz, P.; Muenchow, J.; Iturritxa, E.; Richter, J.; Brenning, A. Hyperparameter tuning and performance assessment of statistical and machine-learning algorithms using spatial data. Ecol. Model. 2019, 406, 109–120. [Google Scholar] [CrossRef] [Green Version]
- Cawley, G.C.; Talbot, N.L.C. On Over-fitting in Model Selection and Subsequent Selection Bias in Performance Evaluation. J. Mach. Learn. Res. 2010, 11, 2079–2107. [Google Scholar]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B Methodol. 1974, 36, 111–133. [Google Scholar] [CrossRef]
- Anselin, L. Local Indicators of Spatial Association—LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- da Silva, A.R.; Fotheringham, A.S. The multiple testing issue in geographically weighted regression. Geogr. Anal. 2016, 48, 233–247. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Gadiaga, A.N.; Linard, C.; Lennert, M.; VanHuysse, S.; Mboga, N.; Wolff, E.; Kalogirou, S. Geographical random forests: A spatial extension of the random forest algorithm to address spatial heterogeneity in remote sensing and population modelling. Geocarto Int. 2021, 36, 121–136. [Google Scholar] [CrossRef] [Green Version]
- Kalogirou, S.; Georganos, S. SpatialML. R Foundation for Statistical Computing. Available online: https://cran.r-project.org/web/packages/SpatialML/SpatialML.pdf (accessed on 1 January 2022).
- Ristea, A.; Al Boni, M.; Resch, B.; Gerber, M.S.; Leitner, M. Spatial crime distribution and prediction f or sporting events using social media. Int. J. Geogr. Inf. Sci. 2020, 34, 1708–1739. [Google Scholar] [CrossRef] [Green Version]
- Lamari, Y.; Freskura, B.; Abdessamad, A.; Eichberg, S.; De Bonviller, S. Predicting Spatial Crime Occurrences through an Efficient Ensemble-Learning Model. ISPRS Int. J. Geo-Inf. 2020, 9, 645. [Google Scholar] [CrossRef]
- Shao, Q.; Xu, Y.; Wu, H. Spatial Prediction of COVID-19 in China Based on Machine Learning Algorithms and Geographically Weighted Regression. Comput. Math. Methods Med. 2021, 2021, 7196492. [Google Scholar] [CrossRef]
- Young, S.G.; Tullis, J.A.; Cothren, J. A remote sensing and GIS-assisted landscape epidemiology approach to West Nile virus. Appl. Geogr. 2013, 45, 241–249. [Google Scholar] [CrossRef]
- Almalki, A.; Gokaraju, B.; Mehta, N.; Doss, D.A. Geospatial and Machine Learning Regression Techniques for Analyzing Food Access Impact on Health Issues in Sustainable Communities. ISPRS Int. J. Geo-Inf. 2021, 10, 745. [Google Scholar] [CrossRef]
- Zhou, X.; Tong, W.; Li, D. Modeling Housing Rent in the Atlanta Metropolitan Area Using Textual Information and Deep Learning. ISPRS Int. J. Geo-Inf. 2019, 8, 349. [Google Scholar] [CrossRef] [Green Version]
- Čeh, M.; Kilibarda, M.; Lisec, A.; Bajat, B. Estimating the Performance of Random Forest versus Multiple Regression for Predicting Prices of the Apartments. ISPRS Int. J. Geo-Inf. 2018, 7, 168. [Google Scholar] [CrossRef] [Green Version]
- Acker, B.; Yuan, M. Network-based likelihood modeling of event occurrences in space and time: A case study of traffic accidents in Dallas, Texas, USA. Cartogr. Geogr. Inf. Sci. 2018, 46, 21–38. [Google Scholar] [CrossRef]
- Keller, S.; Gabriel, R.; Guth, J. Machine Learning Framework for the Estimation of Average Speed in Rural Road Networks with OpenStreetMap Data. ISPRS Int. J. Geo-Inf. 2020, 9, 638. [Google Scholar] [CrossRef]
- Dong, L.; Ratti, C.; Zheng, S. Predicting neighborhoods’ socioeconomic attributes using restaurant data. Proc. Natl. Acad. Sci. USA 2019, 116, 15447–15452. [Google Scholar] [CrossRef] [Green Version]
- Feldmeyer, D.; Meisch, C.; Sauter, H.; Birkmann, J. Using OpenStreetMap Data and Machine Learning to Generate Socio-Economic Indicators. ISPRS Int. J. Geo-Inf. 2020, 9, 498. [Google Scholar] [CrossRef]
- Crosby, H.; Damoulas, T.; Jarvis, S.A. Road and travel time cross-validation for urban modelling. Int. J. Geogr. Inf. Sci. 2020, 34, 98–118. [Google Scholar] [CrossRef]
- Diggle, P.J.; Tawn, J.A.; Moyeed, R.A. Model-based geostatistics. J. R. Stat. Soc. Ser. C Appl. Stat. 1998, 47, 299–350. [Google Scholar] [CrossRef]
- Griffith, D.A. The geographic distribution of soil lead concentration: Description and concerns. URISA J. 2002, 14, 5–14. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| x | X coordinate (EPSG: 28992) |
| y | Y coordinate (EPSG: 28992) |
| zinc | Top soil heavy metal concentration (mg/kg) |
| elev | Relative elevation above local river bed |
| om | Organic matter |
| ffreq | Flooding frequency class |
| soil | Soil type |
| landuse | Land use class |
| lime | Lime class |
| dist | Distance to river Meuse |
| Variable | Description |
|---|---|
| longitude | WGS 84 coordinate |
| latitude | WGS 84 coordinate |
| housing_median_age | Median house age in the district |
| roomsAvg | Average number of rooms per household |
| bedroomsAvg | Average number of bedrooms per household |
| population | Total population in the district |
| households | Total households in the district |
| median_income | Median income of the district |
| median_house_value | Median house price of the district |
| Models | Constructed Spatial Features | Selected Spatial Features | Optimal Mtry | Bandwidth |
|---|---|---|---|---|
| Non-spatial model Meuse | n/a | n/a | 5 | n/a |
| Spatial Lag model Meuse | lag_k5, lag_k10, lag_k15 | lag_k5 | 5 | n/a |
| ESF model Meuse | ev1~ev152 | ev8, ev11, ev12 | 5 | n/a |
| GWR model Meuse | n/a | n/a | n/a | 50 |
| Non-spatial model California | n/a | n/a | 2 | n/a |
| Spatial Lag model California | lag_k5, lag_k10, lag_k15, lag_k50 | lag_k5, lag_k10, lag_k15 | 6 | n/a |
| ESF model California | ev1-ev 200 | 77 features | 6 | n/a |
| GWR model California | n/a | n/a | n/a | 80 |
| Meuse Models | ||||
|---|---|---|---|---|
| Non-Spatial | Spatial Lag | ESF | GWR | |
| R.I | R.I | R.I | Coeff. | Insig. |
| dist (100%) | dist (100%) | dist (100%) | om (0.43) | 93 |
| elev (56%) | elev (44%) | elev (46%) | elev (0.37) | 0 |
| om (25%) | lag_k5 (33%) | om (40%) | dist (0.33) | 0 |
| ffreq (10%) | om (32%) | lime (12%) | ||
| lime (9%) | lime (11%) | ev34 (11%) | ||
| landuse (1%) | ffreq (9%) | ev8 (9%) | ||
| soil (0%) | soil (1%) | ffreq (7%) | ||
| landuse (0%) | ev11 (4%) | |||
| landuse (3%) | ||||
| soil (1%) | ||||
| ev12 (0%) | ||||
| California Models | ||||
| Non-Spatial | Spatial Lag | ESF | GWR | |
| R.I | R.I | R.I | Coeff. | Insig. |
| income (100%) | lag_k5 (100%) | ev1 (100%) | bedroomsAvg (0.67) | 254 |
| households (22%) | lag_k10 (38%) | ev4 (85%) | households (0.66) | 104 |
| population (16%) | income (26%) | ev147 (54%) | roomsAvg (0.64) | 2013 |
| roomAvg (10%) | lag_k15 (18%) | ev10 (43%) | population (0.50) | 143 |
| houseAge (8%) | roomsAvg (7%) | roomsAvg (42%) | income (0.31) | 5814 |
| bedroomsAvg (0%) | houseAge (3%) | ev21 (42%) | houseAge (0.12) | 940 |
| population (2%) | ev8 (39%) | |||
| households (1%) | ev64 (38%) | |||
| bedroomsAvg (0%) | ev136 (37%) | |||
| Models | Models—Outer Folds—RMSE | Test Error | Model Fit All Data | ||||
|---|---|---|---|---|---|---|---|
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Training Error | ||
| Non-spatial model Meuse | 179.54 | 123.25 | 191.55 | 201.07 | 259.77 | 191.04 | 83.59 |
| Spatial Lag model Meuse | 181.05 | 120.44 | 195.43 | 187.23 | 229.00 | 182.63 | 79.69 |
| ESF model Meuse | 149.87 | 109.02 | 182.29 | 176.88 | 241.04 | 171.82 | 75.52 |
| GWR model Meuse | n/a | 177.80 | 134.53 | ||||
| Non-spatial model California | 65,589.35 | 64,799.53 | 66,965.33 | 68,654.93 | 63,721.71 | 65,946.17 | 29,857.57 |
| Spatial Lag model California | 44,018.01 | 43,306.16 | 45,092.36 | 44,457.47 | 43,300.77 | 44,034.95 | 17,949.20 |
| ESF model Meuse California | 70,264.71 | 67,756.02 | 66,949.00 | 66,348.53 | 69,475.80 | 68,158.81 | 20,825.50 |
| GWR model Meuse California | n/a | 49,077.10 | 32,415.91 | ||||
| Models | No of Insignificant LISA Clusters of Residuals | Moran’s I of Residuals |
|---|---|---|
| Non-spatial model Meuse | 126 | 0.20 (0.001) |
| Spatial Lag model Meuse | 134 | 0.029 (0.227) |
| ESF model Meuse | 130 | 0.19 (0.001) |
| GWR model Meuse | 139 | 0.08 (0.029) |
| Non-spatial model California | 15,381 | 0.42 (0.001) |
| Spatial Lag model California | 18,941 | 0.023 (0.999) |
| ESF model Meuse California | 19,514 | 0.019 (0.999) |
| GWR model Meuse California | 18,566 | 0.016 (0.0009) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Kounadi, O.; Zurita-Milla, R. Incorporating Spatial Autocorrelation in Machine Learning Models Using Spatial Lag and Eigenvector Spatial Filtering Features. ISPRS Int. J. Geo-Inf. 2022, 11, 242. https://doi.org/10.3390/ijgi11040242
Liu X, Kounadi O, Zurita-Milla R. Incorporating Spatial Autocorrelation in Machine Learning Models Using Spatial Lag and Eigenvector Spatial Filtering Features. ISPRS International Journal of Geo-Information. 2022; 11(4):242. https://doi.org/10.3390/ijgi11040242
Chicago/Turabian StyleLiu, Xiaojian, Ourania Kounadi, and Raul Zurita-Milla. 2022. "Incorporating Spatial Autocorrelation in Machine Learning Models Using Spatial Lag and Eigenvector Spatial Filtering Features" ISPRS International Journal of Geo-Information 11, no. 4: 242. https://doi.org/10.3390/ijgi11040242
APA StyleLiu, X., Kounadi, O., & Zurita-Milla, R. (2022). Incorporating Spatial Autocorrelation in Machine Learning Models Using Spatial Lag and Eigenvector Spatial Filtering Features. ISPRS International Journal of Geo-Information, 11(4), 242. https://doi.org/10.3390/ijgi11040242