
Urban Change Detection from Aerial Images Using Convolutional Neural Networks and Transfer Learning

 , ,
, ,  and
and
Abstract
:1. Introduction
2. Related Work
3. Problem Description
4. Materials and Methods
4.1. Dataset Selection
- To create a machine learning (ML) model, which enables the ability to obtain interpretable values on the local level for images of different periods and process the results at a detailed level;
- To demonstrate the applicability of the transfer learning approach in the ML model training process.
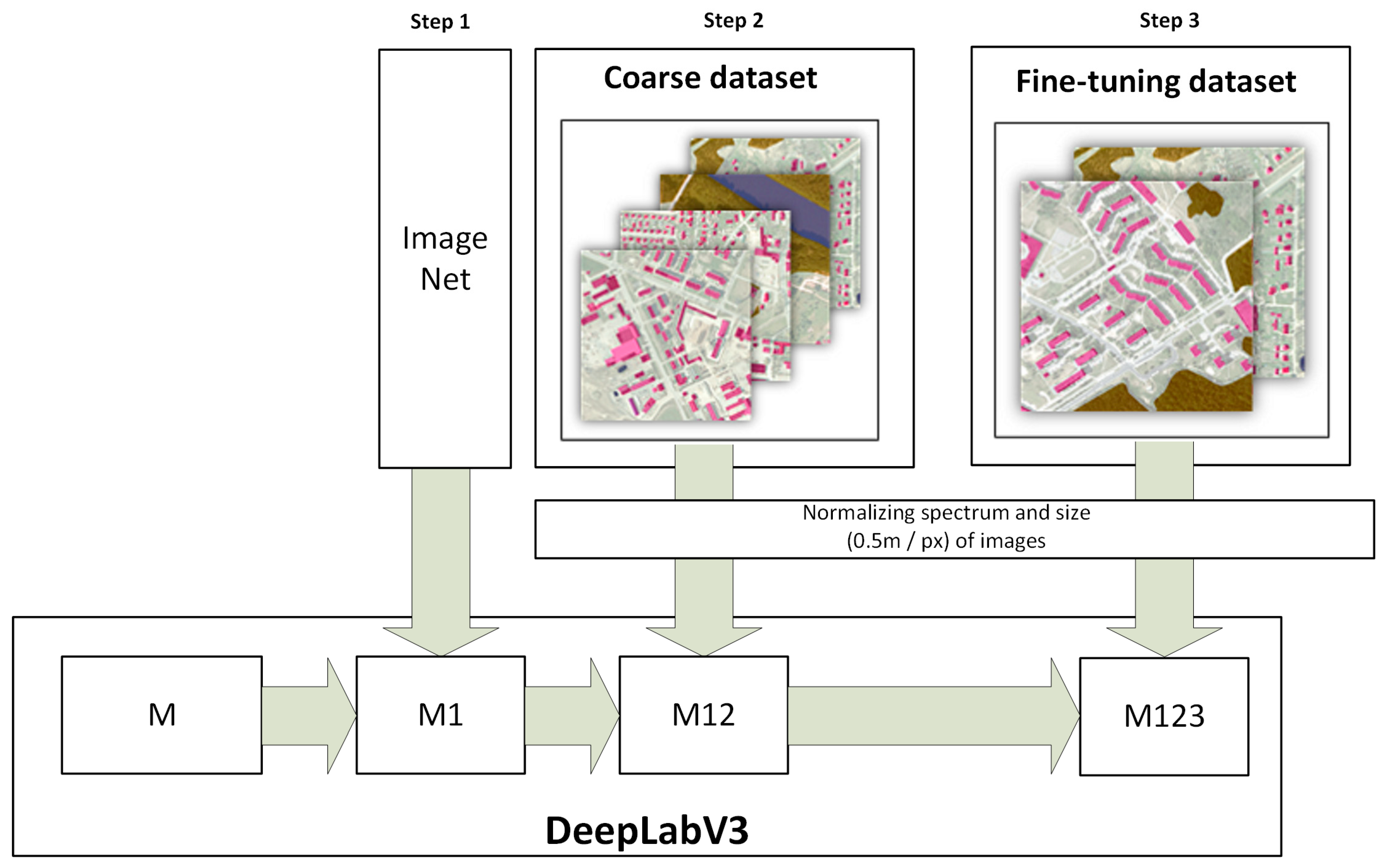
4.2. Methodology Overview
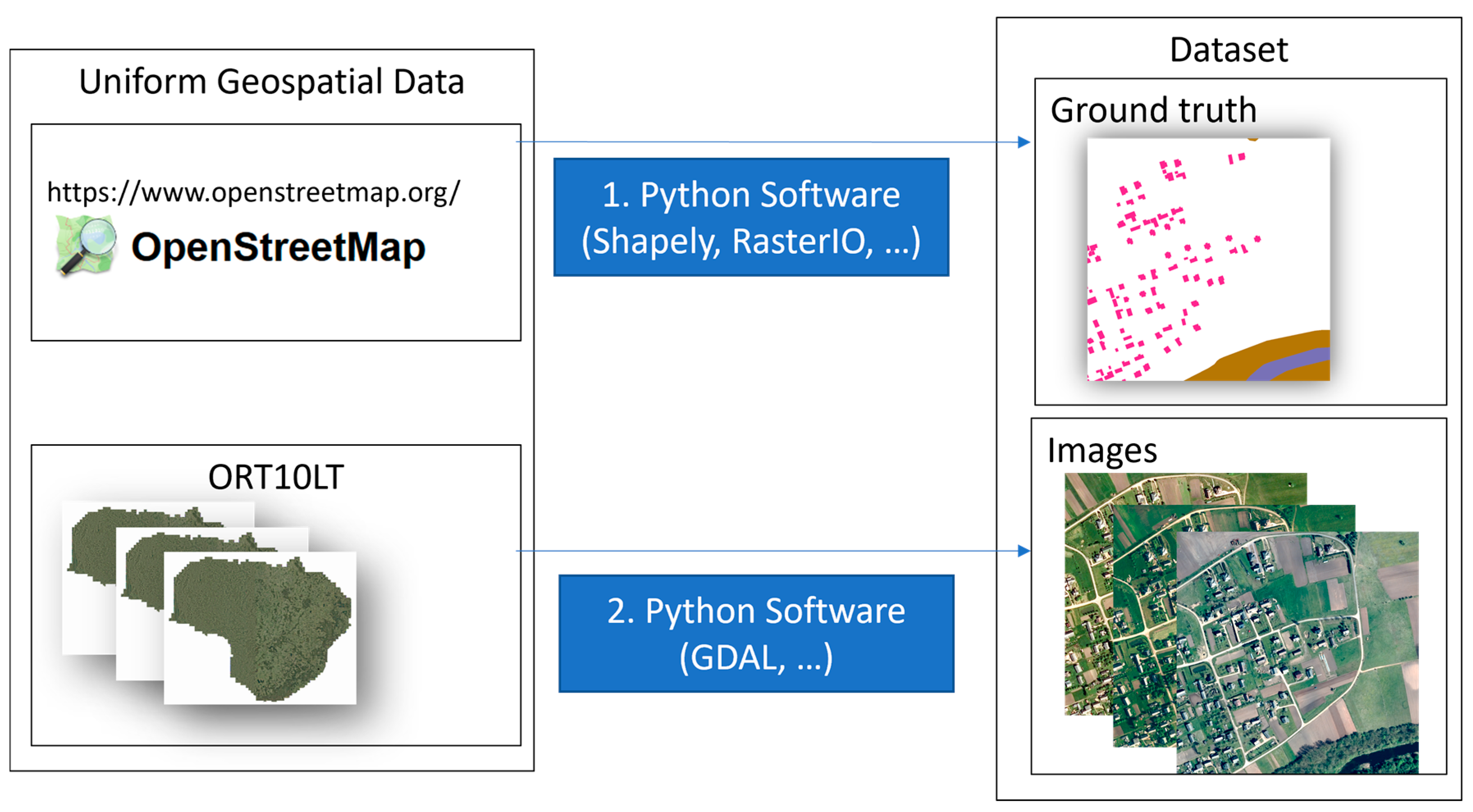
4.3. Dataset Collection and Preprocessing
- Logical—the OSM data do not always match the objects in images due to ill-timed mapping or changes in the environment as time passes. For example, a building is identified in the image but the label in OSM data is absent or new houses have been built recently and are not detected in the images of older periods.
- Quality—the results for images taken in different periods or locations may vary due to lighting and resulting shadows (early morning vs. afternoon); different angles at which the images were taken; different equipment used to take the images which results in different color response and dynamic range (some images are blurry because the photos were taken in early morning or at night).
- Resolution was normalized to 0.5 m/pixel to fit the resolution of the lowest quality images;
- Contrast was normalized using a 2–98% percentile interval; all pixels over and under the interval were clipped to minimum or maximum values;
- Standard computer vision normalization procedure was applied to transform images so that the dataset distribution mean value is equal to 0 and standard deviation value is equal to 1 for each channel. The normalization procedure was performed with the assumption that initial distribution has mean values equal to 0.485, 0.456, and 0.406 and standard deviation values equal to 0.229, 0.224, and 0.225 for red, green, and blue channels, respectively. The values applied to normalize tensors are based on the statistical analysis of over 1.2 million images of ImageNet dataset.
4.4. Training Computer Vision Model
- Input layer: 1024 × 1024 pixels (result taken from 896 × 896 pixels) ~448 m × 448 m (or ~0.2 km2) area;
- Coarse learning: learning rate 5 × 10−4; momentum 0.5; 5000 samples per epoch;
- Fine-tune learning: learning rate 5 × 10−5; momentum 0.1; 100 samples per epoch.
5. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dadashpoor, H.; Azizi, P.; Moghadasi, M. Analyzing spatial patterns, driving forces and predicting future growth scenarios for supporting sustainable urban growth: Evidence from Tabriz metropolitan area, Iran. Sustain. Cities Soc. 2019, 47, 101502. [Google Scholar] [CrossRef]
- Liang, X.; Liu, X.; Li, D.; Zhao, H.; Chen, G. Urban growth simulation by incorporating planning policies into a CA-based future land-use simulation model. Int. J. Geogr. Inf. Sci. 2018, 32, 2294–2316. [Google Scholar] [CrossRef]
- Serasinghe Pathiranage, I.S.; Kantakumar, L.N.; Sundaramoorthy, S. Remote Sensing Data and SLEUTH Urban Growth Model: As Decision Support Tools for Urban Planning. Chin. Geogr. Sci. 2018, 28, 274–286. [Google Scholar] [CrossRef] [Green Version]
- Xie, M.; Jean, N.; Burke, M.; Lobell, D.; Ermon, S. Transfer learning from deep features for remote sensing and poverty mapping. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, AAAI 2016, Phoenix, AZ, USA, 12–17 February 2016; pp. 3929–3935. [Google Scholar]
- Macků, K.; Voženílek, V.; Pászto, V. Linking the quality of life index and the typology of European administrative units. J. Int. Dev. 2022, 34, 145–174. [Google Scholar] [CrossRef]
- Gevaert, C.M.; Persello, C.; Sliuzas, R.; Vosselman, G. Monitoring household upgrading in unplanned settlements with unmanned aerial vehicles. Int. J. Appl. Earth Obs. Geoinf. 2020, 90, 102117. [Google Scholar] [CrossRef]
- Emilien, A.-V.; Thomas, C.; Thomas, H. UAV & satellite synergies for optical remote sensing applications: A literature review. Sci. Remote Sens. 2021, 3, 100019. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change detection based on artificial intelligence: State-of-the-art and challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Cui, B.; Zhang, Y.; Yan, L.; Wei, J.; Wu, H. An unsupervised SAR change detection method based on stochastic subspace ensemble learning. Remote Sens. 2019, 11, 1314. [Google Scholar] [CrossRef] [Green Version]
- Donaldson, D.; Storeygard, A. The view from above: Applications of satellite data in economics. J. Econ. Perspect. 2016, 30, 171–198. [Google Scholar] [CrossRef] [Green Version]
- Celik, T. Unsupervised change detection in satellite images using principal component analysis and κ-means clustering. IEEE Geosci. Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- de Jong, K.L.; Sergeevna Bosman, A. Unsupervised Change Detection in Satellite Images Using Convolutional Neural Networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Xue, D.; Lei, T.; Jia, X.; Wang, X.; Chen, T.; Nandi, A.K. Unsupervised Change Detection Using Multiscale and Multiresolution Gaussian-Mixture-Model Guided by Saliency Enhancement. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1796–1809. [Google Scholar] [CrossRef]
- Liu, J.; Chen, K.; Xu, G.; Sun, X.; Yan, M.; Diao, W.; Han, H. Convolutional Neural Network-Based Transfer Learning for Optical Aerial Images Change Detection. IEEE Geosci. Remote Sens. Lett. 2020, 17, 127–131. [Google Scholar] [CrossRef]
- Zhang, Y.; Fu, L.; Li, Y.; Zhang, Y. Hdfnet: Hierarchical dynamic fusion network for change detection in optical aerial images. Remote Sens. 2021, 13, 1440. [Google Scholar] [CrossRef]
- Jiang, H.; Hu, X.; Li, K.; Zhang, J.; Gong, J.; Zhang, M. PGA-SiamNet: Pyramid feature-based attention-guided siamese network for remote sensing orthoimagery building change detection. Remote Sens. 2020, 12, 484. [Google Scholar] [CrossRef] [Green Version]
- Wurm, M.; Stark, T.; Zhu, X.X.; Weigand, M.; Taubenböck, H. Semantic segmentation of slums in satellite images using transfer learning on fully convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2019, 150, 59–69. [Google Scholar] [CrossRef]
- Jean, N.; Burke, M.; Xie, M.; Davis, W.M.; Lobell, D.B.; Ermon, S. Combining satellite imagery and machine learning to predict poverty. Science 2016, 353, 790–794. [Google Scholar] [CrossRef] [Green Version]
- Suraj, P.K.; Gupta, A.; Sharma, M.; Paul, S.B.; Banerjee, S. On monitoring development indicators using high resolution satellite images. arXiv 2018, arXiv:1712.02282. [Google Scholar]
- Fyleris, T.; Kriščiūnas, A.; Gružauskas, V.; Čalnerytė, D. Deep Learning Application for Urban Change Detection from Aerial Images. In GISTAM 2021: Proceedings of the 7th International Conference on Geographical Information Systems Theory, Applications and Management, Online, 23–25 April 2021; SciTePress: Setúbal, Portugal, 2021; pp. 15–24. [Google Scholar] [CrossRef]
- The Sentinel Missions. Available online: https://www.esa.int/Applications/Observing_the_Earth/Copernicus/The_Sentinel_missions (accessed on 9 February 2022).
- Shermeyer, J.; Van Etten, A. The Effects of Super-Resolution on Object Detection Performance in Satellite Imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Witwit, W.; Zhao, Y.; Jenkins, K.; Zhao, Y. Satellite image resolution enhancement using discrete wavelet transform and new edge-directed interpolation. J. Electron. Imaging 2017, 26, 023014. [Google Scholar] [CrossRef]
- Krupinski, M.; Lewiński, S.; Malinowski, R. One class SVM for building detection on Sentinel-2 images. In Photonics Applications in Astronomy, Communications, Industry, and High-Energy Physics Experiments 2019; International Society for Optics and Photonics: Wilga, Poland, 2019; Volume 1117635, p. 6. [Google Scholar]
- Corbane, C.; Syrris, V.; Sabo, F.; Pesaresi, M.; Soille, P.; Kemper, T. Convolutional Neural Networks for Global Human Settlements Mapping from Sentinel-2 Satellite Imagery. arXiv 2020, arXiv:2006.03267. [Google Scholar] [CrossRef]
- Song, K.; Jiang, J. AGCDetNet:An Attention-Guided Network for Building Change Detection in High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4816–4831. [Google Scholar] [CrossRef]
- Ke, Q.; Zhang, P. CS-HSNet: A Cross-Siamese Change Detection Network Based on Hierarchical-Split Attention. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9987–10002. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 8828, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection (RetinaNet). In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, Y.; Han, Z.; Chen, C.; DIng, L.; Liu, Y. Eagle-Eyed Multitask CNNs for Aerial Image Retrieval and Scene Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6699–6721. [Google Scholar] [CrossRef]
- Ye, Z.; Fu, Y.; Gan, M.; Deng, J.; Comber, A.; Wang, K. Building extraction from very high resolution aerial imagery using joint attention deep neural network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef] [Green Version]
- Wu, G.; Shao, X.; Guo, Z.; Chen, Q.; Yuan, W.; Shi, X.; Xu, Y.; Shibasaki, R. Automatic building segmentation of aerial imagery usingmulti-constraint fully convolutional networks. Remote Sens. 2018, 10, 407. [Google Scholar] [CrossRef] [Green Version]
- Dornaika, F.; Moujahid, A.; El Merabet, Y.; Ruichek, Y. Building detection from orthophotos using a machine learning approach: An empirical study on image segmentation and descriptors. Expert Syst. Appl. 2016, 58, 130–142. [Google Scholar] [CrossRef]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 1873–1876. [Google Scholar] [CrossRef] [Green Version]
- Al-Ruzouq, R.; Hamad, K.; Shanableh, A.; Khalil, M. Infrastructure growth assessment of urban areas based on multi-temporal satellite images and linear features. Ann. GIS 2017, 23, 183–201. [Google Scholar] [CrossRef]
- Albert, A.; Kaur, J.; Gonzalez, M.C. Using convolutional networks and satellite imagery to identify patterns in urban environments at a large scale. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; Part F1296. pp. 1357–1366. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Title | Using Weights Pretrained on the ImageNet (Step 1 in Figure 2) | Training on Coarse Dataset (Step 2 in Figure 2) | Training on Fine-Tuning Dataset (Step 3 in Figure 2) |
|---|---|---|---|
| M2 | 🗸 | ||
| M12 | 🗸 | 🗸 | |
| M3 | 🗸 | ||
| M23 | 🗸 | 🗸 | |
| M13 | 🗸 | 🗸 | |
| M123 | 🗸 | 🗸 | 🗸 |
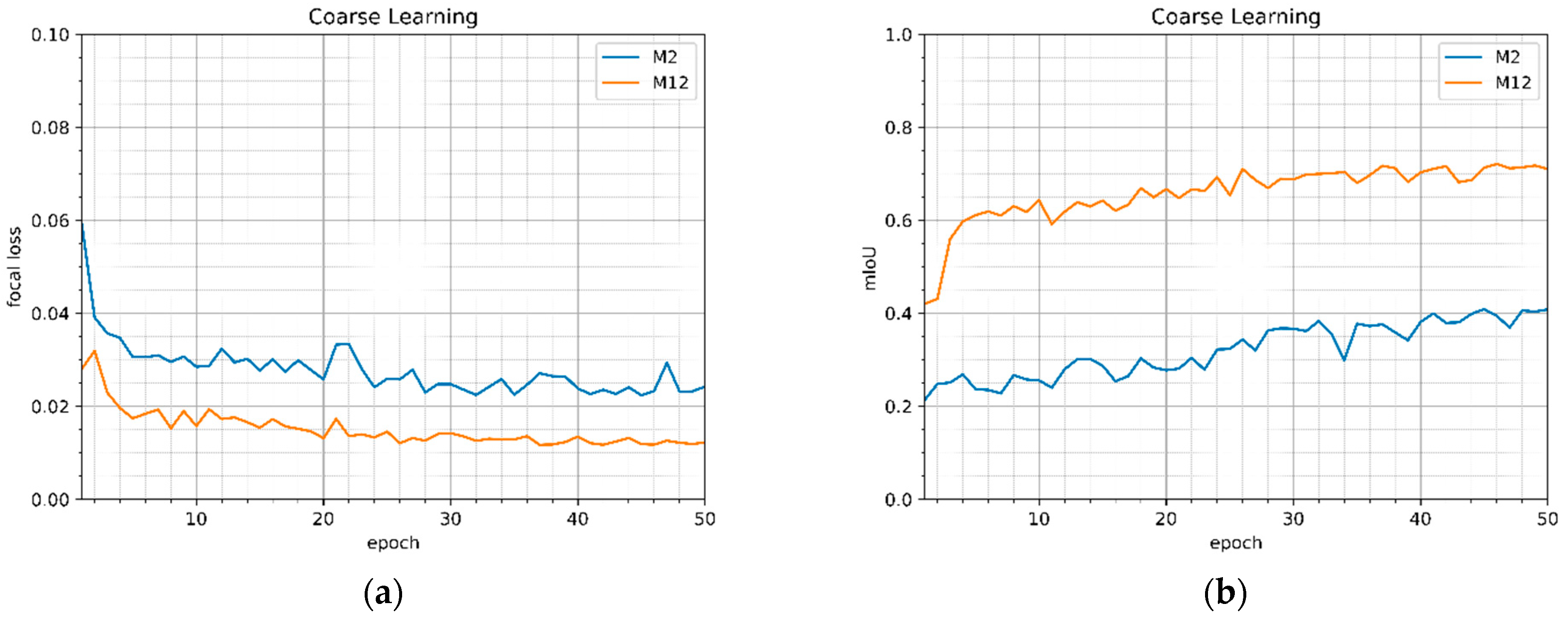
| Model Title | Focal Loss | mIoU | Pixel Accuracy |
|---|---|---|---|
| M2 | 0.02426 | 0.40869 | 0.85503 |
| M12 | 0.01225 | 0.71063 | 0.91519 |
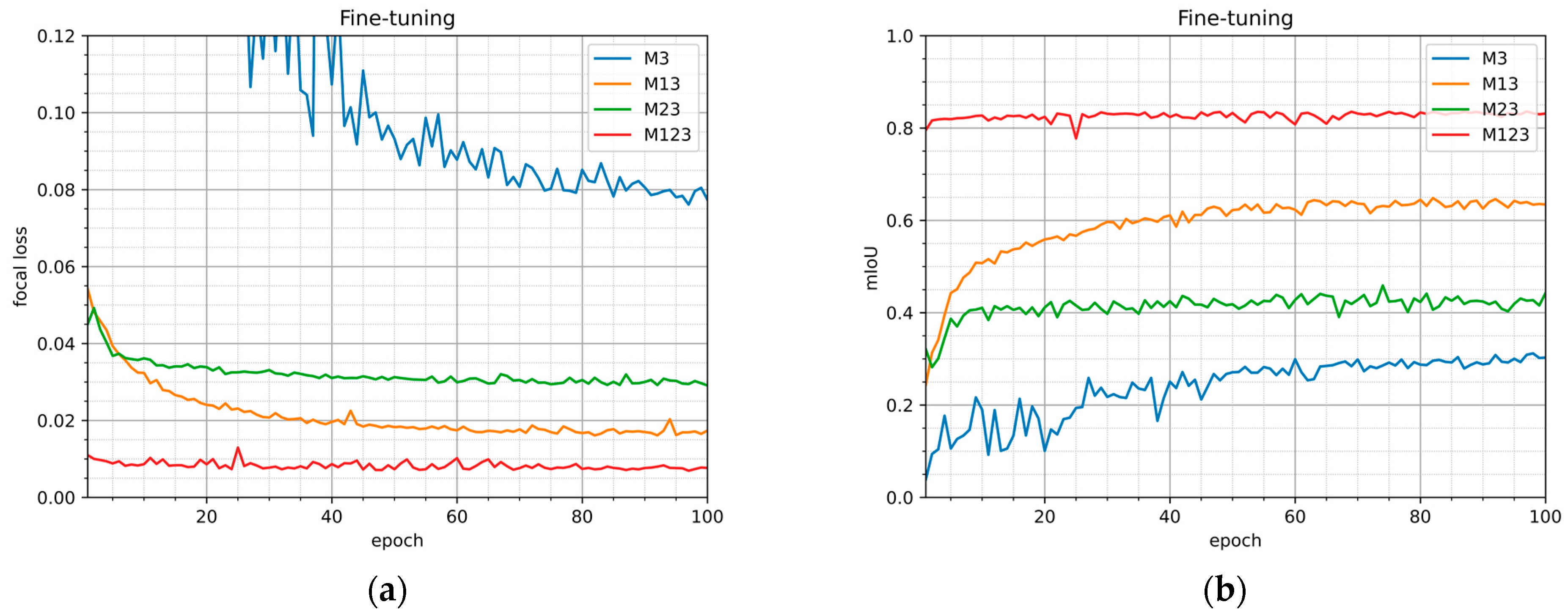
| Model Title | Focal Loss | mIoU | Pixel Accuracy |
|---|---|---|---|
| M3 | 0.07739 | 0.30296 | 0.60999 |
| M13 | 0.01738 | 0.63443 | 0.90958 |
| M23 | 0.02911 | 0.44274 | 0.77934 |
| M123 | 0.00767 | 0.83142 | 0.95199 |
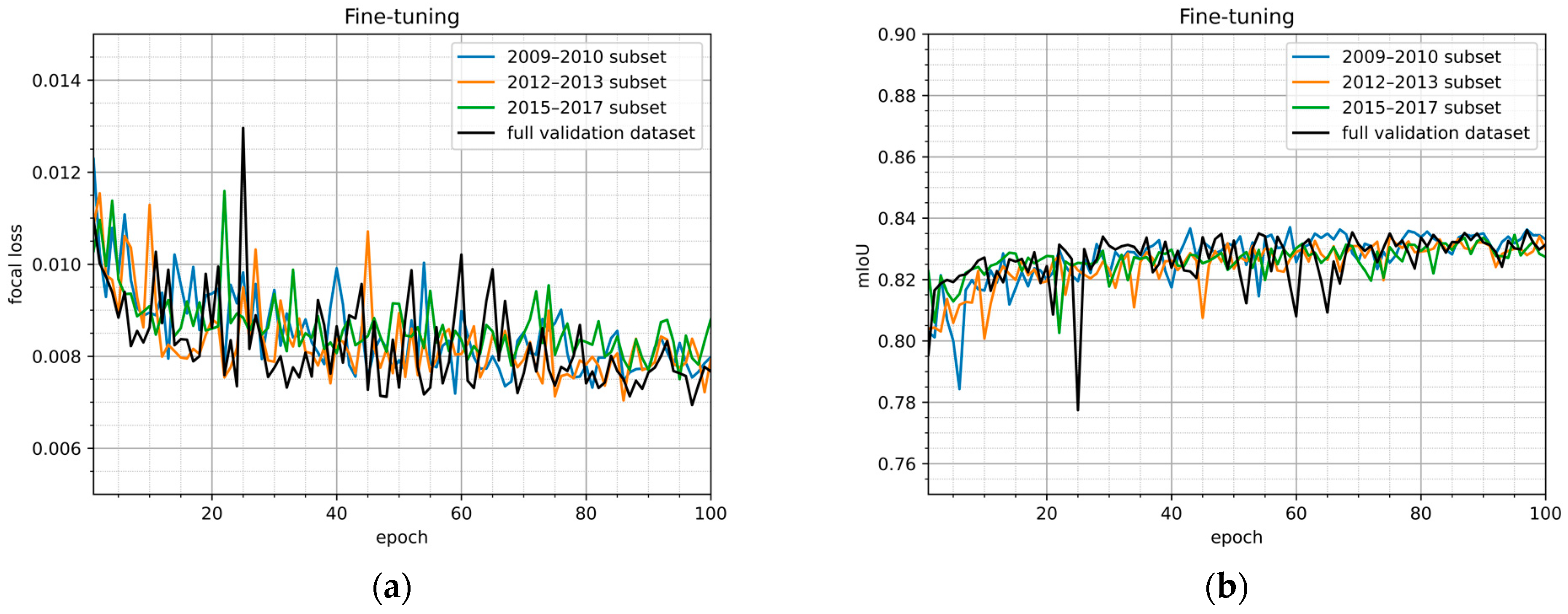
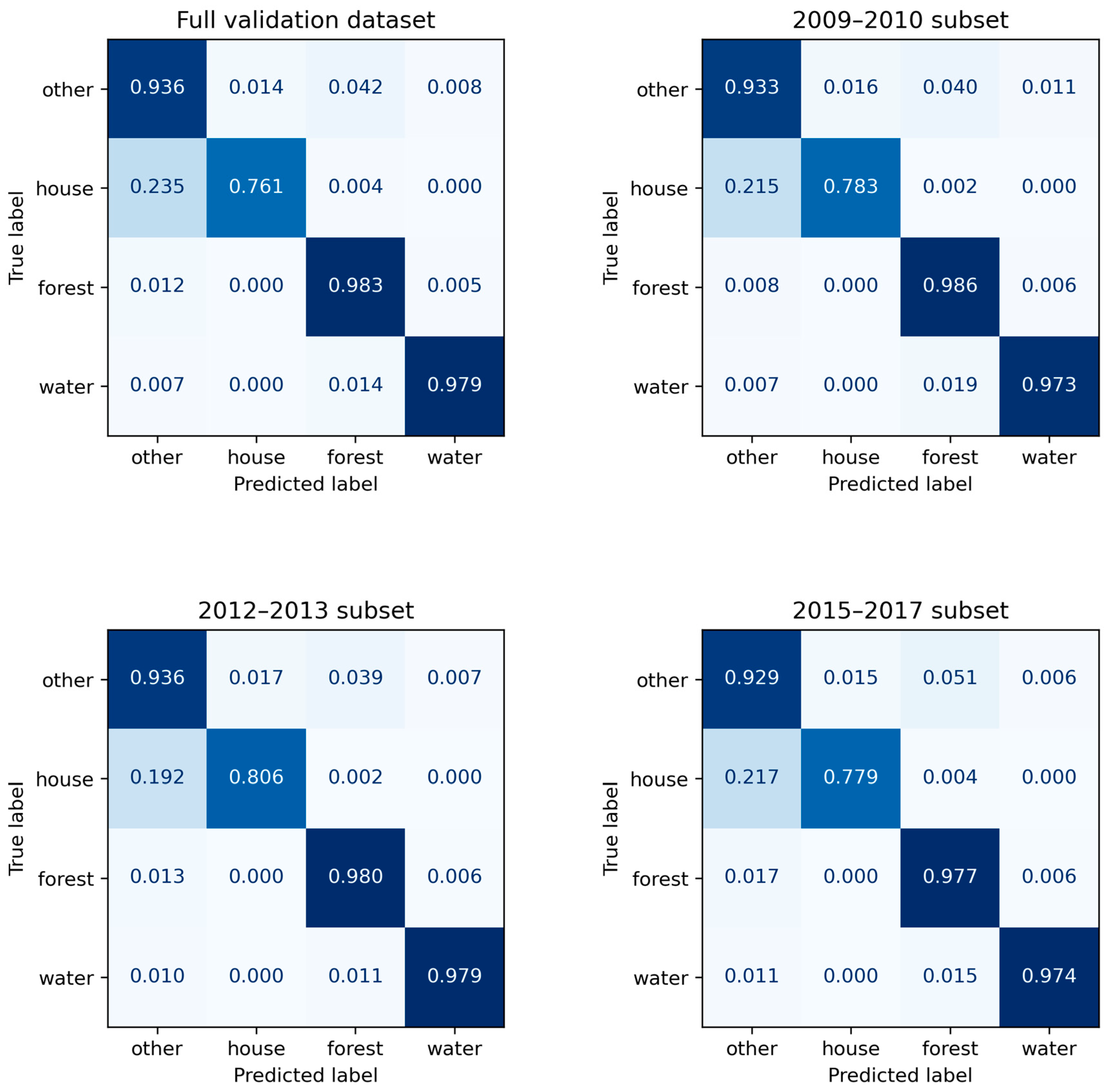
| Model Title | Focal Loss | mIoU | Pixel Accuracy |
|---|---|---|---|
| 2009–2010 subset | 0.00798 | 0.83311 | 0.95185 |
| 2012–2013 subset | 0.00793 | 0.82983 | 0.95234 |
| 2015–2017 subset | 0.00880 | 0.82733 | 0.94491 |
| full validation dataset | 0.00767 | 0.83142 | 0.95199 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fyleris, T.; Kriščiūnas, A.; Gružauskas, V.; Čalnerytė, D.; Barauskas, R. Urban Change Detection from Aerial Images Using Convolutional Neural Networks and Transfer Learning. ISPRS Int. J. Geo-Inf. 2022, 11, 246. https://doi.org/10.3390/ijgi11040246
Fyleris T, Kriščiūnas A, Gružauskas V, Čalnerytė D, Barauskas R. Urban Change Detection from Aerial Images Using Convolutional Neural Networks and Transfer Learning. ISPRS International Journal of Geo-Information. 2022; 11(4):246. https://doi.org/10.3390/ijgi11040246
Chicago/Turabian StyleFyleris, Tautvydas, Andrius Kriščiūnas, Valentas Gružauskas, Dalia Čalnerytė, and Rimantas Barauskas. 2022. "Urban Change Detection from Aerial Images Using Convolutional Neural Networks and Transfer Learning" ISPRS International Journal of Geo-Information 11, no. 4: 246. https://doi.org/10.3390/ijgi11040246
APA StyleFyleris, T., Kriščiūnas, A., Gružauskas, V., Čalnerytė, D., & Barauskas, R. (2022). Urban Change Detection from Aerial Images Using Convolutional Neural Networks and Transfer Learning. ISPRS International Journal of Geo-Information, 11(4), 246. https://doi.org/10.3390/ijgi11040246