

A Complete Reinforcement-Learning-Based Framework for Urban-Safety Perception

Abstract
:1. Introduction
2. Review of Related Fields
2.1. Safety Perception of the City
2.2. Interpretable Scene Understanding
2.3. Decision Making
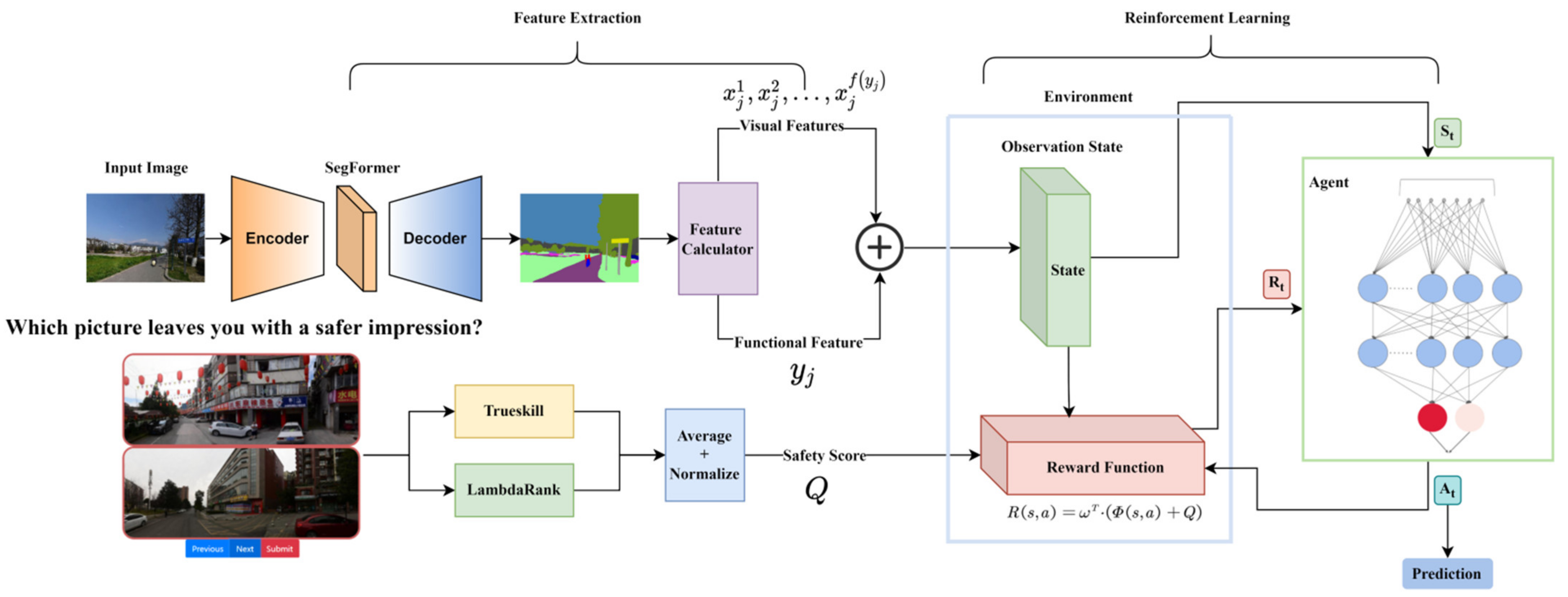
3. Methods and Data Processing
3.1. Building the Dataset
3.2. Expert Rating
- Low-quality images were removed, such as those with tunnels or few elements. Following [41], the most representative features in the street-view images were selected.
- Criteria were proposed for zoning based on the features and actual geographical location of each functional area in the city. We describe zoning in Section 3.3.
- A corresponding expert system for perceptual safety prediction based on different functional areas was designed; this expert system was the basis of our RL method (for both the reward function and the state definition).
- The safety scores were amended to reduce the uncertainty and set the score threshold—that is, images above the threshold were considered safe and labelled “1”. otherwise, the label was “0”. It is worth noting that, even after correction by experts, noise still existed in the labels.
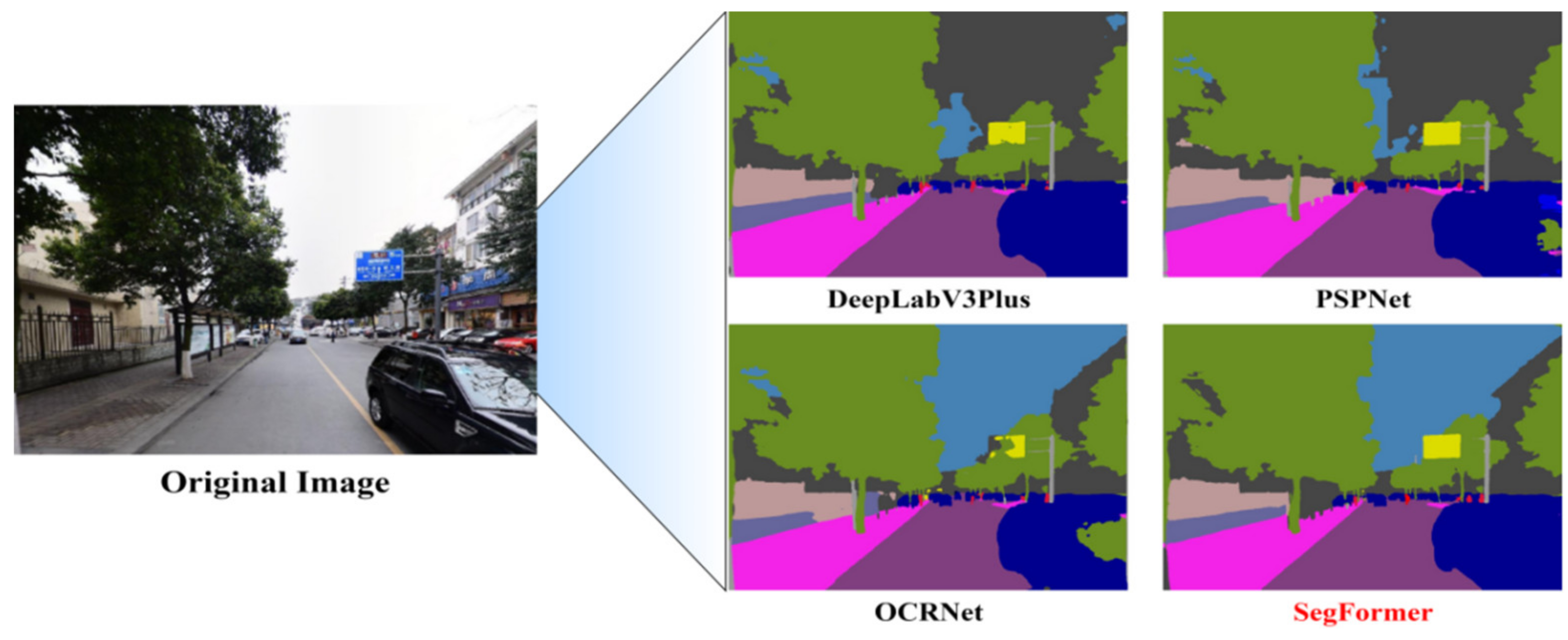
3.3. Feature Extraction
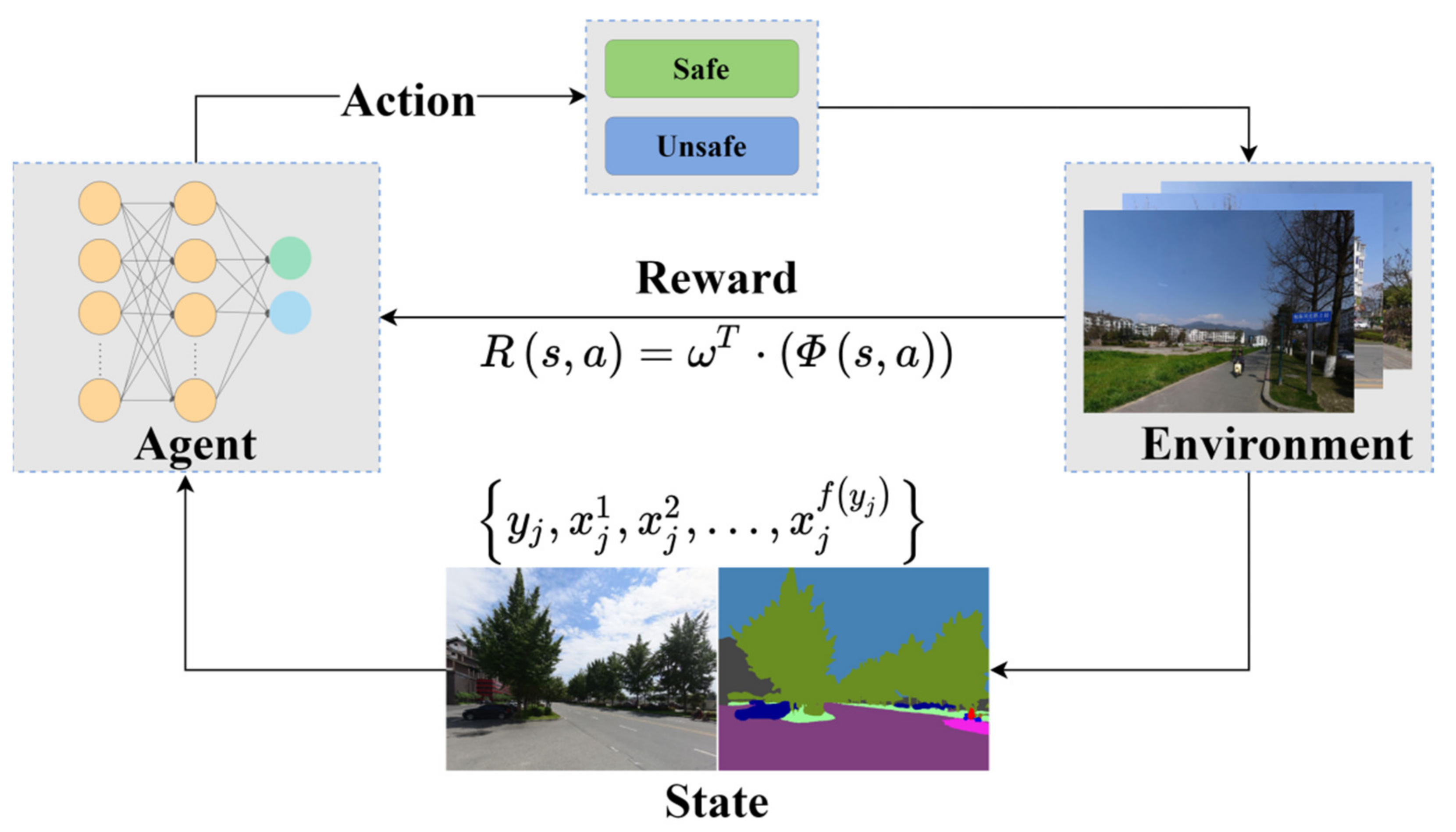
4. System Modelling
4.1. Markov Decision Process
4.2. Image-Based Modelling
5. Experimental Results
5.1. Experimental Setup
5.2. Main Results
5.3. Interpretation of Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kuo, F.E.; Sullivan, W.C. Environment and Crime in the Inner City: Does Vegetation Reduce Crime? Environ. Behav. 2001, 33, 343–367. [Google Scholar] [CrossRef]
- Troy, A.; Morgan Grove, J.; O’Neil-Dunne, J. The relationship between tree canopy and crime rates across an urban–rural gradient in the greater Baltimore region. Landsc. Urban Plan. 2012, 106, 262–270. [Google Scholar] [CrossRef]
- Arietta, S.M.; Efros, A.A.; Ramamoorthi, R.; Agrawala, M. City Forensics: Using Visual Elements to Predict Non-Visual City Attributes. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2624–2633. [Google Scholar] [CrossRef]
- Zhou, H.; Liu, L.; Lan, M.; Zhu, W.; Song, G.; Jing, F.; Zhong, Y.; Su, Z.; Gu, X. Using Google Street View imagery to capture micro built environment characteristics in drug places, compared with street robbery. Comput. Environ. Urban Syst. 2021, 88, 101631. [Google Scholar] [CrossRef]
- Kelling, G.L.; Coles, C.M. Fixing Broken Windows: Restoring Order and Reducing Crime in Our Communities; A Touchstone Book; Simon & Schuster: New York, NY, USA, 1997; ISBN 978-0-684-83738-3. [Google Scholar]
- Quercia, D.; O’Hare, N.K.; Cramer, H. Aesthetic capital: What makes london look beautiful, quiet, and happy? In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Portland, OR, USA, 25 January–1 February 2017; ACM: Baltimore, MD, USA, 2014; pp. 945–955. [Google Scholar]
- Naik, N.; Philipoom, J.; Raskar, R.; Hidalgo, C. Streetscore—Predicting the Perceived Safety of One Million Streetscapes. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; IEEE: Columbus, OH, USA, 2014; pp. 793–799. [Google Scholar]
- Cheng, L.; Chu, S.; Zong, W.; Li, S.; Wu, J.; Li, M. Use of Tencent Street View Imagery for Visual Perception of Streets. ISPRS Int. J. Geo-Inf. 2017, 6, 265. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, D.; Liu, Y.; Lin, H. Representing place locales using scene elements. Comput. Environ. Urban Syst. 2018, 71, 153–164. [Google Scholar] [CrossRef]
- Lindal, P.J.; Hartig, T. Architectural variation, building height, and the restorative quality of urban residential streetscapes. J. Environ. Psychol. 2013, 33, 26–36. [Google Scholar] [CrossRef]
- Dubey, A.; Naik, N.; Parikh, D.; Raskar, R.; Hidalgo, C.A. Deep Learning the City: Quantifying Urban Perception At A Global Scale. arXiv 2016, arXiv:160801769. [Google Scholar]
- Liu, X.; Chen, Q.; Zhu, L.; Xu, Y.; Lin, L. Place-centric Visual Urban Perception with Deep Multi-instance Regression. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; ACM: Mountain View, CA, USA, 2017; pp. 19–27. [Google Scholar]
- Schölkopf, B.; Platt, J.; Hofmann, T. (Eds.) TrueSkill: A Bayesian Skill Rating System. In Advances in Neural Information Processing Systems 19; The MIT Press: Cambridge, MA, USA, 2007; ISBN 978-0-262-25691-9. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- You, C.; Lu, J.; Filev, D.; Tsiotras, P. Advanced planning for autonomous vehicles using reinforcement learning and deep inverse reinforcement learning. Robot. Auton. Syst. 2019, 114, 1–18. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Bellman, R. A Markovian Decision Process. Indiana Univ. Math. J. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Lynch, K. The Image of the City, 33rd ed.; Publication of the Joint Center for Urban Studies; MIT Press: Cambridge, MA, USA, 2008; ISBN 978-0-262-62001-7. [Google Scholar]
- Jacobs, J. The Death and Life of Great American Cities; Vintage Books: New York, NY, USA, 1992; ISBN 978-0-679-74195-4. [Google Scholar]
- Jansson, M.; Fors, H.; Lindgren, T.; Wiström, B. Perceived personal safety in relation to urban woodland vegetation—A review. Urban For. Urban Green. 2013, 12, 127–133. [Google Scholar] [CrossRef]
- Li, F. Multilevel modelling of built environment characteristics related to neighbourhood walking activity in older adults. J. Epidemiol. Community Health 2005, 59, 558–564. [Google Scholar] [CrossRef]
- Stafford, M.; Chandola, T.; Marmot, M. Association Between Fear of Crime and Mental Health and Physical Functioning. Am. J. Public Health 2007, 97, 2076–2081. [Google Scholar] [CrossRef]
- Jackson, J.; Stafford, M. Public Health and Fear of Crime: A Prospective Cohort Study. Br. J. Criminol. 2009, 49, 832–847. [Google Scholar] [CrossRef]
- Liu, L.; Silva, E.A.; Wu, C.; Wang, H. A machine learning-based method for the large-scale evaluation of the qualities of the urban environment. Comput. Environ. Urban Syst. 2017, 65, 113–125. [Google Scholar] [CrossRef]
- He, L.; Páez, A.; Liu, D. Built environment and violent crime: An environmental audit approach using Google Street View. Comput. Environ. Urban Syst. 2017, 66, 83–95. [Google Scholar] [CrossRef]
- Nielsen, I.; Smyth, R. Who wants safer cities? Perceptions of public safety and attitudes to migrants among China’s urban population. Int. Rev. Law Econ. 2008, 28, 46–55. [Google Scholar] [CrossRef]
- Yan, A.F.; Voorhees, C.C.; Clifton, K.; Burnier, C. Do you see what I see?—Correlates of multidimensional measures of neighborhood types and perceived physical activity–related neighborhood barriers and facilitators for urban youth. Prev. Med. 2010, 50, S18–S23. [Google Scholar] [CrossRef]
- Porzi, L.; Rota Bulò, S.; Lepri, B.; Ricci, E. Predicting and Understanding Urban Perception with Convolutional Neural Networks. In Proceedings of the 23rd ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; ACM: Brisbane, Australia, 2015; pp. 139–148. [Google Scholar]
- Ordonez, V.; Berg, T.L. Learning High-Level Judgments of Urban Perception. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8694, pp. 494–510. ISBN 978-3-319-10598-7. [Google Scholar]
- Acosta, S.; Camargo, J.E. Predicting city safety perception based on visual image content. arXiv 2019, arXiv:190206871. [Google Scholar]
- Salesses, P.; Schechtner, K.; Hidalgo, C.A. The Collaborative Image of The City: Mapping the Inequality of Urban Perception. PLoS ONE 2013, 8, e68400. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaur, T.; Gandhi, T.K. Automated Brain Image Classification Based on VGG-16 and Transfer Learning. In Proceedings of the 2019 International Conference on Information Technology (ICIT), Bhubaneswar, India, 19–21 December 2019; pp. 94–98. [Google Scholar]
- Williams, R.J. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. In Reinforcement Learning; Sutton, R.S., Ed.; Springer: Boston, MA, USA, 1992; pp. 5–32. ISBN 978-1-4613-6608-9. [Google Scholar]
- Konda, V.; Tsitsiklis, J. Actor-Critic Algorithms. In Advances in Neural Information Processing Systems; Solla, S., Leen, T., Mül-ler, K., Eds.; MIT Press: Cambridge, MA, USA, 1999; Volume 12. [Google Scholar]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation 7; AT&T Labs: New York, NY, USA, 1999. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In Advances in Neural Information Processing Systems; Solla, S., Leen, T., Müller, K., Eds.; MIT Press: Cambridge, MA, USA, 1999; Volume 12. [Google Scholar]
- Strasburger, H. Seven Myths on Crowding and Peripheral Vision. i-Perception 2020, 11, 204166952091305. [Google Scholar] [CrossRef] [PubMed]
- Schölkopf, B.; Platt, J.; Hofmann, T. (Eds.) Learning to Rank with Nonsmooth Cost Functions. In Advances in Neural Information Processing Systems 19; The MIT Press: Cambridge, MA, USA, 2007; ISBN 978-0-262-25691-9. [Google Scholar]
- Nasar, J.L. Adult Viewers’ Preferences in Residential Scenes: A Study of the Relationship of Environmental Attributes to Preference. Environ. Behav. 1983, 15, 589–614. [Google Scholar] [CrossRef]
- Wohlwill, J.F. Environmental Aesthetics: The Environment as a Source of Affect. In Human Behavior and Environment; Altman, I., Wohlwill, J.F., Eds.; Springer US: Boston, MA, USA, 1976; pp. 37–86. ISBN 978-1-4684-2552-9. [Google Scholar]
- Ewing, R.; Handy, S. Measuring the Unmeasurable: Urban Design Qualities Related to Walkability. J. Urban Des. 2009, 14, 65–84. [Google Scholar] [CrossRef]
- Zhu, D.; Zhang, F.; Wang, S.; Wang, Y.; Cheng, X.; Huang, Z.; Liu, Y. Understanding Place Characteristics in Geographic Contexts through Graph Convolutional Neural Networks. Ann. Am. Assoc. Geogr. 2020, 110, 408–420. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:210515203. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12351, pp. 173–190. ISBN 978-3-030-58538-9. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 833–851. ISBN 978-3-030-01233-5. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 3213–3223. [Google Scholar] [CrossRef]
- Ren, Z.; Wang, X.; Zhang, N.; Lv, X.; Li, L.-J. Deep Reinforcement Learning-Based Image Captioning with Embedding Reward. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1151–1159. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AR, USA, 12–17 February 2016; Volume 30. [Google Scholar] [CrossRef]
- Wang, Z.; Schaul, T.; Hessel, M.; van Hasselt, H.; Lanctot, M.; de Freitas, N. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Description |
|---|---|
| Sky-FoV | The cover ratio of the sky in the field of view |
| Greenery-FoV | The cover ratio of the terrain and vegetation in the field of view |
| Wall-FoV | The cover ratio of the wall in the field of view |
| Sidewalk-FoV | The cover ratio of the sidewalk in the field of view |
| Building-FoV | The cover ratio of the building in the field of view |
| Traffic_light-FoV | The cover ratio of the traffic light in the field of view |
| Traffic_sign-FoV | The cover ratio of the traffic sign in the field of view |
| Visual Entropy | The magnitude of the visual entropy value can reflect the visual complexity and richness of an image |
| Vehicle Number | The number of the vehicles |
| Person Number | The number of the person |
| Electric Wire | Whether there is any electric wire. The value is 0 or 1. |
| No. (j-th) | Functional Area | Features |
|---|---|---|
| 1 | Business Area | GVI, Wall-FoV, Traffic_light-FoV, Traffic_sign-FoV, Electric Wire, Sky-FoV, Building-FoV |
| 2 | Cultural Area | GVI, Wall-FoV, Electric Wire, Sky-FoV, Person Number |
| 3 | Residential Area | Wall-FoV, Electric Wire, Building-FoV, Sky-FoV, Visual Entropy, GVI |
| 4 | Industrial Area | Electric Wire, Wall-FoV, Sidewalk-FoV, Vehicle Number, GVI |
| 5 | Suburban Area | Electric Wire, Wall-FoV, Sky-FoV, Visual Entropy |
| 6 | Others | Visual Entropy, Electric Wire, Building-FoV, GVI, Wall-FoV, Sky-FoV |
| Methods | Input Format | AUC |
|---|---|---|
| SVM | Vector | 0.617 |
| MLP | Vector | 0.611 |
| MLP (Layers = 5) | Image Matrix | 0.540 |
| CNN (Layers = 5) | Image Matrix | 0.550 |
| RL (D3QN) | Vector | 0.686 |
| Methods | AUC | Cosine Similarity | KLD (↓) |
|---|---|---|---|
| PPO | 0.619 | 0.231 | 0.302 |
| A2C | 0.612 | 0.215 | 0.295 |
| SAC | 0.684 | 0.369 | 0.237 |
| D3QN | 0.686 | 0.369 | 0.244 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Zeng, Z.; Li, Q.; Deng, Y. A Complete Reinforcement-Learning-Based Framework for Urban-Safety Perception. ISPRS Int. J. Geo-Inf. 2022, 11, 465. https://doi.org/10.3390/ijgi11090465
Wang Y, Zeng Z, Li Q, Deng Y. A Complete Reinforcement-Learning-Based Framework for Urban-Safety Perception. ISPRS International Journal of Geo-Information. 2022; 11(9):465. https://doi.org/10.3390/ijgi11090465
Chicago/Turabian StyleWang, Yaxuan, Zhixin Zeng, Qiushan Li, and Yingrui Deng. 2022. "A Complete Reinforcement-Learning-Based Framework for Urban-Safety Perception" ISPRS International Journal of Geo-Information 11, no. 9: 465. https://doi.org/10.3390/ijgi11090465
APA StyleWang, Y., Zeng, Z., Li, Q., & Deng, Y. (2022). A Complete Reinforcement-Learning-Based Framework for Urban-Safety Perception. ISPRS International Journal of Geo-Information, 11(9), 465. https://doi.org/10.3390/ijgi11090465