1. Introduction
With the improvement of the spatial resolution of aerial images, footpath (or cycle track)-level objects are recorded well. As shown in
Figure 1, the bikes, drones, and pedestrians are of footpath-level sizes. Some applications, including urban monitoring, military reconnaissance, and national security, have urgent needs in terms of identifying small targets [
1]. For example, pedestrian information is not only a data source for constructing urban human-flow patterns [
2] but also useful for safe landing [
3]. However, the identification of the footpath-level small targets encounters large-scale variation problems.
Figure 1 shows the large-scale variations in aerial image datasets, including the UAVid [
4] and Aeroscapes [
5]. In UAVid, pedestrians (
Figure 1a,b) are considerably smaller than trees and roads. In Aerospaces, bicycles (
Figure 1c) and drones (
Figure 1d) are considerably smaller than roads and cars. This large-scale variation significantly lowers the accuracy of segmenting smaller objects. For example, in the published evaluations of Aerospaces, the intersection-over-union (IoU) score of the bike category with the smallest size is only 15%, whereas that for the sky category with large objects is 94% [
5].
The reason why the large-scale variation issue results in low accuracy of the segmentation of small objects has been studied by [
6]. That is, most state-of-the-art methods, such as the pyramid scene parsing network (PSPNet) [
7] and point-wise spatial attention network (PSANet) [
8], focus on the accumulation of contextual information over significantly large receptive fields to generate high-level semantics. The high-level semantics (
Figure 2c,e) extracted using deep convolutional neural network (CNN) layers mainly depict the holistic information of the large objects and ignore small objects [
9,
10]. Therefore, large objects achieve high accuracy; however, small objects have extremely low accuracy.
Fortunately, the low-level features generated by the shallow layers contain small-object information, which is discovered by [
9,
10]. Consequently, several methods, such as the bilateral segmentation network (BiSeNet) [
12], BiSeNet-v2 [
13], and context aggregation network (CAgNet) [
14] with dual branches, have been proposed and applied to remote sensing tasks. These methods set up a branch with shallow layers to extract low-level features that contain small-object information. The low-level features and high-level semantics extracted by the other branch are fused to make the final prediction. These methods improve the accuracy of the segmentation of small objects to some extent; however, their effects are limited. This is because the low-level features (
Figure 2b,d) are the mixture of both the large and small objects. Specifically, the object details presented in
Figure 2d are mainly for large objects, and we can hardly find the details for pedestrians. The low-level features extracted by shallow layers do not eliminate the predominant effects of large objects. Consequently, large objects push small objects aside when these models are trained.
Different to the dual-branch networks, a study by [
15] uses a holistically nested edge detection (HED) [
16] to produce closed contours with deep supervision. Semantic segmentation is obtained using SegNet [
17] with the help of contours. This study achieves acceptable accuracy in the segmentation of relatively small objects (cars) in the ISPRS two-dimensional semantic labeling datasets (the Potsdam and Vaihingen datasets). However, cars are not small now in aerial images with the improvement of spatial resolution. For example, in the UAVid [
4] and Aeroscapes [
5] datasets, a range of objects (bikes, drones, and obstacles) that are considerably smaller than cars exist. Moreover, the contours extracted by HED exist for both large and small objects. Thus, the use of HED does not change the predominant relationship between large and small objects. Furthermore, the study in [
15] uses a normalized digital surface model (nDSM) and DSM as the input of one of its model branches. However, nDSM and DSM are not always provided; thus, their application is limited.
To the best of our knowledge, the aforementioned small-object problem remains unsolved. We propose a reverse difference mechanism (RDM) to highlight small objects to address this issue. RDM can alter the predominant relationship between large and small objects. Thus, when the model is trained, small objects will not be pushed by large objects. RDM excludes large-object information from low-level features via the guidance of high-level semantics. The low-level features, which are a mixture of both large and small objects, can be the features produced by any shallow layer. The high-level semantics can be the features generated by any deep layer with large receptive fields. We design a novel neural architecture called a reverse difference network (RDNet) based on RDM. In RDNet, a detailed stream (DS) followed by RDM is proposed to obtain small-object semantics. Furthermore, a contextual stream (CS) is designed to generate high-level semantics to ensure sufficient accuracy in the segmentation of large objects. Both the small-object and high-level semantics are concatenated to make a prediction. The code of the RDNet will be available at
https://github.com/yu-ni1989/RDNet, accessed on 21 July 2022. The contributions of this study are as follows.
A reverse difference mechanism (RDM) is proposed to highlight small objects. RDM aligns the low-level features and high-level semantics and excludes the large-object information from the low-level features via the guidance of high-level semantics. Small objects are preferentially learned during training via RDM.
Based on the RDM, a new semantic segmentation framework called RDNet is proposed. The RDNet significantly improves the accuracy of the segmentation of small objects. The inference speed and computational complexity of RDNet are acceptable for a resource-constrained GPU facility.
In RDNet, the DS and CS are designed. The DS obtains more semantics for the outputs of RDM by modeling both spatial and channel correlations. The CS, which ensures the sufficient accuracy of the segmentation of large objects, produces high-level semantics by enlarging the receptive field. Consequently, the higher accuracy scores of the segmentation of both small and large objects are achieved.
3. RDNet
The RDNet is constructed as shown in
Figure 3.
Figure 3 shows the neural architecture; only the RDM, DS, CS, and the loss functions are necessary to be presented in detail. For the backbone, although the experimental tests (
Section 5.3) demonstrate the superior performance of ResNet18 in RDNet, we do not specify the backbone network. Any general-purpose network, such as Xception [
37], MobileNetV3 [
35], GhostNet [
36], EfficientNetV2 [
39], and STDC [
40], can be integrated into RDNet, and we cannot ensure that ResNet18 achieves superior results compared with future work. The aforementioned general-purpose networks can be easily divided into four main layers (
,
,
, and
). If the input image patch has
pixels,
,
,
, and
extract features with reduced resolutions
,
,
, and
, respectively, as shown in
Figure 3. Notably, each
,
,
, and
contains several sublayers. For example, ResNet18 has four main layers, which is well known. If we combine the convolution, batch norm, ReLU, and max-pooling operators at the beginning of ResNet18 with the first layer, the inner layers of ResNet18 can be divided into
,
,
, and
, which produces features with reduced resolutions
,
,
, and
.
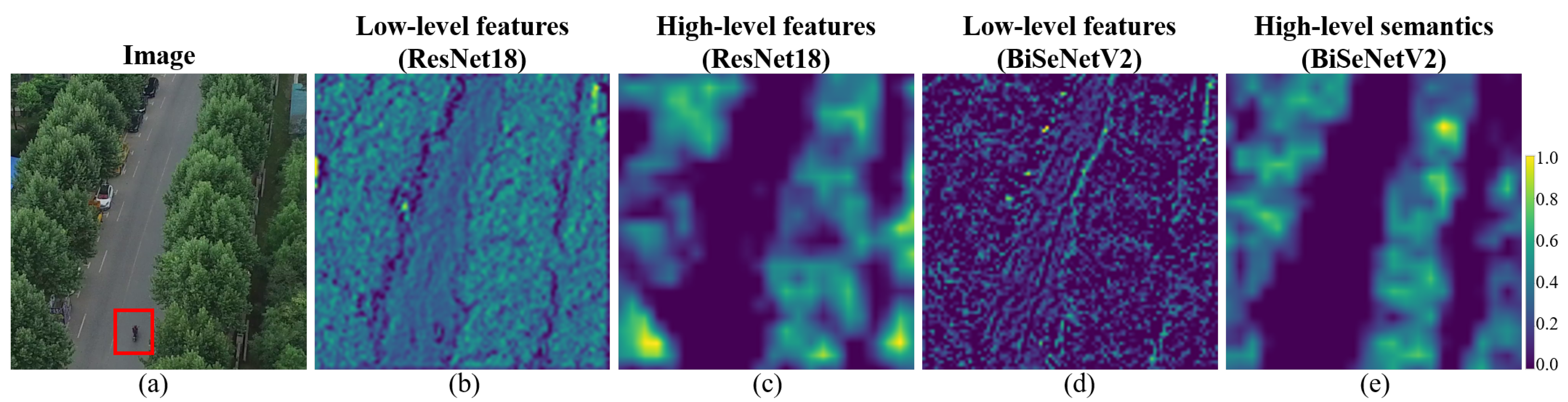
Given an input image patch
, the backbone network is performed, and a set of features are generated. We select the features
and
generated by
and
as the low-level features. We present the saliency maps of the features extracted by
,
,
, and
in ResNet18 in
Figure 4 to demonstrate the rationale behind the selection for low-level features. From
Figure 4b,c,
and
produced by ResNet18 are the mixture of both the large and small objects. Meanwhile,
and
generated by deep layers (
and
in ResNet18) mainly depict large objects (as shown in
Figure 4d,e). We can hardly find the small-object information in
and
.
Subsequently, is processed by the CS to generate high-level semantics . and down-sampled are placed in an RDM (denoted by RDM1). Additionally, and are placed in another RDM (denoted by RDM2). Consequently, the difference features and are produced. Then, and are concatenated and performed by the DS to generate the small-object semantics . Thus, and mainly depict small and large objects, respectively. Finally, and are concatenated to obtain the final prediction .
3.1. RDM
The low-level features
(such as
in
Figure 4) extracted by shallow layers are the mixture of both the large and small objects. The high-level semantics
generated by the deep layers primarily depict large objects (see the saliency map of
in
Figure 4). RDM attempts to exclude large objects from
via the guidance of
; thus, the predominant effects of large objects are eliminated. The principle of RDM differs from the dual-branch framework and skip connection, which have some positive effects on the segmentation of small objects. However, they do not eliminate the predominant effects of large objects. Consequently, when these models are trained, large objects push small objects aside. RDM eliminates the predominant effects of large objects using the idea of alignment and difference, as shown in
Figure 5. The key innovations are two-fold: (1) the reverse difference concept and (2) the semantic alignment between
and
.
The reverse difference concept lays the foundation for RDM. By considering the cosine alignment branch (see
Figure 5) as an instance, after
and
are aligned,
is transformed into
. Subsequently, a difference map
is produced by a difference operator. Here,
is the Sigmoid function which transforms the intensity values in
and
into intervals from 0 to 1. Notably, the difference must subtract
from
. Only in this manner can numerous intensity values on the positions of large objects in
be negative. Subsequently, we use the ReLU function to set all the negative values to zero. Consequently, the large-object information is washed out, and the small-object information is highlighted.
For semantic alignment between
and
,
typically has more channels and lower resolutions than
. The up-sampling and down-sampling can change the resolution but fail to change the number of channels. Even if they have the same number of channels, we cannot ensure semantic alignments between
and
. For example, the
ith channel in
is more likely to contain a specific category of large objects. Does the
ith channel in
contain similar information of the same categories as the
ith channel in
? If not, how do we ensure that the reverse difference mechanism is in effect? RDM provides two alignment modules to align the semantics from different perspectives by fully modeling the relationship between
and
as shown in
Figure 5. The aligned high-level semantics produced by the cosine and neural alignments are
and
, respectively. The difference features
produced by RDM are computed as follows:
where
denotes the concatenation. In the following sections, the details of cosine and neural alignments are presented.
3.1.1. Cosine Alignment
The cosine alignment presented in Algorithm 1 determines the relationship between
and
without learning from the data. It has a mathematical explanation based on cosine similarity. First, we down-sample
as
, which has the same resolution as
. Subsequently,
and
are converted into vector forms along each channel such that
and
, where
. The cosine similarity between each pair of channels in
and
is then computed as
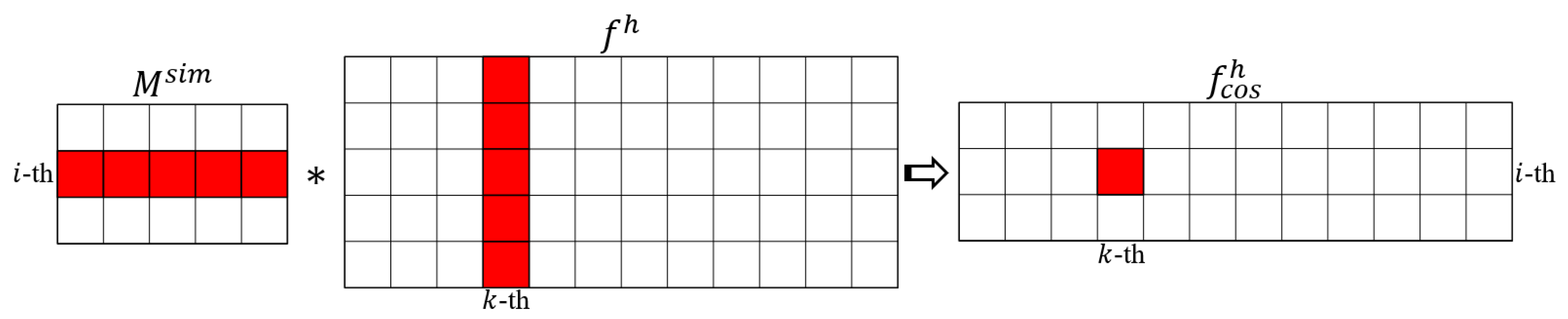
where
and
are vectors that belong to the
i-th and
j-th channels in
and
, respectively. “·” is the dot product between the vectors, and “×” is the product between the scalars. After all pairs of vectors in
and
are performed using Equation (
4), a similarity matrix
is constructed. We do not compute the cosine similarity per element to facilitate the implementation. The matrix multiplication “*” can be used to obtain
as
where
is the
normalization for each channel in
and
.
normalization is essential because it ensures that the matrix multiplication is equal to the cosine similarity.
denotes the transpose of
.
| Algorithm 1 Cosine alignment. |
- 1:
Down-sample as . - 2:
Transform and into vector forms along channels such that and . - 3:
Produce the similarity matrix using and as Equation ( 5). - 4:
Obtain using and as Equation ( 6). - 5:
Transform and up-sample such that . - 6:
return
|
A Softmax function is performed along the
dimension to render
more representable. This transforms the elements in
into a set of normalized weights for
channels. Finally,
and
are multiplied as follows.
where
is the aligned
. The multiplication * reduces the number of channels in
such that
has the same number of channels as
. Furthermore, using Equation (
6), we can obtain an alignment effect. As shown in
Figure 6, when we take the value
on the
i-th row and
k-th column in
as an example,
is computed as:
where
is the value on the
j-th row and
k-th column in
, and
is the value on the
i-th row and
j-th column in
. Consequently,
is a weighted average of
. If the
j-th channel in
is more similar to the
i-th channel in
,
will be larger. Therefore, the equation gives larger weights to the channels in
that are more similar to the
i-th channel in
. As a result, the cosine alignment tries its best to meet the objective that the
i-th channel in
and the
i-th channel in
containing similar large object information.
Finally, is transformed back into the image plane and up-sampled such that . is the aligned high-level semantics produced by the cosine alignment.
3.1.2. Neural Alignment
The neural alignment, which is shown in Algorithm 2, aligns the semantics between
and
using convolutions. Firstly, a convolution layer with
kernels followed by an up-sampling operator is performed to compress
:
where
is the weight matrix in the convolution layer, ⊗ is the convolution,
is the up-sampling, and
is the compressed
. Via Equation (
8),
has the same number of channels as
. Actually,
is the learnable projection bases which projects
into the space we prefer. This procedure has an effect of semantic alignment by iteratively optimizing the projection bases during the training.
| Algorithm 2 Neural alignment. |
- 1:
Project and up-sample as Equation ( 8) to generate . - 2:
Generate the channel attention vector via average pooling using both and . - 3:
Transform into and model the correlation between the channels of and based on . - 4:
Obtain using as Equation ( 9). - 5:
return
|
Then, a mutual channel attention is proposed to enhance the alignment. The traditional channel attention has been used to select informative features via introducing global weights for channels of the input features [
49,
51]. However, the traditional channel attention is a self-attention mechanism which does not have the alignment effect between the features generated by different layers. Here, to consider both the information in
and
, we concatenate
and
together. Based on this, the average pooling layer is performed to generate a channel attention vector
. Subsequently, a convolution layer with
kernels, a batch normalization, and a sigmoid activation are performed on
to model the correlations of the channels in
and
. As a result,
is transformed as
, which can be used directly to select the information of
by an element-by-element multiplication along the
channels. Concretely, using
, the aligned high-level semantics
are formulated as:
where ⊙ is the element-by-element product along the
channels. Finally,
is the output of the neural alignment.
3.2. DS
The generated by RDM is the input to DS. In RDNet, two RDM components produce difference features and . and are concatenated as the final output of the RDM components, where , , and . includes only small-object information with fewer semantics. The DS is proposed to obtain more semantics to facilitate prediction without adding excessive parameters.
The commonly used method adds several convolutional layers with strides, such as ResNet18 to generate semantics. This method significantly increases the number of parameters and computational complexity. Here, we use depth-wise convolution to address these issues. Furthermore, when the stride is set to two or larger, the convolution enlarges the receptive field; however, some extremely small objects, such as pedestrians in UAVid, are ignored. Therefore, we do not use any strides. Additionally, we do not know which kernel size is most suitable. A larger kernel size suppresses small objects, whereas a smaller kernel size generates less semantic information. Here, the DS designs two convolutional branches using
and
kernels to alleviate the negative effects produced by a fixed kernel size, as shown in
Figure 7.
The first branch contains only a single convolutional layer with
kernels and is simple and lightweight. It convolves
using a small kernel size and creates a correlation between all the channels. We use
to denote the output of the first branch. The second branch convolves
using a larger kernel size. It makes spatial correlations using a depth-wise convolution with
kernels and makes a cross-channel correlation using shared kernels. Specifically,
is first processed using a depth-wise convolutional layer to obtain a spatially correlated feature map
. Subsequently, a cross-channel correlation is performed. This adaptively pools
into feature vector
. A two-dimensional convolutional layer with padding and
kernels, followed by sigmoid activation, is then used to make correlations along the channels:
where
is the derived cross-channel correlated feature vector,
is padding,
is sigmoid activation, and
is the weight matrix of the convolution. Subsequently, the features
extracted by the second branch are:
where “•” is the element-by-element product of the image plane. The activated
is expanded to the same dimension as
by an expanding operator
to perform multiplication.
After both branches are performed, the small-object semantics
that fully depict small objects are generated as follows.
where “+” is element-by-element addition.
3.3. CS
The CS is designed to process the output
of
in the backbone network. Here, we generate high-level semantics
by extending the receptive field. This compels
to further focus on large objects. The average pooling pyramid (APP) [
7] is utilized to enlarge the receptive field. Unlike the strategy that directly enlarges the kernel size, APP does not increase the computational complexity [
7]. As shown in
Figure 8, the APP of the CS pools
into three layers with different down-sampled resolutions:
,
, and
.
Although the receptive field is enlarged, it is difficult to generate continuous contextual information that washes out heterogeneity in large-object features. Dual attention [
26] is used to fully model long-range dependencies to address this issue. Dual attention, which includes a position attention module (PAM) and channel attention module (CAM), considers both spatial and channel information. The PAM computes the self-attention map for each position on the feature-image plane, and the CAM computes the self-attention map along the channels. They share similar procedures, which are detailed in [
26], for producing these self-attention maps using matrix multiplication. Then, the input features are enhanced by these self-attention maps. Thus, the enhanced features produced by PAM and CAM contain continuous spatial dependency and channel dependency information, respectively.
In the
i-th layer of
Figure 8,
is averagely pooled as the down-sampled feature
. Two reduced feature maps
and
are first generated by two convolutions with
kernels based on
. Here,
is set to
.
is processed by the PAM to obtain continuous spatial dependence information. Subsequently, a depth-wise convolutional layer with
kernels is used to generate the semantics
.
is processed by CAM to obtain dependence information along the channels. Again, a depth-wise convolutional layer with
kernels is used to generate the semantics
.
After all of the layers are performed, a set of and , are obtained. All and , are up-sampled to the same resolution as and concatenated with . Subsequently, the high-level semantics are obtained by a convolution with kernels.
3.4. The Loss Function
As shown in
Figure 3, the loss function
L is composed of two terms:
where
is the selected main loss which penalizes the errors in the final prediction,
.
is the auxiliary loss which penalizes the errors in the auxiliary prediction
produced by the high-level semantics
.
and
are produced using similar prediction layers. First, the prediction layer convolves the input features using
kernels. Subsequently, batch normalization and ReLU activation are performed. Finally, the prediction is produced using a convolutional layer with
kernels. The differences between the prediction layers for
and
are only the parameters for the two inner convolutions. For
, we set the input and output numbers of the channels of the first convolution as
and 128, where
,
and
are the number of channels for the small-object semantics
and
and the high-level semantics
, respectively. The input and output numbers of the channels of the remaining convolution are set to 128 and
K, where
K is the number of classes. For
, the input and output numbers of the channels for the first convolution are set to
and 64, respectively, and the input and output numbers of the channels for the remaining convolution are set to 64 and
K.
We integrate a threshold
with the standard cross-entropy loss to further highlight small objects without adding prior information about the data using
. For more detail, we compute the individual main loss
of each pixel in
as follows:
where
is the ground-truth label of the
i-th pixel and
K is the number of categories.
is the
i-th vector in
containing probabilistic values belonging to all categories of the
i-th pixel.
is the probability that the
i-th pixel belongs to the
j-th category. Then, an indicator function
is defined as
where
is the indicator of the
i-th pixel in the input image
I, and
.
is computed based on
and
as follows:
where
N denotes the number of pixels in
I. CNN-based models are advantageous for the recognition of large objects and elimination of heterogeneity in large objects. After several training iterations, the losses in the prediction of large objects will be smaller than those of small objects. Larger losses are more likely to occur on pixels in small objects. Therefore, apart from the RDM,
further highlights the small objects during the backward procedure to some extent.
uses the standard cross-entropy loss function without changing the optimization preference for large (dominant) objects. Thus,
favors the preference of
for depicting large objects, which ensures the accuracy of large-object recognition.
is formulated as
5. Experiments
Firstly, we introduce the evaluation metrics used in this study and the implementation details of the training procedure. Subsequently, the experimental settings are discussed. Then, the results of RDNet and the comparisons with existing methods for both the UAVid and Aeroscapes datasets are presented. Finally, we discuss some issues of interest.
5.1. Evaluation Metrics
To keep consistency with existing public evaluations, such as the studies by [
4,
5,
14], we mainly use the IoU scores as the evaluation metrics. For the dataset having a range of classes with small/medium/large objects that pose a challenge to analyze the performance across scales, we divide the existing classes into small, medium, and large groups based on the scale information presented in
Table 1 and
Table 2. Accordingly, the mean IoU score of the classes in each group is computed. Thus, three mean IoU scores
,
, and
are defined for the small, medium, and large groups, respectively. As these metrics are well-known and easily understood, we do not present them in any detail here.
5.2. Implementation Details
The proposed RDNet is implemented based on Pytorch. To train the network, we use stochastic gradient descent as the optimizer. The commonly used learning rate policy is employed, where the initial learning rate is multiplied by for each iteration. Here, and the initial learning rate are set to and , respectively. We train the RDNet on the training set for 10 epochs. In each epoch, we randomly selected 30,000 image patches with a batch size of three. Each patch is in size. In more detail, to randomly select each image patch, we randomly generate two values and to indicate the top-left corner. Then, the image patch is copied from the original image based on the coordinates and . Both the RDNet models for UAVid and Aeroscapes are trained using these settings. As is known, the training procedure usually trains the model iteratively. For each iteration, we actually obtain a trained model. As we focus on the small objects, we use the trained model that gives the highest accuracy scores for the small objects to obtain the final segmentation results. In terms of the comparison methods, we obtain the trained model for testing in the same way.
5.3. Experimental Settings Based on Validation
5.3.1. The Backbone Selection
Currently, there are a large range of general-purpose networks which can be used as the backbone. Our objective is to select a backbone which can make a good trade-off between computational complexity and accuracy. We list the integrations of RDNet with the representative general-purpose networks which have the real-time property in
Table 3. MobileNetV3, GhostNet, STDC, EfficientNetV2, Xception, and ResNet18, which are commonly used CNN-based networks, can be integrated into RDNet in the way shown in
Figure 3. MobileViT is a new general-purpose network that combines the strengths of CNNs and ViTs [
29]. Although the architecture of MobileViT is different with the purely CNN-based networks, it can easily integrate with the RDNet framework. At the beginning of the MobileViT, a MobileNetV2 [
34] block sequence is used to extract a set of low-level features. Subsequently, these low-level features are put into the ViT sequence to generate high-level semantics. We select the low-level feature maps with
and
pixels as the
and
and select the high-level semantics produced by the ViT sequence as the
. Then, the RDNet based on MobileViT can be constructed using the way shown in
Figure 3.
In
Table 3, the number of parameters (Pars.), computation complexity, GPU memory consumption (Mem.), and mIoU scores are presented. The computation complexity is measured by the float-point operations (FLOPs) and frames per second (FPS), which are computed using an image patch with
pixels. The accuracy scores are obtained in the validation set of UAVid. Notably, the validation set is not used for training the model. RDNet(ResNet18), which is the RDNet version using ResNet18 as backbone, obtains the highest accuracy. RDNet(Xception) and RDNet(EfficientNetV2) obtain really close accuracy to RDNet(ResNet18), however, they cannot surpass RDNet(ResNet18). Xception and EfficientNetV2 are constructed based on the depth-wise separable convolutions, which reduces many weights for cross-channel modeling. In contrast, ResNet18 fully models the cross-channel relationship using full convolutional operators. This suggests that the cross-channel modeling in the backbone is beneficial to RDNet. The RDNet(MobileViT) has the potential for accuracy improvements because it contains only 2.08M parameters. Unfortunately, the GPU memory consumption of RDNet(MobileViT) is really huge (28.5G), which limits its application. The RDNet(MobileNetV3) and RDNet(GhostNet) are lightweight and fast. However, they achieve much lower accuracy than the RDNet(ResNet18). From the comparison, the RDNet(ResNet18) obtains better trade-off among parameters, complexity, speed, GPU memory consumption, and accuracy. Therefore, we select the ResNet18 as the default backbone.
5.3.2. The Selection of Comparison Methods
As of now, there are hundreds of networks for semantic segmentation tasks, and we cannot compare all these methods with our RDNet. As our RDNet focuses on small objects, we test the existing small-object-oriented methods for which official codes have been released. They are BiSeNet, ABCNet, SFNet, BiSeNetV2, and GFFNet, which were introduced in
Section 2.2. Notably, there exists a large range of backbone networks; we cannot test all the backbones for each method. Here, we use the backbone provided by the official codes of each method.
Table 3 shows the properties and accuracies of these methods. We can find that most of the small-object-oriented methods have real-time property and prefer ResNet18. In addition, we select three representative networks from traditional methods (see
Section 2.1). The DANet [
26] is one of the self-attention-based methods, and the DeepLabV3 [
21] is one of the methods using atrous convolutions and pyramids. MobileViT [
30] is the representative method using vision transformer [
29]. For the semantic segmentation task, MobileViT [
30] uses the DeepLabV3 architecture and replaces the ResNet101.
In
Table 3, DANet and DeepLabV3, can only achieve higher
scores than BiSeNet when they use ResNet101. In most cases, they receive lower accuracy scores than the small-object-oriented methods, though they use much more complex backbones (ResNet101) as default. More importantly, based on the
scores, the performance for segmenting small objects is more inferior. Although MobileViT achieves a relatively higher
score of segmenting small objects than DANet and DeepLabV3, it still cannot surpass the existing small-object-oriented methods. Furthermore, the GPU memory consumption of MobileViT is huge (27.8G). Therefore, we pay attention mainly to the comparison between RDNet and small-object-oriented methods in more detail in the following. Meanwhile, to fully compare RDNet to the state of the art, we show the published results for each dataset.
5.4. Results on UAVid
This section is divided into two parts: the quantitative and visual results. The details of the UAVid dataset are presented in
Section 4.1. Specifically, the human class has small sizes.
5.4.1. Quantitative Results
Table 4 shows the quantitative results for the UAVid test set. In
Table 4, the comparisons are divided into two groups. The first group shows state-of-the-art results obtained by MSD [
4], CAgNet [
14], ABCNet [
41], and BANet [
31]. MSD, CAgNet, ABCNet, and BANet officially publish their results on UAVid. We directly quote their accuracy scores here. The second group shows the accuracy scores obtained by the small-object-oriented methods that are not included in state-of-the-art results. It shows the results obtained by BiSeNet [
12], GFFNet [
6], SFNet [
33], and BiSeNetV2 [
13]. We trained BiSeNet, GFFNet, SFNet, and BiSeNetV2 ourselves and used the official server (
https://uavid.nl/, accessed on 1 May 2020) of UAVid to obtain the accuracy scores.
In
Table 4, RDNet obtains the highest mIoU score across these methods. More importantly, for each of the small, medium, and large groups, our RDNet obtains the highest accuracy (which is denoted by the
,
and
scores). This means that the performance of segmenting large and medium objects does not become worse when our RDNet improves the accuracy of segmenting small objects. On the contrary, the accuracy scores (
and
) of segmenting the medium and large objects are further improved. For the segmentation of small objects, our RDNet achieves 4.5–18.9% higher
scores than the existing methods. Notably, BiSeNetV2, GFFNet, and SFNet, which are powerful small-object-oriented methods, already have great performance in segmenting small objects, as noted in the introduction in
Section 2.2. Therefore, our RDNet, which obtains higher
than BiSeNetV2, GFFNet, and SFNet, has a stronger ability for segmenting small objects. Moreover, compared with state-of-the-art results, our RDNet achieves 11.8–18.9% higher
scores, which is a significant improvement. Therefore, based on the results in
Table 4, the superiority of our RDNet, especially for the segmentation of small objects, is validated.
5.4.2. Visual Results
To facilitate the visual comparison, we use the prediction maps of the validation set which has the ground-truth. Notably, the validation set is not used for training.
Figure 11 shows the visual results for all classes in UAVid. Notably, we do not present the scenes that do not satisfy the scale-variation issue. Furthermore, SFNet and BiSeNetV2 achieve higher mIoU and
scores than the other existing methods, as shown in
Table 4; therefore, we only visually compare the results of RDNet with those of SFNet and BiSeNetV2 owing to the page limits. Based on the ground-truth (
Figure 11, second column), RDNet provides more reliable results compared with other methods. The small objects extracted by RDNet are more complete, and the segmented large and medium objects are better.
In terms of small objects, we highlight the subareas that challenge the segmentation of small objects in the first and second images (
Figure 11, first and second rows) using red rectangles. The sanitation worker in the first image and the man near a car in the second image are combined with a particularly complex background. The pedestrians in the second image have similar spectral features to the shadow of the buildings. Consequently, both SFNet and BiSeNet-v2 miss these small targets in the results, whereas RDNet identifies all of them (
Figure 11, last column). In terms of large objects, we highlight the subareas that challenge the segmentation of large objects in the second and third images (
Figure 11, second and last rows) using black rectangles. In the second image, the subarea contains trees, vegetation, and roads. These are different types of large objects shading each other, which results in difficulty of recognition. Neither SFNet nor BiSeNet-v2 segments this subarea well, whereas RDNet succeeds. In the last image, the subarea contains a building surrounded by vegetation. BiSeNet-v2 and RDNet misclassify the building, whereas RDNet produces a perfect result.
The visual results show that RDNet obtains superior results for both the small and large objects in UAVid. The accuracy of segmenting large objects is not reduced when RDNet highlights the small objects. On the contrary, the accuracy of segmenting large objects is further improved.
5.5. Results on Aeroscapes
The structure of the results on the Aeroscapes dataset is similar to
Section 5.4. The details of the Aeroscapes dataset are presented in
Section 4.2. Specifically, the person, bike, drone, and obstacle classes have small sizes.
5.5.1. Quantitative Results
We compare the results of RDNet with the state-of-the-art results specified in Aeroscapes and those obtained using BiSeNet, ABCNet, GFFNet, SFNet, and BiSeNetV2. The accuracy values are presented in
Table 5. In terms of the state-of-the-art results, that is, EKT-Ensemble [
5], specific issues must be recognized. In addition to the precise mIoU scores, the evaluation for IoU scores is only provided in a bar chart with an accuracy axis (see details in [
5]). We cite this evaluation by carefully determining the values along the accuracy axis. Therefore, these values are considered approximate (≈) in
Table 5. [
5] assembled different datasets, including PASCAL [
52], CityScapes [
53], ADE20k [
54], and ImageNet [
55] to improve accuracy, owing to the large range of scenes contained in Aeroscapes. The results using this assembly, denoted as EKT-Ensemble, achieve a 57.1% mIoU score.
As shown in
Table 5, RDNet obtains the highest mIoU score among all the methods. More importantly, the
score for segmenting small objects,
score for segmenting medium objects, and
score for segmenting large objects obtained by RDNet are all higher than those obtained by the other methods. This validates that RDNet further improves accuracy for the segmentation of large objects when it improves the accuracy of segmenting small objects. Specifically, the
score is 3.9% higher than that of BiSeNetV2, which ranks the second. For the bike class with the smallest objects, our RDNet obtains at least a 7.8% higher IoU score than the other methods. For the person class with small objects, RDNet obtains at least 5.0% higher accuracy than the other methods. SFNet obtains a higher IoU score for segmenting the obstacle class with small objects. This validates that SFNet has great power for segmenting small objects. However, compared with our RDNet, SFNet obtains lower IoU scores for segmenting the other classes with small objects, including the person, bike, and drone classes. This validates the superiority of RDNet.
5.5.2. Visual Results
Aeroscapes contains numerous scenes with large-scale variations between the classes. Here, we select four images that cover the classes with small objects and the objects challenging the segmentation in
Figure 12. From these visual results, we observe some mistakes in each of the predictions, which demonstrates the challenges of the Aeroscapes dataset. RDNet obtains reasonable segmentation results, in which all objects are recognized. Compared with SFNet and BiSeNet-v2, RDNet obtains superior results with less misclassification in each image. Specifically, the first row of
Figure 12 presents the smallest object, a bike. The result obtained by RDNet are much better than those obtained by SFNet and BiSeNetV2. In the second row of
Figure 12, RDNet obtains superior results for the segmentation of the person and drone classes. In
Table 5, SFNet obtains a higher IoU score for segmenting obstacles than RDNet. However, in the visual results, RDNet can achieve better segmentation results in a range of scenes, such as the third row in
Figure 12. In the last row of
Figure 12, we show the segmentation results of the animal class. RDNet obtains the best results for segmenting animals in the image.
7. Conclusions
In this study, a novel semantic segmentation network called RDNet is proposed for aerial imagery. In RDNet, RDM is first proposed to highlight small objects. RDM develops a reverse difference concept and aligns the semantics for both high-level and low-level features. Consequently, RDM eliminates the predominant effect of large objects in the low-level features. Then, the DS, which models the spatial and cross-channel correlations, is proposed to generate small-object semantics using the output of RDM. Additionally, the CS is designed using an average pooling pyramid and dual attention to generate high-level semantics. Finally, the small-object semantics bearing the small objects and high-level semantics that focus on the large objects are combined to make a prediction.
Two aerial datasets are used to fully analyze the performance of RDNet: UAVid and Aeroscapes. Based on the experimental results, RDNet obtains superior results compared with the existing methods for both datasets. The accuracy scores of segmenting small, medium, and large objects are all improved. More importantly, the accuracy improvement for segmenting small objects is prominent. According to
Table 3, RDNet has less computational complexity and uses less GPU memory compared with the existing small-object-oriented methods. This shows that RDNet achieves superior results using less computing resources. The ablation study demonstrates that the proposed RDM plays a vital role in the accuracy improvement of the segmentation of small objects. The DS further enhances the output of RDM, and the CS ensures good performance in segmenting large objects. Meanwhile, based on the visualization of the output, the positive effect of each module in RDNet is vividly shown.
In the future, the resolution of remote sensing images will be further improved, though the current resolution is so high that footpath-level objects are recorded well. Small object recognition will become more important. RDNet architecture, which highlights small objects for deep-leaning-based models, will be used for more applications in the field of remote sensing.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}