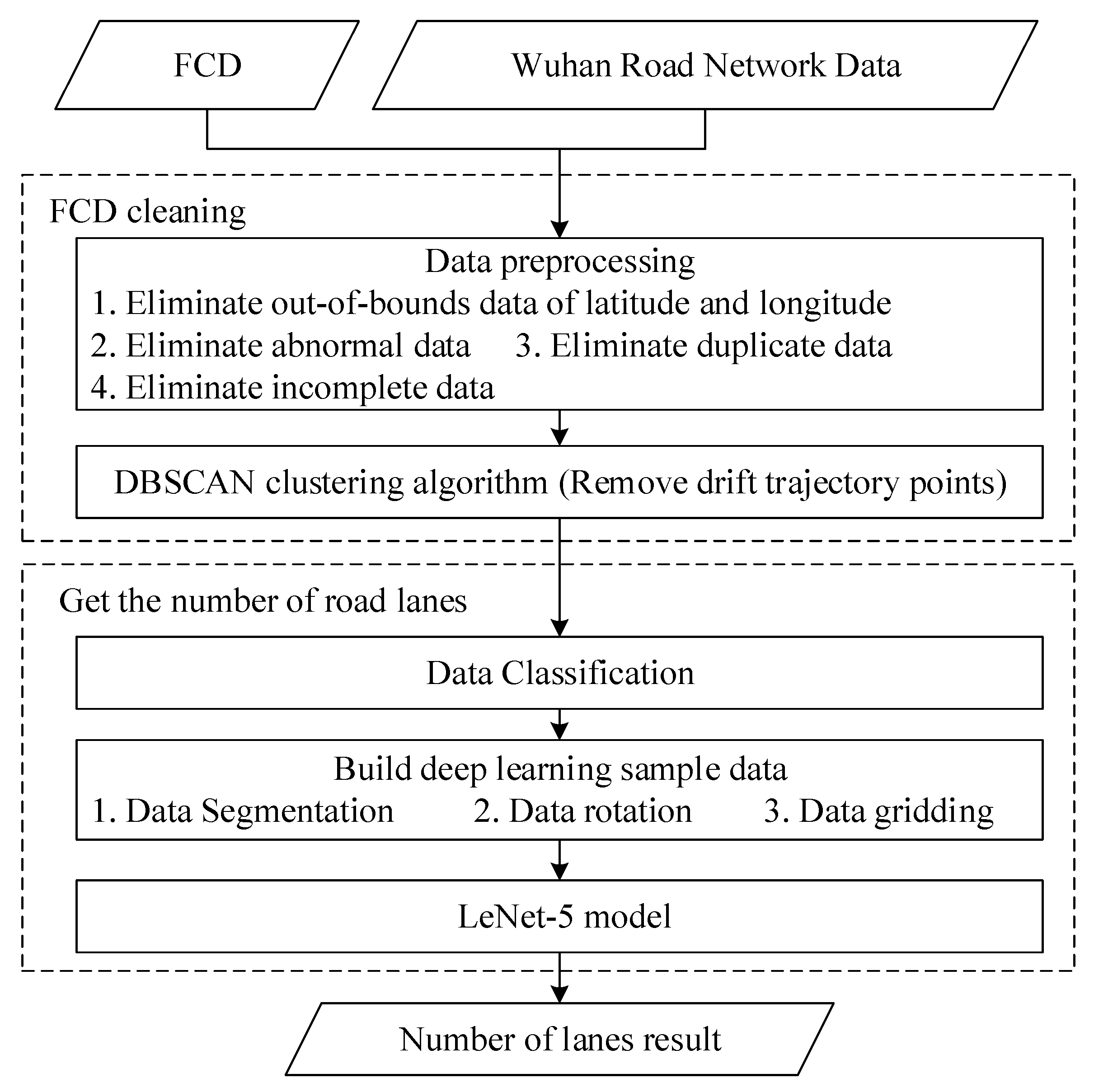
5.1. LeNet-5 Deep Learning Model
Professor LeCun et al. introduced the LeNet-5 convolutional neural network model in 1998, which was effectively employed in handwritten digit recognition [
27,
28]. In addition to the input layer, the conventional LeNet-5 architecture consists of seven layers, characterized by the following features: (1) convolution and pooling layers are successively applied; (2) convolution is utilized to extract sample features; (3) the average pooling method is employed as the pooling layer; (4) the sigmoid function serves as the activation function; (5) the sparse connections between layers can diminish computational costs. The LeNet-5 model architecture for lane number classification is shown in
Figure 10.
According to the distribution characteristics of FCD on the road, the traditional LeNet-5 model has been optimized to enhance the accuracy of lane number information detection. The following aspects have been refined:
(1) Substituting mean pooling with maximum pooling may accentuate the subtle features of the sample and mitigate the computational burden [
29].
(2) Substitute the activation function with the ReLU. The ReLU exhibits a faster convergence rate and simpler operation compared to the sigmoid function, effectively mitigating the loss saturation problem induced by excessive training iterations.
(3) Use Dropout [
30,
31] to suppress overfitting. By discarding neurons from the network according to a predetermined probability, one can effectively curtail overfitting and enhance the robustness of the neural network.
5.2. Urban Road Lane Number Detection Experiment
The detection of the number of urban road lanes is essentially a multi-classification task, as it equates to the classification of urban road types. The experimental environment consists of a dual-channel Intel (R) Xeon (TM) X5650, 3 GHz, 40 GRAM, 64-bit Ubuntu 18.04, utilizing a Python programming language and TensorFlow framework. The study employs a previously constructed deep learning dataset, encompassing a total of 1210 samples. Among them, the number of samples in one-way one-lane is 270, the number of samples in one-way two-lane is 456, and the number of samples in one-way three-lane is 484. The samples are randomly divided into a training dataset and a test dataset according to a ratio of 10:1.
In this study, we employed the LeNet-5 model for experimental purposes. The initial learning rate of the model is 0.00125, the number of trainings is 3500, the batch size is 55, and the optimizer uses Adam. The convolutional neural network was trained on the input samples from the training set in batches. The weights and parameters of the convolutional neural network were derived based on the difference between the output results and the actual results. Subsequently, the parameters were updated according to the learning rate and the error back-propagation method to enhance the accuracy, ultimately yielding a stable LeNet-5 model. In order to provide an intuitive and clear visualization of the training process of the LeNet-5 model, we have depicted the corresponding accuracy curve and loss value curve in the
Figure 11 and
Figure 12.
The loss value curve exhibits a tendency towards stability when the number of training iterations reaches 1500–2000. Upon surpassing 3000 training iterations, the loss value stabilizes at approximately 0.224. Upon completion of the LeNet-5 model training, the recognition accuracy reaches a level of 93.58%.
5.3. Comparative Analysis of Experimental Results
The precision of the LeNet-5 model is subject to several factors, including the activation function, initial learning rate, batch size, and grid size. This study comparatively examines and analyzes the experimental outcomes derived from these aspects during the training dataset process.
(1) Activation function comparison analysis. This study employs sigmoid and ReLU activation functions for a comparative analysis. As illustrated in
Table 2, the ReLU activation function demonstrates a more efficient training process, lower loss values, and superior accuracy when compared to the sigmoid activation function.
(2) The choice of the initial learning rate is crucial, as it serves as a means to regulate the learning progression of the model. Learning rate is a hyperparameter in deep learning. As illustrated in
Table 3, the training time for the LeNet-5 model increases as the learning rate decreases. Notably, when the learning rate is set at 0.00125, the model demonstrates the highest accuracy on the training dataset and the lowest loss value. Hence, the optimal learning rate for the LeNet-5 model is 0.00125.
(3) The selection of the batch size is crucial in the training input neural network, as it denotes the number of samples involved. As illustrated in
Table 4, the loss value for the training dataset is minimized and the accuracy is maximized when the batch size is set at 55. Hence, the batch-size value for the LeNet-5 model has been prudently assigned as 55.
(4) The selection of the grid size is crucial, as it can significantly affect the spatial distribution characteristics of the FCD and, in turn, influence the classification accuracy. As illustrated in
Table 5, the grid size of 32 × 32 yields the minimal loss value and the highest accuracy in the training dataset. Hence, the grid size is meticulously set to 32 × 32.
Specifically, in the selection experiment of activation functions, initial learning rates, batch sizes, and grid sizes, the optimal candidate factors were initially obtained based on empirical knowledge. Three of these candidate factors were then fixed, with another parameter factor adjusted, and the training time, loss values, and accuracy indicators were recorded. Ultimately, following these experiments, it was verified that the optimal candidate factors indeed constituted the best factors.
Optimal parameter settings for training the LeNet-5 model have been identified. Upon completion of the LeNet-5 model training, a total of 110 test dataset samples were input into the trained network for classification. Of these, 102 samples were accurately classified, achieving a recognition accuracy of 92.7%. The model demonstrates comparable recognition accuracy in both the test and training datasets, indicating its effectiveness.
To assess the performance of the deep learning approach presented in this study, we conducted a quantitative comparison with several classification methods, including Kernel Density Estimation [
7], Naïve Bayesian, Constraint Gaussian Mixture Model [
11], Fuzzy Logic [
13], Gradient Lifting Decision Tree [
14], The Least Square Estimate to Constrain Gaussian Mixture Model [
16], and the Weighted Constrained Gaussian Mixture Model and Hidden Markov Model [
17]. The results of the lane number identification comparisons are presented in
Table 6. Based on these findings, our method demonstrates the highest prediction accuracy when compared to other classification techniques.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}