
Applicability Analysis and Ensemble Application of BERT with TF-IDF, TextRank, MMR, and LDA for Topic Classification Based on Flood-Related VGI



Abstract
:1. Introduction
2. Experimental Scenario and Data
2.1. Experimental Scenario
2.2. Data Acquisition and Tagging
2.3. Problem in Different/Experimental Scenario
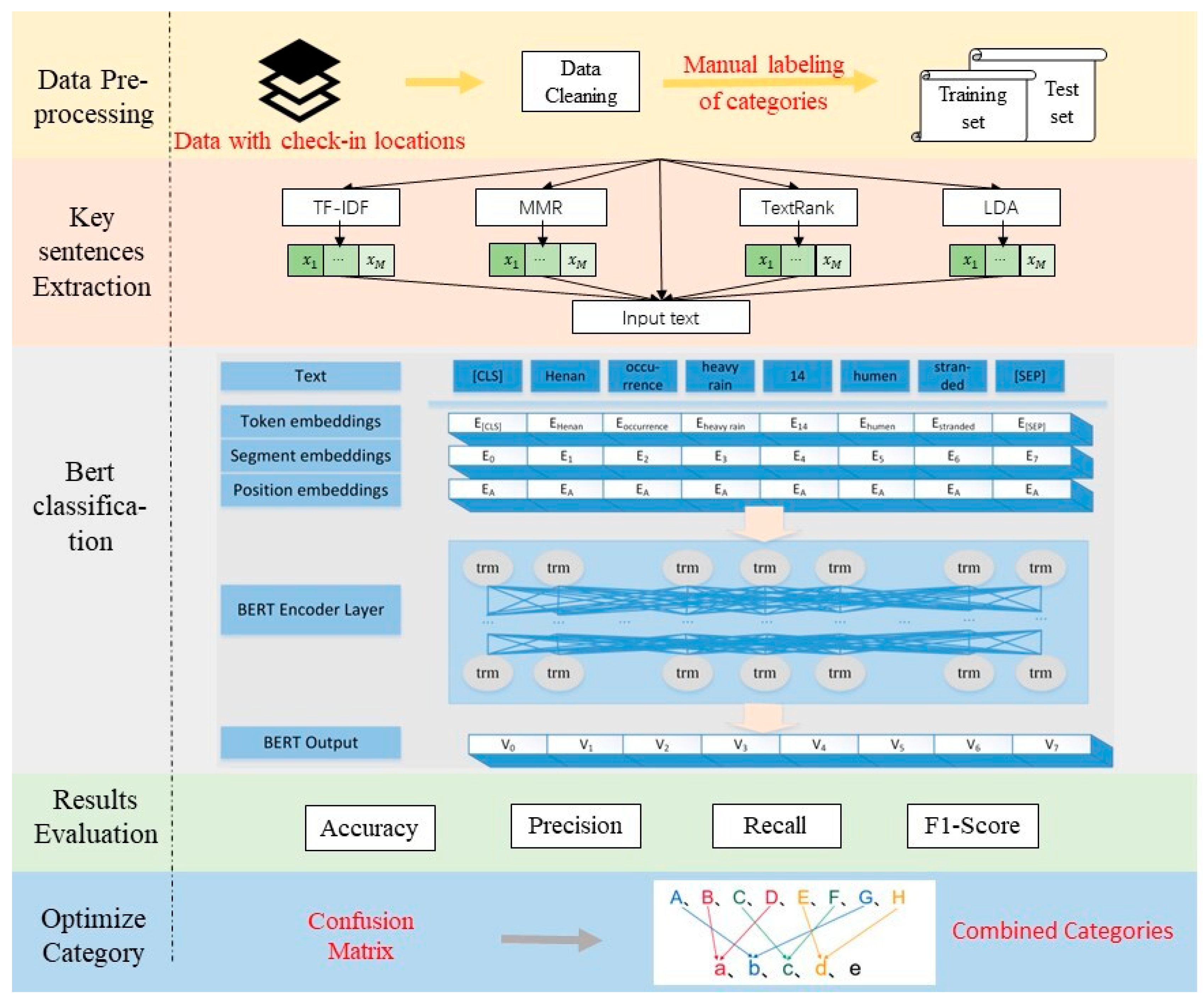
3. Pipeline of Applicability Analysis
3.1. Data Cleaning
3.2. Key Sentence Extraction
3.3. BERT Classification
3.4. Accuracy Evaluation
4. Applicability Analysis Experiments and Results
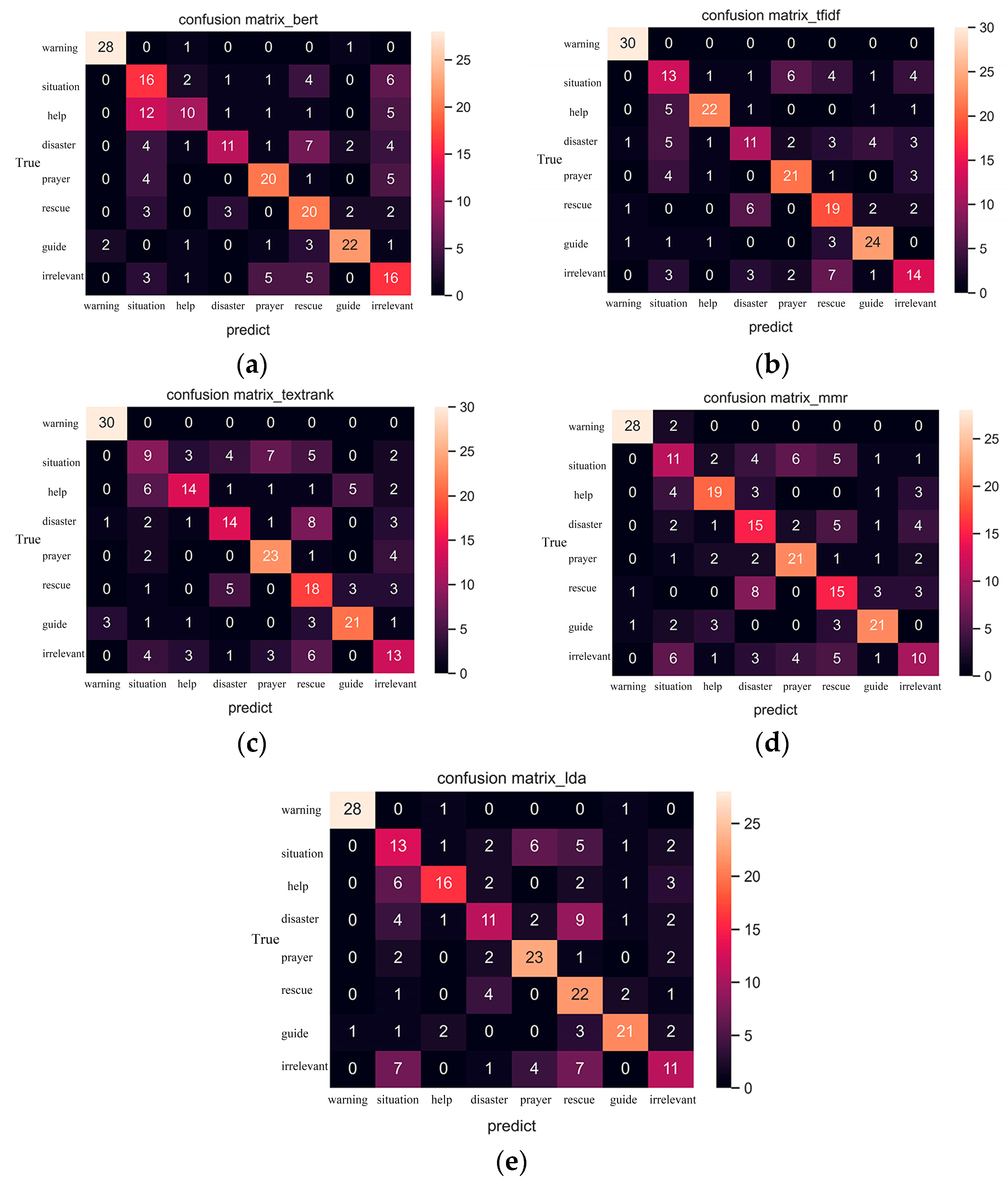
4.1. Topic Classification Results
4.2. Applicability Analysis
4.2.1. User Type Analysis
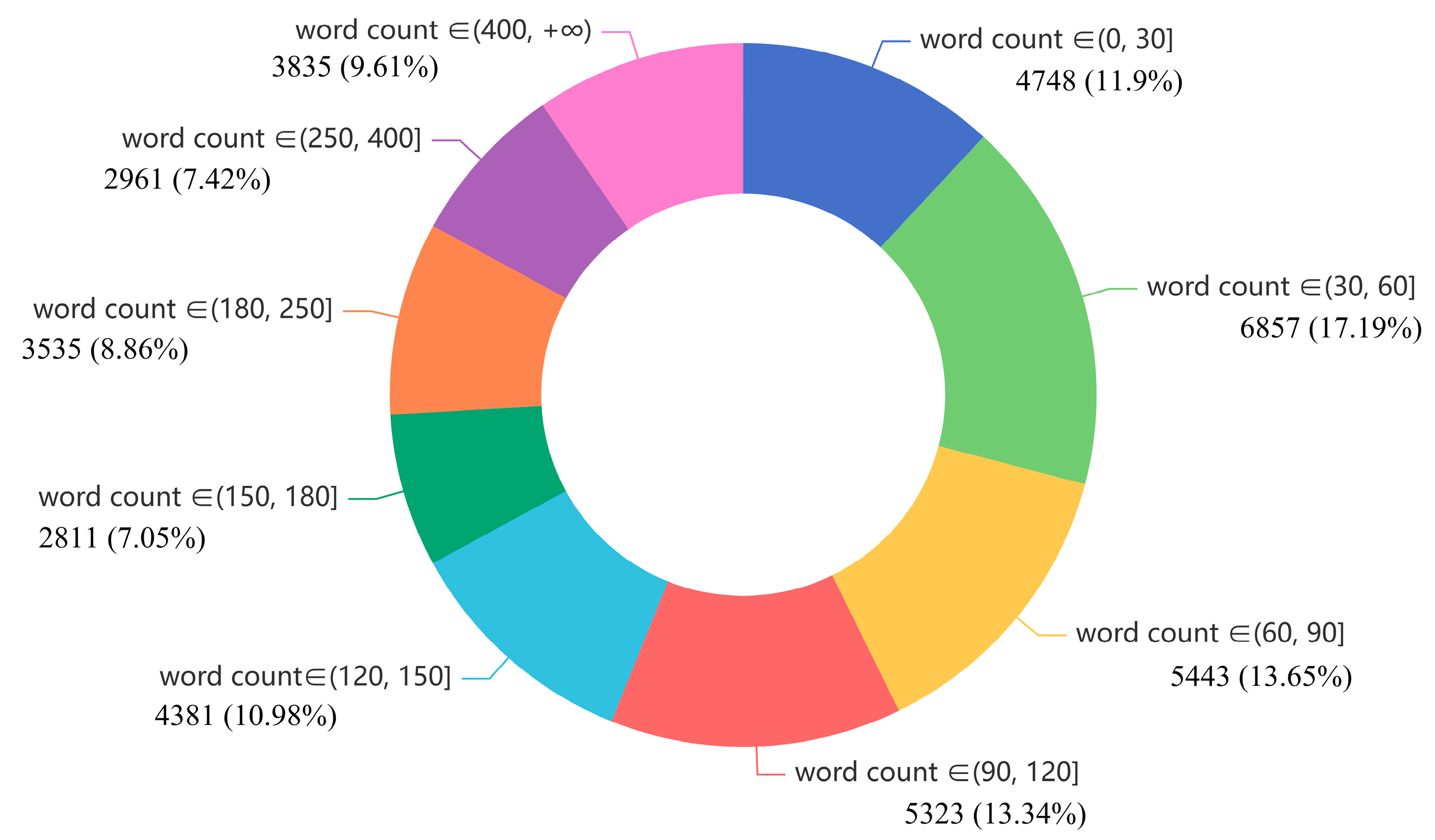
4.2.2. Text length Analysis
5. Spatiotemporal Analysis of the Text Themes
5.1. Validation of Classification Results
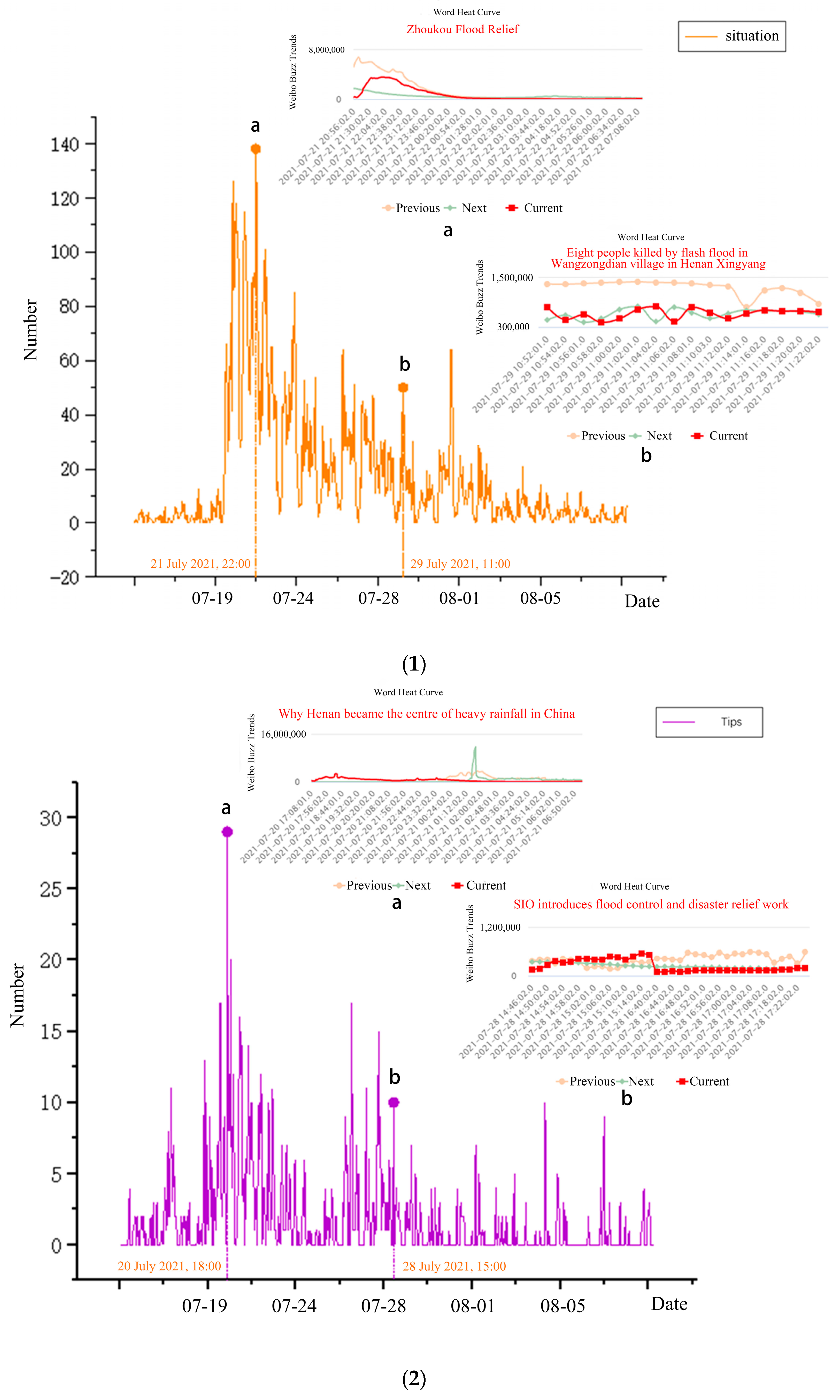
- (1)
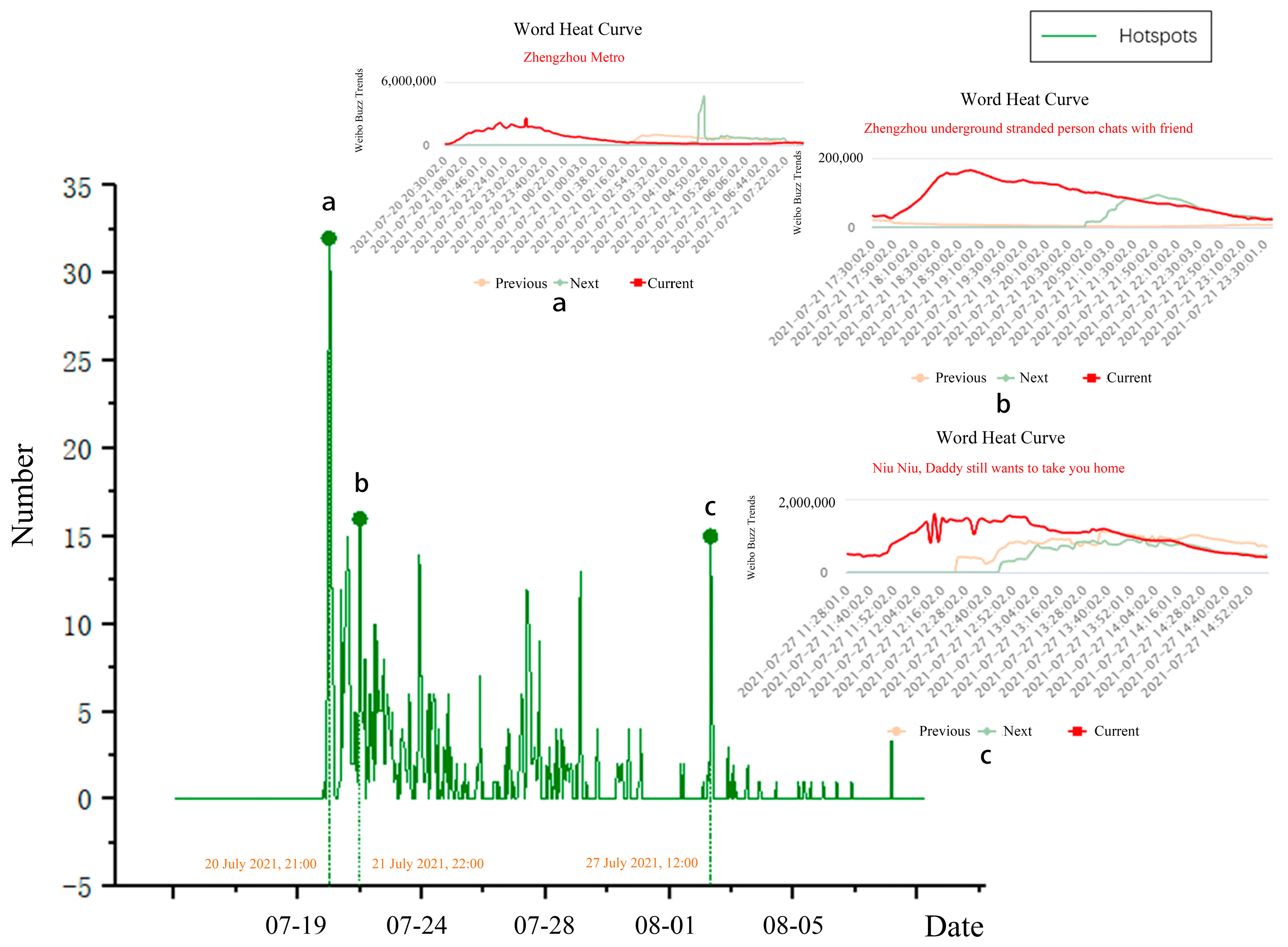
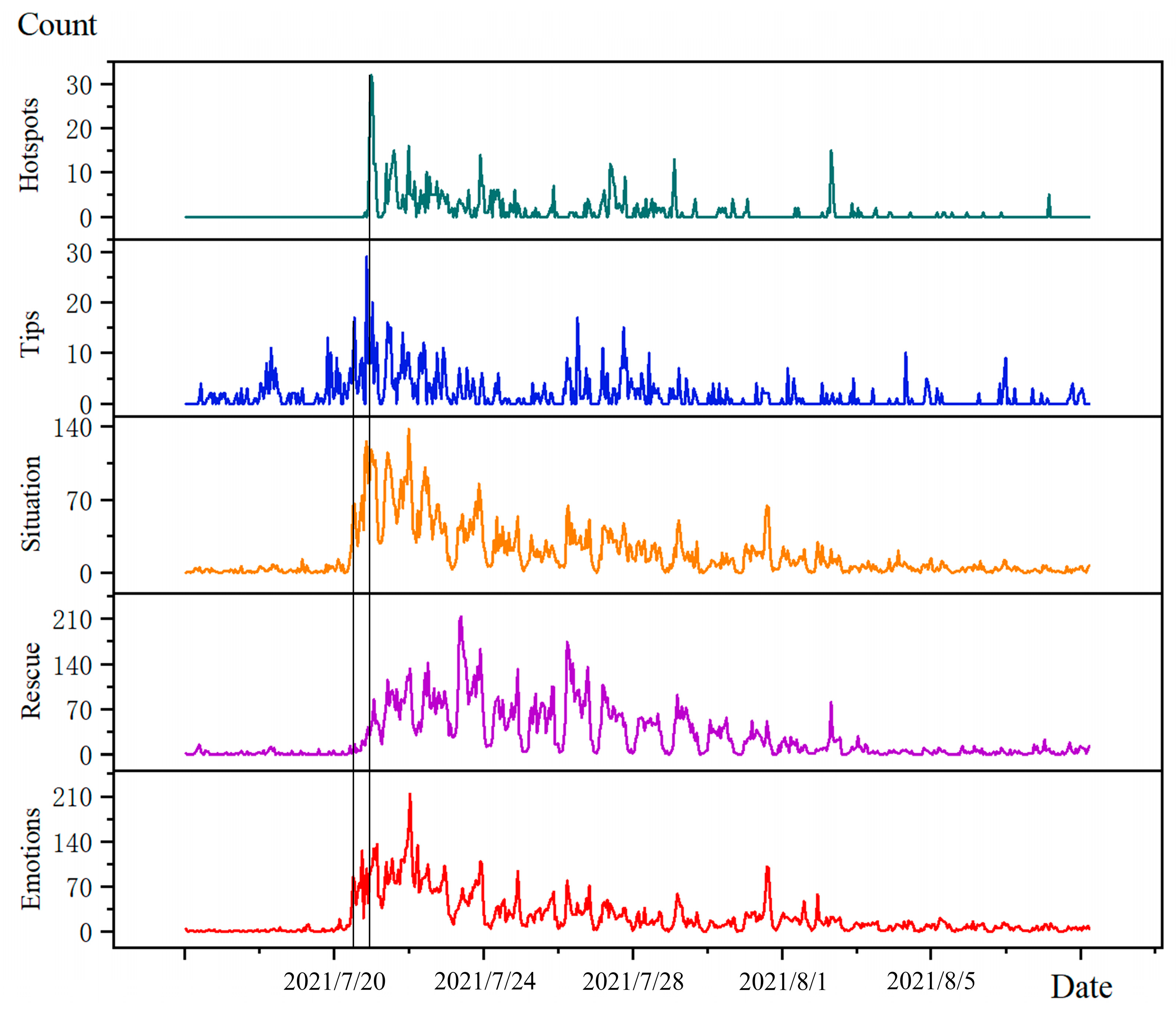
- In the situation category, “Zhoukou Flood Relief” and “Xinxiang torrential rain” were among the top 10 Sina microblog searches by 22:00 on 21 July. “Eight people killed flash flood in Wangzongdian village in Henan Xingyang” trended on the Sina microblog at 11:00 on 29 July after the torrential rain stopped.
- (2)
- In the category of tips, on 20 July, the microblogging search trending list at 18:00 included “Why Henan became the center of heavy rainfall in China” and “Flood control emergency response in Zhengzhou, Henan Province was raised to level 1”; therefore, there was a peak on 28 July, and “The State New Office introduced the flood control and disaster relief work” was on the top lists because the government usually sums up.
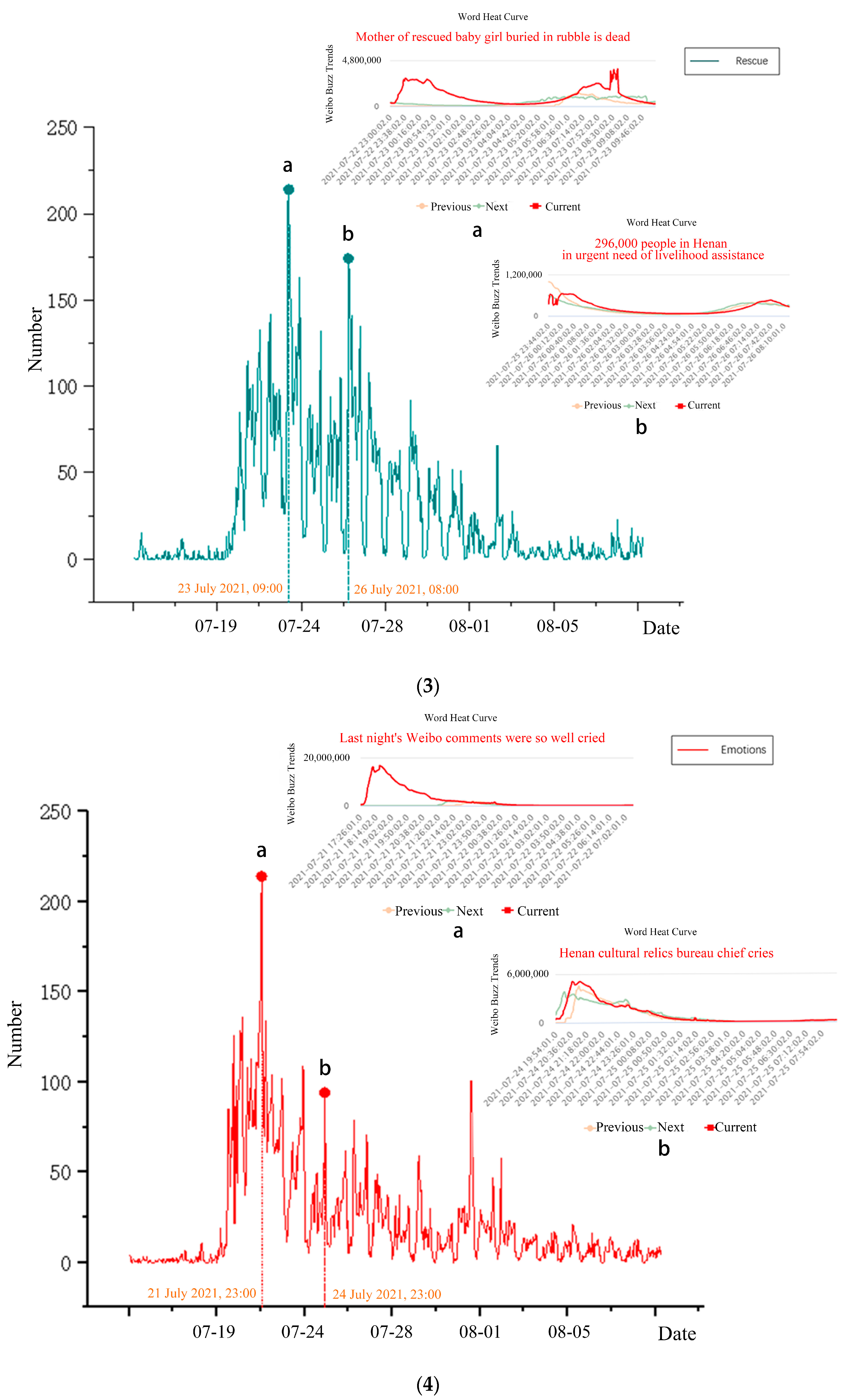
- (3)
- For the rescue category, “Mother of rescued baby girl buried in rubble dead” and “deputy director of Henan Xinmi Development and Reform Commission killed” topped the 23 July rescue reports. Five days after the tragedy, government departments revealed the damage statistics, and “296,000 people in Henan in urgent need of livelihood assistance” caught notice.
- (4)
- Regarding the emotion category, emotional microblogs have search trending terms but less fluctuation. At 23:00, users generally mentioned, “Last night’s Weibo comments were so well cried”, during the 21 July Henan rainfall event. The post, “Henan cultural relics bureau chief cries”, at 22:00 on 24 July, made many internet users grieve the natural calamity that ruined cultural treasures and other objects.
- (5)
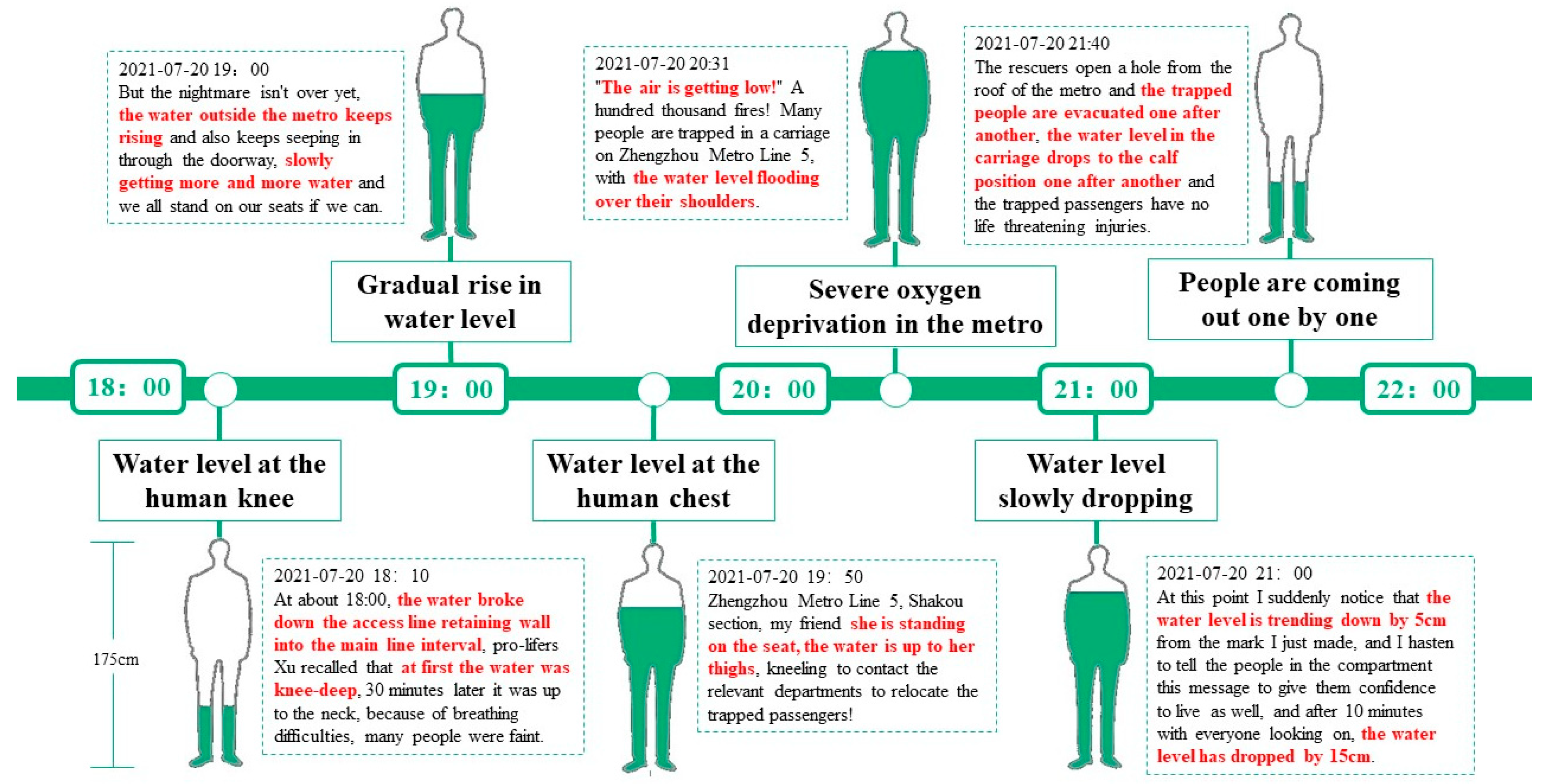
- Hotspots events were mainly focused on “Metro Line 5”, while on 20 and 21 July, the words “Zhengzhou Metro” and “Zhengzhou underground stranded person chats with a friend” appeared, and on 27 July, the 12:00 curve peaked mainly because the words “Niu Niu, Daddy still wants to take you home” inspired the public to mourn the victims of the rainstorm.
5.2. Temporal Analysis
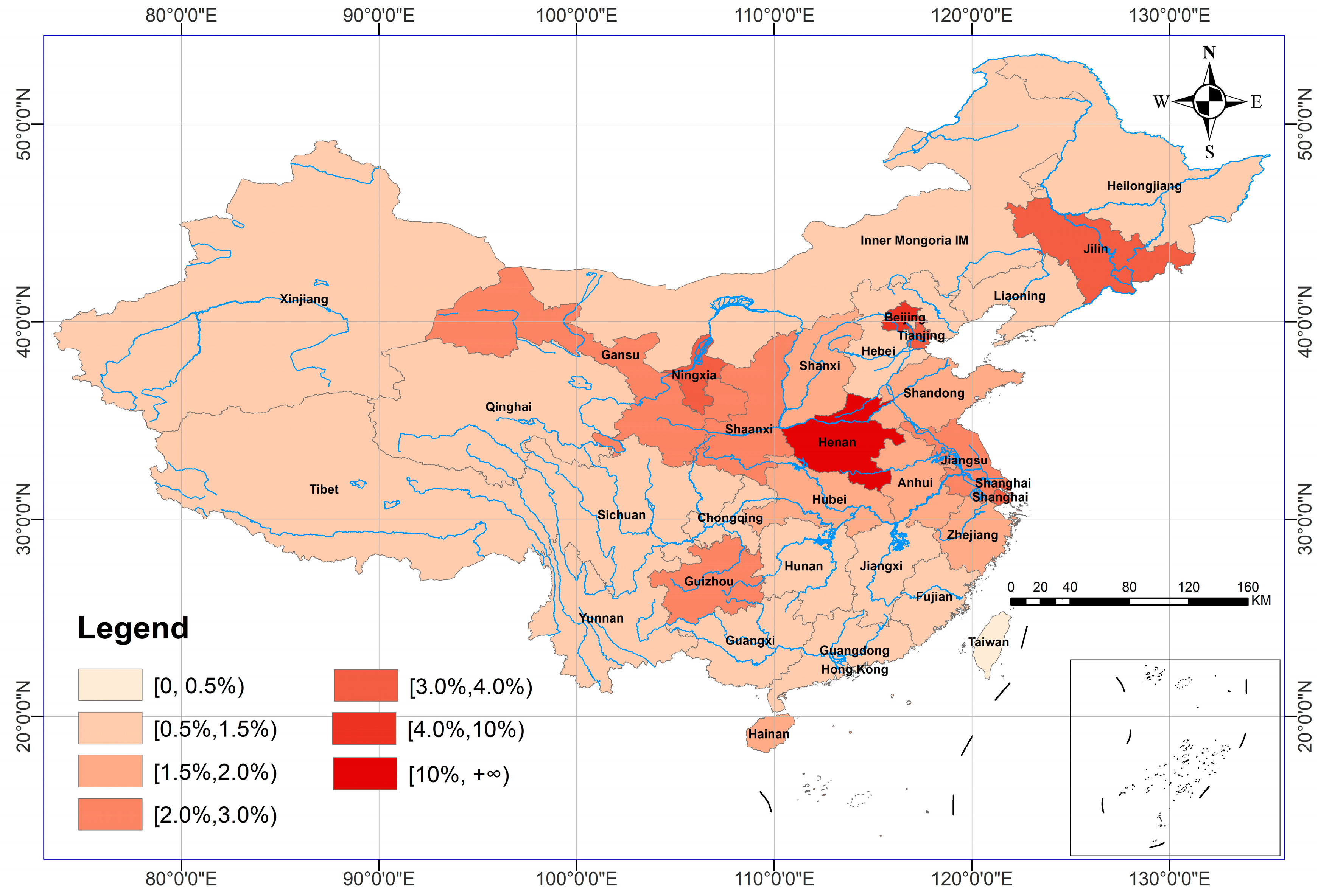
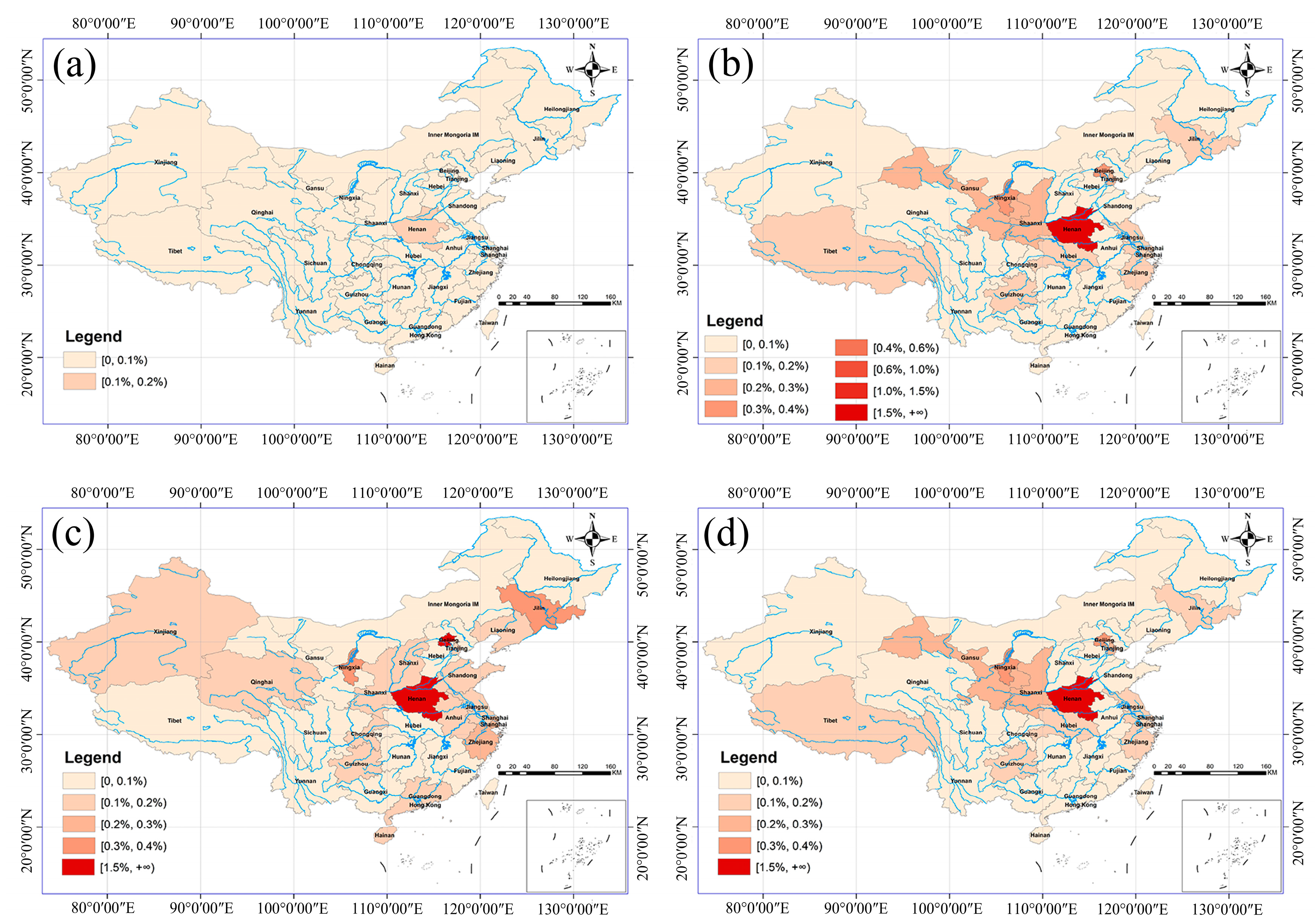
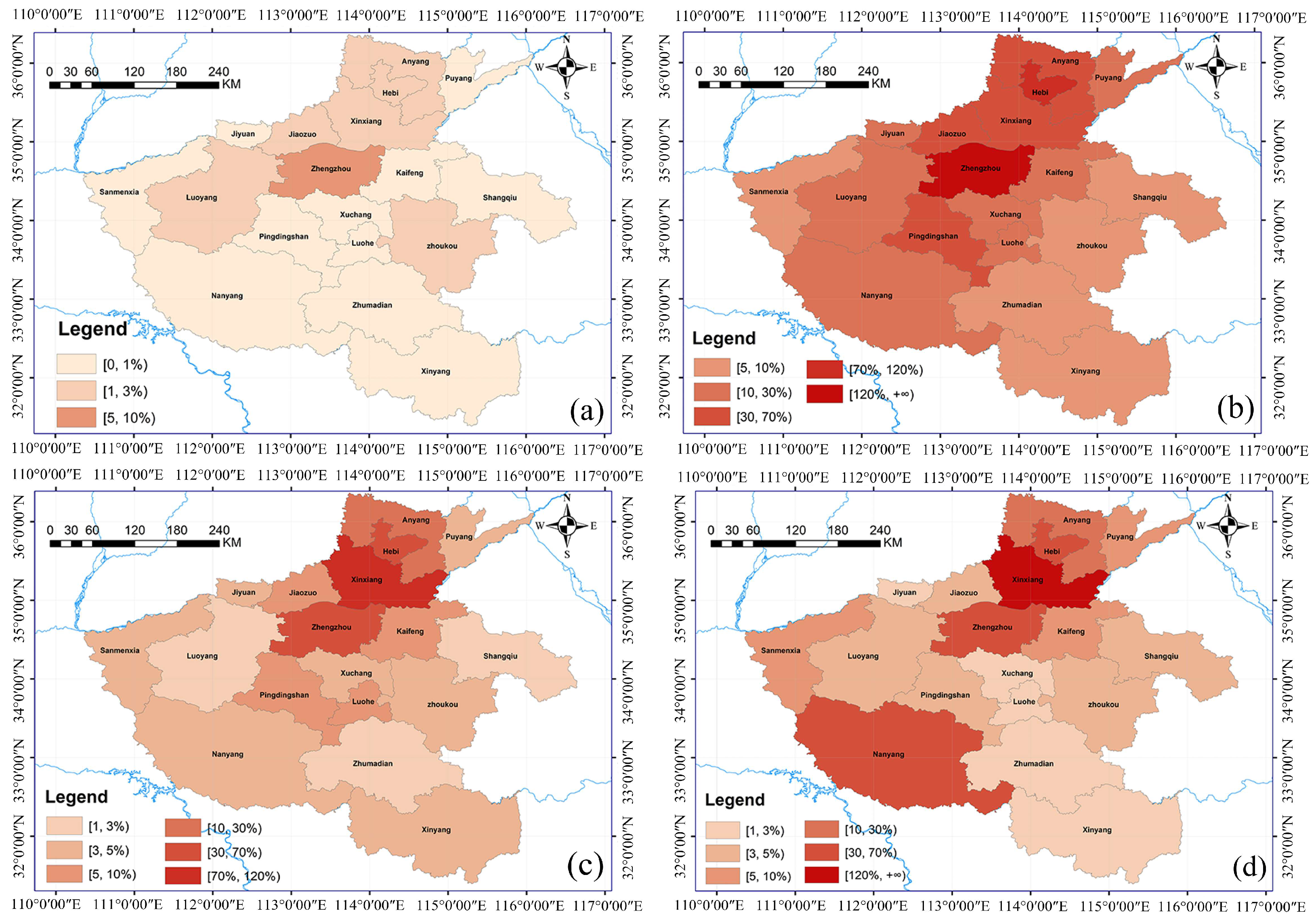
5.3. Spatial Analysis
6. Conclusions
- BERT is superior for classifying microblogs related to government affairs. When there are a small or a high number of words in a We Media Microblog entry, the TF-IDF -BERT classification method is utilized, and the LDA -BERT classification method is utilized when the number of words is medium;
- The intensive rainfall in Henan was unexpected. Disaster information attracted more attention than warning information, but warning information garnered greater attention quickly after the warning-relief statute was passed;
- The microblog hot topics list all have corresponding category topics and are at the top, and as the hot topics change, the number of microblogs for each category decreases until the next hot topic appears.
- Residents of areas around Henan Province and areas that are also suffering from other natural disasters are more concerned about the intense rainfall in Henan Late heat shifted northward in Henan Province, with Zhengzhou, Xinxiang, Anyang, and Hebi having the highest topic heat;
- Issues during the experiments may have reduced precision: the text data are insufficient, with too many categories and a small number. Humans manually annotate categories and add subjectivity. We can improve the dataset in future experiments to improve precision. In addition, the semantics of the microblog check-in data are unclear; therefore, multiple sources of data can be used to improve it.
- Due to human and material limitations, we are unable to designate a substantial number of samples for BERT training. In addition, the irregular use of punctuation by individual users when expressing themselves can pose a challenge in terms of accurately identifying complete sentences when performing the main sentence extraction task. Even though we optimize the data during data pre-processing, this still diminishes the precision of the results to some degree. In addition to these, the studies are based on the Chinese corpus, and no comparative experiments in the English corpus have been undertaken. After that, we can add the English dataset and repeat the experiment to see if the approach is generalizable.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


References
- Tan, L.; Schultz, D.M. Damage Classification and Recovery Analysis of the Chongqing, China, Floods of August 2020 Based on Social-Media Data. J. Clean. Prod. 2021, 313, 127882. [Google Scholar] [CrossRef]
- Liu, Q.; Gao, Y.; Chen, Y. Study on Disaster Information Management System Compatible with VGI and Crowdsourcing. In Proceedings of the IEEE Workshop on Advanced Research and Technology in Industry Applications (WARTIA), Ottawa, ON, Canada, 29–30 September 2014; pp. 464–468. [Google Scholar] [CrossRef]
- Sit, M.A.; Koylu, C.; Demir, I. Identifying Disaster-Related Tweets and Their Semantic, Spatial and Temporal Context Using Deep Learning, Natural Language Processing and Spatial Analysis: A Case Study of Hurricane Irma. Int. J. Digit. Earth 2019, 12, 1205–1229. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Z.; Zheng, X.; Chen, N.; Wang, Y. Extracting the Location of Flooding Events in Urban Systems and Analyzing the Semantic Risk Using Social Sensing Data. J. Hydrol. 2021, 603, 127053. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, B.; Gong, Z. Real-Time Identification of Urban Rainstorm Waterlogging Disasters Based on Weibo Big Data. Nat. Hazards 2018, 94, 833–842. [Google Scholar] [CrossRef]
- Wang, R.Q.; Mao, H.; Wang, Y.; Rae, C.; Shaw, W. Hyper-Resolution Monitoring of Urban Flooding with Social Media and Crowdsourcing Data. Comput. Geosci. 2018, 111, 139–147. [Google Scholar] [CrossRef] [Green Version]
- Restrepo-Estrada, C.; de Andrade, S.C.; Abe, N.; Fava, M.C.; Mendiondo, E.M.; de Albuquerque, J.P. Geo-Social Media as a Proxy for Hydrometeorological Data for Streamflow Estimation and to Improve Flood Monitoring. Comput. Geosci. 2018, 111, 148–158. [Google Scholar] [CrossRef]
- Wang, Z.; Ye, X. Social Media Analytics for Natural Disaster Management. Int. J. Geogr. Inf. Sci. 2018, 32, 49–72. [Google Scholar] [CrossRef]
- Arapostathis, S.G. A Methodology for Automatic Acquisition of Flood-event Management Information From Social Media: The Flood in Messinia, South Greece, 2016. Inf. Syst. Front. 2021, 23, 1127–1144. [Google Scholar] [CrossRef]
- Karmegam, D.; Mappillairaju, B. Spatiooral Distribution of Negative Emotions on Twitter during Floods in Chennai, India, in 2015: A Post Hoc Analysis. Int. J. Health Geogr. 2020, 19, 19. [Google Scholar] [CrossRef]
- Zahra, K.; Imran, M.; Ostermann, F.O. Automatic Identification of Eyewitness Messages on Twitter during Disasters. Inf. Process. Manag. 2020, 57, 102107. [Google Scholar] [CrossRef]
- Szczepanek, R. A Deep Learning Model of Spatial Distance and Named Entity Recognition (SD-NER) for Flood Mark Text Classification. Water 2023, 15, 1197. [Google Scholar] [CrossRef]
- Lin, Y.T.; Yang, M.D.; Han, J.Y.; Su, Y.F.; Jang, J.H. Quantifying Flood Water Levels Using Image-Based Volunteered Geographic Information. Remote Sens. 2020, 12, 706. [Google Scholar] [CrossRef] [Green Version]
- Dou, M.; Wang, Y.; Gu, Y.; Dong, S.; Qiao, M.; Deng, Y. Disaster Damage Assessment Based on Fine-Grained Topics in Social Media. Comput. Geosci. 2021, 156, 104893. [Google Scholar] [CrossRef]
- Zhang, W.; Xu, C. Microblog Text Classification System Based on TextCNN and LSA Model. In Proceedings of the 5th International Conference on Information Science, Computer Technology and Transportation (ISCTT), Shenyang, China, 13–15 November 2020; pp. 469–474. [Google Scholar] [CrossRef]
- Wahid, J.A.; Shi, L.; Gao, Y.; Yang, B.; Wei, L.; Tao, Y.; Hussain, S.; Ayoub, M.; Yagoub, I. Topic2Labels: A Framework to Annotate and Classify the Social Media Data through LDA Topics and Deep Learning Models for Crisis Response. Expert Syst. Appl. 2022, 195, 116562. [Google Scholar] [CrossRef]
- Han, X.; Wang, J.; Zhang, M.; Wang, X. Using Social Media to Mine and Analyze Public Opinion Related to COVID-19 in China. Int. J. Environ. Res. Public Health 2020, 17, 2788. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Shi, H.; Wu, X.; Jiao, L. Sentiment Analysis of Rumor Spread amid Covid-19: Based on Weibo Text. Healthcare 2021, 9, 1275. [Google Scholar] [CrossRef]
- Yu, M.; Huang, Q.; Qin, H.; Scheele, C.; Yang, C. Deep Learning for Real-Time Social Media Text Classification for Situation Awareness—Using Hurricanes Sandy, Harvey, and Irma as Case Studies. Int. J. Digit. Earth 2019, 12, 1230–1247. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, T.; Ye, X.; Zhu, J.; Lee, J. Using Social Media for Emergency Response and Urban Sustainability: A Case Study of the 2012 Beijing Rainstorm. Sustainability 2016, 8, 25. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 24 May 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Hey, T.; Keim, J.; Koziolek, A.; Tichy, W.F. NoRBERT: Transfer Learning for Requirements Classification. In Proceedings of the IEEE 28th International Requirements Engineering Conference (RE), Zurich, Switzerland, 31 August–4 September 2020; pp. 169–179. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, S.; Padmanabhan, A.; Yin, J.; Cao, G. Mapping Spatiotemporal Patterns of Events Using Social Media: A Case Study of Influenza Trends. Int. J. Geogr. Inf. Sci. 2018, 32, 425–449. [Google Scholar] [CrossRef]
- Han, X.; Wang, J. Using Social Media to Mine and Analyze Public Sentiment during a Disaster: A Case Study of the 2018 Shouguang City Flood in China. ISPRS Int. J. Geo-Inf. 2019, 8, 185. [Google Scholar] [CrossRef] [Green Version]
- Cheng, X.; Han, G.; Zhao, Y.; Li, L. Evaluating Social Media Response to Urban Flood Disaster: Case Study on an East Asian City (Wuhan, China). Sustainability 2019, 11, 330. [Google Scholar] [CrossRef] [Green Version]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake News Detection in Social Media with a BERT-Based Deep Learning Approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Cong, P.; Lv, S. A Long-Text Classification Method of Chinese News Based on BERT and CNN. IEEE Access 2022, 10, 34046–34057. [Google Scholar] [CrossRef]
- Onan, A.; Korukoǧlu, S.; Bulut, H. Ensemble of Keyword Extraction Methods and Classifiers in Text Classification. Expert Syst. Appl. 2016, 57, 232–247. [Google Scholar] [CrossRef]
- Huang, X.; Wu, Q. Micro-Blog Commercial Word Extraction Based on Improved TF-IDF Algorithm. In Proceedings of the IEEE International Conference of IEEE Region 10 (TENCON 2013), Xi’an, China, 22–25 October 2013. [Google Scholar] [CrossRef]
- Yang, L.; Ji, D.; Leong, M. Document Reranking by Term Distribution and Maximal Marginal Relevance for Chinese Information Retrieval. Inf. Process. Manag. 2007, 43, 315–326. [Google Scholar] [CrossRef]
- Wu, W.; Li, J.; He, Z.; Ye, X.; Zhang, J.; Cao, X.; Qu, H. Tracking Spatio-Temporal Variation of Geo-Tagged Topics with Social Media in China: A Case Study of 2016 Hefei Rainstorm. Int. J. Disaster Risk Reduct. 2020, 50, 101737. [Google Scholar] [CrossRef]
- Kumar, S. Analyzing the Facebook Workload. In Proceedings of the IEEE International Symposium on Workload Characterization (IISWC), La Jolla, CA, USA, 4–6 November 2012; pp. 111–112. [Google Scholar] [CrossRef]
- Li, W.; Zhao, J. TextRank Algorithm by Exploiting Wikipedia for Short Text Keywords Extraction. In Proceedings of the 3rd International Conference on Information Science and Control Engineering (ICISCE), Beijing, China, 8–10 July 2016; pp. 683–686. [Google Scholar] [CrossRef]
- Shanchen, P.; Jiamin, Y.; Ting, L.; Hua, Z.; Hongqi, C. A Text Similarity Measurement Based on Semantic Fingerprint of Characteristic Phrases. Chin. J. Electron. 2020, 29, 233–241. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, D.; Yuan, Y.; Liu, Q.; Yang, Y. Improvement of TF-IDF Algorithm Based on Knowledge Graph. In Proceedings of the IEEE 16th International Conference on Software Engineering Research, Management and Applications (SERA), Kunming, China, 13–15 June 2018; pp. 19–24. [Google Scholar] [CrossRef]
- Zhang, T.; Ge, S.S. An Improved Tf-IdF Algorithm Based on Class Discriminative Strength for Text Categorization on Desensitized Data. In Proceedings of the 3rd International Conference on Innovation in Artificial Intelligence, Suzhou, China, 15–18 March 2019; Part F1481. pp. 39–44. [Google Scholar] [CrossRef]
- Flores, M.L.; Santos, E.R.; Silveira, R.A. Ontology-Based Extractive Text Summarization: The Contribution of Instances. Comput. Y Sist. 2019, 23, 905–914. [Google Scholar] [CrossRef]
- Ullah, S.; Al Islam, A.B.M.A. A Framework for Extractive Text Summarization Using Semantic Graph Based Approach. In Proceedings of the 6th International Conference on Networking, Systems and Security, Dhaka, Bangladesh, 17–19 December 2019; pp. 48–58. [Google Scholar] [CrossRef]
- Kim, D.; Seo, D.; Cho, S.; Kang, P. Multi-Co-Training for Document Classification Using Various Document Representations: TF–IDF, LDA, and Doc2Vec. Inf. Sci. 2019, 477, 15–29. [Google Scholar] [CrossRef]
- Lu, Q.; Zhu, Z.; Xu, F.; Zhang, D.; Wu, W.; Guo, Q. Bi-Gru Sentiment Classification for Chinese Based on Grammar Rules and Bert. Int. J. Comput. Intell. Syst. 2020, 13, 538–548. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 2017, 5999–6009. [Google Scholar] [CrossRef]
- Chen, N.; Zhang, Y.; Du, W.; Li, Y.; Chen, M.; Zheng, X. KE-CNN: A New Social Sensing Method for Extracting Geographical Attributes from Text Semantic Features and Its Application in Wuhan, China. Comput. Environ. Urban Syst. 2021, 88, 101629. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, L.; Wang, Y. Extracting Key Sentences from Chinese Text. In Proceedings of the 11th Joint International Computer Conference, Chongqing, China, 10–12 November 2005; pp. 364–367. [Google Scholar] [CrossRef]
- Yang, H.; Zhao, L.; Chen, J. Metro System Inundation in Zhengzhou, Henan Province, China. Sustainability 2022, 14, 9292. [Google Scholar] [CrossRef]
- Scheele, C.; Yu, M.; Huang, Q. Geographic Context-Aware Text Mining: Enhance Social Media Message Classification for Situational Awareness by Integrating Spatial and Temporal Features. Int. J. Digit. Earth 2021, 14, 1721–1743. [Google Scholar] [CrossRef]
- Chae, J.; Thom, D.; Jang, Y.; Kim, S.; Ertl, T.; Ebert, D.S. Public Behavior Response Analysis in Disaster Events Utilizing Visual Analytics of Microblog Data. Comput. Graph. 2014, 38, 51–60. [Google Scholar] [CrossRef]
- Deng, G.Q.; Chen, H.; Wang, S.Q. Risk Assessment and Prediction of Rainstorm and Flood Disaster Based on Henan Province, China. Math. Probl. Eng. 2022, 2022, 5310920. [Google Scholar] [CrossRef]
- Liu, S.N.; Wang, J.; Wang, H.J. Assessing 10 Satellite Precipitation Products in Capturing the July 2021 Extreme Heavy Rain in Henan, China. J. Meteorol. Res. 2022, 36, 798–808. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Overall | Government Affairs Microblog | We Media Microblog | |
|---|---|---|---|---|
| Datasets | ||||
| Hubei intensive rainfall datasets | 71.4% | 87.2% | 67.4% | |
| Henan intensive rainfall datasets | 59.7% | 75.0% | 58.0% | |
| Evaluation Factors | Acc | Time | F1 | P | R | |
|---|---|---|---|---|---|---|
| Method | ||||||
| BERT | 57.3% | 4 h 34 min | 56.0% | 58.0% | 53.8% | |
| TF-IDF-BERT | 63.3% | 3 h 30 min | 63.2% | 66.7% | 63.3% | |
| TextRank-BERT | 58.8% | 3 h 31 min | 59.1% | 62.3% | 58.8% | |
| MMR-BERT | 62.0% | 3 h 32 min | 60.9% | 61.7% | 62.1% | |
| LDA-BERT | 60.0% | 3 h 31 min | 60.0% | 61.4% | 60.0% | |
| Evaluation Factors | Acc | Time | F1 | P | R | |
|---|---|---|---|---|---|---|
| Method | ||||||
| BERT | 63.9% | 4 h 11 min | 63.9% | 53.5% | 51.9% | |
| TF-IDF-BERT | 65.3% | 3 h 46 min | 65.1% | 57.5% | 54.1% | |
| TextRank-BERT | 61.5% | 3 h 41 min | 61.5% | 50.1% | 49.8% | |
| MMR-BERT | 64.1% | 3 h 51 min | 64.0% | 57.9% | 55.4% | |
| LDA-BERT | 64.7% | 3 h 49 min | 64.7% | 57.2% | 53.5% | |
| Original Category | Number | Present Category | Number |
|---|---|---|---|
| warning | 160 | tips | 280 |
| guide | 120 | ||
| situation | 235 | situation | 640 |
| disaster | 421 | ||
| help | 423 | rescue | 978 |
| rescue | 570 | ||
| prayer | 711 | emotions | 2031 |
| irrelevant | 1360 | ||
| hotspots | 71 |
| Evaluation Factors | Acc | F1 | P | R | |
|---|---|---|---|---|---|
| Method | |||||
| BERT | 67.5% | 67.4% | 67.6% | 67.5% | |
| TF-IDF-BERT | 69.2% | 68.7% | 68.5% | 69.2% | |
| TextRank-BERT | 66.3% | 65.9% | 65.9% | 66.3% | |
| MMR-BERT | 63.8% | 63.9% | 64.1% | 63.8% | |
| LDA-BERT | 67.1% | 67.2% | 67.7% | 67.1% | |
| Type | Government Affairs Microblog | We Media Microblog | |
|---|---|---|---|
| Method | |||
| BERT | 79.0% | 62.0% | |
| TF-IDF-BERT | 74.0% | 64.0% | |
| TextRank-BERT | 72.0% | 55.5% | |
| MMR-BERT | 69.0% | 51.5% | |
| LDA-BERT | 78.0% | 64.5% | |
| Type | Government Affairs Microblog | We Media Microblog | |
|---|---|---|---|
| Method | |||
| BERT | 87.2% | 67.4% | |
| TF-IDF-BERT | 80.4% | 67.5% | |
| TextRank-BERT | 74.3% | 60.6% | |
| MMR-BERT | 81.5% | 66.9% | |
| LDA-BERT | 79.9% | 67.5% | |
| DataSet | Word Count ∈ [1, 70] | Word Count ∈ (70, 140) | Word Count ∈ (140, +∞) | ||
|---|---|---|---|---|---|
| Acc | |||||
| Method | |||||
| BERT | 65.7% | 58.6% | 61.7% | ||
| TF-IDF-BERT | 68.6% | 57.1% | 68.3% | ||
| TextRank-BERT | 58.6% | 48.6% | 60.0% | ||
| MMR-BERT | 52.9% | 57.1% | 53.3% | ||
| LDA-BERT | 61.4% | 68.6% | 63.3% | ||
| DataSet | Word Count ∈ [1, 70] | Word Count ∈ (70, 140) | Word Count ∈ (140, +∞) | ||
|---|---|---|---|---|---|
| Acc | |||||
| Method | |||||
| BERT | 63.2% | 68.7% | 75.0% | ||
| TF-IDF-BERT | 64.3% | 65.8% | 76.6% | ||
| TextRank-BERT | 55.3% | 62.7% | 69.6% | ||
| MMR-BERT | 63.3% | 67.4% | 74.4% | ||
| LDA-BERT | 63.3% | 70.5% | 73.1% | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, W.; Ge, C.; Yao, S.; Chen, N.; Xu, L. Applicability Analysis and Ensemble Application of BERT with TF-IDF, TextRank, MMR, and LDA for Topic Classification Based on Flood-Related VGI. ISPRS Int. J. Geo-Inf. 2023, 12, 240. https://doi.org/10.3390/ijgi12060240
Du W, Ge C, Yao S, Chen N, Xu L. Applicability Analysis and Ensemble Application of BERT with TF-IDF, TextRank, MMR, and LDA for Topic Classification Based on Flood-Related VGI. ISPRS International Journal of Geo-Information. 2023; 12(6):240. https://doi.org/10.3390/ijgi12060240
Chicago/Turabian StyleDu, Wenying, Chang Ge, Shuang Yao, Nengcheng Chen, and Lei Xu. 2023. "Applicability Analysis and Ensemble Application of BERT with TF-IDF, TextRank, MMR, and LDA for Topic Classification Based on Flood-Related VGI" ISPRS International Journal of Geo-Information 12, no. 6: 240. https://doi.org/10.3390/ijgi12060240
APA StyleDu, W., Ge, C., Yao, S., Chen, N., & Xu, L. (2023). Applicability Analysis and Ensemble Application of BERT with TF-IDF, TextRank, MMR, and LDA for Topic Classification Based on Flood-Related VGI. ISPRS International Journal of Geo-Information, 12(6), 240. https://doi.org/10.3390/ijgi12060240