

mapSR: A Deep Neural Network for Super-Resolution of Raster Map

Abstract
:1. Introduction
2. Related Works
2.1. CNN-Based SR
2.2. Transformer-Based SR
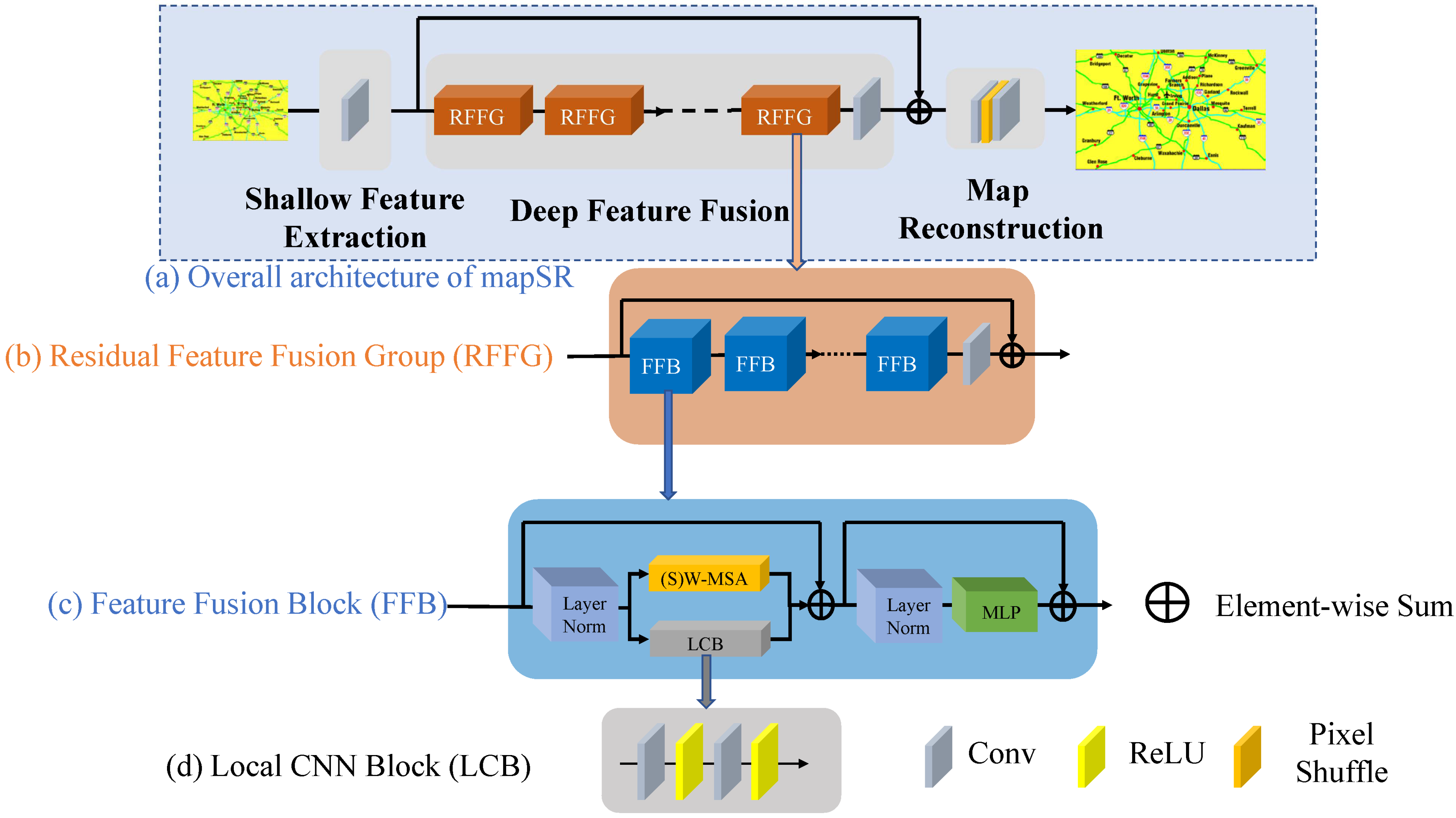
3. Framework of mapSR
3.1. Shallow Feature Extraction Module
3.2. Deep Feature Fusion Module
3.2.1. Attentions with Feature Fusion Blocks
3.2.2. Attention Partition with Shifted Window
3.3. Map Reconstruction
4. Experiments and Discussion
4.1. Experimental Dataset and Implementation
- EDSR: https://github.com/sanghyun-son/EDSR-PyTorch (accessed on 19 June 2023)
- DBPN: https://github.com/alterzero/DBPN-Pytorch (accessed on 19 June 2023)
- RCAN: https://github.com/yulunzhang/RCAN (accessed on 19 June 2023)
- SwinIR: https://github.com/JingyunLiang/SwinIR (accessed on 19 June 2023)
4.2. Results and Discussions
4.2.1. Quantitative Results
4.2.2. Visual Results
4.2.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Herold, M.; Liu, X.; Clarke, K.C. Spatial metrics and image texture for mapping urban land use. Photogramm. Eng. Remote Sens. 2003, 69, 991–1001. [Google Scholar] [CrossRef] [Green Version]
- Foo, P.; Warren, W.H.; Duchon, A.; Tarr, M.J. Do humans integrate routes into a cognitive map? Map- versus landmark-based navigation of novel shortcuts. J. Exp. Psychol. Learn. Mem. Cogn. 2005, 31, 195–215. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qi, J.; Liu, H.; Liu, X.; Zhang, Y. Spatiotemporal evolution analysis of time-series land use change using self-organizing map to examine the zoning and scale effects. Comput. Environ. Urban 2019, 76, 11–23. [Google Scholar] [CrossRef]
- Sagl, G.; Delmelle, E.; Delmelle, E. Mapping collective human activity in an urban environment based on mobile phone data. Cartogr. Geogr. Inf. Sci. 2014, 41, 272–285. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Liu, J.; Zhou, X. Intelligent map reader: A framework for topographic map understanding with deep learning and gazetteer. IEEE Access 2018, 6, 25363–25376. [Google Scholar] [CrossRef]
- Pezeshk, A.; Tutwiler, R.L. Automatic feature extraction and text recognition from scanned topographic maps. IEEE Trans. Geosci. Remote Sens. 2011, 49, 5047–5063. [Google Scholar] [CrossRef]
- Leyk, S.; Boesch, R. Colors of the past: Color image segmentation in historical topographic maps based on homogeneity. Geoinformatica 2010, 14, 1–21. [Google Scholar] [CrossRef]
- Pouderoux, J.; Gonzato, J.; Pereira, A.; Guitton, P. Toponym recognition in scanned color topographic maps. In Proceedings of the Ninth International Conference on Document Analysis and Recognition, Curitiba, Brazil, 23–26 September 2007; Volume 1, IEEE. pp. 531–535. [Google Scholar]
- Zhou, X.; Li, W.; Arundel, S.T.; Liu, J. Deep convolutional neural networks for map-type classification. arXiv 2018, arXiv:1805.10402. [Google Scholar]
- Zhou, X. GeoAI-Enhanced Techniques to Support Geographical Knowledge Discovery from Big Geospatial Data; Arizona State University: Tempe, AZ, USA, 2019. [Google Scholar]
- Li, J.; Pei, Z.; Zeng, T. From beginner to master: A survey for deep learning-based single-image super-resolution. arXiv 2021, arXiv:2109.14335. [Google Scholar]
- Li, K.; Yang, S.; Dong, R.; Wang, X.; Huang, J. Survey of single image super-resolution reconstruction. IET Image Process. 2020, 14, 2273–2290. [Google Scholar] [CrossRef]
- Yang, Z.; Shi, P.; Pan, D. A Survey of Super-Resolution Based on Deep Learning. In Proceedings of the 2020 International Conference on Culture-Oriented Science & Technology, Beijing, China, 28–31 October 2020; pp. 514–518. [Google Scholar]
- Lu, Z.; Li, J.; Liu, H.; Huang, C.; Zhang, L.; Zeng, T. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 457–466. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Dong, C. Activating More Pixels in Image Super-Resolution Transformer. arXiv 2022, arXiv:2205.04437. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE. 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 391–407. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M. Deep Laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Utah, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, A.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Kaiser, L.; Bengio, S.; Roy, A.; Vaswani, A.; Parmar, N.; Uszkoreit, J.; Shazeer, N. Fast decoding in sequence models using discrete latent variables. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2390–2399. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2010, arXiv:2010.11929. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Zhang, D.; Huang, F.; Liu, S.; Wang, X.; Jin, Z. SwinFIR: Revisiting the SWINIR with fast Fourier convolution and improved training for image super-resolution. arXiv 2022, arXiv:2208.11247. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Shin, A.; Ishii, M.; Narihira, T. Perspectives and prospects on transformer architecture for cross-modal tasks with language and vision. Int. J. Comput. Vis. 2022, 130, 435–454. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Map | Scale | EDSR | DBPN | RCAN | SwinIR | mapSR |
|---|---|---|---|---|---|---|
| 1 | X2 | 33.4192 | 33.0892 | 34.0426 | 34.1651 | 34.0485 |
| 2 | 32.8611 | 32.9120 | 34.6523 | 34.1132 | 34.6985 | |
| 3 | 28.6268 | 29.0341 | 30.2361 | 28.8198 | 30.1735 | |
| 4 | 34.8944 | 34.7906 | 35.0431 | 34.8981 | 35.2994 | |
| 5 | 29.8561 | 29.7685 | 30.4396 | 30.2846 | 30.5670 | |
| 6 | 32.8816 | 33.1306 | 34.5478 | 34.1370 | 34.8909 | |
| 7 | 38.8024 | 38.8269 | 42.3373 | 41.0826 | 43.3763 | |
| 8 | 33.4507 | 33.6415 | 36.8867 | 34.5898 | 37.0953 | |
| avg. | 33.0990 | 33.1492 | 34.7732 | 34.0113 | 35.0187 | |
| 1 | X3 | 29.4432 | 29.7042 | 29.9781 | 30.5131 | 29.6464 |
| 2 | 28.6196 | 29.1155 | 29.1369 | 29.0834 | 30.6319 | |
| 3 | 23.0056 | 23.9230 | 24.6834 | 22.7049 | 24.9065 | |
| 4 | 30.0887 | 30.2688 | 30.5821 | 30.7422 | 30.7725 | |
| 5 | 25.0961 | 25.1343 | 25.9240 | 26.4909 | 26.3618 | |
| 6 | 27.9597 | 28.3543 | 28.7026 | 27.9801 | 29.0721 | |
| 7 | 30.8867 | 31.9362 | 33.3526 | 31.1853 | 34.7123 | |
| 8 | 26.2006 | 27.8731 | 29.1660 | 25.5936 | 30.4279 | |
| avg. | 27.6625 | 28.2887 | 28.9407 | 28.0367 | 29.5664 | |
| 1 | X2 | 0.9565 | 0.9551 | 0.9546 | 0.9572 | 0.9559 |
| 2 | 0.9591 | 0.9591 | 0.9591 | 0.9598 | 0.9595 | |
| 3 | 0.9160 | 0.9162 | 0.9165 | 0.9164 | 0.9182 | |
| 4 | 0.9516 | 0.9512 | 0.9493 | 0.9506 | 0.9509 | |
| 5 | 0.8959 | 0.8949 | 0.8964 | 0.8969 | 0.8973 | |
| 6 | 0.9505 | 0.9506 | 0.9494 | 0.9522 | 0.9522 | |
| 7 | 0.9960 | 0.9953 | 0.9984 | 0.9978 | 0.9987 | |
| 8 | 0.9939 | 0.9942 | 0.9979 | 0.9961 | 0.9982 | |
| avg. | 0.9524 | 0.9521 | 0.9527 | 0.9534 | 0.9538 | |
| 1 | X3 | 0.9295 | 0.9318 | 0.9311 | 0.9368 | 0.9221 |
| 2 | 0.9318 | 0.9355 | 0.9356 | 0.9357 | 0.9348 | |
| 3 | 0.8450 | 0.8544 | 0.8625 | 0.8421 | 0.8554 | |
| 4 | 0.9172 | 0.9192 | 0.9194 | 0.9201 | 0.9177 | |
| 5 | 0.8233 | 0.8282 | 0.8320 | 0.8329 | 0.8273 | |
| 6 | 0.9172 | 0.9194 | 0.9214 | 0.9184 | 0.9230 | |
| 7 | 0.9844 | 0.9880 | 0.9914 | 0.9825 | 0.9940 | |
| 8 | 0.9726 | 0.9822 | 0.9866 | 0.9663 | 0.9926 | |
| avg. | 0.9151 | 0.9198 | 0.9225 | 0.9168 | 0.9208 |
| PSNR | EDSR | DBPN | RCAN | SwinIR | mapSR | |
|---|---|---|---|---|---|---|
| X2 | min | 25.1995 | 25.6105 | 25.9346 | 25.1513 | 26.1057 |
| max | 42.3900 | 43.1568 | 48.1815 | 42.7556 | 46.6624 | |
| mean | 33.0666 | 33.8289 | 35.4099 | 33.3637 | 35.4836 | |
| var | 14.6673 | 14.6019 | 17.6664 | 15.7346 | 17.9187 | |
| X3 | min | 19.3009 | 20.3305 | 22.4703 | 20.1624 | 23.1906 |
| max | 37.7150 | 38.0387 | 39.2920 | 38.0245 | 39.6565 | |
| mean | 27.9724 | 28.9612 | 30.0894 | 27.9687 | 30.6727 | |
| var | 12.5503 | 12.9635 | 13.9614 | 12.7918 | 14.7665 | |
| SSIM | EDSR | DBPN | RCAN | SwinIR | mapSR | |
| X2 | min | 0.7051 | 0.7092 | 0.7135 | 0.7069 | 0.7143 |
| max | 0.9985 | 0.9988 | 0.9994 | 0.9988 | 0.9993 | |
| mean | 0.9667 | 0.9700 | 0.9751 | 0.9685 | 0.9754 | |
| var | 0.0011 | 0.0010 | 0.0009 | 0.0011 | 0.0009 | |
| X3 | min | 0.6053 | 0.6120 | 0.6177 | 0.6068 | 0.6207 |
| max | 0.9942 | 0.9957 | 0.9973 | 0.9947 | 0.9980 | |
| mean | 0.9182 | 0.9300 | 0.9402 | 0.9209 | 0.9462 | |
| var | 0.0043 | 0.0038 | 0.0033 | 0.0040 | 0.0030 |
| Map | SwinIR (α = 0) | mapSR (α = 0.01) | mapSR (α = 0.1) | mapSR (α = 1.0) |
|---|---|---|---|---|
| 1 | 34.1651 | 34.0485 | 34.1574 | 34.0989 |
| 2 | 34.1132 | 34.6985 | 34.7030 | 34.6605 |
| 3 | 28.8198 | 30.1735 | 29.9528 | 29.9388 |
| 4 | 34.8981 | 35.2994 | 35.3150 | 35.3195 |
| 5 | 30.2846 | 30.5670 | 30.5625 | 30.5608 |
| 6 | 34.1370 | 34.8909 | 34.8191 | 34.8402 |
| 7 | 41.0826 | 43.3763 | 42.8437 | 42.8933 |
| 8 | 34.5898 | 37.0953 | 36.7510 | 36.4225 |
| avg. | 34.0113 | 35.0187 | 34.8880 | 34.8418 |
| 1 | 0.9572 | 0.9559 | 0.9563 | 0.9559 |
| 2 | 0.9598 | 0.9595 | 0.9599 | 0.9596 |
| 3 | 0.9164 | 0.9182 | 0.9180 | 0.9177 |
| 4 | 0.9506 | 0.9509 | 0.9511 | 0.9510 |
| 5 | 0.8969 | 0.8973 | 0.8975 | 0.8974 |
| 6 | 0.9522 | 0.9522 | 0.9519 | 0.9518 |
| 7 | 0.9978 | 0.9987 | 0.9985 | 0.9985 |
| 8 | 0.9961 | 0.9982 | 0.9979 | 0.9978 |
| avg. | 0.9534 | 0.9538 | 0.9539 | 0.9537 |
| SwinIR (α = 0) | mapSR (α = 0.01) | mapSR (α = 0.1) | mapSR (α = 1.0) | ||
|---|---|---|---|---|---|
| x2 | PSNR | 33.3637 | 35.4836 | 35.4463 | 32.6522 |
| SSIM | 0.9685 | 0.9754 | 0.9753 | 0.9642 | |
| x3 | PSNR | 27.9687 | 30.6727 | 30.6639 | 28.6836 |
| SSIM | 0.9209 | 0.9462 | 0.9460 | 0.9254 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Zhou, X.; Yan, Z. mapSR: A Deep Neural Network for Super-Resolution of Raster Map. ISPRS Int. J. Geo-Inf. 2023, 12, 258. https://doi.org/10.3390/ijgi12070258
Li H, Zhou X, Yan Z. mapSR: A Deep Neural Network for Super-Resolution of Raster Map. ISPRS International Journal of Geo-Information. 2023; 12(7):258. https://doi.org/10.3390/ijgi12070258
Chicago/Turabian StyleLi, Honghao, Xiran Zhou, and Zhigang Yan. 2023. "mapSR: A Deep Neural Network for Super-Resolution of Raster Map" ISPRS International Journal of Geo-Information 12, no. 7: 258. https://doi.org/10.3390/ijgi12070258
APA StyleLi, H., Zhou, X., & Yan, Z. (2023). mapSR: A Deep Neural Network for Super-Resolution of Raster Map. ISPRS International Journal of Geo-Information, 12(7), 258. https://doi.org/10.3390/ijgi12070258