

Land Use and Land Cover Classification in the Northern Region of Mozambique Based on Landsat Time Series and Machine Learning
 ,
,  , ,
, , 
Abstract
:1. Introduction
2. Materials and Methods
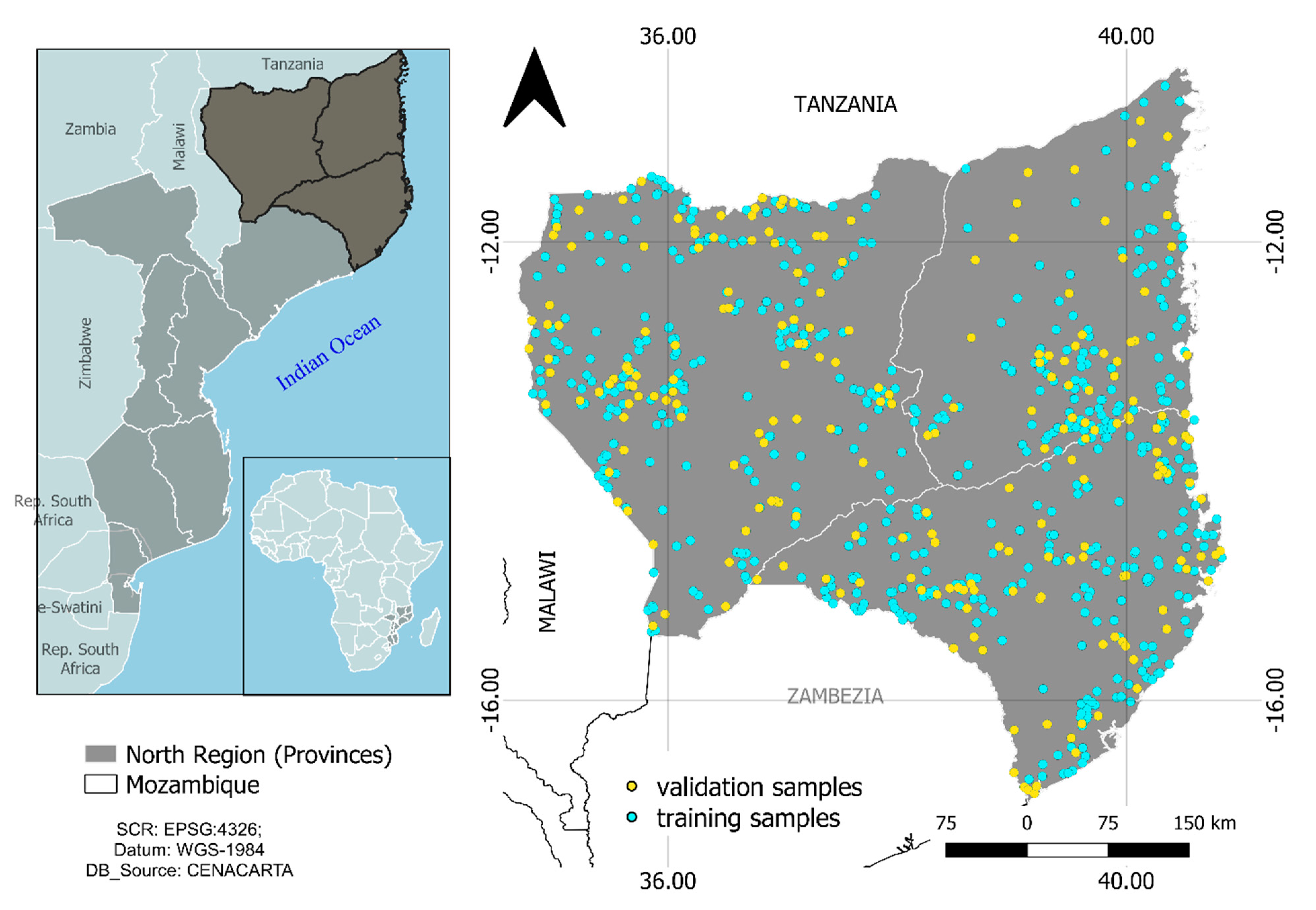
2.1. Study Area
2.2. Data Acquisition
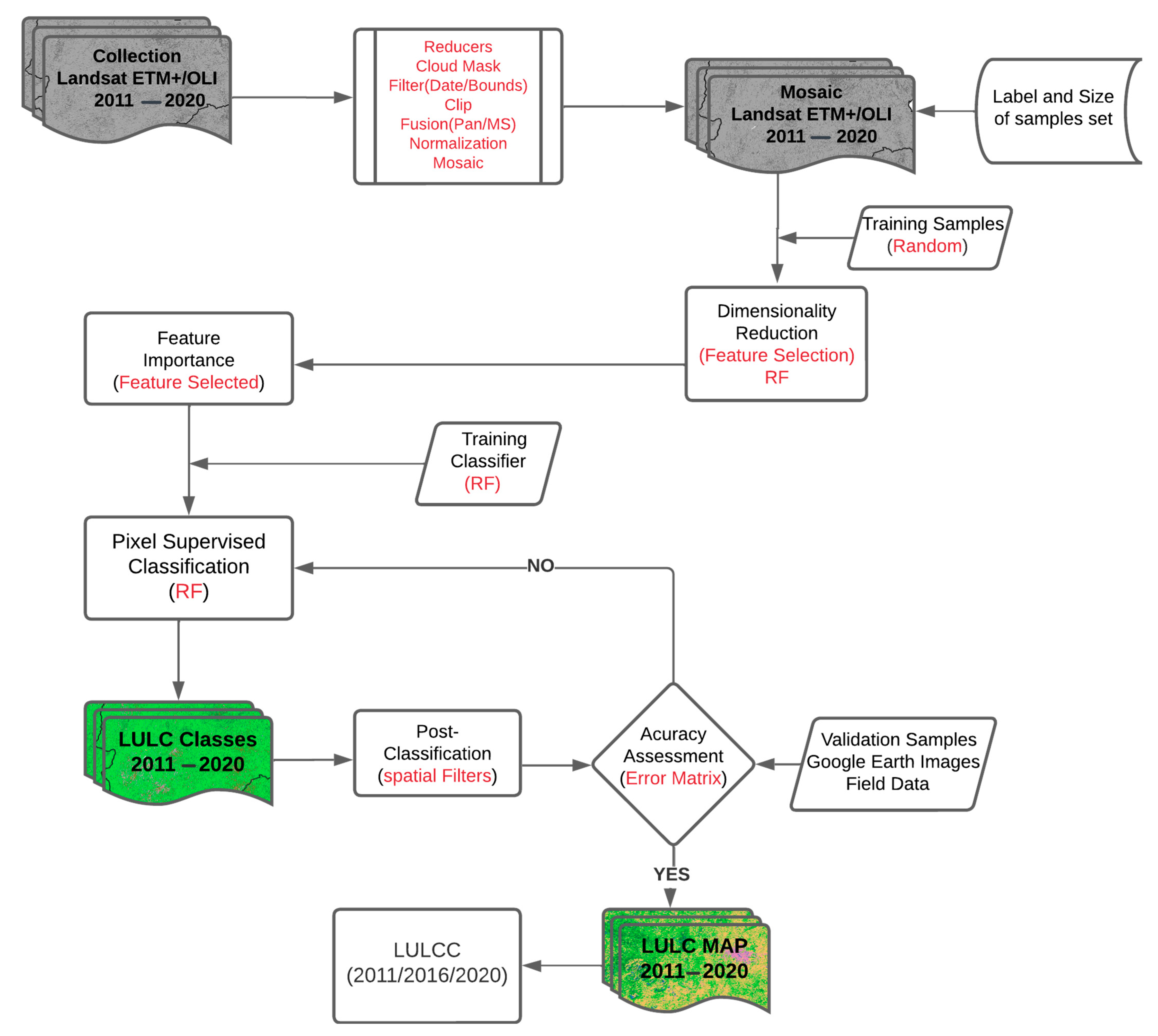
2.3. Methods
2.3.1. LULC Classes and Samples
2.3.2. Feature Selection (FS) Method
2.3.3. LULC Classification and Accuracy Assessment
3. Results
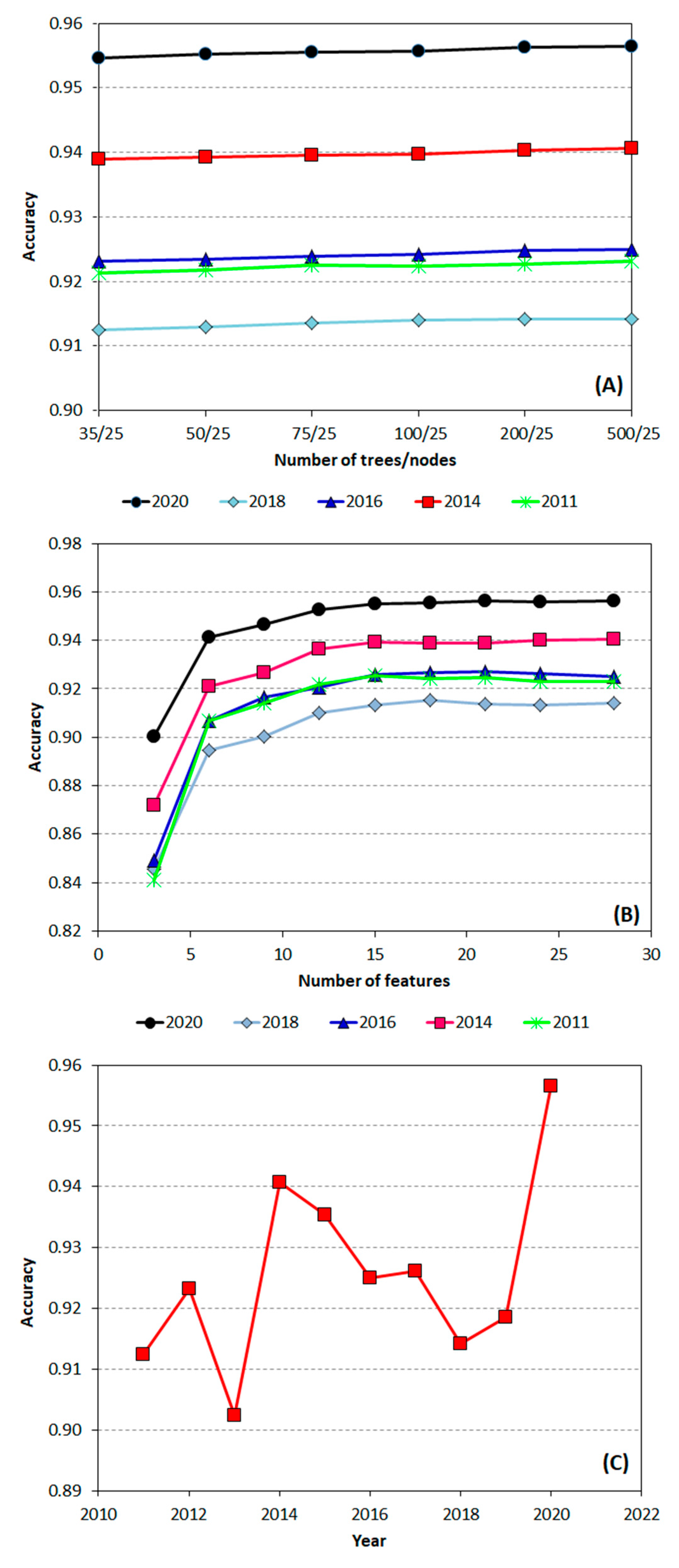
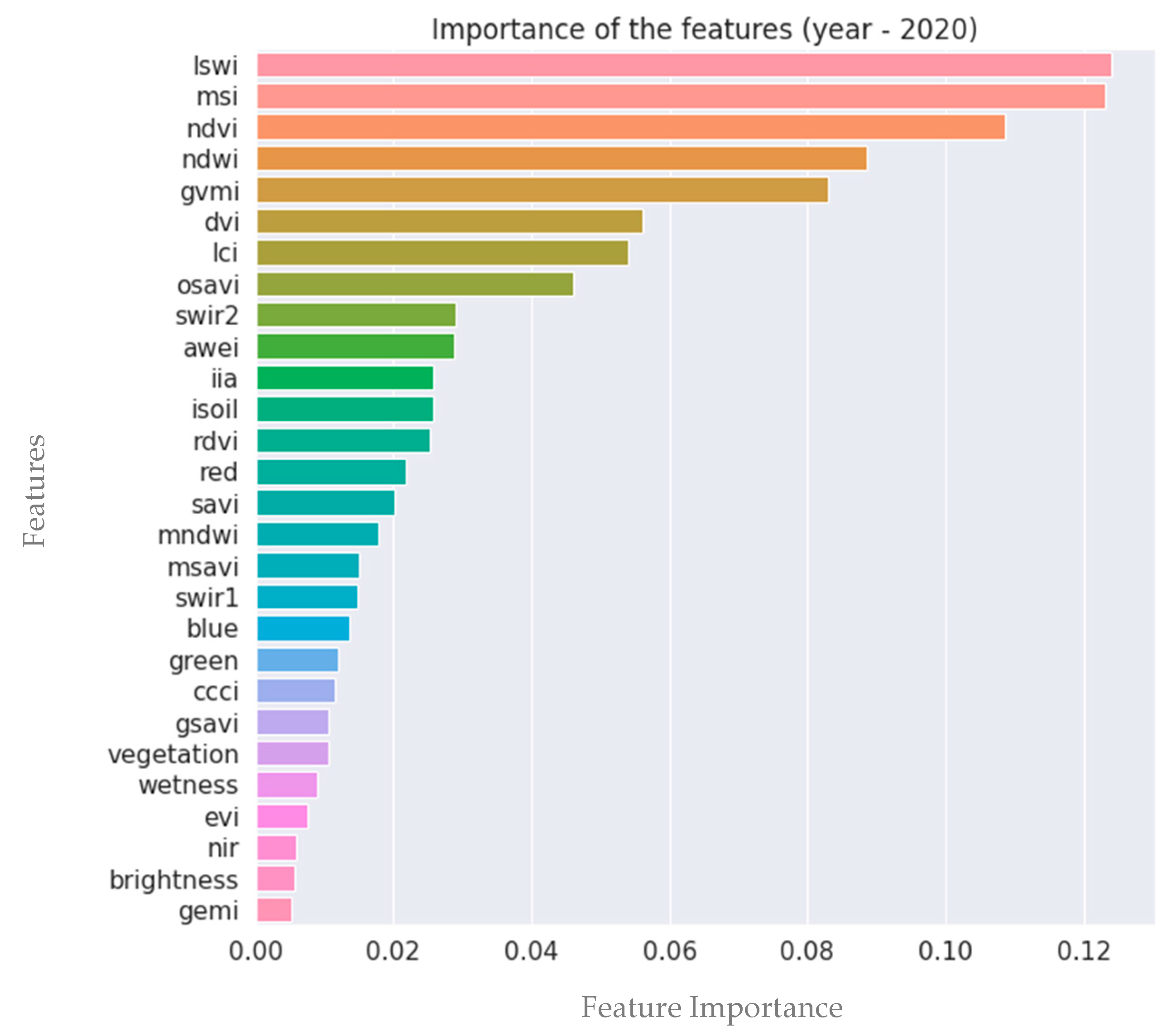
3.1. Feature Selection and Importance of the Variables
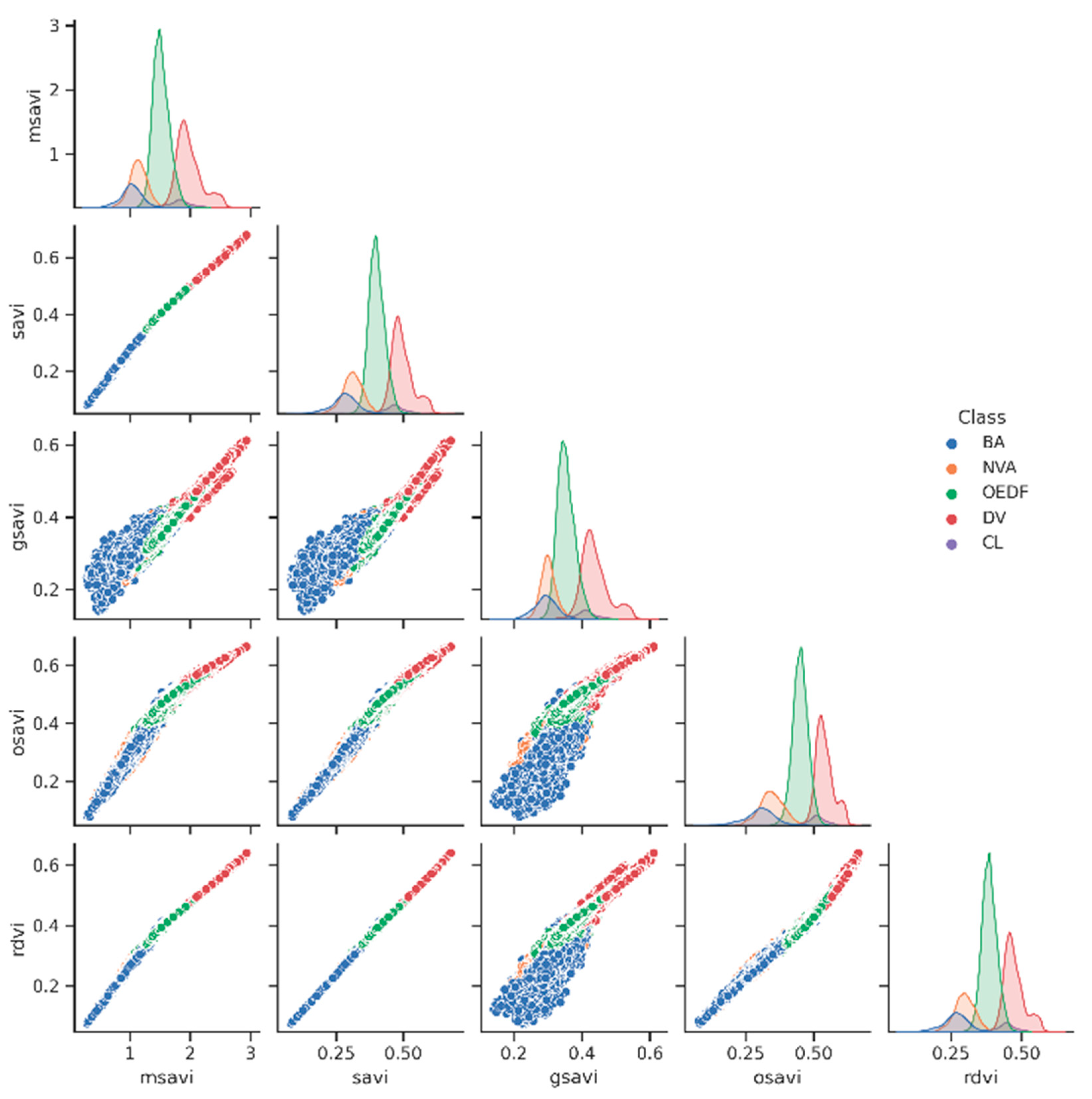
3.2. Separability of the Classes
3.3. Accuracy of the Maps
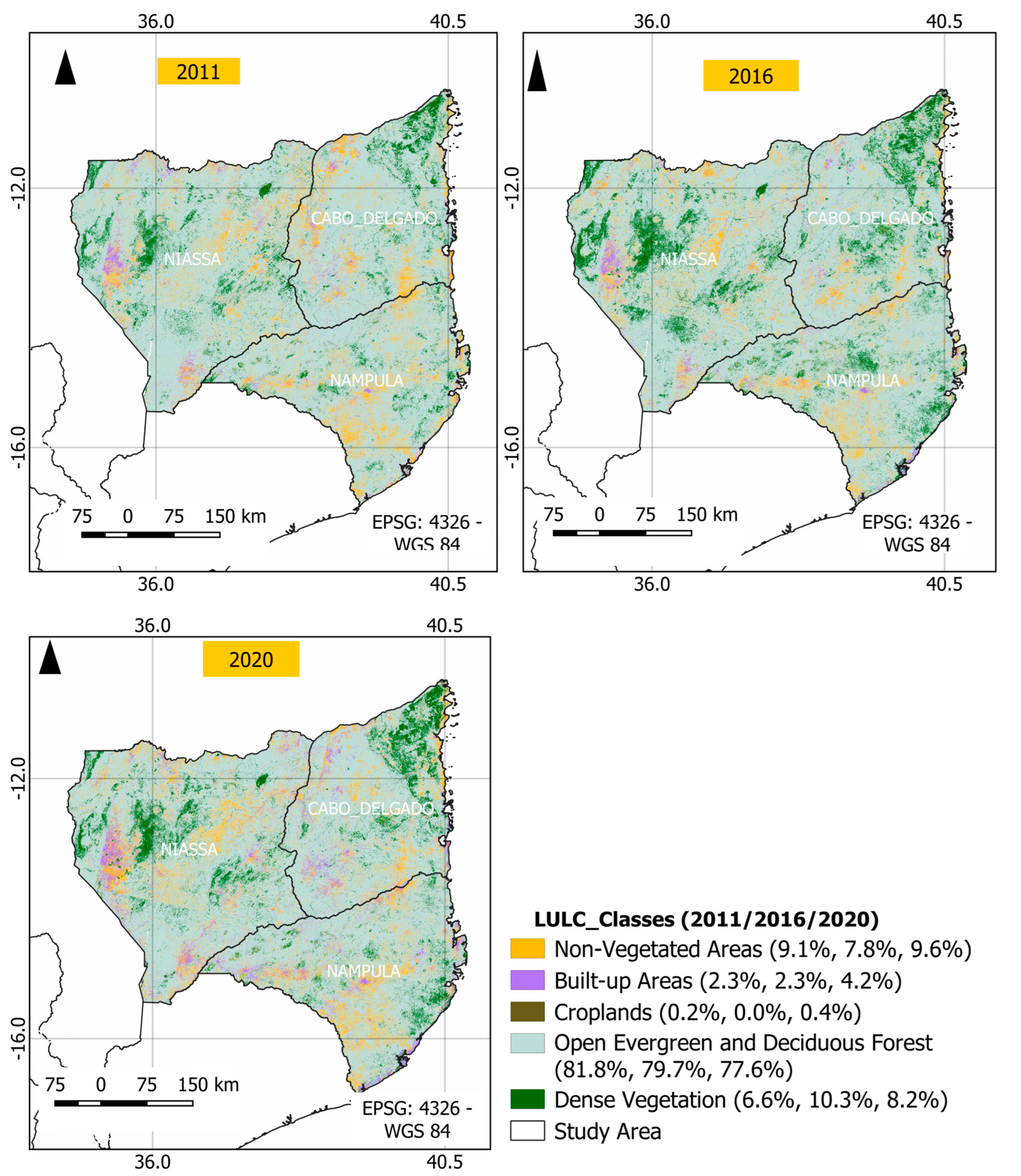
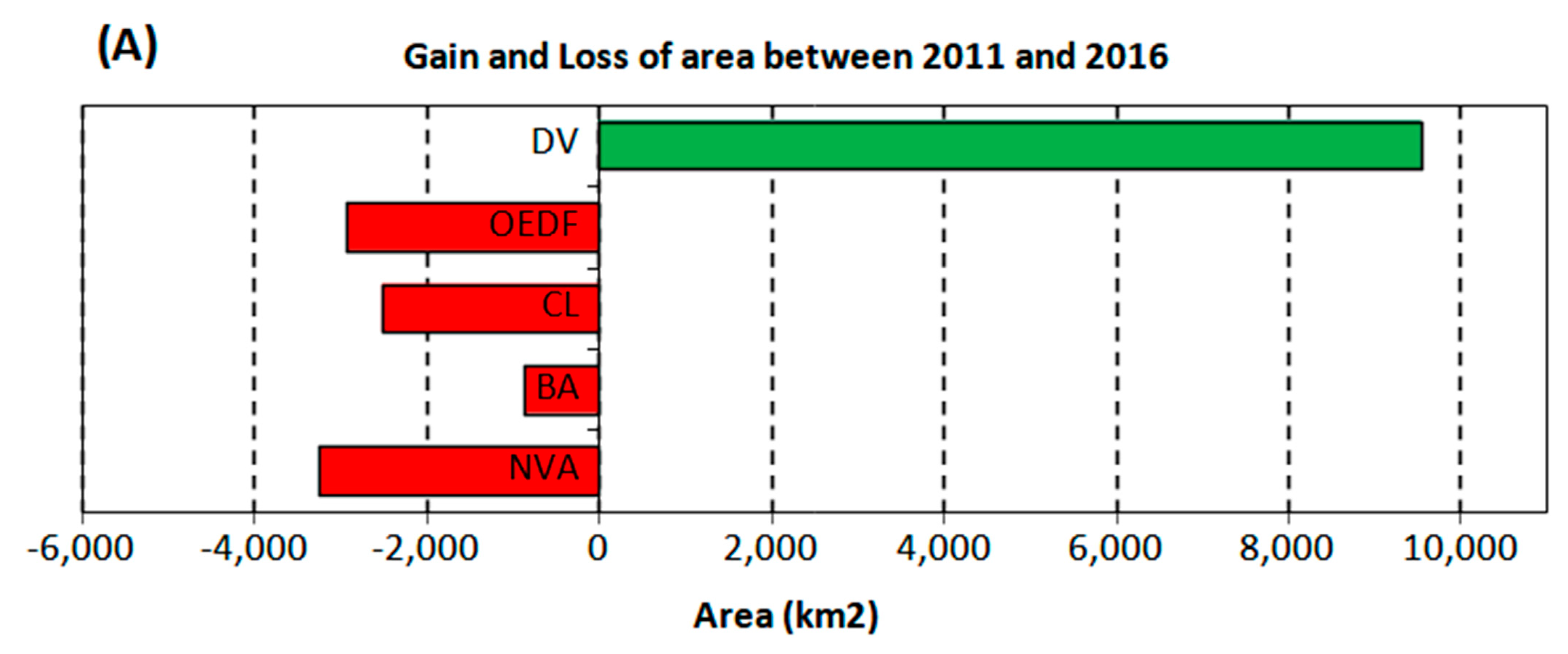
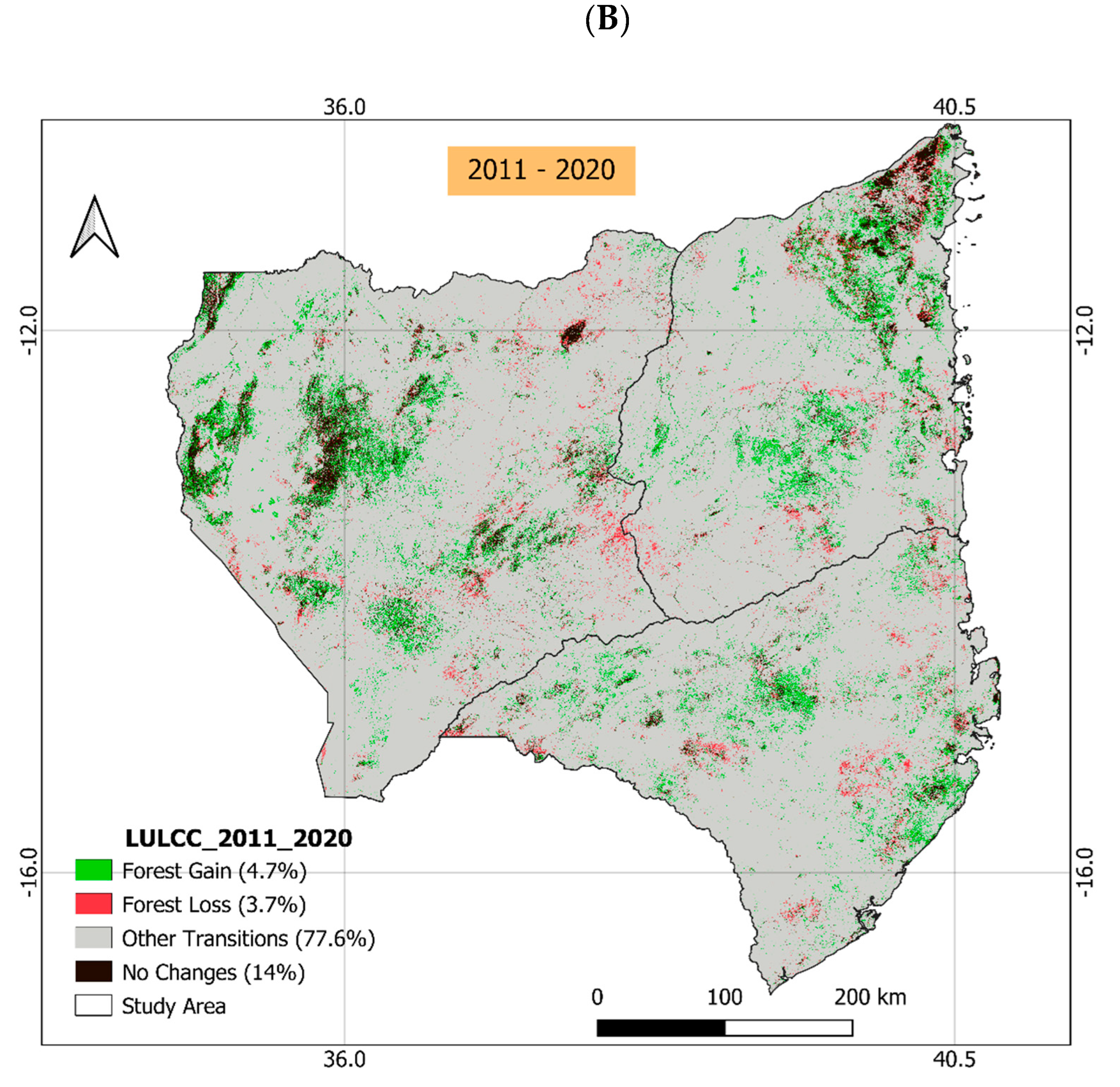
3.4. Land Use and Land Cover in the Northern Region of Mozambique
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chamberlin, J.; Jayne, T.S.; Headey, D. Scarcity amidst Abundance? Reassessing the Potential for Cropland Expansion in Africa. Food Policy 2014, 48, 51–65. [Google Scholar] [CrossRef]
- Marzoli, A. Inventário Florestal Nacional Relatório Final; Direcção Nacional de Terras e Florestas: Maputo, Mozambique, 2007.
- Relatório Do IV Inventário Florestal Nacional; MITADER: Maputo, Mozambique, 2018.
- Ribeiro, N.; Sitoe, A.A.; Guedes, B.S.; Staiss, C. Manual de Silvicultura Tropical; Publicado com apoio da FAO, Projecto GCP/Moz/056/Net; Universidade Eduardo Mondlane: Maputo, Mozambique, 2002. [Google Scholar]
- Desanker, P.V.; Frost, P.G.H.; Justice, C.O.; Scholes, R.J. The Miombo Network: Framework for a Terrestrial Transect Study of Land-Use and Land-Cover Change in the Miombo Ecosystems of Central Africa; IGBP REPORT 41; IGBP Secretariat: Stockholm, Sweden, 1997. [Google Scholar]
- Frost, P. The Ecology of Miombo Woodlands. In The Miombo in Transition: Woodlands and Welfare in Africa; CIFOR: Bogor, Indonesia, 1996; p. 266. ISBN 9798764072. [Google Scholar]
- Maunze, X.H.; Dade, A.; Zacarias, M.d.F.; Cubula, B.; Alfeu, M.; Mangue, J.; Mouzinho, R.; Cassimo, M.N.; Zunguze, C.; Zavale, O.; et al. IV Recenseamento Geral dA População e Habitação 2017: Resultados Definitivos—Moçambique. 2019. Available online: http://mozdata.microdatahub.com/index.php/catalog/98 (accessed on 17 May 2020).
- Sitoe, A.; Salomão, A.; Wertz-Kanounnikoff, S. The Context of REDD+ in Mozambique: Drivers, Agents, and Institutions; Center for International Forestry Research (CIFOR): Bogor, Indonesia, 2012; ISBN 9786028693783. [Google Scholar]
- de Sousa Rodrigues Pereira, M.d.C. Land Cover Change Detection in the Limpopo River Basin, Mozambique. Master’s Thesis, International Institute for Geo-Information Science and Earth Observation, Enschede, The Netherlands, 2004. [Google Scholar]
- Mahamane, M.; Zorrilla-Miras, P.; Verweij, P.; Ryan, C.; Patenaude, G.; Grundy, I.; Nhantumbo, I.; Metzger, M.J.; Ribeiro, N.; Baumert, S.; et al. Understanding Land Use, Land Cover and Woodland-Based Ecosystem Services Change, Mabalane, Mozambique. Energy Environ. Res. 2017, 7, 1–22. [Google Scholar] [CrossRef]
- Mucova, S.A.R.; Filho, W.L.; Azeiteiro, U.M.; Pereira, M.J. Assessment of Land Use and Land Cover Changes from 1979 to 2017 and Biodiversity & Land Management Approach in Quirimbas National Park, Northern Mozambique, Africa. Glob. Ecol. Conserv. 2018, 16, e00447. [Google Scholar] [CrossRef]
- Bey, A.; Jetimane, J.; Lisboa, S.N.; Ribeiro, N.; Sitoe, A.A.; Meyfroidt, P. Mapping Smallholder and Large-Scale Cropland Dynamics with a Flexible Classification System and Pixel-Based Composites in an Emerging Frontier Of. Remote Sens. Environ. 2020, 239, 111611. [Google Scholar] [CrossRef]
- Sitoe, A.; Remane, I.; Ribeiro, N.; Facão, M.P.; Mate, R.; Nhamirre, J.; Walker, S.; Murray, L.; Melo, J. Identificação e Análise Dos Agentes e Causas Directas e Indirectas de Desmatamento e Degradação Florestal Em Moçambique. 2016. Available online: https://www.fnds.gov.mz/index.php/pt/documentos/relatorios/identificacao-e-analise-dos-agentes-e-causas-directas-e-indirectas-de-desmatamento-e-degradacao-florestal-em-mocambique (accessed on 17 May 2020).
- INE. CENSO AGRO-PECUÁRIO 2009–2010: RESULTADOS DEFINITIVOS—MOÇAMBIQUE. 2011. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwjykYS_utyAAxVmhf0HHQAQBxEQFnoECBYQAQ&url=https%3A%2F%2Fwww.fao.org%2Ffileadmin%2Ftemplates%2Fess%2Fess_test_folder%2FWorld_Census_Agriculture%2FCountry_info_2010%2FReports%2FMozambique_2010CAP_VF.pdf&usg=AOvVaw1V1C-w7WGYPR3Wkqxol0aW&opi=89978449 (accessed on 17 May 2020).
- Coetzee, S.; Ivánová, I.; Mitasova, H.; Brovelli, M.A. Open Geospatial Software and Data: A Review of the Current State and A Perspective into the Future. ISPRS Int. J. Geo-Inf. 2020, 9, 90. [Google Scholar] [CrossRef]
- Barbosa, C.C.F.; Novo, E.M.L.M.; Martins, V.S. Introdução Ao Sensoriamento Remoto de Sistemas Aquáticos: Princípios e Aplicações, 1st ed.; INPE: São José dos Campos, Brazil, 2019; ISBN 9788517000959. [Google Scholar]
- Burton, C. Earth Observation and Big Data: Creatively Collecting, Processing and Applying Global Information. Earth Imaging J. 2016, 3, 1–9. [Google Scholar]
- Sidhu, N.; Pebesma, E.; Câmara, G. Using Google Earth Engine to Detect Land Cover Change: Singapore as a Use Case. Eur. J. Remote Sens. 2018, 51, 486–500. [Google Scholar] [CrossRef]
- Dou, P.; Han, Z. Quantifying Land Use/Land Cover Change and Urban Expansion in Dongguan, China, from 1987 to 2020. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 201–209. [Google Scholar] [CrossRef]
- Wang, M.; Mao, D.; Wang, Y.; Song, K.; Yan, H.; Jia, M.; Wang, Z. Annual Wetland Mapping in Metropolis by Temporal Sample Migration and Random Forest Classification with Time Series Landsat Data and Google Earth Engine. Remote Sens. 2022, 14, 3191. [Google Scholar] [CrossRef]
- Ngoy, K.I.; Qi, F.; Shebitz, D.J. Analyzing and Predicting Land Use and Land Cover Changes in New Jersey Using Multi-Layer Perceptron—Markov Chain Model. Earth 2021, 2, 845–870. [Google Scholar] [CrossRef]
- dos Muchangos, A. Moçambique—Paisagens e Regiões Naturais; Tipografia Globo, Lda: Maputo, Mozambique, 1999; ISBN 01048/FBM/93. [Google Scholar]
- Bolfe, É.L.; Batistella, M.; Ronquim, C.C.; Holler, W.A.; Martinho, P.R.R.; Macia, C.J.; Mafalacusser, J. Base de Dados Geográficos Do “Corredor de Nacala”, Moçambique. In Proceedings of the XV Simpósio Brasileiro de Sensoriamento Remoto—SBSR; INPE: Curitiba, Brazil, 2011; pp. 3995–4002. [Google Scholar]
- Macarringue, L.S.; Sano, E.E.; Chaves, J.M.; Bolfe, E.L. Considerações Sobre Precipitação, Relevo E Solos E Análise Do Potencial De Expansão Agrícola Da Região Norte De Moçambique. Soc. Nat. 2017, 29, 109–122. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Kumar, L.; Mutanga, O. Google Earth Engine Applications Since Inception: Usage, Trends and Potential. Remote Sens. 2018, 10, 1509. [Google Scholar] [CrossRef]
- Li, Q.; Qiu, C.; Ma, L.; Schmitt, M.; Zhu, X.X. Mapping the Land Cover of Africa at 10 m Resolution from Multi-Source Remote Sensing Data with Google Earth Engine. Remote Sens. 2020, 12, 602. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, F.; Wan, W.; Yu, H.; Sun, J.; Del Ser, J.; Elyan, E.; Hussain, A. Panchromatic and Multispectral Image Fusion for Remote Sensing and Earth Observation: Concepts, Taxonomy, Literature Review, Evaluation Methodologies and Challenges Ahead. Inf. Fusion 2023, 93, 227–242. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Rmotely Sensed Data-Principles and Practices, 3rd ed.; Taylor & Francis: Boca Raton, FL, USA, 2019; ISBN 9781498776660. [Google Scholar]
- Ronquim, C.C.; Ribeiro, F.; Bolfe, E.; Tosto, S. Uso de Geotecnologias Para Avaliação Da Agropecuária de Moçambique. In Proceedings of the Anais XVI Simposio Brasileiro de Sensoriamento Remoto—SBSR; INPE: Foz do Iguaçu, PR, Brasil, 2013; pp. 6917–6922. [Google Scholar]
- Macarringue, L.S.; Bolfe, É.L.; Fumo, Ó.A. Abordagens Metodológicas No Campo Da Dinâmica de Uso e Cobertura de Terra: Um Olhar Para a Realidade Moçambicana. Geografia 2020, 45, 65–89. [Google Scholar] [CrossRef]
- Stehman, S.V. Sampling Designs for Accuracy Assessment of Land Cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Shetty, S. Analysis of Machine Learning Classifiers for LULC Classification on Google Earth Engine. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2019. [Google Scholar]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A Review of Supervised Object-Based Land-Cover Image Classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Lei, G.; Li, A.; Bian, J.; Yan, H.; Zhang, L.; Zhang, Z.; Nan, X. OIC-MCE: A Practical Land Cover Mapping Approach for Limited Samples Based on Multiple Classifier Ensemble and Iterative Classification. Remote Sens. 2020, 12, 987. [Google Scholar] [CrossRef]
- Alencar, A.; Shimbo, J.Z.; Lenti, F.; Marques, C.B.; Zimbres, B.; Rosa, M.; Arruda, V.; Castro, I.; Ribeiro, J.P.F.M.; Varela, V.; et al. Mapping Three Decades of Changes in the Brazilian Savanna Native Vegetation Using Landsat Data Processed in the Google Earth Engine Platform. Remote Sens. 2020, 12, 924. [Google Scholar] [CrossRef]
- Xiong, J.; Thenkabail, P.S.; Tilton, J.C.; Gumma, M.K.; Teluguntla, P.; Oliphant, A.; Congalton, R.G.; Yadav, K.; Gorelick, N. Nominal 30-m Cropland Extent Map of Continental Africa by Integrating Pixel-Based and Object-Based Algorithms Using Sentinel-2 and Landsat-8 Data on Google Earth Engine. Remote Sens. 2017, 9, 1065. [Google Scholar] [CrossRef]
- Rana, V.K.; Suryanarayana, T.M.V. Performance Evaluation of MLE, RF and SVM Classification Algorithms for Watershed Scale Land Use/Land Cover Mapping Using Sentinel 2 Bands. Remote Sens. Appl. Soc. Environ. 2020, 19, 100351. [Google Scholar] [CrossRef]
- Gómez, C.; White, J.C.; Wulder, M.A. Optical Remotely Sensed Time Series Data for Land Cover Classification: A Review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. Multi-Scale Object-Based Image Analysis and Feature Selection of Multi-Sensor Earth Observation Imagery Using Random Forests. Int. J. Remote Sens. 2012, 13, 4502–4526. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining Data with Random Forests: A Survey and Results of New Tests. Pattern Recognit. 2011, 44, 330–349. [Google Scholar] [CrossRef]
- Ma, L.; Fu, T.; Blaschke, T.; Li, M.; Tiede, D.; Zhou, Z.; Ma, X.; Chen, D. Evaluation of Feature Selection Methods for Object-Based Land Cover Mapping of Unmanned Aerial Vehicle Imagery Using Random Forest and Support Vector Machine Classifiers. ISPRS Int. J. Geo-Inf. 2017, 6, 51. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubonurg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Bessinger, M.; Lück-Vogel, M.; Skowno, A.; Conrad, F. Landsat-8 Based Coastal Ecosystem Mapping in South Africa Using Random Forest Classification in Google Earth Engine. S. Afr. J. Bot. 2022, 150, 928–939. [Google Scholar] [CrossRef]
- Hao, P.; Zhan, Y.; Wang, L.; Niu, Z.; Shakir, M. Feature Selection of Time Series MODIS Data for Early Crop Classification Using Random Forest: A Case Study in Kansas, USA. Remote Sens. 2015, 7, 5347–5369. [Google Scholar] [CrossRef]
- Phan, T.N.; Kuch, V.; Lehnert, L.W. Land Cover Classification Using Google Earth Engine and Random Forest Classifier—The Role of Image Composition. Remote Sens. 2020, 12, 2411. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S.R. Automated Water Extraction Index: A New Technique for Surface Water Mapping Using Landsat Imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Fitzgerald, G.; Rodriguez, D.; O’Leary, G. Measuring and Predicting Canopy Nitrogen Nutrition in Wheat Using a Spectral Index—The Canopy Chlorophyll Content Index (CCCI). Field Crops Res. 2010, 116, 318–324. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and Photographic Infrared Linear Combinations for Monitoring Vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Liu, H.Q.; Huete, A. A Feedback Based Modification of the NDVI to Minimize Canopy Background and Atmospheric Noise. IEEE Geosci. Remote Sens. 1995, 33, 457–465. [Google Scholar] [CrossRef]
- Pinty, B.; Verstraete, M.M. GEMI: A Non-Linear Index to Monitor Global Vegetation from Satellites. Vegetatio 1992, 101, 15–20. [Google Scholar] [CrossRef]
- Ceccato, P.; Gobron, N.; Flasse, S.; Pinty, B.; Tarantola, S. Designing a Spectral Index to Estimate Vegetation Water Content from Remote Sensing Data: Part 1 Theoretical Approach. Remote Sens. Environ. 2002, 82, 188–197. [Google Scholar] [CrossRef]
- Polidorio, A.M.; Imai, N.N.; Tommaselli, A.M.G. Índice Indicador de Corpos d’água Para Imagens Multiespectrais. In Proceedings of the I Simpósio de Ciências Geodésicas e Tecnologias da Geoinformação, Recife, Brazil, 1–3 September 2004. [Google Scholar]
- Datt, B. A New Reflectance Index for Remote Sensing of Chlorophyll Content in Higher Plants: Tests Using Eucalyptus Leaves. J. Plant Physiol. 1999, 154, 30–36. [Google Scholar] [CrossRef]
- Chandrasekar, K.; Sai Sesha, M.V.R.; Roy, P.S.; Dwevedi, R.S. Land Surface Water Index ( LSWI ) Response to Rainfall and NDVI Using the MODIS Vegetation Index Product. Int. J. Remote Sens. 2010, 31, 3987–4005. [Google Scholar] [CrossRef]
- Xu, H. Modification of Normalised Difference Water Index (NDWI) to Enhance Open Water Features in Remotely Sensed Imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Raymond Hunt, E.; Rock, B.N.; Nobel, P.S. Measurement of Leaf Relative Water Content by Infrared Reflectance. Remote Sens. Environ. 1987, 22, 429–435. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with Erts. In Proceedings of the 3rd Earth Resources Technology Satellite-1 Symposium, Washington, DC, USA, 10–14 December 1973; pp. 48–62. [Google Scholar]
- Gao, B. NDWI—A Normalized Difference Water Index for Remote Sensing of Vegetation Liquid Water from Space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Roujean, J.; Breon, F.-M. Estimating PAR Absorbed by Vegetation from Bidirectional Reflectance Measurements. Remote Sens. Environ. 1995, 51, 375–384. [Google Scholar] [CrossRef]
- Huete, A.R. A Soil-Adjusted Vegetation Index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Qi, J.; Chehbouni, A.; Huete, A.R.; Kerr, Y.H.; Sorooshian, S. A Modified Soil Adjusted Vegetation Index. Remote Sens. Environ. 1994, 48, 119–126. [Google Scholar] [CrossRef]
- Sripada, R.P. Determining In-Season Nitrogen Requirements for Corn Using Aerial Color-Infrared Photography; North Carolina State University: Raleigh, NC, USA, 2005. [Google Scholar]
- Rondeaux, G.; Steven, M.; Baret, F. Optimization of Soil-Adjusted Vegetation Indices. Remote Sens. Environ. 1996, 55, 95–107. [Google Scholar] [CrossRef]
- Kauth, R.J.; Thomas, G.S. The Tasselled Cap—A Graphic Description of the Spectral-Temporal Development of Agricultural Crops as Seen by LANDSAT; LARS Symposia Paper 159. 1976. Available online: https://docs.lib.purdue.edu/cgi/viewcontent.cgi?article=1160&context=lars_symp (accessed on 20 September 2021).
- Liu, Q.; Liu, G.; Huang, C.; Liu, S.; Zhao, J. A Tasseled Cap Transformation for Landsat 8 OLI TOA Reflectance Images. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 541–544. [Google Scholar]
- Hurskainen, P.; Adhikari, H.; Siljander, M.; Pellikka, P.K.E.; Hemp, A. Auxiliary Datasets Improve Accuracy of Object-Based Land Use/Land Cover Classification in Heterogeneous Savanna Landscapes. Remote Sens. Environ. 2019, 233, 111354. [Google Scholar] [CrossRef]
- Mateen, S.; Nuthammachot, N.; Techato, K.; Ullah, N. Billion Tree Tsunami Forests Classification Using Image Fusion Technique and Random Forest Classifier Applied to Sentinel-2 and Landsat-8 Images: A Case Study of Garhi Chandan Pakistan. ISPRS Int. J. Geo-Inf. 2023, 12, 9. [Google Scholar] [CrossRef]
- Richard, K.; Abdel-rahman, E.M.; Subramanian, S.; Nyasani, J.O.; Thiel, M.; Jozani, H.; Borgemeister, C.; Landmann, T. Maize Cropping Systems Mapping Using RapidEye Observations in Agro-Ecological Landscapes in Kenya. Sensors 2017, 17, 2537. [Google Scholar] [CrossRef]
- Stromann, O.; Nascetti, A.; Yousif, O.; Ban, Y. Dimensionality Reduction and Feature Selection for Object-Based Land Cover Classification Based on Sentinel-1 and Sentinel-2 Time Series Using Google Earth Engine. Remote Sens. 2020, 12, 76. [Google Scholar] [CrossRef]
- Gautam, V.K.; Gaurav, P.K.; Murugan, P.; Annadurai, M. Assessment of Surface Water Dynamicsin Bangalore Using WRI, NDWI, MNDWI, Supervised Classification and K-T Transformation. Aquat. Procedia 2015, 4, 739–746. [Google Scholar] [CrossRef]
- Zhou, Y.; Dong, J.; Xiao, X.; Xiao, T.; Yang, Z.; Zhao, G.; Zou, Z.; Qin, Y. Open Surface Water Mapping Algorithms: A Comparison of Water-Related Spectral Indices and Sensors. Water 2017, 9, 256. [Google Scholar] [CrossRef]
- Pullanikkatil, D.; Palamuleni, L.; Ruhiiga, T. Assessment of Land Use Change in Likangala River Catchment, Malawi: A Remote Sensing and DPSIR Approach. Appl. Geogr. 2016, 71, 9–23. [Google Scholar] [CrossRef]
- Hu, Y.; Hu, Y. Land Cover Changes and Their Driving Mechanisms in Central Asia from 2001 to 2017 Supported by Google Earth Engine. Remote Sens. 2019, 11, 554. [Google Scholar] [CrossRef]
- Naboureh, A.; Ebrahimy, H.; Azadbakht, M.; Bian, J.; Amani, M. RUESVMs: An Ensemble Method to Handle the Class Imbalance Problem in Land Cover Mapping Using Google Earth Engine. Remote Sens. 2020, 12, 3484. [Google Scholar] [CrossRef]
- De Oliveira, W.N.; Miziara, F.; Ferreira, N.C. Mapeamento Do Uso e Cobertura Do Solo de Moçambique Utilizando a Plataforma Google Earth Engine. Anuário do Inst. Geociências—UFRJ 2019, 42, 336–345. [Google Scholar]
- Mutanga, E. Management of Miombo Forest Resources by Communities, Is It a Reality? A Discussion of Corner Stones for Effective Community Forestry Management to Support Resource Commercialization: December 2009. 2009. Available online: https://www.researchgate.net/profile/Enock-Mutanga-2/publication/239602418_Management_of_miombo_forest_resources_by_communities_is_it_a_reality_A_discussion_of_corner_stones_for_effective_community_forestry_management_to_support_resource_commercialization_December_2009/links/0deec532bbfc98d1a0000000/Management-of-miombo-forest-resources-by-communities-is-it-a-reality-A-discussion-of-corner-stones-for-effective-community-forestry-management-to-support-resource-commercialization-December-2009.pdf (accessed on 14 March 2019).
- CIFOR. Tropical Dry Forests: Under Threat & Under Researched. 2014. Available online: http://copa.acguanacaste.ac.cr:8080/bitstream/handle/11606/590/Tropical%20Dry%20Forest%20Under%20Threat%20&%20Under-Researched.pdf?sequence=1 (accessed on 14 March 2019).
- Magalhães, T.M. Carbon Stocks in Necromass and Soil Pools of a Mozambican Tropical Dry Forest under Different Disturbance Regimes. Biomass Bioenergy 2017, 105, 373–380. [Google Scholar] [CrossRef]
- Zhang, F.; Yang, X. Improving Land Cover Classification in an Urbanized Coastal Area by Random Forests: The Role of Variable Selection. Remote Sens. Environ. 2020, 251, 112105. [Google Scholar] [CrossRef]
- Roy, D.P.; Kovalskyy, V.; Zhang, H.K.; Vermote, E.F.; Yan, L.; Kumar, S.S.; Egorov, A. Characterization of Landsat-7 to Landsat-8 Reflective Wavelength and Normalized Difference Vegetation Index Continuity. Remote Sens. Environ. 2016, 185, 57–70. [Google Scholar] [CrossRef]
- Bey, A.; Meyfroidt, P. Improved Land Monitoring to Assess Large-Scale Tree Plantation Expansion and Trajectories in Northern Mozambique. Environ. Res. Commun. 2021, 3, 115009. [Google Scholar] [CrossRef]
- Jew, E.K.K.; Dougill, A.J.; Sallu, S.M.; O’Connell, J.; Benton, T.G. Miombo Woodland under Threat: Consequences for Tree Diversity and Carbon Storage. For. Ecol. Manag. 2016, 361, 144–153. [Google Scholar] [CrossRef]
- Fleischman, F.; Basant, S.; Chhatre, A.; Coleman, E.A.; Fischer, H.W.; Gupta, D.; Güneralp, B.; Kashwan, P.; Khatri, D.; Muscarella, R.; et al. Pitfalls of Tree Planting Show Why We Need People-Centered Natural Climate Solutions. Bioscience 2020, 70, 947–950. [Google Scholar] [CrossRef]
- Guedes, B.; Sitoe, A.; Rafael, N.; Momade, Z. Mudanças de Cobertura Florestal e Suas Consequências Sobre a Economia Familiar Das Comunidades Rurais No Povoado de Matenga, Distrito de Nhamatanda. In O Papel dos Recursos Naturais Renováveis no Desenvolvimento Sustentável em Moçambique; Observatório do Meio Rural: Maputo, Mozambique, 2013; pp. 42–56. [Google Scholar]
- Rosa, M.R.; Brancalion, P.H.S.; Crouzeilles, R.; Tambosi, L.R.; Piffer, P.R.; Lenti, F.E.B.; Hirota, M.; Santiami, E.; Metzger, J.P. Hidden Destruction of Older Forests Threatens Brazil’s Atlantic Forest and Challenges Restoration Programs. Sci. Adv. 2021, 7, eabc4547. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resolution | Landsat 7 ETM+ | Landsat 8 OLI | |||||
|---|---|---|---|---|---|---|---|
| Spectral resolution | Band | Spectra | Wavelength (μm) | Spectral resolution | Band | Spectra | Wavelength (μm) |
| 1 | Blue | 0.45−0.52 | 2 | Blue | 0.45−0.51 | ||
| 2 | Green | 0.52−0.60 | 3 | Green | 0.53−0.59 | ||
| 3 | Red | 0.63−0.69 | 4 | Red | 0.64−0.67 | ||
| 4 | NIR | 0.77−0.90 | 5 | NIR | 0.85−0.88 | ||
| 5 | SWIR 1 | 1.55−1.75 | 6 | SWIR 1 | 1.57−1.65 | ||
| 7 | SWIR 2 | 2.09−2.35 | 7 | SWIR 2 | 2.11−2.29 | ||
| 8 | PAN | 0.52−0.90 | 8 | PAN | 0.50−0.68 | ||
| Temporal resolution | 16 days | 16 days | |||||
| Radiometric resolution | 8 bits | 12 bits (scaled to 16 bits) | |||||
| Spatial resolution | 30 m | 30 m | |||||
| Number of Samples (Points) * | Sample Separability | Spectral Class | Field Photo |
|---|---|---|---|
| 129,240 |  | Dense Miombo forests, mangroves, gallery forests, and planted forests. Minimum area of 1 ha, with native and exotic semi-perennial trees with at least 3 m height and canopy cover ≥ 30% (mangroves). Transition lands between marine and terrestrial environments. Altitude varying from sea level to 1000 m. |  |
| 201,021 | 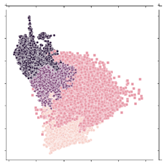 | Open evergreen and deciduous forests. Including grasslands (native pastures and grasses, weeds in flooded areas). Minimum area of 1 ha, temporarily or permanently flooded. |  |
| 61,859 | 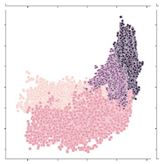 | Non-vegetated areas (dunes, beaches, and fallow lands). |  |
| 11,477 | 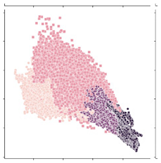 | Croplands. Average size of 2 ha, family farming, and subsistence/irrigation practices. Include both temporary and permanent crops. |  |
| 34,711 |  | Built-up areas (cities, towns, and villages). Low, medium, or high population density, poorly structured. Mostly located along the main access roads. |  |
| Name | Acronym | Formula | Citation |
|---|---|---|---|
| Automated water extraction index | AWEI | [48] | |
| Canopy chlorophyll content index | CCCI | [49] | |
| Difference vegetation index | DVI | [50] | |
| Enhanced vegetation index | EVI | [51] | |
| Global environmental monitoring index | GEMI | (n × (1 − 0.25 × n) − [(Red − 0.125)/(1 − Red)]; | [52] |
| Global vegetation moisture index | GVMI | [53] | |
| Indicative index of water bodies | IIA | [54] | |
| Isoil | - | - | |
| Leaf chlorophyll index | LCI | [55] | |
| Land surface water index | LSWI | [56] | |
| Modified normalized difference water index | mNDWI | [57] | |
| Moisture stress index | MSI | [58] | |
| Normalized difference vegetation index | NDVI | ( | [59] |
| Normalized difference water index | NDWI | [60] | |
| Renormalized difference vegetation index | RDVI | [61] | |
| Soil-adjusted vegetation index | SAVI | ; L = 0.5 | [62] |
| Modified soil-adjusted vegetation index | mSAVI | [63] | |
| Green soil-adjusted vegetation index | GSAVI | [(NIR − Green)]/[(NIR + Green + L)] (1 + L); L = 0.5 | [64] |
| Optimized soil-adjusted vegetation index | OSAVI | ( | [65] |
| Tasselled cap—vegetation | GVI | [66,67] | |
| Tasselled cap—wetness | WET | [66,67] | |
| Tasselled cap—brightness | SBI | [66,67] |
| 2016 (A) (Accuracy = 0.925) | 2020 (A) (Accuracy = 0.956) | ||||||||||||
| NVA | 0.93 | 0.04 | 0 | 0.04 | 0 | NVA | 0.95 | 0.03 | 0 | 0.02 | 0 | ||
| BA | 0.09 | 0.87 | 0 | 0.04 | 0 | BA | 0.07 | 0.9 | 0 | 0.03 | 0 | ||
| CL | 0 | 0 | 0.62 | 0.08 | 0.3 | CL | 0 | 0 | 0.63 | 0.09 | 0.28 | ||
| OEDF | 0.01 | 0 | 0 | 0.95 | 0.04 | OEDF | 0 | 0 | 0 | 0.97 | 0.02 | ||
| DV | 0 | 0 | 0.01 | 0.06 | 0.93 | DV | 0 | 0 | 0.01 | 0.04 | 0.95 | ||
| NVA | BA | CL | OEDF | DV | NVA | BA | CL | OEDF | DV | ||||
| 2016 (B) (Accuracy = 0.815) | 2020 (B) (Accuracy = 0.810) | ||||||||||||
| NVA | 0.94 | 0.03 | 0.01 | 0 | 0.02 | NVA | 0.94 | 0.03 | 0.01 | 0 | 0.02 | ||
| BA | 0.07 | 0.85 | 0.02 | 0 | 0.05 | BA | 0.07 | 0.8 | 0.02 | 0 | 0.05 | ||
| OEDF | 0 | 0 | 0.69 | 0.06 | 0.25 | OEDF | 0 | 0 | 0.69 | 0.06 | 0.25 | ||
| DV | 0 | 0 | 0.08 | 0.92 | 0.01 | DV | 0 | 0 | 0.08 | 0.93 | 0.01 | ||
| GL | 0 | 0 | 0.19 | 0.01 | 0.8 | GL | 0 | 0 | 0.17 | 0.01 | 0.95 | ||
| NVA | BA | OEDF | DV | GL | NVA | BA | OEDF | DV | GL | ||||
| 2016 (C) (Accuracy = 0.807) | 2020 (C) (Accuracy = 0.804) | ||||||||||||
| NVA | 0.86 | 0.03 | 0 | 0.01 | 0 | 0.1 | NVA | 0.94 | 0.03 | 0 | 0.01 | 0 | 0.02 |
| BA | 0.06 | 0.83 | 0 | 0.01 | 0 | 0.1 | BA | 0.07 | 0.86 | 0 | 0.02 | 0 | 0.06 |
| CL | 0 | 0 | 0.62 | 0.07 | 0.03 | 0 | CL | 0 | 0 | 0.59 | 0.18 | 0.19 | 0.04 |
| OEDF | 0 | 0 | 0 | 0.79 | 0.04 | 0.16 | OEDF | 0 | 0 | 0 | 0.69 | 0.06 | 0.25 |
| DV | 0 | 0 | 0.01 | 0.06 | 0.93 | 0 | DV | 0 | 0 | 0.01 | 0.08 | 0.91 | 0.01 |
| GL | 0.02 | 0.01 | 0 | 0.27 | 0.01 | 0.7 | GL | 0 | 0 | 0 | 0.18 | 0.01 | 0.8 |
| NVA | BA | CL | OEDF | DV | GL | NVA | BA | CL | OEDF | DV | GL | ||
| Metric/Class | NVA | BA | CL | OEDF | DV | Kappa | OA |
|---|---|---|---|---|---|---|---|
| 2011 | |||||||
| UA | 80.0 | 82.0 | 50.0 | 92.0 | 75.0 | ||
| PA | 92.0 | 47.0 | 43.0 | 87.0 | 85.0 | 0.74 | 84.69 |
| F1-score | 85.0 | 59.0 | 46.0 | 89.0 | 80.0 | ||
| 2014 | |||||||
| UA | 75.0 | 78.0 | 60.0 | 91.0 | 63.0 | ||
| PA | 82.0 | 42.0 | 47.0 | 83.0 | 87.0 | 0.65 | 80.48 |
| F1-score | 78.0 | 54.0 | 52.0 | 87.0 | 73.0 | ||
| 2016 | |||||||
| UA | 85.0 | 84.0 | 38.0 | 90.0 | 80.0 | ||
| PA | 86.0 | 54.0 | 37.0 | 89.0 | 85.0 | 0.75 | 85.43 |
| F1-score | 85.0 | 66.0 | 38.0 | 89.0 | 82.0 | ||
| 2018 | |||||||
| UA | 96.0 | 75.0 | 61.0 | 95.0 | 79.0 | ||
| PA | 84.0 | 67.0 | 40.0 | 89.0 | 96.0 | 0.80 | 88.71 |
| F1-score | 90.0 | 70.0 | 48.0 | 92.0 | 87.0 | ||
| 2020 | |||||||
| UA | 80.0 | 86.0 | 50.0 | 89.0 | 89.0 | ||
| PA | 89.0 | 32.0 | 33.0 | 94.0 | 87.0 | 0.76 | 86.86 |
| F1-score | 84.0 | 47.0 | 40.0 | 92.0 | 88.0 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Macarringue, L.S.; Bolfe, É.L.; Duverger, S.G.; Sano, E.E.; Caldas, M.M.; Ferreira, M.C.; Zullo Junior, J.; Matias, L.F. Land Use and Land Cover Classification in the Northern Region of Mozambique Based on Landsat Time Series and Machine Learning. ISPRS Int. J. Geo-Inf. 2023, 12, 342. https://doi.org/10.3390/ijgi12080342
Macarringue LS, Bolfe ÉL, Duverger SG, Sano EE, Caldas MM, Ferreira MC, Zullo Junior J, Matias LF. Land Use and Land Cover Classification in the Northern Region of Mozambique Based on Landsat Time Series and Machine Learning. ISPRS International Journal of Geo-Information. 2023; 12(8):342. https://doi.org/10.3390/ijgi12080342
Chicago/Turabian StyleMacarringue, Lucrêncio Silvestre, Édson Luis Bolfe, Soltan Galano Duverger, Edson Eyji Sano, Marcellus Marques Caldas, Marcos César Ferreira, Jurandir Zullo Junior, and Lindon Fonseca Matias. 2023. "Land Use and Land Cover Classification in the Northern Region of Mozambique Based on Landsat Time Series and Machine Learning" ISPRS International Journal of Geo-Information 12, no. 8: 342. https://doi.org/10.3390/ijgi12080342
APA StyleMacarringue, L. S., Bolfe, É. L., Duverger, S. G., Sano, E. E., Caldas, M. M., Ferreira, M. C., Zullo Junior, J., & Matias, L. F. (2023). Land Use and Land Cover Classification in the Northern Region of Mozambique Based on Landsat Time Series and Machine Learning. ISPRS International Journal of Geo-Information, 12(8), 342. https://doi.org/10.3390/ijgi12080342