Abstract
The collaborative use of camera near-field sensors for monitoring the number and status of tourists is a crucial aspect of smart scenic spot management. This paper proposes a near-field perception technical system that achieves dynamic and accurate detection of tourist targets in mountainous scenic areas, addressing the challenges of real-time passive perception and safety management of tourists. The technical framework involves the following steps: Firstly, real-time video stream signals are collected from multiple cameras to create a distributed perception network. Then, the YOLOX network model is enhanced with the CBAM module and ASFF method to improve the dynamic recognition of preliminary tourist targets in complex scenes. Additionally, the BYTE target dynamic tracking algorithm is employed to address the issue of target occlusion in mountainous scenic areas, thereby enhancing the accuracy of model detection. Finally, the video target monocular spatial positioning algorithm is utilized to determine the actual geographic location of tourists based on the image coordinates. The algorithm was deployed in the Tianmeng Scenic Area of Yimeng Mountain in Shandong Province, and the results demonstrate that this technical system effectively assists in accurately perceiving and spatially positioning tourists in mountainous scenic spots. The system demonstrates an overall accuracy in tourist perception of over 90%, with spatial positioning errors less than 1.0 m and a root mean square error (RMSE) of less than 1.14. This provides auxiliary technical support and effective data support for passive real-time dynamic precise perception and safety management of regional tourist targets in mountainous scenic areas with no/weak satellite navigation signals.
1. Introduction
The accurate perception and management of dynamic spatiotemporal information of tourists in mountainous scenic areas have long been critical concerns for the tourism industry and scenic area management worldwide [1,2]. The complex terrain of mountainous areas, coupled with challenges such as lack of visitor cooperation, privacy concerns, and the need to enhance the tourism experience, make quasi-real-time acquisition of spatiotemporal data difficult, complicating security management. Effective visitor perception management strategies, therefore, have a wide range of applications [3,4,5]. Utilizing video cameras in mountainous areas for passive real-time monitoring of visitor numbers is of significant theoretical and practical value, as it can enable the development of a real-time dynamic management system for tracking the spatial and temporal locations of tourists. However, the primary technical challenge lies in achieving passive and accurate tracking and positioning of tourists in complex scenes through the fusion of multi-target tracking technology and precise spatial positioning [6,7]. Scholars, both domestically and internationally, have extensively explored this issue, with object detection methods based on deep learning being widely used [8,9,10]. These technologies, however, are mainly applied in closed environments like parks and schools, and face limitations in complex, open mountain scenic areas. Key challenges in such areas include recognizing small, distant targets and dealing with the occlusion of dynamically moving objects.
In recent years, advancements in deep learning technology have significantly improved multi-object tracking (MOT) detection algorithms [11,12]. MOT involves detecting and continuously tracking objects, enhancing both detection accuracy in video frames and the reliability and stability of dynamic object detection. These advancements have paved the way for near-field perception and the application of dynamic target detection in mountainous areas using distributed cameras. Detection algorithms are categorized into single-stage and two-stage processes based on how target bounding boxes are generated and refined. Single-stage algorithms, like You Only Look Once (YOLO), directly compute category probability and position coordinates without generating a pre-selection box, making them a standard in the industry [13]. In contrast, two-stage algorithms, such as R-CNN [14,15] and Fast R-CNN [16,17], first identify the position of the detected object, and then, classify the pre-selected box for more precise positioning. Single-stage algorithms typically outperform two-stage algorithms in terms of detection speed, especially with innovations like anchor-free box detection and dynamic label allocation, as seen in the YOLOX algorithm. YOLOX offers higher detection accuracy, faster processing speeds, and more flexible end-to-end deployment [18]. However, two-stage algorithms often prioritize detection accuracy over speed.
The YOLOX object detection network comprises three main modules: the backbone network, the neck network, and the detection head network. YOLOX algorithms are divided into two categories based on the backbone network: YOLOX-Darknet53, which builds on YOLOv3; and variants like YOLOX-s, YOLOX-m, YOLOX-l, and YOLOX-x, which use custom backbone networks. YOLOX-Darknet53 employs the Darknet53 feature extractor with 53 convolutional layers, segmenting input images into grid units and predicting bounding boxes for each grid cell, including width, height, coordinates, and object score. Darknet53 can predict multiple categories using multi-label classification, and YOLOX-Darknet53 enhances performance by using an independent logical classifier instead of softmax [19]. This version is suited for tasks requiring more parameters and computational power. Meanwhile, YOLOX-s, YOLOX-m, YOLOX-l, and YOLOX-x utilize CSPDarknet53 from YOLOv4 as the backbone, which improves feature transmission efficiency and makes the network faster and lighter, ideal for embedded devices and real-time performance tasks [20].
In complex mountainous areas, background occlusion significantly impacts the accuracy of tourist detection. Target dynamic tracking technology has proven effective in improving detection accuracy and mitigating the effects of occlusion. Mature tracking algorithms, including SORT [21,22], DeepSORT [23,24], MOTDT [25,26], QDTrack [27,28], attention mechanism algorithms [29,30], and BYTE [31], address these challenges. SORT combines position detection with motion similarity using a Kalman filter to predict target trajectory and calculates the intersection over union (IoU) for matching [21]. DeepSORT enhances long-range matching with appearance-based re-identification using an independent ReID model [23]. MOTDT employs appearance similarity for matching and uses IoU for unmatched trajectories [25], while QDTrack applies bidirectional softmax for probability matching and nearest neighbor search [27]. Attention mechanism algorithms allow for direct box propagation between frames [29]. The BYTE algorithm, introduced by Yifu Zhang et al., simplifies data association and is highly flexible, offering a significant improvement in tracking accuracy [31].
In mountainous scenic areas, the limitations in camera installation positions necessitate multi-scale object detection, as dense foliage, shrubbery, and crowded core attractions often lead to frequent object occlusion. Detecting relatively small objects during feature extraction can generate a substantial amount of redundant features. To address this issue, we incorporate an attention mechanism into the network architecture to enhance the weight of non-redundant features, thereby suppressing the expression of redundant features. Additionally, we introduce an adaptive feature fusion strategy in the feature fusion stage, enabling dynamic and effective adjustment of weights for feature maps at different scales. This approach improves the network’s adaptability and detection performance across varying target scales, thereby enhancing multi-scale object detection. We employ the BYTE tracking algorithm to assist in detection, leveraging short-term temporal information to improve the identification of occluded objects and to address frequent occlusion issues within short timeframes. Furthermore, by integrating detection and positioning algorithms, we convert the two-dimensional pixel coordinates of detected objects into real-world geographic coordinates, providing an effective auxiliary positioning solution for areas within mountainous scenic spots where satellite positioning signals are weak.
To meet the real-time requirements for passive tourist detection in mountainous scenic areas and overcome the challenges of object detection in complex environments, we ultimately propose a method that integrates distributed cameras with positioning technology. By real-time processing of RTSP video streams from distributed cameras using a trained YOLOX model for tourist detection and tracking, and applying a passive geospatial positioning method based on monocular cameras aligned with the BeiDou time–space benchmark, we achieve detection, tracking, and positioning of tourists in these challenging environments. Our objectives include (1) high-precision detection of small, distant tourists in outdoor video frames; (2) dynamic tracking of tourist movements under complex and occluded conditions; and (3) facilitating near-field perception by combining monocular camera geographic positioning with multi-channel video data in mountainous scenic areas.
2. Experimental Data
2.1. The Experimental Area
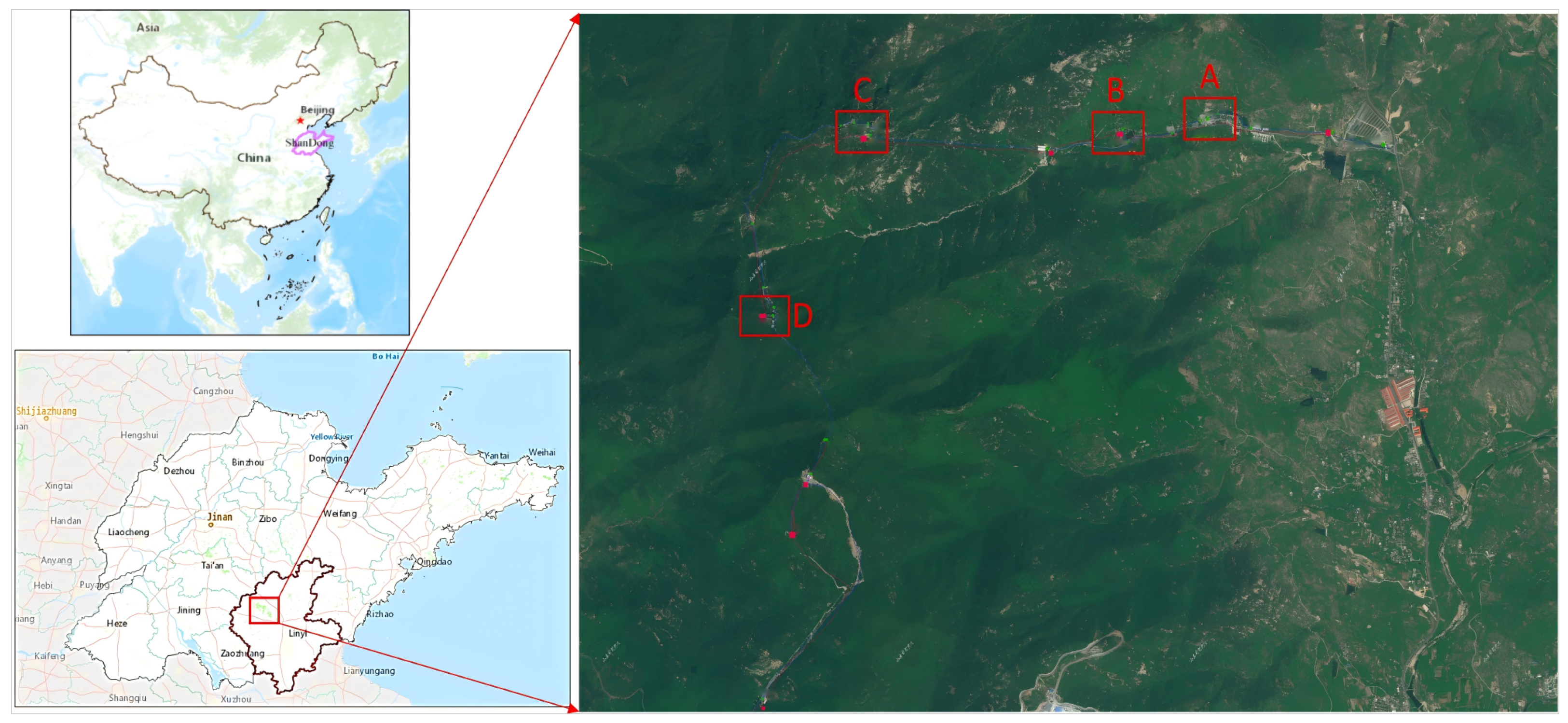
The Tianmeng Mountain Scenic Area in Feixian County, Linyi City, Shandong Province, was selected as the experimental site for this study. Spanning approximately 240 km2, with a core area of about 96 km2 (Figure 1), the scenic area features mountains, forests, waterfalls, and cultural landscapes. Known for its steep terrain and high forest coverage, the area presents several challenges due to its vast size, complex environment, dispersed attractions, dense tree cover, strong sunlight, and frequent obstructions to satellite navigation signals. These challenges include obstructions from trees and shrubs, tourist crowding, long-distance video monitoring, and significant terrain variations. Effective management of the area necessitates dynamic, passive, and accurate perception of tourist information.
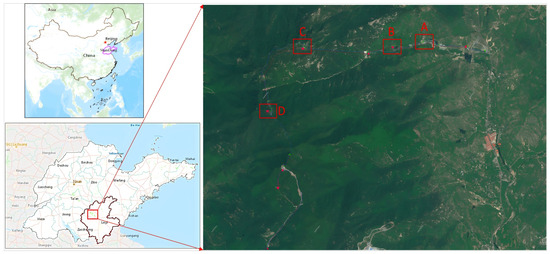
Figure 1.
The study area. (A. Tourist Center B. Xiaodiao Area C. Cable Car Area D. Yu Huang Palace).
Additionally, the area is being developed as a dual-standard 5A national tourist area and national tourism resort, featuring a well-developed network infrastructure with surveillance systems covering main roads and key attractions. This makes it an ideal location for rigorous testing of multi-object tracking and spatial positioning algorithms, including multi-target dynamic tracking and positioning. Four areas within the mountainous region were selected for testing, each posing higher challenges for video-based dynamic perception: Tourist center (A), Xiaodiao area (B), cable car area (C), and Yu Huang Palace (D).
2.2. Data Sources
- Public dataset: The public datasets utilized for training the tourist detection model are primarily sourced from CrowdHuman [32], MOT17 [33], and CityPersons [34]. The CrowdHuman dataset, released by Megvii Technology in China, is designed for pedestrian detection. It contains 24,370 images, mainly sourced from Google searches, with a total of 470,000 human instances. On average, each image includes approximately 22.6 individuals, featuring various levels of occlusion. Each human instance is meticulously annotated with head bounding boxes, visible body region bounding boxes, and full-body bounding boxes. The MOT17 dataset is a comprehensive collection for multiple object tracking, building upon its predecessor, MOT16. Introduced by Milan et al., it serves as a benchmark in multi-object tracking, driving advancements in more sophisticated and precise tracking systems. The dataset includes a variety of scenes, both indoor and outdoor, presented in video format, with each pedestrian thoroughly annotated. The CityPersons dataset, introduced by Shanshan Zhang, Rodrigo Benenson, and Bernt Schiele at the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), comprises 5050 images, with an average of about seven pedestrians per image. Annotations in this dataset include the visible region and full body for each pedestrian.
- Supplementary dataset: The regional supplementary training dataset consists of over 1000 manually collected pedestrian images from the Tianmeng scenic area. All images in this dataset are pre-annotated for the overall pedestrian area and are used to train pedestrian detection models. The images have a resolution of 1920 × 1080 pixels and include over 3500 target samples. To enhance the model’s detection capability, the training process begins with pre-training on publicly available datasets, followed by fine-tuning using the supplementary dataset. This approach is designed to balance the model’s generalization ability with its accuracy in specific scenarios.
3. Related Work
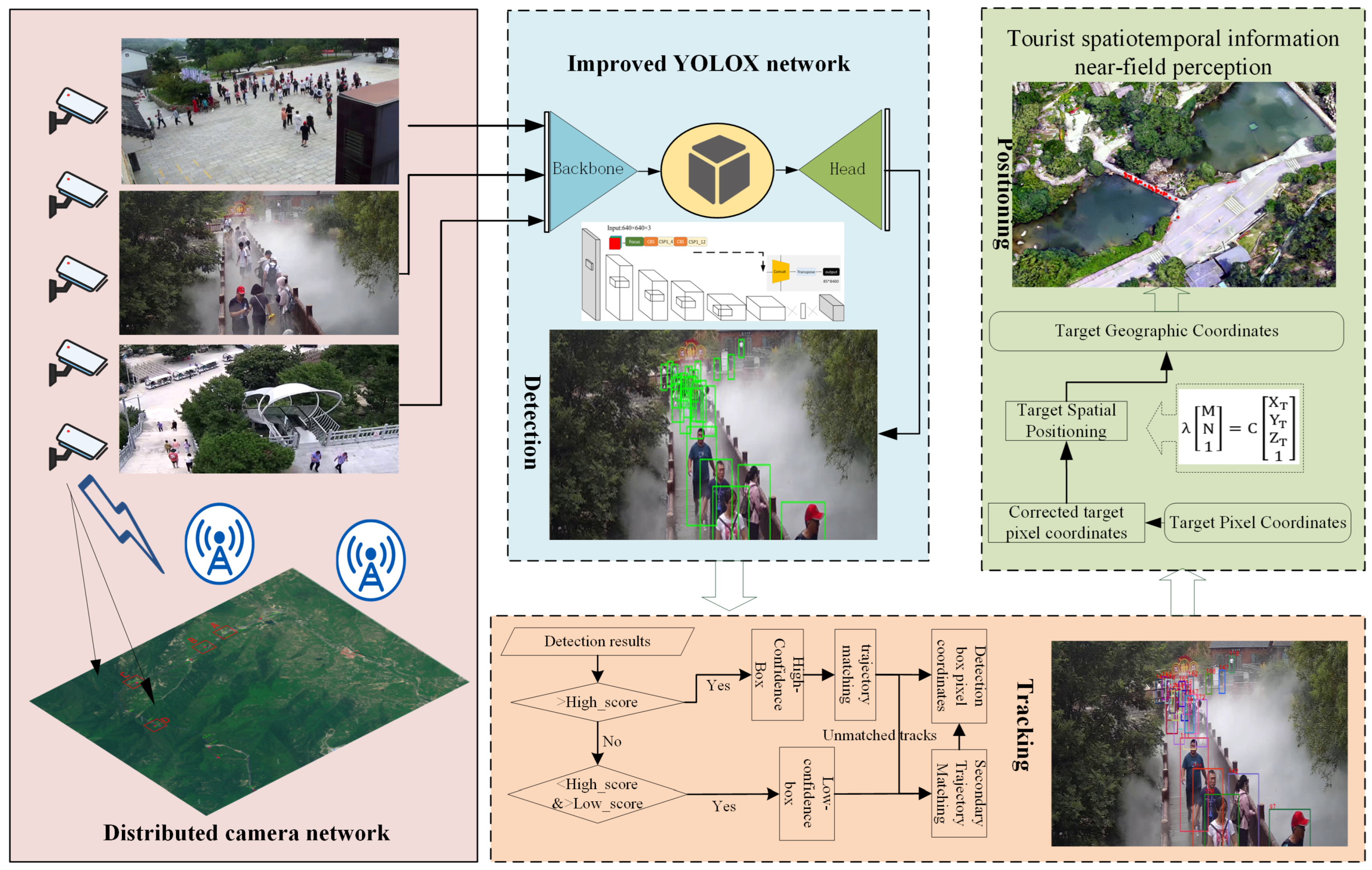
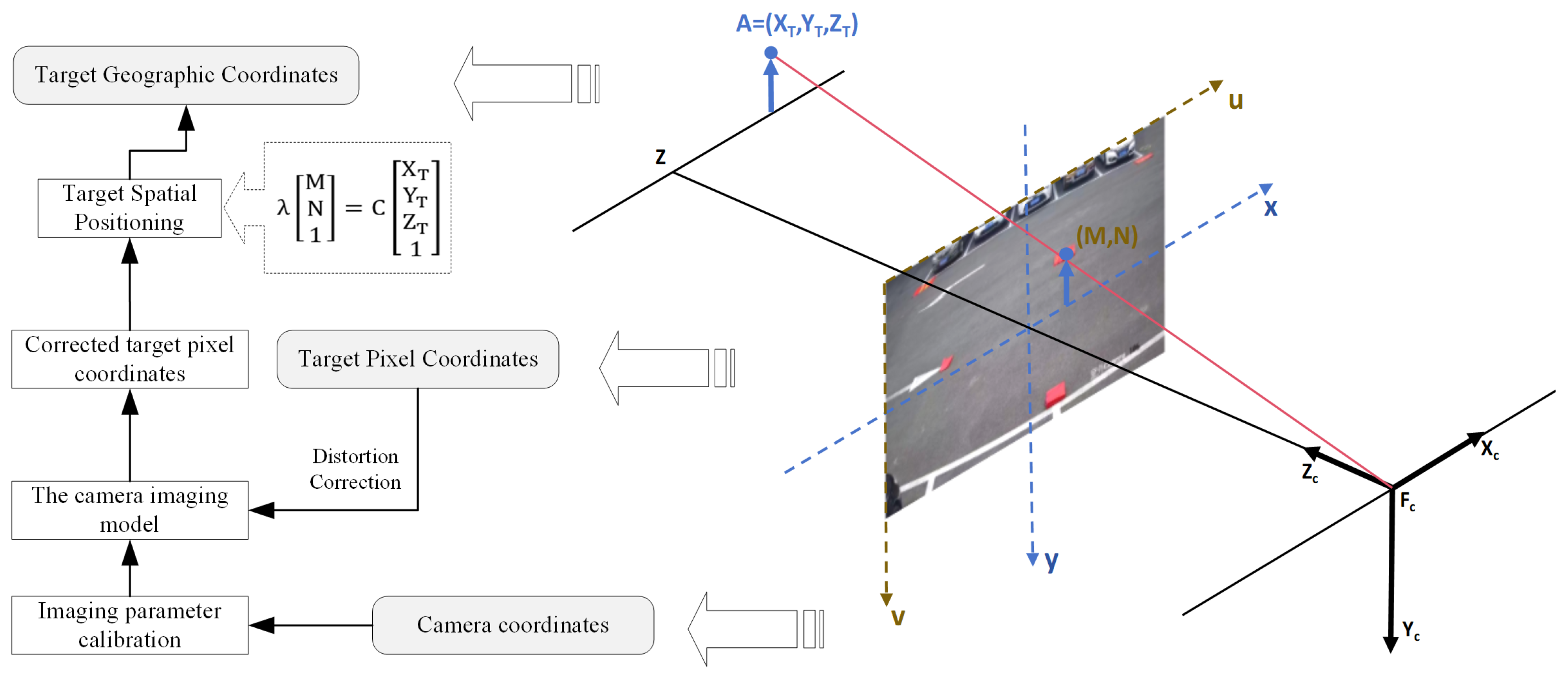
The process of near-field quasi-real-time passive perception of spatiotemporal information of tourists in mountainous scenic areas is illustrated in Figure 2. This process involves three main components: target detection, visual dynamic tracking, and spatial positioning. Initially, cameras are calibrated to form a distributed camera network, integrating multiple cameras into a unified framework. The RTSP video streams from these cameras are then fed into the YOLOX detector for target detection. Tracking is performed using the BYTE data association method, which improves resistance to interference from the complex mountainous background. Finally, the pixel coordinates provided by the detector are combined with the camera imaging model. By performing prior spatial calibration of the cameras, a method for pixel coordinate geographic spatial positioning is established, enabling the conversion of pixel coordinates into real geographical coordinates.
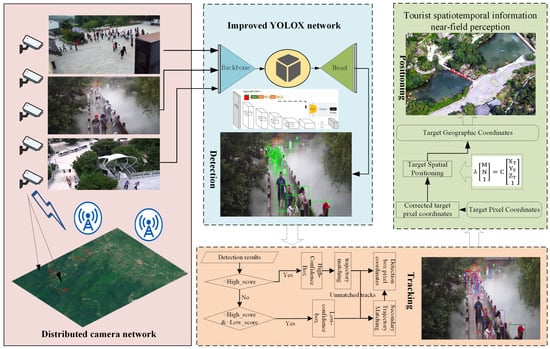
Figure 2.
Technical process of near-field quasi-real-time perception of spatiotemporal information of tourists in mountainous scenic areas based on distributed cameras. (Detection, Tracking, Spatial Positioning).
3.1. Tourist Target Accurate Detection
To address the challenge of detecting distant small targets in mountainous scenic areas, this paper integrates the Convolutional Block Attention Module (CBAM) and the Adaptive Feature Fusion Module (ASFF) into the network. CBAM is specifically designed for convolutional neural networks and consists of two main components: the Spatial Attention Module (SAM) and the Channel Attention Module (CAM) [35]. These modules enhance the importance of non-redundant features and suppress redundant ones. The Spatial Pyramid Pooling (SPP) module performs pooling operations at multiple scales on the convolutional feature map and concatenates the pooled results. This integration allows each position on the feature map to represent contextual information from multiple scales. By adding the CBAM module after the SPP, the network can prioritize processing the most significant parts of the features. The SAM module identifies important locations, while the CAM module emphasizes significant channels.
The ASFF approach, originally proposed by the authors of YOLO, is designed to dynamically fuse features across different scales. It enables the model to adaptively select the most relevant scale at each spatial location of the feature map, thereby enhancing the detection of small objects that may appear at various scales within an image [36]. Integrating ASFF allows the model to benefit from a more refined feature representation, which is particularly advantageous for small-object detection in complex and varied scenic backgrounds. The ASFF method ensures that the contributions of feature maps from different levels are optimally balanced, improving the model’s precision and recall rates for small targets without requiring significant architectural changes or additional computational overhead.
During the training process, this study utilized public datasets along with supplementary datasets from tourist attractions. A large number of publicly available general datasets were primarily used for model pre-training. Subsequently, data collected from the scenic area was used to fine-tune the model’s detection capabilities. This approach strikes a balance between generalization and accuracy in specific scenes, thereby enhancing the YOLOX-x model’s ability to identify occlusions in the scenic area and improve the detection accuracy of the model towards tourists.
3.2. Dynamic Target Automatic Tracking
In mountainous scenic areas, dense foliage and crowded core attractions often present significant challenges for tourist identification due to occlusion. To address this issue, we employ BYTE data association tracking following initial detection. Tracking within individual video frames allows for the improved utilization of low-confidence detection boxes, while tracking across sequential frames takes advantage of temporal information—such as the target’s movement direction and speed—to predict the target’s position in the subsequent frame. This approach provides auxiliary support to detection and enhances the accuracy of identifying occluded targets. By leveraging temporal continuity, the tracking algorithm minimizes missed detections during periods of occlusion, thereby improving overall detection accuracy.
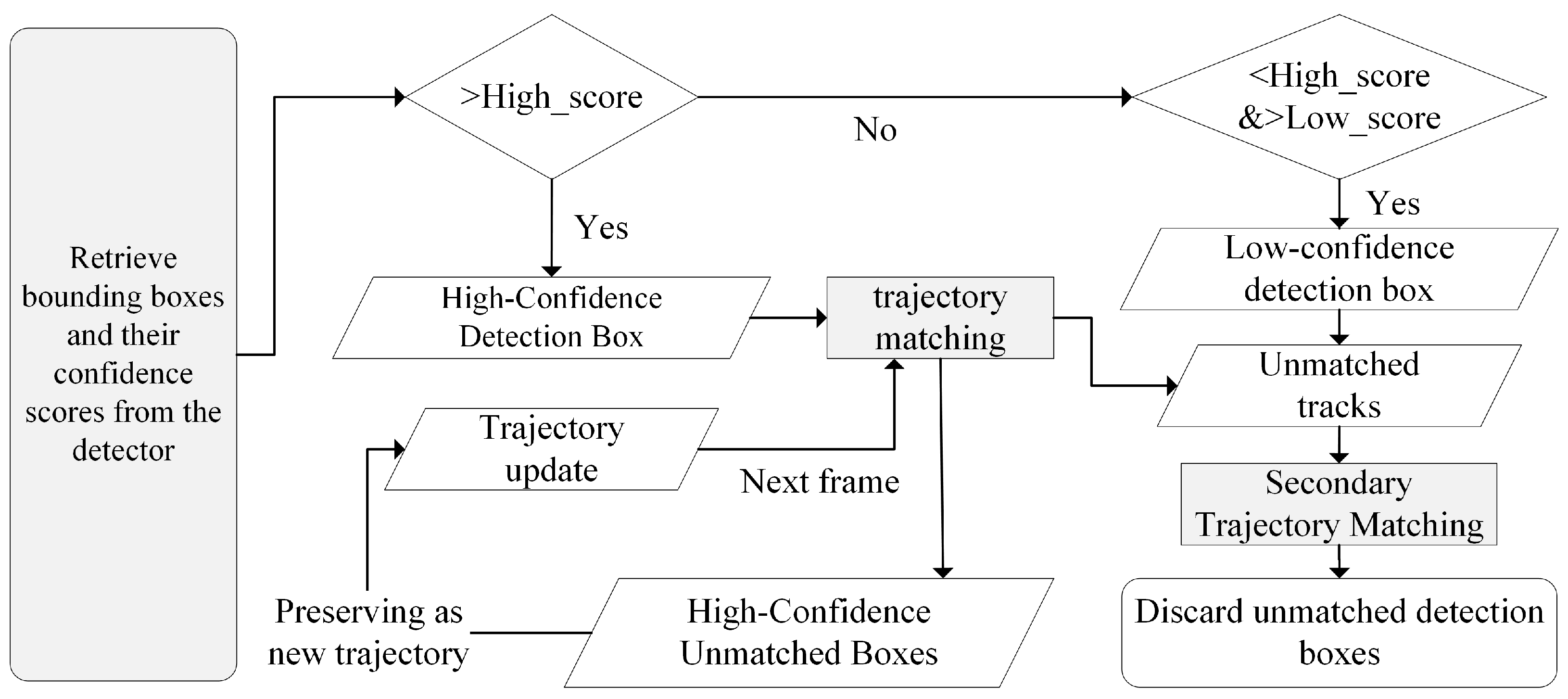
The tracking process for dynamic tourist targets in mountainous scenic areas is depicted in Figure 3. Initially, the detection boxes obtained from the YOLOX detector are classified into high and low confidence levels based on their confidence scores. Matching is then performed using intersection over union (IoU) or ReID features to assess the similarity between the detection boxes and the predicted outcomes from the Kalman filter. This step ensures that high-confidence detection boxes are matched with existing tracks while retaining any high-confidence detection boxes that could not be matched with an existing track, as well as the remaining tracks.
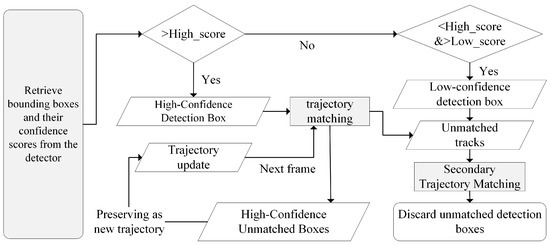
Figure 3.
Flowchart of dynamic tourist target tracking. The arrows in the figure represent the flow of information between different steps in the process. Solid arrows indicate the progression of bounding box detections through various stages, such as confidence evaluation, trajectory matching, and updates. Arrows leading to decision diamonds represent branching based on confidence score thresholds. Unmatched detection boxes and tracks follow separate arrows indicating secondary matching or discarding processes.
In the subsequent phase, a second round of matching is conducted using IoU as the similarity measure, wherein the remaining tracks are paired with low-confidence detection boxes. Since low-confidence detection boxes are often associated with occlusion, blurring, or unstable appearance features, any low-confidence bounding boxes that remain unmatched after the second round of matching are discarded. Finally, high-confidence detection boxes that could not be matched to any track are treated as new tracks and saved. Similarly, tracks that were not matched in either round of matching are also initialized as new tracks.
3.3. Geospatial Positioning of Video Targets
In mountainous scenic areas, certain regions suffer from weak or absent satellite signals, which presents a significant challenge for safety management. To address this, we integrate detection and positioning algorithms. Through detection, we acquire the two-dimensional pixel coordinates of targets, which are then converted into geographic coordinates (latitude and longitude) using matrix transformations. This transformation process typically involves a mapping matrix from image coordinates to geographic coordinates and may also require identifying specific reference points within the area. The workflow primarily includes the following steps:
- Camera calibration: This involves calibrating the camera to obtain its intrinsic and extrinsic parameters. Intrinsic parameters, such as focal length, principal point coordinates, and distortion coefficients, help define the camera’s imaging model. Extrinsic parameters, including the rotation and translation matrices, determine the camera’s position and orientation relative to the monitored scene.
- Pixel coordinate extraction and distortion correction: The pixel coordinates of the detected target are distortion-corrected to eliminate any image distortion introduced by the camera during imaging.
- Spatial positioning: The monitoring area is considered relatively flat or divided into several planes. The spatial positioning of targets is simplified through a plane-constrained approach, which leverages the geometric properties of planes to streamline the calculation process.
The geospatial positioning of video-detected tourist targets represents the final step in accurately capturing the spatiotemporal information of tourists in mountainous scenic areas using distributed cameras. This process is underpinned by the BeiDou unified time–space reference, as illustrated in Figure 4. Initially, the cameras within the scenic area are calibrated to ascertain their intrinsic and extrinsic parameters, thereby establishing the camera’s imaging model. Utilizing this model, the pixel coordinates of detected targets undergo distortion correction, which ensures an accurate representation of the scene’s actual shape, size, and position while mitigating distortion effects. Ultimately, the corrected pixel coordinates are transformed into geographic coordinates. This integrated approach facilitates the precise localization of detected targets within the real world, significantly enhancing the applicability and utility of the detection technology. It also supports extended applications in safety monitoring, incident response, and spatial analysis.
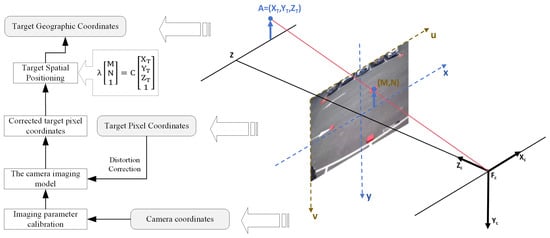
Figure 4.
Geographical spatial positioning diagram of video tourism targets. The arrows in the figure represent the flow of information and coordinate transformations between different systems. Solid arrows indicate transformations from geographical coordinates to pixel coordinates, including spatial positioning, pixel correction, and camera imaging calibration. The arrows connecting the 3D space and 2D image plane illustrate the projection from spatial coordinates to camera coordinates and the corresponding pixel location on the image plane.
A camera can map three-dimensional coordinate points from world coordinates onto a two-dimensional plane. The monocular pinhole camera is a simple and concrete camera model commonly used for this purpose based on the following principles [37]. Assuming there is a point A in space with the world coordinates , and its corresponding image point coordinates in the pixel coordinate system are , the perspective projection formula is as follows [38]. In the formula, are the principal point coordinates; are the camera’s focal lengths; s is the skew parameter; and K is the intrinsic matrix, which is obtained through intrinsic calibration. is the camera’s extrinsic matrix, representing the camera’s orientation and position in the world coordinate system, obtained through extrinsic calibration. is the scale factor.
Since the monitoring area within the scenic area is mostly flat, the plane constraint method is directly used for calculation. Let
Equation (1) can be written as
Since planes are involved, the elevation value of the plane in the monitoring field of view can directly replace in the formula. This allows us to obtain the matrix operation:
Equation (4) represents the mapping model of plane constraints. By combining the pixel coordinates of the detected target, this equation can be used to convert the coordinates into world coordinates. This enables the mapping between pixel coordinates and world coordinates.
4. Results Analysis
4.1. Accurate Detection of Tourists in Multi-Scene Scenic Spots
To determine the optimal position for inserting the attention module, a series of comparative experiments were conducted, as shown in Table 1. In the table, the symbol ✓ indicates the addition of the attention module, while the symbol × indicates the absence of the attention module. The first potential insertion point is located after the initial transformation layer, specifically, within the backbone section, following the initial convolutional layers (CSP1_x, CSP2_x). Inserting the attention module at this position can enhance the network’s early understanding of features, aiding in the capture of basic image information. Another insertion point is after the SPP module, where integrating the attention module can help focus attention at deeper levels of feature extraction and optimize feature representation before multi-scale feature extraction, thereby improving the initial feature quality.

Table 1.
Comparative trials of adding CBAM modules at different locations in the network.
The second potential insertion point is after the concat operation. Post-connection, feature maps from different paths are combined, merging the extracted feature information. The specific position in the diagram is after the concat module in the neck section. Inserting the attention module at this point can enhance the effectiveness of feature fusion, allowing the network to better focus on important parts of the fused features.
The third category of potential insertion points is between the Conv layers within each decoupled head in the head section. Inserting the attention module at this position can adjust the feature map weights before determining the final output, potentially enhancing the network’s attention to predicting bounding boxes and class scores. This adjustment could improve the detection accuracy of small and blurred objects, thereby increasing the overall detection precision and reducing false detections.
Table 1 presents a comparison of the detection performance and inference speed when the CBAM module is integrated into different sections of the YOLOX network. Specifically, placing the CBAM module in the backbone, neck, and head sections resulted in AP0.5 improvements of 2.11%, 2.02%, and 1.56%, respectively, with corresponding increases in detection time of 2.12 ms, 2.86 ms, and 1.62 ms. These results indicate that while the backbone section provides the largest increase in AP, it also incurs a significant increase in inference time. When the CBAM module was simultaneously placed in multiple sections (e.g., backbone and neck), the improvements in AP0.5 were less pronounced, with only a 1.47% increase, while the inference time increased by 4.98 ms. This demonstrates that although CBAM can enhance detection accuracy when placed in a single section, placing it in multiple sections offers diminishing returns in terms of accuracy, while significantly increasing the computational overhead. Therefore, for real-time applications, careful consideration of where to place the CBAM module is essential to balance detection performance and speed. Since the increase in inference time remains within an acceptable range, the configuration that offers the greatest improvement in accuracy was ultimately selected. Specifically, integrating the CBAM module into the backbone section, which yields the highest AP0.5 improvement of 2.11%, was chosen despite the associated 2.12 ms increase in inference time.
To investigate the impact of attention modules combined with adaptive spatial feature fusion on the performance of the YOLOX model, an ablation study was conducted with the training hyperparameters kept unchanged. Adaptive spatial feature fusion enhances the utilization of multi-scale information in object detection by dynamically adjusting the contribution of feature maps at different scales.
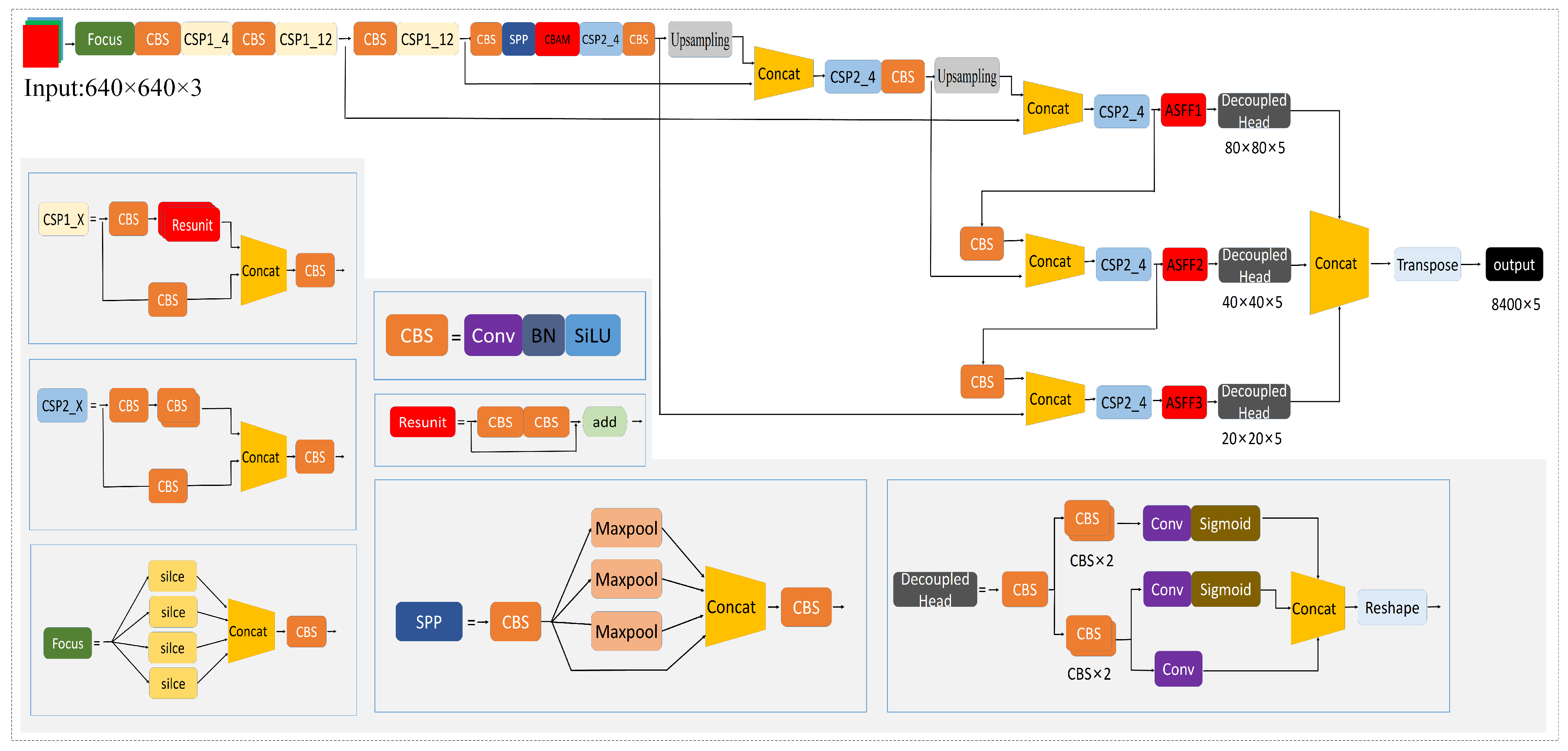
As shown in Table 2, the combination of the attention module and ASFF technology further enhances the detection performance of the YOLOX model. ASFF is an adaptive feature fusion strategy that effectively utilizes multi-scale features output from the neck section, enabling the efficient fusion of high-level semantic information and low-level fine-grained features. Although adding more modules increases the model’s complexity and computational load, observations indicate that ASFF positively impacts detection accuracy. The attention module is best suited for the end of feature extraction, while ASFF is more effective at the end of multi-scale feature fusion in the neck section. The study results demonstrate that the combination of CBAM and ASFF yields the best improvement. Therefore, the optimal model identified in this study is CBAM+ASFF+YOLOX-x, as shown in Figure 5.
Table 2.
Impact of different improvement strategies on the model.
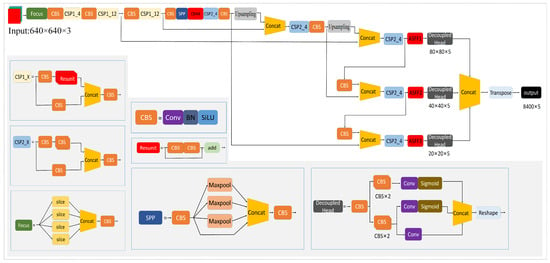
Figure 5.
Improved YOLOX-x target monitoring network architecture.
To evaluate the algorithm’s effectiveness, we selected four different target scenic areas within the scenic area as experimental zones: Tourist center (a), Xiaodiao area (b), cable car area (c), and Yu Huang Palace (d). In each area, we randomly captured 100 frames of video stream and set the confidence threshold at 0.5 for conducting tourist detection in the scenic area’s video streams. The results, as shown in Figure 6, demonstrate that the YOLOX target detection algorithm, combined with near-field cameras distributed throughout the scenic area, accurately identifies each tourist target. The algorithm performs well in handling challenges such as high-density tourist crowds, distant small targets, and partial occlusion among dynamic targets. In surveillance images with a resolution of 1920 × 1080 pixels, the smallest detectable pedestrian size is approximately 30 × 30 pixels, which is the minimum size at which a tourist target object can be clearly discerned by the human eye. The occurrence of misjudgment or missed detection is minimal.

Figure 6.
Detection results of different algorithms in different scenarios. (Different algorithms use different colored detection boxes).
To further verify the accuracy of the algorithm, we compared it with three recent algorithms in the YOLO series: YOLOv7, YOLOv8, and YOLOv9. As shown in Figure 6, the detection results indicate that our algorithm outperforms these alternatives in handling occlusions and detecting objects at greater distances from the camera. Quantitative comparisons are presented in Table 3. Additionally, we conducted quantitative evaluations of the algorithm’s applicability across different scenarios, overall precision, and performance metrics, with the results summarized in Table 4. The detection accuracy for the test samples across four designated areas is approximately 90%, with an average frames per second (FPS) of 25.35 and a mean AP0.5 of 0.8705. The experimental results indicate that the algorithm meets the requirements for precise tourist detection in scenic areas, performing well in scenarios involving small, distant objects and high-density crowds. Overall, the algorithm demonstrates strong accuracy and recall rates.
Table 3.
Comparison of different algorithms.
Table 4.
Quantitative evaluation of target detection accuracy for mountain tourists.
The following are the formulae for calculating the metrics:
In this context, TP (true positive) refers to the number of predicted bounding boxes that exceed both the pre-set confidence threshold and the pre-set intersection over union (IoU) threshold. FP (false positive) refers to the number of predicted bounding boxes that exceed the pre-set confidence threshold but fall below the pre-set IoU threshold. FN (false negative) refers to the number of predicted bounding boxes that are below the pre-set confidence threshold.
4.2. Tourist Target Dynamic Tracking and Precise Positioning
To test the accuracy and reliability of dynamic tourist target tracking in scenic areas, we manually selected dynamic images of monitored frames with occlusions during the tracking process. The entire video stream includes scenarios where tourists appear, become partially occluded, disappear completely, and then, reappear, as seen in Figure 7. The results demonstrate that even when tourists are partially occluded or disappear and reappear, the scenic area tourist target tracking algorithm based on BYTE data association can still perform continuous and effective dynamic tracking of tourist targets. The accuracy of tracking ensures the precision of near-field perception of tourists in the scenic area and also provides a foundation for the accuracy of pedestrian geolocation.

Figure 7.
Dynamic tourist target tracking: (a) target tracking; (b) target occluded; (c) target completely occluded; (d) target reappears.
To test the accuracy of geospatial positioning, we collected the geographical coordinates of ten locations in the scenic area using a total station under the CGCS2000 coordinate system. We then compared these coordinates with the geographical coordinates calculated from pixel coordinates for precision analysis. Each location was tested and located 100 times to obtain an average value. The results, shown in Table 5, revealed a maximum longitude error of 1.3953 m, a maximum latitude error of −0.8837 m, and a largest RMSE of 1.1483. The overall spatial error can be controlled within approximately 1 m, allowing for accurate near-field perception of dynamic spatiotemporal information of tourists in mountainous scenic areas using joint distributed cameras.
Table 5.
Quantitative evaluation table for spatial positioning error of dynamic targets in surveillance videos.
The results of continuous and accurate dynamic monitoring of tourist information based on the proposed near-field quasi-real-time perception system are shown in Figure 8. On the left side of Figure 8, the results of detection, tracking, and positioning by cameras are displayed, while the right side shows the real-time representation of tourist spatiotemporal dynamic information as red dots on a digital map. Figure 8a illustrates the distribution of people around the Xiaodiao Museum bridge at 2:45 PM on 15 July 2024; Figure 8b shows the distribution at 2:46 PM; Figure 8c shows it at 2:47 PM; and Figure 8d shows the distribution at 2:48 PM. The pixel coordinate positions of the target detection boxes, obtained from the distributed camera detection and tracking, are sent to the tourist target geospatial positioning module and converted into geographical coordinates under the BeiDou unified space–time framework. This information can be directly applied to the dynamic management of tourists in complex mountainous scenic areas and related service applications.

Figure 8.
Accurate recognition of spatiotemporal information of scenic spot tourists based on near-field quasi-real-time perception system. The boxes in the figure are the detection result boxes, and (a–d) represent four different moments.
5. Discussion
5.1. Near-Field Passive Quasi-Real-Time Perception System
In response to the need for real-time dynamic detection and positioning of tourists in mountainous scenic areas, this study developed the Near-Field Passive Quasi-Real-Time Perception System. This system addresses the challenges associated with detecting tourists in complex scenes, such as small human targets and motion occlusion in long-distance video imaging. The system was deployed and tested in the Yimeng Mountain area, achieving over 90% accuracy and a processing speed of 25 FPS. This demonstrates the system’s capability to accurately perceive and spatially position visitors in the complex environments of mountainous scenic spots, offering strong fluency and reliable performance. Compared to existing near-field perception systems used in environments like schools and factories, which are also based on distributed cameras, this study introduces several key improvements.
- Improved YOLOX model for dynamic detection: The YOLOX model has been enhanced to more effectively detect tourist targets in complex mountainous scenes. Integrating the Convolutional Block Attention Module (CBAM) into the YOLOX network has been shown to improve detection accuracy by 3.29% to 4.11%, depending on where it is inserted. In this study, the deepest network model, YOLOX-x, was employed to maximize feature extraction capabilities, with the CBAM module strategically placed after the Spatial Pyramid Pooling (SPP) module to enhance feature relevance. This configuration facilitates effective multi-scale feature extraction, improving the detection of tourists of varying sizes within the camera’s field of view while compensating for the complex background.The adaptive feature fusion (ASFF) method further optimizes the contribution of feature maps at different levels, boosting precision and recall rates for small targets without imposing significant computational overhead. These enhancements have markedly improved both the speed and accuracy of detection, ensuring high accuracy and recall rates even in challenging scenarios involving small targets and dense crowds. As a result, YOLOX is highly suitable for real-time target detection in mountainous scenic areas. Additionally, the model’s generalizability and applicability can be further expanded by modifying the network and incorporating other novel self-attention modules.
- Introduction of BYTE tracking algorithm for dynamic target tracking: Dynamic multi-object tracking is a crucial step in achieving precise perception of tourists in mountainous scenic areas. In the tracking process, data association methods are essential, as they calculate the similarity between trajectories and detection boxes, matching them based on this similarity. Location, movement, and appearance serve as key clues for associative matching, enabling continuous tracking and effectively handling occlusions.The BYTE tracking algorithm, known for its flexibility and compatibility with various association methods, was incorporated into this system, significantly improving tracking accuracy. BYTE ensures continuous tracking even when targets are partially occluded, demonstrating its robustness in solving dynamic detection and tracking challenges. By integrating trackers and employing the BYTE data association method, the system enhances detection accuracy and expands application scenarios, focusing on multi-frame video target tracking. Additionally, a local area detection method was introduced to reduce false positives caused by overlapping detection areas, overcoming occlusion issues and improving detection accuracy in complex scenes.
- Construction of a near-field sensing network: A near-field sensing network was developed for tourist information in the Tianmeng Mountain area, based on spatial location correlation and utilizing the unified spatiotemporal benchmark of BeiDou. This network integrates multiple near-field cameras, originally used for decentralized single-point monitoring, into a unified perception system. This transformation from independent video monitoring devices into an interconnected network enables the provision of near-field dynamic information and scene-state awareness. By pulling real-time video streams and combining them with object detection and positioning methods, the network integrates detection, tracking, and positioning processes. This allows for real-time dynamic updates and management of precise spatiotemporal information, directly supporting safety management and the development of smart scenic areas.
In summary, the near-field passive quasi-real-time perception system for tourists in mountainous scenic areas, which combines the BeiDou system and distributed cameras, is a comprehensive engineering system. This technology system effectively utilizes high-precision camera perception equipment in tourist attractions, making it replicable and highly scalable. By completing the same spatiotemporal benchmark calibration of existing cameras, this method can assist in the passive near-field accurate identification and spatial positioning of tourists in complex scene environments of mountainous scenic spots. It has good testing accuracy, meets user needs, and provides strong image processing fluency (greater than 25 FPS) and stable reliability. The potential application market for this system is large, as it offers a feasible method for passive real-time dynamic and accurate perception and safety management of tourist targets in complex scenarios of mountainous scenic spots, especially in the absence of satellite navigation signals.
5.2. Technical Difficulties and Error Analysis
The technical difficulties and challenges mainly involve the dynamic and accurate identification of tourist targets in complex scenes and the precise positioning of targets in rugged terrain. A review of the existing literature reveals that current near-field sensing algorithms, which rely on distributed cameras, primarily concentrate on monitoring indoor, school, or industrial park environments [39]. However, there is a scarcity of research on the near-field perception of tourists in complex mountainous scenic areas. Dynamic detection of tourist targets in mountainous scenic areas poses greater challenges compared to common detection scenarios such as indoors or in parks. Firstly, hot scenic spots often have dense crowds and are surrounded by shrubs and forests, greatly increasing the likelihood of detection targets being occluded [40,41]. Additionally, the dispersed distribution of cameras and the significant variations in terrain result in large differences in the distance between detection targets and cameras, with some targets in the camera’s view having low pixel feature representation [42]. This requires the detection model to have high generalization capabilities and the ability to recognize small targets. Moreover, considering the quasi-real-time requirements for spatiotemporal information of scenic spot tourists, it is necessary for the algorithm to process images at a speed of at least 25 frames per second (FPS) or higher. This places higher demands on the efficiency and smoothness of the detector. Hence, we finally employ the single-stage algorithm YOLOX-x as a large-scale tourist detection model in mountainous areas, based on multiple comparative experiments.
The accuracy of visitor detection directly affects the accuracy of tourist dynamic tracking. A higher detection accuracy allows the tracking algorithm to extract more information, resulting in improved tracking accuracy. Although the BYTE data association tracking method is able to extract information from low-confidence detection boxes, ensuring continuous tracking, even when the target is partially occluded, there is a need for further improvement in the precise perception and dynamic tracking of tourist movement targets across cameras [43]. This is particularly important when considering variations in tourist phenotypic characteristics, such as changes in clothing, lighting conditions, indoor and outdoor settings, as well as shady and sunny slopes. Additionally, relying solely on body features in tourist tracking and recognition algorithms may lead to a trade-off between commission and omission accuracy. This trade-off can have a negative impact on overall accuracy and user experience.
The geospatial positioning of tourist targets primarily relies on calculating their pixel position in surveillance images within a unified space–time reference framework. In terms of video target localization, we utilized the spatial localization method for dynamic targets in surveillance videos developed by Han et al. in 2022 [44]. This method comprises target localization algorithms based on Digital Surface Model (DSM) constraints and target localization algorithms based on plane constraints. These algorithms are simple, user-friendly, and widely applicable. Target spatial positioning converts target data from pixel coordinates to three-dimensional coordinates, providing a standardized geographic reference framework for multi-camera target tracking and passenger flow management. Extensive on-site monitoring and verification data demonstrate that the average controllable spatial positioning error of a single camera, using the BeiDou spatiotemporal benchmark, is approximately 1 m. This level of accuracy is sufficient to meet the specific requirements of tasks such as passenger flow statistics in scenic spots and road congestion warning.
However, it should be acknowledged that there are several potential sources of error in this study: (1) systematic errors that may occur during camera calibration with measuring instruments; (2) detection and tracking errors arising from the discrepancy between generated prediction boxes and actual positions; and (3) computational errors resulting from the reliance on ideal models and the limited consideration of complex real-world terrain, leading to slight deviations in the final geolocation results.
Environmental factors also significantly impact detection accuracy in mountainous scenic areas. Weather phenomena such as fog and rain degrade image quality and increase noise, thus reducing model accuracy in target recognition. Additionally, the region’s varied topography and the large daily variations in sunlight angles especially affect visibility in shadowed or brightly lit areas. Addressing these issues falls within the scope of image preprocessing techniques. FFA-Net, a recent deep learning-based dehazing method [45], and PM-CycleGAN, a cloud removal approach that does not require paired cloud-free images [46], can effectively mitigate the impact of environmental factors. However, our primary focus is on detection challenges within complex mountainous scenes. To ensure real-time performance, we have focused our experimental testing on scenarios with favorable weather and lighting conditions.
5.3. Scalability and Limitations
Our proposed method has achieved notable results, addressing some of the challenges posed by complex mountainous scenic environments and providing auxiliary positioning solutions in areas with weak satellite signals. However, limitations remain in cross-camera sensing, particularly in achieving stable detection and tracking accuracy. To address this, future improvements may include designing an integrated feature transfer network that transmits features of each initially detected object across multiple cameras, enabling cross-camera detection and tracking through a comprehensive integration of all cameras. Additionally, in terms of perception and positioning, averaging across detections could effectively reduce calibration errors, while employing enhanced matching strategies in the detector may reduce the discrepancy between the actual bounding boxes and the model-predicted boxes. These improvements aim to further enhance the accuracy of tourist detection and positioning.
Our deployment in the Yimeng Mountain Scenic Area currently includes a single server for computation and a gigabit switch to provide sufficient bandwidth for video stream transmission. Testing approximately 100 camera streams, each at 1080 p resolution and encoded with H.265, our measurements indicate that each video stream consumes 2–3 Mbps bandwidth for detection. We believe the system has considerable scalability potential. By optimizing the model, for example, by reducing model bit precision and employing TensorRT for acceleration, hardware resource consumption can be significantly reduced. This means that, even with an increase in the number of cameras, the current hardware and gigabit switch could accommodate 200–300 streams, covering nearly all key points and routes within the scenic area.
In large-scale application scenarios, relying solely on centralized computation through local servers may be insufficient to meet real-time and efficiency requirements. Therefore, it is essential to incorporate edge computing and a hybrid local–cloud architecture. Edge computing enables data processing at edge nodes near the data source (e.g., within the camera), reducing data transmission latency and alleviating the load on central servers. By preprocessing video streams and performing preliminary object detection at edge devices, the system can respond more quickly while decreasing network bandwidth demands.
On the other hand, a hybrid local–cloud architecture allows different tasks to be allocated to the most suitable computational resources. Tasks with high real-time requirements can be handled on local servers or edge devices, while large-scale data analysis, historical data storage, and pattern recognition can be offloaded to the cloud. This architecture dynamically distributes the computational load, enhancing processing capacity while providing high flexibility and scalability. The improved detection and positioning algorithms have broad potential applications. By defining areas of interest, the system could enable tourist flow monitoring and diversion management, set warning zones in non-secure areas for safety alerts and emergency responses, and provide dynamic recommendations for popular attractions and optimal routes based on real-time visitor flow data, helping tourists avoid crowded areas. By analyzing visitor dwell time and density data, facility layouts could be optimized to improve the overall quality of service in the scenic area. Furthermore, if integrated effectively with the BeiDou satellite system, the system could enhance visitor sensing and positioning in weak or no-signal coverage areas. Combining active and passive positioning could address the challenge of real-time spatiotemporal information acquisition for tourists in mountainous scenic areas, advancing the development of smart scenic areas.
6. Conclusions
In this paper, we explored a technical system for near-field passive precise perception of tourist spatiotemporal information in mountainous scenic areas. The technology system has been successfully deployed in the Tianmeng Scenic Area. It was demonstrated that the system can successfully achieve real-time dynamic updates and management of precise spatiotemporal information of tourists. The overall recognition accuracy of passive perception of dynamic tourist targets exceeds 95%, with spatial positioning errors of less than 1 m, RMSE below 1.11, and a mean image processing speed exceeding 25 FPS. This enables us to effectively achieve detection, tracking, and positioning of tourists in complex mountainous scenic areas.
The main innovative contributions of this study are as follows:
- The introduction of the CBAM and ASFF modules effectively improves the recognition accuracy of small tourist targets in outdoor long-distance video frames of mountainous scenic spots in the YOLOX network.
- The use of the BYTE target dynamic tracking algorithm enables dynamic tracking of moving tourist targets in complex scenes, addressing the issue of target occlusion in mountainous scenic areas and enhancing the accuracy of model detection.
- By utilizing the spatial position correlation of the BeiDou system, the article achieves comprehensive management and collaborative perception of multiple distributed cameras in mountainous scenic areas within the spatiotemporal benchmark of the BeiDou system. This integration of multiple near-field cameras for scattered single-point monitoring into a unified near-field perception system enables passive and accurate perception of tourist spatiotemporal information in the mountainous scenic field based on multi-channel distributed videos.
This technology effectively addresses the challenge of quasi-real-time acquisition of dynamic information regarding tourists in mountainous scenic areas. It holds significant potential for various application scenarios in the future, including smart cities, public security, and other related fields.
Author Contributions
Conceptualization, Junli Li, Changming Zhu and Xin Zhang; methodology, Kuntao Shi; validation, Fan Yang and Kuntao Shi; formal analysis, Kun Zhang and Qian Shen; data curation, Kuntao Shi and Kun Zhang; writing—original draft preparation, Kuntao Shi; writing—review and editing, Kuntao Shi, Changming Zhu, and Qian Shen; visualization, Kuntao Shi; supervision, Changming Zhu; project administration, Changming Zhu; funding acquisition, Changming Zhu and Junli Li. All authors have read and agreed to the published version of the manuscript.
Funding
This research study was funded by the National Key Research and Development Program of China [grant number 2021YFB1407004] [grant number 2023YFE0103800] and Jiangsu Qinglan Project.
Data Availability Statement
The data used in this study are publicly available from multiple public websites. The images used in this study can be downloaded from the following websites: https://www.crowdhuman.org/ (accessed on 3 January 2024), https://motchallenge.net/data/MOT17/ (accessed on 3 January 2024), https://paperswithcode.com/dataset/citypersons (accessed on 3 January 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, D.; Deng, L.; Cai, Z. Statistical analysis of tourist flow in tourist spots based on big data platform and DA-HKRVM algorithms. Pers. Ubiquit. Comput. 2020, 24, 87–101. [Google Scholar] [CrossRef]
- Liu, J.; Du, J.; Sun, Z.; Jia, Y. Tourism emergency data mining and intelligent prediction based on networking autonomic system. In Proceedings of the 2010 International Conference on Networking, Sensing and Control (ICNSC), IEEE, Chicago, IL, USA, 10–12 April 2010; pp. 238–242. [Google Scholar]
- Ervina, E.; Wulung, S.R.P.; Octaviany, V. Tourist perception of visitor management strategy in North Bandung Protected Area. J. Bus. Hosp. Tour. 2020, 6, 303. [Google Scholar] [CrossRef]
- Qin, S.; Man, J.; Wang, X.; Li, C.; Dong, H.; Ge, X. Applying big data analytics to monitor tourist flow for the scenic area operation management. Discret. Dyn. Nat. Soc. 2019, 2019, 8239047. [Google Scholar] [CrossRef]
- Gstaettner, A.M.; Rodger, K.; Lee, D. Managing the safety of nature Park visitor perceptions on risk and risk management. J. Ecotour. 2022, 21, 246–265. [Google Scholar] [CrossRef]
- Zhou, J. Design of intelligent scenic area guide system based on visual communication. In Proceedings of the 2020 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), IEEE, Vientiane, Laos, 11–12 January 2020; pp. 498–501. [Google Scholar]
- Shen, H.; Lin, D.; Yang, X.; He, S. Vision-based multiobject tracking through UAV swarm. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Hmidani, O.; Alaoui, E.M.I. A comprehensive survey of the R-CNN family for object detection. In Proceedings of the 2022 5th International Conference on Advanced Communication Technologies and Networking (CommNet), IEEE, Virtual, 12–14 December 2022; pp. 1–6. [Google Scholar]
- Terven, J.; Cordova-Esparza, D. A comprehensive review of YOLO architectures in computer vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Afyouni, I.; Al Aghbari, Z.; Razack, R.A. Multi-feature, multi-modal, and multi-source social event detection: A comprehensive survey. Inf. Fusion 2022, 79, 279–308. [Google Scholar] [CrossRef]
- Kalake, L.; Wan, W.; Hou, L. Analysis based on recent deep learning approaches applied in real-time multi-object tracking: A review. IEEE Access 2021, 9, 32650–32671. [Google Scholar] [CrossRef]
- Zheng, D.; Dong, W.; Hu, H.; Chen, X.; Wang, Y. Less is more: Focus attention for efficient detr. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 6674–6683. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Cheng, B.; Wei, Y.; Shi, H.; Feris, R.; Xiong, J.; Huang, T. Revisiting RCNN: On awakening the classification power of Faster RCNN. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11219, pp. 473–490. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Liu, B.; Zhao, W.; Sun, Q. Study of object detection based on Faster R-CNN. In Proceedings of the 2017 Chinese Automation Congress (CAC), IEEE, Jinan, China, 20–22 October 2017; pp. 6233–6236. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-margin softmax loss for convolutional neural networks. arXiv 2017, arXiv:1612.02295. [Google Scholar]
- Mahrishi, M.; Morwal, S.; Muzaffar, A.W.; Bhatia, S.; Dadheech, P.; Rahmani, M.K.I. Video index point detection and extraction framework using custom YoloV4 Darknet object detection model. IEEE Access 2021, 9, 143378–143391. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Bathija, A.; Sharma, G. Visual object detection and tracking using YOLO and SORT. Int. J. Eng. Res. 2022, 8, 11. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Parico, A.I.B.; Ahamed, T. Real time pear fruit detection and counting using YOLOv4 models and deep SORT. Sensors 2021, 21, 4803. [Google Scholar] [CrossRef]
- Chen, L.; Ai, H.; Zhuang, Z.; Shang, C. Real-time multiple people tracking with deeply learned candidate selection and person re-identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Wu, H.; Du, C.; Ji, Z.; Gao, M.; He, Z. SORT-YM: An algorithm of multi-object tracking with YOLOv4-tiny and motion prediction. Electronics 2021, 10, 2319. [Google Scholar] [CrossRef]
- Pang, J.; Qiu, L.; Li, X.; Chen, H.; Li, Q.; Darrell, T.; Yu, F. Quasi-dense similarity learning for multiple object tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 164–173. [Google Scholar]
- Fischer, T.; Huang, T.E.; Pang, J.; Qiu, L.; Chen, H.; Darrell, T.; Yu, F. Qdtrack: Quasi-dense similarity learning for appearance-only multiple object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15380–15393. [Google Scholar] [CrossRef] [PubMed]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Valente, J.; Van Der Voort, M.; Tekinerdogan, B. Effect of attention mechanism in deep learning-based remote sensing image processing: A systematic literature review. Remote Sens. 2021, 13, 2965. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. ByteTrack: Multi-object tracking by associating every detection box. In Computer Vision—ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature: Cham, Switzerland, 2022; Volume 13682, pp. 1–21. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. Crowdhuman: A benchmark for detecting humans in a crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Milan, A.; Leal-Taixe, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Zhang, S.; Benenson, R.; Schiele, B. CityPersons: A diverse dataset for pedestrian detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4457–4465. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Juarez-Salazar, R.; Zheng, J.; Diaz-Ramirez, V.H. Distorted pinhole camera modeling and calibration. Appl. Opt. 2020, 59, 11310–11318. [Google Scholar] [CrossRef] [PubMed]
- Han, S.; Miao, S.; Hao, X.; Chen, R. A spatial localization method for dynamic objects in surveillance video. Survey. Mapp. Bull. 2022, 8, 87. [Google Scholar]
- Jang, B.; Kim, H.; Kim, J.-W. Survey of landmark-based indoor positioning technologies. Inf. Fusion 2023, 89, 166–188. [Google Scholar] [CrossRef]
- Jain, D.K.; Zhao, X.; González-Almagro, G.; Gan, C.; Kotecha, K. Multimodal pedestrian detection using metaheuristics with deep convolutional neural network in crowded scenes. Inf. Fusion 2023, 95, 401–414. [Google Scholar] [CrossRef]
- Yang, G.; Zhu, D. Survey on algorithms of people counting in dense crowd and crowd density estimation. Multimed. Tools Appl. 2023, 82, 13637–13648. [Google Scholar] [CrossRef]
- Yang, R.; Li, W.; Shang, X.; Zhu, D.; Man, X. KPE-YOLOv5: An Improved Small Target Detection Algorithm Based on YOLOv5. Electronics 2023, 12, 817. [Google Scholar] [CrossRef]
- Specker, A.; Beyerer, J. ReidTrack: Reid-only Multi-target Multi-camera Tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 18–22 June 2023; IEEE: New York, NY, USA, 2023; pp. 5442–5452. [Google Scholar]
- Han, S.; Miao, S.; Hao, X.; Chen, R. A Review of the Development of Fusion Technology of Surveillance Videos and Geographic Information. Bull. Surv. Mapp. 2022, 5, 1–6. [Google Scholar]
- Zi, Y.; Xie, F.; Song, X.; Jiang, Z.; Wang, P. Thin cloud removal for remote sensing images using a physical-model-based CycleGAN with unpaired data. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, H.; Jia, H.; Li, C. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).