





A Lightweight Multi-Label Classification Method for Urban Green Space in High-Resolution Remote Sensing Imagery
Abstract
1. Introduction
- A newly formed multi-label classification model of urban green space, which incorporates the Triplet Attention module, is presented. This integration not only minimizes computational demands but also addresses the indirect correspondence between channels and weights. Furthermore, by employing an LSTM network, the model effectively minimizes interference from irrelevant information and amply utilizes effective information, capturing subtle objectives that may otherwise be overlooked. This allows for a more accurate exploration of the correlations between labels.
- Experiments and evaluations conducted on our constructed UGS multi-label dataset prove that the presented model performs better than the existing multi-label classification methods among precision, recall, and mAP.
- Through this study, more detailed attributes of urban green spaces can be extracted from images in an intelligent manner. This has significant implications for the planning and management of urban green spaces. The research findings can provide comprehensive decision support and multi-dimensional analysis for urban management and development, aiding in the formulation of more scientific management strategies. Consequently, the study contributes significantly to environmental protection, ecological research, and social development.
2. Related Work
2.1. Pre-Processing and Dataset
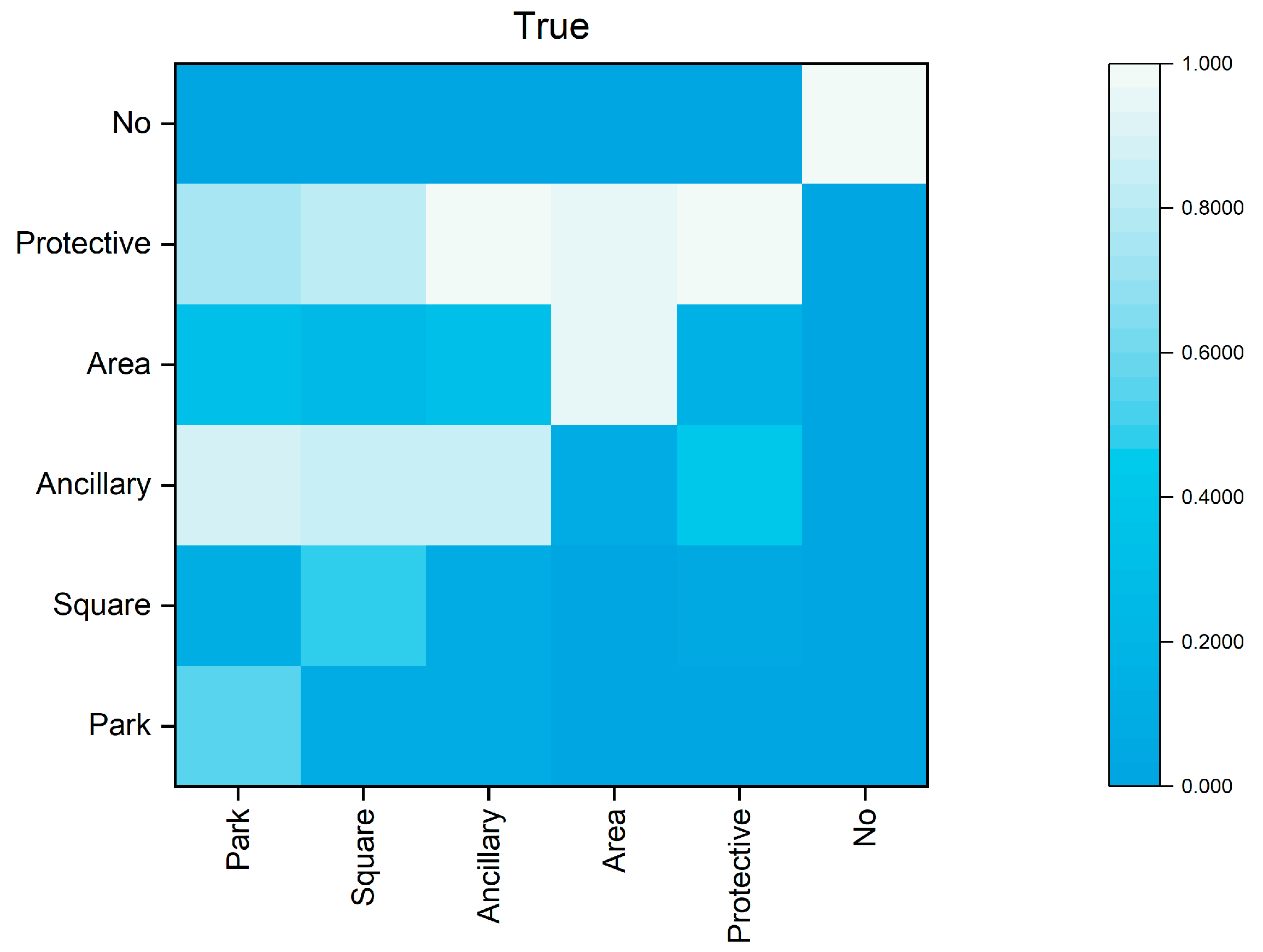
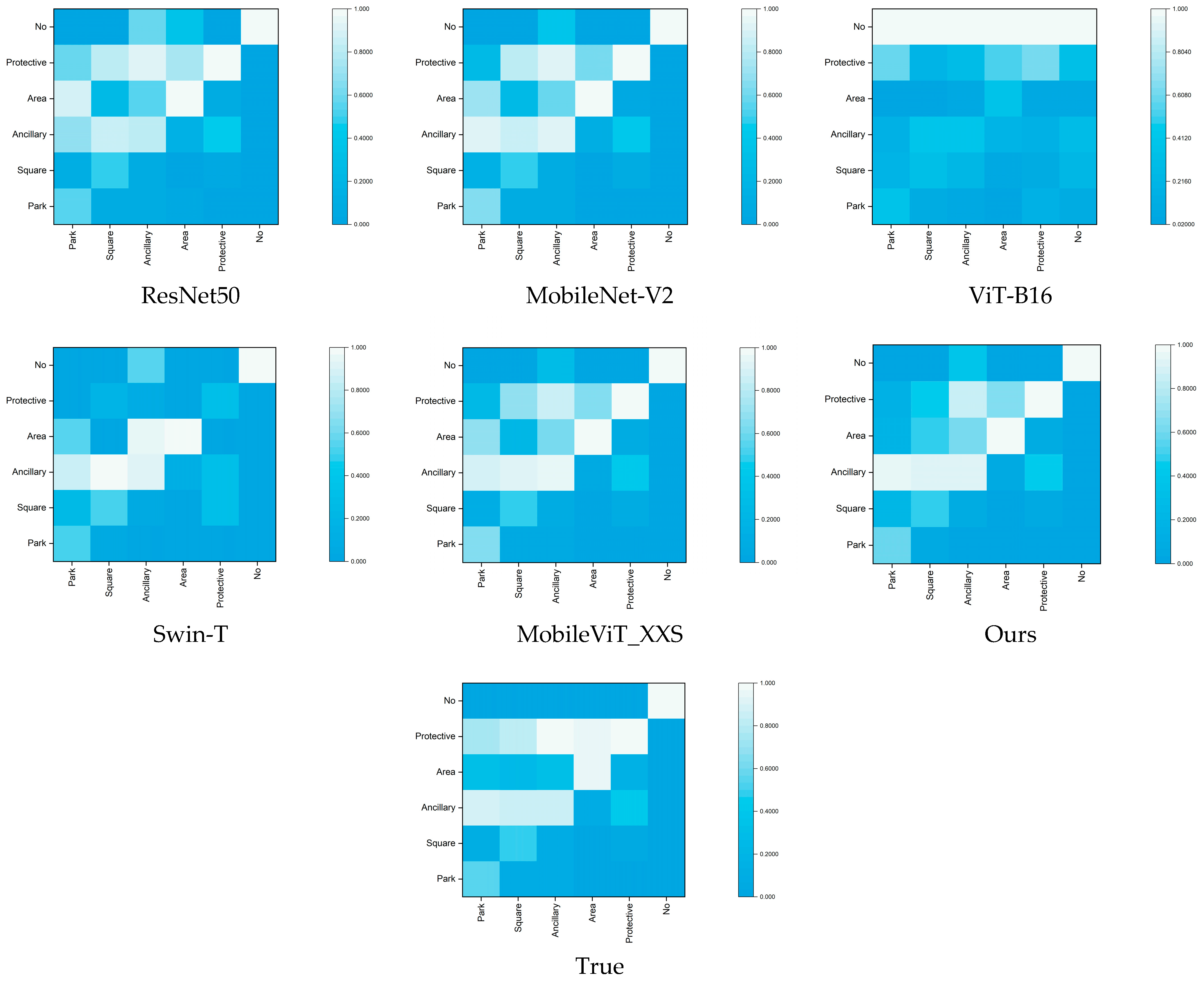
2.2. Confusion Matrix
3. Methodology
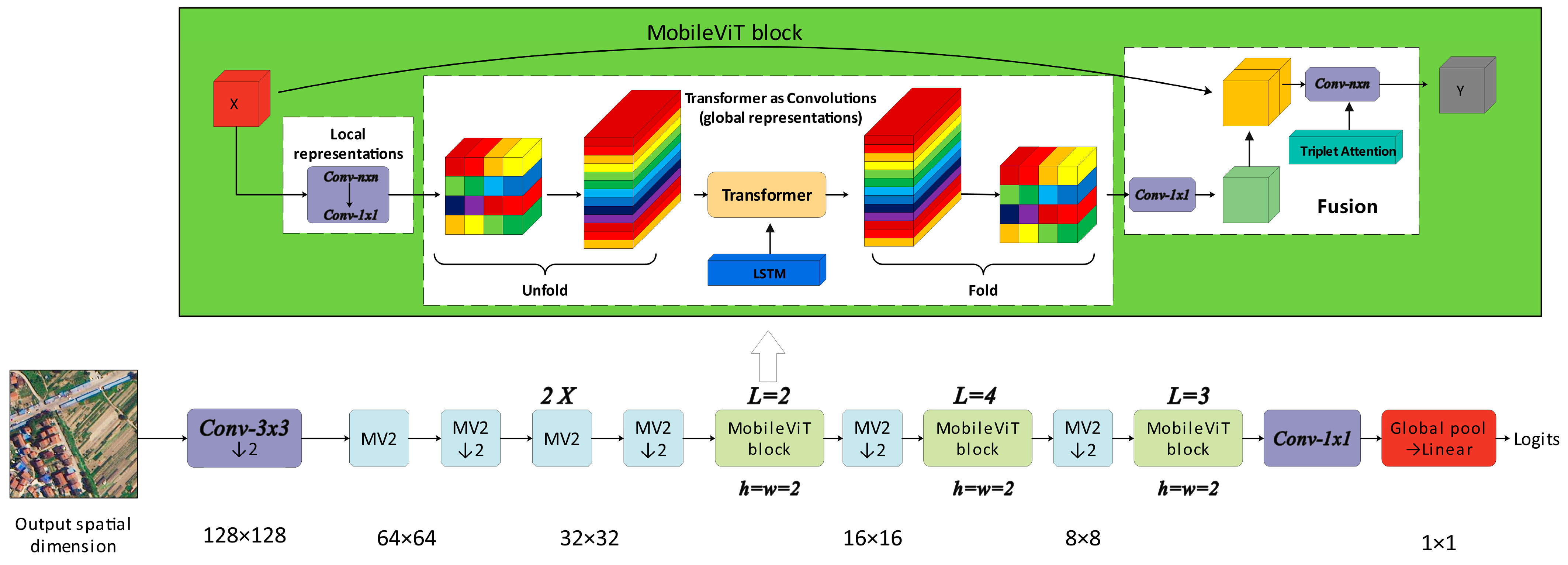
3.1. Feature Extraction
3.2. Attention Module
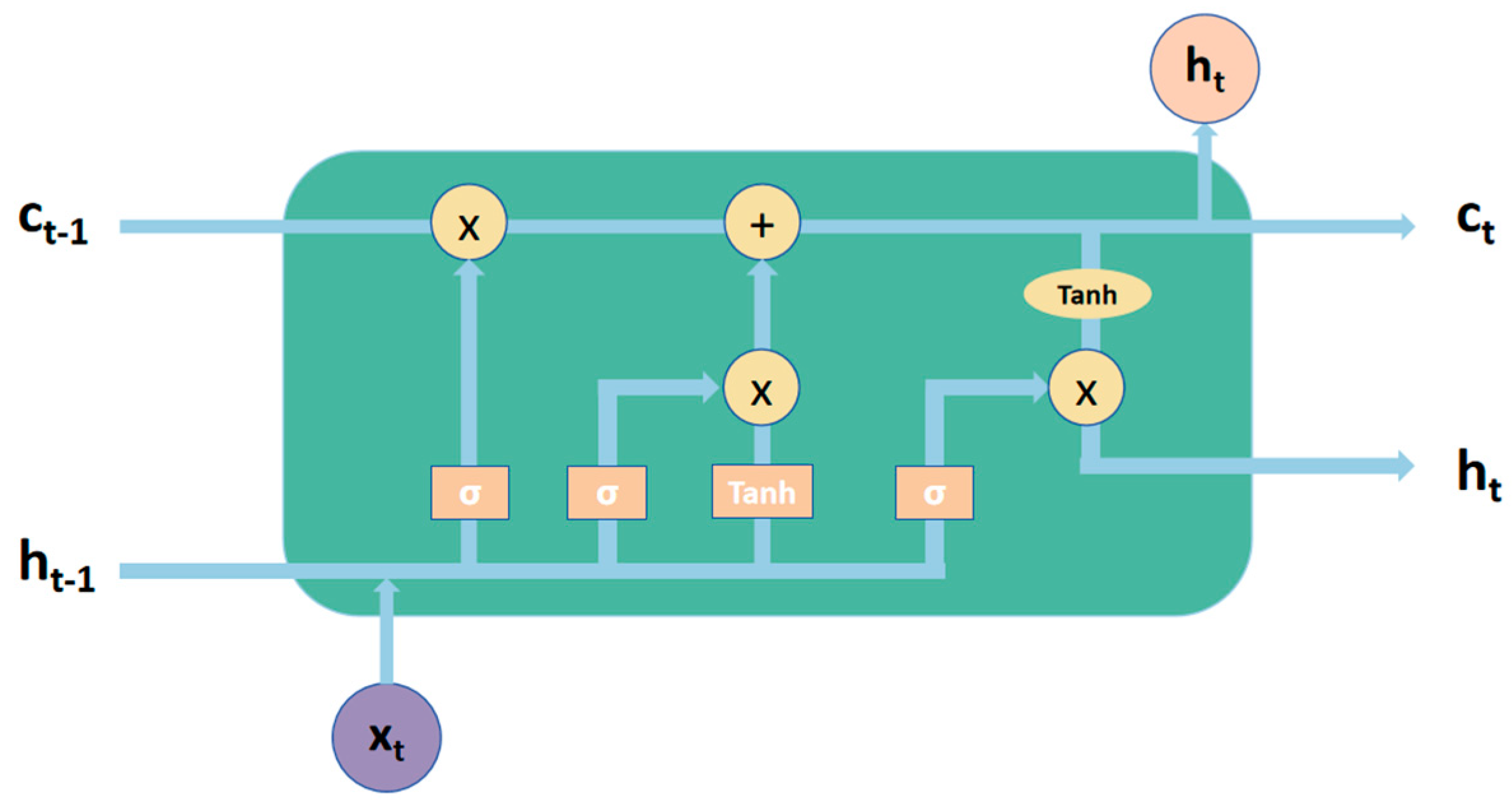
3.3. LSTM for Latent Semantic Dependencies
3.4. Data Augmentation
4. Experiment
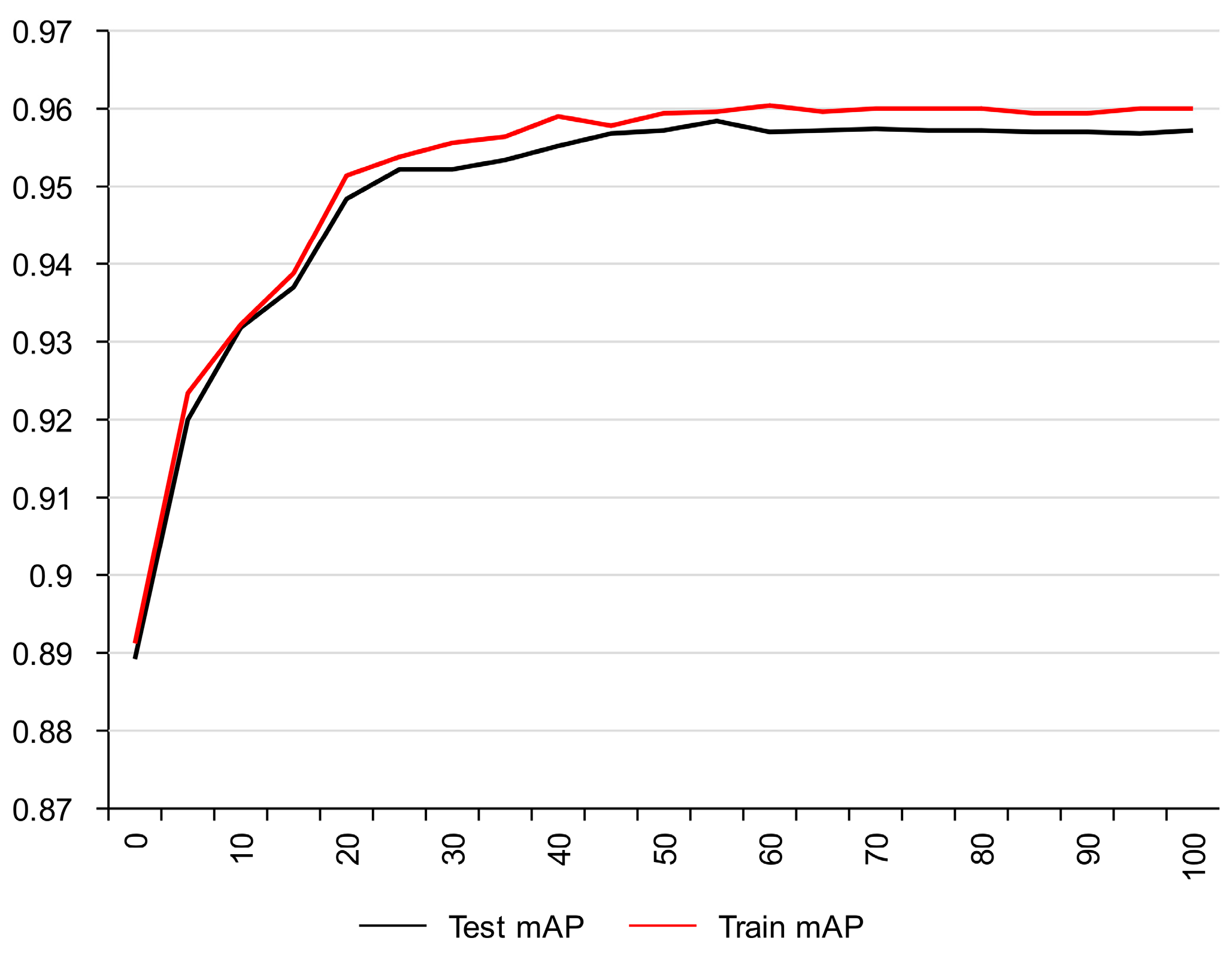
4.1. Evaluation
4.2. Classification Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, J. Landscape sustainability science: Ecosystem services and human well-being in changing landscapes. Landsc. Ecol. 2013, 28, 999–1023. [Google Scholar] [CrossRef]
- Lin, L.; Yan, J.; Ma, K.; Zhou, W.; Chen, G.; Tang, R.; Zhang, Y. Characterization of particulate matter deposited on urban tree foliage: A landscape analysis approach. Atmos. Environ. 2017, 171, 59–69. [Google Scholar] [CrossRef]
- Jenerette, G.D.; Harlan, S.L.; Buyantuev, A.; Stefanov, W.L.; Declet-Barreto, J.; Ruddell, B.L.; Myint, S.W.; Kaplan, S.; Li, X. Micro-scale urban surface temperatures are related to land-cover features and residential heat related health impacts in Phoenix, AZ USA. Landsc. Ecol. 2016, 31, 745–760. [Google Scholar] [CrossRef]
- Yan, J.; Lin, L.; Zhou, W.; Han, L.; Ma, K. Quantifying the characteristics of particulate matters captured by urban plants using an automatic approach. J. Environ. Sci. 2016, 39, 259–267. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Wang, J.; Cadenasso, M.L. Effects of the spatial configuration of trees on urban heat mitigation: A comparative study. Remote Sens. Environ. 2017, 195, 1–12. [Google Scholar] [CrossRef]
- Li, X.; Kamarianakis, Y.; Ouyang, Y.; Turner, B.L., II; Brazel, A. On the association between land system architecture and land surface temperatures: Evidence from a Desert Metropolis—Phoenix, Arizona, USA. Landsc. Urban Plan. 2017, 163, 107–120. [Google Scholar] [CrossRef]
- Adams, M.P.; Smith, P.L. A systematic approach to model the influence of the type and density of vegetation cover on urban heat using remote sensing. Landsc. Urban Plan. 2014, 132, 47–54. [Google Scholar] [CrossRef]
- Bowler, D.E.; Buyung-Ali, L.; Knight, T.M.; Pullin, A.S. Urban greening to cool towns and cities: A systematic review of the empirical evidence. Landsc. Urban Plan. 2010, 97, 147–155. [Google Scholar] [CrossRef]
- Pathak, V.; Tripathi, B.; Mishra, V. Evaluation of anticipated performance index of some tree species for green belt development to mitigate traffic generated noise. Urban For. Urban Green. 2011, 10, 61–66. [Google Scholar] [CrossRef]
- Van Renterghem, T.; Botteldooren, D. Reducing the acoustical façade load from road traffic with green roofs. Build. Environ. 2009, 44, 1081–1087. [Google Scholar] [CrossRef]
- Xiao, R.; Zhou, Z.; Wang, P.; Ye, Z.; Guo, E.; Ji, G.C. Application of 3S technologies in urban green space ecology. Chin. J. Ecol. 2004, 23, 71–76. [Google Scholar]
- Tu, X.; Huang, G.; Wu, J. Review of the relationship between urban greenspace accessibility and human well-being. Acta Ecol. Sin. 2019, 39, 421–431. [Google Scholar]
- Thompson, C.W.; Roe, J.; Aspinall, P.; Mitchell, R.; Clow, A.; Miller, D. More green space is linked to less stress in deprived communities: Evidence from salivary cortisol patterns. Landsc. Urban Plan. 2012, 105, 221–229. [Google Scholar] [CrossRef]
- Kaplan, R. The nature of the view from home: Psychological benefits. Environ. Behav. 2001, 33, 507–542. [Google Scholar] [CrossRef]
- Maas, J.; Verheij, R.A.; Groenewegen, P.P.; De Vries, S.; Spreeuwenberg, P. Green space, urbanity, and health: How strong is the relation? J. Epidemiol. Community Health 2006, 60, 587–592. [Google Scholar] [CrossRef] [PubMed]
- Kuo, F.E.; Sullivan, W.C. Environment and crime in the inner city: Does vegetation reduce crime? Environ. Behav. 2001, 33, 343–367. [Google Scholar] [CrossRef]
- Savard, J.-P.L.; Clergeau, P.; Mennechez, G. Biodiversity concepts and urban ecosystems. Landsc. Urban Plan. 2000, 48, 131–142. [Google Scholar] [CrossRef]
- Bolund, P.; Hunhammar, S. Ecosystem services in urban areas. Ecol. Econ. 1999, 29, 293–301. [Google Scholar] [CrossRef]
- Collins, K.A.; Lawrence, T.J.; Stander, E.K.; Jontos, R.J.; Kaushal, S.S.; Newcomer, T.A.; Grimm, N.B.; Ekberg, M.L.C. Opportunities and challenges for managing nitrogen in urban stormwater: A review and synthesis. Ecol. Eng. 2010, 36, 1507–1519. [Google Scholar] [CrossRef]
- Roy, A.H.; Wenger, S.J.; Fletcher, T.D.; Walsh, C.J.; Ladson, A.R.; Shuster, W.D.; Thurston, H.W.; Brown, R.R. Impediments and solutions to sustainable, watershed-scale urban stormwater management: Lessons from Australia and the United States. Environ. Manag. 2008, 42, 344–359. [Google Scholar] [CrossRef]
- Barbosa, O.; Tratalos, J.A.; Armsworth, P.R.; Davies, R.G.; Fuller, R.A.; Johnson, P.; Gaston, K.J. Who benefits from access to green space? A case study from Sheffield, UK. Landsc. Urban Plan. 2007, 83, 187–195. [Google Scholar] [CrossRef]
- Chen, W.; Huang, H.; Dong, J.; Zhang, Y.; Tian, Y.; Yang, Z. Social functional mapping of urban green space using remote sensing and social sensing data. ISPRS J. Photogramm. Remote Sens. 2018, 146, 436–452. [Google Scholar] [CrossRef]
- Zhang, M.-L.; Zhou, Z.-H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar] [CrossRef]
- Wei, Y.; Xia, W.; Lin, M.; Huang, J.; Ni, B.; Dong, J.; Zhao, Y.; Yan, S. HCP: A flexible CNN framework for multi-label image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1901–1907. [Google Scholar] [CrossRef] [PubMed]
- Tsoumakas, G.; Katakis, I. Multi-label classification: An overview. Int. J. Data Warehous. Min. 2007, 3, 1–13. [Google Scholar] [CrossRef]
- Tarekegn, A.N.; Giacobini, M.; Michalak, K. A review of methods for imbalanced multi-label classification. Pattern Recognit. 2021, 118, 107965. [Google Scholar] [CrossRef]
- Xiao, X.; Wu, Z.-C.; Chou, K.-C. iLoc-Virus: A multi-label learning classifier for identifying the subcellular localization of virus proteins with both single and multiple sites. J. Theor. Biol. 2011, 284, 42–51. [Google Scholar] [CrossRef] [PubMed]
- Lin, W.-Z.; Fang, J.-A.; Xiao, X.; Chou, K.-C. iLoc-Animal: A multi-label learning classifier for predicting subcellular localization of animal proteins. Mol. BioSystems 2013, 9, 634–644. [Google Scholar] [CrossRef]
- Salvatore, C.; Castiglioni, I. A wrapped multi-label classifier for the automatic diagnosis and prognosis of Alzheimer’s disease. J. Neurosci. Methods 2018, 302, 58–65. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, W.; Deng, X.; Zhang, M.; Cheng, Q. Multilabel remote sensing image retrieval based on fully convolutional network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 318–328. [Google Scholar] [CrossRef]
- Wang, J. Deep Learning-Based Lightweighting and Fusion of Label Information for Lung Disease Recognition Study. Master’s Thesis, Dalian Ocean University, Dalian, China, 2024. [Google Scholar]
- Wang, Y. Deep Learning Based Small Sample Classification and Multi-Label Classification of All-Sky Auroral Images. Master’s Thesis, Shaanxi Normal University, Xi’an, China, 2022. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3139–3148. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, Q.-L.; Yang, Y.-B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Liu, W.; Yue, A.; Shi, W.; Ji, J.; Deng, R. An automatic extraction architecture of urban green space based on DeepLabv3plus semantic segmentation model. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019; pp. 311–315. [Google Scholar]
- Xu, Z.; Zhou, Y.; Wang, S.; Wang, L.; Li, F.; Wang, S.; Wang, Z. A novel intelligent classification method for urban green space based on high-resolution remote sensing images. Remote Sens. 2020, 12, 3845. [Google Scholar] [CrossRef]
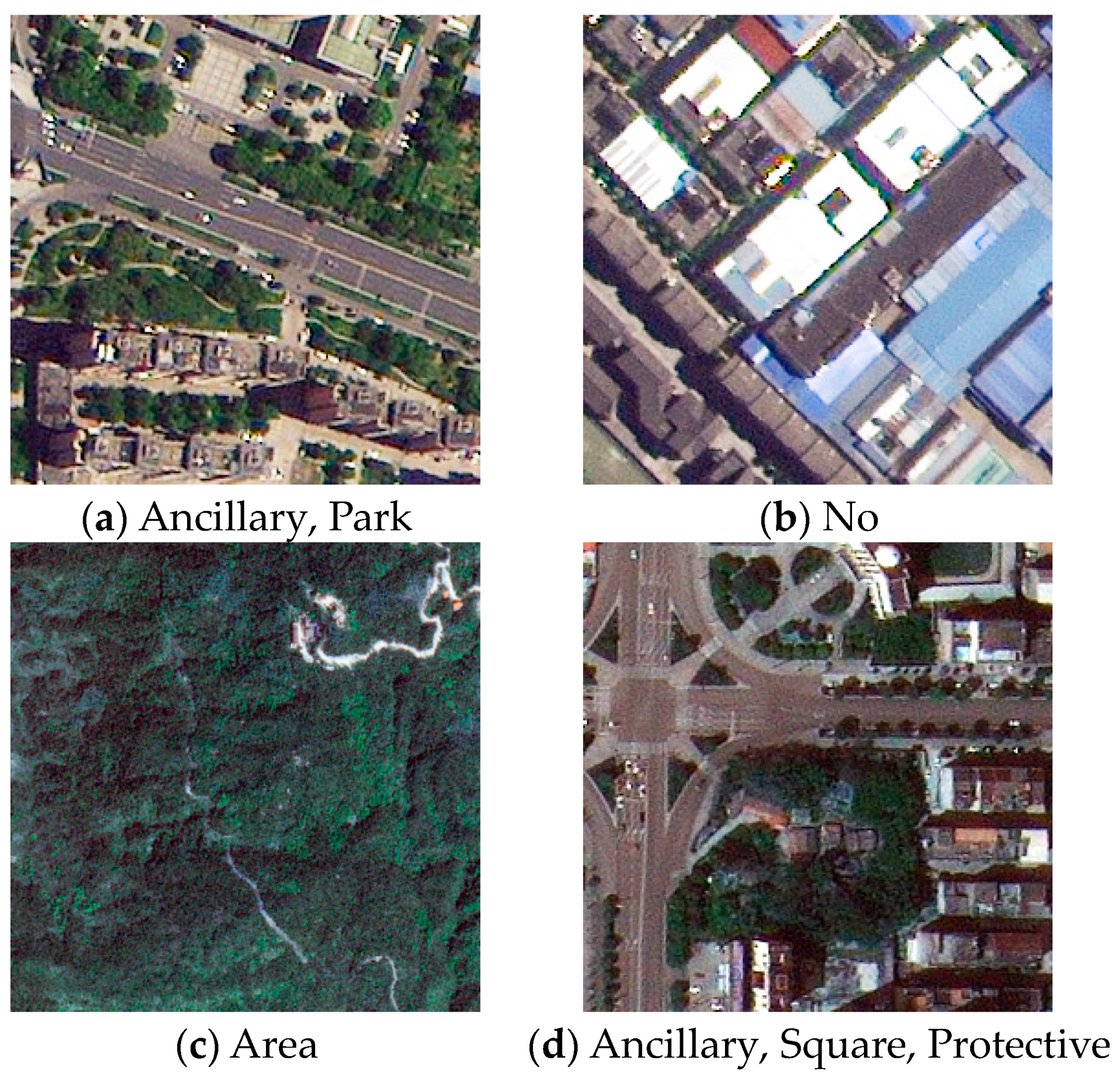




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quantity of Green Spaces in an Image | Quantity of This Kind of Picture | |
|---|---|---|
| 1 | 5405 | |
| 2 | 2143 | |
| 3 | 460 | |
| 4 | 26 | |
| Total | 8034 | |
| Green Space | Quantities | |
|---|---|---|
| Ancillary | 6349 | |
| Park | 1025 | |
| Square | 918 | |
| Protective | 824 | |
| Area | 1426 | |
| No | 633 | |
| Total | 11,175 | |
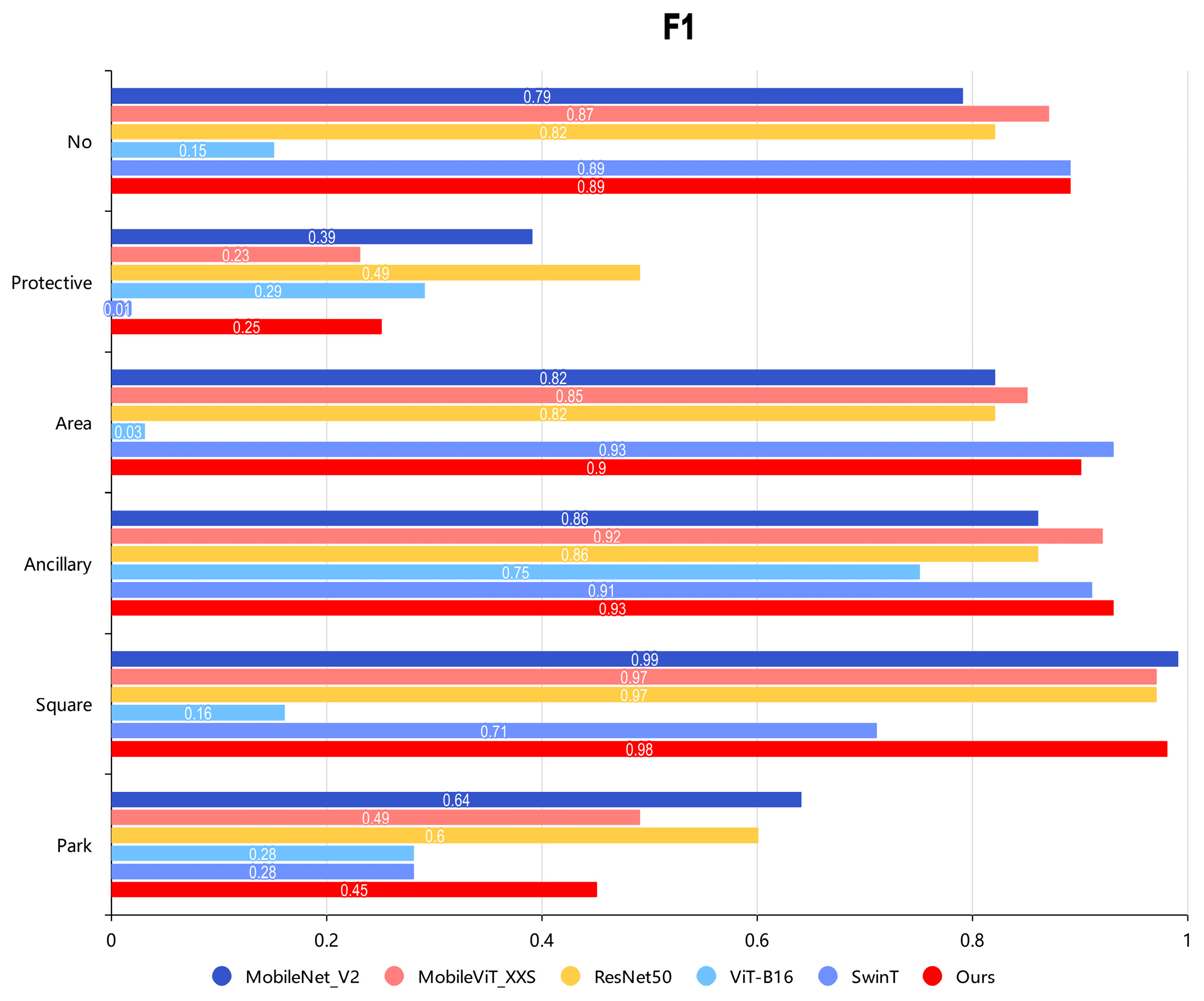
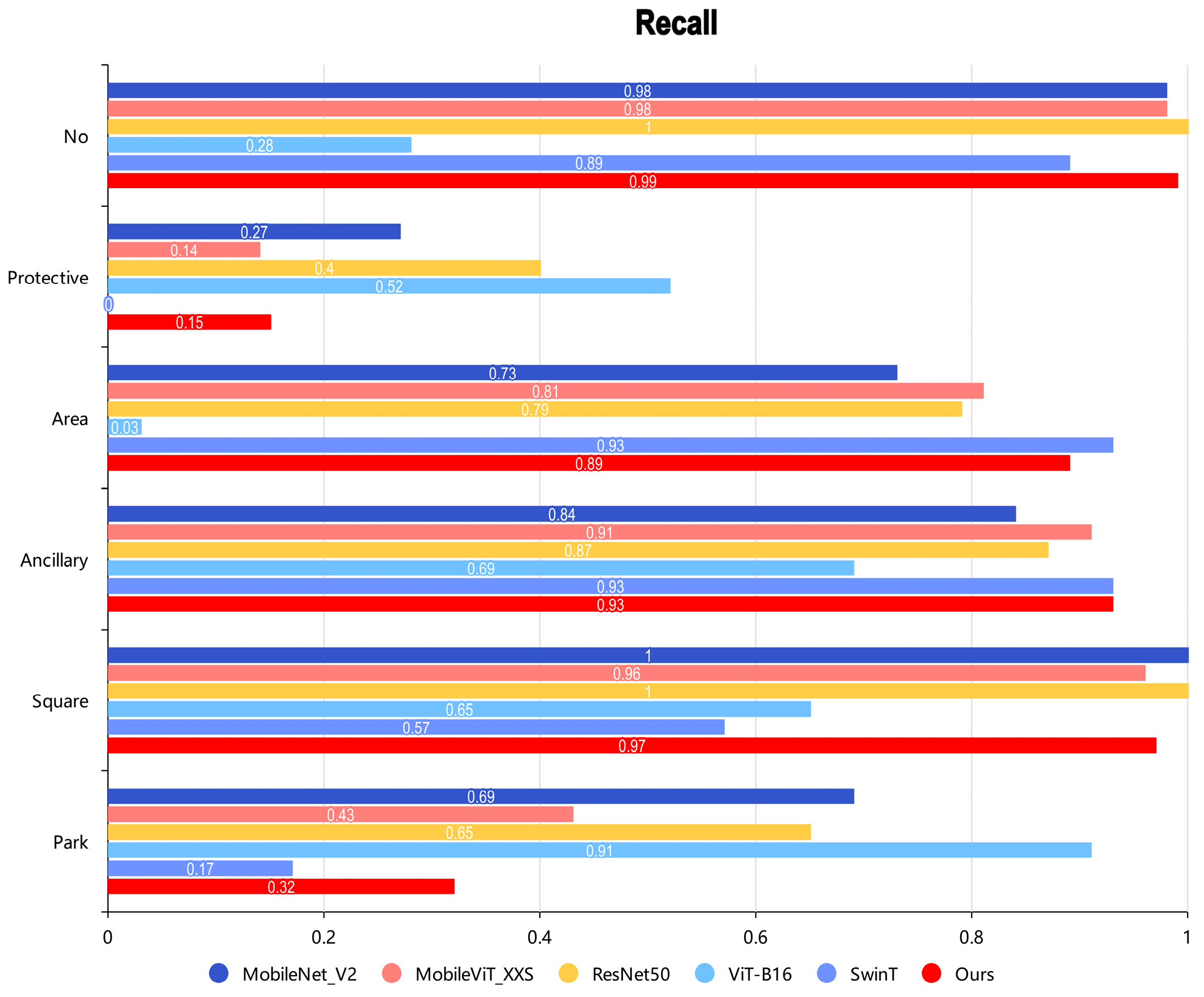
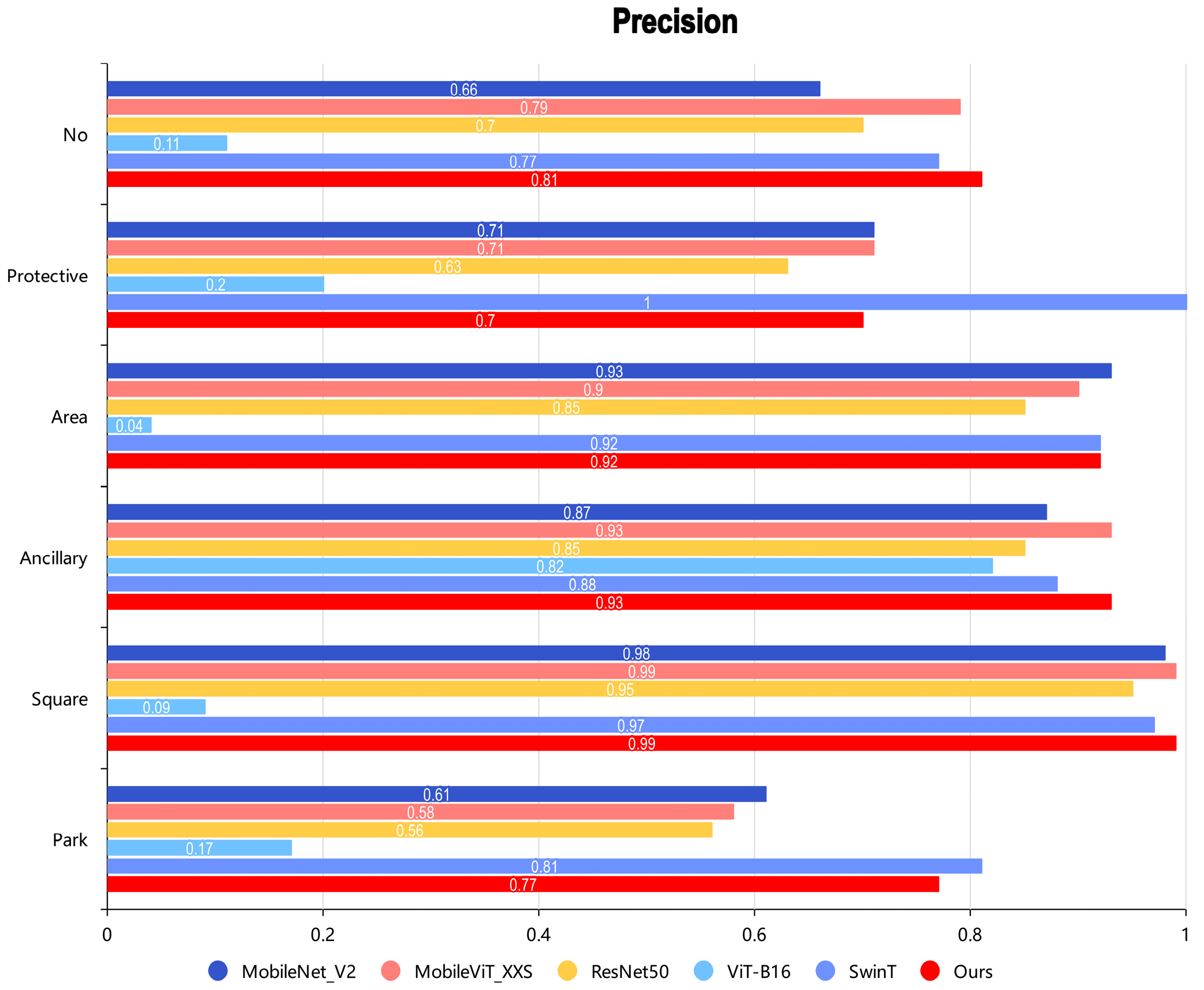
| Model | mAP (%) | F1 (%) | Precision (%) | Recall (%) | FLOPs (M) | Parameters (M) |
|---|---|---|---|---|---|---|
| ResNet50 | 90.62 | 79.71 | 81.06 | 82.24 | 5398.55 | 25.56 |
| MobileNet-V2 | 89.87 | 78.06 | 81.46 | 77.85 | 427.35 | 3.50 |
| ViT-B16 | 54.06 | 28.61 | 22.41 | 45.77 | 21,999.71 | 86.42 |
| Swin-T | 91.12 | 80.15 | 86.38 | 78.93 | 7110.03 | 28.27 |
| MobileViT_XXS | 92.51 | 82.56 | 87.91 | 80.85 | 350.34 | 1.01 |
| Model | mAP (%) | F1 (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|
| MobileViT | 92.51 | 82.56 | 87.91 | 80.85 |
| MobileViT + Triplet Attention | 92.74 | 82.76 | 88.20 | 81.26 |
| MobileViT + LSTM | 93.77 | 85.32 | 90.45 | 83.49 |
| MobileViT + LSTM + Triplet Attention | 94.15 | 85.81 | 91.58 | 83.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, W.; Zhang, D.; Liu, F.; Guo, Y.; Chen, S.; Wu, T.; Hou, Q. A Lightweight Multi-Label Classification Method for Urban Green Space in High-Resolution Remote Sensing Imagery. ISPRS Int. J. Geo-Inf. 2024, 13, 252. https://doi.org/10.3390/ijgi13070252
Lin W, Zhang D, Liu F, Guo Y, Chen S, Wu T, Hou Q. A Lightweight Multi-Label Classification Method for Urban Green Space in High-Resolution Remote Sensing Imagery. ISPRS International Journal of Geo-Information. 2024; 13(7):252. https://doi.org/10.3390/ijgi13070252
Chicago/Turabian StyleLin, Weihua, Dexiong Zhang, Fujiang Liu, Yan Guo, Shuo Chen, Tianqi Wu, and Qiuyan Hou. 2024. "A Lightweight Multi-Label Classification Method for Urban Green Space in High-Resolution Remote Sensing Imagery" ISPRS International Journal of Geo-Information 13, no. 7: 252. https://doi.org/10.3390/ijgi13070252
APA StyleLin, W., Zhang, D., Liu, F., Guo, Y., Chen, S., Wu, T., & Hou, Q. (2024). A Lightweight Multi-Label Classification Method for Urban Green Space in High-Resolution Remote Sensing Imagery. ISPRS International Journal of Geo-Information, 13(7), 252. https://doi.org/10.3390/ijgi13070252