

Extracting Geoscientific Dataset Names from the Literature Based on the Hierarchical Temporal Memory Model


Abstract
1. Introduction
- (1)
- An artificial neural network method developed specifically for extracting the names of geoscientific datasets is proposed. Compared with the GPT-4-based few-shot learning (FSL) method, this method has a higher F1-score.
- (2)
- A new word-encoding method for the HTM model is proposed. This method uses the Unicode values of characters to determine their relative positions in the semantic vector and employs a numerical mapping approach to reduce the encoding length. Compared to the semantic folding method, this approach demonstrates higher accuracy in encoding Chinese characters.
- (3)
- A new decoding structure for the HTM model is proposed. This decoding structure uses a BP neural network to decode the prediction vector for the encoding of the next word. By calculating the similarity of the encoding of the predicted word and the actual next word, the name of the geoscientific dataset is extracted word by word.
2. Related Work
2.1. Progress in Geoscientific Dataset Name Extraction
2.2. Progress in HTM Application
3. Methodology
3.1. General Idea
3.2. HTM Model
3.2.1. Sparse Distributed Representations
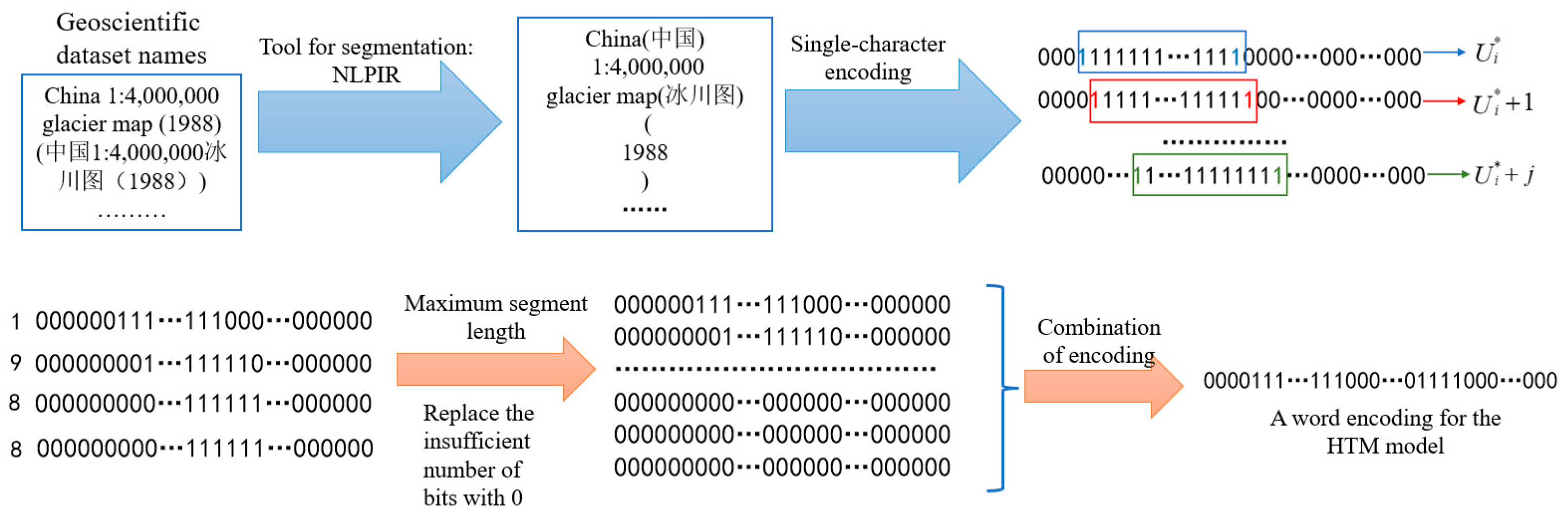
3.2.2. A New Word-Encoding Method for the HTM Model
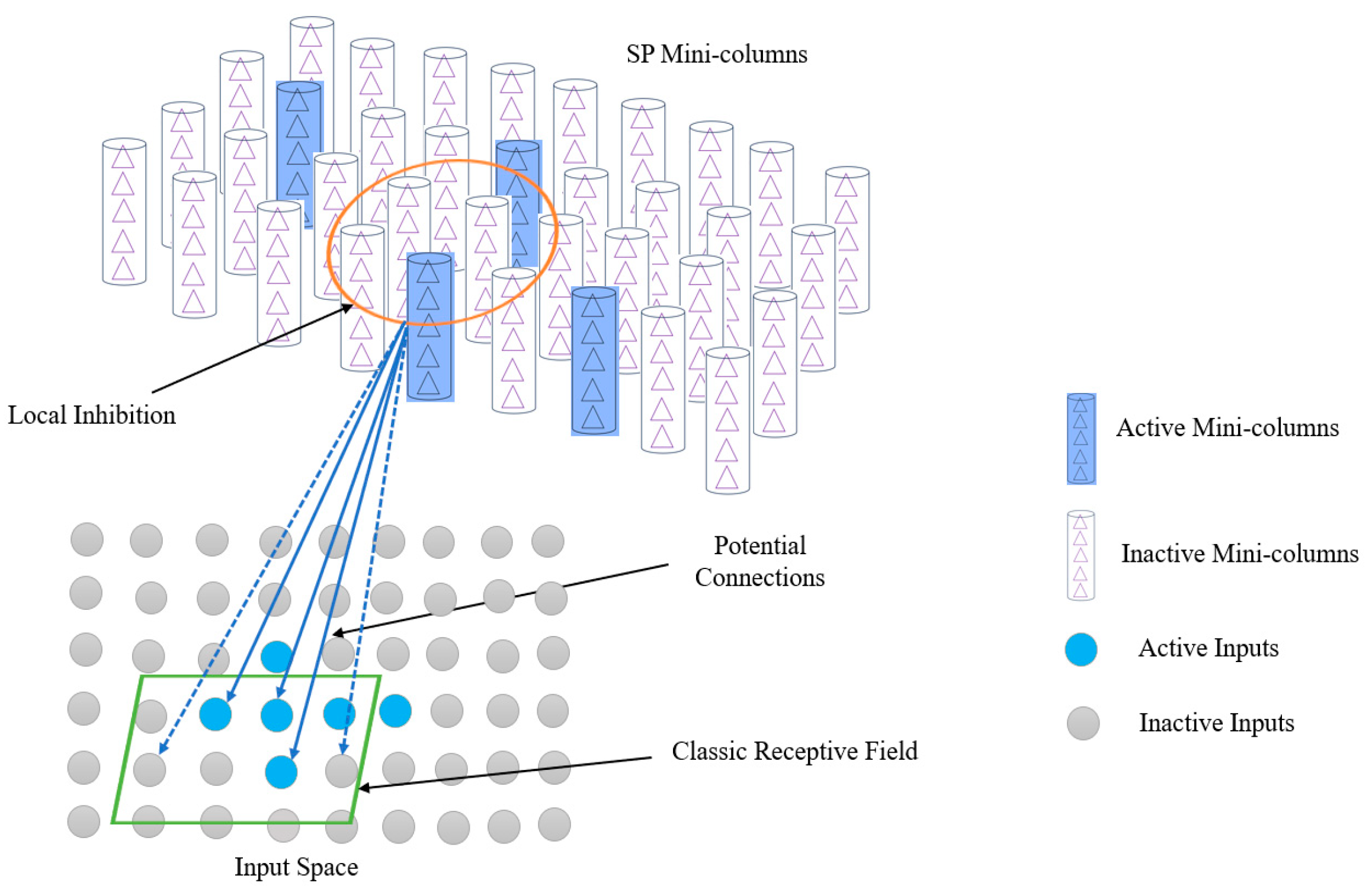
3.2.3. HTM Spatial Pooler
3.2.4. HTM Temporal Memory
3.2.5. Classifier
4. Experimental Section
4.1. Training Corpus
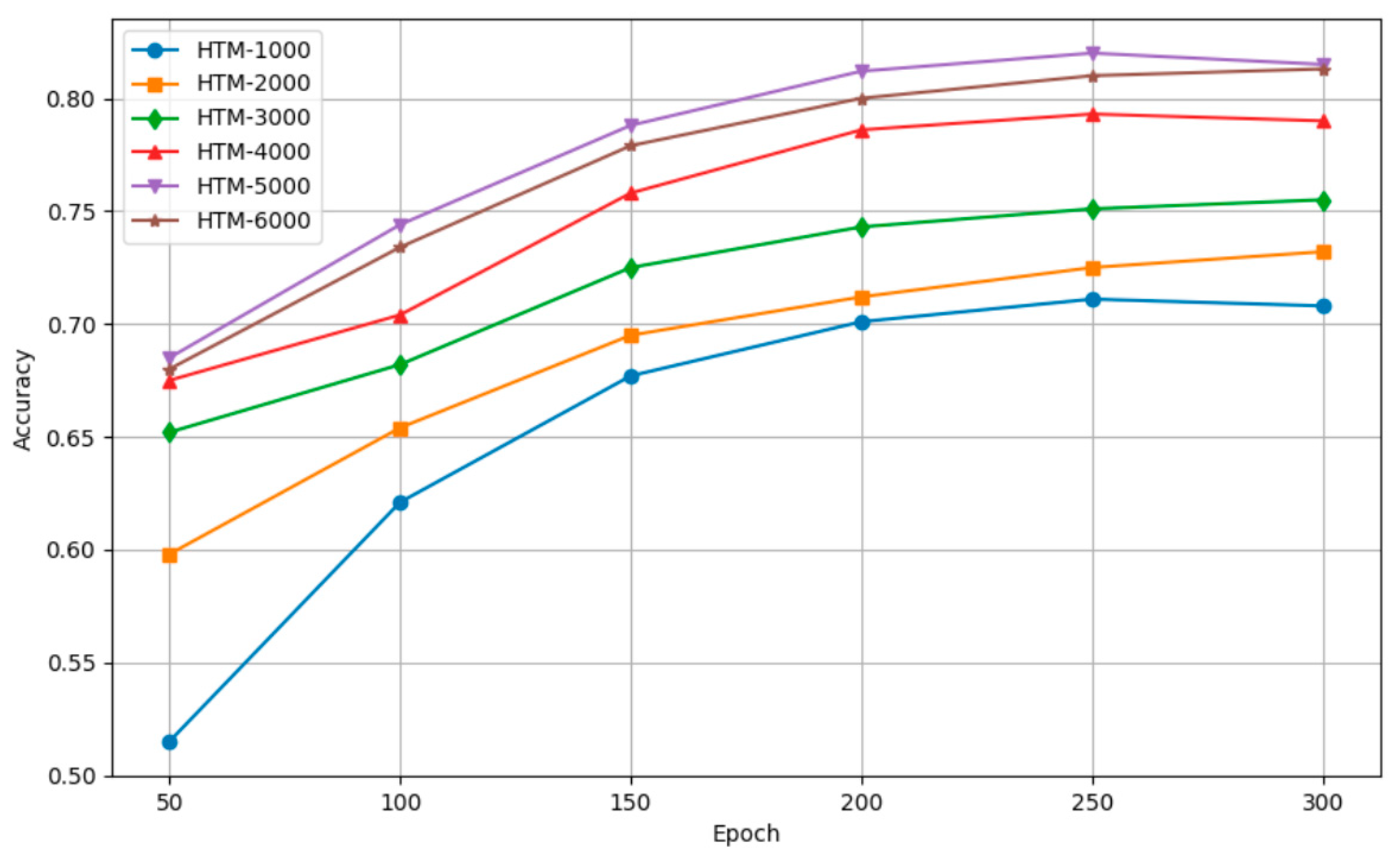
4.2. Creating and Training the HTM Model
5. Evaluation
5.1. Evaluation of Word-Encoding Method Precision

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Word One | Word Two | Standard Similarity | Semantic Folding Similarity | Our Encoding Method Similarity |
|---|---|---|---|---|---|
| 1 | waterway transportation | waterway transportation | 1 | 1 | 1 |
| 2 | oasis city | oasis city | 1 | 1 | 1 |
| 3 | port city | estuary city | 0.91 | 0.62 | 0.67 |
| 4 | tropical rainforest climate | equatorial rain climate | 0.87 | 0.53 | 0.33 |
| 5 | city | cities and towns | 0.86 | 0.58 | 0.50 |
| 6 | transportation | communication and transportation | 0.83 | 1 | 0.71 |
| 7 | nearshore environment | coastal environment | 0.78 | 0.88 | 0.75 |
| 8 | nearshore environment | sublittoral environment | 0.78 | 0.96 | 0.50 |
| 9 | plateau permafrost | frozen ground | 0.78 | 0.22 | 0.58 |
| 10 | cold wave | cold air mass | 0.77 | 0.64 | 0 |
| 11 | iron and steel industry | metallurgical industry | 0.73 | 0.56 | 0.72 |
| 12 | geographical environment | environment | 0.71 | 1 | 0.71 |
| 13 | highway transport | transport | 0.71 | 1 | 0.71 |
| 14 | semi-arid climate | steppe climate | 0.71 | 0.67 | 0.45 |
| 15 | climate | weather | 0.69 | 0.23 | 0 |
| 16 | milk industry | food industry | 0.68 | 0.7 | 0.75 |
| 17 | cultural landscape | landscape | 0.67 | 1 | 0.71 |
| 18 | processing industry | light industry | 0.66 | 0.66 | 0.58 |
| 19 | cold wave | disastrous weather | 0.65 | 0.28 | 0.03 |
| 20 | coal industry | heavy industry | 0.63 | 0.61 | 0.58 |
| 21 | farming industry | industry | 0.61 | 1 | 0.53 |
| 22 | gray desert soil | brown desert soil | 0.60 | 0.82 | 0.67 |
| 23 | marine environment | geographical environment | 0.60 | 0.61 | 0.50 |
| 24 | eco-environment | water environment | 0.59 | 0.61 | 0.58 |
| 25 | tropical soil | subtropical soil | 0.57 | 0.84 | 0.89 |
| … | … | … | … | … | |
| 64 | desert climate | internal water transport | 0.03 | 0.26 | 0.01 |
| 65 | polar climate | mining industry | 0.02 | 0.25 | 0 |
| 66 | desert climate | labor-intensive industry | 0 | 0.2 | 0 |
| Statistical Indicator | Proposed Encoding Method | Semantic Folding Method |
|---|---|---|
| Pearson correlation coefficient | 0.69 | 0.62 |
| p-value | 2.15 × 10−10 | 3.61 × 10−8 |
5.2. Evaluation of Geoscientific Dataset Name-Extraction Accuracy
6. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Parameter Name | Value | Parameter Name | Value |
|---|---|---|---|
| Number of columns | 5000 | Number of cells per column | 6 |
| Input dimensions | 22,476 | Potential radius | 6 |
| Number of active columns | 48 | Connected threshold for synaptic permanence | 0.7 |
| Initial synaptic permanence | 0.1 | Dendritic segment activation threshold | 4 |
| Synaptic permanence increment | 0.1 | Synaptic permanence decrement | 0.1 |
| Extraction Method | Names of Benchmark Geoscientific Datasets | Results of Five Recognition Methods |
|---|---|---|
| Proposed method | The Land Use and Cover Change (LUCC) dataset, The China Annual Land Cover Dataset (CLCD), The regional data of China from GlobeLand30, The spatial distribution data of the Qinghai-Tibet Plateau ecosystems for the years 2000, 2010, and 2020 with a spatial resolution of 30 m, 1:1,000,000 soil type map | The data sources for this article are as follows: (1) Ecosystem-type data. The Land Use and Cover Change (LUCC) dataset from the Data Center for Resources and Environmental Sciences, Chinese Academy of Sciences; the China Annual Land Cover Dataset (CLCD) based on satellite data from Google Earth Engine (GEE); and the regional data of China from GlobeLand30. Based on the aforementioned land use and cover types, they were transformed into ecosystem types such as cropland, forest, grassland, wetland, and settlement, obtaining the spatial distribution data of the Qinghai-Tibet Plateau ecosystems for the years 2000, 2010, and 2020 with a spatial resolution of 30 m. (2) Soil data. The soil property tables and spatial distribution data attached to the 1:1,000,000 soil type map come from the Western Environmental and Ecological Science Data Center, and the soil erodibility factor was estimated using the Nomograph method. |
| GPT-4-based zero-shot learning (ZSL) method | The data sources for this article are as follows: (1) Ecosystem-type data. The Land Use and Cover Change (LUCC) dataset from the Data Center for Resources and Environmental Sciences, Chinese Academy of Sciences; the China Annual Land Cover Dataset (CLCD) based on satellite data from Google Earth Engine (GEE); and the regional data of China from GlobeLand30. Based on the aforementioned land use and cover types, they were transformed into ecosystem types such as cropland, forest, grassland, wetland, and settlement, obtaining the spatial distribution data of the Qinghai-Tibet Plateau ecosystems for the years 2000, 2010, and 2020 with a spatial resolution of 30 m. (2) Soil data. The soil property tables and spatial distribution data attached to the 1:1,000,000 soil type map come from the Western Environmental and Ecological Science Data Center, and the soil erodibility factor was estimated using the Nomograph method. | |
| GPT-4-based few-shot learning (FSL) method | The data sources for this article are as follows: (1) Ecosystem-type data. The Land Use and Cover Change (LUCC) dataset from the Data Center for Resources and Environmental Sciences, Chinese Academy of Sciences; the China Annual Land Cover Dataset (CLCD) based on satellite data from Google Earth Engine (GEE); and the regional data of China from GlobeLand30. Based on the aforementioned land use and cover types, they were transformed into ecosystem types such as cropland, forest, grassland, wetland, and settlement, obtaining the spatial distribution data of the Qinghai-Tibet Plateau ecosystems for the years 2000, 2010, and 2020 with a spatial resolution of 30 m. (2) Soil data. The soil property tables and spatial distribution data attached to the 1:1,000,000 soil type map come from the Western Environmental and Ecological Science Data Center, and the soil erodibility factor was estimated using the Nomograph method. | |
| Proposed method | The Land Use and Cover Change (LUCC) dataset, The China Annual Land Cover Dataset (CLCD), The regional data of China from GlobeLand30, The spatial distribution data of the Qinghai-Tibet Plateau ecosystems for the years 2000, 2010, and 2020 with a spatial resolution of 30 m, 1:1,000,000 soil type map | Data sources for this article: (1) Ecosystem-type data: The Land Use and Cover Change (LUCC) dataset from the Data Center for Resources and Environmental Sciences, Chinese Academy of Sciences; the China Annual Land Cover Dataset (CLCD) based on satellite data from Google Earth Engine (GEE); and the regional data of China from GlobeLand30. Based on land use and cover types, they were transformed into ecosystem types including cropland, forest, grassland, wetland, and settlement, to obtain spatial distribution data of the Qinghai-Tibet Plateau ecosystems for the years 2000, 2010, and 2020 with a spatial resolution of 30 m. (2) Soil data: Soil property tables and spatial distribution data attached to 1:1,000,000 soil type map come from Western Environmental and Ecological Science Data Center, and soil erodibility factor was estimated using the nomograph method. |
| Claude-3-based zero-shot learning (ZSL) method | Data sources for this article: (1) Ecosystem-type data: The Land Use and Cover Change (LUCC) dataset from the Data Center for Resources and Environmental Sciences, Chinese Academy of Sciences; the China Annual Land Cover Dataset (CLCD) based on satellite data from Google Earth Engine (GEE); and the regional data of China from GlobeLand30. Based on land use and cover types, they were transformed into ecosystem types including cropland, forest, grassland, wetland, and settlement to obtain spatial distribution data of the Qinghai-Tibet Plateau ecosystems for the years 2000, 2010, and 2020 with a spatial resolution of 30 m. (2) Soil data: The soil property tables and spatial distribution data attached to 1:1,000,000 soil type map come from the Western Environmental and Ecological Science Data Center, and the soil erodibility factor was estimated using the nomograph method. | |
| Claude-3-based few-shot learning (FSL) method | Data sources for this article: (1) Ecosystem-type data: The Land Use and Cover Change (LUCC) dataset from the Data Center for Resources and Environmental Sciences, Chinese Academy of Sciences; the China Annual Land Cover Dataset (CLCD) based on satellite data from Google Earth Engine (GEE); and the regional data of China from GlobeLand30. Based on land use and cover types, they were transformed into ecosystem types including cropland, forest, grassland, wetland, and settlement, to obtain spatial distribution data of the Qinghai-Tibet Plateau ecosystems for the years 2000, 2010, and 2020 with a spatial resolution of 30 m. (2) Soil data: The soil property tables and spatial distribution data attached to the 1:1,000,000 soil type map come from the Western Environmental and Ecological Science Data Center, and soil erodibility factor was estimated using the nomograph method. |
| Extraction Method | Names of Benchmark Geoscientific Datasets | Results of Five Recognition Methods |
|---|---|---|
| Proposed method | The Fourth Forest Resources Inventory of Guangdong Province, The second National Soil Survey Data for Guangdong (1979–1985), Harmonized World Soil Database, The basic attribute dataset of China’s high-resolution national soil information grid for Guangdong (2010–2018) | The Fourth Forest Resources Inventory of Guangdong Province (partial pilot cities 2013–2016, province-wide 2017–2018) is sourced from Guangdong Provincial Department of Natural Resources in the form of vector layers, with precision to the forestry sub compartment scale. Guangdong Province has 2,403,557 forestry sub compartments, with an average area of about 0.07 km2 each. The second National Soil Survey data for Guangdong (1979–1985), with information such as soil organic carbon content and soil bulk density, is sourced from the Harmonized World Soil Database by the UN Food and Agriculture Organization, with a spatial resolution of 0.25 km × 0.25 km. The basic attribute dataset of China’s high-resolution national soil information grid for Guangdong (2010–2018) also provides information on soil organic carbon content and bulk density, sourced from the Soil Data Center of the National Earth System Science Data Center (http://soil.geodata.cn/ (accessed on 12 April 2022)), with a spatial resolution of 1 km × 1 km. |
| GPT-4-based zero-shot learning (ZSL) method | The Fourth Forest Resources Inventory of Guangdong Province (partial pilot cities 2013–2016, province-wide 2017–2018) was sourced from the Guangdong Provincial Department of Natural Resources in the form of vector layers, with precision to the forestry sub compartment scale. Guangdong Province has 2,403,557 forestry sub compartments, with an average area of about 0.07 km2 each. The second National Soil Survey data for Guangdong (1979–1985), with information including soil organic carbon content and soil bulk density, sourced from the Harmonized World Soil Database by the UN Food and Agriculture Organization, with spatial resolution of 0.25 km × 0.25 km. The basic attribute dataset of China’s high-resolution national soil information grid for Guangdong (2010–2018) also provides information on soil organic carbon content and bulk density, sourced from the Soil Data Center of the National Earth System Science Data Center (http://soil.geodata.cn/ (accessed on 12 April 2022)), with a spatial resolution of 1 km × 1 km. | |
| GPT-4-based few-shot learning (FSL) method | The Fourth Forest Resources Inventory of Guangdong Province (partial pilot cities 2013–2016, province-wide 2017–2018) sourced from the Guangdong Provincial Department of Natural Resources in the form of vector layers, with precision to the forestry sub compartment scale. Guangdong Province has 2,403,557 forestry sub compartments, with an average area of about 0.07 km2 each. The second National Soil Survey data for Guangdong (1979–1985), with information including soil organic carbon content and bulk density, sourced from the Harmonized World Soil Database by the UN Food and Agriculture Organization, with spatial resolution of 0.25 km × 0.25 km. The basic attribute dataset of China’s high-resolution national soil information grid for Guangdong (2010–2018) also provides information on soil organic carbon content and bulk density, sourced from the Soil Data Center of the National Earth System Science Data Center (http://soil.geodata.cn/ (accessed on 12 April 2022)), with spatial resolution of 1 km × 1 km. | |
| Proposed method | The Fourth Forest Resources Inventory of Guangdong Province, The second National Soil Survey Data for Guangdong (1979–1985), Harmonized World Soil Database, The basic attribute dataset of China’s high-resolution national soil information grid for Guangdong (2010–2018) | The Fourth Forest Resources Inventory of Guangdong Province (partial pilot cities 2013–2016, province-wide 2017–2018) sourced from Guangdong Provincial Department of Natural Resources in the form of vector layers, with precision to the forestry sub compartment scale. Guangdong Province has 2,403,557 forestry sub compartments, with an average area of about 0.07 km2 each. The second National Soil Survey data for Guangdong (1979–1985), with information including soil organic carbon content and bulk density, sourced from the Harmonized World Soil Database by the UN Food and Agriculture Organization, with spatial resolution of 0.25 km × 0.25 km. The basic attribute dataset of China’s high-resolution national soil information grid for Guangdong (2010–2018) also provides information on soil organic carbon content and bulk density, sourced from the Soil Data Center of the National Earth System Science Data Center (http://soil.geodata.cn/ (accessed on 12 April 2022)), with spatial resolution of 1 km × 1 km. |
| Claude-3-based zero-shot learning (ZSL) method | The Fourth Forest Resources Inventory of Guangdong Province (partial pilot cities 2013–2016, province-wide 2017–2018) sourced from Guangdong Provincial Department of Natural Resources in the form of vector layers, with precision to the forestry sub compartment scale. Guangdong Province has 2,403,557 forestry sub compartments, with an average area of about 0.07 km2 each. The second National Soil Survey data for Guangdong (1979–1985), with information including soil organic carbon content and bulk density, sourced from the Harmonized World Soil Database by the UN Food and Agriculture Organization, with spatial resolution of 0.25 km × 0.25 km. The basic attribute dataset of China’s high-resolution national soil information grid for Guangdong (2010–2018) also provides information on soil organic carbon content and bulk density, sourced from the Soil Data Center of the National Earth System Science Data Center (http://soil.geodata.cn/ (accessed on 12 April 2022)), with spatial resolution of 1 km × 1 km. | |
| Claude-3-based few-shot learning (FSL) method | The Fourth Forest Resources Inventory of Guangdong Province (partial pilot cities 2013–2016, province-wide 2017–2018) sourced from Guangdong Provincial Department of Natural Resources in the form of vector layers, with precision to the forestry sub compartment scale. Guangdong Province has 2,403,557 forestry sub compartments, with an average area of about 0.07 km2 each. The second National Soil Survey data for Guangdong (1979–1985), with information including soil organic carbon content and bulk density, sourced from the Harmonized World Soil Database by the UN Food and Agriculture Organization, with spatial resolution of 0.25 km × 0.25 km. The basic attribute dataset of China’s high-resolution national soil information grid for Guangdong (2010–2018) also provides information on soil organic carbon content and bulk density, sourced from the Soil Data Center of the National Earth System Science Data Center (http://soil.geodata.cn/ (accessed on 12 April 2022)), with spatial resolution of 1 km × 1 km. |
References
- Li, J.; Zhou, C. Analysis on the Characteristics of Geospatial Data. Sci. Geogr. Sin. 1999, 19, 158–162. [Google Scholar] [CrossRef]
- Lu, M.; Appel, M.; Pebesma, E. Multidimensional Arrays for Analysing Geoscientific Data. ISPRS Int. J. Geo-Inf. 2018, 7, 313. [Google Scholar] [CrossRef]
- Buttlar, J.v.; Zscheischler, J.; Mahecha, M.D. An extended approach for spatiotemporal gapfilling: Dealing with large and systematic gaps in geoscientific datasets. Nonlin. Process. Geophys. 2014, 21, 203–215. [Google Scholar] [CrossRef]
- Sun, K.; Zhu, Y.; Pan, P.; Hou, Z.; Wang, D.; Li, W.; Song, J. Geospatial data ontology: The semantic foundation of geospatial data integration and sharing. Big Earth Data 2019, 3, 269–296. [Google Scholar] [CrossRef]
- Kostoff, R.N. Role of Technical Literature in Science and Technology Development and Exploitation. J. Inf. Sci. 2003, 29, 223–228. [Google Scholar] [CrossRef]
- Ning, B.; Zhao, Y. To Embrace Open Science More Closely. Innovation 2020, 1, 100012. [Google Scholar] [CrossRef] [PubMed]
- Morse, P.; Reading, A.; Lueg, C. Animated analysis of geoscientific datasets: An interactive graphical application. Comput. Geosci. 2017, 109, 87–94. [Google Scholar] [CrossRef]
- Konkol, M.; Kray, C.; Pfeiffer, M. Computational reproducibility in geoscientific papers: Insights from a series of studies with geoscientists and a reproduction study. Int. J. Geogr. Inf. Sci. 2019, 33, 408–429. [Google Scholar] [CrossRef]
- Gil, Y.; David, C.H.; Demir, I.; Essawy, B.T.; Fulweiler, R.W.; Goodall, J.L.; Karlstrom, L.; Lee, H.; Mills, H.J.; Oh, J.H.; et al. Toward the Geoscience Paper of the Future: Best practices for document ing and sharing research from data to software to provenance. Earth Space Sci. 2016, 3, 388–415. [Google Scholar] [CrossRef]
- Zhang, S.; Xu, H.; Jia, Y.; Wen, Y.; Wang, D.; Fu, L.; Wang, X.; Zhou, C. GeoDeepShovel: A platform for building scientific database from geoscience literature with AI assistance. Geosci. Data J. 2023, 10, 519–537. [Google Scholar] [CrossRef]
- Tao, L.; Xie, Z.; Xu, D.; Ma, K.; Qiu, Q.; Pan, S.; Huang, B. Geographic Named Entity Recognition by Employing Natural Language Processing and an Improved BERT Model. ISPRS Int. J. Geo-Inf. 2022, 11, 598. [Google Scholar] [CrossRef]
- Chung, C.-J.F.; Fabbri, A.G. The representation of geoscience information for data integration. Nonrenew. Resour. 1993, 2, 122–139. [Google Scholar] [CrossRef]
- Arias, A.; Dini, I.; Casini, M.; Fiordelisi, A.; Perticone, I.; Pisano, A. Geoscientific Feature Update of the Larderello-Travale Geothermal System (Italy) for a Regional Numerical Modeling. In Proceedings of the World Geothermal Congress 2010, Bali, Indonesia, 25–30 April 2010. [Google Scholar]
- Färber, M.; Albers, A.; Schüber, F. Identifying Used Methods and Datasets in Scientific Publications. In Proceedings of the SDU@AAAI Workshop on Scientific Document Understanding, Online, 19 February 2021. [Google Scholar]
- Heddes, J.; Meerdink, P.; Pieters, M.; Marx, M. The Automatic Detection of Dataset Names in Scientific Articles. Data 2021, 6, 84. [Google Scholar] [CrossRef]
- George, D.; Hawkins, J. A hierarchical Bayesian model of invariant pattern recognition in the visual cortex. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005. [Google Scholar]
- George, D.; Hawkins, J. Towards a Mathematical Theory of Cortical Micro-circuits. PLoS Comput. Biol. 2009, 5, e1000532. [Google Scholar] [CrossRef] [PubMed]
- Klukas, M.; Lewis, M.; Fiete, I. Efficient and flexible representation of higher-dimensional cognitive variables with grid cells. PLOS Comput. Biol. 2020, 16, e1007796. [Google Scholar] [CrossRef]
- Cao, Q.; Wang, S.; Chen, Z.; Li, G.; Li, J. The Method of Extracting Names of Geo-science Data based on Regular Expressions. J. Geo-Inf. Sci. 2023, 25, 1601–1610. [Google Scholar] [CrossRef]
- Afzal, M.T.; Maurer, H.A.; Balke, W.-T.; Kulathuramaiyer, N. Rule based Autonomous Citation Mining with TIERL. J. Digit. Inf. Manag. 2010, 8, 196–204. [Google Scholar]
- Fries, J.A.; Varma, P.; Chen, V.S.; Xiao, K.; Tejeda, H.; Saha, P.; Dunnmon, J.A.; Chubb, H.; Maskatia, S.A.; Fiterau, M.; et al. Weakly supervised classification of aortic valve malformations using unlabeled cardiac MRI sequences. Nat. Commun. 2019, 10, 3111. [Google Scholar] [CrossRef] [PubMed]
- Soni, A.; Viswanathan, D.; Pachaiyappan, N.; Natarajan, S. A Comparison of Weak Supervision methods for Knowledge Base Construction. In Proceedings of the AKBC@NAACL-HLT, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Zech, J.R.; Pain, M.; Titano, J.J.; Badgeley, M.A.; Schefflein, J.; Su, A.; Costa, A.B.; Bederson, J.B.; Lehár, J.; Oermann, E.K. Natural Language-based Machine Learning Models for the Annotation of Clinical Radiology Reports. Radiology 2018, 287, 570–580. [Google Scholar] [CrossRef]
- Cui, B.-G.; Chen, X. An Improved Hidden Markov Model for Literature Metadata Extraction. In Proceedings of the 6th International Conference on Advanced Intelligent Computing Theories and Applications: Intelligent Computing, Changsha, China, 18 August 2010; pp. 205–212. [Google Scholar]
- Zhang, K.; Xu, H.; Tang, J.; Li, J.-Z. Keyword Extraction Using Support Vector Machine. In Proceedings of the Interational Conference on Web-Age Information Management, Hong Kong, China, 17–19 June 2006; pp. 85–96. [Google Scholar]
- Kaur, J.; Gupta, V. Effective Approaches for Extraction of Keywords. Int. J. Comput. Sci. 2010, 7, 144–148. [Google Scholar]
- Han, H.; Giles, C.L.; Manavoglu, E.; Zha, H.; Zhang, Z.; Fox, E.A. Automatic document metadata extraction using support vector machines. In Proceedings of the 2003 Joint Conference on Digital Libraries, Houston, TX, USA, 20 June 2003; pp. 37–48. [Google Scholar]
- Shinde, P.; Shah, S. A Review of Machine Learning and Deep Learning Applications. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 25 April 2018; pp. 1–6. [Google Scholar]
- Zhao, Z.; Yang, Z.; Luo, L.; Wang, L.; Zhang, Y.; Lin, H.; Wang, J. Disease named entity recognition from biomedical literature using a novel convolutional neural network. BMC Med. Genom. 2017, 10, 73. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Delgado, J.; Ebreso, U.; Kumar, Y.; Li, J.J.; Morreale, P. Preliminary Results of Applying Transformers to Geoscience and Earth Science Data. In Proceedings of the 2022 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 14–16 December 2022; pp. 284–288. [Google Scholar]
- Bhattarai, K.; Oh, I.; Sierra, J.; Payne, P.; Abrams, Z.; Lai, A. Leveraging GPT-4 for Identifying Clinical Phenotypes in Electronic Health Records: A Performance Comparison between GPT-4, GPT-3.5-turbo and spaCy’s Rule-based & Machine Learning-based methods. bioRxiv 2023. preprint. [Google Scholar] [CrossRef]
- Yao, R.; Hou, L.; Ye, Y.; Zhang, J.; Wu, J. Method and Dataset Mining in Scientific Papers. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 6260–6262. [Google Scholar]
- Kumar, S.; Ghosal, T.; Ekbal, A. DataQuest: An Approach to Automatically Extract Dataset Mentions from Scientific Papers. In Proceedings of the International Conference on Asian Digital Libraries, Hanoi, Vietnam, 30 November 2021; pp. 43–53. [Google Scholar]
- Younes, Y.; Scherp, A. Question Answering Versus Named Entity Recognition for Extracting Unknown Datasets. IEEE Access 2023, 11, 92775–92787. [Google Scholar] [CrossRef]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3606–3611. [Google Scholar]
- Lin, Z.; Deng, C.; Zhou, L.; Zhang, T.; Xu, Y.; Xu, Y.; He, Z.; Shi, Y.; Dai, B.; Song, Y.; et al. GeoGalactica: A Scientific Large Language Model in Geoscience. arXiv 2023, arXiv:2401.00434. [Google Scholar]
- Ahsan, M.M.T.; Rahaman, M.S.; Anjum, N. From ChatGPT-3 to GPT-4: A Significant Leap in AI-Driven NLP Tools. J. Eng. Emerg. Technol. 2023, 1, 50–60. [Google Scholar] [CrossRef]
- Hosseini, S.; Najafipour, S.; Cheung, N.-M.; Yin, H.; Kangavari, M.R.; Zhou, X. TEAGS: Time-aware text embedding approach to generate subgraphs. Data Min. Knowl. Discov. 2020, 34, 1136–1174. [Google Scholar] [CrossRef]
- Najafipour, S.; Hosseini, S.; Hua, W.; Kangavari, M.R.; Zhou, X. SoulMate: Short-Text Author Linking Through Multi-Aspect Temporal-Textual Embedding. IEEE Trans. Knowl. Data Eng. 2022, 34, 448–461. [Google Scholar] [CrossRef]
- Hosseini, S.; Yin, H.; Zhou, X.; Sadiq, S.; Kangavari, M.R.; Cheung, N.-M. Leveraging multi-aspect time-related influence in location recommendation. World Wide Web 2019, 22, 1001–1028. [Google Scholar] [CrossRef]
- Hosseini, S.; Yin, H.; Zhang, M.; Zhou, X.; Sadiq, S. Jointly Modeling Heterogeneous Temporal Properties in Location Recommendation. In Database Systems for Advanced Applications; Springer: Cham, Switzerland, 2017; pp. 490–506. [Google Scholar]
- Saaki, M.; Hosseini, S.; Rahmani, S.; Kangavari, M.R.; Hua, W.; Zhou, X. Value-Wise ConvNet for Transformer Models: An Infinite Time-Aware Recommender System. IEEE Trans. Knowl. Data Eng. 2023, 35, 9932–9945. [Google Scholar] [CrossRef]
- Malawade, A.; Costa, N.; Muthirayan, D.; Khargonekar, P.; Al Faruque, M.A. Neuroscience-Inspired Algorithms for the Predictive Maintenance of Manufacturing Systems. IEEE Trans. Ind. Inform. 2021, 17, 7980–7990. [Google Scholar] [CrossRef]
- Zeng, H.; Zhao, X.; Wang, L. Multivariate Time Series Anomaly Detection On Improved HTM Model. In Proceedings of the 2021 IEEE International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI), Fuzhou, China, 24–26 September 2021; pp. 759–763. [Google Scholar]
- Krestinskaya, O.; Ibrayev, T.; James, A.P. Hierarchical Temporal Memory Features with Memristor Logic Circuits for Pattern Recognition. IEEE Trans. Comput. -Aided Des. Integr. Circuits Syst. 2018, 37, 1143–1156. [Google Scholar] [CrossRef]
- Irmanova, A.; Krestinskaya, O.; James, A.P. Image Based HTM Word Recognizer for Language Processing. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics—Asia (ICCE-Asia), Jeju, Republic of Korea, 24–26 June 2018; pp. 206–212. [Google Scholar]
- Almehmadi, A.; Bosakowski, T.; Sedky, M.; Bastaki, B.B. HTM Based Anomaly Detecting Model for Traffic Congestion. In Proceedings of the 2020 4th International Conference on Cloud and Big Data Computing, Virtual, UK, 26–28 August 2020; pp. 97–101. [Google Scholar]
- Szoplák, Z.; Andrejková, G. Anomaly Detection in Text Documents using HTM Networks. In Proceedings of the Conference on Theory and Practice of Information Technologies, Muran, Slovakia, 24–28 September 2021; pp. 20–28. [Google Scholar]
- Khan, H.M.; Khan, F.M.; Khan, A.; Asghar, M.Z.; Alghazzawi, D.M. Anomalous Behavior Detection Framework Using HTM-Based Semantic Folding Technique. Comput. Math. Methods Med. 2021, 2021, 5585238. [Google Scholar] [CrossRef] [PubMed]
- Mackenzie, J.; Roddick, J.F.; Zito, R. An Evaluation of HTM and LSTM for Short-Term Arterial Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1847–1857. [Google Scholar] [CrossRef]
- Zyarah, A.M.; Kudithipudi, D. Neuromorphic Architecture for the Hierarchical Temporal Memory. IEEE Trans. Emerg. Top. Comput. Intell. 2019, 3, 4–14. [Google Scholar] [CrossRef]
- Hawkins, J.; George, D.; Niemasik, J. Sequence memory for prediction, inference and behaviour. Philos. Trans. R. Soc. Lond. Ser. B Biol. Sci. 2009, 364, 1203–1209. [Google Scholar] [CrossRef]
- Kostavelis, I.; Gasteratos, A. On the optimization of Hierarchical Temporal Memory. Pattern Recognition Letters 2012, 33, 670–676. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, D. NLPIR: A Theoretical Framework for Applying Natural Language Processing to Information Retrieval. JASIST 2003, 54, 115–123. [Google Scholar] [CrossRef]
- Hawkins, J.; George, D. Hierarchical Temporal Memory Concepts, Theory, and Terminology; Numenta: Redwood City, CA, USA, 2006. [Google Scholar]
- Hawkins, J.; Ahmad, S. Why Neurons Have Thousands of Synapses, a Theory of Sequence Memory in Neocortex. Front. Neural Circuits 2016, 10, 23. [Google Scholar] [CrossRef]
- Cui, Y.; Ahmad, S.; Hawkins, J. The HTM Spatial Pooler—A Neocortical Algorithm for Online Sparse Distributed Coding. Front. Comput. Neurosci. 2017, 11, 111. [Google Scholar] [CrossRef]
- Kanerva, P. Hyperdimensional Computing: An Introduction to Computing in Distributed Representation with High-Dimensional Random Vectors. Cogn. Comput. 2009, 1, 139–159. [Google Scholar] [CrossRef]
- Purdy, S. Encoding data for HTM systems. arXiv 2016, arXiv:1602.05925. [Google Scholar] [CrossRef]
- Bettels, J.; Bish, F.A. Unicode: A Universal Character Code. Digit. Tech. J. Digit. Equip. Corp. 1993, 5, 21–31. [Google Scholar]
- Allen, J.D.; Anderson, D.; Becker, J.; Cook, R.; Davis, M.; Edberg, P.; Everson, M.; Freytag, A.; Iancu, L.; Ishida, R.; et al. The Unicode Standard, Version 7.0; Unicode: Mountain View, CA, USA, 2014. [Google Scholar]
- Cui, Y.; Ahmad, S.; Hawkins, J. Continuous online sequence learning with an unsupervised neural network model. Neural Comput. 2016, 28, 2474–2504. [Google Scholar] [CrossRef] [PubMed]
- Niu, D.; Yang, L.; Cai, T.; Li, L.; Wu, X.; Wang, Z. A New Hierarchical Temporal Memory Algorithm Based on Activation Intensity. Comput. Intell. Neurosci. 2022, 2022, 6072316. [Google Scholar] [PubMed]
- Wielgosz, M.; Pietroń, M. Using Spatial Pooler of Hierarchical Temporal Memory to classify noisy videos with predefined complexity. Neurocomputing 2017, 240, 84–97. [Google Scholar] [CrossRef]
- Wright, L.G.; Onodera, T.; Stein, M.M.; Wang, T.; Schachter, D.T.; Hu, Z.; McMahon, P.L. Deep physical neural networks trained with backpropagation. Nature 2021, 601, 549–555. [Google Scholar] [CrossRef]
- Wen, J.; Zhao Jia, L.; Luo Si, W.; Han, Z. The improvements of BP neural network learning algorithm. In Proceedings of the WCC 2000—ICSP 2000 5th International Conference on Signal Processing Proceedings and 16th World Computer Congress 2000, Beijing, China, 21–25 August 2000; pp. 1647–1649. [Google Scholar]
- Webber, F.D.S. Semantic Folding Theory And its Application in Semantic Fingerprinting. arXiv 2015, arXiv:1511.08855. [Google Scholar] [CrossRef]
- Chen, Z.; Song, J.; Yang, Y. An Approach to Measuring Semantic Relatedness of Geographic Terminologies Using a Thesaurus and Lexical Database Sources. ISPRS Int. J. Geo Inf. 2018, 7, 98. [Google Scholar]
- Greenland, S.; Senn, S.J.; Rothman, K.J.; Carlin, J.B.; Poole, C.; Goodman, S.N.; Altman, D.G. Statistical tests, P values, confidence intervals, and power: A guide to misinterpretations. Eur. J. Epidemiol. 2016, 31, 337–350. [Google Scholar]
- Wang, S.; Sun, X.; Li, X.; Ouyang, R.; Wu, F.; Zhang, T.; Li, J.; Wang, G. GPT-NER: Named Entity Recognition via Large Language Models. arXiv 2023, arXiv:2304.10428. [Google Scholar] [CrossRef]
- Ashok, D.; Lipton, Z.C. PromptNER: Prompting for Named Entity Recognition. arXiv 2023, arXiv:2305.15444. [Google Scholar] [CrossRef]




| Parameter Name | Value | Parameter Name | Value |
|---|---|---|---|
| Number of columns | 5000 | Number of cells per column | 6 |
| Input dimensions | 22,476 | Potential radius | 6 |
| Number of active columns | 48 | Connected threshold for synaptic permanence | 0.7 |
| Initial synaptic permanence | 0.1 | Dendritic segment activation threshold | 4 |
| Synaptic permanence increment | 0.1 | Synaptic permanence decrement | 0.1 |
| Statistical Indicator | Proposed Method | GPT-4 Based Zero-Shot Learning (ZSL) Method | GPT-4 Based Few-Shot Learning (FSL) Method | Claude-3 Based Zero-Shot Learning (ZSL) Method | Claude-3 Based Few-Shot Learning (FSL) Method |
|---|---|---|---|---|---|
| Number of benchmark geoscientific dataset names | 530 | 530 | 530 | 530 | 530 |
| Number of extracted geoscientific dataset names | 600 | 478 | 459 | 534 | 520 |
| Number of correctly extracted geoscientific dataset names | 411 | 340 | 345 | 368 | 378 |
| Precision (%) | 68.5 | 71.1 | 75.2 | 69.4 | 71.3 |
| Recall (%) | 77.5 | 64.2 | 65.1 | 68.9 | 72.7 |
| F1-score | 0.727 | 0.675 | 0.698 | 0.691 | 0.720 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, K.; Chen, Z.; Wu, X.; Li, G.; Li, J.; Wang, S.; Wang, H.; Feng, H. Extracting Geoscientific Dataset Names from the Literature Based on the Hierarchical Temporal Memory Model. ISPRS Int. J. Geo-Inf. 2024, 13, 260. https://doi.org/10.3390/ijgi13070260
Wu K, Chen Z, Wu X, Li G, Li J, Wang S, Wang H, Feng H. Extracting Geoscientific Dataset Names from the Literature Based on the Hierarchical Temporal Memory Model. ISPRS International Journal of Geo-Information. 2024; 13(7):260. https://doi.org/10.3390/ijgi13070260
Chicago/Turabian StyleWu, Kai, Zugang Chen, Xinqian Wu, Guoqing Li, Jing Li, Shaohua Wang, Haodong Wang, and Hang Feng. 2024. "Extracting Geoscientific Dataset Names from the Literature Based on the Hierarchical Temporal Memory Model" ISPRS International Journal of Geo-Information 13, no. 7: 260. https://doi.org/10.3390/ijgi13070260
APA StyleWu, K., Chen, Z., Wu, X., Li, G., Li, J., Wang, S., Wang, H., & Feng, H. (2024). Extracting Geoscientific Dataset Names from the Literature Based on the Hierarchical Temporal Memory Model. ISPRS International Journal of Geo-Information, 13(7), 260. https://doi.org/10.3390/ijgi13070260