



CSMNER: A Toponym Entity Recognition Model for Chinese Social Media
 ,
,  , ,
, ,
Abstract
1. Introduction
- Based on the bidirectional encoder representations from the transformers (BERT) pre-trained model and the improved IDCNN-BiLSTM-CRF (Iterated Dilated Convolutional Neural Network- Bidirectional Long Short-Term Memory- Condi-tional Random Field) model, the CSMNER (Chinese social media named entity recognition) model is proposed. The model uses the improved IDCNN and BiLSTM dual-channel joint feature extraction modules to extract local boundary features and contextual semantic features of toponyms, respectively and introduces the boundary extension (BE) module to enhance the perception of toponym boundary information, ultimately improving the overall performance of the model.
- A Chinese social named entity recognition (CSNER) dataset is constructed. The dataset is sourced from the Sina Weibo platform, containing three entity categories with a total of 68,864 annotated samples. The dataset alleviates the scarcity of corpora for NER in Chinese social media, providing richer and more diverse data support for Chinese NER tasks.
- To verify the superiority of the proposed method, specific modules such as the improved IDCNN, BiLSTM, and BE are investigated and discussed. A series of evaluations are conducted on the MSRA, WeiboNER, and CSNER datasets. Through a comprehensive comparison with other advanced models, comprehensive experimental results on general datasets in NER confirm the effectiveness of the proposed model.
2. Related Work
2.1. Rule-Based Methods
2.2. Gazetteer-Based Methods
2.3. Statistical Methods
2.4. Deep Learning-Based Methods
3. Materials and Methods
3.1. Corpus Collection and Settings
3.1.1. Corpus Sources
3.1.2. Corpus Annotation
3.2. Proposed Method
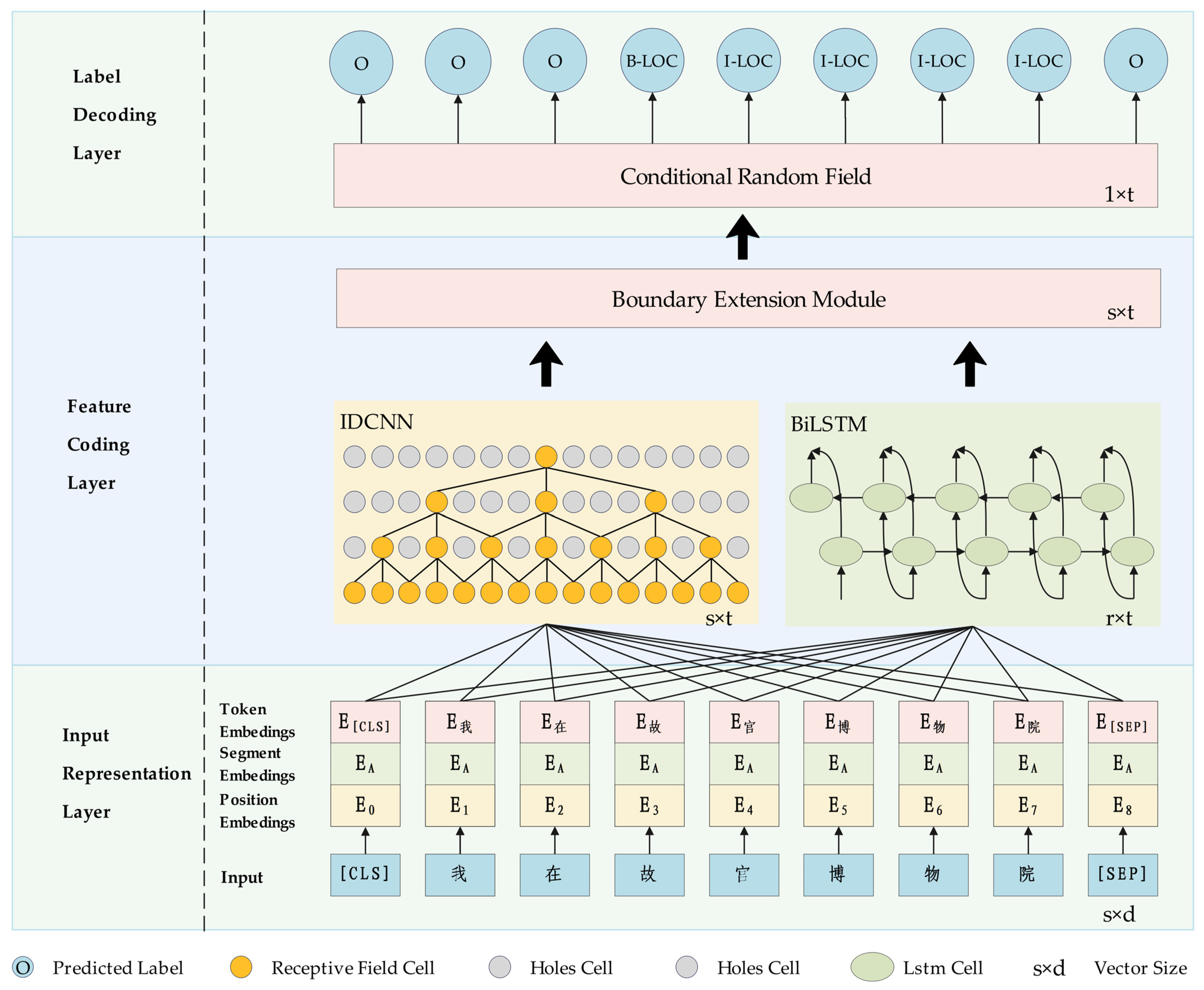
3.2.1. Overall Framework and Workflow of the Model
3.2.2. Input Presentation Layer
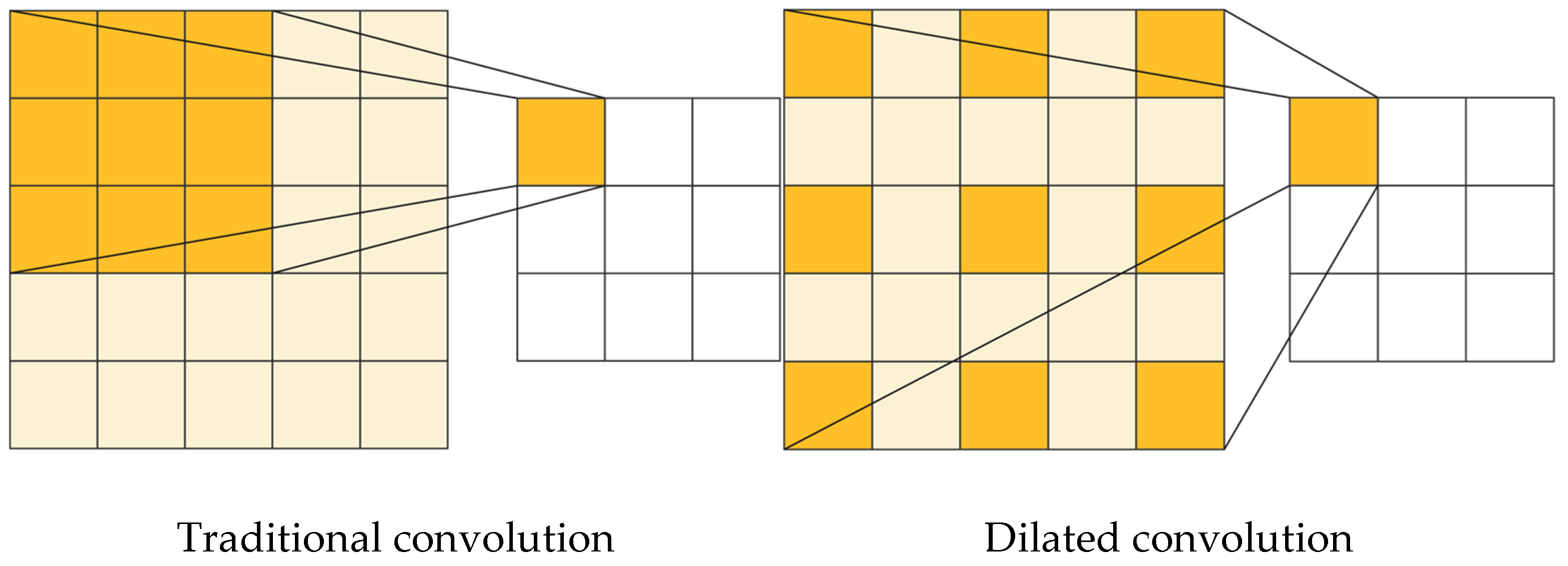
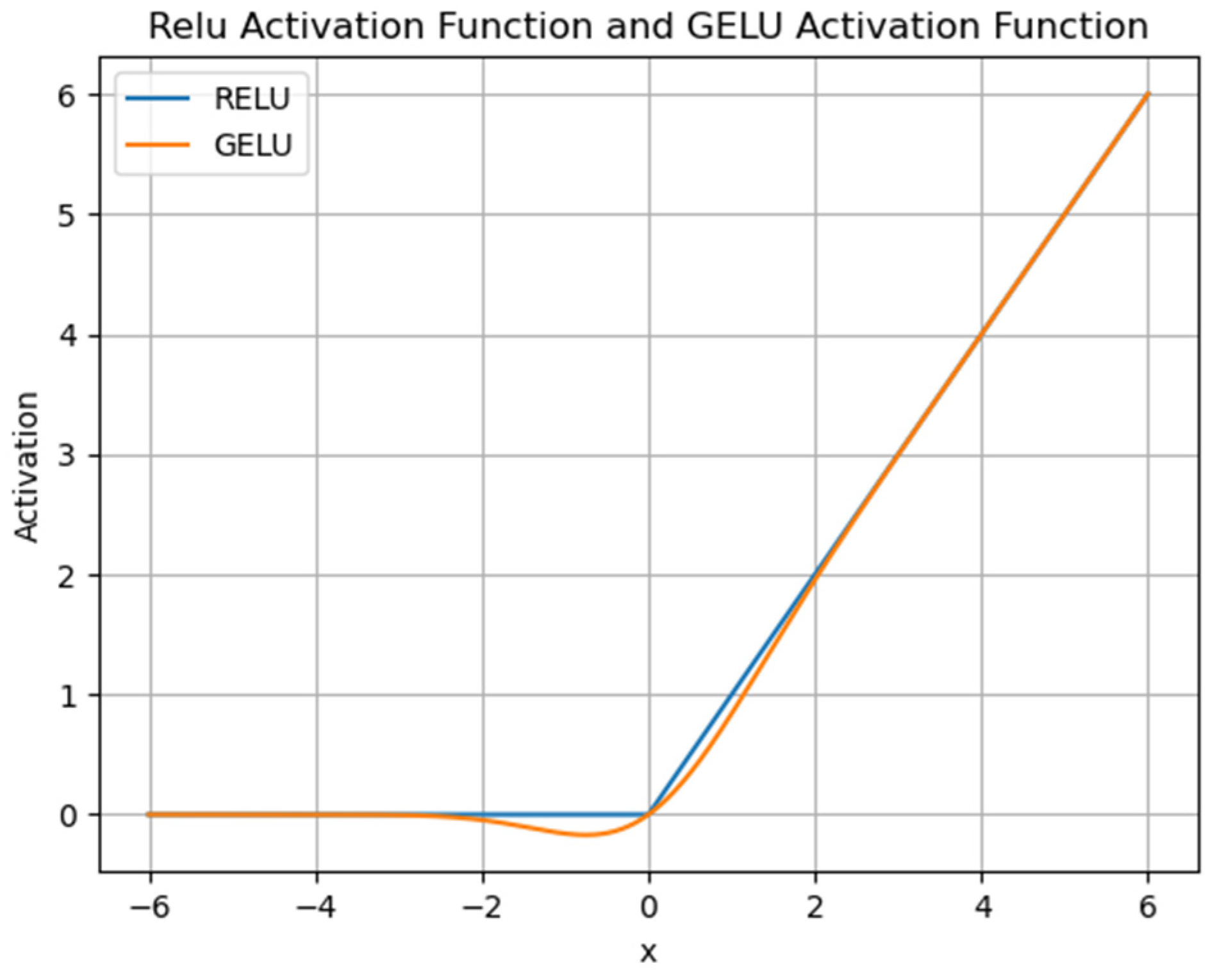
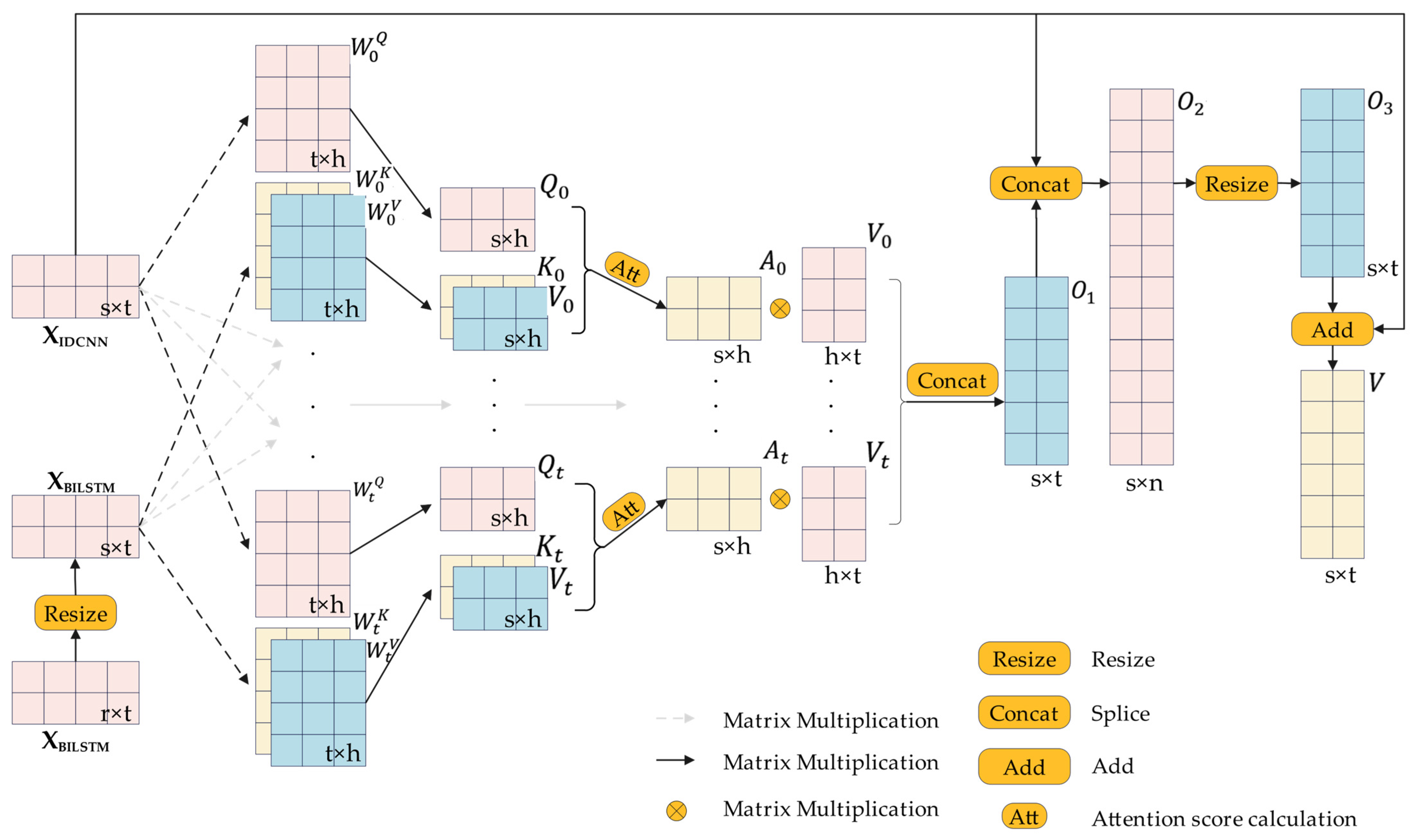
3.2.3. Feature Encoding Layer
3.2.4. Label Decoding Layer
4. Experiment and Discussion
4.1. Experimental Data, Evaluation Metrics, and Experimental Settings
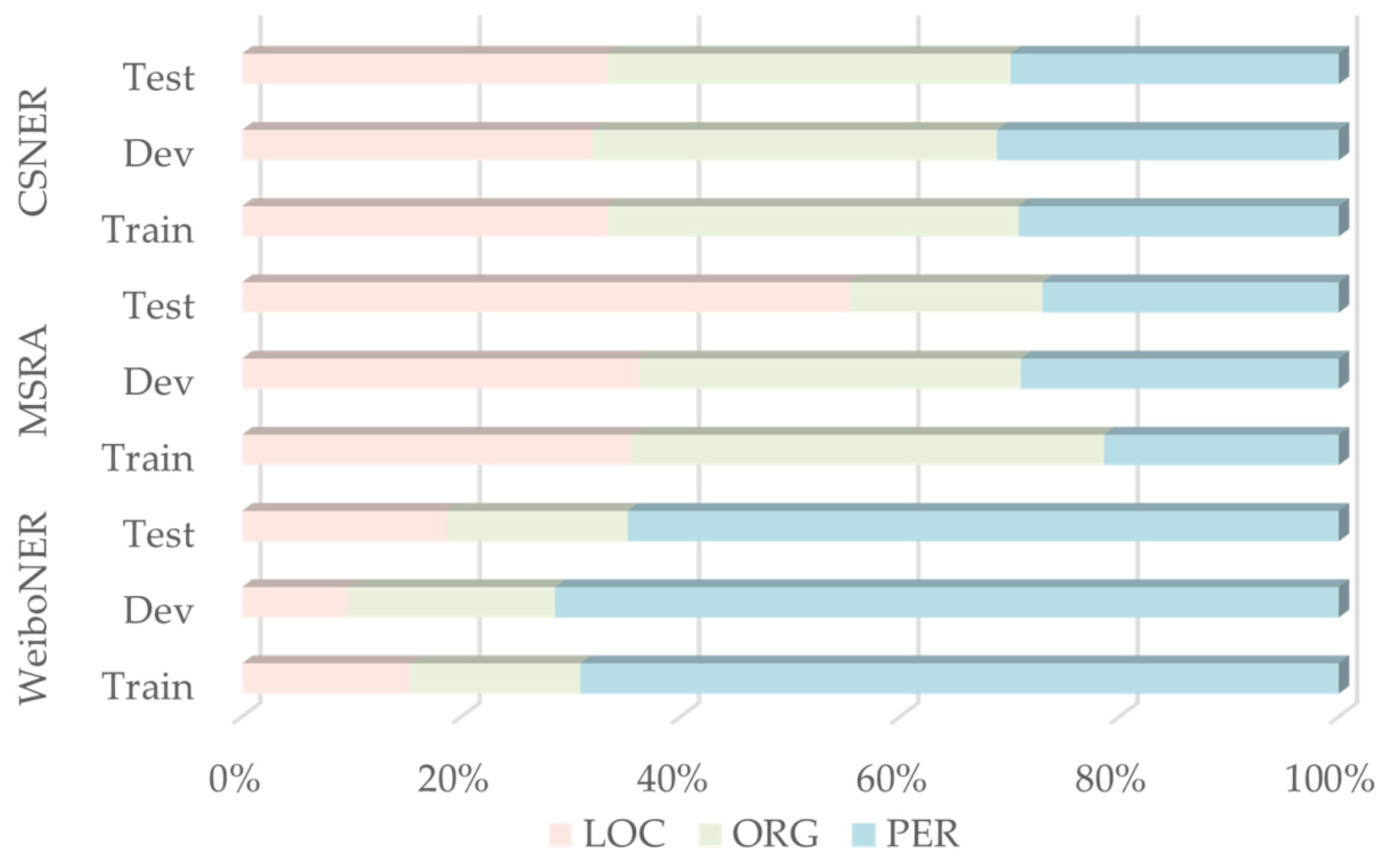
4.1.1. Experimental Datasets
4.1.2. Evaluation Metrics
4.1.3. Experimental Settings
- 1.
- Hyperparameter settings: To illustrate how the experiments were conducted, Table 5 lists some important hyperparameters used in the experiments.
- 2.
- Model training strategy: The model used the BERT-based-Chinese pre-trained model to map text features to 768-dimensional vectors to obtain rich representations at the character level, sentence level, and context. The model selected the Adam optimizer to adaptively adjust the learning rate based on the historical gradient of each parameter and a parameter that set the strength of weight decay was used to control model complexity and prevent overfitting [38]. The model avoided overfitting by using a regularization technique and early stopping strategy [39], with the dropout and patience set to 0.5 and 5, respectively. When the model did not significantly improve within five consecutive epochs, the current best performance result is output, and the training stops, thus improving the training efficiency and avoiding overfitting.
4.2. Performance Comparison
- Qiu et al., proposed a weakly supervised learning model for toponym recognition, which mainly uses the bidirectional LSTM and CRF model and extends them to enhance the model’s ability to recognize multiword toponyms.
- Ma et al. proposed a BERT-BiLSTM-CRF deep learning model by adding a pre-trained BERT representation.
- Zhao et al. proposed a multi-layer deep learning model ERNIE-Gram-IDCNN-BiLSTM-CRF to capture toponym features through dynamic vectors, and a new deep learning framework EIBC.
- Zhang et al., proposed an NER model, LSF-CNER, that fuses lexical and syntactic information.
- Wu et al. proposed an InterFormer module, which simultaneously models character and word sequences of different lengths through a nonplanar grid structure and constructs the NFlat model that decouples lexical fusion and context encoding.
- Song et al. proposed a Chinese NER model with fused graph embedding. The model utilizes the phonetic relations of Chinese characters to construct an undirected graph, represents each Chinese character through the fusion of graph embedding and semantic embedding, and implements prediction using a BiLSTM-CRF network model.
- Deng et al. proposed a Kcr-FLAT Chinese NER model that extracts and encodes three types of syntactic information and fuses them with lexical information using an attention mechanism to address word segmentation errors introduced by lexical information.
- Qin et al. proposed a multitask learning-based model for Chinese NER, MTL-BERT. This model decomposes the NER task into two subtasks—entity boundary annotation and type annotation—and dynamically adjusts the task weights according to the real-time learning effect of the task, thus improving model learning efficiency.
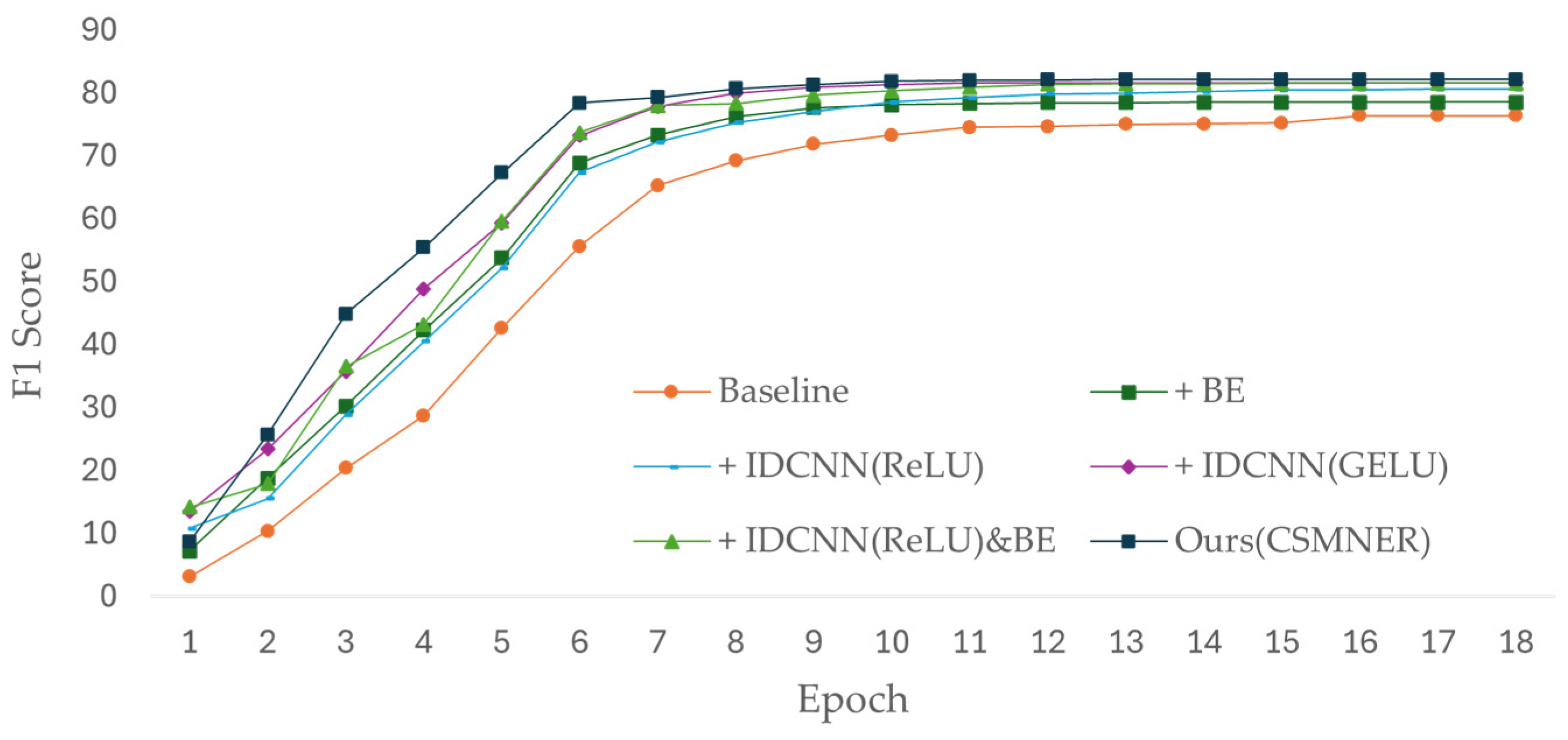
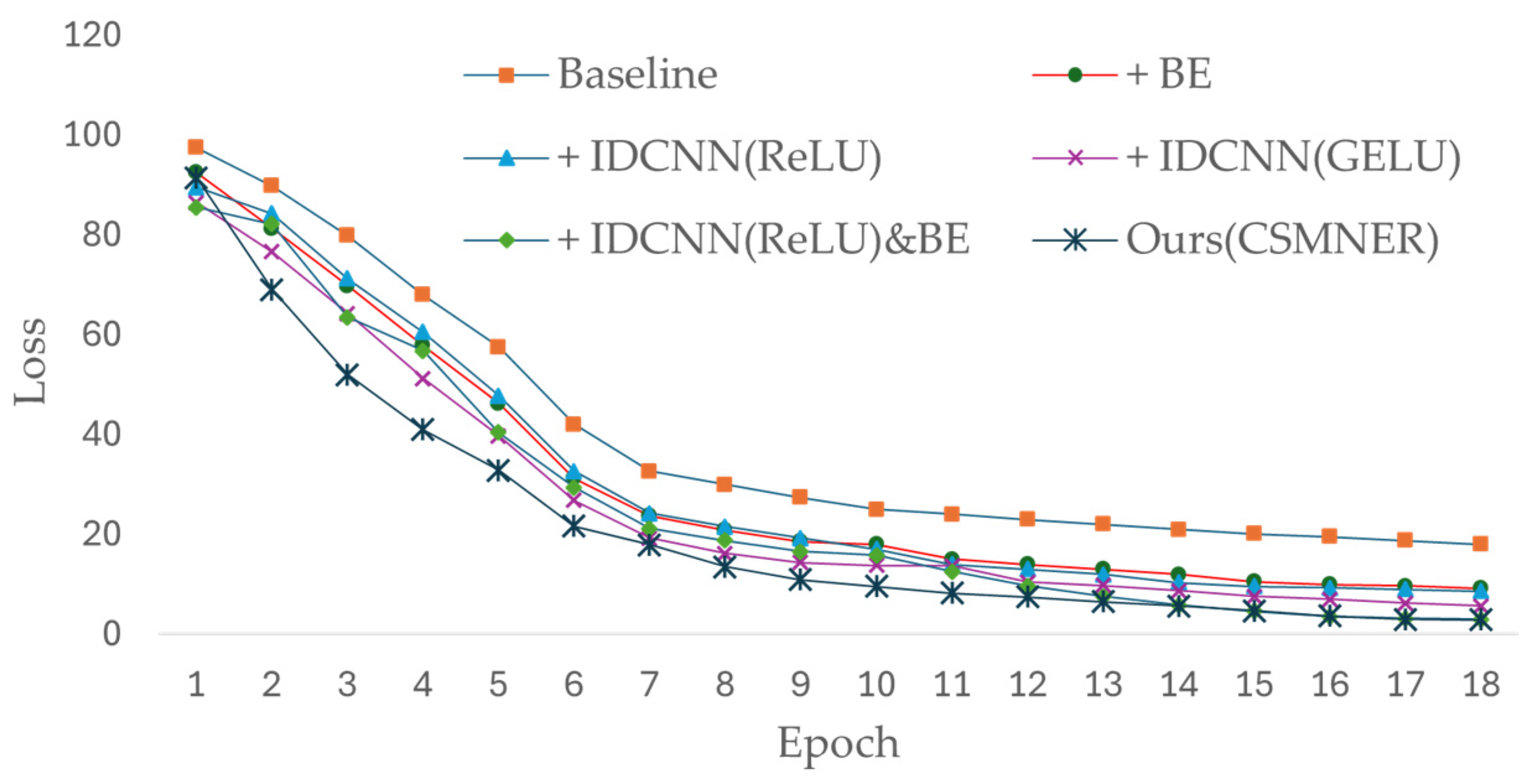
4.3. Ablation Experiment
4.4. Experimental Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Purves, R.; Hollenstein, L. Exploring Place through User-Generated Content: Using Flickr to Describe City Cores. J. Spat. Inf. Sci. 2010, 1, 21–48. [Google Scholar] [CrossRef]
- Xu, L.; Du, Z.; Mao, R.; Zhang, F.; Liu, R. GSAM: A Deep Neural Network Model for Extracting Computational Representations of Chinese Addresses Fused with Geospatial Feature. Comput. Environ. Urban Syst. 2020, 81, 101473. [Google Scholar] [CrossRef]
- Lai, J.; Lansley, G.; Haworth, J.; Cheng, T. A Name-led Approach to Profile Urban Places Based on Geotagged Twitter Data. Trans. GIS 2020, 24, 858–879. [Google Scholar] [CrossRef]
- Gelernter, J.; Zhang, W. Geocoding Location Expressions in Twitter Messages: A Preference Learning Method. J. Spat. Inf. Sci. 2014, 9, 37–70. [Google Scholar] [CrossRef]
- McDonough, K.; Moncla, L.; van de Camp, M. Named Entity Recognition Goes to Old Regime France: Geographic Text Analysis for Early Modern French Corpora. Int. J. Geogr. Inf. Sci. 2019, 33, 2498–2522. [Google Scholar] [CrossRef]
- Hu, Y.; Mao, H.; McKenzie, G. A Natural Language Processing and Geospatial Clustering Framework for Harvesting Local Place Names from Geotagged Housing Advertisements. Int. J. Geogr. Inf. Sci. 2019, 33, 714–738. [Google Scholar] [CrossRef]
- Wallgrün, J.O.; Karimzadeh, M.; MacEachren, A.M.; Pezanowski, S. GeoCorpora: Building A Corpus to Test and Train Microblog Geoparsers. Int. J. Geogr. Inf. Sci. 2018, 32, 1–29. [Google Scholar] [CrossRef]
- Wang, J.; Hu, Y.; Joseph, K. NeuroTPR: A Neuro-Net Toponym Recognition Model For Extracting Locations From Social Media Messages. Trans. GIS 2020, 24, 719–735. [Google Scholar] [CrossRef]
- Paul, C. Robert Pasley Images and Perceptions of Neighbourhood Extents. In Proceedings of the 6th Workshop on Geographic Information Retrieval, Zurich, Switzerland, 18 February 2010; ACM: Zurich, Switzerland, 2010; pp. 1–2. [Google Scholar]
- Jones, C.B.; Purves, R.S.; Clough, P.D.; Joho, H. Modelling Vague Places with Knowledge From the Web. Int. J. Geogr. Inf. Sci. 2008, 22, 1045–1065. [Google Scholar] [CrossRef]
- Montello, D.R.; Goodchild, M.F.; Gottsegen, J.; Fohl, P. Where’s Downtown?: Behavioral Methods for Determining Referents of Vague Spatial Queries. Spat. Cogn. Comput. 2003, 3, 185–204. [Google Scholar] [CrossRef]
- Leidner, J.L.; Lieberman, M.D. Detecting Geographical References in the Form of Place Names and Associated Spatial Natural Language. SIGSPATIAL Spec. 2011, 3, 5–11. [Google Scholar] [CrossRef]
- Giridhar, P.; Abdelzaher, T.; George, J.; Kaplan, L. On Quality of Event Localization from Social Network Feeds. In Proceedings of the 2015 IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom Workshops), St. Louis, MO, USA, 23–27 March 2015; IEEE: St. Louis, MO, USA, 2015; pp. 75–80. [Google Scholar]
- Dutt, R.; Hiware, K.; Ghosh, A.; Bhaskaran, R. SAVITR: A System for Real-Time Location Extraction from Microblogs during Emergencies. In Proceedings of the Web Conference 2018, Lyon, France, 23–27 April 2018. [Google Scholar]
- Qiu, Q.; Xie, Z.; Wang, S.; Zhu, Y.; Lv, H.; Sun, K. ChineseTR: A weakly Supervised Toponym Recognition Architecture Based on Automatic Training Data Generator and Deep Neural Network. Trans. GIS 2022, 26, 1256–1279. [Google Scholar] [CrossRef]
- Milusheva, S.; Marty, R.; Bedoya, G.; Williams, S.; Resor, E.; Legovini, A. Applying Machine Learning and Geolocation Techniques to Social Media Data (Twitter) to Develop a Resource for Urban Planning. PLoS ONE 2021, 16, e0244317. [Google Scholar] [CrossRef] [PubMed]
- Middleton, S.E.; Kordopatis-Zilos, G.; Papadopoulos, S.; Kompatsiaris, Y. Location Extraction from Social Media: Geoparsing, Location Disambiguation, and Geotagging. ACM Trans. Inf. Syst. 2018, 36, 1–27. [Google Scholar] [CrossRef]
- Habib, M.B.; van Keulen, M. A Hybrid Approach for Robust Multilingual Toponym Extraction and Disambiguation. In Language Processing and Intelligent Information Systems; Mieczysław, A., Kłopotek, J.K., Małgorzata, M., Agnieszka, M., Sławomir, T., Wierzchoń, Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7912, pp. 1–15. ISBN 978-3-642-38633-6. [Google Scholar]
- Sharma, P.; Samal, A.; Soh, L.-K.; Joshi, D. A Spatially-Aware Algorithm for Location Extraction from Structured Documents. GeoInformatica 2023, 27, 645–679. [Google Scholar] [CrossRef]
- Sobhana, N.; Mitra, P.; Ghosh, S. Conditional Random Field Based Named Entity Recognition in Geological text. Int. J. Comput. Appl. 2010, 1, 143–147. [Google Scholar] [CrossRef]
- Curran, J.R.; Clark, S. Language Independent NER Using a Maximum Entropy Tagger. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003; Edmonton, AB, Canada, 31 May 2003, Association for Computational Linguistics: Edmonton, AB, Canada, 2003; Volume 4, pp. 164–167. [Google Scholar]
- Lingad, J.; Karimi, S.; Yin, J. Location Extraction from Disaster-Related Microblogs. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13 May 2013; ACM: Rio de Janeiro, Brazil, 2013; pp. 1017–1020. [Google Scholar]
- Santos, R.; Murrieta-Flores, P.; Calado, P.; Martins, B. Toponym Matching through Deep Neural Networks. Int. J. Geogr. Inf. Sci. 2018, 32, 324–348. [Google Scholar] [CrossRef]
- Hu, X.; Al-Olimat, H.S.; Kersten, J.; Wiegmann, M.; Klan, F.; Sun, Y.; Fan, H. GazPNE: Annotation-Free Deep Learning for Place Name Extraction from Microblogs Leveraging Gazetteer and Synthetic Data by Rules. Int. J. Geogr. Inf. Sci. 2022, 36, 310–337. [Google Scholar] [CrossRef]
- Xu, C.; Li, J.; Luo, X.; Pei, J.; Li, C.; Ji, D. DLocRL: A Deep Learning Pipeline for Fine-Grained Location Recognition and Linking in Tweets. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13 May 2019; ACM: New York, NY, USA, 2019; pp. 3391–3397. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Tao, L.; Xie, Z.; Xu, D.; Ma, K.; Qiu, Q.; Pan, S.; Huang, B. Geographic Named Entity Recognition by Employing Natural Language Processing and an Improved BERT Model. ISPRS Int. J. Geo Inf. 2022, 11, 598. [Google Scholar] [CrossRef]
- Ma, X.; Hovy, E. End-to-End Sequence Labeling via Bi-Directional LSTM-CNNs-CRF. arXiv 2016, arXiv:1603.01354. [Google Scholar]
- Zhang, Y.; Yang, J. Chinese NER Using Lattice LSTM. arXiv 2018, arXiv:1805.02023. [Google Scholar]
- Xu, C.; Wang, F.; Han, J.; Li, C. Exploiting Multiple Embeddings for Chinese Named Entity Recognition. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3 November 2019; ACM: New York, NY, USA, 2019; pp. 2269–2272. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K. Kristina Toutanova BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Berragan, C.; Singleton, A.; Calafiore, A.; Morley, J. Transformer Based Named Entity Recognition for Place Name Extraction from Unstructured Text. Int. J. Geogr. Inf. Sci. 2023, 37, 747–766. [Google Scholar] [CrossRef]
- Lu, Y.; Liu, Q.; Dai, D.; Xiao, X.; Lin, H.; Han, X.; Sun, L.; Wu, H. Unified Structure Generation for Universal Information Extraction. arXiv 2022, arXiv:2203.12277. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Zhang, M.; Li, B.; Liu, Q.; Wu, J. Chinese Named Entity Recognition Fusing Lexical and Syntactic Information. In Proceedings of the 2022 the 6th International Conference on Innovation in Artificial Intelligence (ICIAI), Guangzhou, China, 4 March 2022; ACM: Guangzhou, China, 2022; pp. 69–77. [Google Scholar]
- Peng, N.; Dredze, M. Named Entity Recognition for Chinese Social Media with Jointly Trained Embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 548–554. [Google Scholar]
- Kingma, D.P. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar]
- Ma, K.; Tan, Y.; Xie, Z.; Qiu, Q.; Chen, S. Chinese Toponym Recognition with Variant Neural Structures from Social Media Messages Based on BERT Methods. J. Geogr. Syst. 2022, 24, 143–169. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, D.; Jiang, L.; Liu, Q.; Liu, Y.; Liao, Z. EIBC: A Deep Learning Framework for Chinese Toponym Recognition with Multiple Layers. J. Geogr. Syst. 2024, 26, 407–425. [Google Scholar] [CrossRef]
- Wu, S.; Song, X.; Feng, Z.; Wu, X.J. NFLAT: Non-Flat-Lattice Transformer for Chinese Named Entity Recognition. arXiv, 2022; arXiv:2205.05832. [Google Scholar]
- Song, X.; Yu, H.; Li, S.; Wang, H. Robust Chinese Named Entity Recognition Based on Fusion Graph Embedding. Electronics 2023, 12, 569. [Google Scholar] [CrossRef]
- Deng, Z.; Tao, Y.; Lan, R.; Yang, R.; Wang, X. Kcr-FLAT: A Chinese-Named Entity Recognition Model with Enhanced Semantic Information. Sensors 2023, 23, 1771. [Google Scholar] [CrossRef] [PubMed]
- Fang, Q.; Li, Y.; Feng, H.; Ruan, Y. Chinese Named Entity Recognition Model Based on Multi-Task Learning. Appl. Sci. 2023, 13, 4770. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Type | Number of Annotated Entities | Examples (English) | Example (Chinese) | Example of Labeling |
|---|---|---|---|---|---|
| 1 | Location | 9897 | Tiananmen Gate | 天安门 | {“天安门”, [B-LOC, I-LOC, I-LOC]} |
| 2 | Organization | 9119 | European Union | 欧盟 | {“欧盟”, [B-ORG, I-ORG]} |
| 3 | Person | 13,426 | Liu Yang | 刘洋 | {“刘洋”, [B-PER, I-PER]} |
| No. | Original Sentence | Translate Sentences | Word Segmentation Result |
|---|---|---|---|
| 1 | 明天我们将进行一场mindstorming 会议。 | Tomorrow we will have a mindstorming meeting. | [‘明天’, ‘我们’, ‘将’, ‘进行’, ‘一场’, ‘mi’, ‘##nd’, ‘##sto’, ‘##rming’, ‘会议’, ‘。’] |
| 2 | 我在北京故宫博物院 | I’m at the Palace Museum in Beijing. | [‘我’, ‘在’, ‘北京’, ‘故宫’, ‘博物院’] |
| Dataset | Entity Type | Training Set Size | Validation Set Size | Test Set Size |
|---|---|---|---|---|
| WeiboNER | 3 | 1.4 k | 0.3 k | 0.3 k |
| MSRA | 3 | 46.4 k | 4.4 k | 4.4 k |
| CSNER | 3 | 48.2 k | 10.3 k | 10.3 k |
| Dataset | Annotation Example |
|---|---|
| WeiboNER | 日/O 中/O 午/O ,/O 宋/B-PER 同/I-PER 志/I-PER 抵/O 达/O 汉/B-LOC 口/I-LOC 站/I-LOC 转/O 动/O 车/O 回/O 家/O 。/O 哈/O 哈/O |
| MSRA | 把/O 欧/B-LOC 美/B-LOC 、/O 港/B-LOC 台/B-LOC 的/O 图/O 书/O 汇/O 集/O 起/O 来/O |
| CSNER | 又/O 到/O 了/O 可/O 以/O 出/O 门/O 踏/O 青/O 的/O 日/O 子/O 了/O 我/O 的/O 家/O 乡/O 就/O 是/O 宁/B-LOC 波/I-LOC 象/I-LOC 山/I-LOC |
| No. | Parameters | Value |
|---|---|---|
| 1 | Embedding Dimension | 768 |
| 2 | Max Length | 128 |
| 3 | Batch Size | 64 |
| 4 | Learning Rate | 0.00003 |
| 5 | Hidden Layer Size | 512 |
| 6 | Dropout | 0.5 |
| Model | WeiboNER | MSRA | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | |
| Qiu et al., 2022 [15] | 59.00 | 56.00 | 57.00 | 86.00 | 85.00 | 86.00 |
| Ma et al., 2022 [40] | - | - | - | 99.00 | 90.00 | 94.00 |
| Zhao et al., 2023 [41] | 96.98 | 95.85 | 96.41 | |||
| Ours (CSMNER) | 82.35 | 71.62 | 76.61 | 97.49 | 97.17 | 97.33 |
| Model | WeiboNER | MSRA | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | |
| Zhang et al., 2022 [36] | - | - | 67.33 | - | - | 94.83 |
| Wu et al., 2022 [42] | - | - | 61.94 | 94.92 | 94.19 | 94.55 |
| Song et al., 2023 [43] | 51.24 | 41.47 | 45.84 | 65.28 | 69.32 | 67.24 |
| Deng et al., 2023 [44] | - | - | 70.12 | - | - | 96.51 |
| Qin et al., 2023 [45] | 74.90 | 72.70 | 73.80 | 96.50 | 96.60 | 96.50 |
| Ours (CSMNER) | 76.43 | 75.81 | 76.12 | 96.71 | 95.65 | 96.17 |
| Model | Attention | IDCNN (ReLU) | IDCNN (GELU) | WeiboNER | MSRA | CSNER |
|---|---|---|---|---|---|---|
| Baseline | 68.32 | 92.07 | 76.39 | |||
| + BE | ✓ | 70.12 | 92.21 | 78.52 | ||
| + IDCNN (ReLU) | ✓ | 70.93 | 96.01 | 80.70 | ||
| + IDCNN (GELU) | ✓ | 73.64 | 96.19 | 81.67 | ||
| + IDCNN(ReLU)&BE | ✓ | ✓ | 75.35 | 95.71 | 81.62 | |
| Ours (CSMNER) | ✓ | ✓ | 76.12 | 96.17 | 82.14 |
| Original Sentence | 把 | 欧 | 美 | 、 | 港 | 台 | 流 | 行 | 的 | 食 | 品 | 汇 | 集 |
| Translate sentences | Bringing together popular foods from Europe, America, Hong Kong, and Taiwan. | ||||||||||||
| Correct prediction | O | B-LOC | B-LOC | O | B-LOC | B-LOC | O | O | O | O | O | O | O |
| Baseline prediction | O | O | O | O | O | O | O | O | O | O | O | O | O |
| + IDCNN (ReLU) | O | O | O | O | O | O | O | O | O | O | O | O | O |
| + IDCNN (GELU) | O | O | O | O | O | O | O | O | O | O | O | O | O |
| + IDCNN(ReLU)&BE | O | B-LOC | B-LOC | O | B-LOC | I-LOC | O | O | O | O | O | O | O |
| Our (CSMNER) | O | B-LOC | B-LOC | O | B-LOC | B-LOC | O | O | O | O | O | O | O |
| Original Sentence | 走 | 走 | 浪 | 漫 | 的 | 五 | 大 | 道 | 感 | 受 | 浪 | 漫 | 的 | 意 | 大 | 利 | 风 | 景 | 区 |
| Translate sentences | Walk on the romantic Fifth Avenue and feel the romantic Italian scenic area | ||||||||||||||||||
| Correct prediction | O | O | O | O | O | B-L | I-L | I-L | O | O | O | O | O | B-L | I-L | I-L | I-L | I-L | I-L |
| Baseline prediction | O | O | O | O | O | B-L | I-L | I-L | O | O | O | O | O | B-L | I-L | I-L | O | O | O |
| + IDCNN (ReLU) | O | O | O | O | O | B-L | I-L | I-L | O | O | O | O | O | B-L | I-L | I-L | O | O | O |
| + IDCNN (GELU) | O | O | O | O | O | B-L | I-L | I-L | O | O | O | O | O | B-L | I-L | I-L | O | O | O |
| + IDCNN(ReLU)&BE | O | O | O | O | O | B-L | I-L | I-L | O | O | O | O | O | B-L | I-L | I-L | I-L | I-L | I-L |
| Our (CSMNER) | O | O | O | O | O | B-L | I-L | I-L | O | O | O | O | O | B-L | I-L | I-L | I-L | I-L | I-L |
| No. | Example Sentence | Sentence Translation | Predicted Results | Annotated Result | Error Type |
|---|---|---|---|---|---|
| 1 | 这是道观你信吗太原东社街区 | This is a Taoist temple. Can you believe it? Taiyuan Dongshe neighborhood. | Taiyuan | Taiyuan Dongshe neighborhood | Lack of geographical background knowledge, toponym recognition is incomplete |
| 2 | 我的家乡就是平顶山郏县 | My hometown is Pingdingshan Jia County | Pingdingshan, Jia County | Pingdingshan Jia County | Lack of geographical background, identified two toponyms |
| 3 | 中秋豪礼相送快来抢购大连金石滩国家旅游度假区 | Mid-Autumn Gifts for Dalian Jinshitan National Tourist Resort | None | Dalian Jinshitan National Tourist Resort | The context-valid information is confused |
| 4 | 小家伙跟了我一路车子也不要了 | The little guy followed me all the way to the car and didn’t want it. | Number 1 bus | None | No toponyms, semantic error |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, Y.; Zhai, R.; Wu, F.; Yin, J.; Gong, X.; Zhu, L.; Yu, H. CSMNER: A Toponym Entity Recognition Model for Chinese Social Media. ISPRS Int. J. Geo-Inf. 2024, 13, 311. https://doi.org/10.3390/ijgi13090311
Qi Y, Zhai R, Wu F, Yin J, Gong X, Zhu L, Yu H. CSMNER: A Toponym Entity Recognition Model for Chinese Social Media. ISPRS International Journal of Geo-Information. 2024; 13(9):311. https://doi.org/10.3390/ijgi13090311
Chicago/Turabian StyleQi, Yuyang, Renjian Zhai, Fang Wu, Jichong Yin, Xianyong Gong, Li Zhu, and Haikun Yu. 2024. "CSMNER: A Toponym Entity Recognition Model for Chinese Social Media" ISPRS International Journal of Geo-Information 13, no. 9: 311. https://doi.org/10.3390/ijgi13090311
APA StyleQi, Y., Zhai, R., Wu, F., Yin, J., Gong, X., Zhu, L., & Yu, H. (2024). CSMNER: A Toponym Entity Recognition Model for Chinese Social Media. ISPRS International Journal of Geo-Information, 13(9), 311. https://doi.org/10.3390/ijgi13090311