Abstract
Transformer-based subject-sensitive hashing algorithms exhibit good integrity authentication performance and have the potential to ensure the authenticity and convenience of high-resolution remote sensing (HRRS) images. However, the robustness of Transformer-based subject-sensitive hashing is still not ideal. In this paper, we propose a Multi-PatchDrop mechanism to improve the performance of Transformer-based subject-sensitive hashing. The Multi-PatchDrop mechanism determines different patch dropout values for different Transformer blocks in ViT models. On the basis of a Multi-PatchDrop, we propose an improved Swin-Unet for implementing subject-sensitive hashing. In this improved Swin-Unet, Multi-PatchDrop has been integrated, and each Swin Transformer block (except the first one) is preceded by a patch dropout layer. Experimental results demonstrate that the robustness of our proposed subject-sensitive hashing algorithm is not only stronger than that of the CNN-based algorithms but also stronger than that of Transformer-based algorithms. The tampering sensitivity is of the same intensity as the AGIM-net and M-net-based algorithms, stronger than other Transformer-based algorithms.
1. Introduction
High-resolution remote sensing (HRRS) images can offer rich, detailed information about the Earth’s surface [1,2] and are of great significance in urban planning, early disaster warning, agricultural monitoring, and other fields. However, HRRS images are also facing various emerging security threats [3,4], especially AI-based image tampering techniques, posing a great threat to the integrity of HRRS content. A set of tampering instances of HRRS images is shown in Figure 1. Without the help of integrity authentication technology, it is difficult to tell that the tampered HRRS images are different from the original ones. In reality, the tampered HRRS images are even more difficult to detect as there is no original image to compare with.

Figure 1.
Instances of HRRS images being tampered with. (a) Original HRRS images. (b) Tampered images.
Traditional methods generally use cryptographic hashing to implement integrity authentication of data. However, cryptographic hashing is too sensitive to data changes at the binary level and is not suitable for HRRS images. Integrity authentication techniques based on cryptographic hashing, such as blockchain [5], have similar problems. Although perceptual hashing can achieve content-based authentication of HRRS images, its integrity authentication performance no longer satisfies the need for HRRS images due to the development of image tampering technology.
As an emerging data security technology, subject-sensitive hashing has the potential to deal with the increasingly serious threat of HRRS image tampering [6]. One of the core problems of subject-sensitive hashing is how to improve the robustness of an algorithm on the premise of ensuring tampering sensitivity, and the Transformer emerging in recent years has good potential in this regard. Vision Transformers (ViTs) [7,8,9] have been proven to be very effective as a viable alternative to CNNs and have excellent performance in the implementation of subject-sensitive hashing [10]. However, Transformer-based subject-sensitive hashing algorithms still face a series of problems, such as the robustness of JPEG compression, which needs to be improved. In this paper, we delve into Patch Dropout [11] on the performance of subject-sensitive hashing. The main novelties are as follows:
- Inspired by Patch Dropout, we propose a Multi-PatchDrop (MPD) mechanism specifically for a Transformer-based subject-sensitive hashing algorithm to improve the algorithm’s robustness;
- We have made deep improvements to the Swin-Unet model to make it more suitable for subject-sensitive hashing;
- A new subject-sensitive hashing algorithm based on Multi-PatchDrop and Swin-Unet is built.
The rest of this paper is organized as follows. Related work, including subject-sensitive hashing, Transformers, and PatchDropout, is discussed in Section 2. Section 3 discusses the proposed Multi-PatchDrop mechanism and the improved Swin-Unet. Section 4 demonstrates the experimental setup and results. Section 5 presents a discussion. Future works and conclusions are presented in Section 6.
2. Preliminaries
2.1. Subject-Sensitive Hashing
Hashing has been broadly investigated for remote-sensing images [12]. Perceptual hashing [13,14] is a kind of technology that can set the perceptual content of media data such as images and videos as a digital summary and can be used in applications such as image retrieval [15], image copy detection [16], and image integrity authentication [17]. In fact, when a different hashing is used in different applications of remote sensing images, although the names and targets are different, there are certain similarities in attributes and implementation methods. For example, Hashing for Localization (HfL) [12] is designed to locate a specific scene in remote sensing images, and it is also necessary to extract the features of the target image (indicator patch) in some way to generate a hash sequence. Although perceptual hashing overcomes shortcomings of traditional authentication methods that are too sensitive to data changes, it does not take into account the characteristics that different users have different emphases on HRRS image content, does not distinguish the changed data content, and cannot be used for customized integrity authentication in specific fields.
Derived from perceptual hashing, subject-sensitive hashing provides a new approach to solving the integrity authentication problem faced by HHRS images. Subject-sensitive hashing focuses on changes in the content that the user is interested in, taking into account the content changes of other types of features so as not to meet the requirements for digest. However, the robustness of existing subject-sensitive hashing algorithms still needs to be improved, especially the robustness for JPEG compression. Moreover, existing subject-sensitive hashing lacks a mechanism to adjust the performance of an algorithm when the training dataset is determined. In this paper, we propose a Multi-PatchDrop mechanism specifically designed for Transformer-based subject-sensitive hashing to increase the robustness of subject-sensitive hashing and adjust the performance of the algorithm without changing the training data.
2.2. Transformers and PatchDropout
Originally designed for natural language processing, a Transformer [18] has demonstrated advanced performance in a variety of fields, including intelligent speech processing [19], multimodal learning [20,21], and video processing [22]. Unlike convolutional neural networks (CNNs), Transformers rely on the self-attention mechanism for the parallel processing of tokens to acquire global information from the input sequence and achieve the function of feature mapping [23,24]. A Swin Transformer [25] leverages the shift window mechanism to model long-distance dependencies to enhance feature extraction in ViT, greatly enhancing the potential of a Transformer in computer vision [26,27].
The key to the subject-sensitive hashing algorithm is a deep neural network that extracts the subject-sensitive features of HRRS images. U-net [28] and M-net [29] can be used for feature extraction of HRRS images, but the robustness of these CNN-based subject-sensitive hashing algorithms is often poor. Attention mechanism-based models, such as AGIM-net [6] and Attention U-net [30], have greatly improved robustness, but the comprehensive performance of the subject-sensitive hashing algorithm is still not ideal. Compared with CNN-based algorithms, the performance of Transformer-based subject-sensitive hashing algorithms has been greatly improved in the past years [31].
Patch Dropout [11] is a method to efficiently train standard ViT models by randomly discarding input image patches. In our work, we ask another fundamental question: Do all the Transformer blocks need the same Patch Dropout?
Although the Transformer-based model can capture global information at all levels [32,33], the high level focuses more on global semantic information and has a greater impact on the algorithm’s robustness. The lower level is more focused on local information and has a greater impact on the algorithm’s tampering sensitivity. For example, it is generally difficult for a single pixel in an area of an image to change the semantics of the area and, therefore, does not change the corresponding image content. For such pixel-level variations, subject-sensitive hashing should remain robust. Therefore, the original Patch Dropout is not appropriate for direct application in Transformer-based subject-sensitive hashing; it would be more beneficial to improve the algorithm’s robustness by using different patch-drop rates for the lower and higher layers of the Transformer model for subject-sensitive hashing. This is also confirmed in the experiments.
Based on Patch Dropout, we propose a Multi-PatchDrop mechanism to improve the performance of Transformer-based subject-sensitive hashing. We have experimentally proved that randomly discarding a portion of the input tokens not only does not reduce the tampering sensitivity of a Transformer-based subject-sensitive hashing algorithm but also improves the robustness of the algorithm. Unlike the original PatchDropout, which focused on improving the training efficiency of the model, our Multi-Patchdrop focuses more on improving the robustness and tamper sensitivity of a subject-sensitive hashing algorithm.
3. The Proposed Method
In this section, we first discuss the Multi-PatchDrop mechanism, then describe the improved Swin-Unet based on Multi-PatchDrop, and finally describe a subject-sensitive hashing algorithm based on Multi-PatchDrop and Swin-Unet.
3.1. Multi-PatchDrop
Multi-PatchDrop includes multiple patch dropout layers in the ViT model and the portion that generates the value of probability discarding patches for the patch dropout layer.
Significantly different from the original PatchDrop, our proposed Multi-PatchDrop mechanism uses different patch dropout values for different Transformer blocks of the encoder and decoder in ViT models. The Multi-PatchDrop mechanism needs to set two initial values, , representing the initial Patch Dropout values in the encoder and decoder phases, respectively.
Assuming that NLEn represents the number of modules of the encoder in ViT models, the patch dropout value of the Transformer block at the nth module can be expressed as follows:
Also, assuming that NLDe represents the number of layers of the decoder in ViT models, the patch dropout value of the Transformer block of the nth module of the decoder stage can be expressed as follows:
It can be seen from Equations (1) and (2) that patch dropout value tends to increase in both the encoder and decoder stages.
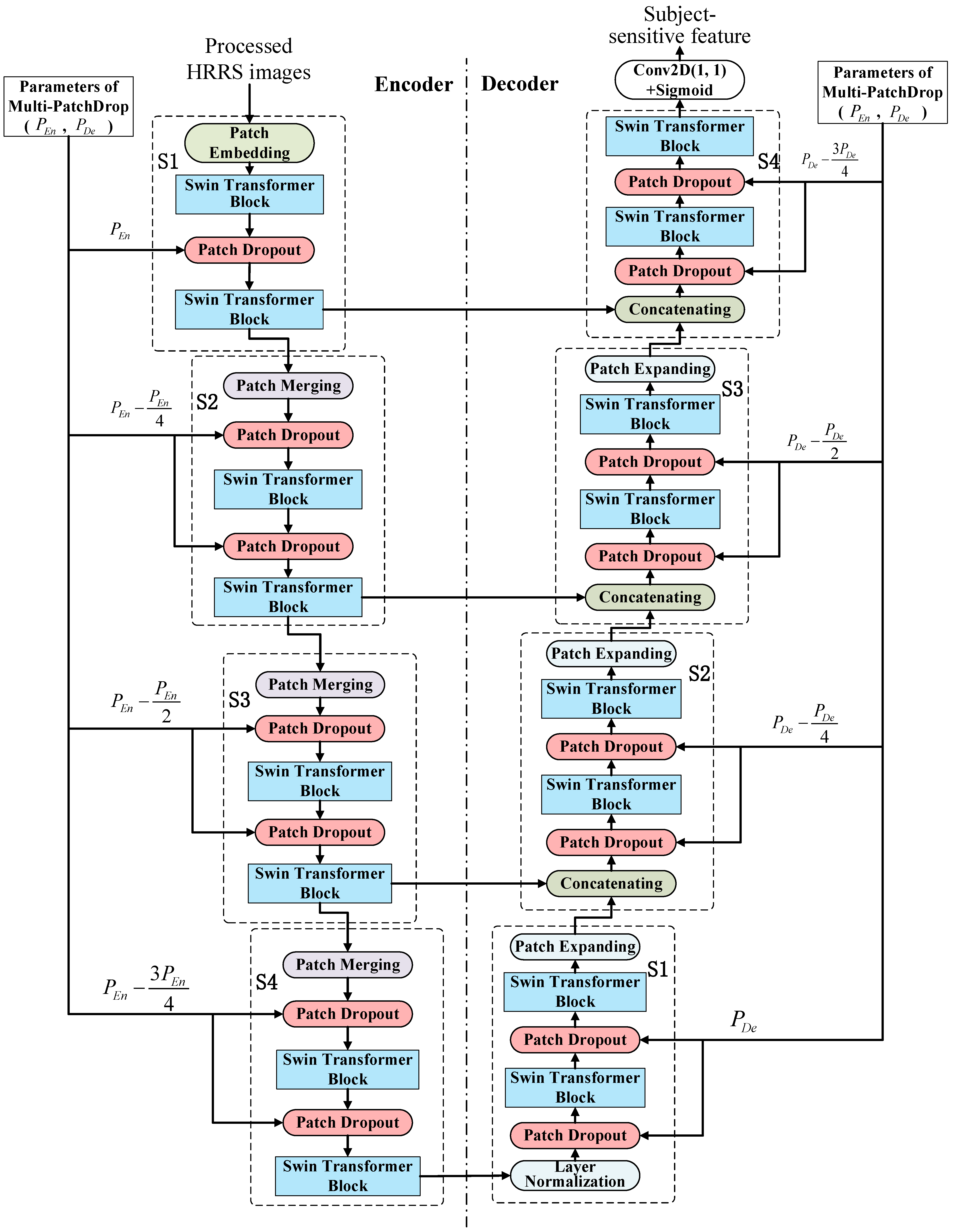
3.2. Improved Swin-Unet Based on Multi-PatchDrop
As shown in Figure 2, the overall structure of our improved Swin-Unet based on Multi-PatchDrop is similar to that of the original Swin-Unet [34], but the differences are also obvious:
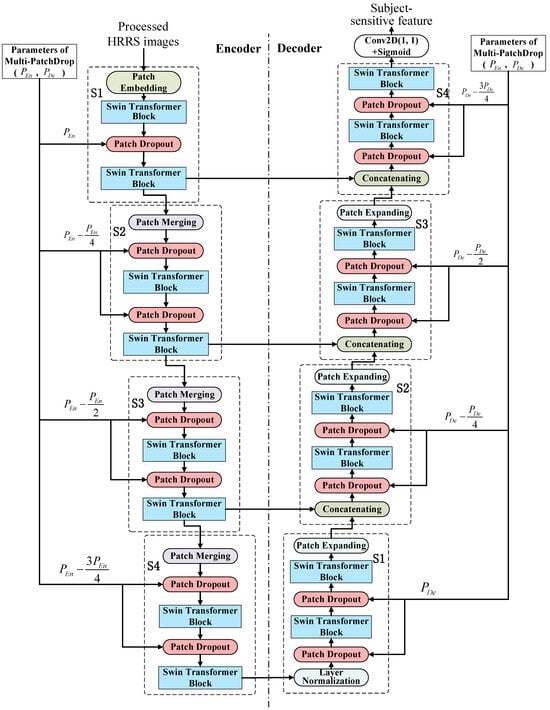
Figure 2.
Architecture of improved Swin-Unet based on Multi-Patchdrop.
- (1)
- The bottleneck of the original Swin-Unet only contains two Swin Transformer modules. In our improved Swin-Unet, we decompose it into two blocks, each containing two Swin Transformer modules. This is because the low-level Transformer is more important to the tampering sensitivity of subject-sensitive hashing, and it is necessary to increase the Swin Transformer block;
- (2)
- A Layer Normalization operation is added between the encoder and decoder to ensure the stable distribution of data features and accelerate the convergence speed of the model;
- (3)
- The biggest difference is that the proposed Multi-Patchout mechanism is integrated into our improved Swin-Unet, while there is no use of Patch Dropout in the original Swin-Unet.
The probability of each patch dropout module randomly dropping patches is determined by Multi-Patchdrop. As can be seen from Section 3.1, the value of the patch dropout of each module is different in the encoder phase: the patch dropout value of the first module is the initial value set, then decrements, and does not decrease to 0. The patch dropout value in the decoder stage is similar, with the first module being the initial value, then decreasing sequentially and not decreasing to 0.
3.3. Overview of Our Proposed Subject-Sensitive Hashing Algorithm
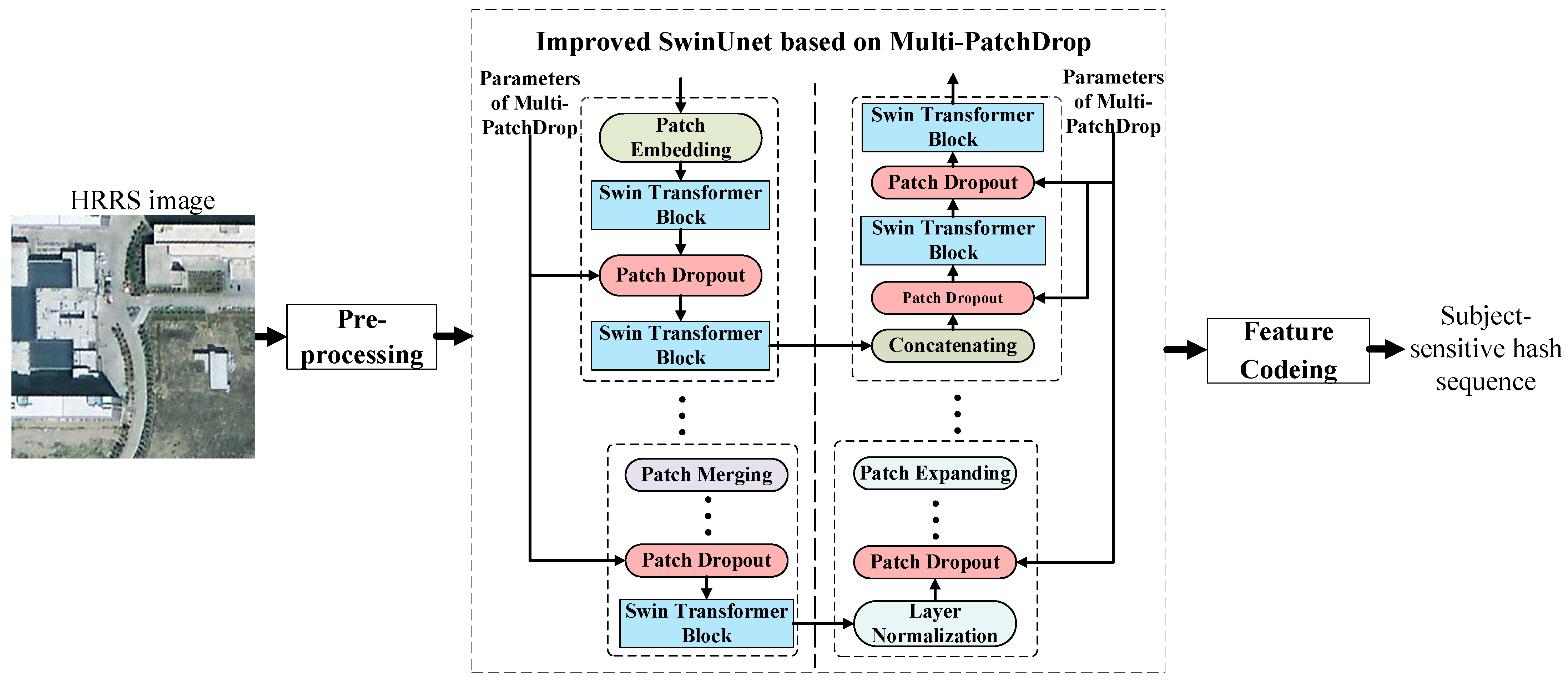
The existing Transformer-based subject-sensitive hashing algorithm [10] improves the robustness to a certain extent by “extracting features by band”, but the computational complexity is increased by about three times. Our algorithm no longer extracts features for each band separately but performs feature extraction after band fusion to reduce the time required to generate the hash sequence of a single HRRS image.
As shown in Figure 3, there are three main steps that make up our proposed subject-sensitive hashing algorithm: preprocessing of HRRS images, feature extraction based on the improved Swin-Unet, and feature encoding. In the pre-processing stage, the size of the HRRS image is adjusted to 224 × 224 pixels to meet the input conditions of the network. In the feature encoding stage, the feature matrix extracted by Swin-Unet is dimensionally reduced, and the vector after dimensionality reduction is converted into 0–1 sequences according to the principle of high-value validity.
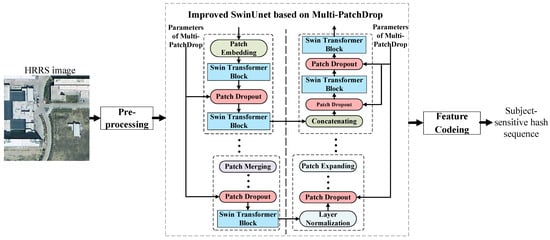
Figure 3.
The proposed subject-sensitive hashing algorithm.
The difference between the two hash sequences is measured by normalizing the Hamming distance (N-Dis) [35], and the N-Dis will be greater than a pre-set threshold T if the image has been tampered with.
To compare the differences in hash sequences more intuitively, we have modified the calculation method of N-Dis as follows:
Compared with the original N-Dis representation, our modified N-Dis calculation method has an additional parameter used to adjust the value of displayed N-Dis. In the experiment in this paper, is set to 10.
In addition, L in Equation (3) denotes the length of a hash sequence, and and denote the i-th binary bit of the two subject-sensitive hash sequences, respectively.
4. Experiments and Analysis
Since buildings are considered to be a paramount class of all man-made objects in HRRS images [36], we took buildings as the subject in this section to test the performance of the algorithm. On the basis of describing the training details of the model and experimental datasets, we first compared the existing algorithm with our algorithm through a group of tampering examples and then focused on comparing the robustness and tampering sensitivity of each algorithm.
4.1. Datasets and Training Details
In order to avoid the fortuity caused by a single training dataset, we use the following two datasets to train each model:
- (1)
- The training datasets used in [6,10]. The dataset contains a total of 3166 training images and is a composite training dataset based on the WHU building dataset [37] combined with manually drawn samples;
- (2)
- Training dataset based on the Inria Aerial dataset [38]. Each image’s size in the Inria Aerial dataset is 5000 × 5000 pixels. To meet the needs of extracting subject-sensitive features, we obtained 11,490 images by cropping these images and then added 30 sets of hand-drawn robust edge images to obtain a dataset with a total of 11,520 training samples.
The datasets used to test the algorithm’s robustness and tampering sensitivity are discussed in Section 4.3 and Section 4.4, respectively.
The improved Swin-Unet we propose is implemented using Keras 2.3.1 with tensorflow 1.15.5 as the backend. The hardware platform for the experiment includes an NVIDIA RTX 2080Ti GPU, an Intel i7-9700K CPU, and a memory of 32 gigabytes. The above hardware platform comes from China Hewlett-Packard Co., Ltd in Beijing, China. Through repeated experiments, were set to (0.4, 0.1) and (0.6, 0.1) in the process of training our improved Swin-Unet based on the WHU dataset and the Inria dataset, respectively. Other parameters during training include the following: Adam was selected as the optimizer, and its initial learning rate was 0.00001; epochs and batch size were set to 100 and 8, respectively; binary focal loss was used as the loss function. The activation function used in the Swin Transformer module was Relu instead of Gelu.
The algorithm based on the following models will be compared with our algorithm: U-net [28], M-net [29], MultiResUnet [39], AGIM-net [6], Attention U-net [30], Attention ResU-Net [40], STDU-net [31], TransUnet [41], and Swin-Unet [34]. Among them, U-net, M-net, and MultiResUnet are CNN-based models; Attentin U-net, AGIM-net, and Attention ResU-Net are attention mechanism-based models; STDU-net, TransUnet, and Swin-Unet are models based on Transformer.
4.2. Instances of Integrity Authentication
To preliminarily compare the algorithms, we illustrate the HRRS image integrity authentication process with a set of examples shown in Figure 4.

Figure 4.
Instances of Integrity Authentication: (a) Original image; (b) JPEG compression; (c) Format conversion; (d) Watermark embedding; (e) Subject-unrelated tampering; (f) Subject-related tampering 1 (Add a building); (g) Subject-related tampering 2 (Delete a building); (h) Random smear tampering.
The original HRRS image shown in Figure 4a is stored in TIFF format. Figure 4b–d shows the results of 95% JPEG compression, conversion to a PNG format, and invisible watermark embedding of the original image. Visually, Figure 4b–d is almost indistinguishable from the original HRRS images, but they have changed dramatically at the binary level. Figure 4e–h is a set of operations to change the content of the HRRS image in the following order: subject-unrelated tampering, subject-related tampering 1 (add a building), subject-related tampering 2 (delete a building), and random smearing tampering.
After the comparison models were trained by the training dataset based on the Inria dataset, the subject-sensitive hash sequences of the images shown in Figure 4a–h were calculated by the subject-sensitive hashing algorithms based on each comparison model. The N-Dis between the subject-sensitive hash sequences of Figure 4b–h and Figure 4a calculated by each comparison algorithm is shown in Table 1.

Table 1.
N-Dis of the algorithms based on each model.
An ideal subject-sensitive hashing algorithm ought to be as robust as possible to operations that do not change the content of the image and should be able to distinguish between operations that do not change an image’s content, subject-unrelated tampering, and subject-related tampering through different thresholds.
As can be seen from Table 1, the U-net-based algorithm, M-net-based algorithm, Attention ResU-Net-based algorithm, and TransUnet-based algorithm failed to keep robustness to JPEG compression when the threshold T was set to 0.1. The Attention U-Net-based algorithm, STDU-net-based algorithm, and our algorithm maintained complete robustness to the operation of Figure 4b–d. When the thresholds were set to 0.5 and 1, respectively, except for the Attention U-Net-based algorithm, all other algorithms could distinguish subject-related and subject-unrelated tampering. Overall, our algorithm and the SDTU-net-based algorithm performed better than other algorithms.
4.3. Algorithms’ Robustness Testing
Robustness testing requires a large number of test images. To test the robustness of the algorithm, we selected 10,000 images from the DOTA dataset [42], GF-2 satellite images, and images from the Inria dataset that did not participate in the training process to construct a dataset named DS10000. The images in DS10000 are stored in TIFF format.
In this paper, the robustness of subject-sensitive hashing is described by the proportion R(T) of HRRS images that maintain robustness at a specified threshold, with a higher value indicating better robustness:
where NumTotal is the number of images used to test robustness, and NumR is the number of samples that maintain robustness at a specified threshold T.
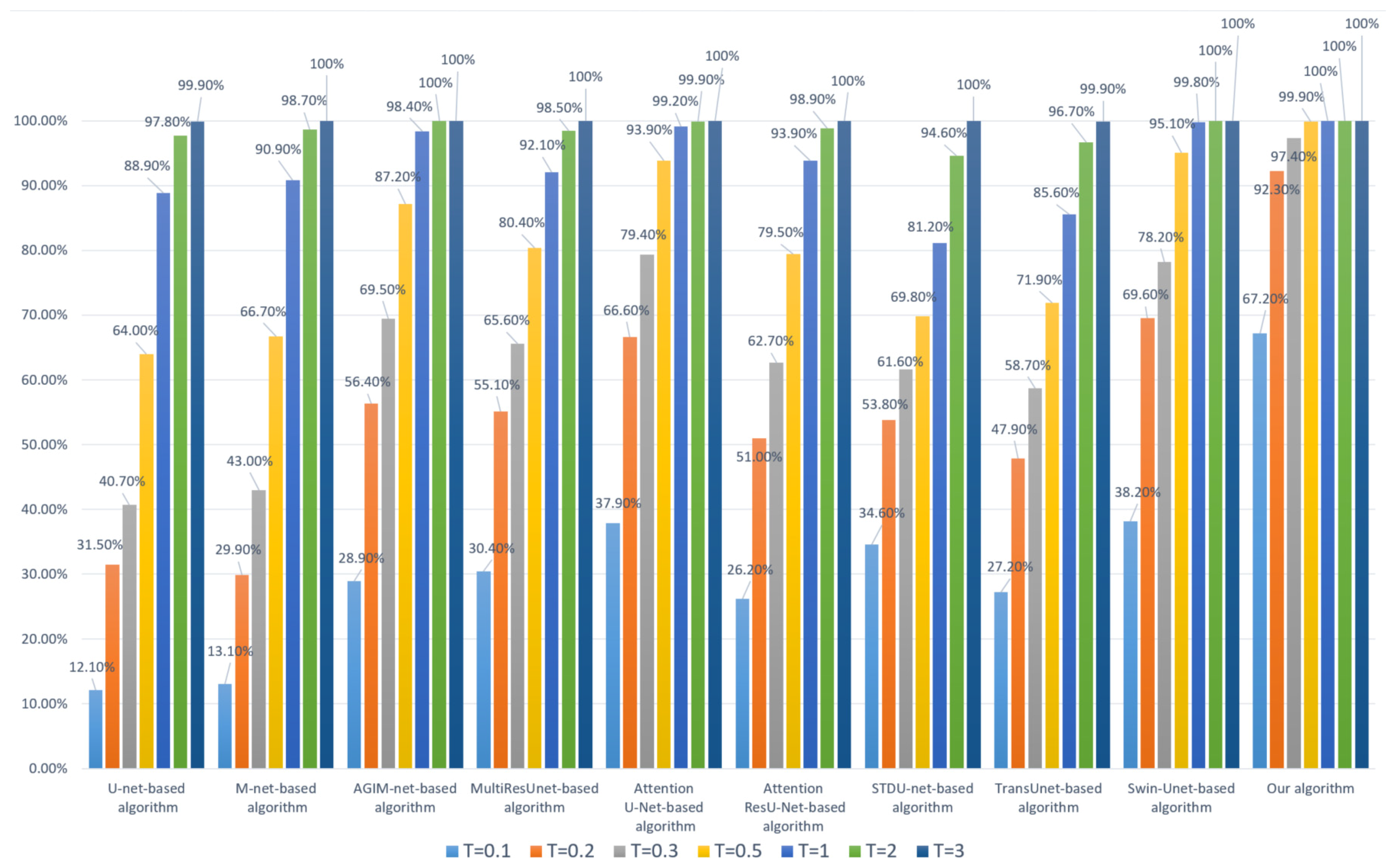
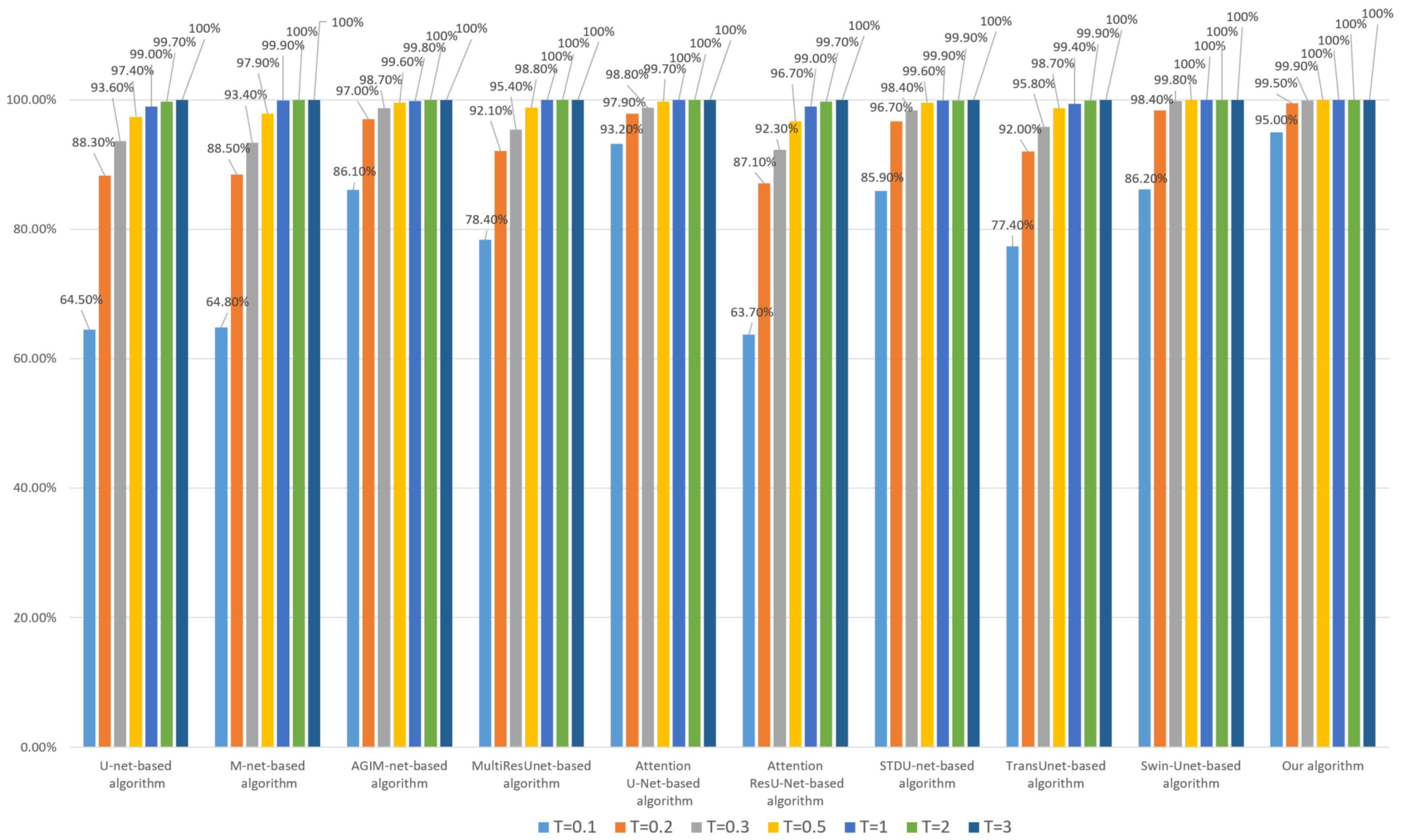
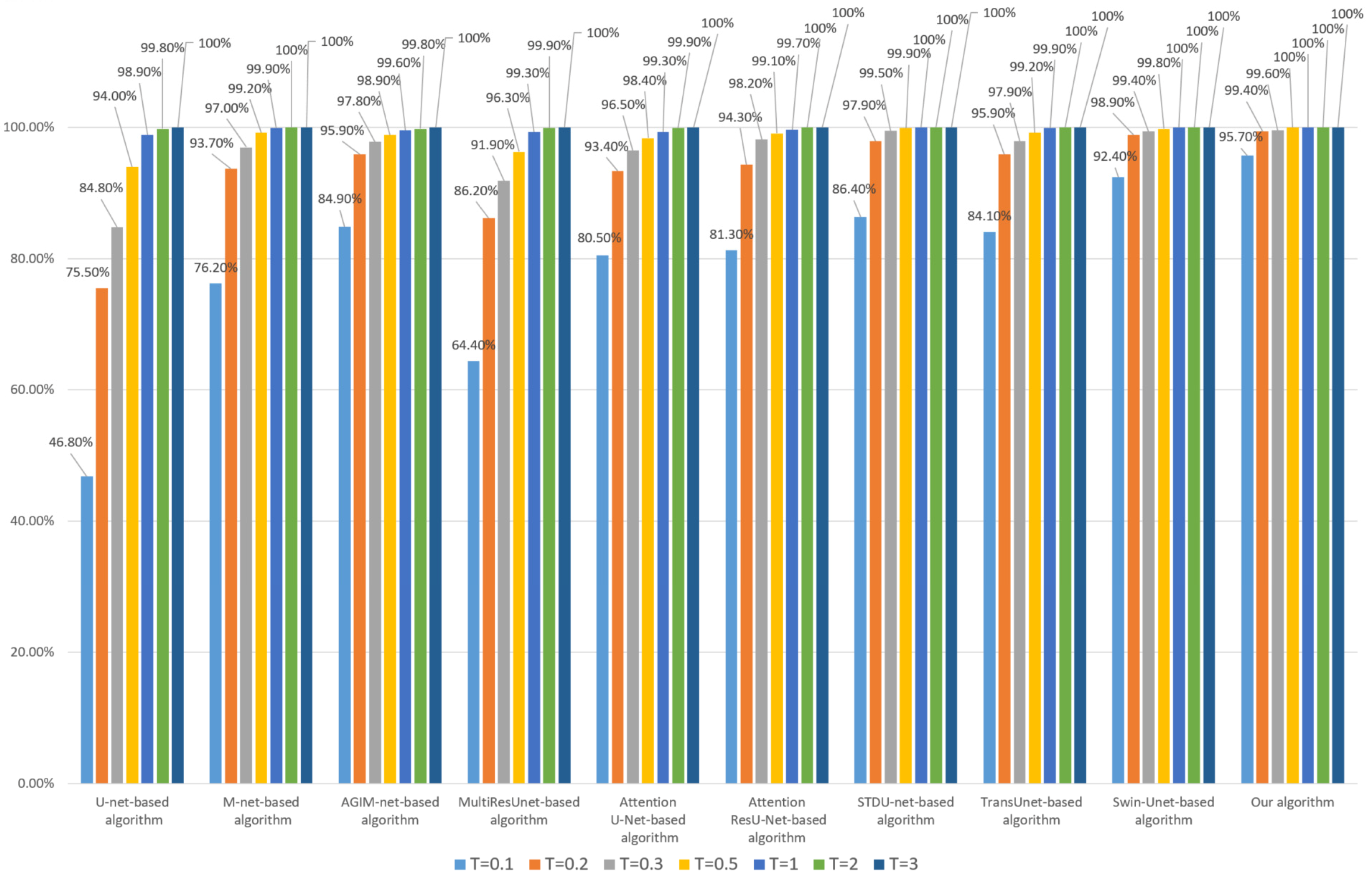
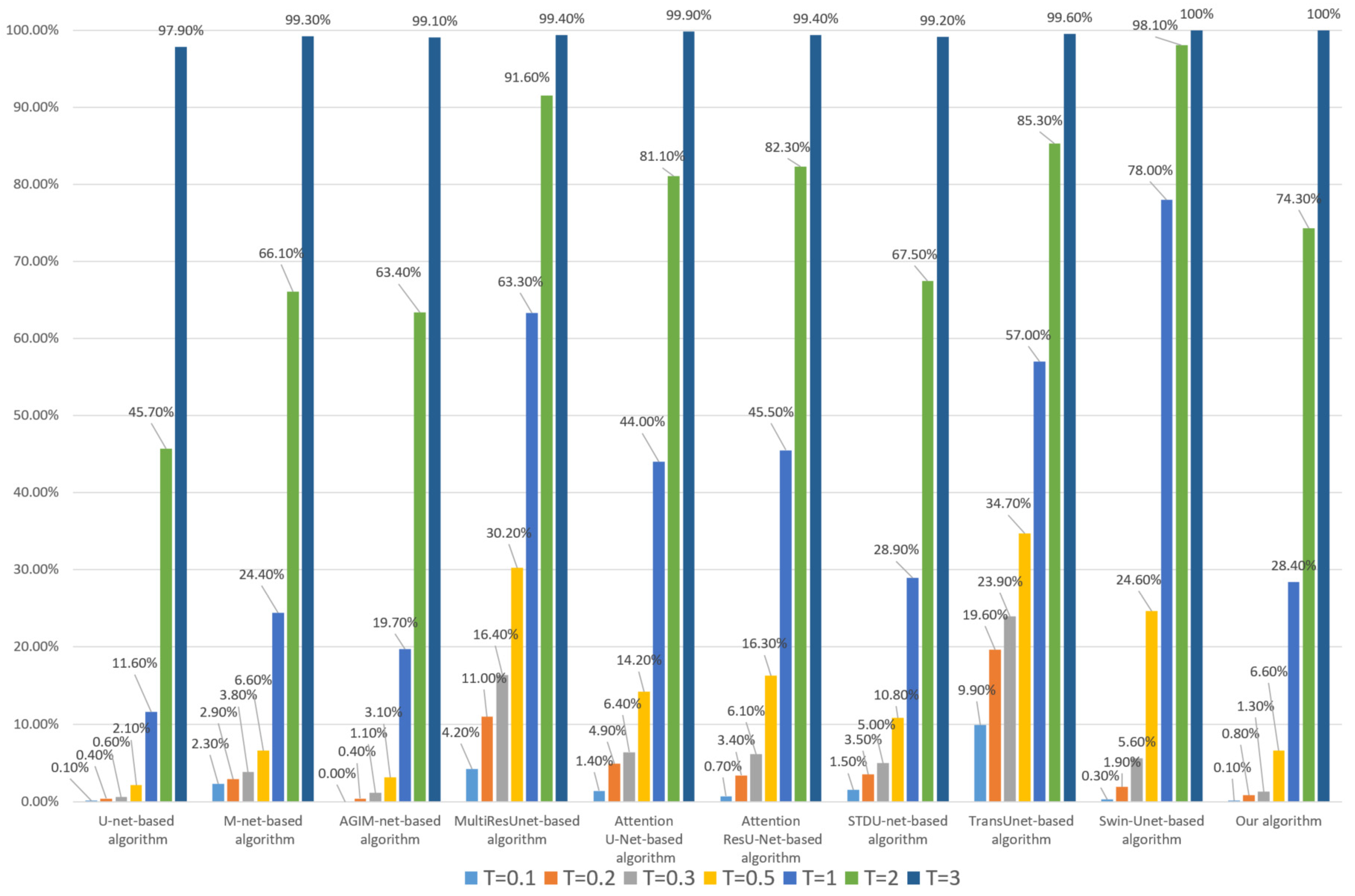
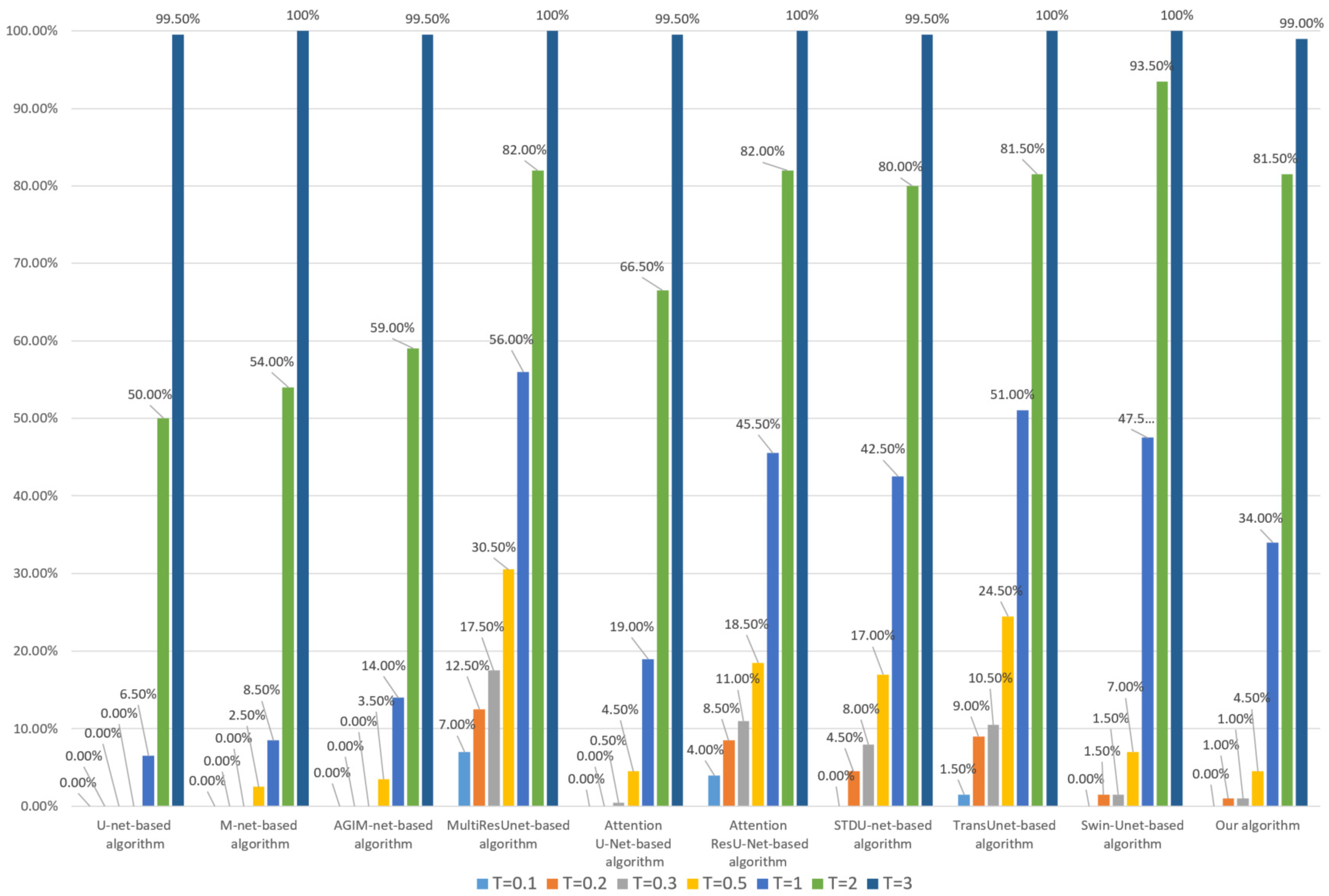
Firstly, we performed a 95% JPEG compression on each image in DS10000. The robustness of the algorithm based on the Inria dataset and WHU dataset is shown in Figure 5 and Figure 6, respectively.
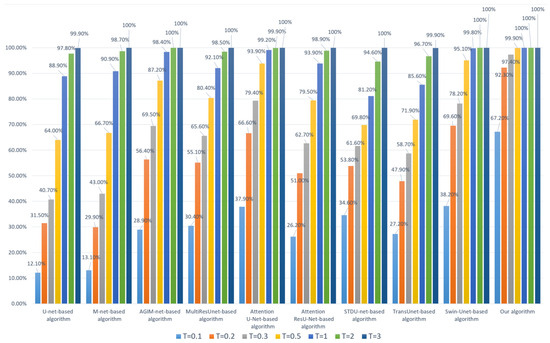
Figure 5.
Robustness of each algorithm to JPEG (based on the Inria Dataset).
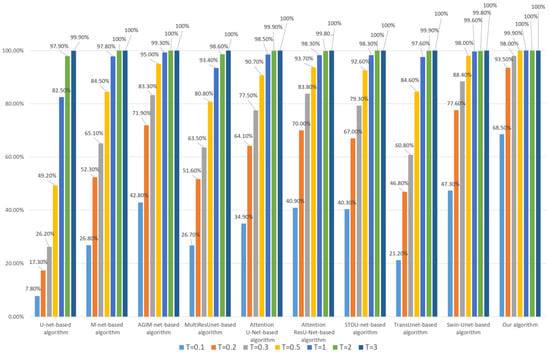
Figure 6.
Robustness of each algorithm to JPEG (based on WHU the dataset).
- (1)
- Whether the model is trained based on the Inria dataset or WHU dataset, our algorithm’s robustness to JPEG compression is the best among all comparison algorithms, especially at lower thresholds. We used two datasets to train the model separately, avoiding the chance of a single dataset;
- (2)
- Compared with algorithms based on Transformer models such as Swin-Unet and STDU-net, our algorithm has been greatly improved, which indicates that the proposed Multi-PatchDrop has a significant effect in improving the robustness of subject-sensitive hashing;
- (3)
- With the increase of the threshold T, each algorithm’s robustness would be enhanced, but the higher threshold reduces the tampering sensitivity of an algorithm.
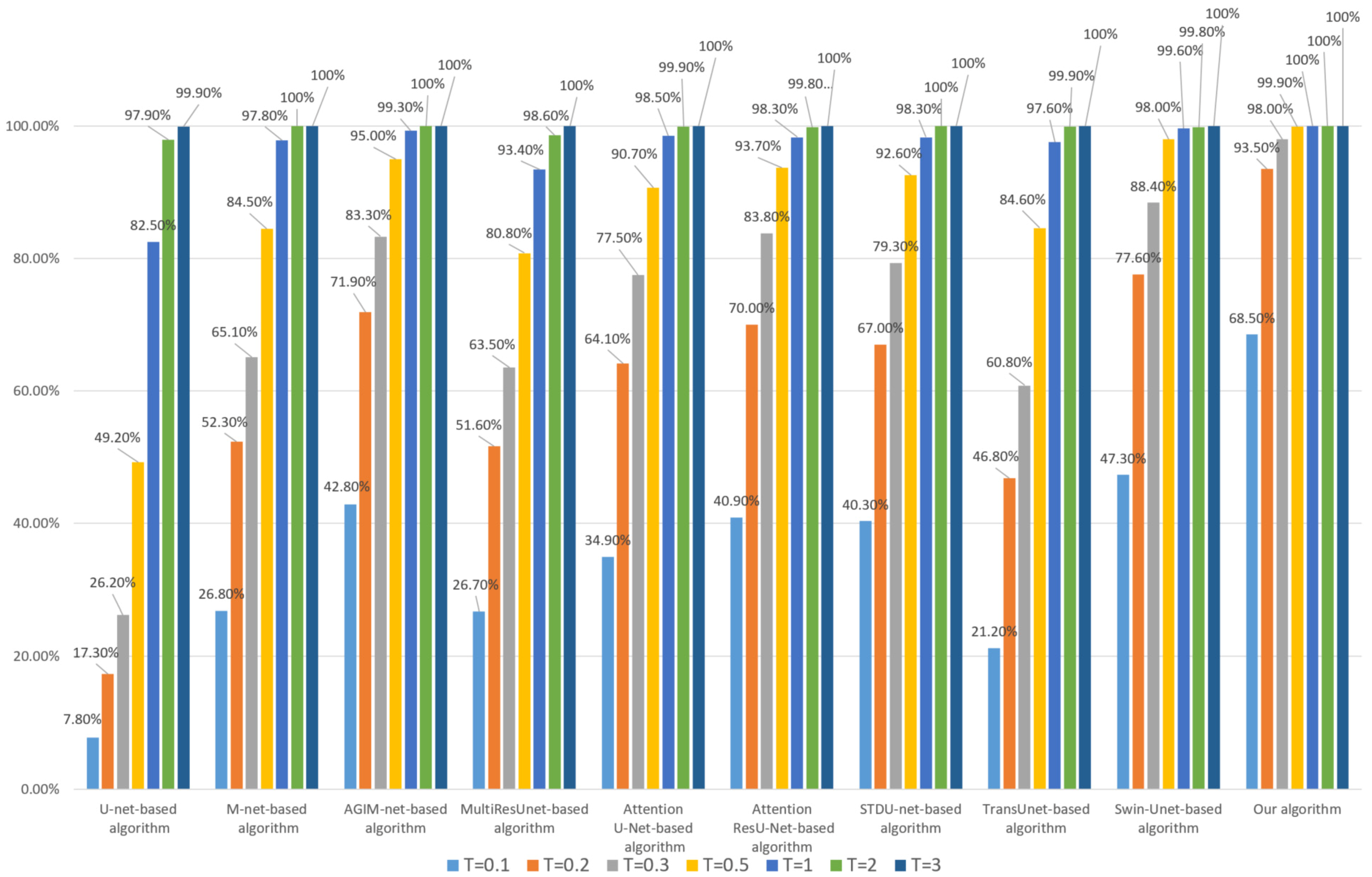
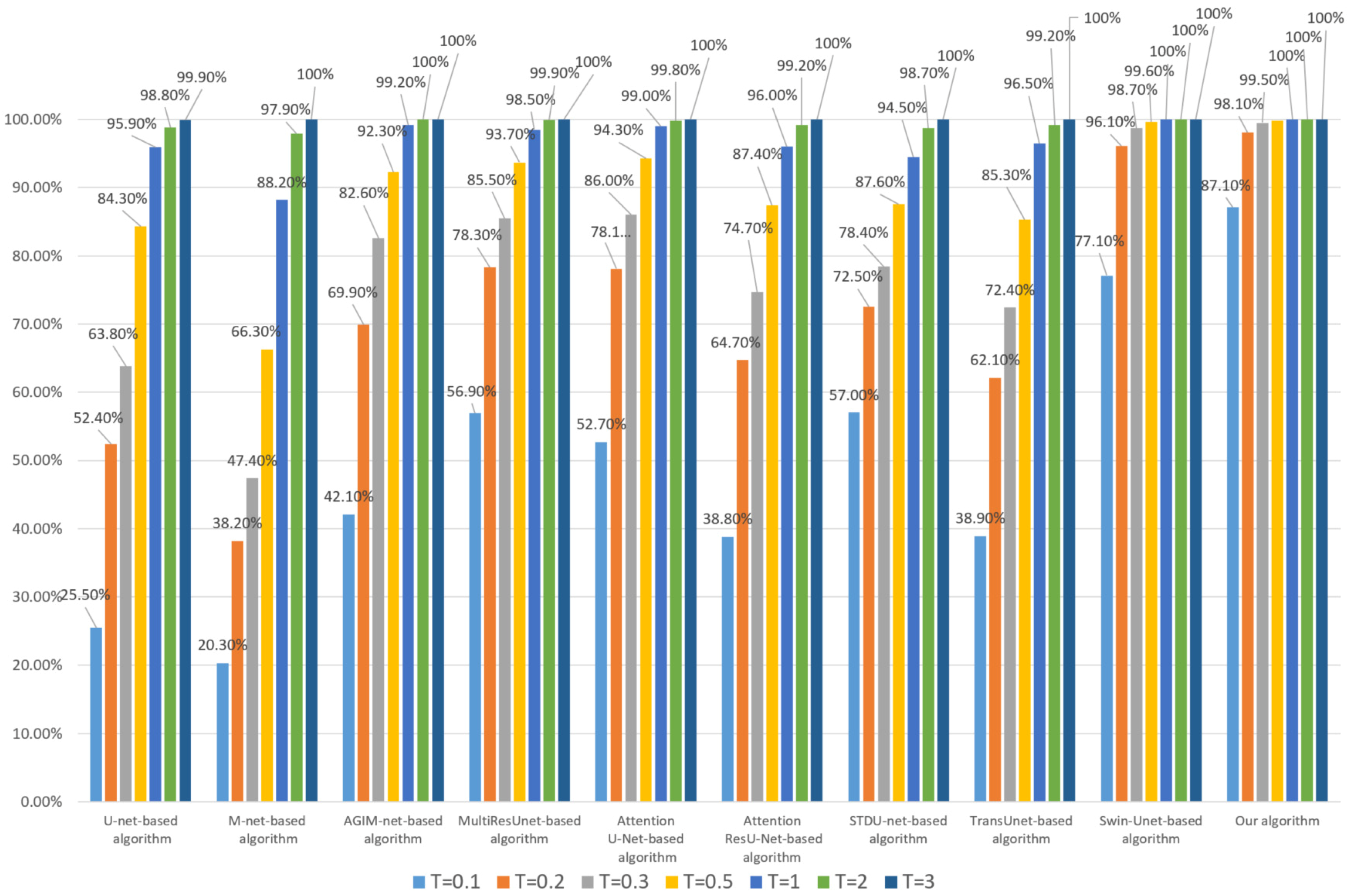
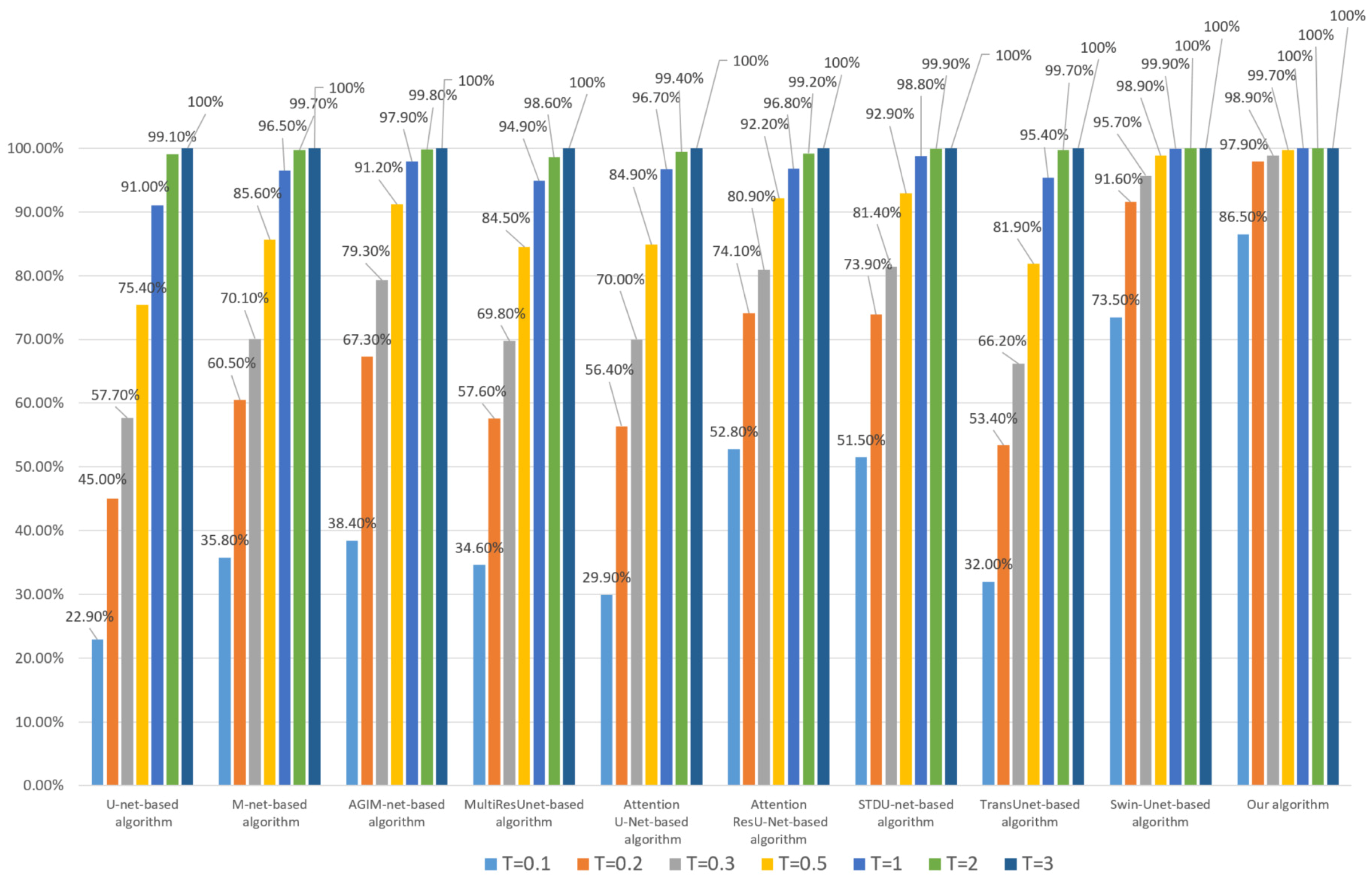
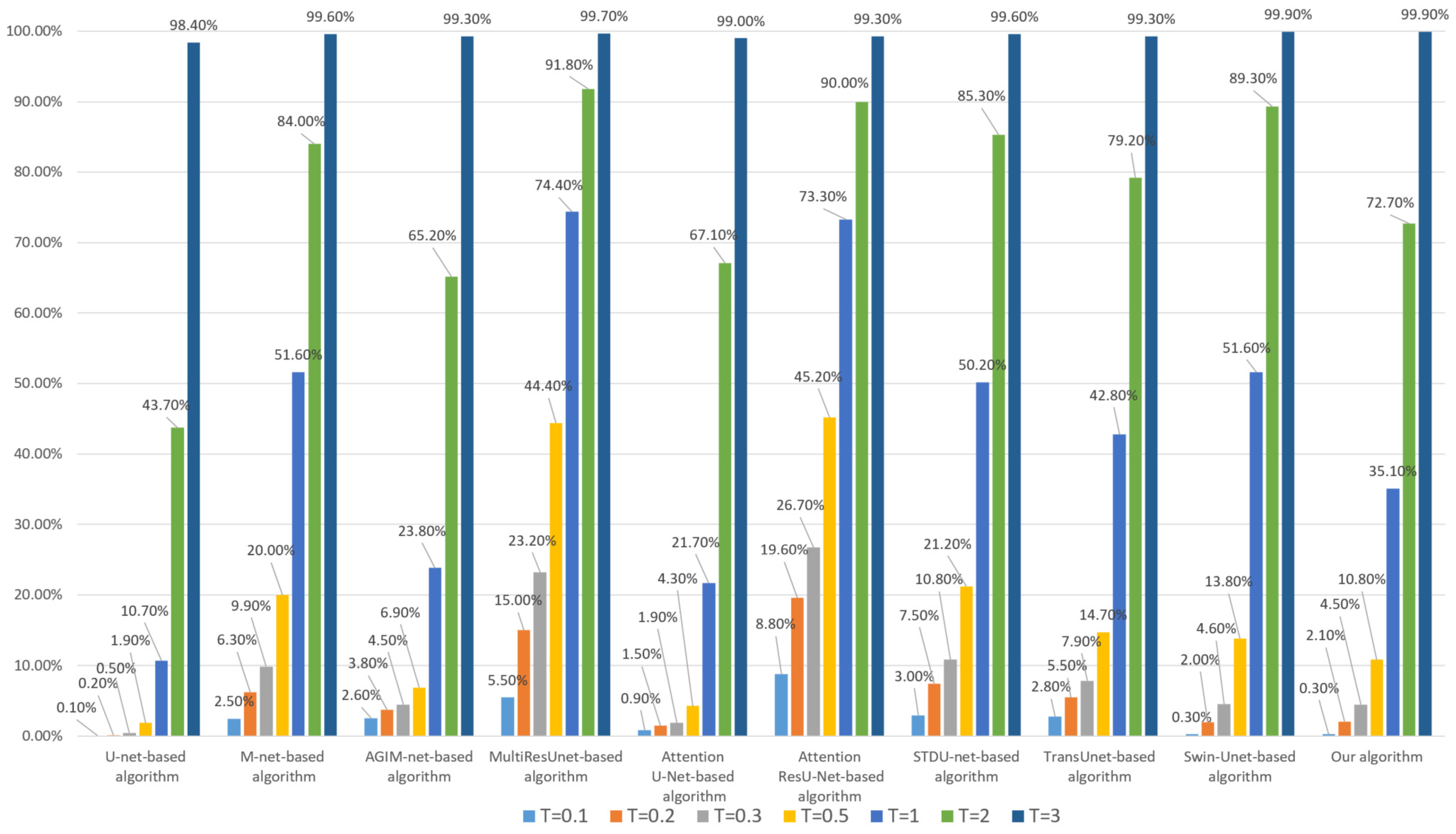
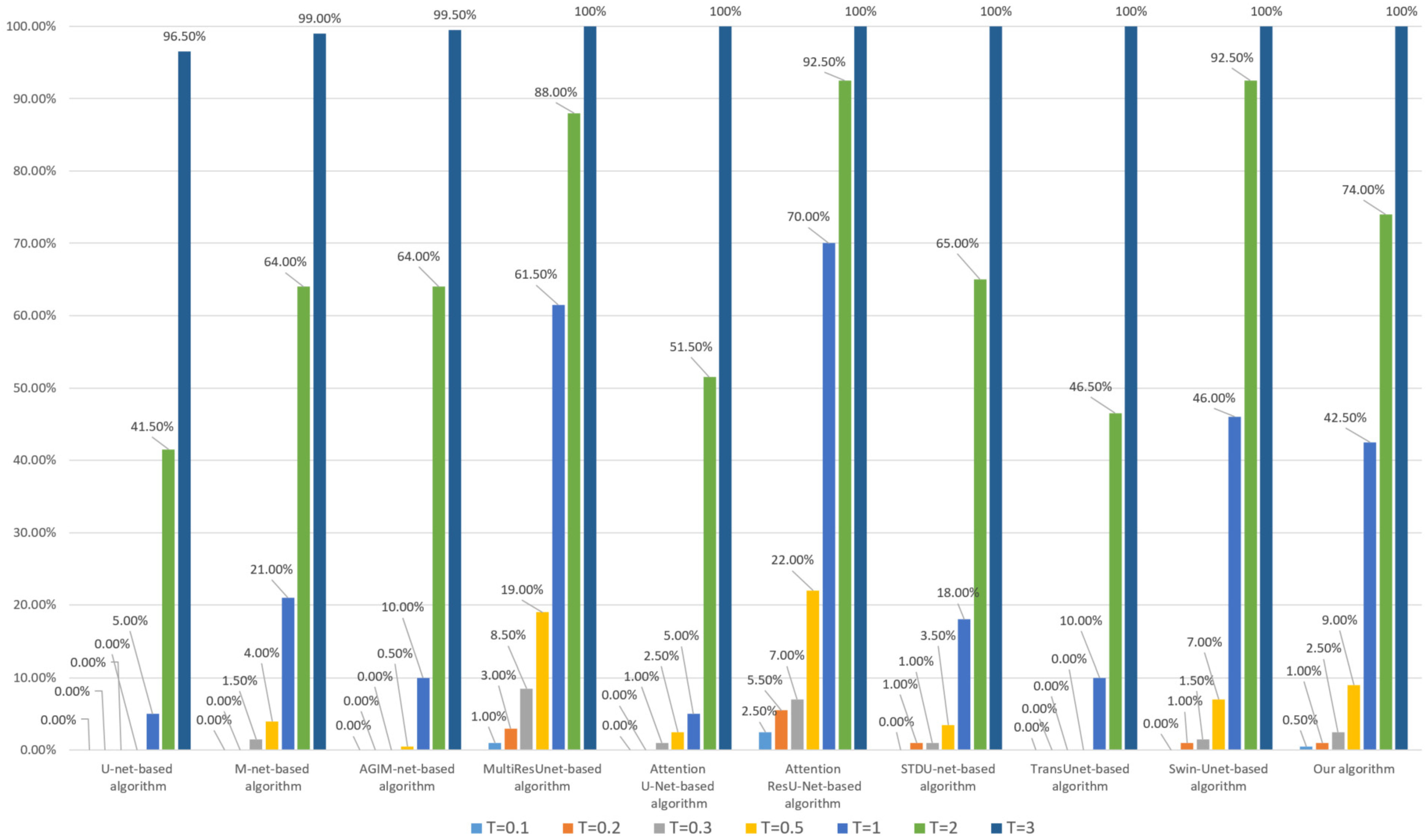
Next, each algorithm’s robustness to invisible watermarking will be tested. For HRRS images stored in TIFF format, multi-band watermark embedding can better ensure the security of watermark information, but the modification of an image is greater than that of single-band watermark embedding. For each HRRS image in dataset DS10000, we embedded 24 bits of watermark information in each band and then tested the robustness of each algorithm. Since each actual digital watermarking algorithm has its own watermark embedding rules, we used the method of randomly selecting pixels to determine the embedding pixels to avoid the chance caused by the explicit watermark embedding mechanism and adopt the method of least significant bit (LSB) to embed watermark information. Robustness test results for watermark embedding based on the Inria dataset and WHU dataset are shown in Figure 7 and Figure 8, respectively.
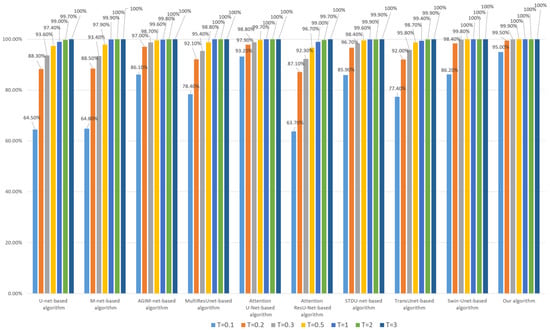
Figure 7.
Robustness of each algorithm to invisible watermark (based on the Inria dataset).
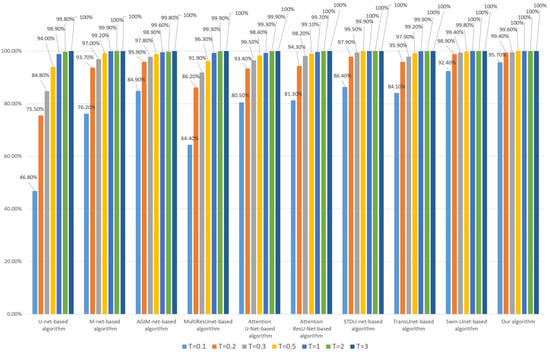
Figure 8.
Robustness of each algorithm to invisible watermark (based on the WHU dataset).
Combining Figure 7 and Figure 8, it can be seen that the Transformer-based algorithm’s robustness to the invisible watermark is significantly stronger than that of the CNN-based algorithm. Especially, the Swin-Unet-based algorithm and our algorithm have good robustness even under the low threshold (less than 0.2), which is unattainable by CNN-based algorithms, such as U-net. Furthermore, our algorithm is slightly better than the Swin-Unet-based algorithm in general and has a more obvious advantage when the threshold T is set to 0.1 and the model training process is based on the Inria dataset. This also illustrates the effectiveness of our Multi-PatchDrop in improving the robustness of Transformer-based subject-sensitive hashing algorithms.
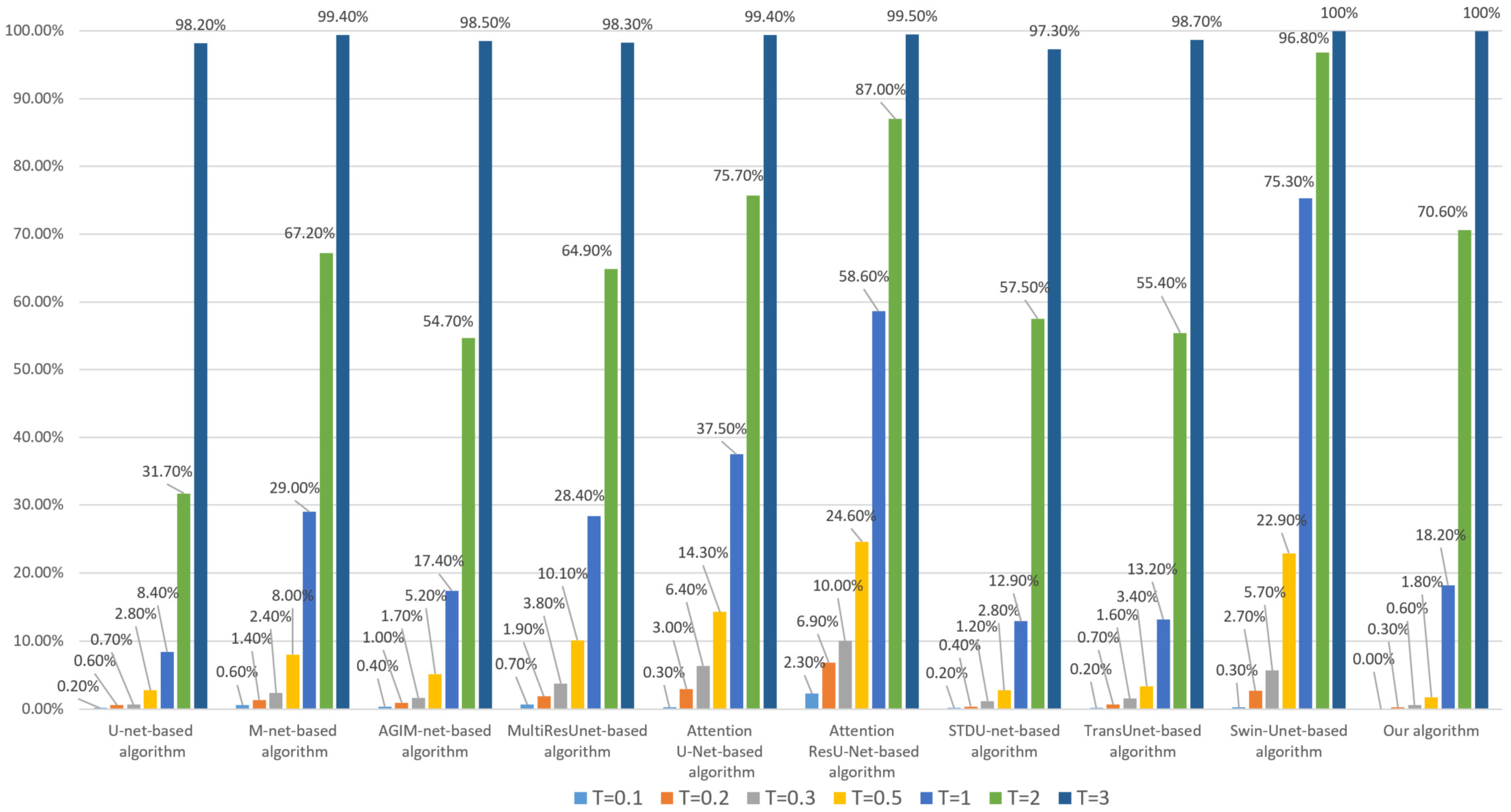
An important aspect of subject-sensitive hashing is that it remains robust to subtle manipulation that does not alter the subject-unrelated content of an image. Here, for each HRRS image in dataset DS10000, we randomly select four pixels and set their values to 255 to simulate the above subtle operation that does not change the subject-related content. The corresponding robustness test results are shown in Figure 9 and Figure 10:
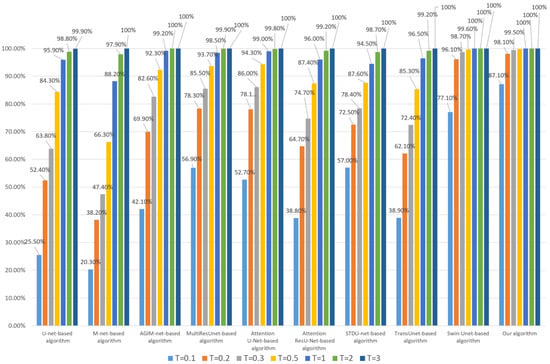
Figure 9.
Robustness of each algorithm to 4-pixel modifications (based on the Inria dataset).
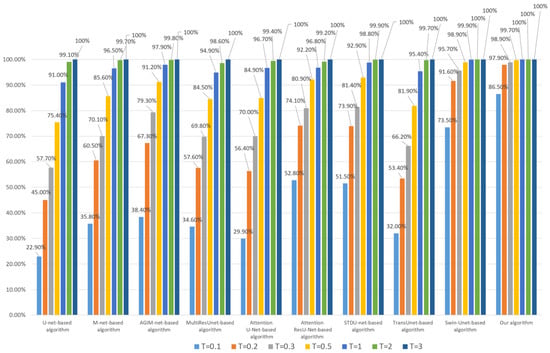
Figure 10.
Robustness of each algorithm to 4-pixel modifications (based on the WHU dataset).
As can be seen from Figure 9 and Figure 10, our algorithm has the best robustness to subtle manipulation among these algorithms. In the case of a low threshold T, not only are the algorithms based on CNN models such as U-Net, M-Net, and MultiResUnet not ideal, but also the algorithms based on the attention mechanism (including AGIM-net and Attention U-Net) are not as robust as our algorithm and Swin-Unet-based algorithm.
4.4. Algorithms’ Tampering Sensitivity Testing
Tampering sensitivity refers to the ability of a subject-sensitive hashing algorithm to detect actions that alter the content of an HRRS image, especially subject-related content. Since experiments in this paper were conducted using buildings as subjects, it is important to detect operations that affect the information on buildings in images.
In this paper, tampering sensitivity is described by the proportion of tampering that fails to detect at a special threshold T, with a lower value indicating better tampering sensitivity:
where NumTotal is the number of images, and NumNS is the number of samples that fail to detect the tampering at a specific threshold T.
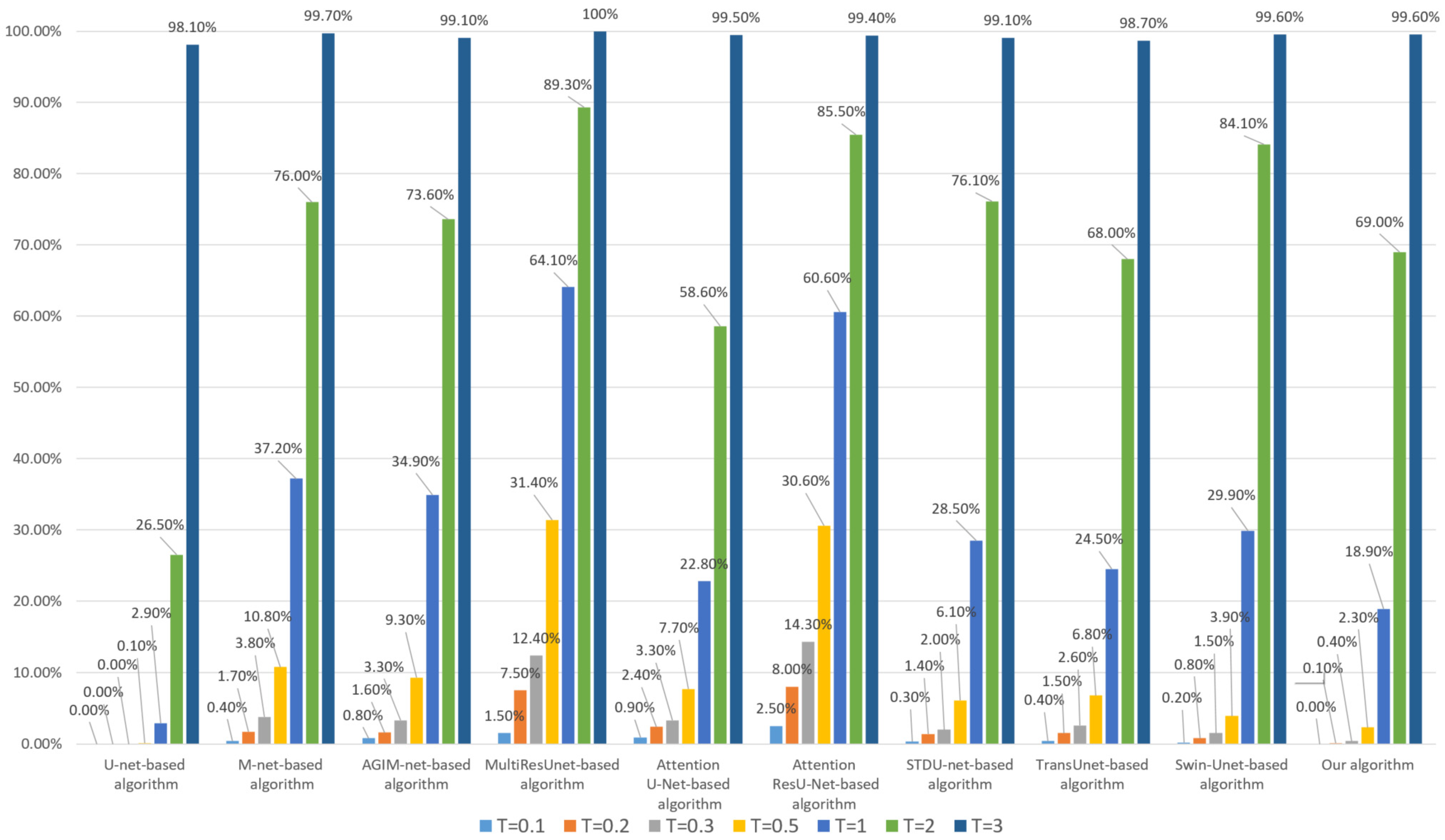
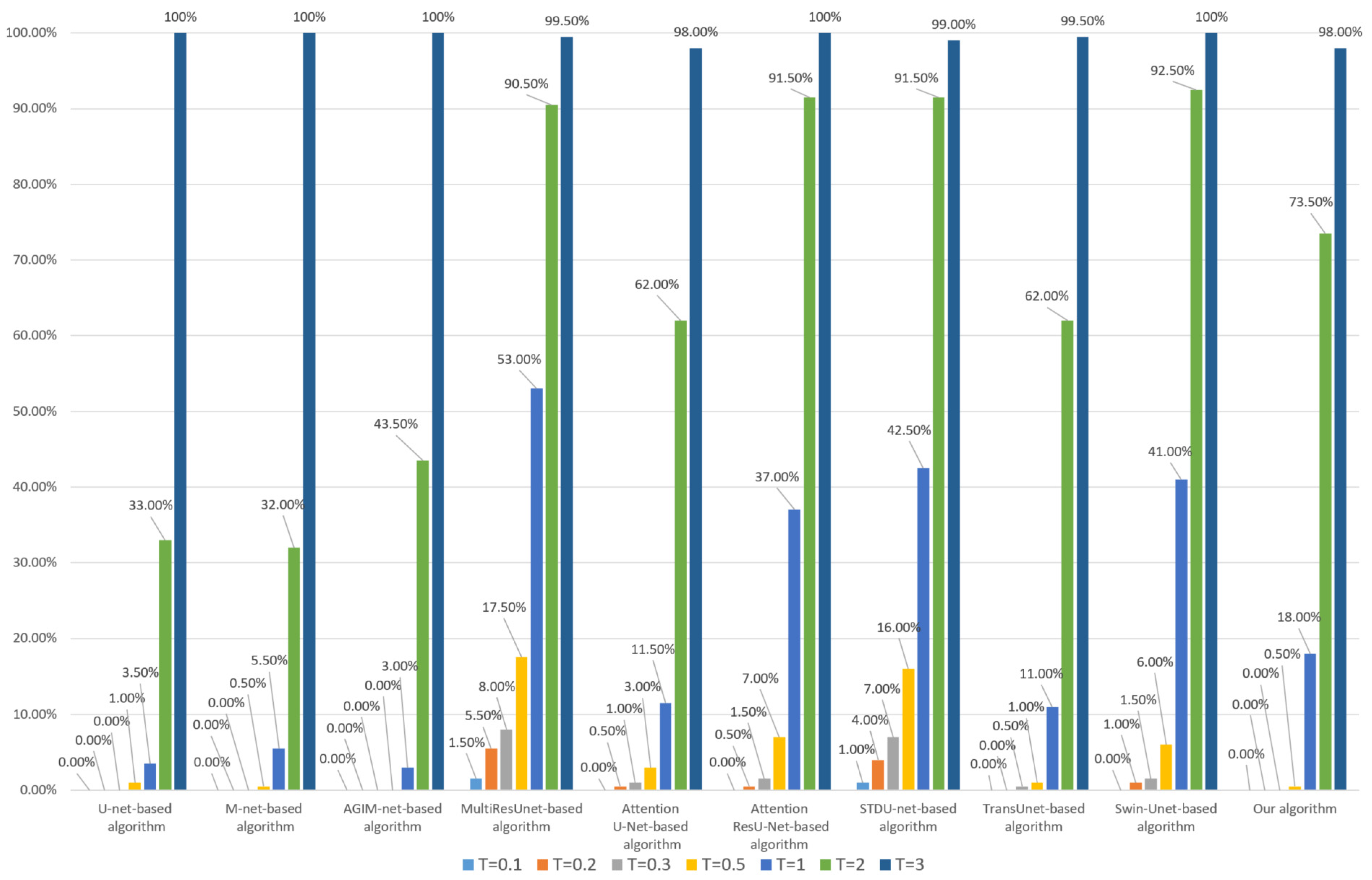
First, we modify each HRRS image in dataset DS10000 with a 24 × 24-pixel area, and the modified pixel values are random integers between 0 and 255. Figure 11 shows a set of examples of these tamper simulations. Since the location and pixel value of the tampered area are random, most of this tampering has an impact on the image, causing damage to the subject-sensitive content, and it is not easy to find the tampering without looking closely. The tampering sensitivity test result is shown in Figure 12 and Figure 13.

Figure 11.
Examples of 24 × 24-pixel subject-related tampering. (a) Original HRRS images. (b) Tampered images.
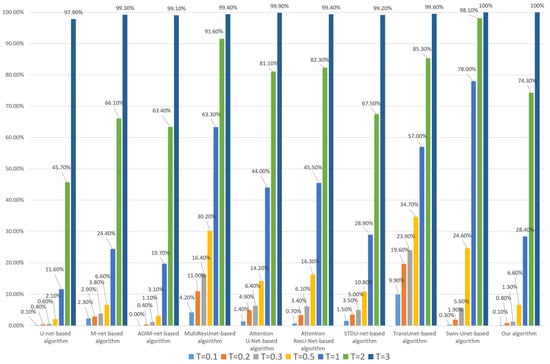
Figure 12.
Tampering sensitivity test for 24 × 24-pixel subject-related tampering (based on the Inria dataset).
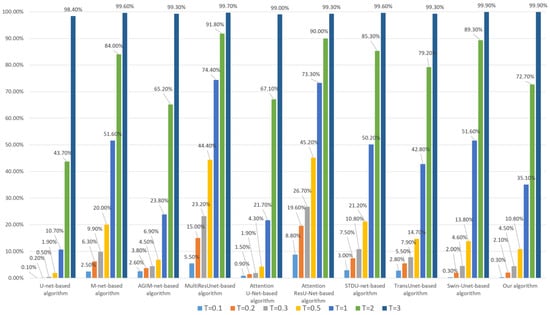
Figure 13.
Tampering sensitivity test for 24 × 24-pixel subject-related tampering (based on the WHU dataset).
As can be seen from Figure 12 and Figure 13, there are some differences in the tampering sensitivity of the algorithms depending on the training dataset. Based on the Inria dataset, our algorithm is superior to the Swin-Unet-based algorithm and STDU-net-based algorithm but slightly inferior to the AGIM-net-based algorithm. When based on the WHU dataset, our algorithm is basically the same as the Swin-Unet-based algorithm, slightly inferior to the U-net-based algorithm but stronger than the AGIM-net-based algorithm and other algorithms. Overall, our algorithm is superior to the Swin-Unet-based algorithm and most other algorithms.
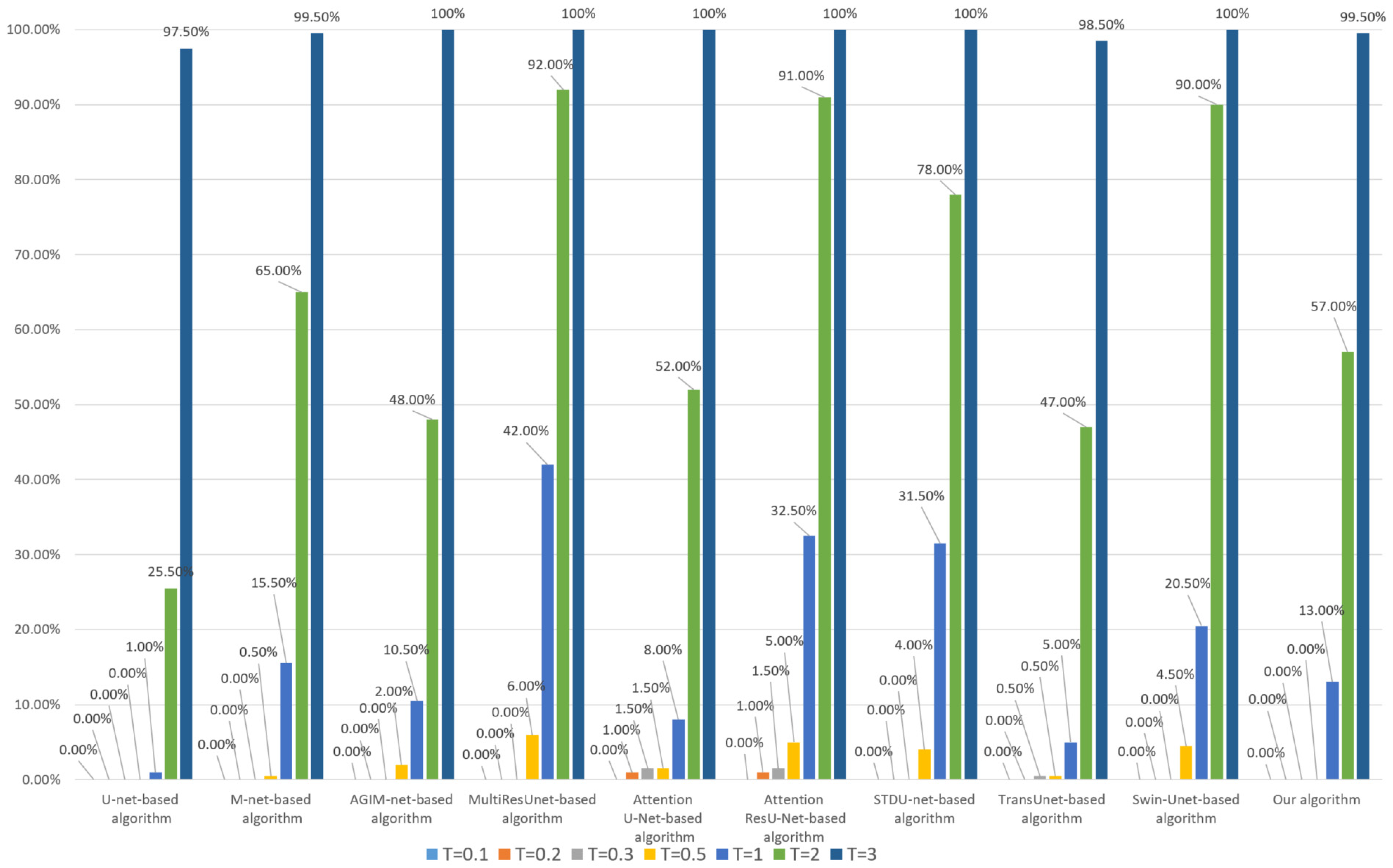
Then, we reduced the tampering granularity: each image in DS10000 was cropped at a random position of 16 × 16 pixels, and the pixel value of the tampered region was 255. A group of examples of the above tampering is shown in Figure 14. As can be seen from Figure 14, although the tampering area is not as large as the 24 × 24-pixel area shown in Figure 11, the damage to the image is also great due to the 255-pixel value of the cropped area. The results of the tampering sensitivity test are shown in Figure 15 and Figure 16.

Figure 14.
Examples of 16 × 16-pixel subject-related tampering. (a) Original HRRS images. (b) Tampered images.
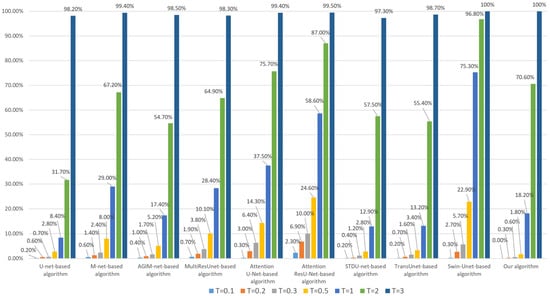
Figure 15.
Tampering sensitivity testing for 16 × 16-pixel subject-related tampering (based on the Inria dataset).
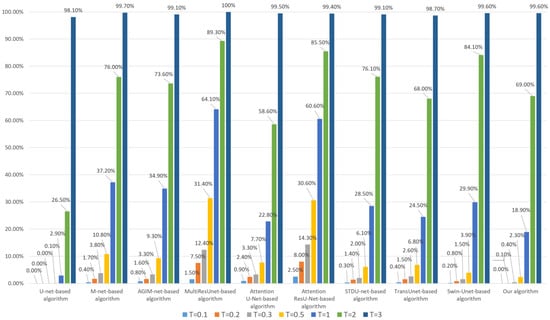
Figure 16.
Tampering sensitivity testing for 16 × 16-pixel subject-related tampering (based on the WHU dataset).
When training each model with the Inria dataset, it can be seen from Figure 15 that the tampering sensitivity of our algorithm is the best at low to medium thresholds and inferior to U-net-based algorithms at high thresholds (greater than 1) but better than those based on Transformer-based algorithm. As can be seen from Figure 16, when the WHU dataset is used to train the model, our algorithm’s tampering sensitivity is generally not as good as that of the U-net-based algorithm but better than other comparison algorithms.
Next, we test each algorithm’s tampering sensitivity to subject-related tampering of deleting buildings. We selected 200 HRRS images from dataset DS10000 and removed certain building information (different from cropping) from each image. A set of images before and after deleting a building is shown in Figure 17. It can be seen that tampering with the deletion of a building not only causes damage to the content of the image but is also very difficult to detect by the human eye. The tampering test results of deleting buildings are shown in Figure 18 and Figure 19.

Figure 17.
Examples of subject-related tampering of deleting buildings. (a) Original HRRS images. (b) Tampered images.
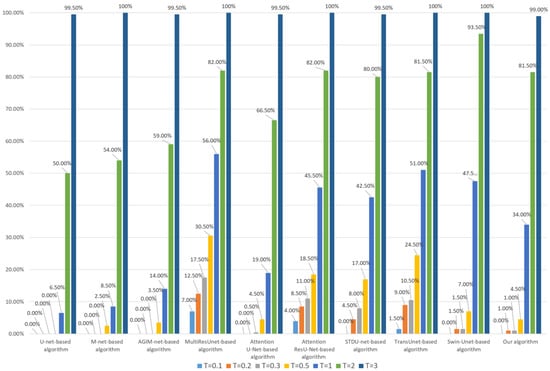
Figure 18.
Tampering sensitivity testing for deletion of buildings (based on the Inria dataset).
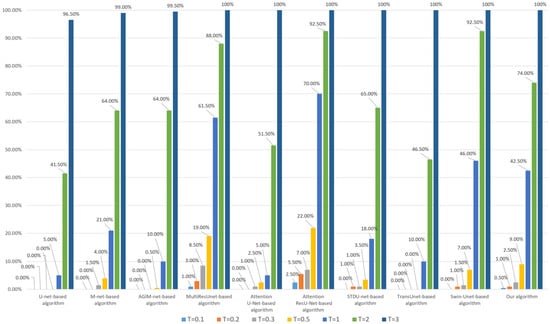
Figure 19.
Tampering sensitivity testing for deletion of buildings (based on the WUH dataset).
As can be seen from Figure 18, when the models are trained based on the Inria dataset, our algorithm’s tampering sensitivity to deleting buildings at a low threshold (less than or equal to 0.3) is close to that of the algorithm based on CNN models such as M-net, basically the same as that of the algorithm based on attention mechanism models such as AGIM-net, and stronger than that of algorithms based on Transformer models. However, when the threshold T is set to a medium–high threshold (greater than or equal to 0.5), Transformer-based algorithms (including ours) are significantly inferior to CNN-based algorithms and attention mechanism-based algorithms. When the model is trained based on the WHU dataset, the conclusion is similar, as can be seen in Figure 19.
In general, CNN-based algorithms and attention mechanism-based algorithms are more sensitive to subject-related tampering of deleting buildings than Transformer-based algorithms. Although our algorithm is slightly inferior to the algorithms based on U-net, M-net, AGIM-net, and Attention Unet, it is better than algorithms based on Transformer models, including Swin-Unet, STDU-net, and TransUnet.
Finally, we test each algorithm’s tampering sensitivity to subject-related tampering of adding builds. We selected 200 HRRS images from dataset DS10000 and added certain building information to each image. A group of images with a building added is shown in Figure 20. As can be seen, similar to deleting buildings, adding buildings is also difficult to detect. The tampering test results are shown in Figure 21 and Figure 22.

Figure 20.
Examples of subject-related tampering of added buildings. (a) Original HRRS images. (b) Tampered images.
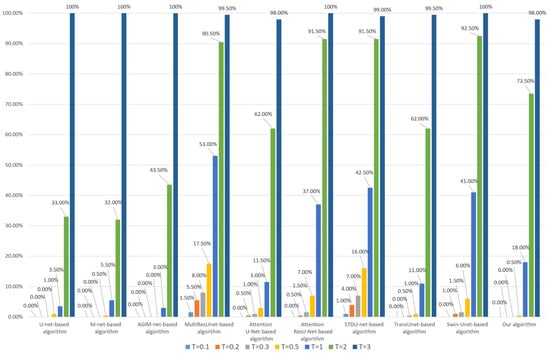
Figure 21.
Tampering sensitivity testing for added buildings (based on the Inria dataset).
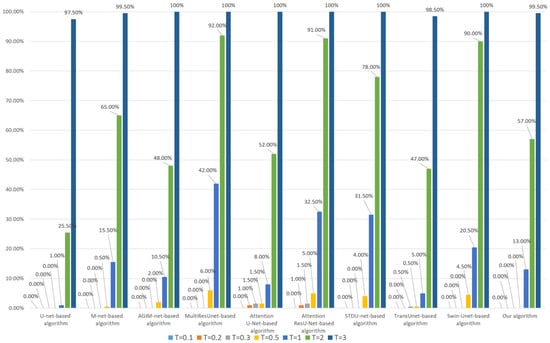
Figure 22.
Tampering sensitivity testing for added buildings (based on the WHU dataset).
As can be seen from Figure 21 and Figure 22, under the medium or low threshold T (less than or equal to 0.5), our algorithm has the best tampering sensitivity to added buildings, regardless of whether the model is trained based on the Inria dataset or the WHU dataset, but it is inferior to U-net-based algorithm, AGIM-net-based algorithm, and Attention U-net based-algorithm at high thresholds (greater than or equal to 1).
5. Discussion
5.1. Comprehensive Evaluation of Algorithm Performance
In this paper, we propose the Multi-PatchDrop mechanism for a Transformer and construct an improved Swin-Unet-based mechanism to implement subject-sensitive hashing for HRRS image integrity authentication. In the experiments in Section 4, in order to avoid the fortuity caused by a single training dataset, we used two separate datasets, the WHU dataset and the Inria dataset, to train each model. From the experiments, our algorithm has the best comprehensive performance:
5.1.1. Robustness
The proposed Multi-PatchDrop mechanism is effective in improving the robustness of Transformer-based subject-sensitive hashing. Our algorithm’s robustness is better than that of Swin-Unet, especially for JPEG compression. After all, the main distinction between our improved Swin-Unet and the original one is the integration of Multi-PatchDrop.
On the other hand, the robustness of the Transformer-based algorithm is significantly stronger than that of the CNN-based algorithm, which is consistent with the research conclusion of the existing literature. For example, the robustness of the U-net-based algorithm is relatively poor, and even when the threshold T is set to a medium value (such as 0.5), its robustness to JPEG compression is less than 50% (based on the WHU dataset) and 64% (based on the Inria dataset).
5.1.2. Tampering Sensitivity
The tampering sensitivity and robustness of subject-sensitive hashing are inherently contradictory. Subject-sensitive hashing algorithms with poor robustness tend to have great tampering sensitivity, and increased tampering sensitivity tends to reduce the robustness of the algorithm. The difficulty in designing a subject-sensitive hashing algorithm is to make the algorithm as robust and tamper-sensitive as possible.
As can be seen from Section 4.4, the tampering sensitivity of the U-net-based algorithm is the best. Although the tampering sensitivity of our proposed algorithm is not as good as that of the U-net-based algorithm on the whole, it is close to the U-net-based algorithm at medium and low thresholds and is basically the same as that of the U-net-based algorithm when the threshold is set to 0.1.
However, our algorithm’s tampering sensitivity is better than that of other Transformer-based algorithms, especially the Swin-Unet-based algorithm. The tampering sensitivity of the M-net or AGIM-net-based algorithm is about the same as ours; not as strong as the U-net, but stronger than MultiResUnet, Attention ResU-Net, and other Transformer-based algorithms.
In general, our algorithm’s tampering sensitivity is only slightly inferior to the U-net-based algorithm, whose robustness is very unsatisfactory.
5.1.3. Digestibility
As an integrity authentication technology, excellent digestibility is a characteristic that a subject-sensitive hashing should have; otherwise, it will lose its use value.
The digestibility of our algorithm is as follows: the length of the output hash sequence is 128 bits, which is the same as the integrity authentication algorithm MD5 in cryptography algorithms and better than SHA-1 (160 bits). Each algorithm compared in the experiments adopts the same flow, but the difference is that different models are used to extract HRRS image features, so the digestibility of each algorithm is the same.
The research in [43] focuses on end-to-end output, which is quite different from our algorithm, and the length of its output hash sequence is 2048 bits, which is not as digestive as our algorithm.
5.1.4. Security
The security of the CNN-based subject-sensitive hashing algorithm basically relies on the unexplainability of deep neural networks. Our algorithm inherits this and goes a step further:
- The complexity of the Transformer network is much greater than that of CNN, and the interpretability is more difficult than that of CNN, which makes the security of the Transformer-based algorithm stronger than that of the CNN-based algorithm.
- Since the Multi-PatchDrop mechanism makes our improved Swin-Unet randomly drop patches during the training process, increasing the difficulty of reversely obtaining HRRS image content from the hash sequence, our algorithm is more secure than the Swin-Unet-based algorithm.
Of course, due to the difficulty of interpretation of deep neural networks, there is still a certain gap between our algorithm and classical algorithms (e.g., hash-based image encryption [44]) in the quantitative analysis of algorithm security, and we will delve into this in the next step.
5.2. Impact of Multi-PatchDrop on Algorithm’s Performance
In this section, we take the WHU dataset as an example to test the impact of Multi-PatchDrop on the performance of the algorithm. While keeping the network of improved Swin-Unet unchanged, we set to different values. After training these models using the WHU dataset, the algorithm’s tampering sensitivity to 16 × 16-pixel tampering and under robustness to a JPEG compression threshold T = 0.2 are shown in Table 2 and Table 3.
Table 2.
Tampering sensitivity test to 16 × 16-pixel tampering with different Multi-PatchDrop parameters (T = 0.2).
Table 3.
Robustness test to JPEG compression with different Multi-PatchDrop parameters (T = 0.2).
As can be seen from Table 2, the algorithm has the best tampering sensitivity when is set to (0.4, 0.1) or (0.6, 0.0). Among them, the former is exactly what we used in the experiment in Section 4, while the latter is not as robust as the former, as can be seen from Table 3. In short, when is set to (0.4, 0.1), the algorithm has the best overall performance.
6. Conclusions and Future Works
In this paper, an improved Swin-Unet algorithm based on the Multi-Patchdrop mechanism is proposed to implement a subject-sensitive hashing algorithm for HRRS images. In this improved Swin-Unet, each Swin Transformer block except the first one is preceded by a Patch Dropout layer to randomly drop a subset of patches, and the probability of dropping patches is different for each Patch Dropout layer, which is determined by the Multi-Patchdrop. Through experiments and discussions, the following conclusions can be drawn:
- (1)
- Multi-PatchDrop can improve the comprehensive performance of Transformer-based subject-sensitive hashing, especially robustness;
- (2)
- Compared with the original Swin-Unet, our improved Swin-Unet based on Multi-PatchDrop is more fit to implement a subject-sensitive hashing algorithm of HRRS images;
- (3)
- Different training datasets have a certain impact on the improved Swin-Unet based on Multi-PatchDrop, but our algorithm performs better than existing methods under different training datasets.
However, there are still some limitations in our algorithm that need to be further addressed: A Transformer model based on Multi-PatchDrop needs to set a different when using different training datasets. In the experiments, we determined through repeated experiments when using the WHU dataset and the Inria dataset. On the other hand, our algorithm can only be applied to HRRS images of three bands or single bands and cannot be directly used for integrity authentication of multispectral images and hyperspectral images. As a result, our future research includes the following:
- (1)
- Study the adaptive mechanism for determining patch dropout value;
- (2)
- Construct a Transformer model based on an adaptive patch dropout mechanism for subject-sensitive hashing;
- (3)
- Explore the Patch dropout mechanism of the Transformer model for the authentication of multispectral images.
Author Contributions
Kaimeng Ding and Yingying Wang conceived the idea; Chishe Wang and Ji Ma assisted with the experiments. Each of the authors has reviewed this manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
The research was funded by grants from (a) the National Natural Science Foundation of China (42101428, 41801303) and (b) the Research Foundation of Jinling Institute of Technology (JIT-B-202111).
Data Availability Statement
WHU Dataset is provided by Shunping Ji et al. (http://gpcv.whu.edu.cn/data (accessed on 4 August 2024)); Inria Aerial Dataset is provided by Emmanuel Maggiori et al. (https://project.inria.fr/aerialimagelabeling/ (accessed on 4 August 2024)).
Conflicts of Interest
All authors declare no conflicts of interest.
References
- Li, X.; Lei, L.; Kuang, G. Multilevel Adaptive-Scale Context Aggregating Network for Semantic Segmentation in High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6003805. [Google Scholar] [CrossRef]
- Han, R.; Fan, X.; Liu, J. EUNet: Edge-UNet for Accurate Building Extraction and Edge Emphasis in Gaofen-7 Images. Remote Sens. 2024, 16, 2397. [Google Scholar] [CrossRef]
- Ouyang, X.; Xu, Y.; Mao, Y.; Liu, Y.; Wang, Z.; Yan, Y. Blockchain-Assisted Verifiable and Secure Remote Sensing Image Retrieval in Cloud Environment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1378–1389. [Google Scholar] [CrossRef]
- Islam, K.A.; Wu, H.; Xin, C.; Ning, R.; Zhu, L.; Li, J. Sub-Band Backdoor Attack in Remote Sensing Imagery. Algorithms 2024, 17, 182. [Google Scholar] [CrossRef]
- Ren, N.; Wang, H.; Chen, Z.; Zhu, C.; Gu, J. A Multilevel Digital Watermarking Protocol for Vector Geographic Data Based on Blockchain. J. Geovisualization Spat. Anal. 2023, 7, 31. [Google Scholar] [CrossRef]
- Ding, K.; Zeng, Y.; Wang, Y.; Lv, D.; Yan, X. AGIM-Net Based Subject-Sensitive Hashing Algorithm for Integrity Authentication of HRRS Images. Geocarto Int. 2023, 38, 2168071. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern. Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Marjani, M.; Mahdianpari, M.; Mohammadimanesh, F.; Gill, E.W. CVTNet: A Fusion of Convolutional Neural Networks and Vision Transformer for Wetland Mapping Using Sentinel-1 and Sentinel-2 Satellite Data. Remote Sens. 2024, 16, 2427. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. ACM Comput. Surv. 2022, 54, 200. [Google Scholar] [CrossRef]
- Ding, K.; Chen, S.; Zeng, Y.; Wang, Y.; Yan, X. Transformer-Based Subject-Sensitive Hashing for Integrity Authentication of High-Resolution Remote Sensing (HRRS) Images. Appl. Sci. 2023, 13, 1815. [Google Scholar] [CrossRef]
- Liu, Y.; Matsoukas, C.; Strand, F.; Azizpour, H.; Smith, K. Patch Dropout: Economizing Vision Transformers Using Patch Dropout. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 3942–3951. [Google Scholar]
- Han, J.; Li, P.; Tao, Y.; Ren, P. Encrypting Hashing Against Localization. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5607414. [Google Scholar] [CrossRef]
- Qin, C.; Liu, E.; Feng, G.; Zhang, X. Perceptual Image Hashing for Content Authentication Based on Convolutional Neural Network With Multiple Constraint. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4523–4537. [Google Scholar] [CrossRef]
- Samanta, P.; Jain, S. Analysis of Perceptual Hashing Algorithms in Image Manipulation Detection. Procedia Comput. Sci. 2021, 185, 203–212. [Google Scholar] [CrossRef]
- Lv, Y.; Wang, C.; Yuan, W.; Qian, X.; Yang, W.; Zhao, W. Transformer-Based Distillation Hash Learning for Image Retrieval. Electronics 2022, 11, 2810. [Google Scholar] [CrossRef]
- Huang, Z.; Liu, S. Perceptual Image Hashing With Texture and Invariant Vector Distance for Copy Detection. IEEE Trans. Multimedia 2021, 23, 1516–1529. [Google Scholar] [CrossRef]
- Wang, X.; Pang, K.; Zhou, X.; Zhou, Y.; Li, L.; Xue, J. A Visual Model-Based Perceptual Image Hash for Content Authentication. IEEE Trans. Inf. Forensics Secur. 2015, 7, 1336–1349. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Girardi, A.M.; Cardell, E.A.; Bird, S.P. Artificial Intelligence in the Interpretation of Video fluoroscopic Swallow Studies: Implications and Advances for Speech–Language Pathologists. Big Data Cogn. Comput. 2023, 7, 178. [Google Scholar] [CrossRef]
- Zhang, K.; Zhao, K.; Tian, Y. Temporal–Semantic Aligning and Reasoning Transformer for Audio-Visual Zero-Shot Learning. Mathematics 2024, 12, 2200. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, X. Bidirectional Feature Fusion and Enhanced Alignment Based Multimodal Semantic Segmentation for Remote Sensing Images. Remote Sens. 2024, 16, 2289. [Google Scholar] [CrossRef]
- Zhang, G.; Hong, X.; Liu, Y.; Qian, Y.; Cai, X. Video Colorization Based on Variational Autoencoder. Electronics 2024, 13, 2412. [Google Scholar] [CrossRef]
- Wang, X.; Guo, Z.; Feng, R. A CNN- and Transformer-Based Dual-Branch Network for Change Detection with Cross-Layer Feature Fusion and Edge Constraints. Remote Sens. 2024, 16, 2573. [Google Scholar] [CrossRef]
- Qin, Y.; Wang, J.; Cao, S.; Zhu, M.; Sun, J.; Hao, Z.; Jiang, X. SRBPSwin: Single-Image Super-Resolution for Remote Sensing Images Using a Global Residual Multi-Attention Hybrid Back-Projection Network Based on the Swin Transformer. Remote Sens. 2024, 16, 2252. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Zhu, X.; Huang, X.; Cao, W.; Yang, X.; Zhou, Y.; Wang, S. Road Extraction from Remote Sensing Imagery with Spatial Attention Based on Swin Transformer. Remote Sens. 2024, 16, 1183. [Google Scholar] [CrossRef]
- Chen, X.; Pan, H.; Liu, J. SwinDefNet: A Novel Surface Water Mapping Model in Mountain and Cloudy Regions Based on Sentinel-2 Imagery. Electronics 2024, 13, 2870. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Adiga, V.; Sivaswamy, J. FPD-M-net: Fingerprint Image Denoising and Inpainting Using M-Net Based Convolutional Neural Networks. In Inpainting and Denoising Challenges; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Ding, K.; Chen, S.; Zeng, Y.; Liu, Y.; Xu, B.; Wang, Y. SDTU-Net: Stepwise-Drop and Transformer-Based U-Net for Subject-Sensitive Hashing of HRRS Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3836–3849. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408820. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Ding, K.; Zhu, C.; Lu, F. An adaptive grid partition based perceptual hash algorithm for remote sensing image authentication. Wuhan Daxue Xuebao 2015, 40, 716–720. [Google Scholar]
- Kokila, S.; Jayachandran, A. Hybrid Behrens-Fisher- and Gray Contrast–Based Feature Point Selection for Building Detection from Satellite Images. J. Geovisualization Spat. Anal. 2023, 7, 8. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S. Building extraction via convolutional neural networks from an open remote sensing building dataset. Acta Geod. Cartogr. Sin. 2019, 48, 448–459. [Google Scholar]
- Emmanuel, M.; Yuliya, T.; Guillaume, C.; Pierre, A. Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium(IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Ibtehaz, N.; Rahman, M. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Net. 2020, 121, 74–87. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Zheng, S.; Duan, C.; Su, J.; Zhang, C. Multistage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8009205. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Xu, D.; Chen, S.; Zhu, C.; Li, H.; Hu, L.; Ren, N. Deep Subject-Sensitive Hashing Network for High-Resolution Remote Sensing Image Integrity Authentication. IEEE Geosci. Remote Sens. Lett. 2024, 21, 6010705. [Google Scholar] [CrossRef]
- Deng, S.; Zhan, Y.; Xiao, D.; Li, Y. Analysis and improvement of a hash-based image encryption algorithm. Commun. Nonlinear Sci. Numer. Simul. 2011, 16, 3269–3278. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).