1. Introduction
The concept of globalization is a technological unification of the world leading to a global information society. Such processes require several steps such as the design and development of well-organized infrastructures able to solve global and regional problems [
1]. To do this, the informatization and georeferenciation of the world’s knowledge is required. This is the task of the “Digital Earth” project. In this framework, remote sensing and earth observation technologies contribute significantly to the progress of Digital Earth. Among the various tasks and objectives of remote sensing sciences is the monitoring of soil characteristics, deterioration, and use (e.g., cultivation or urbanization). Soil degradation and desertification is a phenomenon that affects many countries, especially those with arid and semiarid regions. Common degradation processes include water stress, soil salinization, forest fires, overgrazing and water erosion,
etc. Such processes are often monitored using approaches based on various biophysical and socioeconomic indicators. The evaluation of such indicators has recently been reported [
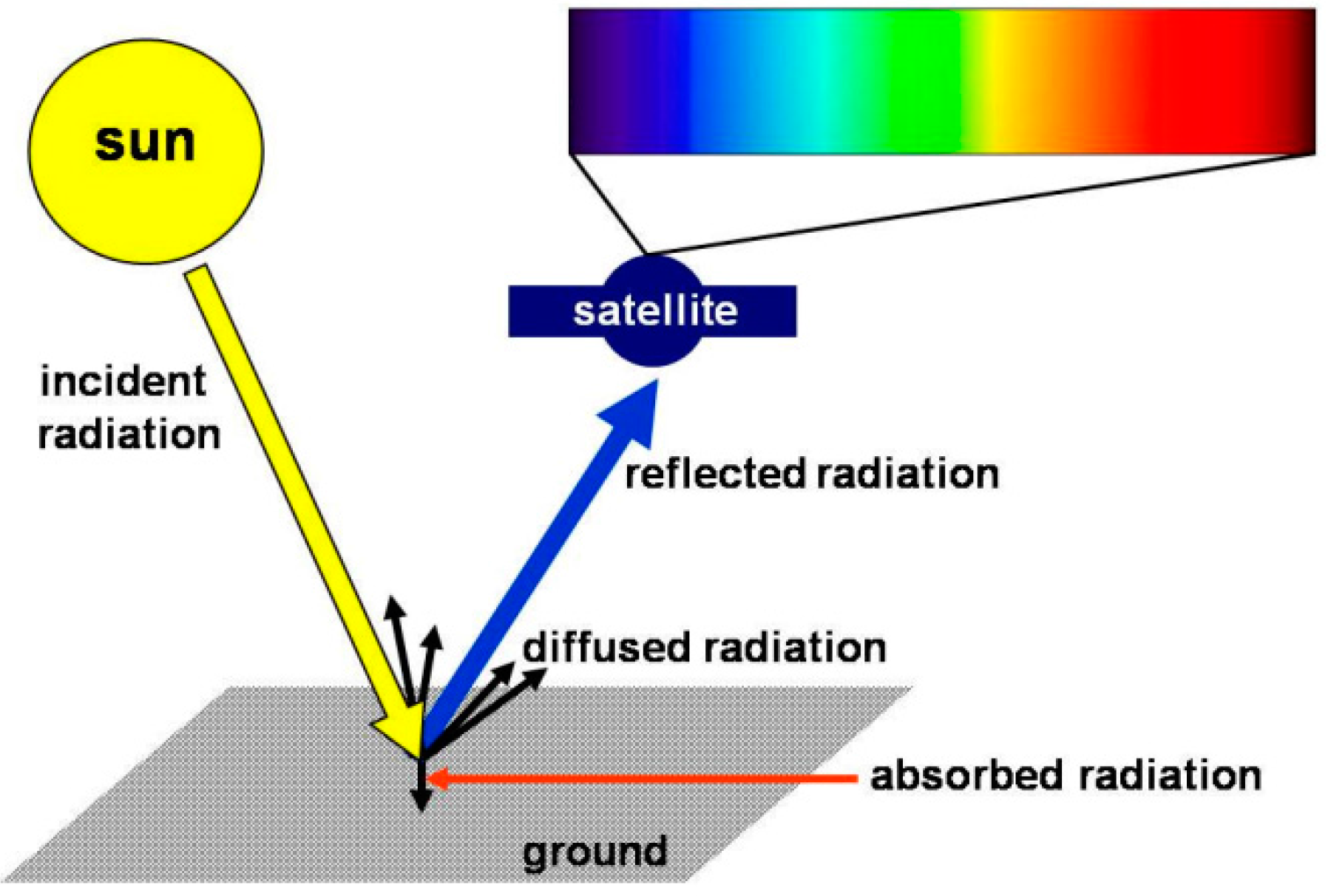
2]. Other approaches are based on the estimation of the vegetation cover fraction and/or the class of the soil by remote sensing using satellite imagery data (usually reflectance spectra). The scheme of the reflectance data acquisition procedure using a satellite is given in
Figure 1.
Figure 1.
Scheme of the remote sensing principle. A fraction of sunlight reflected or scattered by the soil is detected at selected wavelengths by the satellite.
Figure 1.
Scheme of the remote sensing principle. A fraction of sunlight reflected or scattered by the soil is detected at selected wavelengths by the satellite.
Remote sensing estimation of soil class and land use/cover is a complex process that involves several steps. First, the image of the studied area is recorded by the satellite. The quality of satellite image is given by parameters such as spatial, spectral, radiometric, and temporal resolution. The spatial resolution is related to the dimensions of the pixels in a raster image. The pixel corresponds usually to area with dimensions ranging from 1 to 1000 meters. The spectral resolution refers to the wavelength width of the detected frequency bands. The radiometric resolution indicates the ability of an imaging system to discriminate slight differences in the energy of the detected radiation. The temporal resolution is gathered from the frequency of flyover by the satellite.
Over the studied area,
m sampling points are chosen either randomly or using a grid. Soil samples are then collected from the sampling points and classified according to the results of chemical and morphological analysis (
Figure 2).
Figure 2.
Example of random distribution of 15 sampling points over the studied area. From each sampling point, a soil sample is collected. The class of the collected soil samples is determined by means of chemical and morphological analysis.
Figure 2.
Example of random distribution of 15 sampling points over the studied area. From each sampling point, a soil sample is collected. The class of the collected soil samples is determined by means of chemical and morphological analysis.
A table of reflectance spectra of the collected soil samples and their corresponding class constitutes the “database”. The reflectance spectrum of a soil sample depends mostly on the soil chemical composition. Therefore, the reflectance spectra of soils belonging to different classes are expected to be different. Unfortunately, the mathematical law expressing the relation between the reflectance spectrum and the chemical composition of the soil is not known. However, the data in the database contain information that can be used to build an empirical model of the spectrum-soil relationship. The process that leads to obtaining such empirical relation is called “modeling”. The model allows the prediction of the soil class using the reflectance data for arbitrary pixels of the satellite image in places where no sampling and chemical analysis were done. In this way, a map representing the distribution of the various soil classes over the studied area is obtained.
Various mathematical methods are available for the modeling. The choice of the method depends upon the complexity of the data to be modeled. Non-linear methods offer the flexibility required to model complex data structures. Methods based on artificial neural networks are among the most powerful and widespread [
3,
4]. The application of ANNs in science and technology is quite extensive in various branches of chemistry, physics, biology, social sciences, and economy and they cover classification, modeling, pattern recognition purposes,
etc. For example, ANNs are used in chemical kinetics [
5], prediction of the behavior of industrial reactors [
6], modeling kinetics of drug release [
7], prediction of optimal composition of multidrug mixtures [
8], optimization of electrophoretic methods [
9], classification of agricultural products such as onion varieties [
10], and even insect species determination [
11,
12]. Application of ANNs in medical diagnosis has recently been reviewed [
13]. In general, very diverse data such as classification of biological objects, chemical kinetic data, or even clinical parameters can be handled in essentially the same way. Selected examples of ANNs applications in remote sensing are: water quality monitoring [
14], estimation of evapotranspiration [
15], derivation of ocean color products [
16], mapping fractional snow cover [
17], prediction of soil organic matter [
18], spatial assessment of air temperature [
19], mapping contrasting tillage practices [
20], classification of soil texture [
21] prediction of productive fossil localities [
22], sub-pixel mapping and sub-pixel sharpening [
23],
etc. Often, ANNs are used even when some basic conditions for their use are not fulfilled.
The aim of this work is to present the general philosophy and fundamental methodological steps that should be followed, namely in the evaluation of satellite spectral data using ANNs for soil classification purposes. In particular, the importance of the preliminary data exploration use (data screening) by Eigenvalues Analysis (EA) and Principal Components Analysis (PCA) is stressed. The proposed methodology is exemplified to the evaluation of satellite data concerning El-Fayoum area in Egypt and the results of each step are commented on.
2. The Study Area
El-Fayoum depression is a Governorate located 90 km southwest of Cairo (
Figure 3) and characterized by temperate climatic conditions. The total area of the depression is 6068.70 km
2; the land use in this area includes only 1849.64 km
2 (
i.e., 30.48% of the total area). The agricultural land in the depression is 1609.34 km
2. El-Fayoum is connected to the Nile Valley by the Hawara area, where a canal, called Bahr Yousef, is transporting the Nile water. The depression is distinguished by its long history, extending back millions of years, having importance in the emerging Ancient Egyptian, Greek, Roman, Coptic and Islamic eras. It is the only Egyptian Governorate where a salt lake (
i.e., Qaroun Lake), vegetation, and desert with their diverse features and unique combination exist. The climatic data of El-Fayoum district indicate that the total rainfall does not exceed 7.2 mm/year and the mean minimum and maximum annual temperatures are 14.5 and 31.0 °C, respectively. The evaporation rates are coinciding with temperatures, where the lowest evaporation rate (1.9 mm/day) was recorded in January while the highest one (7.3 mm/day) was recorded in June [
24]. According to the aridity index classes [
25], the depression is classified as territory under arid climatic conditions.
The depression has a particular nature, differing from Upper Egypt and the Delta and Oases regions as well. The differences are not limited to agriculture. They extend to geographical and topographical features, as the environment varies between agricultural, desert and coastal areas. The El-Fayoum depression has been formed as a result of basin subsidence, relative to the Nile River, permitting it to break through and to flood the area. This led to the formation of a thick fertile alluvium [
26]. The main identified landforms in El-Fayoum depression are fans, recent and old lake terraces, depressions, plains, and basins [
27]. With the present regime of practiced flooding and rising of water level in the Qaroun Lake, surrounding arable land would be in danger of salinization and water logging.
Figure 3.
Location map of the (a) El-Fayoum depression and (b) satellite image (Landsat ETM 2011).
Figure 3.
Location map of the (a) El-Fayoum depression and (b) satellite image (Landsat ETM 2011).
5. Preliminary Data Analysis
As outlined in the Introduction, the database is used to build an empirical model by which the class of a soil can be predicted correctly from reflectance data. This can be achieved only if the data in the database contain the information that is able to distinguish samples belonging to different soil classes. Preliminary data analysis by EA allows researchers to estimate the number of distinguishable soil classes while PCA enables data compression and visualization.
5.1. Organization of Experimental Data
For each of the m soil samples collected over the studied area, the value of reflectance intensity is recorded at n wavelengths by the satellite. Data are organized in a matrix X with dimensions m × n. Therefore, the elements of the i-th row of the matrix X represent the reflectance spectrum of the i-th soil sample. Further discussion concerns the analysis of the data in the matrix X.
5.2. Data Pre-Processing
Pre-processing of data in the matrix
X consists of: (
i) data inspection to search for missing values and (
ii) mathematical transformation of data. Various methods such as data smoothing [
28] or iterative algorithms [
29,
30] are available to replace missing values with suitable estimates. Common data transformation includes either column centering or standardization or normalization [
31,
32]. In this work, data were autoscaled (
i.e., centering around column means and scaled by column standard deviations).
5.3. Eigenvalues Analysis
Let us consider a matrix
X with
m rows and
n columns containing error-free data. The column standardized matrix
Z is calculated as:
where
1m is a vector of length
m with all elements equal to one,
is the transpose of the vector
which elements are the column mean values of
X and
is the diagonal matrix with dimension
n × n in which the main diagonal elements are equal to the column standard deviations of data in matrix
X. The matrix
Z is used to compute the variance-covariance matrix
D as:
The matrix
D is symmetric and with dimension
m × m. Linear algebra ensures that the variance-covariance matrix is also positive semi-definite and this implies that all its eigenvalues are non-negative. The first step in the analysis of matrix
D is the calculation of its eigenvalues λ
i (
i = 1,…,
m). This can be done using various approaches [
32]. On the principal diagonal of matrix
D are the column variances of the original matrix
Z. Therefore, the trace of
D is equal to the total column variance of
Z:
A property of variance-covariance matrix and its eigenvalues is that:
and, considering Equation (3):
Therefore, the percent of the total variance “explained” by the
i-th eigenvalue is expressed as:
The number of non-zero eigenvalues of a matrix is called “rank”
r. In general, considering a matrix with dimension
m × n:
For the matrix D, the non-zero eigenvalues are only the first r, while the remaining ones are all equal to zero. The rank of D is equal to that of the matrix X.
The number of non-zero eigenvalues (or rank) is interpreted as the number of “factors” responsible for variance in the data. In the case of reflectance data of soils, the rank r of the data matrix X can be interpreted as the number of “distinguishable” soil classes.
Up to now, a matrix
X with error-free data has been considered. However, every measured quantity (such as reflectance values) is subject to measurement errors. The consequence is that errors contribute to the overall variance in data (σ
2). Therefore, all eigenvalues of the matrix
D result as non-zero and its “apparent” rank is equal to
m. The
m-r eigenvalues represent variance due to measurement errors. The aim of eigenvalues analysis is to estimate the true rank
r of the matrix
D. Several criteria are available for this purpose [
32,
33]. A simple method for the estimation of the true rank of the matrix
D recommended in this work is the use of the so-called scree-plot [
31]. First of all, the
n eigenvalues λ
i of the matrix
D are calculated and ordered according to their magnitude. The scree-plot is obtained by plotting the magnitude of eigenvalues λ
i against the corresponding value of
i. As the value of
i increases, the variance explained by the corresponding
i-th eigenvalue decreases. Following this, the tangents to the two branches of the scree-plot are drawn and the value of
r is found as the integer number closest to the intersection point coordinate at the
x axis (
Section 7 “
Examples”). The knowledge of
r value is of fundamental importance for the next application of modeling techniques (such as ANNs).
5.4. Principal Components Analysis
PCA is a technique of exploratory analysis and dimensionality reduction of multivariate data. The eigenvectors and the corresponding eigenvalues of X are obtained by matrix factorization.
An eigenvector is associated with each eigenvalue that is related to the percent of total variance explained by that eigenvalue. The eigenvectors are called “principal components” (PC) and represent successive orthogonal directions of maximum variance in data. Therefore, the eigenvectors define a new coordinate system (principal factor space) in which both the variables and the samples can be represented. Using the scree-plot or other suitable procedure [
32], the rank
r of matrix
D is estimated. Then, the data can be represented in a reduced
r-dimensional factor space.
In general, the data matrix
X can be decomposed into eigenvalues and eigenvectors by several methods. Among these, the singular value decomposition (SVD) represents one of the more robust and accurate. The SVD leads to the factorization of the matrix
X as:
where
U is the matrix of normed scores,
W is the diagonal matrix of eigenvalues square roots, and
V is the matrix of loadings [
31,
32].
The matrix
E =
W2 is the diagonal matrix of eigenvalues. The trace of
E represents the total variance in data. The importance of the
k-th principal component is expressed as percent of explained variance (% var
k) using the
k-th eigenvalue (λ
k):
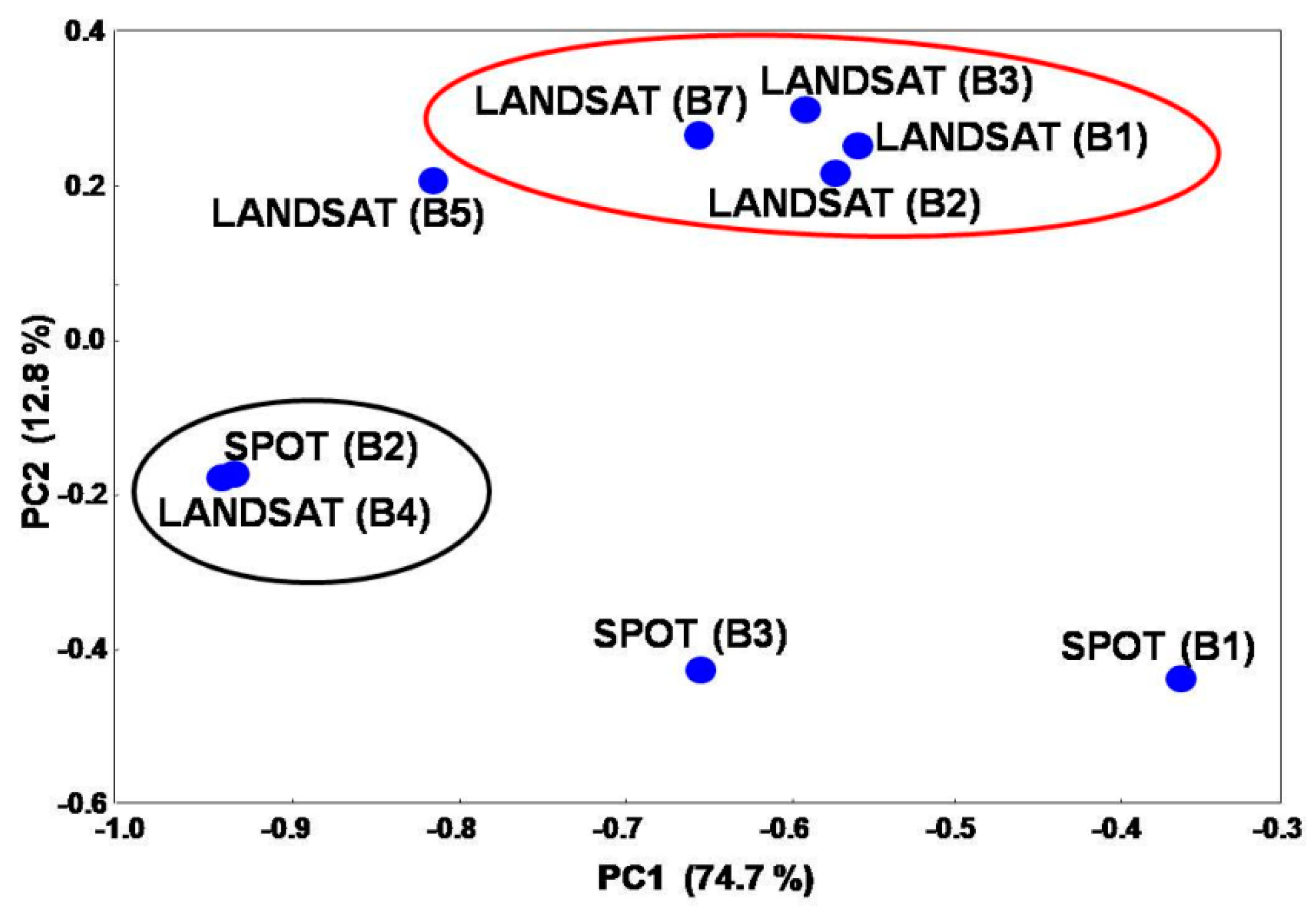
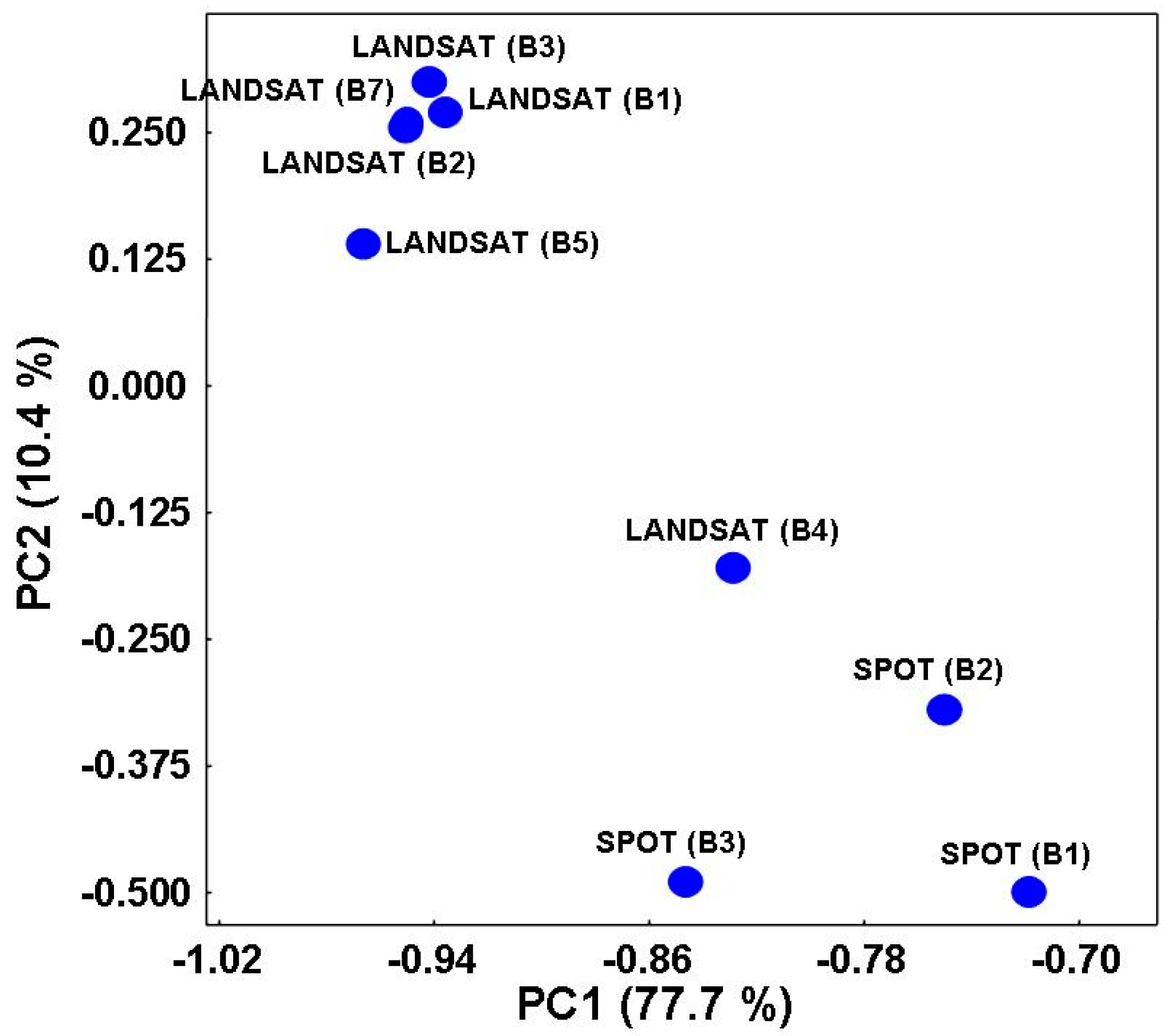
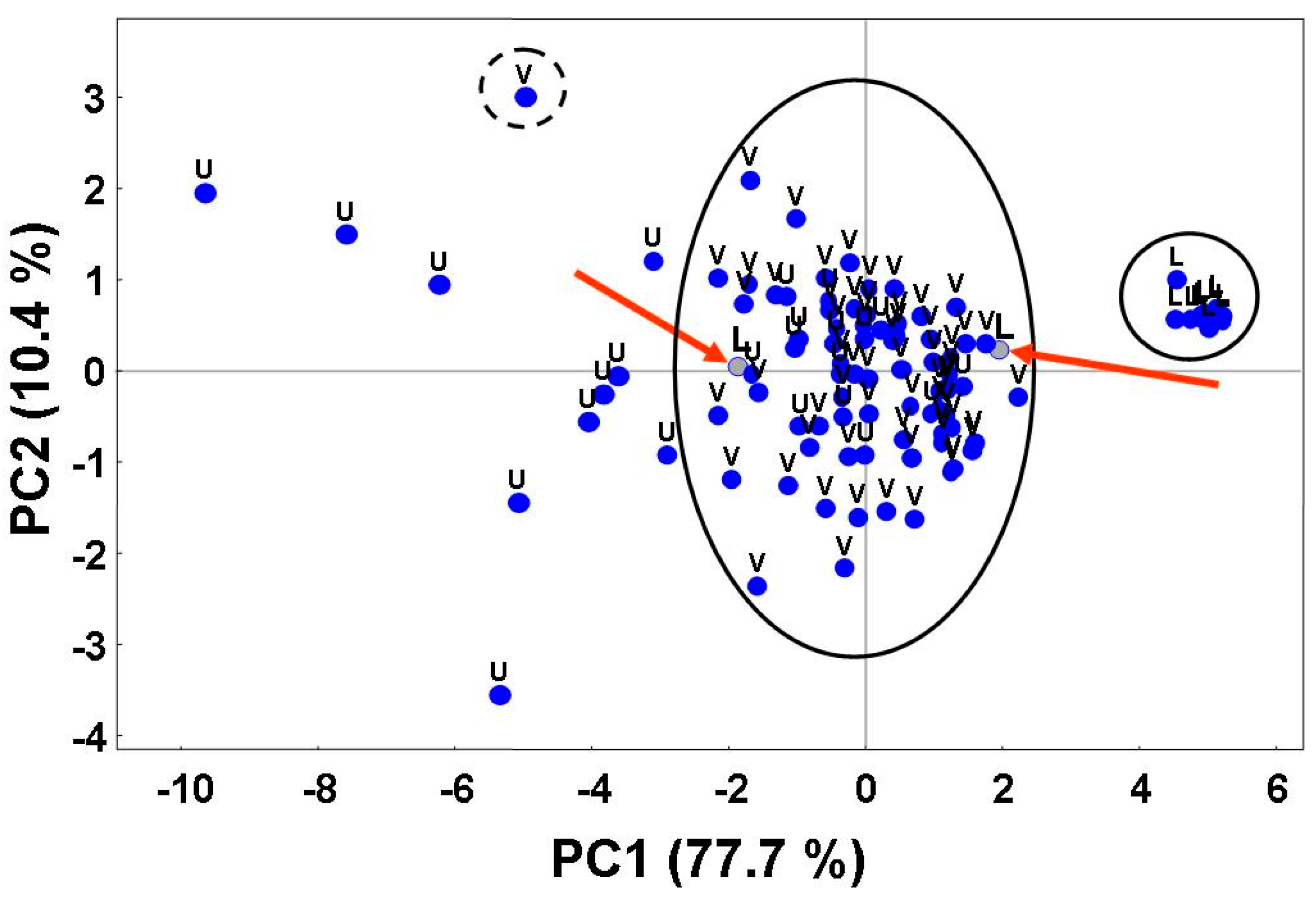
The elements of the k-th column of the matrix VT represent the coordinates of the variables (satellite spectral bands) on the k-th principal component (loadings). Analogously, the elements of the j-th column of the matrix U represent the coordinates of the soil samples on the j-th principal component (scores). By plotting the columns of U, the distribution of the variables in the reduced r-dimensional principal factor space is visualized (loadings plot). In the same way, the distribution of the samples in the reduced factor space is obtained by plotting the columns of the matrix VT (scores plot). From such plot, clusters of “similar” samples can be visualized.
6. Artificial Neural Networks
ANNs are mathematical tools that mimic the structure and function of human brain. They are able to perform “
learning”, “
generalization” and “
prediction” tasks. For this reason, ANNs belong to so called methods of artificial intelligence (AI). The network “
learns” from a series of “
examples” that form the “
training database”. An “
example” is given by a vector
of inputs and a vector
of outputs. In the case of soil classification from satellite data, the vectors
Xi and
Yi contain the reflectance intensities and the class of the
i-th sample, respectively. The objective of the “
learning” is to model the unknown relation
f between the vectors
Xi,p and
Yi,q (Equation (10)):
Because of their inherent non-linear nature, ANNs are able to model complex relationships among data. However, PCA remains fundamental to visualize the underlying structure of the data and to get an idea of possible ANN outcomes. Beside the widespread use of multilayer feed-forward neural networks, several other networks including Bayesian, stochastic, recurrent, or fuzzy ones are available. A review of various classes of neural networks can be found elsewhere [
34,
35].
6.1. Mathematical Background of ANNs
The basic processing unit of a neural network is called a “
neuron” (or “
node”). The neurons are organized in layers and each neuron in a layer is connected with each neuron in the next layer through a weighted connection. The value of the weight
wij indicates the strength of the connection between the
i-th and the
j-th neuron. A neural network is formed by the “
input” layer, one or more “
hidden” layers, and the “
output” layer. The number of hidden layers and that of neurons therein (
z) depends on the complexity of the relation
f to be modeled (Equation (10)). Therefore, in the first step the network architecture must be optimized. The general scheme of a typical three-layered ANN architecture is given in
Figure 4.
Figure 4.
Example of three-layered ANN architecture with one hidden layer. The symbol wij represents the weight of the connection between the i-th and j-th neuron.
Figure 4.
Example of three-layered ANN architecture with one hidden layer. The symbol wij represents the weight of the connection between the i-th and j-th neuron.
The data (
xi) received by the input layer are transferred to neurons in the first hidden layer where they are mathematically processed by calculating their weighted sum and adding a “bias” term (θ
j) according to Equation (11):
where
p and
q are defined as stated above. The resulting value of
netj is transformed using a suitable mathematical function (
transfer function) and transferred to neurons in the next layer. Various transfer functions are available [
35] but the most commonly used is the sigmoid one (Equation (12)):
At the beginning, random values within the interval [−1,1] are assigned to all the connection weights
wij. The “
learning” is achieved by iterative alteration of the connection weights values (
wij) according to a given mathematical rule (
training algorithm). Various algorithms are available [
35,
36]. The most common training algorithm is back-propagation (BP) which searches for the values of the weights
wij that minimize the sum-of-squared residuals (
E) calculated as:
where
yij and
yij* represent the actual and network
j-th output.
The weight change at the
k-th epoch on the neurons in a given layer is calculated as:
where η is a positive constant called “
learning rate”, μ is the “
momentum” term, and Δ
wijk−1 is the change of the weight
wij from the (
k−1)
-th epoch. The learning rate controls the speed of the learning while the momentum term stabilizes the process avoiding local minima. Details can be found in monographs [
35]. A nice and detailed introduction to ANNs can be found elsewhere [
37].
6.2. Optimization of Network Architecture
Optimized network architecture can be obtained using the function given by Equation (13) as a criterion. A widely used approach is to plot the value of
E (Equation (13)) as a function of the number
z of nodes in the hidden layer (
Section 7 “
Examples”). The value of
E decreases as that of
z increases. However, after an optimal value of
z, the change in the value of
E becomes rather poor.
Usually, the optimal value of
z is found from the coordinate of the intersection point of the tangents to the two branches of the plot. Before proceeding with the optimization of ANN architecture, it is advisable to check data in matrix
X for the presence of possible outliers using proper statistical tests [
31]. The effect of outliers on ANN performance has been reported elsewhere [
38]. Methods of outlier detection using ANNs have also been described [
39].
6.3. The Verification of the Network
The training process is carried out using the optimal network architecture found until a proper minimum value of E is reached. The “generalization” ability of the network is checked in the so-called “verification” procedure using data not used in the training. A common approach is to use cross-verification by selecting randomly one or more rows of the matrix X for verification and to use the remaining ones for the training. This process is repeated until each row of X has been used for verification at least once. Modern ANN software allows users to perform training and verification simultaneously. After successful training and verification, the network can be used to classify new samples.
6.4. Structure of the Training Database
As stated above, a suitable training database is used to perform ANN training. Such a database is a table (or matrix) of data concerning samples of soil for which the class is known. Each row of the matrix refers to one soil sample. The first n elements of the row are satellite data while the last element is the output (soil class). ANNs require a “sufficient” number of samples for each class, however, such number depends from the complexity of the problem and general rule is not available.
6.5. Data Pre-Processing before ANN Analysis
Data pre-processing is a recommended step before using ANNs. Such step involves mathematical data transformation. Usually, data are scaled within the interval [0,1]. When the matrix
X contains missing data, various procedures can be applied such as substitution by data smoothing [
28] or removal of the corresponding row and column.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









