
Contextualized Relevance Evaluation of Geographic Information for Mobile Users in Location-Based Social Networks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. The Evaluation of Geographic Relevance
2.2. Potentials of Volunteered Geographic Information
3. Understanding Context
3.1. Definition
- (1)
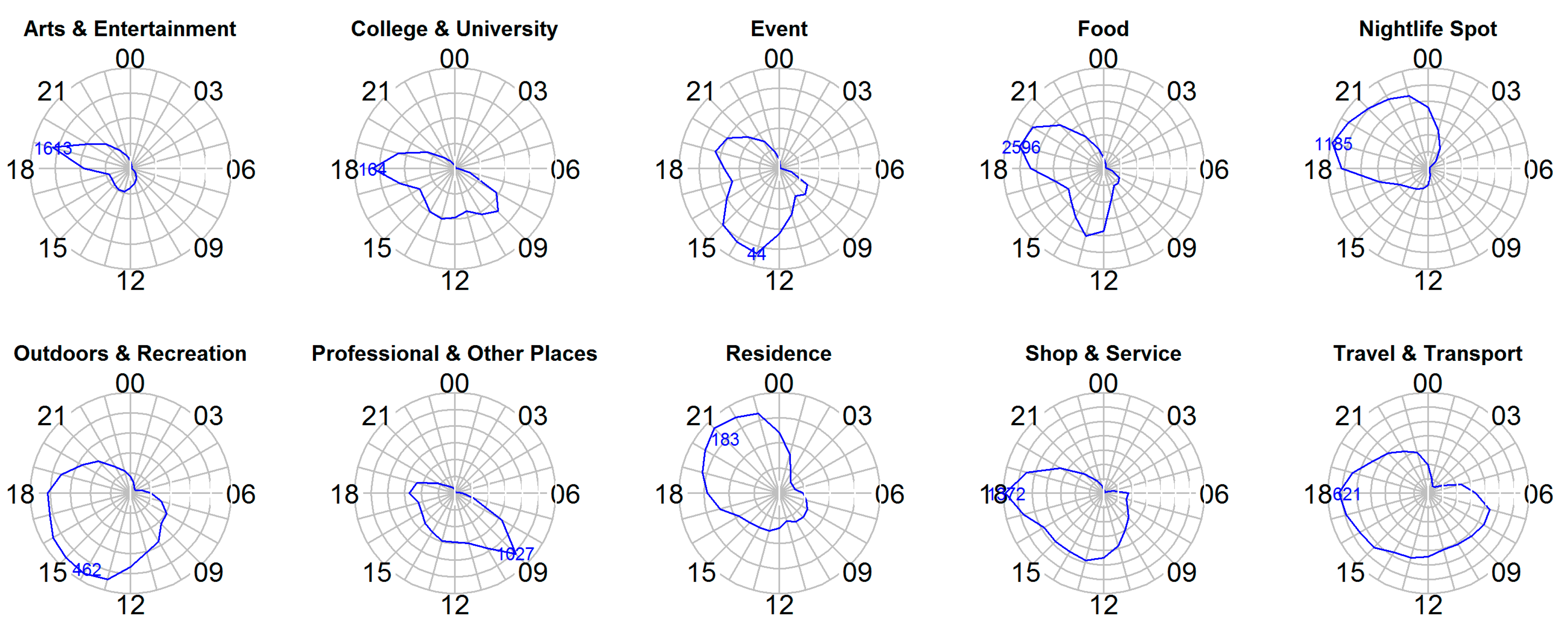
- Temporal. Users tend to have typical mobility patterns over different time periods. Temporal context can be considered on different scales, such as by the season, the days of the week, hours in a day etc. In this paper, we use the last scale, that is, the hours in a day.
- (2)
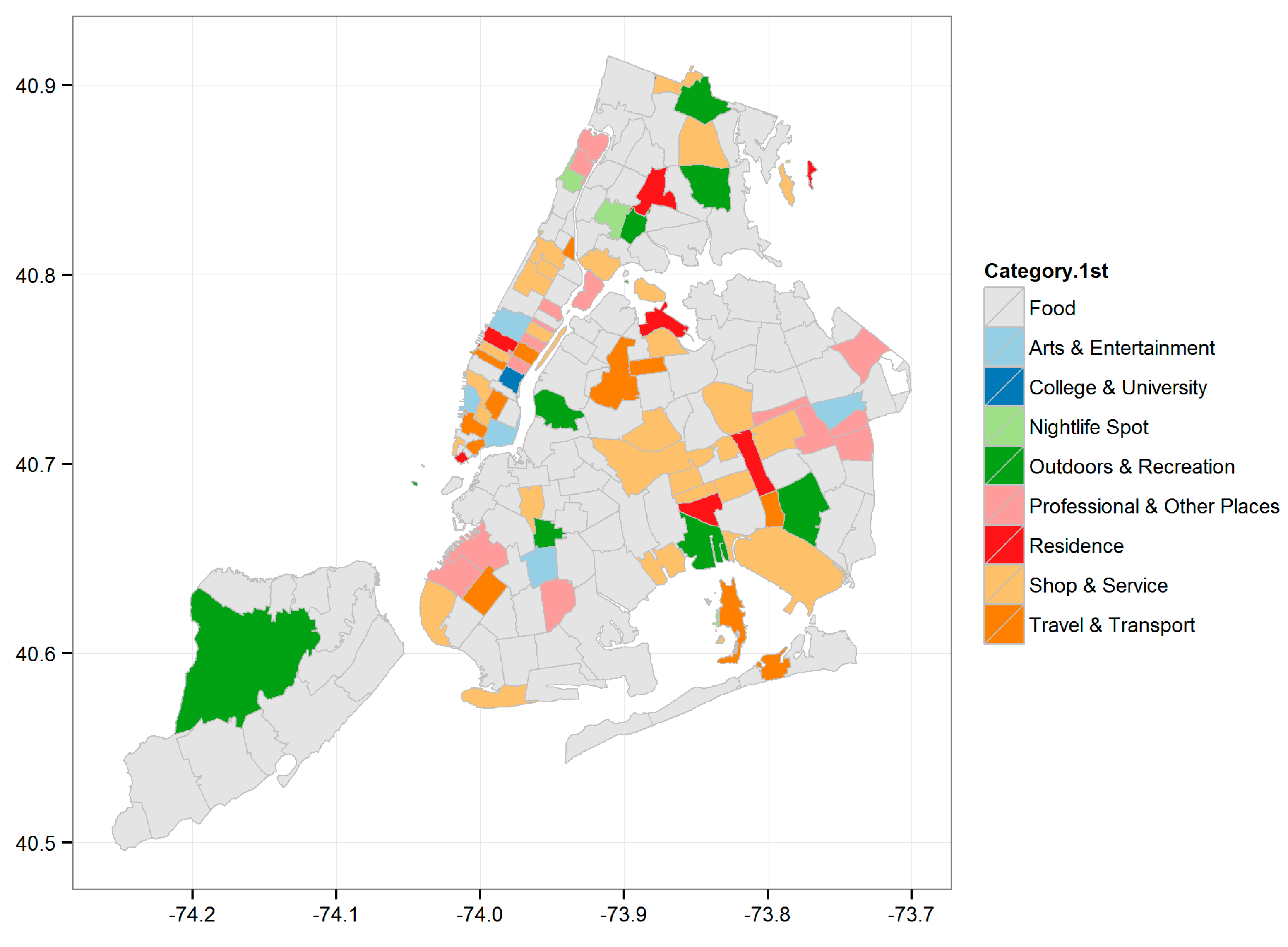
- Spatial. Researchers have confirmed that urban regions typically comprise different functional configurations, such as residential, educational and business, which typically influence the user’s behavior [30]. In this paper, we will observe such influences within administrative postal regions.
3.2. Foursquare: Exemplar of Location-Bassed Social Networks

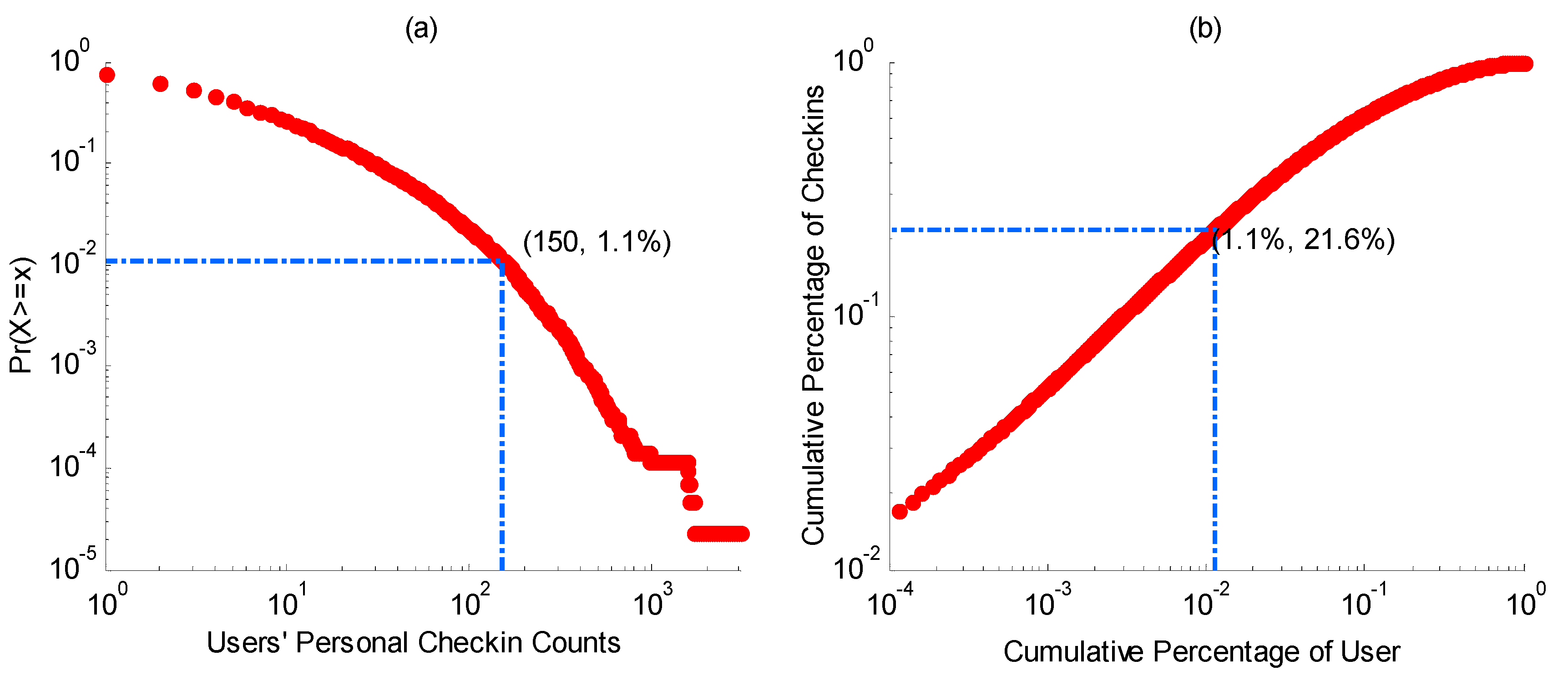
3.3. Revealing Contextual Influences on Mobile Users


4. Contextualized Geographic Relevance Evaluation
4.1. Contextualization
4.2. Global and Individual Patterns
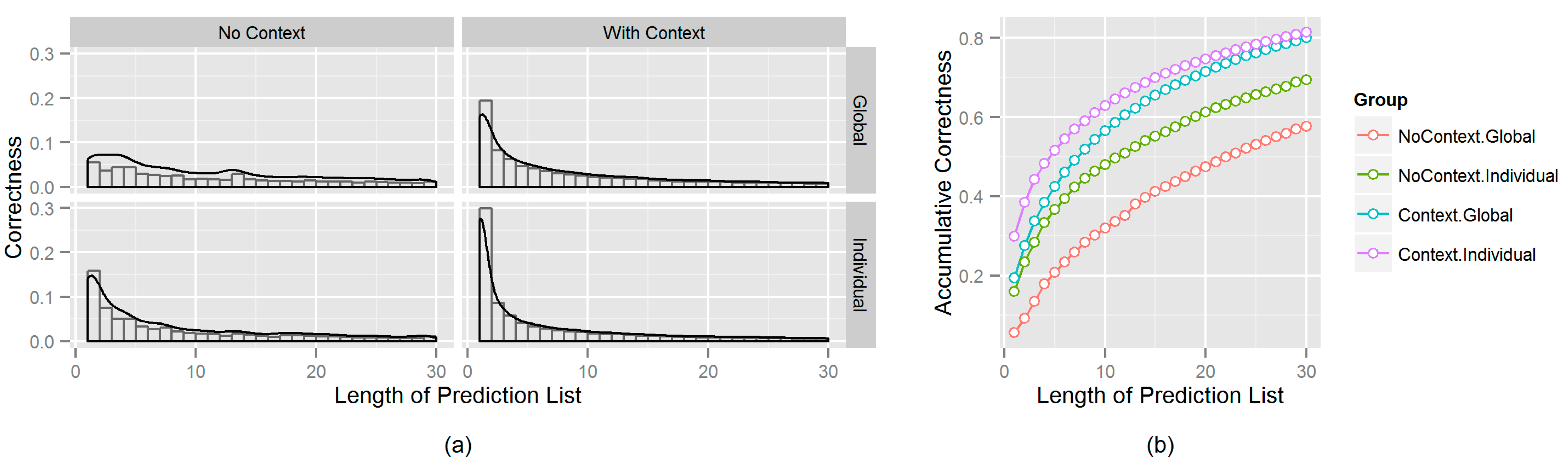
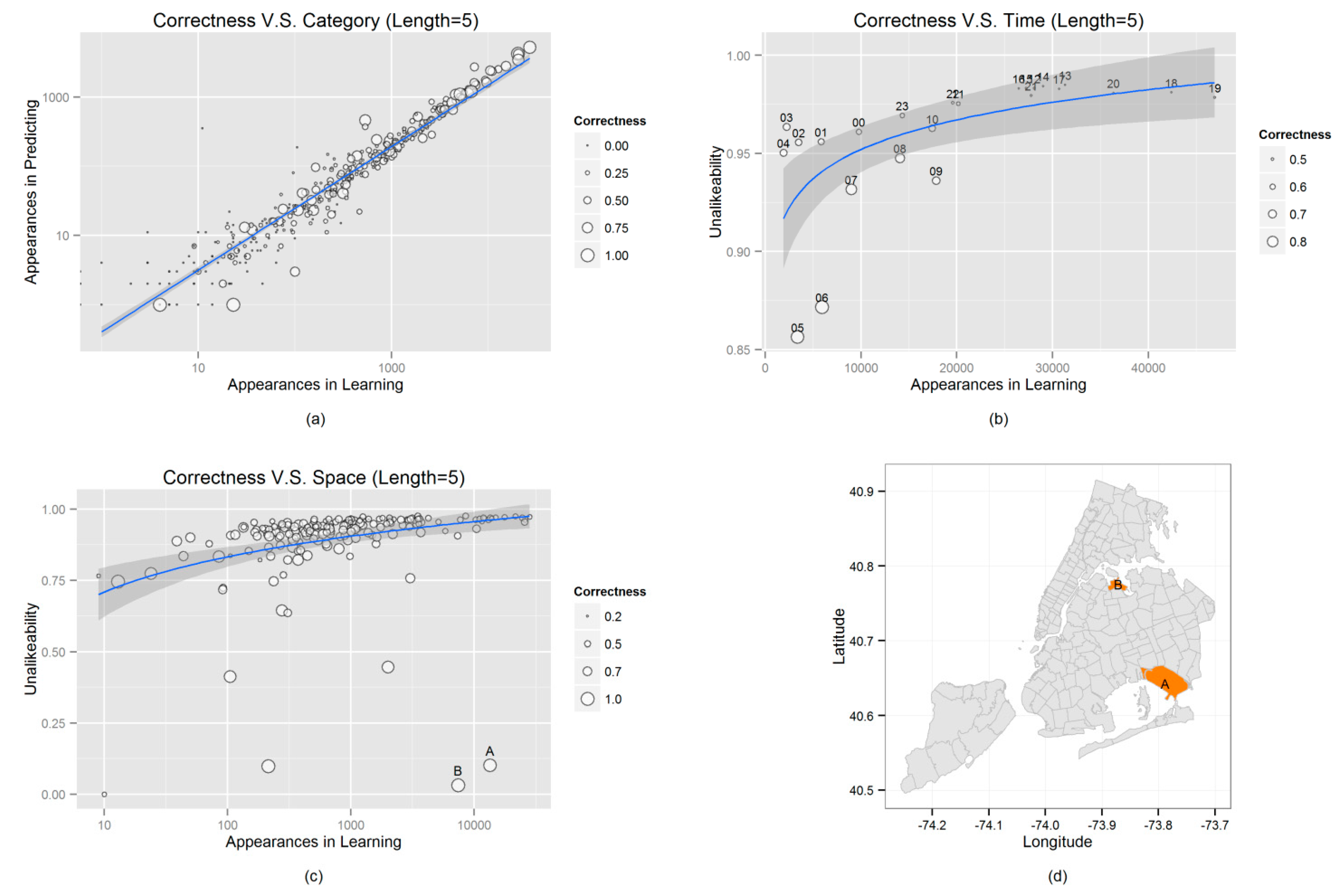
4.3. Experimental Results
- Group 1: Learn global patterns from the learning dataset, and predict, without a context, the record to be predicted;
- Group 2: Learn individual patterns from the learning dataset, and predict without a context;
- Group 3: Learn global patterns from the learning dataset, and predict with a context;
- Group 4: Learn individual patterns from the learning dataset, and predict with a context.


5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Meng, L. The state of the art of map-based mobile services. In Map-based Mobile Services: Design, Interaction and Usability; Meng, L., Zipf, A., Winter, S., Eds.; Springer: Berlin, Germany, 2008; pp. 1–12. [Google Scholar]
- Mountain, D.M. Geographic information retrieval in a mobile environment: Evaluating the needs of mobile individuals. J. Inf. Sci. Eng. 2007, 33, 515–530. [Google Scholar] [CrossRef]
- Raper, J. Geographic relevance. J. Doc. 2007, 63, 836–852. [Google Scholar] [CrossRef]
- Reichenbacher, T. The concept of relevance in mobile maps. In Location Based Services and TeleCartography; Springer: Berlin, Germany, 2007; pp. 231–246. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Context-aware recommender systems. In Recommender Systems Handbook; Springer: New York, NY, USA, 2011; pp. 217–253. [Google Scholar]
- Kaasinen, E. User needs for location-aware mobile services. Pers. Ubiquitous Comput. 2003, 7, 70–79. [Google Scholar] [CrossRef]
- Reichenbacher, T.; Crease, P.; De Sabbata, S. The concept of geographic relevance. In Proceedings of the 6th International Symposium on LBS & TeleCartography, Nottingham, UK, 2–4 September 2009.
- De Sabbata, S.; Reichenbacher, T. A probabilistic model of geographic relevance. In Proceedings of the 6th Workshop on Geographic Information Retrieval—GIR ’10, Zurich, Switzerland, 18–19 February 2010.
- De Sabbata, S.; Reichenbacher, T. Criteria of geographic relevance: An experimental study. Int. J. Geogr. Inf. Sci. 2012, 26, 1495–1520. [Google Scholar] [CrossRef]
- ItoWorld OpenStreetMap - Project Haiti on Vimeo. https://vimeo.com/9182869 (accessed Apr 27, 2015).
- Reimer, A.; Neis, P.; Rylov, M.; Schellhorn, S.; Sagl, G.; Resch, B.; Porto, J.; Zipf, A. Erfahrungsbericht: Crisis mapping zum Taifun Hayan. In Proceedings of Geoinformatik 2014, Hamburg, Germany, 26–28 March 2014.
- Girardin, F.; Fiore, F.; Ratti, C.; Blat, J. Leveraging explicitly disclosed location information to understand tourist dynamics: A case study. J. Locat. Based Serv. 2008, 2, 41–56. [Google Scholar] [CrossRef]
- Jankowski, P.; Andrienko, N. Discovering landmark preferences and movement patterns from photo postings. Trans. GIS 2010, 14, 833–852. [Google Scholar] [CrossRef]
- Ji, R.; Gao, Y.; Zhong, B.; Yao, H.; Tian, Q. Mining flickr landmarks by modeling reconstruction sparsity. ACM Trans. Multimed. Comput. Commun. Appl. 2011, 7. [Google Scholar] [CrossRef]
- Majid, A.; Chen, L.; Chen, G.; Mirzaa, H.T.; Hussain, I.; Woodward, J. A context-aware personalized travel recommendation system based on geotagged social media data mining. Int. J. Geogr. Inf. Sci. 2013, 27, 662–684. [Google Scholar] [CrossRef]
- Sun, Y.; Fan, H.; Bakillah, M.; Zipf, A. Road-based travel recommendation using geo-tagged images. Comput. Environ. Urban Syst. 2015, in press. [Google Scholar]
- Becker, H.; Naaman, M.; Gravano, L. Learning similarity metrics for event identification in social media. In Proceedings of the 3rd ACM International Conference on Web Search and Data Mining, New York, NY, USA, 3–6 February 2010; pp. 291–300.
- Chen, L.; Roy, A. Event detection from flickr data through wavelet-based spatial analysis. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hongkong, China, 2–6 November 2009; pp. 523–532.
- Lee, R.; Sumiya, K. Measuring geographical regularities of crowd behaviors for Twitter-based geo-social event detection. In Proceedings of the 2nd ACM SIGSPATIAL International Workshop on Location Based Social Networks, San Jose, CA, USA, 3–5 November 2010; pp. 1–10.
- Liu, X.; Troncy, R.; Huet, B. Using social media to identify events. In Proceedings of the 3rd ACM SIGMM International Workshop on Social Media, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 3–8.
- Pan, C.; Mitra, P. Event detection with spatial latent Dirichlet allocation. In Proceedings of the 11th Annual International ACM/IEEE Joint Conference on Digital Libraries, Ottawa, ON, Canada, 13–17 June 2011.
- Cho, E.; Myers, S.A.; Leskovec, J. Friendship and mobility: User movement in location-based social networks. In Proceedings of the 17th Acm Sigkdd International Conference on Knowledge Discovery and Data Mining—Kdd ’11, San Diego, CA, USA, 21–24 August 2011; p. 1082.
- Scellato, S.; Noulas, A.; Mascolo, C. Exploiting place features in link prediction on location-based social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1046–1054.
- Noulas, A.; Scellato, S.; Lambiotte, R.; Pontil, M.; Mascolo, C. A tale of many cities: Universal patterns in human urban mobility. PLoS ONE 2012, 7, e37027. [Google Scholar] [CrossRef] [PubMed]
- Wei, L.; Zheng, Y.; Peng, W. Constructing popular routes from uncertain trajectories. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 195–203.
- Bao, J.; Zheng, Y.; Mokbel, M. Location-based and preference-aware recommendation using sparse geo-social networking data. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 07–09 November 2012; pp. 199–208.
- Garcia, A.; Duranti, A.; Goodwin, C. Rethinking Context: Language as an Interactive Phenomenon; Cambridge University Press: Cambridge, UK, 1993; Volume 22. [Google Scholar]
- Reichenbacher, T. Mobile Cartography—Adaptive Visualization of Geographic Information on Mobie Devices. Ph.D. Thesis, Technischen Universität München, Munich, Germany, 2004. [Google Scholar]
- Henricksen, K.; Indulska, J.; Rakotonirainy, A. Modeling context information in pervasive computing systems. IEEE Pervasive Comput. 2002, 79–117. [Google Scholar]
- Batty, M. The size, scale, and shape of cities. Science 2008, 319, 769–771. [Google Scholar] [CrossRef] [PubMed]
- Cramer, H.; Rost, M.; Holmquist, L.E. Performing a check-in: Emerging practices, norms and “conflicts” in location-sharing using foursquare. In Proceedings of the 13th International Conference on Human Computer Interaction with Mobile Devices and Services, Stockholm, Sweden, 30 August–2 September 2011; pp. 57–66.
- Foursquare Category Hierarchy. https://developer.foursquare.com/categorytree (accessed on 1 May 2015).
- Liu, X.; Liu, Y.; Aberer, K.; Miao, C. Personalized point-of-interest recommendation by mining users’ preference transition. In Proceedings of the 22nd ACM International Conference on Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 733–738.
- Souffriau, W.; Vansteenwegen, P.; Vertommen, J.; Berghe, G.V.; van Oudheusden, D. A personalized tourist trip design algorithm for mobile tourist guides. Appl. Artif. Intell. 2008, 22, 964–985. [Google Scholar] [CrossRef]
- Kader, G.D.; Perry, M. Variability for categorical variables. J. Stat. Educ. 2007, 15. [Google Scholar]
- Wikipedia. List of the Busiest Airports in the United States. Available online: http://en.wikipedia.org/wiki/List_of_the_busiest_airports_in_the_United_States (accessed on 4 March 2015).
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Sun, Y.; Fan, H. Contextualized Relevance Evaluation of Geographic Information for Mobile Users in Location-Based Social Networks. ISPRS Int. J. Geo-Inf. 2015, 4, 799-814. https://doi.org/10.3390/ijgi4020799
Li M, Sun Y, Fan H. Contextualized Relevance Evaluation of Geographic Information for Mobile Users in Location-Based Social Networks. ISPRS International Journal of Geo-Information. 2015; 4(2):799-814. https://doi.org/10.3390/ijgi4020799
Chicago/Turabian StyleLi, Ming, Yeran Sun, and Hongchao Fan. 2015. "Contextualized Relevance Evaluation of Geographic Information for Mobile Users in Location-Based Social Networks" ISPRS International Journal of Geo-Information 4, no. 2: 799-814. https://doi.org/10.3390/ijgi4020799
APA StyleLi, M., Sun, Y., & Fan, H. (2015). Contextualized Relevance Evaluation of Geographic Information for Mobile Users in Location-Based Social Networks. ISPRS International Journal of Geo-Information, 4(2), 799-814. https://doi.org/10.3390/ijgi4020799