1. Introduction
Advanced technologies for sensing and computing have resulted in the creation of massive datasets consisting of trajectories of people and vehicles. The development of mobile phones and other handheld GPS devices as well as the widespread use of location-based services (LBS) have contributed to the acquisition of spatial information related to moving objects. Understanding and analyzing the large-scale and complex data that reflect moving objects is crucial for enhancing both quality of life and built environments. As a significant branch of the field of Geographic Information Systems (GIS), real-time GIS technology is devoted to the study of the collection, integration, management and analysis of spatial data streams in real-time contexts, such as emergency response and disaster monitoring.
Scientists in this domain need to store, manage, query and visualize large volumes of dynamic flow data to perform exploratory and analytical tasks. However, they are facing enormous challenges because of a lack of sufficient computing power to support big-data-driven studies. A platform is needed that integrates scalable trajectory databases with intuitive and interactive visualization and high-end computing resources [
1]. The absence of such tools that explicitly support interactive visual analytics is impeding progress in fully utilizing the trajectory data that are becoming available. To accomplish this goal, a fast and robust spatial query method is needed. An appropriate spatial index for moving objects could be used to reduce the time consumed for spatial queries. However, increasing accuracy requirements and the growing amounts of moving object data are driving a corresponding increase in the frequency of spatial data updates, thereby posing considerable challenges for the building of spatial indexes and the real-time execution of spatial queries.
To address this issue, cloud technologies are emerging as a new solution. For example, Hadoop MapReduce can be used to improve the efficiency of polygon overlay analysis in spatial big data (SBD) applications by building a grid spatial index [
2]. S. You et al. proposed an approach using a distributed computing framework based on memory to address the problem of spatial join operations, because the intermediate calculation results of Hadoop must be stored on hard disk, which reduces analytical efficiency because of the excessive disk I/O cost [
3]. Although these cloud technologies offer the benefits of high-performance computing for GIS applications based on static SBD, a novel approach to cloud computing is needed to cope with highly dynamic spatial data.
The major difference between static data and dynamic data is that the former are stored in a distributed file system in the form of data blocks, whereas the latter are streamed from an external sensor device with the help of distributed message-oriented middleware (DMOM), tuple by tuple. Compared with static SBD, for which the relevant problems are predominantly focused on the amount of data, the problems that must be solved to handle dynamic data are predominantly related to the rapid update of the data. Rapidly changing data are known as fast data [
4].
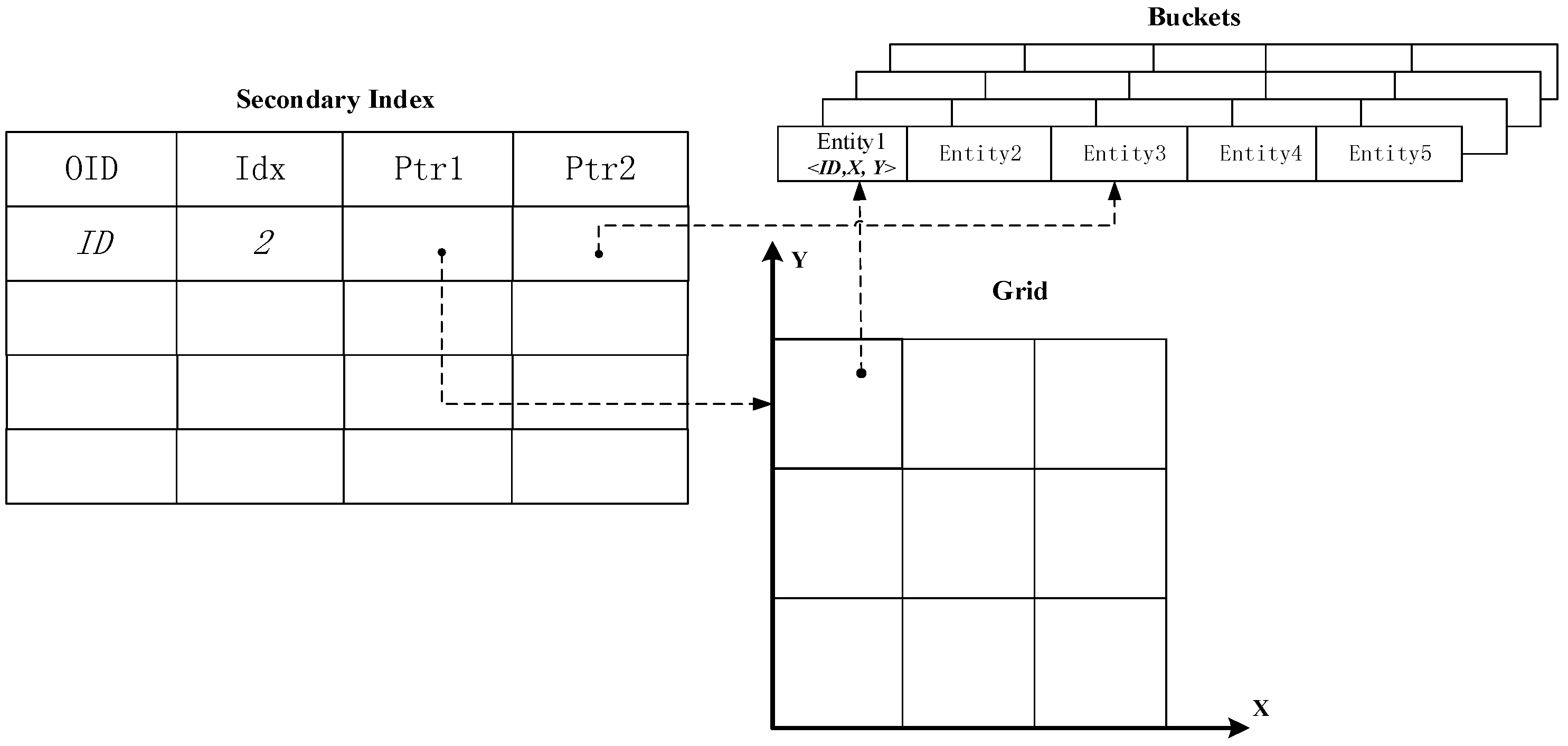
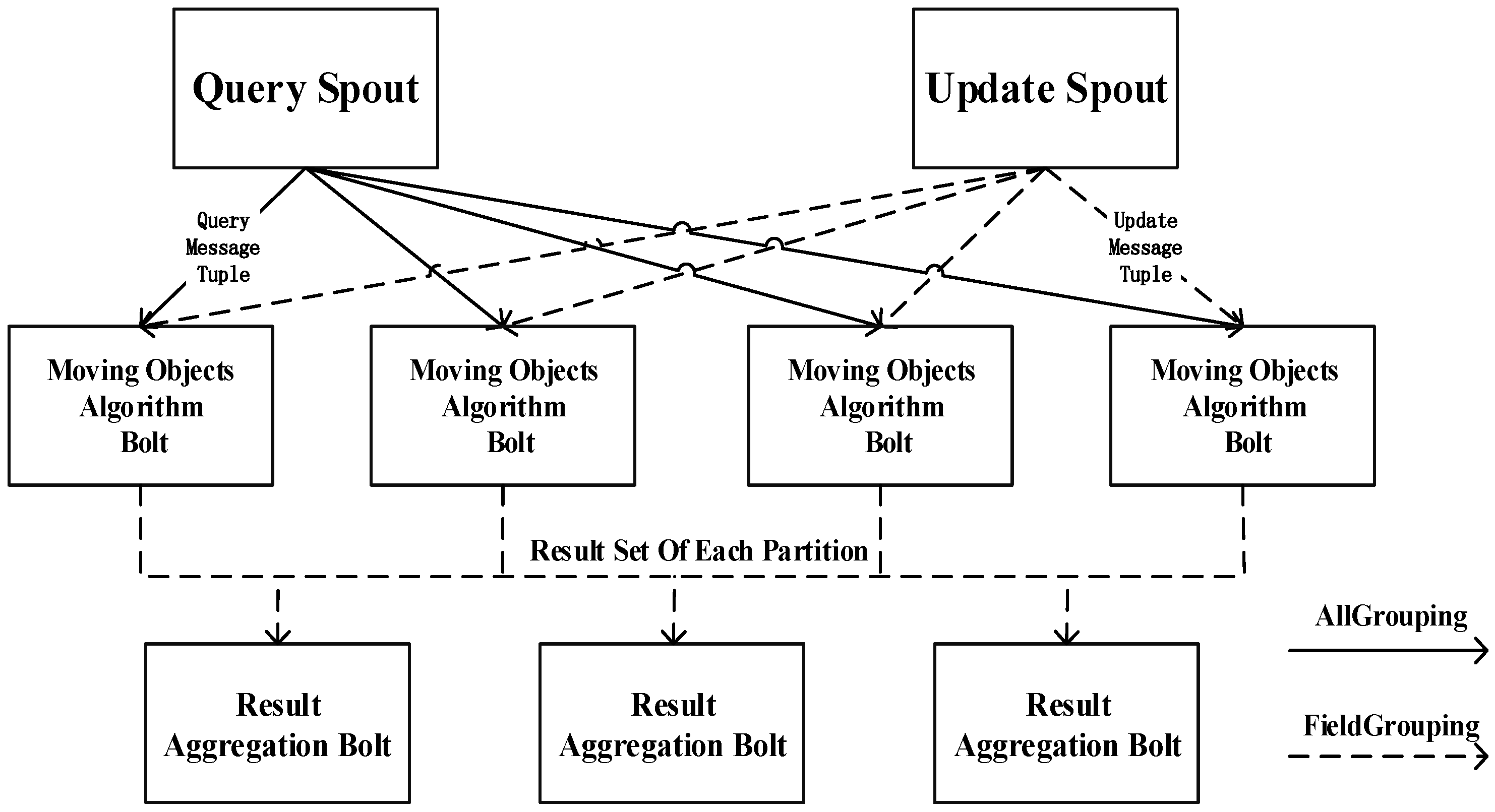
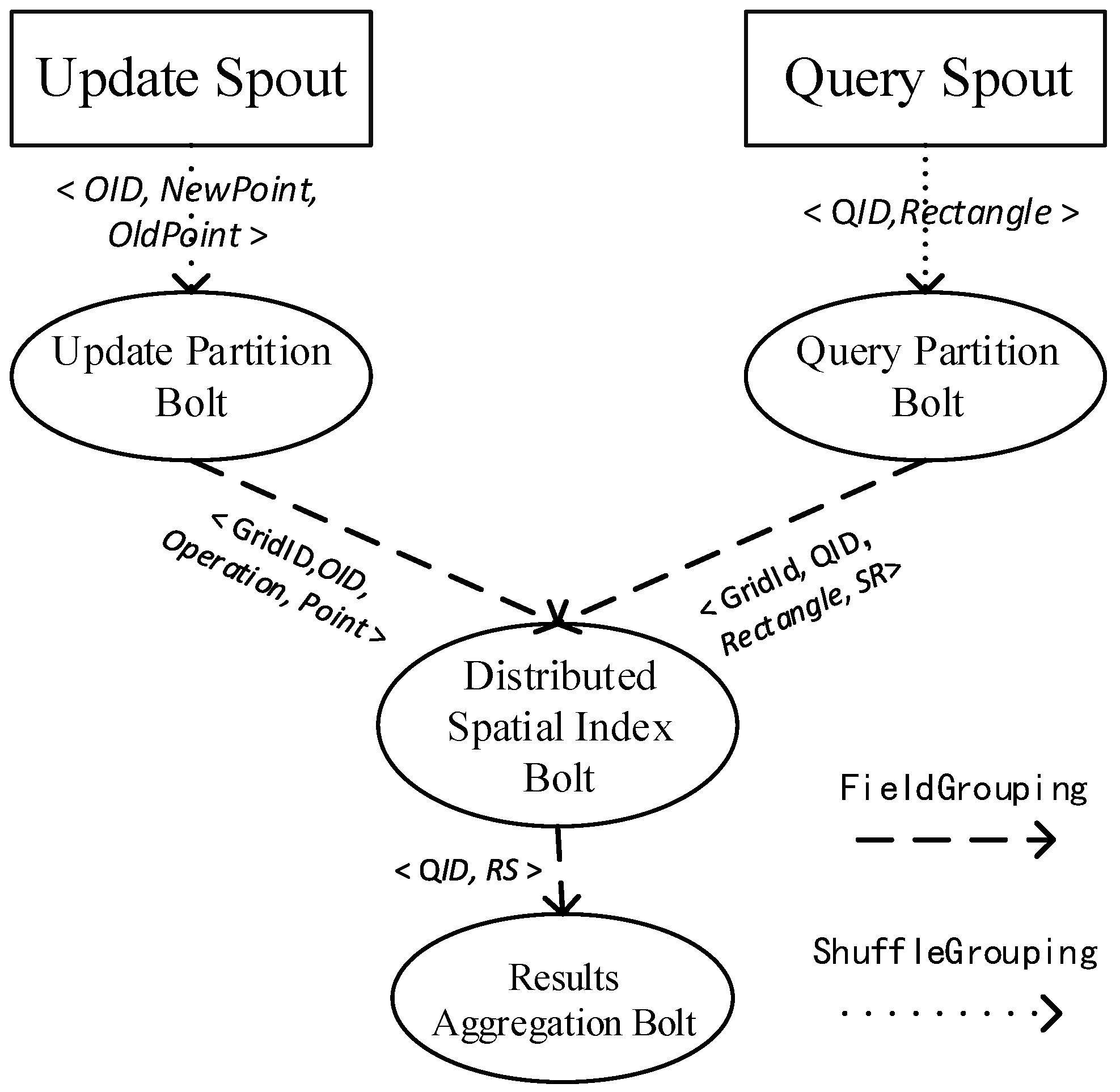
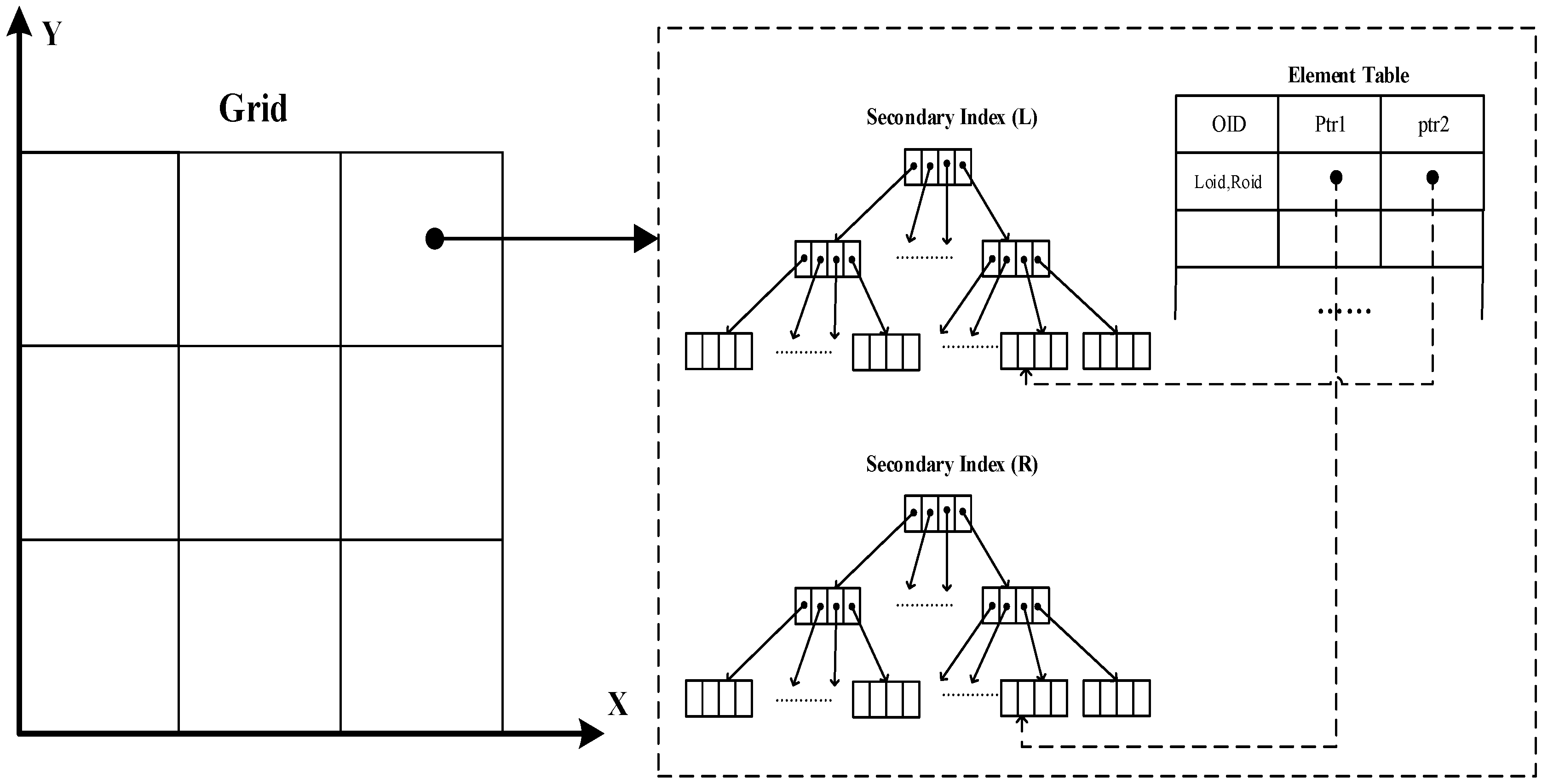
To lay the foundations for effective visual analytics of trajectory datasets, this manuscript presents a method of building a distributed spatial index on an open-source cloud computing framework, namely, Apache Storm, which has been playing an important role in traffic statistics [
5] and network anomaly detection [
6]. Based on this technology, we conduct real-time spatial querying of spatial fast data (SFD), including range querying, KNN querying, and spatial join querying. In particular, we build a secondary index based on the grid-partition index for spatial join queries. According to the experimental results, we find that using a quadtree structure for the secondary index yields the best performance in spatial computing. The proposed approach offers the capability of large-scale data management and support for various types of queries by leveraging Cloud computing platforms. This research will help the research community to conduct mobility-related studies in a more efficient and productive way.
In summary, the main contributions of this paper are as follows:
We propose a distributed index based on a Storm topology for moving objects and then implement range queries and continuous KNN (CKNN) queries using this distributed index. In this way, the pressure of updating data streams in stand-alone nodes can be relieved, and real-time updating for moving objects can be realized.
We design a spatial join algorithm using Storm for moving object streams. Experiments show that a quadtree-based index outperforms other types as the secondary index for distributed querying and updating.
The remainder of the paper is organized as follows.
Section 2 reviews the technological background and related work, including the Storm topology programming paradigm and spatial indexes for moving objects. In
Section 3, we describe the problem setting, and the semantics of various types of spatial queries, in accordance with the characteristics of spatial datasets, are formally presented.
Section 4 proposes two types of spatial query approaches based on Apache Storm.
Section 5 reports several sets of experiment conducted to explore the possible factors that affect the distributed spatial index.
Section 6 describes the conclusion of the study and potential applications of this research.
5. Experimental Study
In this section, we present experiments using the topology described above and analyze its performance results in terms of data updating and querying. In
Section 5.1, we describe the software and hardware environment, the workload and other preparations involved in the experiments. Of the experiments presented
Section 5.2, Study 1 is an experiment conducted to investigate the design of the distributed index for a single dataset. U-Grid, U-R-tree, R-tree and Grid were chosen, and this experiment was performed to compare their efficiency in spatial querying and updating with different numbers of Storm worker processes. Studies 2–4 are range spatial join query experiments in which D-Rtree, D-HashTable and D-QuadTree were chosen as the distributed index.
5.1. Experimental Setting and Workloads
All experiments were performed using seven servers as work nodes, each of which had a 6-Core Intel Xeon(R) 2.6 GHz CPU with 24 hardware threads and 8 GB of RAM. All seven nodes used a 64-bit Linux operating system (Suse Enterprise Server SP2), with Apache Kafka, an open-source distributed publish/subscribe messaging system, serving as the DMOM. Three of the nodes also had Apache ZooKeeper installed to coordinate the distributed systems.
The workloads were produced by a modified version of an open-source network-based moving object trace generator based on Brinkhoff’s algorithm [
47]. The network data were obtained from Jiangsu Province, China (see
Figure 6 and
Figure 7). In the single-dataset experiment, 1 million dynamic points were sent to Kafka at an update rate of 0.7 m/s, and the Storm spout pulled tuples from Kafka into the Storm topology. The four indexes mentioned above were compared with regard to their performance for continuous range queries, CKNN queries and update rates. In the spatial join experiments, we compared the spatial update ratios for different numbers of grid cells and different numbers of moving objects. For the range spatial join queries, instead of using pure query tuples, we mixed update tuples and query tuples in different proportions as inputs to the Storm topology. For these workloads, searches with various scopes were performed.
Table 2 shows the parameters of the workloads for the single-dataset spatial queries. The workloads for the range spatial join queries included two sets of moving objects produced using the same parameters presented in
Table 3. The preparation time is not included in the results for any experiment.
5.2. Experimental Results
● Study 1: Influence of the Storm bolt parallelism on spatial queries for a single dataset
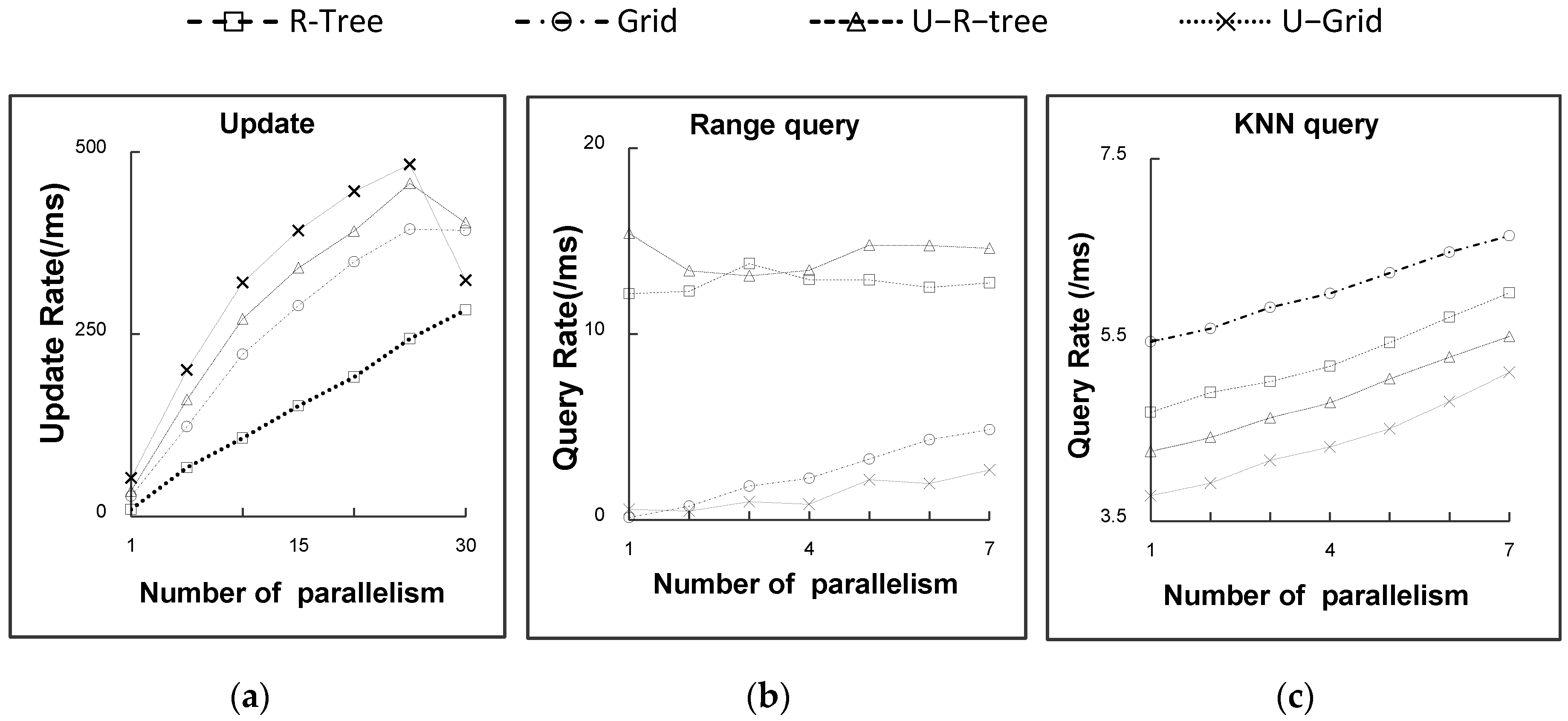
In
Figure 8a, the update efficiencies of the indexes are plotted versus the number of parallel bolts.
Figure 8b,c depict the efficiencies of range queries and CKNN queries, respectively. From
Figure 8a, we can conclude that all four indexes exhibit a trend of an increasing update rate with an increasing degree of parallelism. Once the index has saturated, however, the update efficiency no longer increases and even starts to decrease. This is because the number of different update processes entering different work nodes will increase as the parallelism increases and the transmission of information between work nodes requires considerable time.
Figure 8b,c suggest that increasing the parallelism has a relatively small effect on spatial query performance. Increasing the parallelism will reduce the number of moving objects in each Distributed Spatial Index Bolt executor while giving rise to more inter-node communications. Consequently, whether increasing the degree of parallelism has a positive or negative impact depends on which factor dominates.
The following three experiments demonstrate the potential factors affecting the spatial join performance. Studies 2 and 3 investigate the update performance of the proposed distributed spatial index for different numbers of grid cells over different periods of time. Study 4 addresses how the percentage of query tuples in the workload influences the total throughput of spatial join queries. To ensure reliability, the workloads imported into Kafka for the different experiments were exactly the same. The rate of workload input was 0.7 m/s, which was sufficiently fast to ensure that the data read rate would not become a bottleneck.
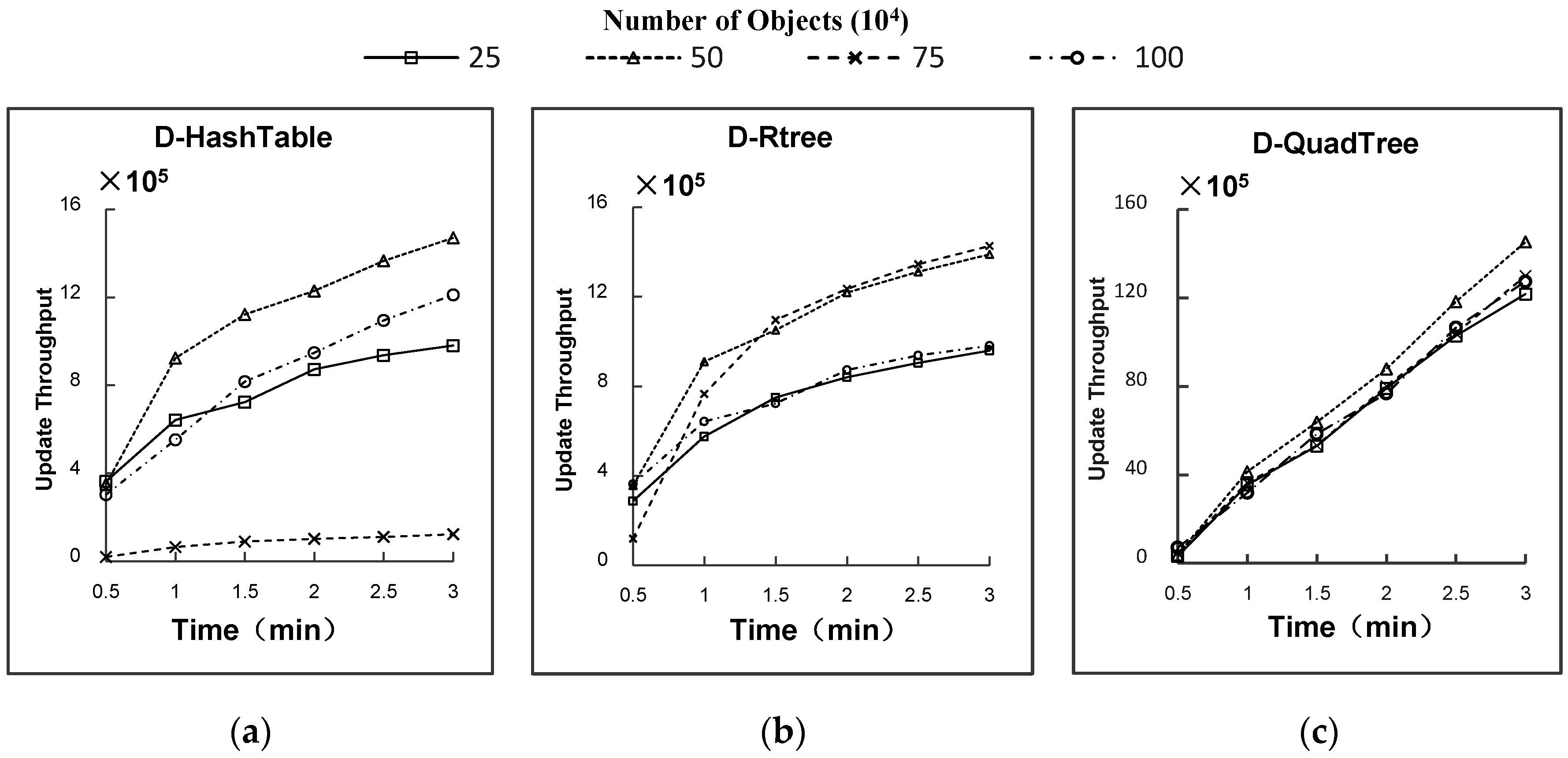
● Study 2:Influence of the number of moving objects on the spatial join performance
From
Figure 9a–c, we can conclude that the update efficiency of D-Quadtree is significantly higher than those of the other indexes. In general, the update rates of the three indexes increase over time, initially rapidly and then more gradually. Because the secondary index does not initially store any data, the query step of the spatial join updating process described in
Section 4.2 initially consumes less time. However, as an increasing amount of data becomes stored in the secondary index, the update efficiency decreases. The number of moving objects has a small effect on D-Quadtree index and a greater effect on D-Hashtable. When the number of objects is 1m, the update efficiency is quite slow. For D-Rtree, the update efficiency is initially rapid and then slows with an increasing number of objects. The update speed is the fastest when the number of objects is 50 m–75 m.
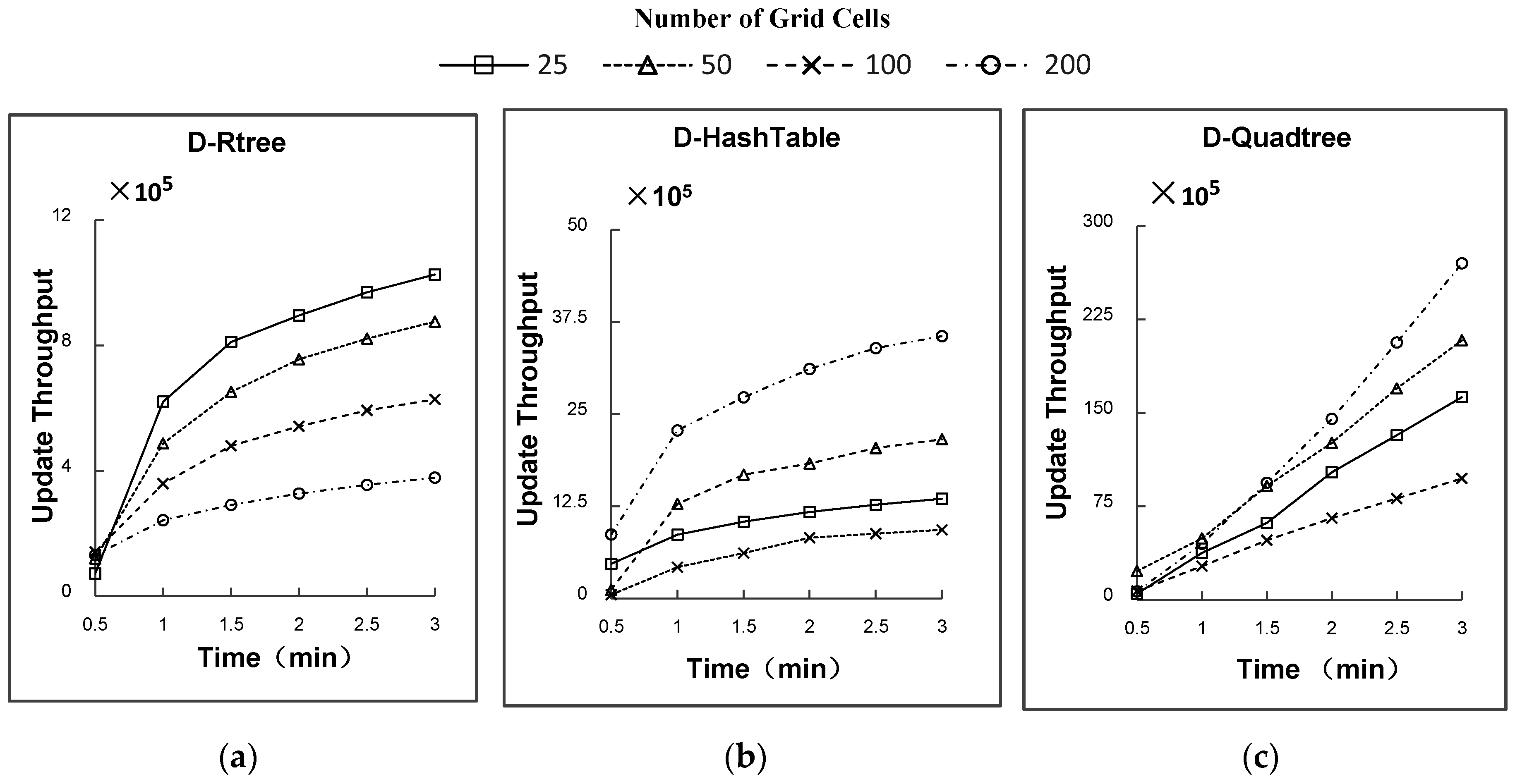
● Study 3:Influence of the number of grid cells on the spatial join performance
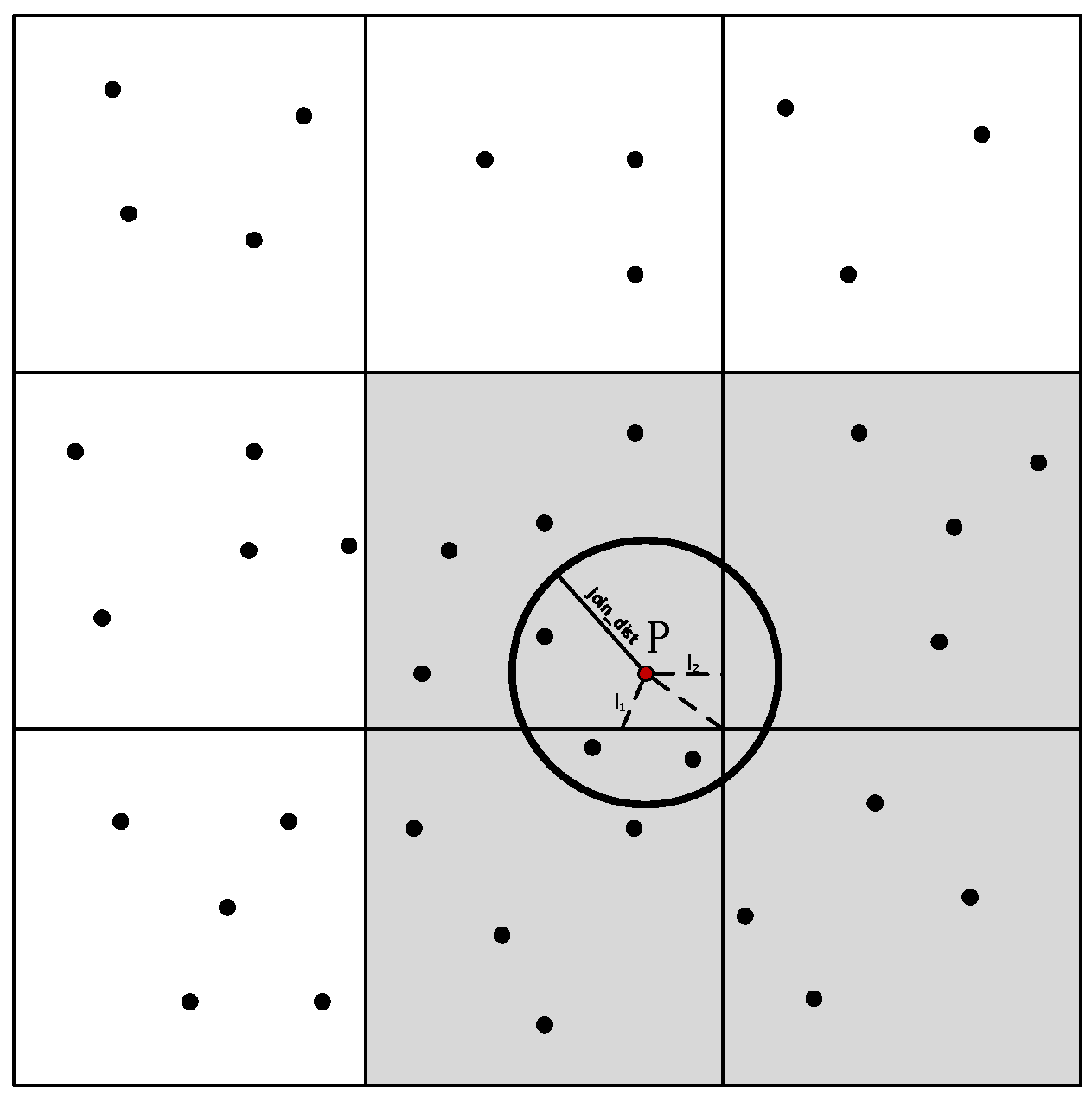
The effect of the number of grid cells on the spatial join performance has two main characteristics: (a) For a specific point, the number of cells into which the grid is partitioned and the number of ACs are directly related, that is, a more finely partitioned grid leads to more ACs, which increases the replication of points and reduces the update efficiency; (b) A grid with larger partitions will lead to an imbalance in the numbers of moving objects in different grid cells. Cells in denser regions of the road network will store more points. As
Figure 10a–c show, for D-Rtree, the first factor dominates, whereas for D-HashTable, the second dominates. Both factors have some impact on D-Quadtree.
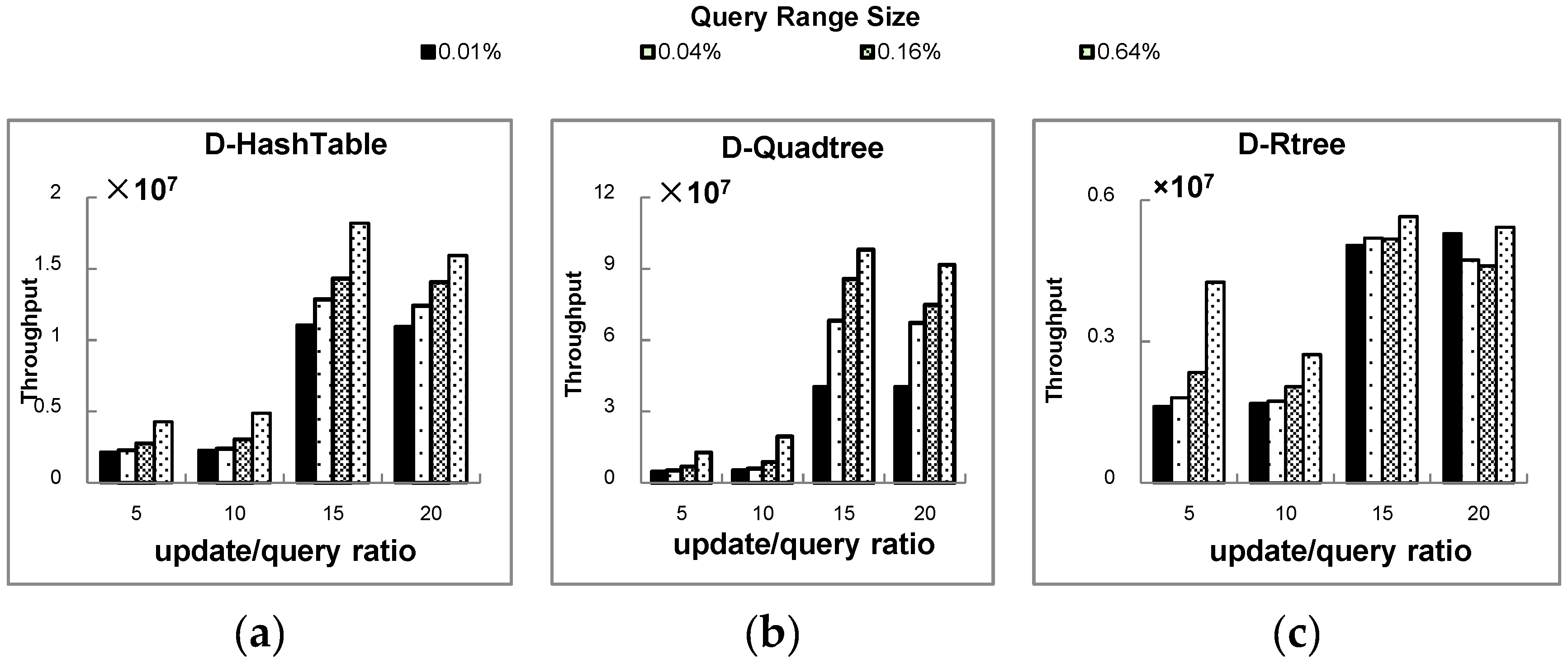
● Study 4: Influence of the query range size on the spatial join performance
Figure 11a–c show that an increase in the update/query message ratio will cause an increase in the total spatial join throughput, especially for D-Quadtree and D-HashTable. This suggests that the query process has a lower latency than the update process. In addition, a larger query range size has a smaller but also positive influence on throughput. This is because Storm sends a query message to each bolt instance for execution. When the query scope is large, the number of working executors is greater.
6. Conclusions and Applications
The mobility of people and vehicles in motion is a basic element of human society. Exploring the patterns and trends of human and vehicle mobility can advance the understanding of regional and urban dynamics and reveal the underlying socioeconomic driving forces at work [
1]. In this paper, we develop distributed spatial indexes for storing rapidly changing SFD for moving objects based on Apache Storm. In particular, two different solutions are proposed, one for spatial queries on a single dataset and one for range spatial join queries between two datasets. Several factors that may affect the efficiency of the distributed index were explored through experiments. The experiments show that a quadtree index offers better computational efficiency regardless of the number of moving objects, the number of grid partitions or the query range size. For such an evaluation, we should consider not only the query efficiency but also the update efficiency of the secondary index. A quadtree index shows the best performance for the following reasons: 1. The add and delete operations in an R-tree may lead to the merging or splitting of leaf nodes. In some special cases, the height of the tree will increase or decrease, which will lead to low efficiency in the updating of an R-tree; 2. A spatial query must iterate through the all elements in a hash table. Consequently, the spatial query efficiency of a hash table index is relatively low. Compared with these two index structures, the quadtree structure offers better computational efficiency in both query operations and update operations and thus exhibits better performance.
Theoretically, for more rapidly changing spatial data, we can increase the number of work nodes to provide more computing resources. However, each tuple message will stream to a single executor when all kinematic points are assigned to the same grid partition. Therefore, in the future, we will investigate how to address hyper-skewed workloads in the proposed Storm-based method. In addition, emerging distributed streaming frameworks, such as Apache Flink, are showing strong vitality and excellent development prospects (in particular, Apache Flink offers much better throughput than Apache Storm with relatively low latency). Our future research work will focus on comparing these frameworks with Storm and selecting the best distributed platforms for GIS applications.
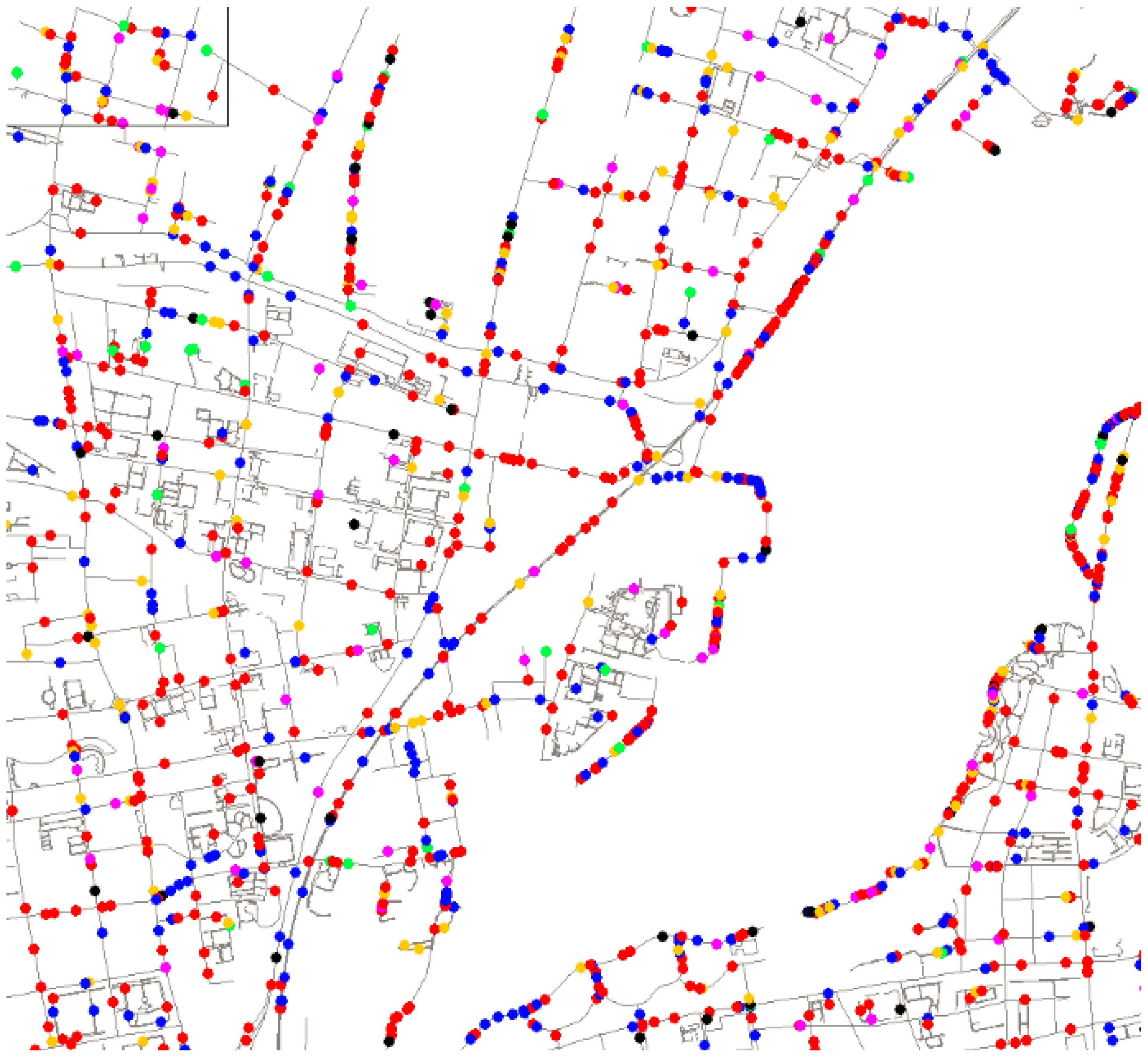
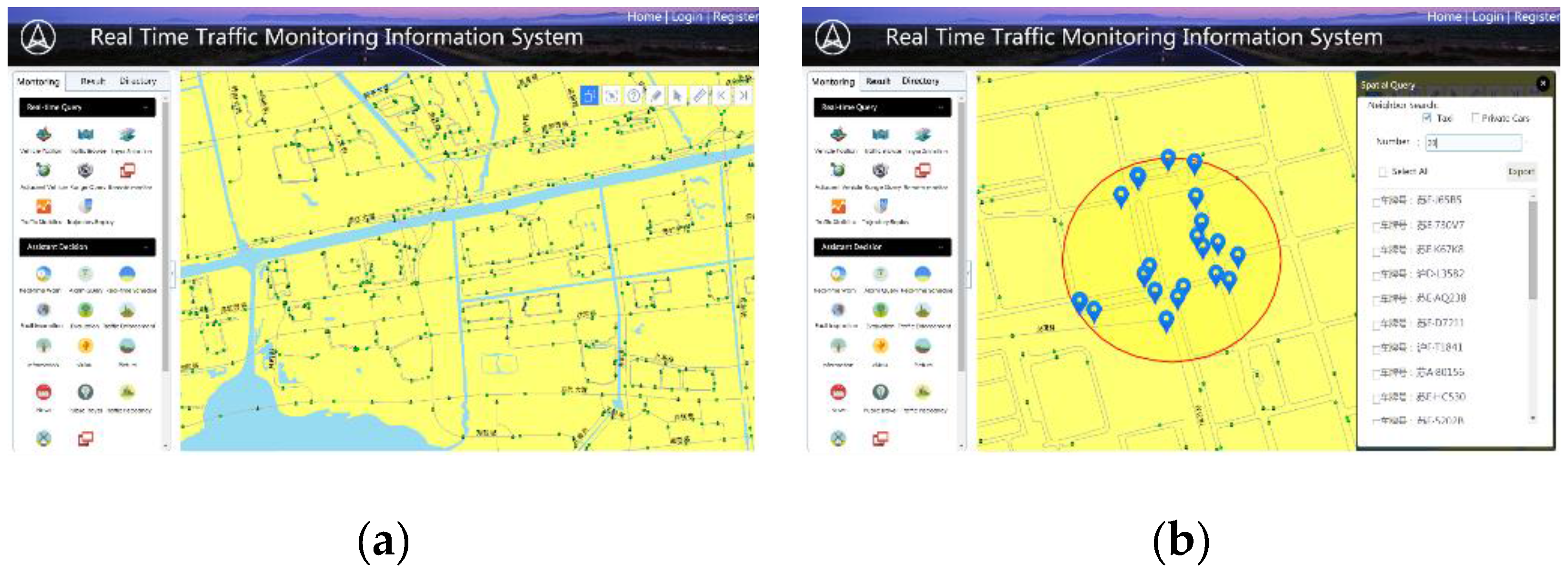
This spatial query approach is an important server-side component in our web information system for real-time traffic monitoring. This system has been successfully applied for traffic monitoring and vehicle scheduling and provides traffic decision support for the government (see
Figure 12). Our tool has facilitated the easy exploration of big trajectory data. The developed method will enable advancements in a broad spectrum of applications by assisting researchers in tackling the challenges posed by big data.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}