
Spatiotemporal Information Extraction from a Historic Expedition Gazetteer


Abstract
:1. Introduction
- extract spatiotemporal information from historic expedition gazetteer texts;
- help understand the temporal relationships between vague timeframes; and
- infer relative timeframes.
2. Related Work
2.1. Geospatial Information Extraction from the Web and Text Documents
2.2. Geo-Parsing
2.3. Temporal Reasoning
3. Data Source, Tools and Methods
3.1. Data Source
3.2. GATE Developer
3.3. ANNIE
3.3.1. ANNIE Tokenizer
3.3.2. ANNIE Sentence Splitter
3.3.3. ANNIE POS Tagger
3.3.4. ANNIE Gazetteer
3.4. JAPE: Regular Expressions over Annotations
3.4.1. JAPE Grammar Rule
- (or) |
- (0 or more occurrences) *
- (0 or one occurrence) ?
- (1 or more occurrences) +
- Line 1 defines the phase name. Each of the phases in the JAPE grammar must have a unique name, for instance, here, the phase is named distancefinder.
- Line 2 defines the input annotations, which the LHS rule uses for pattern-matching, and which must be defined at the start of each grammar. In the absence of an explicit definition of the input annotations, the defaults are Token, SpaceToken and Lookup.
- Line 3 defines the option. There are two types of options (control and debug) that can be set at the beginning of each grammar rule:
- control is a rule-matching method. The control options are Appelt, Brill, All or Once. For instance, the Appelt forces the JAPE grammar rule to trigger a rule with higher priority first.
- debug can be set to either true or false. It notifies a conflict between more than one possible match if it is set to true.
- Line 4 defines the name of the rule; in this example, the name is distance.
- Line 5 defines the priority of the rule. If there are multiple rules in a single phase, the rules with higher priority are triggered and matched prior to the rest.
- Line 6–23 is the LHS of the rule. Here, the rule searches for a part of an input text that is a combination of word and number. This LHS pattern rule has three subpatterns:
- Subpattern one matches a combination of word, punctuation and white space that equals “Ca.” or “ca.”; note the white space before the closing quotations (Line 6–10).
- Subpattern two matches a string of digits in one of the following formats: “9”, “99”, “999”, “9999”, “99999” (Line 11–17).
- Subpattern three matches a combination of punctuation, number, white space and word that resembles “0.1 km” (Line 18–21).
- Line 23 defines the temporary annotation class.
- Line 24 separates the LHS and RHS.
- Line 25 is the RHS of the rule renames the temporary label (Line 23) into a permanent annotation class. In this example, the temporary label distance is renamed into a permanent label (Distance). The new label is recognized as an annotation class by other JAPE phases.
3.4.2. LHS Macros
3.4.3. JAPE Transducer
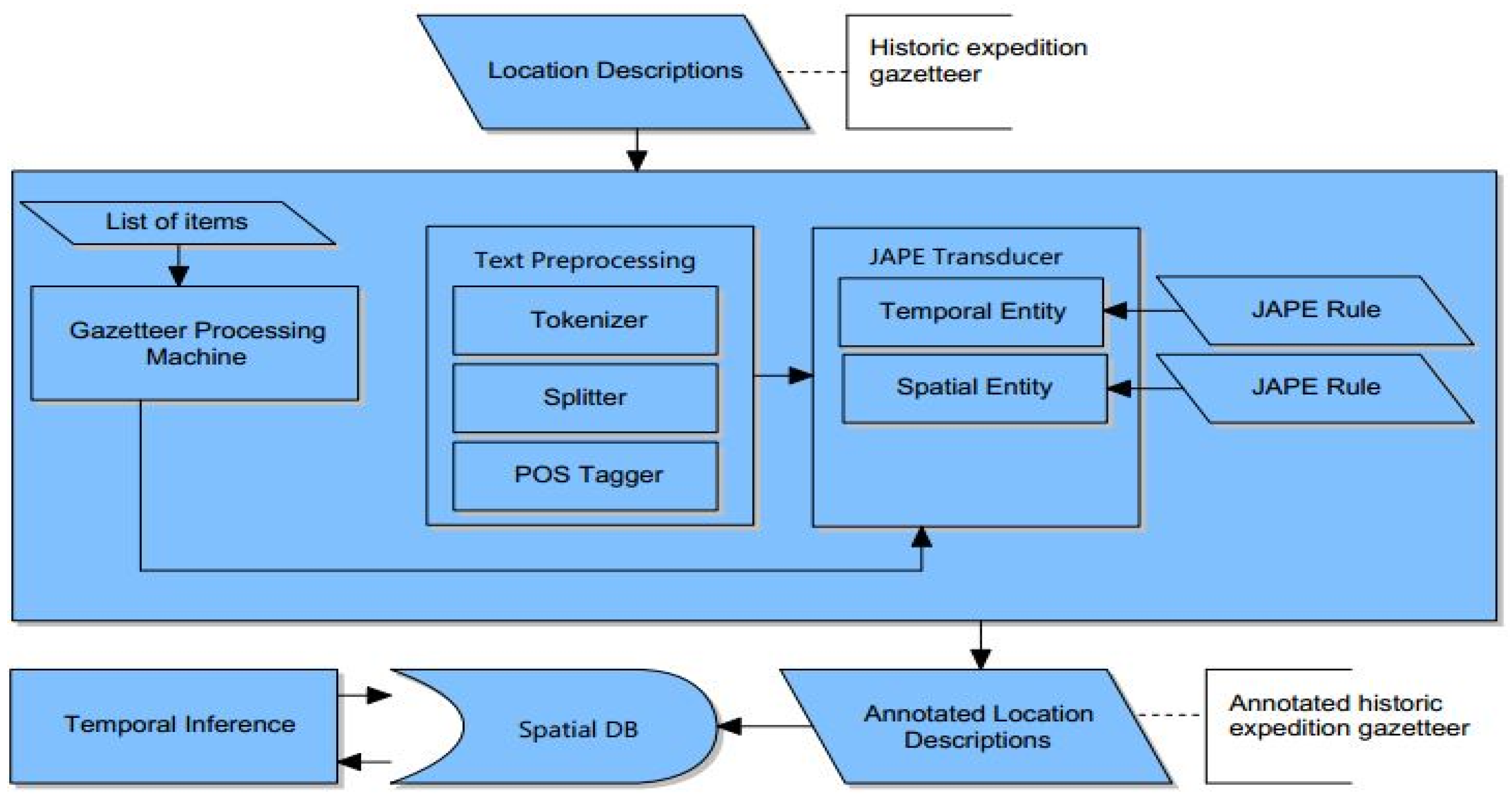
4. Spatiotemporal Information Extraction Framework
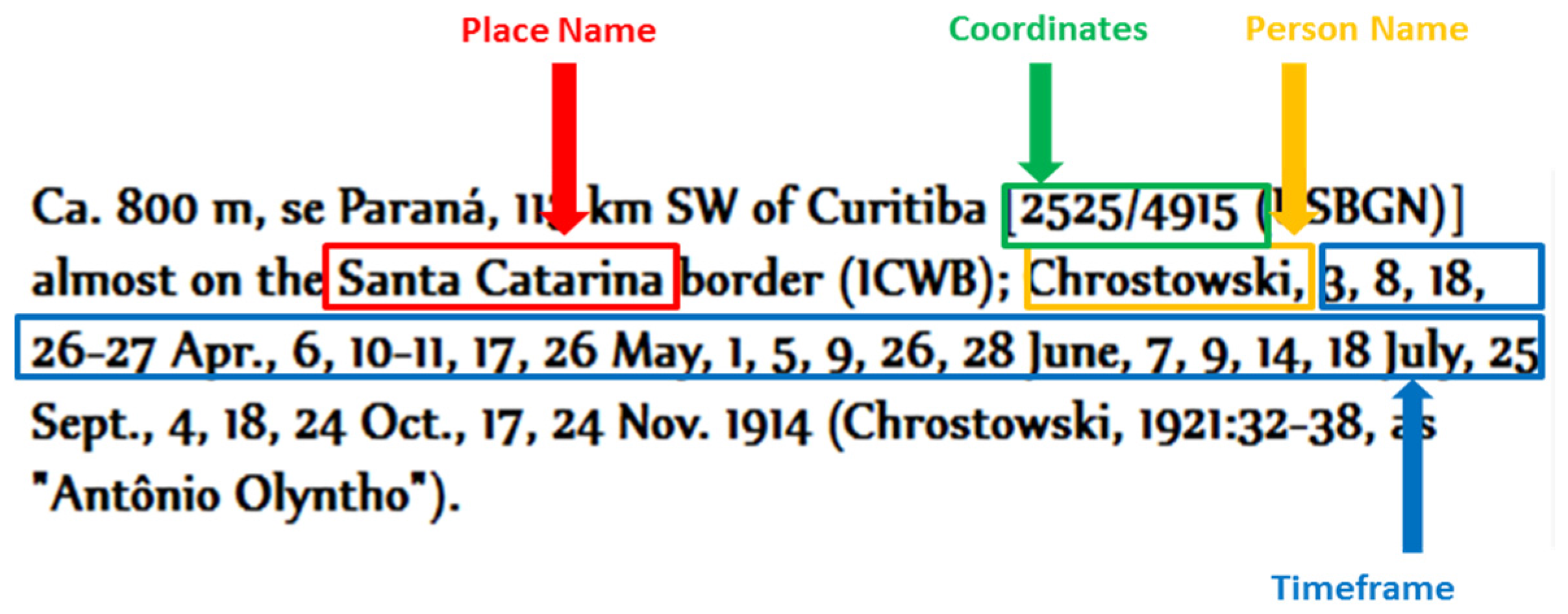
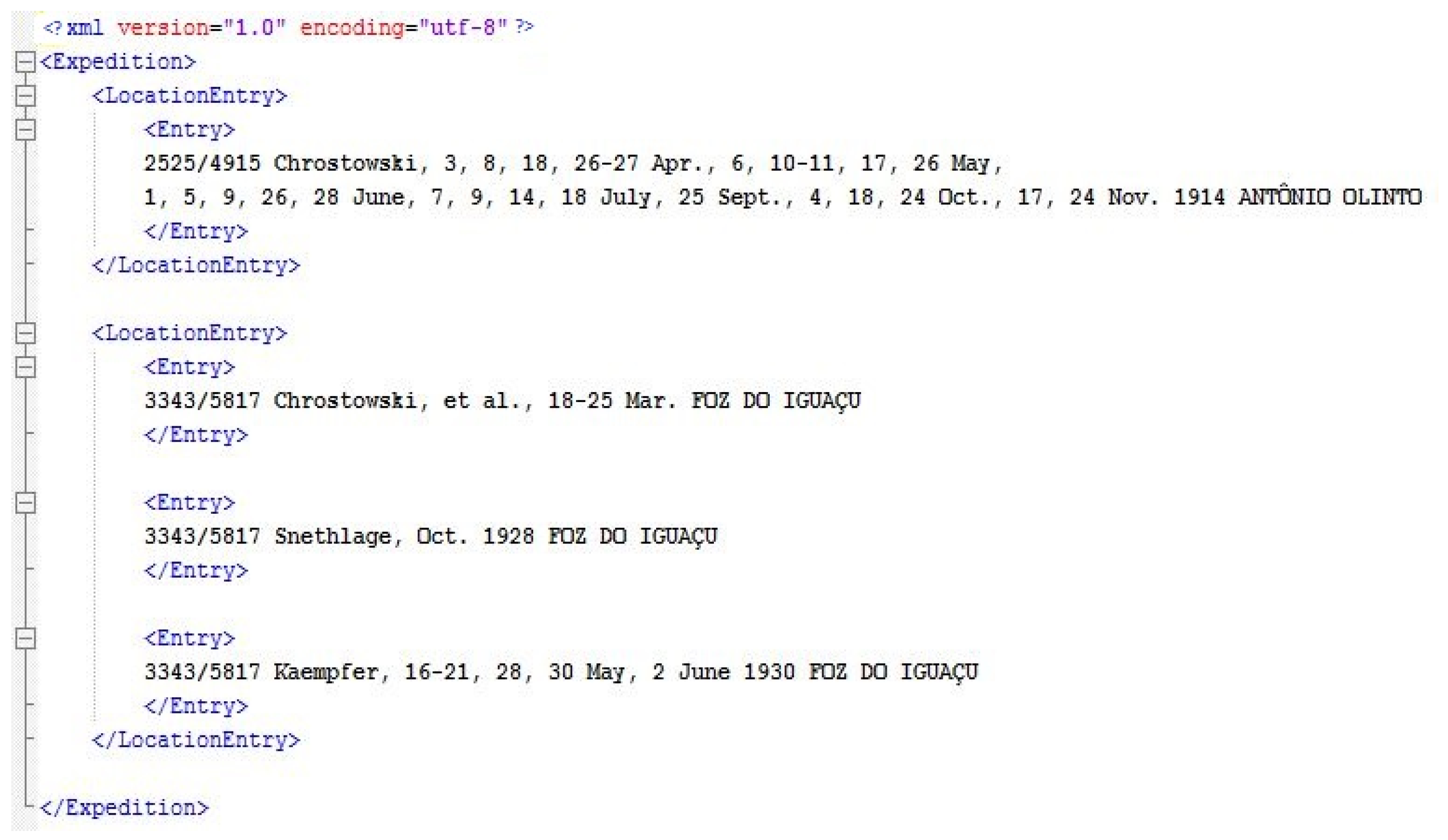
4.1. Raw Data Extraction (Location Descriptions)
4.2. Spatiotemporal Entities
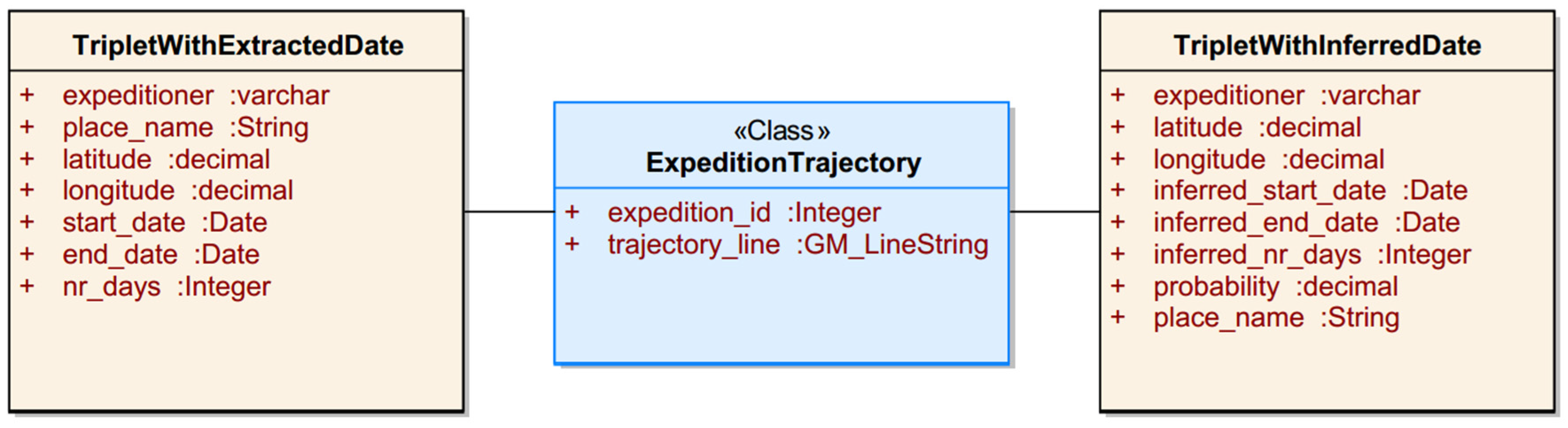
4.2.1. Triplets with Crisp Timeframe
4.2.2. Triplets with Vague Timeframe
4.3. Text Preprocessor
4.4. Gazetteer Processing Machine (List Matching)
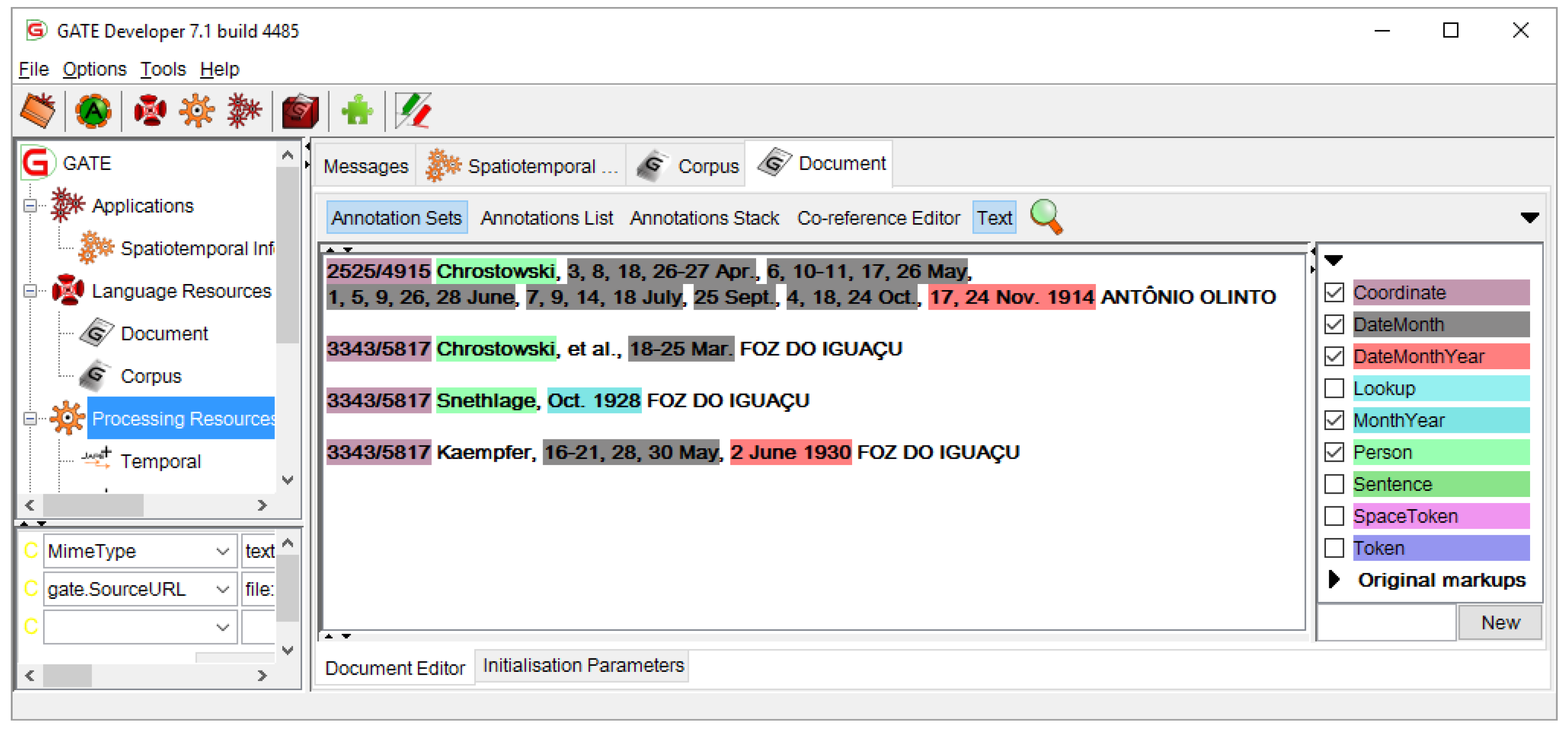
4.5. JAPE Transducer (Pattern Matching)
4.6. Spatial Database
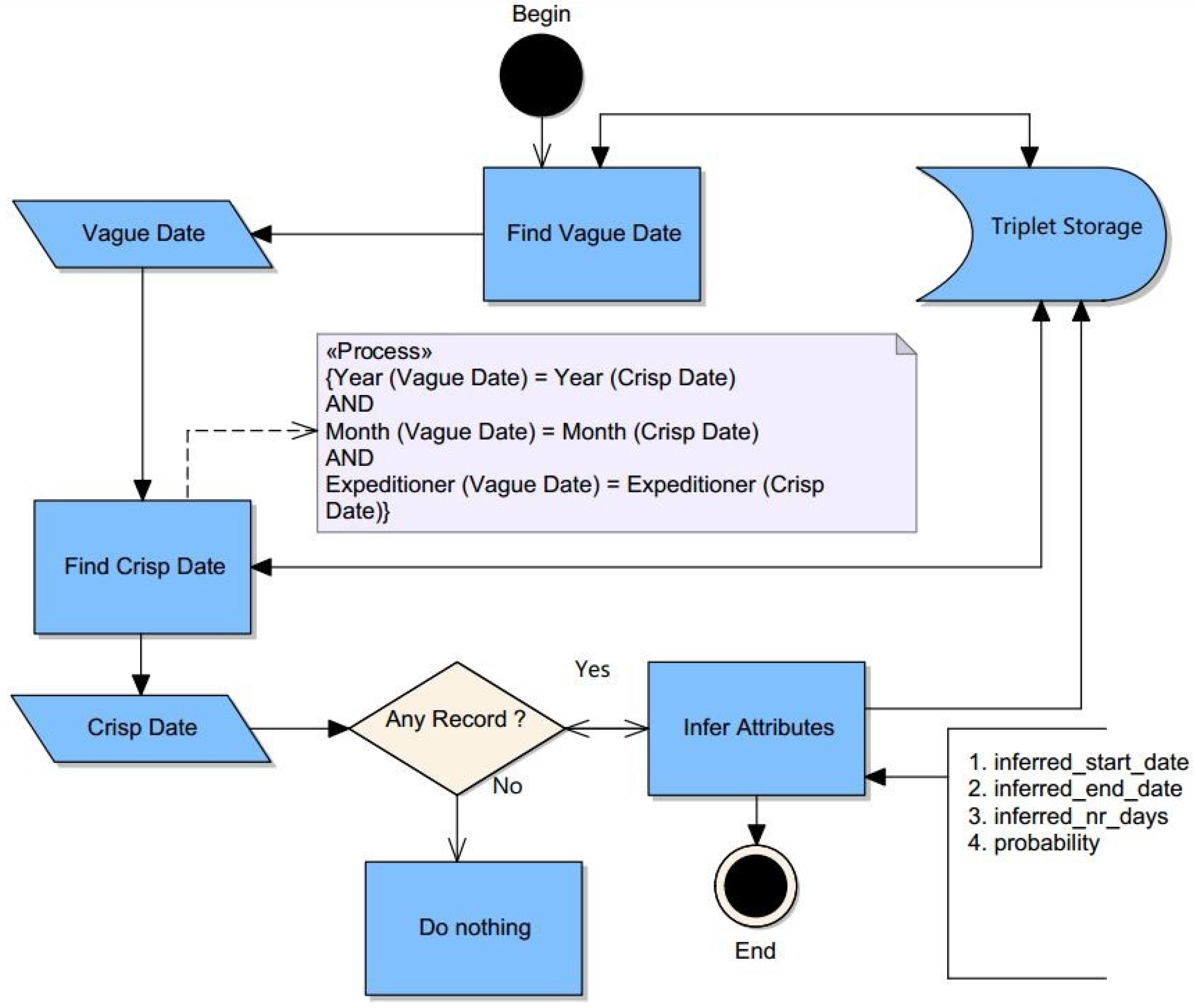
4.7. Temporal Inference
- Data: The extracted vague and crisp triplets (of the same expeditioner) upon which the relative temporal boundaries for the vague triplets are inferred.
- Process: The inference process discussed here is applicable only for the vague triplets which timeframes are captured with the MonthYear annotation class (see Table 2) by the JAPE transducer.
- Result: The result of this algorithm is a set of triplets with inferred temporal boundaries. The triplets with the inferred temporal boundaries are stored in the database.
- Step 1: Finds a parsed and stored vague triplet.
- Step 2: Finds crisp triplets; the crisp dates are constrained to be about the same expeditioner, same month and same year as the vague triplet in Step 1.
- Step 3: Infers relative temporal boundaries and determines their probability of occurrence for those vague triplets in Step 1 relative to those crisp triplets in Step 2.
- Line 8–14 (see Figure 11): Let the vague triplet be VT and the crisp triplet be CT. If the month and year of the VT and CT are similar, for every given VT, a minimum of one or maximum of two temporal boundaries are inferred. If the given CT starts at the first day of the month or ends at the last day of the month, only one temporal boundary is inferred. If the given CT starts and ends between the first and last days of the month, two temporal boundaries are inferred. Given the VT and CT, the following holds (see Figure 12).
4.8. Expedition Route Production
5. Results and Discussion
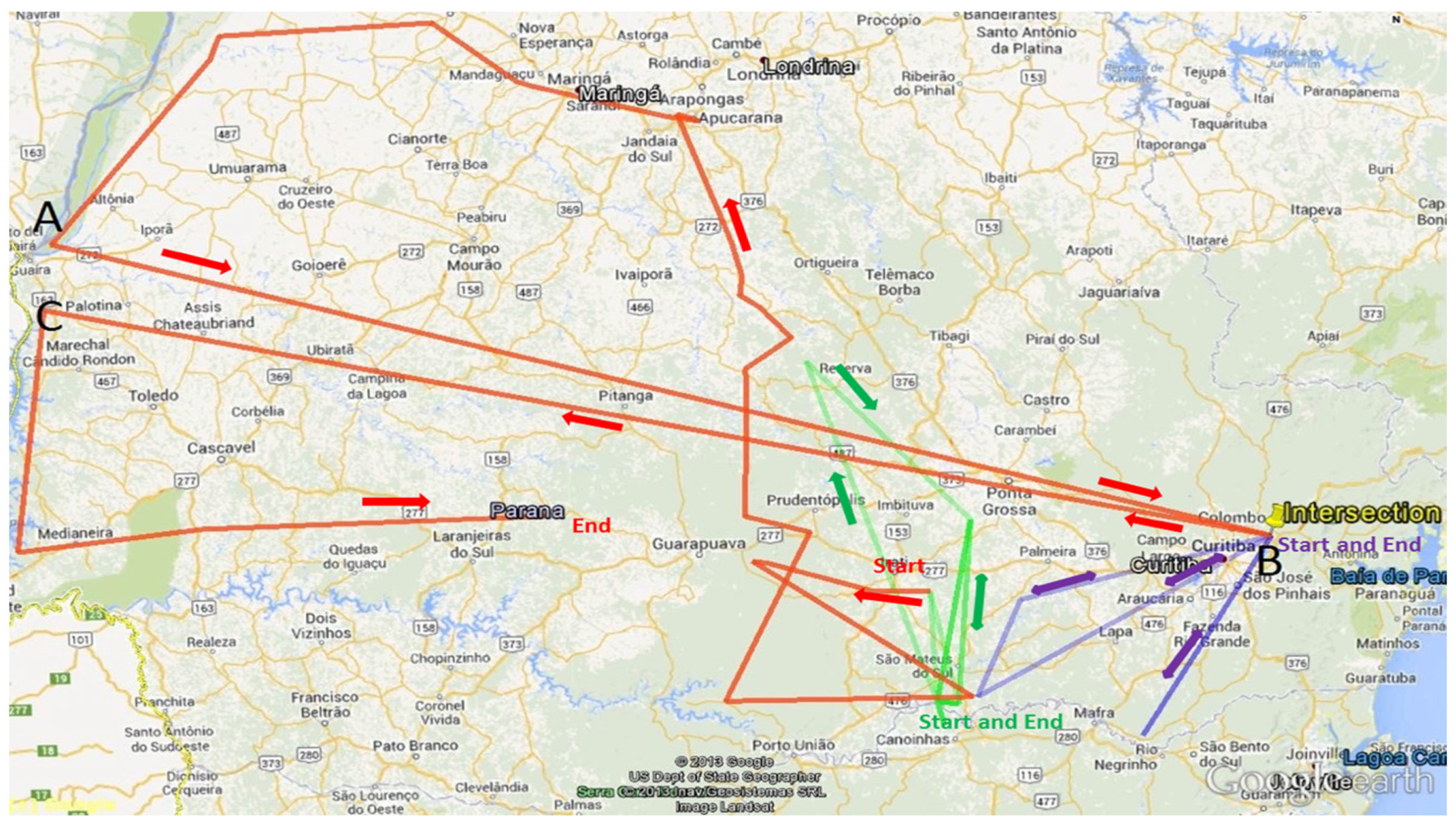
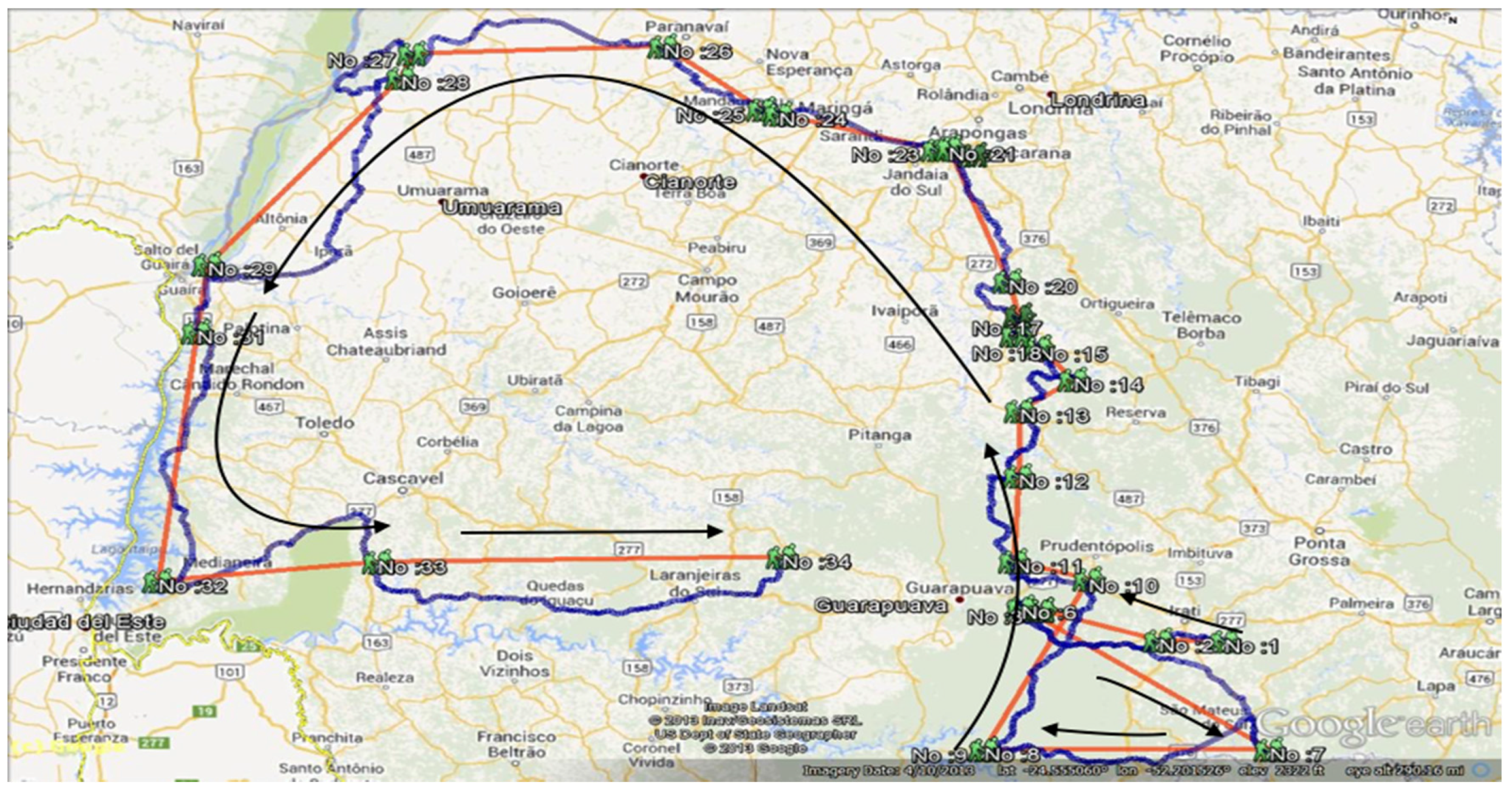
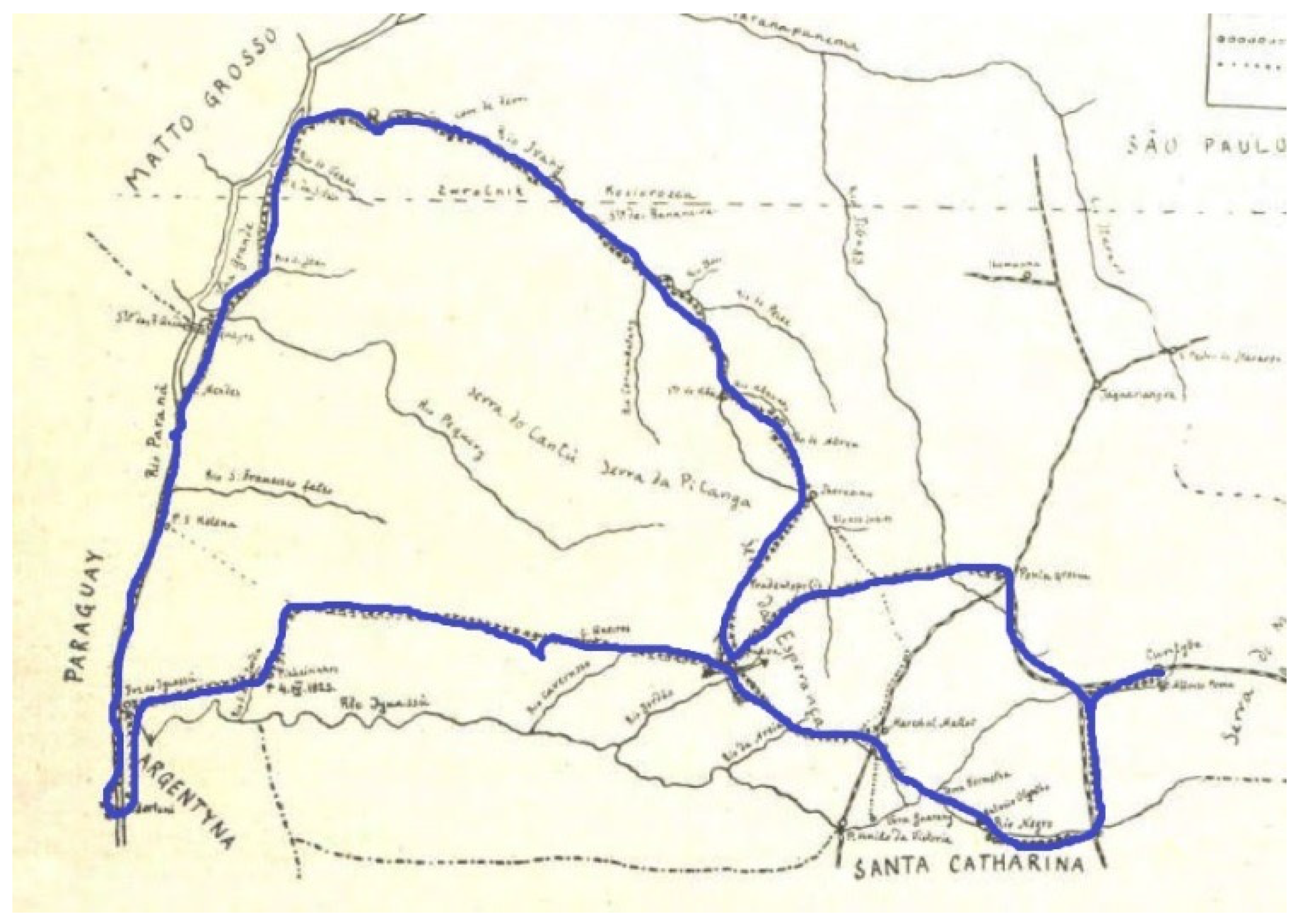
5.1. Expeditioner: Tadeusz Chrostowski
The Third Expedition of Chrostowski: 1921–1923
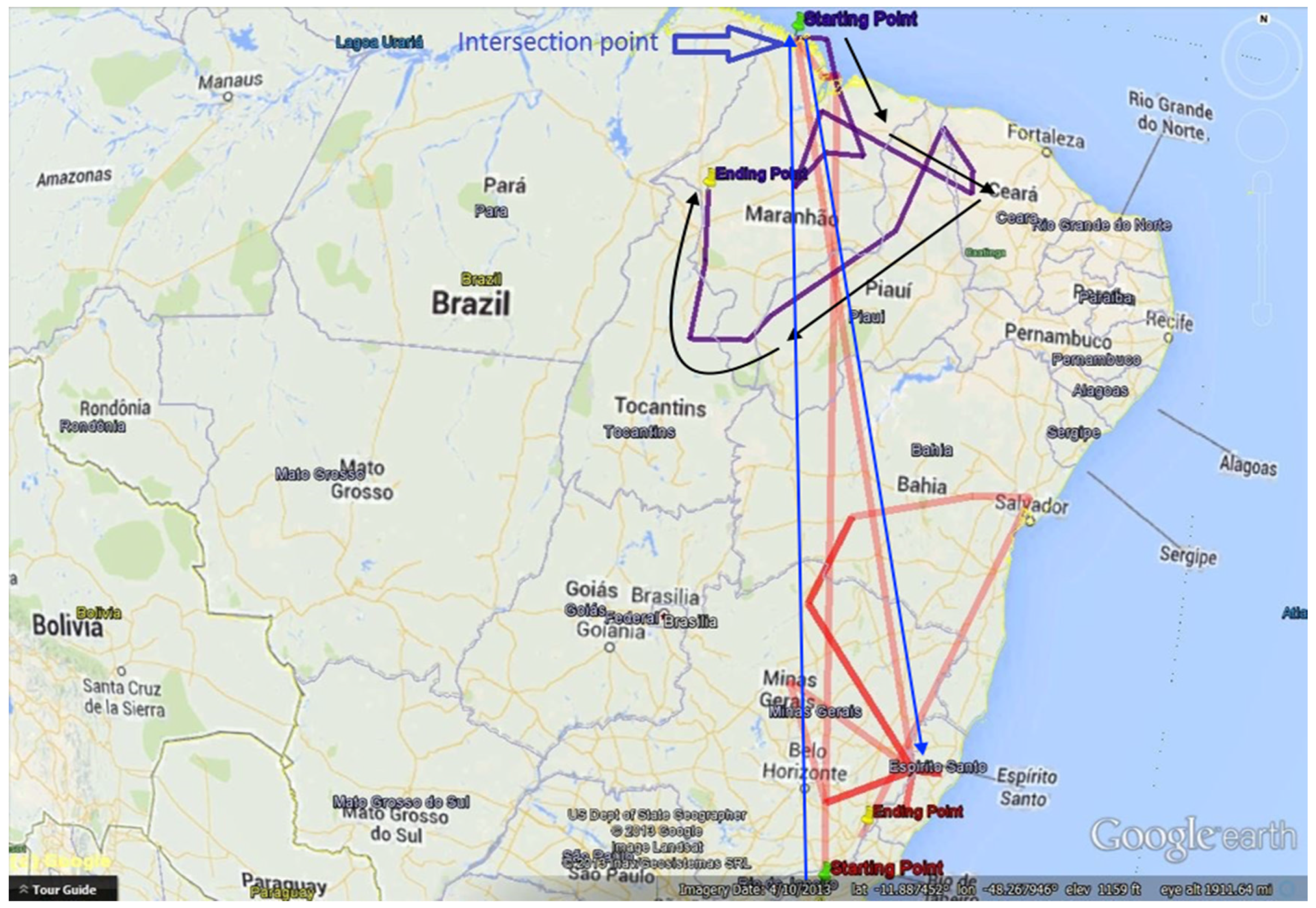
5.2. Expeditioner: Emil Heinrich Snethlage and Maria Emilie Snethlage
6. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bekele, M.K. Spatial tracing of historic expeditions: From text to trajectory. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2014. [Google Scholar]
- Paynter, R.A.; Traylor, M.A. V.1—Ornithological Gazetteer of Brazil; Harvard University: Cambridge, MA, USA, 1991. [Google Scholar]
- Paynter, R.A.; Traylor, M.A. V.2—Ornithological Gazetteer of Brazil; Harvard University: Cambridge, MA, USA, 1991. [Google Scholar]
- Subodh, V.; Christopher, B.J.; Hideo, J.; Mark, S. Spatio-textual indexing for geographical search on the web. In Advances in Spatial and Temporal Databases; Springer: Heidelberg, Germany, 2005. [Google Scholar]
- McCurley, K.S. Geospatial mapping and navigation of the web. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001.
- Chen, Y.Y.; Suel, T.; Markowetz, A. Efficient query processing in geographic web search engines. In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 27–29 June 2006.
- Wu, D.; Cong, G.; Jensen, C.S. A framework for efficient spatial web object retrieval. Int. J. Very Large Data Bases 2012, 21, 797–822. [Google Scholar] [CrossRef]
- Freire, N.; Jos, Y.; Borbinha, Z.; Calado, V.; Martins, B. A metadata geoparsing system for place name recognition and resolution in metadata records. In Proceedings of the 11th Annual International ACM/IEEE Joint Conference on Digital Libraries, Ottawa, ON, Canada, 13–17 June 2011.
- Gelernter, J.; Balaji, S. An algorithm for local geoparsing of microtext. Geoinformatica 2013, 17, 1–33. [Google Scholar] [CrossRef]
- Guillén, R. Geoparsing web queries. In Advances in Multilingual and Multimodal Information Retrieval; Peters, C., Jijkoun, V., Mandl, T., Müller, H., Oard, D., Peñas, A., Petras, V., Santos, D., Eds.; Springer: Berlin, Germany, 2008; Volume 5152, pp. 781–785. [Google Scholar]
- Witmer, J.; Kalita, J. Extracting geospatial entities from Wikipedia. In Proceedings of the IEEE International Conference of Semantic Computing, Berkeley, CA, USA, 14–16 September 2009.
- Zubizarreta, Á.; Fuente, P.; Cantera, J.; Arias, M.; Cabrero, J.; García, G.; Llamas, C.; Vegas, J. Extracting geographic context from the web: Georeferencing in MyMoSe. In Advances in Information Retrieval; Boughanem, M., Berrut, C., Mothe, J., Soule-Dupuy, C., Eds.; Springer: Berlin, Germany, 2009; Volume 5478, pp. 554–561. [Google Scholar]
- Boguraev, B.; Ando, R.K. TimeML-compliant text analysis for temporal reasoning. In Proceedings of the 19th International Joint Conference on Artificial Intelligence, Madrid, Spain, 30 July–5 August 2005; pp. 997–1003.
- Zhang, C.; Zhang, X.; Jiang, W.; Shen, Q.; Zhang, S. Rule-based extraction of spatial relations in natural language text. In Proceedings of the International Conference on Computational Intelligence and Software Engineering, Wuhan, China, 11–13 December 2009.
- Blessing, A.; Schütze, H. Self-annotation for fine-grained geospatial relation extraction. In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010.
- Strötgen, J.; Gertz, M.; Popov, P. Extraction and exploration of spatio-temporal information in documents. In Proceedings of the 6th Workshop on Geographic Information Retrieval, Toronto, ON, Canada, 30 October 2010.
- Brisaboa, N.; Luaces, M.; Places, Á.; Seco, D. Exploiting geographic references of documents in a geographical information retrieval system using an ontology-based index. Geoinformatica 2010, 14, 307–331. [Google Scholar] [CrossRef]
- Drymonas, E.; Pfoser, D. Geospatial route extraction from texts. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Data Mining for Geoinformatics, San Jose, CA, USA, 3–5 November 2010.
- Hall, M.M.; Smart, P.D.; Jones, C.B. Interpreting spatial language in image captions. Cognit. Process. 2011, 12, 67–94. [Google Scholar] [CrossRef] [PubMed]
- Horák, J.; Belaj, P.; Ivan, I.; Nemec, P.; Ardielli, J.; Růžička, J. Geoparsing of Czech RSS news and evaluation of its spatial distribution. In Semantic Methods for Knowledge Management and Communication; Katarzyniak, R., Chiu, T.-F., Hong, C.F., Nguyen, N., Eds.; Springer: Berlin, Germany, 2011; Volume 381, pp. 353–367. [Google Scholar]
- Abascal-Mena, R.; López-Ornelas, E. Geo-information extraction and processing from travel narratives. In Proceedings of the 14th International Conference on Electronic Publishing, Helsinki, Finland, 16–18 June 2010.
- Godo, L.; Vila, L. Possibilistic temporal reasoning based on fuzzy temporal constraints. In Proceedings of the 14th International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995.
- Freksa, C. Temporal reasoning based on semi-intervals. Artif. Intell. 1992, 54, 199–227. [Google Scholar] [CrossRef]
- Nagypál, G.; Motik, B. A fuzzy model for representing uncertain, subjective, and vague temporal knowledge in ontologies. In On the Move to Meaningful Internet Systems 2003: Coopis, Doa, and Odbase; Springer: Berlin, Germany, 2003; pp. 906–923. [Google Scholar]
- Cunningham, H.; Maynard, D.; Bontcheva, K.; Tablan, V.; Ursu, C.; Dimitrov, M.; Dowman, M.; Aswani, N.; Roberts, I.; Li, Y. Developing Language Processing Components with Gate Version 5: (A User Guide); University of Sheffield: South Yorkshire, UK, 2009. [Google Scholar]
- Dicionário Geográfico das Expedições Zoológicas Polonesas ao Paraná. Available online: http://www.ao.com.br/download/polonesa.pdf (accessed on 25 March 2016).
- Straube, F.; Urben-Filho, A. Tadeusz Chrostowski (1878–1923): Biografia e perfil do patrono da ornitologia paranaense. Bol. Inst. Hist. Geogr. Paraná 2002, 52, 35–52. [Google Scholar]
- Life, Expeditions, Collections and Unpublished Field Notes of Dr. Emil Heinrich Snethlage. Available online: http://www.snethlage.info/ (accessed on 20 September 2015).
- Singh, G. From Location Description to Map: Understanding VGI from the Past. Ph.D. Thesis, University of Twente, Enschede, The Netherlands, 2014. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Example | Annotation Class |
|---|---|---|
| 1 | Paraná | State |
| 2 | City of Manacapuru | City |
| 3 | USBGN | Organization |
| 4 | Chrostowski | Person |
| 5 | Feb. | Month |
| No | Entity Type | Pattern | Annotation Class |
|---|---|---|---|
| 1 | Coordinate | 9999/9999, ca. 9999/9999, 9999N/9999, ca. 9999/9999? or Place Name 9999/9999 | Coordinate |
| 2 | Unknown Coordinate | Not located or location? | CoordinateUnknown |
| 3 | Date | 99–99 Month | DateMonth |
| 4 | Date | 99 Month–99 Month 9999 | DateMonthDuration |
| 5 | Date | 99 Month–Month 9999 | DateMonthMonthDuration |
| 6 | Date | 99–99 Month 9999 | DateMonthYear |
| 7 | Date | 99 Month 9999–99 Month 9999 | DateMonthYearDuration |
| 8 | Date | Month 9999 | MonthYear |
| 9 | Date | Month–Month 9999 | MonthDuration |
| 10 | Date | 99, 99–99 Month, 99, 99–99 Month 9999 | DateMonthListYear |
| 11 | Date | Month (?) 9999 (?) | DateVague |
| Expedition | Start Date | End Date | No. Triplets |
|---|---|---|---|
| I | 26 May 1910 | 26 August 1911 | 64 |
| II | 22 January 1914 | 3 July 1914 | 25 |
| III | 25 September 1914 | 2 December 1914 | 7 |
| IV | 10 February 1915 | 10 October 1915 | 1 |
| V | 1 August 1921 | 31 August 1921 | 1 |
| VI | 1 January 1922 | 5 May 1923 | 38 |
| No | Place Name | Lat | Lon | Start Date | End Date | No Dates |
|---|---|---|---|---|---|---|
| 1 | FAZENDA FERREIRA | 26.01 | 51.36 | 1922-03-12 | 1922-03-28 | 17 |
| 2 | UBA, SALTO | 24.3 | 51.28 | 1922-11-18 | 1 | |
| 3 | SALVADOR | 12.59 | 38.31 | 1921-08-01 | 1921-08-31 | 31 |
| 4 | CORONEL QUEIROZ | 25.22 | 52.1 | 1923-05-05 | 1923-07-04 | 60 |
| 5 | CARA PINTADA | 24.88 | 51.26 | 1922-05-15 | 1922-06-04 | 20 |
| 6 | CONCORDIA,RIO | 25.43 | 51.17 | 1922-03-01 | 1922-03-12 | 12 |
| 7 | COBRE, SALTO DO | 23.53 | 51.53 | 1922-12-11 | 1922-12-19 | 9 |
| 8 | SAO DOMINGOS | 25.43 | 51.17 | 1922-02-15 | 1922-02-28 | 14 |
| 9 | APUCARANA | 24.47 | 51.1 | 1922-08-01 | 1922-08-31 | 31 |
| 10 | PARY, CORREDEIRA DO | 23.38 | 52.19 | 1923-01-04 | 1923-01-06 | 3 |
| 11 | PINHEIRINHO | 25.25 | 53.55 | 1923-03-28 | 1923-04-23 | 26 |
| 12 | MUTUM, ILHA DO | 23.15 | 53.43 | 1923-01-14 | 1923-01-15 | 2 |
| 13 | FAZENDA WISNIEWSKY | 26.03 | 50.38 | 1922-02-01 | 1922-02-28 | 28 |
| 14 | MANGUINHOS | 22.47 | 41.56 | 1922-01-01 | 1922-01-31 | 31 |
| 15 | GUARAPUAVA | 25.23 | 51.27 | 1922-04-28 | 1922-05-14 | 17 |
| 16 | BOM, RIO | 23.56 | 51.44 | 1922-12-20 | 1922-12-22 | 3 |
| 17 | AFONSO PENA | 25.32 | 49.06 | 1923-01-25 | 1 | |
| 18 | MALLET | 25.55 | 50.5 | 1922-01-10 | 1922-02-02 | 23 |
| 19 | FENIX | 23.54 | 51.57 | 1922-12-23 | 1923-01-02 | 10 |
| 20 | FERRO, CORREDEIRA DO | 23.12 | 52.54 | 1923-01-07 | 1923-01-13 | 7 |
| 21 | BANANEIRAS,SALTO DAS | 23.4 | 52.13 | 1923-01-03 | 1 | |
| 22 | FOZODO IUACU | 25.33 | 54.35 | 1923-03-18 | 1923-03-25 | 8 |
| 23 | FAZENDA ZAWADSKI | 25.43 | 51.17 | 1922-02-15 | 1922-02-28 | 14 |
| 24 | FAZENDA FIRMIANO | 26 | 50.32 | 1922-03-01 | 1922-03-12 | 12 |
| 25 | PINDAHURA, CACHOEIRA DE | 24.08 | 51.31 | 1922-11-28 | 1922-12-06 | 9 |
| 26 | UBZINHO, RIO | 24.35 | 51.2 | 1922-10-12 | 1922-11-20 | 39 |
| 27 | AREIA, RIO DA | 26.01 | 51.36 | 1922-03-29 | 1922-04-12 | 14 |
| 28 | ARIRANHA, CACHOEIRA | 24.22 | 51.27 | 1922-11-23 | 1922-11-26 | 4 |
| 29 | VERMELHO | 24.61 | 51.26 | 1922-06-06 | 1922-07-05 | 30 |
| 30 | BANHADOS | 25.3 | 51 | 1922-04-13 | 1922-04-17 | 5 |
| 31 | PORTO XAVIER DA SILVA | 23.25 | 53.47 | 1923-01-15 | 1923-01-17 | 3 |
| 32 | CANDIDO DE ABREU | 24.35 | 51.2 | 1922-08-02 | 1922-10-11 | 70 |
| 33 | SETE QUEDAS, SALTO DAS | 24.02 | 54.16 | 1923-01-23 | 1923-02-26 | 34 |
| 34 | CONCORDIA RIO | 24.42 | 51.24 | 1922-03-01 | 1922-03-12 | 12 |
| 35 | TERESA CRISTINA | 24.48 | 51.07 | 1922-07-08 | 1922-07-31 | 24 |
| 36 | RIO DE JANEIRO | 22.54 | 43.14 | 1922-01-01 | 1922-01-31 | 31 |
| 37 | CLARO,RIO | 25.55 | 50.74 | 1922-02-03 | 1922-02-14 | 12 |
| 38 | PORTO MENDES | 24.3 | 54.2 | 1923-02-27 | 1923-03-16 | 20 |
| 39 | URA, SALTO | 24.3 | 51.28 | 1922-11-14 | 1 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bekele, M.K.; De By, R.A.; Singh, G. Spatiotemporal Information Extraction from a Historic Expedition Gazetteer. ISPRS Int. J. Geo-Inf. 2016, 5, 221. https://doi.org/10.3390/ijgi5120221
Bekele MK, De By RA, Singh G. Spatiotemporal Information Extraction from a Historic Expedition Gazetteer. ISPRS International Journal of Geo-Information. 2016; 5(12):221. https://doi.org/10.3390/ijgi5120221
Chicago/Turabian StyleBekele, Mafkereseb Kassahun, Rolf A. De By, and Gaurav Singh. 2016. "Spatiotemporal Information Extraction from a Historic Expedition Gazetteer" ISPRS International Journal of Geo-Information 5, no. 12: 221. https://doi.org/10.3390/ijgi5120221
APA StyleBekele, M. K., De By, R. A., & Singh, G. (2016). Spatiotemporal Information Extraction from a Historic Expedition Gazetteer. ISPRS International Journal of Geo-Information, 5(12), 221. https://doi.org/10.3390/ijgi5120221