
Evaluating Trade Areas Using Social Media Data with a Calibrated Huff Model


Abstract
:1. Introduction
2. Background
2.1. Trade Area Delimitating Method
2.2. Sina Weibo
3. Data and Study Area
3.1. Data Collection and Pre-Processing
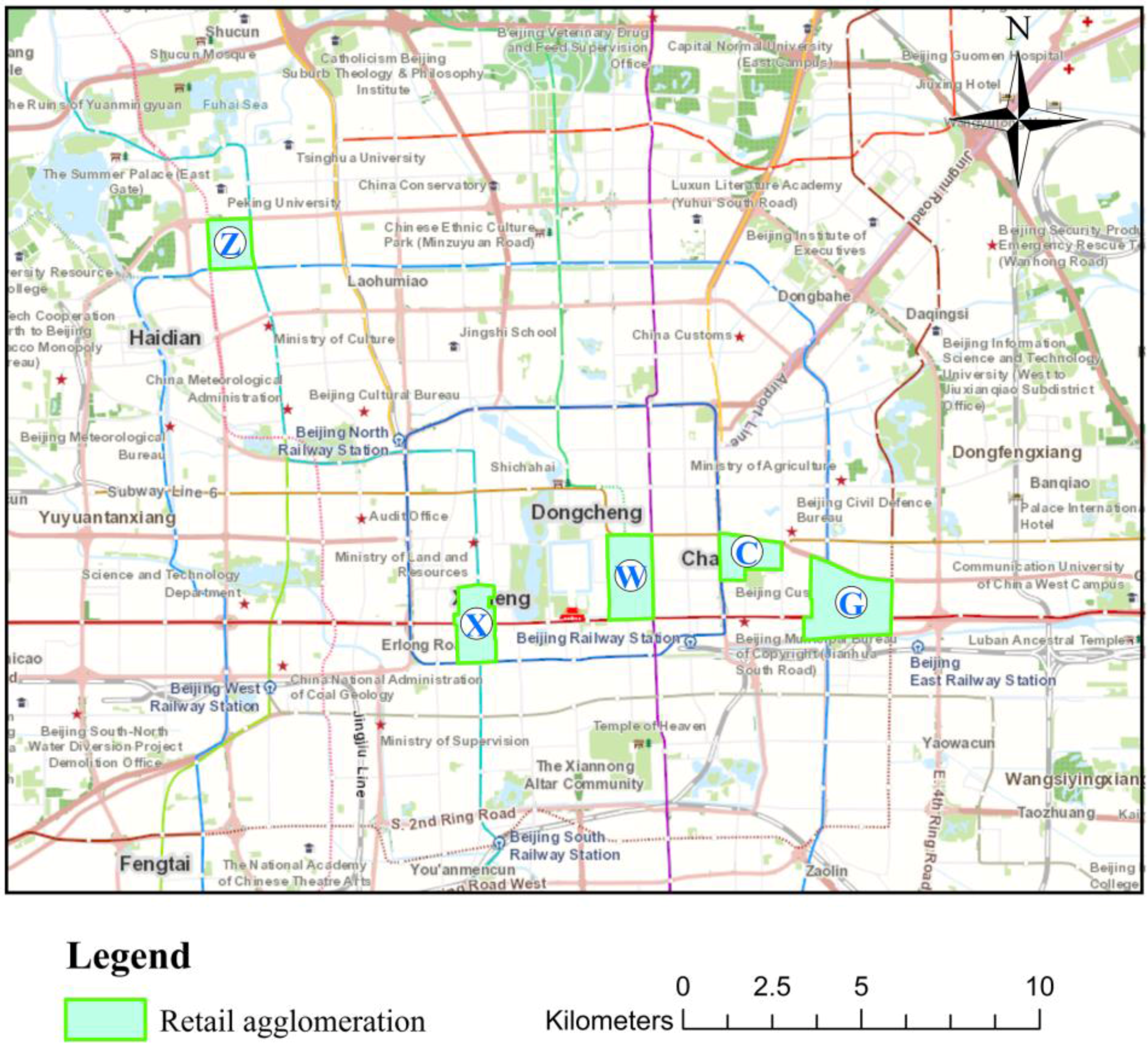
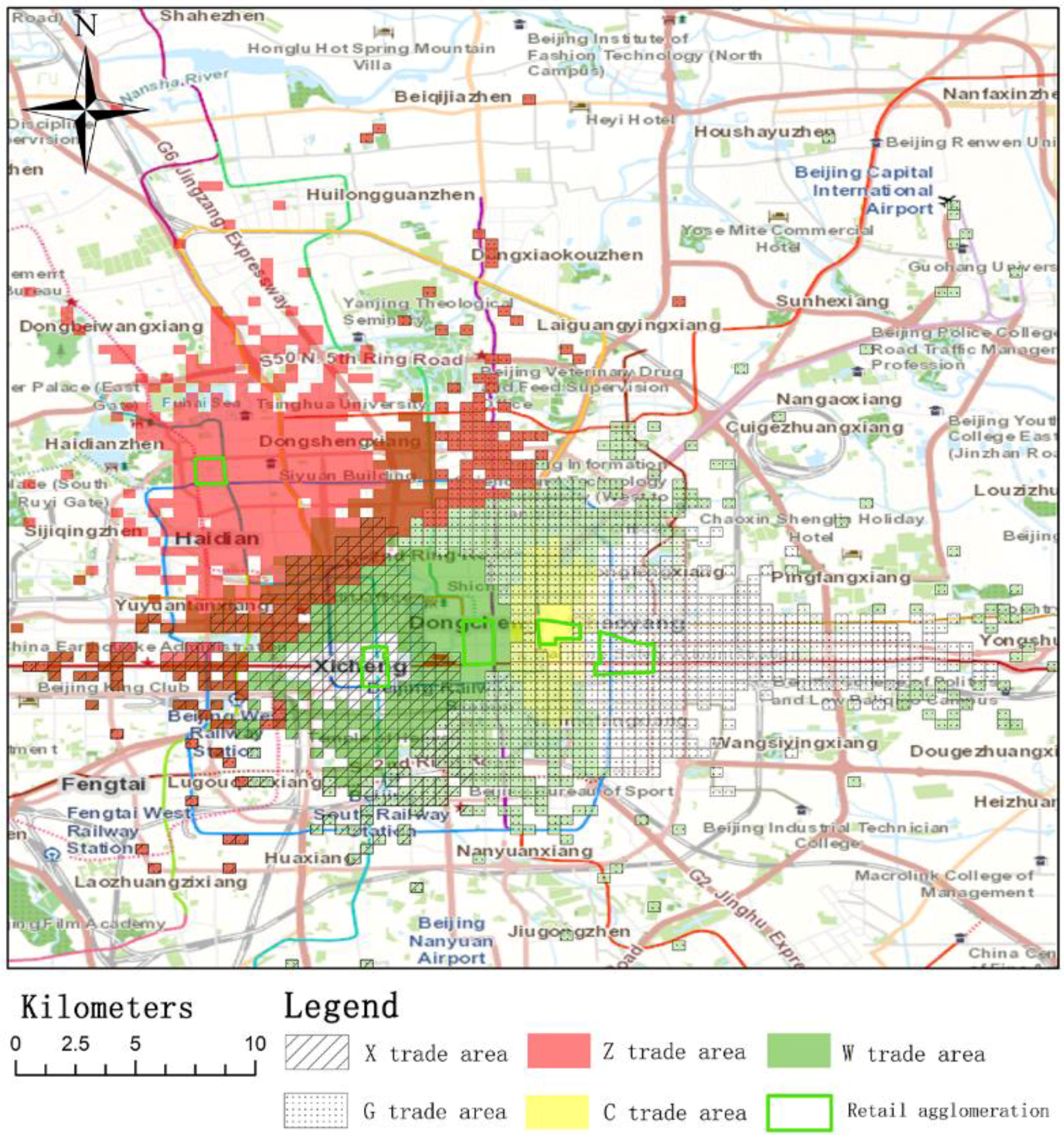
3.2. Study Area
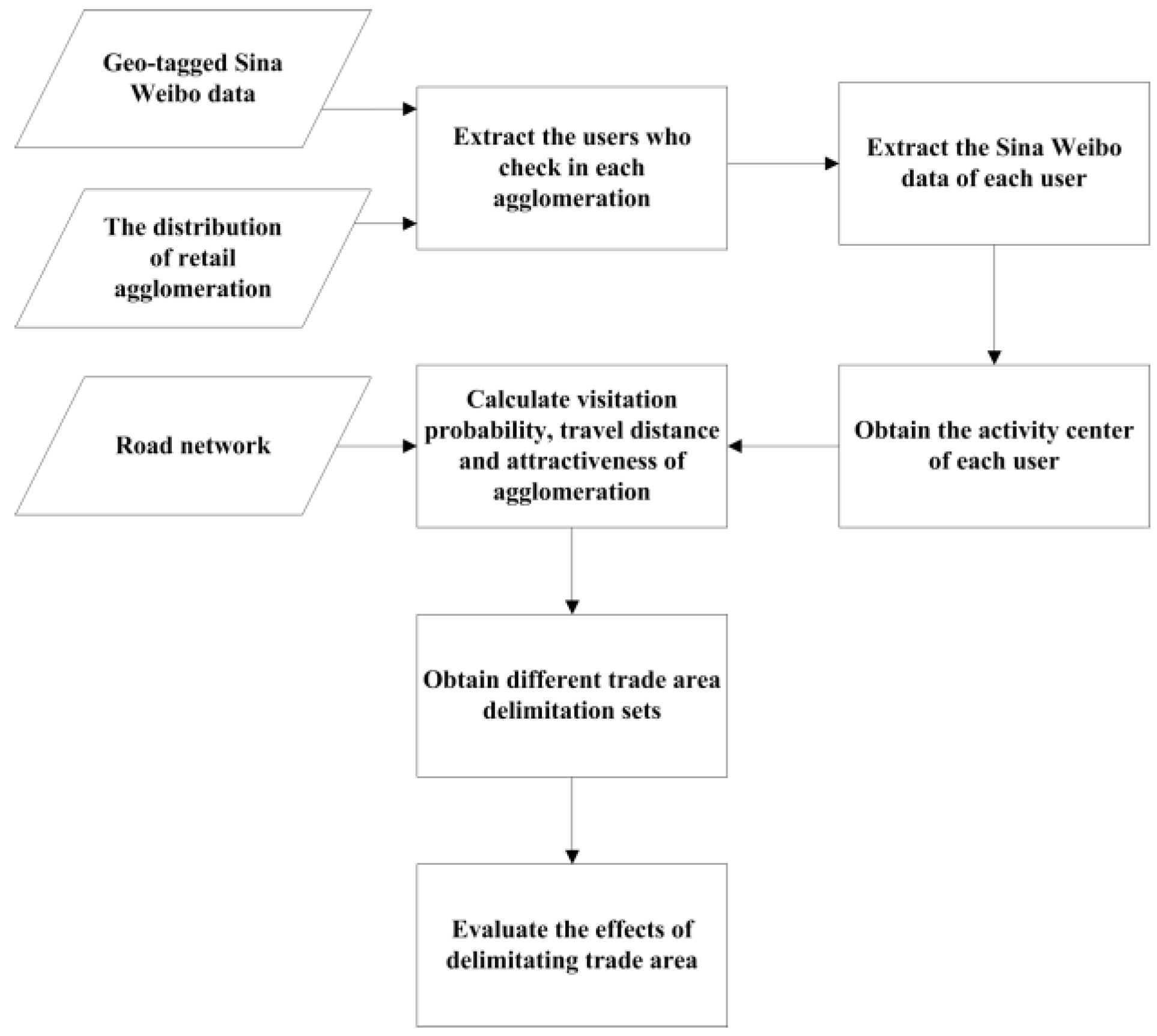
4. Methods
4.1. Extracting Attracted Users
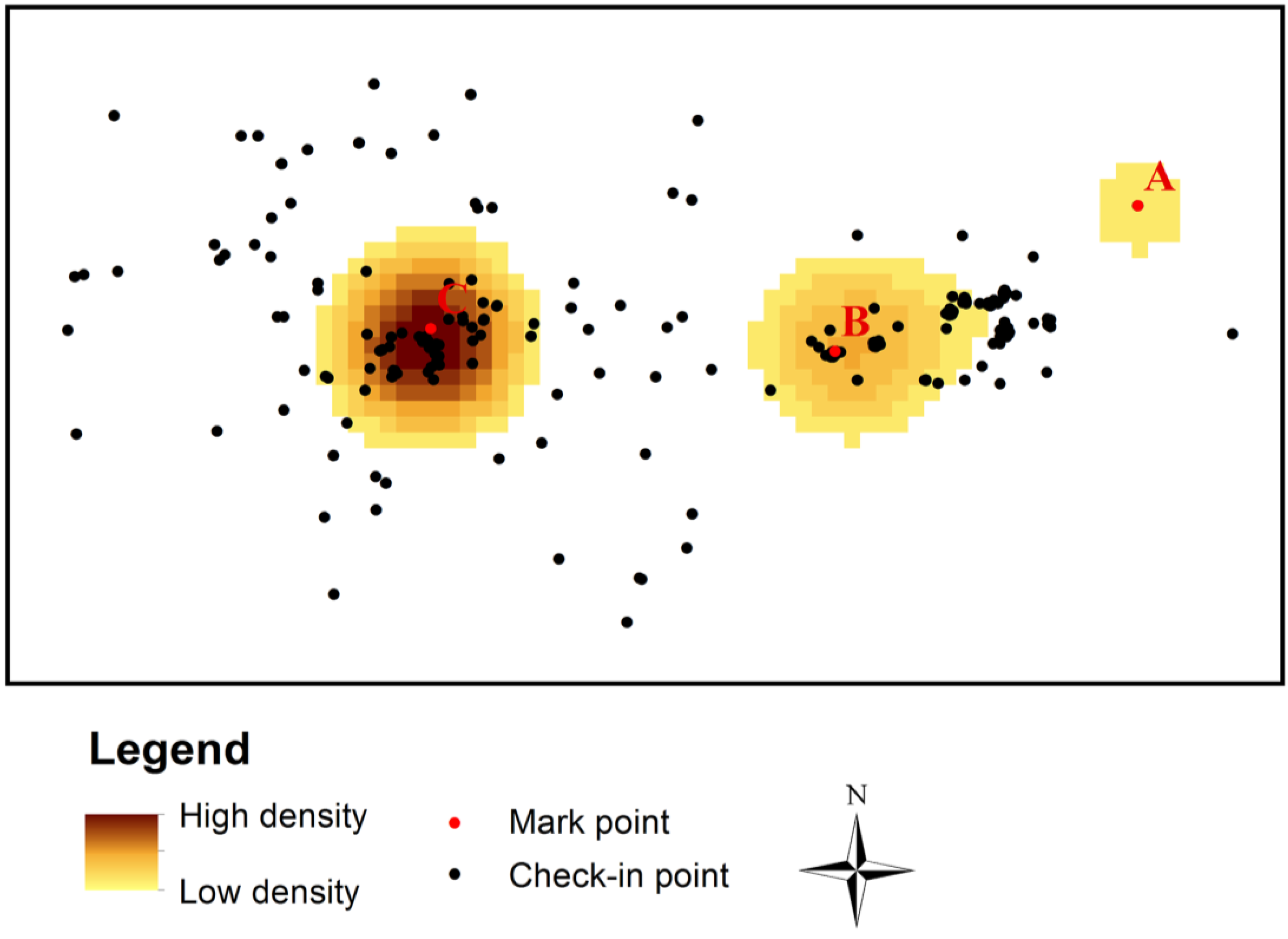
4.2. Extracting Activity Centers
4.3. Calculating Observed Visitation Probability, Travel Distance, and Attractiveness of Retail Agglomeration
4.4. Obtaining Different Trade Area Delimitation Sets
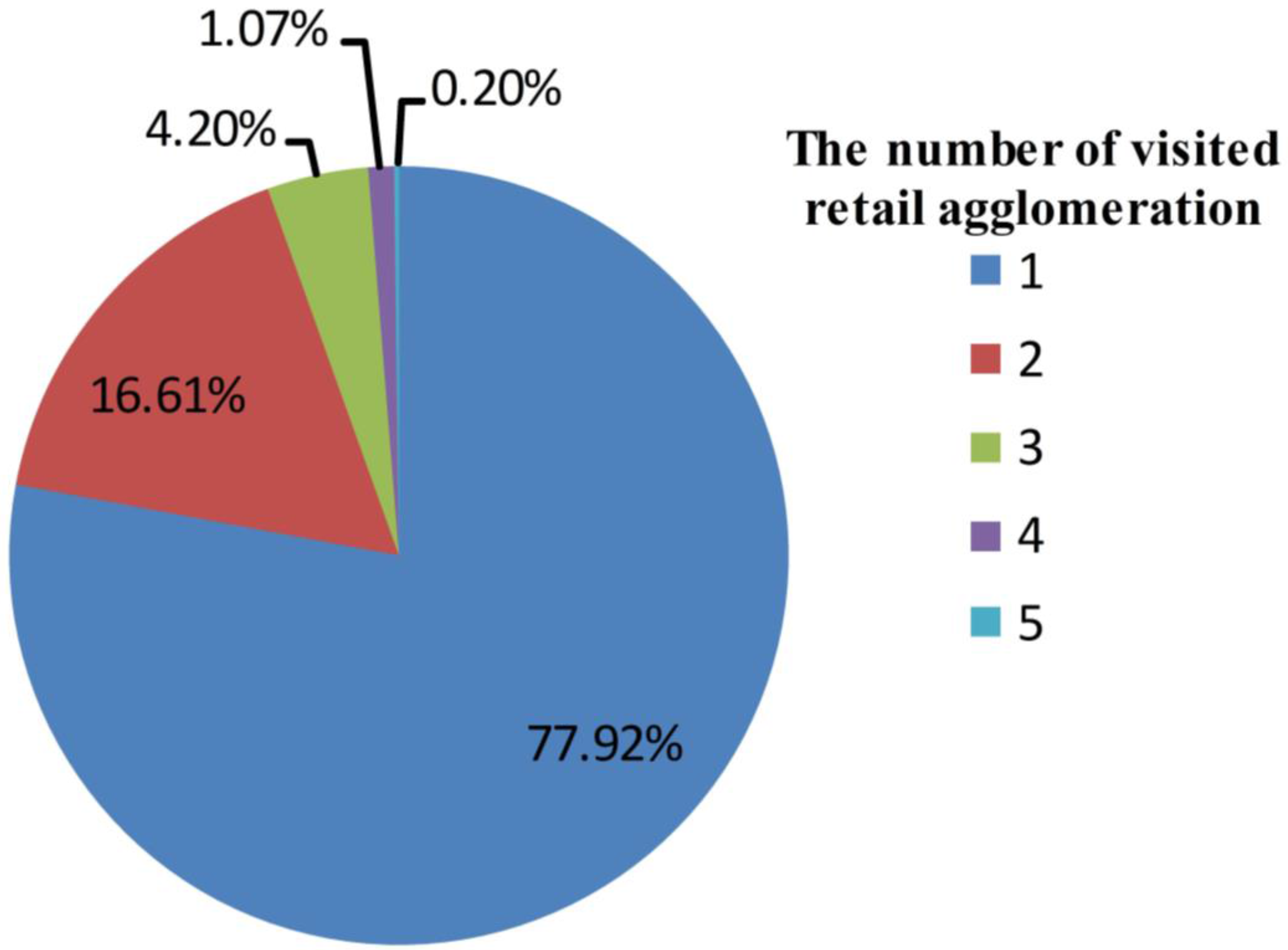
4.4.1. User Selection
4.4.2. Spatial Aggregation
4.5. Evaluation Method and Indices
5. Results and Discussion
5.1. Comparing the Effects of Different Sets
5.2. Trade Area Analysis
6. Conclusions
- (1)
- The age structure of social media users; most social media users are young people and the age structure of users is different from the real world [24]. Our research team will explore the impact of age structure on trade area delimitation.
- (2)
- The modifiable area unit problem (MAUP); we used 400 meter × 400 meter grid cells for aggregation. Different sizes of spatial units may lead to different results. In future work, we aim to obtain the best-fit spatial unit by trying different sizes and shapes of spatial units.
- (3)
- Social media user selection; social media users have many attributes, such as gender, place of household registration, educational levels, and the number of Weibo fans. In trade area analysis, we will categorize users based on these personal characteristics that may influence trade area delimitation.
- (4)
- Retail agglomeration attractiveness; the business area is the most important influencing factor for attractiveness. Other factors such as parking, history, and price level may also influence attractiveness. In order to explore the impact of these other factors, we will collect more statistical information related to each agglomeration.
- (5)
- Textual information; social media data contains a large amount of text information. This information reflects public opinion about commercial facilities and agglomerations. Future studies are needed to explore this rich, textual, semantic information for a better understanding of customer thinking and behavior patterns.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Rosenbloom, B. The trade area mix and retailing mix: A retail strategy matrix. J. Mark. 1976, 40, 58–66. [Google Scholar] [CrossRef]
- Huff, D.L. Defining and estimating a trading area. J. Mark. 1964, 28, 34–38. [Google Scholar] [CrossRef]
- Suárez, V.R.; Gutiérrez-Acuña, J.L.; Rodríguez, D.M. Locating a supermarket using a locally calibrated huff model. Int. J. Geogr. Inf. Sci. 2015, 29, 217–233. [Google Scholar] [CrossRef]
- Li, Y.; Liu, L. Assessing the impact of retail location on store performance: A comparison of Wal-Mart and Kmart stores in Cincinnati. Appl. Geogr. 2012, 32, 591–600. [Google Scholar] [CrossRef]
- O’Kelly, M.E. Trade-area models and choice-based samples: Methods. Environ. Plan. A 1999, 31, 613–627. [Google Scholar] [CrossRef]
- Lin, M.; Lucas, H.C.; Shmueli, G. Research commentary-too big to fail: Large samples and the p-value problem. Inf. Syst. Res. 2013, 24, 906–917. [Google Scholar] [CrossRef]
- Adnan, M.; Leak, A.; Longley, P. A geocomputational analysis of Twitter activity around different world cities. Geo-Spat. Inf. Sci. 2014, 17, 145–152. [Google Scholar] [CrossRef]
- Sun, Y. Investigating “locality” of intra-urban spatial interactions in New York city using foursquare data. ISPRS Int. J. Geo-Inf. 2016. [Google Scholar] [CrossRef]
- Laylavi, F.; Rajabifard, A.; Kalantari, M. A multi-element approach to location inference of twitter: A case for emergency response. ISPRS Int. J. Geo-Inf. 2016. [Google Scholar] [CrossRef]
- Granell, C.; Ostermann, F.O. Beyond data collection: Objectives and methods of research using VGI and geo-social media for disaster management. Comput. Environ. Urban Syst. 2016, in press. [Google Scholar] [CrossRef]
- Hu, Q.; Wang, M.; Li, Q. Urban hotspot and commercial area exploration with check-in data. Acta Geod. Cartogr. Sin. 2014, 43, 314–321. [Google Scholar]
- Qu, Y.; Zhang, J. Trade area analysis using user generated mobile location data. In Proceedings of the 22nd International Conference on World Wide Web, New York, NY, USA, 13–17 May 2013; pp. 1053–1064.
- Christaller, W. Central Places in Southern Germany; Prentice-Hall: Englewood, NJ, USA, 1966. [Google Scholar]
- Applebaum, W.; Cohen, S.B. The dynamics of store trading areas and market equilibrium 1. Ann. Assoc. Am. Geogr. 1961, 51, 73–101. [Google Scholar] [CrossRef]
- Baray, J.; Cliquet, G. Delineating store trade areas through morphological analysis. Eur. J. Oper. Res. 2007, 182, 886–898. [Google Scholar] [CrossRef]
- Aurenhammer, F. Voronoi diagrams—A survey of a fundamental geometric data structure. ACM Comput. Surv. (CSUR) 1991, 23, 345–405. [Google Scholar] [CrossRef]
- Ghosh, A.; Rushton, G. Spatial Analysis and Location-Allocation Models; Van Nostrand Reinhold Company: New York, NY, USA, 1987. [Google Scholar]
- Mendes, A.B.; Themido, I.H. Multi-outlet retail site location assessment. Int. Trans. Oper. Res. 2004, 11, 1–18. [Google Scholar] [CrossRef]
- Applebaum, W. Methods for determining store trade areas, market penetration, and potential sales. J. Mark. Res. 1966, 3, 127–141. [Google Scholar] [CrossRef]
- Cui, C.; Wang, J.; Pu, Y.; Ma, J.; Chen, G. GIS-based method of delimitating trade area for retail chains. Int. J. Geogr. Inf. Sci. 2012, 26, 1863–1879. [Google Scholar] [CrossRef]
- Gautschi, D.A. Specification of patronage models for retail center choice. J. Mark. Res. 1981, 18, 162–174. [Google Scholar] [CrossRef]
- Mark, E.; James, S. How critical is a good location to a regional shopping center? J. Real Estate Res. 1996, 12, 459–468. [Google Scholar]
- Chen, S.; Zhang, H.; Lin, M.; Lv, S. Comparision of microblogging service between Sina Weibo and Twitter. In Proceedings of the 2011 International Conference on Computer Science and Network Technology (ICCSNT), Guangzhou, China, 24–26 December 2011; pp. 2259–2263.
- The Registration of Sina Weibo has Reached 500 Million. Available online: http://tech.sina.com.cn/i/2013-02-25/09348086534.shtml (accessed on 20 May 2016).
- Jiang, W.; Wang, Y.; Tsou, M.H.; Fu, X. Using social media to detect outdoor air pollution and monitor air quality index (aqi): A geo-targeted spatiotemporal analysis framework with Sina Weibo (Chinese Twitter). PLoS ONE 2015, 10, e0141185. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C.; Frankowski, D.; Ludford, P.; Shekhar, S.; Terveen, L. Discovering personally meaningful places: An interactive clustering approach. ACM Trans. Inf. Syst. (TOIS) 2007, 25, 1–31. [Google Scholar] [CrossRef]
- Pan, H.; Li, Y.; Dang, A. Application of network huff model for commercial network planning at suburban–taking Wujin district, Changzhou as a case. Ann. GIS 2013, 19, 131–141. [Google Scholar] [CrossRef]
- Yue, Y.; Wang, H.; Hu, B.; Li, Q.; Li, Y.; Yeh, A.G. Exploratory calibration of a spatial interaction model using taxi GPS trajectories. Comput. Environ. Urban Syst. 2012, 36, 140–153. [Google Scholar] [CrossRef]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Lv, M.; Chen, L.; Chen, G. Discovering personally semantic places from GPS trajectories. In Proceedings of the 21st ACM International Conference on Information and knowledge Management, New York, NY, USA, 29 October–2 November 2012; pp. 1552–1556.
- Campagna, M.; Floris, R.; Massa, P. The role of social media geographic information (SMGI) in spatial planning. In Planning Support Systems and Smart Cities; Lecture Notes in Geoinformation and Cartography; Geertman, S., Ed.; Springer International Publishing: Basel, Switzerland, 2015; pp. 41–60. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231.
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef]
- Zhao, Z.; Shaw, S.L.; Xu, Y.; Lu, F.; Chen, J.; Yin, L. Understanding the bias of call detail records in human mobility research. Int. J. Geogr. Inf. Sci. 2016, 30, 1738–1762. [Google Scholar] [CrossRef]
- Markham, F.; Doran, B.; Young, M. Estimating gambling venue catchments for impact assessment using a calibrated gravity model. Int. J. Geogr. Inf. Sci. 2014, 28, 326–342. [Google Scholar] [CrossRef]
- Batty, M.; Sikdar, P. Spatial aggregation in gravity models: 4. Generalisations and large-scale applications. Environ. Plan. A 1982, 14, 795–822. [Google Scholar] [CrossRef] [PubMed]
- Marquardt, D.W. An algorithm for least-squares estimation of nonlinear parameters. J. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Khatib, Z.; Chang, K.T.; Ou, Y. Impacts of analysis zone structures on modeled statewide traffic. J. Trans. Eng. 2001, 127, 31–38. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, T.; Ye, X.; Zhu, J.; Lee, J. Using social media for emergency response and urban sustainability: A case study of the 2012 Beijing rainstorm. Sustainability 2016, 8, 142–153. [Google Scholar] [CrossRef]
- Wang, Z.; Ye, X.; Tsou, M. Spatial, temporal, and content analysis of Twitter for wildfire hazards. Nat. Hazards 2016, 83, 523–540. [Google Scholar] [CrossRef]
- Li, S.; Ye, X.; Lee, J.; Gong, J.; Qin, C. Spatiotemporal analysis of housing prices in China: A big data perspective. Appl. Spat. Anal. Policy 2016. [Google Scholar] [CrossRef]
- Shaw, S.; Tsou, M.; Ye, X. Human dynamics in the mobile and big data Era. Int. J. Geogr. Inf. Sci. 2016, 30, 1687–1693. [Google Scholar] [CrossRef]
- Yang, X.; Ye, X.; Sui, D.Z. We know where you are: In space and place-enriching the geographical context through social media. Int. J. Appl. Geospat. Res. 2016, 7, 61–75. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Weibo_ID | User_ID | Registration | Post_Time | Text | Lon | Lat | POI_ID | POI_Name |
|---|---|---|---|---|---|---|---|---|
| 37387*** | 360*** | 北京海淀区 (Haidian district in Beijing) | 1 August 2014 12:21:47 | 好久就想来了呢 (I want to come here long time ago) | 116.1396 | 39.73568 | B2094757D06AA7F54793 | 华冠购物中心 (Huaguan shopping center) |
| 37388*** | 218*** | 北京朝阳区 (Chaoyang district in Beijing) | 1 August 2014 21:33:10 | 洗手间里都可以这么的 美[鲜花][心][鲜花] 银泰超赞的商场,我的后花园[嘻嘻][哈哈] (The washroom is so beautiful[flower] [heart][flower]. Intime department store is so gr eat and can be treat as my back garden[smile][smile]) | 116.3855 | 39.8443 | B2094757DA6FA3FF4098 | 银泰百货 (Intime department store) |
| 37391*** | 281*** | 北京海淀区 (Haidian district in Beijing) | 2 August 2014 16:25:52 | 三大屌丝大闹王府井 (Three men go shopping on Wangfujing Street) | 116.3425 | 39.73123 | B2094757D068A0FC4399 | 王府井百货 (Wangfujing department store) |
| Retail Agglomeration | C | X | W | G | Z |
|---|---|---|---|---|---|
| Area (1000 m2) | 48 | 53 | 68 | 81 | 72 |
| Set 1 | Set 2 | Set 3 | Set 4 | Set 5 | Set 6 | Set 7 | Set 8 | Set 9 | Set 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| User Selection | All users | gt 1 | gt 2 | gt 3 | gt 4 | All users | gt 1 | gt 2 | gt 3 | gt 4 |
| Spatial aggregation | No | No | No | No | No | Yes | Yes | Yes | Yes | Yes |
| α | 1.45 | 1.02 | 0.84 | 0.69 | 0.69 | 1.84 | 1.43 | 1.18 | 1.16 | 1.03 |
| λ | 1.27 | 0.71 | 0.51 | 0.43 | 0.32 | 1.44 | 0.94 | 0.62 | 0.49 | 0.32 |
| R2 | 0.25 | 0.19 | 0.16 | 0.14 | 0.09 | 0.64 | 0.48 | 0.33 | 0.19 | 0.09 |
| RMSE | 0.324 | 0.234 | 0.191 | 0.163 | 0.140 | 0.129 | 0.144 | 0.164 | 0.189 | 0.183 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Jiang, W.; Liu, S.; Ye, X.; Wang, T. Evaluating Trade Areas Using Social Media Data with a Calibrated Huff Model. ISPRS Int. J. Geo-Inf. 2016, 5, 112. https://doi.org/10.3390/ijgi5070112
Wang Y, Jiang W, Liu S, Ye X, Wang T. Evaluating Trade Areas Using Social Media Data with a Calibrated Huff Model. ISPRS International Journal of Geo-Information. 2016; 5(7):112. https://doi.org/10.3390/ijgi5070112
Chicago/Turabian StyleWang, Yandong, Wei Jiang, Senbao Liu, Xinyue Ye, and Teng Wang. 2016. "Evaluating Trade Areas Using Social Media Data with a Calibrated Huff Model" ISPRS International Journal of Geo-Information 5, no. 7: 112. https://doi.org/10.3390/ijgi5070112
APA StyleWang, Y., Jiang, W., Liu, S., Ye, X., & Wang, T. (2016). Evaluating Trade Areas Using Social Media Data with a Calibrated Huff Model. ISPRS International Journal of Geo-Information, 5(7), 112. https://doi.org/10.3390/ijgi5070112