
Hypergraph+: An Improved Hypergraph-Based Task-Scheduling Algorithm for Massive Spatial Data Processing on Master-Slave Platforms


Abstract
:1. Introduction
2. Background and Related Work
2.1. Hypergraph and Hypergraph Partitioning
2.2. The Scheduling Heuristics for Data Intensive Applications
3. Hypergraph-Based Task Scheduling Model
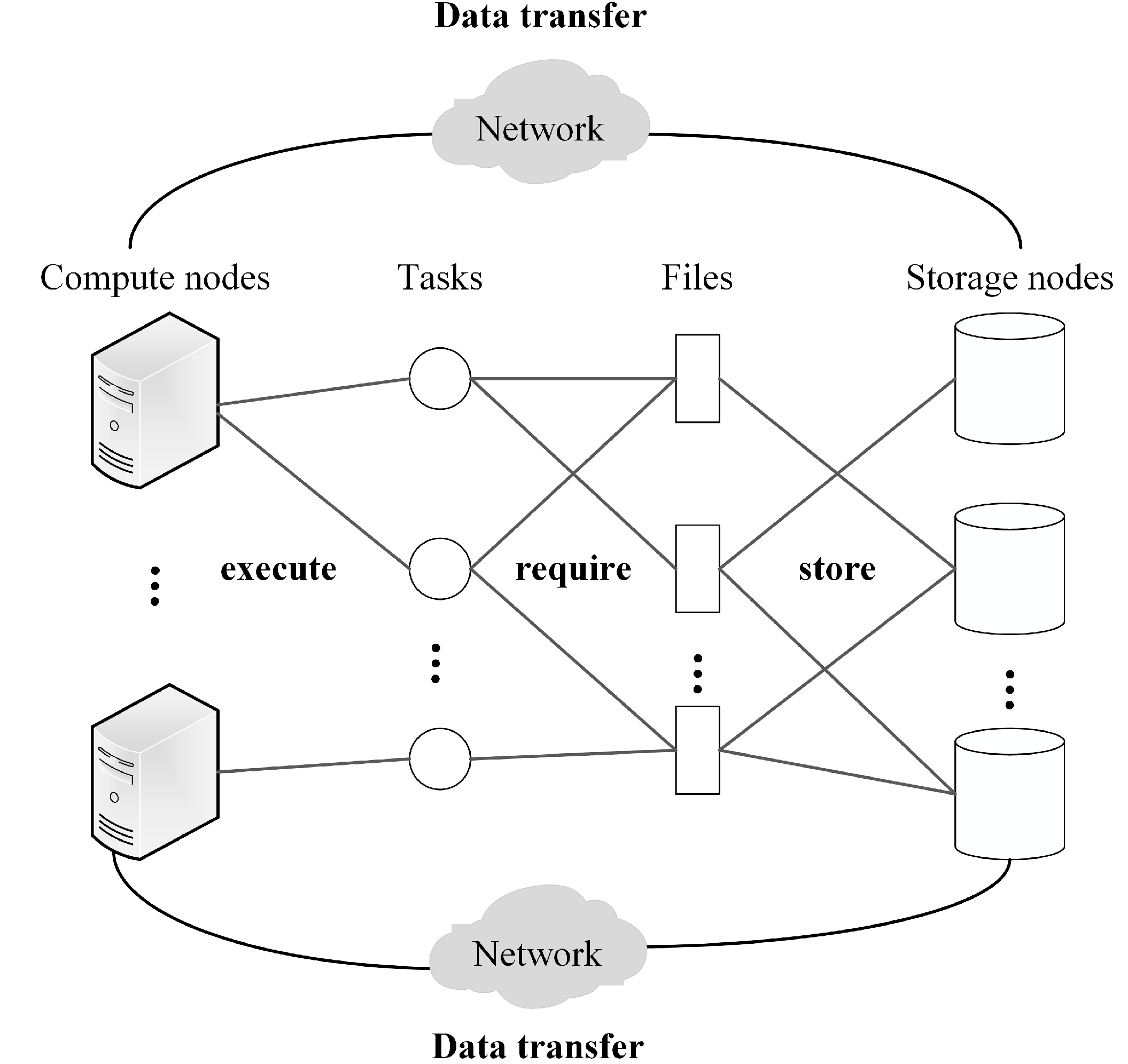
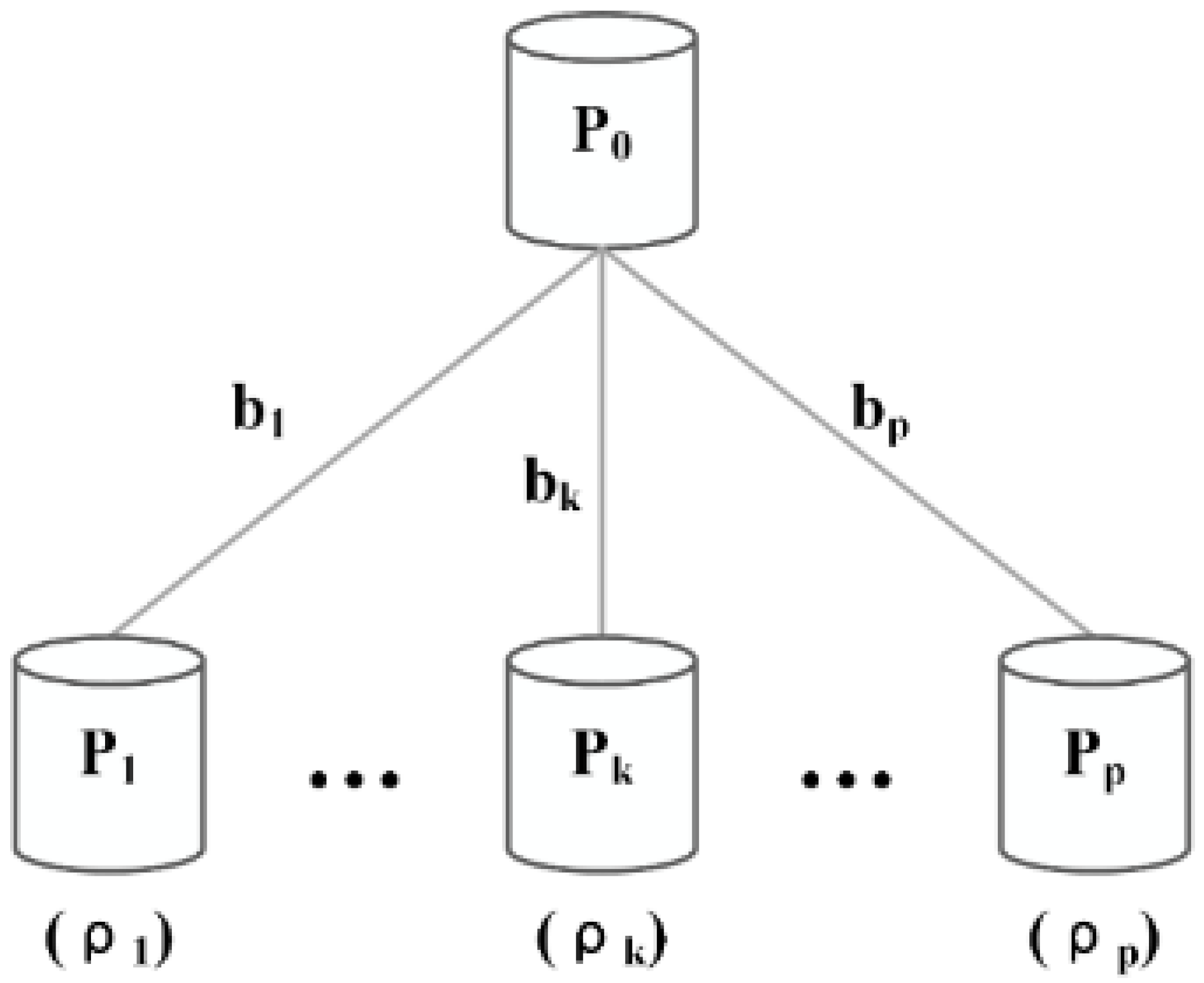
3.1. Platform Model
3.2. Application Model
3.3. Scheduling Objective
4. The Hypergraph+ Scheduling Algorithm
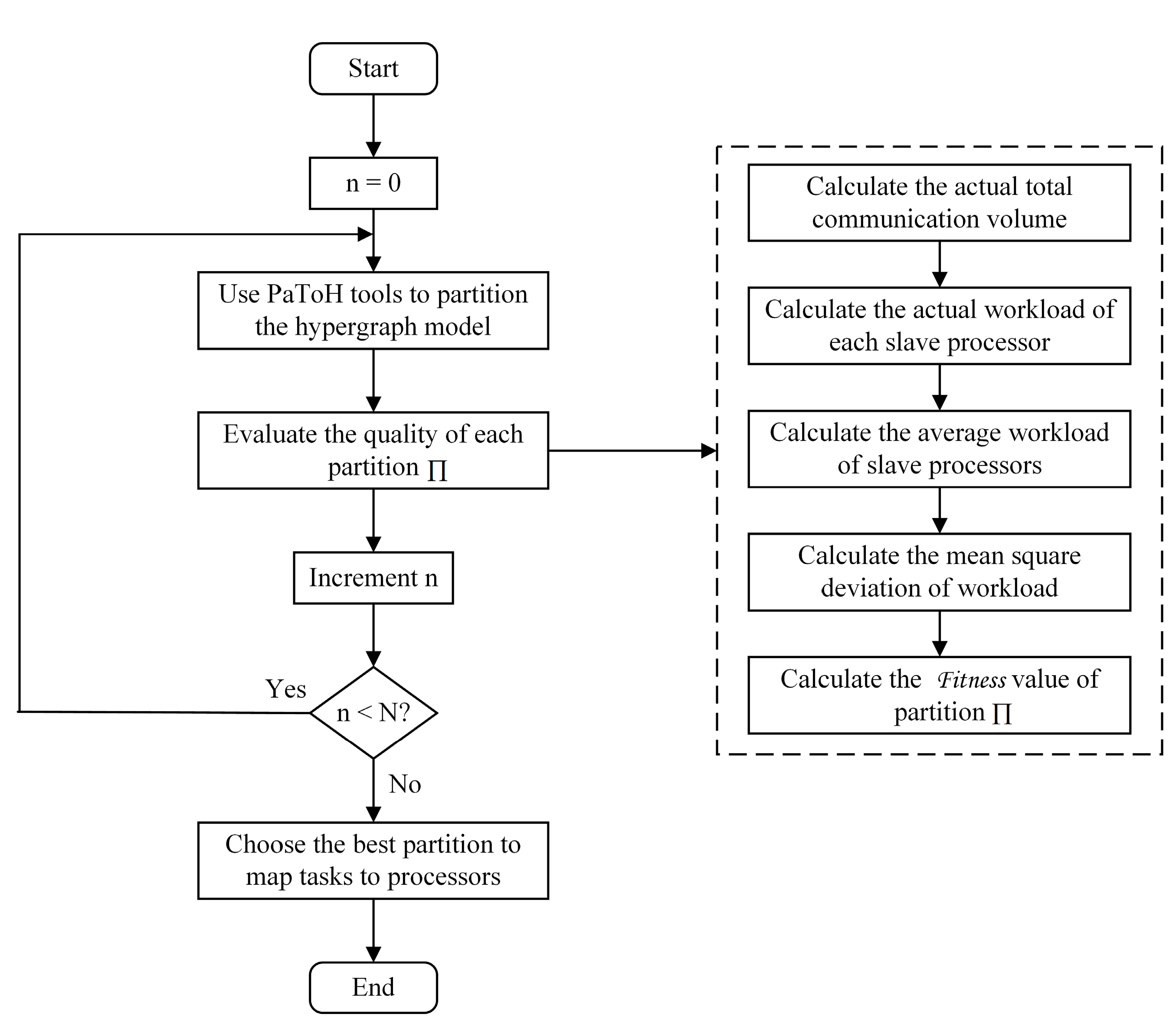
4.1. Hypergraph Partitioning for Matching Tasks
4.2. Ordering Tasks and File Transfers
| Algorithm 1 Ordering tasks for execution |
|
| Algorithm 2 The file transmission heuristic in each processor |
|
5. Experiments and Discussion
5.1. Simulated Resources
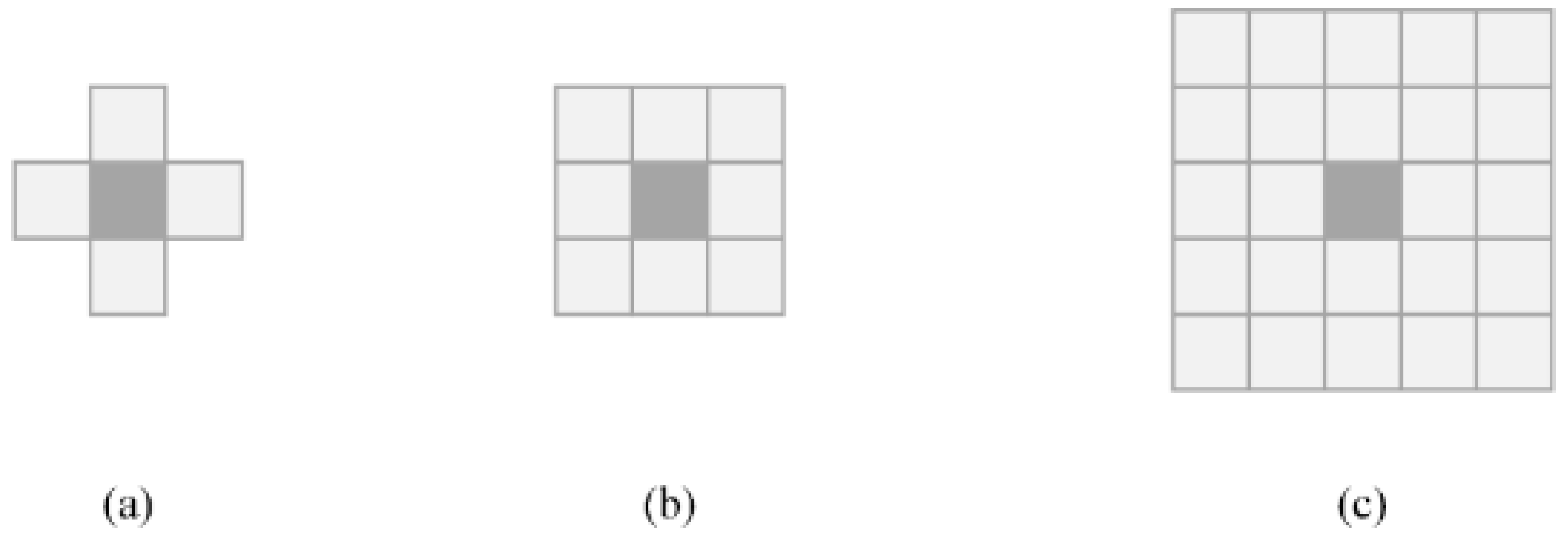
5.2. Experimental Application and Datasets
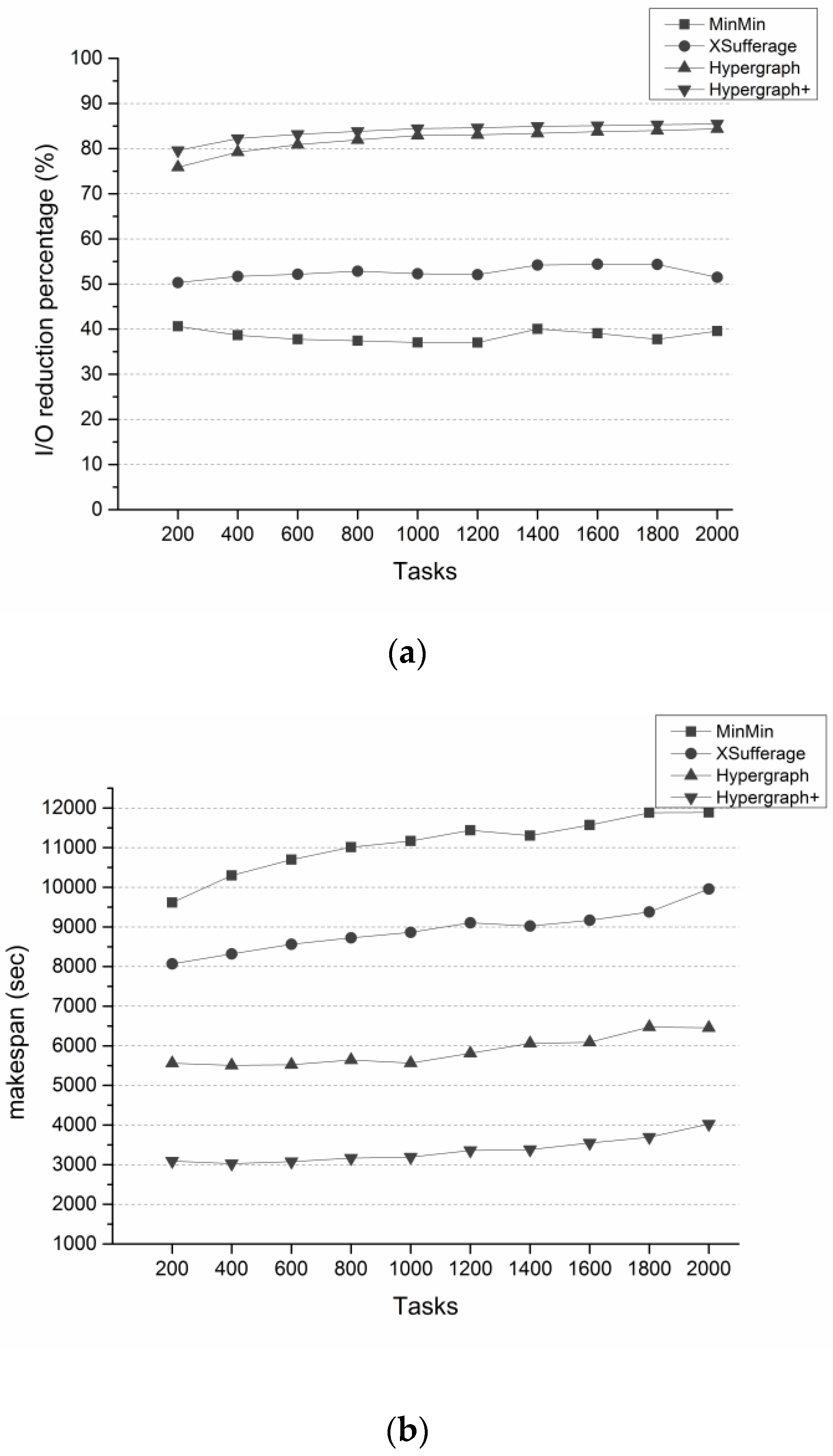
5.3. Evaluation Results and Discussions
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Liu, Y.; Chen, B.; Yu, H.; Zhao, Y.; Huang, Z.; Fang, Y. Applying GPU and POSIX thread technologies in massive remote sensing image data processing. In Proceedings of the 19th International Conference on Geoinformatics 2011, Shanghai, China, 24–26 June 2011; pp. 1–6.
- Song, W.; Yue, S.; Wang, L.; Zhang, W.; Liu, D. Task scheduling of massive spatial data processing across distributed data centers: What’s new? In Proceedings of the 2011 IEEE 17th International Conference on Parallel and Distributed Systems, Tainan, Taiwan, 7–9 December 2011; pp. 976–981.
- Xing, J.; Sieber, R.; Kalacska, M. The challenges of image segmentation in big remotely sensed imagery data. Ann. GIS 2014, 20, 233–244. [Google Scholar] [CrossRef]
- Buyya, R.; Murshed, M. Gridsim: A toolkit for the modeling and simulation of distributed resource management and scheduling for grid computing. CCPE 2002, 14, 1175–1220. [Google Scholar] [CrossRef]
- Maheswaran, M.; Ali, S.; Siegal, H.J.; Hensgen, D.; Freund, R.F. Dynamic matching and scheduling of a class of independent tasks onto heterogeneous computing systems. In Proceedings of the 8th Heterogeneous Computing Workshop (HCW’99), San Juan, Puerto Rico, 12 April 1999; pp. 30–44.
- Casanova, H.; Legrand, A.; Zagorodnov, D.; Berman, F. Heuristics for scheduling parameter sweep applications in grid environments. In Proceedings of the 9th Heterogeneous Computing Workshop (HCW’00), Cancun, Mexico, 1 May 2000; pp. 349–363.
- Khanna, G.; Vydyanathan, N.; Kurc, T.; Catalyurek, U.; Wyckoff, P.; Saltz, J.; Sadayappan, P. A hypergraph partitioning based approach for scheduling of tasks with batch-shared I/O. In Proceedings of the 5th International Symposium on Cluster Computing and the Grid (CCGrid 2005), Cardiff, UK, 9–12 May 2005; pp. 792–799.
- Berge, C. Graphs and Hypergraphs; North-Holland Publishing Company: Amsterdam, The Netherlands, 1973. [Google Scholar]
- Karypis, G.; Kumar, V. Multilevel k-way hypergraph partitioning. VLSI Des. 2000, 11, 285–300. [Google Scholar] [CrossRef]
- Catalyürek, U.V.; Aykanat, C. PaToH (partitioning tool for hypergraphs). In Encyclopedia of Parallel Computing 2011; Springer Science & Business Media: Berlin, Germany, 2011; pp. 1479–1487. [Google Scholar]
- Trifunovic, A.; Knottenbelt, W.J. Parkway 2.0: A parallel multilevel hypergraph partitioning tool. In Proceedings of 19th International Symposium on Computer and Information Sciences (ISCIS 2004), Kemer-Antalya, Turkey, 27–29 October 2004; pp. 789–800.
- Alpert, C.J.; Kahng, A.B. Recent directions in netlist partitioning: A survey. Integr. VLSI J. 1995, 19, 1–81. [Google Scholar] [CrossRef]
- Karypis, G.; Aggarwal, R.; Kumar, V.; Shekhar, S. Multilevel hypergraph partitioning: Applications in VLSI domain. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 1999, 7, 69–79. [Google Scholar] [CrossRef]
- Mobasher, B.; Jain, N.; Han, E.H.; Srivastava, J. Web Mining: Pattern Discovery from World Wide Web Transactions; Technical Report TR96-050; Department of Computer Science, University of Minnesota: Minneapolis, MN, USA, 1996. [Google Scholar]
- Demir, E.; Aykanat, C.; Cambazoglu, B.B. Clustering spatial networks for aggregate query processing: A hypergraph approach. Inf. Syst. 2008, 33, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Catalyürek, U.V.; Aykanat, C. Hypergraph-partitioning-based decomposition for parallel sparse-matrix vector multiplication. IEEE Trans. Parallel Distrib. Syst. 1999, 10, 673–693. [Google Scholar] [CrossRef] [Green Version]
- Cambazoglu, B.B.; Aykanat, C. Hypergraph-partitioning-based remapping models for image-space-parallel direct volume rendering of unstructured grids. IEEE Trans. Parallel Distrib. Syst. 2007, 18, 3–16. [Google Scholar] [CrossRef]
- Kaya, K.; Aykanat, C. Iterative-improvement-based heuristics for adaptive scheduling of tasks sharing files on heterogeneous master-slave environments. IEEE Trans. Parallel Distrib. Syst. 2006, 17, 883–896. [Google Scholar] [CrossRef]
- Doumbouya, M.B.; Kamsu-Foguem, B.; Kenfack, H. Argumentation semantics and graph properties. Inf. Process. Manag. 2016, 52, 319–325. [Google Scholar] [CrossRef]
- Kamsu-Foguem, B.; Tchuenté-Foguem, G.; Foguem, C. Conceptual graph operations for formal visual reasoning in the medical domain. IRBM 2014, 35, 262–270. [Google Scholar] [CrossRef]
- Kamsu-Foguem, B. Knowledge-based support in Non-Destructive Testing for health monitoring of aircraft structures. Adv. Eng. Inf. 2012, 26, 859–869. [Google Scholar] [CrossRef]
- Kosar, T.; Balman, M. A new paradigm: Data-aware scheduling in grid computing. Futur. Gener. Comput. Syst. 2009, 25, 406–413. [Google Scholar] [CrossRef]
- Caíno-Lores, S.; Carretero, J. A survey on data-centric and data-aware techniques for large scale infrastructures. World Acad. Sci. Eng. Technol. Int. J. Comput. Electr. Auto. Cont. Inf. Eng. 2016, 10, 459–465. [Google Scholar]
- Mohamed, H.H.; Epema, D.H. An evaluation of the close-to-files processor and data co-allocation policy in multiclusters. In Proceedings of the IEEE International Conference on Cluster Computing 2004, Los Alamitos, CA, USA, 20–23 September 2004.
- Zhang, Y.F.; Tian, Y.C.; Fidge, C.; Kelly, W. Data-aware task scheduling for all-to-all comparison problems in heterogeneous distributed systems. J. Parallel Distrib. Comput. 2016, 93, 87–101. [Google Scholar] [CrossRef]
- Szmajduch, M.; Kołodziej, J. Data-aware scheduling in massive heterogeneous systems. In Proceedings of the 29th European Conference on Modeling and Simulation ECMS 2015, Varna, Bulgaria, 26–29 May 2015; pp. 608–614.
- da Silva, F.A.; Senger, H. Scalability limits of Bag-of-Tasks applications running on hierarchical platforms. J. Parallel Distrib. Comput. 2011, 71, 788–801. [Google Scholar] [CrossRef]
- Guan, Q.; Clarke, K.C. A general-purpose parallel raster processing programming library test application using a geographic cellular automata model. Int. J. Geogr. Inf. Sci. 2010, 24, 695–722. [Google Scholar] [CrossRef]
- Muthuvelu, N.; Liu, J.; Soe, N.L.; Venugopal, S.; Sulistio, A.; Buyya, R. A dynamic job grouping-based scheduling for deploying applications with fine-grained tasks on global grids. In Proceedings of the 3rd Australasian workshop on Grid computing and e-Research (AusGrid 2005), Newcastle, Australia, 30 January–4 February 2005; pp. 41–48.
- Guan, X.; Wu, H. Leveraging the power of multi-core platforms for large-scale geospatial data processing: Exemplified by generating DEM from massive LiDAR point clouds. Comput. Geosci. 2010, 36, 1276–1282. [Google Scholar] [CrossRef]
- Trifunović, A.; Knottenbelt, W.J. Parallel multilevel algorithms for hypergraph partitioning. J. Parallel Distrib. Comput. 2008, 68, 563–581. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Slave | MIPS | Bandwidth |
|---|---|---|
| P1 | 200 | 170 |
| P2 | 260 | 320 |
| P3 | 160 | 280 |
| P4 | 540 | 630 |
| P5 | 390 | 470 |
| P6 | 410 | 390 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, B.; Guan, X.; Wu, H.; Li, R. Hypergraph+: An Improved Hypergraph-Based Task-Scheduling Algorithm for Massive Spatial Data Processing on Master-Slave Platforms. ISPRS Int. J. Geo-Inf. 2016, 5, 141. https://doi.org/10.3390/ijgi5080141
Cheng B, Guan X, Wu H, Li R. Hypergraph+: An Improved Hypergraph-Based Task-Scheduling Algorithm for Massive Spatial Data Processing on Master-Slave Platforms. ISPRS International Journal of Geo-Information. 2016; 5(8):141. https://doi.org/10.3390/ijgi5080141
Chicago/Turabian StyleCheng, Bo, Xuefeng Guan, Huayi Wu, and Rui Li. 2016. "Hypergraph+: An Improved Hypergraph-Based Task-Scheduling Algorithm for Massive Spatial Data Processing on Master-Slave Platforms" ISPRS International Journal of Geo-Information 5, no. 8: 141. https://doi.org/10.3390/ijgi5080141
APA StyleCheng, B., Guan, X., Wu, H., & Li, R. (2016). Hypergraph+: An Improved Hypergraph-Based Task-Scheduling Algorithm for Massive Spatial Data Processing on Master-Slave Platforms. ISPRS International Journal of Geo-Information, 5(8), 141. https://doi.org/10.3390/ijgi5080141