A Hybrid Process/Thread Parallel Algorithm for Generating DEM from LiDAR Points


Abstract
:1. Introduction
1.1. Background
1.2. Related Work
1.3. Problems
1.4. Our Idea
2. Overall Design of the Hybrid Process/Thread Parallel Algorithm
- All processes partitioned the LiDAR dataset in parallel. We named this procedure the Parallel Partitioning Method Considering Data Buffer (PPDB) (detailed in Section 3.1).
- The master created a task queue based on the partitioned results. Each task was a data block waiting to be processed.
- The master assigned one task number to each slave.
- Each slave read LiDAR points into the memory based on the task number.
- Each slave logically partitioned the data block stored in the memory into small blocks.
- Threads used an asynchronous parallel strategy (detailed in Section 4.2) to perform the DEM generation computation for each small data block.
- Slave requested a new task from the master when it finished the computation of current data block.
- If the task queue was not empty, a new task number would be sent back to the slave, looping this procedure until the task queue was empty.
3. Parallel Data Partitioning for LiDAR Dataset
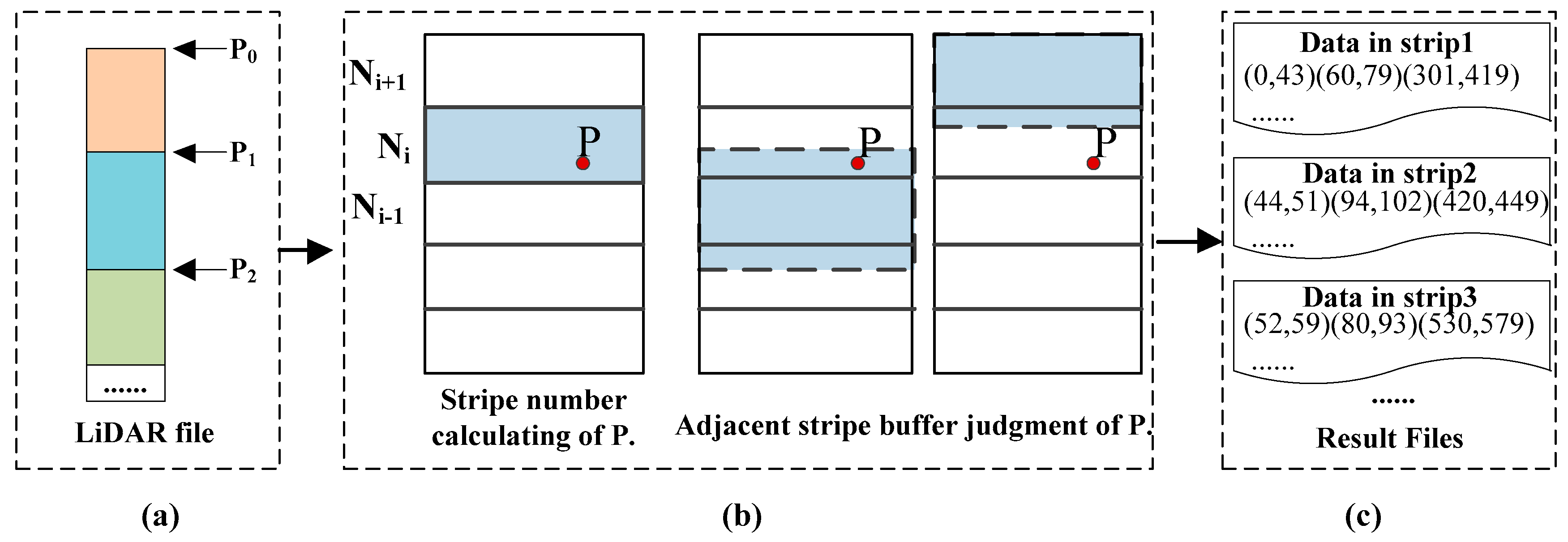
3.1. Parallel Partitioning Method Considering Data Buffer (PPDB) at the Process Level
3.2. Logical Partition at the Thread Level
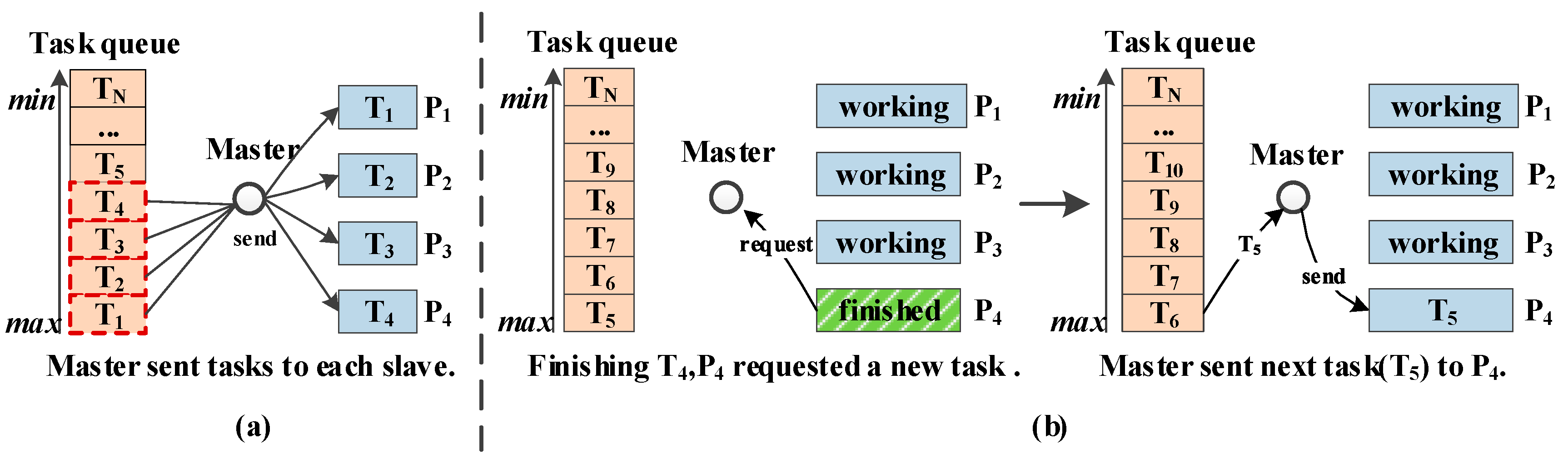
4. Hybrid Process/Thread Dynamic Scheduling Strategy
4.1. Dynamic Scheduling Strategy Based on Computation Quantity
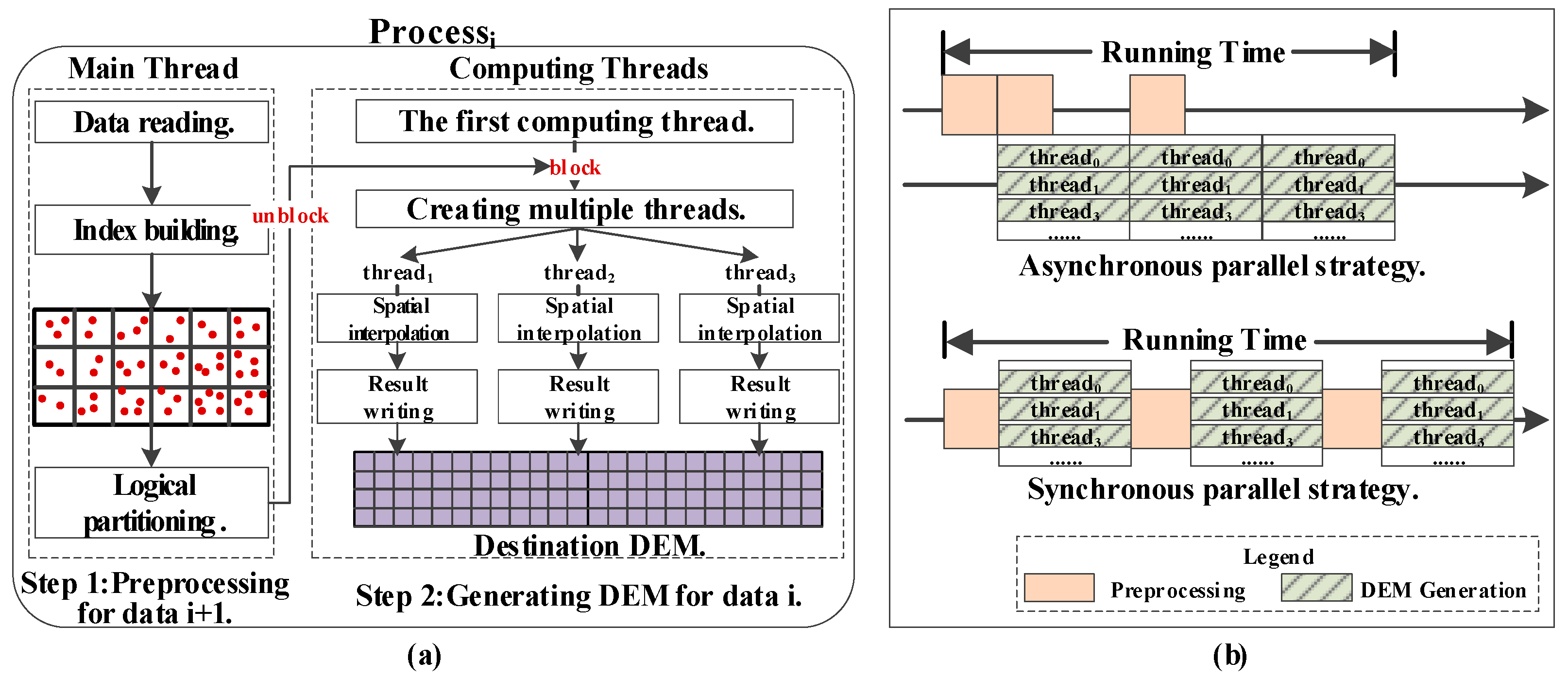
4.2. Asynchronous Parallel Between Threads
4.3. Hybrid Process/Thread Communicating Procedure
5. Experiments and Discussions
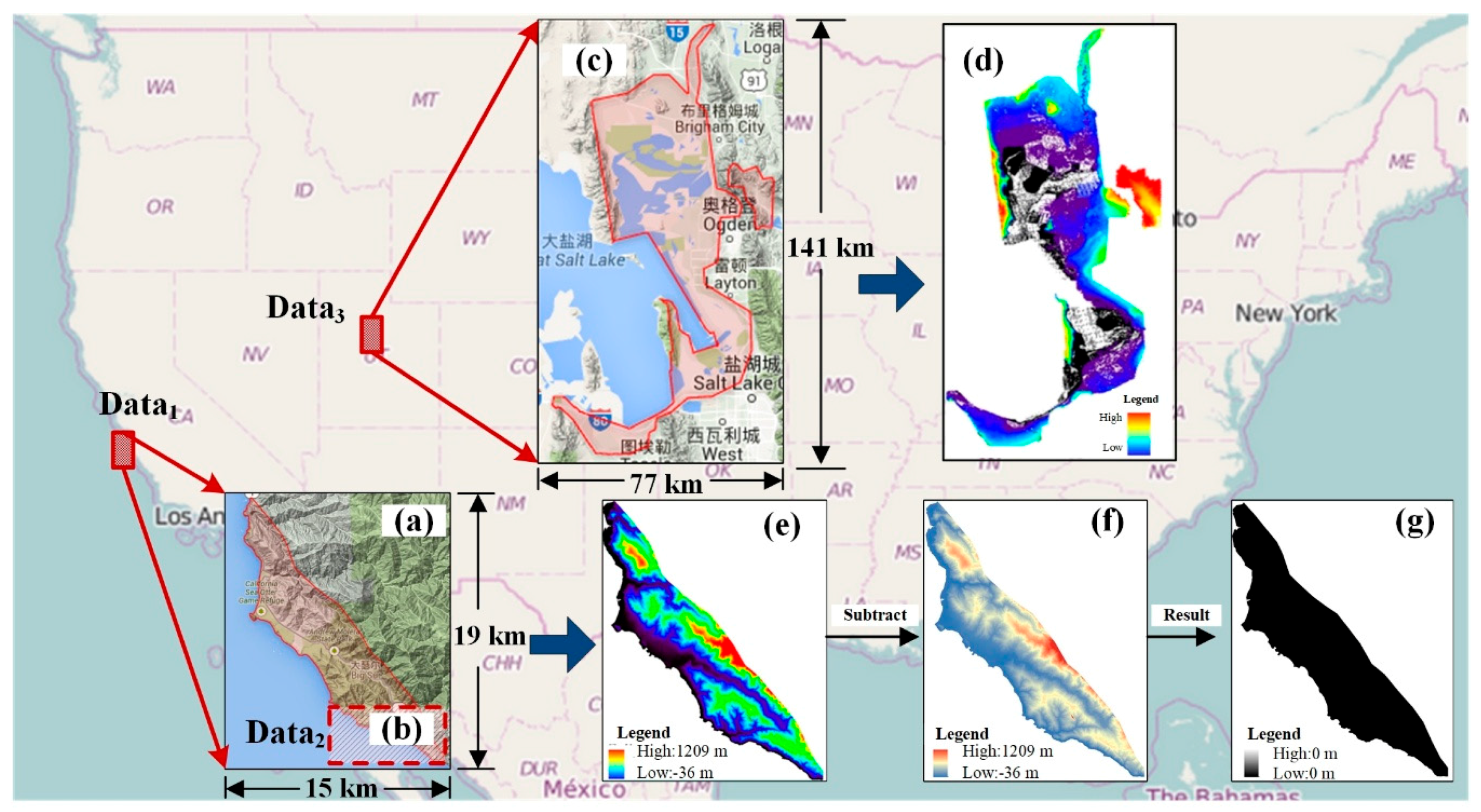
5.1. Environment and Experimental Datasets
5.2. Accuracy Analysis
5.3. Performance Analysis
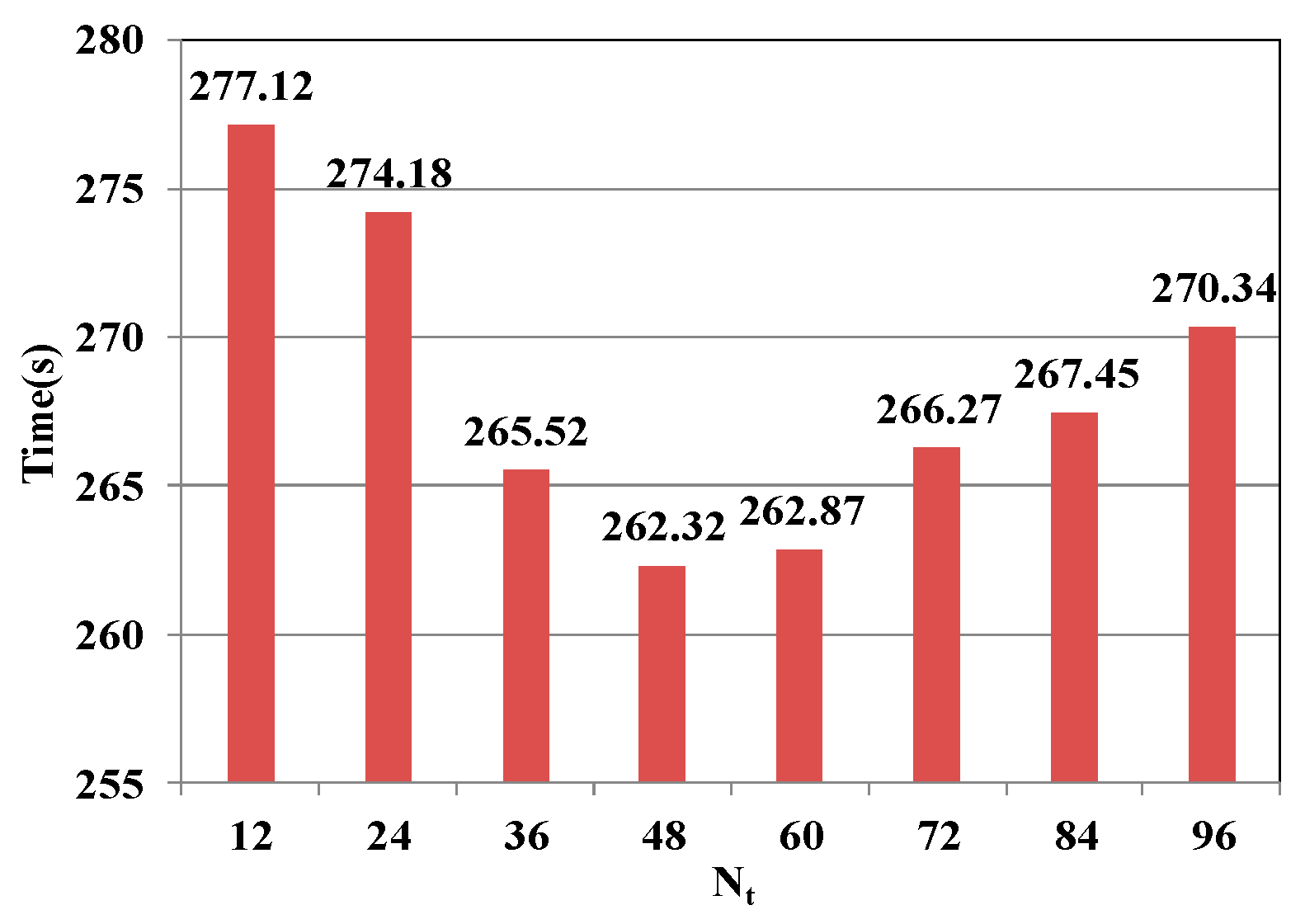
5.3.1. Optimal Number of Data Blocks
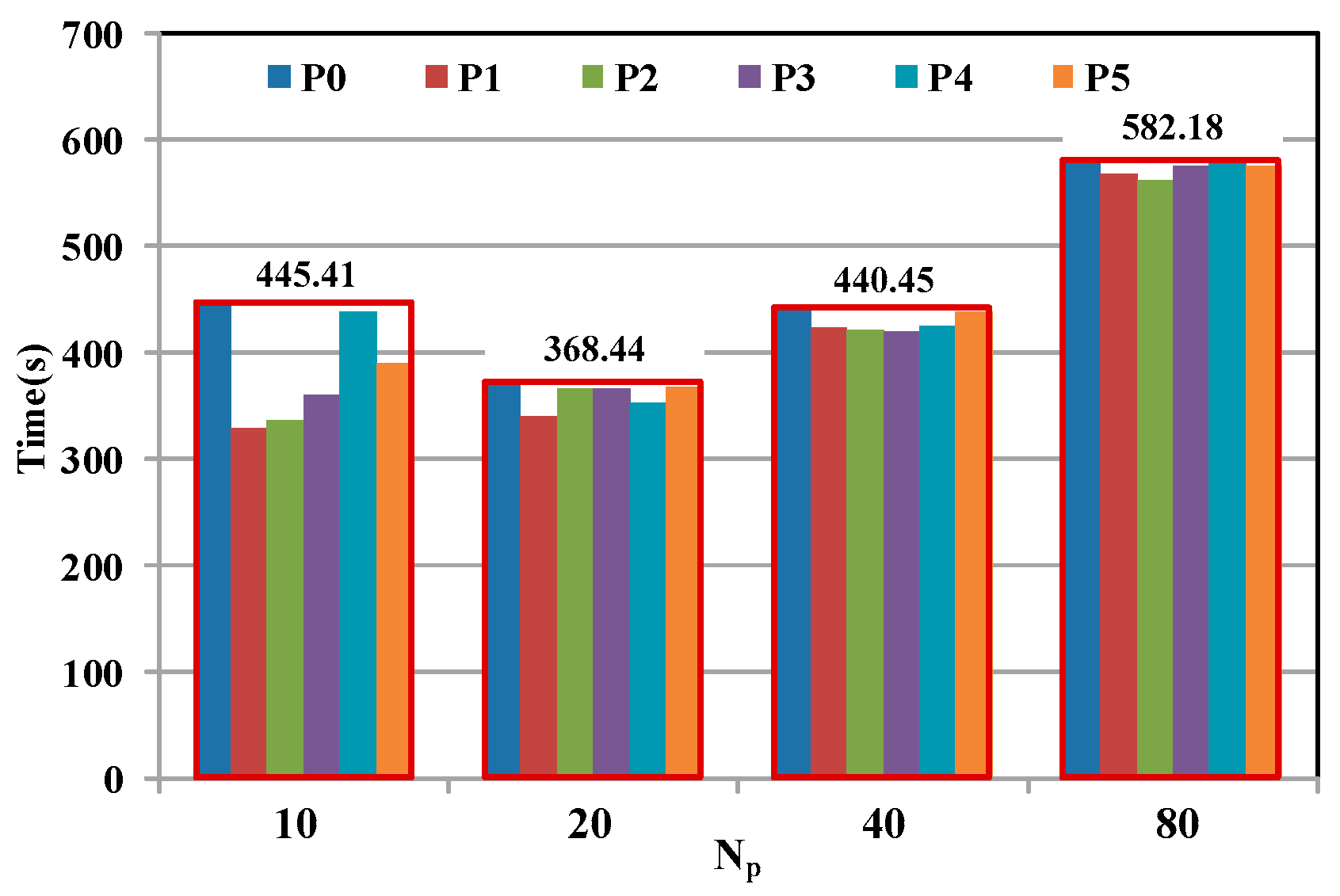
5.3.2. Optimal Combination Manner
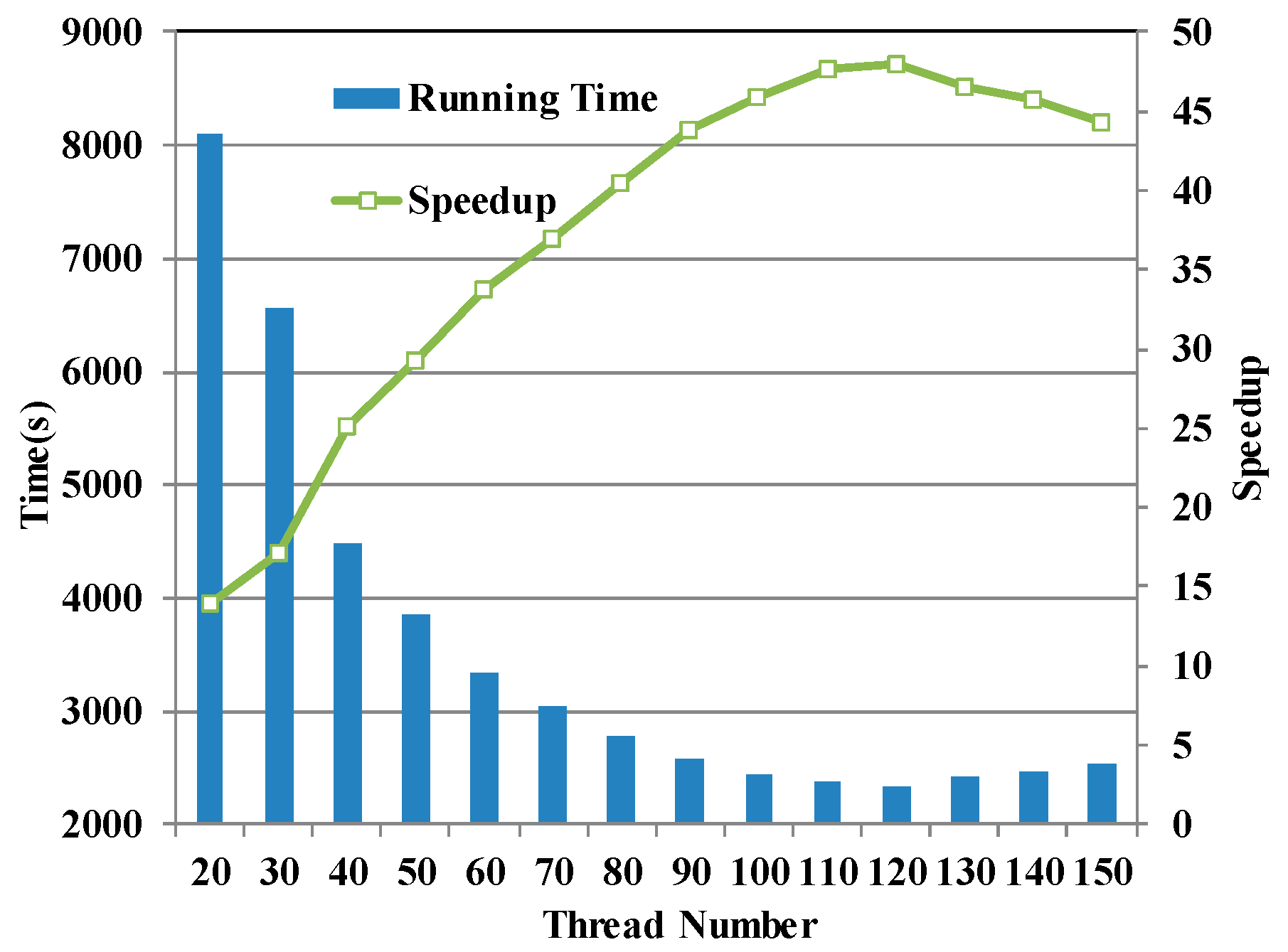
5.3.3. Performance Analysis with the Largest Experimental Dataset
5.4. Comparative Experiments
5.4.1. Comparison with the Static Schedule Strategy
5.4.2. Comparison with the Synchronous Parallel Strategy
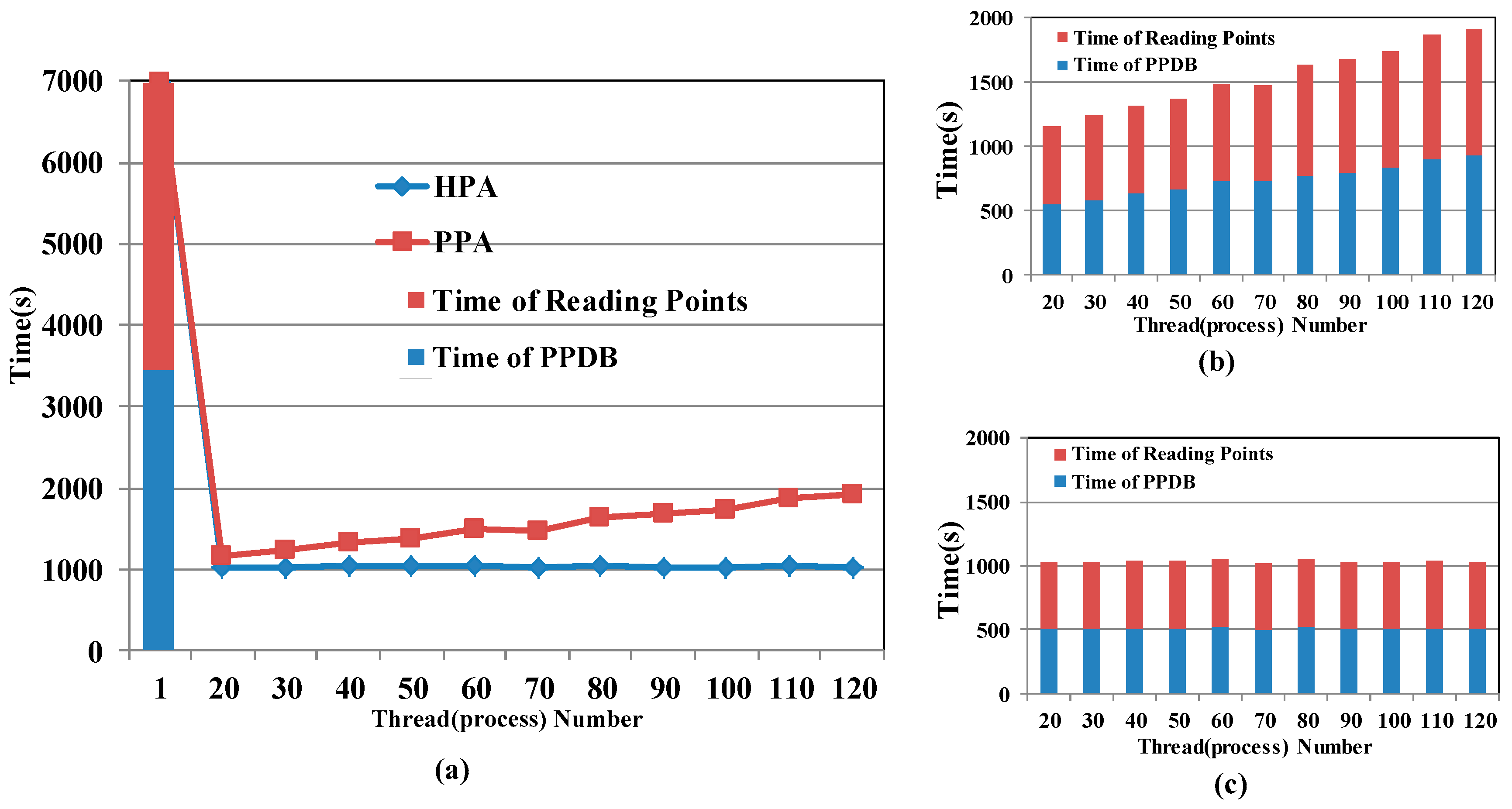
5.4.3. Comparison with Process Parallel Algorithm
6. Discussion
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Jones, K.H. A comparison of algorithms used to compute hill slope as a property of the DEM. Comput. Geosci. 1998, 24, 315–323. [Google Scholar] [CrossRef]
- Floriani, L.D.; Magillo, P. Digital Elevation Models. In Encyclopedia of Database Systems; Liu, L., ÖZSU, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 817–821. [Google Scholar]
- Lloyd, C.D.; Atkinson, P.M. Deriving ground surface digital elevation models from LiDAR data with geostatistics. Int. J. Geogr. Inf. Sci. 2006, 20, 535–563. [Google Scholar] [CrossRef]
- White, S.A.; Wang, Y. Utilizing DEMs derived from LIDAR data to analyze morphologic change in the North Carolina coastline. Remote Sens. Environ. 2003, 85, 39–47. [Google Scholar] [CrossRef]
- Ma, R.J. DEM generation and building detection from Lidar data. Photogramm. Eng. Remote Sens. 2005, 71, 847–854. [Google Scholar] [CrossRef]
- Hu, X.Y.; Li, X.K.; Zhang, Y.J. Fast Filtering of LiDAR Point Cloud in Urban Areas Based on Scan Line Segmentation and GPU Acceleration. IEEE Geosci. Remote Sens. 2013, 10, 308–312. [Google Scholar]
- Ma, H.C.; Wang, Z.Y. Distributed data organization and parallel data retrieval methods for huge laser scanner point clouds. Comput. Geosci. 2011, 37, 193–201. [Google Scholar]
- Wang, Y.; Chen, Z.; Cheng, L.; Li, M.; Wang, J. Parallel scanline algorithm for rapid rasterization of vector geographic data. Comput. Geosci. 2013, 59, 31–40. [Google Scholar] [CrossRef]
- Chen, C.; Chen, Z.; Li, M.; Liu, Y.; Cheng, L.; Ren, Y. Parallel relative radiometric normalisation for remote sensing image mosaics. Comput. Geosci. 2014, 73, 28–36. [Google Scholar] [CrossRef]
- Guan, Q.; Kyriakidis, P.C.; Goodchild, M.F. A parallel computing approach to fast geostatistical areal interpolation. Int. J. Geogr. Inf. 2011, 25, 1241–1267. [Google Scholar] [CrossRef]
- Zhao, L.; Chen, L.; Ranjan, R.; Choo, K.R.; He, J. Geographical information system parallelization for spatial big data processing: A review. Clust. Comput. 2016, 19, 139–152. [Google Scholar] [CrossRef]
- Liu, J.; Zhu, A.X.; Liu, Y.; Zhu, T.; Qin, C.Z. A layered approach to parallel computing for spatially distributed hydrological modeling. Environ. Modell. Softw. 2014, 51, 221–227. [Google Scholar] [CrossRef]
- Guan, X.; Wu, H. Leveraging the power of multi-core platforms for large-scale geospatial data processing: Exemplified by generating DEM from massive LiDAR point clouds. Comput. Geosci. 2010, 36, 1276–1282. [Google Scholar] [CrossRef]
- Huang, F.; Liu, D.; Tan, X.; Wang, J.; Chen, Y.; He, B. Explorations of the implementation of a parallel IDW interpolation algorithm in a Linux cluster-based parallel GIS. Comput. Geosci. 2011, 37, 426–434. [Google Scholar] [CrossRef]
- Han, S.H.; Heo, J.; Sohn, H.G.; Yu, K. Parallel Processing Method for Airborne Laser Scanning Data Using a PC Cluster and a Virtual Grid. Sensors-Basel 2009, 9, 2555–2573. [Google Scholar] [CrossRef] [PubMed]
- Danner, A.; Breslow, A.; Baskin, J.; Wilikofsky, D. Hybrid MPI/GPU interpolation for grid DEM construction. In Proceedings of the International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012; pp. 299–308. [Google Scholar]
- Huang, F.; Bu, S.; Tao, J.; Tan, X. OpenCL Implementation of a Parallel Universal Kriging Algorithm for Massive Spatial Data Interpolation on Heterogeneous Systems. ISPRS Int. J. Geo-Inf. 2016, 5, 96. [Google Scholar] [CrossRef]
- Cappello, F.; Richard, O.; Etiemble, D. Understanding performance of SMP clusters running MPI programs. Future Gener. Comput. Syst. 2001, 17, 711–720. [Google Scholar] [CrossRef]
- Yang, C.T.; Huang, C.L.; Lin, C.F. Hybrid CUDA, OpenMP, and MPI parallel programming on multicore GPU clusters. Comput. Phys. Commun. 2011, 182, 266–269. [Google Scholar] [CrossRef]
- Wu, X.; Taylor, V. Performance modeling of hybrid MPI/OpenMP scientific applications on large-scale multicore supercomputers. J. Comput. Syst. Sci. 2013, 79, 1256–1268. [Google Scholar] [CrossRef]
- Prasad, S.K.; Mcdermott, M.; Puri, S.; Shah, D.; Aghajarian, D.; Shekhar, S.; Zhou, X. A vision for GPU-accelerated parallel computation on geo-spatial datasets. Sigspatial Spec. 2015, 6, 19–26. [Google Scholar] [CrossRef]
- Lee, V.W.; Kim, C.; Chhugani, J.; Deisher, M.; Kim, D.; Nguyen, A.D.; Satish, N.; Smelyanskiy, M.; Chennupaty, S.; Hammarlund, P. Debunking the 100X GPU vs. CPU myth:an evaluation of throughput computing on CPU and GPU. Acm Sigarch Comput. Arch. News 2010, 38, 451–460. [Google Scholar] [CrossRef]
- Zuo, Y.; Wang, S.; Zhong, E.; Cai, W. Research Progress and Review of High-Performance GIS. J. Geo-Inf. Sci. 2017, 19, 437. [Google Scholar]
- Huang, F.; Zhou, J.; Tao, J.; Tan, X.; Liang, S.; Cheng, J. PMODTRAN: A parallel implementation based on MODTRAN for massive remote sensing data processing. Int. J. Digit. Earth 2016, 9, 819–834. [Google Scholar] [CrossRef]
- Chatzimilioudis, G.; Costa, C.; Zeinalipouryazti, D.; Lee, W.C.; Pitoura, E. Distributed in-memory processing of All K Nearest Neighbor queries. In Proceedings of the IEEE International Conference on Data Engineering, Helsinki, Finland, 2016; pp. 1490–1491. [Google Scholar]
- Dong, B.; Li, X.; Wu, Q.; Xiao, L.; Li, R. A dynamic and adaptive load balancing strategy for parallel file system with large-scale I/O servers. J. Parallel Distrib. Comput. 2012, 72, 1254–1268. [Google Scholar] [CrossRef]
- Qian, C.; Dou, W.; Yang, K.; Tang, G. Data Partition Method for Parallel Interpolation Based on Time Balance. Geogr. Geo-Inf. Sci. 2013, 29, 86–90. [Google Scholar]
- Qi, L.; Shen, J.; Guo, L.; Zhou, T. Dynamic Strip Partitioning Method Oriented Parallel Computing for Construction of Delaunay Triangulation. J. Geo-Inf. Sci. 2012, 14, 55–61. [Google Scholar] [CrossRef]
- Ismail, Z.; Khanan, M.F.A.; Omar, F.Z.; Rahman, M.Z.A.; Salleh, M.R.M. Evaluating Error of LiDar Derived DEM Interpolation for Vegetation Area. Int. Arch. Photogramm. Remote Sens. S 2016, XLII-4/W1, 141–150. [Google Scholar] [CrossRef]
- Guan, X.; Wu, H.; Li, L. A Parallel Framework for Processing Massive Spatial Data with a Split-and-Merge Paradigm. Trans. GIS 2012, 16, 829–843. [Google Scholar] [CrossRef]
- Zou, Y.; Xue, W.; Liu, S. A case study of large-scale parallel I/O analysis and optimization for numerical weather prediction system. Future Gener. Comput. Syst. 2014, 37, 378–389. [Google Scholar] [CrossRef]
- Lu, G.Y.; Wong, D.W. An adaptive inverse-distance weighting spatial interpolation technique. Comput. Geosci. 2008, 34, 1044–1055. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Volume | Number of Points | With | Length |
|---|---|---|---|---|
| Data1 | 30 GB | 1.2 billion | 15 km | 19 km |
| Data2 | 4 GB | 0.16 billion | 8 km | 4 km |
| Data3 | 150 GB | 6.0 billion | 77 km | 141 km |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Y.; Chen, Z.; Chen, G.; Han, Y.; Wang, Y. A Hybrid Process/Thread Parallel Algorithm for Generating DEM from LiDAR Points. ISPRS Int. J. Geo-Inf. 2017, 6, 300. https://doi.org/10.3390/ijgi6100300
Ren Y, Chen Z, Chen G, Han Y, Wang Y. A Hybrid Process/Thread Parallel Algorithm for Generating DEM from LiDAR Points. ISPRS International Journal of Geo-Information. 2017; 6(10):300. https://doi.org/10.3390/ijgi6100300
Chicago/Turabian StyleRen, Yibin, Zhenjie Chen, Ge Chen, Yong Han, and Yanjie Wang. 2017. "A Hybrid Process/Thread Parallel Algorithm for Generating DEM from LiDAR Points" ISPRS International Journal of Geo-Information 6, no. 10: 300. https://doi.org/10.3390/ijgi6100300
APA StyleRen, Y., Chen, Z., Chen, G., Han, Y., & Wang, Y. (2017). A Hybrid Process/Thread Parallel Algorithm for Generating DEM from LiDAR Points. ISPRS International Journal of Geo-Information, 6(10), 300. https://doi.org/10.3390/ijgi6100300