An Improved Density-Based Time Series Clustering Method Based on Image Resampling: A Case Study of Surface Deformation Pattern Analysis





Abstract
:1. Introduction
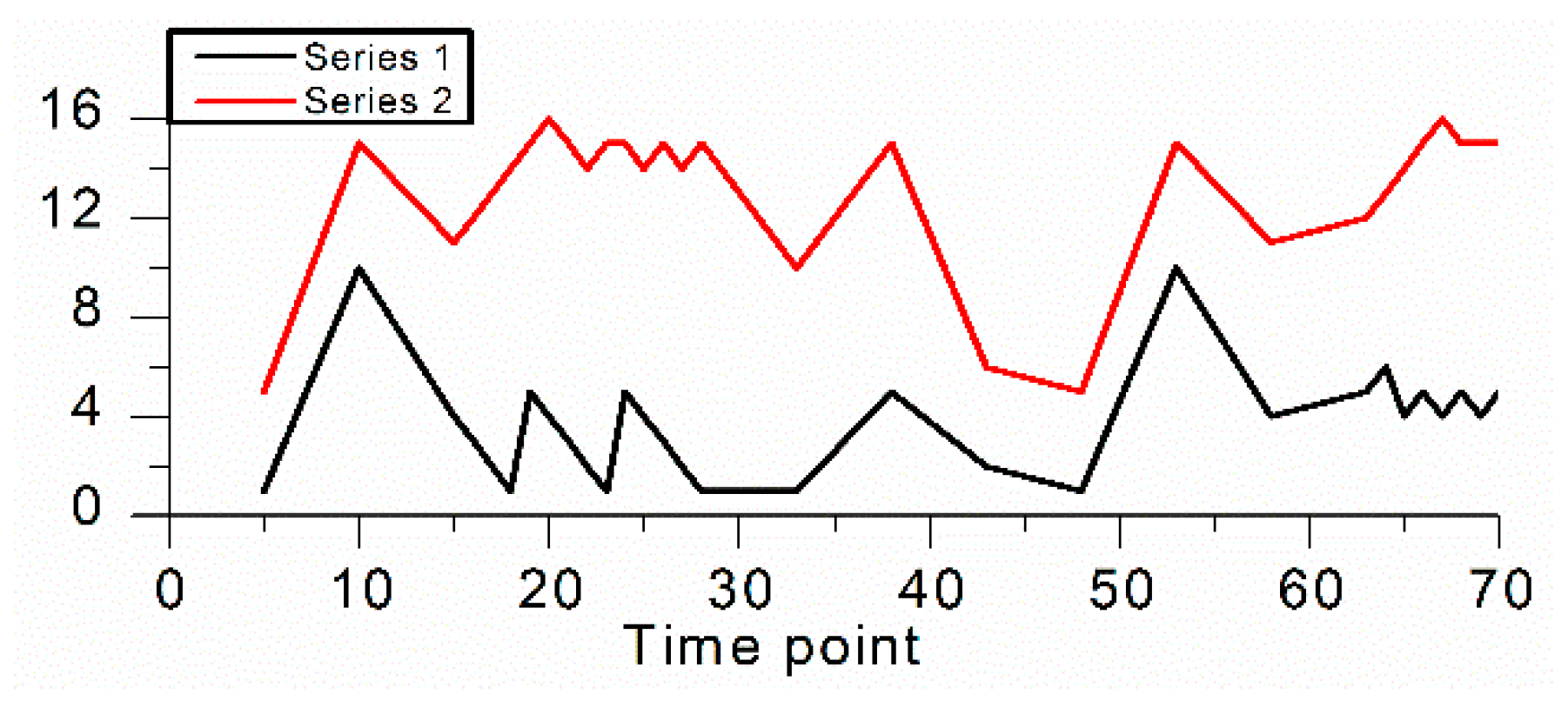
2. Similarity Measurements between Sequences
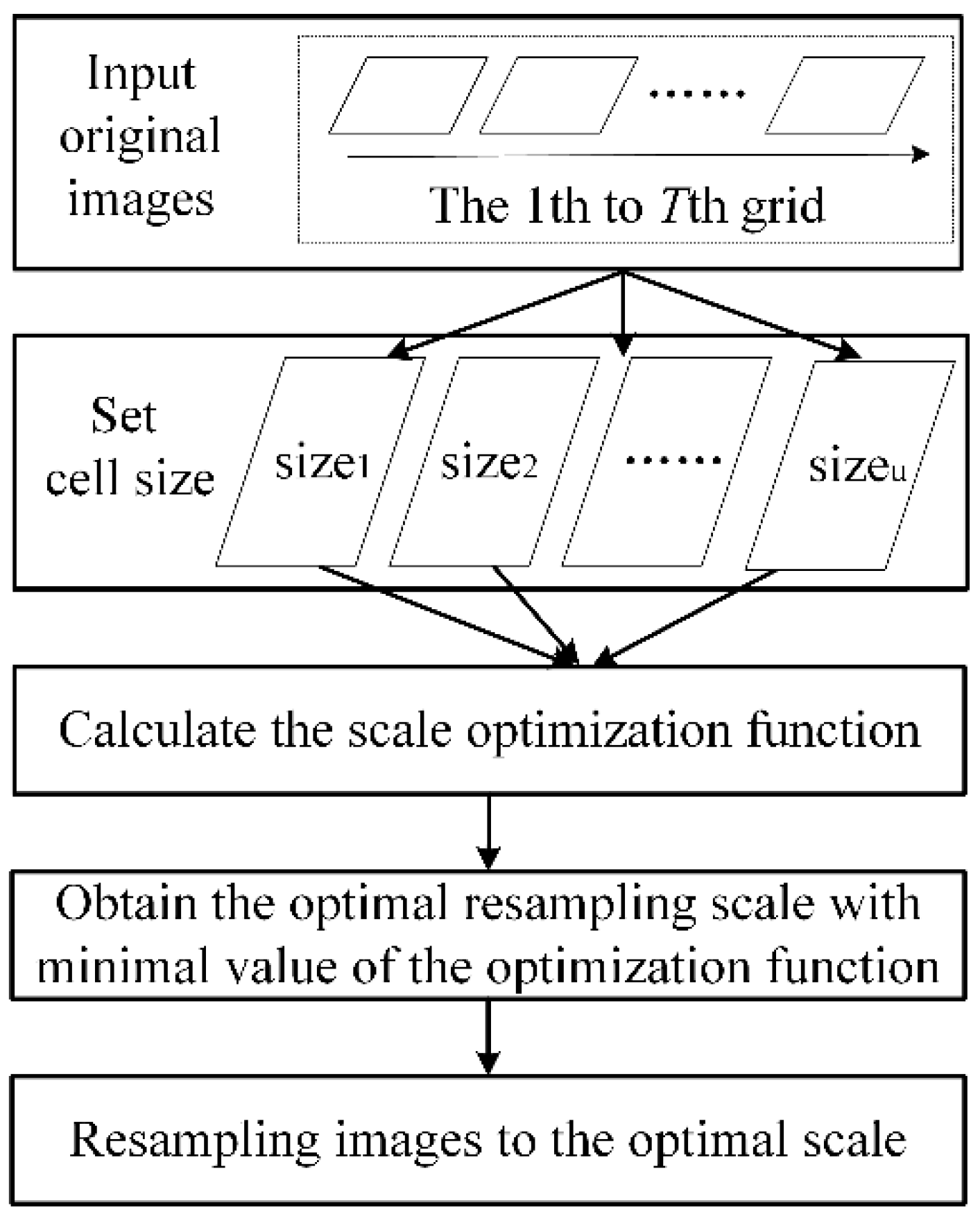
3. Image Resampling
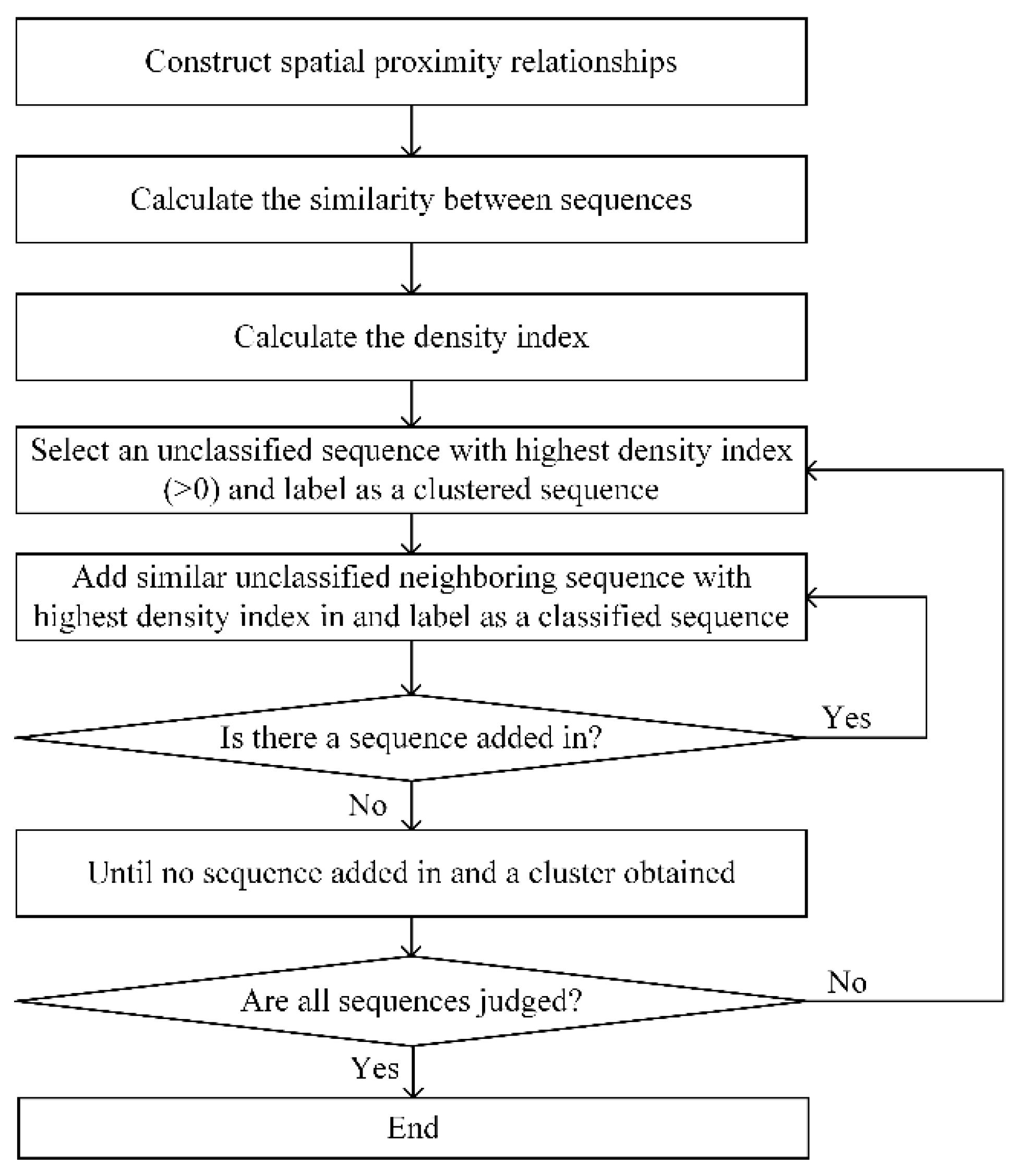
4. Image Time Series Clustering
- Step 1
- The spatial proximity relationships between sequences are constructed. As is well known, the pixels in the images are regularly distributed in the spatial domain, and the neighboring eight-connected sequences of are considered the neighbors of .
- Step 2
- The similarity degree of the spatial-temporal attribute values and similarity degree of the spatial-temporal trends between neighboring sequences are calculated. In addition, the default value of the spatial-temporal attribute threshold of the density-based clustering method can be determined during the procedure by the rule of three standard deviations [20]. is used to judge whether the sequences have similar spatial-temporal attribute values, and is used in Step 3.
- Step 3
- The density indicator is computed. The computation procedure can be divided into two sub-steps as follows:
- (1)
- For every sequence, the spatially directly reachable sequences are calculated, defined as follows. Taking sequences and as an example, is spatially directly reachable from if the following constraints are satisfied:
- (2)
- The density indicator of the sequences is calculated. For sequence , the density indicator is calculated as
where is the number of sequences that are spatially directly reachable from . is the total number of neighbors of . - Step 4
- Time series clustering is implemented. This step can be summarized as the following four operations:
- (1)
- An unclassified sequence is selected with the highest indicator value (larger than zero); this is defined as a temp cluster . Meanwhile, the selected sequence is labeled as a classified sequence.
- (2)
- An unclassified sequence is added. If the sequence meets the following three conditions, it is added to and is labeled a classified sequence.Condition 1: is spatially directly reachable from any sequence in .Condition 2: .Condition 3: .
- (3)
- Operation (2) is repeated, and the cluster is then obtained and Operation (4) is conducted until no sequence can be added to .
- (4)
- Operation (1) is repeated, and the procedure is stopped when all sequences have been determined. The sequence, which does not belong to any cluster, is recognized as noise.
5. Evaluation of the Clustering Results
6. Results and Discussion
6.1. Validation of the DBTSC Algorithm
- (1)
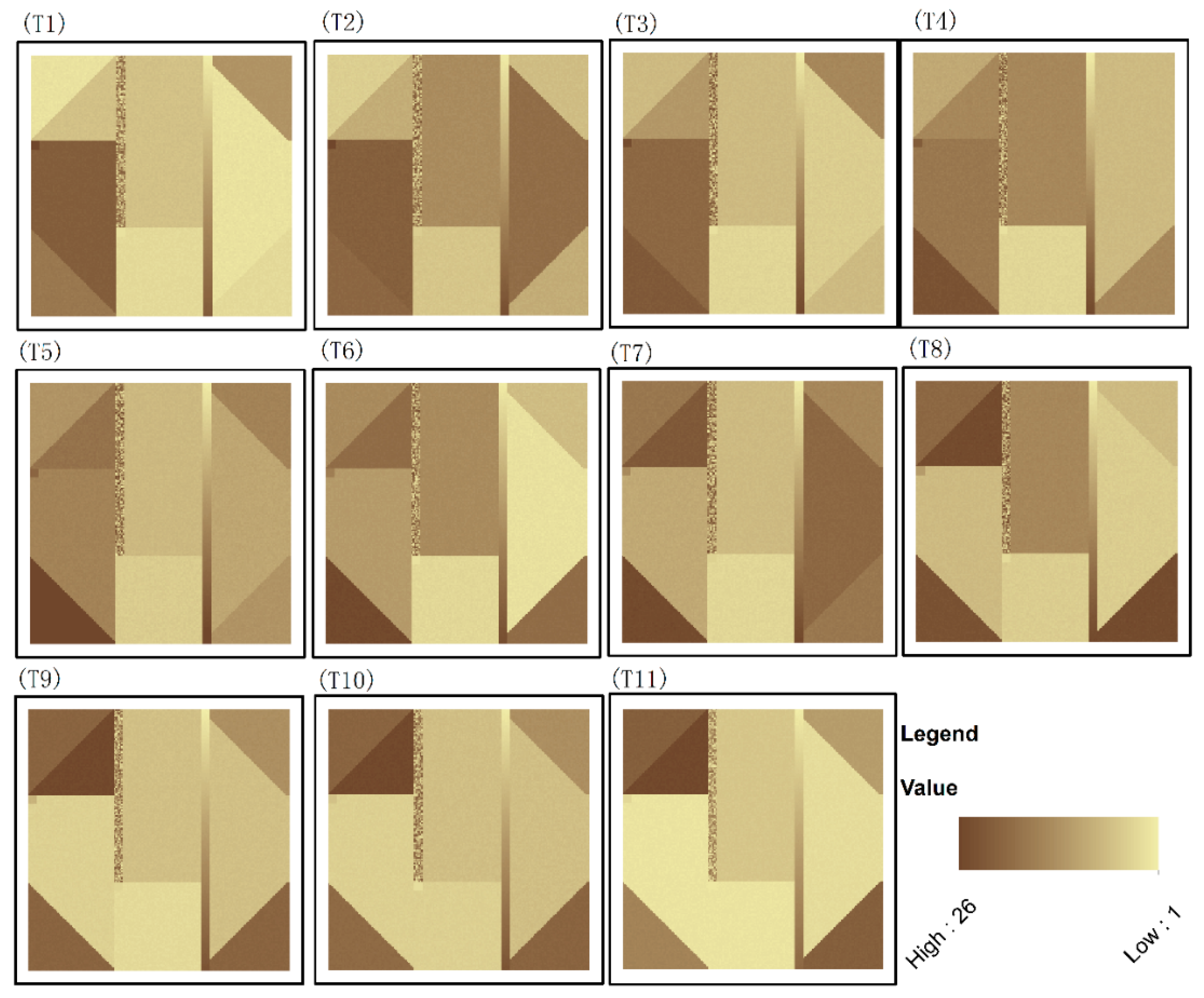
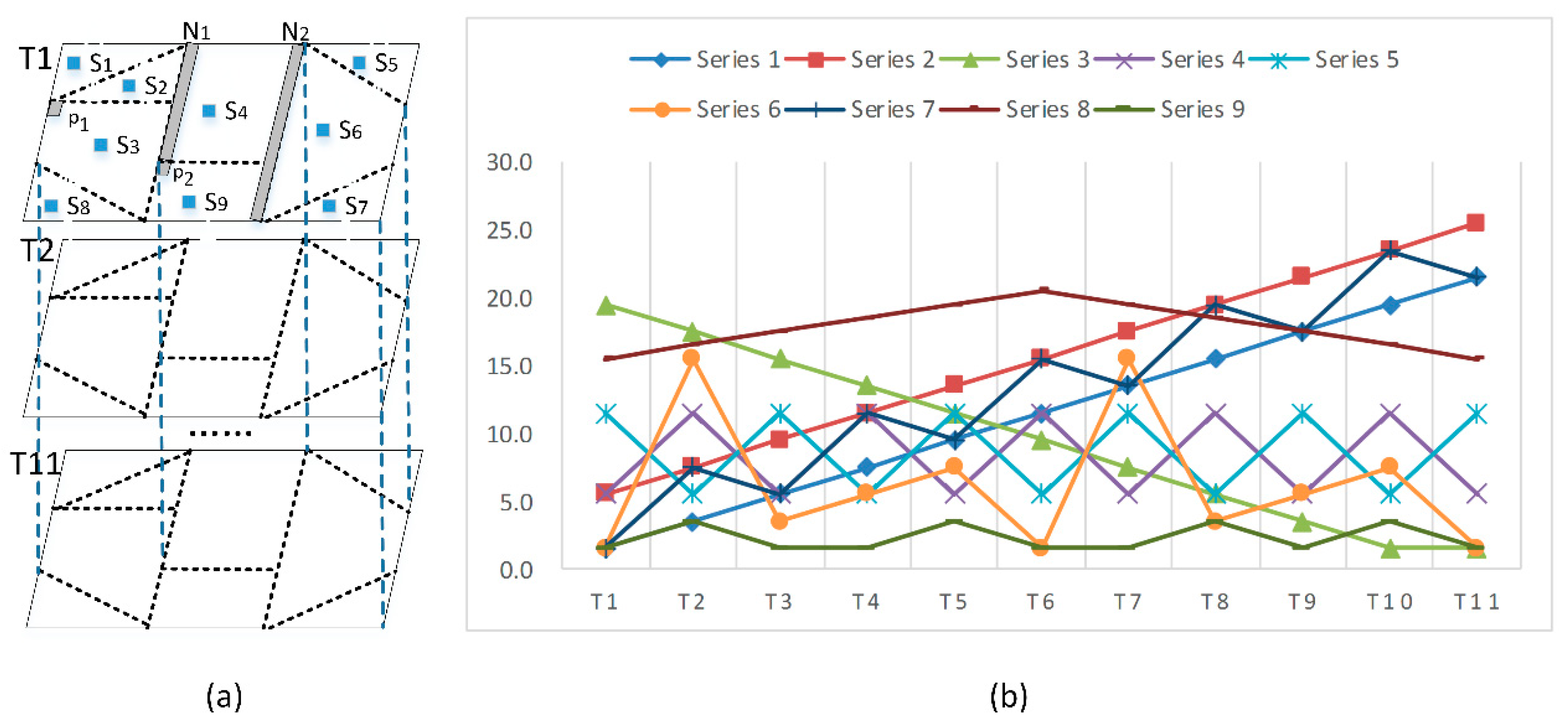
- The time series dataset with equal time intervals holds eleven images, as shown in Figure 4.
- (2)
- (3)
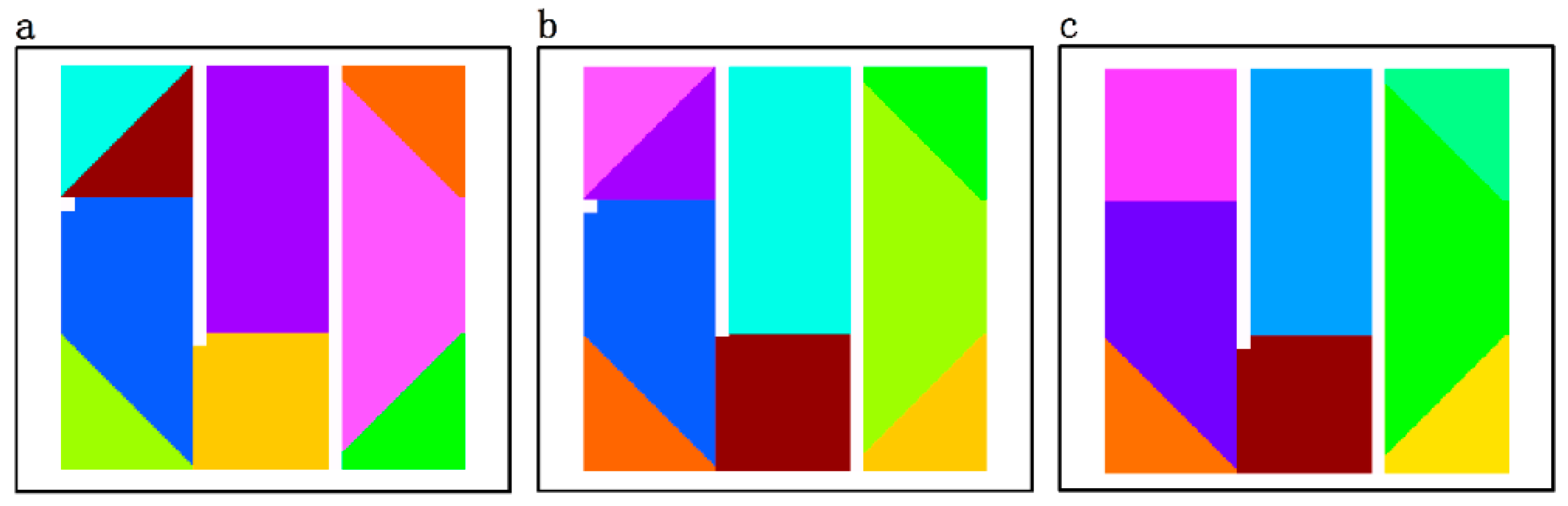
- To simulate the actual situations, four types of noise are set and distributed in the gray-colored areas in Figure 5a. Type 1 comprises the randomly distributed noise, such as the noise in the gray-colored band with spatial-temporal attribute values randomly distributed between 1 and 26. Type 2 comprises the gradiently distributed noises. For example, the spatial-temporal attribute values of noise in the gray-colored band (Figure 5a) gradually change from 1 to 26. Type 3 comprises the noises of spatial-temporal attribute values, such as (Figure 5a). The characteristics of this type of noise are as follows: (1) having similar spatial-temporal attribute trends with neighboring pixels; and (2) having significantly different spatial-temporal attribute values with neighboring pixels. Type 4 comprises the noises of spatial-temporal attribute trends, such as (Figure 5a). This type of noise has significantly different spatial-temporal attribute trends and similar spatial-temporal attribute values with neighboring pixels.
6.2. Comparison of the DBTSC Algorithm with Typical Similarity Measurements and the Proposed Similarity Measurements
6.3. Validation of the DBTSC-IR Method
6.4. Application on Detecting Surface Deformation Patterns
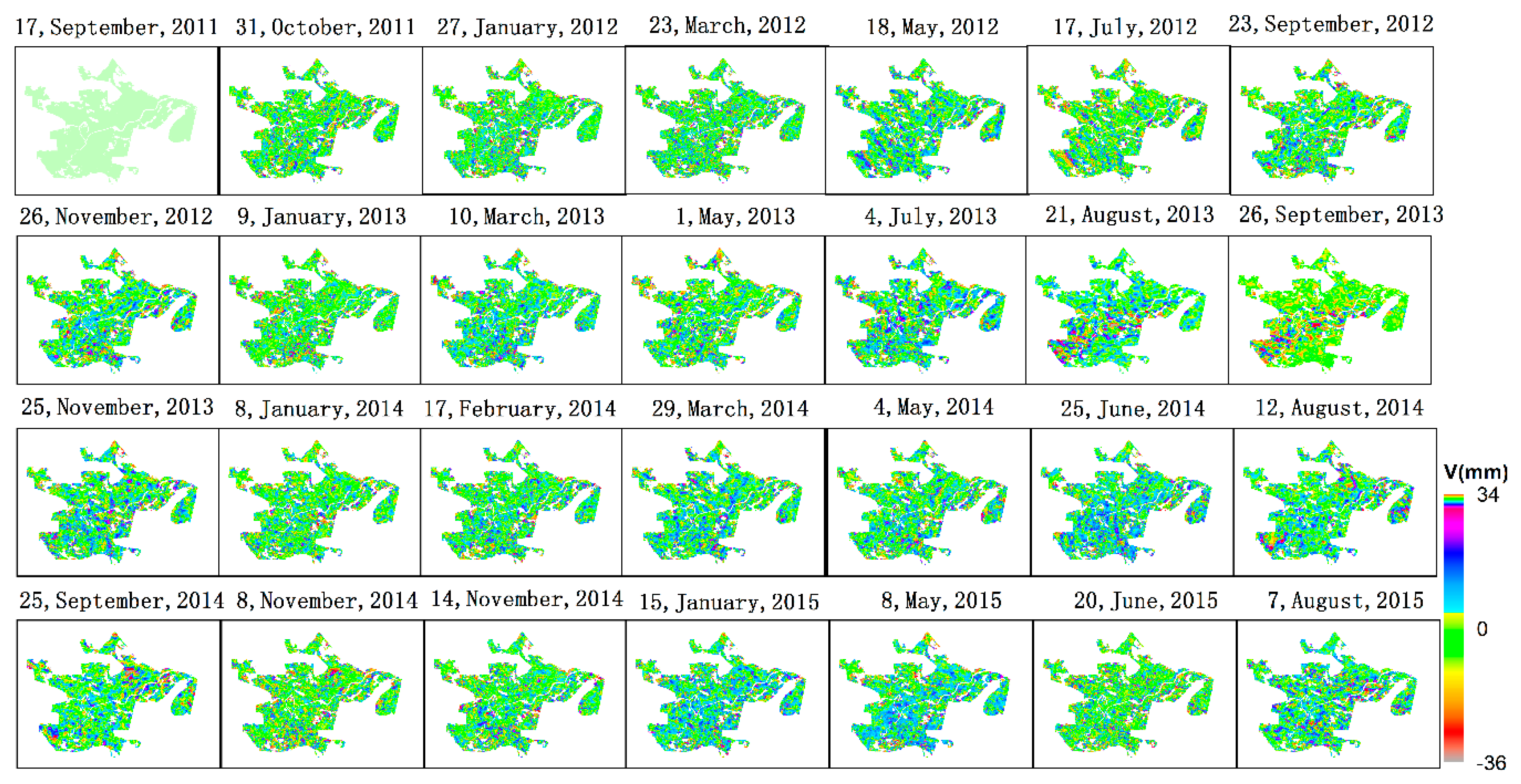
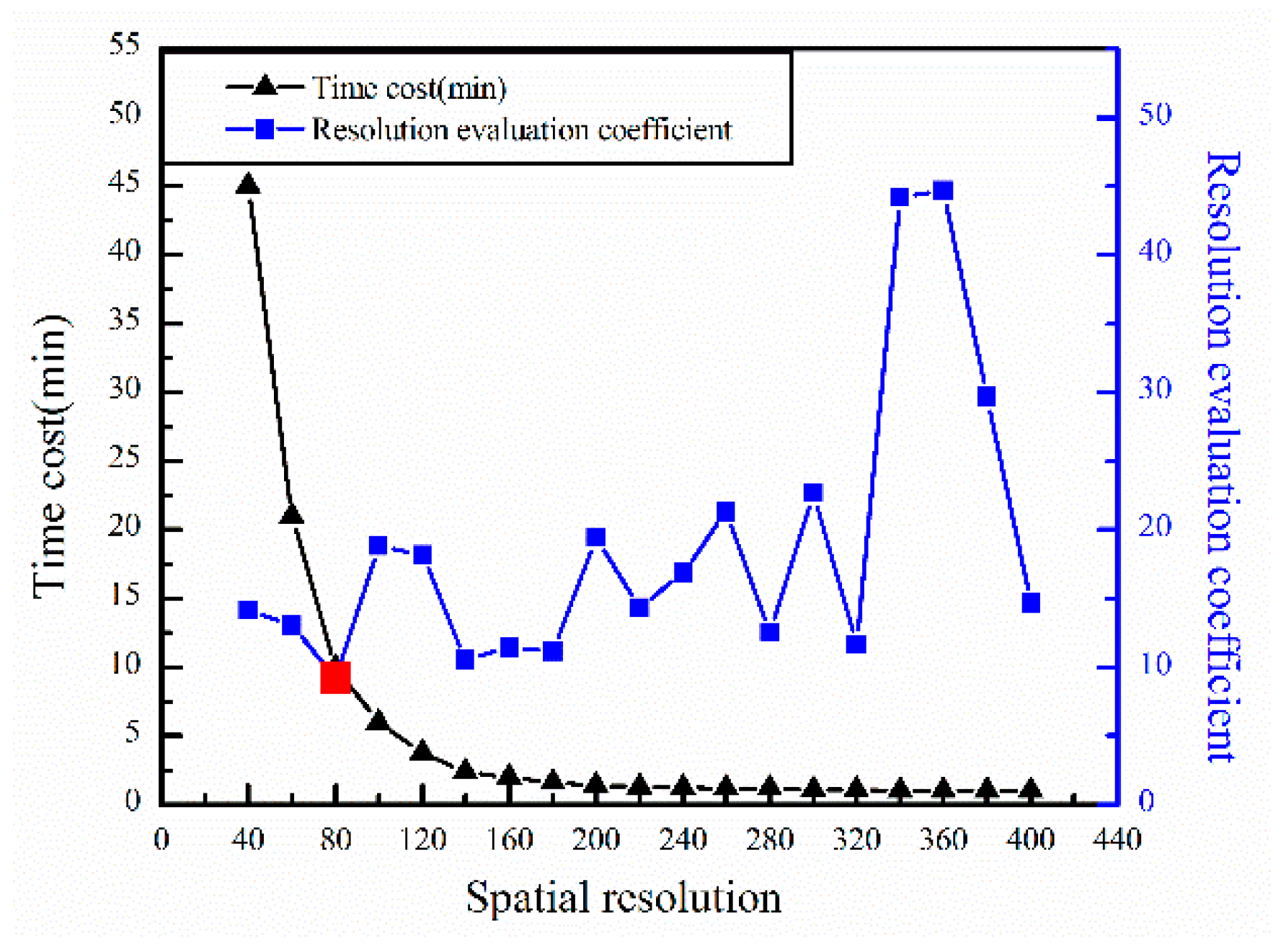
6.4.1. Resampling of Surface Deformation Data
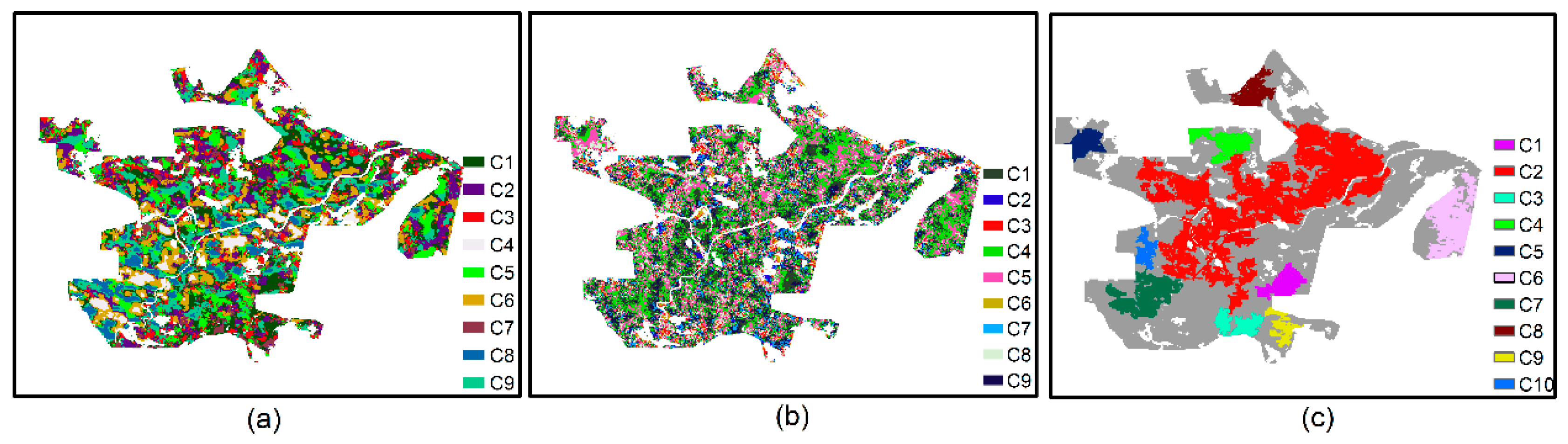
6.4.2. Implementing Pattern Recognition by the DBTSC Algorithm
- (1)
- The proposed DBTSC-IR algorithm can detect clusters with arbitrary shapes under the interference of uneven deformation areas with higher efficiency and accuracy compared with the classical time series clustering algorithms.
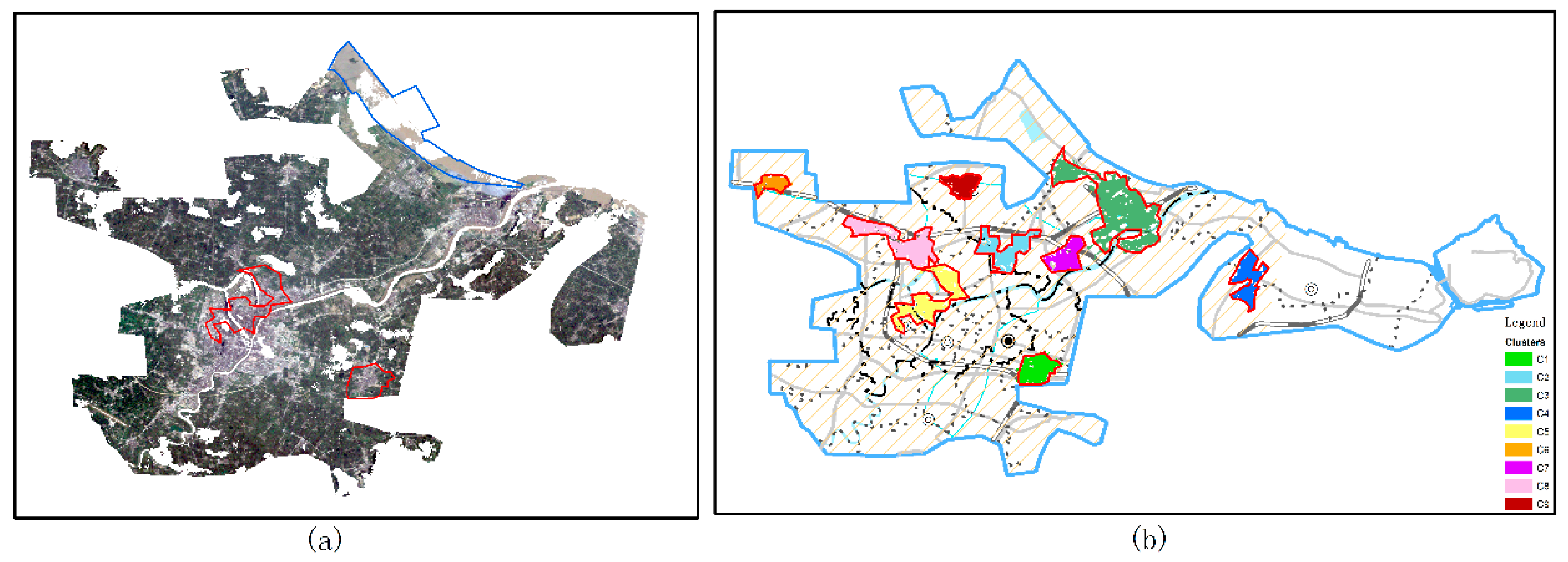
- (2)
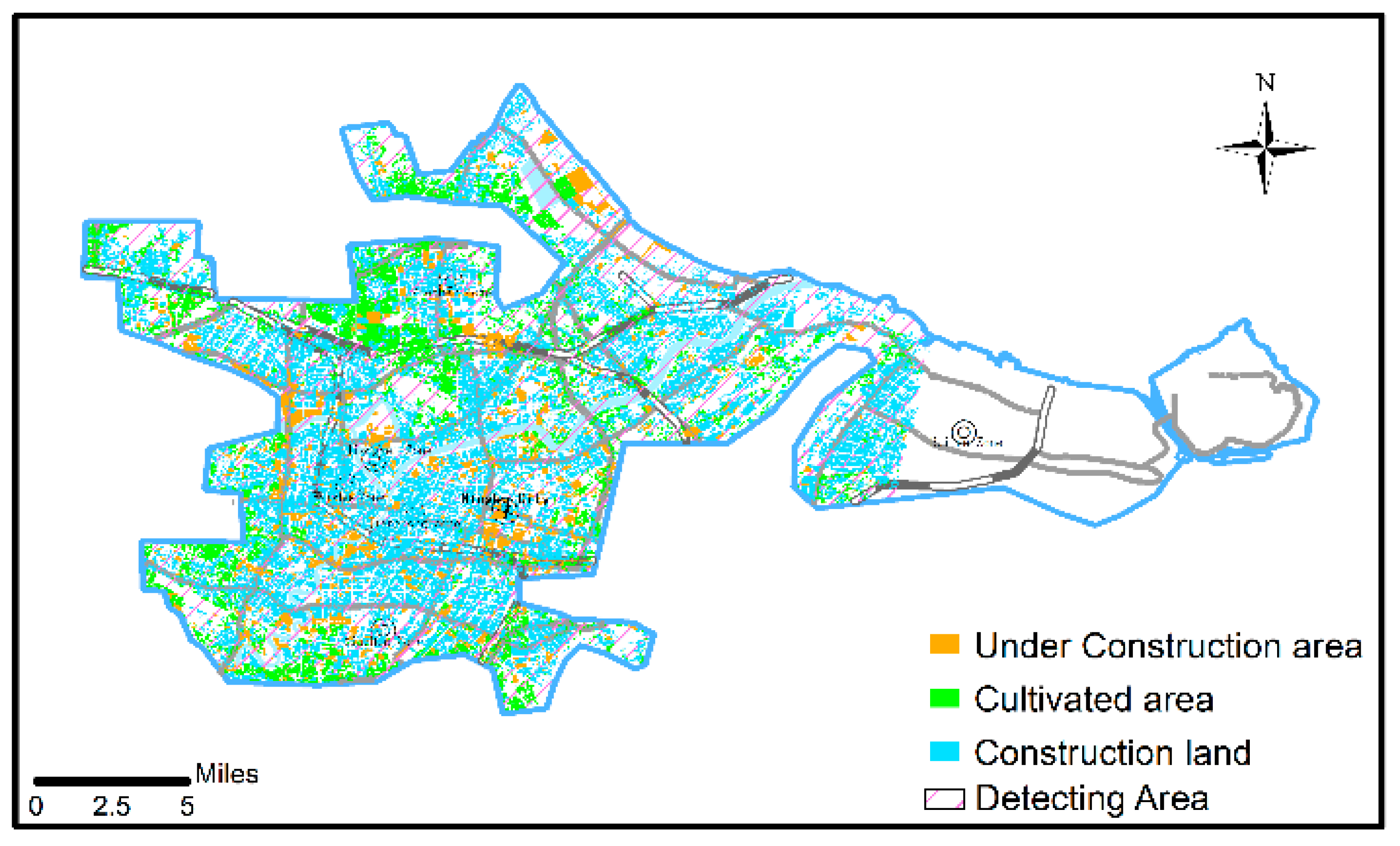
- The results of the DBTSC-IR algorithm can provide a reference for analyzing the patterns of city development. For example, it can separate the old urban district, the newly constructed district, and the zones under construction.
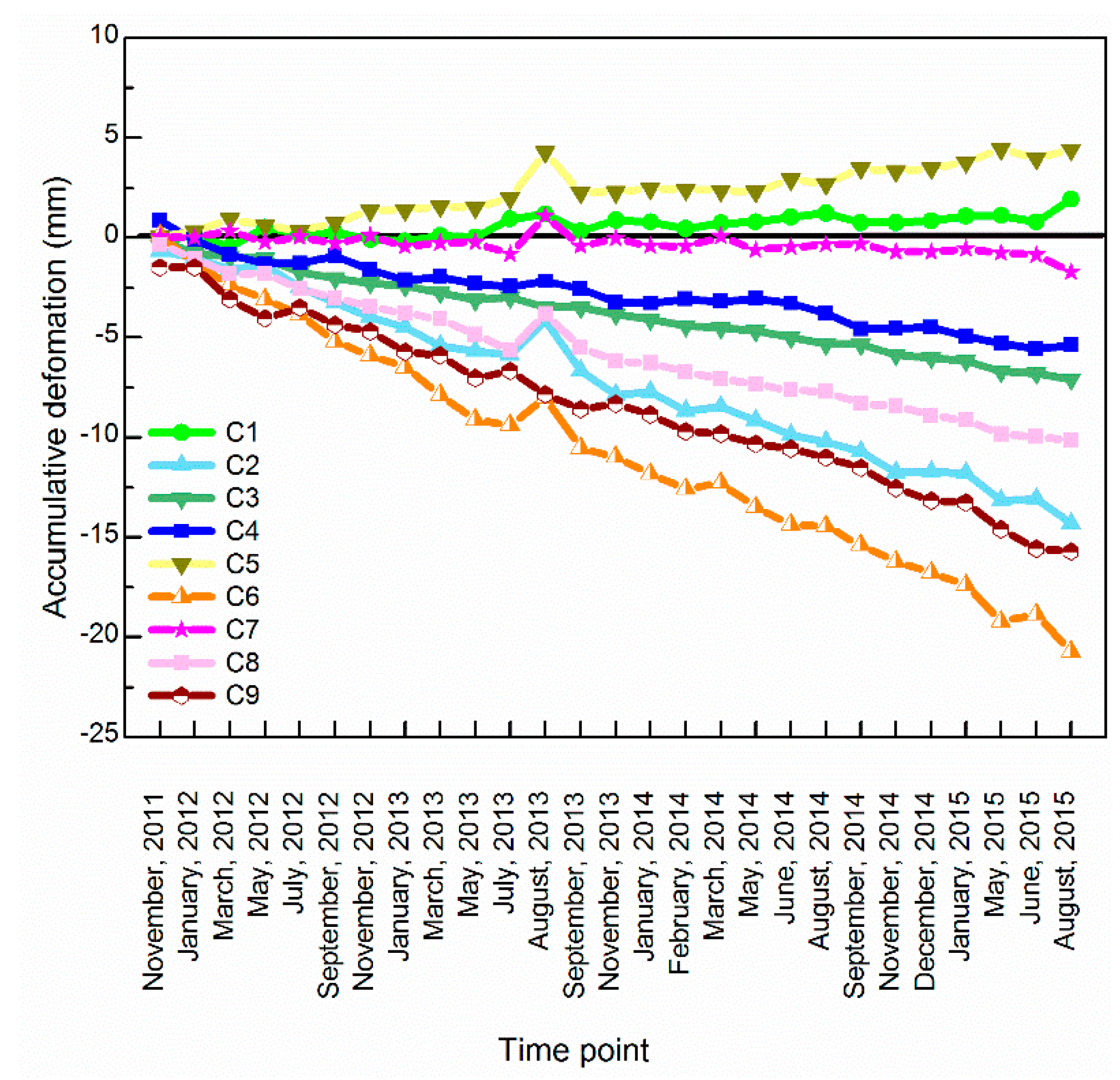
- (3)
- Most of the constructed areas in 20 years continue to have subsidence.
- (4)
- Several districts constructed more than two centuries ago are slightly uplifted due to ground rebound.
- (5)
- The surface deformation in the reclamation area in Ningbo city remains unstable.
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Guyet, T.; Nicolas, H. Long term analysis of time series of satellite images. Pattern Recognit. Lett. 2016, 70, 17–23. [Google Scholar] [CrossRef]
- Bidari, P.S.; Manshaei, R.; Lohrasebi, T.; Feizi, A.; Malboobi, M.A.; Alirezaie, J. Time series gene expression data clustering and pattern extraction in arabidopsis thaliana phosphatase-encoding genes. In Proceedings of the 2008 8th IEEE International Conference on BioInformatics and BioEngineering (BIBE 2008), Athens, Greece, 8–10 October 2008; pp. 1–6. [Google Scholar]
- Kaur, G.; Dhar, J.; Guha, R.K. Minimal variability owa operator combining anfis and fuzzy c-means for forecasting bse index. Math. Comput. Simul. 2016, 122, 69–80. [Google Scholar] [CrossRef]
- Krishna, K.; Narasimha Murty, M. Genetic k-means algorithm. IEEE Trans. Syst. Man Cybern. B Cybern. 1999, 29, 433–439. [Google Scholar] [CrossRef] [PubMed]
- Möller-Levet, C.S.; Klawonn, F.; Cho, K.H.; Wolkenhauer, O. Fuzzy Clustering of Short Time-Series and Unevenly Distributed Sampling Points; Springer: Berlin/Heidelberg, Germany, 2003; pp. 330–340. [Google Scholar]
- Yin, J.; Zhou, D.; Xie, Q.Q. A clustering algorithm for time series data. In Proceedings of the International Conference on Parallel and Distributed Computing, Applications and Technologies, Taipei, Taiwan, 4–7 December 2006; pp. 119–122. [Google Scholar]
- Jiang, D.; Pei, J.; Zhang, A. Dhc: A density-based hierarchical clustering method for time series gene expression data. In Proceedings of the Third IEEE Symposium on Bioinformatics and Bioengineering, Bethesda, MD, USA, 10–12 March 2003; pp. 393–400. [Google Scholar]
- Chis, M.; Grosan, C. Evolutionary hierarchical time series clustering. In Proceedings of the International Conference on Intelligent Systems Design and Applications, Porto, Portugal, 16–18 October 2006; pp. 451–455. [Google Scholar]
- Rodrigues, P.P.; Gama, J.; Pedroso, J. Hierarchical clustering of time-series data streams. IEEE Trans. Knowl. Data Eng. 2008, 20, 615–627. [Google Scholar] [CrossRef]
- Uijlings, J.R.R.; Duta, I.C.; Rostamzadeh, N.; Sebe, N. Realtime video classification using dense hof/hog. In Proceedings of the International Conference on Multimedia Retrieval, Glasgow, UK, 1–4 April 2014; pp. 145–152. [Google Scholar]
- Chandrakala, S.; Sekhar, C.C. A density based method for multivariate time series clustering in kernel feature space. In Proceedings of the IEEE International Joint Conference on Neural Networks and 2008 IEEE World Congress on Computational Intelligence, Hongkong, China, 1–8 June 2008; pp. 1885–1890. [Google Scholar]
- Mörchen, F.; Ultsch, A.; Hoos, O. Extracting interpretable muscle activation patterns with time series knowledge mining. Int. J. Knowl. Based Intell. Eng. Syst. 2005, 9, 2006. [Google Scholar] [CrossRef]
- Zanotto, C.; Giangaspero, M.; Büttner, M.; Braun, A.; Morghen, C.G.; Elli, V.; Panuccio, A.; Radaelli, A. Evaluation of poliovirus vaccines for pestivirus contamination: Non-specific amplification of poliovirus sequences by pan-pestivirus primers. J. Virol. Methods 2002, 102, 167–172. [Google Scholar] [CrossRef]
- Xu, T.; Shang, X.; Yang, M.; Wang, M. Bicluster algorithm on discrete time-series gene expression data. Appl. Res. Comput. 2013, 30, 3552–3557. [Google Scholar]
- Yan, L.; Kong, Z.; Wu, Y.; Zhang, B. Biclustering nonl inearly correlated time series gene expression data. J. Comput. Res. Dev. 2008, 45, 1865–1873. [Google Scholar]
- Warren Liao, T. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Lhermitte, S.; Verbesselt, J.; Verstraeten, W.W.; Coppin, P. A comparison of time series similarity measures for classification and change detection of ecosystem dynamics. Remote Sens. Environ. 2011, 115, 3129–3152. [Google Scholar] [CrossRef]
- Lottering, R.; Mutanga, O. Optimising the spatial resolution of worldview-2 pan-sharpened imagery for predicting levels of gonipterus scutellatus defoliation in kwazulu-natal, south africa. ISPRS J. Photogramm. Remote Sens. 2016, 112, 13–22. [Google Scholar] [CrossRef]
- Orlhac, F.; Soussan, M.; Chouahnia, K.; Martinod, E.; Buvat, I. 18F-FDG pet-derived textural indices reflect tissue-specific uptake pattern in non-small cell lung cancer. PLoS ONE 2015, 10, e0145063. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Deng, M.; Shi, Y.; Wang, J. A density-based spatial clustering algorithm considering both spatial proximity and attribute similarity. Comput. Geosci. 2012, 46, 296–309. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; Liu, D.; Liu, L. An adaptive dual clustering algorithm based on hierarchical structure: A case study of settlement zoning. Trans. GIS 2016. [Google Scholar] [CrossRef]
- Fu, T.-C. A review on time series data mining. Eng. Appl. Artif. Intell. 2011, 24, 164–181. [Google Scholar] [CrossRef]
- Chao, X. A review on correlation coefficients. J. Guangdong Univ. Technol. 2012, 29, 12–17. [Google Scholar]
- Zhang, W. Measuring mixing patterns in complex networks by spearman rank correlation coefficient. Phys. A Stat. Mech. Appl. 2016, 451, 440–450. [Google Scholar] [CrossRef]
- Ramirez-Lopez, L.; Schmidt, K.; Behrens, T.; van Wesemael, B.; Demattê, J.A.M.; Scholten, T. Sampling optimal calibration sets in soil infrared spectroscopy. Geoderma 2014, 226–227, 140–150. [Google Scholar] [CrossRef]
- Heng, X.; Junjie, L.; Guo, J.; Qin, Z.; Shao, L. Approximate query algorithm based on eight-neighbor grid clustering for heterogeneous xml documents. J. Xi'an Jiaotong Univ. 2007, 41, 907–911. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, MA, USA, 2008; pp. 824–825. [Google Scholar]
- Grubesic, T.H.; Wei, R.; Murray, A.T. Spatial clustering overview and comparison: Accuracy, sensitivity, and computational expense. Ann. Assoc. Am. Geogr. 2014, 104, 1134–1156. [Google Scholar] [CrossRef]
- Katebi, H.; Rezaei, A.H.; Hajialilue-Bonab, M.; Tarifard, A. Assessment the influence of ground stratification, tunnel and surface buildings specifications on shield tunnel lining loads (by FEM). Tunn. Undergr. Space Technol. 2015, 49, 67–78. [Google Scholar] [CrossRef]
- Luo, C.-Y.; Shen, S.-L.; Han, J.; Ye, G.-L.; Horpibulsuk, S. Hydrogeochemical environment of aquifer groundwater in shanghai and potential hazards to underground infrastructures. Nat. Hazards 2015, 78, 753–774. [Google Scholar] [CrossRef]
- Toivanen, T.L.; Leveinen, J. Groundwater Level Variation and Deformation in Clays Characteristic to the Helsinki Metropolitan Area; Springer International Publishing: Basel, Switzerland, 2015; pp. 309–312. [Google Scholar]
- Fu, Y. A predictive analysis of groundwater regime and land subsidence in ningbo city. Resour. Surv. Environ. 2014, 35, 142–146. [Google Scholar]
- Chen, B.; Gong, H.; Li, X.; Lei, K.; Ke, Y.; Duan, G.; Zhou, C. Spatial correlation between land subsidence and urbanization in beijing, china. Nat. Hazards 2014, 75, 2637–2652. [Google Scholar] [CrossRef]
- Liao, M.; Wei, L.; Timo, B.; Zhang, L. Application of tomosar in urban deformation surveillance. Shanghai Land Resour. 2013, 34, 7–11. [Google Scholar]
- Liao, M.; Lin, H. Synthetic Aperture Radar Interferometry: Principle and Signal Processing; Surveying and Mapping Press: Beijing, China, 2003. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Wang, X.; Liu, Q.; Chen, Y.; Liu, L. An Improved Density-Based Time Series Clustering Method Based on Image Resampling: A Case Study of Surface Deformation Pattern Analysis. ISPRS Int. J. Geo-Inf. 2017, 6, 118. https://doi.org/10.3390/ijgi6040118
Liu Y, Wang X, Liu Q, Chen Y, Liu L. An Improved Density-Based Time Series Clustering Method Based on Image Resampling: A Case Study of Surface Deformation Pattern Analysis. ISPRS International Journal of Geo-Information. 2017; 6(4):118. https://doi.org/10.3390/ijgi6040118
Chicago/Turabian StyleLiu, Yaolin, Xiaomi Wang, Qiliang Liu, Yiyun Chen, and Leilei Liu. 2017. "An Improved Density-Based Time Series Clustering Method Based on Image Resampling: A Case Study of Surface Deformation Pattern Analysis" ISPRS International Journal of Geo-Information 6, no. 4: 118. https://doi.org/10.3390/ijgi6040118
APA StyleLiu, Y., Wang, X., Liu, Q., Chen, Y., & Liu, L. (2017). An Improved Density-Based Time Series Clustering Method Based on Image Resampling: A Case Study of Surface Deformation Pattern Analysis. ISPRS International Journal of Geo-Information, 6(4), 118. https://doi.org/10.3390/ijgi6040118