
Spatial Context from Open and Online Processing (SCOOP): Geographic, Temporal, and Thematic Analysis of Online Information Sources

Abstract
:1. Introduction
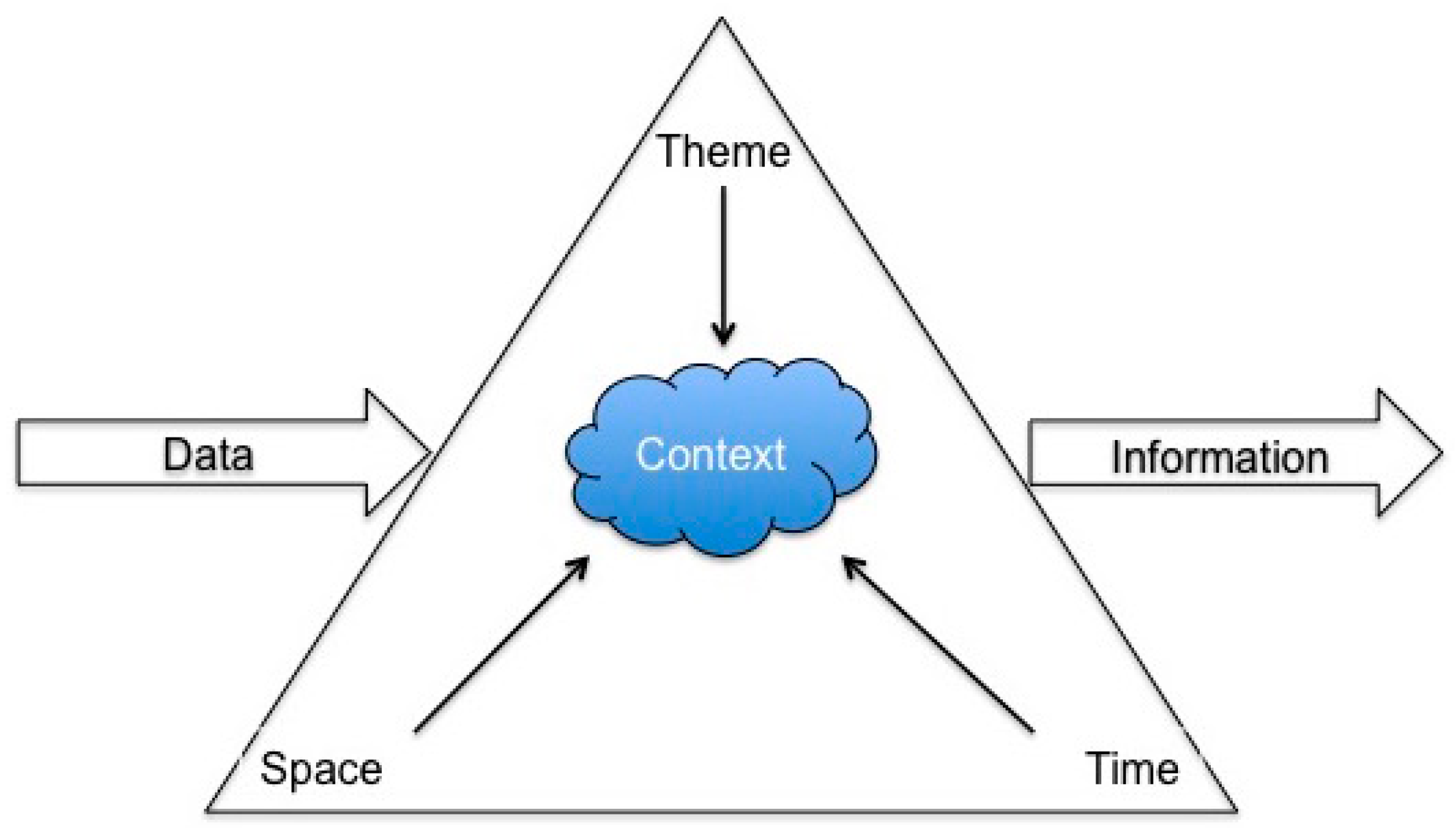
2. Materials and Methods
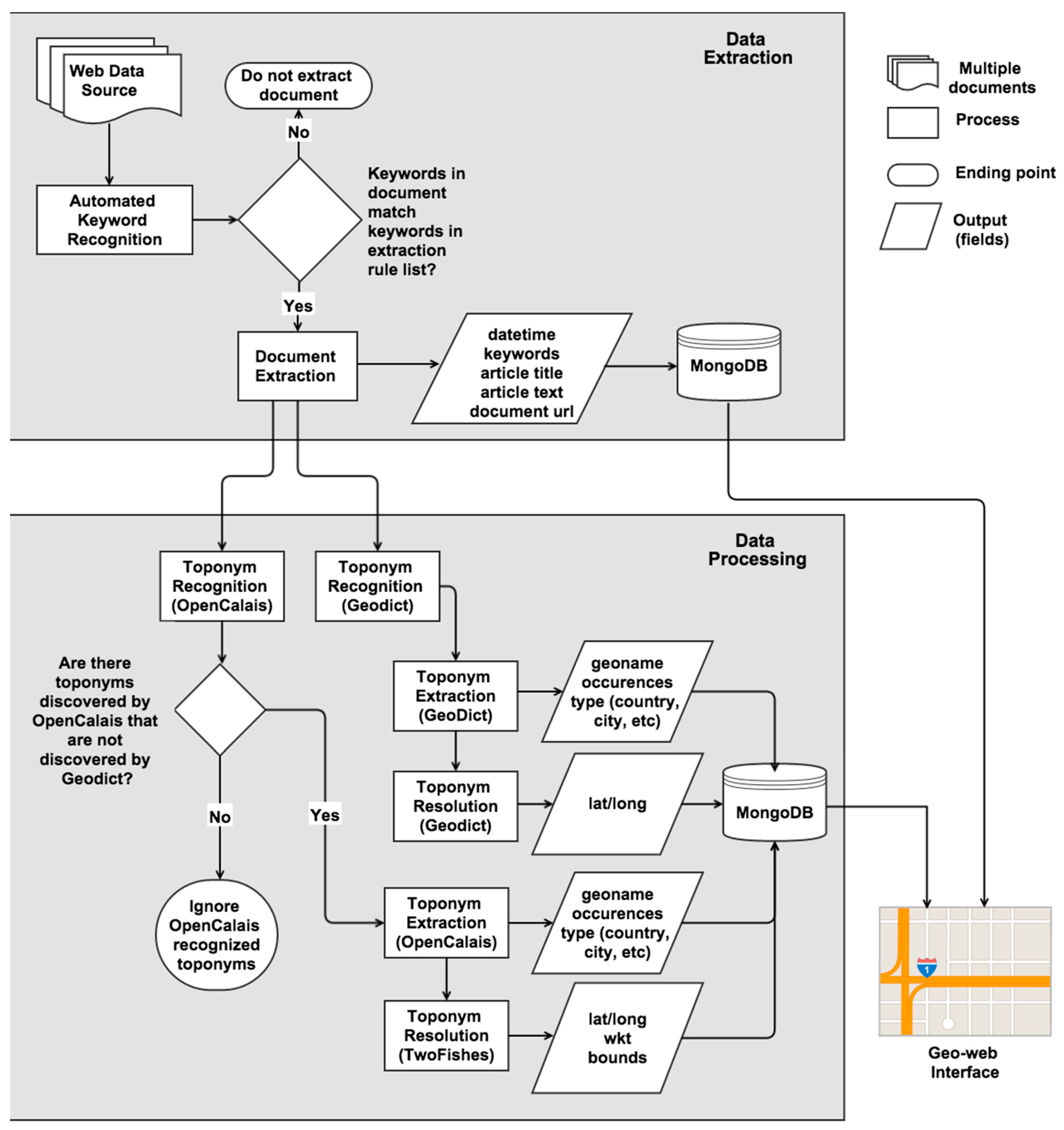
2.1. Project Architecture
2.2. Data Extraction
2.3. Named Entity Recognition
2.4. Concept Mapping
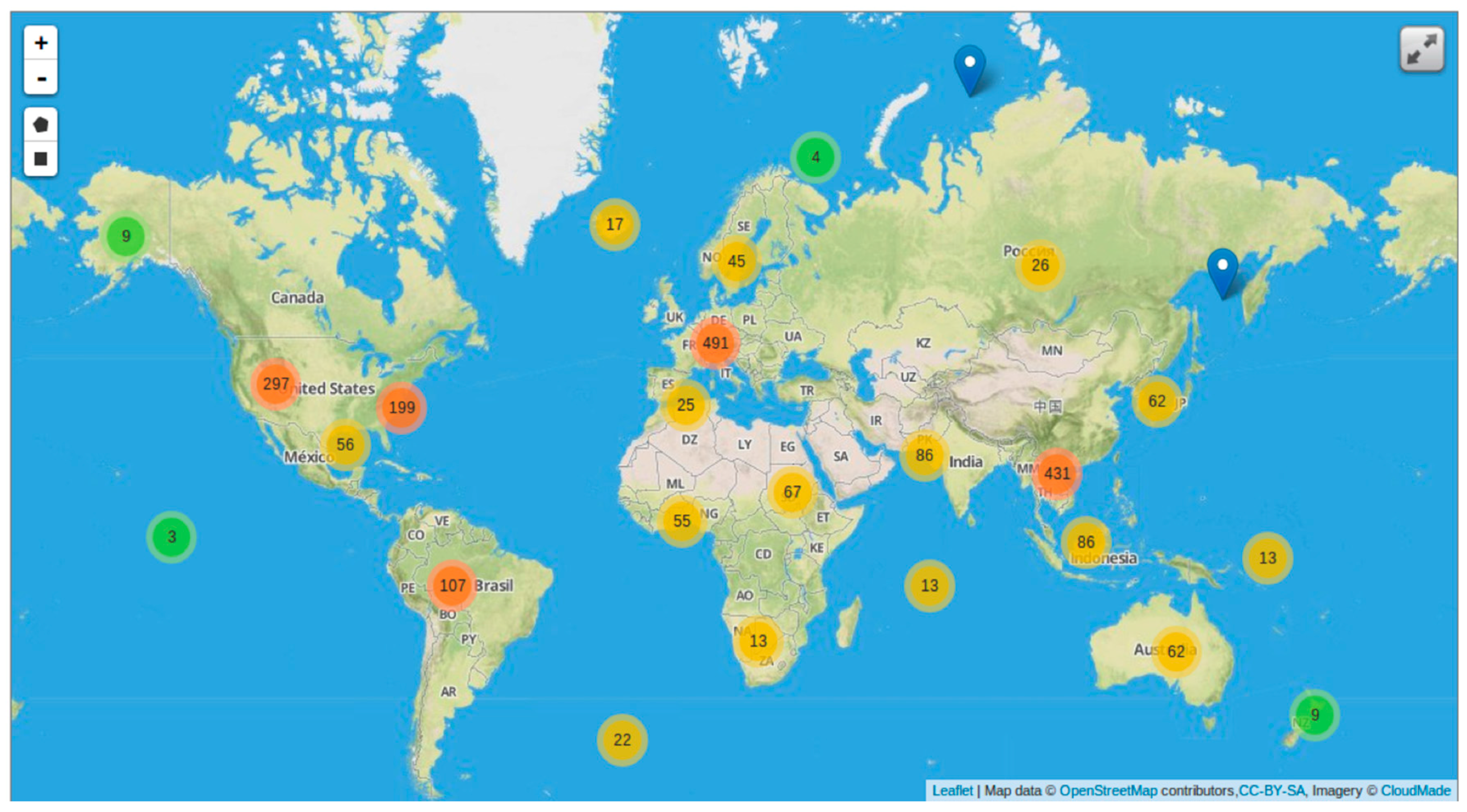
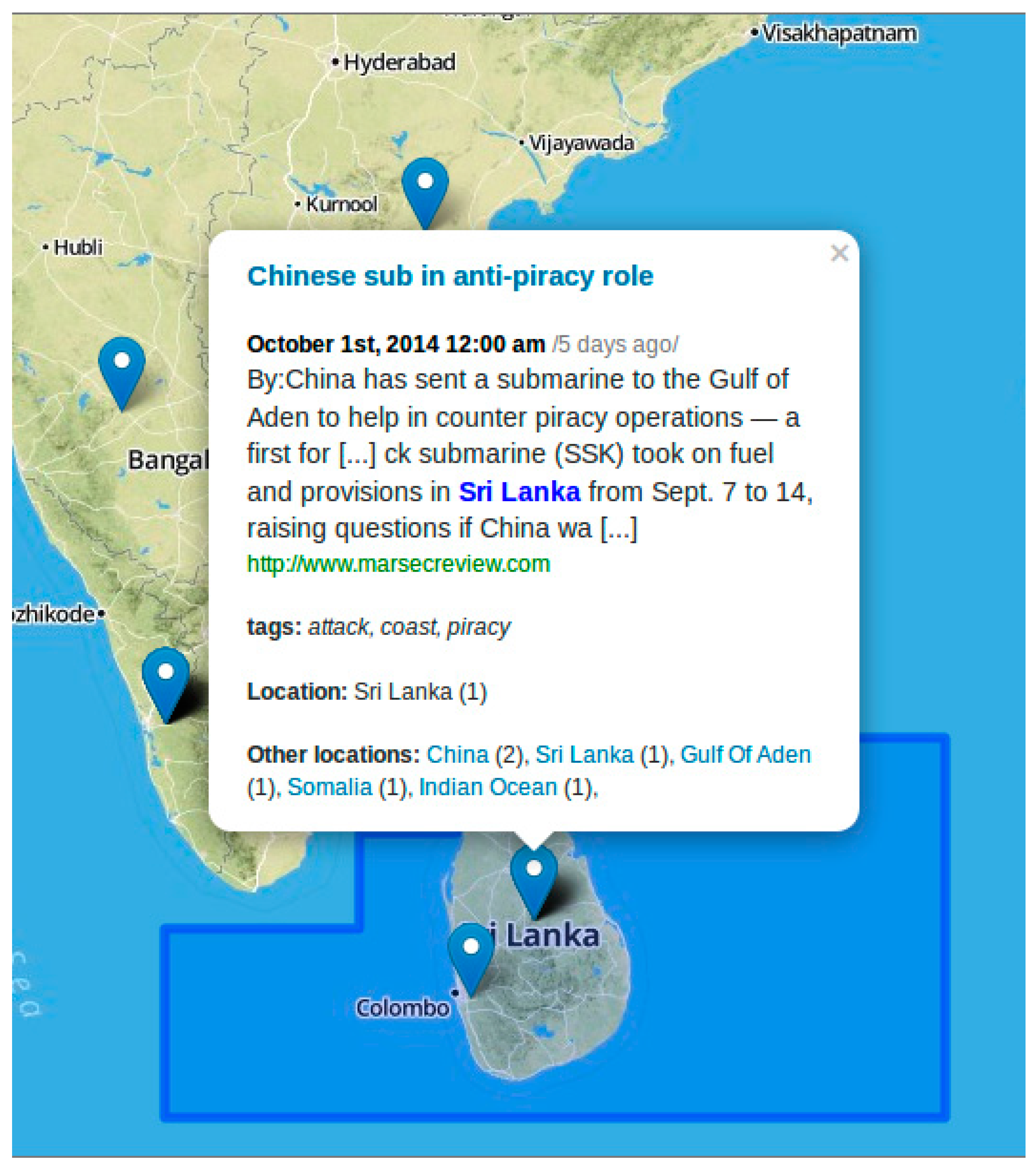
2.5. Geo-Web Interface
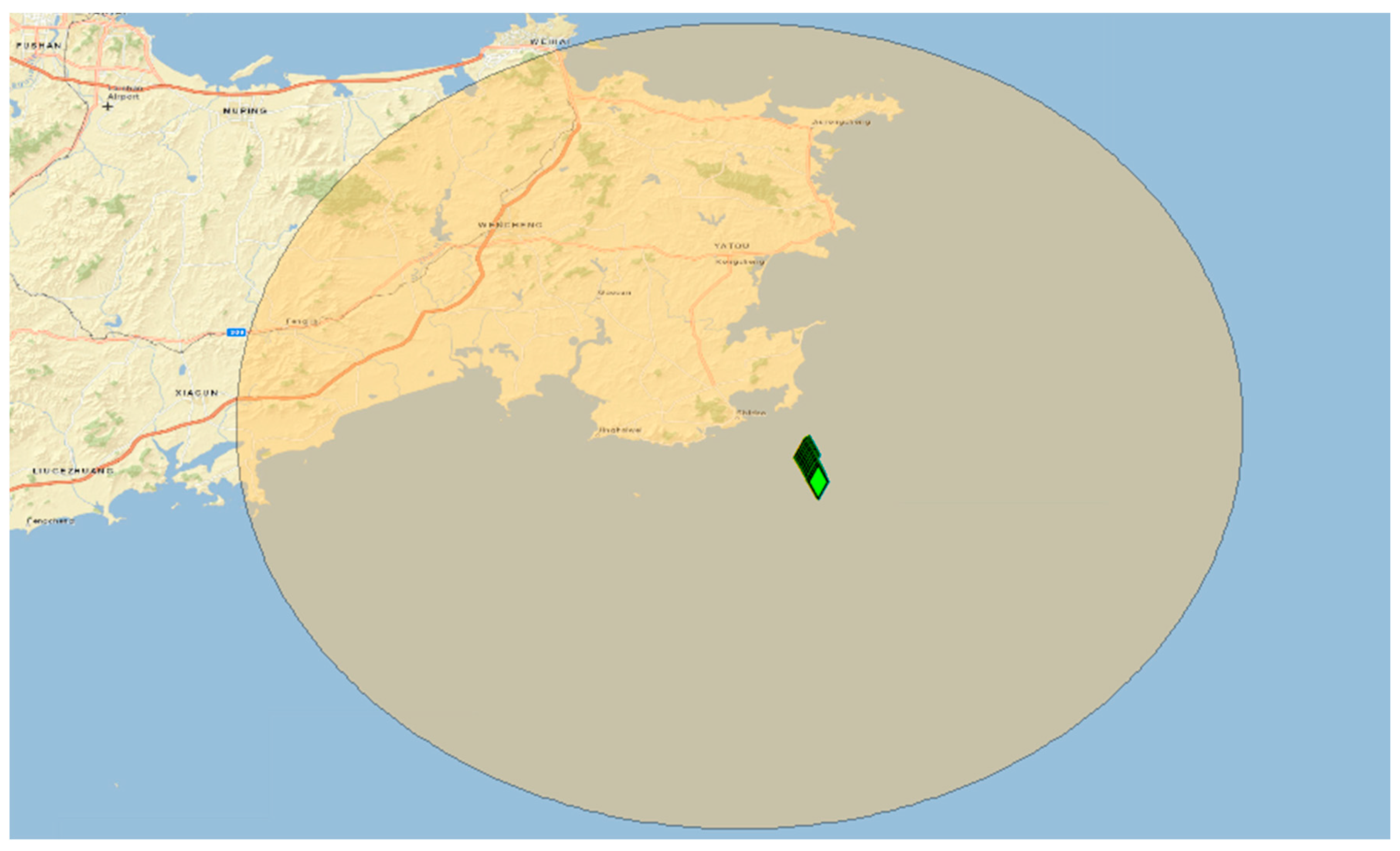
2.6. Case Study: Harvesting Web Information for Maritime Surveillance
2.6.1. Introduction
2.6.2. Methods
3. Results
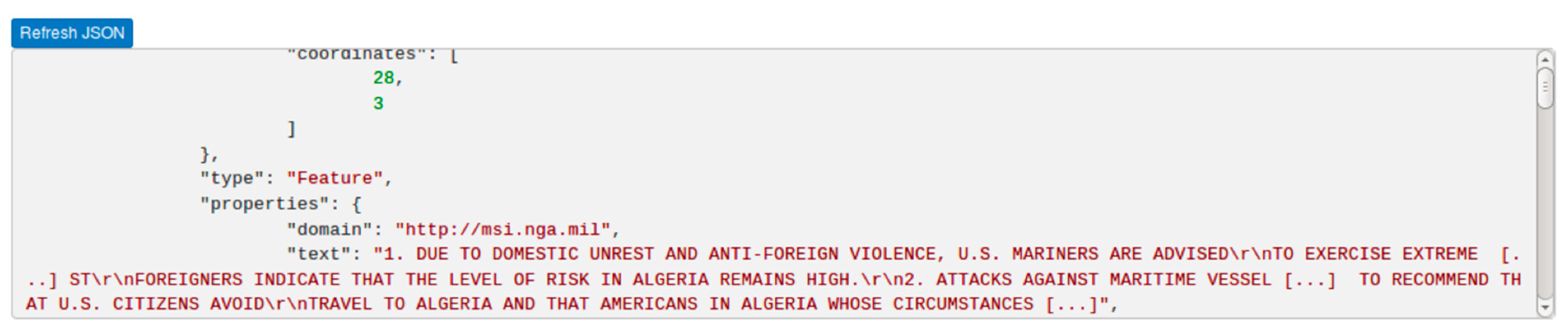
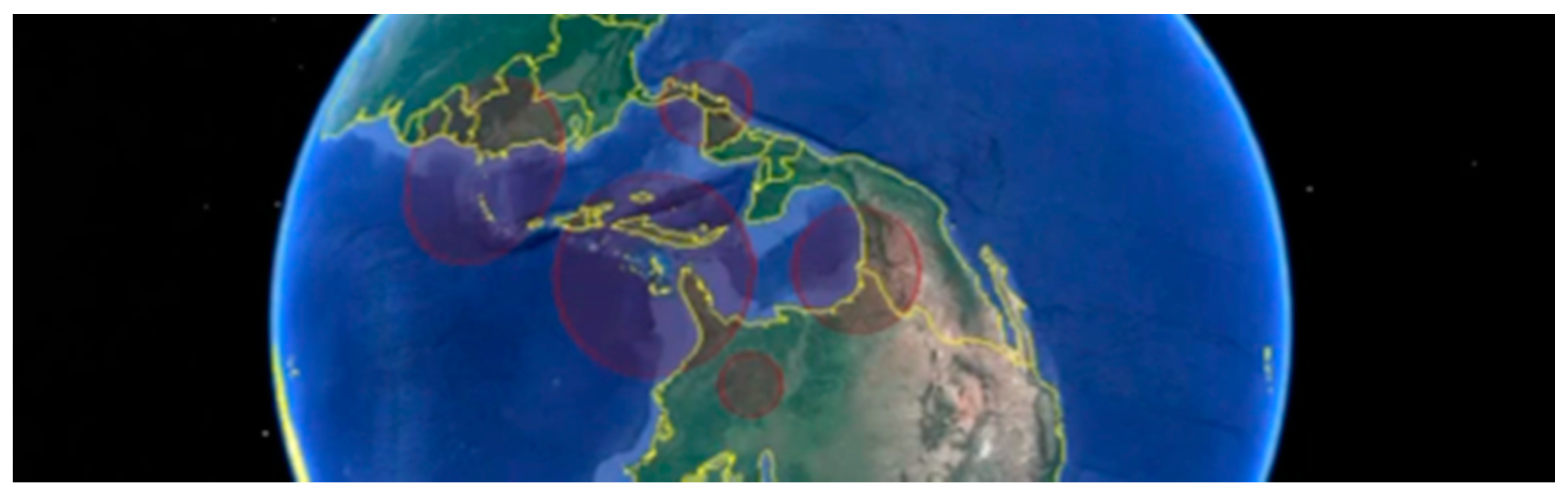
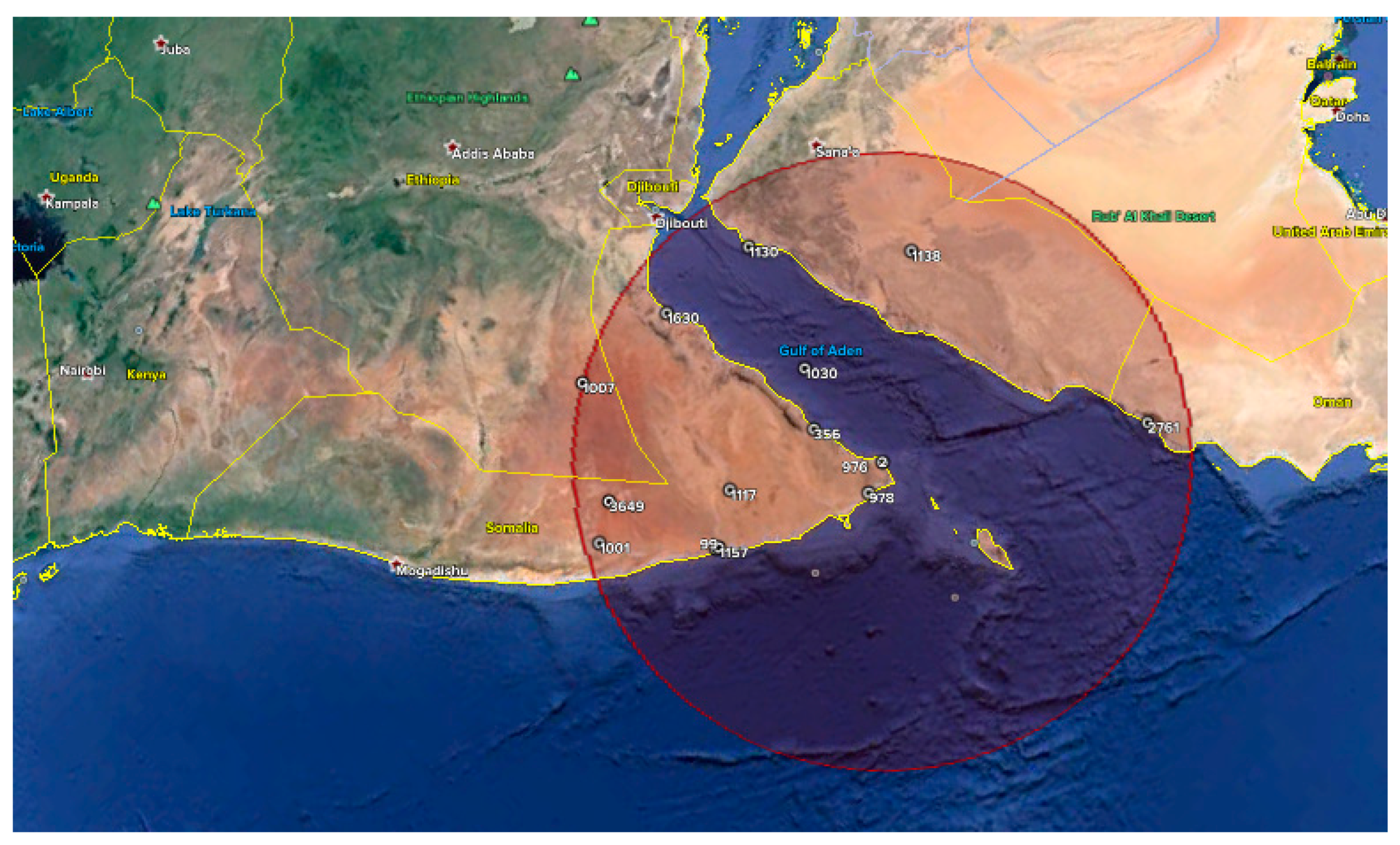
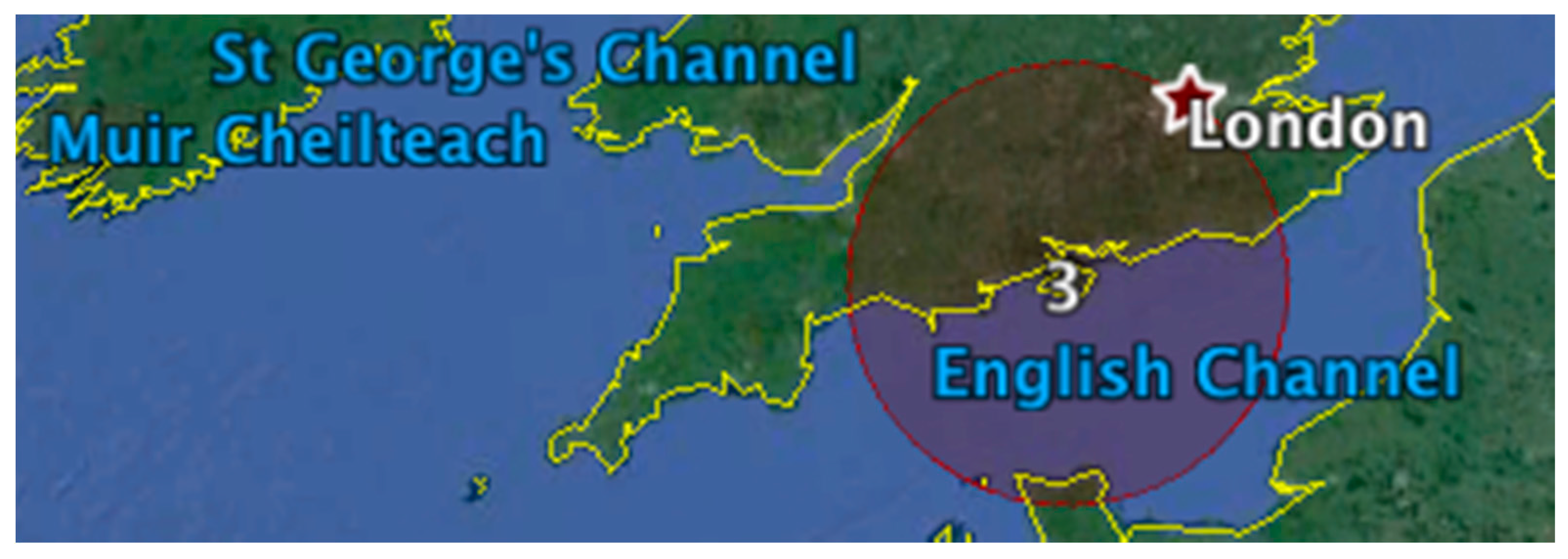
3.1. Toponym Resolution
3.2. Sample Analysis
3.3. Fusion with Authoritative Data
4. Discusssion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Warf, B.; Arias, S. The Spatial Turn: Interdisciplinary Perspectives; Taylor & Francis: New York, NY, USA, 2008. [Google Scholar]
- Berners-Lee, T.; Hall, W.; Hendler, J.; Shadbolt, N.; Weitzner, D.J. Creating a Science of the Web. Science 2006, 313, 769–771. [Google Scholar] [CrossRef] [PubMed]
- Bizer, C. The Emerging Web of Linked Data. IEEE Intell. Syst. 2009, 24, 87–92. [Google Scholar] [CrossRef]
- Kozinets, R.V. Netnography: Doing Ethnographic Research Online; SAGE Publications: London, UK, 2010. [Google Scholar]
- Brovelli, M.A.; Minghini, M.; Molinari, M.; Mooney, P. Towards an Automated Comparison of OpenStreetMap with Authoritative Road Datasets. Trans. GIS 2017, 21, 191–206. [Google Scholar] [CrossRef]
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and Ordnance Survey datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Goodchild, M.F. The quality of big (geo)data. Dialog. Human Geogr. 2013, 3, 280–284. [Google Scholar] [CrossRef]
- Li, L.; Goodchild, M.F.; Xu, B. Spatial, temporal, and socioeconomic patterns in the use of Twitter and Flickr. Cartogr. Geogr. Inf. Sci. 2013, 40, 61–77. [Google Scholar] [CrossRef]
- Hawelka, B.; Sitko, I.; Beinat, E.; Sobolevsky, S.; Kazakopoulos, P.; Ratti, C. Geo-located Twitter as proxy for global mobility patterns. Cartogr. Geogr. Inf. Sci. 2014, 41, 260–271. [Google Scholar] [CrossRef] [PubMed]
- Quercia, D.; Ellis, J.; Capra, L.; Crowcroft, J. Tracking “Gross Community Happiness” from Tweets. In Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work, New York, NY, USA, 11–15 February 2012; ACM: New York, NY, USA, 2012; pp. 965–968. [Google Scholar]
- Mummidi, L.N.; Krumm, J. Discovering points of interest from users’ map annotations. GeoJournal 2008, 72, 215–227. [Google Scholar] [CrossRef]
- Mülligann, C.; Janowicz, K.; Ye, M.; Lee, W.-C. Analyzing the Spatial-Semantic Interaction of Points of Interest in Volunteered Geographic Information. In Spatial Information Theory; Springer: Berlin/Heidelberg, Germany, 2011; pp. 350–370. [Google Scholar]
- MacEachren, A.; Jaiswal, A.; Robinson, A.; Pezanowski, S.; Savelyev, A.; Mitra, P.; Blanford, J. SensePlace2: GeoTwitter analytics support for situational awareness. In Proceedings of the 2011 IEEE Conference on Visual Analytics Science and Technology (VAST), Providence, RI, USA, 23–28 October 2011; pp. 181–190. [Google Scholar]
- Kennedy, L.; Naaman, M.; Ahern, S.; Nair, R.; Rattenbury, T. How flickr helps us make sense of the world: Context and content in community-contributed media collections. In Proceedings of the 15th International Conference on Multimedia, Augsburg, Germany, 23–28 September 2007; ACM: New York, NY, USA, 2007; pp. 631–640. [Google Scholar]
- Rattenbury, T.; Naaman, M. Methods for extracting place semantics from Flickr tags. ACM Trans. Web 2009, 3, 1:1–1:30. [Google Scholar] [CrossRef]
- Feick, R.; Robertson, C. A multi-scale approach to exploring urban places in geotagged photographs. Comput. Environ. Urban Syst. 2014, 53, 96–109. [Google Scholar] [CrossRef]
- Noulas, A.; Mascolo, C.; Frias-Martinez, E. Exploiting Foursquare and Cellular Data to Infer User Activity in Urban Environments. In Proceedings of the 2013 IEEE 14th International Conference on Mobile Data Management, Milan, Italy, 3–6 June 2013; Volume 1, pp. 167–176. [Google Scholar]
- Jones, C.B.; Purves, R.S. Geographical information retrieval. Int. J. Geogr. Inf. Sci. 2008, 22, 219–228. [Google Scholar] [CrossRef]
- Purves, R.S.; Clough, P.; Jones, C.B.; Arampatzis, A.; Bucher, B.; Finch, D.; Yang, B. The design and implementation of SPIRIT: A spatially aware search engine for information retrieval on the Internet. Int. J. Geogr. Inf. Sci. 2007, 21, 717–745. [Google Scholar] [CrossRef]
- Derungs, C.; Palacio, D.; Purves, R.S. Resolving fine granularity toponyms: Evaluation of a disambiguation approach. In Proceedings of the 7th International Conference on Geographic Information Science (GIScience), Columbus, OH, USA, 18–21 September 2012; pp. 1–5. [Google Scholar]
- Croitoru, A.; Crooks, A.; Radzikowski, J.; Stefanidis, A. Geosocial gauge: A system prototype for knowledge discovery from social media. Int. J. Geogr. Inf. Sci. 2013, 27, 2483–2508. [Google Scholar] [CrossRef]
- Holderness, T. Geosocial intelligence. SMART Infrastruct. Facil. Pap. 2014, 33, 17–18. [Google Scholar]
- Stefanidis, A.; Crooks, A.; Radzikowski, J. Harvesting ambient geospatial information from social media feeds. GeoJournal 2013, 78, 319–338. [Google Scholar] [CrossRef]
- De Albuquerque, J.P.; Fan, H.; Zipf, A. A conceptual model for quality assessment of VGI for the purpose of flood management. In Proceedings of the 19th AGILE Conference on Geographic Information Science, Helsinki, Finland, 14–17 June 2016. [Google Scholar]
- Yzaguirre, A.; Smit, M.; Warren, R. Newspaper archives + text mining = rich sources of historical geo-spatial data. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Halifax, NS, Canada, 5–9 October 2015; 2016; Volume 34, p. 12043. [Google Scholar]
- Crampton, J.W.; Graham, M.; Poorthuis, A.; Shelton, T.; Stephens, M.; Wilson, M.W.; Zook, M. Beyond the geotag: Situating “big data” and leveraging the potential of the geoweb. Cartogr. Geogr. Inf. Sci. 2013, 40, 130–139. [Google Scholar] [CrossRef]
- Wagner, M.M.; Moore, A.W.; Aryel, R.M. Handbook of Biosurveillance; Elsevier: London, UK, 2006. [Google Scholar]
- Robertson, C.; Nelson, T.A.; MacNab, Y.C.; Lawson, A.B. Review of methods for space-time disease surveillance. Spat. Spatio-Temporal Epidemiol. 2010, 1, 105–116. [Google Scholar] [CrossRef] [PubMed]
- Brownstein, J.S.; Freifeld, C.C.; Reis, B.Y.; Mandl, K.D. Surveillance Sans Frontières: Internet-Based Emerging Infectious Disease Intelligence and the HealthMap Project. PLoS Med. 2008, 5, e151. [Google Scholar] [CrossRef] [PubMed]
- Freifeld, C.C.; Mandl, K.D.; Reis, B.Y.; Brownstein, J.S. HealthMap: Global infectious disease monitoring through automated classification and visualization of Internet media reports. J. Am. Med. Inf. Assoc. 2008, 15, 150. [Google Scholar] [CrossRef] [PubMed]
- Little, E.G.; Rogova, G.L. Designing ontologies for higher level fusion. Inf. Fusion 2009, 10, 70–82. [Google Scholar] [CrossRef]
- Garcia, J.; Rogova, G. Contextual Knowledge and Information Fusion for Maritime Piracy Surveillance. In NATO Advanced Study Institute (ASI) on Prediction and Recognition of Piracy Efforts Using Collaborative Human-Centric Information Systems; Salamanca: NATO Science for Peace and Security, Sub-Series—E: Human and Societal Dynamics; Ios Press: Amsterdam, The Netherlands, 2013; Volume 109, pp. 80–88. [Google Scholar]
- Miller, H.J.; Goodchild, M.F. Data-driven geography. GeoJournal 2015, 80, 449–461. [Google Scholar] [CrossRef]
- Sinton, D. The inherent structure of information as a constraint to analysis: Mapped thematic data as a case study. Harv. Pap. Geogr. Inf. Syst. 1978, 6, 1–17. [Google Scholar]
- Peuquet, D. It’s about time: A conceptual framework for the representation of temporal dynamics in geographic information systems. Ann. Assoc. Am. Geogr. 1994, 84, 441–461. [Google Scholar] [CrossRef]
- Mennis, J.L.; Peuquet, D.J.; Qian, L. A conceptual framework for incorporating cognitive principles into geographical database representation. Int. J. Geogr. Inf. Sci. 2000, 14, 501–520. [Google Scholar] [CrossRef]
- United Nations Conference on Trade and Development (UNCTAD). Review of Maritime Transport; United Nations: Geneva, Switzerland, 2011; p. 229. [Google Scholar]
- Kazemi, S.; Abghari, S.; Lavesson, N.; Johnson, H.; Ryman, P. Open data for anomaly detection in maritime surveillance. Expert Syst. Appl. 2013, 40, 5719–5729. [Google Scholar] [CrossRef]
- Cheong, M.; Lee, V.C.S. A microblogging-based approach to terrorism informatics: Exploration and chronicling civilian sentiment and response to terrorism events via Twitter. Inf. Syst. Front. 2011, 13, 45–59. [Google Scholar] [CrossRef]
- Kulldorff, M.; Nagarwalla, N. Spatial disease clusters: detection and inference. Stat. Med. 1995, 14, 799–810. [Google Scholar] [CrossRef] [PubMed]
- Kulldorff, M.; Heffernan, R.; Hartman, J.; Assuncao, R.M.; Mostashari, F. A space-time permutation scan statistic for disease outbreak detection. PLoS Med. 2005, 2, e59. [Google Scholar] [CrossRef] [PubMed]
- MacEachren, A.M.; Kraak, M.-J. Research Challenges in Geovisualization. Cartogr. Geogr. Inf. Sci. 2001, 28, 3–12. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N.; Demsar, U.; Dransch, D.; Dykes, J.; Fabrikant, S.I.; Tominski, C. Space, time and visual analytics. Int. J. Geogr. Inf. Sci. 2010, 24, 1577–1600. [Google Scholar] [CrossRef]
- Peng, P.; Chen, H.; Shou, L.; Chen, K.; Chen, G.; Xu, C. DeepCamera: A Unified Framework for Recognizing Places-of-Interest Based on Deep ConvNets. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; ACM: New York, NY, USA, 2015; pp. 1891–1894. [Google Scholar]
- Zhu, Y.; Newsam, S. Land Use Classification Using Convolutional Neural Networks Applied to Ground-level Images. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015; ACM: New York, NY, USA, 2015; pp. 61:1–61:4. [Google Scholar]
- Rauch, E.; Bukatin, M.; Baker, K. A Confidence-based Framework for Disambiguating Geographic Terms. In Proceedings of the HLT-NAACL 2003 Workshop on Analysis of Geographic References, Edmonton, AB, Canada, 31 May 2003; Association for Computational Linguistics: Stroudsburg, PA, USA, 2003; Volume 1, pp. 50–54. [Google Scholar]
- Smith, D.A.; Crane, G. Disambiguating Geographic Names in a Historical Digital Library. In Research and Advanced Technology for Digital Libraries; Constantopoulos, P., Sølvberg, I.T., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 127–136. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Keywords | Toponym Recognized | Correct (Yes/No) | Relevant (Yes/No) |
|---|---|---|---|---|
| 554 | chemical, freight | China | yes | yes |
| 446 | accident, alarm, death | Black Sea | yes | yes |
| 1213 | delay, oil | Panama | yes | yes |
| 457 | Cruise | Antarctica | yes | yes |
| 1016 | death, incident, pirate | United States | no | no |
| 380 | attack, cruise, incident | Fort Lauderdale, FL, USA | yes | yes |
| 808 | cargo, chemical, crash, oil, spill | Houston, TX, USA | yes | yes |
| 1169 | harbour, oil | United States | no | no |
| 877 | Cruise | New Jersey, USA | yes | yes |
| 183 | explosion, fire, oil, spill | Florida, USA | yes | yes |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Robertson, C.; Horrocks, K. Spatial Context from Open and Online Processing (SCOOP): Geographic, Temporal, and Thematic Analysis of Online Information Sources. ISPRS Int. J. Geo-Inf. 2017, 6, 193. https://doi.org/10.3390/ijgi6070193
Robertson C, Horrocks K. Spatial Context from Open and Online Processing (SCOOP): Geographic, Temporal, and Thematic Analysis of Online Information Sources. ISPRS International Journal of Geo-Information. 2017; 6(7):193. https://doi.org/10.3390/ijgi6070193
Chicago/Turabian StyleRobertson, Colin, and Kevin Horrocks. 2017. "Spatial Context from Open and Online Processing (SCOOP): Geographic, Temporal, and Thematic Analysis of Online Information Sources" ISPRS International Journal of Geo-Information 6, no. 7: 193. https://doi.org/10.3390/ijgi6070193
APA StyleRobertson, C., & Horrocks, K. (2017). Spatial Context from Open and Online Processing (SCOOP): Geographic, Temporal, and Thematic Analysis of Online Information Sources. ISPRS International Journal of Geo-Information, 6(7), 193. https://doi.org/10.3390/ijgi6070193