Robust and Parameter-Free Algorithm for Constructing Pit-Free Canopy Height Models



Abstract
:1. Introduction
2. Related Work
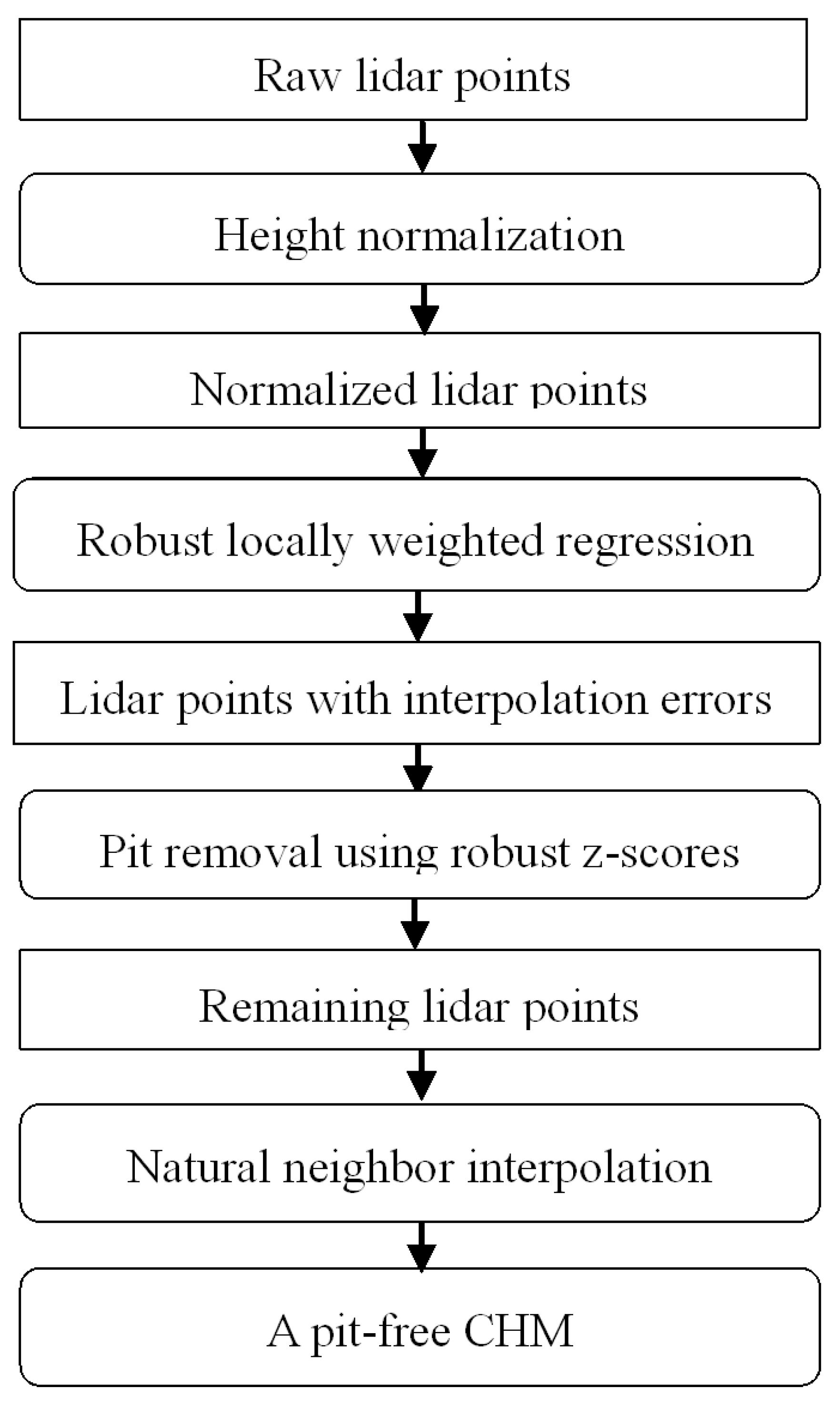
3. Principle of the Proposed Algorithm
3.1. RLWR
- (i)
- Finding the k nearest neighbors of xi from the point cloud. Here, we set k = 12.
- (ii)
- Computing the weights of based on the distance weight function, i.e., Equation (2), where .
- (iii)
- Estimating the polynomial coefficients by minimizing the objective function of LWR, i.e., Equation (3). Here, the linear polynomial is used.
- (iv)
- Estimating at with the computed polynomial coefficients.
- (v)
- Computing the regression residuals for , i.e., .
- (vi)
- Computing the robust weights of based on the robust weight function, i.e., Equation (4).
- (vii)
- Estimating the polynomial coefficients by minimizing the objective function of RLWR, i.e., Equation (5).
- (viii)
- Repeating (v)–(vii) until the polynomial coefficients are stable, or the maximum number of iteration is reached. Cleveland [24] indicated that two iterations are sufficient to obtain a good fit.
- (ix)
- Estimating at with the computed polynomial coefficients. The interpolation error of is expressed as, .
3.2. Pit Detection Using Robust Z-Scores
4. Experiments
4.1. Numerical Test
- (i)
- 1000 points subject to the condition of are randomly sampled from the model, e.g., cone. The average point space is 0.056.
- (ii)
- n data pits are randomly selected and their heights are artificially changed, i.e., their elevations are reduced by 0.3. Here, n = 100 or 200; the contaminating proportion (α) is 10% or 20%.
- (iii)
- Our method and the three other pit-free methods (mean filter, median filter, and HPM) are used to construct CHMs with the contaminated data set.
- (iv)
- Taking the original sample points as check points, the CHMs are assessed in terms of root mean square error (RMSE) and mean error (ME). These are expressed as:where and are the true and simulated values, respectively, at the i-th check point and m is the number of check points, i.e., m = 1000.
4.2. Real-World Example
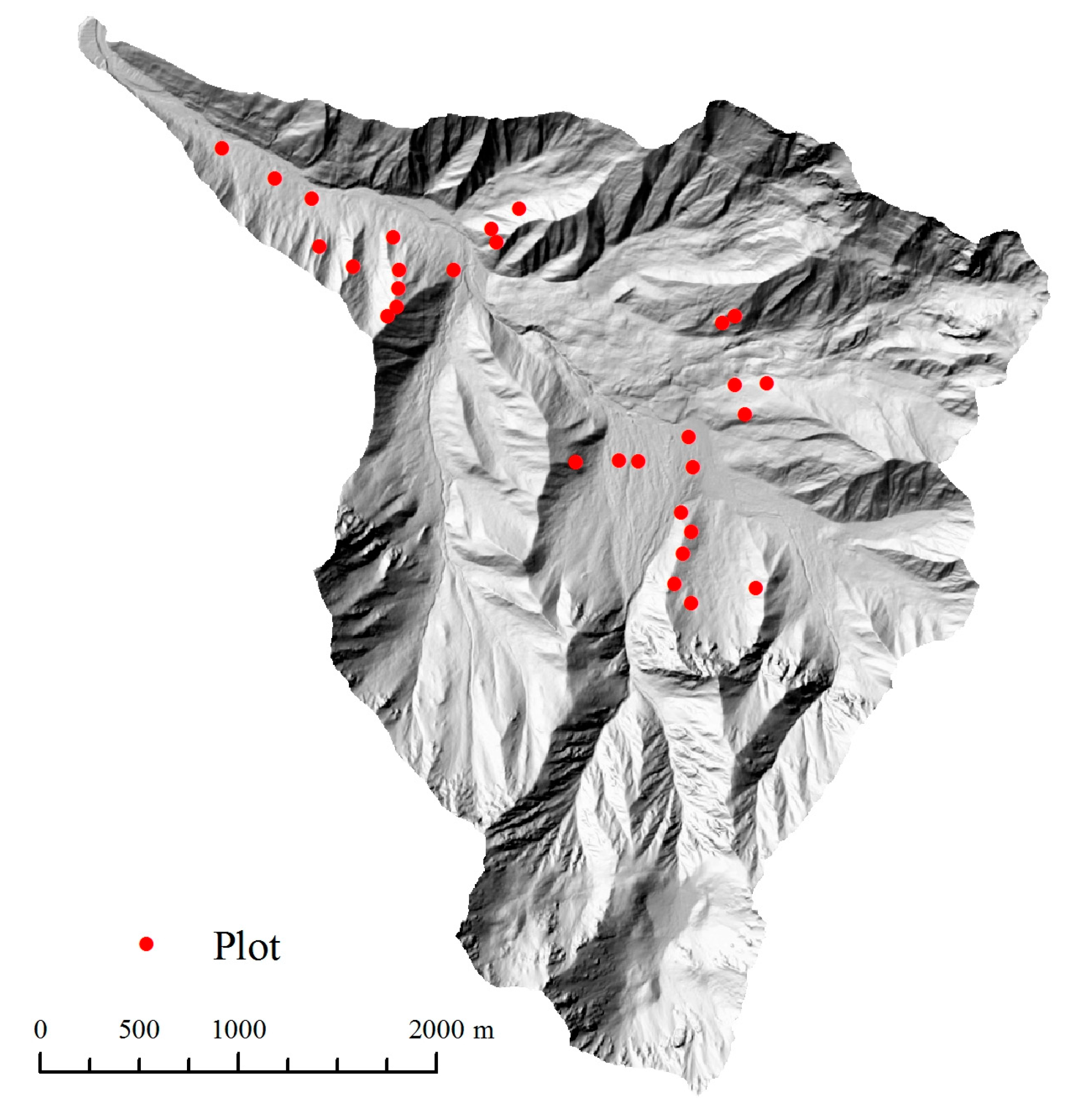
4.2.1. Study Site and Raw Data Sets
4.2.2. Data Processing
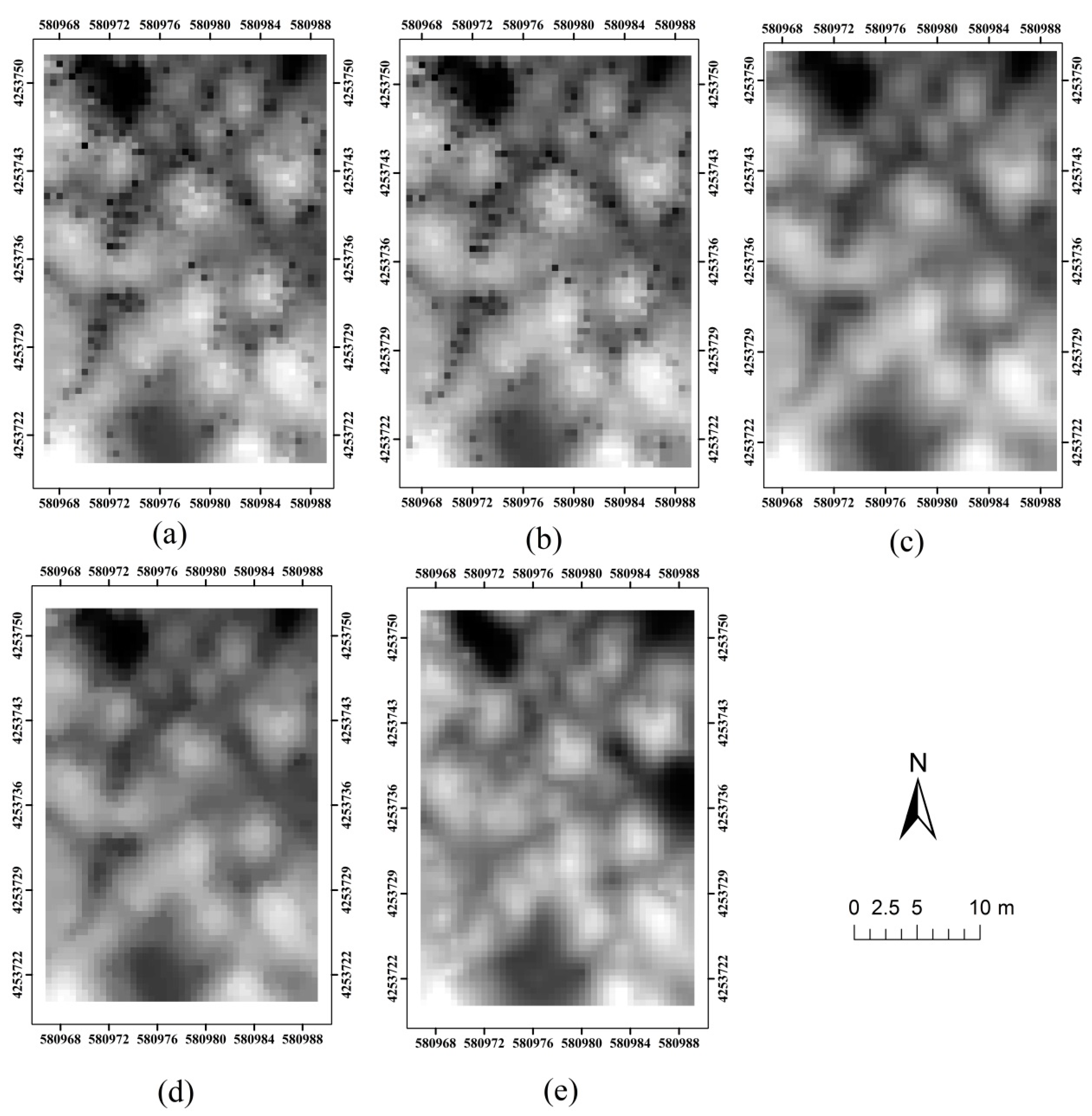
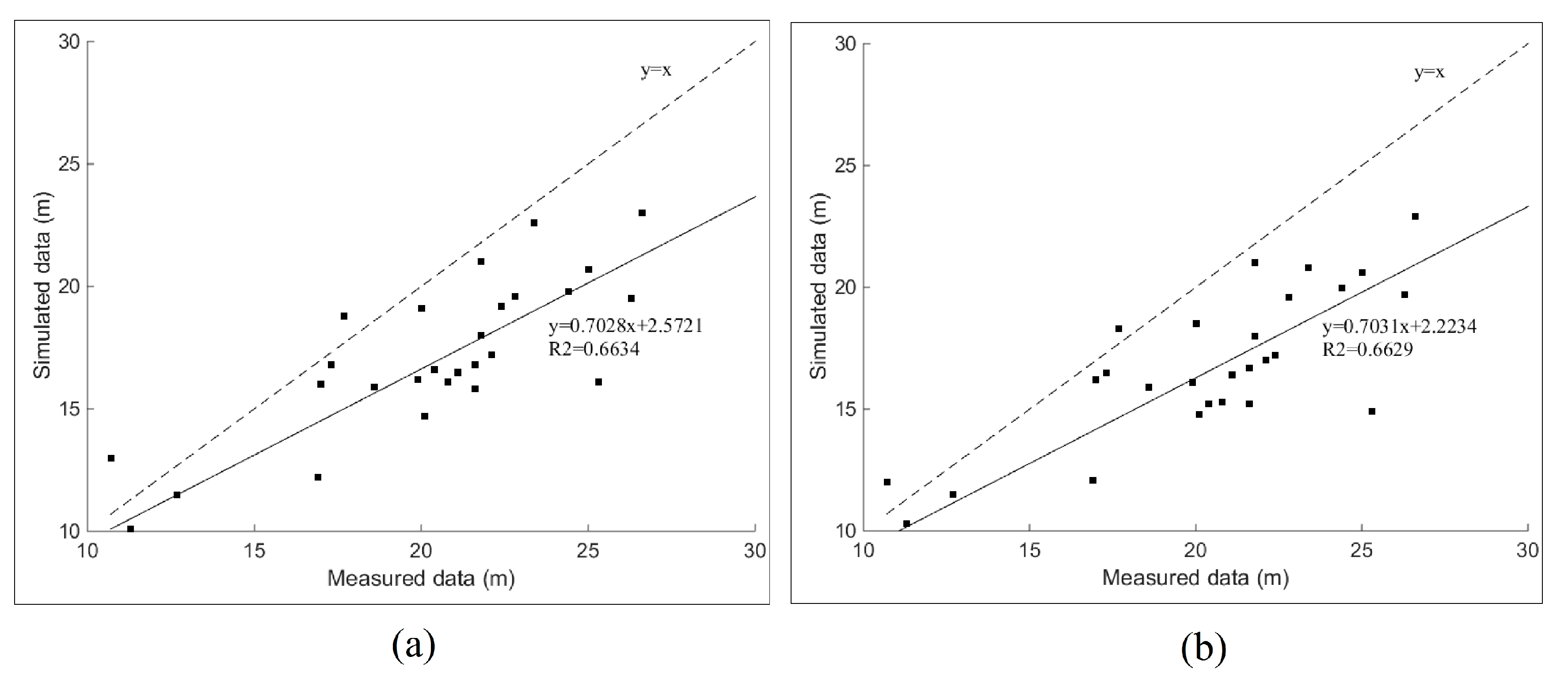
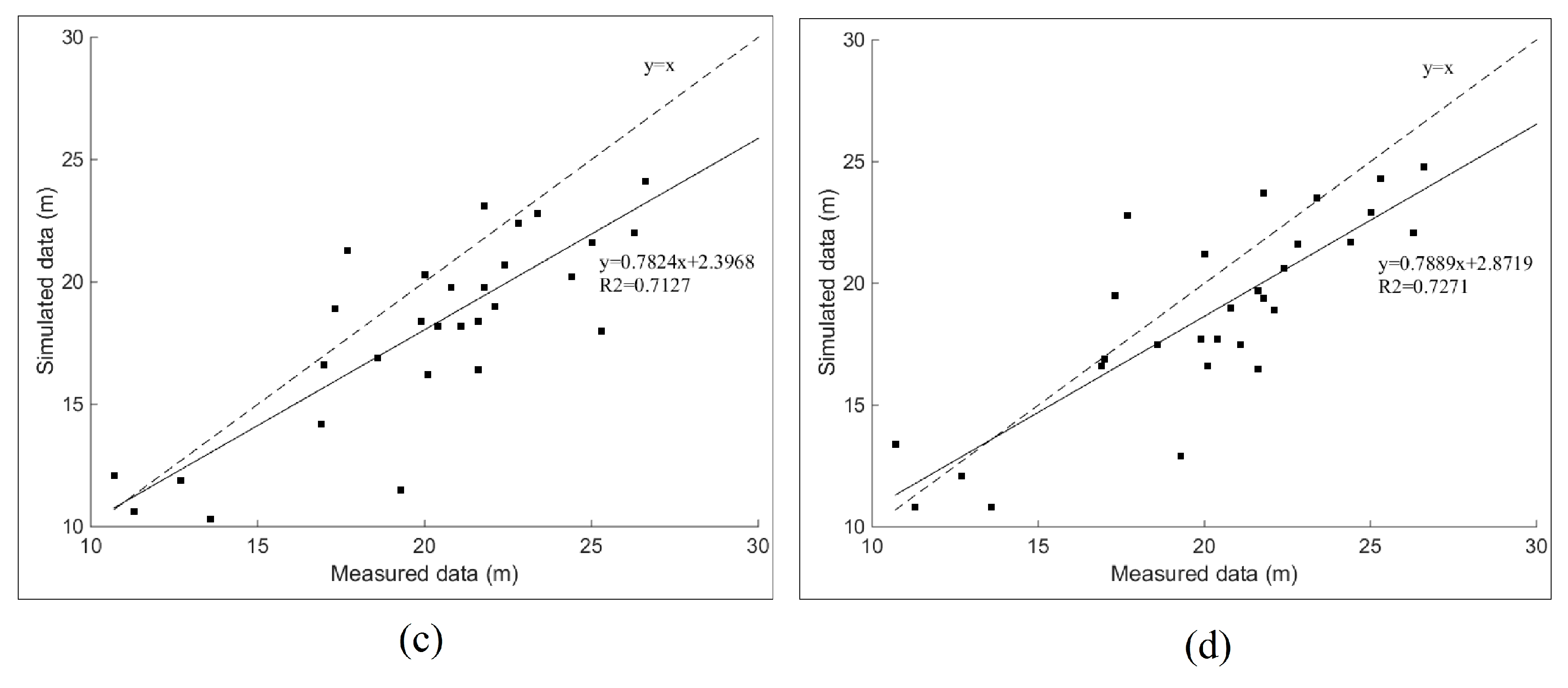
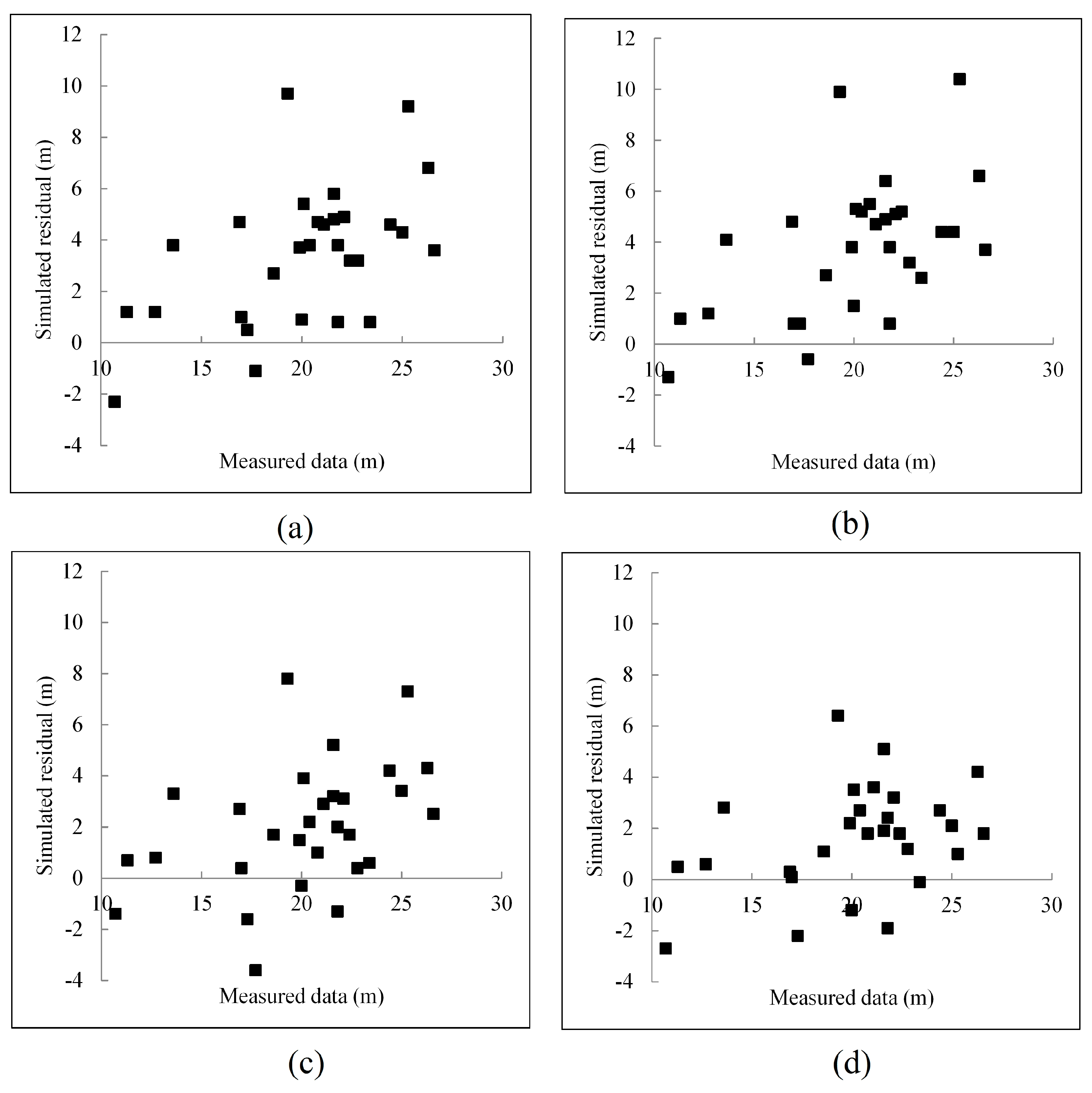
4.2.3. Results
5. Discussion and Conclusions
5.1. Discussion
5.2. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hyyppä, J.; Yu, X.; Hyyppä, H.; Vastaranta, M.; Holopainen, M.; Kukko, A.; Kaartinen, H.; Jaakkola, A.; Vaaja, M.; Koskinen, J. Advances in forest inventory using airborne laser scanning. Remote Sens. 2012, 4, 1190–1207. [Google Scholar] [CrossRef]
- Kato, A.; Moskal, L.M.; Schiess, P.; Swanson, M.E.; Calhoun, D.; Stuetzle, W. Capturing tree crown formation through implicit surface reconstruction using airborne lidar data. Remote Sens. Environ. 2009, 113, 1148–1162. [Google Scholar] [CrossRef]
- Popescu, S.C.; Wynne, R.H.; Nelson, R.F. Estimating plot-level tree heights with lidar: Local filtering with a canopy-height based variable window size. Comput. Electron. Agric. 2002, 37, 71–95. [Google Scholar] [CrossRef]
- Hyyppä, J.; Kelle, O.; Lehikoinen, M.; Inkinen, M. A segmentation-based method to retrieve stem volume estimates from 3-d tree height models produced by laser scanners. IEEE Trans. Geosci. Remote Sens. 2001, 39, 969–975. [Google Scholar] [CrossRef]
- Pouliot, D.; King, D.; Bell, F.; Pitt, D. Automated tree crown detection and delineation in high-resolution digital camera imagery of coniferous forest regeneration. Remote Sens. Environ. 2002, 82, 322–334. [Google Scholar] [CrossRef]
- Brandtberg, T.; Warner, T.A.; Landenberger, R.E.; McGraw, J.B. Detection and analysis of individual leaf-off tree crowns in small footprint, high sampling density lidar data from the eastern deciduous forest in north america. Remote Sens. Environ. 2003, 85, 290–303. [Google Scholar] [CrossRef]
- Koch, B.; Heyder, U.; Weinacker, H. Detection of individual tree crowns in airborne lidar data. Photogramm. Eng. Remote Sens. 2006, 72, 357–363. [Google Scholar] [CrossRef]
- Popescu, S.C.; Wynne, R.H. Seeing the trees in the forest: Using lidar and multispectral data fusion with local filtering and variable window size for estimating tree height. Photogramm. Eng. Remote Sens. 2004, 70, 589–604. [Google Scholar] [CrossRef]
- Persson, A.; Holmgren, J.; Söderman, U. Detecting and measuring individual trees using an airborne laser scanner. Photogramm. Eng. Remote Sens. 2002, 68, 925–932. [Google Scholar]
- Nilsson, M. Estimation of tree heights and stand volume using an airborne lidar system. Remote Sens. Environ. 1996, 56, 1–7. [Google Scholar] [CrossRef]
- Bortolot, Z.J.; Wynne, R.H. Estimating forest biomass using small footprint lidar data: An individual tree-based approach that incorporates training data. ISPRS J. Photogramm. Remote Sens. 2005, 59, 342–360. [Google Scholar] [CrossRef]
- Popescu, S.C. Estimating biomass of individual pine trees using airborne lidar. Biomass Bioenergy 2007, 31, 646–655. [Google Scholar] [CrossRef]
- Naesset, E. Determination of mean tree height of forest stands using airborne laser scanner data. ISPRS J. Photogramm. Remote Sens. 1997, 52, 49–56. [Google Scholar] [CrossRef]
- Leckie, D.; Gougeon, F.; Hill, D.; Quinn, R.; Armstrong, L.; Shreenan, R. Combined high-density lidar and multispectral imagery for individual tree crown analysis. Can. J. Remote Sens. 2003, 29, 633–649. [Google Scholar] [CrossRef]
- Ben-Arie, J.R.; Hay, G.J.; Powers, R.P.; Castilla, G.; St-Onge, B. Development of a pit filling algorithm for lidar canopy height models. Comput. Geosci. 2009, 35, 1940–1949. [Google Scholar] [CrossRef]
- Vosselman, G. Analysis of planimetric accuracy of airborne laser scanning surveys. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2008, 37, 99–104. [Google Scholar]
- Bater, C.W.; Coops, N.C. Evaluating error associated with lidar-derived DEM interpolation. Comput. Geosci. 2009, 35, 289–300. [Google Scholar] [CrossRef]
- Gaveau, D.L.A.; Hill, R.A. Quantifying canopy height underestimation by laser pulse penetration in small-footprint airborne laser scanning data. Can. J. Remote Sens. 2003, 29, 650–657. [Google Scholar] [CrossRef]
- Khosravipour, A.; Skidmore, A.K.; Isenburg, M.; Wang, T.; Hussin, Y.A. Generating pit-free canopy height models from airborne lidar. Photogramm. Eng. Remote Sens. 2014, 80, 863–872. [Google Scholar] [CrossRef]
- Zhao, D.; Pang, Y.; Li, Z.; Sun, G. Filling invalid values in a lidar-derived canopy height model with morphological crown control. Int. J. Remote Sens. 2013, 34, 4636–4654. [Google Scholar] [CrossRef]
- Shamsoddini, A.; Turner, R.; Trinder, J. Improving lidar-based forest structure mapping with crown-level pit removal. J. Spat. Sci. 2013, 58, 29–51. [Google Scholar] [CrossRef]
- Liu, H.; Dong, P. A new method for generating canopy height models from discrete-return lidar point clouds. Remote Sens. Lett. 2014, 5, 575–582. [Google Scholar] [CrossRef]
- Nurunnabi, A.; West, G.; Belton, D. Robust locally weighted regression techniques for ground surface points filtering in mobile laser scanning three dimensional point cloud data. IEEE Trans. Geosci. Remote Sens. 2015, 54, 2181–2193. [Google Scholar] [CrossRef]
- Cleveland, W.S. Robust locally weighted regression and smoothing scatterplots. J. Am. Stat. Assoc. 1979, 74, 829–836. [Google Scholar] [CrossRef]
- Cleveland, W.S.; Devlin, S.J. Locally weighted regression: An approach to regression analysis by local fitting. J. Am. Stat. Assoc. 1988, 83, 596–610. [Google Scholar] [CrossRef]
- Fan, J.; Gijbels, I. Local Polynomial Modelling and Its Applications; CRC Press: London, UK, 1996. [Google Scholar]
- Rousseeuw, P.J.; Hubert, M. Robust statistics for outlier detection. WIRES. Data Min. Knowl. Discov. 2011, 1, 73–79. [Google Scholar] [CrossRef]
- Dong, P. Characterization of individual tree crowns using three-dimensional shape signatures derived from lidar data. Int. J. Remote Sens. 2009, 30, 6621–6628. [Google Scholar] [CrossRef]
- Chen, Q.; Baldocchi, D.; Gong, P.; Kelly, M. Isolating individual trees in a savanna woodland using small footprint lidar data. Photogramm. Eng. Remote Sens. 2006, 72, 923–932. [Google Scholar] [CrossRef]
- Chow, T.E.; Hodgson, M.E. Effects of lidar post-spacing and dem resolution to mean slope estimation. Int. J. Geogr. Inf. Sci. 2009, 23, 1277–1295. [Google Scholar] [CrossRef]
- Rizaev, I.G.; Pogorelov, A.V.; Krivova, M.A. A technique to increase the efficiency of artefacts identification in lidar-based canopy height models. Int. J. Remote Sens. 2016, 37, 1658–1670. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy Measure | Cone | Hemisphere | On Average | ||
|---|---|---|---|---|---|---|
| α = 10% | α = 20% | α = 10% | α = 20% | |||
| Raw CHM | RMSE | 0.0401 | 0.0566 | 0.0642 | 0.0821 | 0.0608 |
| ME | 0.0292 | 0.0554 | 0.0243 | 0.0651 | 0.0435 | |
| HPM | RMSE | 0.0365 | 0.0502 | 0.0461 | 0.0575 | 0.0476 |
| ME | 0.0173 | 0.0351 | 0.0133 | 0.0276 | 0.0233 | |
| Mean | RMSE | 0.0259 | 0.0362 | 0.0508 | 0.0471 | 0.0400 |
| ME | 0.0292 | 0.0553 | 0.0265 | 0.0622 | 0.0433 | |
| Median | RMSE | 0.0242 | 0.0354 | 0.0485 | 0.0470 | 0.0388 |
| ME | 0.0269 | 0.0516 | 0.0160 | 0.0493 | 0.0360 | |
| Our method | RMSE | 0.0130 | 0.0144 | 0.0303 | 0.0322 | 0.0225 |
| ME | −0.0015 | −0.0018 | −0.0015 | −0.0006 | −0.0014 | |
| HPM | Mean | Median | Our Method | |
|---|---|---|---|---|
| ME | 2.1 | 3.5 | 3.9 | 1.4 |
| Std | 2.5 | 2.7 | 2.7 | 2.1 |
| Max | 7.8 | 9.7 | 10.4 | 6.4 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Wang, Y.; Li, Y.; Yue, T.; Wang, X. Robust and Parameter-Free Algorithm for Constructing Pit-Free Canopy Height Models. ISPRS Int. J. Geo-Inf. 2017, 6, 219. https://doi.org/10.3390/ijgi6070219
Chen C, Wang Y, Li Y, Yue T, Wang X. Robust and Parameter-Free Algorithm for Constructing Pit-Free Canopy Height Models. ISPRS International Journal of Geo-Information. 2017; 6(7):219. https://doi.org/10.3390/ijgi6070219
Chicago/Turabian StyleChen, Chuanfa, Yifu Wang, Yanyan Li, Tianxiang Yue, and Xin Wang. 2017. "Robust and Parameter-Free Algorithm for Constructing Pit-Free Canopy Height Models" ISPRS International Journal of Geo-Information 6, no. 7: 219. https://doi.org/10.3390/ijgi6070219
APA StyleChen, C., Wang, Y., Li, Y., Yue, T., & Wang, X. (2017). Robust and Parameter-Free Algorithm for Constructing Pit-Free Canopy Height Models. ISPRS International Journal of Geo-Information, 6(7), 219. https://doi.org/10.3390/ijgi6070219