
Identifying and Analyzing the Prevalent Regions of a Co-Location Pattern Using Polygons Clustering Approach

Abstract
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
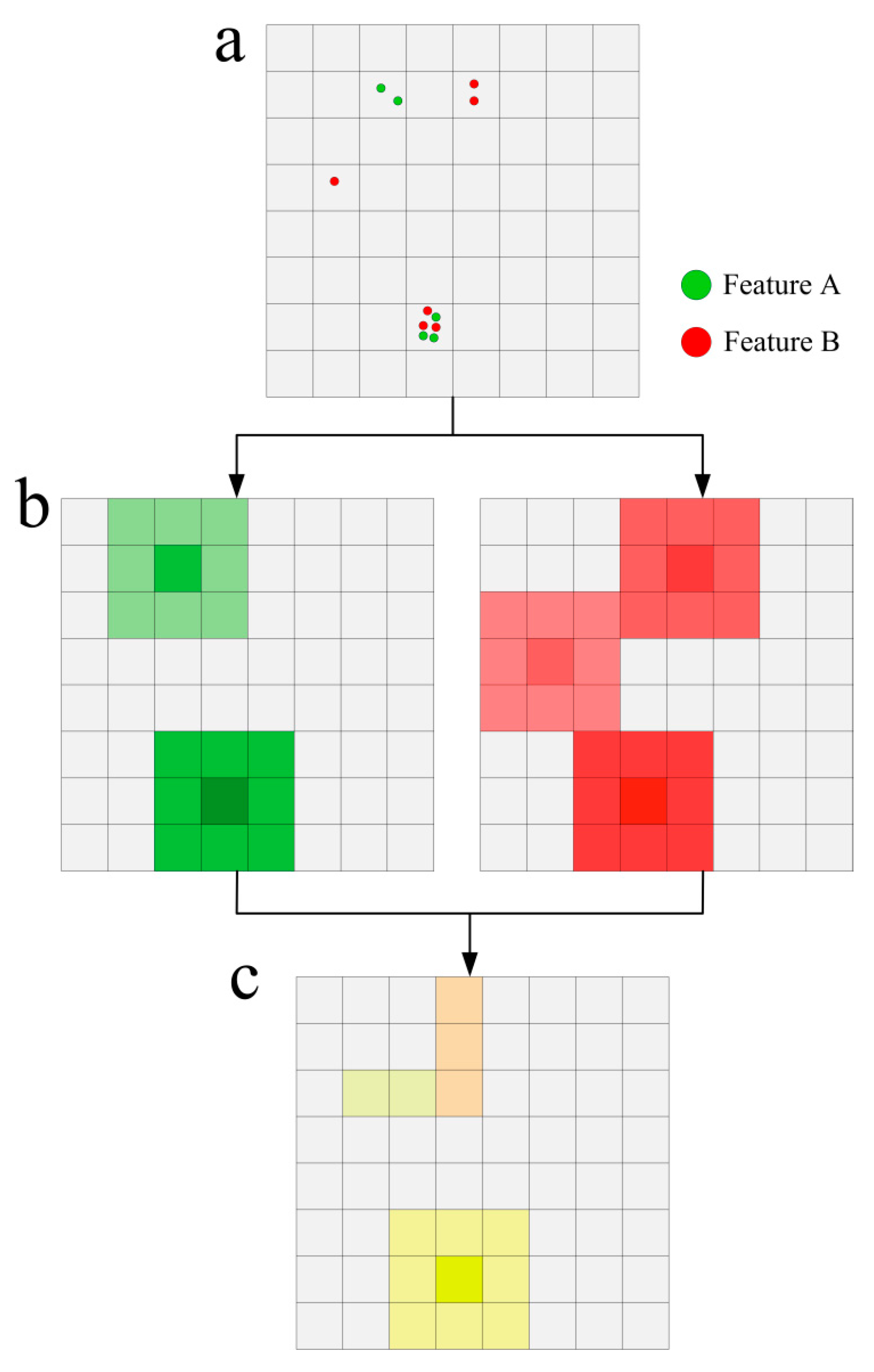
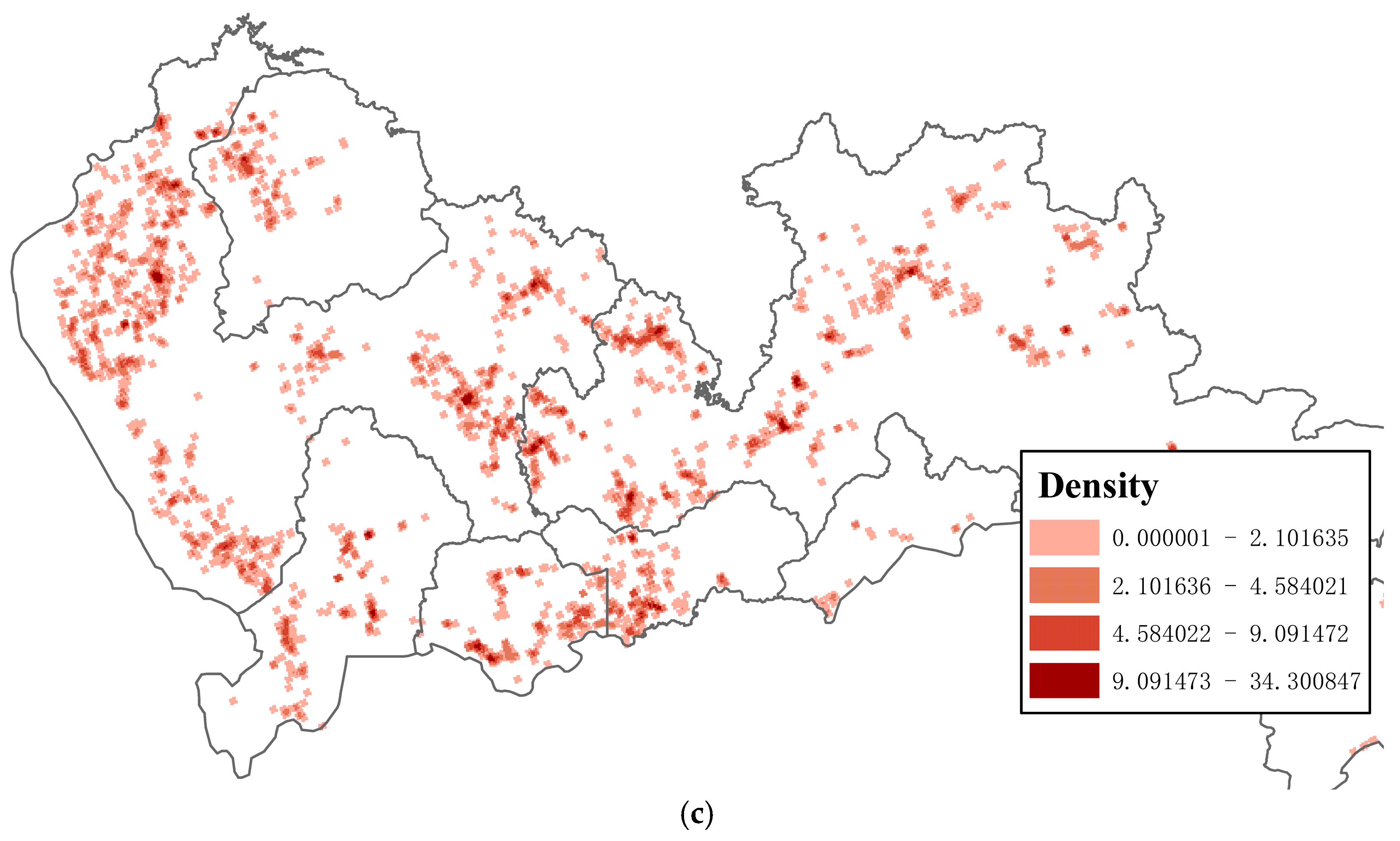
- Spatial heterogeneous characteristics of a co-location pattern are often neglected in previous methods [3,4,24]. They extracted co-location itemsets by measuring the prevalence of co-occurrence of spatial features in the whole study region. It is believed that many geographic processes and relations have spatial extent and should be represented by polygons in spatial database (e.g., pollution hotspots and mixed urban functional areas) [25,26]. In this paper, we propose to use kernel density estimation (KDE) to find the prevalent regions (or polygons) of a co-location pattern. Instead of using KDE for extracting frequent itemsets [27], we show that delimitating the prevalent regions of a co-location pattern can also be achieved using KDE. KDE is useful in our context as it can facilitate the representation of a co-location pattern by tessellating the study region into continuous basic units with prevalence attribute.
- In the real world, a subset of spatial features may be only prevalent in some local areas. These regions and the associated patterns are often influenced by different factors, e.g., spatial interactions and environmental variables. Existing approaches focus on the co-location scoping or the prevalent regions identifying [7,8], lacking of further support of classifying these regions to find the shared common cause(s) between them. In this paper, we investigate the contextual variables in order to develop a comprehensive understanding of the pattern at work. We propose a polygon-based clustering approach. The approach is an extension of the point-based clustering solution. It first generates polygons from multiple point datasets using KDE techniques. Then, it employs a density-based clustering algorithm with polygonal dissimilarity function to cluster the polygons which correspond to the prevalent regions of the pattern of interest. Although Flouvat et al. [2] also introduced a point-based clustering approach to summarize co-locations, their approach is based only on the location-based variable. The polygonal dissimilarity function used in our approach incorporates both location-based and contextual variables to measure the distance between prevalent regions.
2. Polygons Clustering and Analysis for Mining Co-Location Patterns
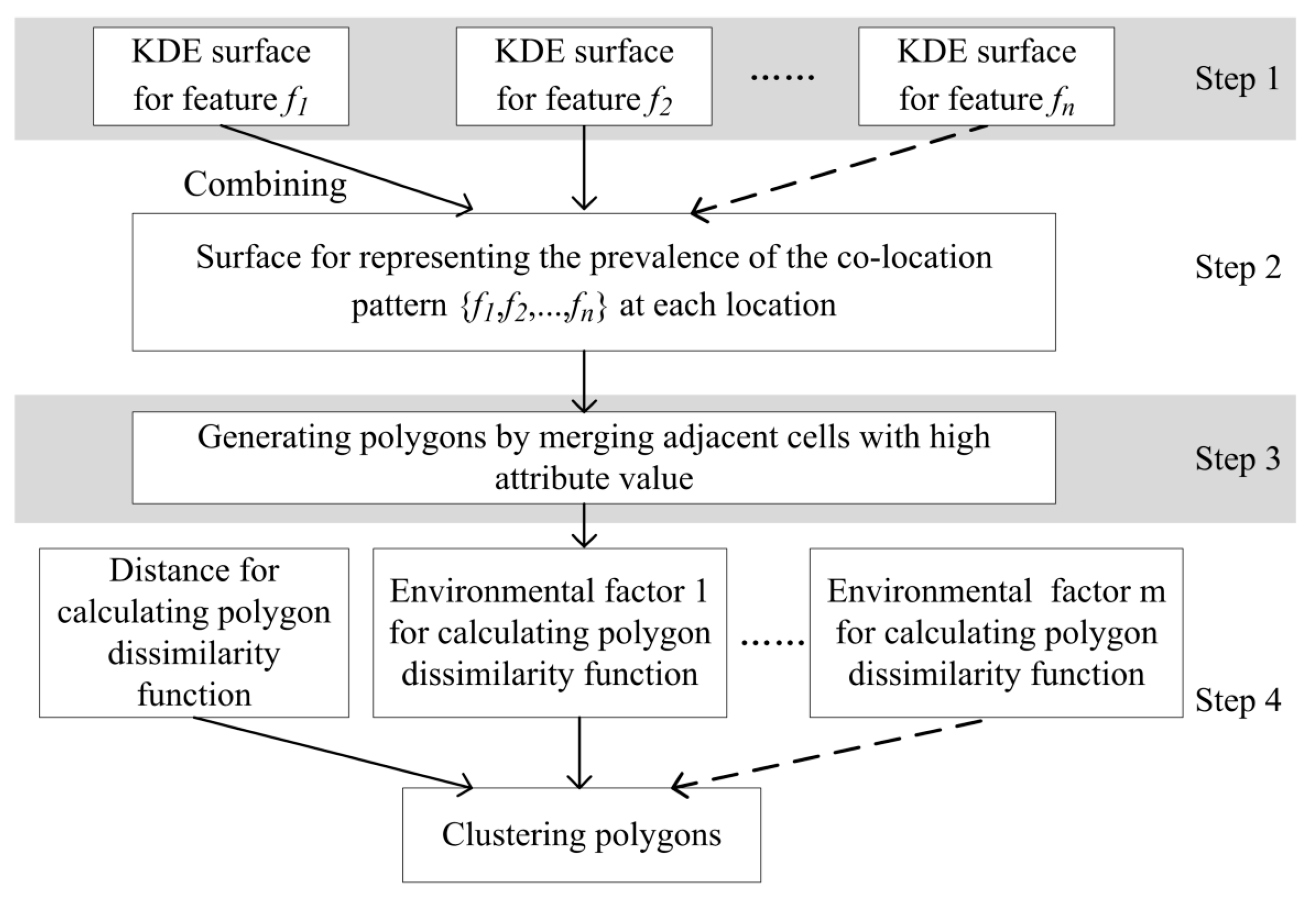
2.1. Framework
- Step 1.
- Generate a KDE surface for each feature evolving in the given pattern {f1, f2, …, fk} (Section 2.2). After this step, multiple grids with density attribute are achieved for representing the intensity distribution of events.
- Step 2.
- Combine multiple KDE surfaces into a final surface with prevalence attribute, which represents the prevalence or strength of the pattern at different locations (Section 2.3). In this step, the local prevalence measure is implemented.
- Step 3.
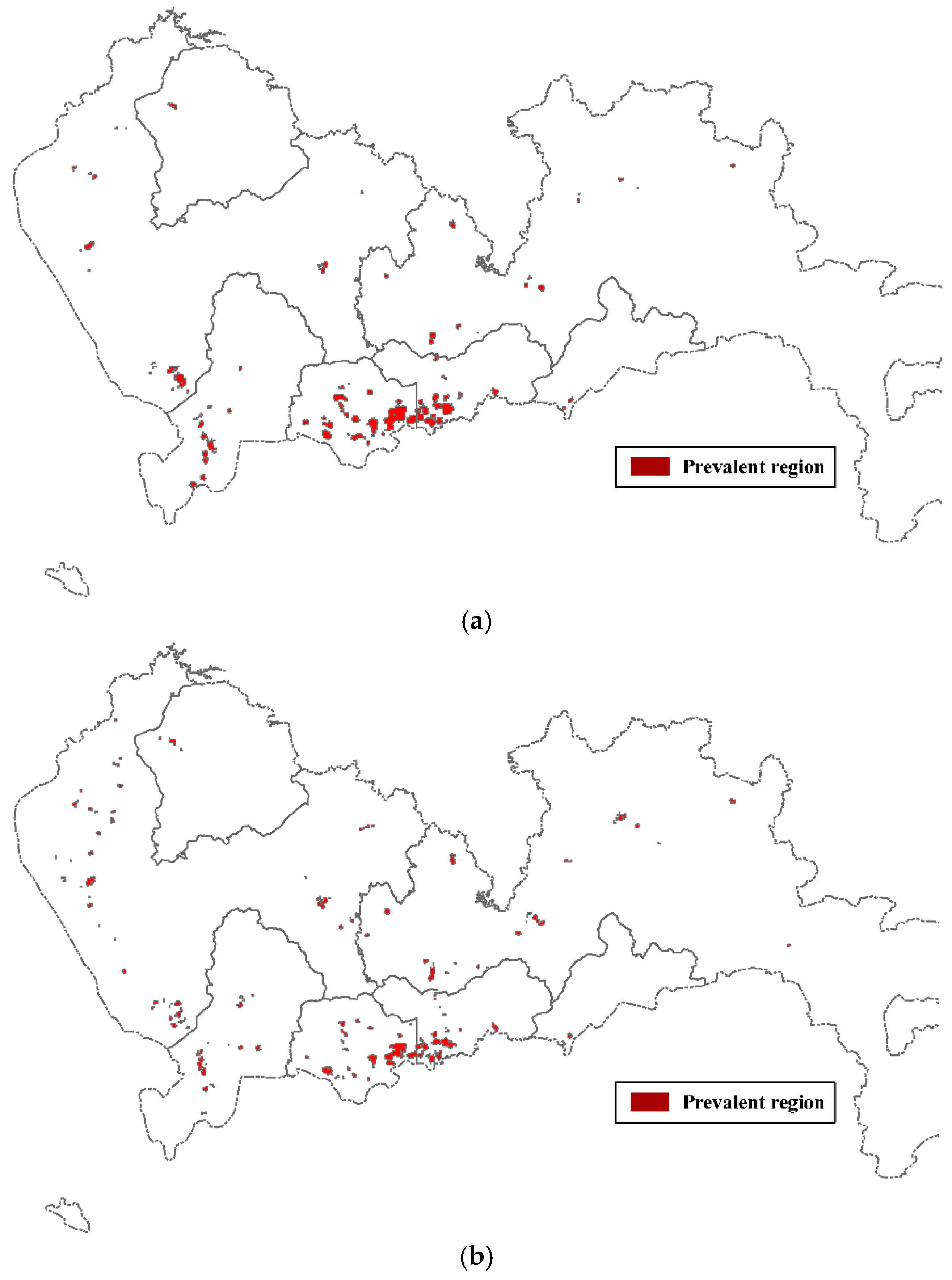
- Generate polygons from the prevalence surface by merging adjacent cells with attribute value equal to or larger than the predefined threshold (Section 2.3).
- Step 4.
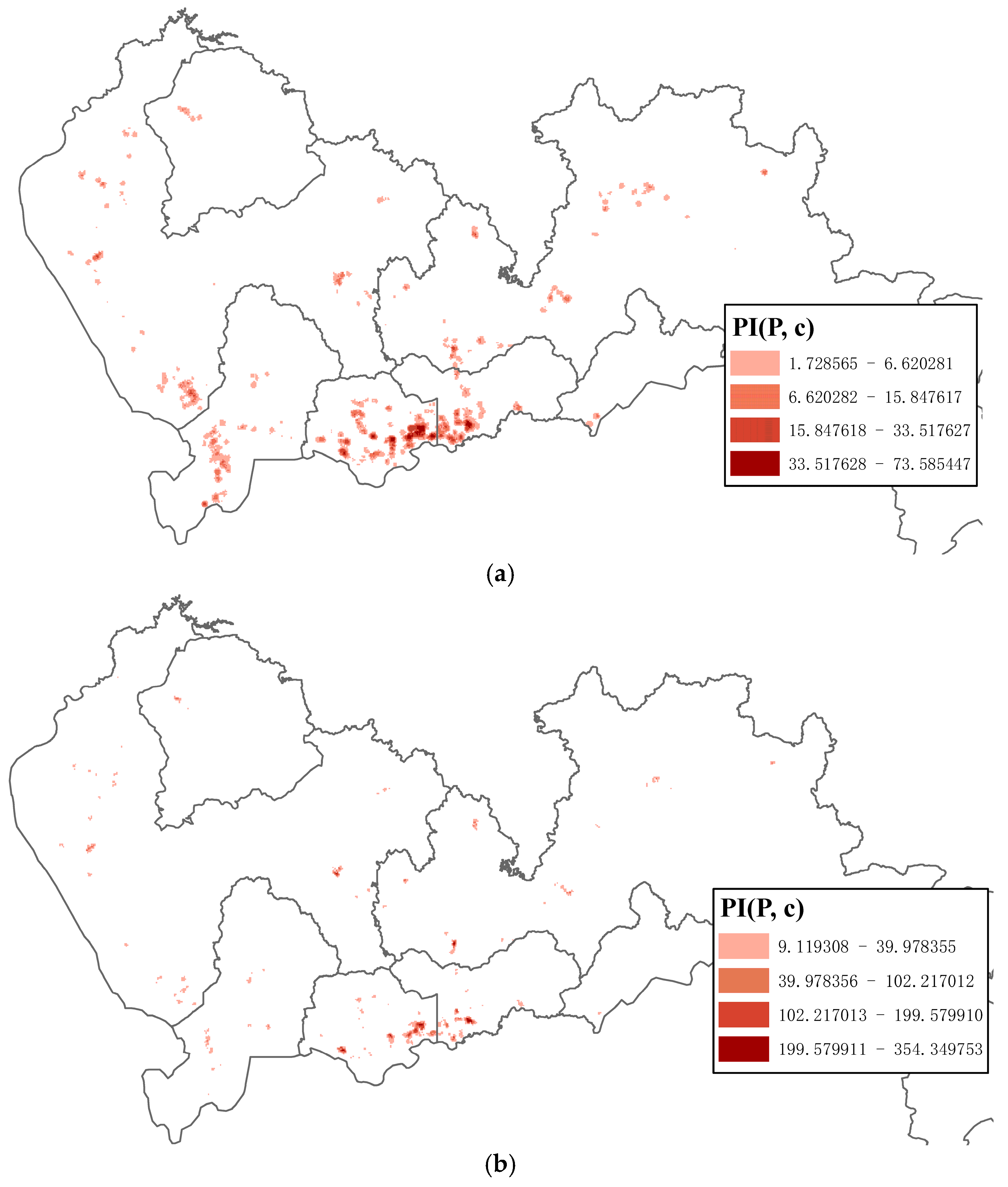
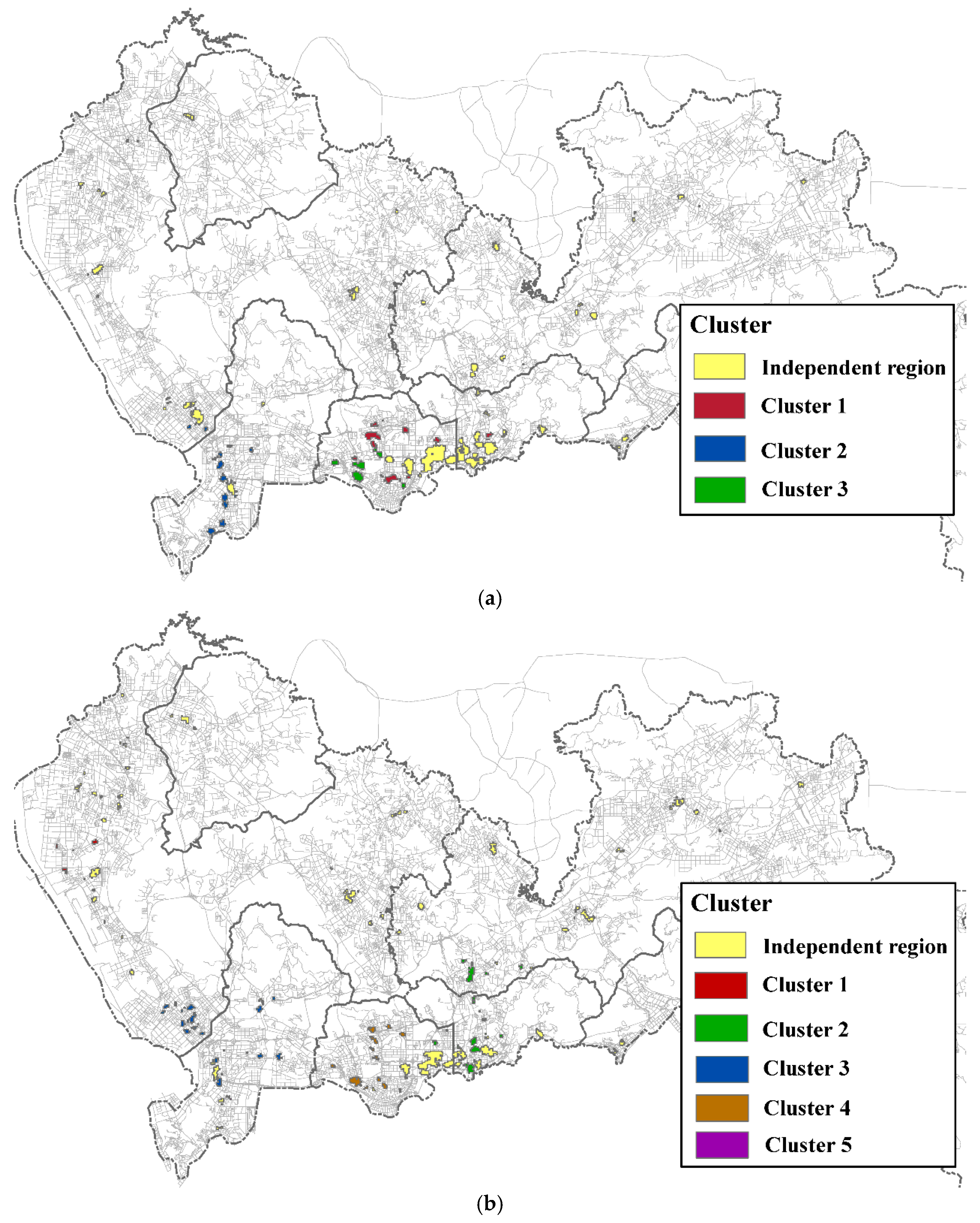
- Measure pair-wise similarity between the polygons by considering both the location-based and contextual variables, and subsequently employing a density-based clustering algorithm to cluster the polygons to create a classification of prevalent regions (Section 2.4).
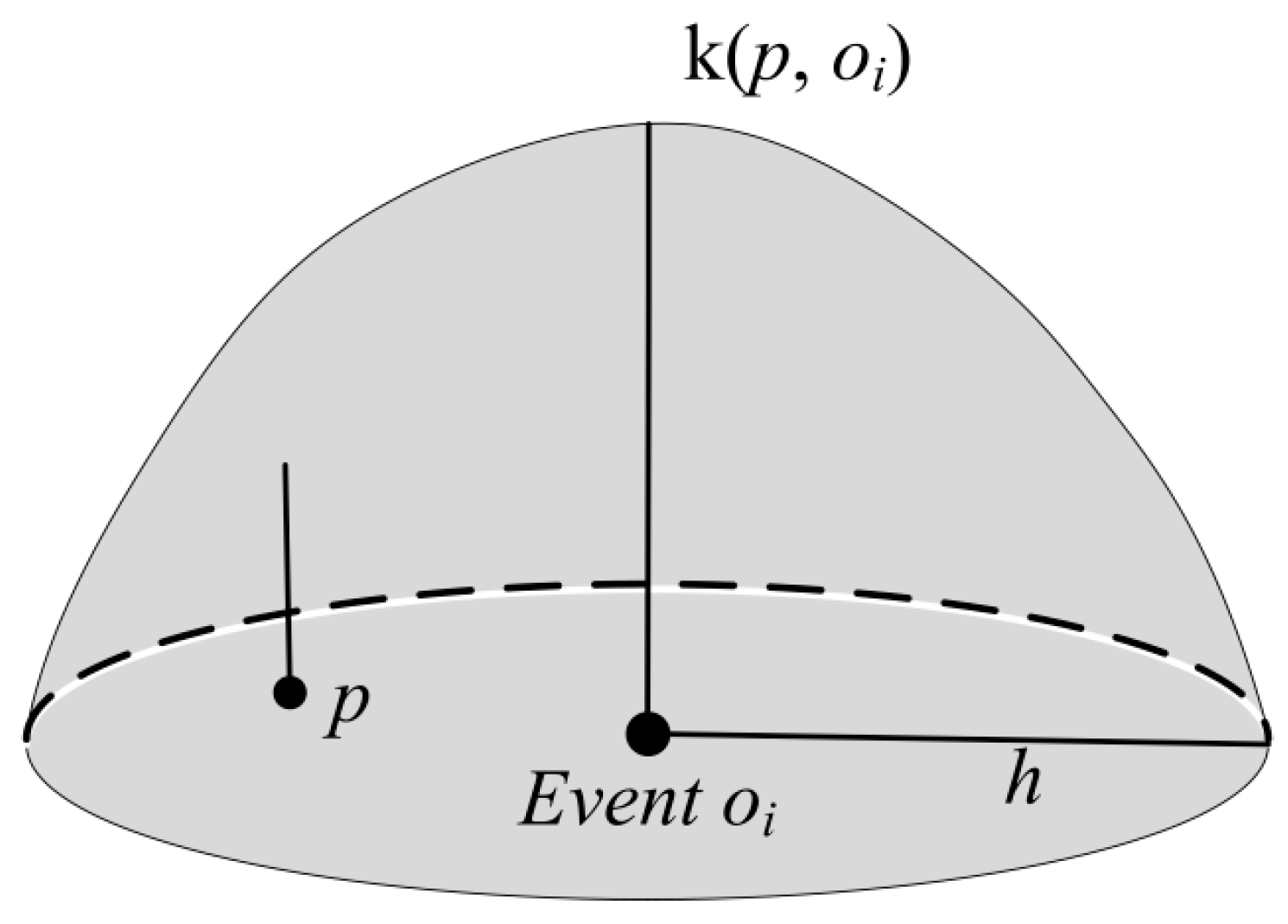
2.2. Generating KDE Surfaces for Point Features
2.3. Combining KDE Surfaces and Identifying Prevalent Regions of a Pattern
2.4. Polygon Dissimilarity Function and Clustering
- (a)
- First, the distance between polygons can be measured by different functions including centroid, separation, min-max, and Hausdorff distance functions [25,26]. Among them, Hausdorff distance is defined as the maximum distance of a point in one set to the nearest point in the other set. Hausdorff distance is appropriate for measuring spatial relations between two polygons due to its adaptability to concave polygons [25]. In this respect, we choose the Hausdorff distance function for our method to accurately measure the geometric distance between two prevalent regions. The mathematical formalization of the Hausdorff distance for two given point sets A and B is defined aswhere d(a, b) is usually taken as the Euclidean distance between points a and b. For simplicity, we use all the vertices on the polygon boundaries to estimate the Hausdorff distance between two polygons.
- (b)
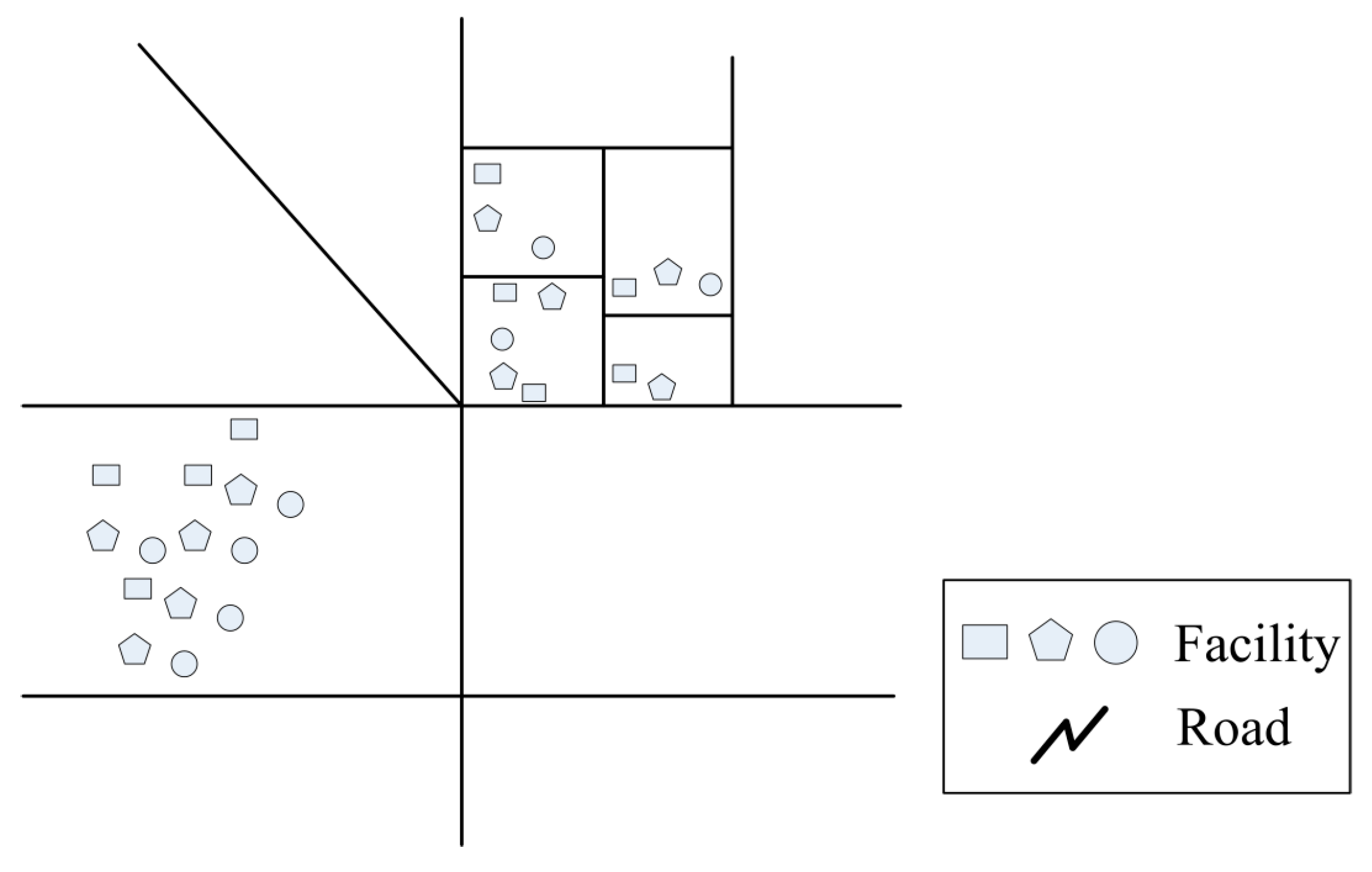
- Second, domain experts usually intend to identify a group of regions from spatial database which are not only similar in their spatial locations, but also share one or several common environmental variable(s). Dissimilarity function based on this condition is different from generic functions used by previous clustering methods [34]. To comprehensively understand co-location patterns across different regions, we cluster all the prevalent polygons by considering their environmental variables related to the pattern, e.g., the underlying street network accessibility and the government facility density. Given two polygons A and B and their associated environmental variables {vA1, vA2, …, vAn} and {vB1, vB2, …, vBn}, we can measure their contextual distance using the standard Euclidean distance function as following.where all the environmental attributes vAi and vBi are normalized for integration. Furthermore, we can also assign different weights to the various variables according to the interest of domains. Our study chooses equal weights for simplicity.
3. Experiments
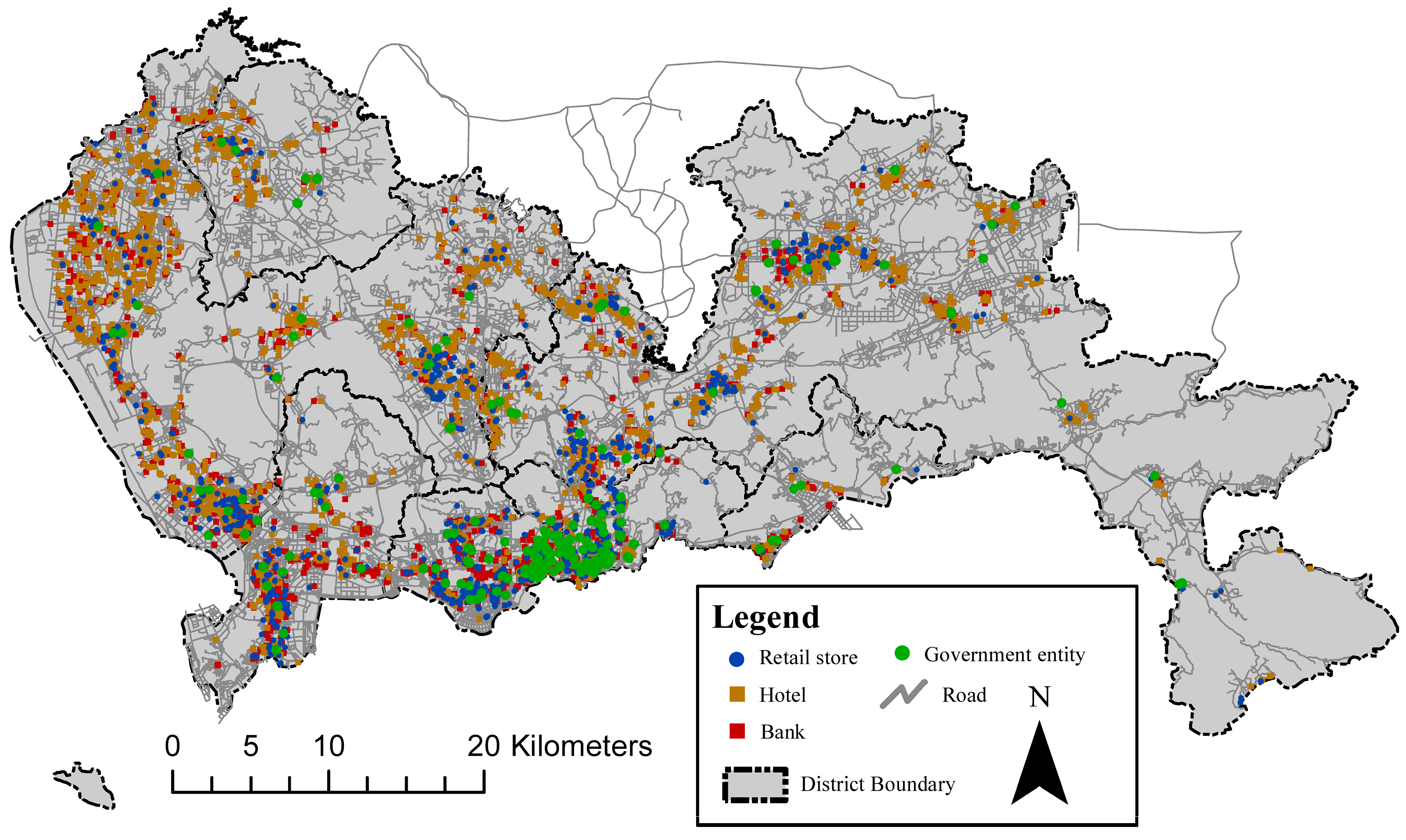
3.1. Data
3.2. Setting
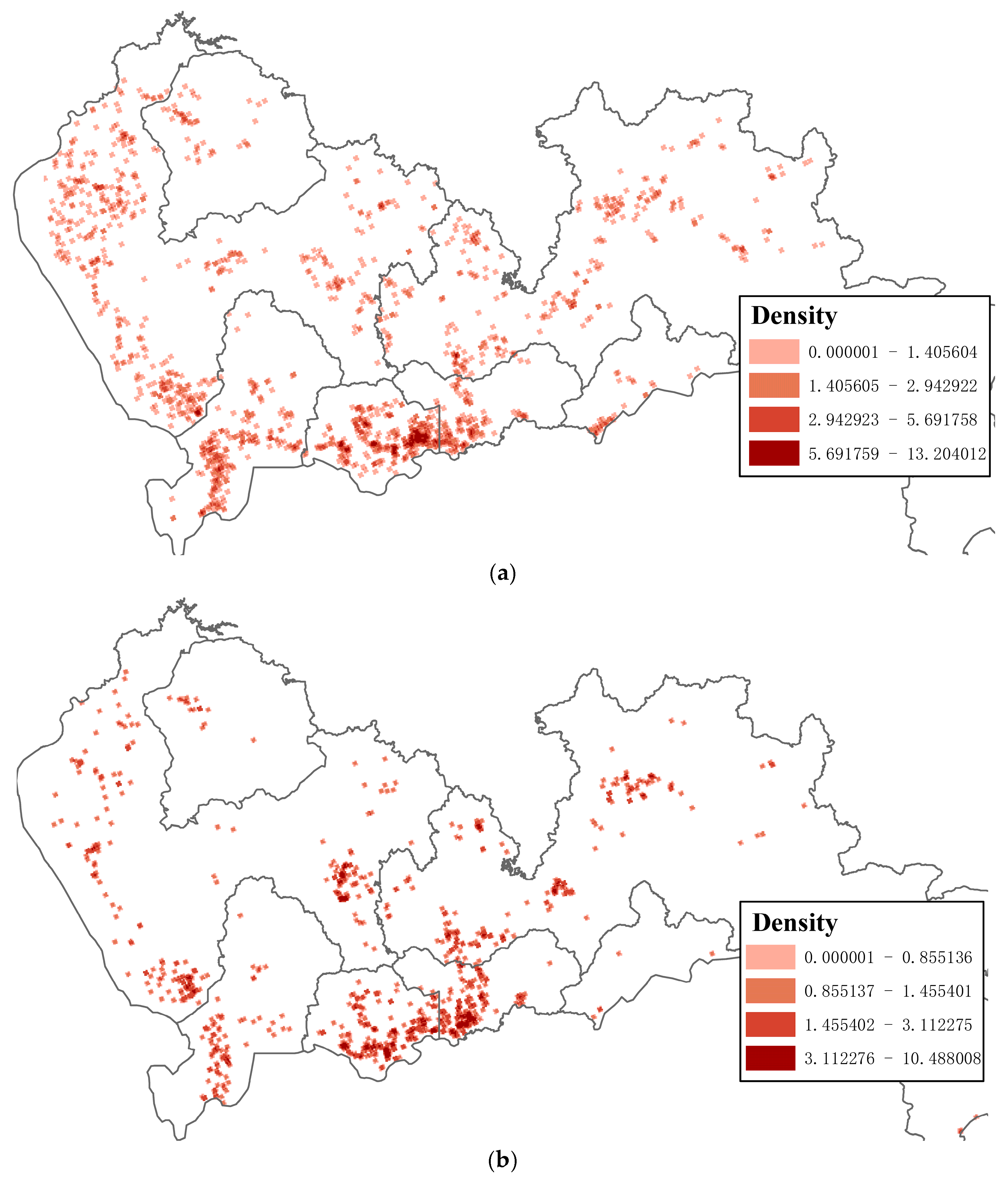
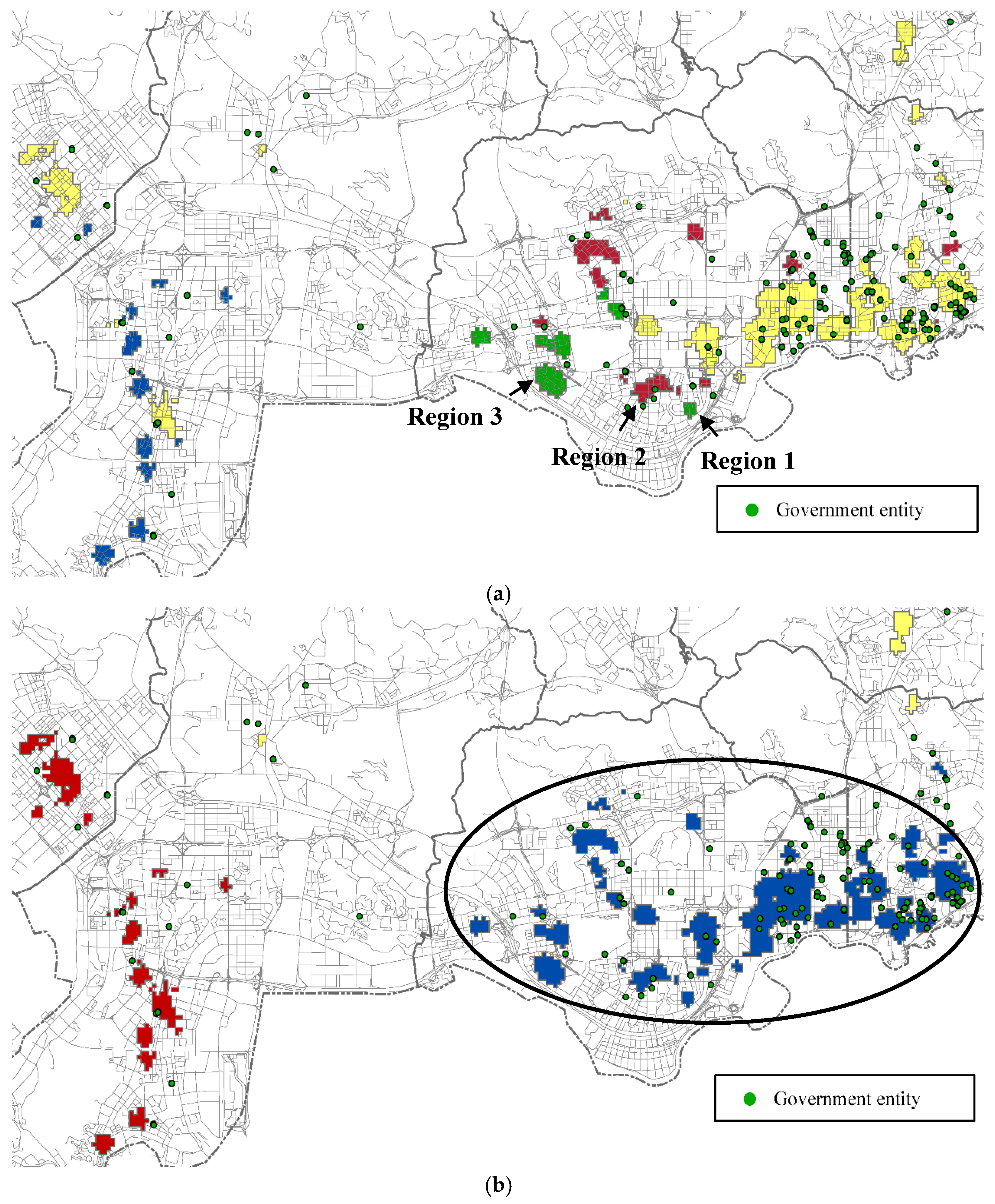
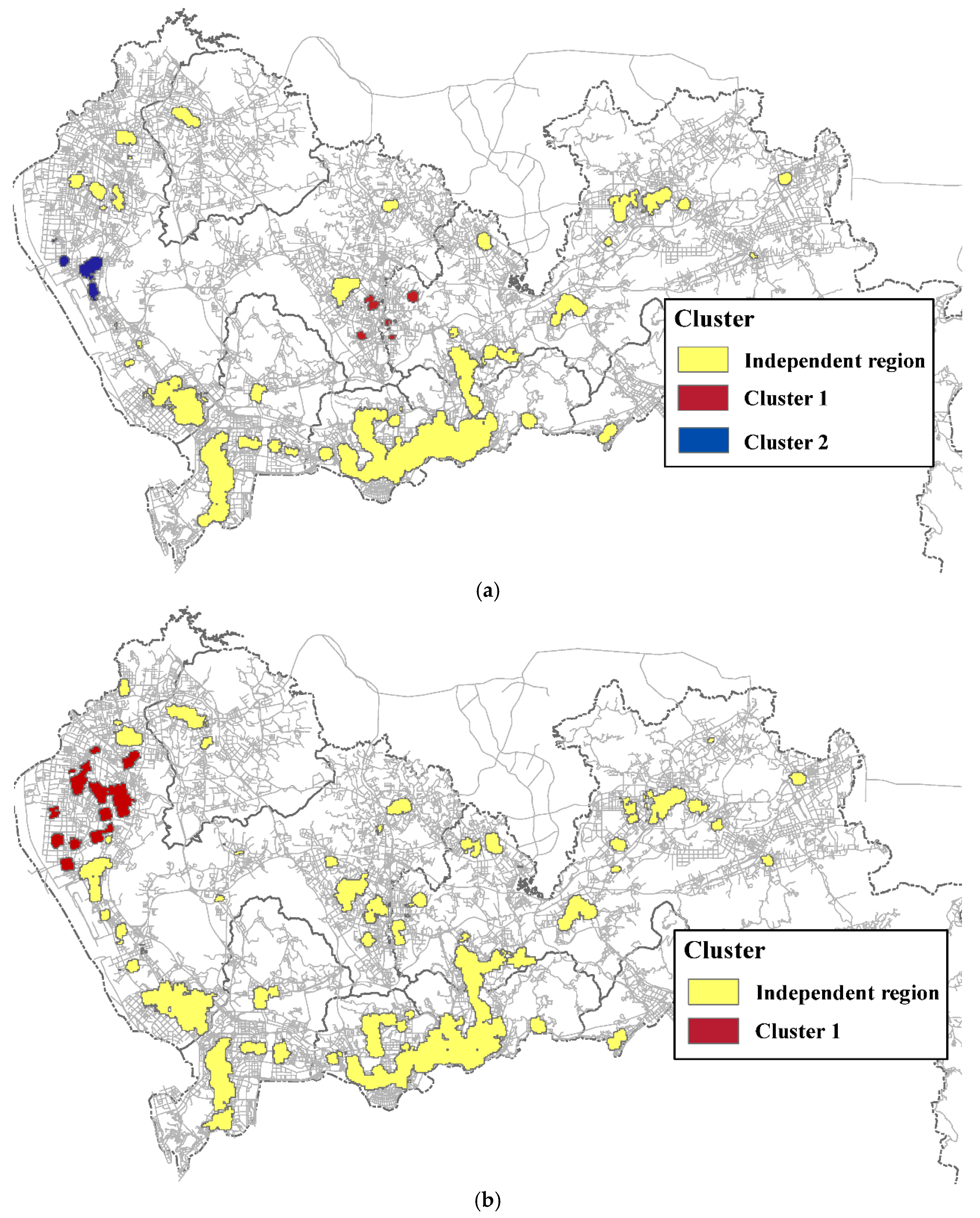
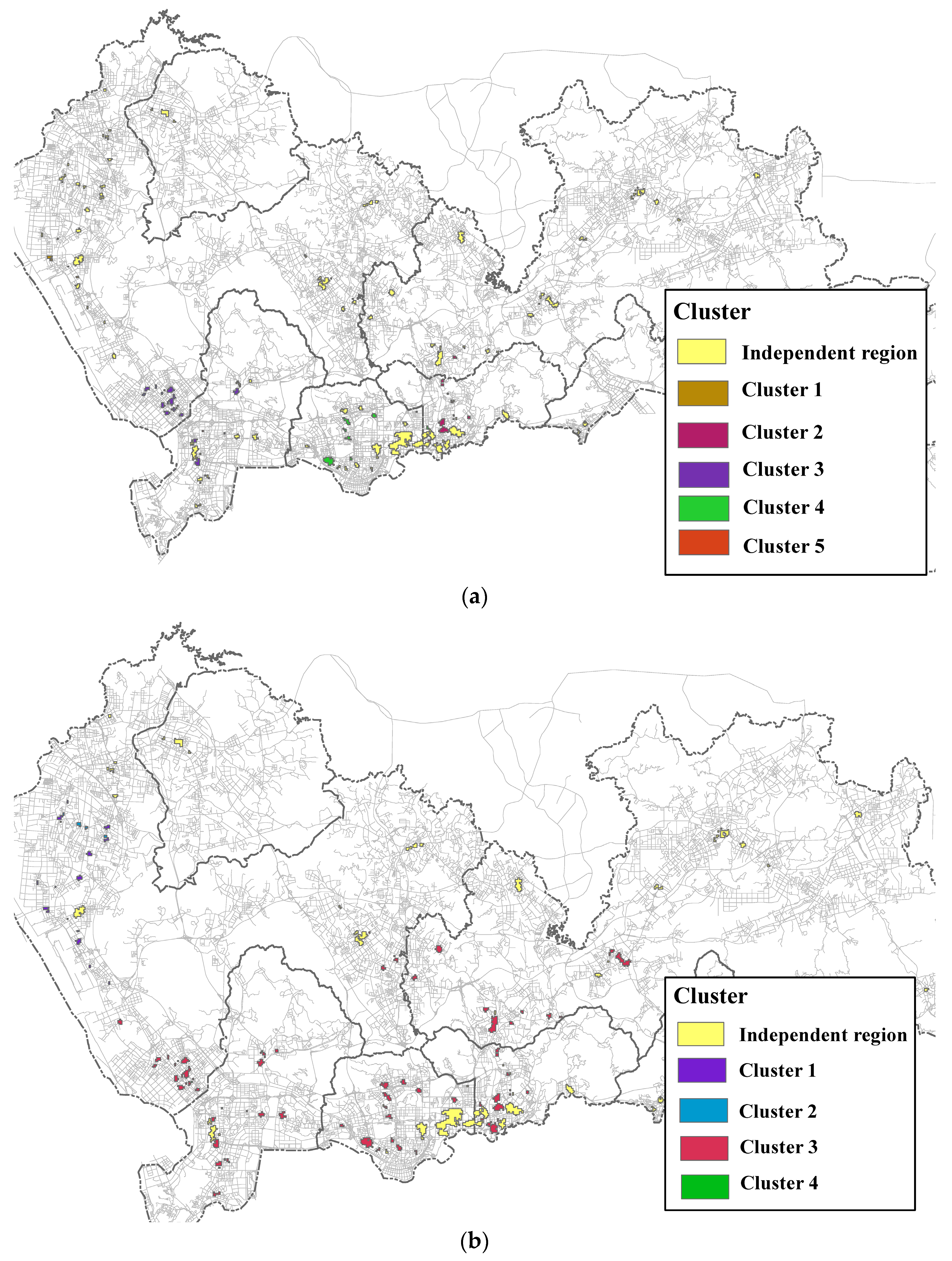
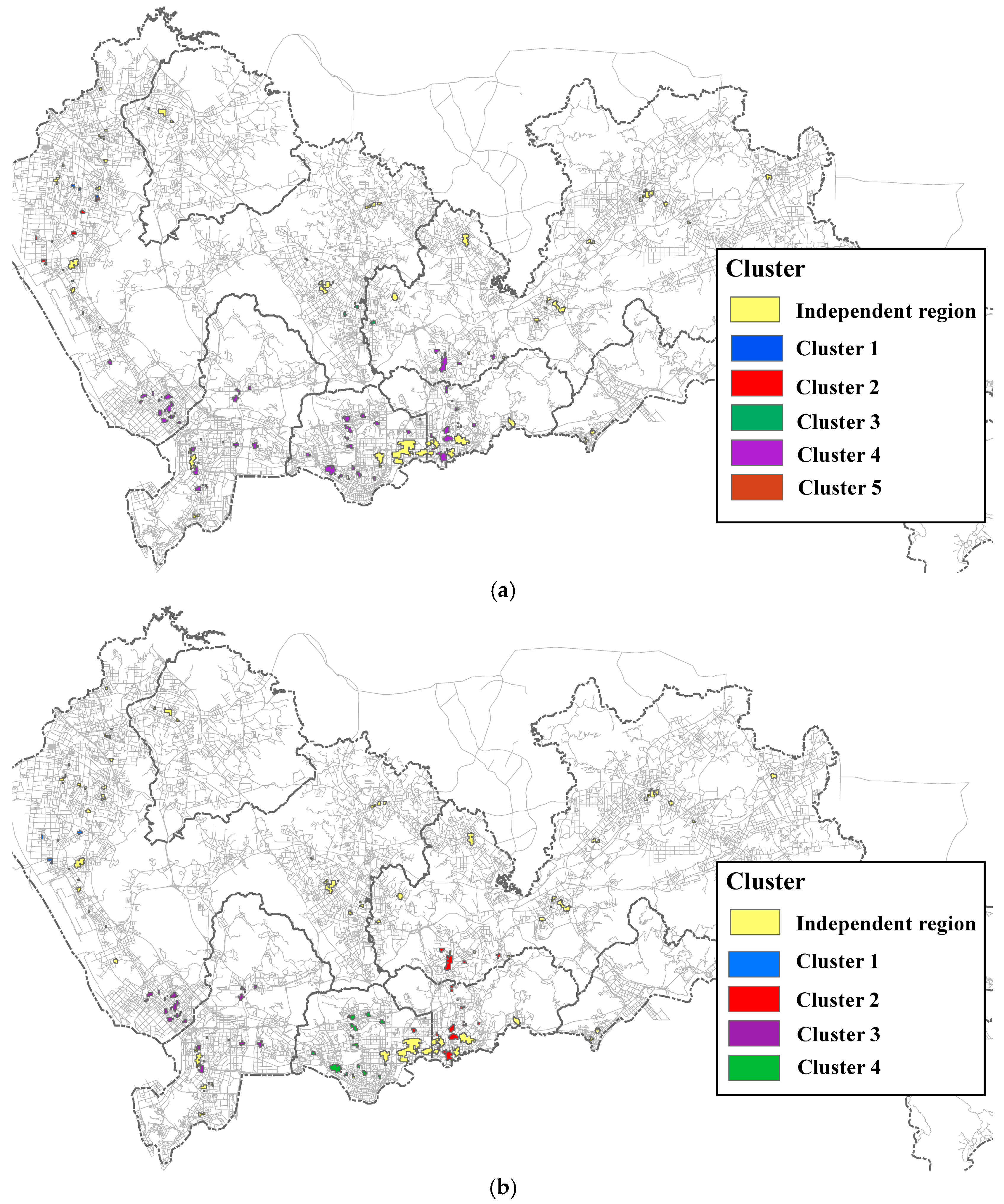
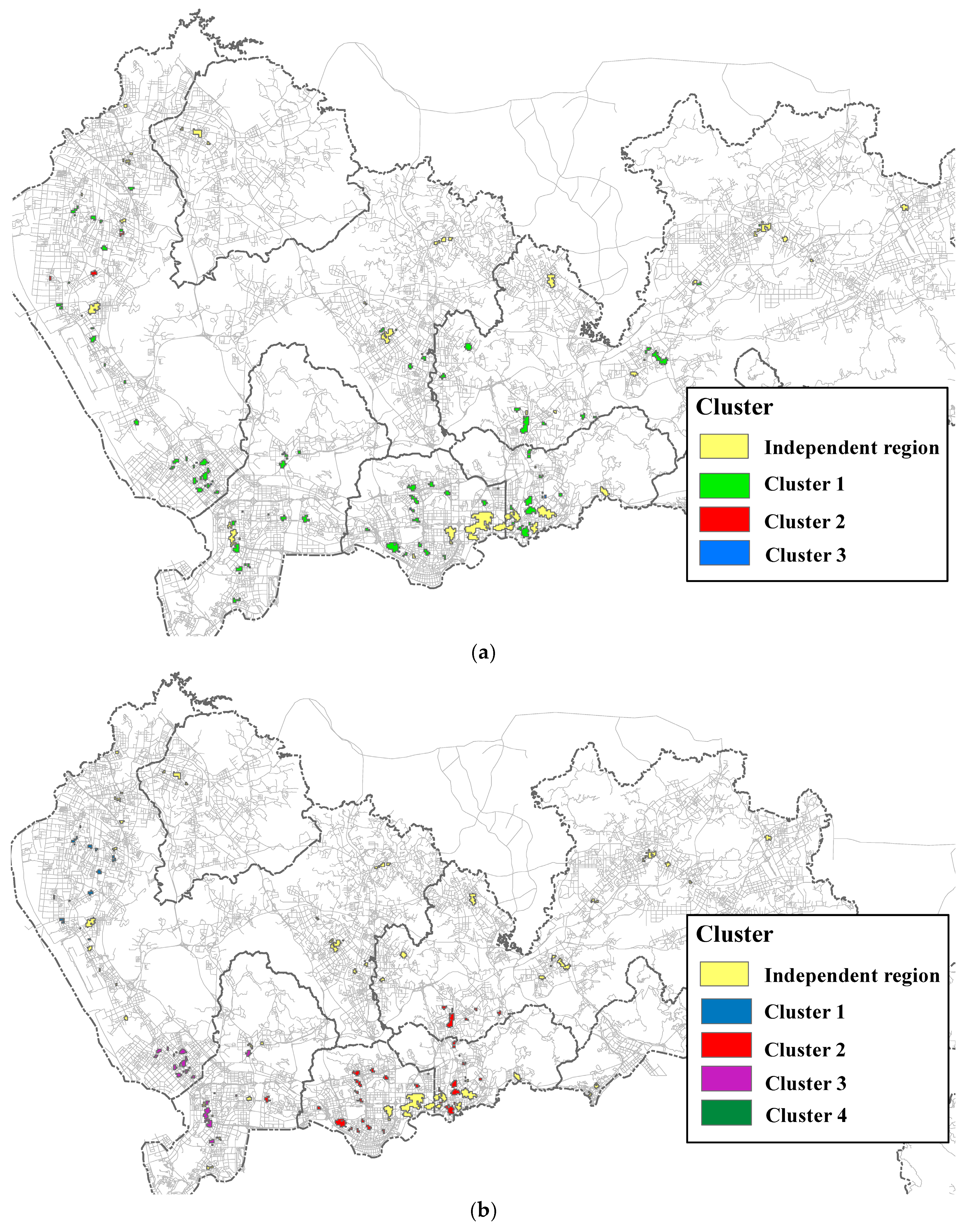
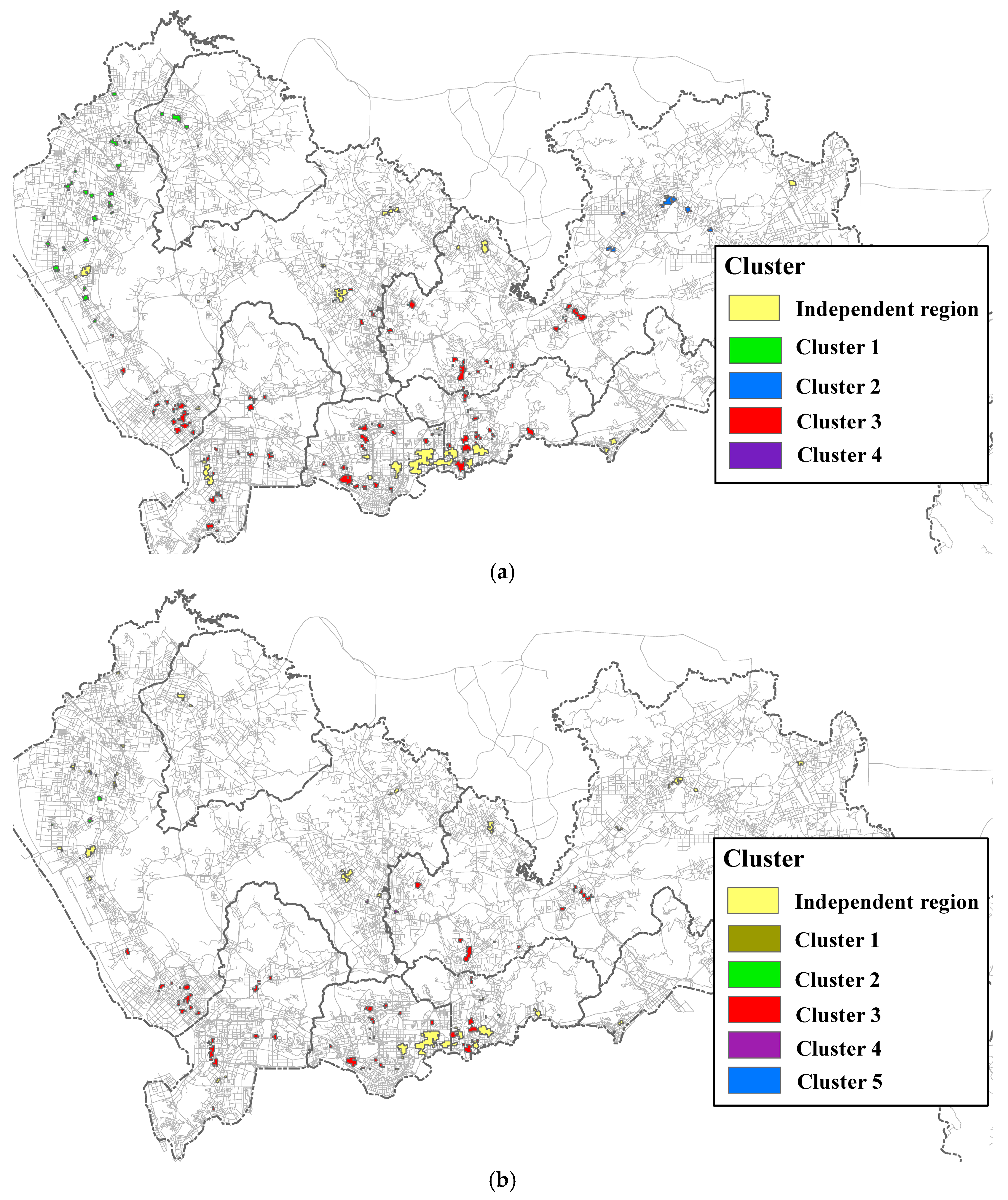
3.3. Results and Analysis
3.4. Effects of Parameter
4. Conclusions and Outlook
- (1)
- Firstly, this paper proposed a new polygon clustering framework for delimitating and classifying the prevalent regions of a co-location pattern.
- (2)
- Secondly, Polygons generated by combining multiple KDE surfaces give the prevalent regions of the pattern of interest, which may be pruned in traditional approaches because of its low prevalence measure value at the global scale. In this way, we can capture some valuable information hidden within a local area.
- (3)
- Thirdly, the addition of environmental datasets provides us a more comprehensive means of classifying the prevalent regions not only from geometric distance perspective but also from contextual perspective. A polygon dissimilarity function based on Hausdorff distance and contextual distance is integrated into the clustering algorithm to identify similar prevalent regions of a pattern that may be formed by several common cause(s). In this way, we can identify whether a local co-location pattern is formed by the features themselves or by their contextual environments (e.g., accessibility).
Acknowledgments
Conflicts of Interest
References
- Bogorny, V.; Kuijpers, B.; Alvares, L. Reducing uninteresting spatial association rules in geographic databases using background knowledge: A summary of results. Int. J. Geogr. Inf. Sci. 2008, 22, 361–386. [Google Scholar] [CrossRef]
- Flouvat, F.; Van Soc, J.F.N.; Desmier, E.; Selmaoui-Folcher, N. Domain-driven co-location mining. GeoInformatica 2015, 19, 147–183. [Google Scholar] [CrossRef]
- Shekhar, S.; Huang, Y. Discovering spatial co-location patterns: A summary of results. In Proceedings of the 7th International Symposium, SSTD 2001, Redondo Beach, CA, USA, 12–15 July 2001. [Google Scholar]
- Huang, Y.; Shekhar, S.; Xiong, H. Discovering colocation patterns from spatial data sets: A general approach. IEEE Trans. Knowl. Data Eng. 2004, 16, 1472–1485. [Google Scholar] [CrossRef]
- Yu, W. Spatial co-location pattern mining for location-based services in road networks. Expert Syst. Appl. 2016, 46, 324–335. [Google Scholar] [CrossRef]
- Yu, W.; Ai, T.; He, Y.; Shao, S. Spatial co-location pattern mining of facility points-of-interest improved by network neighborhood and distance decay effects. Int. J. Geogr. Inf. Sci. 2017, 31, 280–296. [Google Scholar] [CrossRef]
- Ding, W.; Eick, C.F.; Yuan, X.; Wang, J.; Nicot, J.P. On regional association rule scoping. In Proceedings of the International Workshop on Spatial and Spatio-Temporal Data Mining, Omaha, NE, USA, 28–31 October 2007. [Google Scholar]
- Ding, W.; Eick, C.F.; Yuan, X.; Wang, J.; Nicot, J.P. A framework for regional association rule mining and scoping in spatial datasets. GeoInformatica 2011, 15, 1–28. [Google Scholar] [CrossRef]
- Mennis, J.L.; Guo, D. Spatial data mining and geographic knowledge discovery—An introduction. Comput. Environ. Urban Syst. 2009, 33, 403–408. [Google Scholar] [CrossRef]
- Shekhar, S.; Chawla, S. Spatial Databases: A Tour; Prentice Hall: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Akbari, M.; Samadzadegan, F.; Weibel, R. A generic regional spatio-temporal co-occurrence pattern mining model: A case study for air pollution. J. Geogr. Syst. 2015, 17, 249–274. [Google Scholar] [CrossRef]
- Li, J.; Adilmagambetov, A.; Jabbar, M.S.M.; Zaïane, O.R.; Osornio-Vargas, A.; Wine, O. On discovering co-location patterns in datasets: A case study of pollutants and child cancers. GeoInformatica 2016, 20, 651–692. [Google Scholar] [CrossRef]
- Mennis, J.L.; Liu, J.W. Mining association rules in spatio-temporal data: An analysis of urban socioeconomic and land cover change. Trans. GIS 2005, 9, 5–17. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases (VLDB), Santiago, Chile, 12–15 September 1994. [Google Scholar]
- Koperski, K.; Han, J. Discovery of spatial association rules in geographic information databases. In Advances in Spatial Databases; Springer: Berlin/Heidelberg, Germany, 1995; pp. 47–66. [Google Scholar]
- Tobler, W.R. A computer movie simulating urban growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Getis, A.; Ord, J.K. The analysis of spatial association by use of distance statistics. Geogr. Anal. 1992, 24, 189–206. [Google Scholar] [CrossRef]
- Openshaw, S. Developing automated and smart spatial pattern exploration tools for geographical information systems applications. Statistician 1995, 44, 3–16. [Google Scholar] [CrossRef]
- Bembenik, R.; Rybinski, H. FARICS: A method of mining spatial association rules and collocations using clustering and Delaunay diagrams. J. Intell. Inf. Syst. 2009, 33, 41–64. [Google Scholar] [CrossRef]
- Sierra, R.; Stephens, C.R. Exploratory analysis of the interrelations between co-located boolean spatial features using network graphs. Int. J. Geogr. Inf. Sci. 2012, 26, 441–468. [Google Scholar] [CrossRef]
- Leslie, T.F.; Kronenfeld, B.J. The colocation quotient: A new measure of spatial association between categorical subsets of points. Geogr. Anal. 2011, 43, 306–326. [Google Scholar] [CrossRef]
- Guo, L.; Du, S.H.; Haining, R.; Zhang, L.J. Global and local indicators of spatial association between points and polygons: A study of land use change. Int. J. Appl. Earth Obs. Geoinf. 2013, 21, 384–396. [Google Scholar] [CrossRef]
- Miller, H.J.; Han, J. Geographic Data Mining and Knowledge Discovery; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Yoo, J.S.; Shekhar, S. A joinless approach for mining spatial colocation patterns. IEEE Trans. Knowl. Data Eng. 2006, 18, 1323–1337. [Google Scholar]
- Joshi, D.; Soh, L.K.; Samal, A.; Zhang, J. A dissimilarity function for geospatial polygons. Knowl. Inf. Syst. 2014, 41, 153–188. [Google Scholar] [CrossRef]
- Wang, S.; Eick, C.F. A polygon-based clustering and analysis framework for mining spatial datasets. GeoInformatica 2014, 18, 569–594. [Google Scholar] [CrossRef]
- Sengstock, C.; Gertz, M.; Canh, T.V. Spatial Interestingness Measures for Co-location Pattern Mining. In Proceedings of the IEEE 13th International Conference on Data Mining Workshops, Brussels, Belgium, 10 December 2012. [Google Scholar]
- Cressie, N.A.C. Statistics for Spatial Data; John Wiley: Hoboken, NJ, USA, 1991. [Google Scholar]
- Schabenberger, O.; Gotway, C.A. Statistical Methods for Spatial Data Analysis; Chapman Hall/CRC: Boca Raton, FL, USA, 2005. [Google Scholar]
- Yu, W.; Ai, T.; Shao, S. The analysis and delimitation of Central Business District using network kernel density estimation. J. Transp. Geogr. 2015, 45, 32–47. [Google Scholar] [CrossRef]
- O’Sullivan, D.; Unwin., D.J. Geographic Information Analysis; John Wiley: Hoboken, NJ, USA, 2010. [Google Scholar]
- Yoo, J.S.; Bow, M. Mining spatial colocation patterns: A different framework. Data Min. Knowl. Discov. 2012, 24, 159–194. [Google Scholar]
- Monseny, J.; López, R.; Marsal, E. The mechanisms of agglomeration: Evidence from the effect of inter-industry relations on the location of new firms. J. Urban Econ. 2011, 70, 61–74. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996. [Google Scholar]
- Ertoz, L.; Steinback, M.; Kumar, V. Finding clusters of different sizes, shapes, and density in noisy high dimensional data. In Proceedings of the 3rd SIAM International Conference on Data Mining, San Francisco, CA, USA, 1–3 May 2003. [Google Scholar]
- Pio, G.; Ceci, M.; D’Elia, D.; Loglisci, C.; Malerba, D. A Novel Biclustering Algorithm for the Discovery of Meaningful Biological Correlations between microRNAs and their Target Genes. BMC Bioinform. 2013, 14, S8. [Google Scholar] [CrossRef] [PubMed]
- Pio, G.; Ceci, M.; Malerba, D.; D’Elia, D. ComiRNet: A Web-based System for the Analysis of miRNA-gene Regulatory Networks. BMC Bioinform. 2015, 16, S7. [Google Scholar] [CrossRef] [PubMed]
- Okabe, A.; Satoh, T.; Sugihara, K. A kernel density estimation method for networks, its computational method and a GIS-based tool. Int. J. Geogr. Inf. Sci. 2009, 23, 7–32. [Google Scholar] [CrossRef]
- Porta, S.; Strano, E.; Iacoviello, V.; Messora, R.; Latora, V.; Cardillo, A.; Wang, F.; Scellato, S. Street centrality and densities of retail and services in Bologna, Italy. Environ. Plan. B Plan. Des. 2009, 36, 450–465. [Google Scholar] [CrossRef]
- Huang, Y.; Pei, J.; Xiong, H. Mining co-location patterns with rare events from spatial data sets. GeoInformatica 2006, 10, 239–260. [Google Scholar] [CrossRef]
















© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, W. Identifying and Analyzing the Prevalent Regions of a Co-Location Pattern Using Polygons Clustering Approach. ISPRS Int. J. Geo-Inf. 2017, 6, 259. https://doi.org/10.3390/ijgi6090259
Yu W. Identifying and Analyzing the Prevalent Regions of a Co-Location Pattern Using Polygons Clustering Approach. ISPRS International Journal of Geo-Information. 2017; 6(9):259. https://doi.org/10.3390/ijgi6090259
Chicago/Turabian StyleYu, Wenhao. 2017. "Identifying and Analyzing the Prevalent Regions of a Co-Location Pattern Using Polygons Clustering Approach" ISPRS International Journal of Geo-Information 6, no. 9: 259. https://doi.org/10.3390/ijgi6090259
APA StyleYu, W. (2017). Identifying and Analyzing the Prevalent Regions of a Co-Location Pattern Using Polygons Clustering Approach. ISPRS International Journal of Geo-Information, 6(9), 259. https://doi.org/10.3390/ijgi6090259