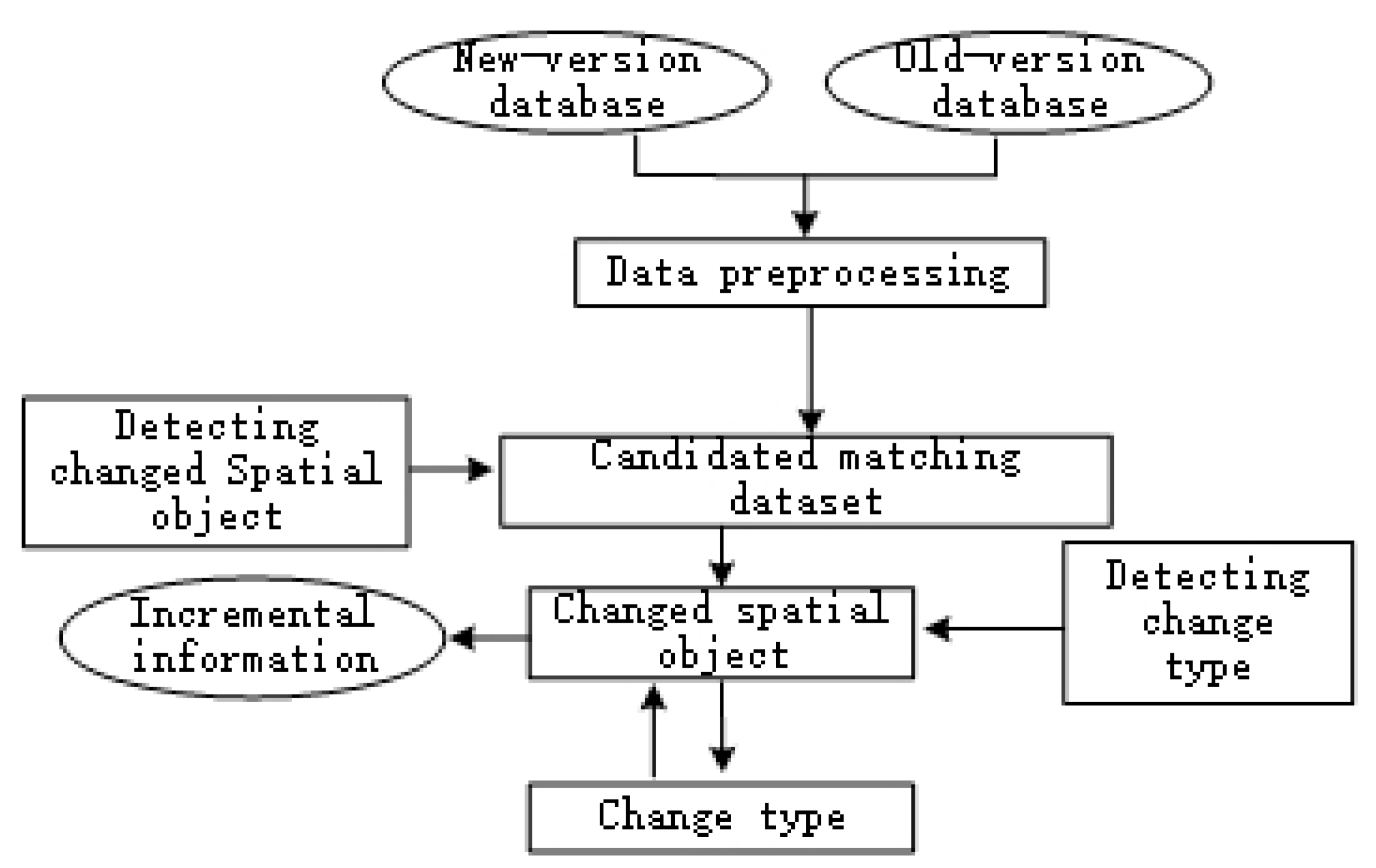
We propose a new, universal method that is based on object matching features and detects both the changing objects and their types of changes. This method first establishes a hierarchical matching model to extract incremental information datasets of area objects in both the old and new versions. Subsequently, based on the attributes, geometric position, size, shape and directional information of the area objects, this method defines appropriate matching operators to define the rules to automatically detect the types of changes. Then, the method detect and extract the nine types of changes of individual area objects. It uses concise detection conditions and operational operators to ensure the accuracy of detection, reduce algorithmic complexity, and achieve effective tracking and management of various changing tracks within the lifecycle of area objects. The incremental information extraction process and its connection with the extraction of incremental objects are shown in
Figure 1.
2.1. Basic Idea
The identification and extraction of change information depends largely on matching objects in the new-version database to the corresponding objects in the old-version database, and the matching accuracy will directly affect the accuracy of the data update. The matching of spatial objects includes both geometric matching and attribute matching. The geometrical characteristics of area objects include their position, size, shape, and direction [
21], whose influence on feature matching should be fully considered. We use
M to represent the matching model, with M = (Attribute, Position, Size, Shape, Direction).
To detect the change information, we propose to use matching operators reflecting information such as attribute, position, size, shape, and direction in the matching model
M to identify the changes of the area object and discriminate the types of changes. When the attribute data are not included in the dataset, other geometric information apart from attribute can also be used to conduct geometric matching and discriminate the types of changes [
32]. Therefore, this study only focuses on geometric matching. The matching operators are screened and combined according to their complexity from the lowest to the highest, reducing the calculation workload while ensuring accuracy. For any two matching objects in the old and new databases under the same measuring scale, if any of the operators matches successfully, the condition judgment value will be denoted as
T; otherwise, it will be denoted as
F. Therefore, when
M = (
T,
T,
T,
T,
T), the match succeeds. After traversing all the objects, those that cannot be successfully matched are the changing ones.
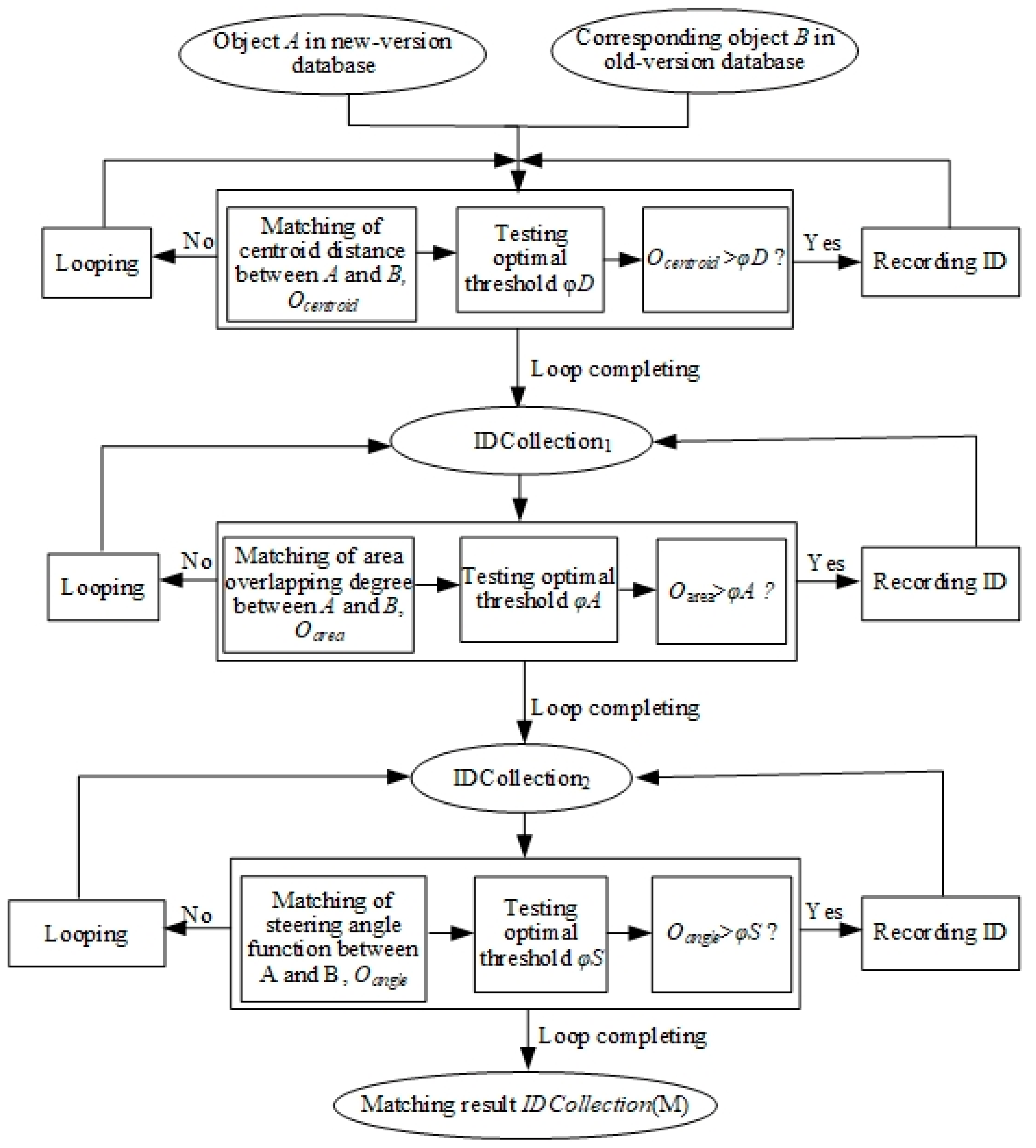
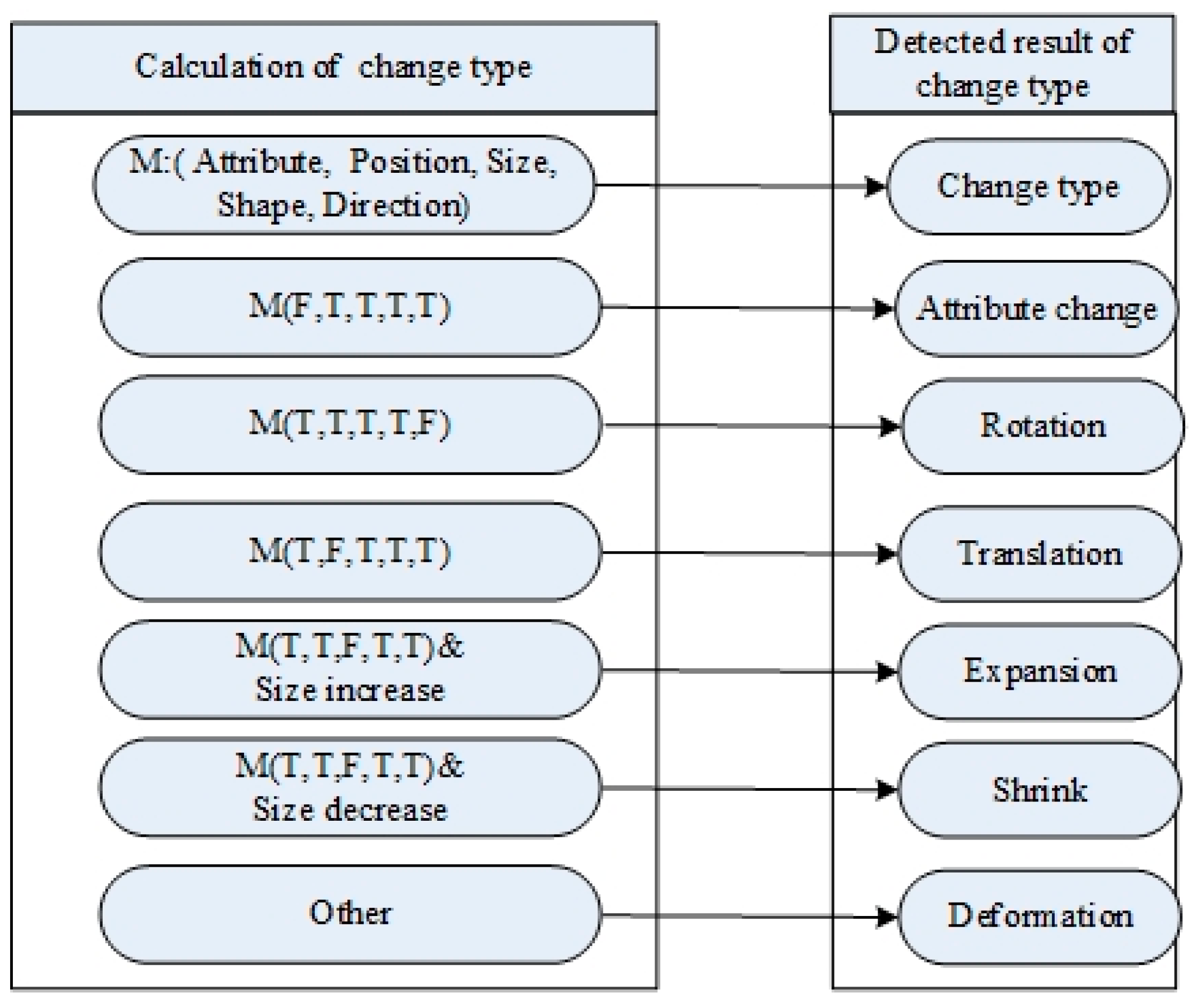
In addition, the types of changes in the objects are detected. Vanish, appearance, and reappearance are a combination of delete and add, while the other six types of changes (attribute change, expansion, shrink, translation, rotation, and deformation) may be inferred using the combination of operators in Model M shown in
Figure 2. For vanish and appearance, we only need to find out whether any one area object in a database intersects with another area object in the other database within the same geographical range. If there is object
A in the new database while there is no corresponding object of
A in the old database, then such change can be classified as appearance, otherwise it belongs to vanish. For reappearance, it is necessary to identify objects in the databases over three periods, in which it is the succession of vanish and appearance. The specific solution and reasoning are shown in the following sections.
2.2. Selection of Hierarchical Matching Operators
Once the changing objects are discriminated, providing attribute data for each, only the attribute fields of two area objects need to be directly matched. However, when selecting geometric discriminant operators, their integrity must be guaranteed. Moreover, the objects’ shape, size, and position should be considered as well to ensure the accuracy of the matching. In addition, the complexity of the algorithm should be taken into account. In the end, the detection model formed by all the operators should not be affected by the data types and the measurement scale, and it should be able to accurately describe both the overall and individual geometric features of the objects.
Among the discriminant operators, the simple and accurate centroid distance operator measures the position similarity of area objects and is used by many researchers [
8,
33]. As an alternative, some scholars use the Hausdorff distance model, the generalized Hausdorff distance model, or the median Hausdorff distance model to measure the position similarity [
25,
34]. This method not only measures the position difference of spatial objects, but also reflects differences between objects in terms of shape and overall distribution. However, only as far as the measurement of position similarity is concerned, the Hausdorff methods are not as accurate as the centroid matching method, lying in that they are highly complicated with heavy computational burden to a great extent.
As far as shape similarity is concerned, there are also various operators to measure shape similarity [
20,
28,
31]. Among them, the steering angle function matching algorithm can accurately describe the local, detailed features of complex graphics on their shape and direction, and it is easier to operate and more accurate than other matching algorithms. In addition, those other operators, for example, the fractal dimension and compactness index, the function describing the distance from edge feature point to the centroid of the area object, the Fourier transform method, the symmetric difference index, and the operator to measure the shape of tangent space, etc. can also measure the shape similarity of area objects [
21,
25,
27]. Although these operators can reflect the shape similarity between two area objects to a certain extent, they either fail to describe the details of the shape or involve complicated calculation.
Additionally, most researchers use the degree of area overlapping as a criterion to measure the size similarity between area objects [
20]. In addition, Hausdorff distance and symmetric difference could also reflect the size similarity of the objects to a certain extent [
11]. However, measuring the size similarity using the degree of area overlapping is not only simple to operate, but is also relatively high accuracy in nature.
In summary, after a systematic analysis and modification of the operators that come from the existing studies, this study uses the centroid discriminant operator to measure the position features of area objects, the area overlapping operator to measure their size features, and the steering angle cumulative function matching operator to measure their shape and direction characteristics. The specific calculation method is as follows:
(1) Centroid discriminant operator. This is an index that reflects the distance (position) between objects. The smaller the centroid distance, the higher the position similarity between two area objects. Here,
F1 and
F2 denote the two area objects to be matched,
D(
F1,
F2) denotes the centroid distance between the two area objects, and r
1 and r
2 represent the half of the diagonal of the minimum enclosing rectangle of
F1 and
F2, respectively, used so as not to be affected by the actual size of the objects. The formula is as follows:
(2) Area discriminant operator. Assume that S(
F1) and S(
F2) represent the area of
F1 and that of
F2, respectively. Formula (2), which discriminates the size similarity between area objects with area difference, is shown as follows:
(3) Steering angle cumulative function discriminant operator. This operator measures the shape similarity between area objects and can measure the direction similarity between them to a certain extent. The principle is as follows: First, a shape feature point in a specific direction in the vertices of the two objects is chosen as a reference point. Giving consideration to information about the direction of the area objects, the reference point is selected per the following standard: the sine value of the angle between the line formed by connecting the reference point to the object centroid and the abscissa axis of the coordinate system should be the maximum, and the
X axis coordinate of the reference point should be larger than that of the object centroid. The angle between the counterclockwise segmental arc of the reference point and the
X axis is then recorded, along with the normalized length (the ratio of arc length to perimeter) of each counterclockwise arc. Then, the normalized length is taken as the
X axis, and the accumulated value of each point along the peripheral steering angle is taken as the
Y axis. Assuming that
F1(x) and
F2(x) are the steering angle cumulative functions of
F1 and
F2, then the steering angle cumulative function discriminant operator formula can be expressed as follows:
Although the operator can simultaneously measure the shape and direction information of area objects, certain shape or direction differences may cause the discriminant operator to be inadequate, in which case the combination of the above three operators cannot discriminate the type of rotation change. Therefore, in the case where the centroid discriminant operator and the area difference discriminant operator are adequate, while the steering angle function discriminant operator is inadequate, the auxiliary discriminant operator is introduced in this paper to discriminate the type of rotation change. If the computed result of the auxiliary operator is larger than the set threshold value, it means that the two objects have the same shape but different directions, and the type of changes can be identified as rotation. The discriminant operator measures the shape difference with the similarity of form factor [
8]. Assume that S(
F1), S(
F2), L(
F1) and L(
F2) represent the areas and perimeters of the two area objects,
F1 and
F2, respectively, then the formula is as follows:
2.3. Extraction of Incremental Information Based on Hierarchical Matching
This study proposes a geometric matching method for area object based on hierarchical matching, with the hierarchy determined by the accuracy of object matching, the increase of operator complexity, and the decrease of the number of filtered objects. Using the matching operators described above, the algorithm filters the three operators with increasing computational complexity layer by layer to reduce the calculational burden and ensure the accuracy of the matching.
In this study, the similarity threshold of the four geometric matching operators (namely
,
and
) are set as
φ1,
φ2,
φ3 and
φ4 respectively. Let IsAttributeMatch denote whether the attributes of the two area objects match or not. If they match, it will be denoted by 1 (True), otherwise by 0 (False). For any
A and
B, which are area objects from the new-version and old-version databases, respectively, the detailed matching method to extract the change information based on hierarchical feature matching is as follows, also as shown in
Figure 2.
The first layer: Matching of centroid distance. This layer determines which pairs of candidate objects meet the 1:1 criterion of centroid distance matching, with the remaining mismatched ones regarded as changed objects. Centroid distance matching is conducted among all objects of the same semantic theme in the new and old databases in pairs. If the centroid distance between two objects is smaller than the given matching threshold φ1, the ID number of the pair of objects will be stored in the ID set IDCollection1 for the matching calculation at the next layer.
The second layer: Matching of area overlapping degree. The algorithm’s first layer returns a one-to-one relationship of the objects, indicating identical positions. Next, a one-to-one relationship at the second layer indicates that the two objects are not only matched in terms of centroid distance but also area similarity, with mismatched objects regarded as the changed ones. In IDCollection1, each pair of objects satisfying centroid distance matching conditions are traversed, calculating the area overlapping degree of the pair. If the overlapping degree is greater than the given area matching threshold φ2, then the two objects meet the criterion of the overlapping degree and will be re-saved to the new ID set (IDCollection2). Pairs of objects ultimately retained are those matched to each other in both centroid distance and area overlapping degree.
The third layer: Matching of steering angle function. The algorithm proceeds only on those pairs matching in the first two layers. If the two objects are matched at the third layer as well, they are successfully matched geometrically; otherwise, they are changed objects. The matching process is similar to that of the second layer. In IDCollection2, each pair of objects is traversed, calculating their steering function matching. If it is greater than the matching threshold (φ3), then the two objects are successfully matched in terms of shape.
After the above hierarchical matching, the finally retained pairs of objects are considered successfully matched, which can be formalized as follows.
MatchingRule: if ((IsAttributeMatch = True) and (PositionResult ≤ φ1) and (AreaResult ≥ φ2) and (ShapeDirectionResult ≥ φ3)) then Matching (A, B). From the above, the matching result set IDCollection (M) is obtained. Unsuccessfully matched objects in the old and new databases are considered to be the changed objects and are recorded as ChangeCollection (N) and ChangeCollection (O), respectively, to be used in the subsequent detection of the types of changes.
Let the numbers of objects in the new and old databases be
m and
n, respectively. We compare the hierarchical matching algorithm proposed in this study and the existing weighted matching algorithm from the perspective of algorithm complexity. Between the two methods, the algorithm complexity of the three operators, namely distance, area, and shape, is the same. If the number of pairs of objects meeting the distance matching is
k1, and that of pairs of objects meeting the distance and area matching at the same time is
k2, then Min(
m,
n) >
k1 > k2. For each operator,
,
, and
, the times of calculations conducted by the hierarchical matching algorithm is
m∗
n,
k1,
k2, respectively, much less than the number of calculations conducted by the weighted algorithm, which is
m*
n, as shown in
Table 1. Therefore, when the time complexity and spatial complexity of each operator are the same, the hierarchical matching algorithm is much less complicated than the weighted matching algorithm.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}