Fine Resolution Probabilistic Land Cover Classification of Landscapes in the Southeastern United States



Abstract
:1. Introduction
2. Materials and Methods
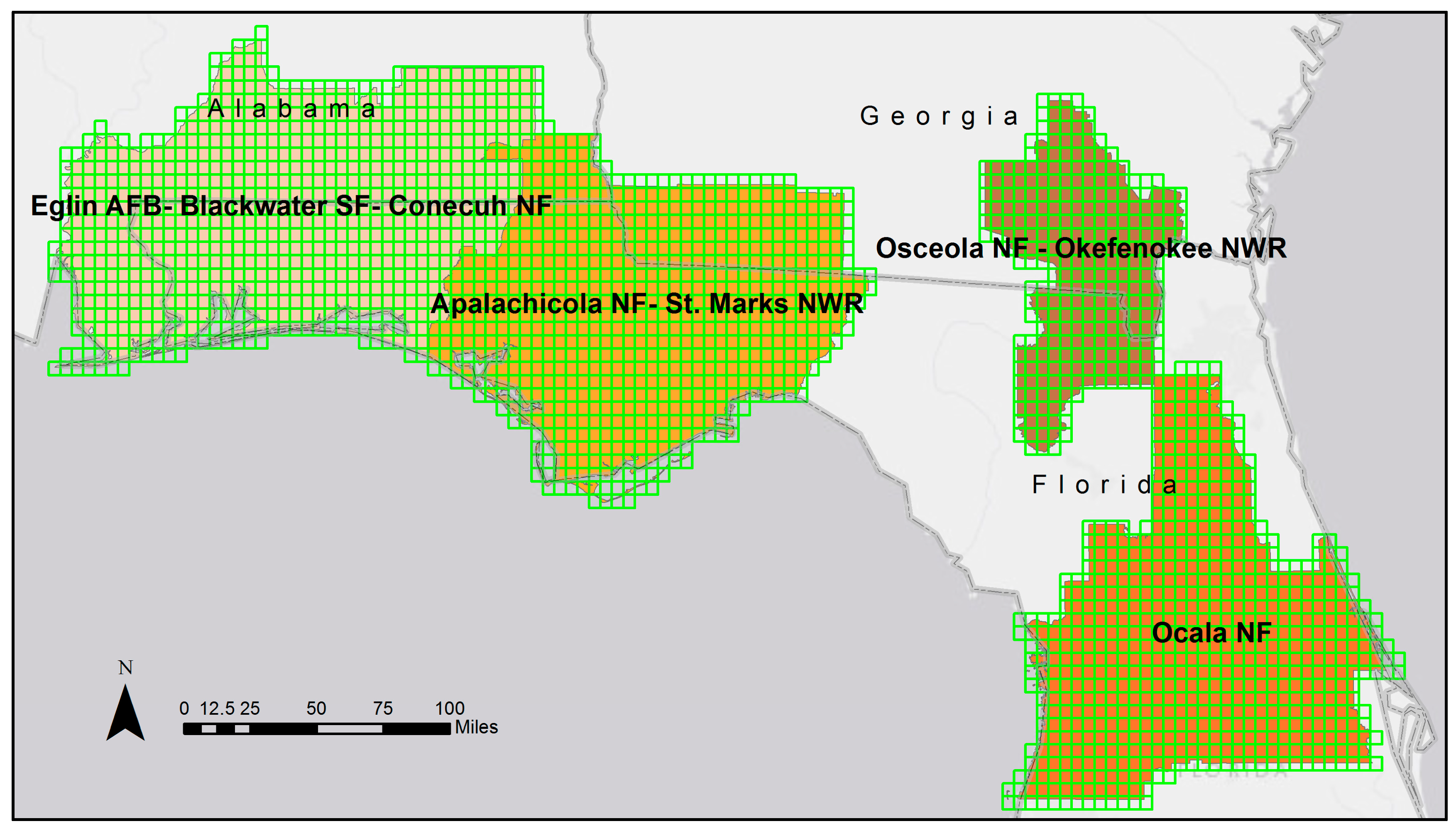
2.1. Study Area
2.2. Methods Overview
2.3. Imagery and Data
2.4. Predictive Surfaces
2.5. Classified Samples
2.6. Modeling
3. Results
3.1. PCA
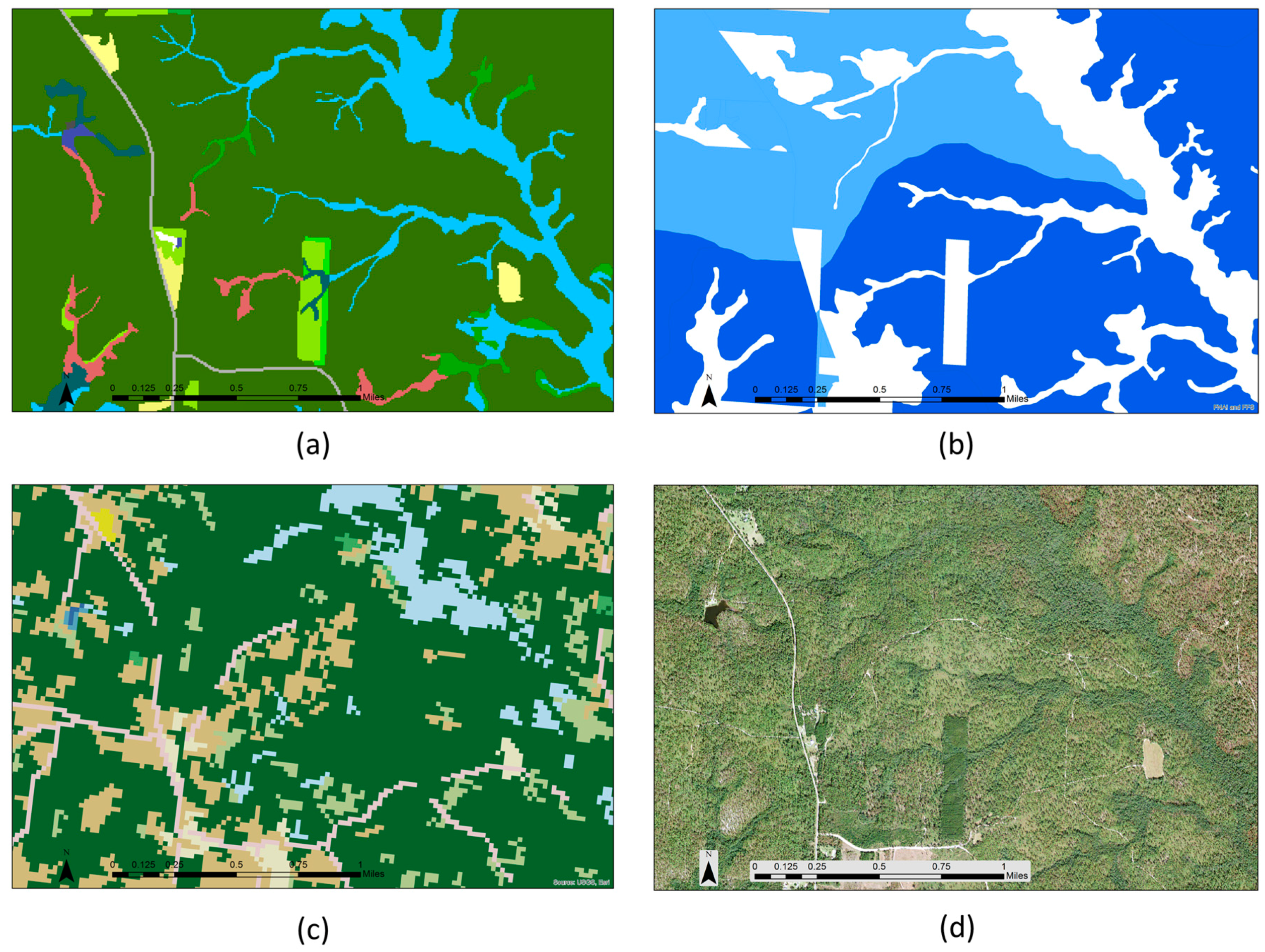
3.2. Modeled Outputs
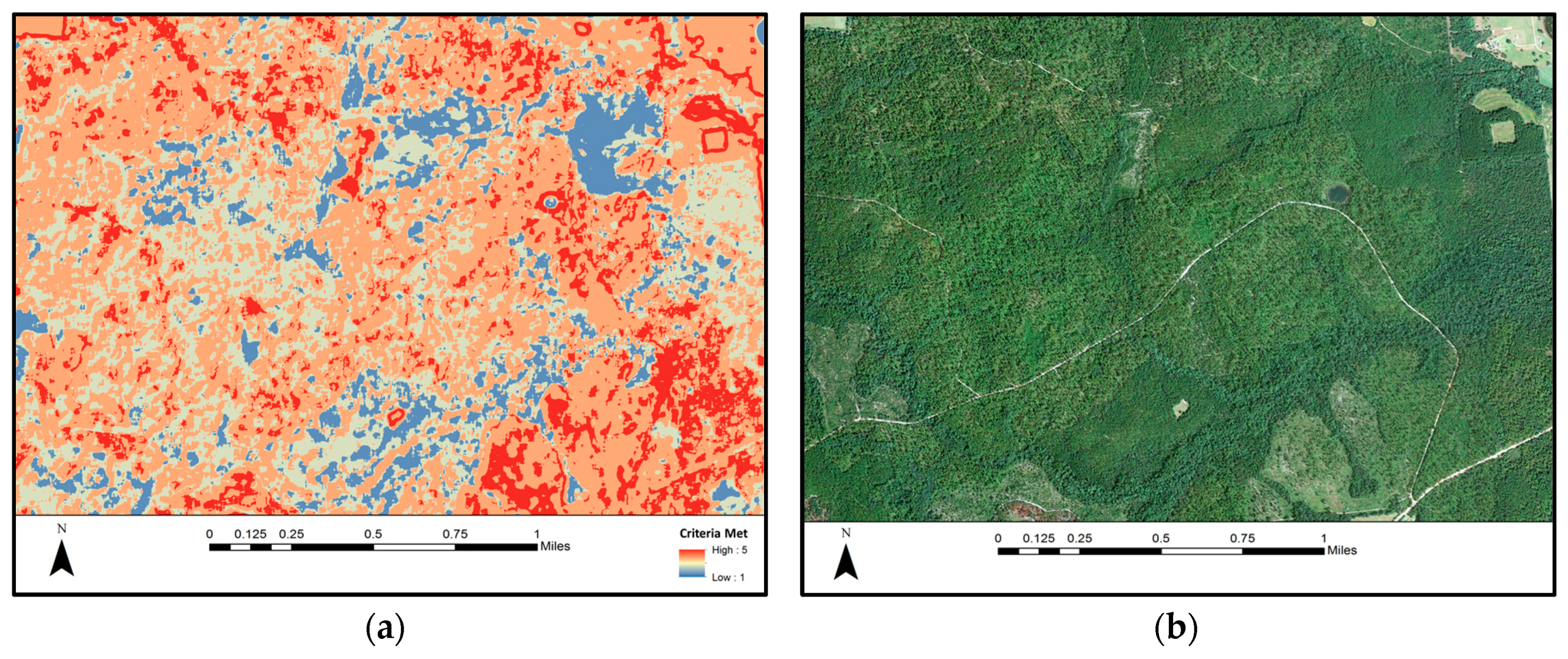
3.3. Example of Use
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gao, J. Digital Analysis of Remotely Sensed Imagery, 1st ed.; McGraw-Hill: New York, NY, USA, 2009; pp. 249–290. [Google Scholar]
- Feddema, J.J.; Oleson, K.W.; Bonan, G.B.; Mearns, L.O.; Buja, L.E.; Meehl, G.A.; Washington, W.M. The Importance of Land-Cover Change in Simulating Future Climates. Science 2005, 310, 1674–1678. [Google Scholar] [CrossRef] [PubMed]
- Skidmore, A.K.; Pettorelli, N.; Coops, N.C.; Geller, G.N.; Hansen, M.; Lucas, R.; Mücher, C.A.; O’Connor, B.; Paganini, M.; Pereira, H.M.; et al. Agree on biodiversity metrics to track from space. Nature 2015, 523, 403–405. [Google Scholar] [CrossRef] [PubMed]
- Falcucci, A.; Maiorano, L.; Boitani, L. Changes in land-use/land-cover patterns in Italy and their implications for biodiversity conservation. Landsc. Ecol. 2007, 22, 617–631. [Google Scholar] [CrossRef]
- Mahiny, A.S.; Clarke, K.C. Guiding SLEUTH land-use/land-cover change modeling using multicriteria evaluation: Towards dynamic sustainable land-use planning. Environ. Plan. B Plan. Des. 2012, 39, 925–944. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Tomppo, E.O. Remote sensing support for national forest inventories. Remote Sens. Environ. 2007, 110, 412–419. [Google Scholar] [CrossRef]
- Van Leeuwen, W.J.D. Monitoring the Effects of Forest Restoration Treatments on Post-Fire Vegetation Recovery with MODIS Multitemporal Data. Sensors 2008, 8, 2017–2042. [Google Scholar] [CrossRef] [PubMed]
- Koetz, B.; Morsdorf, F.; van der Linden, S.; Curt, T.; Allgöwer, B. Multi-source land cover classification for forest fire management based on imaging spectrometry and LiDAR data. For. Ecol. Manag. 2008, 256, 263–271. [Google Scholar] [CrossRef]
- Flamenco-Sandoval, A.; Ramos, M.M.; Masera, O.R. Assessing implications of land-use and land-cover change dynamics for conservation of a highly diverse tropical rain forest. Biol. Conserv. 2007, 138, 131–145. [Google Scholar] [CrossRef]
- Basu, S.; Ganguly, S.; Nemani, R.R.; Mukhopadhyay, S.; Zhang, G.; Milesi, C.; Michaelis, A.; Votava, P.; Dubayah, R.; Duncanson, L.; et al. A Semiautomated Probabilistic Framework for Tree-Cover Delineation From 1-m NAIP Imagery Using a High-Performance Computing Architecture. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5690–5708. [Google Scholar] [CrossRef]
- Nagel, P.; Yuan, F. High-resolution Land Cover and Impervious Surface Classifications in the Twin Cities Metropolitan Area with NAIP Imagery. Photogramm. Eng. Remote Sens. 2016, 82, 63–71. [Google Scholar] [CrossRef]
- Forester, J.D.; Ives, A.R.; Turner, M.G.; Anderson, D.P.; Fortin, D.; Beyer, H.L.; Smith, D.W.; Boyce, M.S. State-space models link elk movement patterns to landscape characteristics in Yellowstone National Park. Ecol. Monogr. 2007, 77, 285–299. [Google Scholar] [CrossRef]
- Homer, C.G.; Dewitz, J.A.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.D.; Wickham, J.D.; Megown, K. Completion of the 2011 National Land Cover Database for the conterminous United States—Representing a decade of land cover change information. Photogramm. Eng. Remote Sens. 2015, 81, 345–354. [Google Scholar]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Woods, B.; Clymer, B.; Heverhagen, J.; Knopp, M.; Saltz, J.; Kurc, T. Parallel four-dimensional Haralick texture analysis for disk-resident image datasets. Concurr. Comput. 2007, 19, 65–87. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Supervised Machine Learning: A Review of Classification Techniques. In Emerging Artificial Intelligence Applications in Computer Engineering, 1st ed.; Maglogiannis, I., Karpouzis, K., Wallace, B.A., Soldatos, J., Eds.; IOS Press: Amsterdam, The Netherlands, 2007; pp. 3–25. [Google Scholar]
- Hayes, M.M.; Miller, S.N.; Murphy, M.A. High-resolution landcover classification using Random Forest. Remote Sens. Lett. 2014, 5, 112–121. [Google Scholar] [CrossRef]
- Civco, D.L. Artificial neural networks for land-cover classification and mapping. Int. J. Geogr. Inf. Syst. 1993, 7, 173–186. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Cleve, C.; Kelly, M.; Kearns, F.R.; Moritz, M. Classification of the wildland-urban interface: A comparison of pixel- and object-based classifications using high-resolution aerial photography. Comput. Environ. Urban Syst. 2008, 32, 317–326. [Google Scholar] [CrossRef]
- Hogland, J.S.; Anderson, N.M.; Chung, W.; Wells, L. Estimating forest characteristics using NAIP imagery and ArcObjects. In Proceedings of the 2014 ESRI Users Conference, San Diego, CA, USA, 14–18 July 2014; Available online: http://proceedings.esri.com/library/userconf/proc14/papers/155_181.pdf (accessed on 16 January 2018).
- Hogland, J.S.; Anderson, N.M. Estimating FIA plot characteristics using NAIP imagery, function modeling, and the RMRS raster utility coding library. In Proceedings of the New Directions in Inventory Techniques and Applications: Forest Inventory and Analysis (FIA) Symposium, Portland, OR, USA, 8–10 December 2015; U.S. Department of Agriculture, Forest Service, Pacific Northwest Research Station: Washington, DC, USA, 2015; pp. 340–344. [Google Scholar]
- Rodriguez-Galiano, V.F.; Chica-Olmo, M.; Abarca-Hernandez, F.; Atkinson, P.M.; Jeganathan, C. Random Forest classification of Mediterranean land cover using multi-seasonal imagery and multi-seasonal texture. Remote Sens. Environ. 2012, 121, 93–107. [Google Scholar] [CrossRef]
- Hogland, J.; Billor, N.; Anderson, N. Comparison of standard maximum likelihood classification and polytomous logistic regression used in remote sensing. Eur. J. Remote Sens. 2013, 46, 623–640. [Google Scholar] [CrossRef]
- Foody, G.M. Fuzzy modeling of vegetation from remotely sensed imagery. Ecol. Model. 1996, 85, 3–12. [Google Scholar] [CrossRef]
- Land Cover Data Project. Available online: http://chesapeakeconservancy.org/conservation-innovation-center/high-resolution-data/land-cover-data-project/ (accessed on 7 November 2017).
- America’s Longleaf. 2009 Range-Wide Conservation Plan for Longleaf. Available online: http://www.americaslongleaf.org/media/86/conservation_plan.pdf (accessed on 12 May 2015).
- Noss, R.; LaRoe, E.; Scott, J. Endangered Ecosystems of the United States: A Preliminary Assessment of Loss and Degradation; Biological Report 28; National Biological Service: Washington, DC, USA, 1995. [Google Scholar]
- Oswalt, C.M.; Cooper, J.; Brockway, D.G.; Brooks, H.W.; Walker, J.L.; Connor, K.F.; Oswalt, S.N.; Conner, R.C. History and Current Condition of Longleaf Pine in the Southern United States; General Technical Report SRS-166; U.S. Department of Agriculture Forest Service, Southern Research Station: Ashville, NC, USA, 2012; 51p.
- Cooperative Land Cover, Version 3.2. Published October 2016. Available online: http://myfwc.com/research/gis/applications/articles/cooperative-land-cover/ (accessed on 16 January 2018).
- LPEGDB Version 3 Summary Report—Florida Natural Areas Inventory. Available online: http://www.fnai.org/PDF/LPEGDB_v3_Summary_Report_Sep_2015.pdf (accessed on 16 January 2018).
- National Agriculture Imagery Program (NAIP) Information Sheet. Available online: http://www.fsa.usda.gov/Internet/FSA_File/naip_info_sheet_2013.pdf (accessed on 14 May 2014).
- Wold, S.; Esbensen, K.; Geladi, P. Principal Component Analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- RMRS Raster Utility. Available online: http://www.fs.fed.us/rm/raster-utility (accessed on 24 January 2018).
- Hogland, J.; Anderson, N. Improved analyses using function datasets and statistical modeling. In Proceedings of the 2014 ESRI Users Conference, San Diego, CA, USA, 14–18 July 2014; Environmental Systems Research Institute: Redlands, CA, USA, 2014. [Google Scholar]
- Hogland, J.; Anderson, N. Function Modeling Improves the Efficiency of Spatial Modeling Using Big Data from Remote Sensing. Big Data Cogn. Comput. 2017, 1, 1–14. [Google Scholar] [CrossRef]
- United States Geological Survey File Transfer Protocol [USGS FTP] (2016) Staged NAIP. Available online: ftp://rockyftp.cr.usgs.gov/vdelivery/Datasets/Staged/NAIP/ (accessed on 16 September 2016).
- Maxwell, A.E.; Warner, T.A.; Vanderbilt, B.C.; Ramezan, C.A. Land Cover Classification and Feature Extraction from National Agriculture Imagery Program (NAIP) Orthoimagery: A Review. Photogramm. Eng. Remote Sens. 2017, 83, 737–747. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer Science+Business Media, LLC: New York, NY, USA, 2006; pp. 179–224. [Google Scholar]
- Hogland, J.; St. Peter, J.; Anderson, N. Raster Surfaces Created from the Longleaf Mapping Project. Fort Collins, CO: Forest Service Research Data Archive. 2017. Available online: https://doi.org/10.2737/RDS-2017-0014 (accessed on 16 January 2018).
- America’s Longleaf. 2014 Longleaf Pine Maintenance Condition Class Definitions. Available online: http://www.americaslongleaf.org/media/14299/final-lpc-maintenance-condition-class-metrics-oct-2014-high-res.pdf (accessed on 2 May 2016).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Description |
|---|---|
| Shadow | Shadows associated with an object |
| Pavement | Roads, driveways, and other paved objects |
| Building | Buildings |
| Tree Crown Light | Light green trees usually broadleaf |
| Tree Crown Dark | Dark green trees usually coniferous |
| Shrub | Green shrub species |
| Green Grass | Growing grass |
| Water | Lakes, ponds, streams and ocean |
| Burn | Recently burned charred areas |
| Bare Ground | Exposed soil or rock |
| Tree Crown Grey | Grey tree canopy usually senesced broadleaf |
| Dry Grass | Dormant grass |
| Crops | Platted or irrigated areas that did not have exposed soil |
| Components | Alabama | Georgia | Florida |
|---|---|---|---|
| 1 | 39.84% | 36.45% | 42.08% |
| 2 | 69.12% | 65.90% | 68.67% |
| 3 | 77.95% | 76.43% | 77.58% |
| 4 | 84.34% | 82.95% | 84.09% |
| 5 | 89.65% | 88.20% | 89.85% |
| 6 | 93.53% | 92.77% | 93.60% |
| 7 | 95.69% | 95.34% | 95.69% |
| 8 | 97.21% | 97.16% | 97.33% |
| 9 | 98.38% | 98.23% | 98.46% |
| 10 | 99.20% | 99.15% | 99.31% |
| 11 | 99.64% | 99.61% | 99.67% |
| 12 | 100.00% | 100.00% | 100.00% |
| State | Modeled Average Error |
|---|---|
| Alabama | 9.1% |
| Florida | 9.3% |
| Georgia | 8.9% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
St. Peter, J.; Hogland, J.; Anderson, N.; Drake, J.; Medley, P. Fine Resolution Probabilistic Land Cover Classification of Landscapes in the Southeastern United States. ISPRS Int. J. Geo-Inf. 2018, 7, 107. https://doi.org/10.3390/ijgi7030107
St. Peter J, Hogland J, Anderson N, Drake J, Medley P. Fine Resolution Probabilistic Land Cover Classification of Landscapes in the Southeastern United States. ISPRS International Journal of Geo-Information. 2018; 7(3):107. https://doi.org/10.3390/ijgi7030107
Chicago/Turabian StyleSt. Peter, Joseph, John Hogland, Nathaniel Anderson, Jason Drake, and Paul Medley. 2018. "Fine Resolution Probabilistic Land Cover Classification of Landscapes in the Southeastern United States" ISPRS International Journal of Geo-Information 7, no. 3: 107. https://doi.org/10.3390/ijgi7030107
APA StyleSt. Peter, J., Hogland, J., Anderson, N., Drake, J., & Medley, P. (2018). Fine Resolution Probabilistic Land Cover Classification of Landscapes in the Southeastern United States. ISPRS International Journal of Geo-Information, 7(3), 107. https://doi.org/10.3390/ijgi7030107