POI Information Enhancement Using Crowdsourcing Vehicle Trace Data and Social Media Data: A Case Study of Gas Station



Abstract
1. Introduction
- First, using sparse vehicle GPS trace to extract the spatial information of gas stations has two key points to be solved: one is to extract the refueling stop sub-track from each trace. However, vehicle trace contains various stop behaviors and there is no model and algorithm to identity and extract refueling stop behavior sub-tracks. Therefore, it needs to establish a refueling stop behavior model to distinguish the refueling behavior from other stop behaviors and propose an efficient algorithm to extract refueling stop tracks by coupling the model. The other problem is that it requires a new way to extract the spatial information accurately from the collective refueling tracks.
- Second, social media data not only contains attribute data of gas stations (e.g., name, address), but also contains review information of different dimensions (e.g., service, product). Therefore, it is necessary to present a new method to mine the attribute and dimensional sentiment semantic information from the unstructured comment text data simultaneously.
- Third, an efficient method should be proposed to enhance the POI information by fusing the two kinds of different dimension information from different sources.
- The vehicle refueling stop behavior model and the velocity sequence linear clustering algorithm (VSLC) are proposed to identity and extract refueling stop sub-tracks from each trace. Then, the spatial information of gas stations is extracted from collective refueling stop tracks by the Delaunay triangulation.
- A new way of coupling the text mining method and tripartite graph model is presented to extract the attribute information and dimension sentiment semantic of gas stations from the social media data of www.dazhongdianping.com (Dianping) [15].
- The POI information is enhanced using a matching method by fusing the spatial and attribute information extracted from different VGI data.
- An experiment using 15-day taxi GPS traces and social media data from Dianping in Beijing, China verifies the novel method.
2. Related Work
2.1. Activity Stop Behavior Detection from GPS Trajectory for Extracting POI Information
2.2. Extracting POIs’ Semantic Information from Social Media Data
2.3. POI Informationen Ehancement Using Multisourced VGI Data
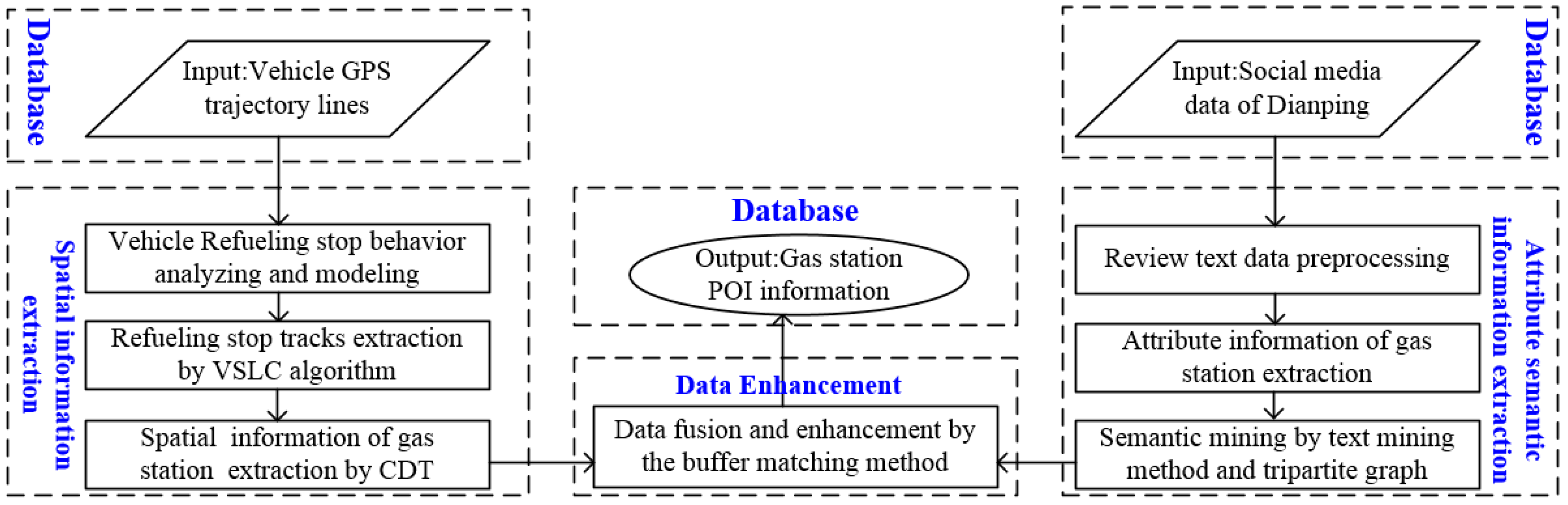
3. Methodology
- First, after modeling the refueling stop behavior using trajectory movement parameters, the vehicle refueling stop sub-trajectories are extracted by the proposed VSLC, and then the gas station spatial information is extracted from collective stop tracks by the Delaunay triangulation.
- Second, attribute information and each dimension sentiment evaluation of the gas station are extracted by the text mining method and tripartite graph model.
- Third, the spatial information, attribute information and review semantic information of the gas station are integrated to enhance the POI information by using the buffer matching method.
3.1. Spatial Information of Gas Station Extraction from Sparse Vehicle Trajectory Data
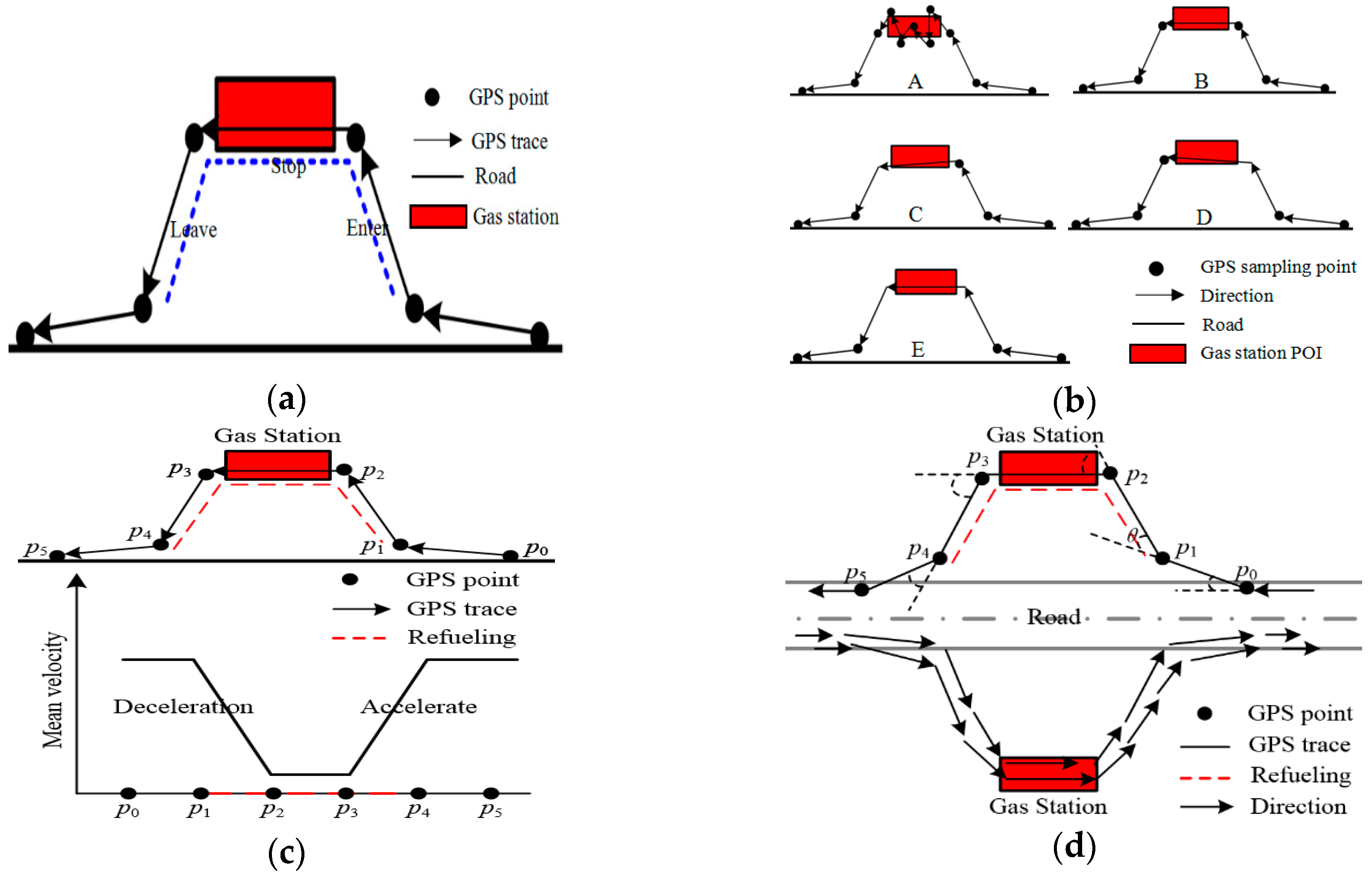
3.1.1. Refueling Stop Behavior Analyzing and Modeling Using Movement Parameters
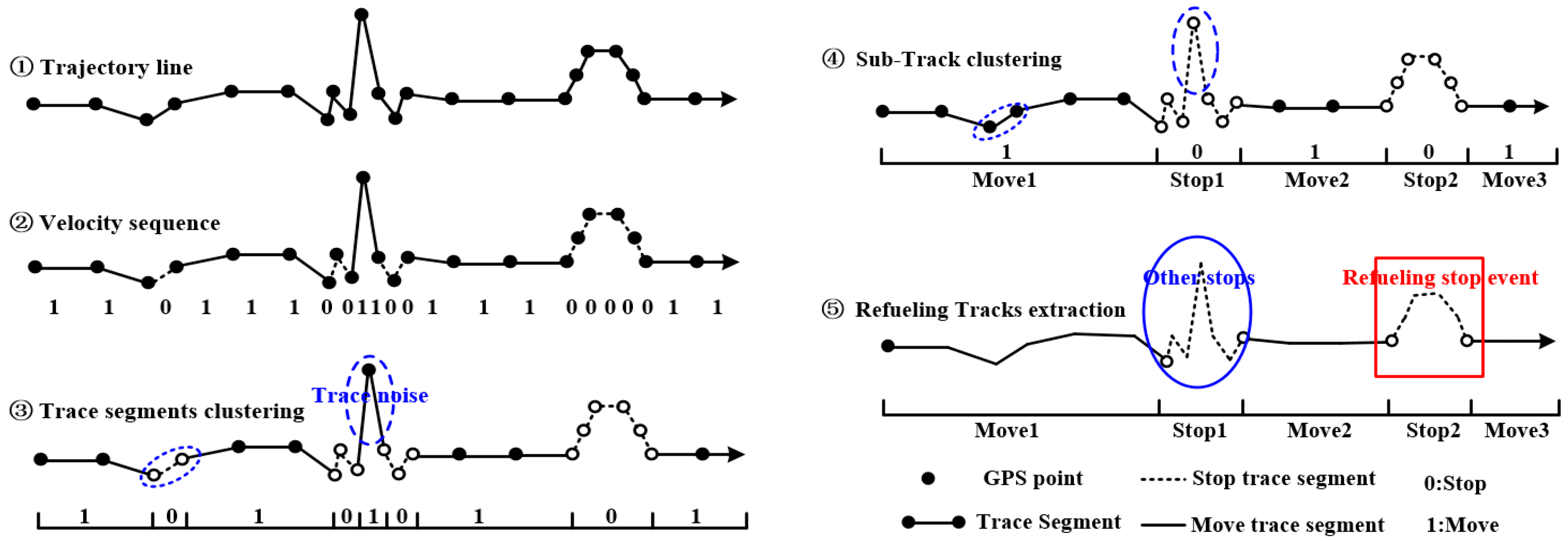
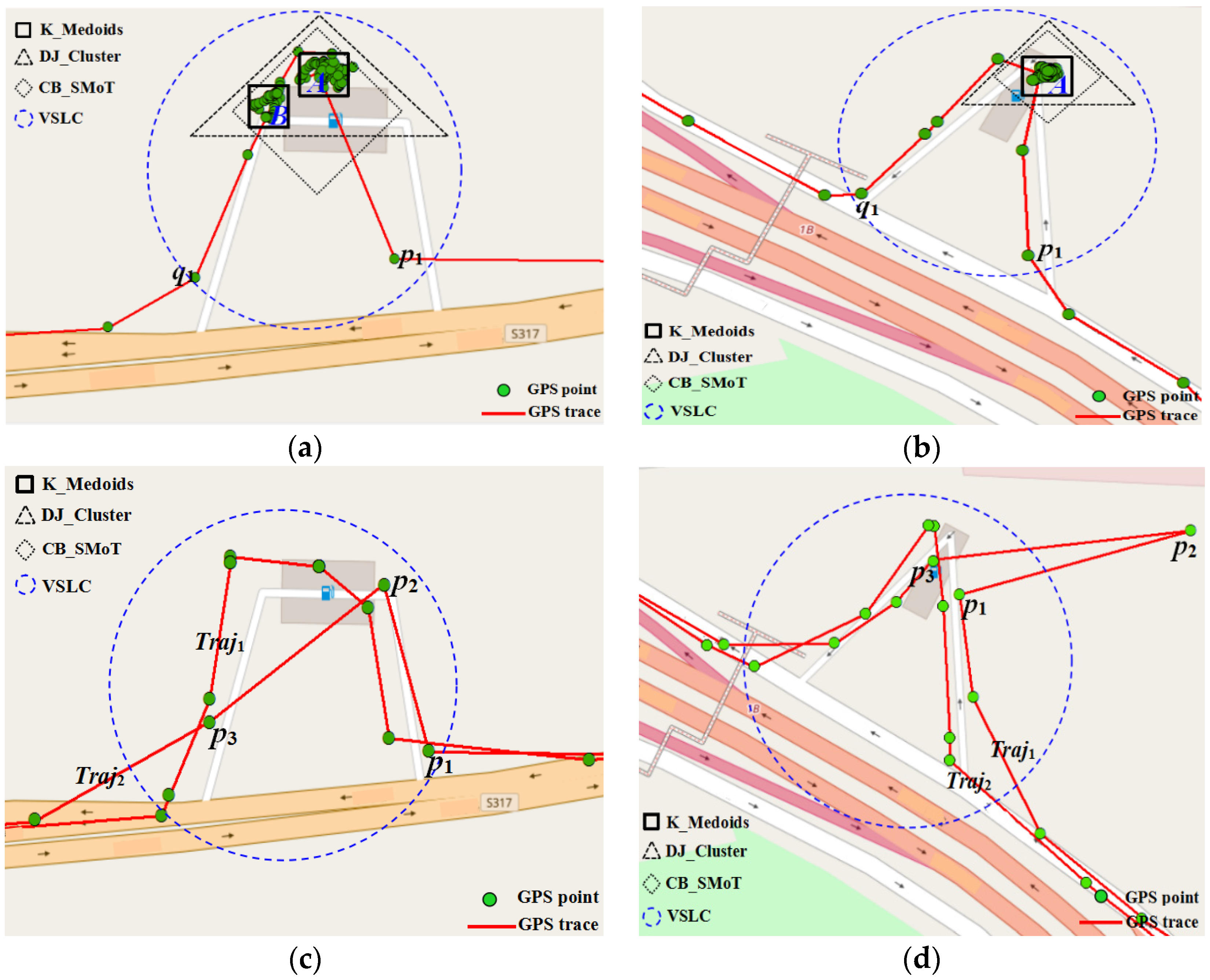
3.1.2. Refueling Stop Tracks Extraction Using Velocity Sequence Linear Clustering Algorithm
- Step 1, parameters values are defined. Determine the average speed threshold MaxAv, minimum movement duration threshold MinMove, and minimum stop duration threshold MinStop.
- Step 2, trajectory segments speed serialization. For each trace, the average velocity of each trace segment as represented by TSAv is calculated. The trace segment is considered in the stop state when TSAv ≤ MaxAv, and the state is represented by 0; conversely, the trajectory segment is considered in the move state, and the state is represented by 1, as per Step 2 in Figure 3.
- Step 3, clustering trajectory segments. Sub-tracks are generated by merging trajectory segments with the same state in accordance with the direction of time, as per Step 3 in Figure 3.
- Step 4, extracting stop sub-tracks. For each sub-track generated in Step 3, if the time duration of the sub-track is lower than MinMove or MinStop, the sub-track is changed into opposite state as trajectory noise. Then, extract the stop sub-tracks by direction clustering sub-tracks again according to the state, as per Step 4 in Figure 3.
- Step 5, extracting refueling stop sub-tracks. For each stop sub-track, the stop sub-track can be considered as refueling stop tracks when the trajectory features accord with the RE model in Section 3.1.1, as per Step 5 in Figure 3.
- Step 6, collective refueling stop tracks extraction. When all vehicle traces are processed repeat the above steps, the extraction results are the collective refueling stop tracks.
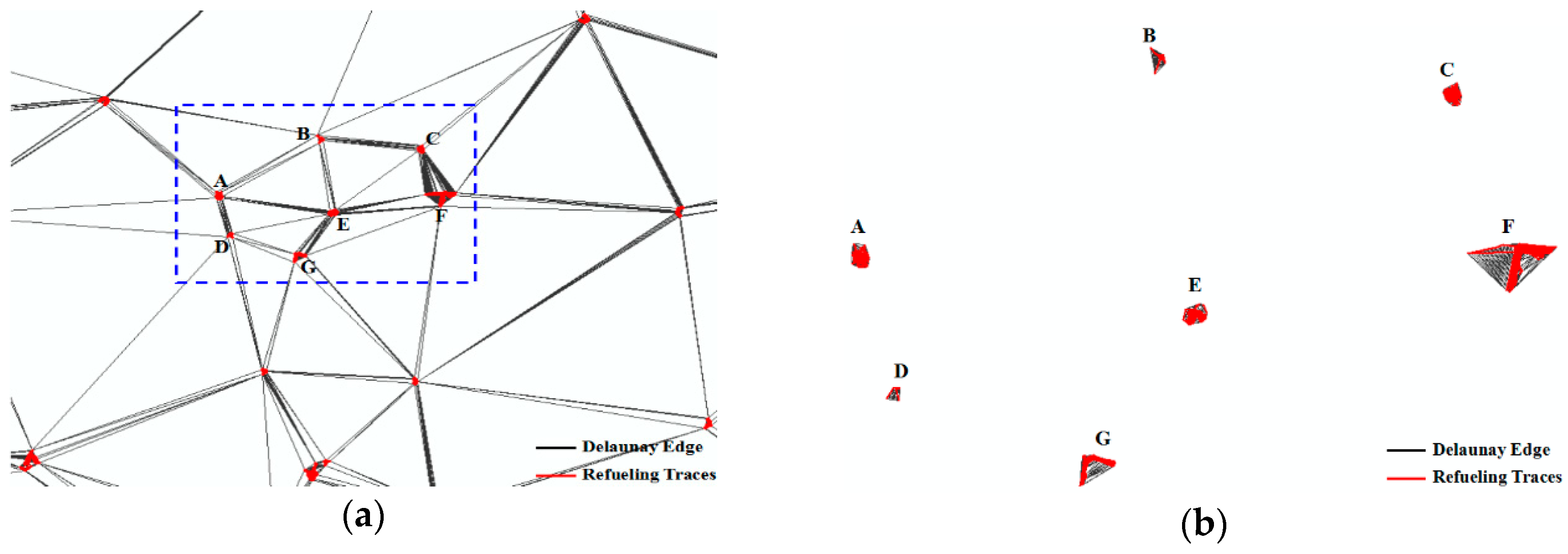
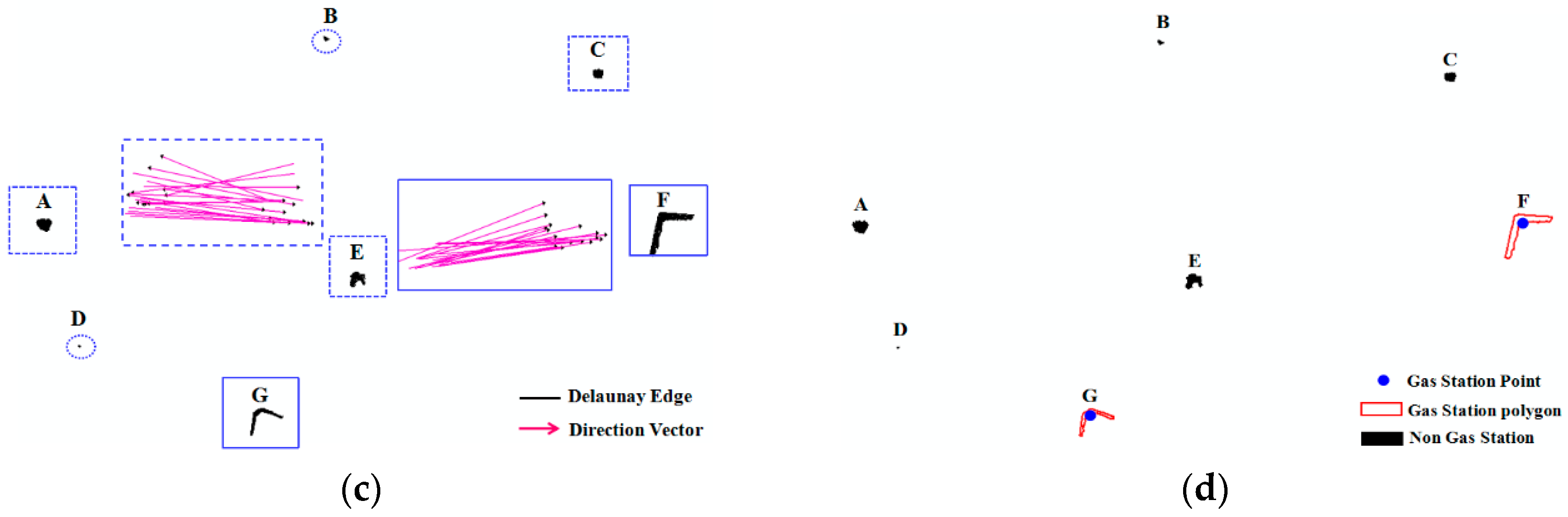
3.1.3. Spatial Geometric Information Extraction Using Collective Refueling Stop Tracks
3.2. Attribute and Semantic Information of Gas Station Extraction from Social Media Data
3.2.1. Social Media Data from Dianping
3.2.2. Attribute and Semantic Information Extraction Using the Text Mining Method
- Step 1, text reprocessing. Review text reprocessing including sentence segmentation, tokenization, removing stop words, and POS tagging by the NLP module of Python [43].
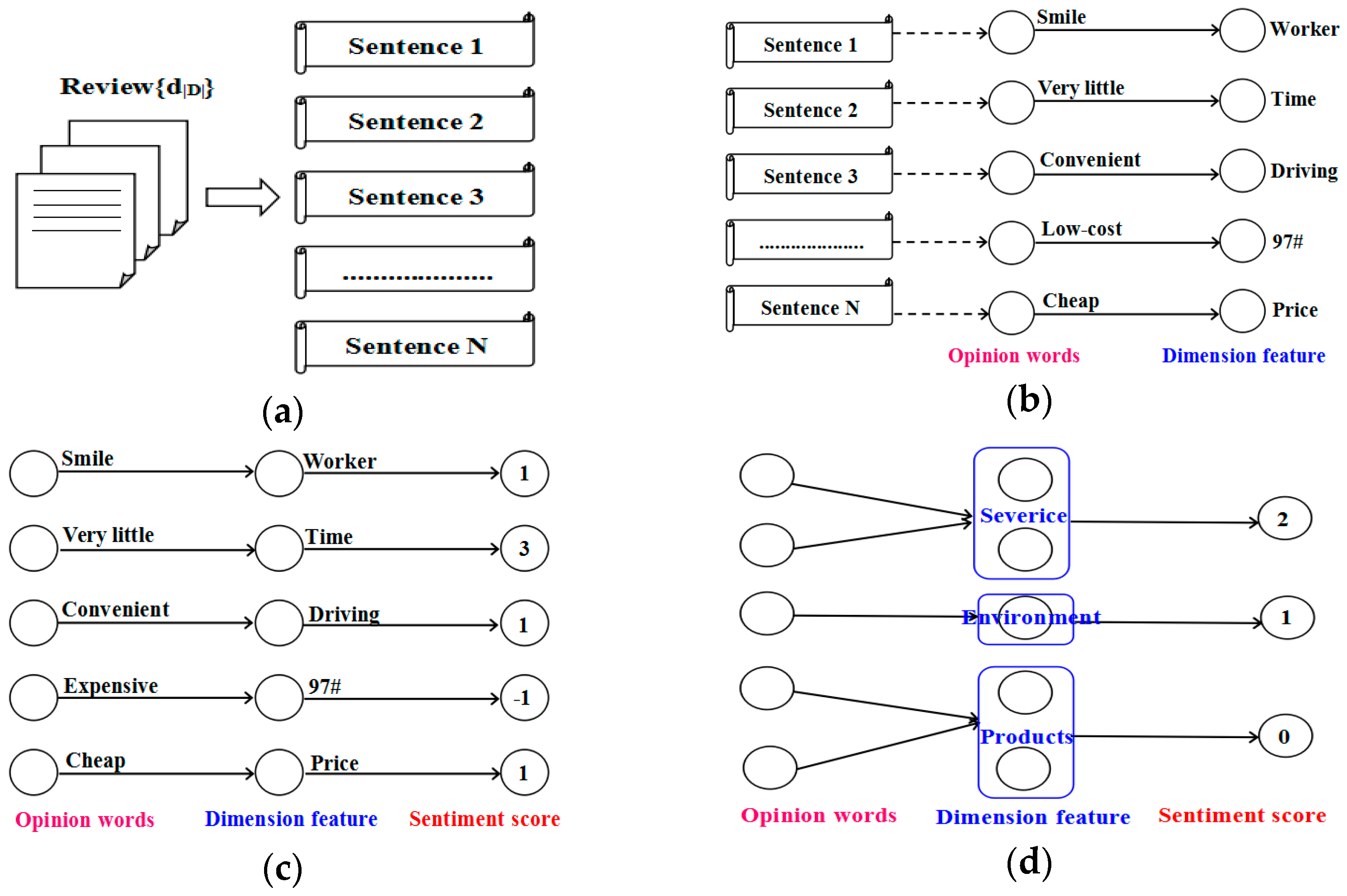
- Step 2, extracting feature-opinion word pairs. The assumption was that each sentence was an evaluation of a dimension of the feature object [44]. The direct links of opinion words (sentiment) and noun words (feature) in a clause, e.g., co-occurrence, were extracted according to syntactic structure and the sentiment dictionary. This step collected all the co-occurrence pairs between noun words and opinion words in sentences and modeled the problem as a bipartite graph, as shown in Figure 5b.
- Step 3, sentiment scores calculation. Each sentence was a sentiment unit, the sentiment values of feature were calculated by considering the effect of opinion words, negative words, and degree words. The sentiment value can be calculated as follows:n is the number of opinion words of the sentence; pi is the sentiment polarity of the sentiment word i; and wi is the degree of the sentiment word i. The sentiment polarity including positive, neutral, and negative [43] and using 1, 0, and −1 to indicate them. The degree words were classified into three grades: strong, middle, and weak, which are presented by 3, 2, and 1 respectively. Then, a tripartite graph was constructed by incorporating the sentiment scores, as shown in Figure 5c.
- Step 4, feature word merging. Considering that different sentences may be the evaluation of the same feature of the gas station, and indirect links between the opinion words and noun words are links through inter-sentences, the feature words of the tripartite graph were merged into four dimensions according to the dimensional dictionary defined previously. In Figure 5d, the dimension sentiment information of the gas station extraction by tripartite graph.
- Step 5, dimension sentiment scores calculation. Dimension sentiment scores were calculated for each dimension in a gas station. Calculation scores in the k dimension of document d as follows:m is the number of sentences in the document d marked with the k dimension. The dimension score of each gas station was obtained, as shown in Figure 5d.
- Step 6, the algorithm was stopped when all the documents of the gas station were processed.
3.3. POI Information Fusion and Enhancement
4. Experimental and Evaluation
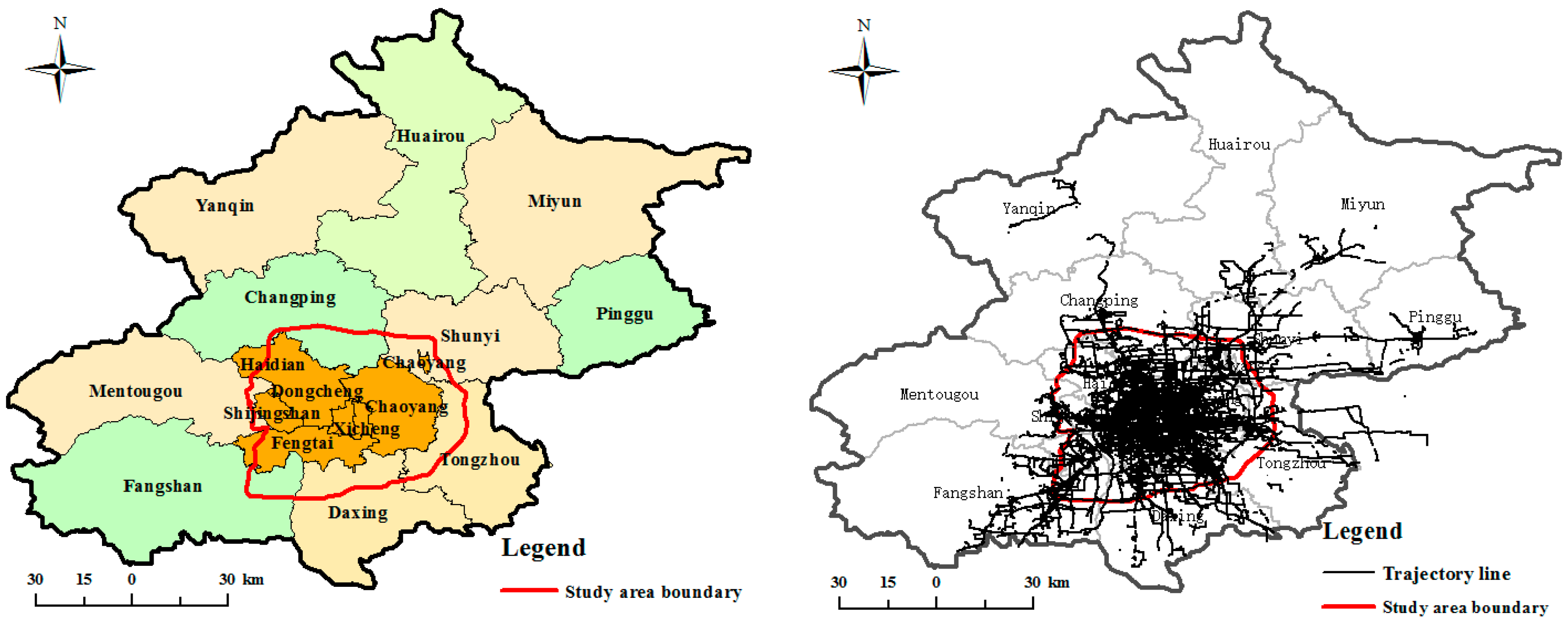
4.1. Experimental Data
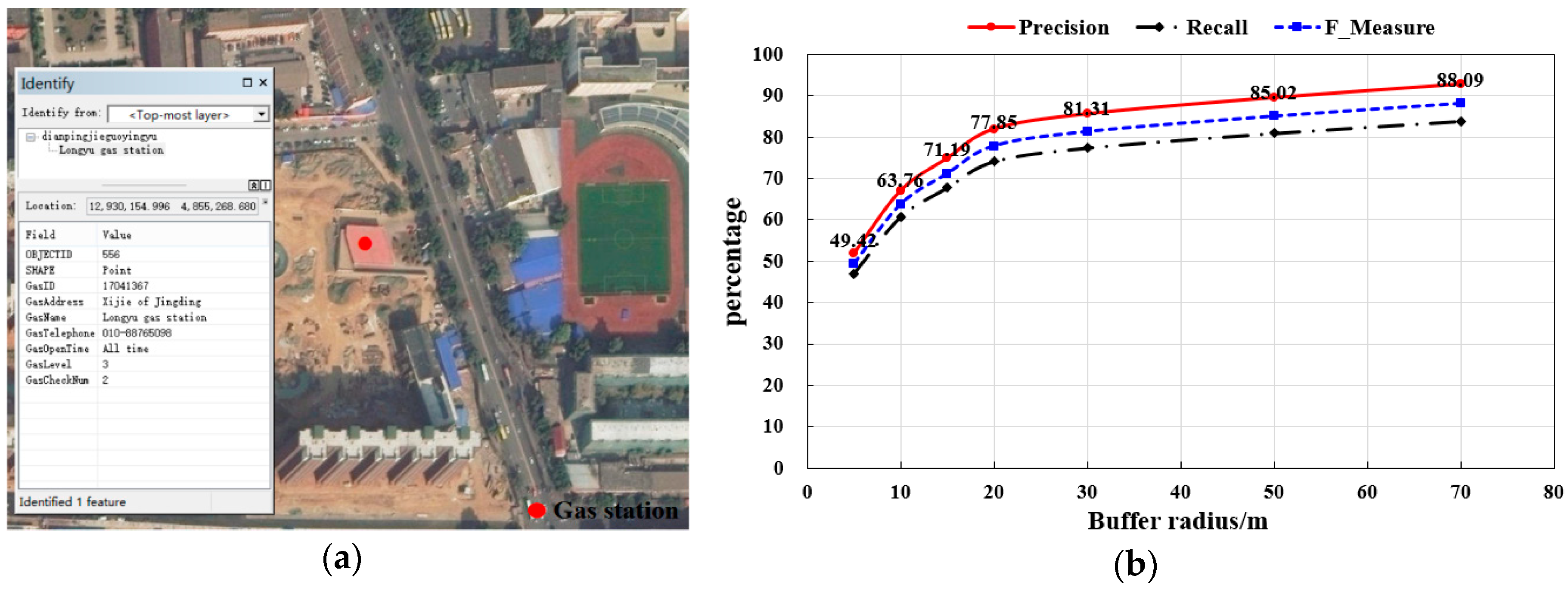
4.2. Refueling Stop Events Extraction Experimental and Evaluation
4.2.1. Evaluation of Refueling Stop Extraction Algorithm
4.2.2. Parameters Setting and Evaluation
4.3. Gas Station Information Enhancement and Evaluation
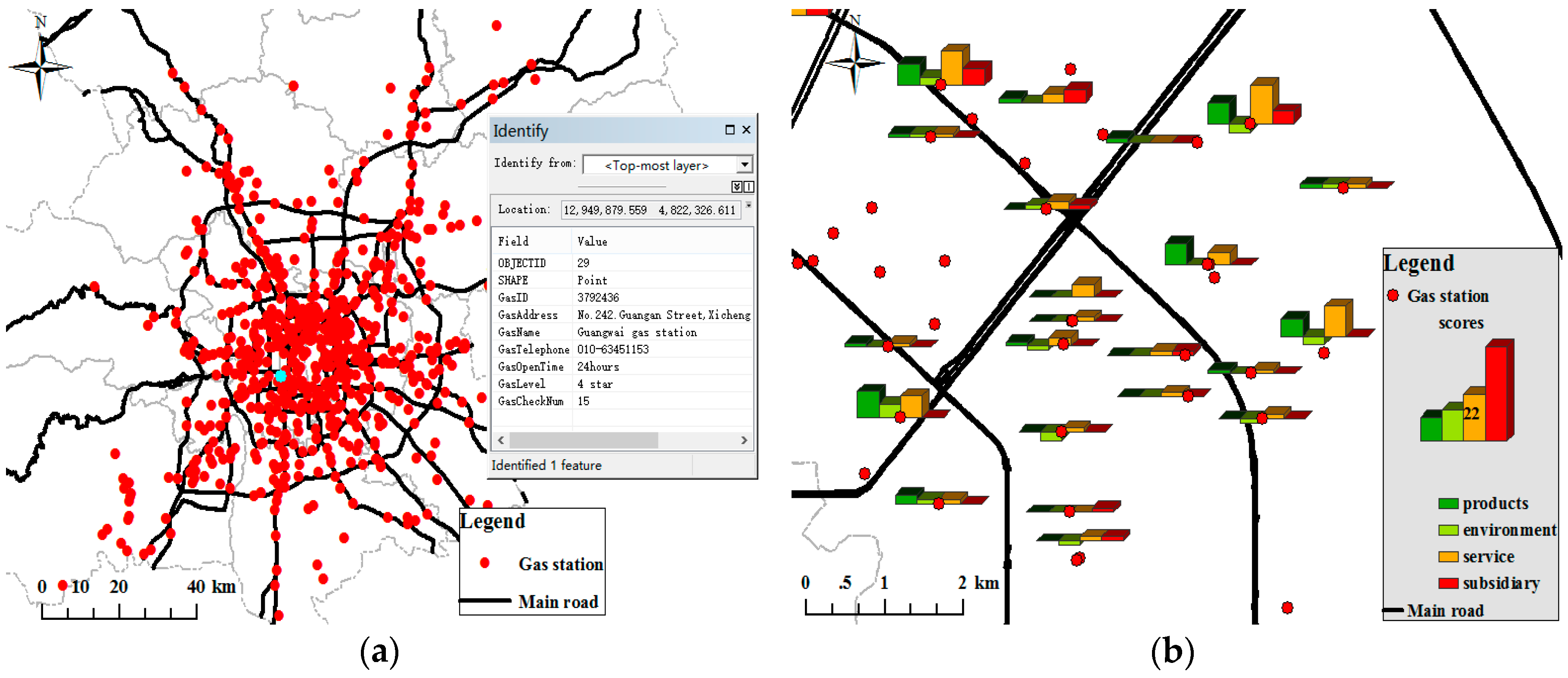
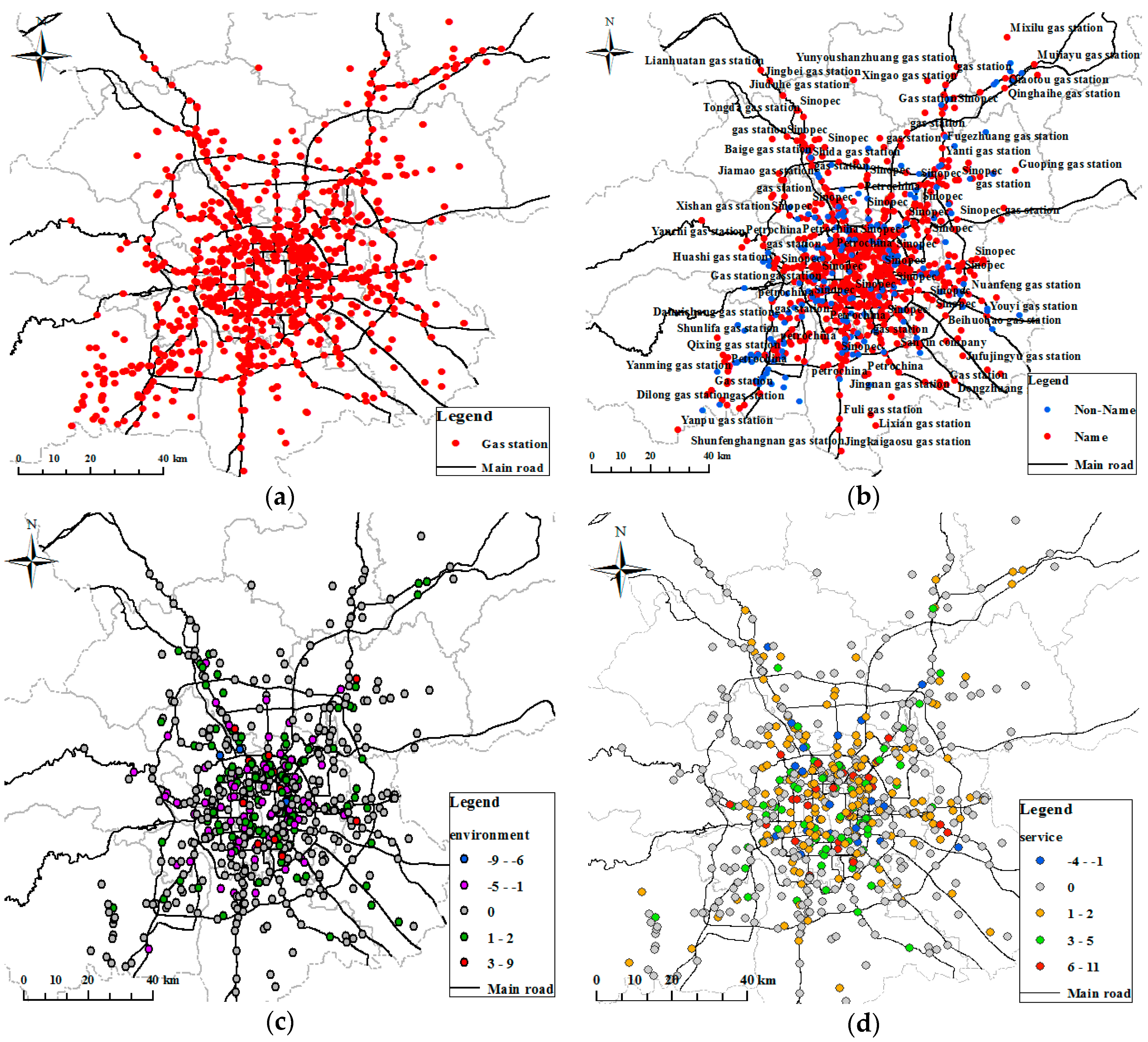
4.3.1. Gas Station Spatial Information Extraction from Vehicle GPS Trajectories
4.3.2. Gas Station Attribute Semantic Information Extraction from Dianping
4.3.3. Final Gas Station POI Map and Evaluation
4.4. Discussion
- First, some gas stations were not extracted due to only using taxi GPS traces. It needs to use multiple sources of trajectory data (e.g., car, electric vehicle GPS trace) to detect more refueling stop events. How to accurately detect refueling events and extract gas stations from different sources of trace data, since the positioning accuracy or sampling frequency might be variable in different datasets, is still a challenge [32].
- Second, mining unstructured comment data is a significant challenge. In this work, mining sentiment information by constructing an emotion and feature dictionary that used sentences as a unit. However, it needs prior knowledge and manual operation. Further work needs to improve the sentiment semantic mining method, such as using a Deep Learning [33] technology.
- Third, the attribute semantic information of the experimental results was still incomplete. As social UGC data are added by non-professional volunteers, some gas stations did not have attributes, comments or only part of attributes, which resulted in the extraction attribute semantic information being incomplete and inaccurate. Multi-web sources and multimodal data (such as video, photos) need to be fused to extract more detailed attribute data [6,33].
- Four, mining hidden information, such as the detection of outdated POI, POI demolition, POI temporary maintenance, and POI change relations [6], etc. In this paper, it was far from enough to use the time information of the comments and vehicle tracks to detect outdated POI. Identifying outdated or emerging POI relations is an important future work to enhance the POI data quality. Moreover, UGC review data and other VGI data should be integrated to perceive the temporal dynamic change of the POI place attribute semantic in the future.
5. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Chuang, H.M.; Chang, C.H.; Kao, T.Y.; Cheng, C.T.; Huang, Y.Y.; Cheong, K.P. Enabling maps/location searches on mobile devices: Constructing a POI database via focused crawling and information extraction. Int. J. Geogr. Inf. Sci. 2016, 30, 1405–1425. [Google Scholar] [CrossRef]
- Liu, Y.; Seah, H.S. Points of interest recommendation from GPS trajectories. Int. J. Geogr. Inf. Sci. 2015, 29, 953–979. [Google Scholar] [CrossRef]
- Chang, C.H.; Chuang, H.M.; Huang, C.Y.; Su, Y.S.; Li, S.Y. Enhancing POI search on maps via online address extraction and associated information segmentation. Appl. Intell. 2016, 44, 539–556. [Google Scholar] [CrossRef]
- Wang, J.; Wang, C.; Song, X.; Raghavan, V. Automatic intersection and traffic rule detection by mining motor-vehicle GPS trajectories. Comput. Environ. Urban Syst. 2017, 64, 19–29. [Google Scholar] [CrossRef]
- Touya, G.; Antoniou, V.; Olteanu-Raimond, A.M.; Van Damme, M.D. Assessing crowdsourced POI quality: Combining methods based on reference data, history, and spatial relations. ISPRS Int. J. Geo-Inf. 2017, 6, 80. [Google Scholar] [CrossRef]
- Lamprianidis, G.; Skoutas, D.; Papatheodorou, G.; Pfoser, D. Extraction, integration and analysis of crowdsourced points of interest from multiple web sources. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Crowdsourced and Volunteered Geographic Information, Dallas, TX, USA, 4–8 November 2014; pp. 16–23. [Google Scholar]
- Mazimpaka, J.D.; Timpf, S. Trajectory data mining: A review of methods and applications. J. Spat. Inf. Sci. 2016, 13, 61–99. [Google Scholar] [CrossRef]
- Shan, Z.; Wu, H.; Sun, W.; Zheng, B. COBWEB: A robust map update system using GPS trajectories. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Grand Front Osaka, Umeda, Japan, 7–11 September 2015; pp. 927–937. [Google Scholar]
- Reinoso, F.; Ariza-López, J.; Barrera, D. A fitted B-spline method to derive a representative 3D axis from a set of multiple road traces. Geocarto Int. 2016, 31, 832–844. [Google Scholar] [CrossRef]
- Yang, W.; Ai, T.; Lu, W. A Method for Extracting Road Boundary Information from Crowdsourcing Vehicle GPS Trajectories. Sensors 2018, 18, 1261. [Google Scholar] [CrossRef] [PubMed]
- Siła-Nowicka, K.; Vandrol, J.; Oshan, T. Analysis of human mobility patterns from GPS trajectories and contextual information. Int. J. Geogr. Inf. Sci. 2016, 30, 881–906. [Google Scholar] [CrossRef]
- Chuang, H.M.; Chang, C.H. Verification of poi and location pairs via weakly labeled web data. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 743–748. [Google Scholar]
- Rattenbury, T.; Naaman, M. Methods for extracting place semantics from Flickr tags. ACM Trans. Web 2009, 3, 1. [Google Scholar] [CrossRef]
- Steiger, E.; Albuquerque, J.P.; Zipf, A. An advanced systematic literature review on spatiotemporal analyses of Twitter data. Trans. GIS 2015, 19, 809–834. [Google Scholar] [CrossRef]
- DianPing. Available online: htpp://www.dianping.com (accessed on 5 May 2018).
- Tu, W.; Cao, J.; Yue, Y.; Shaw, S.-L.; Zhou, M.; Wang, Z.; Chang, X.; Xu, Y.; Li, Q. Coupling mobile phone and social media data: A new approach to understanding urban functions and diurnal patterns. Int. J. Geogr. Inf. Sci. 2017, 31, 2331–2358. [Google Scholar] [CrossRef]
- Liu, H.; Kan, Z.; Wu, H.; Tang, L. Vehicle’ Refueling Activity Modeling and Space-time Distribution Analysis. Bull. Surv. Mapp. 2016, 9, 29–34. [Google Scholar]
- Spaccapietra, S.; Parent, C.; Damiani, M.L.; Macedo, J.A.D.; Porto, F.; Vangenot, C. A conceptual view on trajectories. Data Knowl. Eng. 2008, 65, 126–146. [Google Scholar] [CrossRef]
- Alvares, L.O.; Bogorny, V.; Kuijpers, B.; de Macedo, J.A.F.; Moelans, B.; Vaisman, A. A model for enriching trajectories with semantic geographical information. In Proceedings of the 15th annual ACM international symposium on Advances in geographic information systems, Seattle, WA, USA, 7–9 November 2007; p. 22. [Google Scholar]
- Xie, K.; Deng, K.; Zhou, X. From trajectories to activities: A spatio-temporal join approach. In Proceedings of the 2009 ACM International Workshop on Location Based Social Networks, Seattle, WA, USA, 3 November 2009; pp. 25–32. [Google Scholar]
- Niu, H.; Liu, J.; Fu, Y.; Liu, Y.; Lang, B. Exploiting human mobility patterns for gas station site selection. In Proceedings of the International Conference on Database Systems for Advanced Applications, Dallas, TX, USA, 16–19 April 2016. [Google Scholar]
- Ashbrook, D.; Starner, T. Using GPS to learn significant locations and predict movement across multiple users. Pers. Ubiquitous Comput. 2003, 7, 275–286. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise; KDD: Portland, OR, USA, 1996; pp. 226–231. [Google Scholar]
- Zhou, C.; Frankowski, D.; Ludford, P.; Shekhar, S.; Terveen, L. Discovering personally meaningful places: An interactive clustering approach. ACM Trans. Inf. Syst. 2007, 25, 12. [Google Scholar] [CrossRef]
- Palma, A.T.; Bogorny, V.; Kuijpers, B.; Alvares, L.O. A clustering-based approach for discovering interesting places in trajectories. In Proceedings of the 2008 ACM Symposium on Applied Computing, Fortaleza, Brazil, 16–20 March 2008; pp. 863–868. [Google Scholar]
- Rocha, J.A.M.; Times, V.C.; Oliveira, G.; Alvares, L.O.; Bogorny, V. DB-SMoT: A direction-based spatio-temporal clustering method. In Proceedings of the 2010 5th IEEE International Conference Intelligent Systems, London, UK, 7–9 July 2010; pp. 114–119. [Google Scholar]
- Zhao, X.-L.; Xu, W.-X. A clustering-based approach for discovering interesting places in a single trajectory. In Proceedings of the 2009 IEEE Second International Conference on Intelligent Computation Technology and Automation, ICICTA 2009, Zhangjiajie, China, 10–11 October 2009; pp. 429–432. [Google Scholar]
- Luo, T.; Zheng, X.; Xu, G.; Fu, K.; Ren, W. An improved DBSCAN algorithm to detect stops in individual trajectories. ISPRS Int. J. Geo-Inf. 2017, 6, 63. [Google Scholar] [CrossRef]
- Xiang, L.; Gao, M.; Wu, T. Extracting stops from noisy trajectories: A sequence oriented clustering approach. ISPRS Int. J. Geo-Inf. 2016, 5, 29. [Google Scholar] [CrossRef]
- Fu, Z.; Tian, Z.; Xu, Y.; Qiao, C. A two-step clustering approach to extract locations from individual GPS trajectory data. ISPRS Int. J. Geo-Inf. 2016, 5, 166–183. [Google Scholar] [CrossRef]
- Zhang, F.; Yuan, N.J.; Wilkie, D.; Zheng, Y.; Xie, X. Sensing the Pulse of Urban Refueling Behavior: A Perspective from Taxi Mobility. ACM Trans. Intell. Syst. Technol. 2015, 6, 37. [Google Scholar] [CrossRef]
- Li, J.; Qin, Q.; Han, J.; Tang, L.A.; Lei, K.H. Mining trajectory data and geotagged data in social media for road map inference. Trans. GIS 2015, 19, 1–18. [Google Scholar] [CrossRef]
- Qian, X.; Lu, X.; Han, J.; Du, B.; Li, X. On Combining Social Media and Spatial Technology for POI Cognition and Image Localization. Proc. IEEE 2017, 105, 1937–1952. [Google Scholar] [CrossRef]
- Spyrou, E.; Korakakis, M.; Charalampidis, V.; Psallas, A.; Mylonas, P. A Geo-Clustering Approach for the Detection of Areas-of-Interest and Their Underlying Semantics. Algorithms 2017, 10, 35. [Google Scholar] [CrossRef]
- Liu, J.; Huang, Z.; Chen, L.; Shen, H.; Yan, Z. Discovering areas of interest with geo-tagged images and check-ins. In Proceedings of the 20th ACM international conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 589–598. [Google Scholar]
- Dokuz, A.S.; Celik, M. Discovering socially important locations of social media users. Expert Syst. Appl. 2017, 86, 113–124. [Google Scholar] [CrossRef]
- Liu, X.; He, J.; Yao, Y.; Zhang, J.; Liang, H.; Wang, H.; Hong, Y. Classifying urban land use by integrating remote sensing and social media data. Int. J. Geogr. Inf. Sci. 2017, 31, 1675–1696. [Google Scholar] [CrossRef]
- Dodge, S.; Weibel, R.; Forootan, E. Revealing the physics of movement: Comparing the similarity of movement characteristics of different types of moving objects. Comput. Environ. Urban Syst. 2009, 33, 419–434. [Google Scholar] [CrossRef]
- Ministry of Housing and Urban and Rural Construction in People’s Republic of China; State Administration of Quality Supervision, Inspection and Quarantine of People’s Republic of China. Code for Design and Construction of Filling Station: GB 50156-2012; China Planning Press: Beijing, China, 2012.
- Yang, W.; AI, T. Road centerline rxtraction from crowdsoucing trajectory data. Geogr. Geo-Inf. Sci. 2016, 32, 1–7. [Google Scholar]
- Deng, M.; Liu, Q.; Cheng, T.; Shi, Y. An adaptive spatial clustering algorithm based on Delaunay triangulation. Comput. Environ. Urban Syst. 2011, 35, 320–332. [Google Scholar] [CrossRef]
- Peng, H.; Cambria, E.; Hussain, A. A review of sentiment analysis research in Chinese language. Cogn. Comput. 2017, 9, 423–435. [Google Scholar] [CrossRef]
- Resch, B.; Usländer, F.; Havas, C. Combining machine-learning topic models and spatiotemporal analysis of social media data for disaster footprint and damage assessment. Cartogr. Geogr. Inf. Sci. 2017, 45, 362–376. [Google Scholar] [CrossRef]
- Yang, L.; Liu, B.; Lin, H.; Lin, Y. Combining local and global information for product feature extraction in opinion documents. Inf. Process. Lett. 2016, 116, 623–627. [Google Scholar] [CrossRef]
- McKenzie, G.; Janowicz, K.; Adams, B. A weighted multi-attribute method for matching user-generated points of interest. Cartogr. Geogr. Inf. Sci. 2014, 41, 125–137. [Google Scholar] [CrossRef]
- Database of Beijing City Government Data Resources. Available online: http://www.bjdata.gov.cn/ (accessed on 5 May 2018).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset No. | Trajectory Amount | Trajectory Points | Sampling Rate | Time Duration | Labeled Stops | Refueling Stops |
|---|---|---|---|---|---|---|
| 1 | 350 | 87,780 | irregular (10–120 s) | 7 days | 1886 | 286 |
| 2 | 5 | 9815 | irregular (10–120 s) | 1 days | 64 | 6 |
| K_Medoids | DJ-Cluster | CB_SMoT | VSLC | |
|---|---|---|---|---|
| Parameters | K = 7 | eps = 60 m minPoint = 8 | area = 0.3 time = 300 s | MaxAv = 6 km/h MinStop = 300 s MinMove = 120 s |
| Time complexity | O(t(n − k)2) | O(tnlogn) | O(n2) | O(n) |
| Elapsed Time(s) | 208.9 | 197.2 | 98.1 | 8.72 |
| Precision | 0.46 | 0.71 | 0.78 | 0.83 |
| Recall | 0.57 | 0.68 | 0.72 | 0.76 |
| F_Measure | 0.51 | 0.69 | 0.75 | 0.79 |
| K_Medoids | DJ-Cluster | CB_SMoT | VSLC | |
|---|---|---|---|---|
| Parameters | K = 9 | eps = 60 m minPoint = 8 | area = 0.3 time = 300 s | MaxAv = 6 km/h MinStop = 300 s MinMove = 120 s |
| Extracted Stops | 54 | 56 | 68 | 66 |
| Correct Stops | 24 | 47 | 48 | 53 |
| Refueling stops | 1 | 2 | 2 | 5 |
| Precision | 0.45 | 0.83 | 0.71 | 0.81 |
| Recall | 0.38 | 0.73 | 0.75 | 0.83 |
| F_Measure | 0.41 | 0.78 | 0.73 | 0.82 |
| Attribute Information | Sentiment Semantic Information | |||||||
|---|---|---|---|---|---|---|---|---|
| Name | Address | Tele | Open | Products | Environment | Service | Subsidy | |
| Extracted | 616 | 616 | 363 | 112 | 383 | 351 | 467 | 266 |
| Correct | 608 | 598 | 327 | |||||
| Reference | 820 | 786 | 368 | no 1 | no | no | no | no |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, W.; Ai, T. POI Information Enhancement Using Crowdsourcing Vehicle Trace Data and Social Media Data: A Case Study of Gas Station. ISPRS Int. J. Geo-Inf. 2018, 7, 178. https://doi.org/10.3390/ijgi7050178
Yang W, Ai T. POI Information Enhancement Using Crowdsourcing Vehicle Trace Data and Social Media Data: A Case Study of Gas Station. ISPRS International Journal of Geo-Information. 2018; 7(5):178. https://doi.org/10.3390/ijgi7050178
Chicago/Turabian StyleYang, Wei, and Tinghua Ai. 2018. "POI Information Enhancement Using Crowdsourcing Vehicle Trace Data and Social Media Data: A Case Study of Gas Station" ISPRS International Journal of Geo-Information 7, no. 5: 178. https://doi.org/10.3390/ijgi7050178
APA StyleYang, W., & Ai, T. (2018). POI Information Enhancement Using Crowdsourcing Vehicle Trace Data and Social Media Data: A Case Study of Gas Station. ISPRS International Journal of Geo-Information, 7(5), 178. https://doi.org/10.3390/ijgi7050178