1. Introduction
Geographic data (spatial databases, topographic maps, thematic maps, classified images, remote sensing products, etc.) supports decision-making in several fields, such as climate change, crop forecasting, forest fires, national defense, civil protection and spatial planning. A suitable quality is essential in order to ensure that decisions based on it are technically the best. There are different components to describe this quality. One of them is thematic accuracy, as is established by the international standard ISO 19157 [
1], which includes the following so-called data quality elements: classification correctness, non-quantitative attribute correctness, and quantitative attribute accuracy. Classification correctness is usually represented by means of the so-called confusion matrix (also referred to as misclassification matrix or error matrix), which is one of the data quality measures included in [
1]. In [
2], it is recommended to always report the raw confusion matrix, so that the user of the data can derive any metric suitable for their needs.
In this setting, the Kappa coefficient [
3] has been widely used for thematic accuracy assessment. It summarizes, in a single value, all the data included in the confusion matrix. It has also been included in [
1] as a data quality measure for classification correctness. Since it was introduced as a measure of agreement, not for accuracy assessment, it can be seen by using simple numerical examples that Kappa is not an appropriate coefficient for accuracy assessment [
4]. In consequence, given two independent classifications, it is not appropriate to compare both Kappa coefficients in order to assess the similarity of the two respective confusion matrices.
We propose an alternative procedure to evaluate whether two confusion matrices represent the same accuracy level. This proposal takes into account a multinomial distribution for the matrices, and uses a measure based on the squared Hellinger distance to evaluate the equality of both multinomial distributions. The context is presented in
Section 2, the basic statements of the proposal are given in
Section 3, in
Section 4, the method is applied over a set of predefined matrices which are perturbed to explore how the
p-value evolves, and finally,
Section 5 includes a numerical example.
2. Description of the Context
Suppose that
categories
are given (i.e., land-cover categories, etc.) and
n sample units from the categories
are observed for
. In a general way, we will consider the
n sample units are drawn according with a simple random sampling. Note that for particular application contexts, other sampling schemes may be preferred, and some corrections should be done in the data analysis. All sample units were classified into categories through a certain classification method, and such classification is summarized in a contingency table called confusion matrix. The
element
represents the number of samples that actually belong to
, and are classified into
for
. In this way, the columns and rows of the contingency table correspond, respectively, to reference (index
j) and classified (index
i) data (
Table 1). So, the elements in the diagonal are correctly classified items, and the off-diagonal elements contain the number of confusions, namely, the errors due to omissions and commissions.
Two widely adopted indices for thematic accuracy controls upon confusion matrices are overall accuracy (
OA) and the Kappa coefficient (
ĸ) (see [
5] or [
6]).
OA is the ratio between the number of elements that are correctly classified and the total number of elements in the matrix
where
is the total number of sample units. The Kappa coefficient is a measure based on the difference between the agreement indicated by
OA, and the chance agreement estimated by the marginal values as
where
,
and
being the sum of each column and row, respectively.
Both indices are global, and do not allow for a category-wise control. Some authors have criticized its use ([
7,
8,
9], among many others).
Along this line, it is possible to determine if two independent OA or ĸ values, associated with two confusion matrices, are significantly different. Therefore, two analysts, two classification strategies, the same analyst over time, etc. can be compared. The corresponding null hypothesis under consideration can be expressed as or , where and are the OA and Kappa coefficient for both confusion matrices. However, not rejecting the null hypothesis does not mean that the confusion matrices are similar, because many different matrices could obtain the same value of OA or ĸ.
In the case of the Kappa coefficient, [
4] have shown that evaluating the significant difference between classifications by means of the difference of the corresponding Kappa coefficient is not appropriate. They proved this fact with simple numeral examples, and the main reason is the origin of the Kappa coefficient as a measure of agreement (in which context, the invariance property is essentially required), and not as a measure of accuracy assessment. Such invariance is not welcome because the main interest is how reference data are correctly classified (fixed number
of samples in each category
), not how classified data contain the correct data (
not fixed).
3. Proposal to Test the Similarity of Two Confusion Matrices
In statistics, homogeneity is a generic term used when certain statistical properties can be assumed to be the same. The prior section has shown that the difference in the OA and ĸ values has been used as a similarity measure of two confusion matrices. In this section, we propose an alternative which takes advantage of the underlying sampling model and deals with a confusion matrix as a multinomial distributed random vector. This way, the similarity between confusion matrices can be stated as the equality (or homogeneity) of both underlying multinomial distributions. The proposal considers the individual cell values instead of aggregated information from such matrices, which is the case of OA and ĸ. Therefore, equality between the multinomial distributions will hereafter mean that both matrices are similar.
Several distance measures can be considered for discriminating between multinomial distributions. Among them, it can be highlighted that the family of phi-divergences introduced by Csiszár in 1963 (see [
10] (p. 1787)) has been extensively used in testing statistical hypotheses involving multinomial distributions. Examples in goodness-of-fit tests, homogeneity of two multinomial distributions and in model selection can be found in [
11,
12,
13], among many others.
From this family, we will use the squared Hellinger distance (SHD). Under the premise that a confusion matrix can be modelled as a multinomial distribution, with frequent values of zero, this choice allows us to take advantage of two things: first, the good statistical properties of the family of phi-divergences, and second, the fact that SHD is well defined, even if zero values are observed.
Therefore, in what follows, each confusion matrix is considered as a random vector,
X and
Y, which are independent and whose values have been grouped into
classes, or equivalently, taking values in
with probabilities
and
, respectively. The idea of equality is expressed by means of the following null hypothesis
The Hellinger distance (HD) is a probabilistic analog of the Euclidean distance. For two discrete probability distributions,
and
, their Hellinger distance
is defined as
where the
in the definition is for ensuring that
(see [
14]). Therefore, the value of this similarity measure is in the range
.
Let
and
be two independent random samples from
X and
Y, with sizes
n and
m, respectively. Let
be the observed relative frequencies which are the maximum likelihood estimators of
and
,
, respectively. For testing
, we consider the following test function based on SHD:
where
and
is the 1-α percentile of the null distribution of
. A reasonable test for testing
should reject the null hypothesis for large values of
. To decide when to reject
, that is, to calculate
or, equivalently, to calculate the
p-value of the observed value of the test statistic,
,
being the observed value of the test statistic
, we need to know the null distribution of
, which is clearly unknown. Therefore, it has to be approximated. One option is to approximate the null distribution of
by means of its asymptotic null distribution. The following theorem states this fact.
Theorem 1. Given the maximum likelihood estimators of P and Q, say, under the null hypothesis that P = Q, we haveif as . Note that means convergence in distribution. Proof. The SHD can be seen as a particular case of a
f-dissimilarity between populations [
10]. According to notation in ([
10], p. 303, Equation (4.1)) given the probability vectors associated with two multinomial distributions
P and
Q, the test statistic
is based on
, where
.
The results follows from the corollary 3.1.b) in [
10], because f(1) = 0 and the value of the only eigenvalue of matrix HD
λ is
. Note that
and
. ☐
Asymptotically, the null distribution of
is a chi-square distribution with
M − 1 degrees of freedom. However, for small and moderate sample sizes, the behavior of this approximation is rather poor (see for example [
15,
16]). To overcome this problem, we approximate the null distribution of the test statistic by means of a bootstrap estimator.
Let
and
be two independent samples of sizes
n and
m, from the multinomial distribution with parameter
p0, where
is an estimator of the common parameter under
given by
and given
the relative frequencies for the bootstrap samples,
stands for the bootstrap value of
, which is obtained by replacing
with
, for
i = 1,2, ...,
M. The next result gives the weak limit of the conditional distribution of
given the data.
P* denotes the conditional probability law given the data.
Theorem 2. Ifwith, then Proof. The proof of the theorem follows the same steps as the one of Theorem 1 in [
16]. ☐
As a consequence, the null distribution of is consistently estimated by its bootstrap estimator.
In order to evaluate the goodness of the bootstrap approximation to the null distribution of the test statistic
Tn,m, a simulation experiment was carried out in [
17].
4. Analysis of the Test over Predefined Matrices
From
Section 3, we have a test statistic based on the SHD, and we can obtain the
p-value in order to decide whether to reject
, that is to say, to consider two confusion matrices as similar or not, or equivalently, two multinomial distributions as homogeneous or not. With the aim of exploring how this
p-value evolves when differences appear between two matrices, we considered applying the method to a predefined confusion matrix and introducing perturbations. From each perturbation, we obtain a perturbed matrix and computed the
p-value.
Not one but three predefined confusion matrices were considered, in order to take into account different values of OA. Four categories ( = 4) and balanced (equal) diagonal values were considered, where OA is 0.95 (matrix CM95), 0.80 (matrix CM80), and 0.50 (matrix CM50). The matrices were set at relative values, that is to say that they were divided by , and therefore, .
For the sake of simplicity, we delimited the scope of the analysis. A context was supposed in which the analyst is mainly worried about the number of features that are correctly classified, therefore ignoring how the off-diagonal values are distributed. The proposed method, based on the underlying multinomial model, can be easily adapted to this context. The grouping (sum) of the off-diagonal values (
Table 2) implies that the size of the vector that represents the matrix is
, not
. For matrix CM
95, CM
80 and CM
50 the vectors are, respectively:
where the last components of the vectors are
.
Given that the number of perturbed matrices can be infinite, we explored perturbations () introduced in the range (0 ± 0.10) for each diagonal value, with 0.02 per step, that modify OA in the range (0 ± 0.40). All combinations from this exploration provide a total of perturbed matrices between 9495 (CM95) and 14,640 (CM50). The number of perturbed matrices is different for each matrix due to the restriction given by .
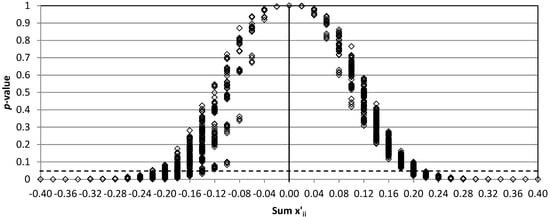
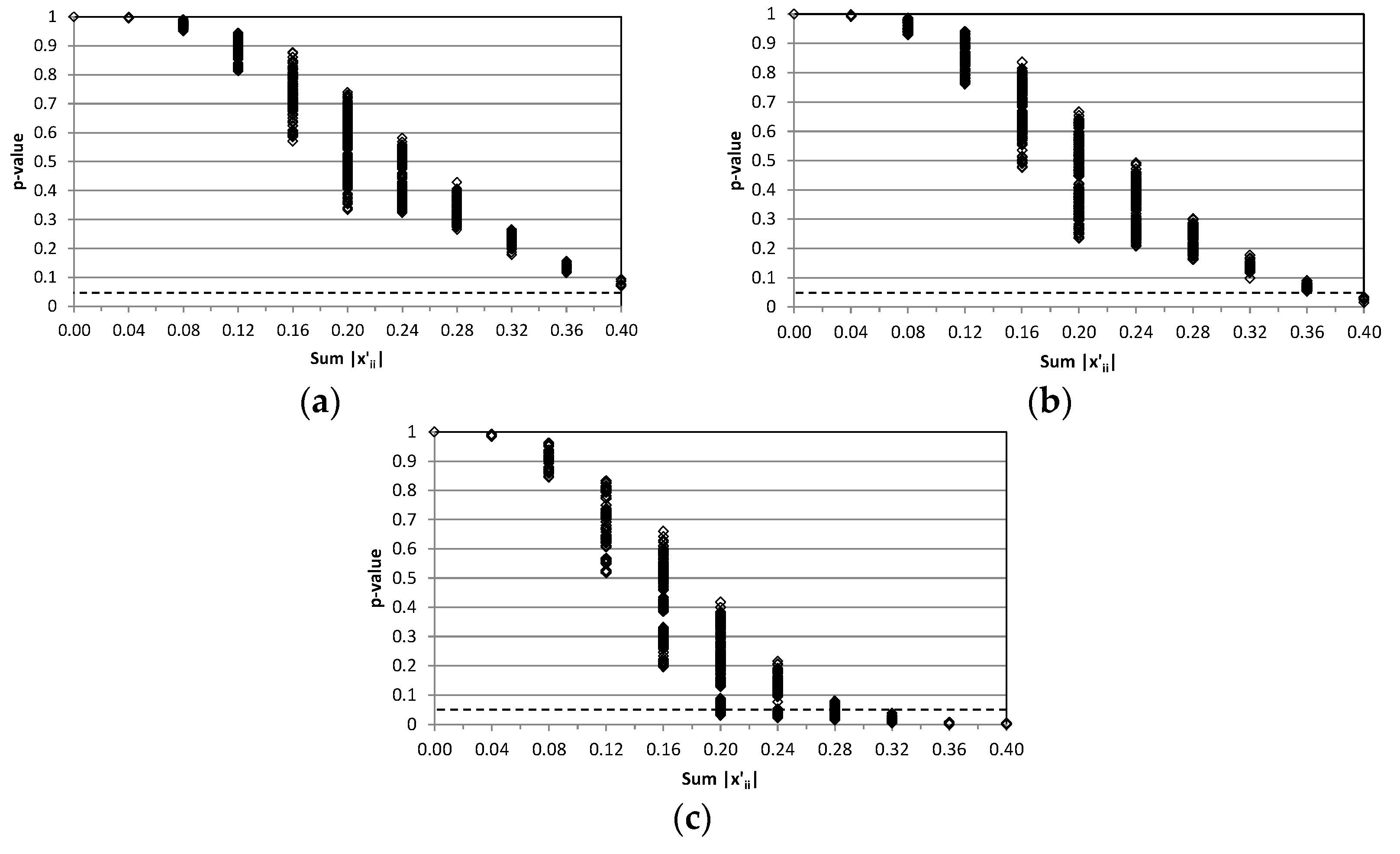
In order to analyze the results, we first considered a significant situation, that where the perturbations compensate for one another and OA remains the same (therefore, the fifth element of the vector is also unchanged). In this case, the number of perturbed matrices is reduced to 890 in all three confusion matrices. If an analyst used the OA value to test the similarity of any of them in relation to the predefined matrix, the hypothesis that they are similar would not be rejected. The same conclusion would be obtained if ĸ were used, and the off-diagonal values tend to be symmetrical. Nevertheless, the perturbations could be such that the assumption of similarity may be compromised.
From the application of the proposed test, the bootstrap
p-value associated with the null hypothesis of Equation (3) was obtained for each underlying multinomial distribution from each perturbed matrix. All computations were performed using programs written in the R language [
18]. In
Figure 1 the
p-values are represented for each matrix (CM
95, CM
80, and CM
50), where the
x-axis is the sum of the absolute values of the perturbations
From
Figure 1, there becomes apparent some similarities between the three charts. They start with
p-values concentrated around 1.0, because of the small perturbations that were introduced into the matrix. They also end with a small range in
p-values when
is high, which makes sense because the null hypothesis should be strongly rejected. The range is wider for medium values of
. This means that the result of the test depends largely on how the perturbations are distributed, although their sum is zero (
OA remains the same). Lower
p-values are obtained if the values of the perturbations are heterogeneous. For example, for CM
50 and
, the maximum and minimum
p-value is 0.031 and 0.418 for a vector of perturbations of
and
, respectively.
However, there are differences between the charts in
Figure 1. If we take matrix CM
95, it can be said that the null hypothesis that the underlying multinomial distributions are equal is not rejected in any of the 890 perturbed matrices (at significance level 5%). All the
p-values are higher than 0.07. Therefore, all the perturbed matrices are similar to CM
95. If we take matrix CM
80, there are few changes in relation to matrix CM
95, but some (not many)
p-values in the range of 0.025–0.07 can be found when
is 0.36 or 0.40. In matrix CM
50, the situation changes substantially. The
p-values decrease faster in the chart, and low
p-values (<0.05) can be found when
. Moreover, when
the rejection of the null hypothesis is clear, since nearly all the
p-values are lower than 0.05. This result is logical, since the same perturbation represents a greater change when the diagonal value is lower.
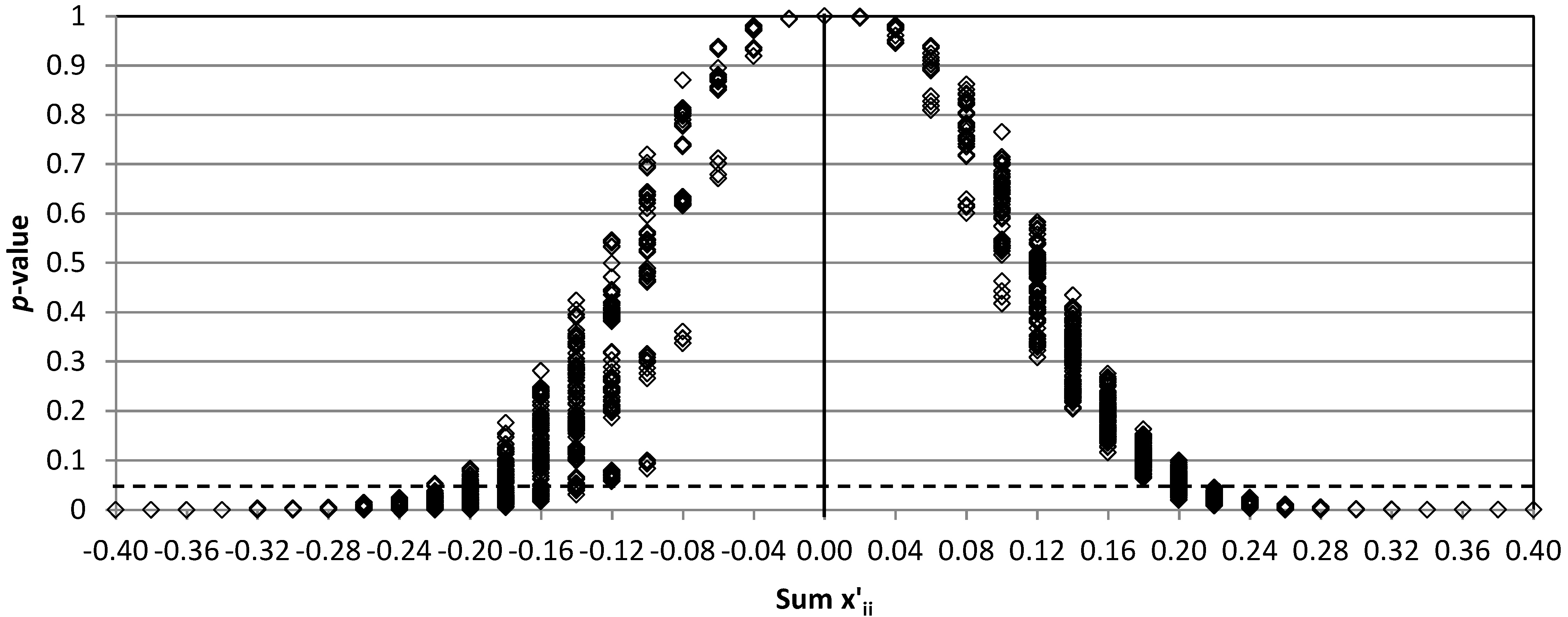
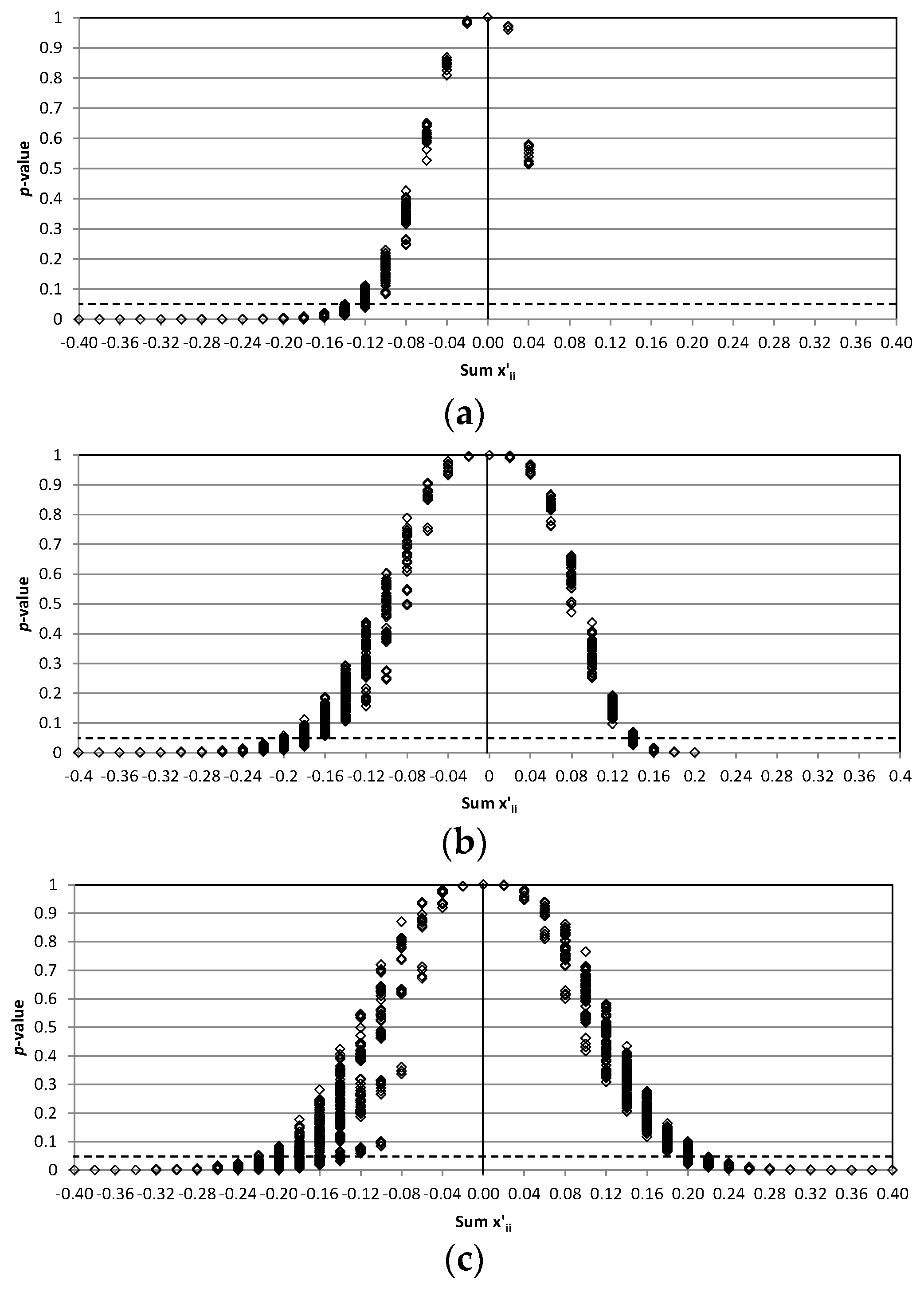
Another situation that can be considered is that in which the entire diagonal improves or worsens. That is to say that in a single perturbed matrix, there are no perturbations of different sign, but they are all positive or all negative. In contrast to the former case, the fifth component of the vector does not remain the same.
Figure 2 shows the
p-values for CM
95, CM
80, and CM
50. The
x-axis is the sum of the values of the perturbations
, which is positive if
OA improves, or negative if
OA worsens. The number of perturbed matrices when
OA improves is different for each matrix due to the restriction given by
. This restriction affects particularly CM
95 (only 14 perturbed matrices) and C
80 (580), but not the matrix CM
50 (1295).
Similarly to
Figure 1, in
Figure 2, the charts start with
p-values concentrated around 1.0 when the perturbations are low, but it is noted that the
p-values drop more quickly than in
Figure 1. It is obvious that the change in the value of
OA here supposes a great difference. As has been explained, the statistic
is based on the SHD. As a consequence, it is sensitive to a change in any of the components of the vector, either the first four components (diagonal values) or the fifth component (off-diagonal grouped values).
Focusing on a clear rejection of the null hypothesis (most
p-values around 0.05 or lower), this occurs for CM
95 when
, for CM
80 when
or
, and for CM
50 when
or
. In the case of CM
50, there are isolated cases of rejection in wide range of
p-values when
. This wider range means that the results of the test depend to a large extent on how the perturbations are distributed to obtain a same value of
. Other trends that can be appreciated in the
p-values from
Figure 2 are they drop faster for matrix CM
95, CM
80 and CM
50, in this order, which can be interpreted as a higher sensibility when
OA is high, and the range is also broader when
OA worsens, which can be interpreted as a higher sensibility for a worsening than for an improvement.
5. Applied Example
In this section, a full example is performed by taking two matrices from [
6]. Matrix P (
Table 3) has four categories (
= 4) and was derived from an unsupervised classification with sample size
from a Landsat Thematic Mapper image with
OA1 = 0.74 and
ĸ1 = 0.65. Matrix Q (
Table 4) was derived from the same image and classification approach, but provided by a different analyst and sample size
, with
OA2 = 0.73 and
ĸ2 = 0.64. The
p-value for a two-sided test of the null hypothesis
is 0.758, therefore, the hypothesis that both Kappa coefficients are equal should not be rejected, but this does not necessarily mean that the matrices are similar.
As an alternative to that employed in [
6] with the Kappa coefficient, the HD between both matrices, 0.096, can be easily obtained. Applying the proposal from
Section 3, it can be known whether this value is high enough to consider that the matrices are not similar. The calculation process involves the following steps:
Take the observed relative frequencies and , corresponding to the matrices to be compared by columns () = (0.1497, 0.0138, 0, 0.0092, 0.0092, 0.1866, 0.0253, 0.0161, 0.0506, 0.0115, 0.1958, 0.0069, 0.0552, 0.0184, 0.04377, 0.2073) and () = (0.1339, 0.0178, 0, 0.0119, 0.0119, 0.2708, 0.0238, 0.0208, 0.0357, 0.0148, 0.1636, 0.0089, 0.0714, 0.0238, 0.0267, 0.1636). Obtain the observed value of the test statistic from the initial samples, as .
Repeat for , B = 10,000 times:
Generate 2B independent bootstrap samples, and from the multinomial distribution , where
Calculate , for each couple of samples.
Approximate the p-value by means of , whose value is p = 0.573.
As a result, the hypothesis that both distributions are equal (Equation (3)) would not be rejected, and in consequence, both confusion matrices exhibit a similar level of accuracy. Taking into account that
OA hardly changes between both matrices, and that the changes are mainly concentrated in the diagonal values, there is a chart from
Section 4 which represents a case similar to this example. It is the chart for CM
80 in
Figure 1. In this example, we have a value of
, but we can see that not until values of
are near to 0.4 does the
p-value approach 0.05.
To reinforce our proposal, we applied on the diagonal of matrix P the vector of relative perturbations
(
). Matrix R (
Table 5) is the perturbed matrix which is obtained when
(the sample size of matrix Q).
ĸ is almost equal in both matrices P (
ĸ1 = 0.65) and R (
ĸ3 = 0.64), while
OA remains the same. Nevertheless, a
p-value of 0.002 (
) is obtained from our proposed method, thus, the hypothesis that both distributions are equal is rejected, and the confusion matrices are, therefore, not similar.
6. Conclusions
A new proposal for testing the similarity of two confusion matrices has been proposed. The test considers the individual cell values in the matrices and not aggregated information, in contrast to the tests based on global indices, like overall accuracy (OA) or the Kappa coefficient (ĸ). It takes into account a multinomial distribution for the matrices and uses the Hellinger distance, which can be applied even if values of zero are present in the matrices. The inconvenience that the null distribution of the test if unknown is overcome by means of a bootstrap approximation, whose goodness has been evaluated. The proposed method is useful for analyses which need to compare classifications results derived from different approaches, mainly classification strategies.
For a better understanding of the behavior of the test, it was applied over three predefined matrices with different values of OA. Perturbations were introduced in each predefined matrix to derive a set of perturbed matrices to be compared with and obtain their p-value. For the sake of simplicity, this analysis was delimited by ignoring how the off-diagonal values are distributed. In order to delimitate the data to be analyzed, the range and step values are fixed for the perturbation. Charts of the p-values are presented in two cases: when OA remains the same and when the entire diagonal improves or worsens. Results indicate that the similarity depends on different aspects. It is remarkable that lower p-values are obtained for a perturbed matrix if the values of the perturbations are heterogeneous. Finally, a numerical example of the proposed method is shown.
A full analysis, without grouping the off-diagonal values, remains an open challenging question. Future research includes the application of the method to individual categories, since the hypothesis of an underlying multinomial model is applicable to a single row or column in the confusion matrix. This means that attention could be focused on the producer’s accuracy or the user’s accuracy of any of the categories. The proposal could also be useful for land-change studies; in this case, the test would indicate whether trends are maintained over time or not.

 ,
, 



{kind=link}
{kind=link}
{kind=link}