CS Projects Involving Geoinformatics: A Survey of Implementation Approaches




Abstract
:1. Introduction
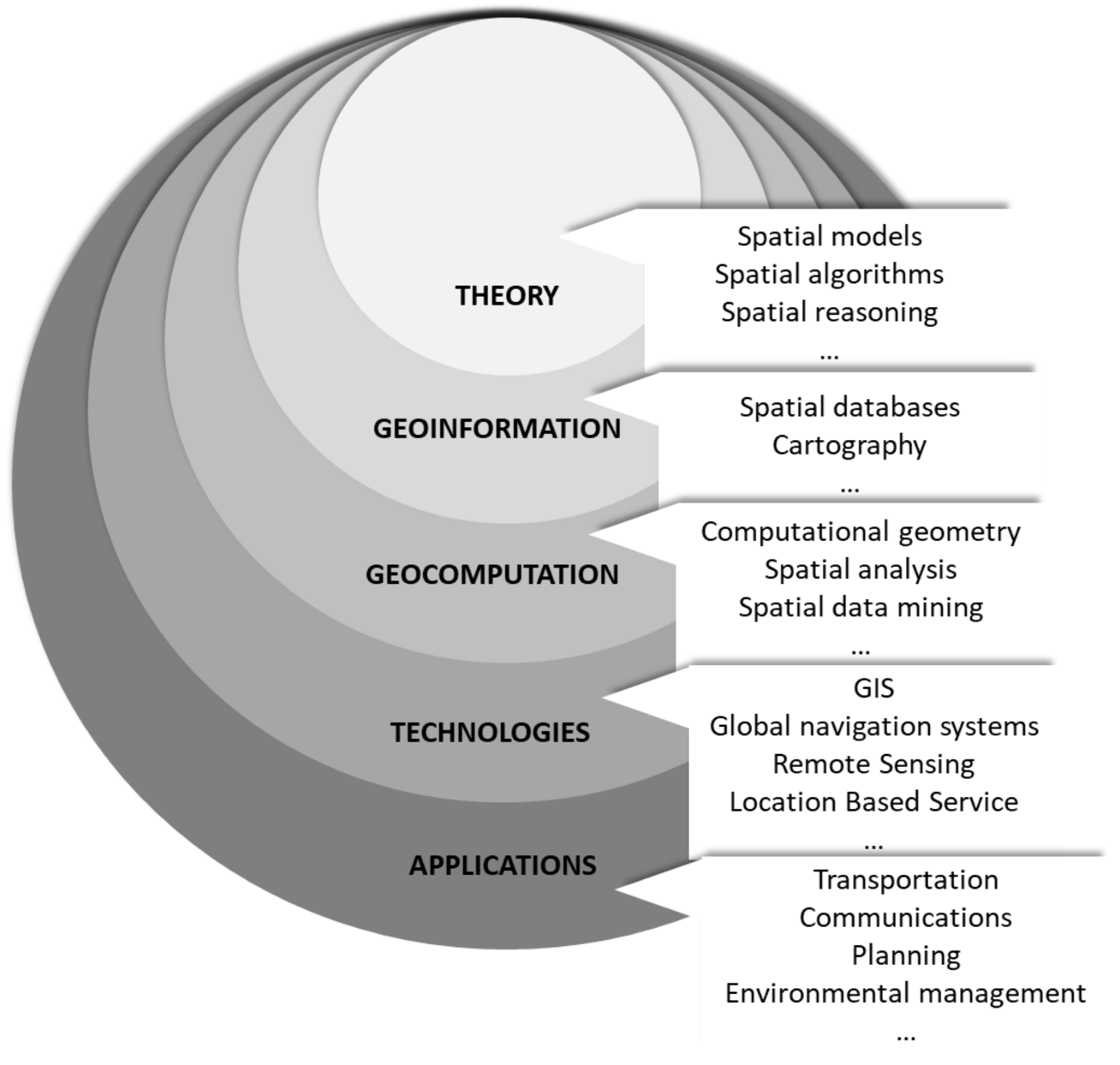
1.1. Geoinformatics: A Tentative Definition
1.2. Reference Framework
2. Materials and Methods
2.1. Schema of the Categorization
2.1.1. Recruitment
- Project website-based: This happens when the broadcast of the initiative and the opportunity to join it are mainly entrusted to a project-dedicated website;
- Smart app-based: The opportunity to join to the CS project is offered by means of a mobile application connected to the Internet;
- Web platform-based: The initiative is promoted and supported by thematic web platforms or multi-project websites. Users and visitors of the platform are informed of the existence of many ongoing initiatives. Sometimes they are assisted in selecting suitable initiatives (e.g., based on the user preferences or location) and encouraged to take part. Sometimes the web platform also takes charge of data collection, management, and access, as well as user interactions;
- Social media-based: The use of social networks is the channel to encourage recruitment of volunteers;
- Local facility-based: Participation is not promoted on the web, but in real locations. This typically occurs when visitors of museums, natural oases, or public offices are informed of a CS initiative and encouraged to join it;
- Association/network-based: The recruitment is proposed within associations or relies on the diffusion among collaborators—both professionals and amateurs;
- Education/academia-based: Proposals of participation specifically designed for school or academic classes and their teachers.
2.1.2. Data Generation
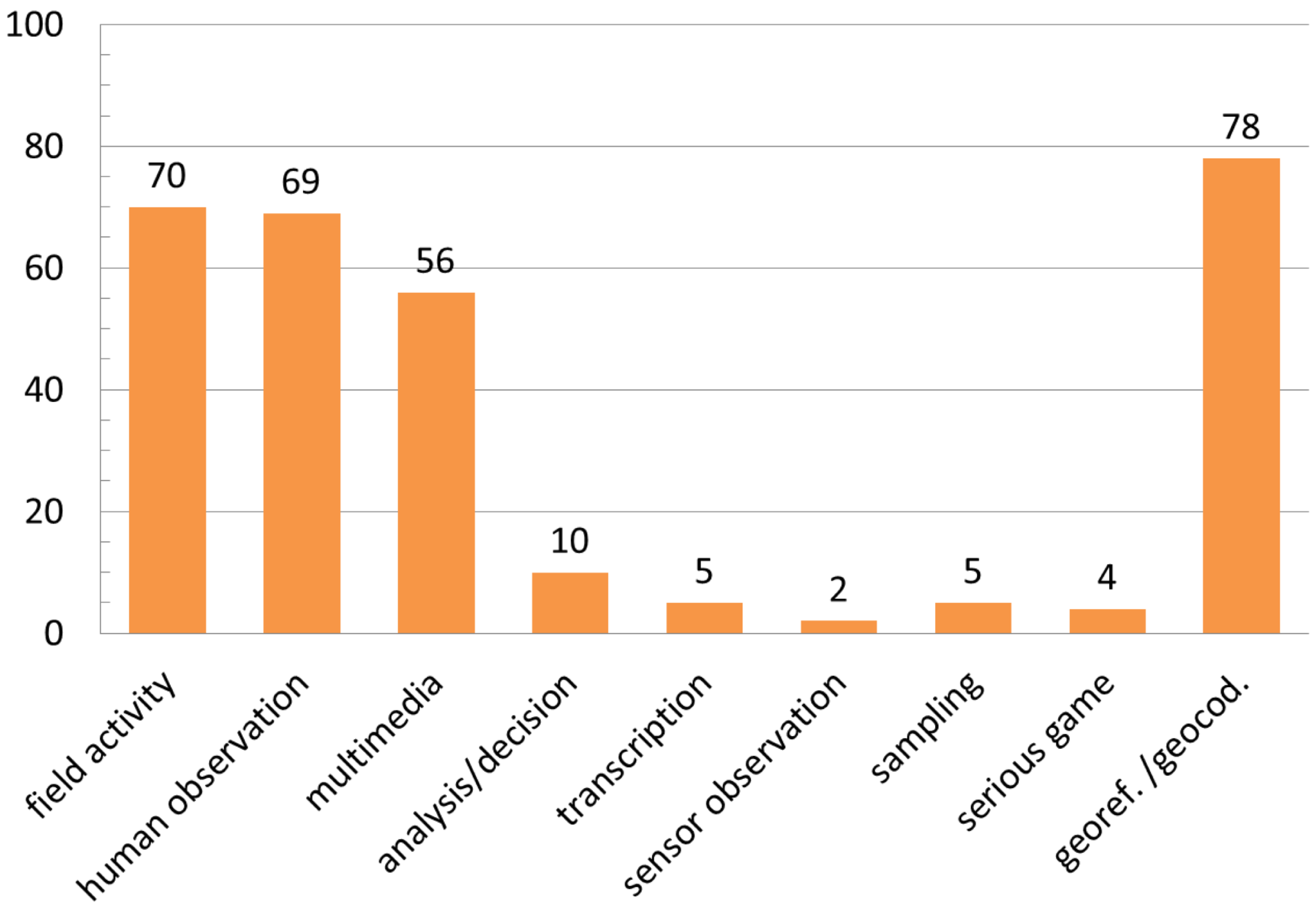
- Field activity: Participants are asked to perform activities in particular places or environments in order to generate data and information (e.g., sample collections, field observations, etc.);
- Guided human observation: Volunteers are asked to report what they see, hear, feel, and experience in a given situation, aided by means of schemas, forms, protocols, conditioned data entry, etc.;
- Transcription: Aimed at producing digital copies of documents (such as museum specimens’ labels or old log-books), or translating documents in a different language, such that data generation consists of a transcription task;
- Sensor observation: Typical for data acquired by sensors and transmitted directly or by volunteer intervention to a cyber-infrastructure;
- Sampling: Used when real objects or specimens should be collected in the field by participants (soil, plants, animals, etc.) and analyzed subsequently by experts;
- Multimedia data capture: Proposed to participants either as a way to create data (or metadata), or even as a token for proving the veracity of the volunteered observation. Multimedia may consist of photographs, videos, or audio files;
- Human analysis or decision: Human skills, logic, or critical thinking are required. In these cases, data derive directly from human deduction or interpretation (e.g., pattern finding, sound/images recognition, object classification, etc.);
- Serious game: Volunteers are enabled to produce data and information just by playing a game. Data are automatically extracted from users’ interactions and decisions made during the game. Serious gamers are often aware of the contribution they are giving to research, but are involved by means of typical gaming mechanisms and environment: competitions, interactive interfaces, stimulating messages, amusing activities, etc. Occasionally, games are used to train volunteers (e.g., to recognize species) instead of producing data, but even in this case, this approach is useful for improving the initiative;
- Georeferencing and geocoding: Used for relating elements to a geographic reference system. Georeferencing can be applied to physical entities (e.g., a lake, a measurement station), to representations of physical entities (e.g., aerial photos), or even to abstract concepts and events as long as they they are related to a geographic location (e.g., nesting area of a bird, point of sighting of a cetacean). Geocoding transforms physical addresses (e.g., buildings centroids, postal code centroids, administrative boundary centroids) into geographic locations represented in numerical coordinates. They are often associated with gazetteers, and can be used effectively in CS to make data “human-readable”, even those with complex spatial relations, to display them, and to make them spatially searchable.
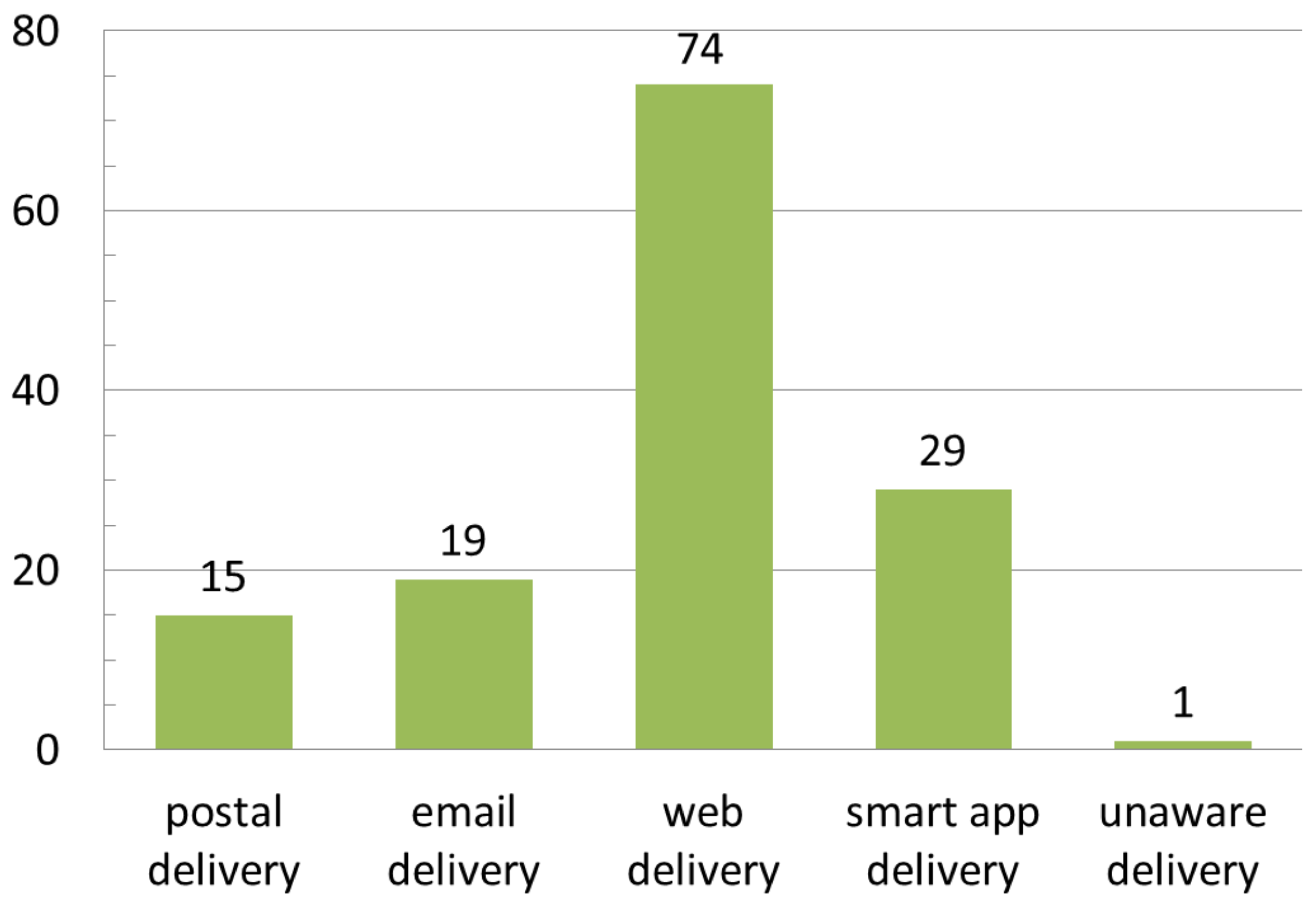
2.1.3. Data Delivery
- Postal delivery: Used for sending physical contributions in non-digital format (e.g., samples, paper documents, etc.);
- Email delivery: Requires data to be in a digital format (images, numerical, categorical, textual, etc.), within given constraints on attachment dimension in bytes. Both an email address and an Internet connection are required. Unlike postal delivery, email delivery is almost immediate;
- Web delivery: The exchange of digital data by means of standard communication protocols on the Internet, such as FTP and HTTP. In the case of HTTP, the volunteer is usually required to fill web forms or check boxes, or to select features or geographic areas. The volunteer performs this activity on websites or web platforms, or by means of specific web applications. Data delivery via social media messaging and sharing is included in this approach;
- Smart app delivery: A special case of web delivery performed only via mobile applications, without using a web browser. It requires a mobile device (phone/tablet or watch) that is connected to the Internet;
- Unaware delivery: Happens when the (web) contributor is not completely aware of creating data for the project, or is unaware of the specific kind of data he/she is creating. This strategy can be adopted in serious gaming, but also in other contexts, sometimes raising ethical questions on privacy and consensus.
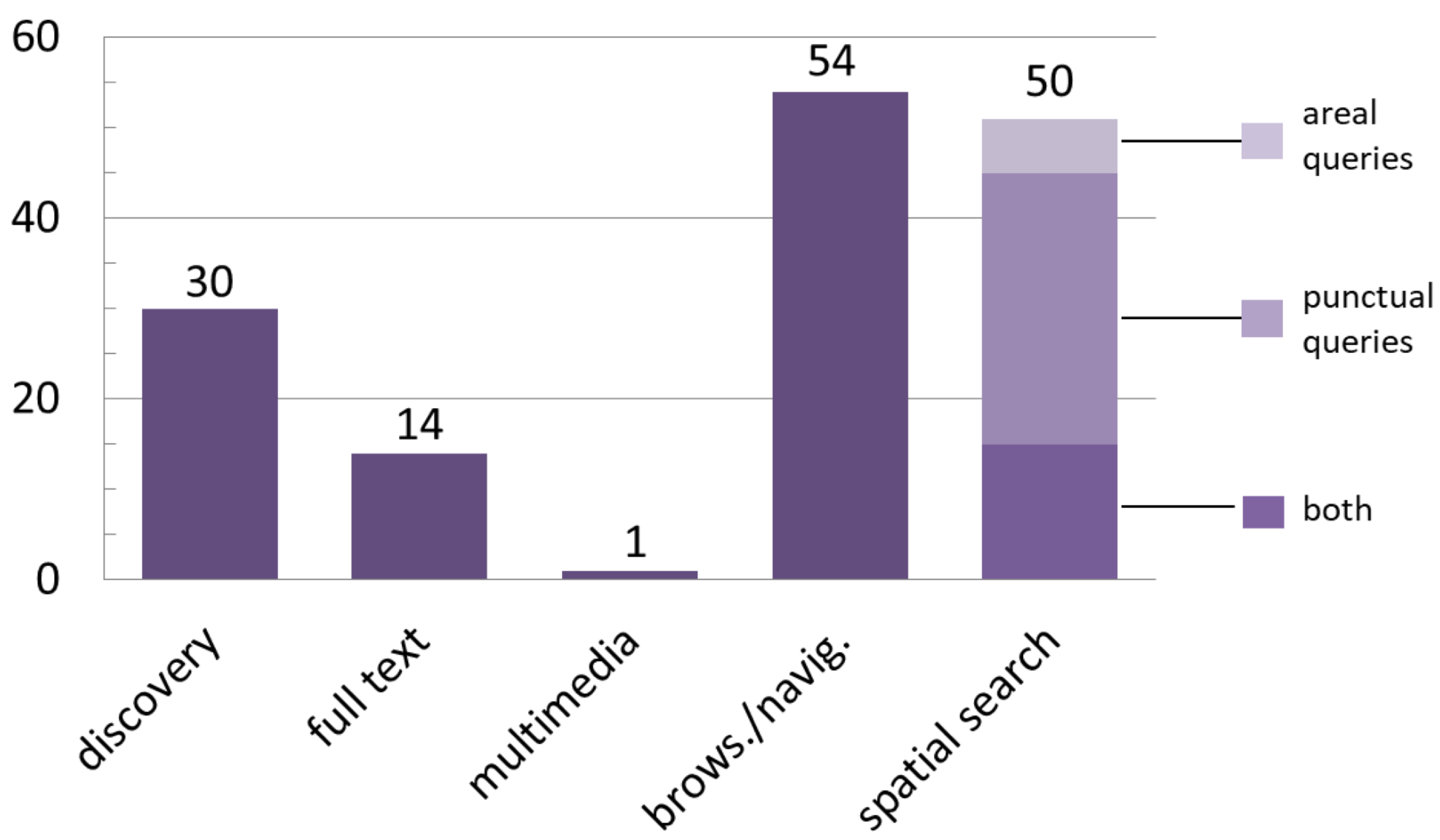
2.1.4. Data Search
- Discovery service: Enables web users to search for spatial data sets and services by retrieval mechanisms on metadata. Search criteria can be expressed by keywords, geographic references, timespan, and author names, among others;
- Full text search: Indicates the possibility of retrieving documents, web pages, or any piece of data containing text on the basis of the presence of the search terms within it;
- Multimedia search: Allows the retrieval of multimedia information in different formats, such as images, audio files, video, etc. The query can be a text (in this case, the metadata are matched to retrieve the multimedia object), or multimedia content, such as an image (which is used as an example to retrieve similar multimedia contents). It can be implemented by content-based visual or audio information retrieval systems;
- Browsing & navigation: It is very common for users to explore data on the web by navigating dedicated websites guided by menus and interactive lists or maps, links, and action buttons. The browsing and navigation possibilities are encouraged by the availability of mutually linked interactive data and metadata;
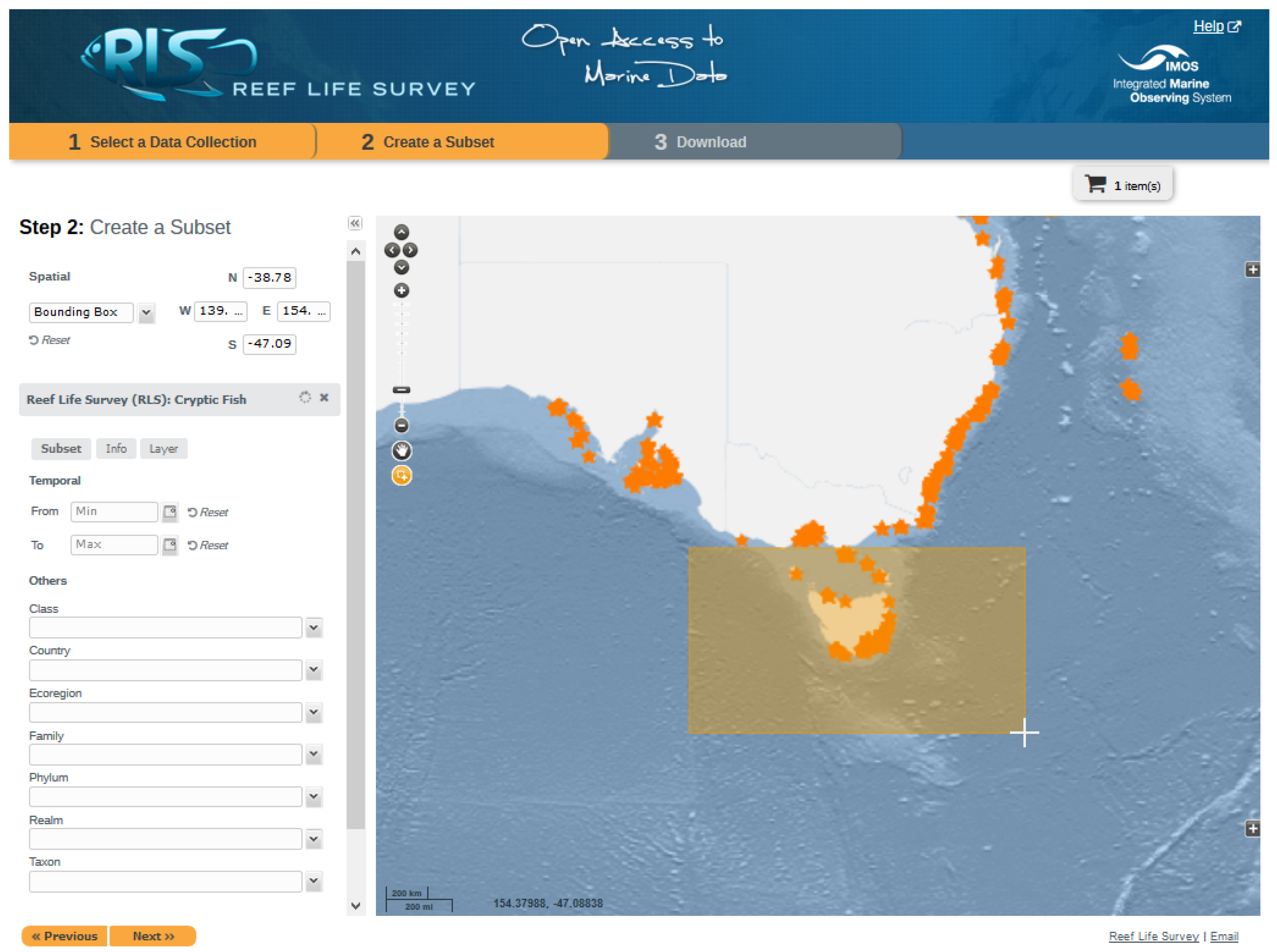
- Spatial search: Requires an interactive map, on which users can specify points or areas of interest (e.g., by clicking on a position of the map, or by drawing a bounding box, circle, or polygon) in which to perform the data search. Alternatively, a spatial search can be run by entering spatial queries by means of specific tools and interfaces, which often translate addresses into coordinates (e.g., geocoding tools exploiting gazetteers). The analysis differentiates the cases of punctual queries and range (areal) queries.
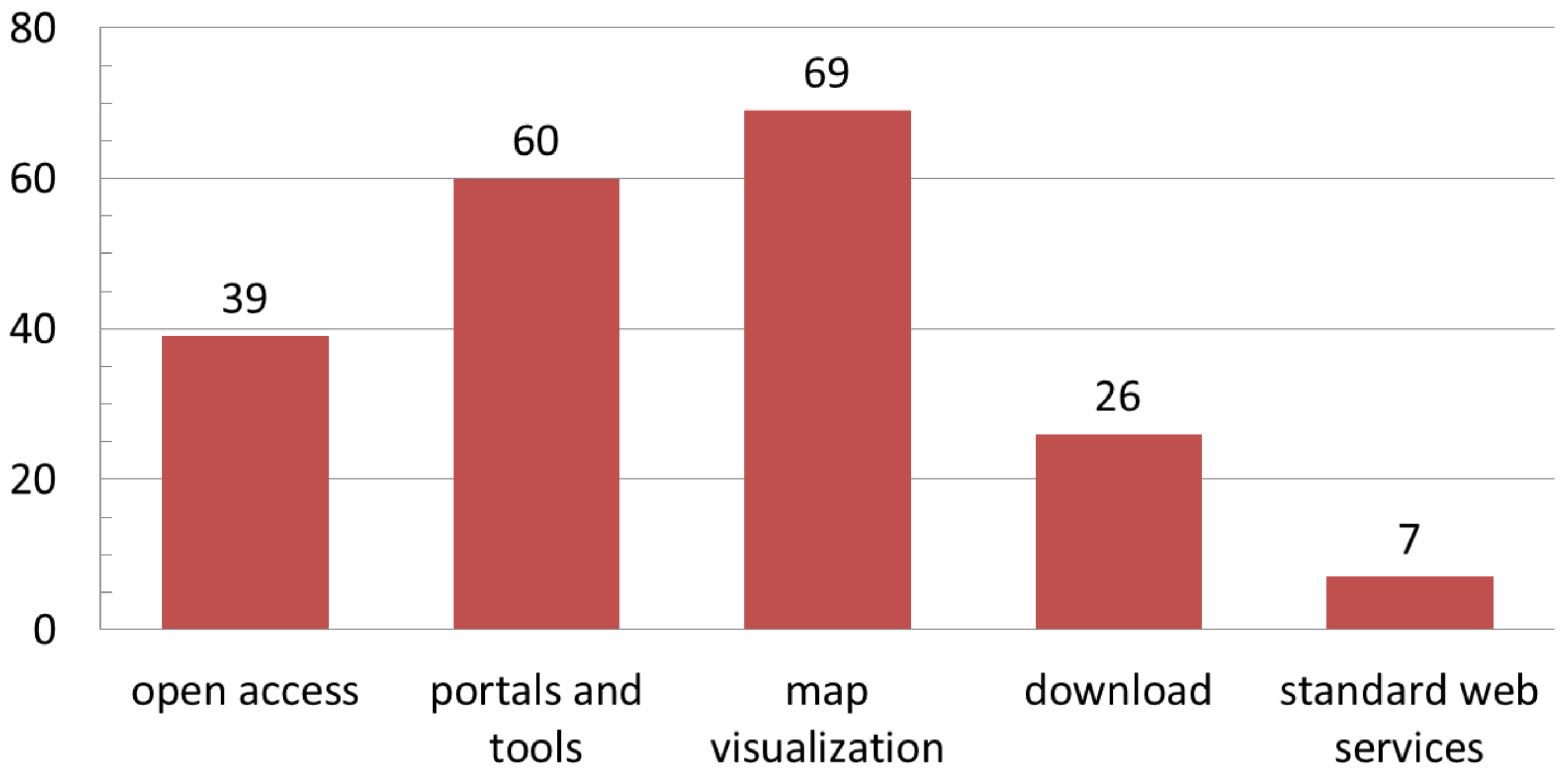
2.1.5. Data Visualization and Access
- Open access: Refers to the possibility for a generic web user to examine the collected data by any of the following approaches. The policy of open access lets any web user visualize the whole data collection. A restricted policy on data access instead imposes constraints on data consultation. There may be constraints on accessing certain data (e.g., sensitive data related to protected species), or on parts of data and metadata (e.g., occurrence can be provided, but not locations and timespan), or again, data can be made accessible only to logged-in users or those having special access permissions;
- Web portal and tools access: Includes a broad range of web environments used by CS project designers to provide general or dedicated access to data. The dedicated environment can lean on predefined forms, web applications and platforms, specific hardware for 3D and virtual reality fruition, etc.;
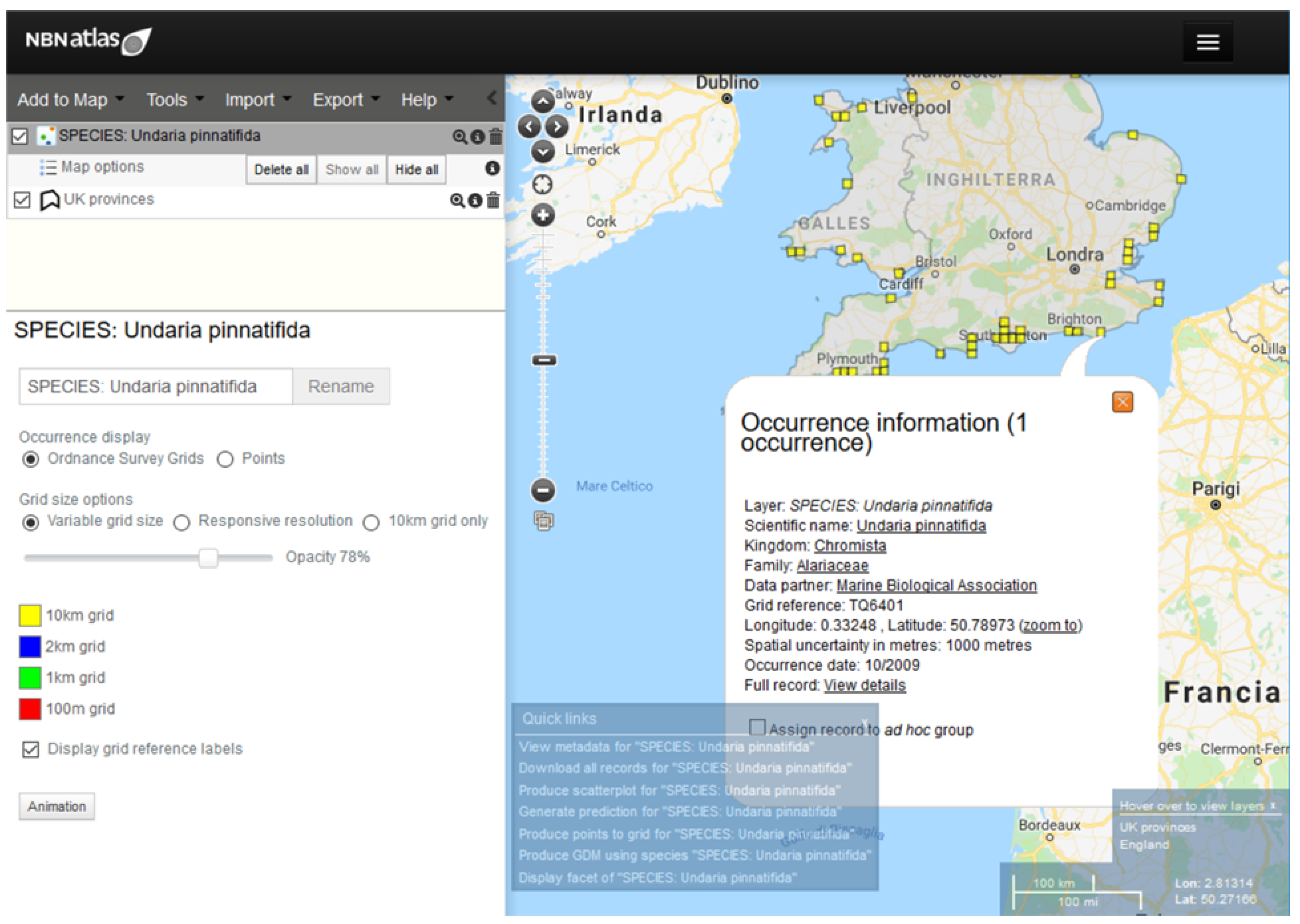
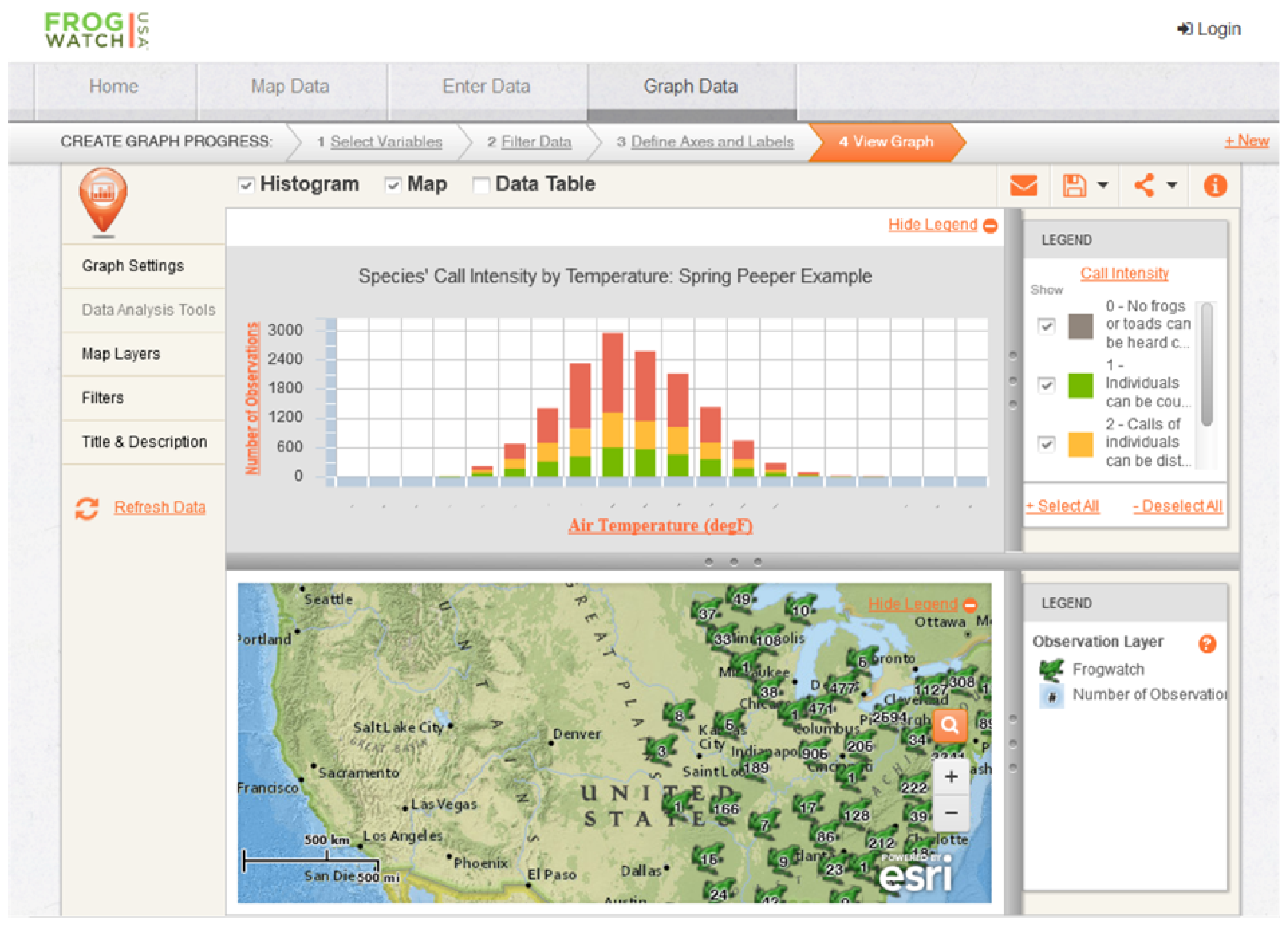
- Map visualization: Displays some data content in the form of a map or a virtual globe, depending on the geographic reference associated. Maps can represent each data item separately, for instance, as punctual or polygonal features, clustered as groups, or aggregated information (e.g., a density map). The map can be published as a simple image or as an interactive web map;
- Download: When this feature is enabled, web users can access data by downloading it in one or more data format;
- Standard web services access: It can transfer machine-readable file formats and support interoperable machine-to-machine interaction over the web. This means that multiple standard clients can access the same service, avoiding the duplication of data repositories and fostering their reuse. Specific standard web services for spatial data are the ones provided by the Open Geospatial Consortium (OGC) [24] to access maps, features, coverages, sensor observations, and metadata catalogues.
2.1.6. Operations on Data
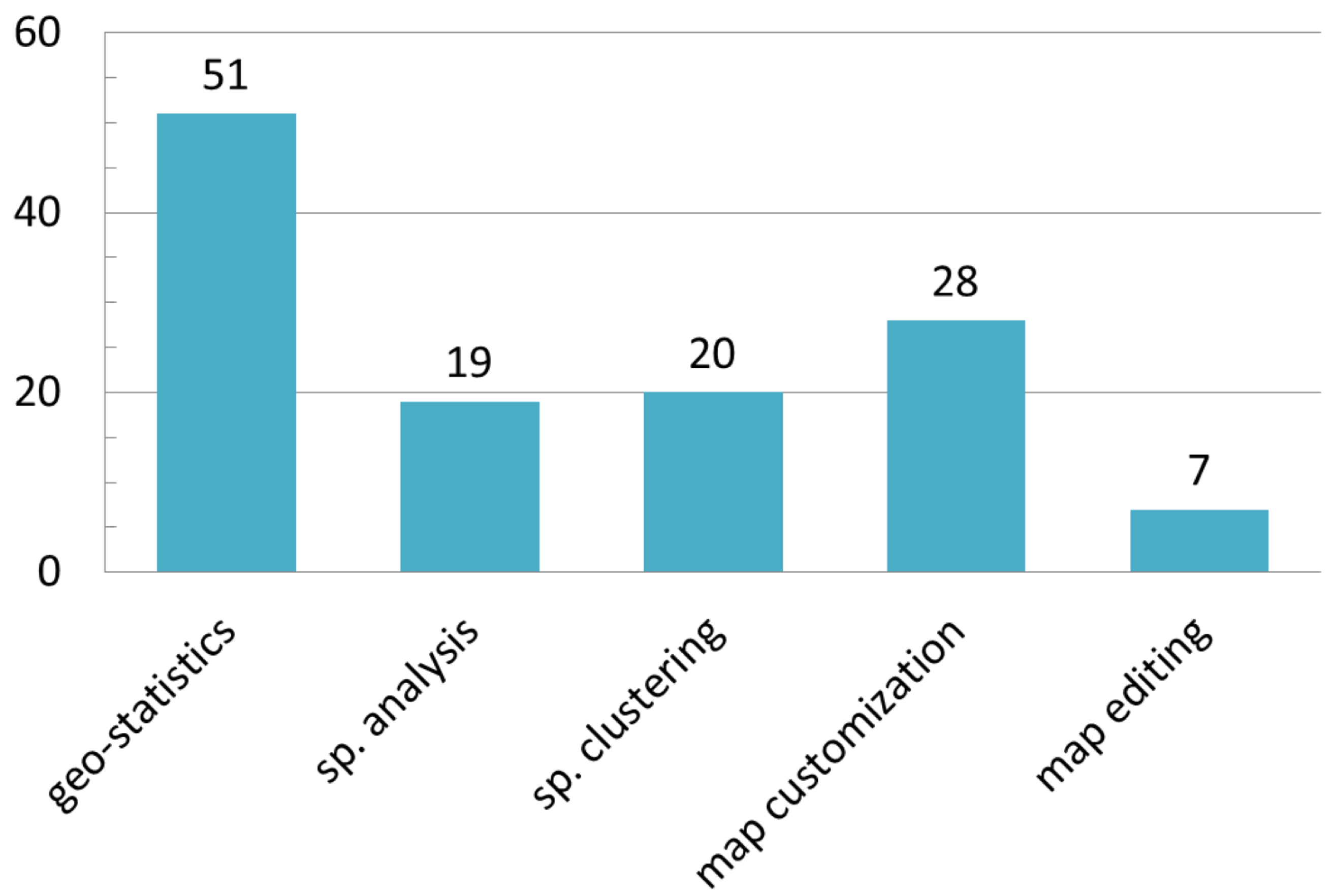
- (Geo)statistics and summaries: Comprehends all processes to organize geodata in order to offer an interpretation through summaries, graphs, indexes and trend indicators, interpolations, and more;
- Spatial analysis and spatial properties calculation: Includes a wide variety of techniques aimed at computing metric and topological properties of geodata sets;
- Spatial clustering: Refers to algorithms that identify groups of spatial data which share some spatial proximity and possibly, similar attributes;
- Map customization: Refers to enabling the customized or personalized representation of geodata on a map by the end user. The personalization can concern the legend styles, the selection/deselection of elements and layers, or other options that modify the data display without modifying the content;
- Map editing: Allows users to make changes directly to the dataset by interacting with the map client (e.g., adding features or modifying the geometry of spatial objects).
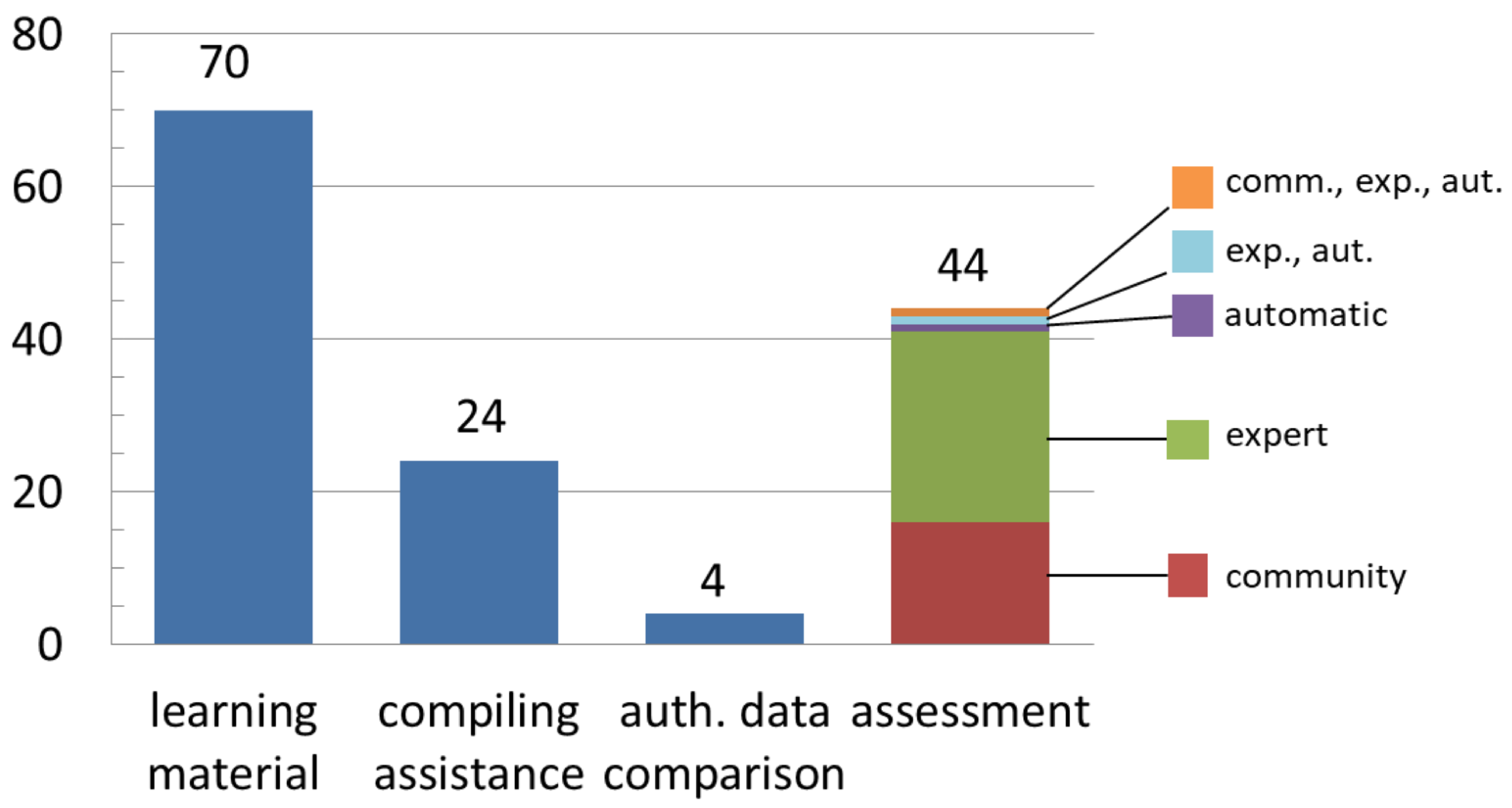
2.1.7. Qualification/Validation
- Learning material: Consists of providing volunteers with tutorials, interactive guides, or other types of instructions. It is an easy but effective ex-ante strategy to improve the quality of the contributions and prevent misreporting. Nevertheless, it is typically optional, so it does not guarantee a common preparation baseline for all volunteers;
- Compiling assistance: Gathers all techniques that help—and seldom constrain—the volunteer while compiling his/her contribution. They include the use of controlled vocabularies, geographic gazetteers, auto-completion, templates with automatic error-checking capabilities, checklist configuration tools, etc.;
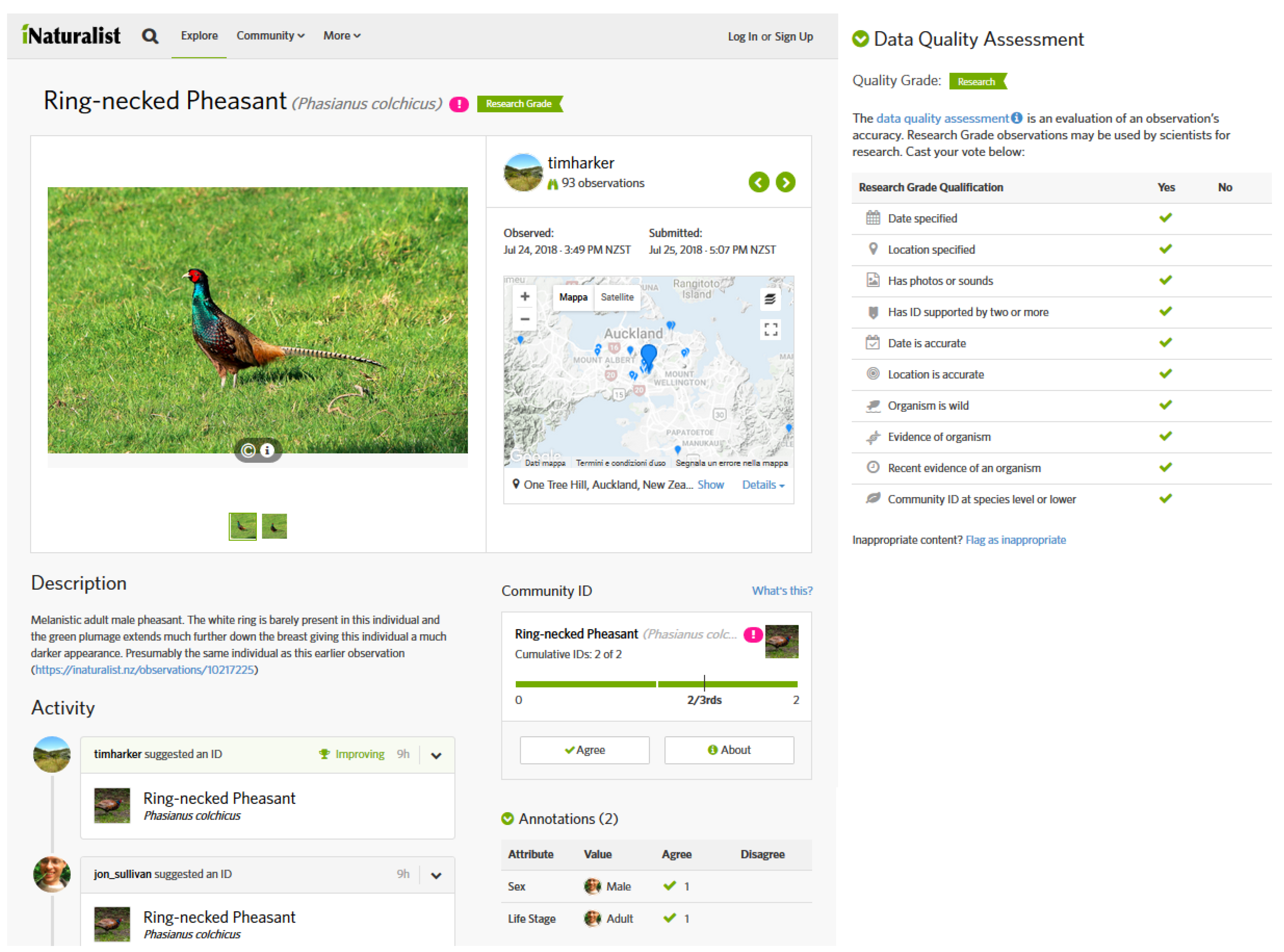
- Assessment: Quality assessment can be performed after the delivery of the contributions by a panel of experts, by automatic techniques, or by the community of volunteers. We took into account who among experts, automatic agents, and community performed the assessment. A special kind of assessment is the auto-assessment. It asks contributors to report their level of confidence in the data generation. This kind of assessment is in fact an ex-ante strategy that enriches the metadata;
- Cross-comparison with authoritative data: An ex-post strategy that is commonly used to identify the accuracy of datasets and to validate geographic data and information. Cross-referencing is performed by comparing VGI with authoritative information from administrative or commercial datasets. Nevertheless, in some cases, the accuracy of crowd-sourced geographic information can exceed that of authoritative information, as reported in reference [28].
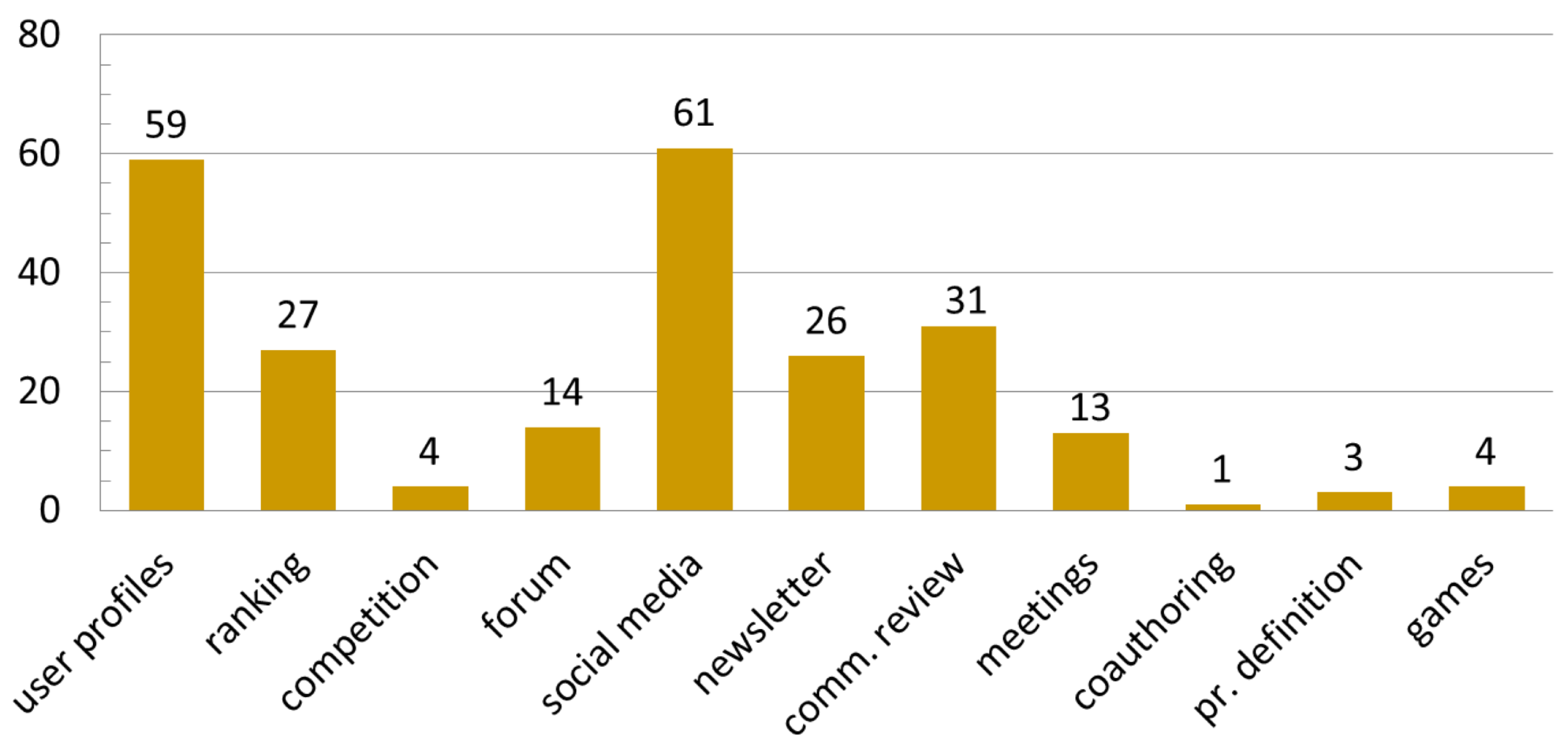
2.1.8. User Interaction and Participation
- User profiles: Often the participants are encouraged (or asked) to create virtual profiles in order to access data or to deliver contributions. Registered users can keep logs of their activities and reach goals and awards and can share their work both inside and outside the community. User profiles are also useful to the scientific team for contacting the users, requiring clarifications, involving them in local initiatives, sending periodic messages and newsletters, assigning them privileges or tasks, or for producing usage statistics. Encoding user position in a profile can aid the implementation of location-based functionalities;
- Scores and ranking: These techniques are aimed at motivating and honoring the most active and good contributors. They can be specialized in different tasks and different areas and can also be exploited for quality assessment. They require users to register in the project web infrastructure. This approach may also employ geoinformatic techniques, such as assigning the scores depending on the user position;
- Competitions and prizes: As with the previous ones, these produce some healthy competitiveness among the participants, motivating them and rewarding them for the quantity or quality of their contributions. Rewards can be symbolic, or can be award money and prizes;
- Forum: An online discussion site where the community of volunteers can share experiences, ask for help, and search for information. Often some mediators are selected within the administrative and scientific staff or among the most experienced volunteers;
- Social media: Social media act as a megaphone for many CS initiatives, managing to reach many contacts and visualizations immediately. They can even be used to collect contributions, suggestions, or to keep users informed on the project status. Social media capability to share images and multimedia files is often a useful support for projects that would have low dissemination power otherwise. Additionally, in this case, geoinformatics technologies can be exploited to target specific areas;
- Newsletter: An easy way to keep subscribers updated and engaged in the project. It reports project progress, calls for performing particular tasks, highlights important dates and events, and even publicly acknowledges the best contributors. When its automatic delivery is not available, it can be replaced by manual sending to a mailing list;
- Community review: this group includes the different technologies that can be implemented to allow the community to comment, integrate, report, or review the resources shared by the project;
- Meetings and events: periodic social events can be useful in CS projects, not only for performing training and data collection (e.g., during bio blitz), but also for reinforcing bonds among volunteers and to arouse the interest of the local communities;
- Co-authoring: In some cases, especially when professionals, associations, or expert amateurs are involved as volunteers, contributions can be encouraged, recognizing co-authorship in scientific papers, magazine publications, etc.;
- Project definition: This engages citizens right from the project design stage, or gives them the opportunity to independently develop sub-projects. Among the advantages, this strategy allows researchers to better understand the needs of communities, and to more easily obtain the favor of the public or private parties involved;
- Games: The use of games in CS projects is part of the phenomena called gamification and serious gaming, namely, the use of typical game design elements and principles in non-game contexts, not only for entertainment. This use of games, in fact, strengthens participants’ engagement and can be exploited by science both to train volunteers or to encourage them to perform certain tasks while having fun.
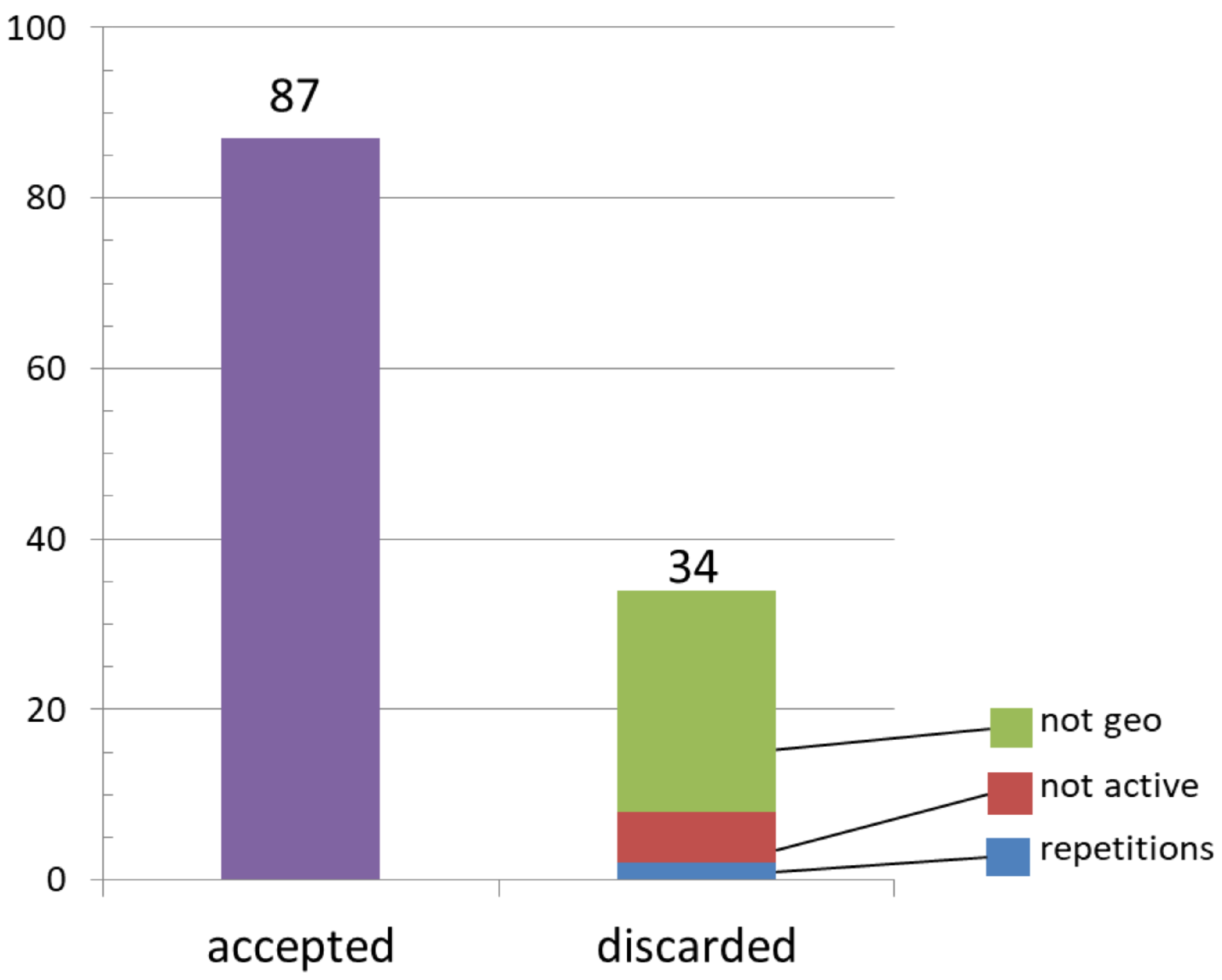
2.2. Selection of CS Projects
- Identifying CS projects by submitting queries such as “CS projects” to search engines and analyzing the first-ranked retrieved web pages;
- Adopting an existing-unofficial-list to start with and then refining it.
- Linguistic bias, due to the fact that we adopted the English list (which is the longest one but not necessary the most representative);
- Lexicon bias, due to the many initiatives that are not self-defined as “citizen science”, even if they involve not-expert or not-professional volunteers in contributing to research. These initiatives tended to be excluded from the collection simply for lexical reasons;
- Methodological bias, because we chose to base the selection of the dataset on a single list which was not assumed to be statistically representative of the whole CS realm. We are also aware that non-web-based projects are not included in the selection, since the list requires the availability of some web description of the initiative. This is also necessary for our direct analysis.
- Temporal bias, because the dataset includes only active CS projects and is not representative of completed initiatives, or of past technologies to collect, process, and share geographical information, even if they have been highly fruitful, popular, or significant. Moreover, the analysis was conducted during the period from September 2017 to March 2018 and reports information on the status of the projects at that time. It is possible that further initiatives or those advertised for a very limited timespan were missed.
3. Results and Discussion
3.1. Recruitment
3.2. Data Generation
3.3. Data Delivery
3.4. Data Search, Visualization, and Access
3.5. Operations on Data
3.6. Qualification/Validation
3.7. User Interaction and Participation
3.8. Concluding Remarks
- The disorientation of volunteer contributors and their dispersion within too many proposals;
- The lack of a shared knowledge base;
- The low robustness of project implementation choices.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Selected Projects

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project Name | Area | Began |
|---|---|---|
| Air Quality Eggs | Ithaca, NY, USA | |
| GeoTag-X | Worldwide | 2012 |
| Loss of the Night | Germany | 2013 |
| Globe at Night | Worldwide | |
| CidadĆo Cientista | Brazil | 2004 |
| Geo-Wiki | Worldwide | 2008 |
| BugGuide | USA, Canada | 2003 |
| Manta Matcher | Worldwide | 2012 |
| Whistler Biodiversity Project | Canada | 2004 |
| Citclops | Europe | 2012 |
| Monarch Larva Monitoring Project | Canada, USA | |
| Track a Tree | UK | 2014 |
| Backyard Bark Beetles | USA | 2014 |
| Track My Fish | Canada | 2012 |
| Wakame Watch | UK | 2014 |
| Ontario BioBlitz | Canada (Ontario) | 2012 |
| Natusfera | Europe | 2016 |
| DigiVol | Australia | 2011 |
| Herbonauten | worldwide, Germany | 2016 |
| Herbarium@home | UK | 2006 |
| Agent Exoplanet | Goleta, CA, USA | |
| Great World Wide Star Count | Worldwide | 2007 |
| Big Butterfly Count | UK | 2010 |
| Crowdcrafting | Worldwide | 2011 |
| Observation.org | Worldwide | |
| Cicada Watch | Northeastern America | 2013 |
| NatureWatch NZ | New Zealand | 2006 |
| CyanoTracker | Worldwide | 2014 |
| Pennsylvania Amphibian and Reptile Survey | Pennsylvania, US | |
| BeeSpotter | USA (IL, IN, MO, OH) | 2007 |
| North American Field Herping Association | North America | 2007 |
| Hare Survey | UK | 2015 |
| Big Moss Map | UK | 2015 |
| Hazelnut Project, The | USA | 2000 |
| Mitten Crab Recording Project | UK | |
| NatureWatch | Canada | |
| Landscape Watch Hampshire | Landscape Change Consortium | 2015 |
| Anecdata | Worldwide | 2013 |
| B.C. Cetacean Sightings Network | Canada (British Columbia) | 1999 |
| Project Discovery II | Worldwide | 2017 |
| Teatime4Science | Worldwide | 2016 |
| SciStarter | Worldwide | 2011 |
| Project Name | Area | Began |
|---|---|---|
| Striped AmBASSadors | NS, Canada | 2010 |
| Project Splatter | UK | 2013 |
| Pieris Project | Worldwide | |
| Garden Wildlife Health | UK | 2013 |
| Report-a-weed | Canada | |
| Cape Citizen Science | South Africa | 2015 |
| Portland Urban Coyote Project | Portland, Oregon, USA | 2011 |
| FrogWatch USATM | USA | 1998 |
| Cities at Night | Global | 2014 |
| Reef Life Survey | Australia | |
| eButterfly | USA, Canada | 2010 |
| Floodcrowd | UK | 2015 |
| TreeSnap | USA | 2017 |
| Big Bug Hunt | USA, UK | 2016 |
| Project Roadkill | Worldwide | 2014 |
| Species Observations System | Norway | 2008 |
| Artportalen | Sweden | 1999 |
| MammalMAP | Africa | 2012 |
| Old Weather | Worldwide | |
| Aquila Project | West Kimberley North Western Australia | 2010 |
| Monarch Health | Canada, USA | |
| Habitat Network | North America | 2012 |
| The Shore Thing Project | UK | 2006 |
| iNaturalist | Global | 2008 |
| AppEAR | Argentina, South America | 2015 |
| Bumble Bee Watch | Canada, USA | 2014 |
| Mosquito Alert | Spain | 2013 |
| Local Environmental Observer Network | Worldwide | 2012 |
| Ontario Reptile and Amphibian Atlas | Canada (Ontario) | |
| Massachusetts Herpetological Atlas | USA | 1992 |
| Vermont Reptile and Amphibian Atlas | USA (VT) | 1995 |
| Michigan Herp Atlas Project | USA (MI) | 2004 |
| Herpetological Education and Research Project | North America | 2007 |
| Turtle Survey and Analysis Tools | Australia | 2014 |
| Amphibian Migrations and Road Crossings | New York, USA | |
| HerpMapper | Global | 2013 |
| CrowdWater | Worldwide | 2017 |
| iSeahorse | Global | 2013 |
| Go Viral Study | USA | 2013 |
| Ontario Butterfly Atlas Online | Canada (Ontario) | 1969 |
| Reef Environmental Education Foundation | Key Largo, USA (FL), Worldwide | 1990 |
| Marine Metres Squared | New Zealand | |
| eOceans | Global | 2014 |
| Monarch Watch | Canada, USA | 1992 |
| eShark | Global | 2005 |
| Project name | Area | Began |
|---|---|---|
| Operation Wallacea | UK | 1996 |
| Identify animals | New Zealand | 2015 |
| BioNote | Worldwide | 2016 |
| Flying ant survey | UK | 2012 |
| Science Gossip Biodiversity Heritage Library | Worldwide | 2015 |
| Galaxy Zoo | Worldwide | 2007 |
| Galaxy Explorer | Australia | 2015 |
| Project Soothe | Worldwide | 2014 |
| ARTigo | Worldwide | 2007 |
| VerbCorner | Worldwide | 2013 |
| AgeGuess | Worldwide | 2012 |
| Diver Safety Guardian | Europe and Africa | 1994 |
| Project Dive Exploration | North America | |
| Radio Galaxy Zoo | Worldwide | 2013 |
| Orca Game | Worldwide | 2013 |
| Reading Nature’s Library | UK | |
| Mark2Cure | USA (CA) | 2012 |
| Disk Detective | Worldwide | 2014 |
| Stardust@Home | Worldwide | 2006 |
| VT Fish Diaries | USA (VT) | 2015 |
| Artsobservasjoner | Norway | 2008 |
| Digital Access to a Sky Century @ Harvard | USA | 2001 |
| Weather Detective | Australia | 2014 |
| Clumpy | Worldwide | 2012 |
| theSkyNet | Worldwide | 2011 |
| Smithsonian Transcription Center | USA | 2014 |
| Doing It Together Science DITOs | Europe | 2016 |
| Notes from Nature | Worldwide | |
| Fraxinus | Worldwide | 2013 |
| Cochrane Crowd | Worldwide | 2016 |
| Plankton Project | Worldwide | 2013 |
| Foldit | Worldwide | 2008 |
| SETI@home | Worldwide | 1999 |
| Socientize | Worldwide | 2012 |
References
- Kemp, K. Encyclopedia of Geographic Information Science; SAGE: Thousand Oaks, CA, USA, 2008. [Google Scholar]
- Geoinformatics Laboratory of Pittsburgh University, 2017. Available online: http://gis.sis.pitt.edu/images/GeoinformaticsDiagram.jpg (accessed on 29 March 2018).
- Gore, A. The Digital Earth. Aust. Surv. 1998, 43, 89–91. [Google Scholar] [CrossRef]
- Gould, M.; Craglia, M.; Goodchild, M.F.; Annoni, A.; Camara, G.; Kuhn, W.; Mark, D.; Masser, I.; Maguire, D.; Liang, S.; et al. Next-generation digital earth: A position paper from the vespucci initiative for the advancement of geographic information science. Int. J. Spat. Data Infrastruct. Res. 2008, 43, 146–167. [Google Scholar]
- Goodchild, M.F. Citizens as sensors: the world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef] [Green Version]
- Turner, A. Introduction to Neogeography; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2006. [Google Scholar]
- Sui, D.; Elwood, S.; Goodchild, M. Crowdsourcing Geographic Knowledge: Volunteered Geographic Information (VGI) in Theory and Practice; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- See, L.; Mooney, P.; Foody, G.; Bastin, L.; Comber, A.; Estima, J.; Fritz, S.; Kerle, N.; Jiang, B.; Laakso, M.; et al. Crowdsourcing, Citizen Science or Volunteered Geographic Information? The Current State of Crowdsourced Geographic Information. ISPRS Int. J. Geo-Inf. 2016, 5, 55. [Google Scholar] [CrossRef]
- Jokar Arsanjani, J.; Vaz, E. Special Issue Editorial: Earth Observation and Geoinformation Technologies for Sustainable Development. Sustainability 2017, 9, 760. [Google Scholar] [CrossRef]
- Arsanjani, J.J. Remote Sensing, Crowd Sensing, and Geospatial Technologies for Public Health: An Editorial. Int. J. Environ. Res. Public Health 2017, 14, 405. [Google Scholar] [CrossRef] [PubMed]
- Pirasteh, S.; Li, J. Global Changes and Natural Disaster Management: Geo-Information Technologies; Springer: Berlin, Germany, 2017. [Google Scholar]
- ISPRS. IJGI, Special Issue Geoweb 2.0, 2015. Available online: https://www.mdpi.com/journal/ijgi/special_issues/geoweb-2.0 (accessed on 29 March 2018).
- Follett, R.; Strezov, V. An analysis of citizen science based research: Usage and publication patterns. PLoS ONE 2015, 10, e0143687. [Google Scholar] [CrossRef] [PubMed]
- The USA Citizen Science Initiative. Available online: https://www.citizenscience.gov/ (accessed on 29 March 2018).
- Australian Citizen Science Association (ACSA). Available online: http://csna.gaiaresources.com.au/ (accessed on 29 March 2018).
- COST_Actions CA15212, Citizen Science to Promote Creativity, Scientific Literacy, and Innovation Throughout Europe, 2016. Available online: http://www.cost.eu/COST_Actions/ca/CA15212 (accessed on 29 March 2018).
- Wiggins, A.; Crowston, K. From conservation to crowdsourcing: A typology of citizen science. In Proceedings of the 2011 44th Hawaii International Conference on System Sciences (HICSS), Kauai, HI, USA, 4–7 January 2011; pp. 1–10. [Google Scholar]
- Serrano Sanz, F.; Holocher-Ertl, T.; Kieslinger, B.; Sanz Garcıa, F.; Silva, C. White Paper on Citizen Science for Europe; Socientize Consortium, European Commission: Brussels, Belgium, 2014. [Google Scholar]
- Roy, H.E.; Pocock, M.J.; Preston, C.D.; Roy, D.B.; Savage, J.; Tweddle, J.; Robinson, L. Understanding cItizen Science and Environmental Monitoring: Final Report on Behalf of UK Environmental Observation Framework; NERC/Centre for Ecology & Hydrology: Wallingford, UK, 2012. [Google Scholar]
- Wiggins, A.; Bonney, R.; Graham, E.; Henderson, S.; Kelling, S.; LeBuhn, G.; Litauer, R.; Lots, K.; Michener, W.; Newman, G. Data Management Guide for Public Participation in Scientific Research; DataONE: Albuquerque, NM, USA, 2013; pp. 1–41. [Google Scholar]
- Law, E.; Williams, A.C.; Wiggins, A.; Brier, J.; Preece, J.; Shirk, J.; Newman, G. The Science of Citizen Science: Theories, Methodologies and Platforms. In Proceedings of the Companion of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing, Portland, OR, USA, 25 February–1 March 2017; ACM: New York, NY, USA, 2017; pp. 395–400. [Google Scholar]
- Eitzel, M.; Cappadonna, J.L.; Santos-Lang, C.; Duerr, R.E.; Virapongse, A.; West, S.E.; Kyba, C.C.M.; Bowser, A.; Cooper, C.B.; Sforzi, A.; et al. Citizen science terminology matters: Exploring key terms. Citiz. Sci. Theory Pract. 2017, 2. [Google Scholar] [CrossRef]
- Newman, G.; Wiggins, A.; Crall, A.; Graham, E.; Newman, S.; Crowston, K. The future of citizen science: Emerging technologies and shifting paradigms. Front. Ecol. Environ. 2012, 10, 298–304. [Google Scholar] [CrossRef]
- Open Geospatial Consortium. Available online: http://www.opengeospatial.org/ (accessed on 29 March 2018).
- Bordogna, G.; Carrara, P.; Criscuolo, L.; Pepe, M.; Rampini, A. On predicting and improving the quality of Volunteer Geographic Information projects. Int. J. Digit. Earth 2016, 9, 134–155. [Google Scholar] [CrossRef]
- Criscuolo, L.; Carrara, P.; Bordogna, G.; Pepe, M.; Zucca, F.; Seppi, R.; Oggioni, A.; Rampini, A. Handling quality in crowdsourced geographic information. In European Handbook of Crowdsourced Geographic Information; Capineri, C., Ed.; Ubiquity Press: London, UK, 2016; p. 57. [Google Scholar]
- Wiggins, A.; Newman, G.; Stevenson, R.D.; Crowston, K. Mechanisms for data quality and validation in citizen science. In Proceedings of the 2011 IEEE Seventh International Conference on e-Science Workshops (eScienceW), Stockholm, Sweden, 5–8 December 2011; pp. 14–19. [Google Scholar]
- Goodchild, M.F.; Li, L. Assuring the quality of volunteered geographic information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Wikipedia Page: List of Citizen Science Projects. Available online: https://en.wikipedia.org/wiki/List_of_citizen_science_projects (accessed on 29 March 2018).
- Ess, C.; Sudweeks, F. On the edge: Cultural barriers and catalysts to IT diffusion among remote and marginalized communities. New Media Soc. 2001, 3, 259–269. [Google Scholar] [CrossRef]
- International Telecommunication Union, ICT Data and Statistics Division of the Telecommunication Development Bureau. Available online: https://www.itu.int/en/ITU-D/Statistics/Documents/facts/ICTFactsFigures2017.pdf (accessed on 29 March 2018).
- OpenStreetMap. Available online: https://www.openstreetmap.org/ (accessed on 29 March 2018).
- Google Earth. Available online: https://earth.google.com/web (accessed on 29 March 2018).
- Campelo, C.; Elízio, C.; Bertolotto, M.; Corcoran, P. Volunteered Geographic Information and the Future of Geospatial Data; IGI Global: Hershey, PA, USA, 2017. [Google Scholar]
- Mirowski, P. Against Citizen Science, 2017. Available online: https://aeon.co/essays/is-grassroots-citizen-science-a-front-for-big-business (accessed on 29 March 2018).
- Sturm, U.; Schade, S.; Ceccaroni, L.; Gold, M.; Kyba, C.; Claramunt, B.; Haklay, M.; Kasperowski, D.; Albert, A.; Piera, J.; et al. Defining principles for mobile apps and platforms development in citizen science. Res. Ideas Outcomes 2017, 3, e21283. [Google Scholar] [CrossRef]
- Bordogna, G.; Frigerio, L.; Kliment, T.; Brivio, P.A.; Hossard, L.; Manfron, G.; Sterlacchini, S. Contextualized VGI Creation and Management to Cope with Uncertainty and Imprecision. ISPRS Int. J. Geo-Inf. 2016, 5, 234. [Google Scholar] [CrossRef]
- Billiet, C.; de Weghe, N.V.; Deploige, J.; Tré, G.D. Visualizing and Reasoning With Imperfect Time Intervals in 2-D. IEEE Trans. Fuzzy Syst. 2017, 25, 1698–1713. [Google Scholar] [CrossRef]
- Rocchini, D.; Foody, G.M.; Nagendra, H.; Ricotta, C.; Anand, M.; He, K.S.; Amici, V.; Kleinschmit, B.; Förster, M.; Schmidtlein, S.; et al. Uncertainty in ecosystem mapping by remote sensing. Comput. Geosci. 2013, 50, 128–135. [Google Scholar] [CrossRef]
- Karam, R.; Favetta, F.; Laurini, R.; Chamoun, R.K. Uncertain Geoinformation Representation and Reasoning: A Use Case in LBS Integration. In Proceedings of the 2010 Workshops on Database and Expert Systems Applications, Bilbao, Spain, 30 August–3 September 2010; pp. 313–317. [Google Scholar] [CrossRef]
- Bastin, L.; Schade, S.; Mooney, P. Volunteered Metadata, and Metadata on VGI: Challenges and Current Practices. In Mobile information Systems leveraging Volunteered Geographic Information for Earth Observation; Bordogna, G., Carrara, P.P., Eds.; Springer: Berlin, Germany, 2018. [Google Scholar]

















© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Criscuolo, L.; Bordogna, G.; Carrara, P.; Pepe, M. CS Projects Involving Geoinformatics: A Survey of Implementation Approaches. ISPRS Int. J. Geo-Inf. 2018, 7, 312. https://doi.org/10.3390/ijgi7080312
Criscuolo L, Bordogna G, Carrara P, Pepe M. CS Projects Involving Geoinformatics: A Survey of Implementation Approaches. ISPRS International Journal of Geo-Information. 2018; 7(8):312. https://doi.org/10.3390/ijgi7080312
Chicago/Turabian StyleCriscuolo, Laura, Gloria Bordogna, Paola Carrara, and Monica Pepe. 2018. "CS Projects Involving Geoinformatics: A Survey of Implementation Approaches" ISPRS International Journal of Geo-Information 7, no. 8: 312. https://doi.org/10.3390/ijgi7080312
APA StyleCriscuolo, L., Bordogna, G., Carrara, P., & Pepe, M. (2018). CS Projects Involving Geoinformatics: A Survey of Implementation Approaches. ISPRS International Journal of Geo-Information, 7(8), 312. https://doi.org/10.3390/ijgi7080312