A Model for Animal Home Range Estimation Based on the Active Learning Method



Abstract
:1. Introduction
1.1. Previous Work
1.2. Purpose and Organization
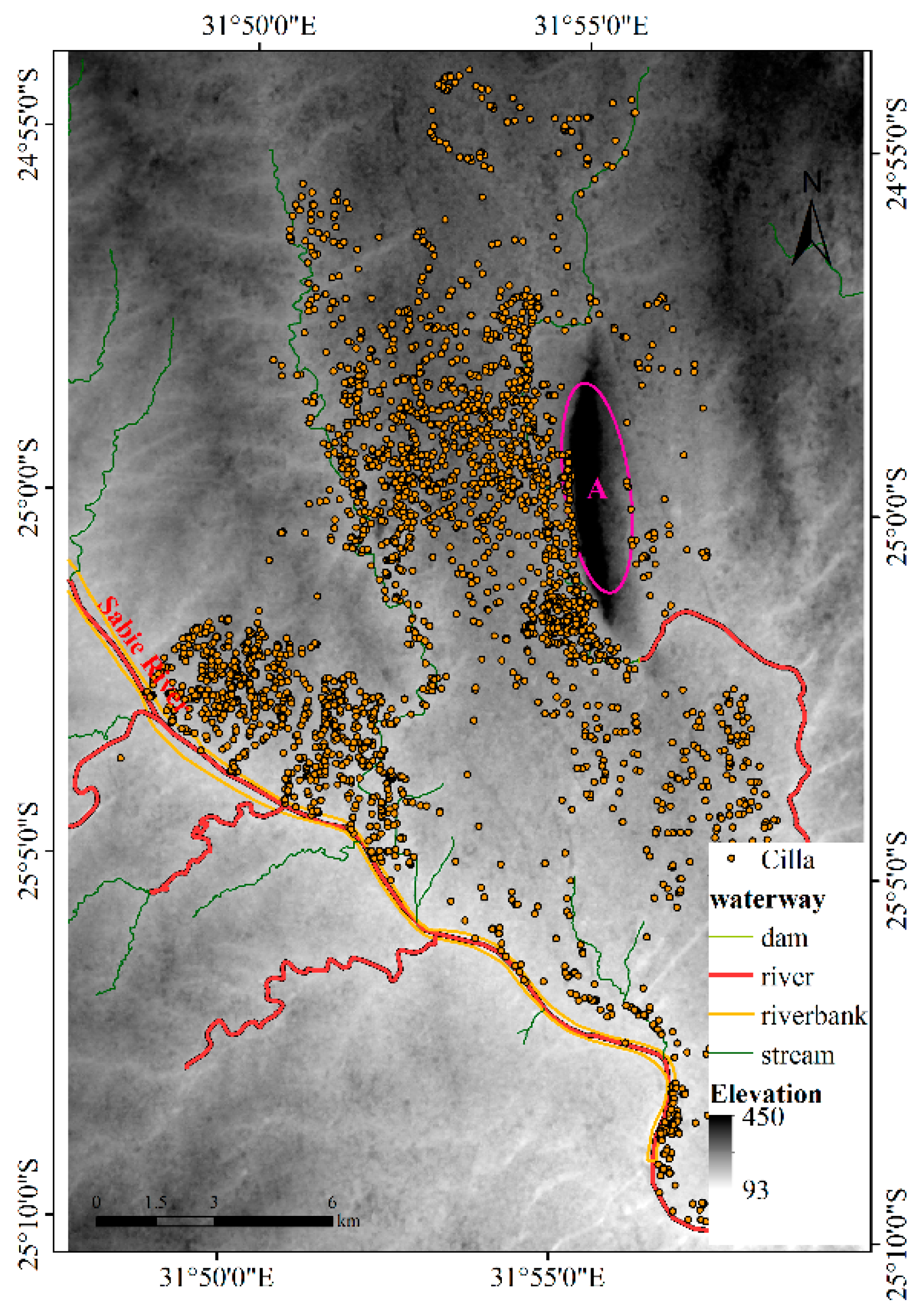
2. Materials
3. Methods
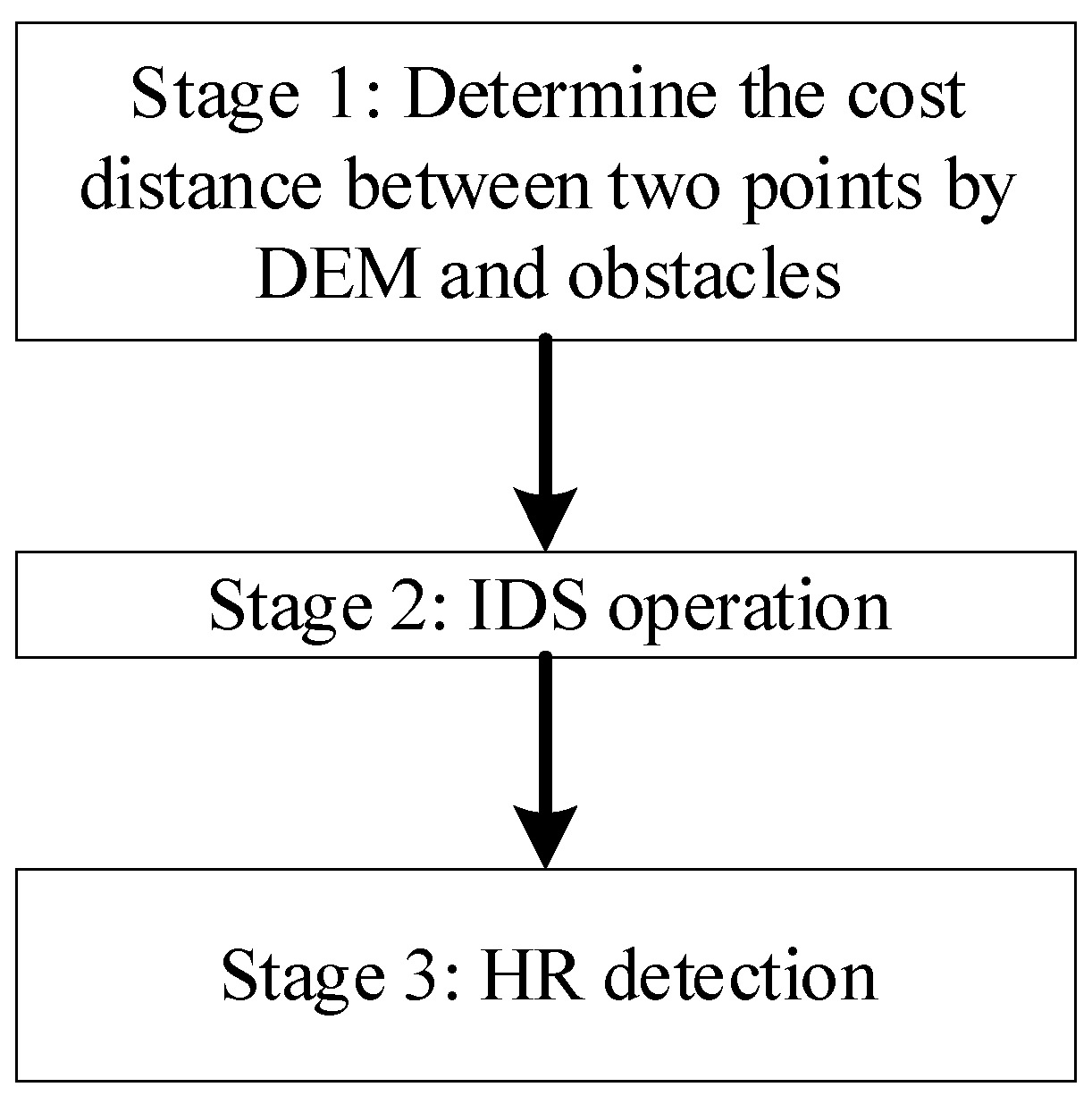
3.1. Framework of the DFHRE
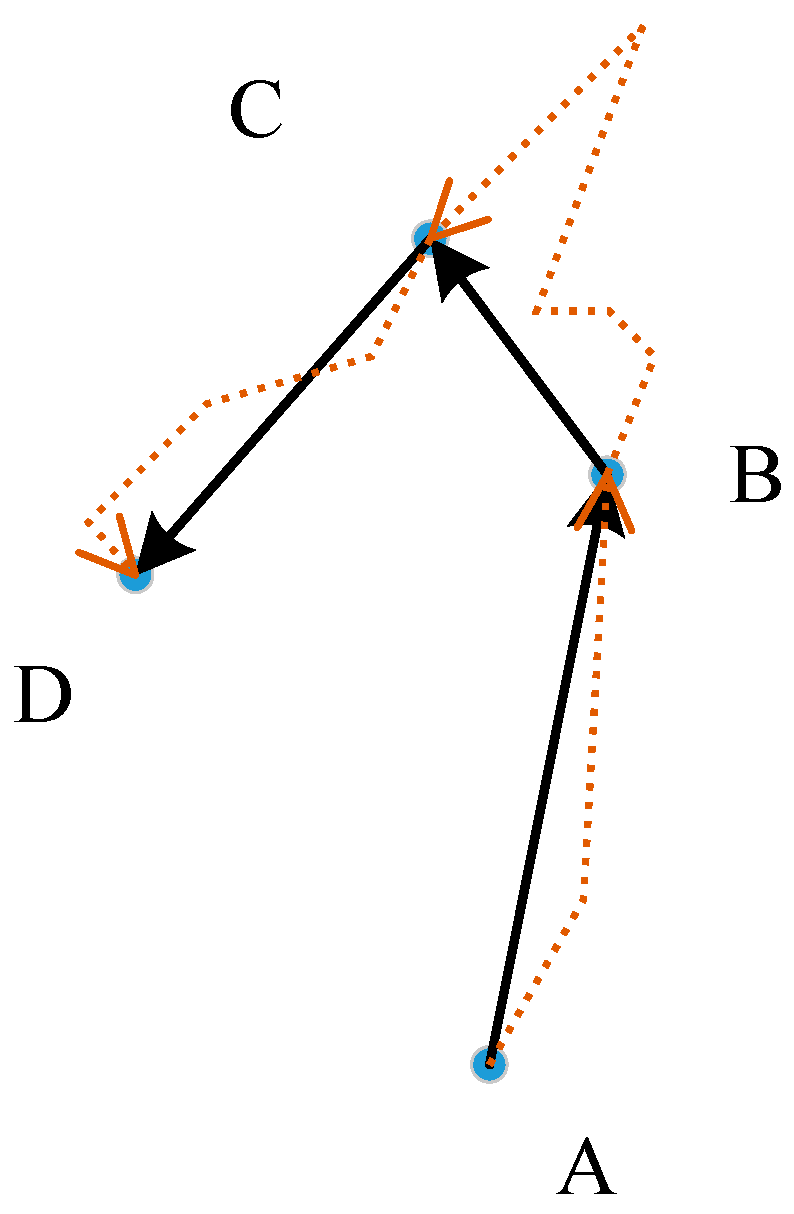
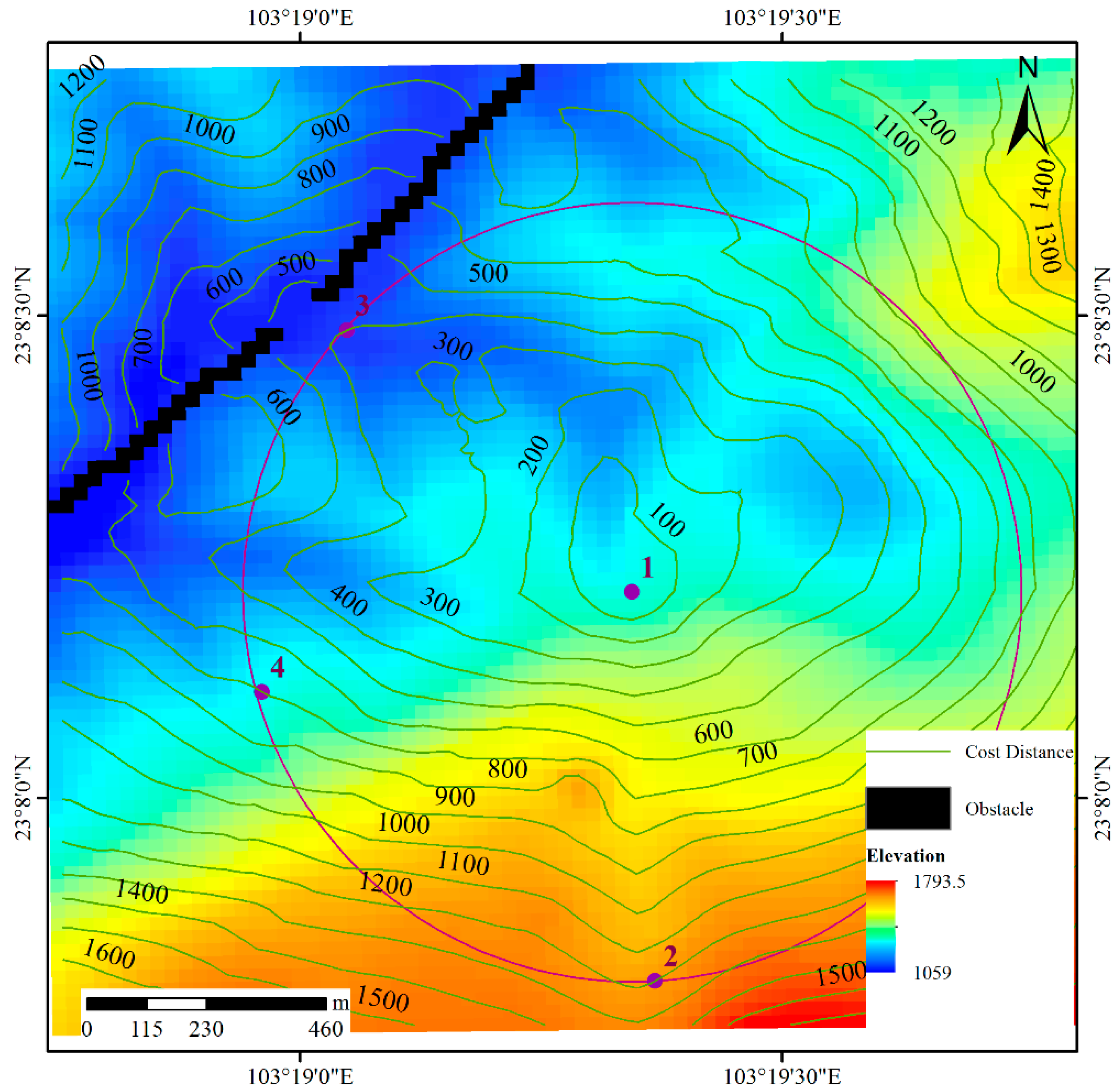
3.2. Determining the Cost Distance
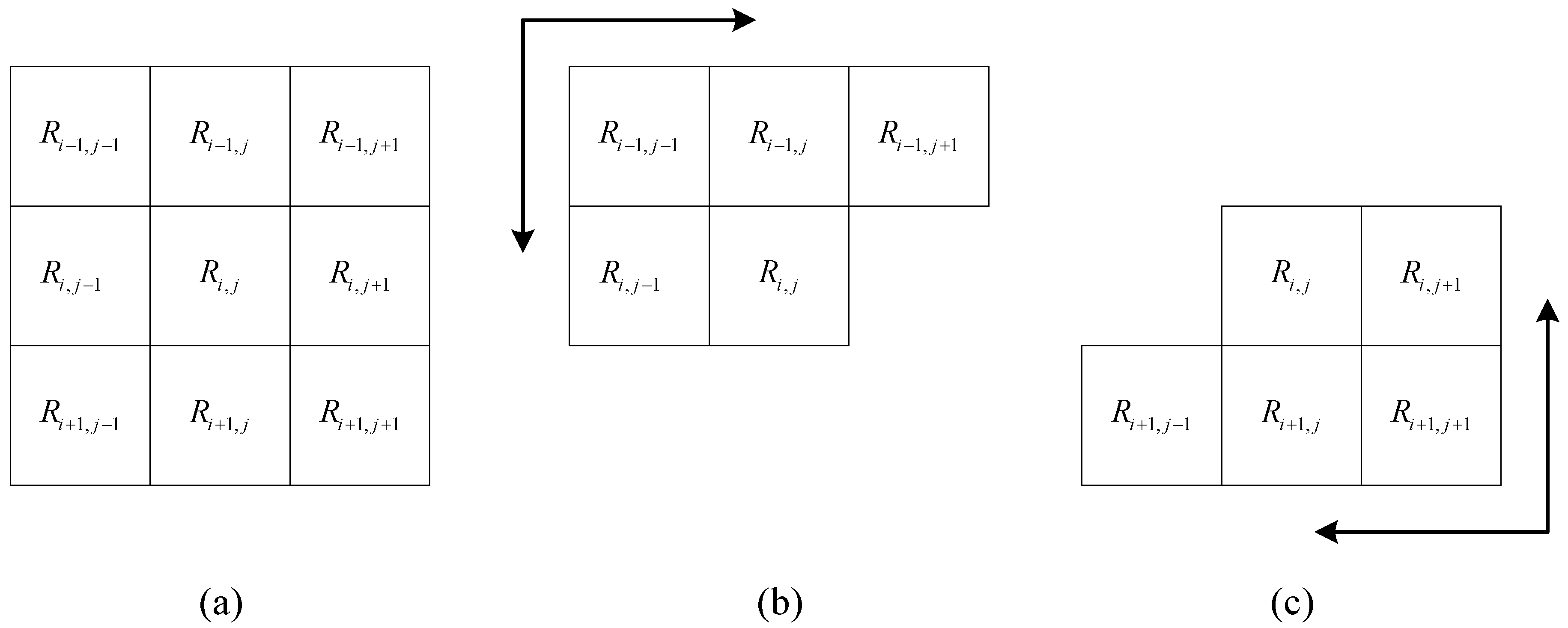
- Step 1: Let the image size be M × N. The distance matrix D(M × N) is used to express the distance of any point to the original point, and the initial distance is set to a very large value, such as the maximum value of the integer type. If point (m, n) is the original point, set D(m, n) is equal to 0.
- Step 2: Scan matrix D from the upper left corner to the lower right corner, where i = 0, 1, 2, …, M–1 and j = 0, 1, 2, …, N–1, as shown in Figure 8b. The distance matrix D is updated by:where S is the resolution of the raster data and k is the parameter used to adjust the movement difficulty. If is an obstacle, no further steps are required.
- Step 3: Scan matrix D from the lower right corner to the upper left corner, where i = M–1, M–2, …, 0 and j = N–1, N–2, …, 0, as shown in Figure 8c. The distance matrix D is updated as follows.If is an obstacle, no further steps are required.
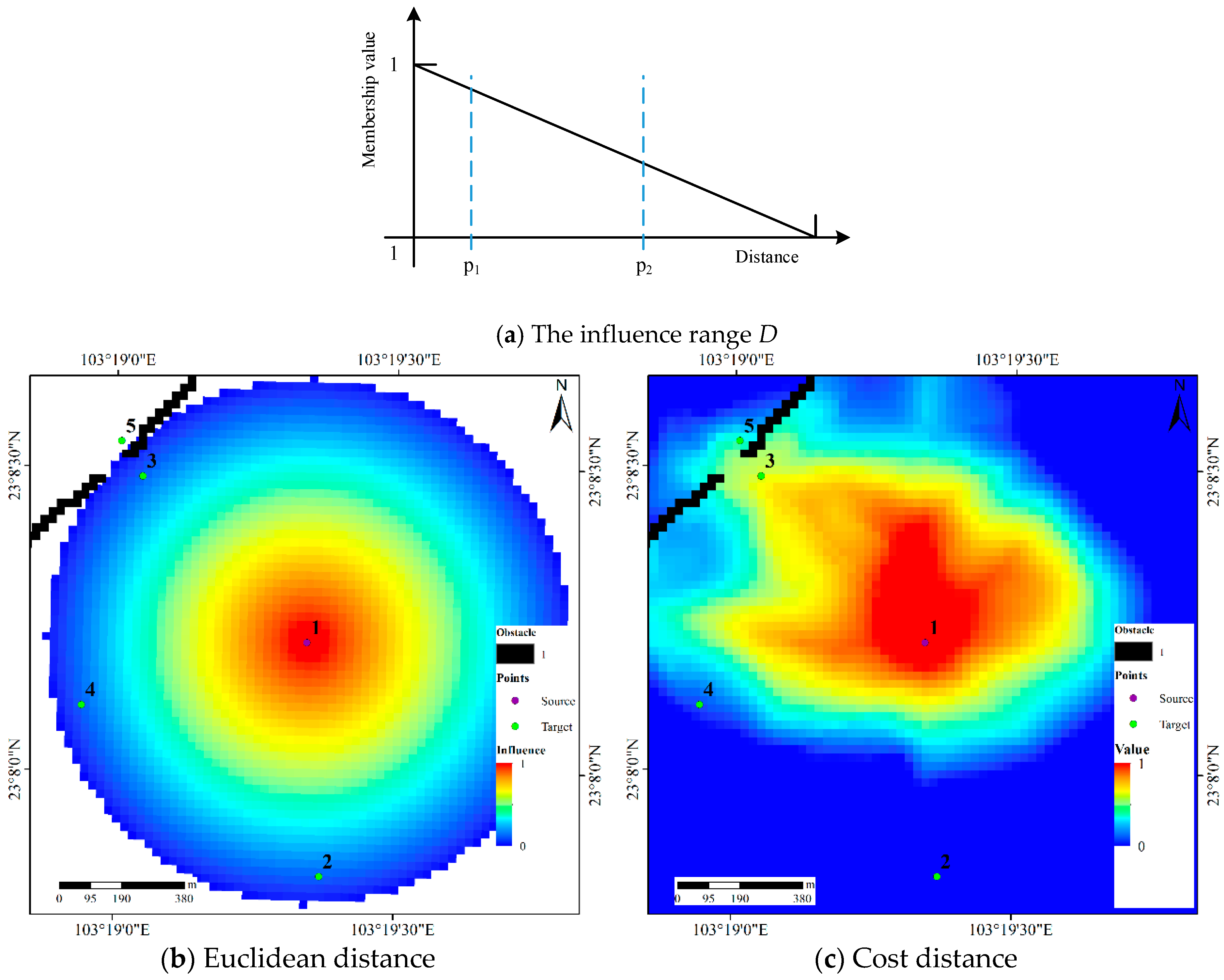
3.3. Determining the Possibility Distribution with IDS Operations
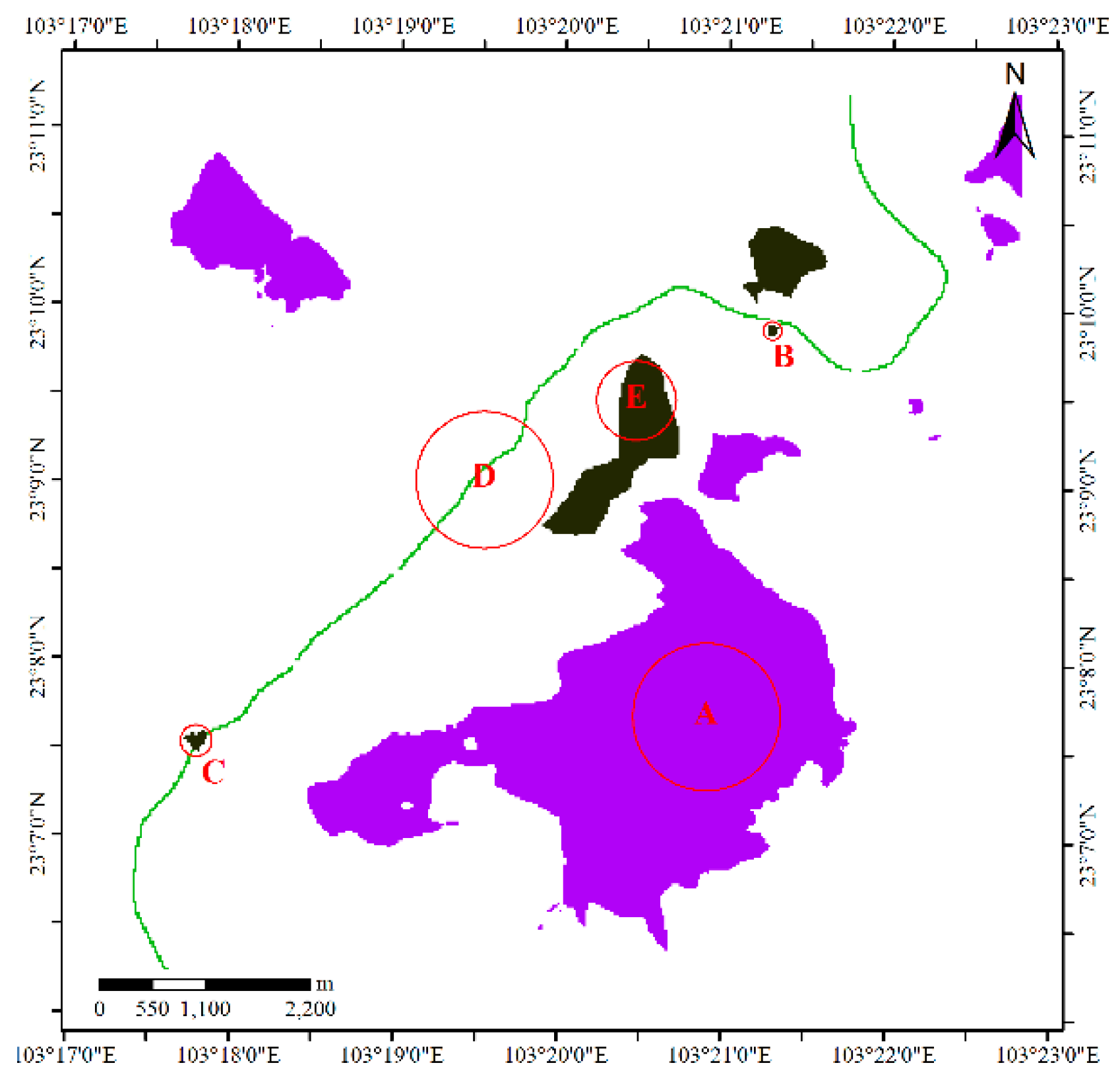
3.4. Detecting Core Areas and HRs
3.5. Determining the Initial Parameters
3.6. Implementation in Java
4. Results and Discussion
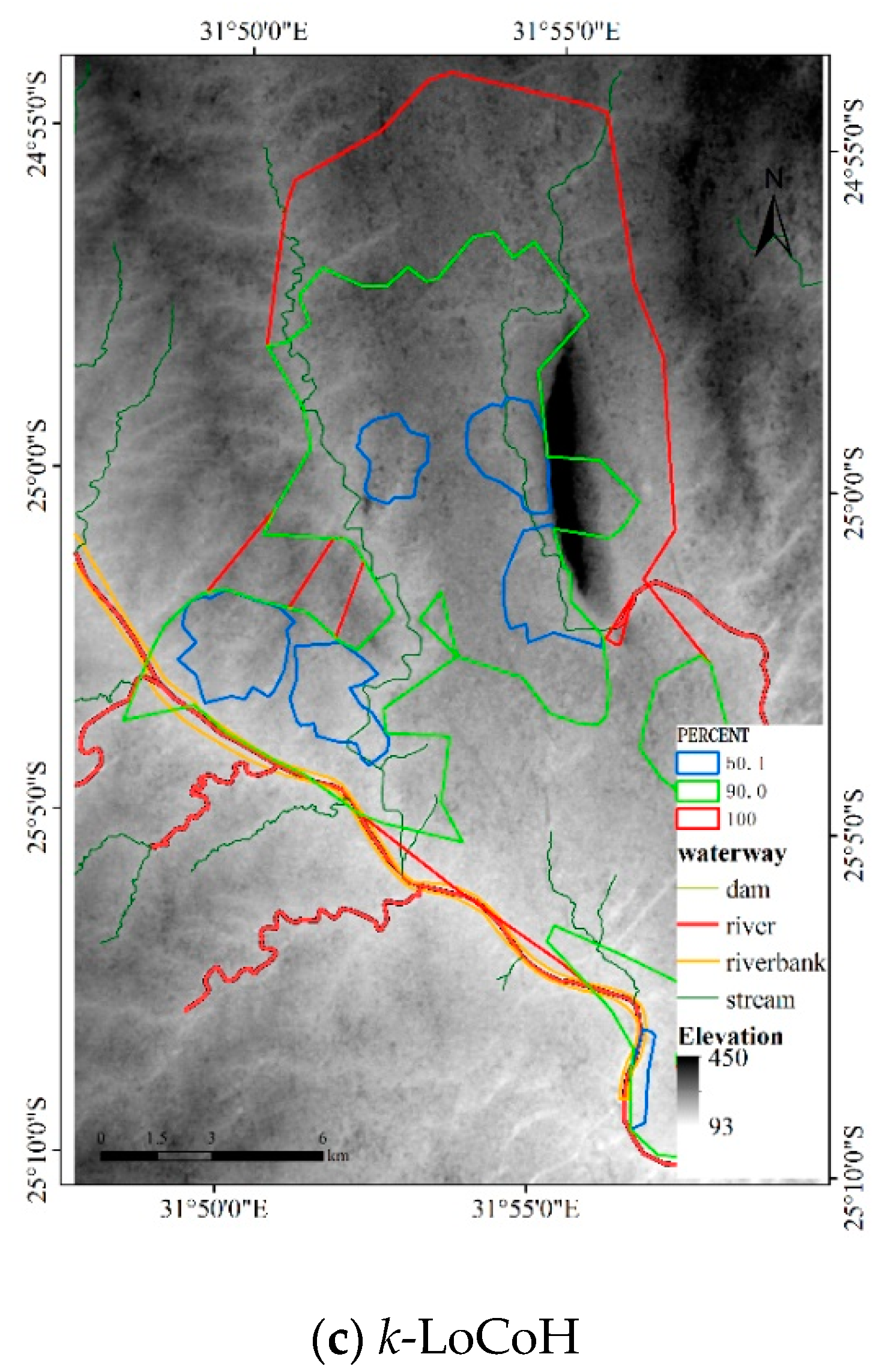
4.1. Results
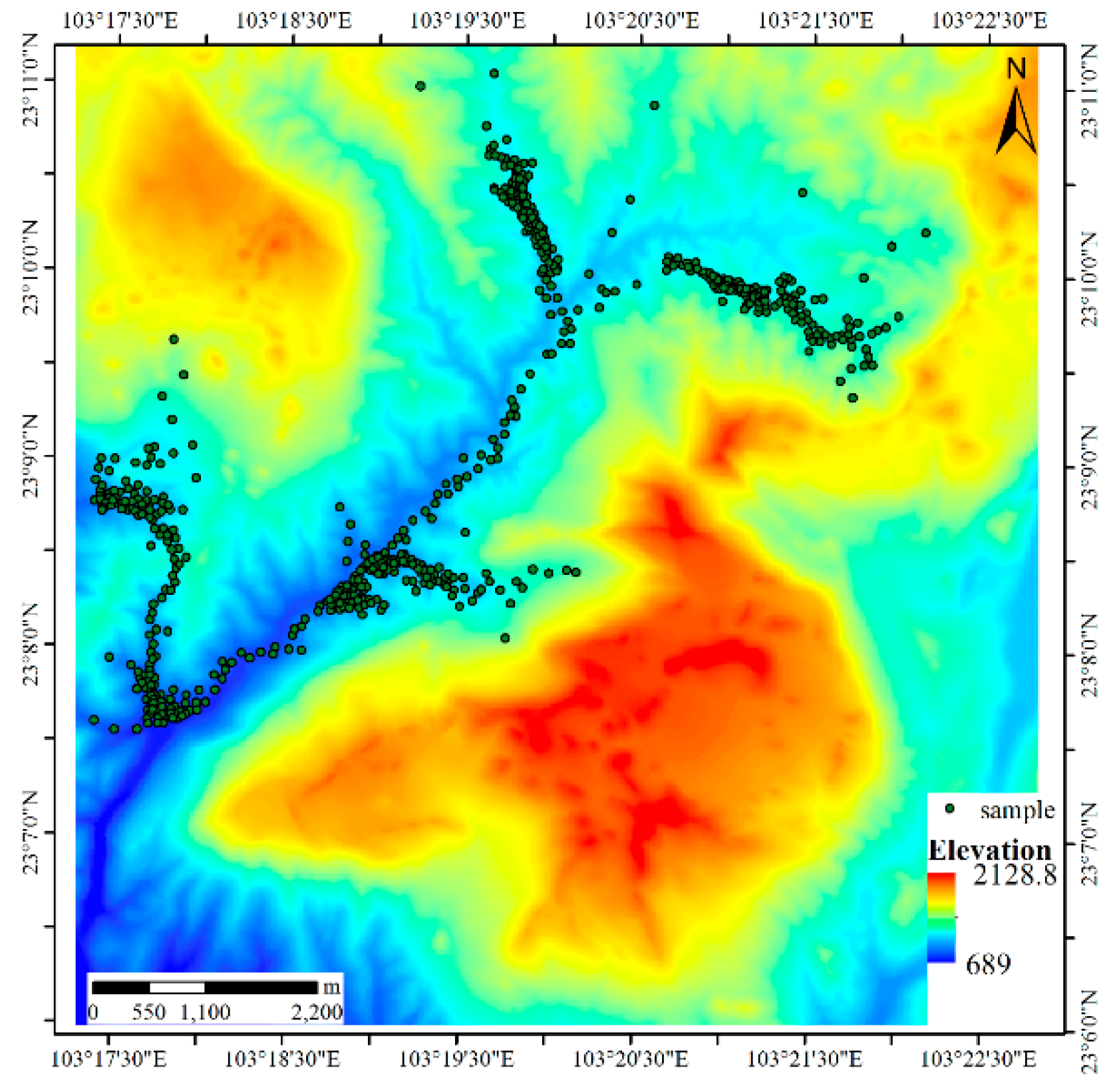
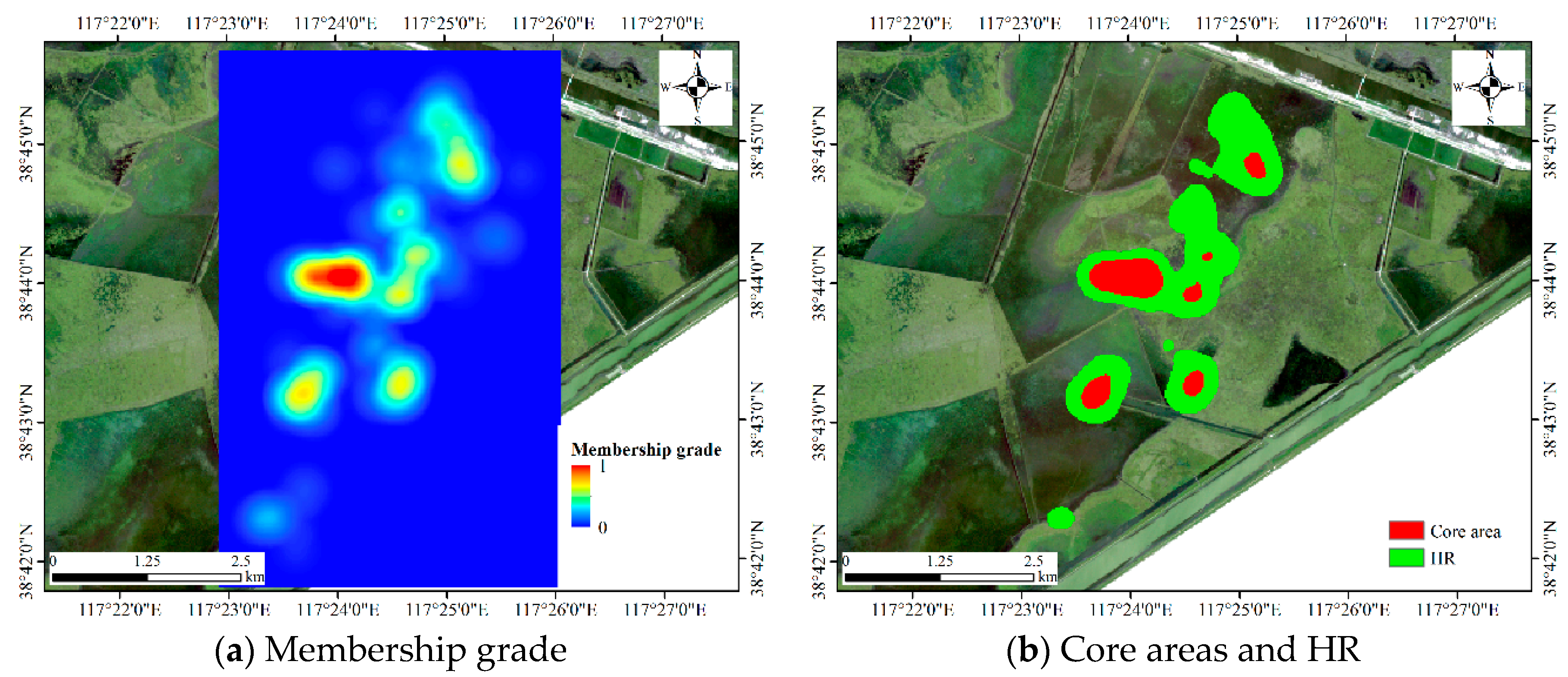
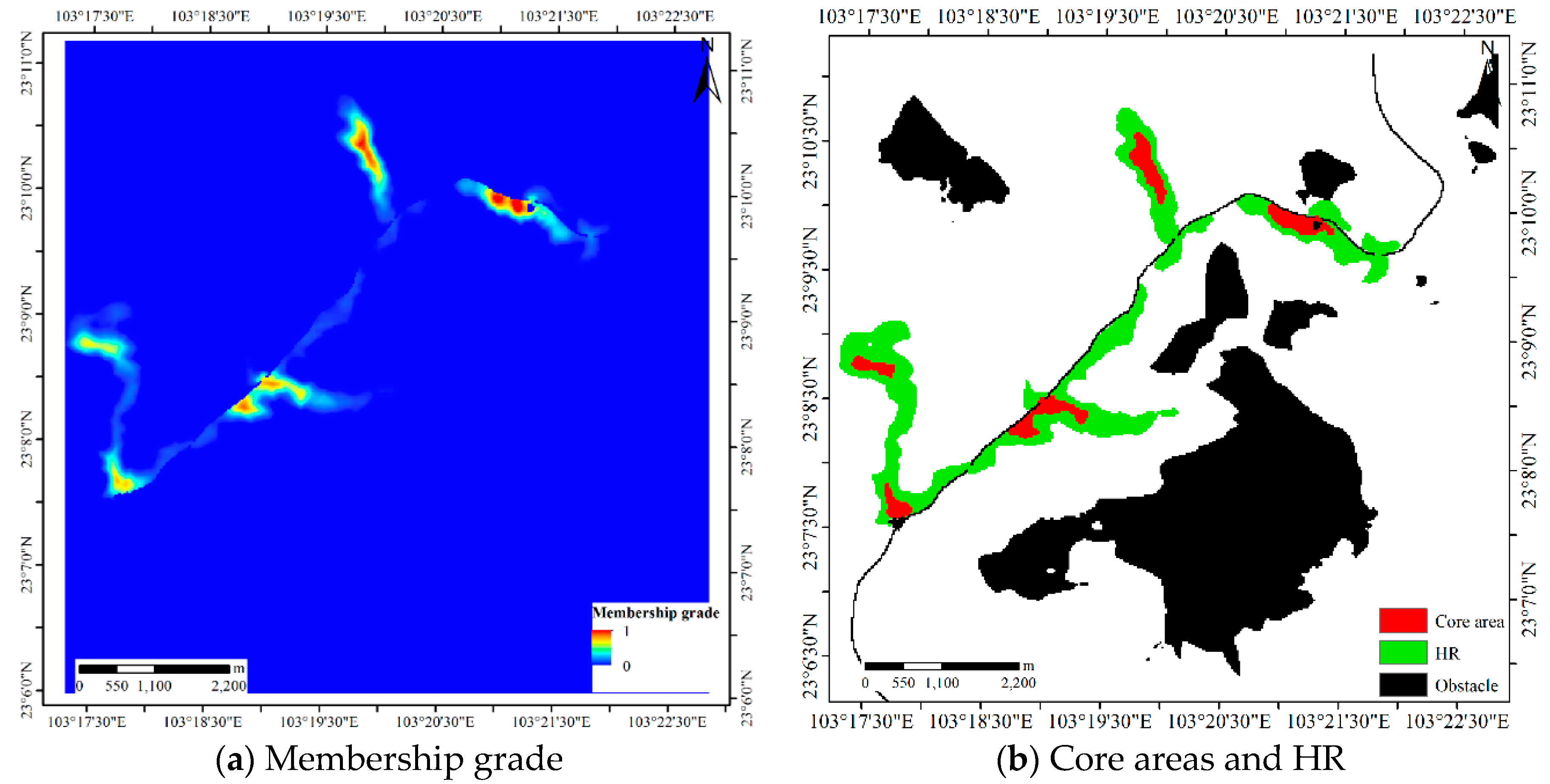
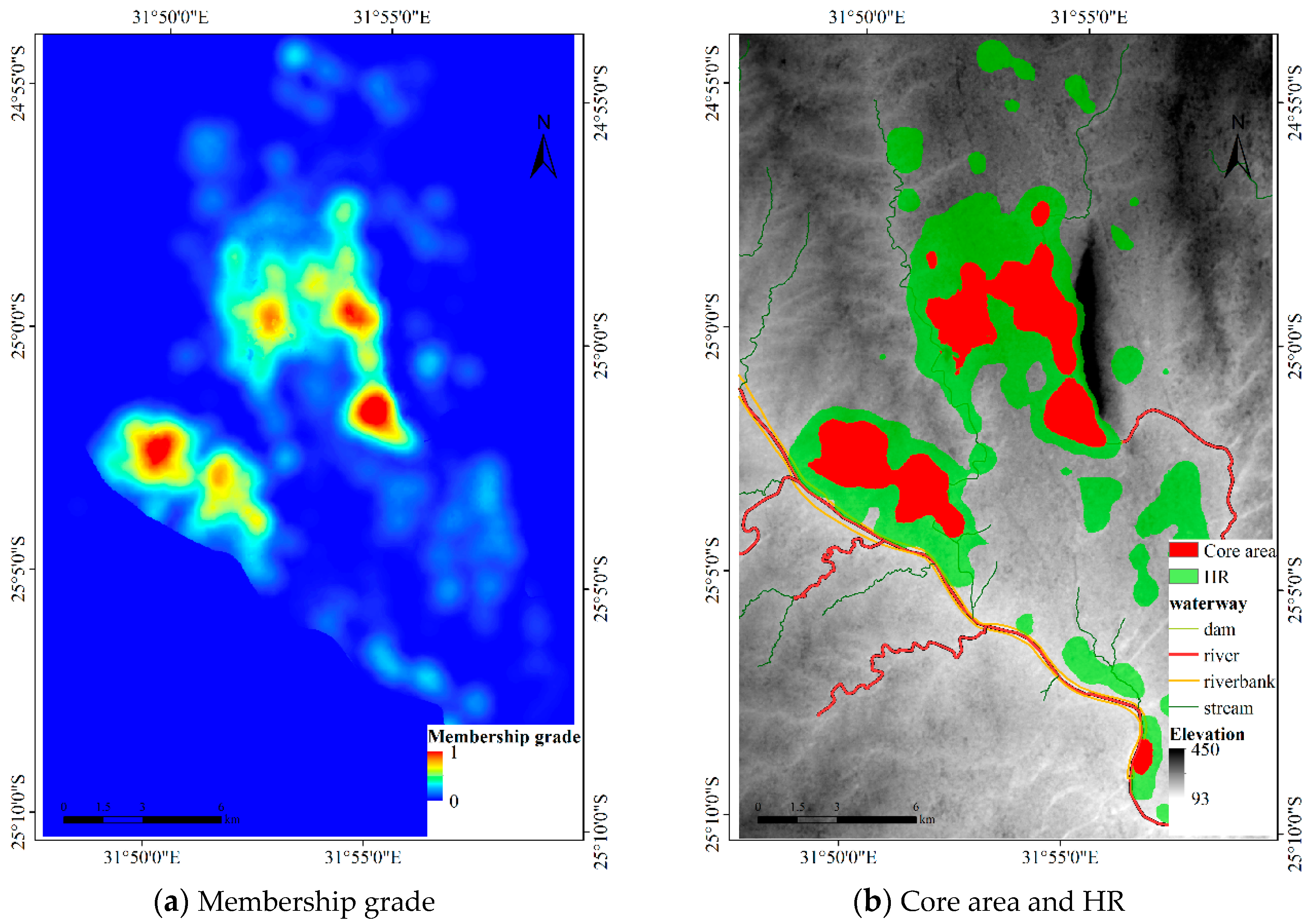
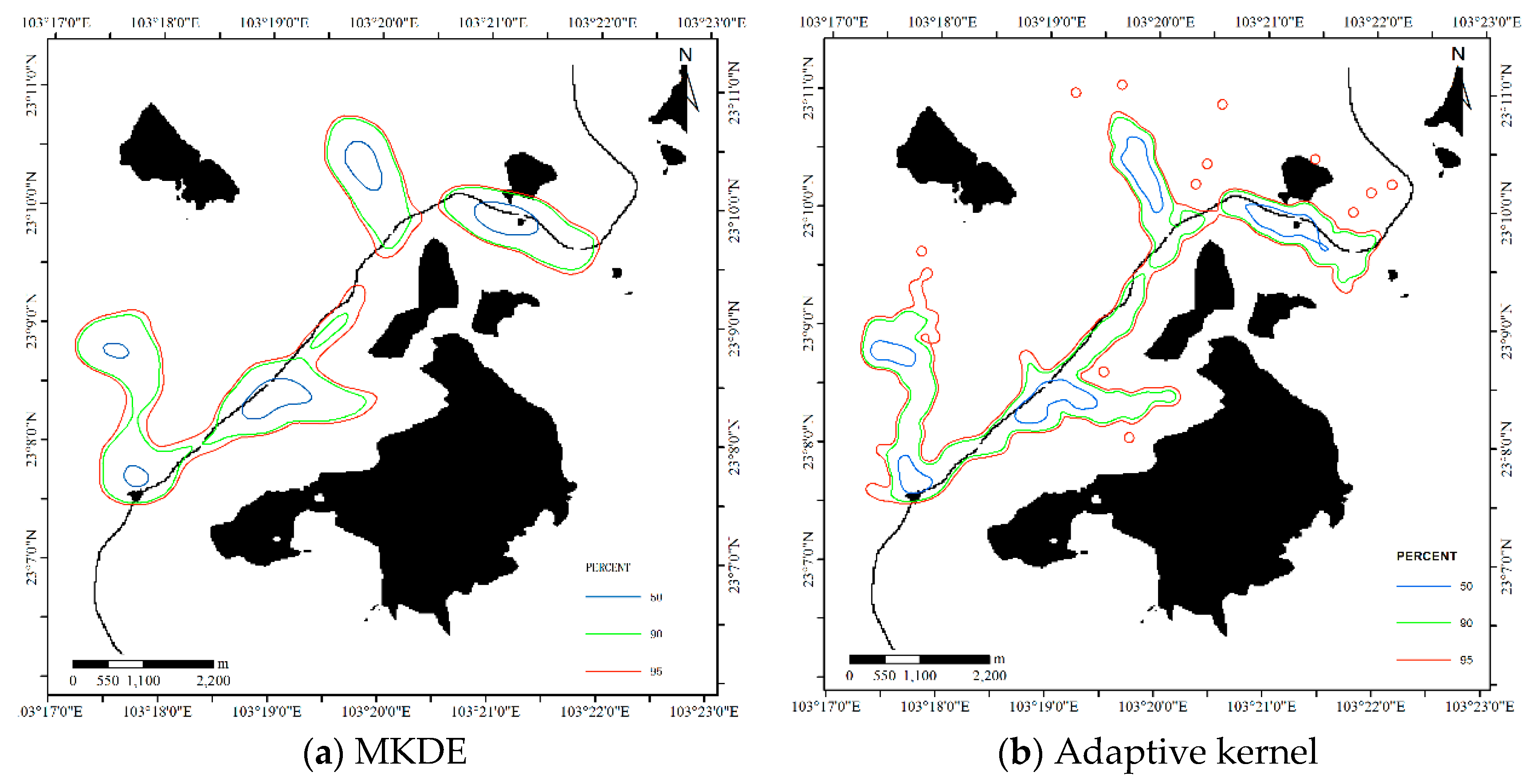
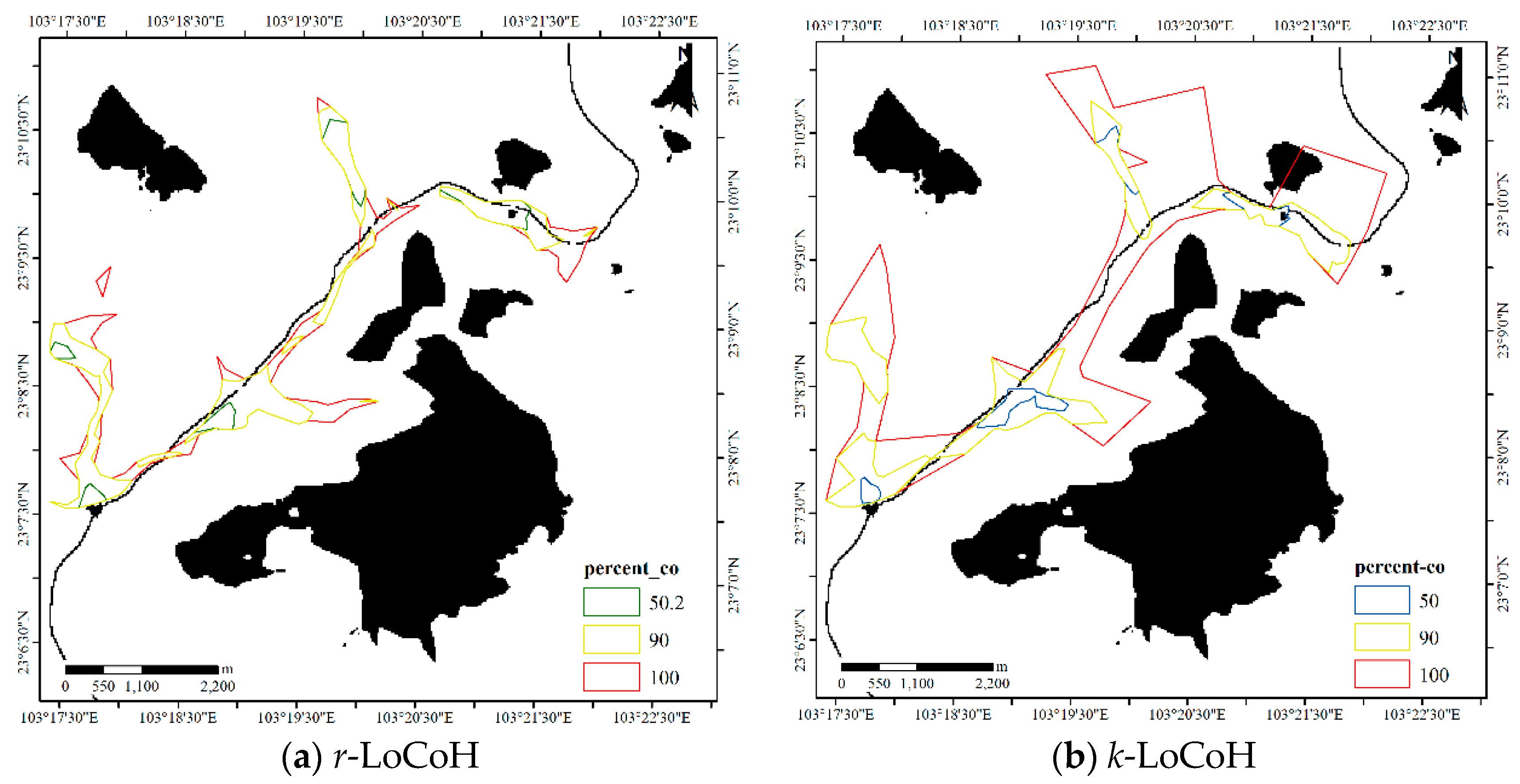
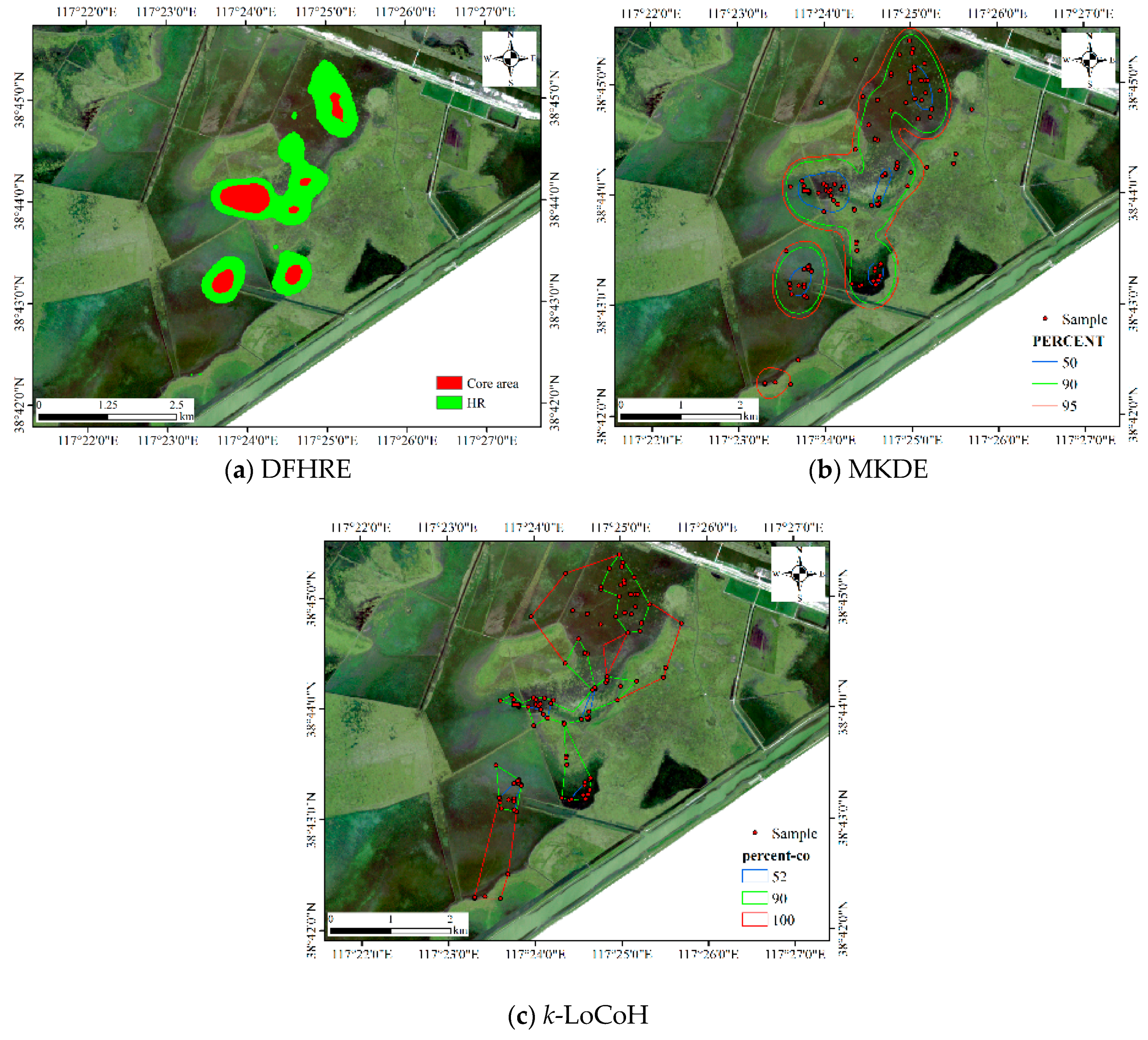
4.1.1. Results for Dataset 1
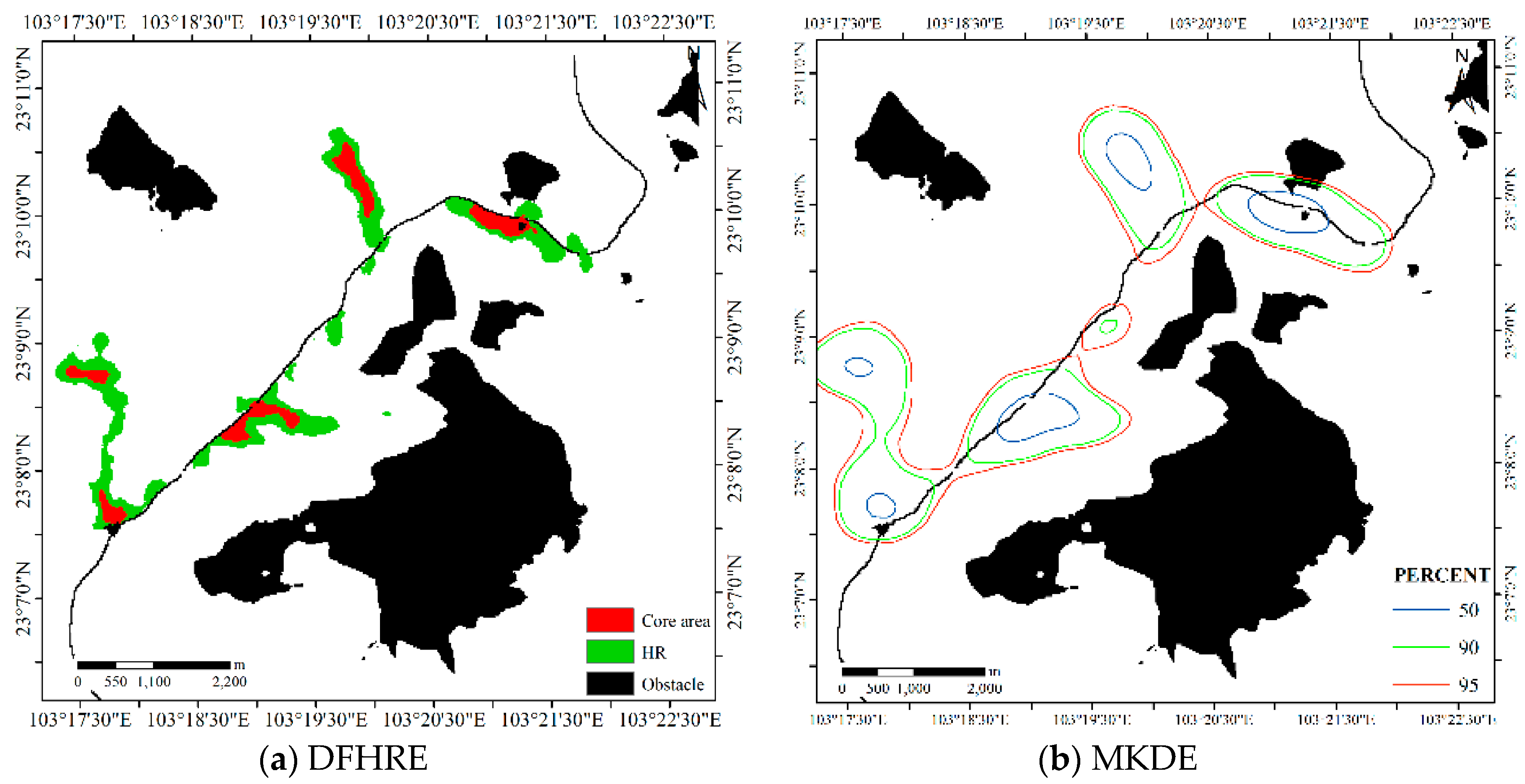
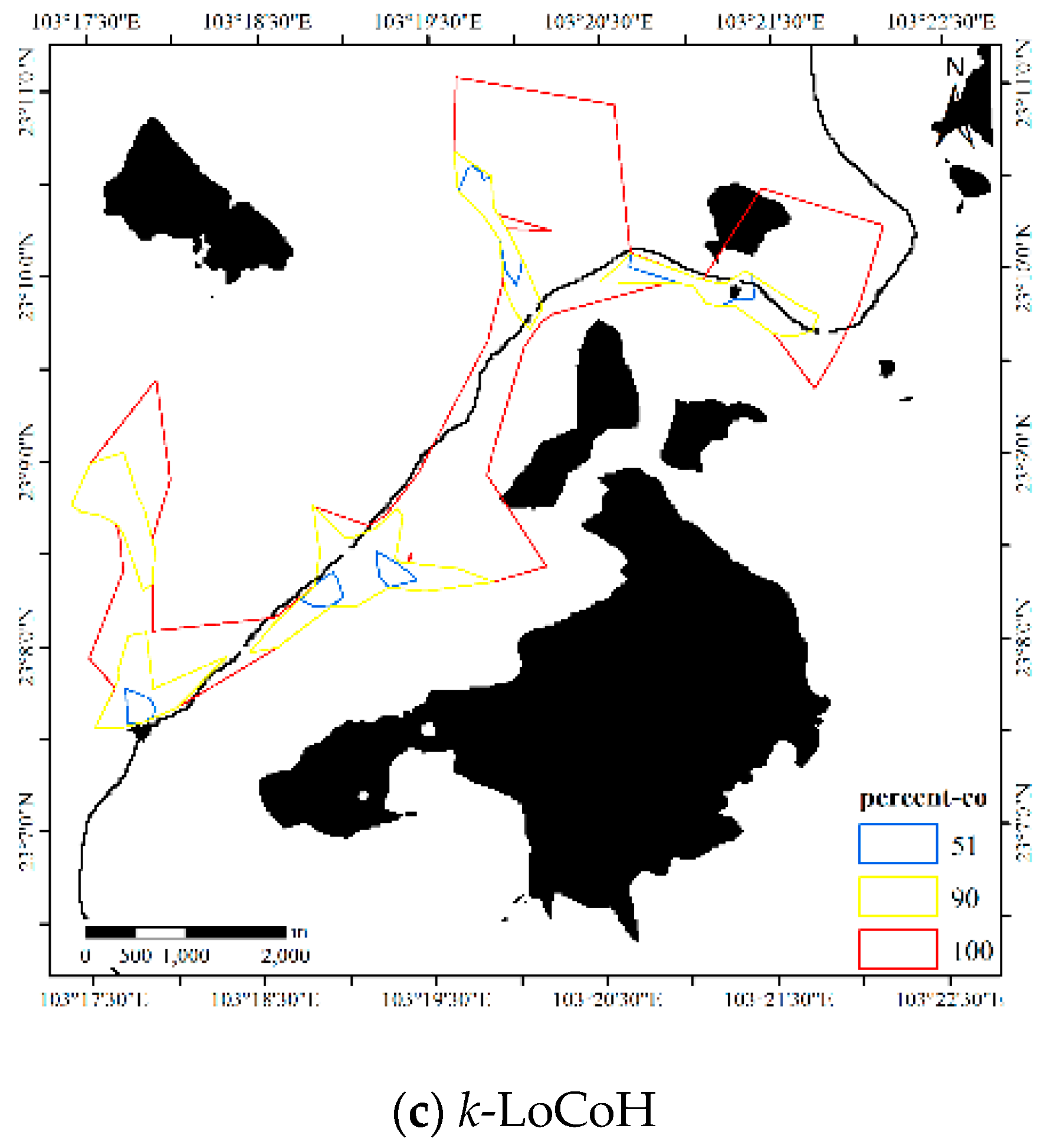
4.1.2. Results for Dataset 2
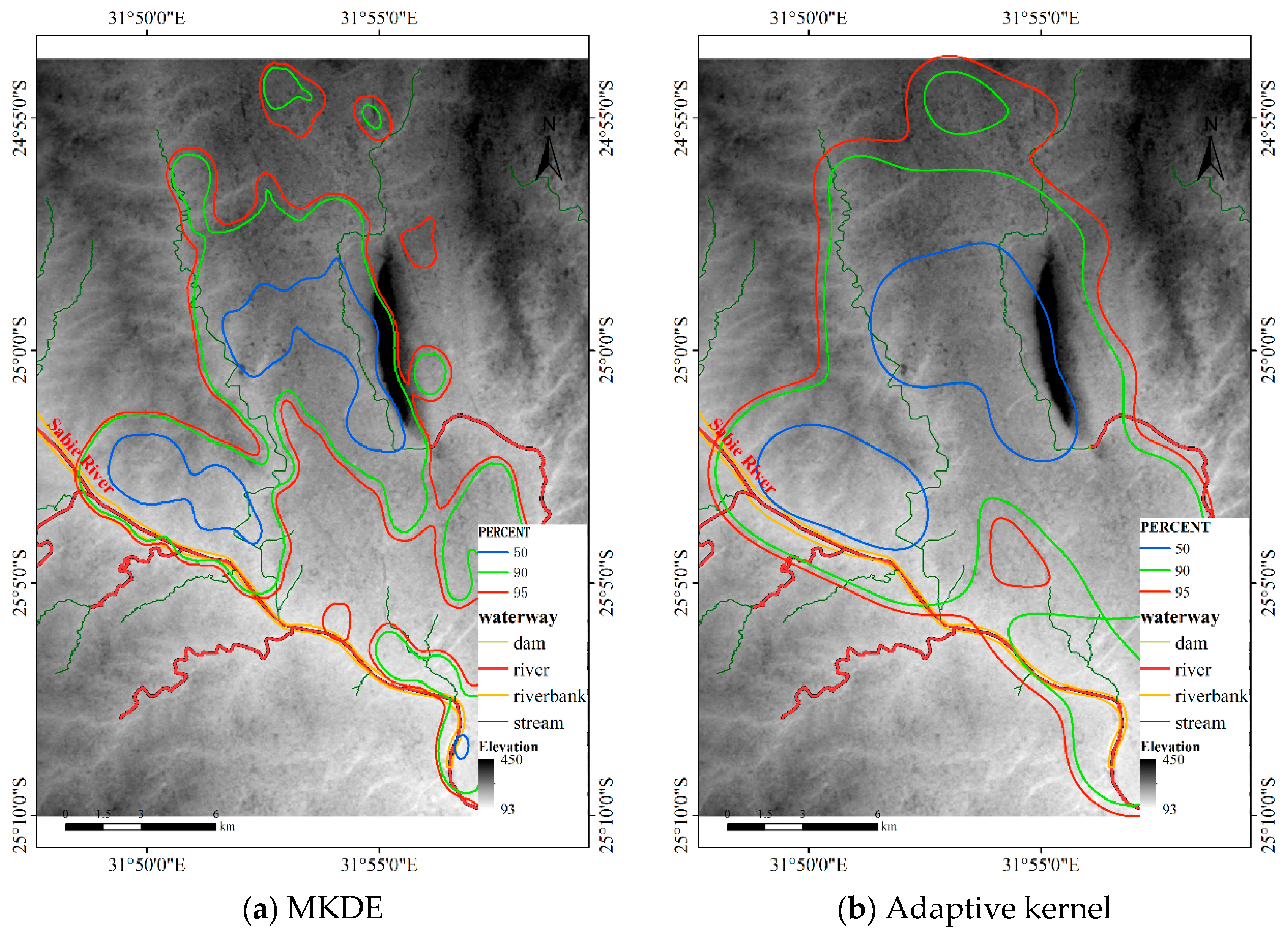
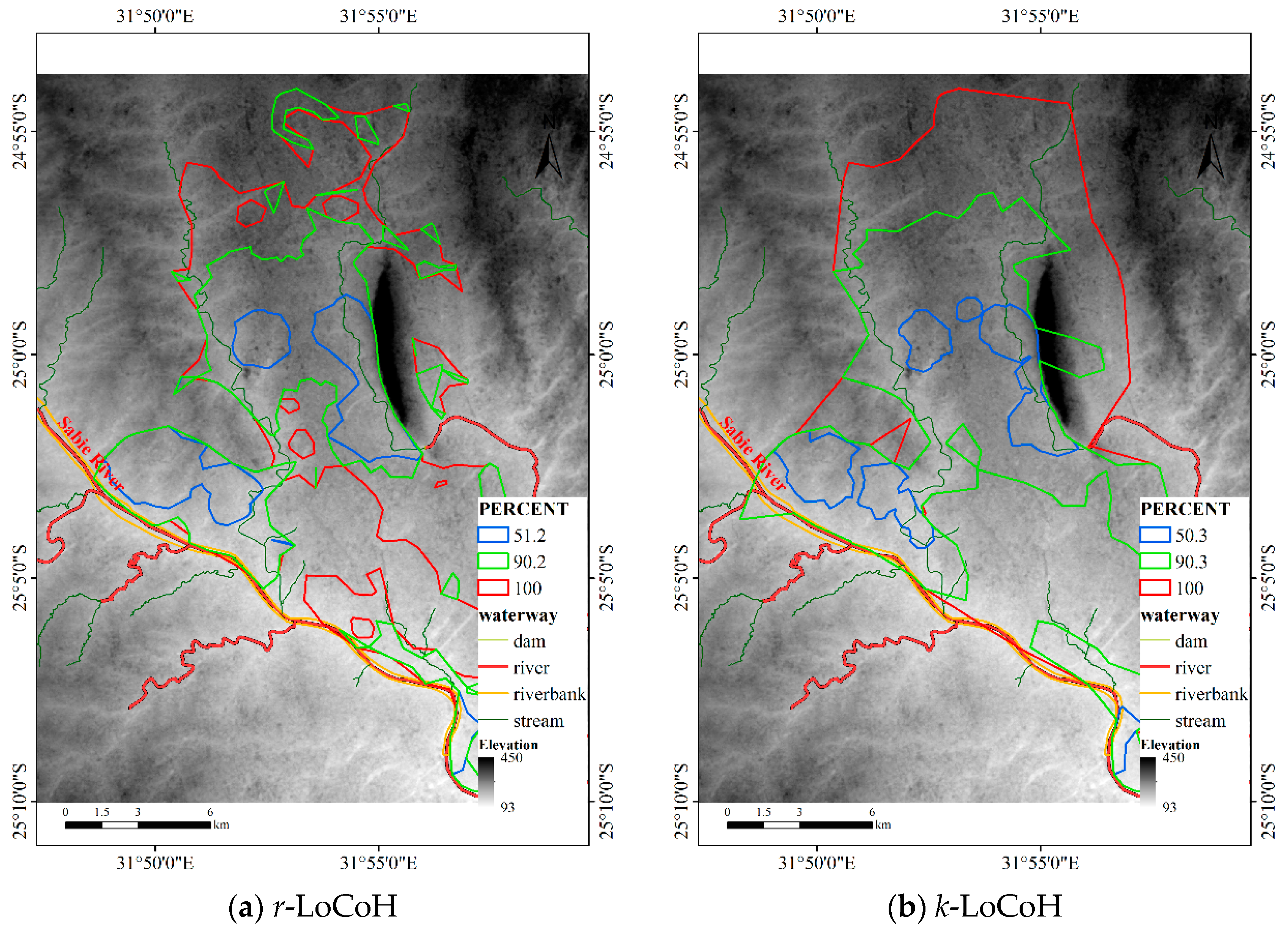
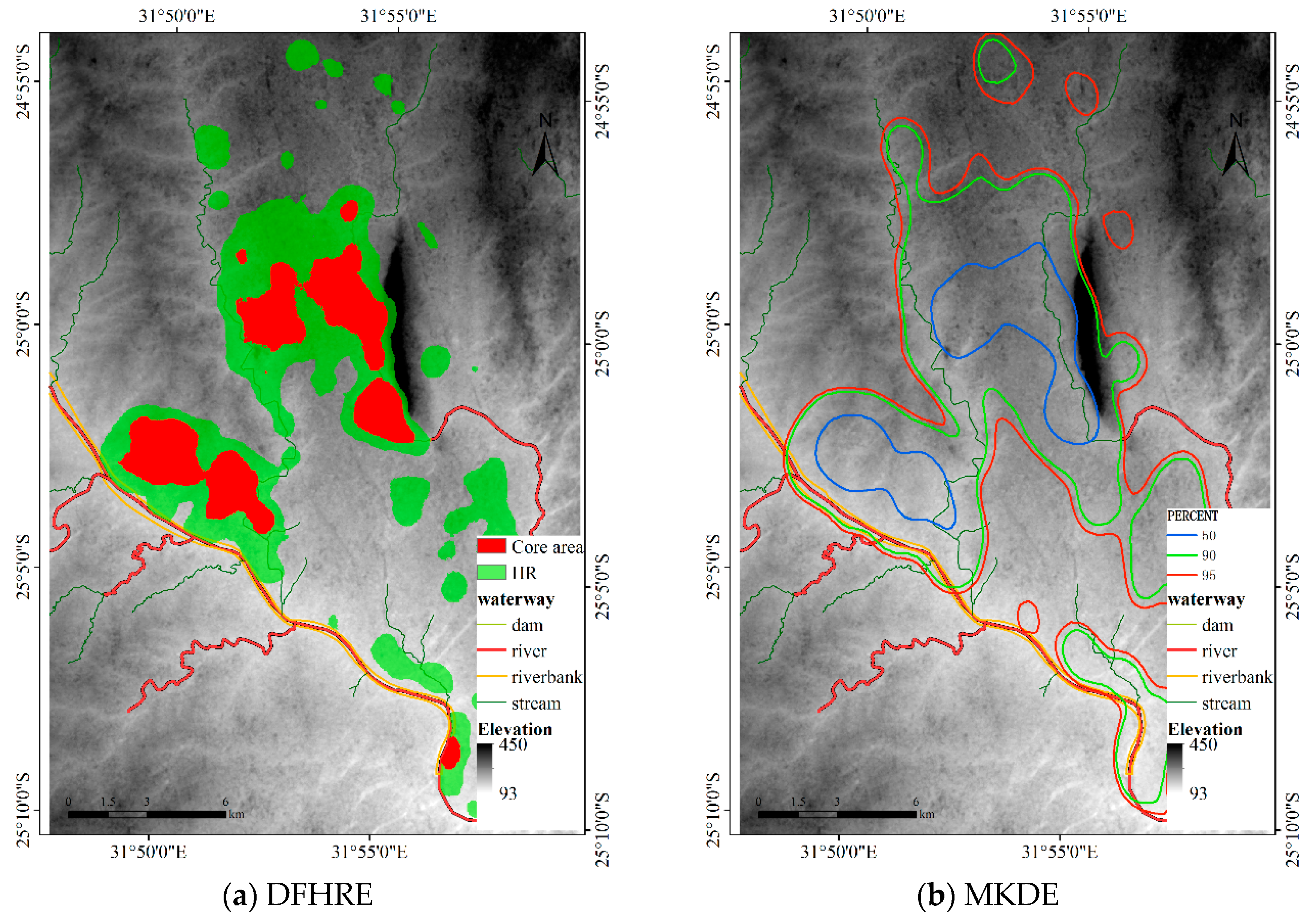
4.1.3. Results for Dataset 3
4.2. Analysis of the DFHRE
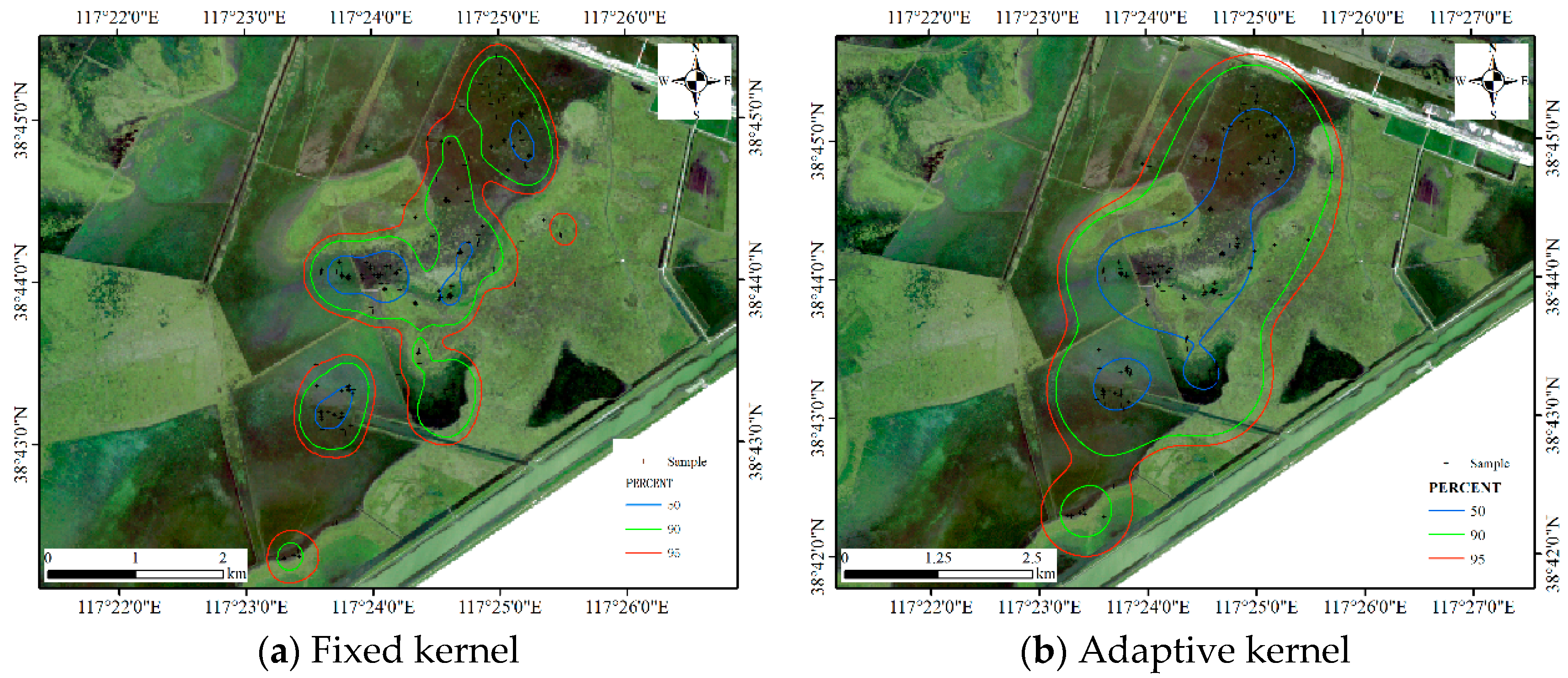
4.3. Comparisons with Other Estimators
4.3.1. Comparison for Dataset 1
4.3.2. Comparison for Dataset 2
4.3.3. Comparison for Dataset 3
4.3.4. Cross Validation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Getz, W.M.; Wilmers, C.C. A local nearest-neighbor convex-hull construction of home ranges and utilization distributions. Ecography 2004, 27, 489–505. [Google Scholar] [CrossRef] [Green Version]
- Burt, W.H. Territoriality and home range concepts as applied to mammals. J. Mammal. 1943, 24, 346–352. [Google Scholar] [CrossRef]
- Yiu, S.; Parrini, F.; Karczmarski, L.; Keith, M. Home range establishment and utilization by reintroduced lions (Panthera leo) in a small South African wildlife reserve. Integr. Zool. 2017, 12, 318–332. [Google Scholar] [CrossRef] [PubMed]
- Fleming, C.H.; Fagan, W.F.; Mueller, T.; Olson, K.A.; Leimgruber, P.; Calabrese, J.M. Rigorous home range estimation with movement data: A new autocorrelated kernel density estimator. Ecology 2015, 96, 1182–1188. [Google Scholar] [CrossRef] [PubMed]
- Schradin, C.; Schmohl, G.; Rödel, H.G.; Schoepf, I.; Treffler, S.M.; Brenner, J.; Bleeker, M.; Schubert, M.; König, B.; Pillay, N. Female home range size is regulated by resource distribution and intraspecific competition: A long-term field study. Anim. Behav. 2010, 79, 195–203. [Google Scholar] [CrossRef]
- Van Beest, F.M.; Rivrud, I.M.; Loe, L.E.; Milner, J.M.; Mysterud, A. What determines variation in home range size across spatiotemporal scales in a large browsing herbivore? J. Anim. Ecol. 2011, 80, 771–785. [Google Scholar] [CrossRef]
- Tuqa, J.H.; Funston, P.; Musyokib, C.; Ojwang, G.O.; Gichuki, N.N.; Bauer, H.; Tamis, W.; Dolrenry, S.; Van‘t Zelfde, M.; de Snoo, G.R.; et al. Impact of severe climate variability on lion home range and movement patterns in the Amboseli ecosystem, Khenya. Glob. Ecol. Conserv. 2014, 2, 1–10. [Google Scholar] [CrossRef]
- Powell, R.A. Animal Home Ranges and Territories and Home Range Estimators. In Research Techniques in Animal Ecology: Controversies and Consequences; Boitani, L., Fuller, T.K., Eds.; Columbia University Press: New York, NY, USA, 2000; pp. 65–110. [Google Scholar]
- Chirima, G.J.; Owen-Smith, N. Comparison of Kernel Density and Local Convex Hull Methods for Assessing Distribution Ranges of Large Mammalian Herbivores. Trans. GIS 2017, 21, 359–375. [Google Scholar] [CrossRef]
- Row, J.R.; Blouin-Demers, G. Kernels are not accurate estimators of home-range size for herpetofauna. Copeia 2006, 4, 797–802. [Google Scholar] [CrossRef]
- Nilsen, E.B.; Pedersen, S.; Linnell, J.D.C. Can minimum convex polygon home ranges be used to draw biologically meaningful conclusions? Ecol. Res. 2008, 23, 635–639. [Google Scholar] [CrossRef]
- Downs, J.A.; Horner, M.W. A Characteristic-Hull Based Method for Home Range Estimation. Trans. GIS 2009, 13, 527–537. [Google Scholar] [CrossRef]
- Worton, B.J. Kernel methods for estimating the utilization distribution in home-range studies. Ecology 1989, 70, 164–168. [Google Scholar] [CrossRef]
- Ostro, L.E.T.; Young, T.P.; Silver, S.C.; Koontz, F.W. A geographic information system method for estimating home range size. J. Wildl. Manag. 1999, 63, 748–755. [Google Scholar] [CrossRef]
- Getz, W.M.; Fortmann-Roe, S.; Cross, P.C.; Lyons, A.J.; Ryan, S.J.; Wilmers, C.C. LoCoH: Non-parametric kernel methods for constructing home ranges and utilization distributions. PLoS ONE 2007, 2, e207. [Google Scholar] [CrossRef]
- Horne, J.S.; Garton, E.O.; Krone, S.M.; Lewis, J.S. Analyzing animal movements using Brownian bridges. Ecology 2007, 88, 2354–2363. [Google Scholar] [CrossRef]
- Wells, A.G.; Blair, C.C.; Garton, E.O.; Rice, C.G.; Horne, J.S.; Rachlow, J.L.; Wallin, D.O. The Brownian bridge synoptic model of habitat selection and space use for animals using GPS telemetry data. Ecol. Model. 2014, 273, 242–250. [Google Scholar] [CrossRef]
- Long, J.A.; Nelson, T.A. Time Geography and Wildlife Home Range Delineation. J. Wildl. Manag. 2012, 76, 407–413. [Google Scholar] [CrossRef]
- Long, J.A. Modeling movement probabilities within heterogeneous spatial fields. J. Spat. Inf. Sci. 2018, 16, 85–116. [Google Scholar] [CrossRef]
- Kranstauber, B. Modelling animal movement as Brownian bridges with covariates. Mov. Ecol. 2019, 7, 22. [Google Scholar] [CrossRef]
- Péron, G. Modified home range kernel density estimators that take environmental interactions into account. Mov. Ecol. 2019, 7, 16. [Google Scholar] [CrossRef] [Green Version]
- Zadeh, L.A. Fuzzy sets as a basis for a theory of possibility. Fuzzy Sets Syst. 1978, 1, 3–28. [Google Scholar] [CrossRef]
- Drakopoulos, J.A. Probabilities, possibilities, and fuzzy sets. Fuzzy Sets Syst. 1995, 75, 1–15. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H.; Sandri, S. On Possibility/Probability Transformations. In Fuzzy Logic; Lowen, R., Roubens, M., Eds.; Springer: Dordrecht, The Netherlands, 1993; pp. 103–112. [Google Scholar]
- Shouraki, S.B.; Honda, N. Recursive fuzzy modeling based on fuzzy interpolation. J. Adv. Comput. Intell. 1999, 3, 114–125. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; Miao, L.; Xie, G.; Yuan, F. A Comparison of Autumn Habitat Selection of Cervus nippon and Sus scrofa in Taohongling National Nature Reserve, China. Sichuan J. Zool. 2015, 34, 300–305. [Google Scholar]
- Zhang, S.; Guo, R.; Liu, W.; Weng, D.; Cheng, Z. Research Progress and Prospect of Cervus nippon kopschi. J. Zhejiang For. Sci. Technol. 2016, 36, 90–94. [Google Scholar]
- Calabrese, J.M.; Fleming, C.H.; Gurarie, E. ctmm: An R package for analyzing animal relocation data as a continuous-time stochastic process. Methods Ecol. Evol. 2016, 7, 1124–1132. [Google Scholar] [CrossRef]
- Yang, C.; Hu, H.; Hu, P.; Cao, F. Solution of Euclidean Shortest Path Problem Space with Obstacles. Geomat. Inf. Sci. Wuhan Univers. 2012, 37, 1495–1499. [Google Scholar]
- Lele, S.R.; Keim, L.L. Weighted distributions and estimation of resource selection probability functions. Ecology 2006, 87, 3021–3028. [Google Scholar] [CrossRef]
- Horne, J.S.; Garton, E.O.; Rachlow, J.L. A synoptic model of animal space use: Simultaneous estimation of home range, habitat selection, and inter/intra-specific relationships. Ecol. Model. 2008, 214, 338–348. [Google Scholar] [CrossRef]
- Merrikh-Bayat, F.; Shouraki, S.B. The neuro-fuzzy computing system with the capacity of implementation on a memristor crossbar and optimization-free hardware training. IEEE Trans. Fuzzy Syst. 2014, 22, 1272–1287. [Google Scholar] [CrossRef]
- Javadian, M.; Shouraki, S.; Kourabbaslou, S.S. A novel density-based fuzzy clustering algorithm for low dimensional feature space. Fuzzy Sets Syst. 2017, 318, 34–55. [Google Scholar] [CrossRef]
- Adriaensen, F.; Chardon, J.P.; De Blust, G.; Swinnen, E.; Villalba, S.; Gulinck, H.; Matthysn, E. The application of ‘least-cost’ modelling as a functional landscape model. Landsc. Urban Plan. 2003, 64, 233–247. [Google Scholar] [CrossRef]
- Becker, D.; de Andrés-Herrero, M.; Willmes, C.; Weniger, G.; Bareth, G. Investigating the Influence of Different DEMs on GIS-Based Cost Distance Modeling for Site Catchment Analysis of Prehistoric Sites in Andalusia. ISPRS Int. J. Geo-Inf. 2017, 6, 36. [Google Scholar] [CrossRef]
- Downs, J.A.; Heller, J.H.; Loraamm, R.; Stein, D.O.; McDaniel, C.; Onorato, D. Accuracy of home range estimators for homogeneous and inhomogeneous point patterns. Ecol. Model. 2012, 225, 66–73. [Google Scholar] [CrossRef]
- Downs, J.A.; Horner, M.W.; Tucker, A.D. Time-geographic density estimation for home range analysis. Ann. GIS 2011, 17, 163–171. [Google Scholar] [CrossRef]
- Steiniger, S.; Hunter, A.J.S. OpenJUMP HoRAE—A free GIS and Toolbox for Home-Range Analysis. Wildl. Soc. Bull. 2012, 36, 600–608. [Google Scholar] [CrossRef]
- Berger, K.M.; Gese, E.M. Does interference competition with wolves limit the distribution and abundance of coyotes? J. Anim. Ecol. 2007, 76, 1075–1085. [Google Scholar] [CrossRef] [Green Version]
- Chacón, J.E.; Duong, T. Multivariate plug-in bandwidth selection with unconstrained pilot bandwidth matrices. Test 2010, 19, 375–398. [Google Scholar] [CrossRef]
- Chacón, J.E.; Duong, T. Multivariate Kernel Smoothing and Its Applications; Chapman & Hall: Boca Raton, FL, USA, 2018. [Google Scholar]
- Rodgers, A.R.; Kie, J.G.; Wright, D.; Beyer, H.L.; Carr, A.P. HRT: Home Range Tools for ArcGIS. Version 2.0; Ontario Ministry of Natural Resources and Forestry, Centre for Northern Forest Ecosystem Research: Thunder Bay, ON, Canada, 2015.
- Geotools. Available online: https://geotools.org/ (accessed on 19 February 2018).
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Core Area (m2) | HR (m2) |
|---|---|---|
| DFHRE | 754,400 | 4,124,000 |
| Fixed kernel | 738,432 | 42,23,832 |
| Adaptive kernel | 4,340,866 | 12,513,091 |
| r-LoCoH (r = 500) | 723,752 | 2,118,506 |
| k-LoCoH (k = 16) | 247,620 | 1,736,049 |
| Isopleth | Core Area (m2) | HR (m2) |
|---|---|---|
| DFHRE | 813,750 | 366,8125 |
| Fixed kernel | 1,251,385 | 7,339,245 |
| Adaptive kernel | 1,544,052 | 6,826,268 |
| r-LoCoH (r = 500) | 868,200 | 2,655,871 |
| k-LoCoH (k = 16) | 682,955 | 3,524,019 |
| Isopleth | Core Area (m2) | HR (m2) |
|---|---|---|
| DFHRE | 29,290,500 | 101,241,000 |
| Fixed kernel | 31,807,074 | 124,029,946 |
| Adaptive kernel | 60,533,862 | 232,011,617 |
| r-LoCoH (r = 1000) | 32,101,265 | 90,196,218 |
| k-LoCoH (k = 59) | 26,282,337 | 126,126,900 |
| Data | Method | Core | HR | ||||
|---|---|---|---|---|---|---|---|
| Full (m2) | Half (m2) | Reduction (%) | Full (m2) | Half (m2) | Reduction (%) | ||
| Dataset 1 | DFHRE | 754,400 | 711,200 | 5.73% | 4,124,000 | 3,479,600 | 15.63% |
| MKDE | 738,432 | 940,039 | −27.30% | 4,223,832 | 5,313,703 | −25.80% | |
| k-LoCoH | 247,620 | 327,806 | −32.38% | 1,736,049 | 1,890,265 | −8.88% | |
| Dataset 2 | DFHRE | 813,750 | 808,750 | 0.61% | 3,668,125 | 3,211,250 | 12.46% |
| MKDE | 1251,385 | 1,529,783 | −22.25% | 7,339,245 | 8,027,278 | −9.37% | |
| k-LoCoH | 682,955 | 639,636 | 6.34% | 3,524,019 | 2,834,798 | 19.56% | |
| Dataset 3 | DFHRE | 29,290,500 | 27,856,800 | 4.89% | 101,241,000 | 95,163,300 | 6.00% |
| MKDE | 31,807,074 | 33,326,862 | −4.78% | 124,029,946 | 134,312,919 | −8.29% | |
| k-LoCoH | 26,282,337 | 26,145,740 | 0.52% | 126,126,900 | 124,467,800 | 1.32% | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Du, S.; Ma, Z.; Huo, H.; Peng, G. A Model for Animal Home Range Estimation Based on the Active Learning Method. ISPRS Int. J. Geo-Inf. 2019, 8, 490. https://doi.org/10.3390/ijgi8110490
Guo J, Du S, Ma Z, Huo H, Peng G. A Model for Animal Home Range Estimation Based on the Active Learning Method. ISPRS International Journal of Geo-Information. 2019; 8(11):490. https://doi.org/10.3390/ijgi8110490
Chicago/Turabian StyleGuo, Jifa, Shihong Du, Zhenxing Ma, Hongyuan Huo, and Guangxiong Peng. 2019. "A Model for Animal Home Range Estimation Based on the Active Learning Method" ISPRS International Journal of Geo-Information 8, no. 11: 490. https://doi.org/10.3390/ijgi8110490
APA StyleGuo, J., Du, S., Ma, Z., Huo, H., & Peng, G. (2019). A Model for Animal Home Range Estimation Based on the Active Learning Method. ISPRS International Journal of Geo-Information, 8(11), 490. https://doi.org/10.3390/ijgi8110490