Urban Parcel Grouping Method Based on Urban Form and Functional Connectivity Characterisation

Abstract
:1. Introduction
2. Related Work
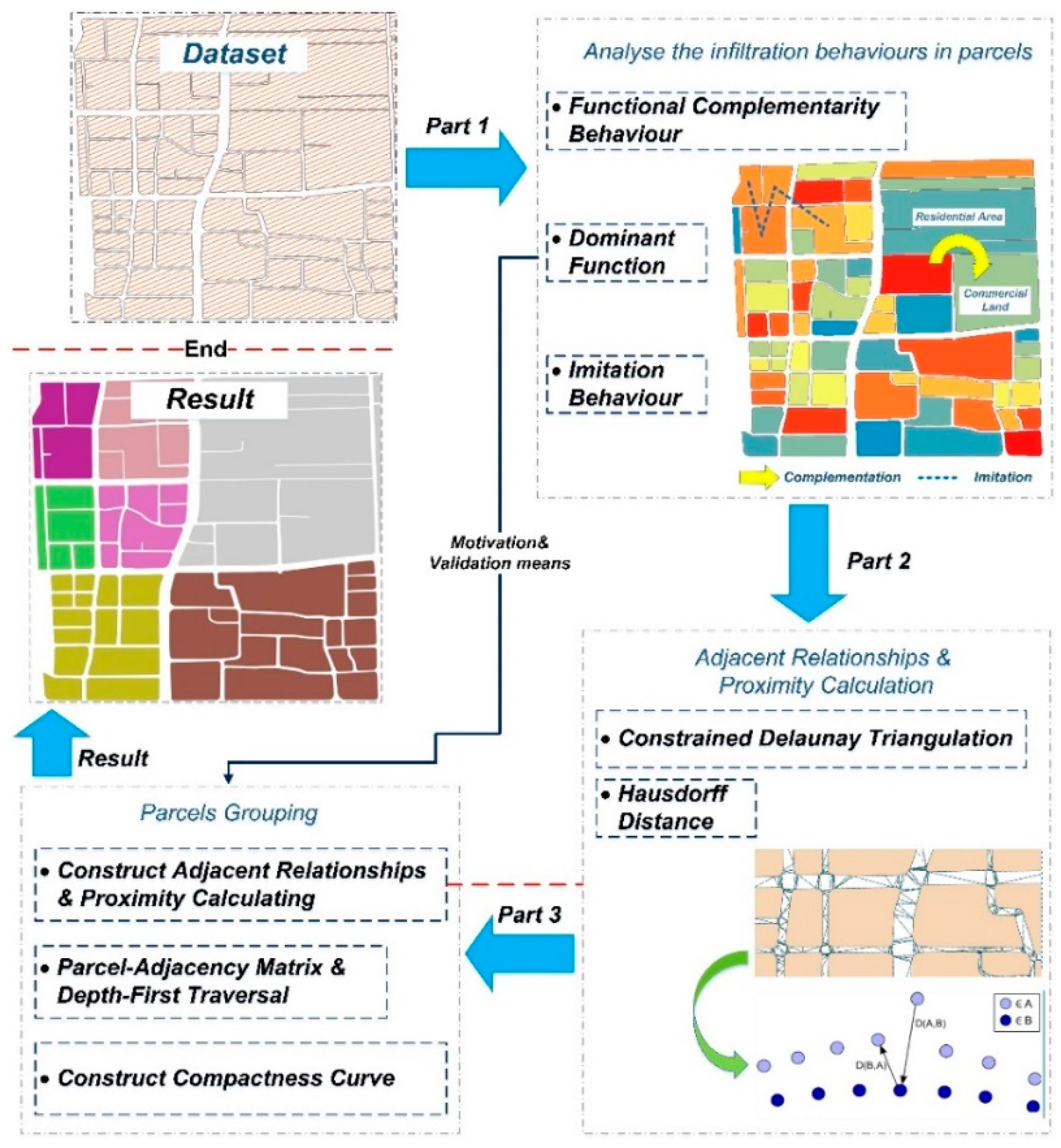
3. Materials and Methods
3.1. Study Area and Data Source
3.1.1. Study Area
3.1.2. Experimental Urban Parcel Datasets and Environment
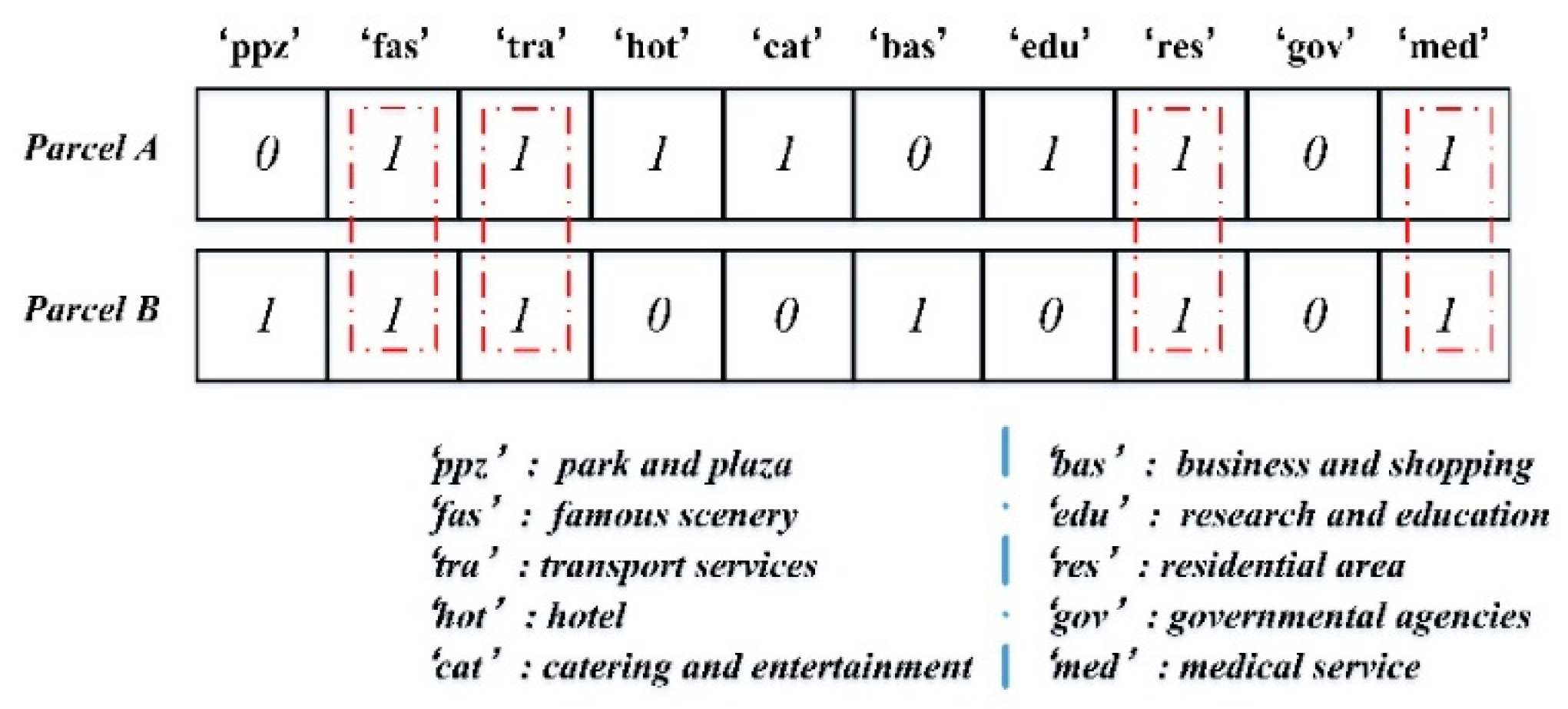
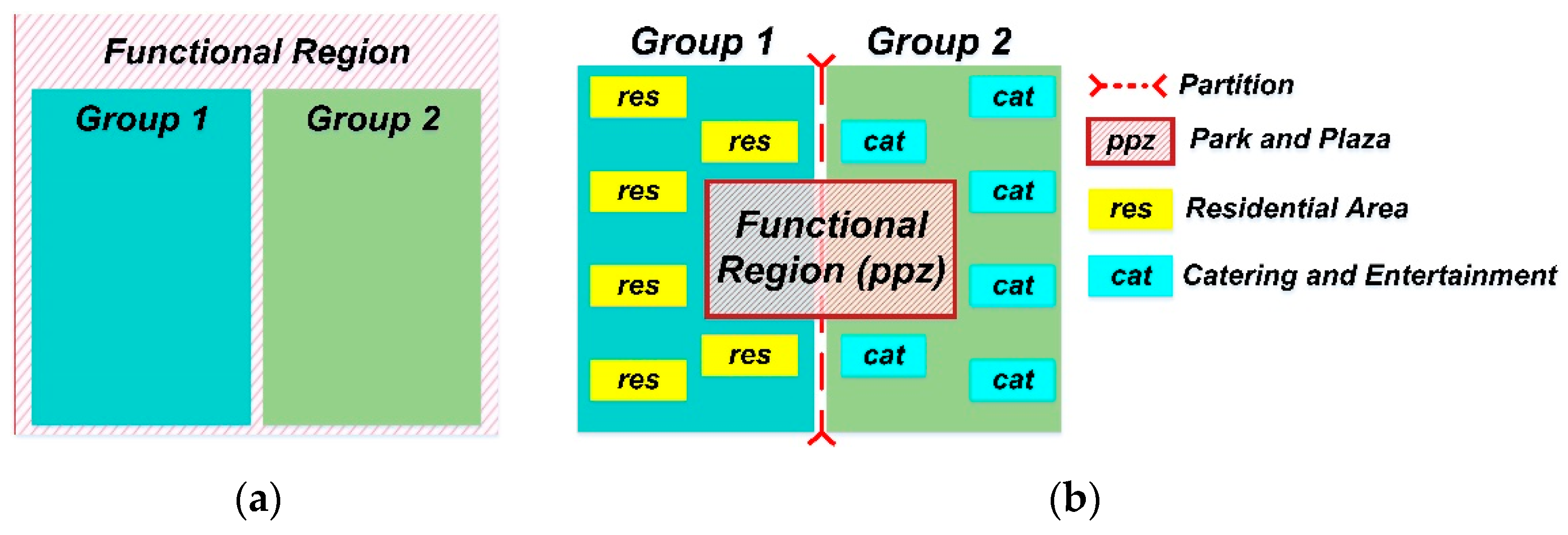
3.2. Infiltration Behaviours of Components among Urban Parcels
3.3. Expression and Establishment of Adjacent Parcel Relationship
3.3.1. Identification of Adjacent Relationships among Parcels
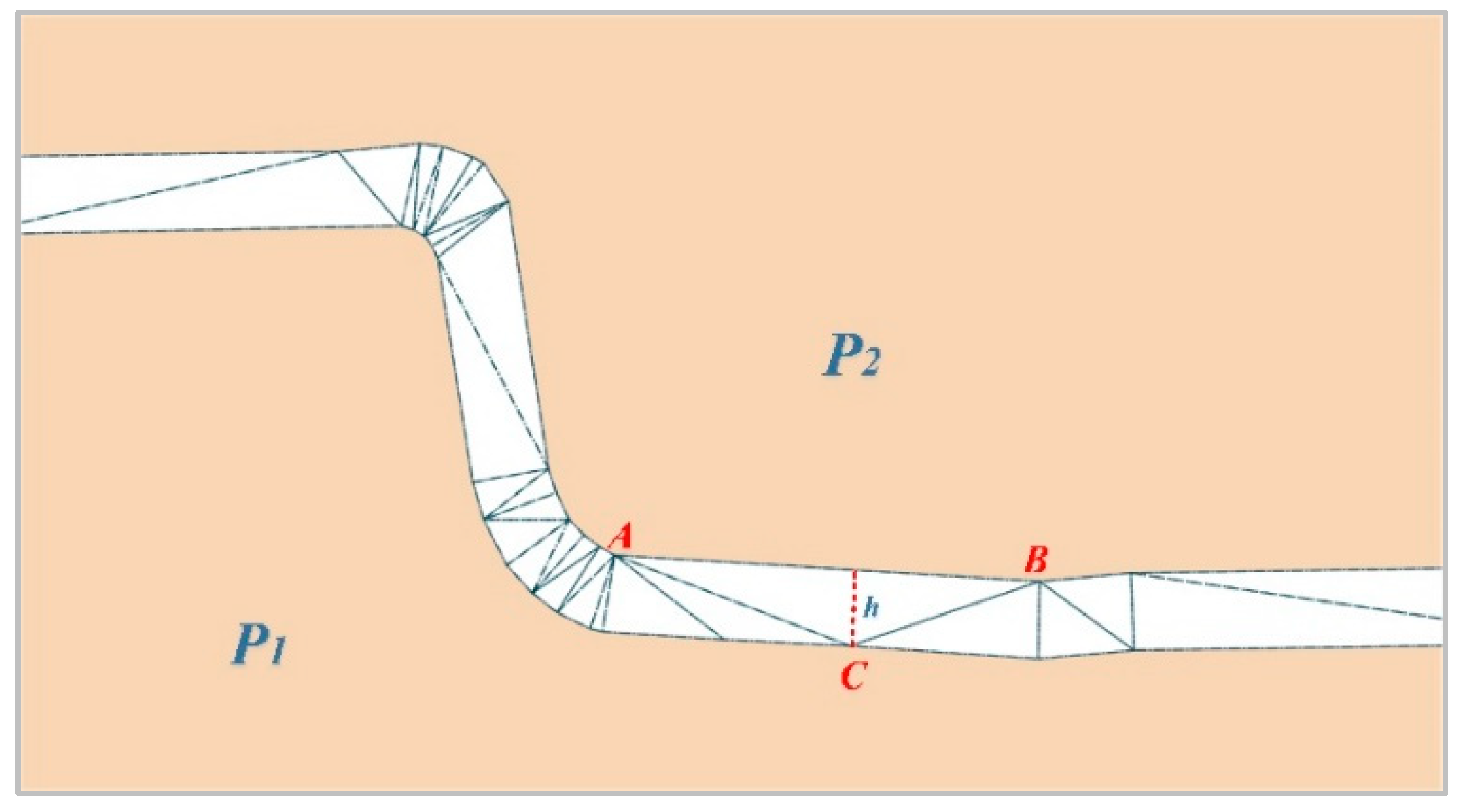
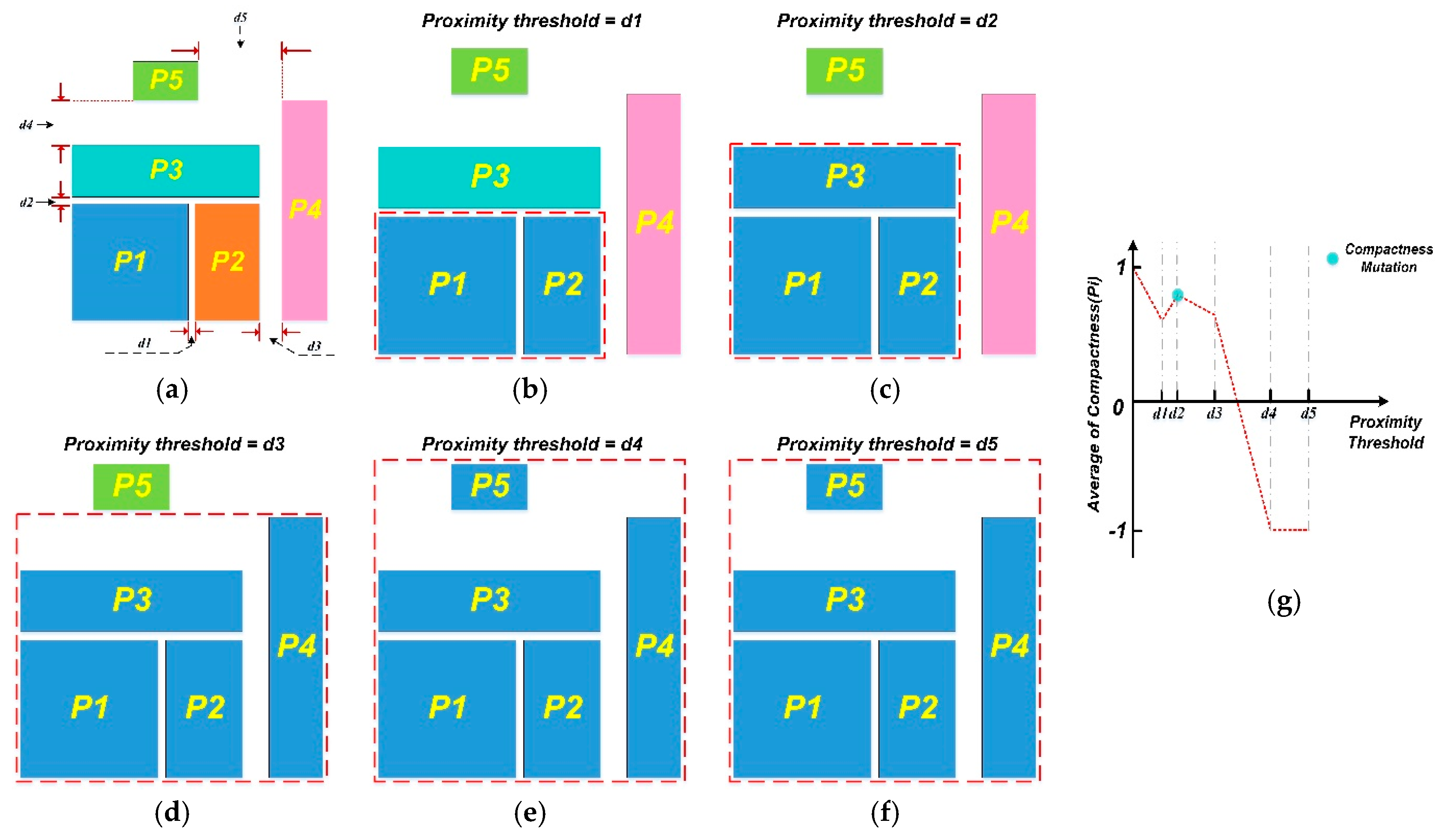
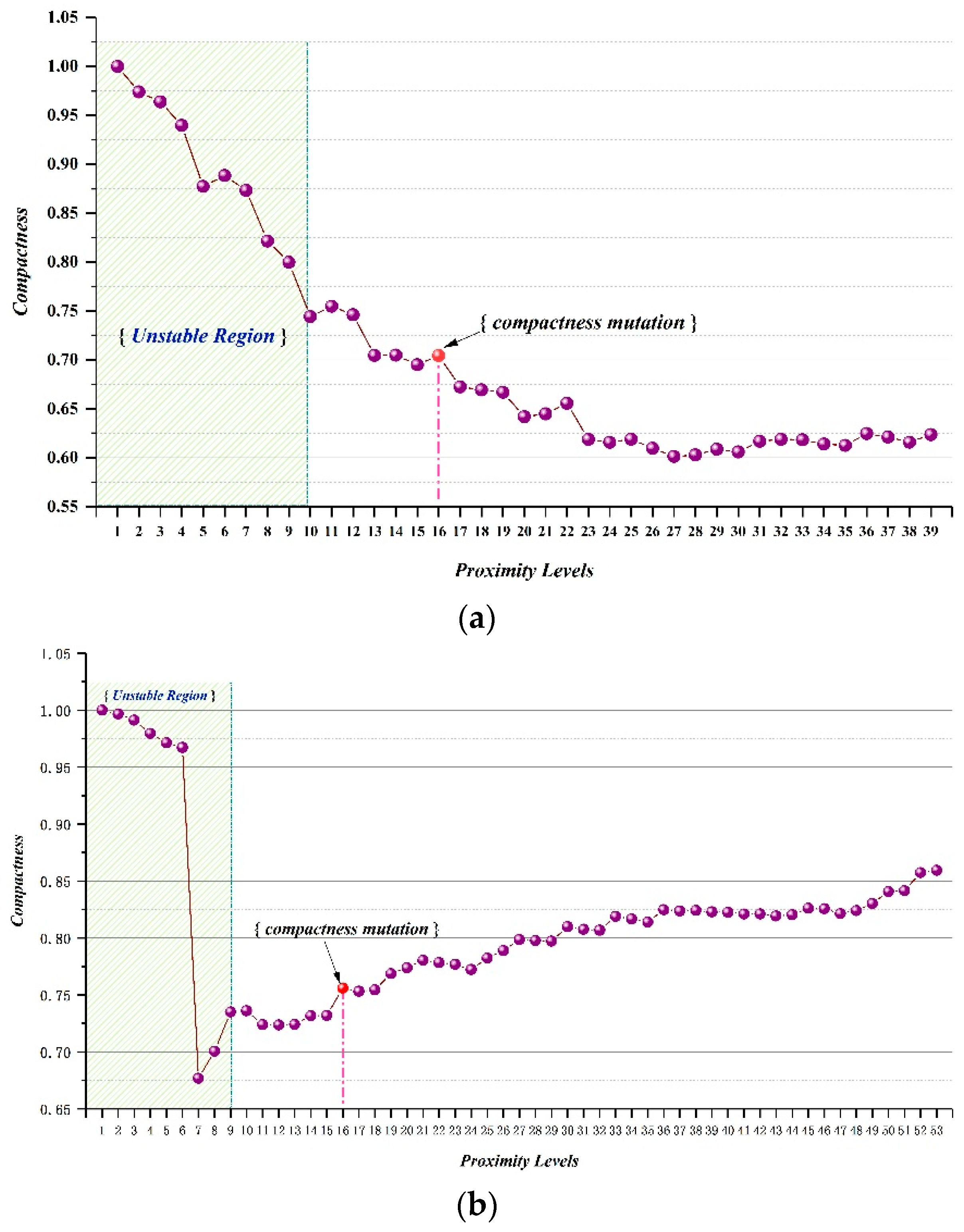
3.3.2. Method for Measuring the Proximity of Parcels
3.4. Urban Parcel Grouping Method
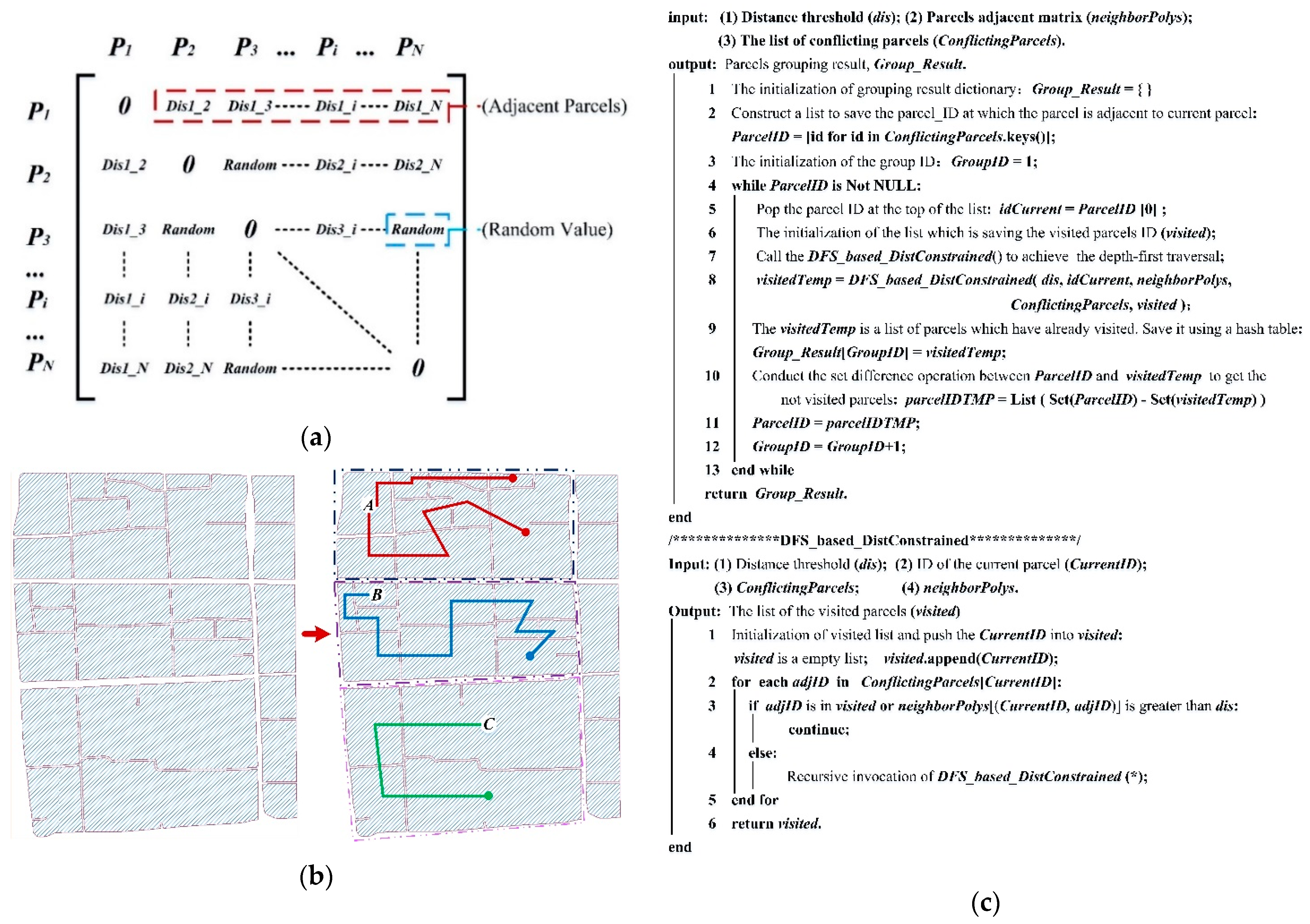
3.4.1. Description of Urban Parcel Grouping (UPG) Algorithm
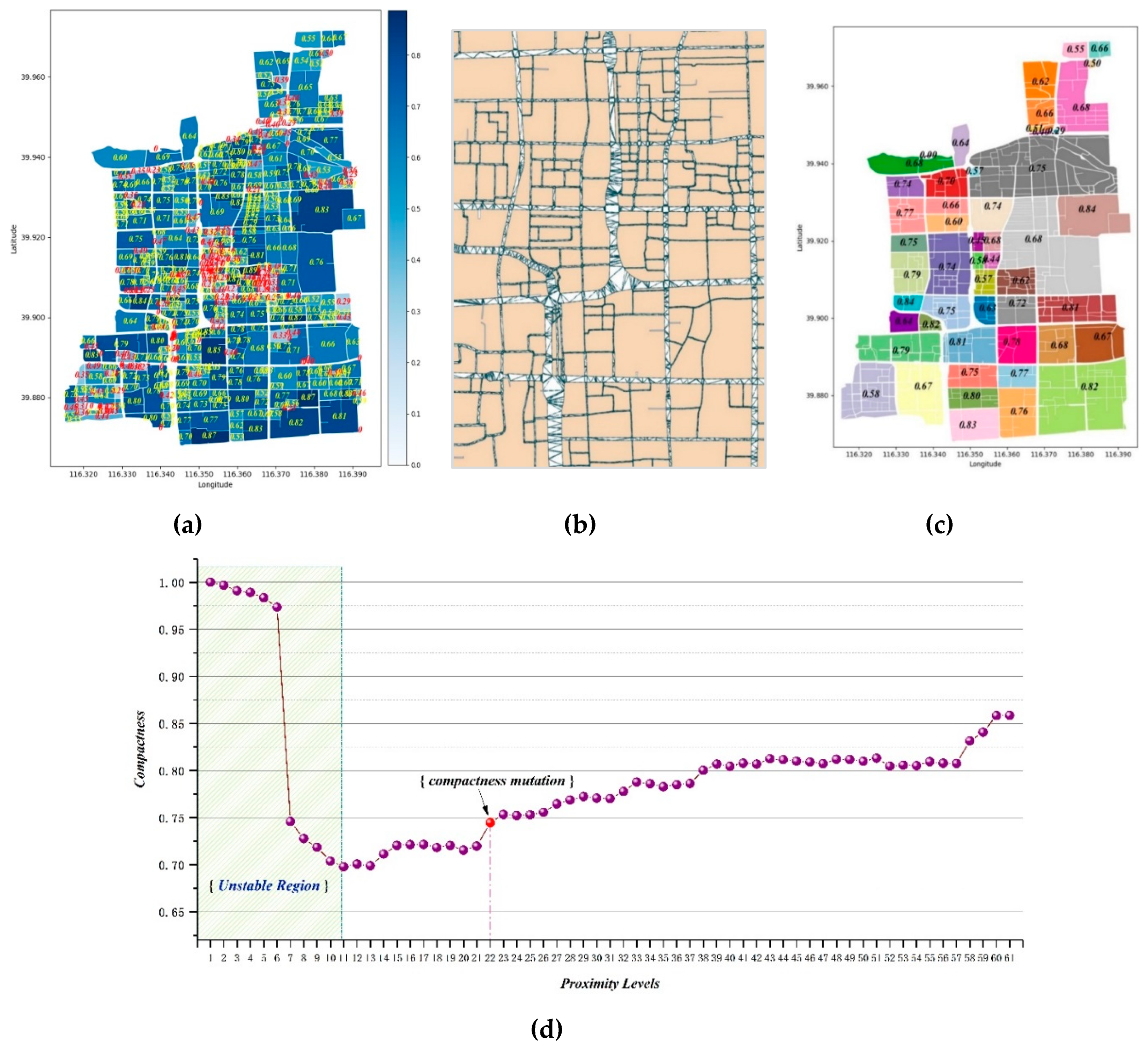
3.4.2. Method of Obtaining the Optimum Grouping Result
4. Results
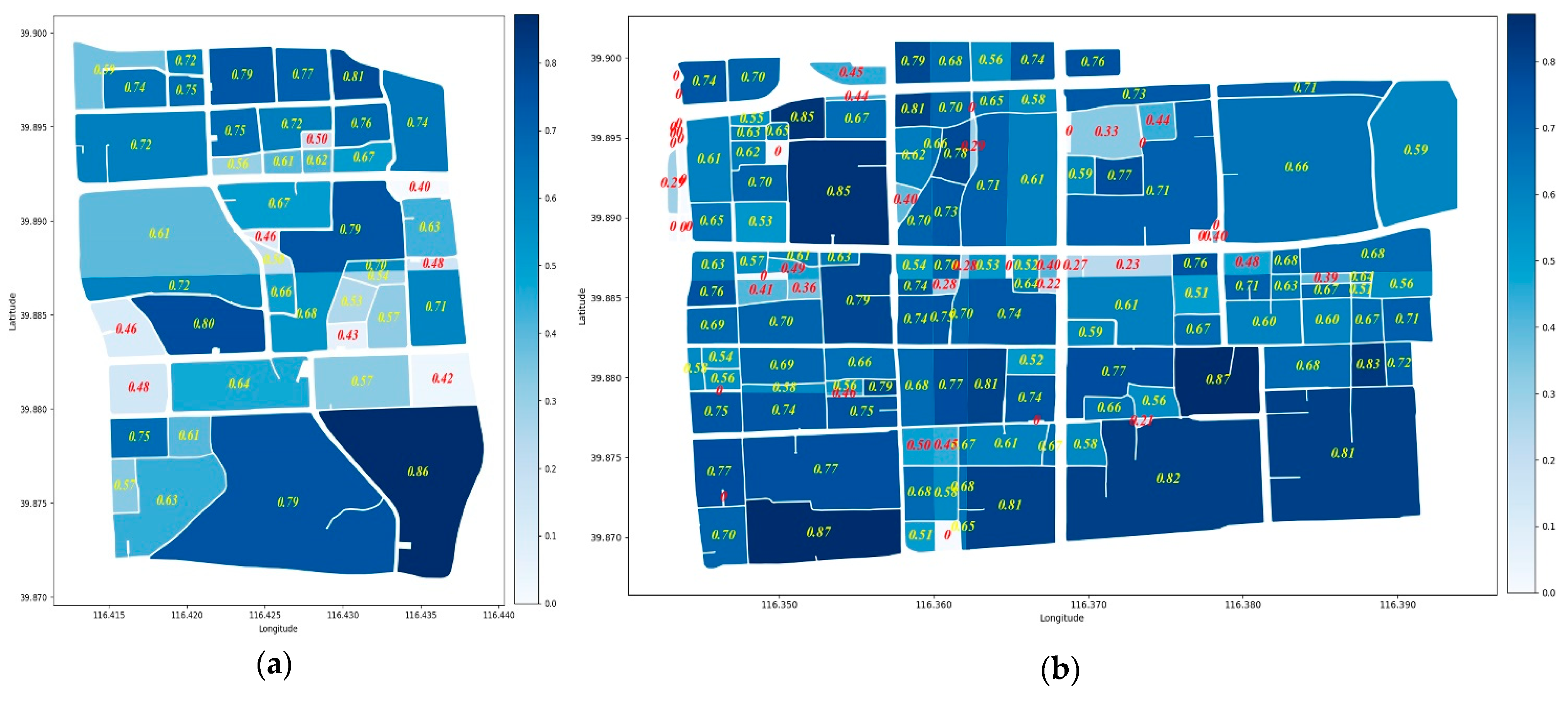
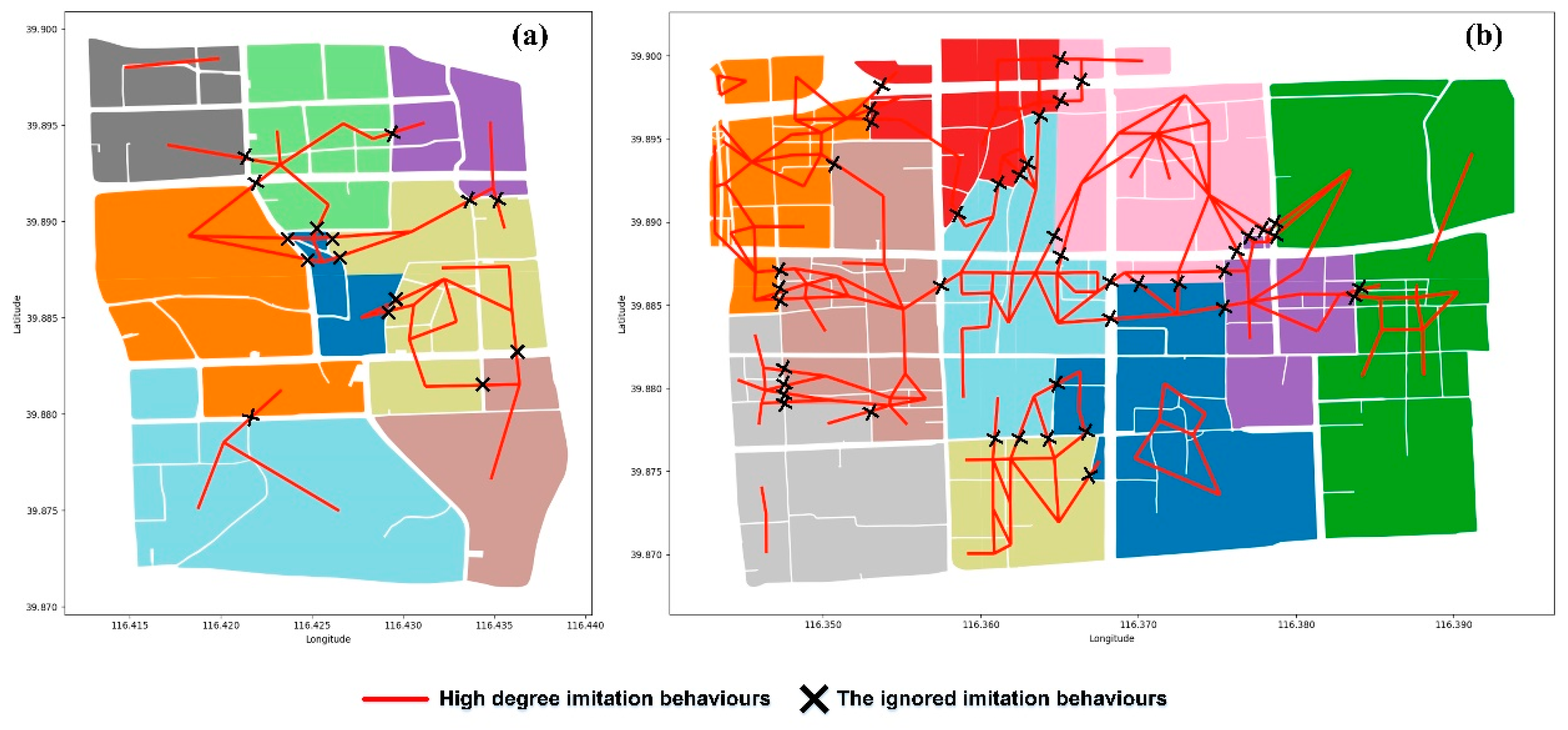
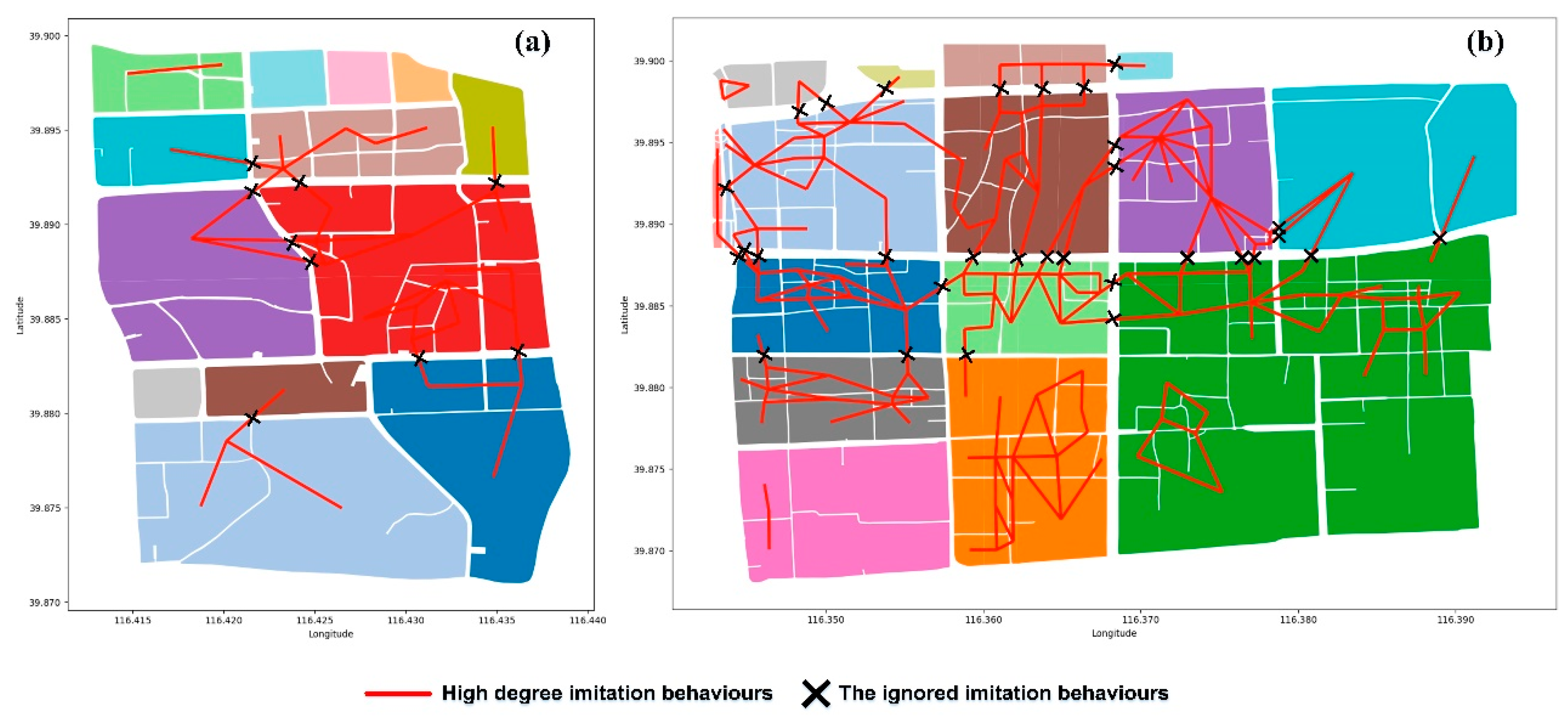
4.1. Analysis of Infiltration Behaviour
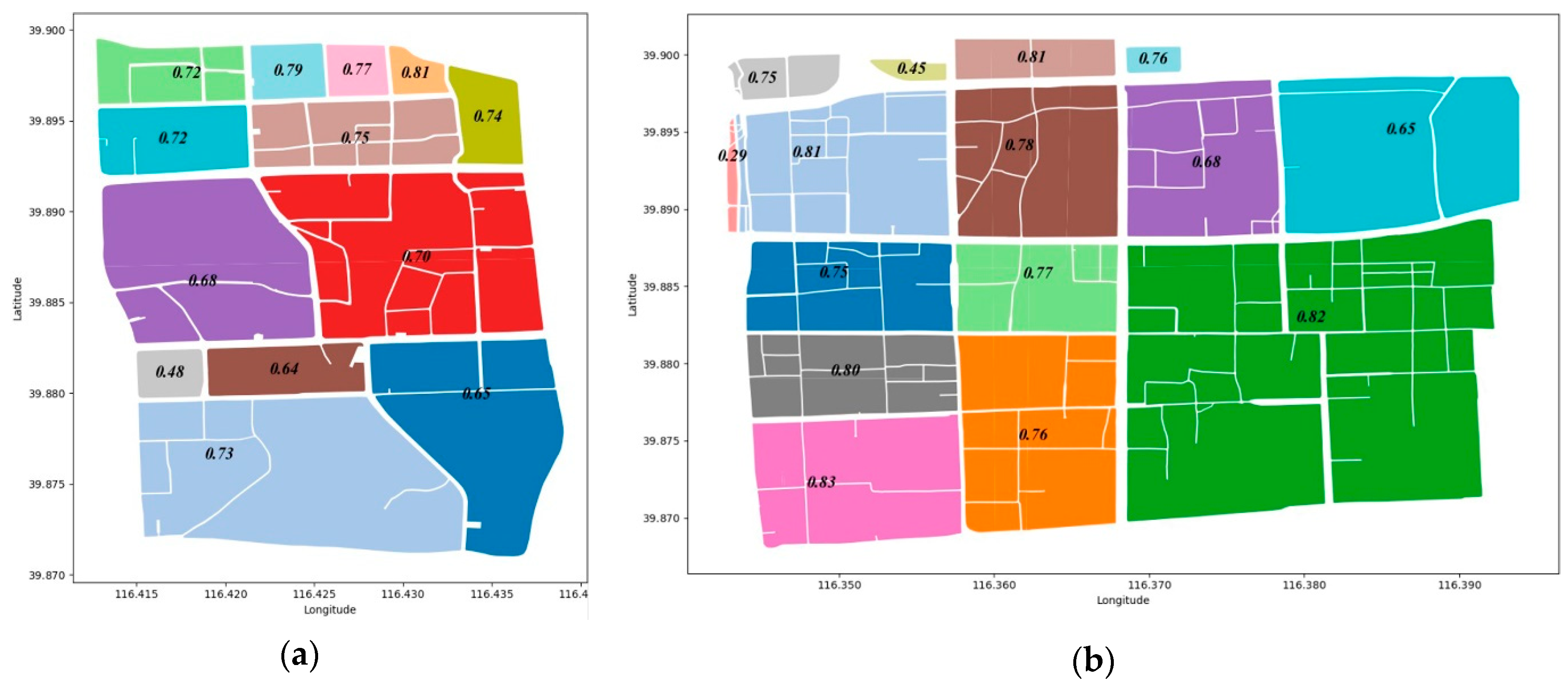
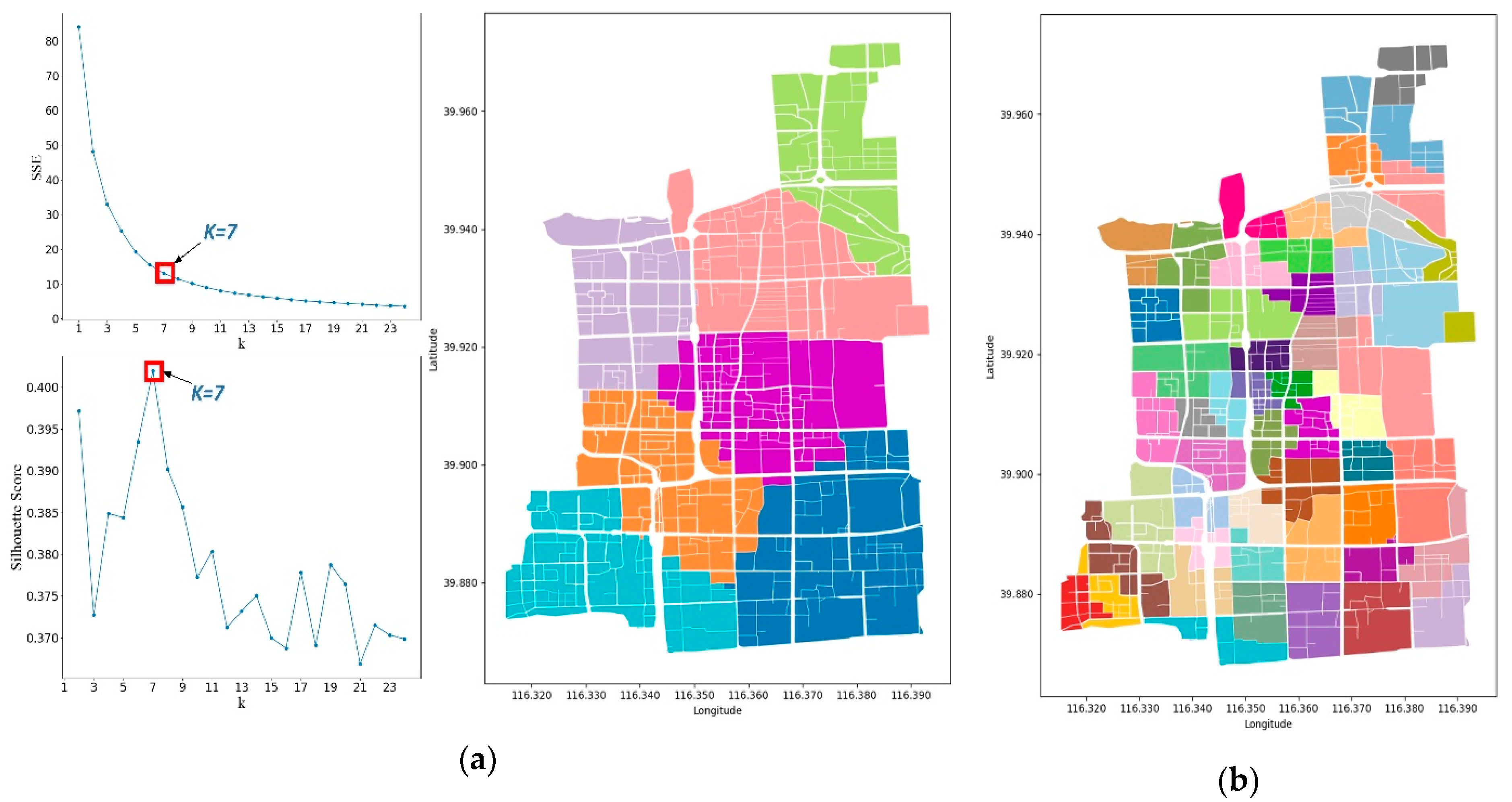
4.2. Results of Urban Parcel grouping Method
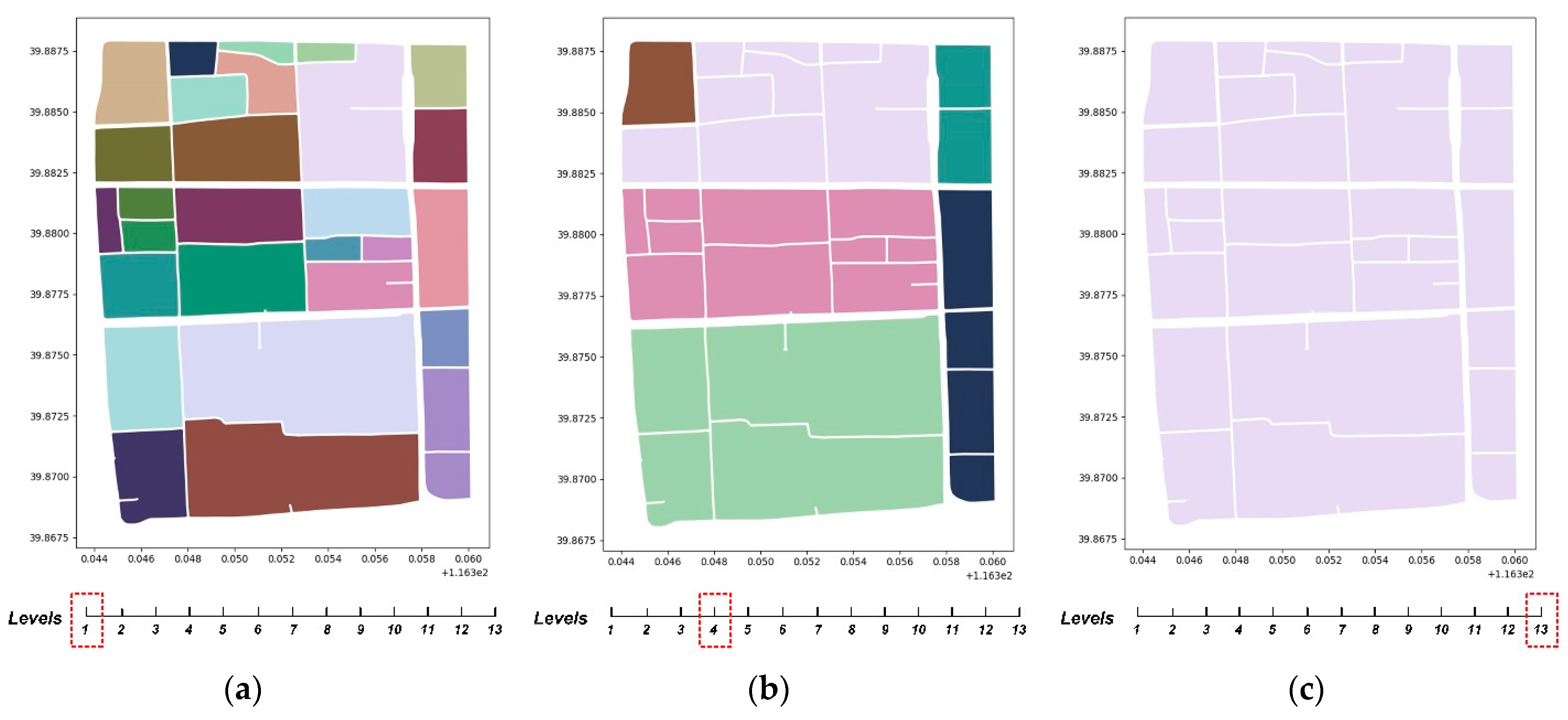
4.2.1. Parcel grouping Method Based on the Centroid Proximity
4.2.2. Analysis of the UPG Method
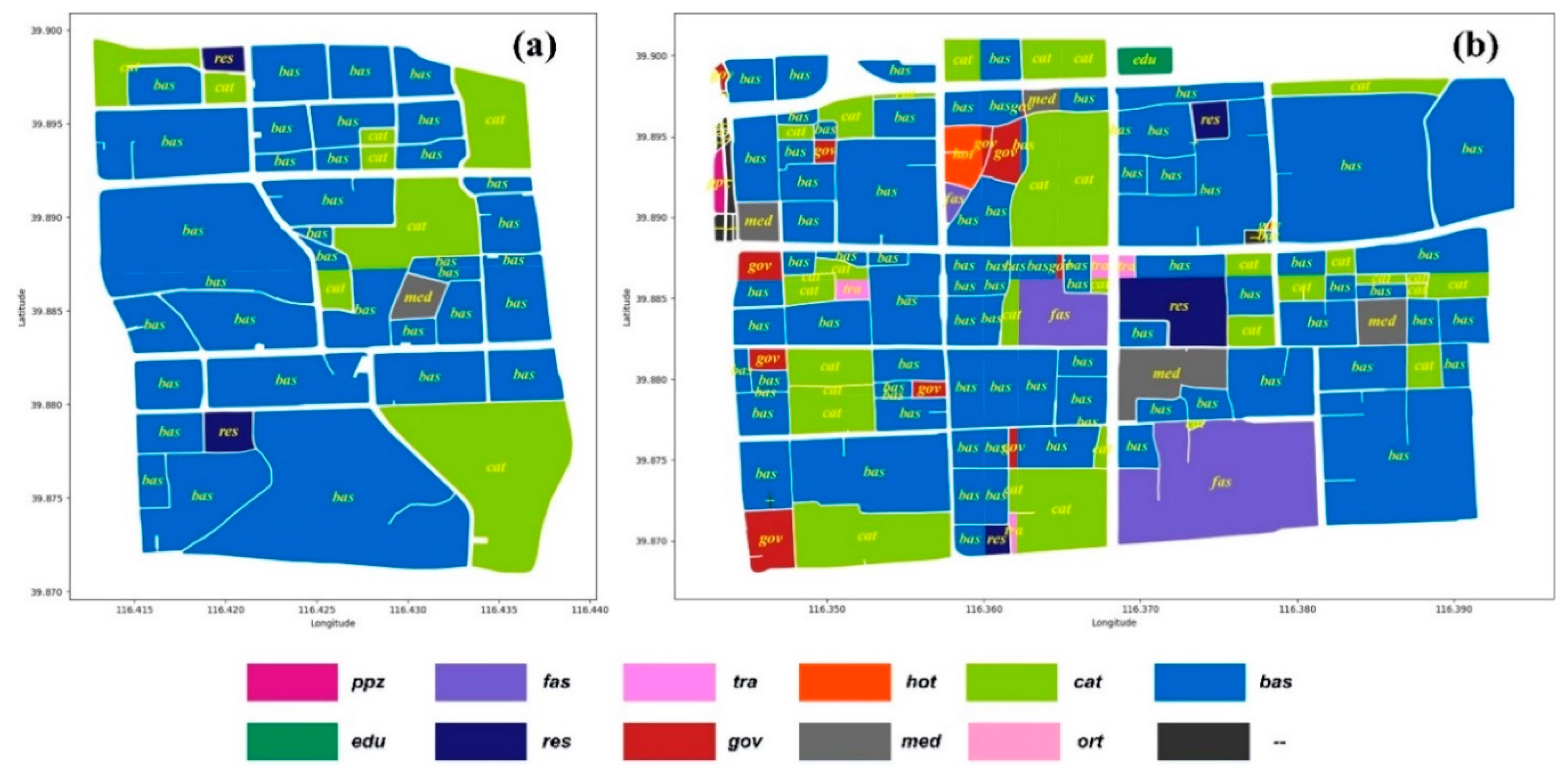
4.3. Practical Application of the UPG
5. Discussion
6. Conclusions and Further Research
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liu, X.; Long, Y. Automated identification and characterization of parcels with OpenStreetMap and points of interest. Environ. Plan. B Plan. Des. 2015, 43, 341–360. [Google Scholar] [CrossRef]
- Krier, R. Town Spaces: Contemporary Interpretations in Traditional Urbanism: Krier-Kohl-Architects; Birkhauser: Basel, Switzerland, 2006; pp. 8–18. [Google Scholar]
- Cheng, J.; Turkstra, J.; Peng, M.; Du, N.; Ho, P. Urban land administration and planning in China: Opportunities and constraints of spatial data models. Land Use Policy 2006, 23, 604–616. [Google Scholar] [CrossRef]
- Stevens, D.; Dragicevic, S. A GIS-based irregular cellular automata model of land-use change. Environ. Plan. B Plan. Des. 2007, 34, 708–724. [Google Scholar] [CrossRef]
- Pinto, N.N.; Antunes, A.P. A cellular automata model based on irregular cells: Application to small urban areas. Environ. Plan. B Plan. Des. 2010, 37, 1095–1114. [Google Scholar] [CrossRef]
- Frank, L.D.; Sallis, J.F.; Conway, T.L.; Chapman, J.E.; Saelens, B.E.; Bachman, W. Many pathways from land use to health: Associations between neighborhood walkability and active transportation, body mass index, and air quality. J. Am. Plan. Assoc. 2006, 72, 75–87. [Google Scholar] [CrossRef]
- Jabareen, Y.R. Sustainable urban forms: Their typologies, models, and concepts. J. Plan. Educ. Res. 2006, 26, 38–52. [Google Scholar] [CrossRef]
- Alberti, M.; Booth, D.; Hill, K.; Coburn, B.; Avolio, C.; Coe, S.; Spirandelli, D. The impact of urban patterns on aquatic ecosystems: An empirical analysis in Puget lowland sub-basins. Landsc. Urban Plan. 2007, 80, 345–361. [Google Scholar] [CrossRef]
- Moudon, A.V. Urban morphology as an emerging interdisciplinary field. Urban Morphol. 1997, 1, 3–10. [Google Scholar]
- Gil, J.; Beirao, J.N.; Montenegro, N.; Duarte, J.P. On the discovery of urban typologies: Data mining the many dimensions of urban form. Urban Morphol. 2012, 16, 27–40. [Google Scholar]
- Yoshida, H.; Omae, M. An approach for analysis of urban morphology: Methods to derive morphological properties of city blocks by using an urban landscape model and their interpretations. Comput. Environ. Urban Syst. 2005, 29, 223–247. [Google Scholar] [CrossRef]
- Ariza-Villaverde, A.B.; Jiménez-Hornero, F.J.; Ravé, E.G.D. Multifractal analysis of axial maps applied to the study of urban morphology. Comput. Environ. Urban Syst. 2013, 38, 1–10. [Google Scholar] [CrossRef]
- Batty, M. Building a science of cities. Cities 2012, 29, S9–S16. [Google Scholar] [CrossRef] [Green Version]
- Jiang, B.; Liu, X. Scaling of geographic space from the perspective of city and field blocks and using volunteered geographic information. Int. J. Geogr. Inf. Sci. 2012, 26, 215–229. [Google Scholar] [CrossRef] [Green Version]
- Long, Y.; Shen, Y.; Jin, X. Mapping Block-Level Urban Areas for All Chinese Cities. Ann. Am. Assoc. Geogr. 2016, 106, 96–113. [Google Scholar] [CrossRef]
- Jacobs, P. Human Aspects of Urban form: Towards a Man—Environment Approach to Urban form and Design, 1st ed.; Amos Rapoport; Urban and Regional Planning Series; Pergamon Press: Oxford, UK, 1977; Volume 15, p. viii + 438. ISBN 0-08-017974-6. [Google Scholar] [CrossRef]
- Handy, S. Methodologies for exploring the link between urban form and travel behavior. Transp. Res. Part D Transp. Environ. 1996, 1, 151–165. [Google Scholar] [CrossRef]
- Maoh, H.; Kanaroglou, P. Geographic clustering of firms and urban form: A multivariate analysis. J. Geogr. Syst. 2007, 9, 29–52. [Google Scholar] [CrossRef]
- Tratalos, J.; Fuller, R.A.; Warren, P.H.; Davies, R.G.; Gaston, K.J. Urban form, biodiversity potential and ecosystem services. Landsc. Urban Plan. 2007, 83, 308–317. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, J.; Yu, D.; Ma, Q. The relationship between urban form and air pollution depends on seasonality and city size. Environ. Sci. Pollut. Res. 2018, 25, 15554–15567. [Google Scholar] [CrossRef]
- Li, C.; Wang, Z.; Li, B.; Peng, Z.-R.; Fu, Q. Investigating the relationship between air pollution variation and urban form. Build. Environ. 2019, 147, 559–568. [Google Scholar] [CrossRef]
- Schepers, P.; Lovegrove, G.; Helbich, M. Urban form and road safety: Public and active transport enable high levels of road safety. In Integrating Human Health into Urban and Transport Planning; Springer: Cham, Switzerland, 2019; pp. 383–408. [Google Scholar]
- Najaf, P.; Thill, J.-C.; Zhang, W.; Fields, M.G. City-level urban form and traffic safety: A structural equation modeling analysis of direct and indirect effects. J. Transp. Geogr. 2018, 69, 257–270. [Google Scholar] [CrossRef]
- Yu, B.; Shu, S.; Liu, H.; Song, W.; Wu, J.; Wang, L.; Chen, Z. Object-based spatial cluster analysis of urban landscape pattern using nighttime light satellite images: A case study of China. Int. J. Geogr. Inf. Sci. 2014, 28, 2328–2355. [Google Scholar] [CrossRef]
- Ubaura, M. Changes in Land Use After the Great East Japan Earthquake and Related Issues of Urban Form. In The 2011 Japan Earthquake and Tsunami: Reconstruction and Restoration; Springer: Berlin/Heidelberg, Germany, 2018; pp. 183–203. [Google Scholar]
- Zheng, Y.; Capra, L.; Wolfson, O.; Yang, H. Urban computing: Concepts, methodologies, and applications. ACM Trans. Intell. Syst. Technol. 2014, 5, 1–55. [Google Scholar] [CrossRef]
- Yuan, N.J.; Zheng, Y.; Xie, X.; Wang, Y.; Zheng, K.; Xiong, H. Discovering Urban Functional Zones Using Latent Activity Trajectories. IEEE Trans. Knowl. Data Eng. 2015, 27, 712–725. [Google Scholar] [CrossRef]
- Montgomery, J. Making a city: Urbanity, vitality and urban design. J. Urban Des. 1998, 3, 93–116. [Google Scholar] [CrossRef]
- Long, Y.; Liu, X. Featured graphic. How mixed is Beijing, China? A visual exploration of mixed land use. Environ. Plan. A 2013, 45, 2797–2798. [Google Scholar] [CrossRef]
- Liu, X.; He, J.; Yao, Y.; Zhang, J.; Liang, H.; Wang, H.; Hong, Y. Classifying urban land use by integrating remote sensing and social media data. Int. J. Geogr. Inf. Sci. 2017, 31, 1675–1696. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Wong, D.W.S. The Modifiable Areal Unit Problem in Multivariate Statistical Analysis. Environ. Plan. A Econ. Space 1991, 23, 1025–1044. [Google Scholar] [CrossRef]
- Longley, P.A.; Goodchild, M.F.; Maguire, D.J.; Rhind, D.W. Geographic Information Science and Systems; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Kwan, M.-P. The uncertain geographic context problem. Ann. Assoc. Am. Geogr. 2012, 102, 958–968. [Google Scholar] [CrossRef]
- Zhao, P.; Kwan, M.-P.; Zhou, S. The Uncertain Geographic Context Problem in the Analysis of the Relationships between Obesity and the Built Environment in Guangzhou. Int. J. Environ. Res. Public Health 2018, 15, 308. [Google Scholar] [CrossRef]
- Amrhein, C.G. Searching for the elusive aggregation effect: Evidence from statistical simulations. Environ. Plan. A Econ. Space 1995, 27, 105–119. [Google Scholar] [CrossRef]
- Ferrari, L.; Rosi, A.; Mamei, M.; Zambonelli, F. Extracting urban patterns from location-based social networks. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Location-Based Social Networks, Chicago, IL, USA, 1 November 2011; ACM: New York, NY, USA, 2011; pp. 9–16. [Google Scholar]
- Gao, S.; Janowicz, K.; Couclelis, H. Extracting urban functional regions from points of interest and human activities on location-based social networks. Trans. GIS 2017, 21, 446–467. [Google Scholar] [CrossRef]
- Tu, W.; Hu, Z.; Li, L.; Cao, J.; Jiang, J.; Li, Q.; Li, Q. Portraying Urban Functional Zones by Coupling Remote Sensing Imagery and Human Sensing Data. Remote Sens. 2018, 10, 141. [Google Scholar] [CrossRef]
- Wang, Y.; Gu, Y.; Dou, M.; Qiao, M. Using Spatial Semantics and Interactions to Identify Urban Functional Regions. ISPRS Int. J. Geo-Inf. 2018, 7, 130. [Google Scholar] [CrossRef]
- Ratti, C.; Sobolevsky, S.; Calabrese, F.; Andris, C.; Reades, J.; Martino, M.; Claxton, R.; Strogatz, S.H. Redrawing the Map of Great Britain from a Network of Human Interactions. PLoS ONE 2010, 5, e14248. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Kang, C.; Gong, L.; Liu, Y. Incorporating spatial interaction patterns in classifying and understanding urban land use. Int. J. Geogr. Inf. Sci. 2016, 30, 334–350. [Google Scholar] [CrossRef]
- Yu, L. Revisiting several basic geographical concepts: A social sensing perspective. Acta Geogr. Sin. 2016, 4, 4. [Google Scholar]
- Regnauld, N. Contextual building typification in automated map generalization. Algorithmica 2001, 30, 312–333. [Google Scholar] [CrossRef]
- Steinhauer, J.H.; Wiese, T.; Freksa, C.; Barkowsky, T. Recognition of abstract regions in cartographic maps. In Lecture Notes in Computer Science, Proceedings of the International Conference on Spatial Information Theory, Morro Bay, CA, USA, 19–23 September 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 306–321. [Google Scholar]
- Rainsford, D.; Mackaness, W. Template matching in support of generalisation of rural buildings. In Advances in Spatial Data Handling; Springer: Berlin/Heidelberg, Germany, 2002; pp. 137–151. [Google Scholar]
- Christophe, S.; Ruas, A. Detecting building alignments for generalisation purposes. In Advances in Spatial Data Handling; Springer: Berlin/Heidelberg, Germany, 2002; pp. 419–432. [Google Scholar]
- Ware, J.M.; Jones, C.B. Conflict reduction in map generalization using iterative improvement. GeoInformatica 1998, 2, 383–407. [Google Scholar] [CrossRef]
- Li, Z.; Yan, H.; Ai, T.; Chen, J. Automated building generalization based on urban morphology and Gestalt theory. Int. J. Geogr. Inf. Sci. 2004, 18, 513–534. [Google Scholar] [CrossRef]
- Boffet, A.; Serra, S.R. Identification of spatial structures within urban blocks for town characterization. In Proceedings of the 20th International Cartographic Conference, Beijing, China, 6–10 August 2001; pp. 1974–1983. [Google Scholar]
- Cetinkaya, S.; Basaraner, M.; Burghardt, D. Proximity-based grouping of buildings in urban blocks: A comparison of four algorithms. Geocarto Int. 2015, 30, 618–632. [Google Scholar] [CrossRef]
- Yan, H.; Weibel, R.; Yang, B. A multi-parameter approach to automated building grouping and generalization. Geoinformatica 2008, 12, 73–89. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, L.; Mathiopoulos, P.T.; Deng, H. A Gestalt rules and graph-cut-based simplification framework for urban building models. Int. J. Appl. Earth Obs. Geoinf. 2015, 35, 247–258. [Google Scholar] [CrossRef]
- Chen, J.; Hu, Y.; Li, Z.; Zhao, R.; Meng, L. Selective omission of road features based on mesh density for automatic map generalization. Int. J. Geogr. Inf. Sci. 2009, 23, 1013–1032. [Google Scholar] [CrossRef]
- Yang, B.; Luan, X.; Li, Q. Generating hierarchical strokes from urban street networks based on spatial pattern recognition. Int. J. Geogr. Inf. Sci. 2011, 25, 2025–2050. [Google Scholar] [CrossRef]
- Li, C.; Yin, Y.; Liu, X.; Wu, P. An Automated Processing Method for Agglomeration Areas. ISPRS Int. J. Geo-Inf. 2018, 7, 204. [Google Scholar] [CrossRef]
- Haunert, J.-H.; Wolff, A. Area aggregation in map generalisation by mixed-integer programming. Int. J. Geogr. Inf. Sci. 2010, 24, 1871–1897. [Google Scholar] [CrossRef]
- Luan, X.; Yang, B.; Qiuping, L.I. A mixed integer programming model of block aggregation for grid pattern maintenance in urban network. Acta Geod. Cartogr. Sin. 2014. [Google Scholar] [CrossRef]
- Shen, Y.; Karimi, K. Urban function connectivity: Characterisation of functional urban streets with social media check-in data. Cities 2016, 55, 9–21. [Google Scholar] [CrossRef] [Green Version]
- Manaugh, K.; Kreider, T. What is mixed use? Presenting an interaction method for measuring land use mix. J. Transp. Land Use 2013, 6, 63–72. [Google Scholar] [CrossRef]
- Ortega-Álvarez, R.; MacGregor-Fors, I. Living in the big city: Effects of urban land-use on bird community structure, diversity, and composition. Lands. Urban Plan. 2009, 90, 189–195. [Google Scholar] [CrossRef]
- Guéziec, A. Surface Simplification Inside a Tolerance Volume; IBM TJ Watson Research Center: New York, NY, USA, 1996. [Google Scholar]
- Joshi, D.; Samal, A.K.; Soh, L.-K. Density-based clustering of polygons. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence and Data Mining, Nashville, TN, USA, 30 March–2 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 171–178. [Google Scholar] [CrossRef] [Green Version]
- Joshi, D.; Soh, L.-K.; Samal, A. Redistricting using heuristic-based polygonal clustering. In Proceedings of the 2009 Ninth IEEE International Conference on Data Mining, Miami, FL, USA, 6–9 December 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 830–835. [Google Scholar] [CrossRef]
- Atallah, M.J. A linear time algorithm for the Hausdorff distance between convex polygons. Inform. Process. Lett. 1983, 17, 207–209. [Google Scholar] [CrossRef] [Green Version]
- Bai, Y.-B.; Yong, J.-H.; Liu, C.-Y.; Liu, X.-M.; Meng, Y. Polyline approach for approximating Hausdorff distance between planar free-form curves. Comput.-Aided Des. 2011, 43, 687–698. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Cai, J.; Ottens, H.F.L.; Sliuzas, R. Beijing. Cities 2013, 31, 491–506. [Google Scholar] [CrossRef]
- Gehl, J. Life between Buildings: Using Public Space; Island Press: Washington, DC, USA, 2011. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Subclass ID | Abbreviated Name |
|---|---|---|
| Park and Plaza | ‘7300’ | PPZ |
| Famous Scenery | ‘9080’ | FAS |
| Transport Services | ‘4102’, ‘1202’, ‘4500’, ‘8085’, ‘4082’, ‘8087’, ‘8083’, ‘8100’, ‘8301’, ‘8401’ | TRA |
| Hotel | ‘5380’ | HOT |
| Catering and Entertainment | ‘1380’, ‘6081’ | CAT |
| Business and Shopping | ‘1199’, ‘1600’, ‘2003’, ‘1980’ | BAS |
| Research and Education | ‘1701’ | EDU |
| Residential Area | ‘1900’ | RES |
| Governmental Agencies | ‘7085’ | GOV |
| Medical Service | ‘7280’ | MED |
| Others | ‘7180’, ‘7880’ | OTR |
| Parcel ID | Number of Parcels | Number of POIs | Main Components |
|---|---|---|---|
| parcel 1 | 46 | 3182 | ① Business & Shopping; ② Catering & Entertainment |
| parcel 2 | 157 | 6527 | ① Business & Shopping; ② Catering & Entertainment; ③ Famous Scenery; ④ Residential Area |
| Proximity Threshold | Compactness(Pi) | Average of Compactness(Pi) | ||||
|---|---|---|---|---|---|---|
| P1 | P2 | P3 | P4 | P5 | ||
| d1 | ↓1 | ↓ | 1 | 1 | 1 | ≈ ≈ 0.7 |
| d2 | ↑ | ↑ | ↓ | 1 | 1 | ≈ ≈ 0.82 |
| d3 (≈3*d2) | ↑ | ↑ | ↓ | ↓ | 1 | ≈≈ 0.72 |
| d4 (≈2*d3) | −1 | −1 | −1 | −1 | −1 | −1 |
| d5 (≈1.5*d4) | −1 | −1 | −1 | −1 | −1 | −1 |
| Parcel ID | Average Increase of MLU within Groups | Whether Same Dominant Functions were Separated | Ratio (times) of Ignored the High-Degree Imitation Behaviours |
|---|---|---|---|
| Parcel 1 | +0.38 | No | 45.45% (15) |
| Parcel 2 | +3.87 | Yes | 21.88% (42) |
| Parcel ID | Average Increase of MLU within Groups | Whether Same Dominant Functions were Separated | Ratio (times) of Ignored the High-Degree Imitation Behaviours |
|---|---|---|---|
| Parcel 1 | +0.24 | No | 27.27% (9) |
| Parcel 2 | +2.45 | No | 16.15% (31) |
| Method | Number of Groups (k) | Number of Hard Segmentations | Ratio (Number of Hard Segmentation/k) |
|---|---|---|---|
| k-means++ | k = 7 | 4 | 57.14% |
| k-means++ | k = 51 | 20 | 39.22% |
| UPG | k = 51 | 5 | 9.80% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, P.; Zhang, S.; Li, H.; Dale, P.; Ding, X.; Lu, Y. Urban Parcel Grouping Method Based on Urban Form and Functional Connectivity Characterisation. ISPRS Int. J. Geo-Inf. 2019, 8, 282. https://doi.org/10.3390/ijgi8060282
Wu P, Zhang S, Li H, Dale P, Ding X, Lu Y. Urban Parcel Grouping Method Based on Urban Form and Functional Connectivity Characterisation. ISPRS International Journal of Geo-Information. 2019; 8(6):282. https://doi.org/10.3390/ijgi8060282
Chicago/Turabian StyleWu, Peng, Shuqing Zhang, Huapeng Li, Patricia Dale, Xiaohui Ding, and Yuanbing Lu. 2019. "Urban Parcel Grouping Method Based on Urban Form and Functional Connectivity Characterisation" ISPRS International Journal of Geo-Information 8, no. 6: 282. https://doi.org/10.3390/ijgi8060282
APA StyleWu, P., Zhang, S., Li, H., Dale, P., Ding, X., & Lu, Y. (2019). Urban Parcel Grouping Method Based on Urban Form and Functional Connectivity Characterisation. ISPRS International Journal of Geo-Information, 8(6), 282. https://doi.org/10.3390/ijgi8060282