1. Introduction
With the fast advances of ubiquitous and mobile computing, processing the location-based queries on spatial objects [
1,
2,
3,
4,
5,
6] has become essential for various applications, such as traffic control systems, location-aware advertisements, and mobile information systems. Currently, most of the conventional location-based queries focus exclusively on a single type of objects (e.g., the nearest neighbor query finds a closest restaurant or hotel to the user). In other words, the different types of objects (termed
the heterogeneous objects) are independently considered in processing the location-based queries, which means that the neighboring relationship between the heterogeneous objects is completely ignored. Let us consider a scenario where the user wants to stay in a hotel, have lunch in a restaurant, and go to the movies. Here, the hotel, the restaurant, and the theater refer to the heterogeneous objects. If the nearest neighbor queries are independently processed for the heterogeneous objects, the user is able to know his/her closest hotel, restaurant, and theater, which, however, may actually be far away from each other. Therefore, in addition to the spatial closeness of the heterogeneous objects to the query point, the neighboring relationship between the heterogeneous objects should also play an important role in determining the query result.
In the previous work [
7], we present the
location-based aggregate queries to provide information of the heterogeneous objects by taking into account both the neighboring relationship and the spatial closeness of the heterogeneous objects. In order to preserve the neighboring relationship between the heterogeneous objects, the location-based aggregate queries aim at finding the heterogeneous objects closer to each other by constraining their distance to be within a user-defined distance
d. The set of objects satisfying the constraint of distance
d is termed
the heterogeneous neighboring object set (or
HNO set). On the other hand, for maintaining the spatial closeness of the heterogeneous objects to the query point, four types of location-based aggregate queries are presented to provide information of
HNO set according to specific user requirement. They are
the shortest average-distance query (or
SAvgDQ),
the shortest minimal-distance query (or
SMinDQ),
the shortest maximal-distance query (or
SMaxDQ), and
the shortest sum-distance query (or
SSumDQ), which are described respectively as follows.
Consider the n types of objects, , , …, . Assume that there are mHNO sets, , , …, , where , , and . Given a query point q, a set of objects among these m HNO sets is determined, such that
- -
for the
SAvgDQ, the average distance of
to
q is equal to
where
refers to the distance between objects
and
q.
- -
for the
SMinDQ, the distance of an object
to
q is equal to
- -
for the
SMaxDQ, the distance of an object
to
q is equal to
- -
for the
SSumDQ, the traveling distance from
q to
is equal to
where
is the shortest distance that, starting from
q, visits each object in
exactly once.
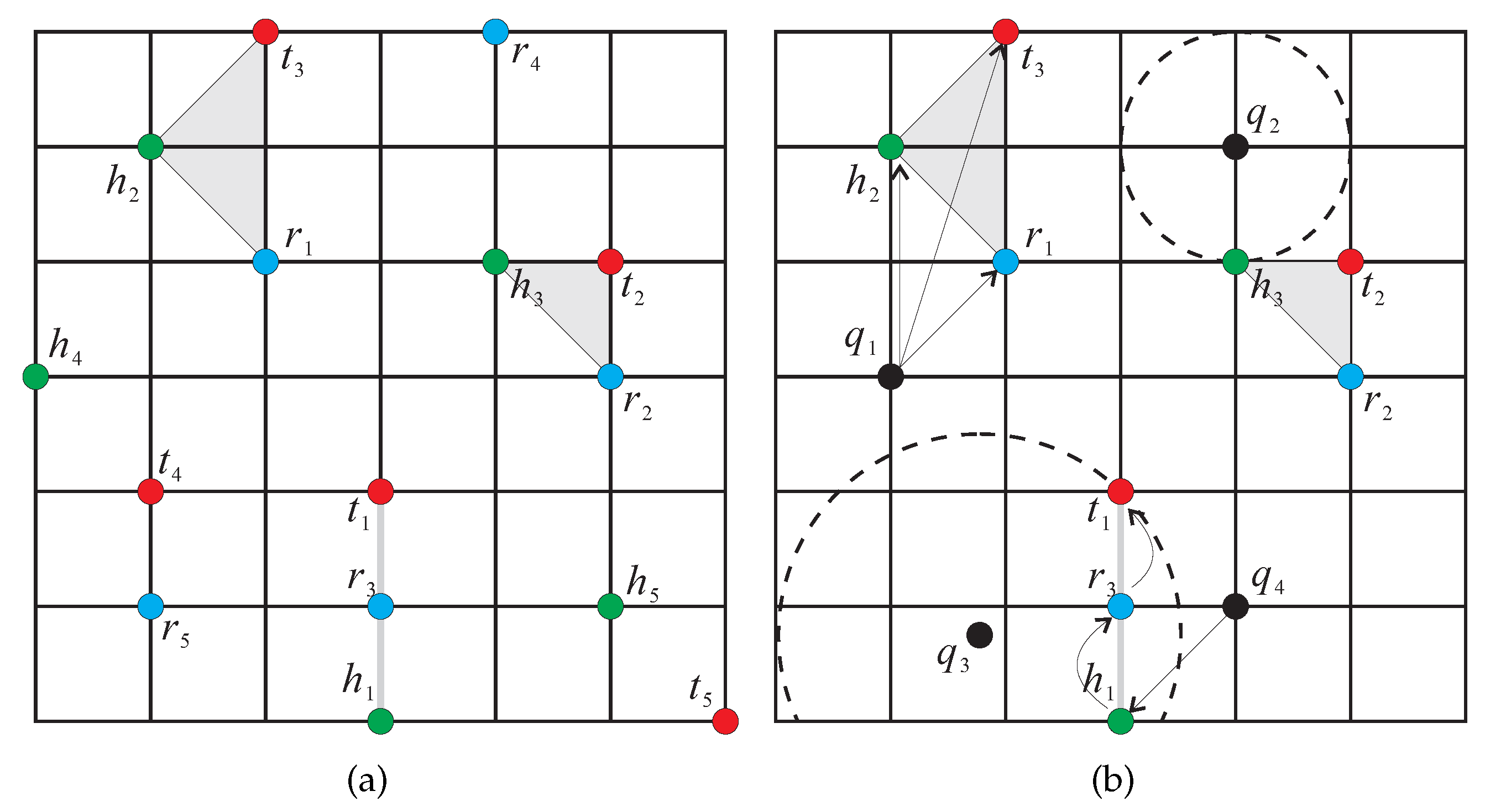
Let us use
Figure 1 to illustrate how to process the four types of location-based aggregate queries (i.e., the
SAvgDQ, the
SMinDQ, the
SMaxDQ, and the
SSumDQ). As shown in
Figure 1a, there are three types of data objects in the space, the hotels
to
, the restaurants
to
, and the theaters
to
. Assume that the user-defined distance
d is set to 2 (that is, the distance between any two objects should be less than or equal to 2), which leads to three
HNO sets,
,
, and
(shown as the gray areas). Take the query point
in
Figure 1b, issuing the
SAvgDQ, as an example. For each
HNO set, the distance between each object in the
HNO set and the query point
needs to be first computed and then the
HNO set with the shortest average-distance to
is the result set of the
SAvgDQ (i.e., the set
). Meanwhile, the
SMinDQ and the
SMaxDQ issued by the query points
and
, respectively, also need to be evaluated. When the
SMinDQ is considered, the distances of the objects closest to
in
,
, and
, respectively, are compared to each other, and then the
HNO set (i.e.,
) containing
’s nearest neighbor is returned as the result set. In contrast to the
SMinDQ, the
SMaxDQ takes the furthest object in each
HNO set into account. For the query point
, its furthest objects in the three
HNO sets are
,
, and
, respectively. Among them, object
has the shortest distance to
, and hence the
SMaxDQ retrieves the set
because it contains
. Consider the
SSumDQ issued from the query point
, which is processed simultaneously by the system. The shortest traveling path for each of the three
HNO sets ,
, and
has to be determined so as to find the
HNO set resulting in a shortest traveling distance from
. Finally, the set
can be the
SSumDQ result because of its shortest path
.
The processing techniques developed in [
7] focus only on efficiently processing a location-based aggregate query (corresponding to
SAvgDQ,
SMinDQ,
SMaxDQ, or
SSumDQ). However, in highly dynamic environments, where users can obtain object information through the portable computers (e.g., laptops, 3G mobile phones, and tablet PCs), multiple location-based aggregate queries must be issued by the users from anywhere and anytime (For instance, in
Figure 1, the
SAvgDQ, the
SMinDQ, the
SMaxDQ, and the
SSumDQ are issued from different query points at the same time.) It means that, when there is a large number of location-based aggregate queries processed concurrently, the time spent on sequentially evaluating the location-based aggregate queries would dramatically increase. Even worse, at the time at which a location-based aggregate query terminates, the query result may already be outdated. As a result, it is necessary to design the distributed processing techniques to rapidly evaluate multiple location-based aggregate queries.
To achieve the objective of distributed processing of location-based aggregate queries, we adopt the most notable platform,
MapReduce [
8], for processing multiple queries over large-scale datasets by involving a number of share-nothing machines. For data storage, an existing distributed file system (DFS), such as Google File System (GFS) or Hadoop Distributed File System (HDFS), is usually used as the underlying storage system. Based on the partitioning strategy used in the DFS, data are divided into equal-sized chunks, which are distributed over the machines. For query processing, the MapReduce-based algorithm executes in several
jobs, each of which has three phases:
map,
shuffle, and
reduce. In the map phase, each participating machine prepares information to be delivered to other machines. As for the shuffle phase, it is responsible for the actual data transfer. In the reduce phase, each machine performs calculation using its local storage. The current job finishes after the reduce phase. If the process has not been completed, another MapReduce job starts. Depending on the applications, the MapReduce job may be executed once or multiple times.
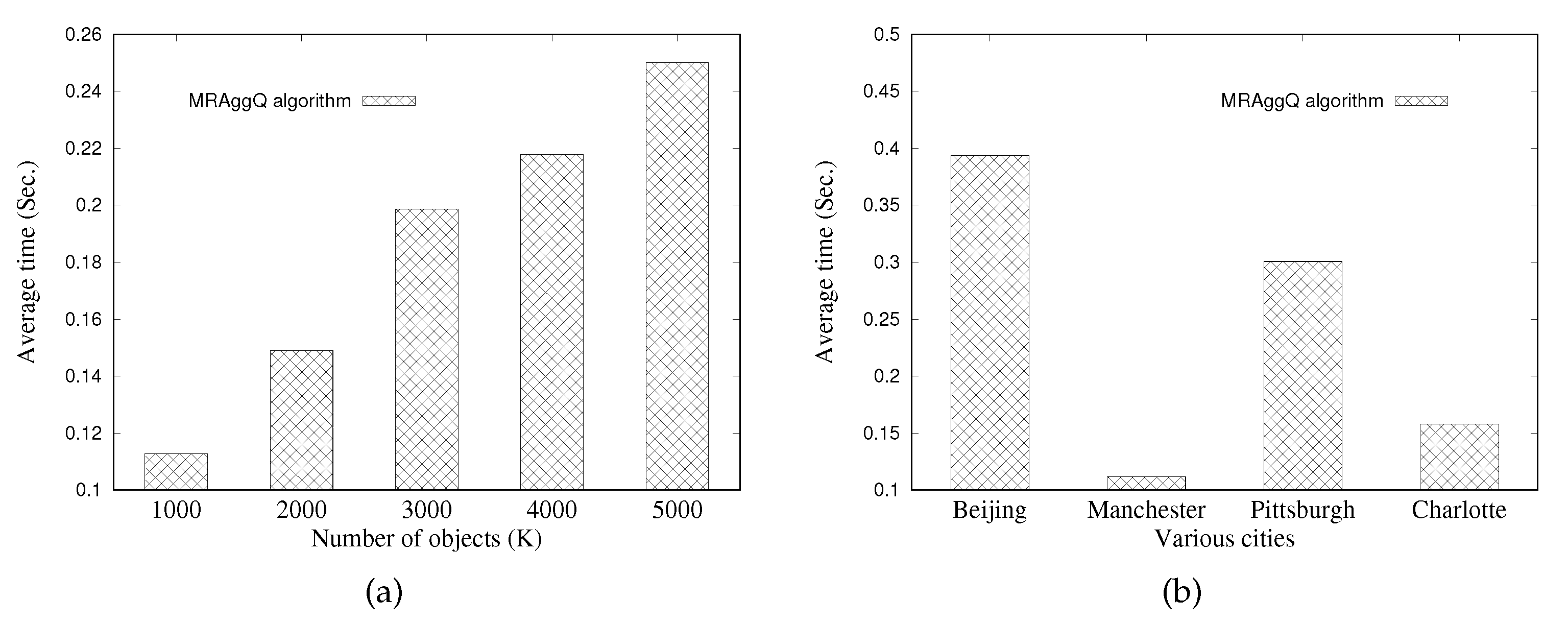
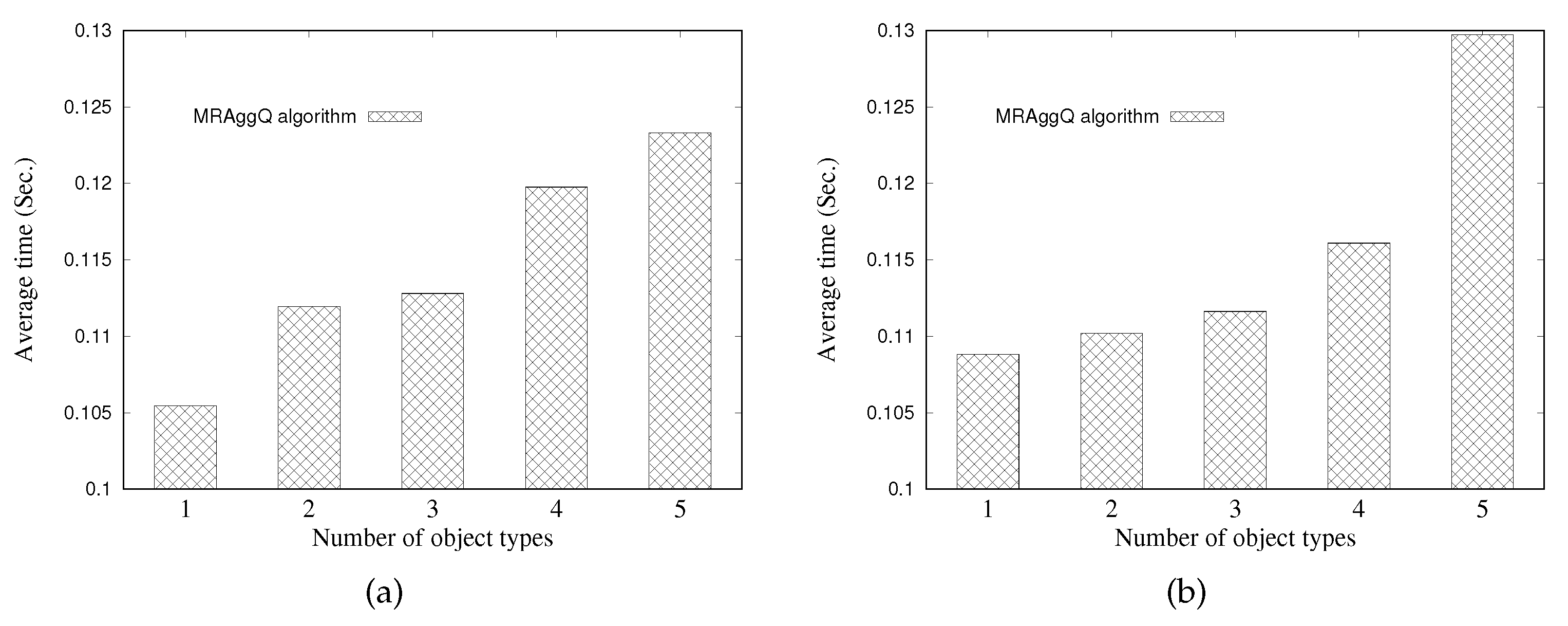
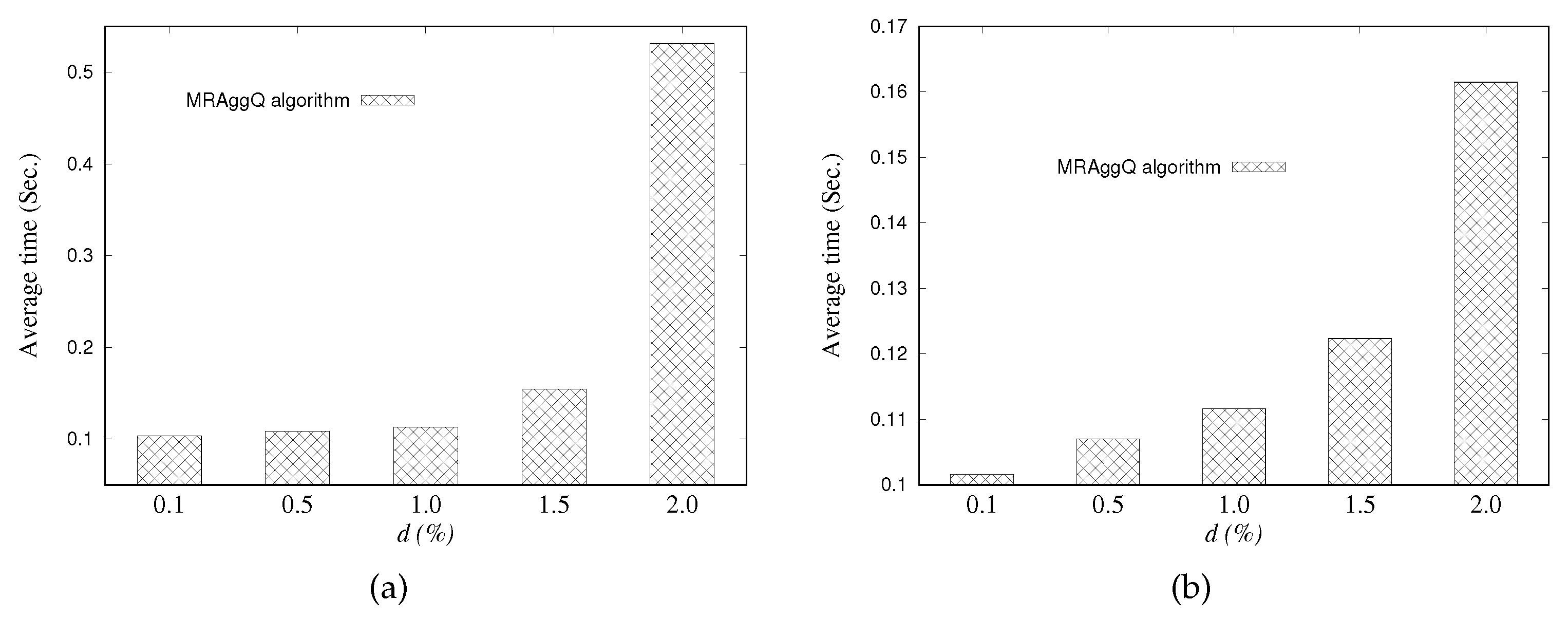
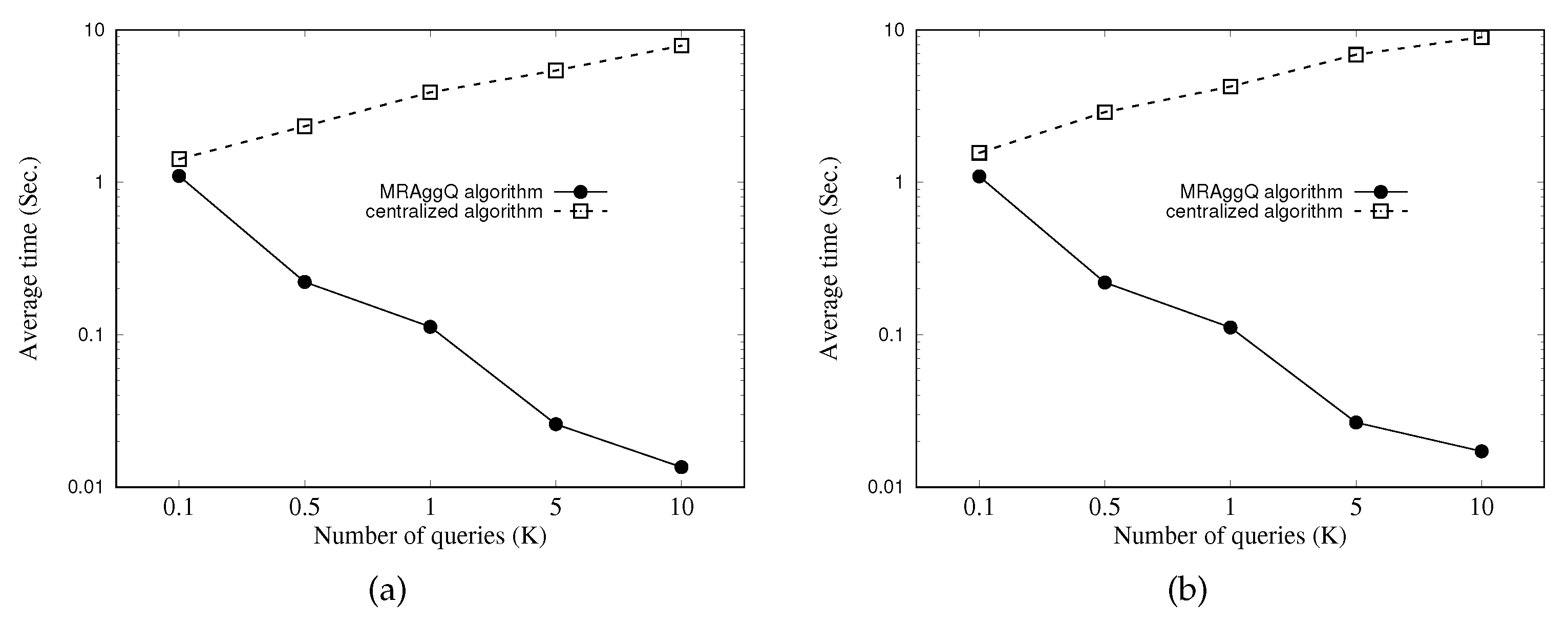
In this paper, we focus on developing the MapReduce-based methods to efficiently answer multiple location-based aggregate queries (consisting of numerous SAvgDQ, SMinDQ, SMaxDQ, and SSumDQ issued concurrently from different query points) in a distributed manner. We first utilize a grid structure to manage the heterogeneous objects in the space by taking into account the storage balance, and information of the partitioned object data in each grid cell is stored in the DFS. Next, we propose a distributed processing algorithm, namely the MapReduce-based aggregate query algorithm (MRAggQ algorithm for short), which is composed of four phases: the Inner HNO set determining phase, the Outer HNO set determining phase, the Aggregate-distance computing phase, and the Result set generating phase, each of which executes a MapReduce job to finish the procedure. Finally, we conduct a comprehensive set of experiments over synthetic and real datasets, demonstrating the efficiency, the robustness, and the scalability of the proposed MRAggQ algorithm, in terms of the average running time in performing different workloads of location-based aggregate queries.
The rest of this paper is organized as follows. In
Section 2, we review the previous work on processing various types of location-based queries in centralized and distributed environments.
Section 3 describes the grid structure used for maintaining information of the heterogeneous objects. In
Section 4, we present how the
MRAggQ algorithm can be used to process multiple location-based aggregate queries efficiently.
Section 5 shows extensive experiments on the performance of the proposed methods. In
Section 6, we conclude the paper with directions on future work.
3. Grid Structure
In our model, there are
n types of data objects (i.e., the heterogeneous objects) in the space. As the location database contains large amounts of information that need to be maintained, a grid structure is used to manage such information by partitioning the space into multiple gird cells, each of which stores data of objects enclosed in it. In order to balance the storage load of each grid cell, the data space is partitioned into
equal-sized cells by considering a pre-defined parameter
. Initially, all the heterogeneous objects are grouped into
cells. Then, the number of objects enclosed in a cell is compared with the parameter
. Once the object number is greater than
, the data space covering all objects is repartitioned into
cells. Similarly, if there still exists a cell within which the object number exceeds
, then the data space needs to be repartitioned into
cells. This partitioning process continues until each cell
satisfies the condition that the number of objects in
is less than or equal to
. By exploiting the parameter
, the storage overhead for maintaining information of objects can be evenly distributed among the cells.
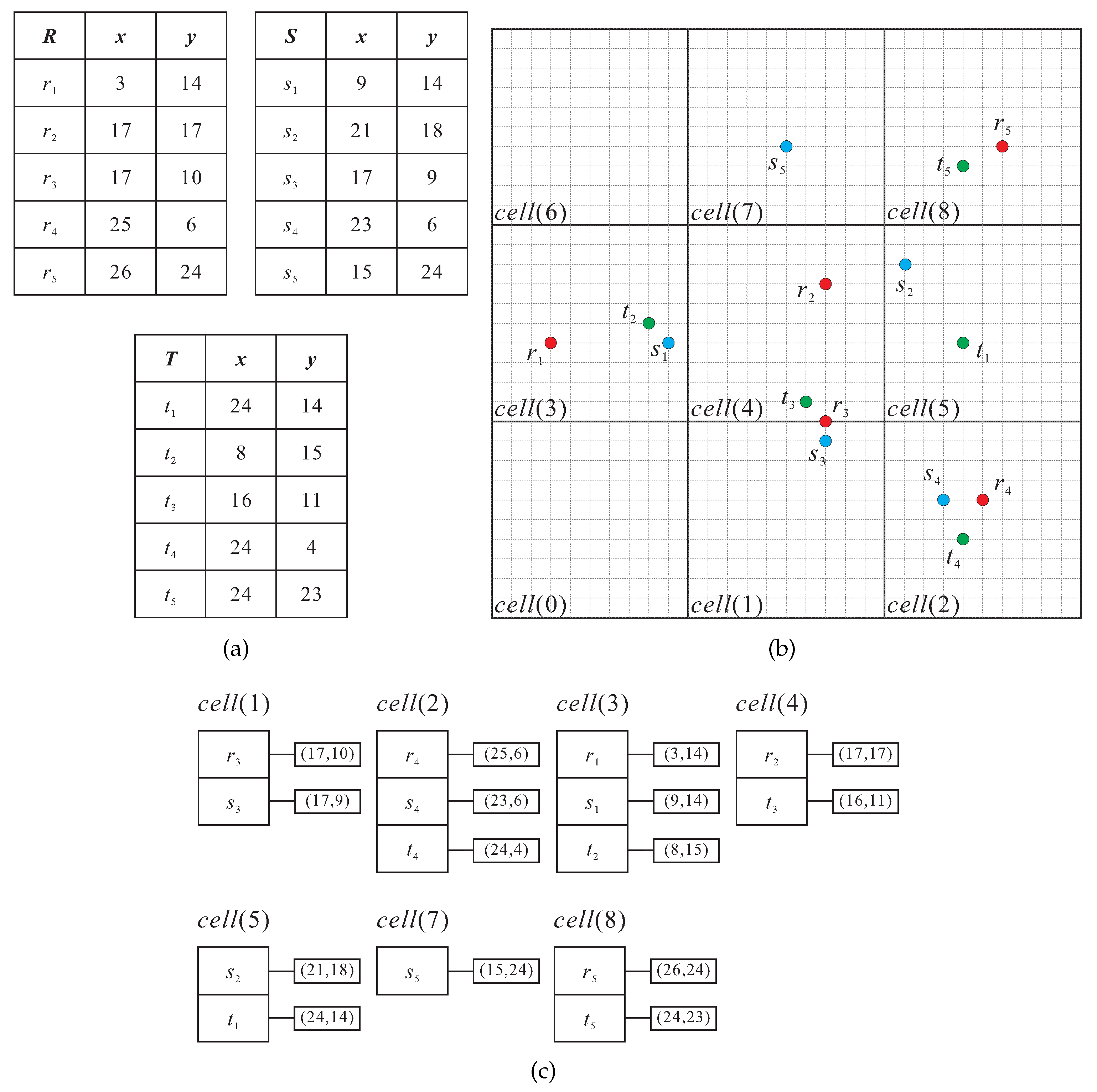
Figure 2 shows an example of how the data space is divided by taking into account the storage load of each cell. As shown in
Figure 2a, there are three types of data objects,
R,
S, and
T in the space, each of which has five objects with coordinate
(e.g., object
’s coordinate
refers to
). Suppose that the pre-defined parameter
is set to 3. The data space would be divided into
cells, so as to guarantee that the number of objects in each cell does not exceed 3. The final divided grid cells, which are numbered from 0 to 8, are shown in
Figure 2b.
In order to provide parallel processing of the heterogeneous objects using MapReduce, information of the grid structure is stored in a distributed storage system, the HDFS, by default. The HDFS consists of multiple DataNodes for storing data and a NameNode for monitoring all DataNodes. In the HDFS, a file is broken into multiple equal-sized chunks and then the NameNode allocates the data chunks among the DataNodes for query processing. Returning to the example in
Figure 2, the cells,
to
, are treated as the chunks and kept on the HDFS. Take the cell
as an example, as objects
and
are enclosed in
, in the HDFS, the chunks with respect to
will store
and
with their coordinates
and
, respectively. Note that the cells
and
need not be kept on the HDFS because there is no object in them.
Figure 2c shows how the grid structure for the heterogeneous objects is stored on the HDFS.
4. Mapreduce-Based Aggregate Query Algorithm
Given the
n types of data objects,
,
, …,
, a set of query points
Q (where a query point
corresponds to a
SAvgDQ, a
SMinDQ, a
SMaxDQ, or a
SSumDQ), and the user-defined distance
d, the main goal of the MapReduce-based aggregate query (MRAggQ) algorithm is to efficiently determine, for each query point
q, the
HNO set with the shortest distance in a distributed manner. Recall that a set of objects
(where
and
) can be included in the result set of the location-based aggregate queries only if the following two conditions hold: (1) the distance between any two objects in
is less than or equal to
d (as a necessary condition) and (2)
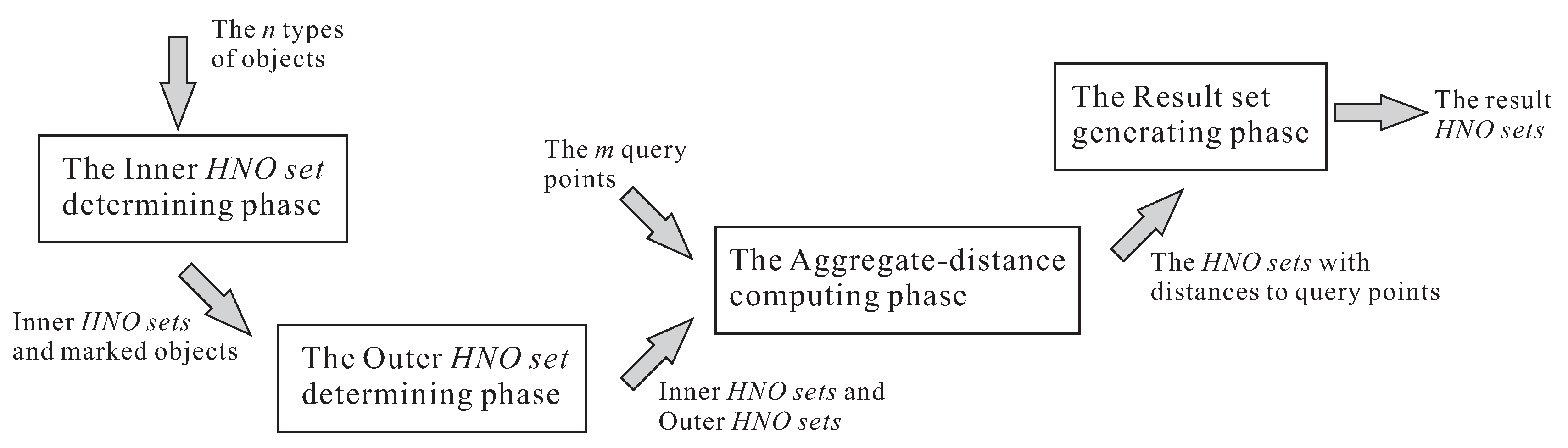
has the shortest average, minimal, maximal, or sum distance to the query point. As a result, the MRAggQ algorithm is developed according to the two conditions. The proposed MRAggQ algorithm consists of four phases, in which the first and last two phases are in charge of checking the conditions (1) and (2), respectively. In the following, we briefly describe the purposes of the four phases and then discuss the details separately. To provide an overview of the MRAggQ algorithm, a flowchart and a pseudo code for the four phases are also given in
Figure 3 and Algorithm 1, respectively:
The first phase, the Inner HNO set determining phase, aims at finding, for each cell , the sets of objects that are enclosed in and are within the distance d from each other. Here, we term the object sets found in this phase the Inner HNO sets.
The second phase, the Outer HNO set determining phase, focuses on finding the HNO sets that have not been discovered from the previous phase. It means that the objects constituting a HNO set determined in this phase cannot be fully enclosed in a cell. Instead, the objects are distributed over different cells. We term the HNO sets discovered in this phase the Outer HNO sets.
The third phase, the Aggregate-distance computing phase, is responsible for computing the aggregate-distances of all HNO sets obtained from the previous two phases to each query point contained in the query set Q, according to the type of location-based aggregate queries (i.e., the aggregate-distance may be the average, the minimal, the maximal, or the sum distance).
The last phase, the Result set generating phase, sorts the aggregate-distances of all HNO sets computed in the previous phase, so as to output the HNO set with the shortest aggregate-distance for each query point in Q.
| Algorithm 1: The MRAggQ algorithm |
| Input: The n types of objects, and the set of m query points |
| Output: The result HNO set for each query point |
| /* The Inner HNO set determining phase | */ |
| finding the Inner HNO sets enclosed in ; |
| determining the marked objects for ; |
| /* The Outer HNO set determining phase | */ |
| finding the Outer HNO sets based on the marked objects; |
| combing the Inner and the Outer HNO sets; |
| /* The Aggregate-distance computing phase | */ |
| computing the average, min, max, or sum distances of the HNO sets to the m query points; |
| /* The Result set generating phase | */ |
| sorting the HNO sets according to their distances to each query point; |
| returning the HNO set with the shortest distance to each query point; |
4.1. Inner HNO Set Determining Phase
Given the n types of objects stored on the HDFS, the goal of the Inner HNO set determining phase is to process in parallel, determining the Inner HNO sets for each cell , each of which is composed of n types of objects enclosed in . In this phase, a MapReduce job consisting of the map step, the shuffle step, and the reduce step is executed to finish the procedure. In the map step, each cell in the form of (i.e., pair) is extracted from the HDFS as input. The pair generated by the map step is then transmitted to another machine in the shuffle step, where the recipient machine is determined solely by value of . That is, if the pairs have a common key , all of them will arrive at an identical machine for processing in the reduce step. This is because for the n pairs (where ) with the same key , a set composed of the n objects , , …, has a chance to be the Inner HNO set as all the objects are enclosed in the cell . In the reduce step, two processing tasks are carried out in each participating machine, by taking into account the key-value pairs received from the shuffle step.
The first task is to compute the distance between any two objects and enclosed in , where and , based on their coordinates and . Consider a set of objects enclosed in the cell . If the computed distances of all object pairs are less than or equal to the distance d, then is an Inner HNO set of . Hence, a key-value pair in the form of , is returned as output.
The second task, as a preliminary to the next phase, the Outer
HNO set determining phase, focuses on marking some objects enclosed in cell
that may constitute an Outer
HNO set with the other objects enclosed in different cells. We term the objects determined by the second task the
marked objects. For an object
enclosed in
, it can be the marked object only if the circle centered at
with radius
d is not fully contained in
. Otherwise (i.e., the circle is enclosed by
), there exists no object enclosed in another cell
and whose distance to object
is less than or equal to
d, and thus
must not be contained in the Outer
HNO sets. Suppose that the data space is divided into
cells, where each equal-sized cell is represented as a rectangle with widths
and
on the
x-axis and
y-axis, respectively. An object
with coordinates
is a marked object in cell
if the following condition holds:
Similar to the first task, a key-value pair with respect to each marked object
(i.e.,
) will be generated after executing the second task. The generated key is mainly used to guarantee that the
n types of objects constituting an Outer
HNO set can be processed in the same machine. Note that, if such objects are considered in different machines, some of the Outer
HNO sets may be lost. In order to give each marked object
enclosed in the cell
a key
, we first merge
cells into a rectangle
R bounding the cell
, where the parameters
and
are estimated based on the following equation:
Then, the key of the marked object
is set to the union of the ids of these cells. To establish better understanding of the main idea behind Equation (
2), we take the cell
in
Figure 2b as an example, where the user-defined distance
and both the widths
and
of each cell are equal to 10. Based on Equation (
2), a rectangle
R consisting of
cells is constructed to enclose the cell
(here,
R can be represented as
,
,
, and
). Let us consider the rectangle
R corresponding to
. As the minimal distance between
and each of the other three cells,
,
, and
is less than or equal to
d, it is possible that an Outer
HNO set is composed of one or more marked objects in
and the rest in the other three cells. As such, we should give all the marked objects enclosed in the rectangle
R a common key,
, so as to process them in the same machine. In addition, the keys
,
, and
are assigned to the marked objects enclosed in their corresponding rectangle
R in the same way.
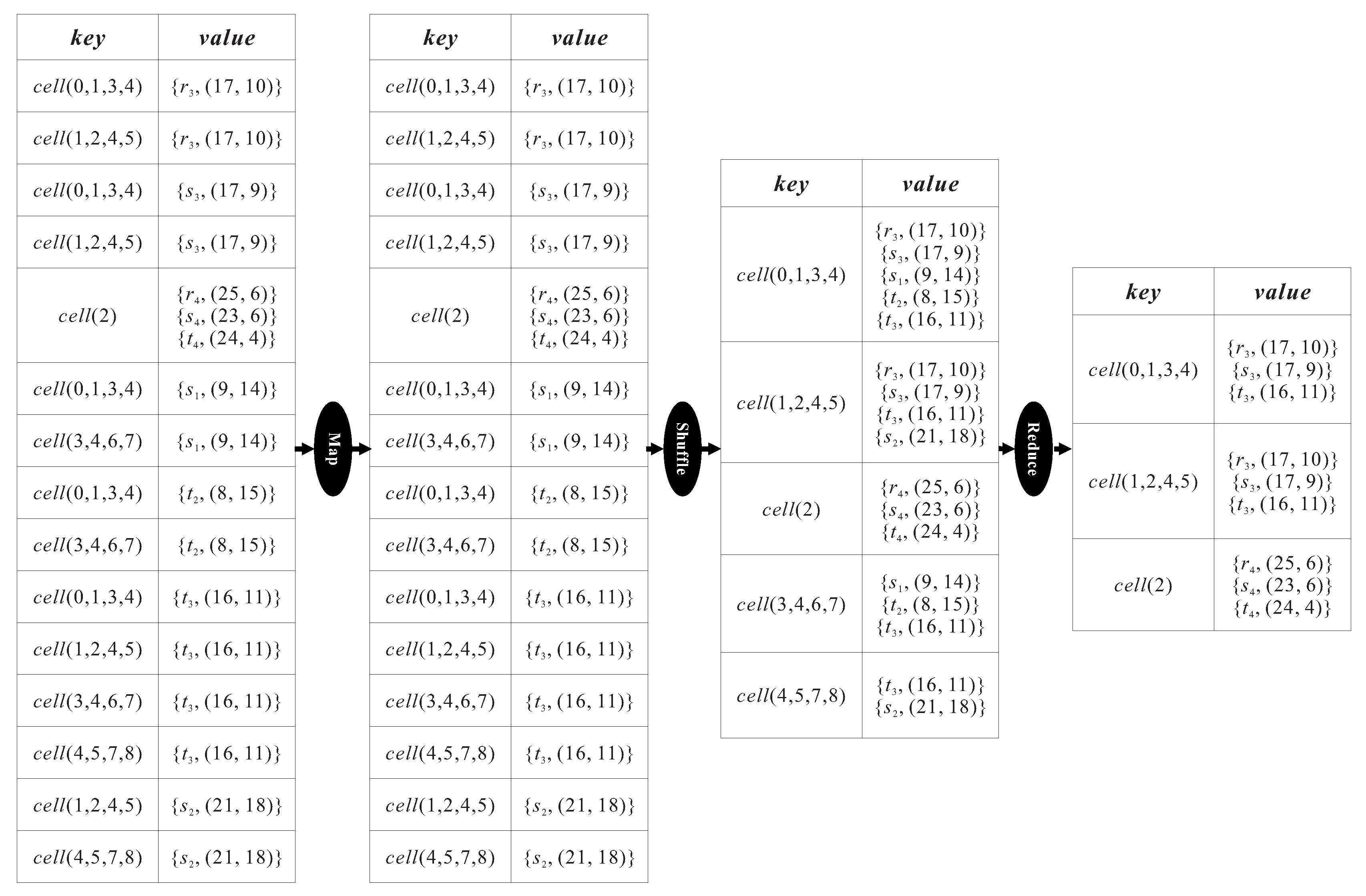
Figure 4 is a concrete example, which continues the previous example in
Figure 2, illustrating the data flow of the MapReduce job for the Inner
HNO set determining phase. In the map step, a key
for each object
is extracted and transformed into key-value pair,
(e.g.,
for the object
). Then, the key-value pairs with the same key are shuffled to the same machine for processing. For example,
and
arrive at the same machine because of their common key
. In the reduce step, each participating machine carries out the first task (i.e., determining the Inner
HNO sets) by computing the distance between objects received from the shuffle step to compare with the distance
. In this figure,
,
is output, so that
is an Inner
HNO set enclosed in the cell
. Meanwhile, the second task (i.e., finding the marked objects) is executed in each machine to find the marked objects enclosed in a cell based on Equation (
1) and give each marked object a key according to Equation (
2). Take the marked object
enclosed in the cell
as an example. Four key-value pairs,
,
,
,
, and
,
will be output from the machine in charge of
, as there is a chance that
constitutes an Outer
HNO set with the other marked objects enclosed in its surrounding cells. Finally, the Inner
HNO sets and the marked objects with respect to each cell, discovered in the Inner
HNO set determining phase, are passed to the next phase.
4.2. Outer HNO Set Determining Phase
The Outer
HNO set determining phase focuses on finding the
HNO sets that have not been discovered (i.e., the Outer
HNO sets), by exploiting information of the marked objects obtained from the previous phase. Similarly, a MapReduce job is applied in the Outer
HNO set determining phase, where (1) the map step receives the result of the previous phase and the key-value pairs are emitted, (2) the shuffle step dispatches the pairs with the same key to an identical machine for checking whether the Outer
HNO sets exist, and (3) the reduce step computes the distance between the marked objects to compare with the distance
d. Having executed the Outer
HNO set determining phase, each key-value pair in the form of
,
is returned as output, where
c refers to either a cell id (meaning that
,
is an Inner
HNO set) or multiple cell ids (that is, an Outer
HNO set). Continuing the example in
Figure 4, the key-value pairs corresponding to an Inner
HNO set,
,
, and the marked objects,
and so on, are emitted in the map step of the Outer
HNO set determining phase, as shown in
Figure 5. In the shuffle step, the marked objects with the common key are assigned to the same machine for computing the distance between any two marked objects based on their coordinates. For instance, five marked objects
,
,
,
, and
with the key
will be considered in the same machine. In the reduce step, each participating machine computes the distance between the marked objects assigned by the shuffle step (note that only the distances between different types of marked objects are computed), and then outputs the Outer
HNO sets. In this figure, the key-value pairs,
and
,
are returned as they satisfy the constraint of distance
d. As we can see,
is a duplicate set and needs to be eliminated. The duplicate elimination will be carried out in the last phase, the Result set generating phase.
4.3. Aggregate-Distance Computing Phase
After executing the first two phases (i.e., the Inner HNO set determining phase and the Outer HNO set determining phase), all of the HNO sets in the space can be discovered in a distributed manner. In the sequel, the third phase, the Aggregate-distance computing phase, is designed to compute in parallel the aggregate-distance of each HNO set according to the type of location-based aggregate queries. Suppose that Q is a set of m query points, , , …, , at which a SAvgDQ, a SMinDQ, a SMaxDQ, or a SSumDQ is issued. A query table with respect to Q needs to be broadcast to each machine so as to estimate the aggregate-distances between the HNO sets processed by this machine and each query point in Q. Each tuple of the query table has two fields: the query id (where j can be 1, 2, 3, and 4, indicating SAvgDQ, SMinDQ, SMaxDQ, and SSumDQ, respectively) and the coordinates . In the map step of the Aggregate-distance computing phase, in addition to the key-value pair , for each HNO set, a key-value pair , , …, with regard to the query points is also emitted, so that the query set Q can be transmitted along with each HNO set to the same machine for query processing. Having executed the shuffle step, the HNO set and the query set with the same key are grouped together. For each participating machine, the task of computing the aggregate-distance between each HNO set and each query point assigned by the shuffle step is carried out in the reduce step, in which the aggregate-distance refers to the average, minimal, maximal, or sum distance according to the query type (i.e., the value of j). Finally, each key-value pair in the form of is returned as output, where is the aggregate-distance between the HNO set and the query point .
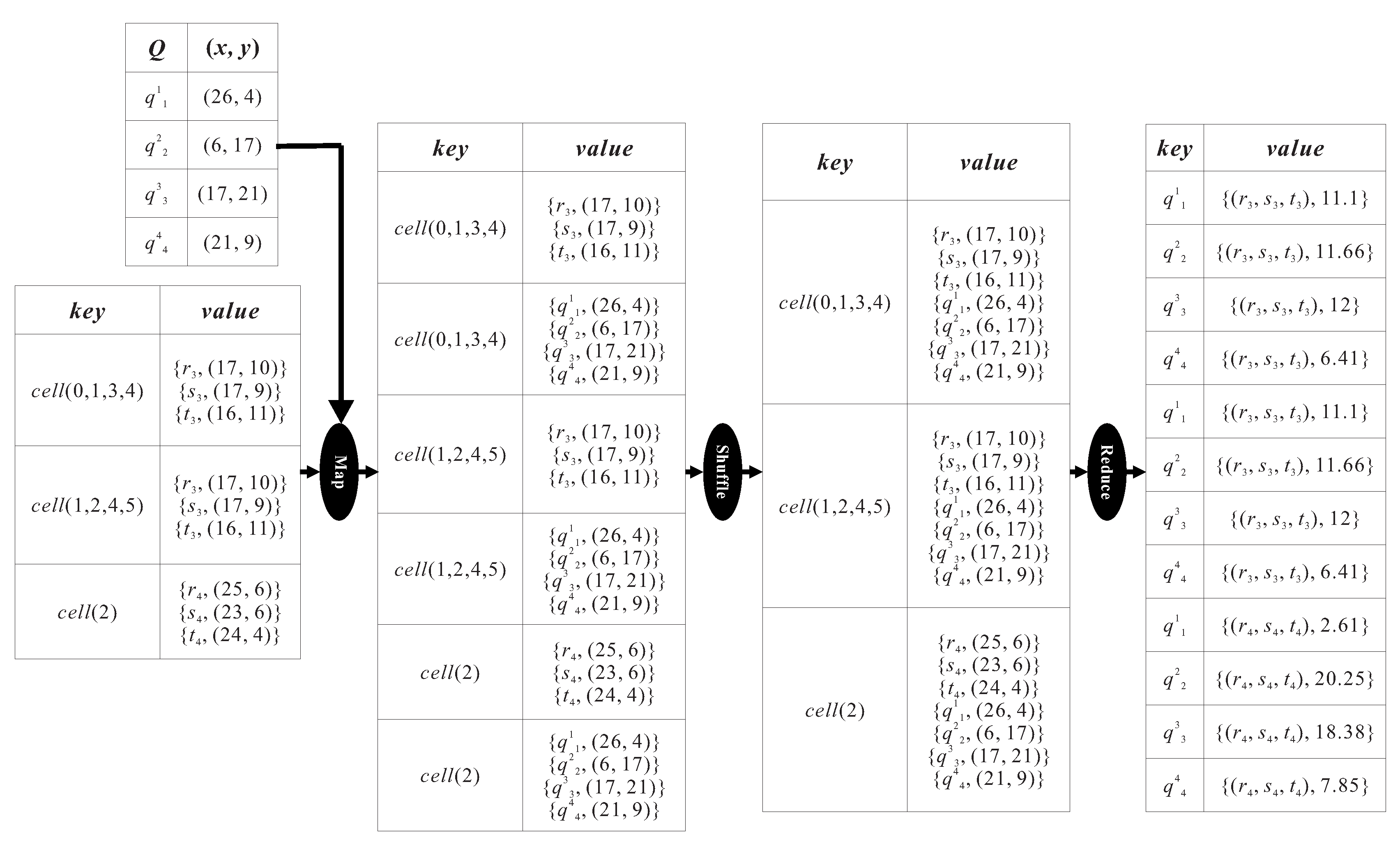
As shown in
Figure 6, continuing the example of
Figure 5, the query table maintains four query points
to
with their coordinates and query types, in which
,
,
, and
issue the
SAvgDQ, the
SMinDQ, the
SMaxDQ, and the
SSumDQ, respectively. In the map step, the key-value pairs
,
,
,
, and
,
,
,
obtained from the previous phase (i.e., the Outer
HNO set determining phase) are emitted. For the sake of grouping the
HNO sets and the query points, the key-value pairs,
,
,
and so on, are also generated based on the keys
,
, and
. The shuffle step dispatches the pairs with the same key to the same machine for computing the aggregate-distance between the
HNO sets and the query points. Take the key-value pair with regard to the key
as an example. The machine in charge of
runs the reduce step to compute the average distance of the
HNO set to the query point
as the query type
. Then, a key-value pair
is output, meaning that the average distance is equal to
. Similarly, in the reduce step, the min, max, and sum distances of
to
,
, and
, are estimated as
, 12, and
, respectively. After the key-value pairs have been output by all the participating machines, the last phase, the Result set generating phase, will sort the
HNO sets in ascending order of their aggregate-distance to determine the query result.
4.4. Result Set Generating Phase
The goal of the last phase, the Result set generating phase, is to determine the HNO set with the shortest aggregate-distance for each query point in a distributed manner. Once a MapReduce job starts, the key-value pairs received from the previous phase are directly emitted in the map step. According to the key , the HNO sets having the same will be assigned to an identical machine in the shuffle step because their aggregate-distances to the query point need to be compared so as to determine the query result for . For the machine receiving the key-value pairs with respect to , the first task of the reduce step is to eliminate the duplicate value in the form of . Then, the second task is to sort the HNO sets in ascending order of their aggregate-distance , and finally output the HNO set with smallest as the query result.
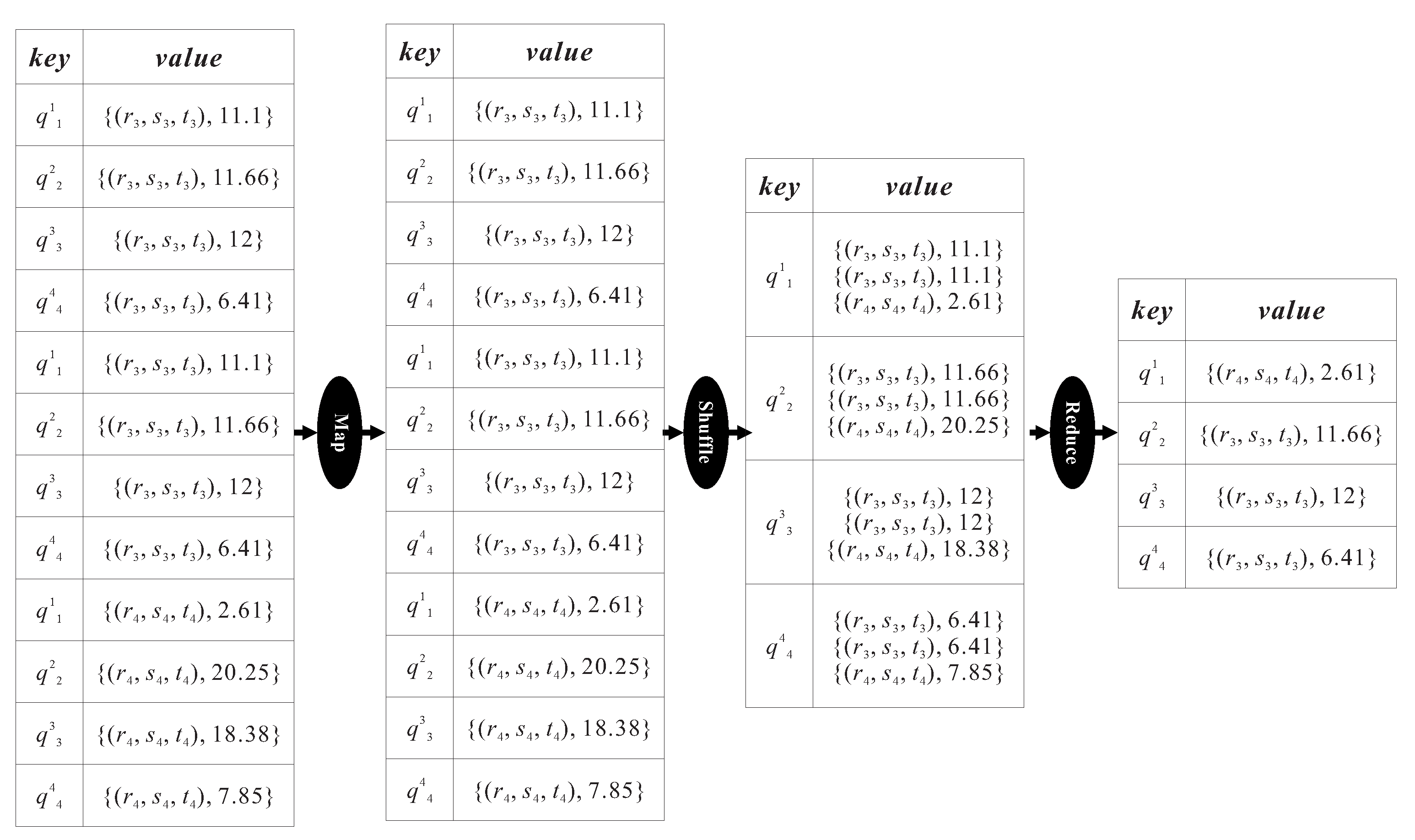
Figure 7 gives an illustration of how the Result set generating phase is executed using the key-value pairs generated from the previous phase (shown in
Figure 6). In the map step, all key-value pairs which use the query id as the key (e.g.,
) are emitted so that the pairs with the same key can be grouped together for processing after the shuffle step. For instance, the pairs
and
are assigned to the same machine because of their common key
. By executing the reduce step in each machine, the duplicates are first removed and then the
HNO set with the shortest aggregate-distance for each query point is output. In this figure, the
HNO set is the result for the query point
, and the
HNO set is the result for the other three query points
,
, and
.














{kind=link}
{kind=link}
{kind=link}
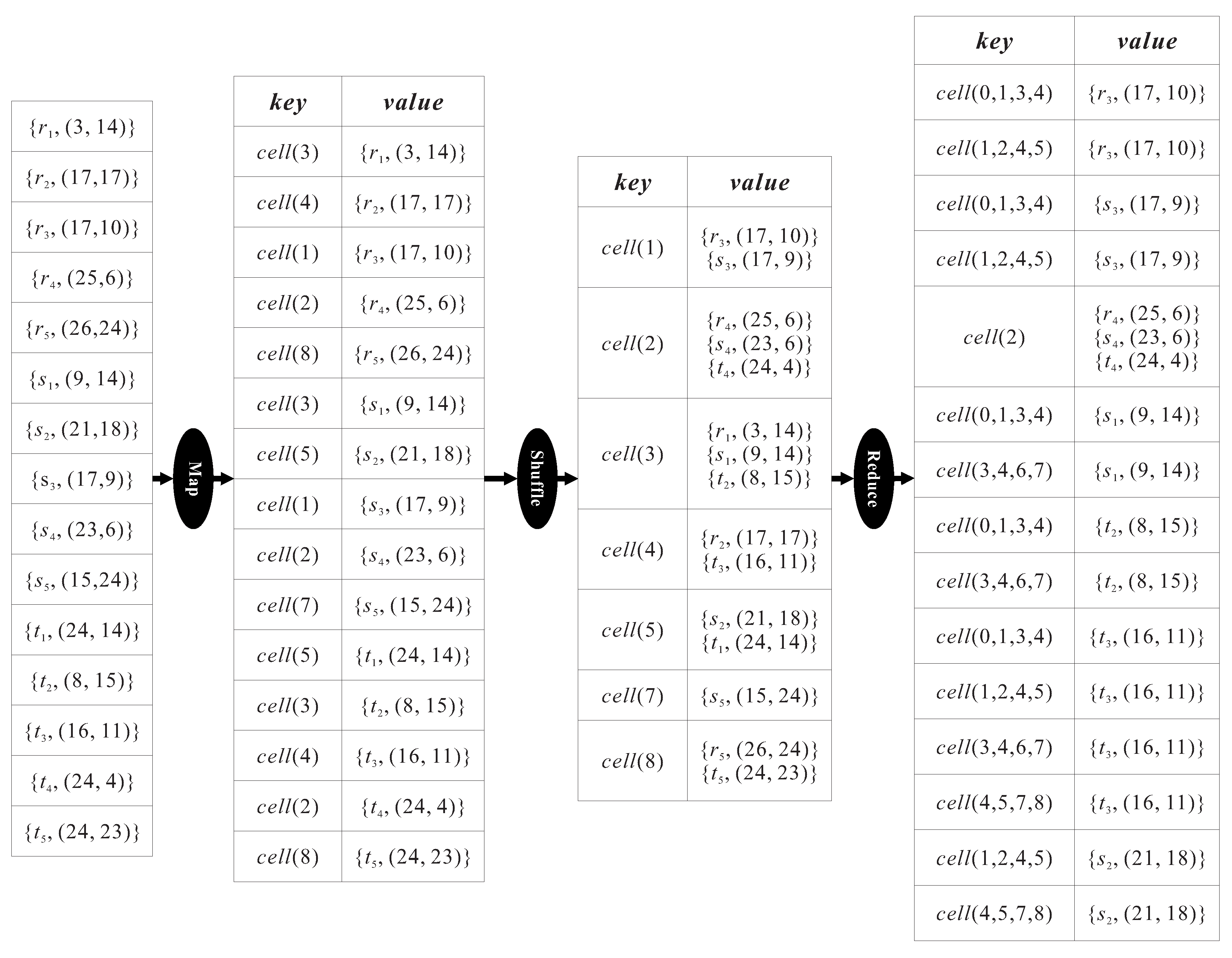{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}