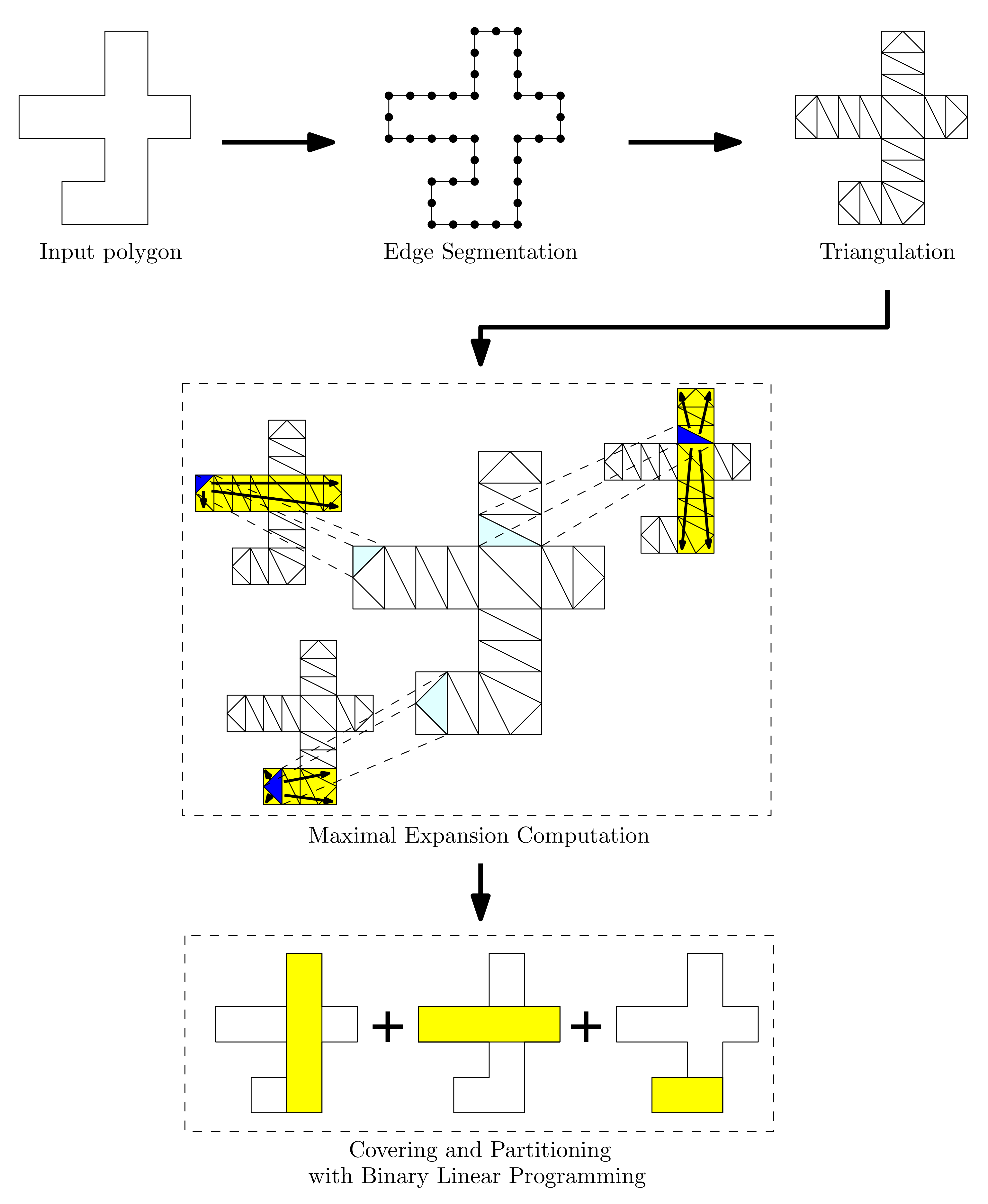
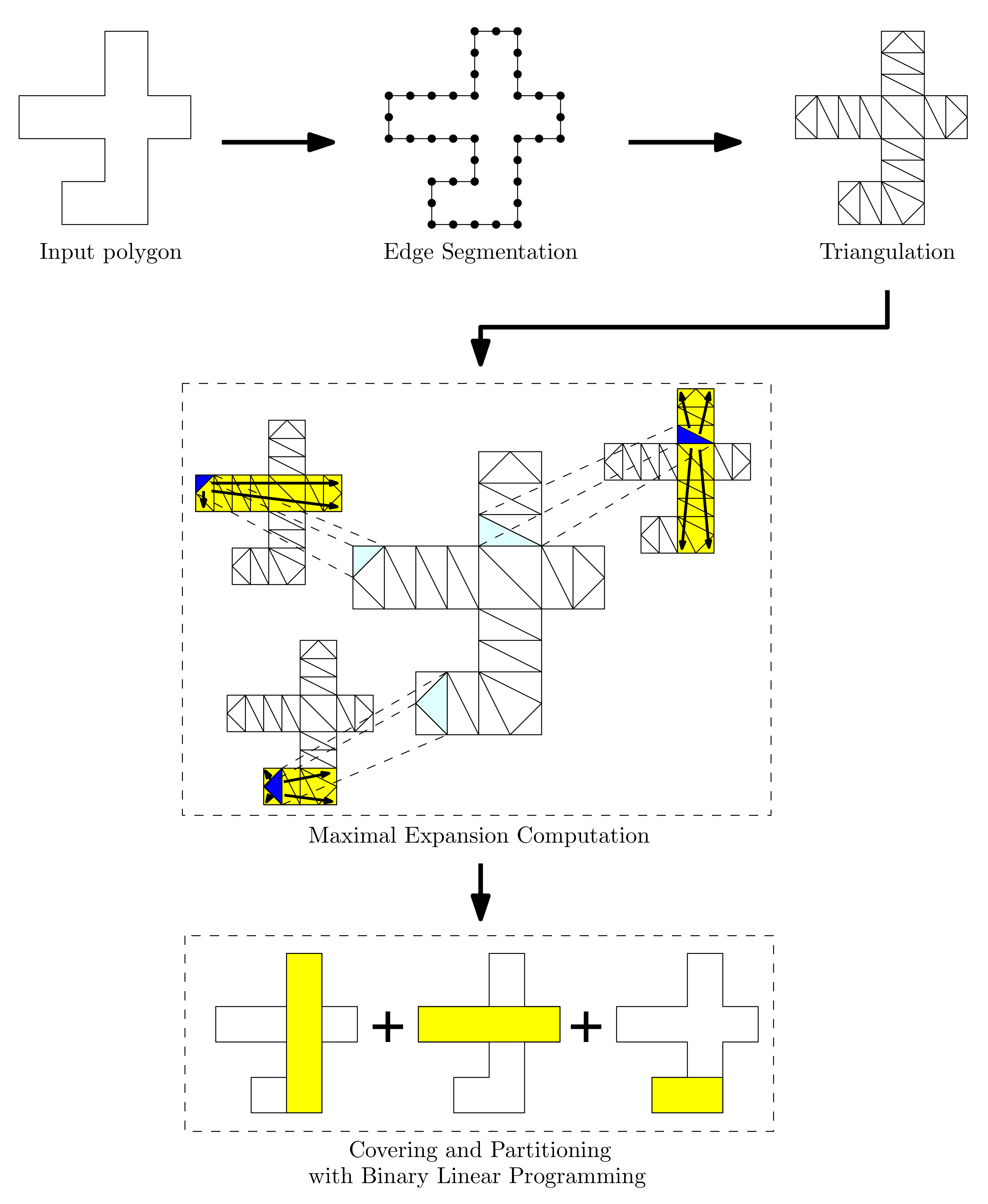
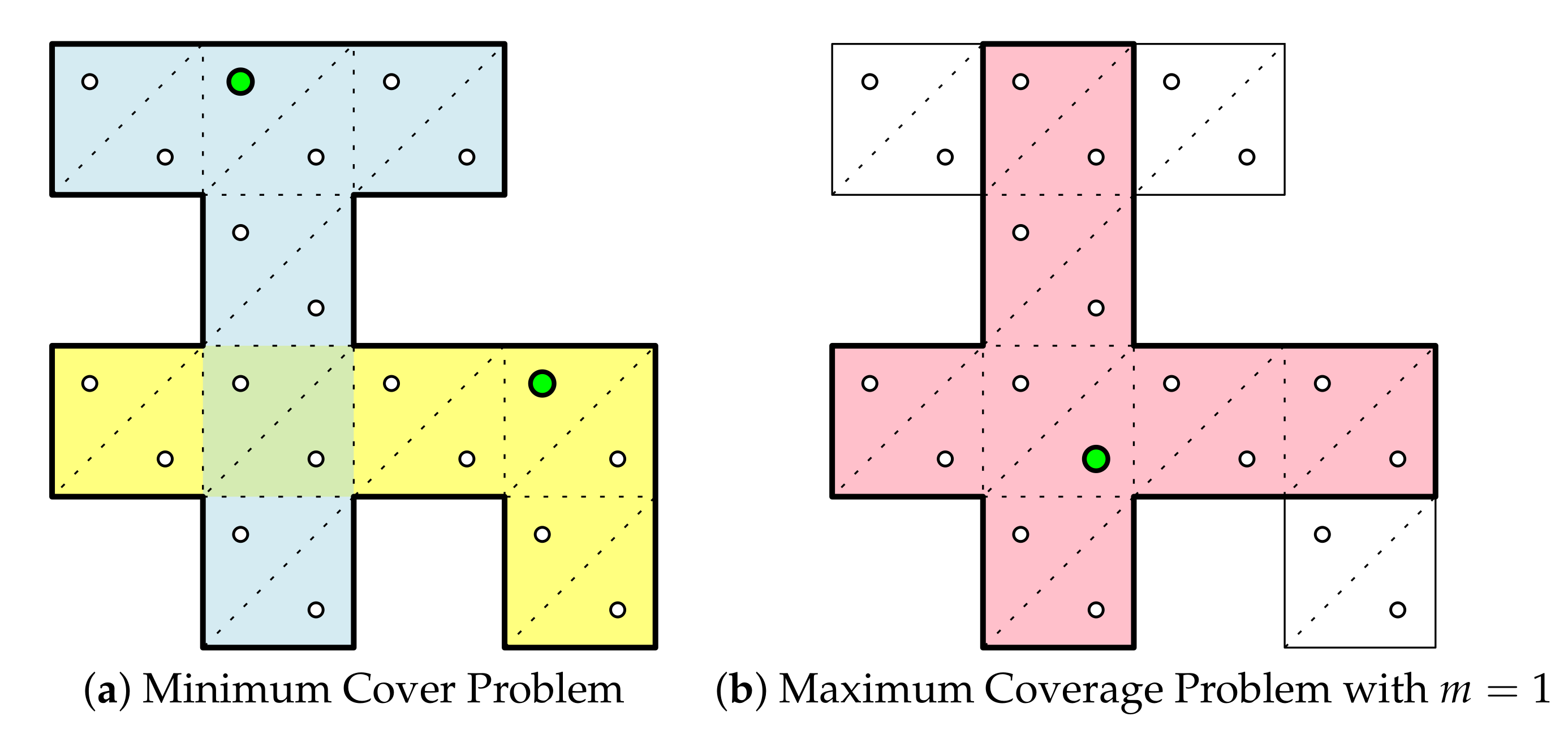
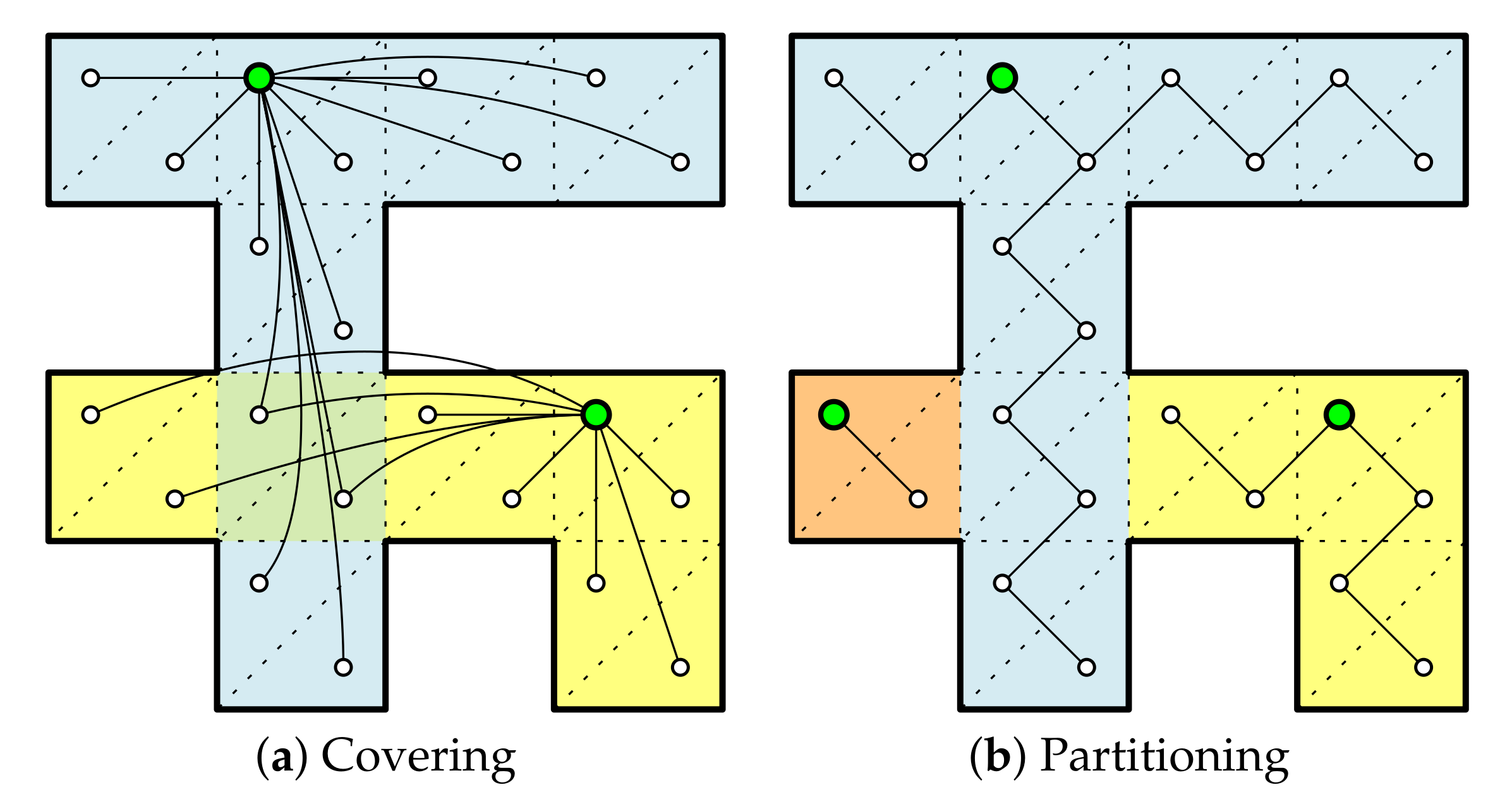
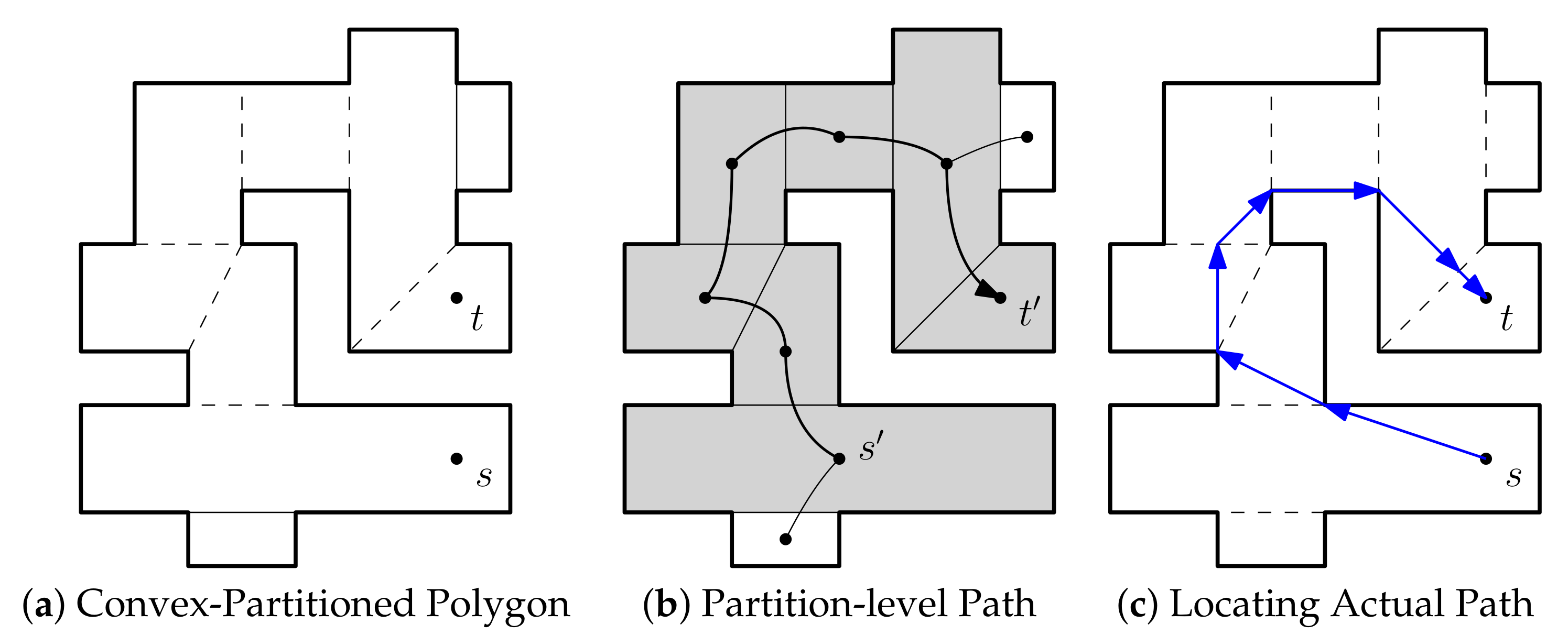
This section is dedicated to describe the notion of expansions, and the procedure to compute them. An expansion is a union of triangulated facets and it plays a role as a unit component of the binary linear programming for the final covering and partitioning task. The flexibility of our framework is based on the fact that we can make a variety of instances of expansions by setting detailed rules in computing expansions and defining a new constraint checking function. In this section, we present a simple expansion computation algorithm and several constraints that can come up in many applications in indoor spaces.
4.1. Computing Expansion
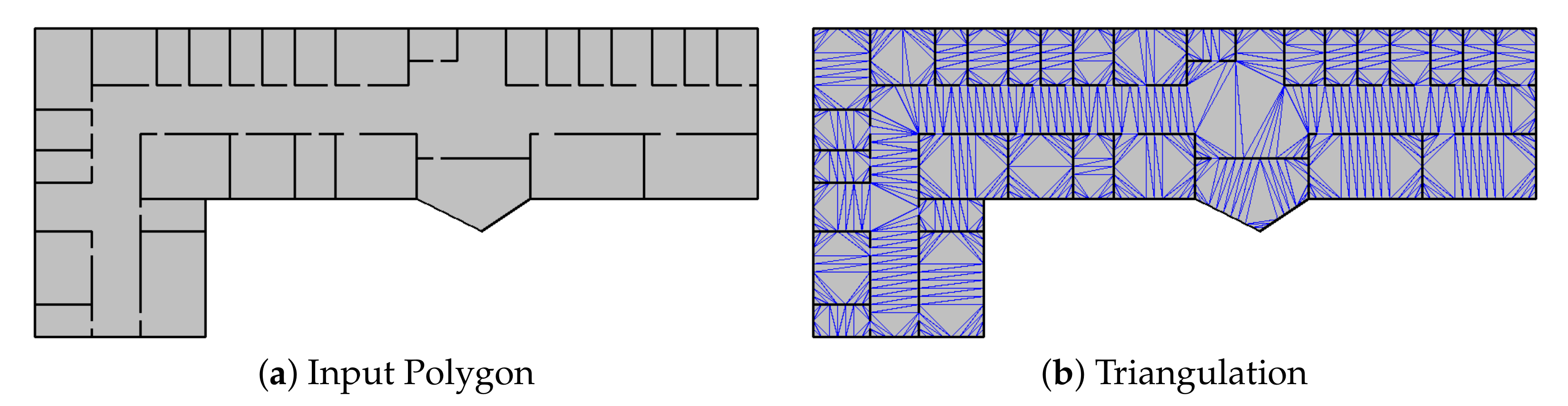
The set of triangular facets produced by constrained Delaunay triangulation is used as basic units in further covering or partitioning steps. We start from a triangular facet to merge with adjacent facets. The initial facet is called a seed facet and the merged polygon of the connected facets an expansion.
Definition 1 (Expansion)
. Given a input polygon P triangulated into a set of facets, a setis an expansion from a seed facetif the geometric union of all facetsforms a single (connected) polygon.
We compute the maximal expansions with seed facets in this step, and introduce a constraint checking function f in order to determine the maximality of an expansion.
Definition 2 (Maximal Expansion)
. An expansionof a seed facetis maximal with respect to a constraint checking function, ifyieldsfor all the facetsthat are adjacent to some of currently expanded facets.
The computation of a maximal expansion of a seed facet is explained in detail as follows. It is done in an iterative traversal manner on the dual graph, in which each facet is denoted by a node, and two nodes are connected via a link if the corresponding facets share an edge of the facets. The iterative traversal of the graph to compute the maximal expansions is as described in Algorithm 1.
| Algorithm 1 Compute maximal expansion |
| 1: procedure Expand(s: seed facet, S: set of facets to cover: f: constraint checking function) |
| 2: Initialize queue C |
| 3: add an element s into queue C |
| 4: . |
| 5: while do // repeat until queue C is not empty |
| 6: remove an element from queue C. |
| 7: if then |
| 8: |
| 9: For any unvisited facet adjacent to t, add into queue C |
| 10: end if |
| 11: end while |
| 12: return E |
| 13: end procedure |
This algorithm receives a seed facet as the input. Starting from the seed facet, we expand the region E by including new facets that satisfy the constraint checking function f and are adjacent with the seed facet or one of the facets in the current expansion. We assume that any seed facet satisfies the constraint as itself, i.e., for any ; otherwise the polygon may not be covered completely in some cases. When there is no more facet to include, it returns the currently merged polygon as the maximal expansion. The constraint checking function f takes three arguments: the seed facet, the current expansion, and a facet to newly add. The reason we make the function take its arguments separately is because we can define the constraint checking function in a much efficient way than the case in which the function takes only the merged geometry. If the constraint checking function gives false, it means that adding t does not satisfy the condition and we do not include it to the expansion set. We repeat this task until all the adjacent facets are completely processed.
Algorithm 1 iterates all the facets and calls the constraint checking function, it runs in time where n is the number of facets and is the time taken by the constraint checking function with at most n facets. For constraints we discuss in this paper, we have , thus Algorithm 1 runs in linear time.
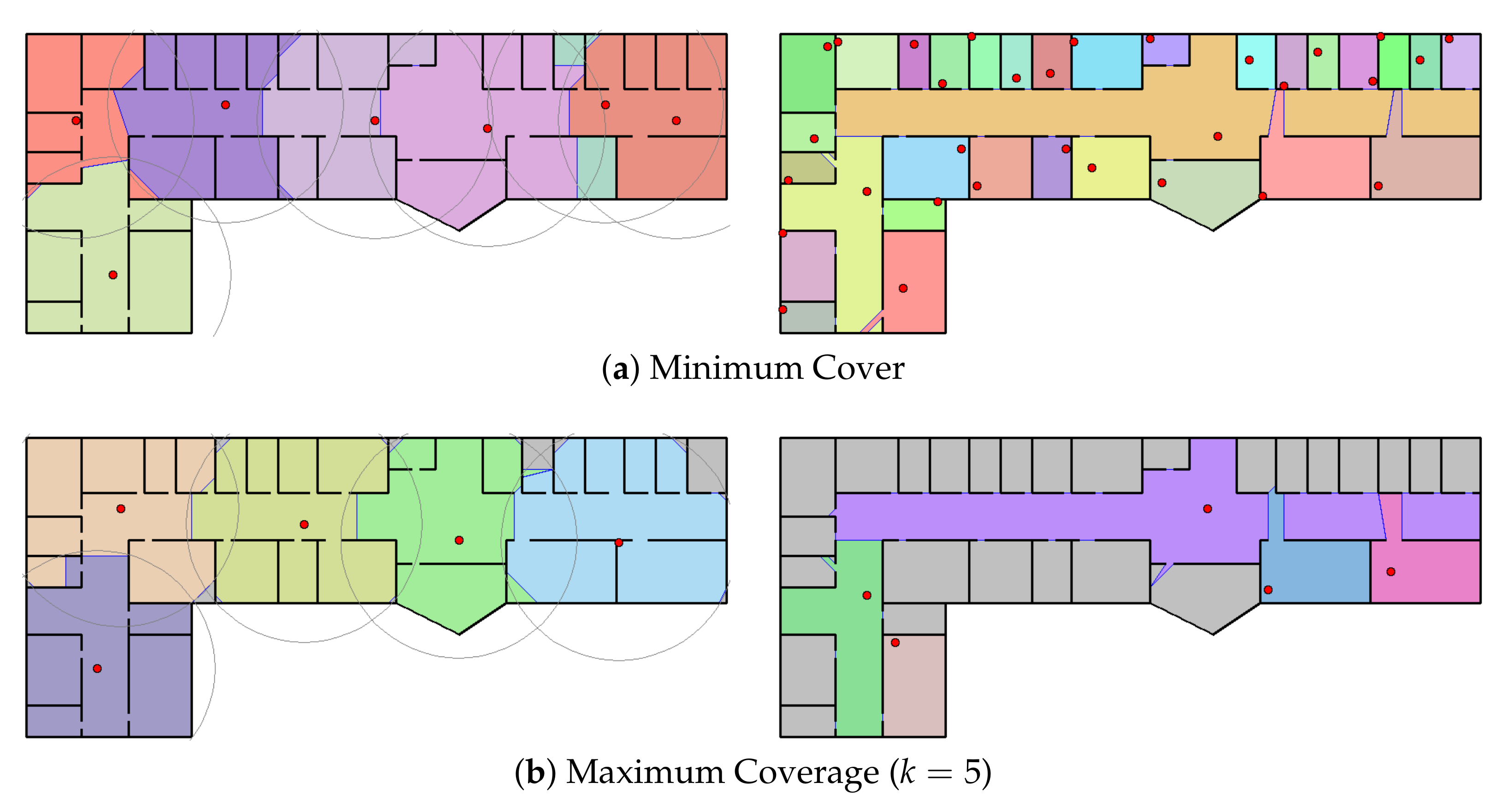
We compute the maximal expansions for each facet as a seed. Then we can obtain maximal expansions as many as the number of facets. We can use these maximal expansions to get the covers or partitions using the binary linear program, which will be discussed in the next section. However, it takes a quadratic time when we iterate over all the facets as seeds, because it runs in linear time per seed facet. Alternatively, we can use only a subset of facets. We can pick
facets at random for some
and compute their maximal expansions. We empirically show the performance of this strategy with respect to
in
Section 7.
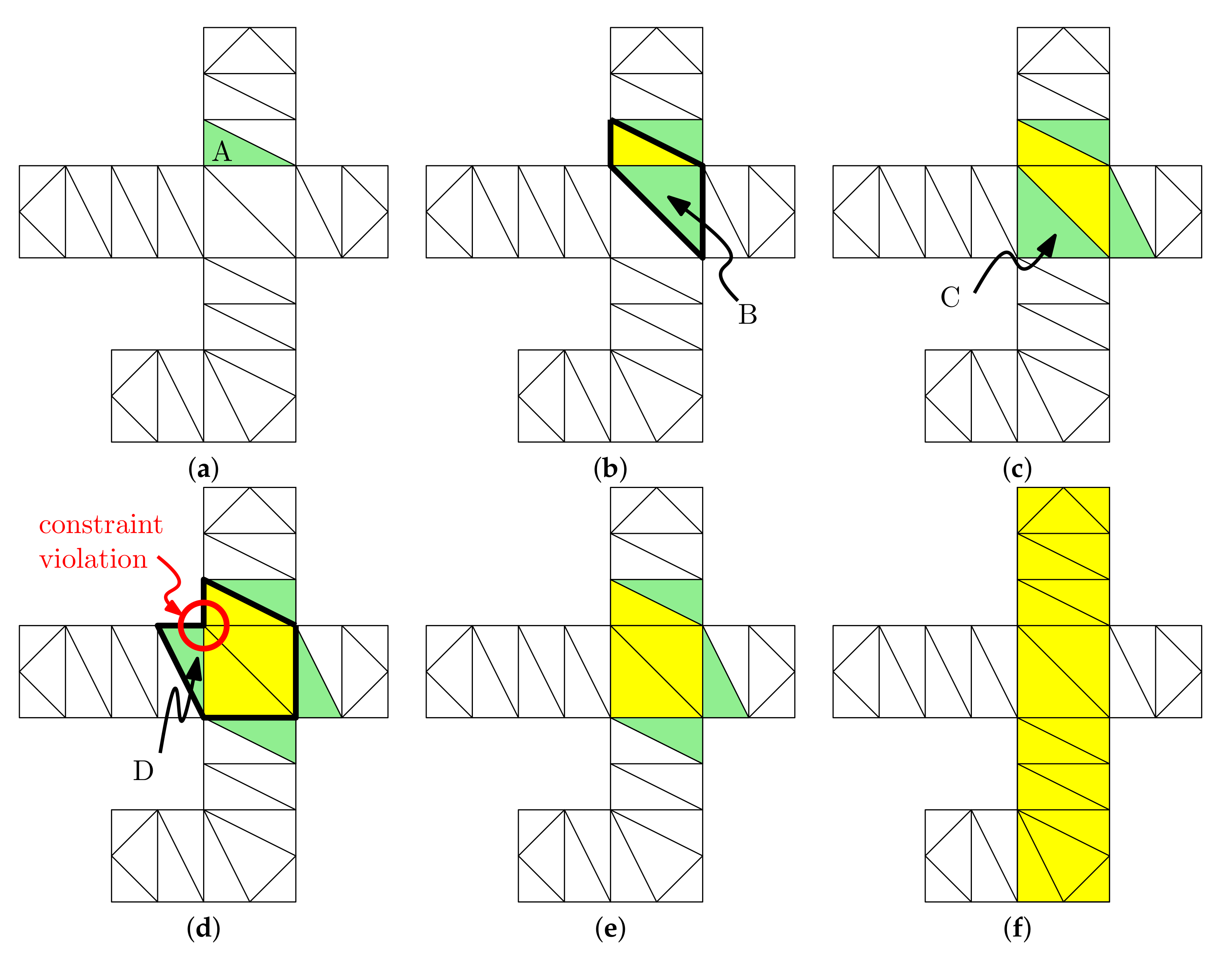
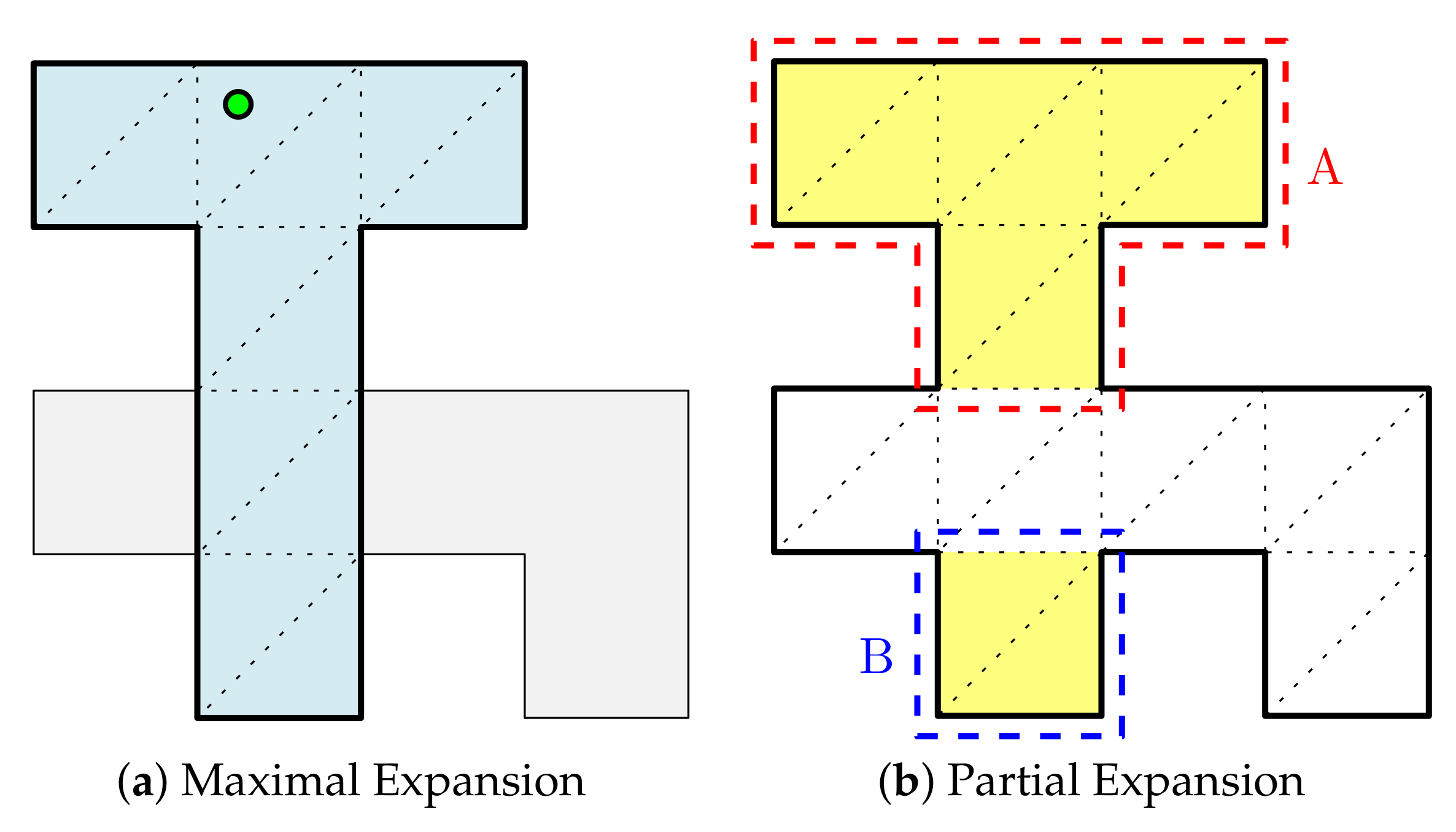
Figure 2 illustrates the process of computing the maximal expansion of a seed facet. Suppose the given constraint is convexity, so the resulting expansion should be a convex polygon. Starting from a seed facet
A as depicted in
Figure 2a, we add it into the queue. In
Figure 2b, two facets are adjacent to
A. Since
is still convex, we include
B into the expansion. Again, let us assume that we choose the facet indicated by
C in
Figure 2c, which leads to the next state as described in
Figure 2d. When we choose the facet indicated by
D, the resulting expansion would form a polygon described by the thick boundary in
Figure 2d, which has a concave vertex as indicated by a red circle. It violates the convexity constraint so we withdraw this selected facet. In
Figure 2e, we can see that the facet is removed from the candidate facet queue (as it is not indicated by green). When we repeat this process until the queue is empty, we can obtain the maximal expansion as in
Figure 2f.
Note that we can choose another green facet that satisfies the convexity constraint rather than
C in
Figure 2c. In this case, we may obtain a different maximal expansion. One may be afraid that we may miss some essential maximal expansions that are indispensable to cover the input polygon with the minimum cost. However, if we use a sufficient number of seed facets (possibly, all facets), these essential maximal expansions are likely to be obtained. For example, with the convexity constraint, a maximal expansion can be obtained by starting from any of facets in it. A large maximal expansion, which would be more useful for covering the space, is likely to have a large number of facets therein. It means that this maximal expansion has more seed facets from which it can be expanded. In other words, even if we fail to obtain a particular desired maximal expansion when we start the expansion from a seed facet, we still have a chance to obtain it from other seed facets.
Although we have a random choice for the simplicity here, we can use a particular strategy for the facet choice during the expansion procedure. For example, we can use a deterministic strategy that produces a unique maximal expansion from a seed facet such like choosing a facet sharing a longer edge with the current expansion. While there are many alternative options, we leave the extensive study on expansion strategies as the future work.
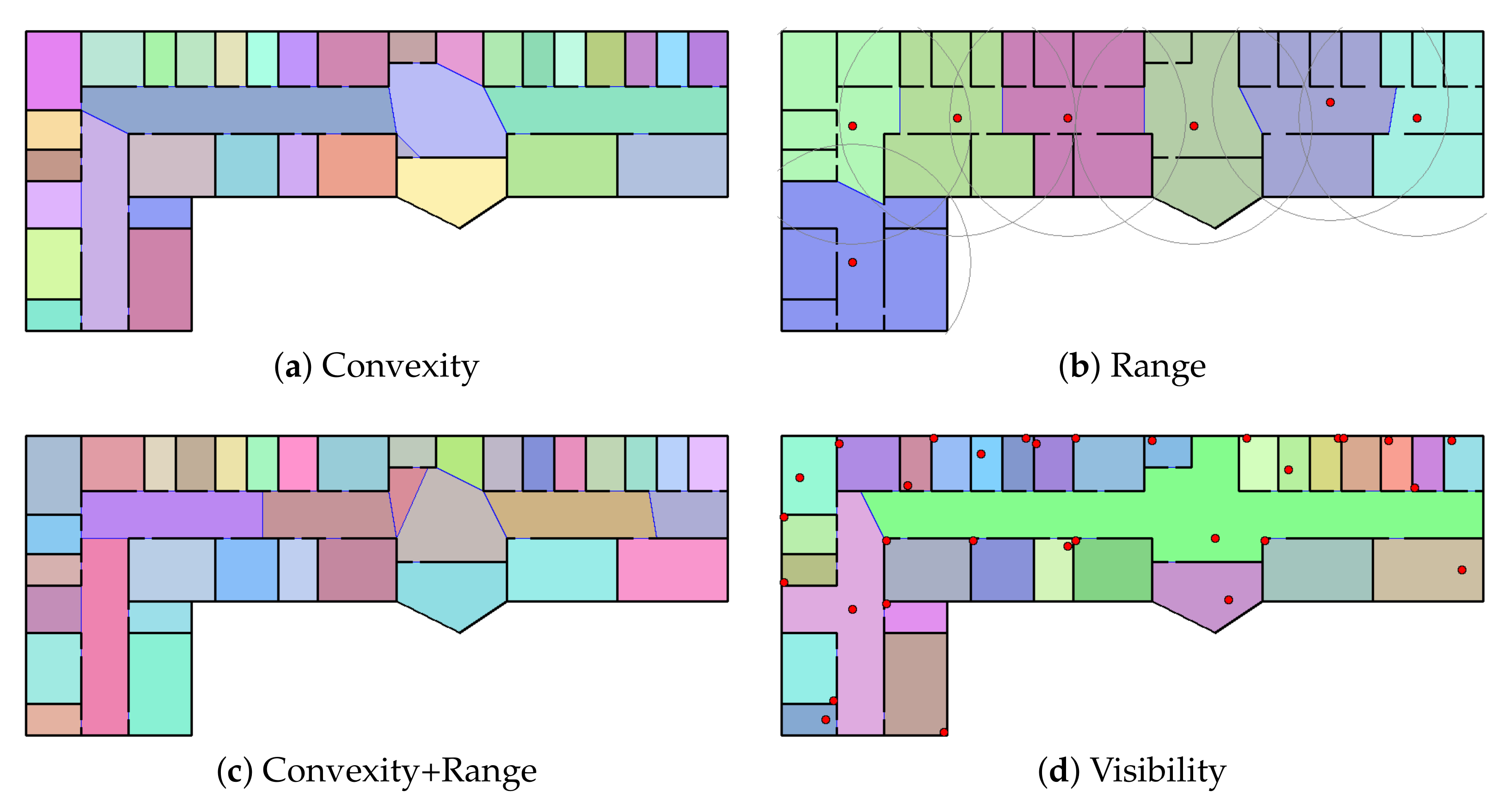
4.2. Constraint Design
In this subsection, we discuss the constraint checking function of Algorithm 1 in
Section 4.1. As we mentioned, resulting maximal expansions, as well as covering and partitioning results, depend on what constraint is given. Thus it is important to design a constraint that fits the requirement of the target application. As examples, we present three simple constraints in this subsection, which are expected to be frequently used in many applications. We also present some tricks that efficiently evaluate the constraint checking functions, which are illustrated in
Figure 3.
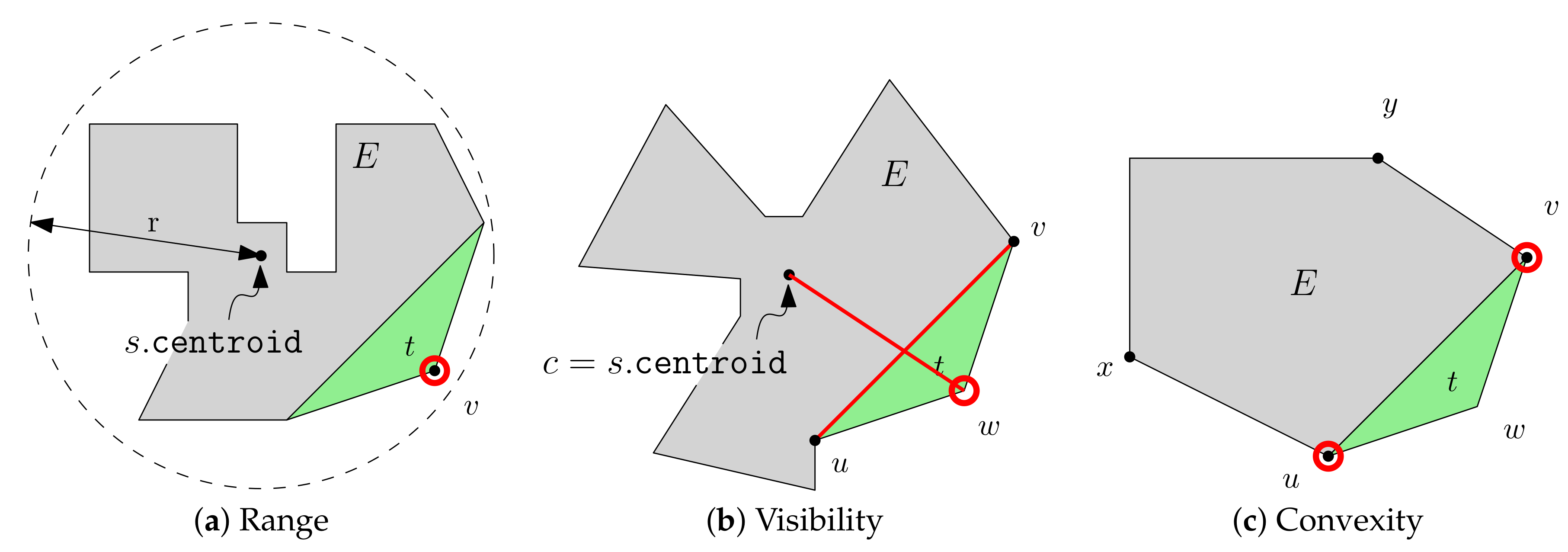
4.2.1. Range Constraint
First we design a constraint checking function f for the range constraint. Recall that f takes three arguments: seed facet s, current expansion E, and facet t to add, and checks if it does not violate the given constraint when we add t to E.
Because we have already triangulated the input polygon,
t is a triangle, and its two vertices are on the boundary of the current expansion
E. It is therefore sufficient to check if the other vertex that resides on the exterior of
E within the constrained range
r from
s. By setting the centroid of the seed facet
s as the center of the covered range, we can define the checking function
as follows:
where,
v is the vertex of
t that resides on
E’s exterior,
r is the constrained range.
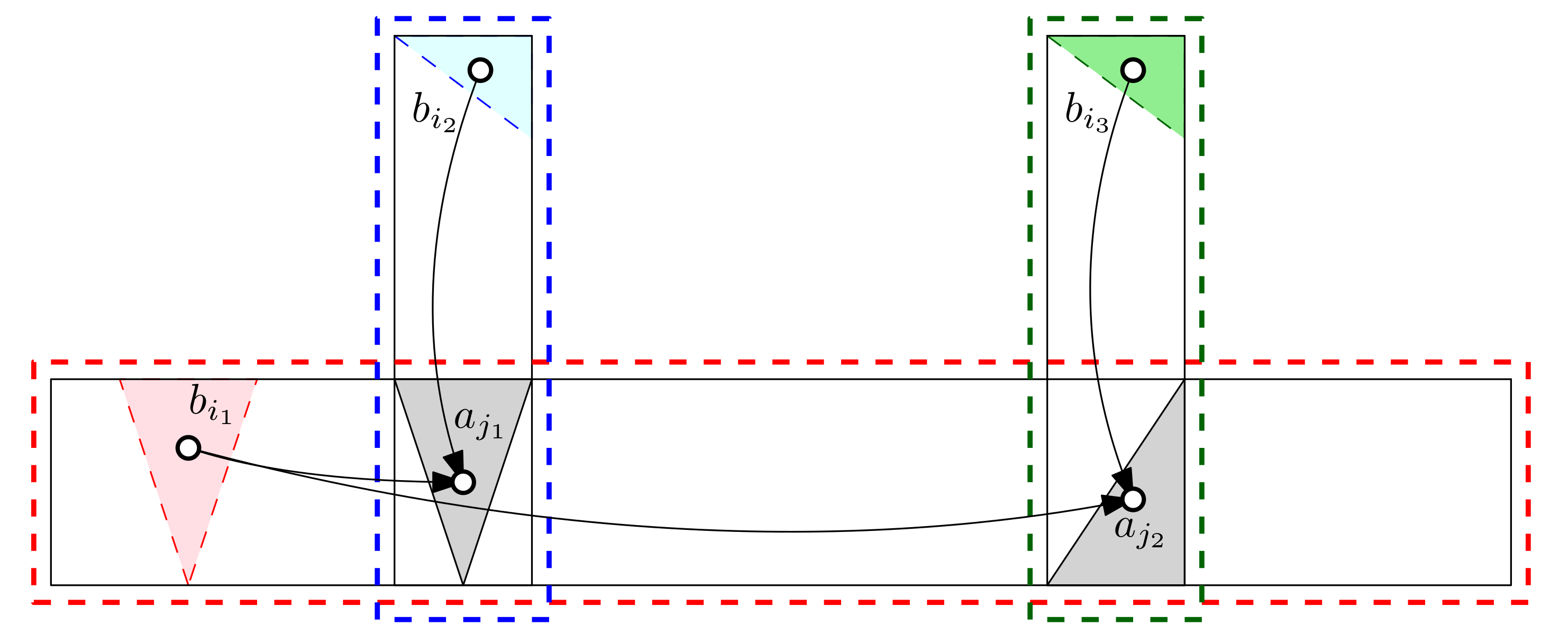
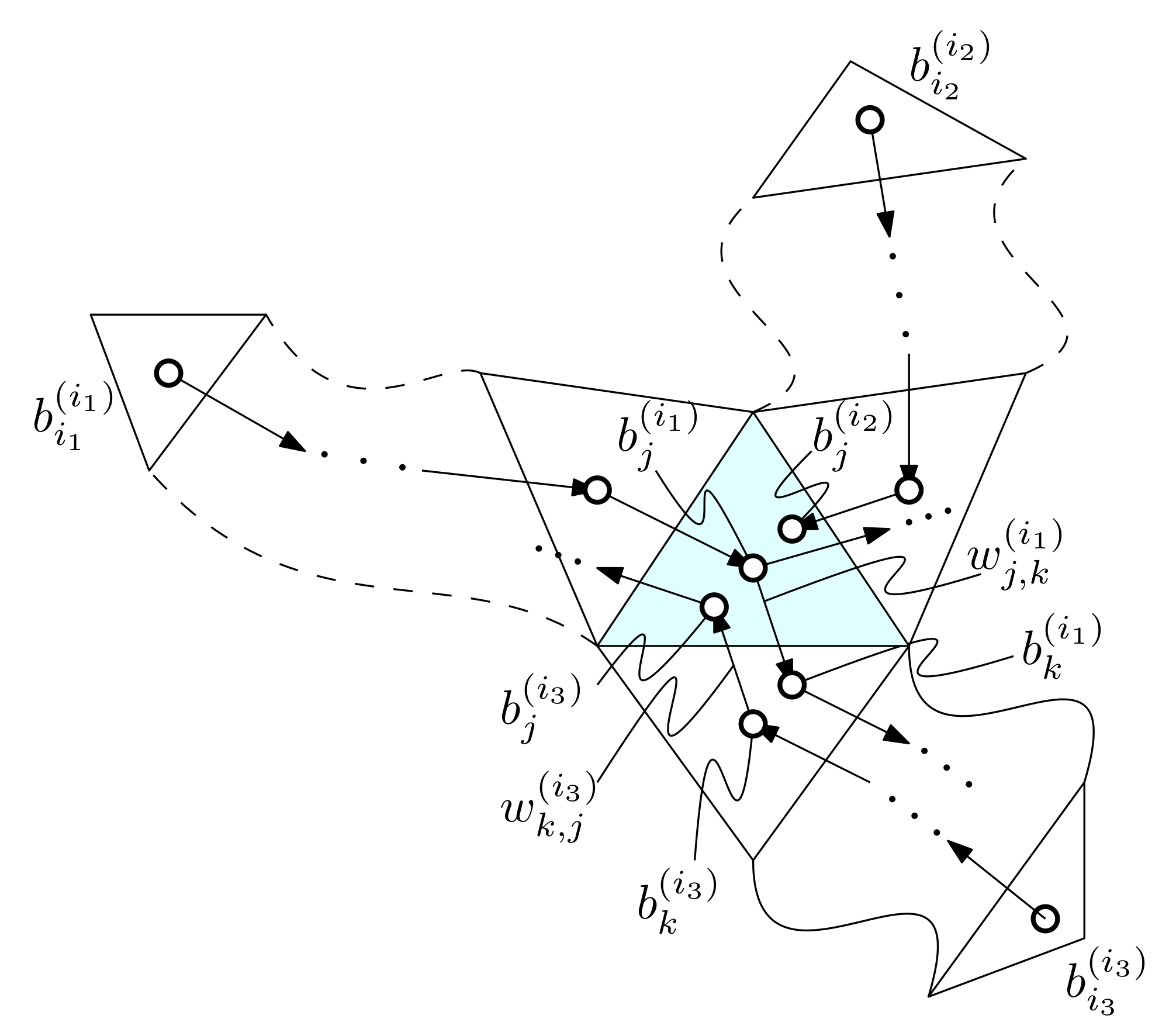
4.2.2. Visibility Constraint
The visibility constraint forces the resulting expansion to be visible from a specific point inside the seed facet. For simplicity, we shall use the centroid of the seed facet for checking the visibility. We need to implement the constraint checking function to determine whether is visible from the centroid c of triangle s.
Recall that E is expanded from s, and one edge of t, say , is on the boundary of E and visible from c. Let us denote by w the other vertex of t. Then we can see that is visible from c if and only if two segments and intersects at a single point.
The resulting function
can be defined as follows:
where
are the vertices on
E’s boundary,
w is the vertex of
t that resides on
E’s exterior, and
c is
s’s centroid.
4.2.3. Convexity Constraint
With the convexity constraint, the resulting expansions are restricted to be convex polygons. When we expand a triangle from the current expansion polygon, two vertices of the triangle are on the boundary of the current expansion polygon. We need to check whether inserting the other vertex of the triangle into the middle of the edge produces concave angles with the resulting polygon. Let
be these two vertices shared by the current expansion polygon and the triangle to add, and the other vertex of the triangle is denoted by
w. The preceding and succeeding vertices of
u and
v are denoted by
x and
y, respectively, as shown in
Figure 3c. After adding the triangle to the expansion polygon, the resulting polygon has a sequence of consecutive vertices
ash shown in
Figure 2c. To check the convexity, it is sufficient to determine whether
and
. Now we define the checking function
for the convexity as follows:
where
u and
v are common vertices of
E, and
w is the other vertex of the triangle
t to add, and
x (and
y) is the preceding (and succeeding) vertex of
u (and
v, resp.).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}